
Submitted:
02 July 2024
Posted:
02 July 2024
You are already at the latest version
Abstract
Computational models of homologous protein groups are essential in sequence bioinformatics. Due to the diversity and rapid evolution of viruses, the grouping of protein sequences from virus genomes is particularly challenging. The low sequence similarities of homologous genes in viruses require specific approaches for sequence- and structure-based clustering. Furthermore, the annotation of virus genomes in public databases is not as consistent and up-to-date as for many cellular genomes. To tackle these problems, we have developed VOGDB, a database of Virus Orthologous Groups. VOGDB is a multi-layer database that progressively groups viral genes into groups connected by increasingly remote homology. The first layer is based on pair-wise sequence similarities, the second layer is based on the sequence profile alignments and the third layer uses predicted protein structures to find the most remote homology. VOGDB groups allow for more sensitive homology searches of novel genes and increase the chance of predicting annotations or inferring phylogeny. VOGDB uses all virus genomes from RefSeq and partially re-annotates them. VOGDB is updated with every RefSeq release. The unique feature of VOGDB is inclusion of both prokaryotic and eukaryotic viruses in the same clustering process which makes it possible to explore old evolutionary relationships of the two groups. VOGDB is freely available at https://vogdb.org under the CC BY 4.0 license.
Keywords:
protein families
; orthologous groups
; databases
; viruses
; phages
1. Introduction
Viruses are a diverse group of biological entities that share the property of being obligate cellular parasites. Unlike in cellular organisms, no common genes or gene families are shared between all viruses [1]. This raises fundamental questions about virus ancestry and evolution. Moreover, the number of viruses on earth is huge (more than particles) [2,3] and it is estimated they carry between and unique genes [4]. Most of the viral diversity is currently unexplored and for the most sequenced viral genes, little is known about their function [5].
Viral genes not only encode a high number of different functions, which leads to a huge diversity of viral genomes, but also form heterogeneous groups of genes having similar function [6]. Due to the nature of viral lifestyle and their quick replication, mutations and selection, viruses explore the sequence space of genes in less evolutionary time than cellular organisms do [7,8]. Because of the heterogeneity of viral proteins, it is often difficult to find homologs in databases by traditional bioinformatics, such as pairwise sequence alignments.
The computational inference of gene homology is valuable for annotating genes that are known from their sequence, but have not been experimentally characterized. Homologous genes have diverged from a common ancestral gene and are likely to have same or similar functions in different organisms. A particularly informative computational observation is gene orthology. Orthologous genes have diverged from a common ancestor by a process of speciation (as opposed to the gene duplication in paralogy). Orthologous genes are more likely to keep the ancestral function [9]. Orthologous genes from multiple organisms form orthologous groups. Homologous relationships are deduced from sequence comparisons due to the assumption that important sequence motifs will stay conserved during evolution [10]. However, due to the absence of universal phylogenetic markers for all viruses and frequent horizontal gene transfers between viruses and viruses as well as viruses and hosts, no universal concepts for the orthology of viral protein families are so far available in bioinformatics.
Due to quick viral evolution, it is often impossible to detect homology by pairwise alignment of two protein sequences, especially for proteins that diverged longer time ago. However, by building a sequence model based on the group of easily detectable homologs, a conserved pattern becomes discernible, which can be used to connect more distant groups [11]. This approach is widely used by databases that cluster together viral proteins, including pVOG [12], which focuses on prokaryotic viruses, as well as the viral sequences of eggNOG [13]. The PHROGs database [14] clusters phage genomes in two steps, first by grouping them based on the direct sequence comparison and later by clustering group Hidden Markov Models (HMM) to capture remote homology. However, none of these databases represents the high number and broad diversity of virus genome sequences available to date.
We therefore introduce VOGDB, a comprehensive database of virus orthologous groups, virus protein families and virus protein structural folds. VOGDB provides these three layers of homologous groups for all viral proteins from RefSeq genomes [15]. The layers are intended to gather proteins with the increasing evolutionary distance reflected in the higher sequence divergence. Contrary to the prokaryotic genomes from RefSeq, where PGAP [16] is used for the consistent re-annotation of genomes, virus genomes in RefSeq keep their annotation from their GenBank [17] submission. VOGDB, making use of all virus genomes from RefSeq, addresses the problem of inconsistent and outdated annotation by filtering and partial re-annotation, in order to ensure higher quality of final clusters. The first layer VOGDB is constructed by all against all pair-wise sequence comparisons and represents the easily detectable homologs. The second layer is created by clustering sequence models (HMMs) from the first layer to capture homology of proteins that diverged beyond the point where homology can be detected by pair-wise alignments. In the third layer we group together families from the second layer by their shared features within predicted 3D structures. This layer represents remotely homologous groups whose members diverged to a degree that sequence comparison methods can’t detect their similarity anymore. As there is no standard way to validate viral orthologous groups, we suggest an approach based on the homogeneity of functional and structural annotations in terms of SwissProt [18] keywords and SCOPe [19] superfamily labels. The calculation of homogeneity was also applied to other similar databases (pVOG, PHROGs and COG), to compare if VOGDB shows similar homogeneity despite its higher number and wider diversity of genome sequences. pVOG and PHROGs are databases with viral proteins and are directly comparable to the first and second layers from VOGDB. The COG database contains prokaryotic proteins grouped by orthology and was included as a control.
2. Material and Methods
2.1. Preprocessing of Input Data
Input from RefSeq
The input data are all of the complete viral genomes from RefSeq [15] which have at least one protein annotated. Around 98% of records from RefSeq enter the VOGDB pipeline meaning VOGDB represents almost the entire viral portion of RefSeq. All sequence records with the same taxonomy ID, strain and isolate are considered one genome in VOGDB, further called VOGDB genomes.
Polyproteins
Polyproteins are present in DNA viruses and almost all RNA and Retroviruses. A polyprotein is translated as a large polypeptide from a single ORF and is later cleaved into functional proteins [20]. At the moment, no general computational strategy exists that would predict the cleavage sites in polyproteins and find the borders of the individual peptides. We have developed a strategy to annotate the individual peptides from the polyprotein sequence. First, individual peptides originating from a polyprotein or from RefSeq records that have been validated by the VOGDB team are collected in a peptide reference database. Second, non-annotated or incompletely annotated polyproteins are then reannotated by the best non-overlapping pairwise sequence alignments against the peptide reference database. Within VOGDB, annotated or reannotated peptides replace the respective segments of their initial polyprotein records and together with the rest of the proteins are called VOGDB proteins.
2.2. Creation of the First Layer Clusters - VOGs
VOGDB proteins are used as the input to the COGSoft pipeline with the aim of constructing clusters of recently diverged proteins [21]. In short, all against all PSI-BLAST [22] search is done followed by the COGtriangles [21] procedure to find orthologous groups. We use the strict clustering which doesn’t allow for a single protein to be a member of multiple clusters. For each orthologous group, a multiple sequence alignment of all member proteins is calculated using Clustal Omega [23]. From the multiple alignment we calculate Hidden Markov Models (HMM) using hmmbuild from HMMER [24]. The resulting groups are called VOGs to reflect that they are a viral equivalent to orthologous groups.
Functional annotation
Annotations of VOGDB clusters are made with the aim of describing most of the cluster members as specifically as possible and therefore we are using a consensus of the annotations of the individual proteins as the cluster annotation. vVGs are functionally annotated, if possible, by deriving functional annotations from hits to the most recent SwissProt [18] database or from the annotations as provided by RefSeq. To retrieve the annotation from SwissProt we used BLAST [25] to search the SwissProt database with the members of a VOG. For an individual protein from a VOG we retained the functional annotation of a maximum of 5 hits if the e-value was less than and the alignment coverage was more than 90%. All annotations of all proteins in a VOG are collected and the most common annotation string found for a VOG is used as the annotation for that VOG. In cases when it is not possible to get the annotation from SwissProt, we collect annotations of proteins in a VOG as they are in RefSeq and use the most common annotation string as the annotation for the VOG.
As an additional step in the annotation process, we maintain a list of SwissProt keywords with which we associate a functional category. Every functional annotation of VOGs belongs to one or more functional categories: virus replication (Xr), virus structure (Xs), viral protein beneficial for the host (Xh), viral protein beneficial for the virus(Xp) and unknown function(Xu).
Naming
VOG are named with a prefix "VOG" and a number padded with zeroes. To facilitate the comparison of the results between releases, we implemented a stable numbering scheme. VOGs from the older release are compared to the VOGs from the newer release and the newer VOG get the name of the largest older VOG for which 50% or more of the proteins are found in the new VOG. For VOGs that don’t get the name from the previous release, a new number is created.
2.3. Creation of the Second Layer Clusters - VFAMs
Clustering using MCL
To create second layer clusters (VFAMs), we first need to align HMMs of VOGs. The alignment is done using hhalign function from HH-Suite [26]. The alignment scores are used directly, without pre-processing, as input to the MCL clustering algorithm [27] where VOGs are clustered with the inflation value of 2. Clustered sequences are aligned with Clustal Omega [23] and a HMM of the alignment is calculated by the function hmmbuild from HMMER [24]. The functional annotation of VFAMs are obtained in the same way as for VOGs. Naming works the same as for VOGs, but with a different prefix "VFAM".
2.4. Creation of the Third Layer Clusters - VFOLDs
Third layer of VOGDB consists of VFOLDs, clusters of VFAMs grouped based on the shared structural features. A few experimentally resolved structures of viral proteins are available in the public databases like pdb [28]. Therefore, we used alphafold 2 [29] to predict structures of viral proteins in VFAMs. Since there are more than 500000 proteins in VFAMs, predicting this number of structures would not be feasible. The strategy was to select one representative for every VFAM and cluster the representatives instead of the whole VFAMs. To select a representative, we have aligned all members of VFAM to the HMM of that VFAM and selected the highest scoring member as a candidate for which the structure would be predicted by alphafold 2. After obtaining structure predictions for all representatives, we did the clustering using the FoldSeek tool [30] with the default settings. Functional annotations of VFOLDs are obtained in the same way as for VOGs and VFAMs.
2.5. Quality Assessment of the Clustering Results
The quality of the clustering was assessed by the homogeneity of functional annotations of cluster members and the structural superfamily membership of cluster members. Homogeneity of clusters from VOGDB was compared to the homogeneity of a random model. We obtained the random model by randomly scrambling functional annotation keywords or structure superfamily labels between annotated proteins and calculated the homogeneity. The randomization step was repeated 1000 times. For functional annotations we searched SwissProt with all protein members of a group, used the keyword of the top-level functional annotation of the hits and calculated the relative frequency of the most common annotation compared to all retrieved annotations. To assess the homogeneity of structural patterns, we used a similar approach, but instead of searching SwissProt, we searched astral95 database (v2.08) [19] using cd-hit [31]. Hits were associated with protein structural superfamilies as described in the SCOPe database [19]. The homogeneity for superfamilies was calculated as relative frequency of the most common superfamily per group. Comparison of the homogeneity to the random model was done using the Kolmogorov-Smirnov test.
3. Results
Database
As the RefSeq database is updated bi-montly, VOGDB is updated with every RefSeq release and the new release is made available shortly after the newest version of RefSeq is released. The release number of VOGDB is the same as the release number of RefSeq which was used to build it. As an example in the text, the VOGDB version 221 based on the RefSeq 221 will be used and it contains 14974 VOGDB genomes. The polyprotein reannotation step predicted 5499 additional peptides from 995 polyproteins.
Content
In the VOGDB release 221, 606019 of viral proteins were clustered and produced 59196 of VOGs, 38576 of VFAMs and 30516 of VFOLDs (Figure 1). Due to the clustering, 352350 of proteins have functional annotation, compared to 333379 of the initial proteins from RefSeq that were not annotated as hypothetical proteins. The size distribution of the groups from all three layers shows the expected pattern observed in the similar databases where there are many of the smaller groups and a few of the larger groups. The distribution of the VOGs, VFAMs and VFOLDs according to their size is visualized in the Figure 2. A feature of VOGs, VFAMs and VFOLDs is the information on the lowest common ancestor (LCA) of the viruses contributing proteins to the groups. Particularly interesting groups are those with LCA "Viruses" which means that proteins from different viral realms got clustered together. There are 2441 such VOGs (4.1%) and 1443 VFAMs (3.7%) and 1515 VFOLDs (4.8%).
3.1. Quality Assessment
As there is not yet a universal standard procedure to evaluate the clustering of the viral proteins into orthologous groups, we assessed the quality of the VOGDB clusters using the homogeneity of functional annotation and structural classification. If the clustering would perfectly group the proteins by structure and function, all proteins in one cluster would have the same and unique functional and structural annotation. The level of granularity needs to ensure maximal information for the entire database. Too coarse granularity would overestimate the homogeneity and too fine would underestimate it. We selected the SwissProt keywords and the SCOPe superfamilies as the granularity level at which we calculate the homogeneity. Because there is a limited number of keywords describing the function, we estimated the baseline of the homogeneity from the random model described earlier. Quality assessment based on the homogeneity (Figure 3) shows that both functional and structural homogeneity of groups from different layers of VOGDB are significantly larger than the baseline for all of the size bins (Kolmogorov-Smirnov test, p-value <).
Comparison with similar databases
To evaluate the homogeneity of functional annotations and structural features, we calculated the homogeneity of the COG database (the release form 2020) [32], the PHROG database (v3) [14] and the pVOG database (May 2016) [12] in the same way as for the VOGDB layers. Clusters in the pVOG database are created similarly as VOGs and the PHROGs clusters are similar to VFAMs. However, VOGDB has a bigger scope than pVOG and PHROG by including both phages and eukaryotic viruses and is therefore faced with a harder clustering task. The COG database was included as a control as it was creating using similar clustering methodology and is manually curated. Figure 4 shows that the homogeneity of VOGDB layers is in the same range as the homogeneity of databases grouping prokaryotic orthologs (COG), phage orthologs (pVOG) and phage remote homologs (PHROG). Homogeneity of clusters from pVOG and VOGs are very similar, which is expected as both are created using COGSoft [21].
3.2. Availability
Webpage
VOGDB is accessible online at https://vogdb.org where it is possible to browse the clusters and see the statistics of the latest release. The webpage is updated regularly as a new version of VOGDB is calculated.
Available files
Apart from being accessible via the webpage, we offer all of the resulting files for download. The files offered are formatted similarly to the files offered by EggNOG database [33]. Most important files offered are HMMs of the clusters and multiple sequence alignments, files with the lowest common ancestry, files with functional annotation of clusters and predicted structures of VFAM representatives.
4. Discussion and Application Examples
Limitations
VOGDB is so far the most complete database for virus orthologous groups, virus protein families and virus protein structural similarities. However, it is based on the annotations provided by the underlying RefSeq database. So far, several annotation quality filters and the re-annotation of polyproteins are the only means that VOGDB uses to ensure high accuracy of its input data. A consistent re-annotation of all virus genomes is not in the scope of VOGDB. Nevertheless, such re-annotation will become increasingly important to sustain the value of comparative genomics of viruses. The VOGDB groups can be a valuable tool towards this aim, e.g. by predicting protein-coding genes that were missed in the original genome annotations.
Support for bioinformatic workflows
Viral hallmark genes [34] could be defined as genes that are found in diverse viruses, but have no or only few homologs in cellular organisms and are therefore indicative of the viral origin of a sequence. HMMs of VOGs and VFAMs that represent viral hallmark genes can be used to predict viral sequences from unknown genomes [35] and to estimate the contamination of a viral sequence with bacterial genes [36]. HMMs of groups of viral proteins (either hallmark or not) could be used as input for various other tools. For example, the tool HMM-GraspX [37] uses protein family HMMs to guide the assembly which is useful if the aim of the analysis is to analyze viruses in samples with low abundance of viral reads or when the focus on specific families is needed [38]. For VOGDB clusters, we calculate the virus specificity based on the number of hits to cellular organisms based on the HMM-HMM search to the most recent eggNOG database [33]. The virus specificity information can be used to identify clusters representing the viral hallmark genes. Table 1 shows the number of virus specific VOGs and VFAMs at different stringency criteria, accepting few cellular homologs as expected e.g. from proviruses.
Usage for metagenome analysis
VOGDB is useful for analyzing metagenomic datasets that intentionally or accidentally contain virus nucleic acid sequences. When pair-wise sequence database searches fail to reveal hits, homology searches with databases containing HMMs, as from VOGDB, are more sensitive and allow for more proteins to be annotated. Besides the functional annotation, lineage information of the genome carrying the gene can be inferred. By mapping all genes of a viral contig to VFAMs and using the information about the lowest common ancestor of VFAMs, one can estimate the lineage of the whole contig (Figure 5). When comparing viromes, the overlaps of the contents of the groups from VOGDB can be used to estimate relatedness and similarity.
5. Conclusions
VOGDB is a novel resource in the field of virus bioinformatics and it offers unique features compared to the similar databases and will complement the current toolbox for studying viral genomes. By including both phages and eukaryotic viruses from RefSeq, VOGDB has the biggest scope of all virus orthology databases and it still ranks similarly with them in terms of the homogeneity of functional annotations and structural classes. The three layers of grouping give the opportunity to analyze the gene clusters connected by the increasingly remote homology. Downloadable files, including functional annotations of clusters and HMMs, as well as bi-monthly updates that follow the RefSeq releases, make VOGDB a universal tool for downstream workflows in virus bioinformatics.
VOGDB is under constant development and new knowledge about viruses is quickly implemented (for example the new phage taxonomy [40]). On the other hand, the stable naming of clusters allows for the comparability of the results obtained by different releases of the database.
References
- Villarreal, L. Evolution of Viruses. In Encyclopedia of Virology; Elsevier; pp. 174–184. [CrossRef]
- Hendrix, R.W.; Smith, M.C.M.; Burns, R.N.; Ford, M.E.; Hatfull, G.F. Evolutionary Relationships among Diverse Bacteriophages and Prophages: All the World’s a Phage. 96, 2192–2197. [CrossRef]
- Mushegian, A.R. Are There 10 31 Virus Particles on Earth, or More, or Fewer? 202. [CrossRef]
- Koonin, E.V.; Krupovic, M.; Dolja, V.V. The Global Virome: How Much Diversity and How Many Independent Origins? 25, 40–44. [CrossRef]
- Krishnamurthy, S.R.; Wang, D. Origins and Challenges of Viral Dark Matter. 239, 136–142. [CrossRef]
- Kuchibhatla, D.B.; Sherman, W.A.; Chung, B.Y.W.; Cook, S.; Schneider, G.; Eisenhaber, B.; Karlin, D.G. Powerful Sequence Similarity Search Methods and In-Depth Manual Analyses Can Identify Remote Homologs in Many Apparently “Orphan” Viral Proteins. 88, 10–20. [CrossRef]
- Stern, A.; Andino, R. Viral Evolution. In Viral Pathogenesis; Elsevier; pp. 233–240. [CrossRef]
- Koonin, E.V.; Dolja, V.V.; Krupovic, M. The Logic of Virus Evolution. 30, 917–929. [CrossRef]
- Koonin, E.V. Orthologs, Paralogs, and Evolutionary Genomics. 39, 309–338. [CrossRef]
- Pearson, W.R. An Introduction to Sequence Similarity (“Homology”) Searching. 42, 3.1.1–3.1.8. [CrossRef]
- Yoon, B.J. Hidden Markov Models and Their Applications in Biological Sequence Analysis. 10, 402–415. [CrossRef]
- Grazziotin, A.L.; Koonin, E.V.; Kristensen, D.M. Prokaryotic Virus Orthologous Groups (pVOGs): A Resource for Comparative Genomics and Protein Family Annotation. 45, D491–D498. [CrossRef]
- Huerta-Cepas, J.; Szklarczyk, D.; Forslund, K.; Cook, H.; Heller, D.; Walter, M.C.; Rattei, T.; Mende, D.R.; Sunagawa, S.; Kuhn, M.; et al. eggNOG 4.5: A Hierarchical Orthology Framework with Improved Functional Annotations for Eukaryotic, Prokaryotic and Viral Sequences. 44, D286–D293. [CrossRef]
- Terzian, P.; Olo Ndela, E.; Galiez, C.; Lossouarn, J.; Pérez Bucio, R.E.; Mom, R.; Toussaint, A.; Petit, M.A.; Enault, F. PHROG: Families of Prokaryotic Virus Proteins Clustered Using Remote Homology. 3, lqab067. [CrossRef]
- Haft, D.H.; Badretdin, A.; Coulouris, G.; DiCuccio, M.; Durkin, A.S.; Jovenitti, E.; Li, W.; Mersha, M.; O’Neill, K.R.; Virothaisakun, J.; et al. RefSeq and the Prokaryotic Genome Annotation Pipeline in the Age of Metagenomes. 52, D762–D769. [CrossRef]
- Li, W.; O’Neill, K.R.; Haft, D.H.; DiCuccio, M.; Chetvernin, V.; Badretdin, A.; Coulouris, G.; Chitsaz, F.; Derbyshire, M.K.; Durkin, A.S.; et al. RefSeq: Expanding the Prokaryotic Genome Annotation Pipeline Reach with Protein Family Model Curation. 49, D1020–D1028. [CrossRef]
- Benson, D.A.; Cavanaugh, M.; Clark, K.; Karsch-Mizrachi, I.; Ostell, J.; Pruitt, K.D.; Sayers, E.W. GenBank. 46, D41–D47. [CrossRef]
- Boutet, E.; Lieberherr, D.; Tognolli, M.; Schneider, M.; Bansal, P.; Bridge, A.J.; Poux, S.; Bougueleret, L.; Xenarios, I. UniProtKB/Swiss-Prot, the Manually Annotated Section of the UniProt KnowledgeBase: How to Use the Entry View. 1374, 23–54, [26519399]. [CrossRef]
- Chandonia, J.M.; Guan, L.; Lin, S.; Yu, C.; Fox, N.K.; Brenner, S.E. SCOPe: Improvements to the Structural Classification of Proteins – Extended Database to Facilitate Variant Interpretation and Machine Learning. 50, D553–D559. [CrossRef]
- Yost, S.A.; Marcotrigiano, J. Viral Precursor Polyproteins: Keys of Regulation from Replication to Maturation. 3, 137–142, [23602469]. [CrossRef]
- Kristensen, D.M.; Kannan, L.; Coleman, M.K.; Wolf, Y.I.; Sorokin, A.; Koonin, E.V.; Mushegian, A. A Low-Polynomial Algorithm for Assembling Clusters of Orthologous Groups from Intergenomic Symmetric Best Matches.
- Altschul, S.F.; Madden, T.L.; Schäffer, A.A.; Zhang, J.; Zhang, Z.; Miller, W.; Lipman, D.J. Gapped BLAST and PSI-BLAST: A New Generation of Protein Database Search Programs. 25, 3389–3402. [CrossRef]
- Sievers, F.; Wilm, A.; Dineen, D.; Gibson, T.J.; Karplus, K.; Li, W.; Lopez, R.; McWilliam, H.; Remmert, M.; Söding, J.; et al. Fast, Scalable Generation of High-Quality Protein Multiple Sequence Alignments Using Clustal Omega. 7, 539, [21988835]. [CrossRef]
- Eddy, S.R. Accelerated Profile HMM Searches. 7, e1002195. [CrossRef]
- Altschul, S.F.; Gish, W.; Miller, W.; Myers, E.W.; Lipman, D.J. Basic Local Alignment Search Tool. 215, 403–410. [CrossRef]
- Steinegger, M.; Meier, M.; Mirdita, M.; Vöhringer, H.; Haunsberger, S.J.; Söding, J. HH-suite3 for Fast Remote Homology Detection and Deep Protein Annotation. 20, 473. [CrossRef]
- Van Dongen, S. Graph Clustering Via a Discrete Uncoupling Process. 30, 121–141. [CrossRef]
- Burley, S.K.; Bhikadiya, C.; Bi, C.; Bittrich, S.; Chao, H.; Chen, L.; Craig, P.A.; Crichlow, G.V.; Dalenberg, K.; Duarte, J.M.; et al. RCSB Protein Data Bank (RCSB.Org): Delivery of Experimentally-Determined PDB Structures alongside One Million Computed Structure Models of Proteins from Artificial Intelligence/Machine Learning. 51.
- Jumper, J.; Evans, R.; Pritzel, A.; Green, T.; Figurnov, M.; Ronneberger, O.; Tunyasuvunakool, K.; Bates, R.; Žídek, A.; Potapenko, A.; et al. Highly Accurate Protein Structure Prediction with AlphaFold. 596, 583–589. [CrossRef]
- Van Kempen, M.; Kim, S.S.; Tumescheit, C.; Mirdita, M.; Lee, J.; Gilchrist, C.L.M.; Söding, J.; Steinegger, M. Fast and Accurate Protein Structure Search with Foldseek. [CrossRef]
- Fu, L.; Niu, B.; Zhu, Z.; Wu, S.; Li, W. CD-HIT: Accelerated for Clustering the next-Generation Sequencing Data. 28, 3150–3152. [CrossRef]
- Galperin, M.Y.; Wolf, Y.I.; Makarova, K.S.; Vera Alvarez, R.; Landsman, D.; Koonin, E.V. COG Database Update: Focus on Microbial Diversity, Model Organisms, and Widespread Pathogens. 49, D274–D281. [CrossRef]
- Hernández-Plaza, A.; Szklarczyk, D.; Botas, J.; Cantalapiedra, C.P.; Giner-Lamia, J.; Mende, D.R.; Kirsch, R.; Rattei, T.; Letunic, I.; Jensen, L.J.; et al. eggNOG 6.0: Enabling Comparative Genomics across 12 535 Organisms. 51, D389–D394. [CrossRef]
- Koonin, E.V.; Senkevich, T.G.; Dolja, V.V. The Ancient Virus World and Evolution of Cells. 1, 29. [CrossRef]
- Guo, J.; Bolduc, B.; Zayed, A.A.; Varsani, A.; Dominguez-Huerta, G.; Delmont, T.O.; Pratama, A.A.; Gazitúa, M.C.; Vik, D.; Sullivan, M.B.; et al. VirSorter2: A Multi-Classifier, Expert-Guided Approach to Detect Diverse DNA and RNA Viruses. 9, 37. [CrossRef]
- Nayfach, S.; Camargo, A.P.; Schulz, F.; Eloe-Fadrosh, E.; Roux, S.; Kyrpides, N.C. CheckV Assesses the Quality and Completeness of Metagenome-Assembled Viral Genomes. 39, 578–585. [CrossRef]
- Zhong, C.; Edlund, A.; Yang, Y.; McLean, J.S.; Yooseph, S. Metagenome and Metatranscriptome Analyses Using Protein Family Profiles. 12, e1004991. [CrossRef]
- Laffy, P.W.; Wood-Charlson, E.M.; Turaev, D.; Jutz, S.; Pascelli, C.; Botté, E.S.; Bell, S.C.; Peirce, T.E.; Weynberg, K.D.; Van Oppen, M.J.H.; et al. Reef Invertebrate Viromics: Diversity, Host Specificity and Functional Capacity. 20, 2125–2141. [CrossRef]
- Villarroel, J.; Larsen, M.; Kilstrup, M.; Nielsen, M. Metagenomic Analysis of Therapeutic PYO Phage Cocktails from 1997 to 2014. 9, 328. [CrossRef]
- Turner, D.; Shkoporov, A.N.; Lood, C.; Millard, A.D.; Dutilh, B.E.; Alfenas-Zerbini, P.; Van Zyl, L.J.; Aziz, R.K.; Oksanen, H.M.; Poranen, M.M.; et al. Abolishment of Morphology-Based Taxa and Change to Binomial Species Names: 2022 Taxonomy Update of the ICTV Bacterial Viruses Subcommittee. 168, 74. [CrossRef]
Figure 1.
Schema of the layered structure of the database. For each layer different tools were used to create clusters. Clusters from every next layer are built from the clusters of the previous layer and are connected by more remote homology.
Figure 1.
Schema of the layered structure of the database. For each layer different tools were used to create clusters. Clusters from every next layer are built from the clusters of the previous layer and are connected by more remote homology.
Figure 2.
Number of groups per layer in different size bins. Size bins represent the range of the number of proteins for groups in a certain bin. The distribution with many smaller clusters and fewer of the larger ones is what is also observed in the similar databases.
Figure 2.
Number of groups per layer in different size bins. Size bins represent the range of the number of proteins for groups in a certain bin. The distribution with many smaller clusters and fewer of the larger ones is what is also observed in the similar databases.
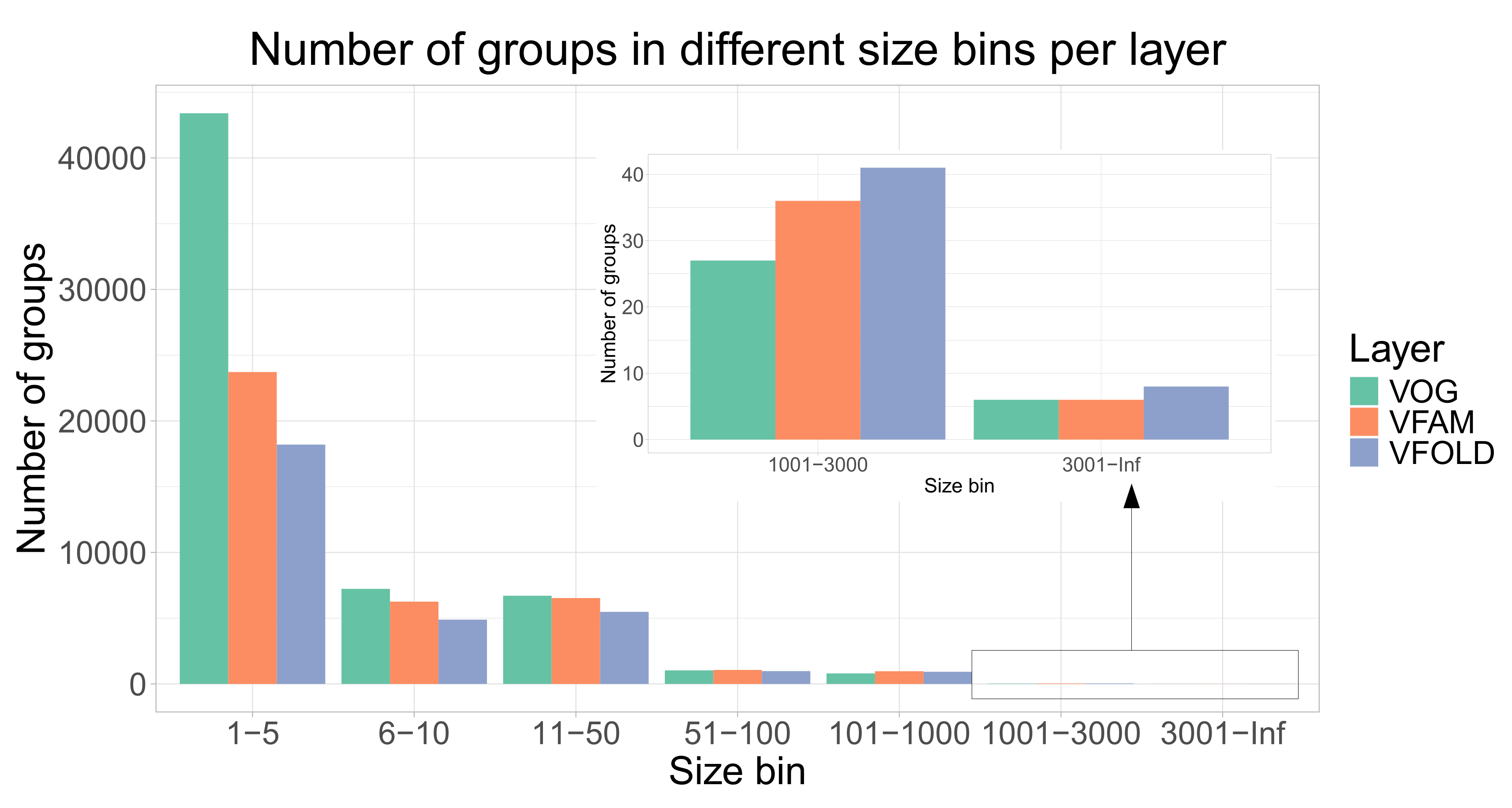
Figure 3.
Homogeneity of functional annotations and protein structure classifications in VOGDB layers compared to the random model. The groups from each layer are put into size bins based on the number of proteins with functional and structural annotation. The random model is created by randomly redistributing the functional and structural annotation labels between the proteins with respective annotation for 1000 times and calculating the overall homogeneity. The results show that groups from VOGDB layers are significantly more homogeneous in terms of SwissProt keywords and structural classifications based on the SCOPe superfamilies (Kolmogorov-Smirnov test, p <).
Figure 3.
Homogeneity of functional annotations and protein structure classifications in VOGDB layers compared to the random model. The groups from each layer are put into size bins based on the number of proteins with functional and structural annotation. The random model is created by randomly redistributing the functional and structural annotation labels between the proteins with respective annotation for 1000 times and calculating the overall homogeneity. The results show that groups from VOGDB layers are significantly more homogeneous in terms of SwissProt keywords and structural classifications based on the SCOPe superfamilies (Kolmogorov-Smirnov test, p <).
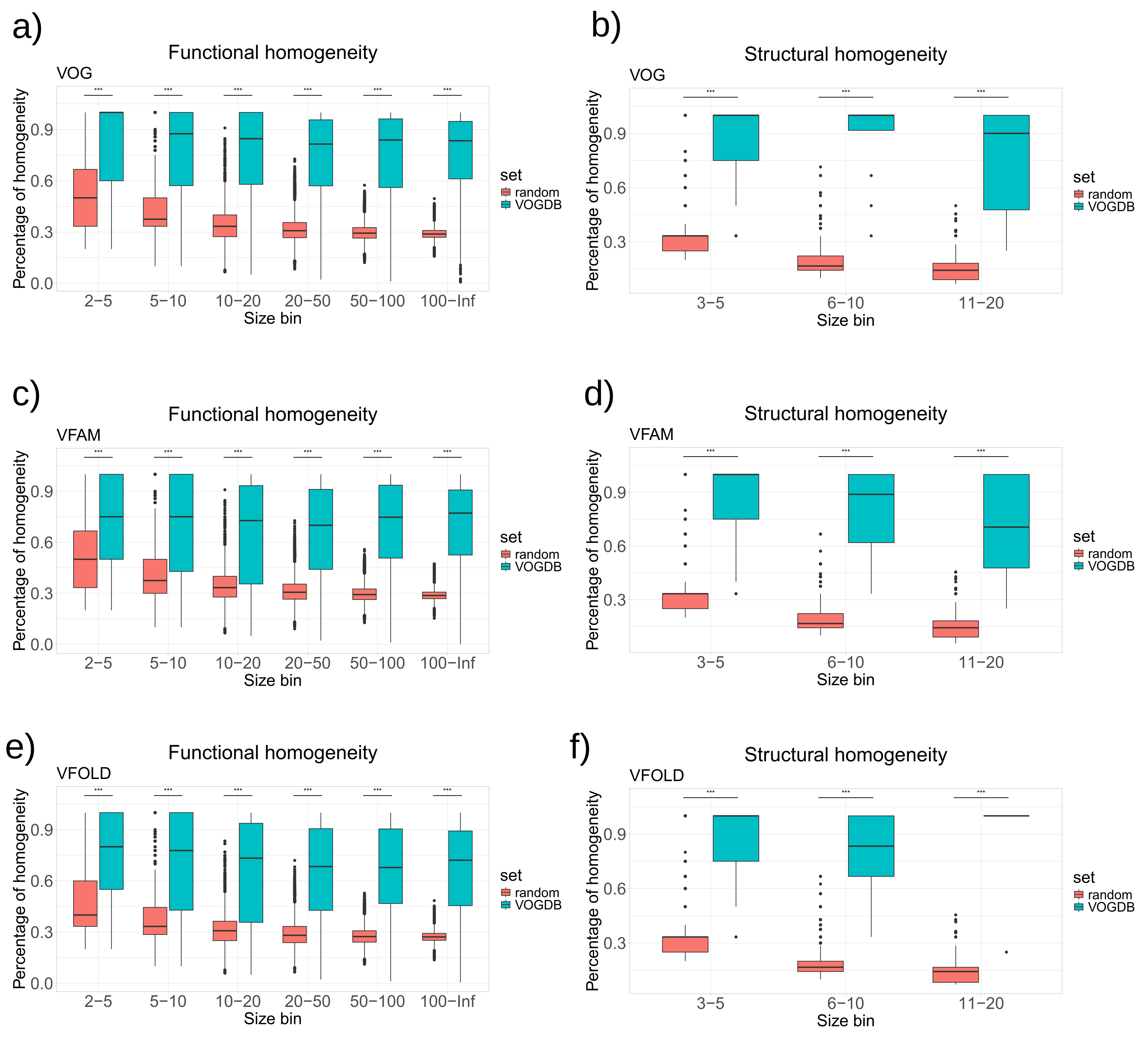
Figure 4.
Homogeneity of SwissProt keywords (a) and SCOPe superfamilies (b) for layers from VOGDB and the other databases with orthologous/homologous groups: pVOG (phage orthologous groups), PHROG (phage remote orthologous groups) and COG (prokaryotic orthologous groups). The databases are split into size bins according to the number of proteins with a functional or structural annotation. Bins containing less than 3 proteins are not shown. The results show that the function and structure based homogeneity of the layers from VOGDB are in the same range as in other similar databases.
Figure 4.
Homogeneity of SwissProt keywords (a) and SCOPe superfamilies (b) for layers from VOGDB and the other databases with orthologous/homologous groups: pVOG (phage orthologous groups), PHROG (phage remote orthologous groups) and COG (prokaryotic orthologous groups). The databases are split into size bins according to the number of proteins with a functional or structural annotation. Bins containing less than 3 proteins are not shown. The results show that the function and structure based homogeneity of the layers from VOGDB are in the same range as in other similar databases.
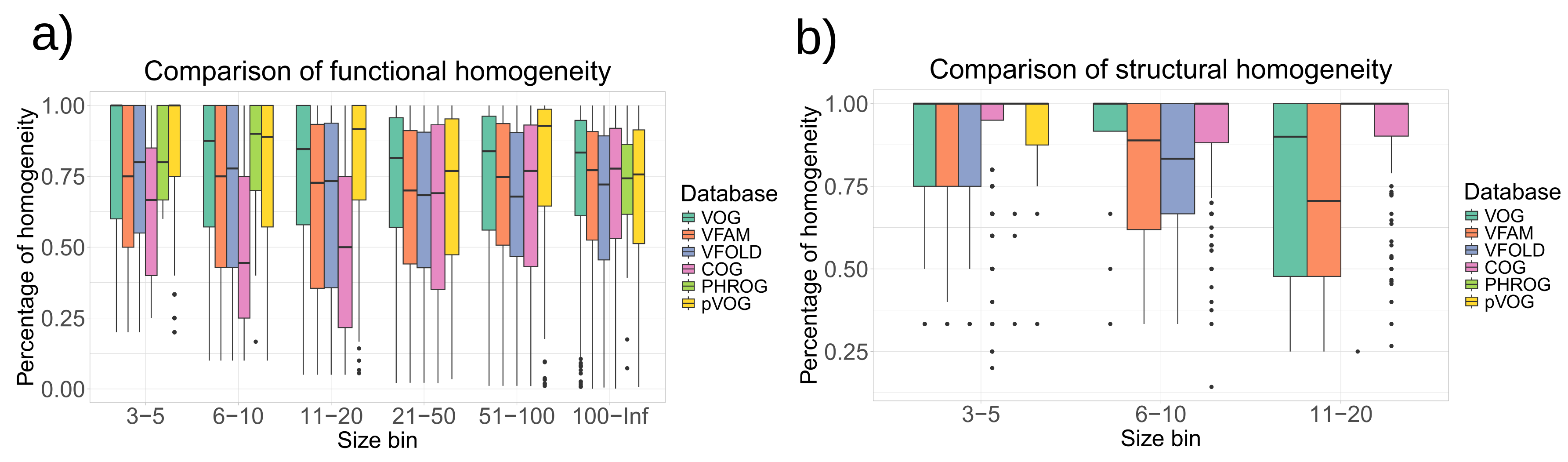
Figure 5.
Taxonomic classification of a viral contig with 6 identified genes retrieved from a phage cocktail metagenome [39] (ERS1989570). If genes from a viral contig can be mapped to VFAMs, we can use the LCA of the VFAMs to deduce the possible taxonomic classification of a contig. The lowest level that could be reach is the lowest level of all LCAs that don’t contradict each other. In this example, the lowest taxonomic level that could be reached is the genus Pbunavirus since other genes are mapped to VFAMs that have LCA compatible with the genus Pbunavirus.
Figure 5.
Taxonomic classification of a viral contig with 6 identified genes retrieved from a phage cocktail metagenome [39] (ERS1989570). If genes from a viral contig can be mapped to VFAMs, we can use the LCA of the VFAMs to deduce the possible taxonomic classification of a contig. The lowest level that could be reach is the lowest level of all LCAs that don’t contradict each other. In this example, the lowest taxonomic level that could be reached is the genus Pbunavirus since other genes are mapped to VFAMs that have LCA compatible with the genus Pbunavirus.
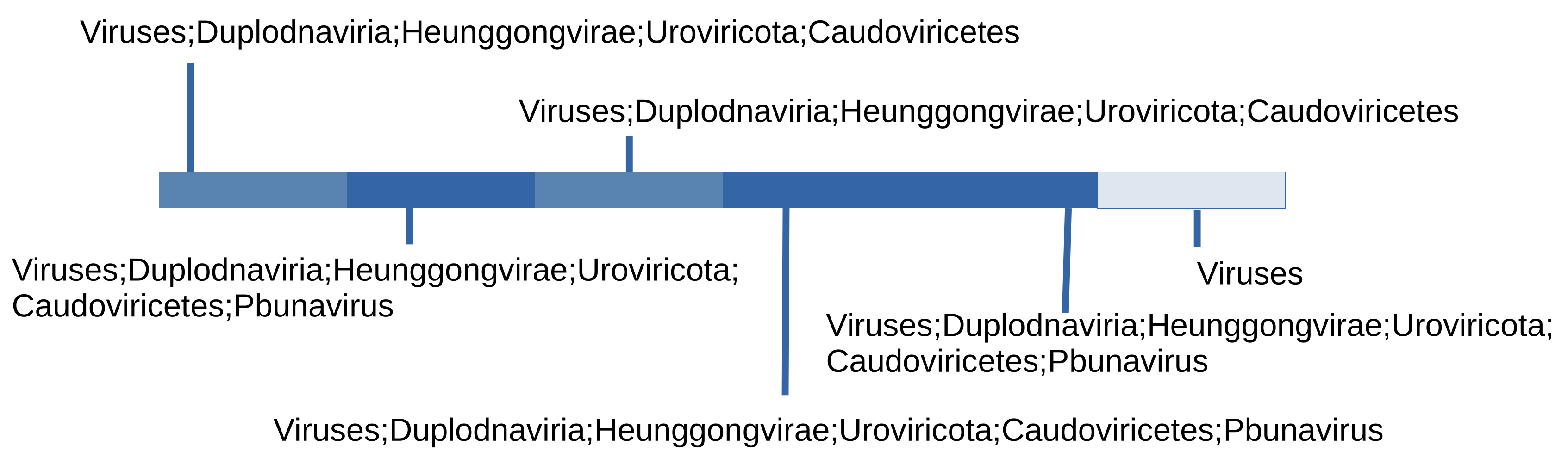

Table 1.
Virus specificity of vFAMs. Virus specific vFAMs are useful for identifying the viral hallmark genes, the genes definitive for the viral state and with only a very remote homology to cellular genes. In VOGDB, viral specificity is defined with three stringency levels. Strict, medium and low with hits to maximally two, three or four cellular genomes with e-value up to , and .
Table 1.
Virus specificity of vFAMs. Virus specific vFAMs are useful for identifying the viral hallmark genes, the genes definitive for the viral state and with only a very remote homology to cellular genes. In VOGDB, viral specificity is defined with three stringency levels. Strict, medium and low with hits to maximally two, three or four cellular genomes with e-value up to , and .
| Layer | Strict | Medium | Low |
|---|---|---|---|
| vOG | 38562 | 45613 | 48627 |
| vFAM | 28500 | 32546 | 33951 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



