
Submitted:
10 July 2024
Posted:
11 July 2024
You are already at the latest version
Abstract
Global climate change primarily affects the spatiotemporal variation of physical quantities such as relative humidity, atmospheric pressure, ambient temperature, and notably, precipitation levels. Accurate precipitation predictions remain elusive, necessitating tools for detailed spatiotemporal analysis to better understand climate impacts on the environment, agriculture, and society. This study compares three learning models: ARIMA (Autoregressive Integrated Moving Average), RF-R (Random Forest Regression), and LSTM-NN (Long Short-Term Memory Neural Network), utilizing monthly precipitation data (in millimeters) from 757 locations in Boyacá, Colombia. The LSTM-NN model outperformed others, precisely replicating precipitation observations in both training and testing datasets, significantly reducing the root mean square error (RMSE) with average monthly deviations of approximately 19 mm per location. Evaluation metrics (RMSE, MAE, R², MSE) underscore the LSTM model’s robustness and accuracy in capturing precipitation patterns. Consequently, the LSTM model was chosen to predict precipitation over a 16-month period starting from August 2023, offering a reliable tool for future meteorological forecasting and planning in the region.
Keywords:
deep learning
; climate change
; satellite imagery
; artificial intelligence
; precipitation
; remote sensing
1. Introduction
The emission of greenhouse gases attributed directly or indirectly to human activity is causing global climate change. These greenhouse gases are mainly composed of four gases: carbon dioxide (CO2), nitrous oxide (N2O), methane (CH4), and ozone (O3) [1]. One of the emissions that contributes most to climate change is (CO2) according to [2] energy-related (CO2) emissions (mainly produced by hydropower and natural gas) will rise by about 20% by 2035. This emission generates spatiotemporal variations of state variables such as humidity, pressure, and temperature, changes that directly affect the energy balance of the atmosphere, which defines the occurrence of rainfall or clear skies, which as expressed by [3] is expected to increase the greenhouse effect as the concentration of (CO2) in the atmosphere increases.
In Colombia, the IDEAM (Institute of Hydrology, Meteorology and Environmental Studies) knows climate change, indicating that throughout the 21st century, precipitation will increase towards the center and north of the Pacific region and decrease between 15% and 36% in the Caribbean and Andean regions. This prolonged increase in precipitation is reflected this year with permanent precipitation events and, according to [4], will persist until late 2022 and early 2023. This would mark the first "triple episode" La Niña of this century, spanning three consecutive northern hemisphere winters, corresponding to summer in the southern hemisphere. This project aims to implement a methodology to develop predictive models of total monthly precipitation using new cutting-edge technologies such as deep learning for water supply consumption in the department of Boyacá.
With the rise of artificial intelligence, the importance of massive data for science, and in particular geography, stands out. Remote sensing plays an important role, allowing the acquisition of images of the earth's surface from aerial or space sensors [5,6], which complements the acquisition of information from different sensors or meteorological devices necessary to know the spatiotemporal behavior of precipitation, such as surface weather stations, altitude stations, hundreds of weather radars in addition to some 200 research satellites among others [7], from the above, one can gain an idea of the magnitude of the global network of meteorological and hydrological observations. This abundance of information facilitates analysis, modelling, and prediction of this phenomenon by utilizing various emerging technologies focused on artificial intelligence, such as machine learning (ML) and deep learning (DL).
The effects of climate change have led to an increase in global precipitation, a phenomenon known as La Niña. This is particularly evident in Colombia, affecting the Andean, Pacific, and Caribbean regions. Figure 1(a) illustrates the recent occurrence of the third triple episode of La Niña (ENSO), which had a 70% probability of persisting until the end of March 2023. Forecasts indicated a 60% probability of an El Niño event from May through July 2023, with a 90% probability of continuing through October 2023, as shown in Figure 1(b). This leaves a 10% probability of an ENSO Neutral period and virtually no chance of another La Niña event by the end of October 2023.
Statistical and numerical applications are often not as effective in predicting precipitation accurately and timely, and although weather stations offer short-term predictions, forecasting long-term precipitation remains challenging [9,10]. Therefore, advancements are being made by integrating them with emerging technologies like artificial intelligence. For instance, [11] implemented machine learning and observed that the forecast was able to achieve a better precipitation prediction compared to a deviation between 46% and 91% experienced in June 2019 in India. This progress involves leveraging historical data and employing time series models to implement various machine learning (ML) and deep learning (DL) models, such as the OP-ELM algorithm, which demonstrated successful monthly rainfall predictions in China [12].
There are several versions of ML, as demonstrated by [13] in their study predicting the normalized precipitation index using monthly data from 1949 to 2013 at four meteorological stations. Techniques include M5tree, extreme learning machine (ELM), and online sequential ELM (OSELM). The ELM model made the best predictions for (months 3, 6, and 12) with the lowest root mean square error (RMSE) value, except for the predicted values for month 1, where the M5tree model obtained the best result.
DL is an emerging technique for dealing with complex systems such as the prediction of meteorological variables. Therefore, [14] proposes a hybrid DL approach, using a combination of one-dimensional convolutional neural network (Conv1D) and multilayer perceptron (MLP) (hereafter Conv1D-MLP) to predict precipitation applied to twelve different locations. This result is better and was compared with a support vector regression (SVM) machine learning approach. However, models with immediate rainfall prediction over large areas cannot yet be generated, so [15] proposes a dual-input, dual-encoder recurrent neural network (RNN) to predict rainfall threat within the next two hours in China, obtaining an accuracy of 52.3% within 30 min, 50.3% within 1 hour and 50% for 2 hours. Similarly, using 92 meteorological stations in China, [16] combines the surface altitude of the stations with the precipitation prediction, grouping by the k-means method as implemented by [17]; the stations surrounding the target, and employing a convolutional neural network (CNN) thus obtaining better results in existing threat index and mean squared error (MSE).
In Simtokha region, Bhutan [18] using rainfall data studied the predictive ability of a model based on bidirectional long-term memory with controlled recurrent unit (BLSTM-GRU). This model was compared with other existing models such as the linear regression method, MLP, CNN, long-term memory (LSTM), and controlled recurrent unit (GRU). The proposed model was the best among the other 5 models, outperforming the LSTM model by 41.1% with a score of 0.0128 mean squared error (MSE) value. Similarly, including georeferencing of weather stations, [19] uses sequences of weather radar measurements of hourly precipitation levels with RNN and LSTM models. This ensures that the training set is more or less independent in reducing the value of MSE and RMSE in the predictions.
When working with time series data, ensembles are trained to respect the ascending order of the data in time to generate the training and validation data partition. However, proposing a STConvS2S (Spatiotemporal Convolutional Sequence to Sequence Network) model DL architecture, [20] for training the model, does not respect the temporal order of the historical data and leaving the data sequence identical to the output sequence results in 23% better prediction to future sequences and 5 times faster training than the RNN-based model used as an evaluation benchmark. However, it is complicated to find the best method of modelling the precipitation variable and the different parameters surrounding it. For this reason, [9] evaluated a model in Australia based on ML optimized with DL to predict daily rainfall, and used GridSearchCV to find the best parameters for the different models over a daily span of 10 years from 2007 to 2017 from 26 geographically diverse rain gauge locations.
With the rise of ML and DL systems, remote sensing plays an important role since, according to [21], it allows the acquisition of terrestrial information from sensors installed on space platforms and the use of satellite images to perform multi-temporal analyses, understood as spatiotemporal changes [22,23]. In 2020, using a CNN model with different architectures such as (GoogLeNet, AlexNet, and LeNet, among others) [24] on 2D images as input precipitation data with three different heights: 100, 3000, and 5500 meters above sea level. The output variable is an image that indicates to which class it belongs, converting the model to a binary class defined by a rainfall probability threshold between 0 and 100%. The main result is that CNNs can predict precipitation with lower computational capacity than traditional methods [25]. Two data sources are used for training and testing the CNN model. The first was from CEH, and the second was GEAR (Centre for Ecology and Hydrology Gridded Estimate of Areal Rainfall), providing monthly rainfall across Britain between 1890 and 2017. The results obtained from video-based rainfall prediction using different CNN architectures can provide valuable post-processing to traditional numerical weather prediction models.
The main concern for researchers studying precipitation in different geographical areas and climates worldwide has been the selection of suitable ML or DL methods. Hence, [26 - 29] also presents various approaches to predict precipitation. Table 1 evaluates techniques such as the Lagrangian convolutional neural network (L-CNN), ELM model, LSTM model, Multilayer perceptron model (MLP), CNN model, and others.
Formulation of the research question
What computational elements are necessary to implement a predictive model supported by deep learning that facilitates the spatiotemporal analysis of the monthly total precipitation in the Department of Boyacá?
2. Materials and Methods
2.1. Dataset
The CHIRPS 2.0 dataset, though global, will be utilized to gather precipitation data specifically for the Boyacá department, Colombia. This dataset will be collected monthly and used exclusively to predict precipitation values in millimeters (mm). Thus, the primary focus of the project is the research and development of deep learning models, without an immediate practical application.
The results obtained will serve as a foundation and reference for the macro project "Application of Machine Learning in the Spatiotemporal Prediction of Total Monthly Precipitation in the Boyacá Department," identified by the code SGI 3535 and developed by the GALASH research group at the Pedagogical and Technological University of Colombia.
2.2. Methodology
2.2.1. Case Study
This project is currently underway in the Boyacá department, situated in the Andean region of central Colombia. Boyacá is well-known for its agricultural activity, emphasizing the importance of precipitation forecasting in decision-making related to agriculture and water resource management in the region. Figure 2 clearly illustrates the geographic location of Boyacá.
To implement methodologies for developing predictive models of total monthly precipitation using satellite images, we adapted the ML-OPS model methodology, as illustrated in Figure 3. This approach enhances the quality and coherence of the project solution by integrating artificial intelligence, ensuring rigorous quality control in model development and implementation. The process of implementing the models to be evaluated comprises the following stages:
- Step 1: Data Acquisition (ML)
During the background review, a dataset (CHIRPS) containing monthly precipitation information was identified in millimeters worldwide which has a size of 6.64GB with a spatial resolution of 0.05° (5.5Km), which includes 3 floating type data, Longitude (unit: degrees north), Latitude (unit: degrees east), precipitation (unit: mm) and a time type data (unit: yyyy/mm/dd). From this dataset geographic filtering was performed to obtain only the coordinates of the department of Boyacá with the following characteristics:
- Spatial resolution of 0.05° x 0.05° (5Km x 5Km).
- Data repositories of satellite images with information on precipitation, weather, and geographical coordinates.
- 2.
- Stage 2 Developmental Learning (DEV)
According to the literature, the algorithms that gave the best response in predictions were used, therefore, an LSTM-NN deep learning model was analyzed and compared with ARIMA time series and Regressive Random Forests (RF- regressive) machine learning algorithms, where: A training set with 387,584 observations was defined. The multivariate dataset was obtained as input using scaled data using the Sklearn Pre-processing Class.
MinMaxScaler which normalized the data so that a range from -1 to 1 was established, obtaining at the output a monthly precipitation value with scaled data in each of the geographic coordinates of the existing data, in addition to improving performance by tuning the hyperparameters according to the model evaluated, for example, in the ARIMA and RF-regression models, stationarity characteristics were evaluated.
A Dickey-Fuller (DF) test was performed on the time series to check whether the data exhibit a unit root autoregressive process [30], which indicates whether the model is stationary. Once the time series rejects the null hypothesis and the data are stationary, it confirms stationarity. On the other hand, the number of trees in the random forest is determined by evaluating the lowest RMSE value between 0 and 200 trees.
The models were evaluated using RMSE, MAE, MAPE, and R2 metrics (see equations 7, 8, 9, and 10), and it was determined which model achieved the best performance on the evaluation set and minimized the error. The selected model was then used to make predictions for 16 months, comprising the remaining 4 months of the year 2023 (September to December) and the 12 months of the year 2024.
- 3.
- Stage 3 Monitoring and Supervision (OPS)
Various tests are conducted on the models until hyperparameters are identified, which provide satisfactory results on both the training dataset and various test datasets. This is done to maximize the model's accuracy on the test set and continuously reduce residual errors in future predictions.
2.3. Evaluation Models
2.3.1. ARIMA Model (Autoregressive Integrated Moving Average)
It is a model used to predict future trends in time series and regression data. Introduced by Box and Jenkins in the 1970s, the ARIMA model forecasts the future value of a variable as a linear combination of past values and past errors [31]. It is expressed as follows: the autoregressive model order (p), differencing order (d), and the moving average model order (q) [32,33].
The ARIMA (p, d, q) model for time series {t = 1, 2, 3, n}
Where is the true value, t is the random error in time, and are the coefficients; p, d and q are the integers which are usually autoregressive, differenced and moving average polynomials respectively.
2.3.2. RF-R Model (Random Forest Regression Model)
It is a classifier structured as a tree. Given the set of classifiers {h (Xξk), k = 1}, where each (ξk) is independent, this model relies on a combination of tree predictors. These predictors depend on the values of an independently sampled random vector. Each tree makes a decision and outputs a unit vote for the class [34]. Finally, the results of the random subsets created are averaged and a prediction value is obtained as shown in Figure 4.
2.3.3. LSTM Model (Long Short-time Memory Neural Network)
The LSTM model was first proposed by Hochreiter and Schmidhuber in 1997, and has since become particularly renowned as one of the best time series prediction methods [35] In its design, the LSTM model comprises gating units and memory cells of a neural network. These memory cells store recent data, and when new information arrives, it is controlled by the combination of the cell state, which is then updated. Each time new information is received by the memory cell, the output is processed with this new information. The LSTM network is particularly effective for long-term problems, as it can retain information over extended periods. Its structure includes two tanh layers, as depicted in Figure 5.
The LSTM model can selectively exclude data from the cell through its gate structures, as these gates control whether data enters the cell or not. The gates are governed by the sigmoid function, which generates values ranging from 0 to 1. A value of 0 indicates that "nothing happens," while a value of 1 signifies that "everything happens" [37].
The gating mechanism is implemented using the sigmoid function and dot product operation (refer to equation 2). There are three types of gates utilized in LSTM networks: the update gate, the forget gate, and the output gate, as identified in equations 3, 4, and 5 [35,36]. These gates facilitate the flow of information from one cell to another. Consequently, the LSTM cell produces two outputs: the activation and the candidate value, as illustrated in equation 6.
Where σ is the sigmoid function, and the expression is .
2.4. Evaluation Metrics
2.4.1. Root Mean Squared Error (RMSE)
It is the error between the distance of the residual values in the prediction and their actual value.
2.4.2. Mean Absolute Error (MAE)
It is an average error of absolute differences between the prediction and its actual value, being less sensitive to outliers.
2.4.3. Mean Absolute Percentage Error (MAPE)
It is a percentage error between the predicted value and the actual values and gives a scale-independent view of the error.
2.4.4. R Square (R2)
It is the percentage of accuracy between the predicted measurement and the actual measurement.
3. Results
In surveying and geography, spatial analysis is a widely used technique for collecting information from specific sampling points. Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS), which integrates infrared precipitation data with station data, was used for this project. This dataset was developed by the Climate Hazards Group at the University of California, Santa Barbara [38].
The CHIRPS dataset provides more than 35 years of comprehensive and accurate precipitation information worldwide. For this study, infrared precipitation data were extracted from January 1981 to August 2023 for Boyacá Department. The data were acquired at a resolution of 0.05°, with each degree corresponding to 111.1 km, resulting in a data acquisition resolution of approximately 5.5 km.
Using tools such as Python [39], Google Collaboratory [40], TensorFlow [41], Keras [42], Matplotlib [43], among others, the project was developed as follows:
3.1. Data Set Acquisition
The downloaded dataset was processed in the netcdf (.nc) format, containing monthly precipitation records worldwide, spanning 43 years and 8 months, with 3 variables: longitude, latitude, and precipitation in (mm), along with a time variable indicating the date of measurement in datetime [ns] format. This format enables manipulation of the dates and times at which the data was collected, as illustrated in Figure 6. It provides the dataset with the spatiotemporal focus required for predicting precipitation, comprising a total of 387,584 observations.
The coordinates were utilized to filter the CHIRPS precipitation data for Boyacá, Colombia, using the department's polygon. Subsequently, the dataset was organized to visualize the spatiotemporal dimension for climate analysis through time, as depicted in Figure 7, illustrating the spatiotemporal precipitation of Boyacá in the year 2022.
An analysis of historical precipitation values from 2020 to 2023 was conducted using box plots, presenting quantitative distribution through quartiles, as shown in Figure 8. Based on the acquired and organized stationary precipitation data, along with statistical analysis, patterns, trends, and relationships between the dataset's characteristics can be identified. According to [44], the box plot facilitates the establishment of relationships between samples and the identification of outliers.
Examining the distribution of precipitation in Boyacá, it is noted that in the year 2020, the maximum precipitation occurred in October, reaching approximately 500 mm. This value may suggest a geographic point with significant monthly rainfall, such as a moor or an outlier within the dataset for that year. Upon investigating outliers, it is found that the coordinates corresponding to latitude: 7.024998, longitude: -72.125008, located in the municipality of Cubará, Boyacá, northeast of the region, experience high rainfall, indicating it is not an outlier but rather a location with a high probability of precipitation.
In 2021, the dry season months (January to March) did not exceed an average of 100 mm of monthly rainfall, although March saw rainfall exceeding 200 mm. The rainy season, averaging between 150 and 200 mm, persisted from April to October, with October being the wettest month, recording rainfall over 400 mm.
In 2022, the effects of climate change were evident, with precipitation values from May to November surpassing 500 mm per month at evaluated points in Boyacá. In November, data exceeded 700 mm per month, representing an increase compared to previous years when precipitation values did not exceed 400 mm.
For 2023, rainfall ranged between 150 mm and a maximum of 300 mm until March. From April to October, the El Niño phenomenon was expected, resulting in decreased departmental precipitation, averaging 200 mm per month. This analysis indicates that the dry season occurs between January and March, with December having moderate rainfall. Months with average rainfall are between April and August, while the highest rainfall occurs from September to November, with October experiencing the highest rainfall in the last two years, 2021 and 2022.
3.2. Development of Predictive Models
The results of the ARIMA, RFR and LSTM models are presented below.
3.2.1. Design Model Arima
A Dickey-Fuller (DF) test was conducted on the time series to determine whether the data adhere to a unit root autoregressive process [30], indicating the stationarity of the model. Once the time series rejects the null hypothesis and the data are stationary, the dataset is divided, with 70% allocated for training and the remaining 30% for testing. Precipitation is selected as the target variable. The best model for the training set is identified as the autoregressive and differenced ARIMA model (4,1,0) (2,1,0) (12), lacking moving average characteristics (i.e., a stationary model), with 4 lag observations in the autoregressive model and 1 degree of differencing.
Finally, the model's predictions were evaluated, achieving an 81% similarity to the observed precipitation in both the training and test datasets, with residual errors averaging 27.98 mm compared to the actual measurements. The error trend across most data points exhibited a mean of zero and a uniform variance, although there were instances where the residual error exceeded 200 mm, as illustrated in Figure 9.
3.2.2. Random Forest Regression Design
In this model, seasonal variables of year and month are included in each observation of the input dataset. Additionally, one year's worth of data has been included for each observation. Consequently, a dataset with 17 variables (latitude, longitude, precipitation, year, month, L1, ..., L12) was obtained, where precipitation serves as the target variable and the other variables act as labels for prediction.
Seventy percent of the data was allocated for training, with the remaining 30 percent reserved for model evaluation. A Random Forest regression model with 83 decision trees was created. This specific number of trees was chosen as it produced the lowest RMSE value among the 0 to 205 trees evaluated, as shown in Figure 10.
The study achieved an 87% similarity between the model's precipitation predictions and the observations from the training and test datasets. When plotting the model's response against the test dataset, it was observed that the predictions closely matched the actual behavior in most instances. However, there were a few outliers where the predictions deviated by approximately 12 mm from the actual values, resulting in an overall error of 23.21 mm, as illustrated in Figure 11.
3.2.3. LSTM-NN Model Design
Several training runs were conducted for the LSTM model, exploring different hyperparameter values. The best model achieved included a sequential class instance with 128 memory units in the hidden layers, utilizing a linear activation function and a mean squared error (MSE) loss function, with a learning rate set to RMSprop. Seventy percent of the data was allocated for training, with the remaining 30 percent reserved for model evaluation.
Furthermore, validation for overfitting was performed on the training and test datasets, as illustrated in Figure 12. Upon converting the predictions to full scale, the LSTM model demonstrated 92% effectiveness in reproducing the precipitation values of the dataset. This resulted in a 16-percentage point reduction in residual error compared to the Random Forest Regression (RF-R) model. Additionally, the LSTM model showed a decrease in the number of significant errors, with only a few iterations exhibiting values above 100 mm and one instance with approximately 200 mm, as shown in Figure 13.
In the evaluation metrics, three models were compared: the ARIMA model, the LSTM-NN model, and the Random Forest Regressor. The ARIMA model demonstrated efficiency but exhibited 10% lower reliability in predictions compared to the LSTM-NN model, as detailed in Table 2. Additionally, the root mean square error (RMSE) of the ARIMA model was more than 10% higher than that of the other two evaluated models. Consequently, the LSTM-NN emerged as the best model for reproducing observations from the dataset, with an error rate of 0.8% and a superior RMSE metric compared to the second-best model, the Random Forest Regressor. The monthly precipitation errors, whether above or below the actual measurements, were approximately 10 mm.
Based on the evaluated results, the LSTM-NN model emerges as the most effective in reproducing precipitation observations from both the training and test datasets. Consequently, this model was implemented to predict the next 48 months, starting from the last month, which is August 2023.
3.3. LSTM-NN Model Implementation
The implementation was based on the LSTM-NN model capturing spatiotemporal patterns of monthly precipitation data for the Boyacá Department with the following architecture:
- LSTM layer with 128 hidden units
The decision to use an LSTM layer with 128 units was based on its ability to yield the best results, leading to an improvement in the RMSE value. It's worth noting that increasing the number of hidden layers in the model tends to result in more accurate predictions. However, it's important to exercise caution, as the number of layers determines the amount of information the layer can learn. Therefore, there is a risk of overfitting the training and test data if this number is increased excessively.
- Rectified Linear Unit (ReLu) activation function
This function was used so that training would be fast, so that there would be no saturation, as occurs with functions such as sigmoidal and hyperbolic tangent, and it is computationally simpler to implement.
- Dense output layer
The objective of the prediction is to perform a regression, therefore a dense layer with a unit is used, being the prediction on the precipitation variable.
- Adam Optimizer (Adaptive Moment Estimation)
It is a method to accelerate the training of neural networks and achieve a near-linear acceleration rate with the increase of computational nodes [45]. It was selected to speed up the LSTM model, as it can adapt to learning each parameter individually and can lead to lower prediction error compared to other algorithms.
- Loss Function Mean Squared Error (MSE)
The MSE loss function gives more importance to large errors or outliers by providing a quadratic loss function as it squares and subsequently averages the values. This method is used in many identifications, prediction and optimal filtering applications [46].
- Sliding windows method
A sliding window approach was employed, wherein several previous months (t+n) were used to make predictions. This concept, known as sliding windows, is utilized to repair the input data for the training model. Subsequently, an algorithm was developed to construct a dataset comprising n number of previous months, with the output obtained for k following months using the architecture of the LSTM model mentioned above (refer to Figure 14).
The Sliding Windows model significantly enhances the accuracy of short-term monthly precipitation prediction when utilizing deep long-term memory (LSTM) recurrent neural networks, which segment the input data [47]. In this project, the 48-month window size was reconsidered to account for the El Niño and La Niña phenomena present in the region. Therefore, a 48-month window was established to predict at (t+16), commencing the first prediction in September 2023 for each dataset and concluding in December 2024. The process, detailing the handling of training data windows, is illustrated in Figure 15.
The dataset contains a total of 757 geographical points of latitude and longitude of the Boyacá department. Once validated, the model was trained and run-on Google Collaboratory, which has the advantage of running Python 3 code in a runtime environment that uses T4 GPU hardware acceleration and high RAM capacity. A CSV-type dataset was generated with columns: latitude, longitude, time and precipitation prediction in millimeters (mm), which allows the generation of heat maps and box plots for each month.
3.3.1. LSTM-NN Forecast with 48-Month Window
The training of this model was conducted in Google Collaboratory, following the specified configurations and utilizing 100 epochs, lasting approximately 2 hours.
Figure 16 illustrates the spatiotemporal precipitation data and values represented in box plots obtained for the 4 remaining months of the year 2023, starting in September. The data indicates that precipitation for September does not exceed 150 mm per month for the entire department of Boyacá, a value very close to the average precipitation for this month. The box plots provide a clearer visualization of the precipitation values, showing that the distribution of precipitation in September 2023 will range between 10 and 80 mm per month, with a maximum of 100 mm.
Furthermore, the months of October to December exhibit an average precipitation of 180 to 200 mm in most parts of the department. However, precipitation values reach up to 500 mm in November in the northeast and southeast parts of the department, coinciding with the second winter period of the year in Boyacá.
For October to December 2023, it is observed that municipalities in the central region and those near the border with the Santander Department tend to experience relatively dry conditions, with monthly precipitation not exceeding 180 mm. However, municipalities located at the extremes and borders with departments the Antioquia, Caldas, Cundinamarca, and Norte Santander are expected to experience a gradual increase in precipitation from September to December, with anticipated values ranging from 300 mm to 600 mm, respectively
Similarly, the spatiotemporal prediction of precipitation for the year 2024 was conducted, revealing, as depicted in Figure 17, an expectation of low to moderate rainfall between 100 and 300 mm for January and February, with some outlier data exceeding 450 mm. In March, rainfall is anticipated to decrease to between 100 and 190 mm, with a maximum of 290 mm, and some outlier data not exceeding 350 mm.
April, May, and June are forecast to be the driest months, despite April and May being winter months, with expected rainfall between 50 and 100 mm per month, reaching maximums of 200 mm across all three months. In July, rainfall is anticipated to return to low to moderate levels, similar to the beginning of the year, ranging between 180 and 290 mm, with outliers exceeding 450 mm. August is expected to be the month with the highest rainfall, with intense rainfall predicted between 300 and 500 mm, and some municipalities in the department may experience maximums of up to 700 mm. Rainfall is forecasted to decrease during the last four months of the year, with expected low rainfall ranging between 100 and 250 mm per month. In the north-eastern and south-eastern parts of the department, rainfall may range between 350 and 400 mm per month.
4. Discussion
The ARIMA, Random Forest regression, and LSTM models yielded favorable results when evaluating the RMSE, MAE, and R2 metrics, as summarized in Table 2. Of these, the neural network with long-term memory (LSTM) emerged as the best model for predicting time series with precipitation and location data. It achieved predictions closely aligned with real data and improved prediction accuracy for different outliers, resulting in high residual error values. The visualization of prediction results is crucial for decision-making and preventive measures across various fields. Heat maps depicting monthly rainfall patterns at different points within the department of Boyacá enable the identification of months with the most intense precipitation (La Niña phenomenon), as well as moderate and dry months (El Niño phenomenon) in the 123 municipalities of Boyacá.
According to the spatiotemporal precipitation prediction maps obtained by the LSTM model, in September 2023, there will be minimal rainfall, with maximum data reaching 100 mm. From October to December, there will be low to moderate rainfall in the municipalities closest to the department's borders, not exceeding 200 mm. This trend is expected to continue until March 2024, with values ranging between 200 and 300 mm maximum. These levels will decrease from March until May, with the three months predicted to have the least rainfall for 2024, with precipitation values of 100 mm and maximums of 200 mm. In July, moderate rainfall is forecasted between 180 and 280 mm monthly, similar to the beginning of the year, and it will increase in August, which is expected to be the wettest month, ranging from 300 to 450 mm, with maximums reaching 700 mm at the department’s borders. Finally, rainfall will decrease with an average value of 170 mm per month from September to December, similar to the beginning of the year.
The impact of Boyacá's topography influences rainfall prediction, as 24% of Colombia's paramo areas are located in the department of Boyacá. Therefore, to identify mountainous areas, valleys, or plains, it is suggested to include a topography control as a variable or label for model training to improve prediction accuracy and decrease errors.
It was possible to design and implement the prediction with the windows method for the training dataset with the deep learning model LSTM-NN, which allowed making predictions of precipitation for the department of Boyacá for 16 months, corresponding to September 2023 to December 2024. These predictions are visualized in heat maps that allow the identification of monthly precipitation patterns in the region and also in box plots that, with a statistical format, fulfill the purpose of showing the minimum, maximum, and average precipitation values for each month to be analyzed. This visualization is appropriate as it can facilitate decision-making in different areas such as planning water management in the municipalities, planning the sowing of the different crops produced in the department, or mitigating drought catastrophes for the coming months.
For future work, it may be beneficial to consider combining models to reduce residual errors and increase accuracy. Additionally, including the variable altitude could be explored further, as Colombia's geography contains both mountainous and flat areas, which can significantly influence intense or low rainfall in the model. Furthermore, the results of this project enable the adaptation of this model to generate predictions for any geographical area of the country, simply by identifying the geographical area to be analyzed.5.
5. Conclusions
The evaluation of the ARIMA, Random Forest regression, and LSTM models was conducted to determine the most effective approach for precipitation forecasting. The LSTM-NN model emerged as the most accurate for predicting precipitation in Boyacá over the next 4 to 12 months, covering the period from September 2023 to August 2024. Consequently, the design and implementation of precipitation predictions using the sliding window method on the training dataset were successfully achieved with the LSTM-NN deep learning model.
The dataset used for this project was derived from the Climate Hazards Group InfraRed Precipitation with Station data (CHIRPS), which integrates infrared precipitation data with station data. This dataset, developed by the Climate Hazards Group at the University of California, Santa Barbara, was crucial for ensuring the accuracy and completeness of the predictions.
The predictions are presented through heat maps and box plots, facilitating the identification of monthly precipitation patterns in the region. These visualizations provide essential statistical information, such as minimum, maximum, and mean precipitation values for each month. This innovative data visualization and interpretation approach has enabled an effective analysis of the predictions, offering crucial insights for decision-making across various domains. These include water management planning in municipalities, scheduling crop planting cycles, and mitigating potential drought or flood catastrophes in the coming months.is section is not mandatory but can be added to the manuscript if the discussion is unusually long or complex.
Author Contributions
Conceptualization, Johann.Niño., Marco.Suarez.; methodology, Johann.Niño.; software, Johann.Niño.; validation, Johann.Niño., Marco.Suarez. and José.Reyes.; formal analysis, Johann.Niño.; investigation, Johann.Niño.; resources, Johann.Niño., Marco.Suarez. and José.Reyes.; data curation, Johann.Niño.; writing—original draft preparation, Johann.Niño.; writing—review and editing, Johann.Niño., Marco.Suarez.; visualization, Johann.Niño.; supervision, Marco.Suarez.; project administration, Marco.Suarez. All authors have read and agreed to the published version of the manuscript.” Please turn to the CRediT taxonomy for the term explanation. Authorship must be limited to those who have contributed substantially to the work reported.
Funding
This study was supported by the Pedagogical and Technological University of Colombia SGI 3535 research project.
Data Availability Statement
The datasets used for training and testing, the processes developed for each algorithm, and the graphs of the results obtained in this study can be found in the GitHub repository: https://github.com/S4ntiago14/Rainfall_Boyaca.git. The repository includes scripts for data preprocessing, model training, and results visualization, ensuring transparency and reproducibility of our research findings.
References
- Mohibullah, Imdadullah, and I. Ashraf, “Estimation of CO2 mitigation potential through renewable energy generation,” First International Power and Energy Conference, (PECon 2006) Proceedings, no. i, pp. 24–29, 2006. [CrossRef]
- R. H. Mabel and Y. U. Lopez, “Strategies of Environmental Management to Eliminate the Carbon Footprint Generated by the use of Conventional Energies in a Hospital Institution Level 4,” 2018 IEEE ANDESCON, ANDESCON 2018 - Conference Proceedings, 2018. [CrossRef]
- F. A. Adame Erazo, H. Fernando, C. Silva, F. Trejo Zárraga, K. Lizeth, and R. Bohórquez, “Air pollution scenarios generated by solid waste management: a current challenge in the department of Boyacá, Colombia.” [Online]. Available: https://orcid.
- © 2022 Organización Meteorológica Mundial (OMM) Instituto Internacional de Investigación sobre el Clima y la Sociedad (IRI), “El Niño/La Niña Hoy,” https://public.wmo.int/es/el-ni%C3%B1ola-ni%C3%B1a-hoy.
- J. G. Puebla, “Big data and new geographies: The digital footprint of human activity,” Doc Anal Geogr, vol. 64, no. 2, pp. 195–217, 2018. [CrossRef]
- L. Rodriguez, “Teledetección ambiental: La observación de la Tierra desde el Espacio.,” Entorno Geográfico, Mar. 2016. [CrossRef]
- © 2022 Organización Meteorológica Mundial (OMM), “Organización Meteorológica Mundial,” El cambio climático pone en riesgo la seguridad energética. https://www.portalambiental.com.mx/sabias-que/20221012/el-cambio-climatico-pone-en-riesgo-la-seguridad-energetica-del-mundo.
- “Situación actual y perspectivas.” [Online]. Available: https://public.wmo.int/es/acerca-de-la-omm/miembros.
- M. Raval, P. Sivashanmugam, V. Pham, H. Gohel, A. Kaushik, and Y. Wan, “Automated predictive analytics tool for rainfall forecasting,” Sci Rep, vol. 11, no. 1, Dec. 2021. [CrossRef]
- H. Zhang, H. A. Loáiciga, F. Ren, Q. Du, and D. Ha, “Semi-empirical prediction method for monthly precipitation prediction based on environmental factors and comparison with stochastic and machine learning models,” Hydrological Sciences Journal, pp. 1928–1942, 2020. [CrossRef]
- M. S. Balamurugan and R. Manojkumar, “Study of short-term rain forecasting using machine learning based approach,” Wireless Networks, vol. 27, no. 8, pp. 5429–5434, Nov. 2021. [CrossRef]
- H. Li, Y. He, H. Yang, Y. Wei, S. Li, and J. Xu, “Rainfall prediction using optimally pruned extreme learning machines,” Natural Hazards, vol. 108, no. 1, pp. 799–817, Aug. 2021. [CrossRef]
- Z. M. Yaseen, M. Ali, A. Sharafati, N. Al-Ansari, and S. Shahid, “Forecasting standardized precipitation index using data intelligence models: regional investigation of Bangladesh,” Sci Rep, vol. 11, no. 1, Dec. 2021. [CrossRef]
- M. I. Khan and R. Maity, “Hybrid Deep Learning Approach for Multi-Step-Ahead Daily Rainfall Prediction Using GCM Simulations,” IEEE Access, vol. 8, pp. 52774–52784, 2020. [CrossRef]
- F. Zhang, X. Wang, J. Guan, M. Wu, and L. Guo, “Rn-net: A deep learning approach to 0–2 h rainfall nowcasting based on radar and automatic weather station data,” Sensors, vol. 21, no. 6, pp. 1–14, Mar. 2021. [CrossRef]
- P. Zhang, W. Cao, and W. Li, “Surface and high-altitude combined rainfall forecasting using convolutional neural network,” Peer Peer Netw Appl, vol. 14, no. 3, pp. 1765–1777, May 2021. [CrossRef]
- H. Xie, L. Wu, W. Xie, Q. Lin, M. Liu, and Y. Lin, “Improving ECMWF short-term intensive rainfall forecasts using generative adversarial nets and deep belief networks,” Atmos Res, vol. 249, Feb. 2021. [CrossRef]
- M. Chhetri, S. Kumar, P. P. Roy, and B. G. Kim, “Deep BLSTM-GRU model for monthly rainfall prediction: A case study of Simtokha, Bhutan,” Remote Sens (Basel), vol. 12, no. 19, pp. 1–13, Oct. 2020. [CrossRef]
- T. Aditya Sai Srinivas, R. Somula, K. Govinda, A. Saxena, and A. Pramod Reddy, “Estimating rainfall using machine learning strategies based on weather radar data,” International Journal of Communication Systems, vol. 33, no. 13, Sep. 2020. [CrossRef]
- R. Castro, Y. M. Souto, E. Ogasawara, F. Porto, and E. Bezerra, “STConvS2S: Spatiotemporal Convolutional Sequence to Sequence Network for weather forecasting,” Neurocomputing, vol. 426, pp. 285–298, Feb. 2021. [CrossRef]
- Y. Poveda-Sotelo, M. A. Bermúdez-Cella, and P. Gil-Leguizamón, “Evaluation of supervised classification methods for the estimation of spatiotemporal changes in the Merchán and Telecom paramos, Colombia,” Boletin de Geologia, vol. 44, no. 2, pp. 51–72, 2022. [CrossRef]
- V. Barraza et al., “Monitoring and modeling land surface dynamics in Bermejo River Basin, Argentina: Time series analysis of MODIS and AMSR-E data,” in 2012 IEEE International Geoscience and Remote Sensing Symposium, 2012, pp. 6408–6411. [CrossRef]
- V. Maggioni, E. I. Nikolopoulos, E. N. Anagnostou, and M. Borga, “Modeling satellite precipitation errors over mountainous terrain: The influence of gauge density, seasonality, and temporal resolution,” IEEE Transactions on Geoscience and Remote Sensing, vol. 55, no. 7, pp. 4130–4140, Jul. 2017. [CrossRef]
- O. Micolini, L. O. Ventre, A. Martina, R. E. Ayme, N. J. Ortmann, and B. G. Trejo, “A data-driven approach to weather forecast using convolutional neural networks,” in 2020 IEEE Congreso Bienal de Argentina, ARGENCON 2020 - 2020 IEEE Biennial Congress of Argentina, ARGENCON 2020, Institute of Electrical and Electronics Engineers Inc., Dec. 2020. [CrossRef]
- A.P. Barnes, T. R. Kjeldsen, and N. McCullen, “Video-Based Convolutional Neural Networks Forecasting for Rainfall Forecasting,” IEEE Geoscience and Remote Sensing Letters, vol. 19, 2022. [CrossRef]
- J. Ritvanen, B. Harnist, M. Aldana, T. Makinen, and S. Pulkkinen, “Advection-Free Convolutional Neural Network for Convective Rainfall Nowcasting,” IEEE J Sel Top Appl Earth Obs Remote Sens, vol. 16, pp. 1654–1667, 2023. [CrossRef]
- M. Bouaziz, E. Medhioub, and E. Csaplovisc, “A machine learning model for drought tracking and forecasting using remote precipitation data and a standardized precipitation index from arid regions,” Journal of Arid Environments, vol. 189. Academic Press, Jun. 01, 2021. [CrossRef]
- C. Z. Basha, N. Bhavana, P. Bhavya, and S. V, “Rainfall Prediction using Machine Learning & Deep Learning Techniques,” in 2020 International Conference on Electronics and Sustainable Communication Systems (ICESC), 2020, pp. 92–97. [CrossRef]
- H. A. Y. Ahmed and S. W. A. Mohamed, “Rainfall Prediction using Multiple Linear Regressions Model,” in Proceedings of: 2020 International Conference on Computer, Control, Electrical, and Electronics Engineering, ICCCEEE 2020, Institute of Electrical and Electronics Engineers Inc., Feb. 2021. [CrossRef]
- E. Lizarazu-Alanez and J. A. Villaseñor-Alva, “efectos de rompimientos bajo la hipótesis nula de la prueba dickey-fuller para raíz unitaria effects of breaks under the null hypothesis with the dickey-fuller test for unit root.”, Agrociencia vol.41 no.2 Texcoco feb./mar. 2007.
- A. A. Adebiyi, A. O. Adewumi, and C. K. Ayo, “Stock price prediction using the ARIMA model,” in Proceedings - UKSim-AMSS 16th International Conference on Computer Modelling and Simulation, UKSim 2014, Institute of Electrical and Electronics Engineers Inc., 2014, pp. 106–112. [CrossRef]
- Y. Du, “Application and analysis of forecasting stock price index based on combination of ARIMA model and BP neural network,” in 2018 Chinese Control And Decision Conference (CCDC), 2018, pp. 2854–2857. [CrossRef]
- X. Zhu and M. Shen, “Based on the ARIMA model with grey theory for short term load forecasting model,” in 2012 International Conference on Systems and Informatics (ICSAI2012), 2012, pp. 564–567. [CrossRef]
- L. Breiman, “Random Forests,” Mach Learn, vol. 45, no. 1, pp. 5–32, 2001. [CrossRef]
- S. Hochreiter and J. Schmidhuber, “Long Short-Term Memory,” Neural Comput, vol. 9, no. 8, pp. 1735–1780, Nov. 1997. [CrossRef]
- M. A. Istiake Sunny, M. M. S. Maswood, and A. G. Alharbi, “Deep Learning-Based Stock Price Prediction Using LSTM and Bi-Directional LSTM Model,” in 2nd Novel Intelligent and Leading Emerging Sciences Conference, NILES 2020, Institute of Electrical and Electronics Engineers Inc., Oct. 2020, pp. 87–92. [CrossRef]
- A. Wang and C. Ren, “Prediction of receiving field strength based on SVM-LSTM hybrid model in the coal mine,” in 2021 IEEE 3rd International Conference on Communications, Information System and Computer Engineering, CISCE 2021, Institute of Electrical and Electronics Engineers Inc., May 2021, pp. 813–816. [CrossRef]
- Climate Hazards Center UC Santa Barbara Santa Barbara, “CHIRPS: Rainfall Estimates from Rain Gauge and Satellite Observations,” https://data.chc.ucsb.edu/products/CHIRPS-2.0/.
- Python Software Foundation, “Python.” Accessed: May 12, 2024. [Online]. Available: https://www.python.org/.
- Google Research, “Colaboratory.” Accessed: May 12, 2024. [Online]. Available: https://colab.research.google.com/.
- Google Research, “TensorFlow.” Accessed: May 12, 2024. [Online]. Available: https://www.tensorflow.org/.
- Keras Authors, “Keras.” Accessed: May 12, 2024. [Online]. Available: https://keras.io/.
- Matplotlib Development Team, “Matplotlib.” Accessed: May 12, 2024. [Online]. Available: https://matplotlib.org/.
- C. Thirumalai, I. Member, and A. Professor Senior, “Data analysis using Box and Whisker plot for Stationary shop analysis”. [CrossRef]
- R. N. Singarimbun, E. B. Nababan, and O. S. Sitompul, “Adaptive Moment Estimation to Minimize Square Error in Backpropagation Algorithm,” in 2019 International Conference of Computer Science and Information Technology, ICoSNIKOM 2019, Institute of Electrical and Electronics Engineers Inc., Nov. 2019. [CrossRef]
- S. Dash and S. R. Das, “Analysis of BER and MSE performance in nonlinear equalization using modified recurrent network,” in IET Chennai Fourth International Conference on Sustainable Energy and Intelligent Systems (SEISCON 2013), 2013, pp. 292–296. [CrossRef]
- V. Urošević y S. Dimitrijević; “Optimum input sequence size for a sliding window-based LSTM neural network used in short-term electrical load forecasting,” in 2021 29th Telecommunications Forum (TELFOR), 2021, pp. 1–4. [CrossRef]
Figure 1.
Probability of La Niña and El Niño (ENSO) Occurrence from 2022 to 2023 (a) The probability of occurrence of La Niña phenomenon "ENSO” 2022 to March 2023; (b) the probability of occurrence of El Niño "ENSO" April 2023 to October 2023. Taken from: [8].
Figure 1.
Probability of La Niña and El Niño (ENSO) Occurrence from 2022 to 2023 (a) The probability of occurrence of La Niña phenomenon "ENSO” 2022 to March 2023; (b) the probability of occurrence of El Niño "ENSO" April 2023 to October 2023. Taken from: [8].
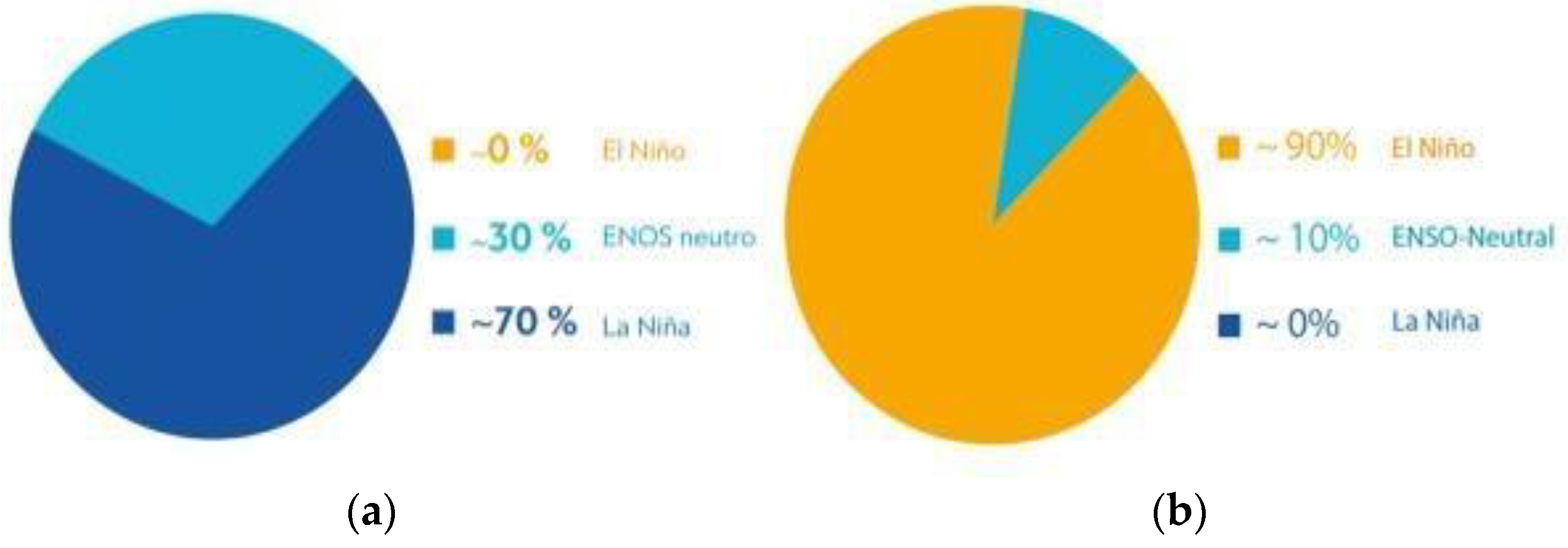
Figure 2.
Geographic location of the Boyacá department. Source: Author (2023).
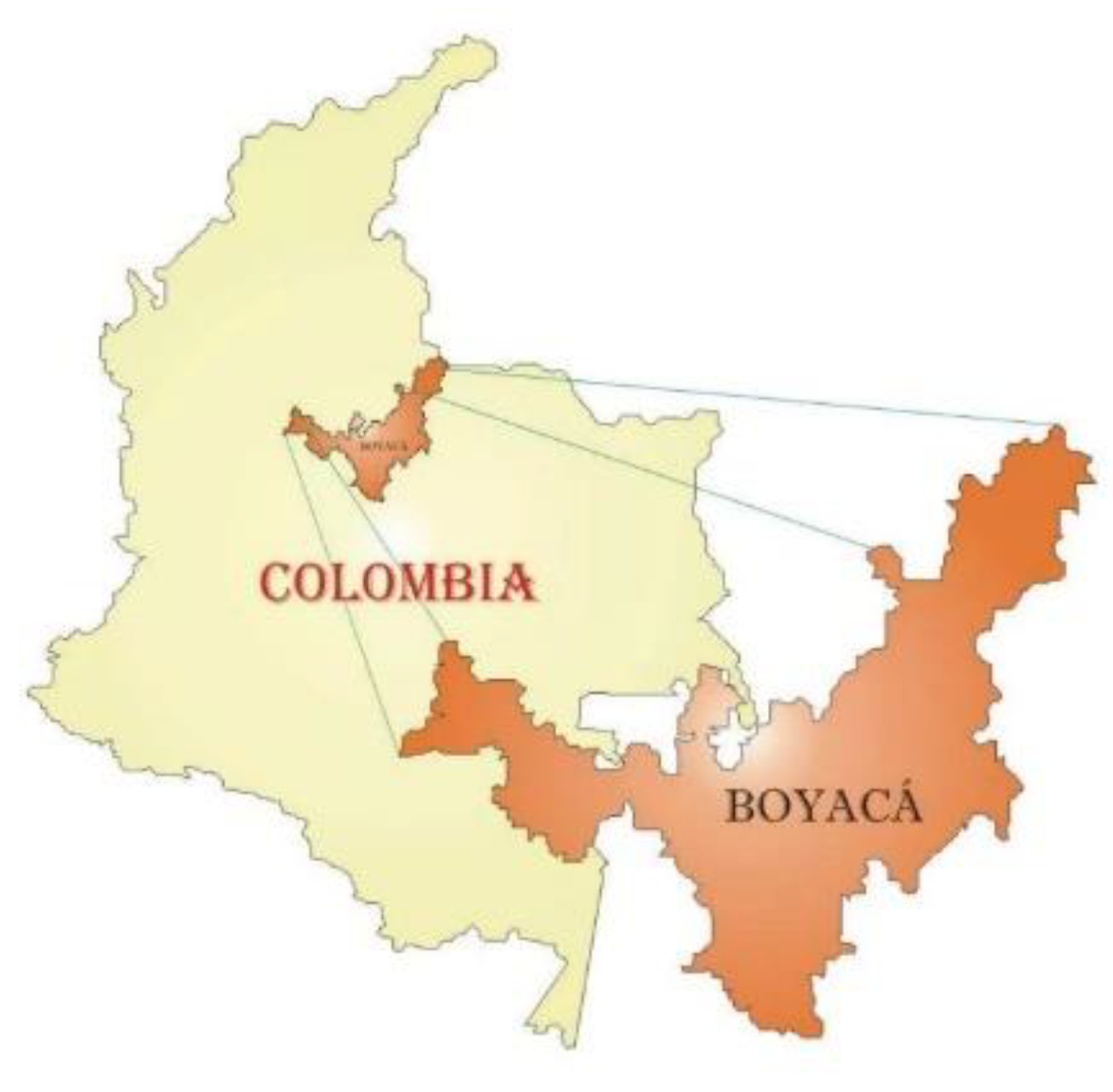
Figure 3.
Illustration of project methodology based on the ML-OPS model. Source: Author (2023).
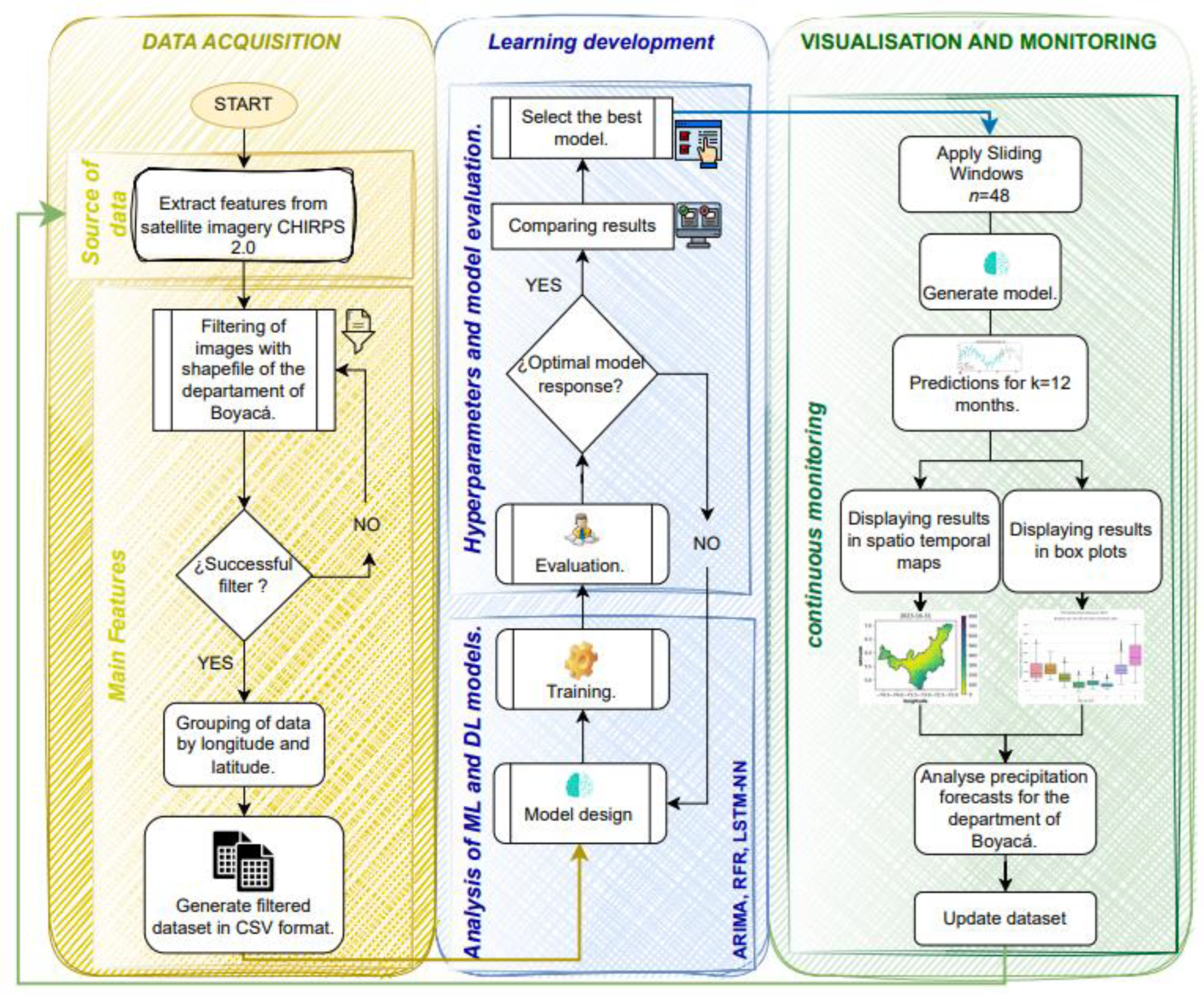
Figure 4.
Random Forest flowchart. Source: Author (2023).
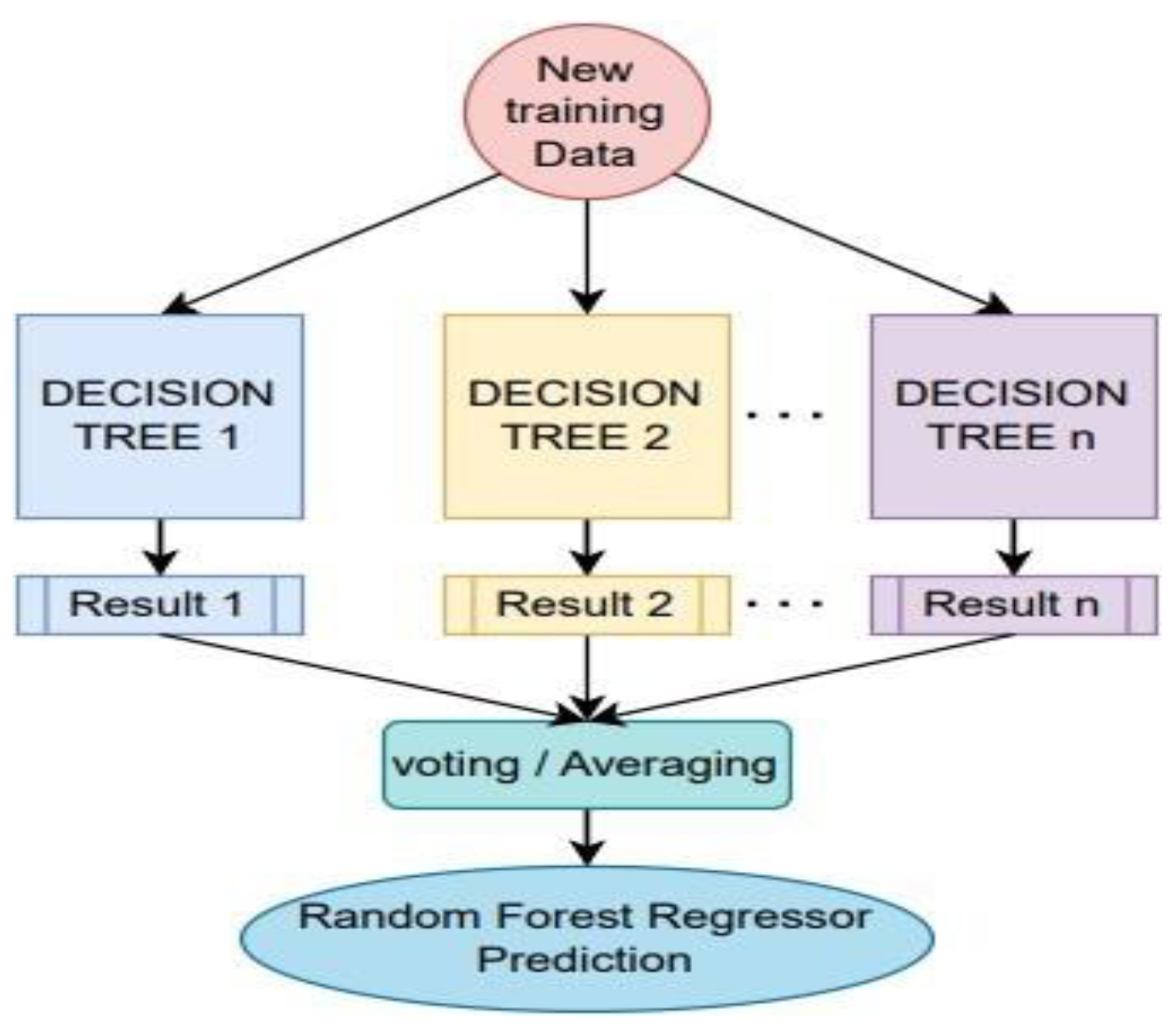
Figure 5.
LSTM model structure [36].
Figure 5.
LSTM model structure [36].
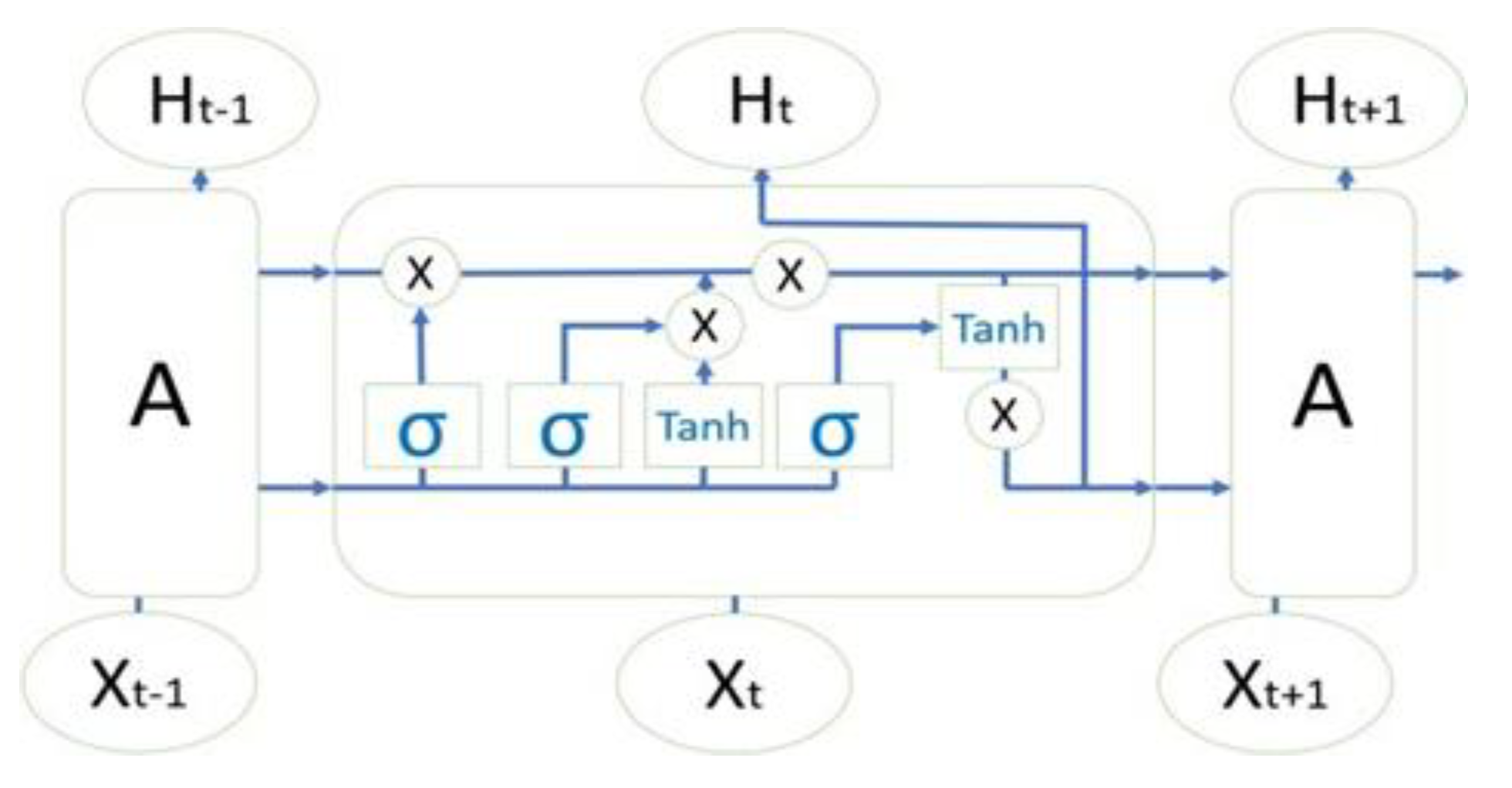
Figure 6.
Monthly total precipitation dataset for Boyacá. Source: Author (2023).
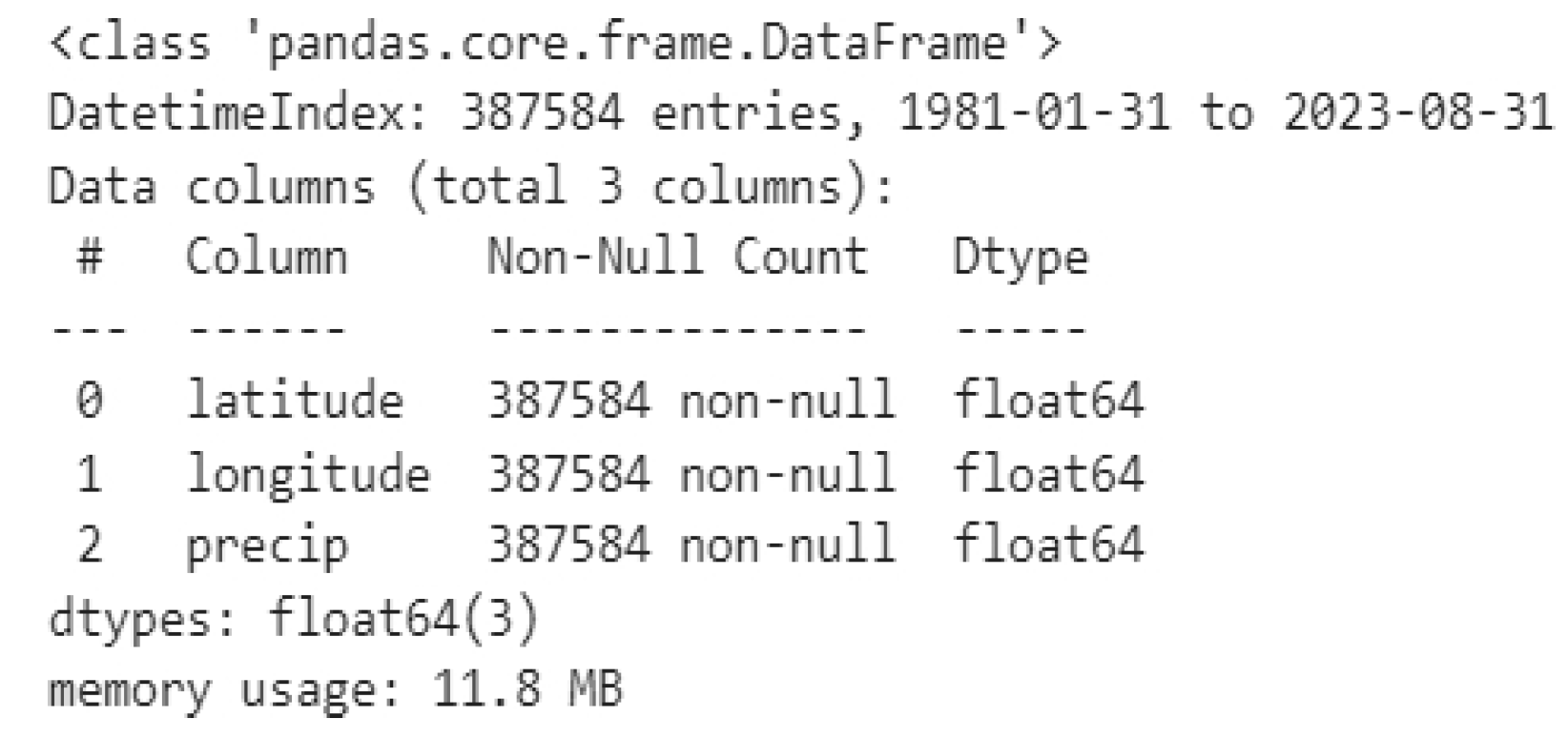
Figure 7.
Spatiotemporal graphs of precipitation for the year 2022 in Boyacá. Source: Author (2023).
Figure 7.
Spatiotemporal graphs of precipitation for the year 2022 in Boyacá. Source: Author (2023).
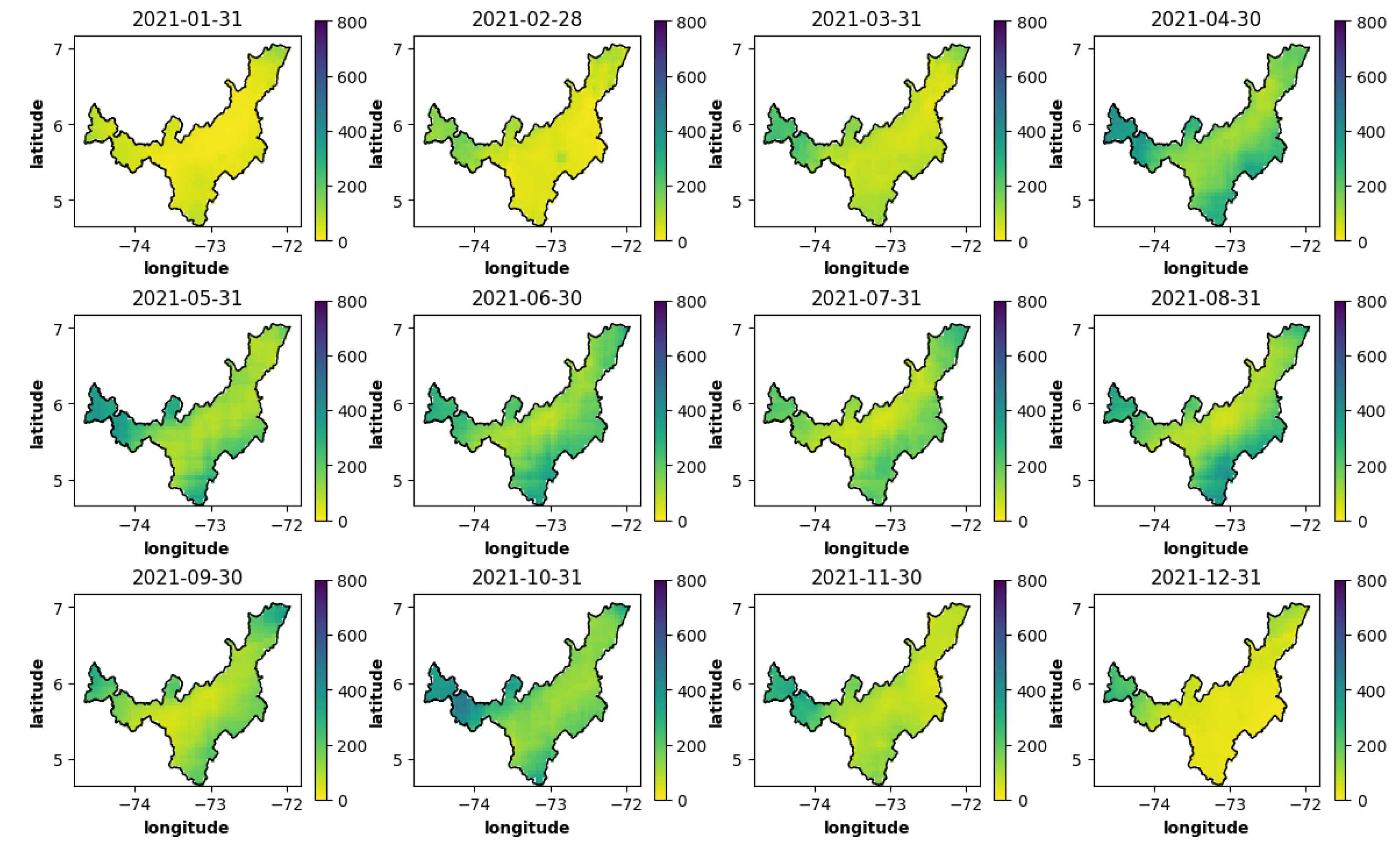
Figure 8.
Monthly precipitation box plots for Boyacá from 2020 to 2023. Source: uthor (2023).
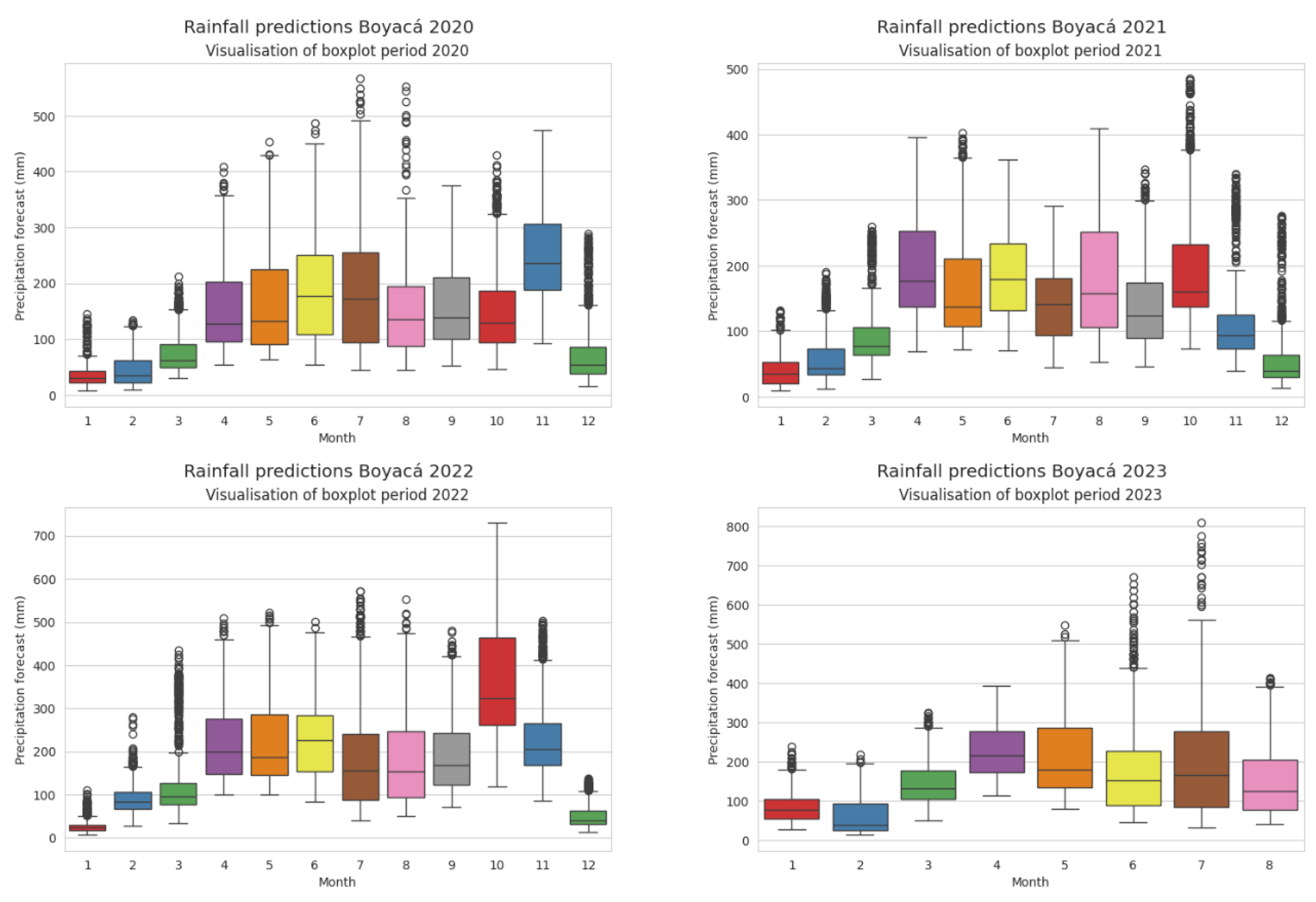
Figure 9.
Simple error calculation of original vs. predicted precipitation with ARIMA model. Source: Author (2023).
Figure 9.
Simple error calculation of original vs. predicted precipitation with ARIMA model. Source: Author (2023).
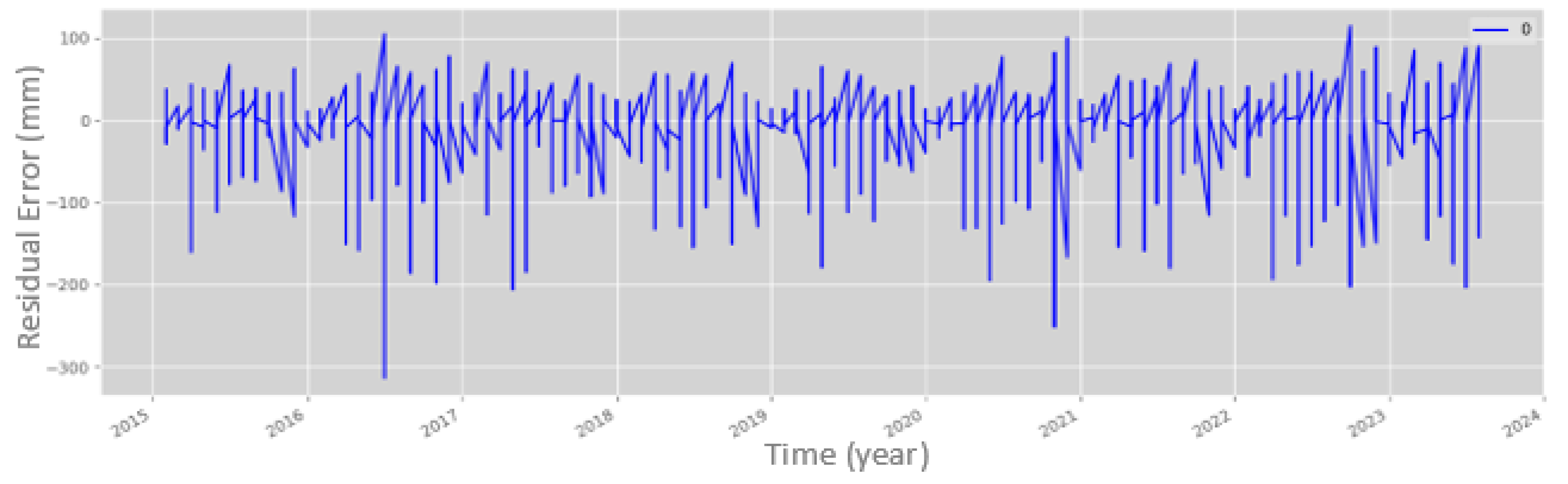
Figure 10.
RMSE values between 0 and 200 trees for the RFR model. Source: Author (2023).
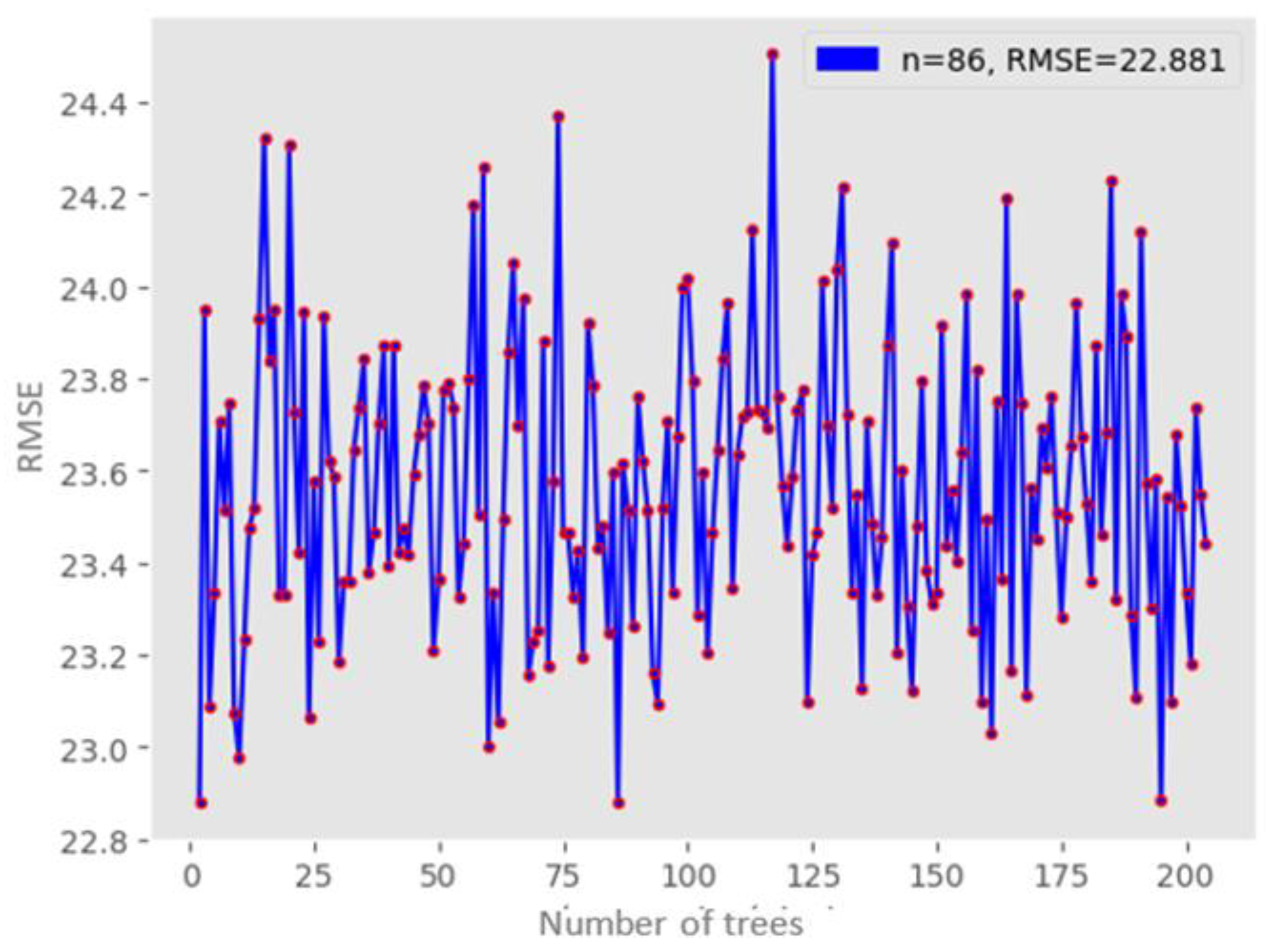
Figure 11.
Simple error calculation of original vs. predicted precipitation with RFR model. Source: Author (2023).
Figure 11.
Simple error calculation of original vs. predicted precipitation with RFR model. Source: Author (2023).
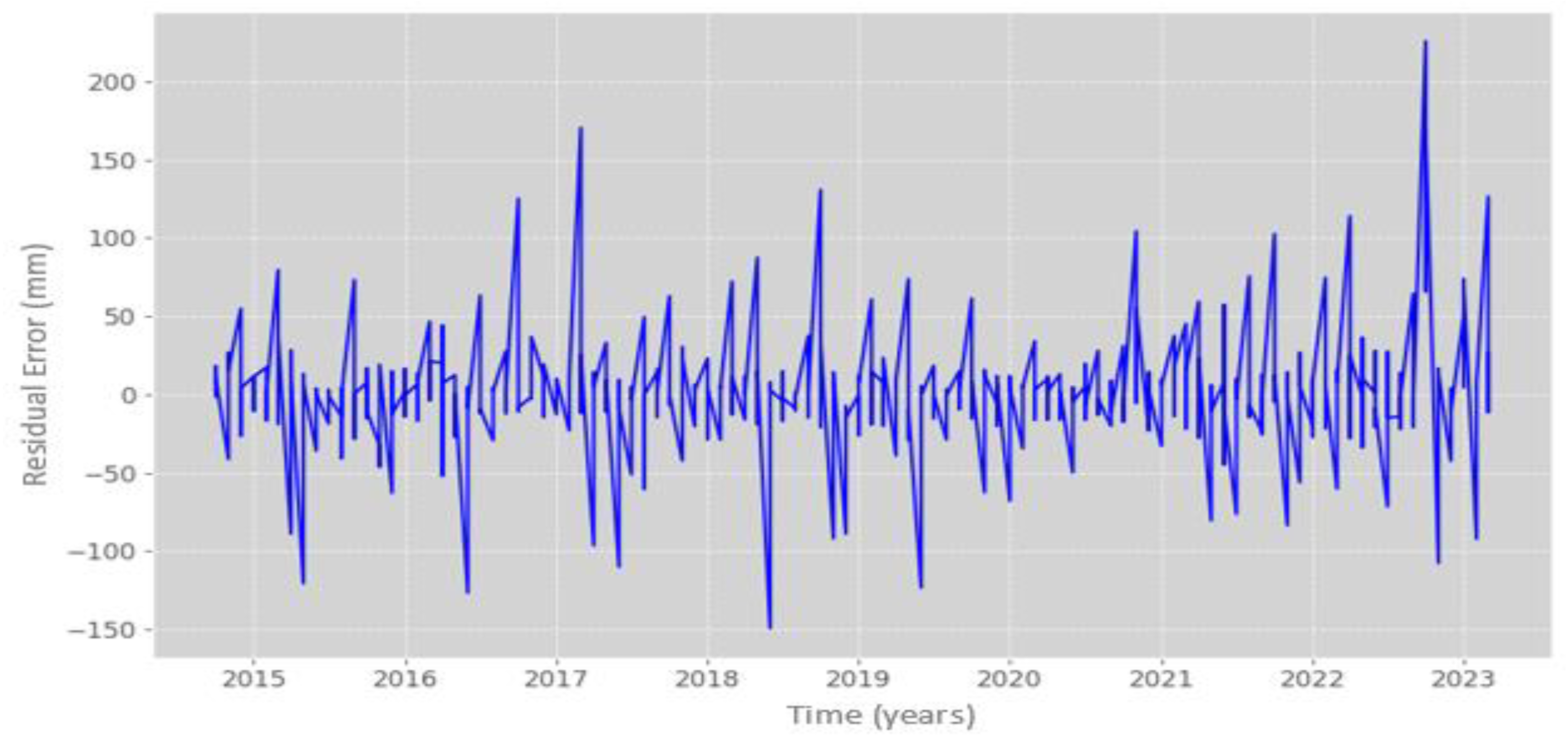
Figure 12.
RMSE for training and testing the LSTM model. Source: Author (2023).
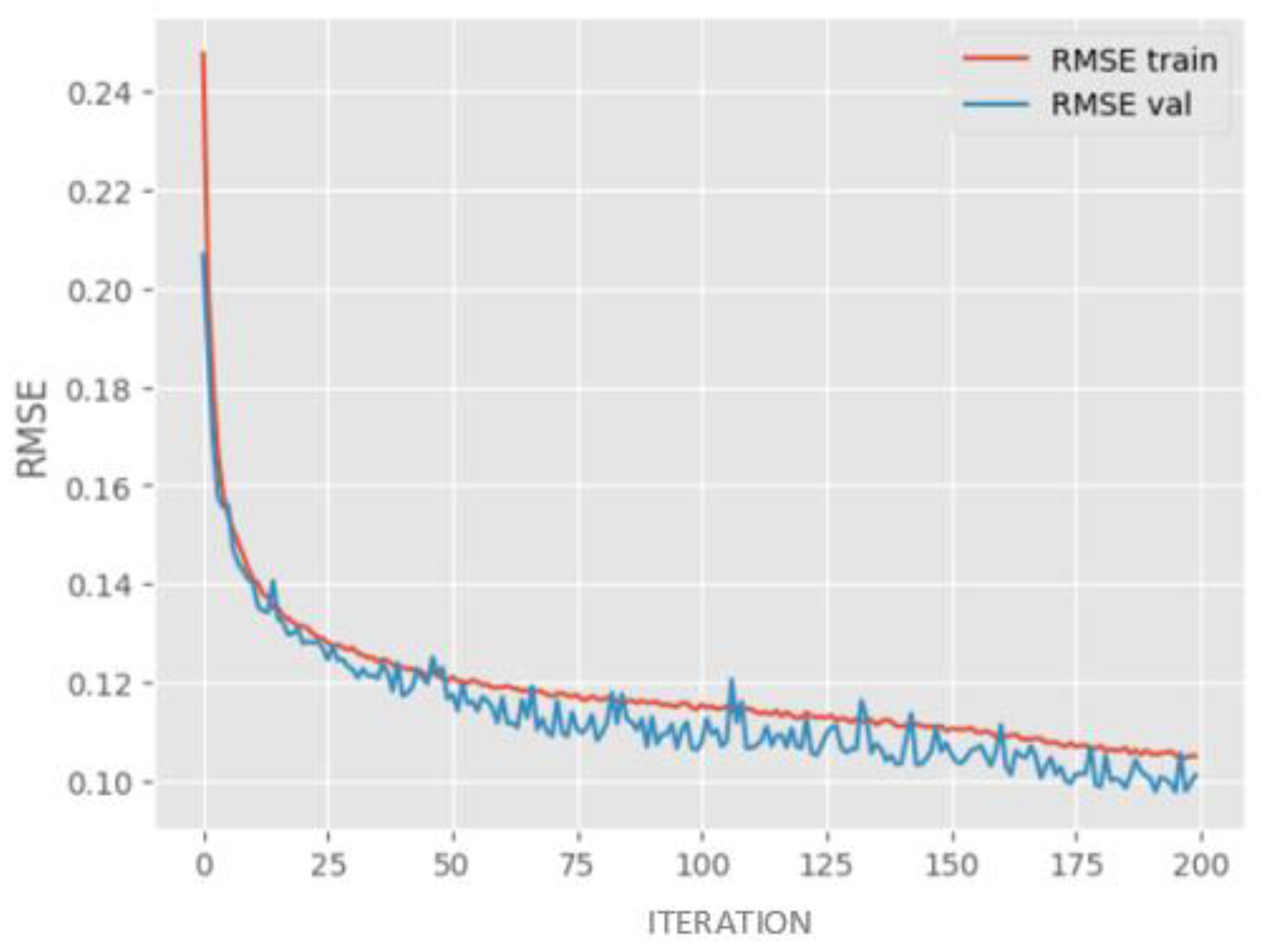
Figure 13.
Calculation of simple errors of original precipitation vs. predicted precipitation with the LSTM model. Source: Author (2023).
Figure 13.
Calculation of simple errors of original precipitation vs. predicted precipitation with the LSTM model. Source: Author (2023).
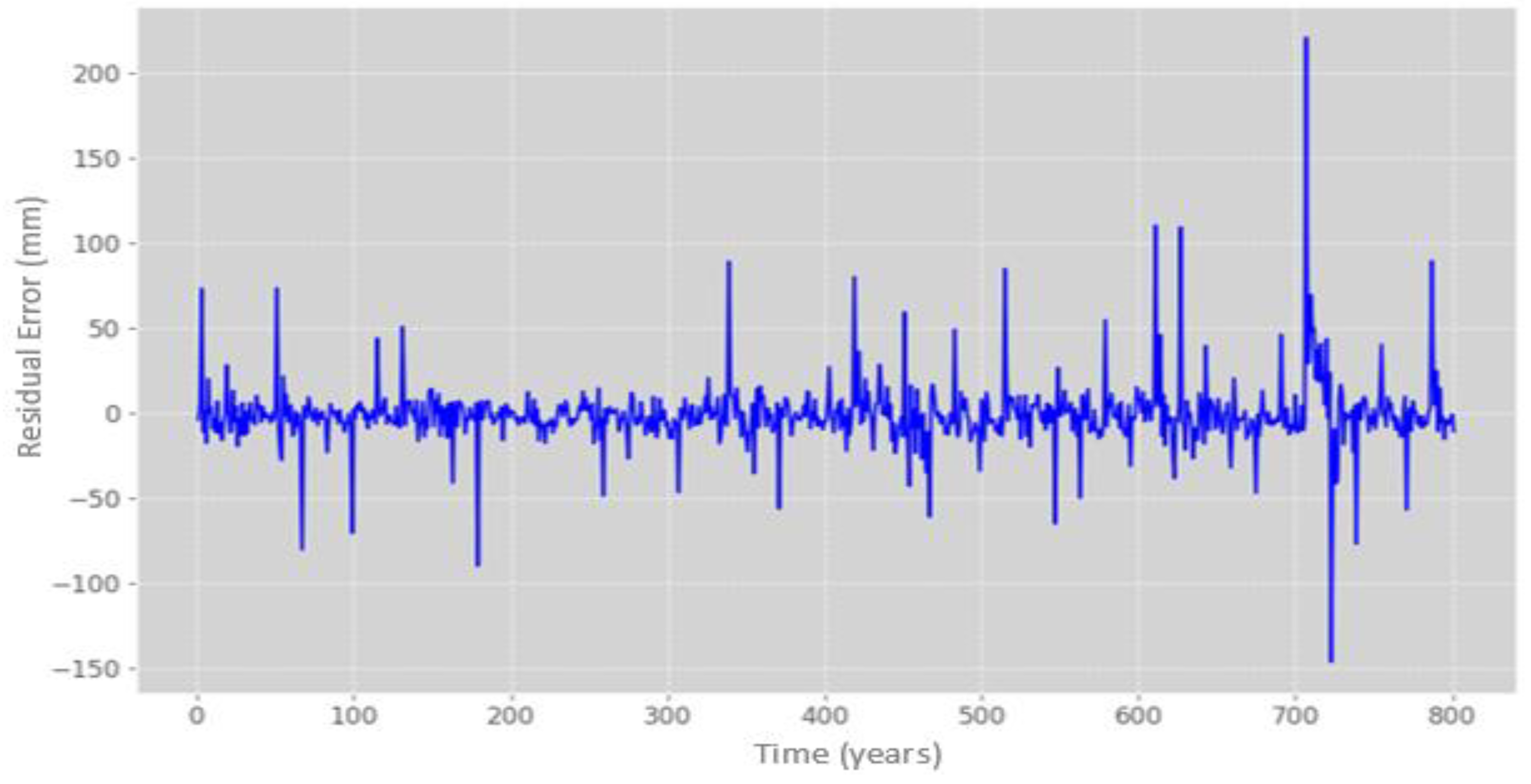
Figure 14.
LSTM model training flow - n months window. Source: Author (2023).
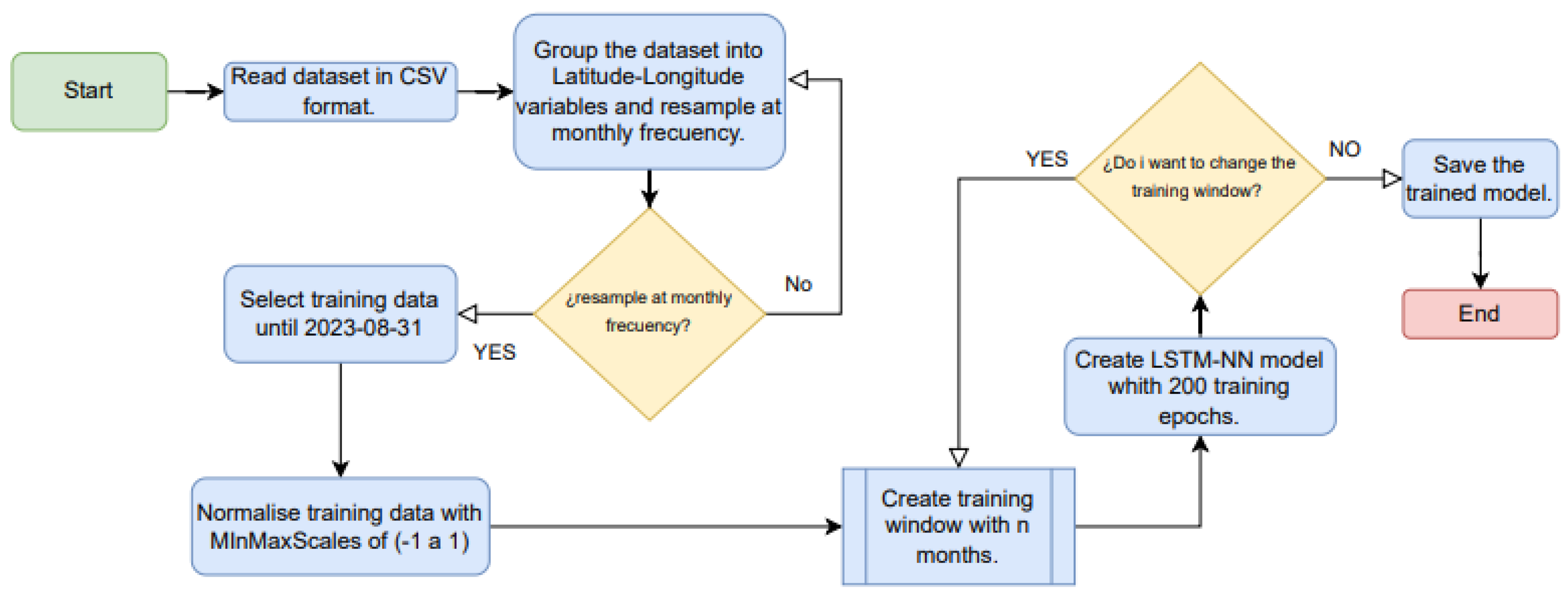
Figure 15.
Process diagram of LSTM model for predicting (t+k) using n windows. Source: Author (2023).
Figure 15.
Process diagram of LSTM model for predicting (t+k) using n windows. Source: Author (2023).
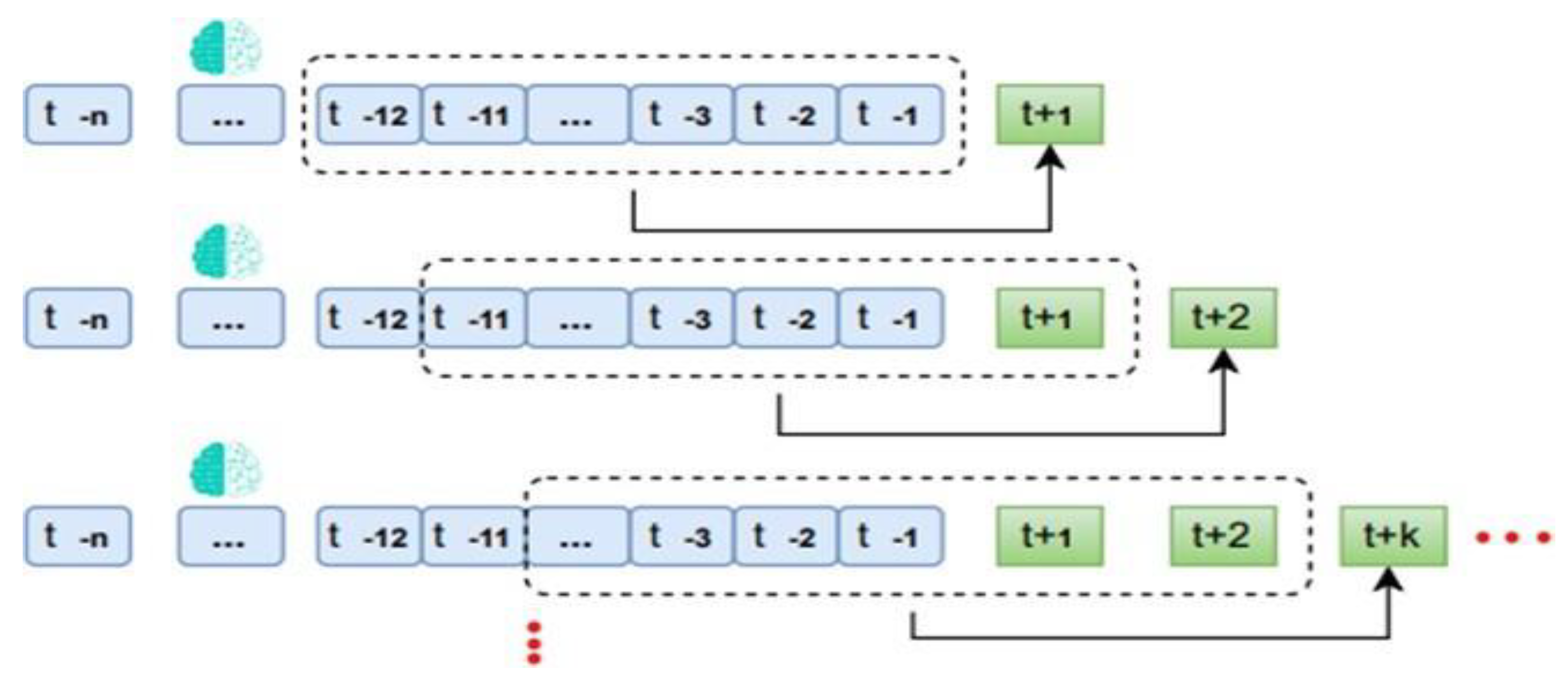
Figure 16.
Visualization of 2023 forecasts in maps and box plots with a 48-month window. Source: Author (2023).
Figure 16.
Visualization of 2023 forecasts in maps and box plots with a 48-month window. Source: Author (2023).
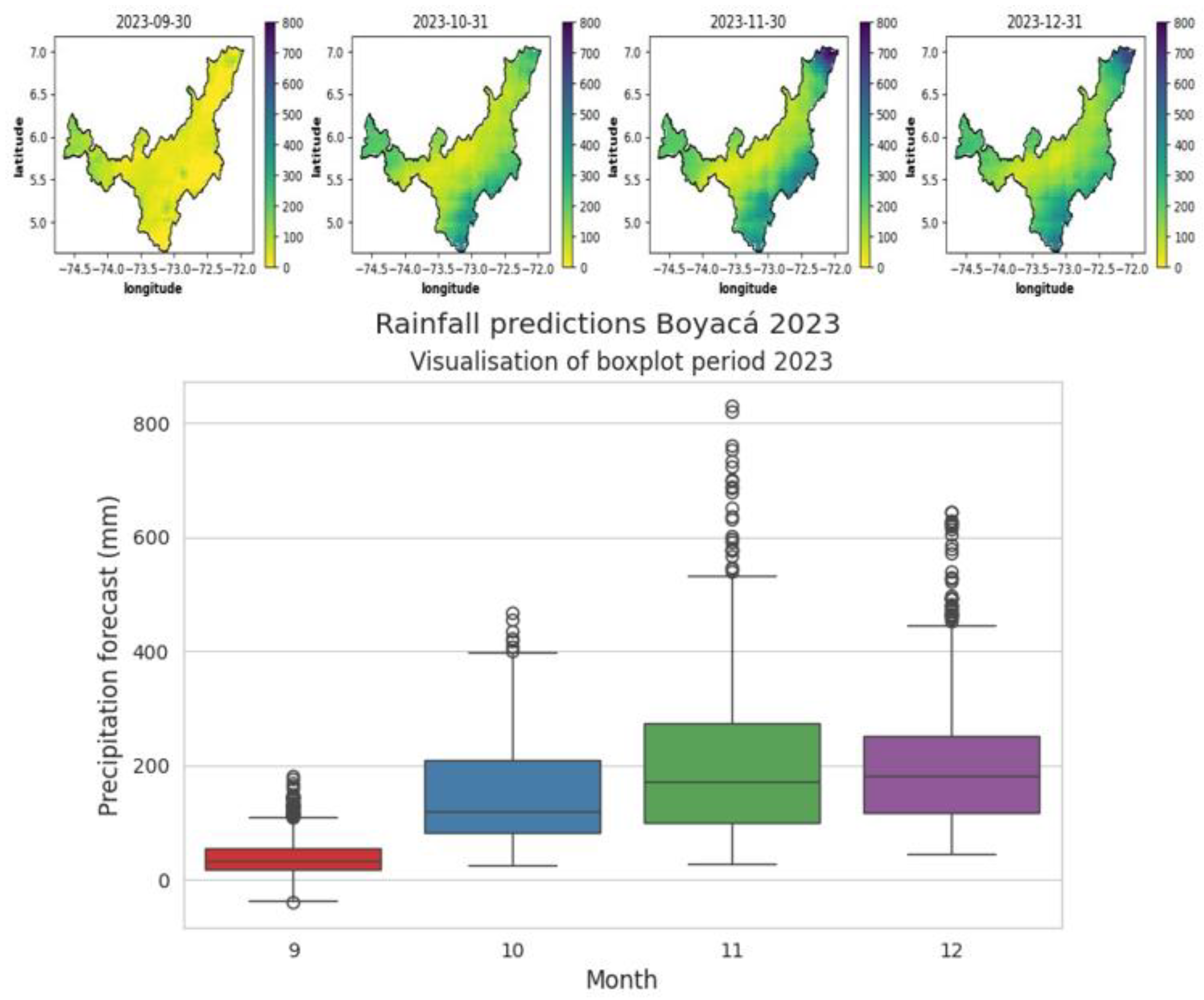
Figure 17.
Visualization of predictions in maps and box plots for the year 2024 with a 48-month window. Source: Author (2023).
Figure 17.
Visualization of predictions in maps and box plots for the year 2024 with a 48-month window. Source: Author (2023).
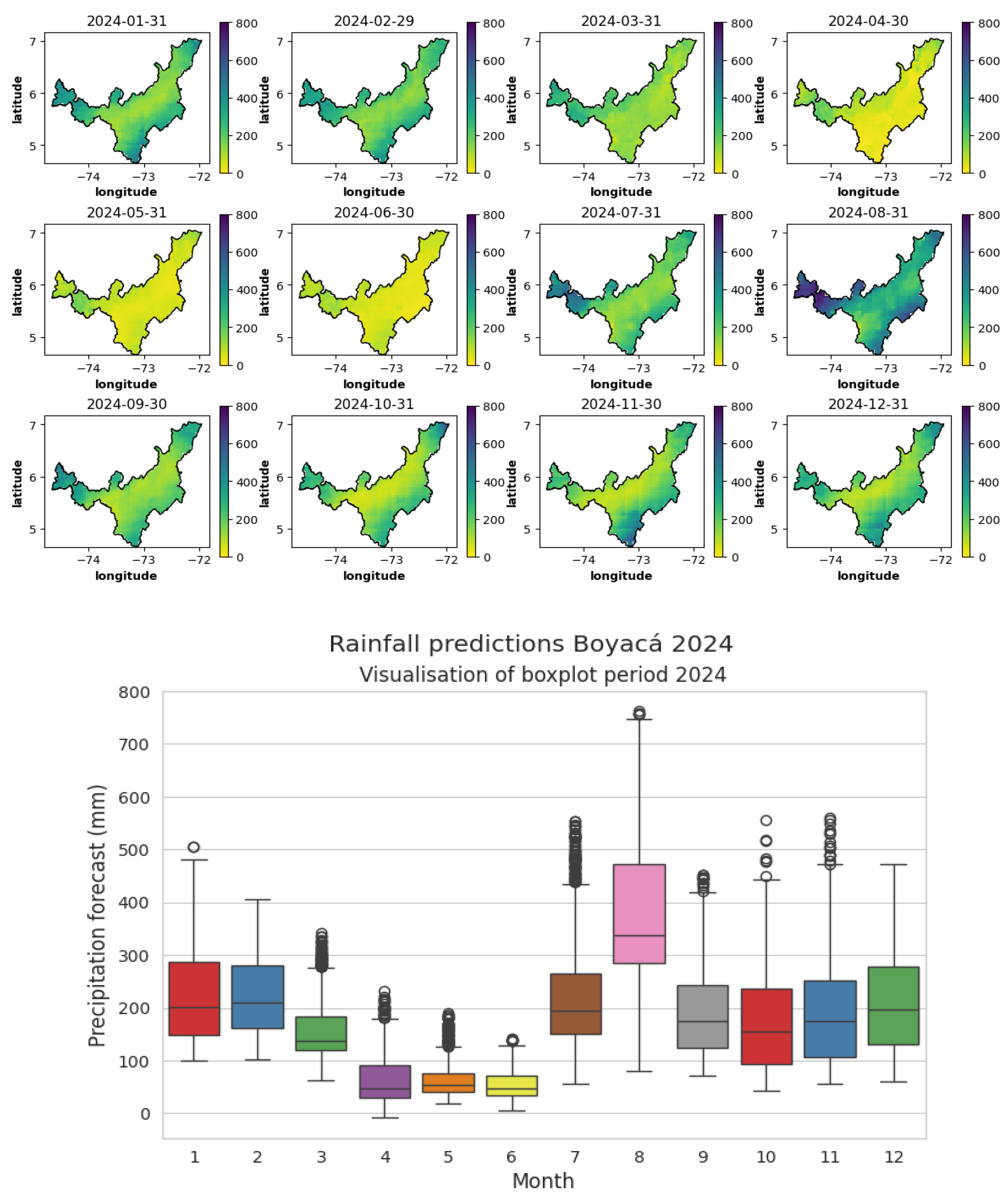

Table 1.
Comparison of different training dataset methodologies, techniques, and evaluation metrics from 2021 to the present for predicting precipitation.
Table 1.
Comparison of different training dataset methodologies, techniques, and evaluation metrics from 2021 to the present for predicting precipitation.
| AUTHOR | TECHNIQUE | MEASURE PRECISION | DATASET | PLACE-TIME |
|
[26] |
L-CNN. |
POD, FAR, ETS, MAE, ME. | 11 polarimetric Doppler radars that operate in C-band. |
Daily Precipitation from 2019 to 2021 in Finland. |
|
[27] |
ELM |
RMSE, MAE, R2, RPD. | SPI CHIRPS 2.0 climatology project. |
12,15,18 and 24 months rainfall from 1981 to 2019 in Eastern Tunisia (Mediterranean). |
|
[28] |
MLP and AUTO- ENCODERS |
RMSE, MSE | - | Weather stations in India. |
|
[29] |
LSTM and ConvNet |
RMSE | Rainfall Climatology Project Global (GPCP) |
Monthly precipitation from 1979 to 2018 globally. |
1 Source: Author (2023).
Table 2.
Evaluation metrics of the models evaluated on the test dataset.
| MODEL | RMSE | MAE | MAPE | R2 |
| ARIMA (4,1,0) *(2,1,0,12) | 27.98 | 15.96 | 17.30 | 0.81 |
| RANDOM FOREST (regression) | 23.21 | 12.07 | 11.25 | 0.87 |
| LSTM-NN | 19.43 | 10.39 | 9.68 | 0.92 |
| Source: Author (2023). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



