Submitted:
19 August 2024
Posted:
21 August 2024
You are already at the latest version
Abstract
This research article provides an unconditional proof of an inequality proposed by \textit{Srinivasa Ramanujan} involving the Prime Counting Function $\pi(x)$, \begin{align*} (\pi(x))^{2}<\frac{ex}{\log x}\pi\left(\frac{x}{e}\right) \end{align*} for every real $x\geq \exp(547)$, using specific order estimates of the \textit{Mertens Function}, $M(x)$. The proof primarily hinges upon investigating the underlying relation between $M(x)$ and the \textit{Second Chebyshev Function}, $\psi(x)$, in addition to applying the meromorphic properties of the \textit{Riemann Zeta Function}, $\zeta(s)$ with an intention of deriving an improved approximation for $\pi(x)$.
Keywords:
Riemann Zeta Function
; Mertens Function
; Chebyshev Function
; arithmetic function
; error estimates
; Perron’s Formula
; M¨obius Inversion Formula
; Dirichlet Partial Summation Formula
MSC: [2020] Primary 11A41; 11A25; 11N05; 11N37; 11N56; Secondary 11M06; 11M26
1. Introduction and Motivation
The motivation for investigating the distribution of prime numbers over the real line first reflected in the writings of famous mathematician Ramanujan, as evident from his letters [20] [pp. xxiii-xxx , 349-353] to one of the most prominent mathematicians of 20th century, G. H. Hardy during the months of Jan/Feb of 1913, which are testaments to several strong assertions about prime numbers, especaially the Prime Counting Function, [cf. Definition (3)].
In the following years, Hardy himself analyzed some of thoose results [21,22] [, pp. 234-238] and even wholeheartedly acknowledged them in many of his publications, one such notable result is the Prime Number Theorem [cf. Theorem 2].
Ramanujan provided several inequalities regarding the behaviour and the asymptotic nature of . One of such relation can be found in the notebooks written by Ramanujan himself has the following claim.
Theorem 1.
(Ramanujan’s Inequality [1]) For x sufficiently large, we shall have,
Worth mentioning that, Ramanujan indeed provided a simple, yet unique solution in support of his claim. Furthermore, it has been well established that, the result is not true for every positive real x. Thus, the most intriguing question that the statement of Theorem 1 poses is, is there any such that, Ramanujan’s Inequality will be unconditionally true for every ?
A brilliant effort put up by F. S. Wheeler, J. Keiper, and W. Galway in search for such using tools such as MATHEMATICA went in vain, although independently Galway successfully computed the largest prime counterexample below at . However, Hassani [19] [Theorem 1.2] proposed a more inspiring answer to the question in a way that, ∃ such with (1) being satisfied for every , but one has to neccesarily assume the Riemann Hypothesis. In a recent paper by A. W. Dudek and D. J. Platt [2] [Theorem 1.2], it has been established that, ramanujan’s Inequality holds true unconditionally for every . Although this can be considered as an exceptional achievement in this area, efforts of further improvements to this bound are already underway. For instance, Mossinghoff and Trudgian[24] made significant progress in this endeavour, when they established a better estimate as, . One recent even better result by Axler [23] suggests that, the lower bound for x, namely can in fact be further improved upto using similar techniques as described in [2], although modifying the error term accordingly.
This article shall provide in detail, a new proof of Ramanujan’s Inequality, using a completely different technique by introducing the notion of Mertens Function [11,12]. We shall utilize one of the most significant order properties of [13], namely, in order to find an improved estimate for [cf. Section 3.3]. Thus in turn, we shall verify the inequality in the final part of the article [cf. Section 4]. As an application to this method, we shall be able to refine the lower bound for x even further in order for Theorem 1 to hold true without any further assumptions.
2. Arithmetic Functions
As for definition, Arithmetic Functions are in fact complex-valued functions on the set of Natural Numbers .
For the convenience of the readers, let us first introduce some notations, under standard assumption that, .
Definition 1.
We say is asymptotic to , and denote it by, if, .
Definition 2.
(Big O Notation) Given , the notation, implies that, the quotient, is bounded for all ; i.e., ∃ a constant such that,
In this section, we shall discuss about a few specific important such type of arithmetic functions pertaining to the context of the paper and the proof of the original result.
2.1. Prime Counting Function
Definition 3.
For each ,we define,
The most important contribution of is undoubtedly to the Prime Number Theorem [8,16], which can be stated as follows.
Theorem 2.
For every real , the following estimate is valid.
Equivalently,
.
For an elementary proof of above, readers can refer to [17].
2.2. Chebyshev Function
Chebyshev ψ Function [7] has the following definition.
Definition 4.
For each , we define,
Where ,
is said to be the "Mangoldt Function" .
An important observation is,
In fact, one can use the function in order tosimplify the statement of the Prime Number Theorem (2). In other words, one can deduce that, proving the theorem is equivalent to proving the following statement [6],
2.3. Mbius Function
We start with the formal definition.
Definition 5.
(Mbius Function) is defined as follows:
One can in fact use definition (5) to deduce the following property regarding the Mbius Function.
Proposition 1.
[15] [Theorem 2.1 , pp. 25]
2.4. Mertens Function
Definition 6.
The Mertens Function [13] has the representation,
Remark 1.
In general, there’s a notion of the Extended Mertens Function,
This is also known as the Mertens Hypothesis. [ Interested readers can refer to [3, Theorem 14.28, pp. 374]
The primary objective for Mertens behind introducing the function (As defined in (1)) was its underlying relation to the location of the zeros of the Riemann Zeta Function , the reason being largely due to it’s consequences for the distribution of the primes, also hailed as one of the most important unsolved problems in Analytic Number Theory. We shall be working with a particular order estimate of in later sections of the text, although readers are encouraged to consult [9,10,13,14] for further details.
2.5. Some Necessary Derivations
Proposition 2.
The Dirichlet Series Representation[3, Theorem 3.13 , pp. 62] for is given by:
denoting the Riemann Zeta Function.
Proposition 3.
The following order estimates hold true:
- 1.
- 2.
- 3.
Proof.
-
Near , we have the expansion for :Where, denotes the Euler Constant. Thus,Using Perron’s Formula, we have:where and T is a parameter to be chosen later.We evaluate the integral using the following steps.Step 1: Integral aroundConsider a small semicircle (say) of radius around having the following parametrization, , .In this region,and,Thus, the integrand becomes:Therefore,Again, the integral of over a symmetric interval around zero is zero. Therefore, the integral around the small semicircle contributes a negligible amount of .Step 2: Integral along the vertical lineFor the part of the integral along the vertical line, say, L: , , where , i.e.,It can indeed be verified that, is bounded on L as, does not have any pole for . Specifically, for with , is bounded away from zero, so is bounded.An appropriate choice of gives us a bound on the integral:Since is bounded by some constant K and . Subsequently,Since , , and for large x, this term is small.Step 3: Error term from the integralThe total error term combining both parts is:It can be observed that, the residue term around contributes to x, and the error terms contribute to .Choosing small enough (such as ),Thus, combining all terms and dividing by x to normalize, we obtain.
-
As for the proof, we can use Perron’s formula for any arithmetic function ,where and T be a suitably chosen parameter.Consider the Dirichlet series involving :Applying this to (12):We thus study the following integral,using following steps.Step 1: Integral aroundConsider a small semicircle (say) of radius around having the following parametrization, , , and a priori from the fact that, near ,and,Thus, on , we have,Hence, the integrand becomes,(Expanding and simplifying, the leading term integrates to zero due to symmetry of the integrand around zero ).Step 2: Integral along the vertical lineFor the part of the integral along the vertical line, say, L: , , where , i.e.,It can be checked that, is bounded on L. Specifically, for with , both and are bounded, so is bounded by some constant K. Hence,Choosing ,Since , , and for large x, this term is small.Step 3: Error term from the integralThe total error term combining both parts is:Important to note that the residue term around contributes negligibly as , and the error terms contribute upto . (This can be achieved by considering small enough (such as ). Therefore, we conclude that,
-
A priori from the definition of and applying Perron’s Formula for yields,As for computing the integral in (13) over the vertical line L: , , where , our aim is to try shifting the contour of integration to a vertical line closer to the critical strip. For our convenience, we choose where, . Using the fact that has no zeros for , we intend on obtaining a suitable bound for in this region.Observe that for , is bounded away from zero, implying is also bounded. Specifically, for ,for some constant A. On the other hand,Subsequently, the error term from the vertical line integral can be estimated as, , for any small .Hence, we need to choose T appropriately to control the error term in Perron’s formula. Using the Cauchy Residue Theorem [18] [Chapt. 5.1 , pp. 120] and estimating the integral, we set and consider the main term and error terms:This ensures that the main contribution comes from the vertical integral and the error terms are bounded appropriately. Accordingly,By choosing sufficiently small, we can make the bound as close to as desired.
□
3. Order Estimates involving
In this section, we shall rely upon the definitions of Chebyshev ψ-Function, in order to come up with a suitable estimate for in terms of the Mertens Function, .
3.1. Relation between and
Theorem 3.
The following holds true for the Chebyshev ψ function, :
Proof.
A priori from the definition of involving the Von Mangoldt Function, , we apply the Mbius Inversion Formula [15] [Section 14.1, pp. 30] on to obtain,
(N.B. Here, we set , so that the inner sum is over k with .)
We approximate the sum of by integrating the logarithm function from 1 to , and then applying Integration by Parts.
Subsequently, from (9) we get,
A priori using the results obtained in proposition (3),
Furthermore,
Combining (17) and (18) yields,
Since asymptotically, hence we conclude that,
And the proof is thus complete. □
3.2. An important approximation for
A tricky application of the Prime Number Theorem (2) yields the following estimate,
or some constant . However, it is indeed possible to obtain a simpler, and more effective bound for the Chebyshev ψ-Function.
Lemma 1.
We have,
Proof.
This proof thouroughly utilizes results from Analytic Number Theory, specifically the properties of the Chebyshev function and the distribution of primes. We shall also leverage results from the analytic properties of the Riemann zeta function .
Important to note that, the proof relies on properties of the Riemann zeta function and its non-trivial zeros. However, we do not assume the Riemann Hypothesis (RH) here explicitly.
The explicit formula for involves the zeros of :
where the sum is over the non-trivial zeros of , and the term arises due to the existence of pole at .
Suppose, be a non-trivial zero of . The zeros are symmetric about the real axis, so we consider only the upper half-plane. For each zero of , the term contributes to . To estimate the error term, consider the sum over the non-trivial zeros ,
In addition to above, we use the fact that the non-trivial zeros have, . The contribution of each such can be bounded by,
Now, the number of zeros with is . We choose to cover the relevant range of zeros.
Combining these estimates, we obtain,
Including the logarithmic term from the pole at , the error term in becomes,
Since we know that the error term actually involves due to the density of the zeros of and more refined approximations, thus, we can further improve our estimate to,
as desired. □
As the title of this section suggests, we shall now proceed towards understanding how we can approximate using properties of .
Theorem 4.
The following holds for the Prime counting function, :
Proof.
Before we delve into the proof, notice that is zero except when n is a power of a prime, specifically . We can hence rewrite as,
The error term in (23) comes from the higher powers of primes,
Which is then dominated by the term corresponding to . In other words,
Combining the main term and the error terms in (23),
On the contrary, an application of the Prime Number Theorem allows us to have the following approximation,
Given our earlier discussion, the error term, can be bounded by,
To isolate from (25), we divide both sides by ,
Substituting the error term bound:
A priori using the fact that, asymptotically, and combining the error terms, and applying Theorem 2 again enables us to assert that,
□
3.3. An Improved Estimate for
First, let us recall that, (14) in Theorem 3 gives us an order estimate for in terms of , whereas, we have derived a unique representation of applying properties of , and analytic properties of , as mentioned in (22) in Theorem 4.
We substitute (14) into (22) to obtain,
Combining the error terms,
Note that, asymptotically. Thus, the dominant error term is . As a consequence, we have the following improved estimate for as follows.
Theorem 5.
4. Proving Ramanujan’s Inequality
In order to prove Ramanujan’s Inequality, our primary intention will be to investigate the sign of the function,
for large values of x using the relationship between and the Mertens function . Given the complexity of the order relations an the extent of robust computations involving these functions as discussed in the previous section, we’ll have to analyze the expressions and error terms cautiously.
4.1. An order expression for
4.2. Asymptotic Behavior of indivudual Terms
A priori using (cf. Prop. (3)) involving the Mertens function ,
So, we can further approximate each term of (31) as follows,
As a consequence,
For sufficiently large values of x. Therefore, we conclude that, , for large values of x, and this concludes our proof of the inequality.
Later, we shall try to establish a better range of the values of x for which Ramanujan’s Inequality does hold true.
5. A modified Bound for
The derivations which we’ve made in the previous sections yielded several order estimates involving , and especially . In this section, we shall discuss how this method enables us to find more optimal bounds for .
5.1. Upper Bound for
A priori from Lemma (1), we have that for some positive constant ,
Substituting this into the the estimate (22) of Theorem 4 involving ,
5.2. Lower Bound for
A priori using (32) we can derive,
Therefore, applying the above derivation to (27) in Theorem 5, we assert that,
for some positive constant .
Theorem 6.
The following bounds on is valid for sufficiently large values of x :
for positive constants .
Remark 2.
The result (37) in Theorem 6 provides an alternative justification to the validity of the famousPrime Number Theorem. This can be observed from the fact that, is bounded on both sides by a constant multiple of plus an error term, which can be minimized for large values of x.
6. An improved condition for Ramanujan’s Inequality
Adhering to Sterneck’s deduction [5], as mentioned in section of this text, we shall investigate the function for its sign for large values of x, with every intention of improving the claim made by Dudek and Platt [2, cf. Th. 2].
6.1. Monotonicity of the function
Our aim in this section is to establish the following claim.
Proposition 4.
The function as defined in (28) is monotone decreasing for .
Proof.
We intend on verifying that, for every large x and for every arbitraily chosen.
Observe from definition that the difference,
Now we evaluate,
Using the explicit forms (27):
Therefore,
For small , we use the linear approximation:
And,
Thus, we can compute further in (40) as follows,
Similarly,
As for the second term in (38),
Using the earlier approximations for and )
Hence, substituting (43) and (44) in (38) and simplifying,
We utilize Sterneck’s conjecture,
to bound the difference as follows,
Subsequently, enables us to conclude from (45) and (46),
Since for any and the error term is smaller, it implies,
Thus, is monotone decreasing for large x such that, .
□
Remark 3.
Note that, Sterneck’s Conjecture only establishes the fact that,
where, . But in this case, since, we’re dealing with , hence, we’ve modified the lower bound for x accordingly.
6.2. A better range for the values of x
Just to recall, Proposition 4 comments on the monotonicity of for x within a certain interval. Thus for every sufficiently large , we must have,
provided, , i.e., . Therefore, we have our following improved bound on x in order to satisfy (1).
Theorem 7.
The Ramanujan’s Inequality (1) is unconditionally true for every .
6.3. Numerical Estimates for
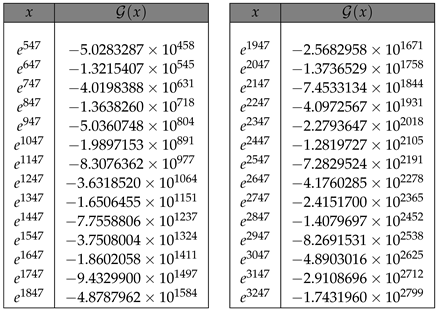
A priori from Proposition 4, we have formally established that, the function as defined in (28) is in fact monotone decreasing for large values of x. Applying MATHEMATICA 1, we can indeed provide ample numerical evidence in support of our claim proposed in Theorem 7.
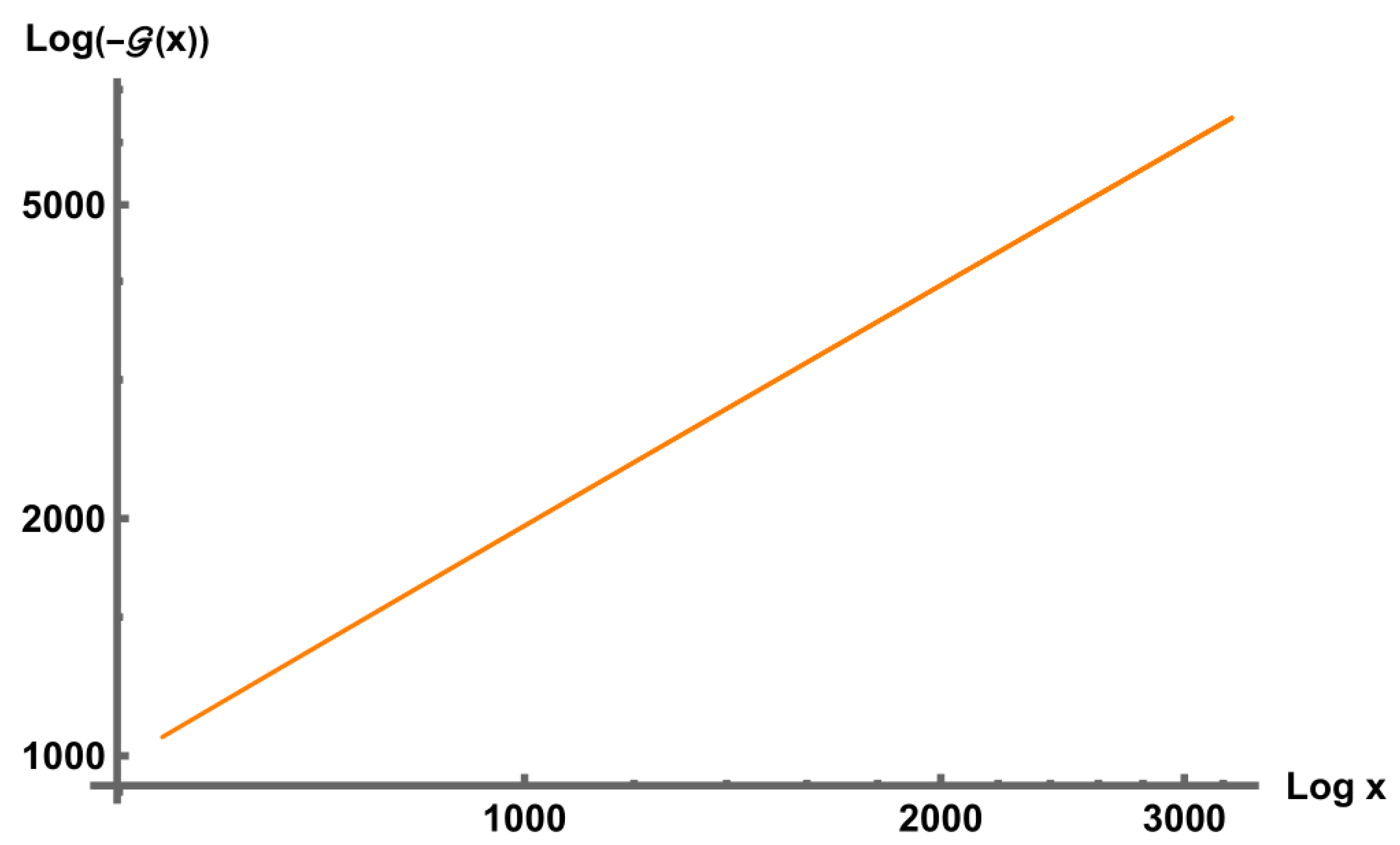
In fact, using Table 1 and Figure 1 we can observe and study the decrement in the values of for increasing values of x in scaled appropriately. Another important comment to make is that, (1) in Theorem 1 has been well established [23] for every . Hence, it only suffices to check the sign changes for in the above chosen interval. Furthermore, we can assert from the data given in the Table (Table 1) that,
which along with Proposition 4, establishes our result in Theorem 7.
Figure 1.
Plot of with respect to

7. Future Research Prospects
In summary, we’ve utilized specific order estimates for the Prime Counting Function , the Second Chebyshev Function and the Mertens Function in order to conjure up an improved bound for the famous Ramanujan’s Inequality. Although, one can derive other approximations for in order to improve this result even further. It’ll surely be interesting to observe whether it’s at all feasible to apply any other techniques for this purpose.
On the other hand, one can surely work on some modifications of Ramanujan’s Inequality For instance, Hassani studied (1) extensively for different cases [19], and eventually claimed that, the inequality does in fact reverses if one can replace e by some satifying, , although it retains the same sign for every .
In addition to above, it is very much possible to come up with certain generalizations of Theorem 1. In this context, we can study Hassani’s stellar effort in this area where, he apparently increased the power of from 2 upto and provided us with this wonderful inequality stating that for sufficiently large values of x [25],
Finally, and most importantly, we can choose to broaden our horizon, and proceed towards studying the prime counting function in much more detail in order to establish other results analogous to Theorem 1, or even study some specific polynomial functions in and also their powers if possible. One such example which can be found in [26] eventually proves that, for sufficiently large values of x,
Whereas, significantly the inequality reverses for the specific case when, (Cubic Polynomial Inequality) (cf. Theorem [26]).
Hopefully, further research in this context might lead the future researchers to resolve some of the unsolved mysteries involving prime numbers, or even solve some of the unsolved problems surrounding the iconic field of Number Theory.
Data Availability Statement
I as the sole author of this article confirm that the data supporting the findings of this study are available within the article.
Acknowledgments
I’ll always be grateful to Adrian W. Dudek (Adjunct Associate Professor, Department of Mathematics and Physics, University of Queensland, Australia) for inspiring me to work on this problem and pursue research in this topic. His leading publications in this area helped me immensely in detailed understanding of the essential concepts. Furthermore, I’ll always be grateful to Tadej Kotnik (Faculty of Electrical Engineering, University of Ljubljana, Slovenia) for helping me understand a lot of concepts and new derivations related to Mertens Functions. His immense help and support was hugely beneficial for me in writing this article.
Conflicts of Interest
I as the author of this article declare no conflicts of interest.
References
- Ramanujan Aiyangar, Srinivasa, Berndt, Bruce C, Ramanujan’s Notebooks: Part IV; Springer-Verlag: New York, NY, USA, 1994.
- Dudek, Adrian W. , Platt, David J., On Solving a Curious Inequality of Ramanujan. Experimental Mathematics 2015, 24, 289–294. [Google Scholar] [CrossRef]
- Titchmarsh, E. C. , The Theory of the Riemann Zeta-function, Oxford University Press, 1951. Second edition revised by D. R. Heath-Brown, published by Oxford University Press, 1986.
- Mertens, F. , U¨ber eine zahlentheoretische Funktion, Sitzungsber. Akad. Wiss. Wien 1897, 106, 761–830. [Google Scholar]
- Von Sterneck, R. D. , Die zahlentheoretische Funktion σ(n) bis zur Grenze 5000000, Sitzungsber. Akad. Wiss. Wien 1912, 121, 1083–1096. [Google Scholar]
- De, Subham, On the Order Estimates for Specific Functions of ζ(s) and its Contribution towards the Analytic Proof of The Prime Number Theorem. arXiv 2023, arXiv:2308.16303. [CrossRef]
- Schoenfeld, L. , Sharper bounds for the Chebyshev Functions θ(x) and ψ(x). II, Mathematics of Computation 2020, 30, 337–360. [Google Scholar] [CrossRef]
- Ingham, A. E. , The distribution of prime numbers, Cambridge University Press, 1932. Reprinted by Stechert-Hafner, 1964, and (with a foreword by R. C. Vaughan) by Cambridge University Press, 1990.
- MacLeod, R. A. , A new estimate for the sum M(x)=∑n≤xμ(n), Acta Arith. 1967, 13, 49–59; Erratum, ibid. 1969, 16, 99–100. 13.
- Diamond, H. G. , McCurley, K. S., Constructive elementary estimates for M(x), In M. I. Knopp, editor, Analytic Number Theory, Lecture Notes in Mathematics 899, pp. 239-253, Springer, 1982.
- Costa Pereira, N. , Elementary estimate for the Chebyshev function ψ(x) and the M¨obius function M(x), Acta Arith. 1989, 52, 307–337. Acta Arith.
- Dress, F. , El Marraki, M. , Fonction sommatoire de la fonction de Mobius. 2, Majorations asymptotiques elementaires, Exp. Math. 1993, 2, 99–112. [Google Scholar]
- De, Subham, "On Some Specific Order Estimates for the Mertens Function and Its Relation to the Non-trivial Zeros of ζ(s)", Preprints 2023, 2023090723. [CrossRef]
- Kotnik, T. , van de Lune, J. , On the order of the Mertens function, experimental mathematics 2004, 13, 473–481. [Google Scholar]
- Apostol, T. M. , Introduction to Analytic Number Theory, Springer: 1976.
- Jameson, G.J.O. , The Prime Number Theorem, Cambridge; New York: Cambridge University Press, London Mathematical Society student texts, Vol. 53, 2003. [Google Scholar]
- De, Subham, On the proof of the Prime Number Theorem using Order Estimates for the Chebyshev Theta Function, International Journal of Science and Research (IJSR), 2023, 12, 1677-1691. 12. [CrossRef]
- Ahlfors, L, Complex Analysis, McGraw-Hill Education, 3rd edition, Jan. 1, 1979.
- Hassani, Mehdi, “On an Inequality of Ramanujan Concerning the Prime Counting Function”, Ramanujan Journal 2012, 28, 435–442. 28.
- Ramanujan, S, “Collected Papers”, Chelsea, New York, 1962.
- Hardy, G. H. , A formula of Ramanujan in the theory of primes, 1. London Math. Soc. 1937, 12, 94–98. [Google Scholar]
- Hardy, G. H. , Collected Papers, vol. II, Clarendon Press, Oxford, 1967.
- Axler, Christian, On Ramanujan’s prime counting Inequality, arXiv. 2022; arXiv:2207.02486.
- Mossinghoff, M. J. , Trudgian, T. S. Nonnegative Trigonometric Polynomials and a Zero-Free Region for the Riemann Zeta-Function. arXiv, 2014; arXiv:1410.3926. [Google Scholar]
- Hassani, Mehdi, Generalizations of an inequality of Ramanujan concerning prime counting function. Appl. Math. E-Notes 2013, 13, 148–154.
- De, Subham, Inequalities involving Higher Degree Polynomial Functions in π(x), arXiv. 2024; arXiv:2407.18983. [CrossRef]
| 1 | Codes are available at: https://github.com/subhamde1/Paper-11.git
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



