
Submitted:
10 July 2024
Posted:
10 July 2024
You are already at the latest version
Abstract
Alzheimer's disease (AD) is a multifaceted neurodegenerative disorder characterized by cognitive decline and neuronal loss, representing a most challenging health issue. We present a computational analysis of transcriptomic data of AD tissues vs. healthy controls, focused on elucidation of functional roles played by long non-coding RNAs (lncRNAs) throughout the AD progression. We first assembled our own lncRNA transcripts from the raw RNA-Seq data generated from 527 samples of dorsolateral prefrontal cortex, resulting in the identification of 31,574 novel lncRNA genes. Based on co-expression analyses between mRNAs and lncRNAs, a co-expression network is constructed. Maximal subnetworks with dense connections are identified as functional clusters. Pathway enrichment analyses are conducted over mRNAs and lncRNAs in each cluster, which serve as the basis for the inference of functional roles played by lncRNAs involved in each of the key steps in an AD development model that we have previously build based on transcriptomic data of protein-encoding genes. Detailed information is presented about the functional roles by lncRNAs in activities related to stress response, reprogrammed metabolism, cell-polarity, and development. Our analyses have also revealed that lncRNAs have discerning power in distinguishing between AD samples of each stage and healthy controls. This study represents the first of its kind.
Keywords:
Alzheimer's disease
; long non-coding RNAs
; oxidative stress
; Fenton reaction
1. Introduction
Alzheimer’s disease (AD) is a complex disease with numerous pathological changes, such as altered homeostasis of extra- and intracellular pH [1,2], disrupted equilibrium of crucial intracellular ions such as and [3,4], chronic inflammation, heightened oxidative stress [5,6], elevated neurotoxicity, and extensive neuronal apoptosis [7,8]. While considerable attention has been devoted to unraveling the causes and consequences of amyloid-beta (Aβ) plaque development and Tau-based neurofibrillary tangle (NFT) formation in the past three decades, recent studies have raised doubts regarding their proposed central roles in the reduced cognitive capacities in AD patients [9]. Instead, a preponderance of evidence suggests extensive neuronal death in specific cerebral regions as the key determinant of the cognitive decline in the affected individuals [10]. Although great amounts of omics data and information amassed in the field of AD research, disentangling the intricate causal relationships among these pathological conditions and their relevance to the extensive neuronal loss remains a great challenge. Numerous hypotheses have been put forward regarding the drivers and key mechanisms of the development of AD, including oxidative stress in mitochondria [11], and dysregulated intracellular pH, which can impair the functions of acidic organelles like endosomes and lysosomes, thereby detrimental to the host neurons [12,13]. Additionally, the formation of Tau aggregates can precipitate cell death [14], while overexpression of the amyloid precursor protein (APP) may contribute to Aβ-associated neuronal death in advanced AD tissues [14].
Like in studies of other human diseases, vast majority of the published work on AD has been protein-centric [15] while the roles played by long non-coding RNAs (lncRNAs) have been largely un- or underexplored [13]. Limited knowledge about lncRNAs in the pathogenesis of AD includes those involved in amyloid formation [16], Tau protein hyperphosphorylation [17], and oxidative-stress response [18]. As a comparison, the functional roles played by lncRNAs under physiological conditions have been extensively studied in brain development, homeostasis, oxidative stress response, plasticity, and evolution [11,12,13]. It has been well established that 40% of the human lncRNA genes are expressed in the brain, hence there should be no surprise if lncRNAs play important roles in AD pathogenesis.
In this study, we have performed transcript-level assembly of all RNAs from raw RNA-seq data collected from the prefrontal cortex tissues of both healthy individuals and AD patients, which are publicly available [19]. The reason for doing our own assembly of transcripts is that the available transcripts of RNA-genes in AD tissues in the public domain are far from being adequate for meaningful analyses. Specifically, transcripts for only 11,300 lncRNA genes have been detected in AD tissues and made publicly available, which is clearly too low, knowing that overall, 228,048 transcripts for 48,479 lncRNA genes have been detected in healthy human tissues and publicly available. Our assembly resulted in 431,781 transcripts for 55,098 lncRNA genes, having considerably expanded the numbers of both the transcripts and the genes.
It has been well established that AD tissue cells have increased intracellular pH with a pH at roughly 7.037 and decreased extracellular pH at 6.85, compared to the normal ones at ~7.028 [20] and 6.9 [21,22]. We have conducted a computational analysis of the transcriptomic data of AD tissues vs. controls, coupled with computational chemistry analyses, to address two main questions: (1) what are the causes and consequences of AD cells intracellular alkalization? and (2) what are the causes and consequences of AD cells extracellular acidification? Our answers to these questions naturally give rise to a model for AD formation and development (manuscript under review), consisting of the following key steps and illustrated in Figure 1:
1) chronic inflammation (chemically, the levels of and are significantly increased) coupled with iron and/or copper accumulation leads to persistent Fenton reaction in mitochondria:
2) mitochondrial persistent Fenton reactions drive the pH up, leading to cell death if not neutralized; 3) multiple acidifying metabolic reprograms are induced to produce H+ to keep the pH stable, with the key ones being hydrolysis of glutamine to glutamate and N, catalyzed by GLS:
and hyperphosphorylation of the Tau proteins bound with microtubules, which produces one H+ per phosphorylation, resulting in acidic Tau fiber structure [23]; 4) persistently produced Glu are released into the extracellular space; 5) the over-produced and released glutamates drive the neighboring neurons hyperexcited, which gives rise to over-production and release of acidic synaptic vesicles, hence resulting in acidification of the extracellular space; 6) under physiological conditions, the H+ released by synaptic vesicles will be neutralized by bicarbonates released by nearby astrocytes while under the condition of increasing extracellular acidification, the release rate of bicarbonate by astrocytes could not keep up with the release rate of synaptic vesicles, forming one vicious cycle involving increased extracellular K+ level and further decreased extracellular pH; 7) as the disease evolves, the extracellular level of glutamate accumulation increases, as a result of a second vicious cycle involving decreased extracellular Na+ level, further decreased extracellular pH, and reduced ability to clear extracellular glutamates; 8) a key response to progressively increasing extracellular acidification, cells increase their release rate of , resulting in extracellular Fenton reaction:
which helps to slow down the extracellular acidification in two ways: the persistent production of and the formation of alkaline A plaques [24] as the result of interactions between and A monomers [25].
Our analyses have revealed that extracellular acidosis represents the leading cause for neuronal cell death in AD, followed by the formation of A plaques only in advanced stage AD while its plays a role in slowing down the extracellular acidosis in the early phase of the disease (manuscript under review).
Compared to this summary of our previous work, the current study focuses on the functional roles played by lncRNAs throughout the disease development of AD. To study the progression of AD, we have developed a pseudo-time course based on the AD tissue samples under study, arranged in the increasing order of the sum of the absolute values of the differential expressions of genes in a disease tissue vs. controls. Using this ordered list, we have made the following observations regarding lncRNA gene’s involvement in AD pathogenesis:
1. Expressed lncRNAs are primarily involved in the upregulated functions in AD tissues, ranging from immune activities, metabolisms to cell polarity and stress-responses, which seem to play driving roles of the disease progression, while only a few lncRNAs are involved in downregulated functions;
2. The most enriched pathways by lncRNAs expressed in AD tissues are relevant to oxidative stress;
3. LncRNA-mediated reprogrammed metabolisms are involved in alleviating intracellular alkaline stress and extracellular acidic stress; and
4. LncRNA as biomarkers have strong predictive power in distinguishing (early-stage) AD patients from healthy controls.
To the best of our knowledge, this is the first large-scale analysis of the functional roles played by lncRNAs throughout AD development.
2. Results
2.1. Identification and Characterization of Novel lncRNAs
We have assembled the transcriptome from raw RNA-seq data of 527 AD and control tissue samples, and then removed transcripts for protein genes (Data and Methods). This resulted in 55,098 predicted lncRNAs. The clinical information of these samples was summarized in Supplementary Table S1.
Of these lncRNAs, 31,574 are of high-quality and novel, namely not present in the GENCODE database [26], as summarized in Figure 2A and detailed in Data S1. 41.79% of these transcripts were in intergenic regions, 46.24% in the intronic regions, and 11.97% are antisense of protein-encoding genes (Figure 2B), suggesting their possible roles in transcription regulation of the relevant protein genes.
Previous studies have shown that lncRNAs in mammals are shorter in length and have fewer exons than protein-coding genes [27,28,29]. To examine whether the lncRNAs expressed in AD samples have the same characteristics, we have compared the structures of our assembled lncRNA transcripts (Figure 2C-E), using the two-sided Wilcoxon test [30]. We note that the lnRNAs tend to have considerably shorter average lengths than mRNAs, 1,521 bp vs. 1,842 bp with p-value < 2.22e-16 as shown in Figures 2C and S1. And they tend to reside in shorter open reading frames (ORFs) vs. protein genes, having averages 279 bp vs 759 bp with p-value < 2.22e-16 as shown in Figures 2D and S1; and each encoded by smaller numbers of exons, two vs. five with p-value < 2.22e-16 (Figures 2E and S1).
2.2. LncRNAs’ Roles in AD Formation and Development
To study how the phenotypic changes of the disease with the progression of AD, consider bin1, bin2, bin3, bin4 (Figure 3A). Construct a lncRNA-mRNA interaction network over samples in each bin (see METHODS), resulting in 45, 54, 47, and 35 clusters in the four bins, respectively. This is followed by a pathway enrichment analysis over samples in each bin, resulting in a total of 8,000 distinct pathways.
We grouped these pathways into six categories: development-related, immune activity, metabolism, neural function, cell polarity, and stress response. We note: (1) the number of downregulated pathways in each category remains generally stable across the four bins, namely throughout the progression of an AD; (2) the numbers of upregulated pathways in the categories of development-related, immune activity, metabolism, cell polarity, and stress response each increase with the disease progression, while those in neural function remain relatively stable (Figure 3B-C). Most of the developmental pathways consist of muscle, cell morphology, and a few others. Consequently, we hypothesize that lncRNAs are primarily involved in cell polarity, stress response, immunity, and metabolism in AD. In the following, we investigate how lncRNAs may involve these pathways throughout the AD progression.
Figure 4 summarizes the key components of our protein-centric model for AD development (manuscript under review). Here we study how lncRNAs contribute to the key components in this model along the disease progression from bin1 through bin4. We have quantified the contribution by each pathway to AD progression from bin1 to bin4, where the level of contribution is defined using the discerning score by each feature (see METHODS).
2.2.1. Contributions to key AD Phenotypes Via Cell-Polarity Changes
We note that cell-polarity related pathways are consistently making the highest levels of contribution to AD progression across all four bins (Figure 5A and S2, Table S2). The most contributing cell-polarity pathways are filament-bundle assembly, microtubule polymerization or depolymerization, metal ion transport, and transport of acidic organic compounds (Table S2).
In AD, filament bundle assembly refers to the formation of intracellular Tau fibril bundles and the formation of extracellular Aβ plaques [14]. The process of intracellular Tau fiber formation starts from the disassociation between the Tau proteins and microtubules that they bind, resulting in free Tau monomers in the intracellular space and then the formation of Tau aggregates.
We note that the number of lncRNAs involved in microtubule depolymerization via freeing up Tau proteins ranges 14, 5, 208, to 185 from bin1 through bin4, respectively (Figure 5B, Table S3). Examples include lncRNA ENST00000666526.1, which enhances the transcription of KIFC3, involved in microtubule transport and positioning [31], and STMN1 that promotes microtubule depolymerization [32]. Interestingly, lncRNAs are also involved in inhibiting microtubule depolymerization, with the number of such lncRNAs ranging from 18, 30, 278, to 3,387 across the four bins, respectively (Figure 5B, Table S3). One example is lncRNA MSTRG.54738.1 involved in suppressing the expressions of STMN1 and SPAST, where the latter is a microtubule-severing protein involved in regulating microtubule dynamics (Table S3) [33]. We postulate that the differences in the numbers of lncRNAs involved in promoting vs. those in inhibiting microtubule depolymerization reflect a shift in the homeostasis of cellular populations of microtubules.
We also note that the number of lncRNAs involved in Tau-fiber formation ranges from 17, 11, 170, to 182 from bin1 to bin4 while the number of those in inhibiting Tau-fiber formation ranges from 21, 137, 175, to 3,056, respectively (Figure 5C, Table S4). For example, lncRNA MSTRG.44295.1 exhibits the strongest promotion of BRSK2 transcripts across the four bins (Table S4). Interestingly, BRSK2 is also heavily suppressed by lncRNAs, with MSTRG.61027.1 showing the greatest inhibitory potency (Table S4). Again, these data suggest that there are opposing forces in promoting and inhibiting the formation of Tau fibers, which is consistent with published studies [34] and our own data (Figure 5C, S3). To further understand this, a pathway-enrichment analysis over mRNAs correlated with lncRNAs involved in Tau fiber formation, as well as with lncRNAs in inhibiting its formation. We note that (1) pathways correlated with Tau-fiber formation are predominantly involved in intracellular alkaline-stress response; and (2) pathways relevant to inhibiting Tau fibers are neuronal death (Table S4).
Similar observations are made about lncRNAs involvement in the development of Aβ plaques. Specifically, in the early-stage samples (bin1 and bin2), lncRNAs are mostly involved in promotion of Aβ plaque formation, while in the advanced stage samples (bin3, bin4), lncRNAs are heavily involved in inhibition of Aβ plaque formation (Figure 5D). Examples include: (1) lncRNAs in Table S5 are in involved in expressing CLU, a protein crucial for Aβ plaque formation; and (2) lncRNA MSTRG.19468.1 is involved in inhibiting Aβ plaque formation (Table S5). Our explanation is that the formation of Aβ plaques serves roles in slowing down the extracellular acidosis process, as the copper-mediated extracellular Fenton reactions produce OH- and the alkaline Aβ plaque structures as outlined in the Introduction while with the increase in both the density and sizes of Aβ plaques, they become increasingly toxic to the nearby neurons [24].
2.2.2. Contribution to Stress Generation
The most significant stressors throughout AD development are intracellular alkalization and extracellular acidification, both being the results of mitochondrial Fenton reactions (Figure 4 and manuscript under review). Our previous study [35] has revealed that AD involves at least two classes of Fenton reactions, one in mitochondria, either iron or copper mediated, which we consider as an initial driver of the formation of AD, and one in extracellular space, predominantly copper-mediated, which serves a positive role in slowing-down extracellular acidosis through the formation of Aβ plaques that become deadly as they continue to accumulate [36].
The basis for Fenton reactions is the over-production and accumulation of and by the local astrocytes. LncRNAs are involved in promotion of and production in bin1 and bin2 and in inhibition of their production in bin3 and bin4 (Figures 6A and S4). The key proteins involved in production are COX2, SOD2 and MFN2. LncRNA ENST00000560481.2 is a key promoter of the expressions of these proteins, while lncRNA ENST00000667795.1 is a key inhibitor (Table S6). Similarly, the key proteins involved in production are APP, GNAI2 and MAPT, with lncRNA ENST00000666526.1 being a key promoter (Table S6), while HVCN1, AGT, MAPT, CYBA and APP are involved in inhibiting the production of , with lncRNA MSTRG.16333.1 being a key inhibitor (Table S6).
Regarding the roles played by lncRNAs in mitochondrial iron and copper transport, we note: the numbers of lncRNAs involved in iron accumulation in mitochondria are 4, 7, 48, and 54, respectively, while those involved in inhibitory roles are 2, 0, 16, and 5, respectively (Figure 6B, Table S7). Key relevant lncRNAs include MSTRG.45979.1 promoting iron/copper accumulation and MSTRG.21672.6 for inhibiting such accumulation (Figure 6B, Table S7).
In addition, lncRNAs are also involved in promoting extracellular copper release, with their numbers ranging in 113, 29, 260, and 173 from bin1 throughout bin4, and the numbers of lncRNAs involved in copper release are 63, 354, 360, and 3,357 from bin1 to bin4, respectively (Figure S4, Table S8). Among these, MSTRG.24138.1 and MSTRG.16333.1 are examples, one for promoting and the other for inhibiting copper release (Figure S4, Table S8).
Synapse assembly, driven by neuronal firing triggered by extracellular glutamates, leads to the release of H+-rich synaptic vesicles, a key contributor to extracellular acidosis (see Introduction) (Figure S4, Table S9). LncRNAs such as MSTRG.43821.1 are predominantly involved in inhibiting synaptic assembly (Table S9).
2.2.3. Contribution to Stress-Response Via Metabolic Reprogramming
Numerous reprogrammed metabolisms are induced in AD tissue cells, responding to intracellular alkalization or extracellular acidification. One class of reprogrammed metabolisms, in which lncRNAs are heavily involved are lipid metabolism, particularly cholesterol metabolism (see Table S2). Specifically, the numbers of lncRNAs involved in promoting cholesterol synthesis are 10, 10, 210, and 246 from bin1 through bin4, respectively, while the numbers of lncRNAs involved in inhibitory roles of cholesterol biosynthesis and metabolism are 14, 60, 245, and 3,644 from bin1 through bin4, respectively (Figure S4, Table S10). This is not surprising knowing that cholesterols have both pro- and anti-inflammatory functions [37].
Knowing that AD cells are stressed with persistent intracellular alkalinity, we have analyzed all the 1,258 enzymes, each catalyzing H+-producing reactions [38]. A principal component analysis is conducted over these enzymes across all the AD samples under study. Remarkably, the first principal component, or PC1, across samples in bin4 can explain 0.978 of the variance ratios of the gene expressions of these enzymes (Figure S5), strongly suggesting their consistent roles in alleviating intracellular alkaline stress. LncRNAs are involved in promoting H+-generating enzymes from bin1 through bin4, acount for 32, 15, 188, 95 in numbers, respectively, while the numbers of lncRNAs involved in inhibiting these enzymes are 5, 17, 205, to 33 from bin1 through bin4 (Figure 6C, Table S11). Among the top 5% of H+-producing enzymes contributing to PC1 in each bin, kinases dominate (Table S12). GLS is among these enzymes consistently involved in mitigating the alkalizing stress due to mitochondrial Fenton reactions throughout all bins. Our study found that 50% of the lncRNAs that promote the production of H+ enzymes are involved in promoting GLS-related transcripts, such as ENST00000479552.1 (Table S12).
In addition, the number of lncRNAs involved in promoting transporters that acidify the intracellular space (Figure 6D) ranges from 3, 28, 182 to 3,308 from bin1 to bin4, while the number of lncRNAs involved in inhibiting such transporters ranges from 8, 2, 91 to 136 (Table S13), suggesting that how the balance is shifted towards producing more acidic molecules.
Table 1 lists the numbers of lncRNAs with high discerning scores involved in immune activity, metabolic reprogramming, cell polarity, and stress response pathways from bin1 through bin4.
2.3. LncRNA’s Discerning Power in Distinguishing AD Samples from Controls
The above analyses have revealed that lncRNAs are involved in the regulation of at least 22 pathways strongly associated with AD phenotypes, as shown in Figure 7A and Table 2. We aim to identify a subset of these lncRNAs that can well distinguish between normal and AD tissues (or tissues of a specific stage of AD), which could potentially be used as blood biomarkers for AD detection. It is noteworthy that compared to proteins, lncRNAs tend to have longer half-lives in blood circulation as they tend to be more resistant to degradation [39,40,41].
Among the lncRNA-containing pathways, lncRNAs involved in regulating Na+/K+-ATPase, suppressed by extracellular acidosis [42], exhibit the best performance in distinguishing normal from AD samples, with AUC = 0.7866 (Figure 7B, Table 2), which is significantly better than AUC = 0.655 achieved by CSF Aβ40/42 prediction [43]. In distinguishing normal from late-stage AD samples, the lncRNAs involved in regulating superoxide anion generation performs the best, with AUC=0.944 (Figure 7C, Table 2), considerably better than AUC = 0.853 achieved by plasma p-tau181 prediction [44].
Furthermore, in distinguishing normal from the earliest stage AD samples, lncRNAs involved in regulating extracellular copper achieved a performance level at AUC = 0.8783 (Figure 7D, Table 2). In distinguishing the earliest-stage from the late-stage AD samples, the lncRNAs involved in regulating astrocytes achieved AUC = 0.9718 (Figure 7E, Table 2). Detailed information on these lncRNAs can be found in Table S14.
3. Concluding Remarks
We have conducted a computational analysis of the functional roles played by lncRNAs throughout the development of an AD. As the first step of this analysis, we have conducted transcript-level assembly from the raw RNA-seq data, resulting in a total of 55,098 lncRNAs with 30,102 being novel ones.
The basis of our functional analyses of lncRNAs is the pathways enriched by mRNAs having known functional annotations, strongly co-expressed with the lncRNAs, coupled with the predicted functions as cis or trans regulators.
To elucidate how the functional roles played by lncRNAs change with the progression of the disease, we have defined a distance between the AD samples and the controls, which gives rise to the ordered list of AD samples from the early to the advanced stage. This provides an approximation to the disease progression. Our overall discovery can be summarized as follows:
1. Across all four bins representing different stages of AD progression, cell-polarity related pathways consistently contribute significantly. Notably, filament-bundle assembly, microtubule polymerization or depolymerization, metal ion transport, and transport of acidic organic compounds are among the most contributing pathways, for each of which lncRNAs are actively involved throughout AD progression.
2. Intracellular alkalization, extracellular acidification, and oxidative stress are major stressors and significantly contribute to AD progression. LncRNAs are involved in both the stress generation and stress responses, including iron and copper accumulation as well as the formation of Tau fibers and Aβ plaques.
3. Intracellular alkalization and extracellular acidification induce multiple acidifying metabolic reprogramming in AD cells for survival. LncRNAs are involved in activating majority of these reprogrammed metabolisms.
4. Figure 4 outlines the steps in our AD model, and lncRNAs are involved in most of these steps.
5. LncRNAs have strong discerning power in distinguishing AD samples from the controls, as well as in distinguishing AD samples of specific stage from the controls.
In summary, this study significantly expands our understanding of how lncRNAs participate in the progression of AD for the first time. The identification and characterization of novel lncRNAs provide valuable insights into their functional roles. Pseudo-time provided by AD samples arranged in a specific order offers highly useful information regarding how various phenotypes of AD change as the disease progresses. These findings may have significant implications for the development of diagnostic biomarkers and therapeutic targets for AD, paving the way for new avenues in research on lncRNA-based interventions for neurodegenerative diseases.
4. Materials and Methods
4.1. Data
Gene expression data: The raw reads of 529 samples were downloaded from ROSMAP cohort [45], consisting of transcriptomes of 146 MCI (mild cognitive impairment), 193 AD, and 189 region-matched control tissues. All libraries were prepared with the strand-specific RNA-seq paired-end protocol and each on average consisting of 4.28484 million reads. The detailed information about these samples is given in Supplementary Table S1.
Enzymes and reactions: The balanced equation of the chemical reaction catalyzed by each enzyme encoded in the human genome, along with the number of H+ produced or consumed, is retrieved from the HumanCyc database [46].
4.2. Methods
4.2.1. RNA-seq Processing and lncRNA Identification
High-quality clean reads were obtained by using the clipping adapters and low-quality reads identified by using SOAPnuke [47]. Each library was individually mapped to the GENCODE genome (version 34) using HISAT2 (version 2.7) [48] with the default parameters. The resulting alignment files were used as input for transcript assembly by using StingTie (version 2.1.1) [27] and the Homo sapiens reference annotation of GENCODE (release 34). All StringTie output files were merged into one unified transcriptome using the merge option of StringTie. Gffcompare [27] was employed to compare the resulting transcriptome (GTF format) with the reference annotation. For consistency in nomenclature, we adopt StringTie’s default “MSTRG” as the starting point when naming all assembled transcripts.
4.2.2. The Prediction Process Consists of Two Steps
Step 1: screening for protein-coding potentials. Transcript lengths and the number of exons were collected in the basic screening step. Here, transcripts having lengths > 200 nt and at least two exons were selected as lncRNA candidates [29]. The protein-coding potential of a transcript was predicted jointly using five methods: CPC (Coding Potential Calculator) [49], CNCI (Coding-Non-Coding Index) [50], CPAT (Coding Potential Assessment Tool) [51], PLEK [52], and CPPred [53].
Step 2: a candidate is predicted to be a lncRNA if all five methods predict it to be a lncRNA. If the transcript is newly expressed (not in GENCODE), it is assigned one of the following codes: i (transcript contained entirely in an intron), y (containing a reference within its introns), p (not inside but within 2 Kb of a known transcript), or u (in an intergenic region). All lncRNAs are then classified into three types: intergenic lncRNAs, antisense lncRNAs, and intronic lncRNAs.
4.2.3. Differential Analysis of All Assembled Transcripts
Differential expression analyses between the (MCI AD) samples and controls were conducted using the “DESeq2” function [54]. For read-count data, transcripts with |FC| ≥ 1.3 having a statistical significance p-value < 0.05 were considered differentially expressed transcripts (DETs), where FC is for fold change.
The TPM values of all genes from Ballgown [55] were used to assess correlations between a lncRNA and mRNAs using the Spearman correlation test, where correlation coefficients > 0 with p-values < 0.05 are used as the cutoffs for co-expressed transcript pairs.
4.2.4. Ordering Disease Samples by the Level of Deviation from Control Tissues
A differential expression analysis is conducted on each sample in (MCI AD) compared to the controls, yielding a differential intensity (V) value for each sample, defined as the sum of the absolute values of differential expressions over all DETs with p-value < 0.05. We aim to arrange the (MCI AD) samples in the increasing order of the V values as an approximation to the disease progression. However, the order so defined is not very stable for different values of parameters {FC, p-value}, giving rise to different orderings of the samples when different values for {FC, p-value} are used. Hence, we have conducted an analysis of the relationships between the different orderings of the disease samples and the quality of the approximation to the disease progression, using measures such as the increasing or decreasing trends of death rate, extracellular acidity, intracellular alkalinity, and a few others along the disease progression axis.
The result of the analysis indicates that the ordering that optimizes the following empirical function achieves the best approximation to the disease progression. Note that each set of values of {FC, p-value} gives rise to a distinct ordering of the samples and the associated {Vi} values, where FC is selected from the range (1.1, 4.0) and p-value from (0.0005, 0.05), using 0.1 and 0.0001 as the increments for the former and the latter, respectively:
Subject to 1. the first |MCI| samples in the current ordering contain at least % of MCI samples,
2. the last (|MCI| + |AD|/2) samples contain at least % of AD samples,
where |X| denotes the number of elements in set X, and is set to 55 based on our empirical analysis results.
The following provides a justification for why this list is useful for studies of the AD progression, along with its applications. We note that (1) the levels of both intracellular alkalinization and extracellular acidification progressively go up with this approximation as shown in Figure 2A; and (2) the same is observed about the levels of A formation, Tau-fibril formation, oxidative stress, and neuronal apoptosis as shown in Figure 2A, which are consistent with previous studies [1,2], thus supporting the validity of this approximation scheme to disease progression.
For a given list of samples ordered as above, we partition it to four equal-sized sub-lists: bin1, bin2, bin3, and bin4 (possibly except for the last one), representing four periods of the disease evolution (Figure 2A).
4.2.5. ssGSEA Gene-Set Scores for Individual Samples
For gene-set enrichment analysis (GSEA) over individual samples, we employed the “gsva()” function in R, utilizing the “ssgsea” method, tailored specifically for GSEA on individual samples [56], which builds on the empirical cumulative distribution function (ECDF) of gene expression ranks. First, gene expression data are ranked across samples. Then, for each specified gene set, the ECDF is computed based on the ranks of the genes within and outside the set. This comparison allows the method to determine the extent to which genes within the gene set are enriched by the highly ranked genes. Positive enrichment scores signify an overrepresentation of the gene set among highly ranked genes, while negative scores indicate being enriched by lowly ranked genes.
4.2.6. Co-Expression Analyses
The following is used to estimate the co-expression level between a gene g and a gene set M in terms of their expression levels. Let PC1 and PC2 be the first and second principal components of the expression levels of gene set M. A linear regression model was constructed as below:
where { are parameters to be determined through minimizing ||.
4.2.7. Predicting Target Genes or Pathways of Cis and Trans Regulation by lncRNA
A lncRNA can participate in the regulation of expressions of genes in its genomic neighborhood, referred to as cis-regulation, or genes distant from its genomic location, called trans-regulation [57,58]. Prediction of target genes regulated by a lncRNA via the cis mechanism relies on locational relationships. Genes within a range of 100 kb upstream or downstream of a lncRNA are considered as cis-regulated target genes by the lncRNA if they are co-expressed with the lncRNA [59,60]. Trans-regulated genes by a lncRNA are determined based on sequence complementarity between the lncRNA and each target gene and being co-expressed between the two. RIsearch [61] is used here to predict trans-regulated genes by a lncRNA, where the prediction criteria also include the level of the free energy in the formed secondary structure between lncRNA and mRNA sequences (energy < -10) [62].
We further define the regulatory relationship between a lncRNA and a pathways as: a lncRNA is considered as a regulator of a pathway if an optimal regression model of the lncRNA against the principal components (PCs) of the pathway across all the relevant samples yields a high R2 value and an F_test p_value < 0.05, and if the lncRNA is predicted to be a cis or trans regulator of any gene (or transcript) in the pathway, with a Spearman correlation coefficient |r| > 0 and a p-value < 0.05 and the lncRNA strongly correlated with the first PC of the pathway.
4.2.8. Construction of lncRNA-mRNA Interaction Network and Identification of Functional Modules
For a set of disease samples, we construct a lncRNA-mRNA interaction network, based on co-expressed lncRNA-mRNA pairs, using the method given [63], for all mRNAs of protein-coding genes. Specifically, for each pair of lncRNA and mRNA, we calculate the Pearson correlation coefficient (PCC) between the expression levels of the pair. All pairs with |PCC| > 0 constitute the interaction network, referred to as a bi-color network, following the definition in [64]. We have then applied the Markov clustering algorithm [65] to identify maximal subnetworks having dense intra-interactions of the network, referred to as clusters.
For all the identified clusters, we select those each consisting of at least 10% lncRNAs and at least three genes. Pathway enrichment is conducted over each set of gene clusters against three databases: KEGG [66], REACTOME [67], and GO Biological Process [56] using Clusterprofiler [68] and p-value < 0.05 as the threshold.
The enriched pathways are grouped into six categories: immune activities, metabolisms, stress-response, development-related, cell polarity, and neural functions. Here, we consider glial cells, such as astrocytes and microglia, as immune cells.
The idea in defining the mRNA-lncRNA interaction network and conducting the network-based clustering is to assign lncRNAs, particularly the novel ones, to pathways enriched by functionally well-annotated mRNAs, therefore giving some functional information to the lncRNAs.
4.2.9. The Discerning Power of lncRNAs in Distinguishing Control from AD Samples
Consider three sample sets: controls, bin1, and , for normal, early, advanced AD samples, and D = (controls ), respectively. Let their sizes be s1, s2 and s3. For the three sample sets, each of their element has a label 1, 2, or 3, if it belongs to the first, second or the third set, respectively. We aim to demonstrate that some lncRNA-containing pathways have the discerning power in separating the three sets.
For each pathway considered, we use its first principal component across all the samples to represent the pathway. Define ave (, i) as the average expression level of all genes in in sample . Sort all samples in D in the ascending order of ave (, i), and then partition the sorted list into three sub-lists , , with | = si, for i . Define the discerning score as
where refers to the label of d as defined above. Consider the density distribution of over all partitions of D. We consider a having discerning power if the p-value for its in is < 0.05.
Supplementary Materials
The following supporting information can be downloaded at: https://github.com/zhenyuh19/A-Model-for-the-Development-of-Alzheimer-s-Disease/tree/main, Figure S1: Summary of exon count and length for mRNA, old lncRNA, and new lncRNA; Figure S2: Evaluation of contribution of all four bin pathways to AD samples; Figure S3: Number of neuronal apoptosis pathways and neuron death promoted by lncRNA in the formation of Tau fibers; Figure S4: Statistics of lncRNA associated with pathologic hypotheses of AD; Figure S5: PCA contribution rate statistics of H+-producing enzyme genes in late-stage AD (Bin4); Table S1: Clinical information of ROSMAP prefrontal cortex samples; Table S2: The four bin pathways contributed to the six categories of pathway statistics in the top 20%; Table S3: Statistics of lncRNAs regulating microtubule depolymerization in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating microtubule depolymerization; Table S4: Statistics of lncRNAs regulating Tau fibrillization in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating Tau fibrillization; Table S5: Statistics of lncRNAs regulating amyloid formation in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating amyloid formation; Table S6: Statistics of lncRNAs regulating hydrogen peroxide in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating hydrogen peroxide and superoxide anion generation; Table S7: Statistics of lncRNAs regulating mitochondrial iron sulfur and copper transport in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating mitochondrial iron sulfur; Table S8: Statistics of lncRNAs regulating extracellular copper in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating mitochondrial iron sulfur; Table S9: Statistics of lncRNAs regulating synapse assembly in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating synapse assembly; Table S10: Statistics of lncRNAs regulating cholesterol in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating cholesterol; Table S11: Statistics of lncRNAs regulating H-producing enzyme in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating H-producing enzyme; Table S12: PCA analysis of H+-producing enzymes reveals the ranking of each gene’s contribution to PC1 explained variance ratio; Table S13: Statistics of lncRNAs regulating aciding loading transporter in cis and trans, along with mRNA enrichment results associated with lncRNAs regulating aciding loading transporter; Table S14: LncRNAs predicted as markers regulating each AD phenotype and cellular stress; Supplementary Data S1: New lncRNA Sequences and Genome Annotations.
Author Contributions
Conceptualization, Z.Y.H. and Y.X.; methodology, Z.Y.H. and Y.X.; software, Z.Y.H.; formal analysis, Z.Y.H.; investigation, Z.Y.H. and X.C.M.; data curation, Z.Y.H., Q.F.C., X.J.W and Z.A.; writing—original draft preparation, Z.Y.H.; writing—review and editing, Y.X.; visualization, Z.Y.H., Q.F.C., X.J.W; supervision, Y.X.; project administration, Y.X.; funding acquisition, Y.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number T2350010 and The APC was funded by the Key Laboratory of Metabolism and Health of Guangdong Ordinary Colleges and Universities, grant number 2022KSYS007.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting the reported results can be found at https://github.com/zhenyuh19/A-Model-for-the-Development-of-Alzheimer-s-Disease/tree/main.
Acknowledgments
The senior author thanks Southern University of Science and Technology for its start-up fund. We are grateful to the participants in the Religious Order Study, the Memory and Aging Project. Without their contributions, there will be not this project. Additionally, we extend our gratitude to Xiaojuan Wu for her assistance in data collection and result visualization.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Schwartz, L.; Peres, S.; Jolicoeur, M.; da Veiga Moreira, J. Cancer and Alzheimer’s disease: intracellular pH scales the metabolic disorders. Biogerontology 2020, 21, 683–694. [Google Scholar] [CrossRef] [PubMed]
- Xiong, Z.-G.; Pignataro, G.; Li, M.; Chang, S.-Y.; Simon, R.P. Acid-sensing ion channels (ASICs) as pharmacological targets for neurodegenerative diseases. Curr. Opin. Pharmacol. 2007, 8, 25–32. [Google Scholar] [CrossRef] [PubMed]
- Guan, P.-P.; Cao, L.-L.; Yang, Y.; Wang, P. Calcium Ions Aggravate Alzheimer’s Disease Through the Aberrant Activation of Neuronal Networks, Leading to Synaptic and Cognitive Deficits. Front. Mol. Neurosci. 2021, 14. [Google Scholar] [CrossRef] [PubMed]
- Vitvitsky, V.M.; Garg, S.K.; Keep, R.F.; Albin, R.L.; Banerjee, R. Na+ and K+ ion imbalances in Alzheimer's disease. Biochim. et Biophys. Acta (BBA) - Mol. Basis Dis. 2012, 1822, 1671–1681. [Google Scholar] [CrossRef] [PubMed]
- Verdile, G.; Keane, K.N.; Cruzat, V.F.; Medic, S.; Sabale, M.; Rowles, J.; Wijesekara, N.; Martins, R.N.; Fraser, P.E.; Newsholme, P. Inflammation and Oxidative Stress: The Molecular Connectivity between Insulin Resistance, Obesity, and Alzheimer’s Disease. Mediat. Inflamm. 2015, 2015, 1–17. [Google Scholar] [CrossRef] [PubMed]
- Zuo, L.; Prather, E.R.; Stetskiv, M.; Garrison, D.E.; Meade, J.R.; Peace, T.I.; Zhou, T. Inflammaging and oxidative stress in human diseases: From molecular mechanisms to novel treatments. Int. J. Mol. Sci. 2019, 20, 4472. [Google Scholar] [CrossRef] [PubMed]
- Dickson, D.W. Apoptotic mechanisms in Alzheimer neurofibrillary degeneration: cause or effect? J. Clin. Investig. 2004, 114, 23–27. [Google Scholar] [CrossRef] [PubMed]
- Chi, H.; Chang, H.-Y.; Sang, T.-K. Neuronal Cell Death Mechanisms in Major Neurodegenerative Diseases. Int. J. Mol. Sci. 2018, 19, 3082. [Google Scholar] [CrossRef]
- Haass, C.; Selkoe, D. If amyloid drives Alzheimer disease, why have anti-amyloid therapies not yet slowed cognitive decline? PLOS Biol. 2022, 20, e3001694. [Google Scholar] [CrossRef]
- Niikura, T.; Tajima, H.; Kita, Y. Neuronal Cell Death in Alzheimers Disease and a Neuroprotective Factor, Humanin. Curr. Neuropharmacol. 2006, 4, 139–147. [Google Scholar] [CrossRef]
- Wang, X.; Wang, W.; Li, L.; Perry, G.; Lee, H.-G.; Zhu, X. Oxidative stress and mitochondrial dysfunction in Alzheimer’s disease. Biochim. Biophys. (BBA)—Mol. Basis Dis. 2014, 1842, 1240–1247. [Google Scholar] [CrossRef] [PubMed]
- T. Pohlkamp et al., ‘Endosomal Acidification by NHE6-depletion Corrects ApoE4-mediated Synaptic Impairments and Reduces Amyloid Plaque Load’. bioRxiv, Mar. 23, 2021. [CrossRef]
- E. Im et al., ‘Lysosomal dysfunction in Down Syndrome and Alzheimer mouse models is caused by selective v-ATPase inhibition by Tyr682 phosphorylated APP βCTF’. bioRxiv, Jan. 26, 2023. [CrossRef]
- Serrano-Pozo, A.; Frosch, M.P.; Masliah, E.; Hyman, B.T. Neuropathological Alterations in Alzheimer Disease. Cold Spring Harb. Perspect. Med. 2011, 1, a006189–a006189. [Google Scholar] [CrossRef] [PubMed]
- Drummond, E.; Wisniewski, T. Alzheimer’s disease: experimental models and reality. Acta Neuropathol. 2016, 133, 155–175. [Google Scholar] [CrossRef] [PubMed]
- Olufunmilayo, E.O.; Holsinger, R.M.D. Roles of Non-Coding RNA in Alzheimer’s Disease Pathophysiology. Int. J. Mol. Sci. 2023, 24, 12498. [Google Scholar] [CrossRef] [PubMed]
- Lan, Z.; Chen, Y.; Jin, J.; Xu, Y.; Zhu, X. Long Non-coding RNA: Insight Into Mechanisms of Alzheimer's Disease. Front. Mol. Neurosci. 2022, 14, 821002. [Google Scholar] [CrossRef] [PubMed]
- Shan, X.; Tashiro, H.; Lin, C.-L.G. The Identification and Characterization of Oxidized RNAs in Alzheimer's Disease. J. Neurosci. 2003, 23, 4913–4921. [Google Scholar] [CrossRef] [PubMed]
- Bennett, D.A.; Buchman, A.S.; Boyle, P.A.; Barnes, L.L.; Wilson, R.S.; Schneider, J.A. Religious Orders Study and Rush Memory and Aging Project. J. Alzheimer's Dis. 2018, 64, S161–S189. [Google Scholar] [CrossRef] [PubMed]
- Rijpma, A.; van der Graaf, M.; Meulenbroek, O.; Rikkert, M.G.O.; Heerschap, A. Altered brain high-energy phosphate metabolism in mild Alzheimer's disease: A 3-dimensional 31P MR spectroscopic imaging study. NeuroImage: Clin. 2018, 18, 254–261. [Google Scholar] [CrossRef] [PubMed]
- Lyros, E.; Ragoschke-Schumm, A.; Kostopoulos, P.; Sehr, A.; Backens, M.; Kalampokini, S.; Decker, Y.; Lesmeister, M.; Liu, Y.; Reith, W.; et al. Normal brain aging and Alzheimer's disease are associated with lower cerebral pH: an in vivo histidine 1H-MR spectroscopy study. Neurobiol. Aging 2020, 87, 60–69. [Google Scholar] [CrossRef]
- Decker, Y.; Németh, E.; Schomburg, R.; Chemla, A.; Fülöp, L.; Menger, M.D.; Liu, Y.; Fassbender, K. Decreased pH in the aging brain and Alzheimer's disease. Neurobiol. Aging 2021, 101, 40–49. [Google Scholar] [CrossRef]
- Gong, C.-X.; Grundke-Iqbal, I.; Iqbal, K. Dephosphorylation of Alzheimer's disease abnormally phosphorylated tau by protein phosphatase-2A. Neuroscience 1994, 61, 765–772. [Google Scholar] [CrossRef] [PubMed]
- Ciudad, S.; Puig, E.; Botzanowski, T.; Meigooni, M.; Arango, A.S.; Do, J.; Mayzel, M.; Bayoumi, M.; Chaignepain, S.; Maglia, G.; et al. Aβ(1-42) tetramer and octamer structures reveal edge conductivity pores as a mechanism for membrane damage. Nat. Commun. 2020, 11, 1–14. [Google Scholar] [CrossRef]
- A. Farooqui, ‘Contribution of Dietary Carbohydrates in Induction of Oxidative Stress’, in Inflammation and Oxidative Stress in Neurological Disorders: Effect of Lifestyle, Genes, and Age, A. A. Farooqui, Ed., Cham: Springer International Publishing, 2014, pp. 237–261. [CrossRef]
- Harrow, J.; Frankish, A.; Gonzalez, J.M.; Tapanari, E.; Diekhans, M.; Kokocinski, F.; Aken, B.L.; Barrell, D.; Zadissa, A.; Searle, S.; et al. GENCODE: The reference human genome annotation for The ENCODE Project. Genome Res. 2012, 22, 1760–1774. [Google Scholar] [CrossRef] [PubMed]
- Shumate, A.; Wong, B.; Pertea, G.; Pertea, M. Improved transcriptome assembly using a hybrid of long and short reads with StringTie. PLOS Comput. Biol. 2022, 18, e1009730. [Google Scholar] [CrossRef] [PubMed]
- Tsai, C.-H.; Lin, T.-C.; Chang, Y.-H.; Tsai, H.-K.; Huang, J.-H. Identification and comparative analysis of long non-coding RNAs in the brain of fire ant queens in two different reproductive states. BMC Genom. 2022, 22, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Tang, H.; Li, C.; Huang, N.; Miao, J.; Chen, L.; Luo, K.; Li, F.; Liu, S.; Liao, S.; et al. Long non-coding RNA and circular RNA and coding RNA profiling of plasma exosomes of osteosarcoma by RNA seq. Sci. Data 2023, 10, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wilcoxon signed-rank test - Handbook of Biological Statistics’. Accessed: Mar. 13, 2024. [Online]. Available: https://www.biostathandbook.com/wilcoxonsignedrank.
- Ju, J.-Q.; Zhang, H.-L.; Wang, Y.; Hu, L.-L.; Sun, S.-C. Kinesin KIFC3 is essential for microtubule stability and cytokinesis in oocyte meiosis. Cell Commun. Signal. 2024, 22, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Ozon, S.; Guichet, A.; Gavet, O.; Roth, S.; Sobel, A. DrosophilaStathmin: A Microtubule-destabilizing Factor Involved in Nervous System Formation. Mol. Biol. Cell 2002, 13, 698–710. [Google Scholar] [CrossRef] [PubMed]
- Eckert, T.; Le, D.T.-V.; Link, S.; Friedmann, L.; Woehlke, G. Spastin's Microtubule-Binding Properties and Comparison to Katanin. PLOS ONE 2012, 7, e50161. [Google Scholar] [CrossRef]
- Cowan, C.M.; Mudher, A. Are Tau Aggregates Toxic or Protective in Tauopathies? Front. Neurol. 2013, 4, 114. [Google Scholar] [CrossRef]
- Introduction to Condensed Matter Chemistry - 1st Edition | Elsevier Shop’. Accessed: Apr. 16, 2024. [Online]. Available: https://shop.elsevier. 1614.
- Rival, T.; Page, R.M.; Chandraratna, D.S.; Sendall, T.J.; Ryder, E.; Liu, B.; Lewis, H.; Rosahl, T.; Hider, R.; Camargo, L.M.; et al. Fenton chemistry and oxidative stress mediate the toxicity of the β-amyloid peptide in a Drosophila model of Alzheimer’s disease. Eur. J. Neurosci. 2009, 29, 1335–1347. [Google Scholar] [CrossRef]
- Bauer, R.; Brüne, B.; Schmid, T. Cholesterol metabolism in the regulation of inflammatory responses. Front. Pharmacol. 2023, 14, 1121819. [Google Scholar] [CrossRef]
- Trupp, M.; Altman, T.; A Fulcher, C.; Caspi, R.; Krummenacker, M.; Paley, S.; Karp, P.D. Beyond the genome (BTG) is a (PGDB) pathway genome database: HumanCyc. Genome Biol. 2010, 11, O12–O12. [Google Scholar] [CrossRef]
- Gencel-Augusto, J.; Wu, W.; Bivona, T.G. Long Non-Coding RNAs as Emerging Targets in Lung Cancer. Cancers 2023, 15, 3135. [Google Scholar] [CrossRef]
- Li, R.; Zhu, H.; Luo, Y. Understanding the Functions of Long Non-Coding RNAs through Their Higher-Order Structures. Int. J. Mol. Sci. 2016, 17, 702. [Google Scholar] [CrossRef]
- Luo, J.; Qu, L.; Gao, F.; Lin, J.; Liu, J.; Lin, A. LncRNAs: Architectural Scaffolds or More Potential Roles in Phase Separation. Front. Genet. 2021, 12. [Google Scholar] [CrossRef]
- Salonikidis, P.S.; Kirichenko, S.N.; Tatjanenko, L.V.; Schwarz, W.; Vasilets, L.A. Extracellular pH modulates kinetics of the Na+,K+-ATPase. Biochim. et Biophys. Acta (BBA) - Biomembr. 2000, 1509, 496–504. [Google Scholar] [CrossRef]
- Janelidze, S.; Stomrud, E.; Palmqvist, S.; Zetterberg, H.; van Westen, D.; Jeromin, A.; Song, L.; Hanlon, D.; Hehir, C.A.T.; Baker, D.; et al. Plasma β-amyloid in Alzheimer’s disease and vascular disease. Sci. Rep. 2016, 6, 26801. [Google Scholar] [CrossRef]
- Karikari, T.K.; Benedet, A.L.; Ashton, N.J.; Rodriguez, J.L.; Snellman, A.; Suárez-Calvet, M.; Saha-Chaudhuri, P.; Lussier, F.; Kvartsberg, H.; Rial, A.M.; et al. Diagnostic performance and prediction of clinical progression of plasma phospho-tau181 in the Alzheimer’s Disease Neuroimaging Initiative. Mol. Psychiatry 2020, 26, 429–442. [Google Scholar] [CrossRef]
- Bennett, D.A.; Schneider, J.A.; Arvanitakis, Z.; Wilson, R.S. Overview and Findings from the Religious Orders Study. Curr. Alzheimer Res. 2012, 9, 628–645. [Google Scholar] [CrossRef]
- Caspi, R.; Altman, T.; Dreher, K.; Fulcher, C.A.; Subhraveti, P.; Keseler, I.M.; Kothari, A.; Krummenacker, M.; Latendresse, M.; Mueller, L.A.; et al. The MetaCyc database of metabolic pathways and enzymes and the BioCyc collection of pathway/genome databases. Nucleic Acids Res. 2011, 40, D742–D753. [Google Scholar] [CrossRef]
- Chen, Y.; Chen, Y.; Shi, C.; Huang, Z.; Zhang, Y.; Li, S.; Li, Y.; Ye, J.; Yu, C.; Li, Z.; et al. SOAPnuke: a MapReduce acceleration-supported software for integrated quality control and preprocessing of high-throughput sequencing data. GigaScience 2017, 7, 1–6. [Google Scholar] [CrossRef]
- Zhang, Y.; Park, C.; Bennett, C.; Thornton, M.; Kim, D. Rapid and accurate alignment of nucleotide conversion sequencing reads with HISAT-3N. Genome Res. 2021, 31, 1290–1295. [Google Scholar] [CrossRef]
- Kang, Y.-J.; Yang, D.-C.; Kong, L.; Hou, M.; Meng, Y.-Q.; Wei, L.; Gao, G. CPC2: a fast and accurate coding potential calculator based on sequence intrinsic features. Nucleic Acids Res. 2017, 45, W12–W16. [Google Scholar] [CrossRef]
- Han, S.; Liang, Y.; Li, Y.; Du, W. Long Noncoding RNA Identification: Comparing Machine Learning Based Tools for Long Noncoding Transcripts Discrimination. BioMed Res. Int. 2016, 2016, 1–14. [Google Scholar] [CrossRef]
- Wang, L.; Park, H.J.; Dasari, S.; Wang, S.; Kocher, J.-P.; Li, W. CPAT: Coding-Potential Assessment Tool using an alignment-free logistic regression model. Nucleic Acids Res. 2013, 41, e74–e74. [Google Scholar] [CrossRef]
- Li, A.; Zhang, J.; Zhou, Z. PLEK: a tool for predicting long non-coding RNAs and messenger RNAs based on an improved k-mer scheme. BMC Bioinform. 2014, 15, 1–10. [Google Scholar] [CrossRef]
- Tong, X.; Liu, S. CPPred: coding potential prediction based on the global description of RNA sequence. Nucleic Acids Res. 2019, 47, e43–e43. [Google Scholar] [CrossRef]
- Love, M.I.; Huber, W.; Anders, S. Moderated estimation of fold change and dispersion for RNA-seq data with DESeq2. Genome Biol. 2014, 15, 550. [Google Scholar] [CrossRef]
- Frazee, A.C.; Pertea, G.; Jaffe, A.E.; Langmead, B.; Salzberg, S.L.; Leek, J.T. Ballgown bridges the gap between transcriptome assembly and expression analysis. Nat. Biotechnol. 2015, 33, 243–246. [Google Scholar] [CrossRef]
- Subramanian, A.; Tamayo, P.; Mootha, V.K.; Mukherjee, S.; Ebert, B.L.; Gillette, M.A.; Paulovich, A.; Pomeroy, S.L.; Golub, T.R.; Lander, E.S.; et al. Gene set enrichment analysis: A knowledge-based approach for interpreting genome-wide expression profiles. Proc. Natl. Acad. Sci. USA 2005, 102, 15545–15550. [Google Scholar] [CrossRef]
- Ponting, C.P.; Oliver, P.L.; Reik, W. Evolution and Functions of Long Noncoding RNAs. Cell 2009, 136, 629–641. [Google Scholar] [CrossRef]
- E Kornienko, A.; Guenzl, P.M.; Barlow, D.P.; Pauler, F.M. Gene regulation by the act of long non-coding RNA transcription. BMC Biol. 2013, 11, 1–59. [Google Scholar] [CrossRef]
- Liu, S.; Wu, J.; Zhang, W.; Jiang, H.; Zhou, Y.; Liu, J.; Mao, H.; Liu, S.; Chen, B. Whole-Transcriptome RNA Sequencing Uncovers the Global Expression Changes and RNA Regulatory Networks in Duck Embryonic Myogenesis. Int. J. Mol. Sci. 2023, 24, 16387. [Google Scholar] [CrossRef]
- Li, X.; Shahid, M.Q.; Wen, M.; Chen, S.; Yu, H.; Jiao, Y.; Lu, Z.; Li, Y.; Liu, X. Global identification and analysis revealed differentially expressed lncRNAs associated with meiosis and low fertility in autotetraploid rice. BMC Plant Biol. 2020, 20, 1–19. [Google Scholar] [CrossRef]
- Wenzel, A.; Akbaşli, E.; Gorodkin, J. RIsearch: fast RNA–RNA interaction search using a simplified nearest-neighbor energy model. Bioinformatics 2012, 28, 2738–2746. [Google Scholar] [CrossRef]
- Sun, H.; Cao, X.; Sumayya; Ma, Y. ; Li, H.; Han, W.; Qu, L. Genome-wide transcriptional profiling and functional analysis of long noncoding RNAs and mRNAs in chicken macrophages associated with the infection of avian pathogenic E. coli. BMC Veter- Res. 2024, 20, 1–17. [Google Scholar] [CrossRef]
- Altmann, A.; Toloşi, L.; Sander, O.; Lengauer, T. Permutation importance: a corrected feature importance measure. Bioinformatics 2010, 26, 1340–1347. [Google Scholar] [CrossRef]
- Guo, X.; Gao, L.; Liao, Q.; Xiao, H.; Ma, X.; Yang, X.; Luo, H.; Zhao, G.; Bu, D.; Jiao, F.; et al. Long non-coding RNAs function annotation: a global prediction method based on bi-colored networks. Nucleic Acids Res. 2012, 41, e35–e35. [Google Scholar] [CrossRef]
- J. Enright, S. J. Enright, S. Van Dongen, and C. A. Ouzounis, ‘An efficient algorithm for large-scale detection of protein families’, Nucleic Acids Res., vol. 30, no. 7, pp. 1575–1584, Apr. 2002.
- Kanehisa, M.; Goto, S. KEGG: Kyoto Encyclopedia of Genes and Genomes. Nucleic Acids Res. 2000, 28, 27–30. [Google Scholar] [CrossRef]
- Reactome’. Accessed: Dec. 29, 2019. [Online]. Available: http://bmdb.cbi.pku.edu.cn/Reactome.php.
- Wu, T.; Hu, E.; Xu, S.; Chen, M.; Guo, P.; Dai, Z.; Feng, T.; Zhou, L.; Tang, W.; Zhan, L.; et al. clusterProfiler 4.0: A universal enrichment tool for interpreting omics data. Innovation 2021, 2, 100141. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
A model for two vicious cycles driven by Fenton reactions throughout the progression of AD.
Figure 1.
A model for two vicious cycles driven by Fenton reactions throughout the progression of AD.
Figure 2.
Prediction of novel lncRNAs in AD tissues. A. Venn analysis of the predicted novel lncRNAs using five software: CNCI, CPC, CPP2, PLEK and CAPT. B. Classification of predicted novel lncRNAs. C. Exon numbers in protein-coding genes, known lncRNA genes, and novel lncRNAs. D. ORF length distributions of protein coding genes, known lncRNAs, and novel lncRNAs. E. Sequence lengths of protein-coding genes, known lncRNAs, and novel lncRNAs.
Figure 2.
Prediction of novel lncRNAs in AD tissues. A. Venn analysis of the predicted novel lncRNAs using five software: CNCI, CPC, CPP2, PLEK and CAPT. B. Classification of predicted novel lncRNAs. C. Exon numbers in protein-coding genes, known lncRNA genes, and novel lncRNAs. D. ORF length distributions of protein coding genes, known lncRNAs, and novel lncRNAs. E. Sequence lengths of protein-coding genes, known lncRNAs, and novel lncRNAs.
Figure 3.
Statistics related to the pathological progression of lncRNAs in AD. A. The relative changes in the levels of Aβ plaques, Tau fibers, intracellular alkalinity, extracellular acidity, oxidative stress, and apoptosis compared to controls throughout the disease progression. B. Category statistics of different upregulated pathways in different bins. C. Category statistics of different downregulated pathways in different bins.
Figure 3.
Statistics related to the pathological progression of lncRNAs in AD. A. The relative changes in the levels of Aβ plaques, Tau fibers, intracellular alkalinity, extracellular acidity, oxidative stress, and apoptosis compared to controls throughout the disease progression. B. Category statistics of different upregulated pathways in different bins. C. Category statistics of different downregulated pathways in different bins.
Figure 4.
A schematic of our model, composed of key events and logical relationships, where each arrow represents a causal relationship.
Figure 4.
A schematic of our model, composed of key events and logical relationships, where each arrow represents a causal relationship.
Figure 5.
LncRNAs contributing to key AD phenotypes through cell-polarity changes. A. Statistics of the top 20% of pathways for each group of pathways in each bin. B. The regulatory trends of lncRNAs associated with microtubule depolymerization from bin1 through bin4. C. The numbers of lncRNAs involved in Tau fiber formation across the four bins. D. The numbers of lncRNAs involved in Aβ plaque formation across the four bins.
Figure 5.
LncRNAs contributing to key AD phenotypes through cell-polarity changes. A. Statistics of the top 20% of pathways for each group of pathways in each bin. B. The regulatory trends of lncRNAs associated with microtubule depolymerization from bin1 through bin4. C. The numbers of lncRNAs involved in Tau fiber formation across the four bins. D. The numbers of lncRNAs involved in Aβ plaque formation across the four bins.
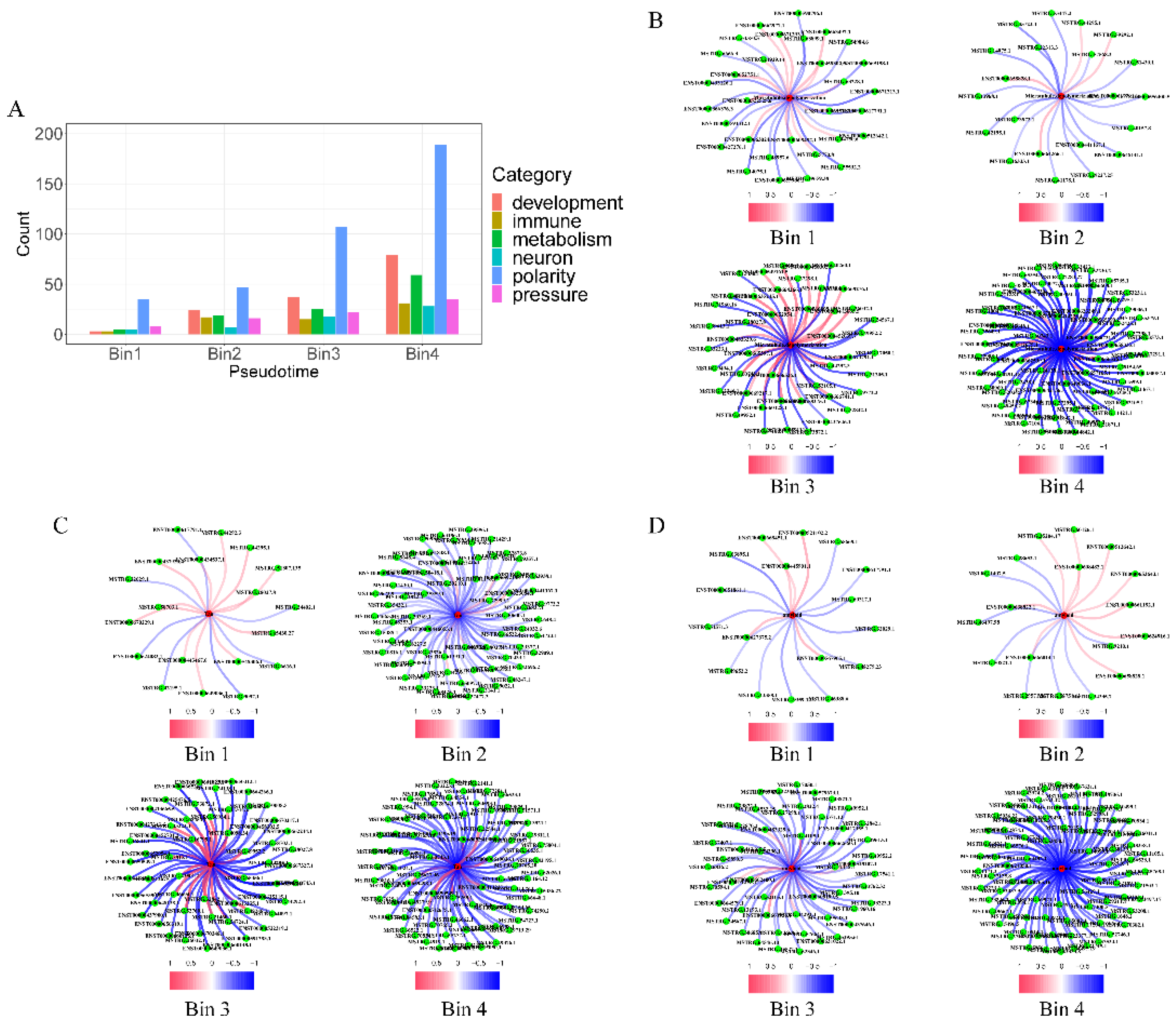
Figure 6.
LncRNAs involved in induction of metabolic reprogramming for relieving stresses. A. The numbers of lncRNAs involved in superoxide anion generation across the four bins. B. The numbers of lncRNAs involved in mitochondrial iron sulfur clustering synthesis across the four bins. C. The numbers of lncRNAs involved in H+-producing enzymes across the four bins. D. The numbers of lncRNAs involved in acid loading transporter across the four bins.
Figure 6.
LncRNAs involved in induction of metabolic reprogramming for relieving stresses. A. The numbers of lncRNAs involved in superoxide anion generation across the four bins. B. The numbers of lncRNAs involved in mitochondrial iron sulfur clustering synthesis across the four bins. C. The numbers of lncRNAs involved in H+-producing enzymes across the four bins. D. The numbers of lncRNAs involved in acid loading transporter across the four bins.
Figure 7.
Assessment of lncRNAs’ discerning power between AD and control samples. A. AUC scores by lncRNAs in distinguishing all AD samples vs. controls, late-stage AD samples vs. controls, earliest-stage AD samples vs. controls, and early-stage AD samples vs. mid-late-stage AD samples. B. ROC curves by lncRNAs involved in Na+/K+-ATPase in distinguishing all AD samples vs. controls. C. ROC curves by lncRNAs involved in regulating superoxide anion generation in differentiating late-stage AD samples vs. controls. D. ROC curves by lncRNAs regulating extracellular copper in discriminating earliest-stage AD samples vs. controls. E. ROC curves by lncRNAs involved in regulating astrocytes in distinguishing early-stage AD samples vs. mid-late-stage AD samples.
Figure 7.
Assessment of lncRNAs’ discerning power between AD and control samples. A. AUC scores by lncRNAs in distinguishing all AD samples vs. controls, late-stage AD samples vs. controls, earliest-stage AD samples vs. controls, and early-stage AD samples vs. mid-late-stage AD samples. B. ROC curves by lncRNAs involved in Na+/K+-ATPase in distinguishing all AD samples vs. controls. C. ROC curves by lncRNAs involved in regulating superoxide anion generation in differentiating late-stage AD samples vs. controls. D. ROC curves by lncRNAs regulating extracellular copper in discriminating earliest-stage AD samples vs. controls. E. ROC curves by lncRNAs involved in regulating astrocytes in distinguishing early-stage AD samples vs. mid-late-stage AD samples.
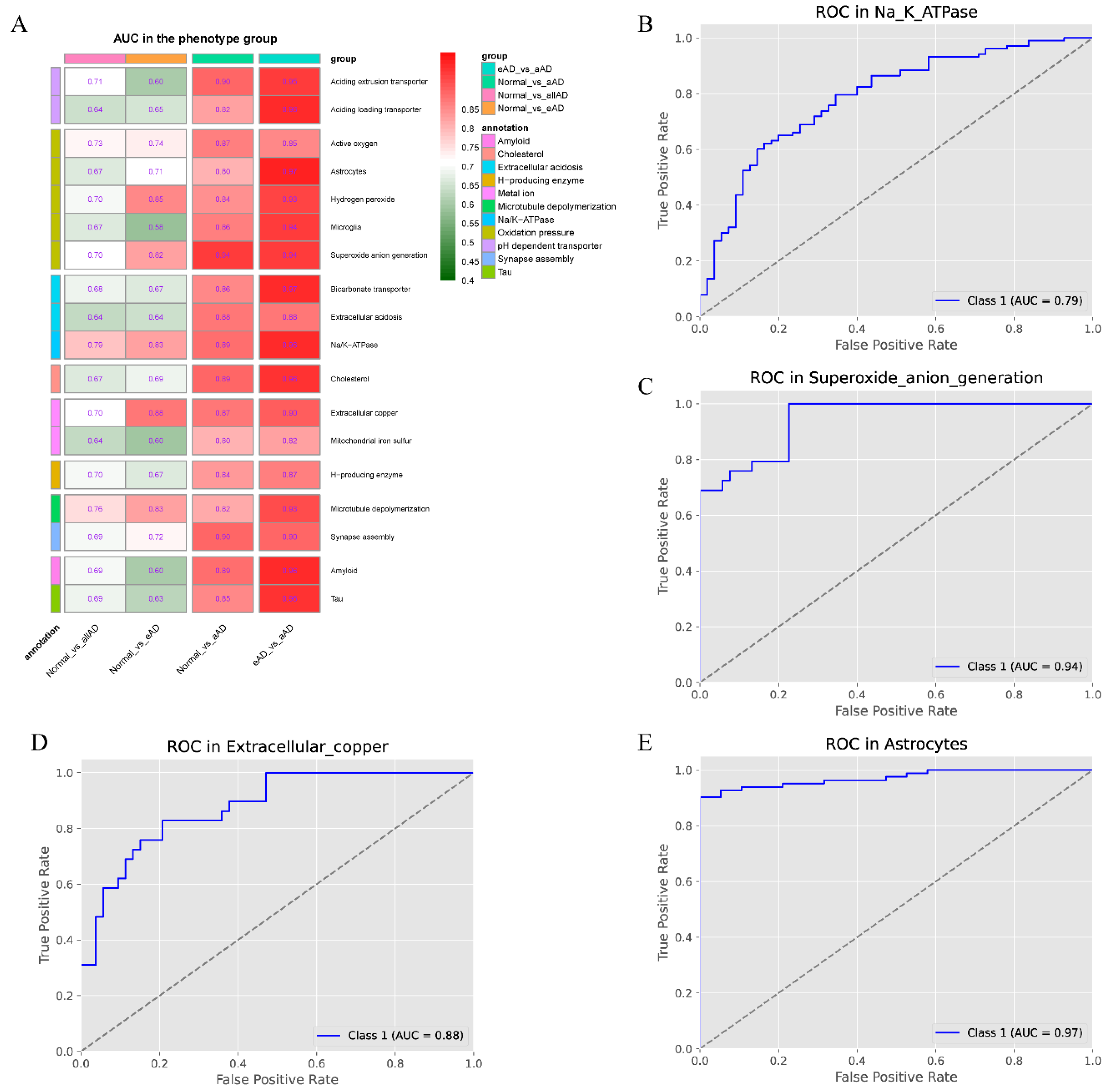

Table 1.
The number of lncRNAs with high discerning scores involved in immune activity, metabolic reprogramming, cell polarity, and stress-response from bin1 through bin4.
Table 1.
The number of lncRNAs with high discerning scores involved in immune activity, metabolic reprogramming, cell polarity, and stress-response from bin1 through bin4.
| Pesudotime | Immune activity | Metabolic reprogramming | Cell polarity | Stress response |
|---|---|---|---|---|
| Bin1 | 160 | 339 | 876 | 827 |
| Bin2 | 1069 | 729 | 1569 | 1291 |
| Bin3 | 863 | 1362 | 1522 | 1421 |
| Bin4 | 1916 | 5156 | 5230 | 5204 |
Table 2.
AUC scores achieved by lncRNAs in distinguishing between all AD samples vs. controls, late-stage AD samples vs. controls, early-stage AD patients vs. controls, and early-stage vs. late-stage AD samples.
Table 2.
AUC scores achieved by lncRNAs in distinguishing between all AD samples vs. controls, late-stage AD samples vs. controls, early-stage AD patients vs. controls, and early-stage vs. late-stage AD samples.
| Phenotype | Normal_vs_allAD | Normal_vs_eAD | Normal_vs_aAD | eAD_vs_aAD |
|---|---|---|---|---|
| Aciding extrusion transporter | 0.7124 | 0.6018 | 0.8998 | 0.9499 |
| Aciding loading transporter | 0.6448 | 0.6539 | 0.825 | 0.9602 |
| Active oxygen | 0.7297 | 0.7365 | 0.8673 | 0.8543 |
| Astrocytes | 0.6653 | 0.7124 | 0.8029 | 0.9718 |
| Hydrogen peroxide | 0.6981 | 0.851 | 0.8412 | 0.9339 |
| Microglia | 0.6669 | 0.581 | 0.8614 | 0.9429 |
| Superoxide anion generation | 0.7015 | 0.823 | 0.944 | 0.9416 |
| Bicarbonate transporter | 0.6819 | 0.6675 | 0.8595 | 0.9685 |
| Extracellular acidosis | 0.6373 | 0.6425 | 0.8783 | 0.878 |
| Na+/K+-ATPase | 0.7866 | 0.8256 | 0.8881 | 0.9615 |
| Cholesterol | 0.6694 | 0.6871 | 0.8939 | 0.9557 |
| Extracellular copper | 0.701 | 0.8783 | 0.8718 | 0.9018 |
| Mitochondrial iron sulfur | 0.6378 | 0.5979 | 0.8022 | 0.8228 |
| H-producing enzyme | 0.6971 | 0.6662 | 0.8399 | 0.8652 |
| Microtubule depolymerization | 0.7562 | 0.8256 | 0.8198 | 0.9268 |
| Synapse assembly | 0.6909 | 0.7235 | 0.8979 | 0.8967 |
| Amyloid | 0.6914 | 0.6012 | 0.8855 | 0.9634 |
| Tau | 0.6858 | 0.6291 | 0.8549 | 0.957 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



