
Submitted:
10 July 2024
Posted:
11 July 2024
You are already at the latest version
Abstract
Accurate computational prediction of B-cell epitopes can greatly enhance biomedical research and rapidly advance efforts to develop therapeutics, monoclonal antibodies, vaccines, and immunodiagnostic reagents. Previous research efforts have primarily focused on the development of computational methods to predict linear epitopes rather than conformational epitopes, although the latter is much more biologically predominant. Several conformational B-cell epitope prediction methods have recently been published, but their predictive performances are weak. Here, we present a review of the latest computational methods and assess their performances on a diverse test set of 29 non-redundant unbound antigen structures. Our results demonstrate that ISPIPab outperformed all other methods. Finally, we suggest new strategies and opportu-nities to improve computational predictions of conformational B-cell epitopes.
Keywords:
B-cell epitopes
; conformational epitopes
; computational identification of epitopes
1. Introduction
B-cell epitopes (BCE), also known as antigenic determinants, are regions on the surfaces of antigen proteins that are recognized by and bonded to antibodies via agglutination. BCE are generally classified as either linear or conformational. Linear BCE are sequentially consistent with the primary structure of the antigen (Figure 1), while conformational or discontinuous BCE are spatially proximal within the three-dimensional structure of the antigen (Figure 2). However, greater than 90% of BCE are presumed to be discontinuous in nature [1], and a recent analysis found that only 4% are truly linear [2].
Accurate mapping of BCE is critical in biomedical research to develop therapeutics, antibodies, peptide-based vaccines, and immunodiagnostic reagents [3,4,5]. Experimental methods used to map epitopes can be grouped into either structural or functional studies [6]. X-ray crystallography and NMR are the two most reliable structural methods for BCE mapping [7,8]. However, these methods are expensive, time-consuming, and inefficient [9]. Functional studies have proven to be relatively more cost-effective and efficient and include new techniques such as mimotope analysis and display technologies [10,11]. Other functional mapping studies include peptide screenings for antibody binding as well as antibody-antigen mutant reactivity testing [12].
Computational approaches present complementary techniques to experimental methods for identifying BCE, and their complexities and accuracy have gradually improved in recent decades [9]. Two distinct classes of BCE prediction methods have been developed and both use a variety of machine learning approaches to integrate several input features [13]. First, linear BCE prediction methods are based on amino acid properties, including antigenicity, flexibility, hydrophilicity, solvent accessibility, and secondary structure [14,15,16,17,18,19]. Second, discontinuous BCE prediction methods integrate structural and surface patch features, including hydrophilicity scale, epitopic residue propensity score, residue protrusion index, and residue compactness among several other input vectors [1,20,21,22]. However, most available BCE prediction methods are designed for linear epitope prediction due to their simpler computational development and sole reliance on primary structural data, which has greater availability [13]. Despite the much greater biological prevalence of discontinuous as opposed to linear BCE, the development of prediction methods for the former have received significantly less attention [6]. Previous work has found that structure-based methods are superior to sequence-based methods [23]. However, currently available computational BCE prediction methods continue to lag, as they are largely inaccurate and their development is limited by the availability of resolved antigen-antibody complex structures as well as the ongoing challenges in extracting discontinuous epitopes for antibody development [24,25,26].
Further distinctions among linear and discontinuous BCE prediction method classes exist when considering the requirements for antibody-specific or antibody-independent predictions. The development of antibody-independent BCE predictors has received greater attention as compared to antibody-specific BCE predictors, and a recent comparison asserts the former class boasts greater overall performance according to several statistical measures, but lower precision [27,28]. While antibody-specific approaches are more targeted and controlled, they require that the paired antibody be successfully screened and identified. However, prior knowledge of the cognate antibody is not always known and thus requires significant screening. Current antibody-specific methods cannot efficiently screen the approximately 1016-1018 possible antibodies, rendering this method inapplicable in many cases which have limited background biological information [28,29]. Furthermore, conformational changes are expected to different degrees during antigen-antibody binding, and an understanding of these changes is only available with the resolved bound antigen-antibody complex, which is also not commonly available [30]. Overall, this underscores the need for the development of generic methods that can accurately predict BCE, especially those using solely the unbound antigen structure.
BCE prediction faces an additional challenge as antibody-antigen interactions can occur across multiple regions on the surface of an antigen of interest (Figure 3). Currently, it remains unknown whether any region of an antigen’s surface can theoretically be targeted by antibodies [28]. However, it is certain that specific regions are targeted much more favorably during immune responses, an immunological phenomenon known as epitope immunodominance [31,32]. The ability to accurately predict immunodominant and subdominant BCE has significant applicability in biomedical research to develop antibodies or vaccines that target these sites. Therefore, the consideration of multiple epitopes should be a critical factor in the development of computational BCE prediction methods. Zhang et al. developed CBEP, which uses primary sequence features as well as a K-means clustering algorithm to identify multiple epitopes using residue spatial locations and a threshold parameter [33]. Additionally, the method developed by Ren et al. uses sequential information and various patterns of propensities for BCE prediction alongside a clustering method with a pre-defined optimal cutoff distance of 6 Å between any pair of residues belonging to the same cluster to identify multiple epitopes [34]. Our recent work combines our computational method, ISPIPab, with hierarchical clustering to predict multiple epitopes. After calculating the pairwise distances between the geometric centers of predicted epitopal residues, a dendrogram is constructed. The optimal number of clusters for each antigen corresponds to the number of vertical lines in the dendrogram cut by a horizontal line that can traverse the maximum distance vertically without intersecting a cluster. Thus, the number of distinct predicted epitopes is determined dynamically for each antigen [35].
In recent years, several discontinuous BCE prediction methods have been published. Consequently, there are calls for independent evaluations of the available methods with an emphasis on including confusion matrix-based performance metrics, such as F1-score and MCC, to better assess predictive performance [24,28,36,37,38,39]. This review compares the performance of the latest computational methods for the prediction of conformational BCE epitopes on a set of antigens selected with ≤30% sequence identity and to span a range of protein lengths and CATH protein family classifications.
2. Materials and Methods
2.1. Databases for BCE Epitopes
Experimental protein data has grown tremendously in recent decades, including B-cell epitope data, which is critical for the development of well-trained and accurate BCE prediction methods [40]. Several web-based databases host relevant BCE data, which is both automatically and manually curated. The Protein Data Bank (PDB), maintained by the RCSB, stores three-dimensional structures of proteins and complexes derived from X-ray crystallography, NMR, and cryo-EM studies with over 200,000 entries [41]. The automated web-based summary, SACS, catalogs antigen-antibody complexes and information extracted from the PDB [42]. The Immune Epitope Database (IEDB), managed by the La Jolla Institute for Allergy and Immunology, is the most popular and used BCE database. The IEDB catalogs experimentally determined linear and discontinuous epitopes as well as T-cell epitopes studies and MHC assays from published literature. The IEDB also hosts several epitope prediction methods and analysis tools. At this moment, the IEDB hosts data from over 1.4 million B-cell assays and 1.6 million peptidic epitopes [43,44]. BciPep, established by the Institute of Microbial Technology, catalogs experimentally determined linear BCE data. BciPep currently lists thousands of epitopes with a focus on those from various pathogenic organisms, including viruses, fungi, bacteria, and protozoa. The epitopes are of varying immunogenicity and compiled from the literature as well as other public databases [45]. The Conformational Epitope Database (CED), established by the Institute for Chemical Research, compiles data of discontinuous epitopes. The CED is manually curated with limited entries and features only high-quality conformational epitopes described in the literature. Entries include source antigens, cognate antibodies, and relevant immunological properties, and epitope locations which can be visualized within the interface [46]. Additionally, Epitome extracts epitopes from all known resolved antigen-antibodies complexes. The database includes descriptions of the epitopal residues as well as sequential and structural environments, and can be viewed through a Jmol interface [47]. AntiJen, established by the Edward Jenner Institute for Vaccine Research, is another useful database that integrates kinetic, thermodynamic, functional, and cellular data within the context of immunology and vaccinology. AntiJen includes more than 31,000 comprehensive entries from experimental studies and includes data of peptide binding to MHC ligands, TCR–MHC complexes, T-cell epitopes, TAP, B-cell epitope molecules, and immunological protein–protein interactions [48]. Finally, the HIV Molecular Immunology Database, established by the Los Alamos National Laboratory, catalogs and annotates HIV epitopes compiled from the literature with over 10,000 HIV-specific B-cell and T-cell assays. The entries include descriptions of escape mutations, antibody sequences, TCR usage, cross-reactivity, associations between immune responses and rates of therapy and progression among other information [49].
2.2. Dataset Used to Compare Performance
Jespersen et al. curated a dataset of 335 antibody-antigen complexes with experimentally identified epitope residues which includes entries from the IEDB and PDB. The complexes include structures with <3 Å resolution, antigens with greater than 60 residues, and B-cell heavy-light chain receptors. The authors removed redundancies by clustering the antibodies and antigens at 90% and 70% sequence identity thresholds, respectively, which returned 202 antibody-antigen clusters [50].
We expanded our dataset by searching for antigen-antibody complexes in the SACS database that included antigens between 100-450 residues, resolutions of <3 Å, and entries published after 2005. This returned 2196 complexes, and the BCE were determined using the CSU program which employed a cutoff value of 4.0 Å between any atom in a residue in the antigen and an atom in the antibody of the complex and establishes a legitimate contact type according to CSU [51].
Since we sought to assess predictive performance on unbound antigen structures, we searched for analogous unbound antigens in the PDB that shared >95% sequence identity to the bound complexed antigens. We further refined the antigen datasets by removing redundancy at a sequence identity threshold of ≤30%. Collectively, this returned 76 and 35 uncomplexed monomer antigens from the Jespersen et al. and SACS datasets, respectively, for a total of 111 unbound antigens. The epitope residues on the unbound antigen structures were identified by sequentially aligning them to those determined in their analogous bound antigen structures. 82 of these antigens were used to train our ISPIPab method and the remaining 29 antigens were used for testing. These 29 non-redundant antigens are of varying lengths (Figure 4) and represent a variety of CATH classifications (Figure 5) [52]. The PDB IDs of these test set antigens is included in Table A1.
2.3. Computational Methods Evaluated for Epitope Prediction
As described above, our evaluation tested the predictive performances of recently developed computational methods, including those developed specifically for discontinuous BCE prediction, and all methods were antibody or partner independent.
2.3.1. ISPIPab
ISPIPab [35] is a meta-method recently developed that integrates the predictions of SPPIDER [53], ISPRED4 [54], and DockPred [55] using XGBoost to predict B-cell epitopes. ISPIPab is based on the hypothesis that computational BCE prediction can be improved through integrating independent classifiers that leverage structure-based, template-free, and docking-based approaches [56]. We demonstrated that ISPIPab’s BCE predictive performance outperformed that of its individual classifiers, comparable meta-methods, and BCE-specific prediction methods. Finally, ISPIPab includes a hierarchical clustering methodology that clusters predicted epitope residues into potential epitope regions, thus accounting for the presence of multiple epitopes. We demonstrated that ISPIPab accurately predicts experimentally known epitopes as well as putative epitopes that may yet to be experimentally determined.
2.3.2. EPSVR
Liang et al. describes the development of the discontinuous BCE prediction method EPSVR. EPSVR uses the three-dimensional antigen structure as its input and integrates six scoring terms—including residue epitope propensity, conservation score, side chain energy score, contact number, surface planarity score, and secondary structure composition—through support vector regression implemented using the LIBSVM package [57]. An independent evaluation using a test set of 19 unbound antigen structures from CED with a sequence identity threshold of <35% found that EPSVR had greater percent accuracy (24.7%) than PEPITO (17.0%) [22], SEPPA (17.2%) [20], EPCES (17.8%) [38], EPITOPIA (18.8%) [58], ElliPro (14.3%) [21], and DiscoTope 1.2 (15.5%) [1]. Another review found that EPSVR had a greater AUC value (0.606) compared to SEPPA (0.589), DiscoTope 1.2 (0.579), EPITOPIA (0.572), and EPCES (0.569) [59].
2.3.3. Epitope3D
Silva et al. describes the development of epitope3D, a discontinuous BCE prediction method. The authors curated a dataset of antibody–antigen complexes using the ANARCI tool [60] with antigens of at least 25 residues and compiled 1351 complexes. Unbound antigens were identified through >70% sequence similarity to the bound antigen, and epitopal residues were aligned through several steps. The antigens were clustered using CD-HIT [61] with a 70% similarity cutoff which returned 245 unbound antigen structures, 180 of which were used for training. Epitope3D leverages the concept of graph-based signatures that model epitope and non-epitope regions as graphs, thereby extracting distance patterns to develop the method. The authors also presented an independent test set of 45 unbound antigen and concluded that epitope3D significantly outperformed SEPPA 3.0 [62], BepiPred 2.0 [63], DiscoTope 2.0 [23], and ElliPro according to the F1-score, MCC, and BACC metrics [37].
2.3.4. BepiPred
Clifford et al. describes the development of BepiPred 3.0, a sequence-based BCE prediction method for both linear and discontinuous epitopes. The authors curated their BP3 dataset that includes 1466 antigen-antibody complexes from the PDB with crystal structures of resolutions <3 Å, R-factor <0.3, and antigens of more than 38 residues. The dataset was further refined using an epitope collapse strategy and clustering at 70% sequence identity using MMseqs2 [64]. BepiPred 3.0 exploits protein language model embeddings to accurately predict local and global protein structural features using only amino acid sequences. For comparative evaluation, BepiPred 3.0 was retrained using a five-fold cross-validation setup on 200 antigens and tested on the same 45 antigen test set curated by Silva et al. BepiPred 3.0 had the best ROC-AUC performance (0.71) as compared to epitope3D (0.59), BepiPred 2.0 (0.58), SEPPA 3.0 (0.55), DiscoTope 2.0 (0.51), and ElliPro (0.49). The authors concluded that protein language models can improve BCE prediction, and their sequence-based method outperforms structure-based methods, even in cases of discontinuous epitopes [65].
2.3.5. SEPPA
Zhou et al. describes the development of SEPPA 3.0, which uses three-dimensional antigen structures to perform BCE predictions. SEPPA 2.0 introduced relative ASA preference of unit patch and consolidated amino acid index features to develop a logistic regression model alongside the unit-triangle propensity and clustering coefficient classification parameters introduced in the original model [66]. SEPPA 3.0 improves its predictive performance by updating its training dataset with 767 bound antigen structures and incorporating additional features to enhance the prediction of N-linked glycoprotein antigens. According to the authors’ evaluation, SEPPA 3.0 had greater ROC-AUC values (0.749) than EPITOPIA (0.664), DiscoTope 2.0 (0.660), PEPITO (0.676), CBTOPE (0.541) [67], SEPPA 2.0 (0.651), and BepiPred 2.0 (0.591) as well as balanced accuracy for BCE predictions on general and N-linked glycoprotein antigens.
2.3.6. DiscoTope
DiscoTope, which was first released in 2006, predicts BCE using three-dimensional antigen structures. DiscoTope 2.0 integrates half-sphere exposure surface measure, spatial neighborhood, and amino acid composition features and was found to be a top performing method in a recent review [28]. DiscoTope 3.0, which was recently released, features inverse folding structure representations and a positive unlabeled learning strategy that are adapted for BCE prediction on both solved and predicted structures [68]. DiscoTope shares a similar training set to that of BepiPred 3.0, using 582 antibody-antigen complexes with <3 Å resolution and an R-factor <0.3. Using MMseqs2, redundancies to the BepiPred 3.0 test set were removed at a 20% sequence identity threshold, and antigen sequences were clustered at a 50% sequence identity threshold. This resulted in 1125 and 281 antigen clusters that were selected for training and validation, respectively. On an independent test set of 24 non-redundant antigens, DiscoTope 3.0 was shown to outperform BepiPred 3.0, ScanNet [69], and SEMA [70].
We also tested the application of generic protein interface prediction methods to BCE prediction, as our previous work demonstrated that they could outperform BCE-specific prediction methods.
2.3.7. VORFFIP
VORFFIP is a strong-performing complex structure-based protein interface prediction method that integrates heterogeneous data—including various residue level structural and energetic features, evolutionary sequence conservation, and crystallographic B-factors—using a two-step random forest classifier to assign residues with interfacial probability scores. Trained and validated on unbound proteins from the Benchmark 3.0 dataset, VORFFIP was found to compare favorably against other reported protein interface prediction methods [71].
2.3.8. Spatom
Spatom, recently developed by Wu et al., is a structure-based protein interface prediction method. Spatom first defines a weighted digraph for a protein structure to characterize the spatial contacts of residues, followed by the development of a weighted digraph convolution to aggregate both spatial local and global information. Finally, the method adds an improved graph attention layer to drive the predicted sites to form more continuous interfaces [72]. Spatom was trained and tested using the Protein–Protein Docking Benchmark 5.5, which provides 542 unbound structures from 271 diverse protein-protein complexes, including antibody-antigen complexes [73]. On a test set of 80 proteins, Spatom was shown to outperform DeepPPISP [74], SPPIDER, MaSIF-site [75], GraphPPIS [76], and ScanNet. Notably, the authors presented several examples of accurate BCE predictions on antigen structures to demonstrate the versatility of the method.
The aforementioned computational methods return interface or epitope probability scores (p) that range between 0-1 for each residue in each antigen. Since we do not have prior knowledge of the number of epitopal residues located on any given antigen, a dynamic threshold was implemented to determine the threshold for the number of top scoring residues considered as epitopal in each antigen. The dynamic threshold, N, was calculated using the following equation proposed by Zhang et al.: N=6.1 R 0.3, where R is the number of surface-exposed residues on the antigen [77]. Through the dynamic threshold, we returned a set of predicted epitope residues per antigen for each computational method that was tested.
Using the dynamic threshold to determine the predicted epitopal residues and experimental data or CSU to determine the true epitopal residues, the elements of the confusion matrix—TP, TN, FP, and FN—were calculated. The predictive performance of each method was assessed using the F1-score, Matthew’s correlation coefficient (MCC), and the areas under the receiver operating characteristic (ROC-AUC) and precision-recall (PR-AUC) curves. Finally, to assess whether the F1-scores were normally distributed and test the null hypothesis, the nonparametric Kolmogorov–Smirnov (KS) single and two-sample tests were used. The differences in F1-scores and MCC were considered statistically significant if the p-value of the KS test was <0.05.
3. Results
Our test set of 29 unbound antigens only had one experimentally identified epitope and were diverse, belonging to several different protein folds, were of varying lengths, and the overall set had a sequence identity threshold of ≤30%. We predicted the BCE on these antigens using ISPIPab as well as DiscoTope 3.0, DiscoTope 2.0, EPSVR, SEPPA 3.0, BepiPred 3.0, epitope3D, VORFFIP, and Spatom. Each of these methods were accessed via their respective web servers. A dynamic threshold was implemented for each antigen to determine the number of residues considered as epitopal for each method and performance was evaluated using F1-score, MCC, ROC-AUC, and PR-AUC (Table 1).
Figure 6.
Comparison of ROC curves for the different prediction algorithms.
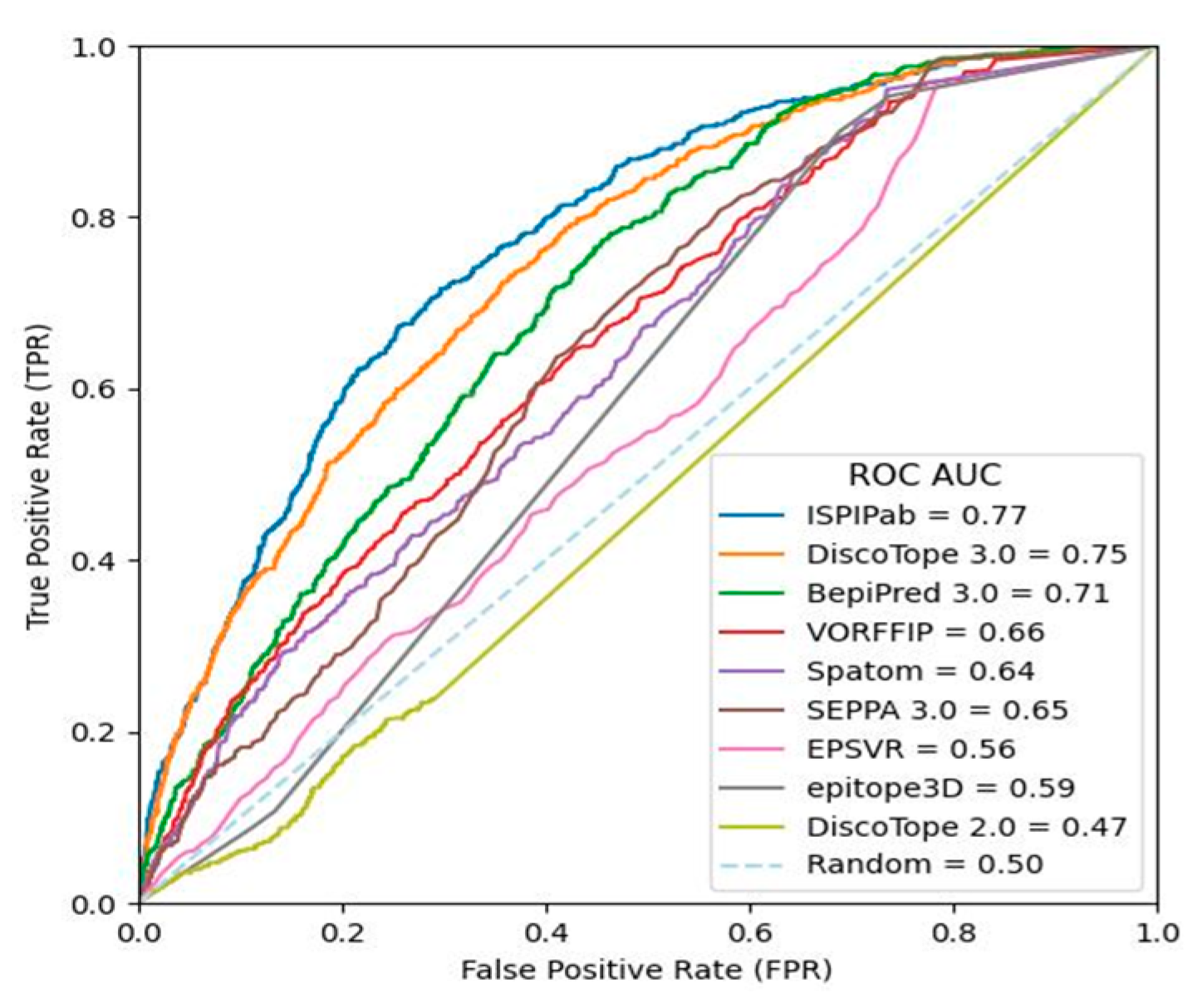
Figure 7.
Comparison of PR curves for the different prediction algorithms.
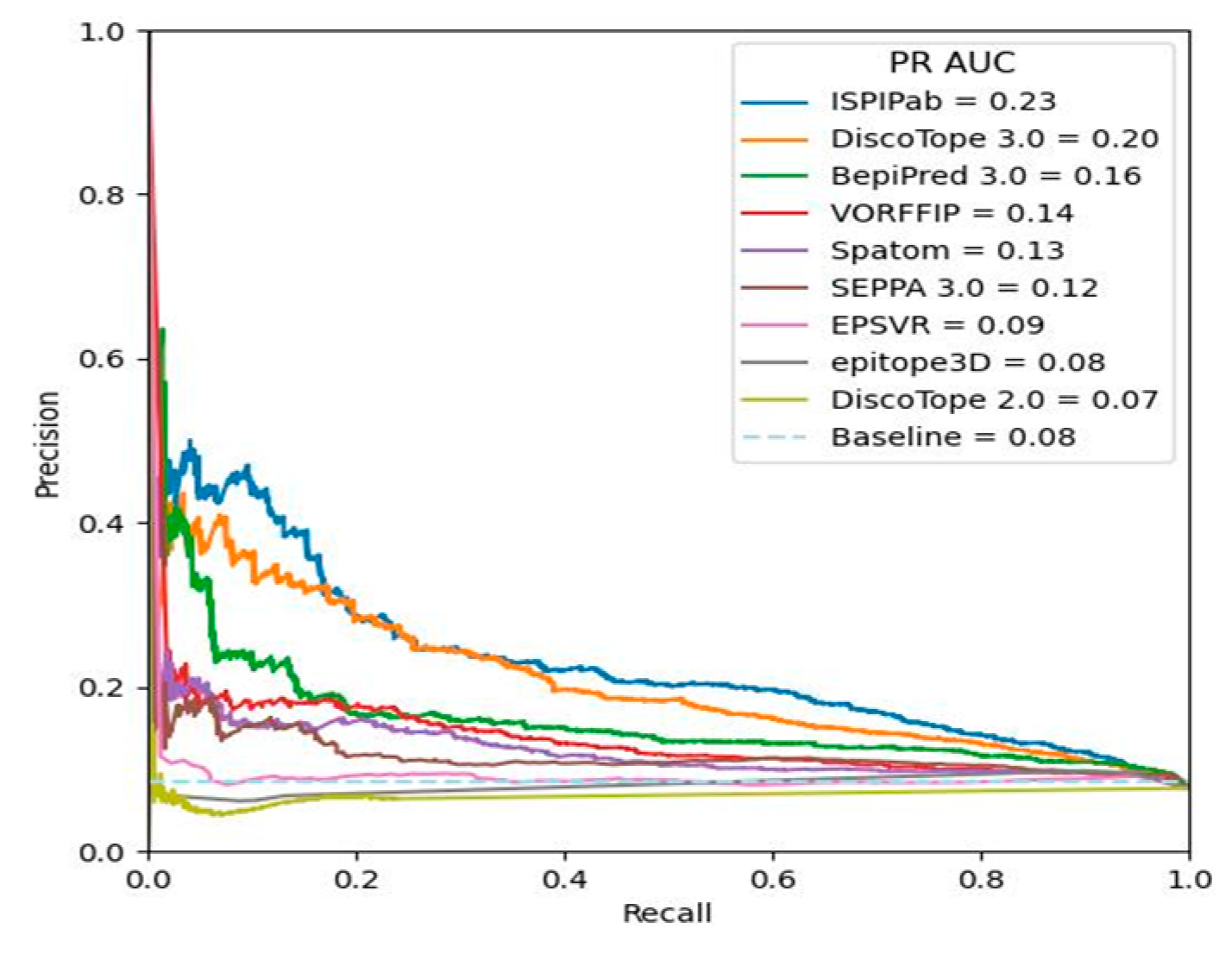
The F1-scores and MCC do not follow a normal distribution as tested by a single-sample KS test. ISPIPab has the greatest average F1-score (0.312) and MCC (0.230) compared to all other methods that were tested. ISPIPab’s F1-score and MCC performance were greater than those of SEPPA, VORFFIP, DiscoTope 2.0, EPSVR, Spatom, and epitope3D and was shown to be statistically significant with p-values <0.05 using the two-sample KS test. However, according to the F1-score metric, ISPIPab’s performance as compared to BepiPred 3.0 and DiscoTope 3.0 were not statistically significant, both with p-values of 0.29. Similarly, ISPIPab’s MCC performance was not statistically significant as compared to BepiPred 3.0 and DiscoTope 3.0 with p-values of 0.19 and 0.11, respectively.
ISPIPab also outperformed the tested methods according to the ROC-AUC and PR-AUC metrics. ISPIPab’s ROC-AUC was 0.77, which is slightly greater than that of DiscoTope 3.0, which had an ROC-AUC of 0.75. The only method to perform worse than random was DiscoTope 2.0, which had an ROC-AUC value of 0.47. These trends were similarly evident according to the PR-AUC metric. ISPIPab had the greater AUC (0.23), followed by DiscoTope 3.0 (0.20) and BepiPred 3.0 (0.16), with only DiscoTope 2.0 performing worse than random.
Notably, VORFFIP, a generic protein interface prediction method, had greater predictive performance than SEPPA 3.0, epitope3D, DiscoTope 2.0, and EPSVR according to all four metrics. Spatom, another generic method, had greater performance than epitope3D and DiscoTope 2.0 according to all four metrics. Spatom also had greater ROC-AUC and PR-AUC values than SEPPA 3.0, but a lower average F1-score and MCC. Collectively, these results suggest that generic protein interface methods can be applied to BCE prediction and more reliably predict BCE than several BCE-specific prediction methods. Thus, future evaluations of computational BCE prediction should include the latest generations of generic protein interface prediction methods to better survey the progress and state of computational BCE prediction.
Moreover, ISPIPab, which integrates the generic methods ISPRED4, DockPred, and SPPIDER also demonstrates superior performance among the tested methods. This strengthens our previous hypothesis that a meta-method based upon orthogonal methods that each depend on different structural properties of proteins improves interface predictive performance as compared to any individual classifier alone across a diverse class of proteins. Meta-learning approaches have previously been applied successfully in the area of BCE prediction [57,78]. Thus, considering the publication of several BCE prediction methods in recent years, efforts to develop meta-methods based upon BCE prediction tools should be renewed and compared to generic meta-methods in an effort to improve BCE predictive performance.
4. Conclusions
This review included several differences from other reviews previously published and builds upon their progress. First, our review focuses on discontinuous rather than linear BCE prediction methods. Second, other reviews test predictions on the bound antigen structure, while we test predictions on the unbound structures, which better assess the genericity and applicability of the methods. Third, our test dataset features a lower sequence identity threshold of ≤30% with antigens of varying lengths and different CATH classifications, thus better assessing the methods’ predictive performances on a diverse set of antigens with reduced biases. And fourth, our evaluation employs a dynamic threshold which determines the number of predicted epitope residues on the basis of the number of surface-exposed residues for each antigen. Therefore, the number of predicted epitopal residues is independent of the tested method and is determined dynamically based on the structure of the antigen of interest. The results demonstrate the ISPIPab outperformed all other computational methods we surveyed according to F1-score, MCC, ROC-AUC, and PR-AUC. Furthermore, we demonstrated that other generic protein interface prediction methods also outperformed BCE-specific methods.
4.1. Inaccessible Web Servers
While this review evaluated a variety of recently published computational BCE prediction methods, there are several other reported methods that have previously shown to be robust but whose web servers are currently unavailable and thus could not be evaluated. These methods include CEP [79], PEASE [80], EpiPred [81], EPITOPIA, PEPOP [82], CBEP, EPMeta and BEpro/PEPITO, and the last three methods are particularly notable. A recent review found BEpro/PEPITO was a top-performing method, comparable to DiscoTope 2.0, yet it remains inaccessible [28]. Additionally, EPMeta and CBEP are among the few BCE meta-learning and clustering methods, respectively, published in recent years. As predictive performance of conformational BCE is notoriously weak, new strategies are especially needed [83]. The inaccessibility of all these methods therefore presents setbacks to promising areas, such as meta-learning and clustering, that can advance the state of computational BCE prediction.
4.2. Limited Availability of Complexed Antibody-Antigen Structures
As discussed above, crystallization of antibody-antigen complexes and mapping of BCE is a costly and time-consuming process. Currently available complexes present just a fraction of all possible antigens and their cognate antibodies [65]. The limited availability of experimentally solved structures presents challenges in improving BCE predictive performance [68]. Therefore, the collection of additional experimental data and resolved structures across a diverse range of antigens with respect to CATH classifications and sizes is in strong demand. Consequently, additional data can provide better training for BCE prediction methods and allow for the generation of larger independent test sets. Thus, the successes and failures of computational BCE prediction can be better surveyed and improved accordingly.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org. The PDB IDs of the bound as well as the analogous unbound 29 test set antigens is given in the Supplementary Table A1. Table also includes the total number of epitopic residues and the corresponding residue numbers of these epitopes in the unbound antigens.
Author Contributions
M. Carroll and E. Rosenbaum completed the required calculations. M. Carroll wrote the manuscript. R. Viswanathan proposed the initial work, provided the guidance, revised and edited the manuscript. All authors have read and agreed to the published version of the manuscript. Authorship must be limited to those who have contributed substantially to the work reported.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Andersen, P.H.; Nielsen, M.; Lund, O. Prediction of residues in discontinuous B-cell epitopes using protein 3D structures. Protein Sci. 2006, 15, 2558–2567. [Google Scholar] [CrossRef] [PubMed]
- Ferdous, S.; Kelm, S.; Baker, T.S.; Shi, J.; Martin, A.C. B-cell epitopes: Discontinuity and conformational analysis. Mol. Immunol. 2019, 114, 643–650. [Google Scholar] [CrossRef] [PubMed]
- Van Regenmortel, M.H. Immunoinformatics may lead to a reappraisal of the nature of B cell epitopes and of the feasibility of synthetic peptide vaccines. J Mol Recognit 2006, 19, 183–7. [Google Scholar] [CrossRef]
- Dudek, N.L.; Perlmutter, P.; Aguilar, M.I.; Croft, N.P.; Purcell, A.W. Epitope Discovery and Their Use in Peptide Based Vaccines. Curr. Pharm. Des. 2010, 16, 3149–3157. [Google Scholar] [CrossRef] [PubMed]
- Leinikki, P.; et al. Synthetic peptides as diagnostic tools in virology. Adv Virus Res 1993, 42, 149–86. [Google Scholar] [PubMed]
- Potocnakova, L.; Bhide, M.; Pulzova, L.B. An Introduction to B-Cell Epitope Mapping and In Silico Epitope Prediction. J. Immunol. Res. 2016, 2016, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Rux, J.J.; Burnett, R.M. Type-Specific Epitope Locations Revealed by X-Ray Crystallographic Study of Adenovirus Type 5 Hexon. Mol. Ther. 2000, 1, 18–30. [Google Scholar] [CrossRef] [PubMed]
- Mayer, M.; Meyer, B. Group Epitope Mapping by Saturation Transfer Difference NMR To Identify Segments of a Ligand in Direct Contact with a Protein Receptor. J. Am. Chem. Soc. 2001, 123, 6108–6117. [Google Scholar] [CrossRef]
- Sun, P.; Ju, H.; Liu, Z.; Ning, Q.; Zhang, J.; Zhao, X.; Huang, Y.; Ma, Z.; Li, Y. Bioinformatics Resources and Tools for Conformational B-Cell Epitope Prediction. Comput. Math. Methods Med. 2013, 2013, 1–11. [Google Scholar] [CrossRef]
- Huang, J.; Ru, B.; Dai, P. Bioinformatics Resources and Tools for Phage Display. Molecules 2011, 16, 694–709. [Google Scholar] [CrossRef]
- Moreau, V.; Granier, C.; Villard, S.; Laune, D.; Molina, F. Discontinuous epitope prediction based on mimotope analysis. Bioinformatics 2006, 22, 1088–1095. [Google Scholar] [CrossRef] [PubMed]
- Morris, G.E. Epitope mapping. Methods Mol Biol 2005, 295, 255–68. [Google Scholar] [PubMed]
- Zheng, D.; Liang, S.; Zhang, C. B-Cell Epitope Predictions Using Computational Methods. Methods Mol Biol 2023, 2552, 239–254. [Google Scholar] [PubMed]
- Parker, J.M.R.; Guo, D.; Hodges, R.S. New hydrophilicity scale derived from high-performance liquid chromatography peptide retention data: correlation of predicted surface residues with antigenicity and x-ray-derived accessible sites. Biochemistry 1986, 25, 5425–5432. [Google Scholar] [CrossRef] [PubMed]
- Hopp, T.P.; Woods, K.R. Prediction of protein antigenic determinants from amino acid sequences. Proc. Natl. Acad. Sci. 1981, 78, 3824–3828. [Google Scholar] [CrossRef] [PubMed]
- A Emini, E.; Hughes, J.V.; Perlow, D.S.; Boger, J. Induction of hepatitis A virus-neutralizing antibody by a virus-specific synthetic peptide. J. Virol. 1985, 55, 836–839. [Google Scholar] [CrossRef]
- Pellequer, J.-L.; Westhof, E.; Van Regenmortel, M.H. Correlation between the location of antigenic sites and the prediction of turns in proteins. Immunol. Lett. 1993, 36, 83–99. [Google Scholar] [CrossRef]
- Kolaskar, A.S.; Tongaonkar, P.C. A semi-empirical method for prediction of antigenic determinants on protein antigens. FEBS Lett. 1990, 276, 172–174. [Google Scholar] [CrossRef]
- Karplus, P.A.; Schulz, G.E. Prediction of chain flexibility in proteins. Sci. Nat. 1985, 72, 212–213. [Google Scholar] [CrossRef]
- Sun, J.; Wu, D.; Xu, T.; Wang, X.; Xu, X.; Tao, L.; Li, Y.X.; Cao, Z.W. SEPPA: a computational server for spatial epitope prediction of protein antigens. Nucleic Acids Res. 2009, 37, W612–W616. [Google Scholar] [CrossRef]
- Ponomarenko, J.; Bui, H.-H.; Li, W.; Fusseder, N.; E Bourne, P.; Sette, A.; Peters, B. ElliPro: a new structure-based tool for the prediction of antibody epitopes. BMC Bioinform. 2008, 9, 514–514. [Google Scholar] [CrossRef]
- Sweredoski, M.J.; Baldi, P. PEPITO: improved discontinuous B-cell epitope prediction using multiple distance thresholds and half sphere exposure. Bioinformatics 2008, 24, 1459–1460. [Google Scholar] [CrossRef] [PubMed]
- Kringelum, J.V.; Lundegaard, C.; Lund, O.; Nielsen, M. Reliable B Cell Epitope Predictions: Impacts of Method Development and Improved Benchmarking. PLOS Comput. Biol. 2012, 8, e1002829. [Google Scholar] [CrossRef] [PubMed]
- Bukhari, S.N.H.; et al. Machine Learning Techniques for the Prediction of B-Cell and T-Cell Epitopes as Potential Vaccine Targets with a Specific Focus on SARS-CoV-2 Pathogen: A Review. Pathogens 2022, 11. [Google Scholar] [CrossRef] [PubMed]
- Levitt, M. Nature of the protein universe. Proc. Natl. Acad. Sci. 2009, 106, 11079–11084. [Google Scholar] [CrossRef]
- Sela-Culang, I.; Ofran, Y.; Peters, B. Antibody specific epitope prediction—emergence of a new paradigm. Curr. Opin. Virol. 2015, 11, 98–102. [Google Scholar] [CrossRef] [PubMed]
- Zhao, L.; Wong, L.; Li, J. Antibody-Specified B-Cell Epitope Prediction in Line with the Principle of Context-Awareness. IEEE/ACM Trans. Comput. Biol. Bioinform. 2011, 8, 1483–1494. [Google Scholar] [CrossRef] [PubMed]
- Cia, G.; Pucci, F.; Rooman, M. Critical review of conformational B-cell epitope prediction methods. Briefings Bioinform. 2023, 24. [Google Scholar] [CrossRef]
- Briney, B.; Inderbitzin, A.; Joyce, C.; Burton, D.R. Commonality despite exceptional diversity in the baseline human antibody repertoire. Nature 2019, 566, 393–397. [Google Scholar] [CrossRef]
- Brown, M.C.; Joaquim, T.R.; Chambers, R.; Onisk, D.V.; Yin, F.; Moriango, J.M.; Xu, Y.; Fancy, D.A.; Crowgey, E.L.; He, Y.; et al. Impact of Immunization Technology and Assay Application on Antibody Performance – A Systematic Comparative Evaluation. PLOS ONE 2011, 6, e28718. [Google Scholar] [CrossRef]
- Kaur, M.; Chug, H.; Singh, H.; Chandra, S.; Mishra, M.; Sharma, M.; Bhatnagar, R. Identification and characterization of immunodominant B-cell epitope of the C-terminus of protective antigen of Bacillus anthracis. Mol. Immunol. 2009, 46, 2107–2115. [Google Scholar] [CrossRef]
- Ito, H.-O.; Nakashima, T.; So, T.; Hirata, M.; Inoue, M. Immunodominance of conformation-dependent B-cell epitopes of protein antigens. Biochem. Biophys. Res. Commun. 2003, 308, 770–776. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhao, X.; Sun, P.; Gao, B.; Ma, Z. Conformational B-Cell Epitopes Prediction from Sequences Using Cost-Sensitive Ensemble Classifiers and Spatial Clustering. BioMed Res. Int. 2014, 2014, 1–12. [Google Scholar] [CrossRef]
- Ren, J.; Song, J.; Ellis, J.; Li, J. Staged heterogeneity learning to identify conformational B-cell epitopes from antigen sequences. BMC Genom. 2017, 18, 113. [Google Scholar] [CrossRef] [PubMed]
- R.Viswanathan, M.C. R.Viswanathan, M.C., A. Roffe, J.E. Fajardo, A. Fiser, Computational Prediction of Multiple Antigen Epitopes. Bioinformatics, Under Review, 2024.
- Yao, B.; Zheng, D.; Liang, S.; Zhang, C. Conformational B-Cell Epitope Prediction on Antigen Protein Structures: A Review of Current Algorithms and Comparison with Common Binding Site Prediction Methods. PLOS ONE 2013, 8, e62249. [Google Scholar] [CrossRef] [PubMed]
- da Silva, B.M.; et al. epitope3D: a machine learning method for conformational B-cell epitope prediction. Brief Bioinform 2022, 23. [Google Scholar] [CrossRef] [PubMed]
- Liang, S.; Zheng, D.; Zhang, C.; Zacharias, M. Prediction of antigenic epitopes on protein surfaces by consensus scoring. BMC Bioinform. 2009, 10, 302–302. [Google Scholar] [CrossRef] [PubMed]
- Ponomarenko, J.V.; E Bourne, P. Antibody-protein interactions: benchmark datasets and prediction tools evaluation. BMC Struct. Biol. 2007, 7, 64–64. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.; Zhang, W. Databases for B-cell epitopes. Methods Mol Biol. 2014, 1184, 135–48. [Google Scholar] [PubMed]
- Berman, H.M.; et al. The Protein Data Bank. Nucleic Acids Res 2000, 28, 235–42. [Google Scholar] [CrossRef]
- Allcorn, L.C.; Martin, A.C.R. SACS—Self-maintaining database of antibody crystal structure information. Bioinformatics 2002, 18, 175–181. [Google Scholar] [CrossRef]
- Vita, R.; Zarebski, L.; Greenbaum, J.A.; Emami, H.; Hoof, I.; Salimi, N.; Damle, R.; Sette, A.; Peters, B. The Immune Epitope Database 2.0. Nucleic Acids Res. 2009, 38, D854–D862. [Google Scholar] [CrossRef]
- Ponomarenko, J.; Papangelopoulos, N.; Zajonc, D.M.; Peters, B.; Sette, A.; Bourne, P.E. IEDB-3D: structural data within the immune epitope database. Nucleic Acids Res. 2010, 39, D1164–D1170. [Google Scholar] [CrossRef]
- Saha, S.; Bhasin, M.; Raghava, G.P. Bcipep: A database of B-cell epitopes. BMC Genom. 2005, 6, 79–79. [Google Scholar] [CrossRef]
- Huang, J.; Honda, W. CED: a conformational epitope database. BMC Immunol. 2006, 7, 7–7. [Google Scholar] [CrossRef]
- Schlessinger, A. Epitome: database of structure-inferred antigenic epitopes. Nucleic Acids Res. 2006, 34, D777–D780. [Google Scholar] [CrossRef]
- Toseland, C.P.; Clayton, D.J.; McSparron, H.; Hemsley, S.L.; Blythe, M.J.; Paine, K.; A Doytchinova, I.; Guan, P.; Hattotuwagama, C.K.; Flower, D.R. AntiJen: a quantitative immunology database integrating functional, thermodynamic, kinetic, biophysical, and cellular data. Immunome Res. 2005, 1, 4–4. [Google Scholar] [CrossRef]
- Korber B, M.J. , Brander C, Koup R, Haynes B, Walker BD, HIV Molecular Immunology Database, T.B.a.B. Los Alamos National Laboratory, Editor. 1998: Los Alamos, New Mexico.
- Jespersen, M.C.; Mahajan, S.; Peters, B.; Nielsen, M.; Marcatili, P. Antibody Specific B-Cell Epitope Predictions: Leveraging Information From Antibody-Antigen Protein Complexes. Front. Immunol. 2019, 10, 298. [Google Scholar] [CrossRef]
- Sobolev, V.; Sorokine, A.; Prilusky, J.; E Abola, E.; Edelman, M. Automated analysis of interatomic contacts in proteins. Bioinformatics 1999, 15, 327–332. [Google Scholar] [CrossRef]
- Orengo, C.; Michie, A.; Jones, S.; Jones, D.; Swindells, M.; Thornton, J. CATH – a hierarchic classification of protein domain structures. Structure 1997, 5, 1093–1109. [Google Scholar] [CrossRef]
- Porollo, A.; Meller, J. Prediction-based fingerprints of protein-protein interactions. Proteins 2007, 66, 630–45. [Google Scholar] [CrossRef]
- Savojardo, C.; Fariselli, P.; Martelli, P.L.; Casadio, R. ISPRED4: interaction sites PREDiction in protein structures with a refining grammar model. Bioinformatics 2017, 33, 1656–1663. [Google Scholar] [CrossRef]
- Viswanathan, R.; et al. , Protein-protein binding supersites. PLoS Comput Biol 2019, 15, e1006704. [Google Scholar] [CrossRef]
- Walder, M.; Edelstein, E.; Carroll, M.; Lazarev, S.; Fajardo, J.E.; Fiser, A.; Viswanathan, R. Integrated structure-based protein interface prediction. BMC Bioinform. 2022, 23, 1–16. [Google Scholar] [CrossRef]
- Liang, S.; Zheng, D.; Standley, D.M.; Yao, B.; Zacharias, M.; Zhang, C. EPSVR and EPMeta: prediction of antigenic epitopes using support vector regression and multiple server results. BMC Bioinform. 2010, 11, 381–381. [Google Scholar] [CrossRef]
- Rubinstein, N.D.; Mayrose, I.; Martz, E.; Pupko, T. Epitopia: a web-server for predicting B-cell epitopes. BMC Bioinform. 2009, 10, 287–287. [Google Scholar] [CrossRef]
- Zhang, W.; Niu, Y.; Xiong, Y.; Zhao, M.; Yu, R.; Liu, J. Computational Prediction of Conformational B-Cell Epitopes from Antigen Primary Structures by Ensemble Learning. PLOS ONE 2012, 7, e43575. [Google Scholar] [CrossRef]
- Dunbar, J.; Krawczyk, K.; Leem, J.; Marks, C.; Nowak, J.; Regep, C.; Georges, G.; Kelm, S.; Popovic, B.; Deane, C.M. SAbPred: a structure-based antibody prediction server. Nucleic Acids Res. 2016, 44, W474–W478. [Google Scholar] [CrossRef]
- Fu, L.; Niu, B.; Zhu, Z.; Wu, S.; Li, W. CD-HIT: Accelerated for clustering the next-generation sequencing data. Bioinformatics 2012, 28, 3150–3152. [Google Scholar] [CrossRef]
- Zhou, C. , et al. SEPPA 3.0-enhanced spatial epitope prediction enabling glycoprotein antigens. Nucleic Acids Res 2019, 47, W388–W394. [Google Scholar] [CrossRef]
- Jespersen, M.C.; Peters, B.; Nielsen, M.; Marcatili, P. BepiPred-2.0: improving sequence-based B-cell epitope prediction using conformational epitopes. Nucleic Acids Res. 2017, 45, W24–W29. [Google Scholar] [CrossRef]
- Steinegger, M.; Söding, J. MMseqs2 enables sensitive protein sequence searching for the analysis of massive data sets. Nat. Biotechnol. 2017, 35, 1026–1028. [Google Scholar] [CrossRef]
- Clifford, J.N.; et al. BepiPred-3.0: Improved B-cell epitope prediction using protein language models. Protein Sci 2022, 31, e4497. [Google Scholar] [CrossRef]
- Qi, T.; Qiu, T.; Zhang, Q.; Tang, K.; Fan, Y.; Qiu, J.; Wu, D.; Zhang, W.; Chen, Y.; Gao, J.; et al. SEPPA 2.0—more refined server to predict spatial epitope considering species of immune host and subcellular localization of protein antigen. Nucleic Acids Res. 2014, 42, W59–W63. [Google Scholar] [CrossRef]
- Ansari, H.R.; Raghava, G.P. Identification of conformational B-cell Epitopes in an antigen from its primary sequence. Immunome Res. 2010, 6, 6–6. [Google Scholar] [CrossRef]
- Høie, M.H.; Gade, F.S.; Johansen, J.M.; Würtzen, C.; Winther, O.; Nielsen, M.; Marcatili, P. DiscoTope-3.0: improved B-cell epitope prediction using inverse folding latent representations. Front. Immunol. 2024, 15, 1322712. [Google Scholar] [CrossRef]
- Tubiana, J.; Schneidman-Duhovny, D.; Wolfson, H.J. ScanNet: an interpretable geometric deep learning model for structure-based protein binding site prediction. Nat. Methods 2022, 19, 730–739. [Google Scholar] [CrossRef]
- Shashkova, T.I.; Umerenkov, D.; Salnikov, M.; Strashnov, P.V.; Konstantinova, A.V.; Lebed, I.; Shcherbinin, D.N.; Asatryan, M.N.; Kardymon, O.L.; Ivanisenko, N.V. SEMA: Antigen B-cell conformational epitope prediction using deep transfer learning. Front. Immunol. 2022, 13, 960985. [Google Scholar] [CrossRef]
- Segura, J.; Jones, P.F.; Fernandez-Fuentes, N. Improving the prediction of protein binding sites by combining heterogeneous data and Voronoi diagrams. BMC Bioinform. 2011, 12, 352–352. [Google Scholar] [CrossRef]
- Wu, H.; Han, J.; Zhang, S.; Xin, G.; Mou, C.; Liu, J. Spatom: a graph neural network for structure-based protein–protein interaction site prediction. Briefings Bioinform. 2023, 24. [Google Scholar] [CrossRef]
- Vreven, T.; Moal, I.H.; Vangone, A.; Pierce, B.G.; Kastritis, P.L.; Torchala, M.; Chaleil, R.; Jiménez-García, B.; Bates, P.A.; Fernandez-Recio, J.; et al. Updates to the Integrated Protein–Protein Interaction Benchmarks: Docking Benchmark Version 5 and Affinity Benchmark Version 2. J. Mol. Biol. 2015, 427, 3031–3041. [Google Scholar] [CrossRef]
- Zeng, M.; Zhang, F.; Wu, F.-X.; Li, Y.; Wang, J.; Li, M. Protein–protein interaction site prediction through combining local and global features with deep neural networks. Bioinformatics 2019, 36, 1114–1120. [Google Scholar] [CrossRef]
- Gainza, P.; Sverrisson, F.; Monti, F.; Rodolà, E.; Boscaini, D.; Bronstein, M.M.; Correia, B.E. Deciphering interaction fingerprints from protein molecular surfaces using geometric deep learning. Nat. Methods 2019, 17, 184–192. [Google Scholar] [CrossRef]
- Yuan, Q.; Chen, J.; Zhao, H.; Zhou, Y.; Yang, Y. Structure-aware protein–protein interaction site prediction using deep graph convolutional network. Bioinformatics 2021, 38, 125–132. [Google Scholar] [CrossRef]
- Zhang, Q.C.; Deng, L.; Fisher, M.; Guan, J.; Honig, B.; Petrey, D. PredUs: a web server for predicting protein interfaces using structural neighbors. Nucleic Acids Res. 2011, 39, W283–W287. [Google Scholar] [CrossRef]
- Hu, Y.-J.; Lin, S.-C.; Lin, Y.-L.; Lin, K.-H.; You, S.-N. A meta-learning approach for B-cell conformational epitope prediction. BMC Bioinform. 2014, 15, 378. [Google Scholar] [CrossRef]
- Kulkarni-Kale, U.; Bhosle, S.; Kolaskar, A.S. CEP: a conformational epitope prediction server. Nucleic Acids Res. 2005, 33, W168–W171. [Google Scholar] [CrossRef]
- Sela-Culang, I.; Ashkenazi, S.; Peters, B.; Ofran, Y. PEASE: predicting B-cell epitopes utilizing antibody sequence. Bioinformatics 2014, 31, 1313–1315. [Google Scholar] [CrossRef]
- Krawczyk, K.; Liu, X.; Baker, T.; Shi, J.; Deane, C.M. Improving B-cell epitope prediction and its application to global antibody-antigen docking. Bioinformatics 2014, 30, 2288–2294. [Google Scholar] [CrossRef]
- Demolombe, V.; de Brevern, A.G.; Felicori, L.; Nguyen, C.; de Avila, R.A.M.; Valera, L.; Jardin-Watelet, B.; Lavigne, G.; Lebreton, A.; Molina, F.; et al. PEPOP 2.0: new approaches to mimic non-continuous epitopes. BMC Bioinform. 2019, 20, 1–14. [Google Scholar] [CrossRef]
- Zeng, X.; Bai, G.; Sun, C.; Ma, B. Recent Progress in Antibody Epitope Prediction. Antibodies 2023, 12, 52. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Shown at the top left is the unbound structure of hyaluron-glucosaminidase (PDB ID: 1FCQ) with the epitope residues shown as pink spheres. The epitope residue names and numbers are listed on the top right and shown bolded in red within the FASTA sequence. Based on the sequential proximity, the epitope is linear.
Figure 1.
Shown at the top left is the unbound structure of hyaluron-glucosaminidase (PDB ID: 1FCQ) with the epitope residues shown as pink spheres. The epitope residue names and numbers are listed on the top right and shown bolded in red within the FASTA sequence. Based on the sequential proximity, the epitope is linear.

Figure 2.
Shown at the top left is the unbound structure of integrin alpha-1 (PDB ID: 1CK4) with the epitope residues shown as pink spheres. The epitope residue names and numbers are listed on the top right and shown bolded in red within the FASTA sequence. Since the residues are only spatially proximal, the epitope is conformational.
Figure 2.
Shown at the top left is the unbound structure of integrin alpha-1 (PDB ID: 1CK4) with the epitope residues shown as pink spheres. The epitope residue names and numbers are listed on the top right and shown bolded in red within the FASTA sequence. Since the residues are only spatially proximal, the epitope is conformational.
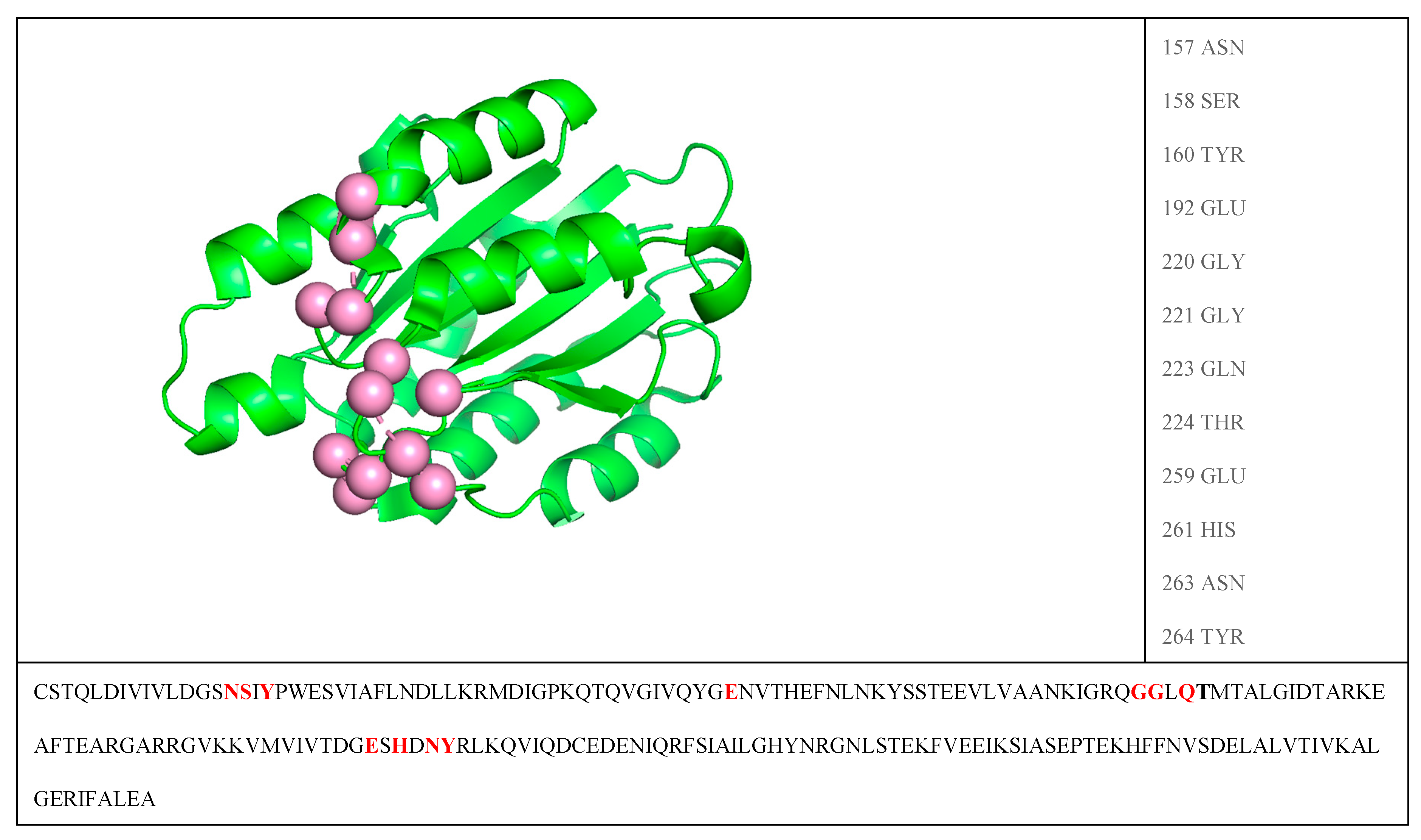
Figure 3.
Three distinct experimentally determined epitopes for human interleukin 6 (PDB ID: 1ALU) when complexed with (A) olokizumab, (B) camelid, and (C) Llama Fab fragment 68F2 antibodies with the epitope residues shown as pink spheres.
Figure 3.
Three distinct experimentally determined epitopes for human interleukin 6 (PDB ID: 1ALU) when complexed with (A) olokizumab, (B) camelid, and (C) Llama Fab fragment 68F2 antibodies with the epitope residues shown as pink spheres.
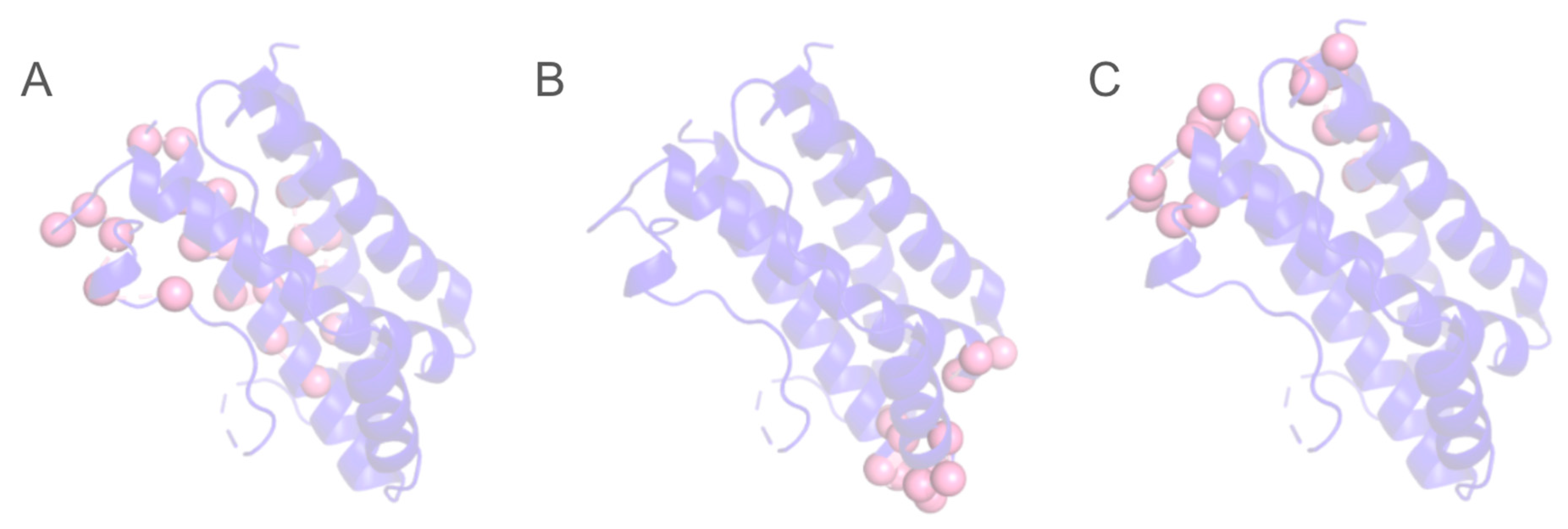
Figure 4.
Distribution of the number of residues among the 29 test set antigens. One antigen with 723 residues is not included in the figure.
Figure 4.
Distribution of the number of residues among the 29 test set antigens. One antigen with 723 residues is not included in the figure.
Figure 5.
CATH family classifications of test set antigens. CATH classifications were not available for all 29 antigens.
Figure 5.
CATH family classifications of test set antigens. CATH classifications were not available for all 29 antigens.

Table 1.
Comparison of <F1-score>, <MCC>, ROC-AUC, and PR-AUC determined on the test set with the surveyed computational methods.
Table 1.
Comparison of <F1-score>, <MCC>, ROC-AUC, and PR-AUC determined on the test set with the surveyed computational methods.
| ISPIPab | VORFFIP | DiscoTope 2.0 | DiscoTope 3.0 | EPSVR | Spatom | SEPPA 3.0 | BepiPred 3.0 | epitope3D | |
|---|---|---|---|---|---|---|---|---|---|
| <F1-score> | 0.312±0.16 | 0.192 ±0.18 | 0.133 ±0.17 | 0.241±0.16 | 0.162±0.21 | 0.161±0.17 | 0.179±0.14 | 0.241±0.16 | 0.109±0.10 |
| <MCC> | 0.230 ±0.17 | 0.090 ±0.18 | 0.017 ±0.19 | 0.143 ±0.17 | 0.054±0.23 | 0.048±0.19 | 0.067±0.18 | 0.145±0.17 | -0.015±0.09 |
| ROC-AUC | 0.77 | 0.66 | 0.47 | 0.75 | 0.56 | 0.64 | 0.65 | 0.71 | 0.59 |
| PR-AUC | 0.23 | 0.14 | 0.07 | 0.20 | 0.09 | 0.13 | 0.12 | 0.16 | 0.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



