
Submitted:
16 July 2024
Posted:
17 July 2024
You are already at the latest version
Abstract
Aiming at solving difficulties related to aero-engine classification and identification, the infrared spectra of aero-engine hot jets are measured by telemetry Fourier transform infrared spectrometer, and a six types aero-engine hot jet spectrum data set is generated. The spectrum data set were randomly sampled at a ratio of 8:1:1 to generate training set, validation set and prediction set. In this paper, a Peak Finding Siamese Convolutional Neural Network (PF-SCNN) is designed to match and classify spectrum data. In the first place, the matching pairs of training set and validation set are made independently with the labels of positive and negative samples creating. The spectrum feature extraction and distance similarity calculation are carried out by the Siamese convolutional neural network (SCNN). When entering the prediction phase, the prediction set and training set are integrated to predict in the trained model. The prediction set labels are ultimately determined by matching them with the training set labels having the highest similarities to ensure accurate predictions. To improve the operation efficiency of the SCNN, a peak finding method is introduced to extract the spectrum peaks. Peak positions of high frequency are counted, while the peak data are extracted. The peak data are used to take the place of the original data for training and prediction. The performance measures are defined as Accuracy, Precision, Recall, Confusion matrix and F1-score, and the prediction accuracy was up to 99%. The experimental results indicate that the proposed PF-SCNN is suitable for our spectral dataset and can complete the task of infrared spectrum classification of aero-engine hot jets.
Keywords:
infrared spectrum detection
; FT-IR
; aero-engine hot jet
; siamese convolutional neural network networks
; peak finding
1. Introduction
The categorization features of aero-engines are frequently connected to fuel type, combustion mode, and emission characteristics. varied types of aero-engines will create varied gas compositions and emissions during combustion. Specific infrared absorption and emission spectra are formed through vibrations and rotations of these molecules. Infrared spectroscopy [1,2,3] is a technique employed for the purpose of detecting the molecular structure and chemical composition of substances. Infrared spectroscopy determines the wavelength and intensity of absorbed or emitted light by measuring the energy level transitions of substance molecules under infrared radiation. It constructs a spectrum to analyze molecular structure, and determines the type and content of substances. Fourier Transform Infrared Spectrometer (FT-IR Spectrometer) [4] provides a significant means for the measurement of infrared spectrum. The interferometer is used to acquire an interferogram, while the interferogram is transformed into a spectrogram through Fourier transform. Passive FTIR is frequently employed for the detection of air pollutants, offering omnidirectional data collection capabilities and enabling continuous, long-range real-time monitoring as well as rapid target analysis. This method is more appropriate for the measurement of the aero-engines hot jet spectrum.
When the aero-engine hot jet spectrum data set is established, the rapid classification of unknown spectrum data becomes the focus of our research. Hyperspectral image classification (HSIC) method provides us with the classification idea of FT-IR spectra. The classical method of HSIC for spectrum classification is to extract spectrum features by dimensionality reduction methods such as principal component analysis (PCA) [5], independent component analysis (ICA) [6] and linear discriminant analysis (LDA) [7]. The spectrum features are combined with SVM[8], XGBoost[9], Random Forest[10], Neural Network[11] and other classifiers to complete the classification task [12]. Similarly, HSIC also uses deep learning methods for feature extraction, such as automatic encoder (AE) [13], recurrent neural network (RNN) [14], convolutional neural network (CNN) [15], Transformer [16],Siamese network [17], etc. Siamese network is a kind of network structure used to judge the degree of similarity of data. Siamese network is realized by constructing weight sharing between two networks. It is often used in target tracking [18,19], change detection [20], Image registration [21] and other fields. There are three structures of Siamese network [22], including Siamese network in which two branches share weights, pseudo- Siamese networks in which two branches have independent weights, and 2-channel networks in which two inputs are superimposed. Huang[23] uses two branch networks of the Siamese network to perform feature extraction and calculate feature similarity on the metric layer. JIA[17] and Miao[24] combine AE with the Siamese network, and NANNI [25] uses K-means clustering to extract barycenter input to the Siamese network and combine SVM to complete classification. LIU [26] used siamese convolutional neural network(SCNN) to extract features and combined with SVM to complete classification. The FT-IR spectroscopic method employed in this paper diverges from the conventional hyperspectral technology. Hyperspectral technology utilizes the dispersive spectrometer to collect the continuous narrow-band spectrum, generally measuring the band from visible light to near-infrared region, while the FT-IR spectrometer collects the complete interferogram of the infrared region and converts it into the spectrum without imaging. Through the utilization of FT-IR spectrometer, it is possible to acquire more intricate and comprehensive molecular-level spectral features, which can be categorized based on the infrared characteristics of the molecules. Given the unique characteristics of FT-IR spectra, we have applied the spectral classification method from HSIC [27,28] to develop a customized classification network for FT-IR spectra. The Siamese network [29,30,31] enables efficient feature extraction and simultaneous support without requiring an extensive amount of labeled data, making it the preferred approach in this study.
SCNN is employed to perform spectrum matching similarity for the purpose of training and validating the data set. In the prediction process, the predicted data are combined with the training data, and a trained network is used to determine the similarity of data pairs. Subsequently, the label of the prediction set is determined by associating it with the training set label that exhibits maximum similarity, thereby completing the prediction process. To enhance operational efficiency of SCNN, a peak finding (PF) method is introduced for spectrum peak extraction through peak finding and counting high-frequency peak positions. The extracted peak data is then utilized instead of original data for both training and prediction purposes. Following evaluation of experiment results, PF-SCNN designed in this paper achieves an accuracy rate of 99%, indicating promising prospects for application in spectrum classification and recognition.
The paper’s contributions can be summarized in three aspects.
- To achieve the classification of aero-engines, this paper employs an infrared spectroscopy detection method to measure the spectra of aero-engines’ hot jets, which are significant sources of aero-engines’ infrared radiation, using an FTIR spectrometer. The FT-IR spectrometer’s infrared spectrum offers characteristic molecular-level information about substances, thereby enhancing the scientific of classifying aero-engines based on their infrared spectra.
- This paper presents a SCNN for classifying the hot jet spectrum of aero-engines using a data matching method. The network is based on 1DCNN, and feature similarity is calculated using the Euclidean distance metric. Subsequently, a spectral comparison method is employed for the purpose of performing spectrum classification.
- The objective of this paper is to propose an algorithm for identifying peaks that will optimize the training and prediction speed of the SCNN. The algorithm identifies the peak value in the mid-infrared spectrum data and quantifies the high-frequency peaks, which are subsequently employed as input for the SCNN.
The paper is divided into five sections: Section 1 provides the research background, summarizes the current status of spectrum classification methods and Siamese networks, and briefly outlines the method, contributions, and structure of the paper. In Section 2, detailed descriptions are provided for the experiment on aero-engine hot jet spectrum measurement design, data preprocessing, and spectrum dataset production. Section 3 covers PF-SCNN, encompassing overall network design, base network design, peak finding algorithm, and network training method. Section 4 analyzes the experiments and results including performance measures and experiment outcomes as well as CO2 feature vector classifier classification methods and ablation experiment analysis. Section 5 presents a summary of this paper.
2. Experimental Design and Dataset Production for Hot Jet Infrared Spectrum Measurement of Aero-Engines
Aero-engine hot jet infrared spectrogram measurement experiment and data set production are described in this section, which consists of aero-engine spectrum measurement experiment design, spectrum data preprocessing and data set production.
2.1. Aero-Engine Spectrum Measurement Experiment Design
Initially, we employed the outfield measurement method to gather infrared spectrum data of six types of aero-engine hot jet. The specific parameters of the two telemetry FT-IR spectrometers utilized in the experiment are detailed in Table 1:
The experimental site layout is depicted in Figure 1:
The environmental parameters during the aero-engine hot jet measurement outfield experiment are presented in Table 2:
The primary constituent of an aero-engine’s hot jet is the mixed gas, and its spectrum is contingent upon both the radiation emitted by the mixed gas itself and the combined influence of numerous intricate factors including pressure, temperature, humidity, and measurement distance. The performance of experiments affected by environmental factors is reflected in the following aspects: Environmental temperature affects the spectrometer’s response, while environmental humidity influences spectrum intensity. Additionally, the observed distance reflects the absorption and attenuation of the spectrum due to atmospheric transport along the measurement path.
At present, our experimental distance is relatively close, and the temperature of the mixed gas is also 300-400℃, which is very different from the background temperature, so the atmospheric and environmental impact can be temporarily ignored.
2.2. Spectrum Data Preprocessing and Data Set Production
Brightness Temperature Spectrum (BTS) [32] is a widely used technology in passive FT-IR gas detection. Brightness Temperature [K] of the actual object is equivalent to the temperature of the blackbody when the intensities of spectra are identical at the same wavelength.
The radiosity spectrum is equivalent to the BTS, which is represented by T(v), can be obtained from the formula:
In the given expression, represents the wave number and the unit of wave number is cm-1, while pertains to the radiosity associated with wave number v.
denotes the Planck’s constant, stands for the Boltzmann constant, represents the speed of light.
The experimentally measured BTS after the conversion of the aero-engine hot jet is depicted in Figure 2, with wave number on the horizontal axis and Kelvin temperature on the vertical axis. Additionally, key components of the hot jet are annotated in the figure.
Experimentally measured BTS after conversion of the aero-engine hot jet is shown in Figure 2, where the horizontal coordinate is wave number and the vertical coordinate is Kelvin temperature. Meanwhile, we have marked the important components of the hot jet in the figure:
Based on outfield experiment and preprocessing, we acquire a spectrum data set, as illustrated in Table 3:
There are 1851 valid spectrum data in the dataset. In accordance with the principles of deep learning partitioning, we allocate the data into training, validation, and prediction sets at an 8:1:1 ratio. The training set includes 10,000 positive and 10,000 negative sample pairs selected randomly, while the validation set contains 1,000 positive and 1,000 negative sample pairs.
3. Architectural Design of Peak Finding Siamese Convolutional Neural Network
In this section, the PF-SCNN is presented for classifying infrared spectra, comprising four key components: overall network structure design, base network architecture, peak finding algorithm, and network training methodology.
3.1. Overall Network Structure Design
The Siamese network for data classification comprises three essential modules: feature extraction, sample comparison, and classification decision. The Siamese network diagram of this paper is depicted in Figure 3:
According to SCNN module design above, the detailed PF-SCNN structure is designed as demonstrated in Figure 4. The PF-SCNN consists of three main parts: peak finding module, base network module, and category prediction module.
During the training stage, positive and negative sample pairs are created with corresponding label sets. If the categories are the same, assign a label value of 1; otherwise, assign a value of 0. The mid-infrared spectral peaks is extracted and detected in the peak finding module. The input data and peak finding module are shown in the blue background in the figure.
The base network layer is shown in the figure as the part with a yellow background color, consisting of CNN layer, FC layer, and Compare layer. It extracts features of data pairs and outputs distance similarity, and approximates the predicted labels of the training set to true labels through a comparison function, thus completing model training.
The category prediction module is represented with a green background. At this stage, a data pair is established between the predicted data and all the trained data. The similarity score for each piece of predicted data in relation to all the trained data is computed by inputting it into the trained network. The maximum similarity score for each piece of predicted data is selected, and then the corresponding trained data number and category label are utilized to finalize the prediction.
3.2. Base Network Architecture
The base network module is used to train the positive and negative sample pairs, complete the feature extraction of the above network and compare the content of the two modules with the samples. The base network part consists of convolution layers, maximum pooling layers, an extension layer, a fully connected layer and a self-defined Lambda layer.
① One-dimensional convolutional layer (Cov1D Layer): The convolutional layer extracts features, while the Cov1D layer performs linear and translation-invariant operations through convolution. This enhances signal characteristics and reduces noise.
The convolution between two functions, in terms of mathematical expression, can be defined as:
Convolution is the result of overlapping two functions, where one function is flipped and shifted by . In the case of two-dimensional tensors, convolution can be represented as:
In the expression, is the index of and is the index of .
② Maximum pooling layer (MaxPool Layer): The MaxPool Layer, a component of CNN, serves as a method for downsampling by reducing data processing while preserving essential information. Operations such as the convolution layer, pooling layer, and activation function layer can be interpreted as mapping original data to the feature space of hidden layers.
③ Flattening layer: The flattening layer, positioned between the Cov and FC layers, converts the feature map from the former into one-dimensional feature vectors for input into the latter. This transformation is essential as it enables the fully connected layer to process one-dimensional input using the dot product of weight matrix and input vector to compute output.
④ Fully connected layers (FC Layer): The FC layer translates the learned distributed feature representation into the sample label space, combining and outputting them as a single value to reduce the impact of feature position on the classifier.
⑤ Comparison Layer: Keras provides Lambda functions for creating a dedicated layer to apply function transformations to the data, in the form of a Lambda layer. Depending on our data comparison requirements, we can choose a distance function to compare two feature vectors. In data comparison, distance is commonly used as a constraint method for evaluating the similarity between two feature vectors. The distances of vectors typically include Euclidean distance (L2 norm), Manhattan distance, Cosine similarity, Chebyshev distance, Hamming distance, Jaccard similarity, Pearson correlation coefficient, and others. We choose Euclidean distance, which can be expressed as:
where and are two feature vectors. represents the number of feature vectors.
3.3. Peak Finding Algorithm
The molecular structure of the substance has a direct influence on the intensity, frequency and shape of the infrared spectrum, which is reflected in the number, position, shape and intensity of the infrared spectrum. The important means of infrared spectrum analysis is to analyze the position, intensity and shape of characteristic peaks, so we construct a peak finding algorithm to finding the peaks[33].
Sliding window method is a commonly used method to find extreme values, which is mainly used to solve the problem of subsequences in arrays or linked lists. The basic idea is to find the desired extreme value by maintaining a window (that is, a continuous sequence of subsequences in an array or linked list) and dynamically adjusting the size and position of the window during sliding.
The formula for local maximum retrieval by sliding window is as follows:
where is the current sequence number, represents the window threshold, and the window range is from to .
The local minimum search formula is:
The index of the local extremum can be found by the following formula:
We perform peak finding algorithm in the mid-infrared region and illustrate the operational flow of the algorithm using pseudo-code:
| Algorithm 1: Peak finding and peak statistics algorithm |
| Input: Spectrum data |
| Output: Peak data |
| ① Crop the mid-infrared band (400-4000cm-1) of spectrum data. ② Data smoothing. ③ Set the parameters of the sliding window peak finding algorithm. ④ Count the wavenumber position of each peak. ⑤ The wave number positions associated with high frequency were identified by applying threshold value proportions. ⑥ According to the peak wave number position, the points near each data are extracted as the peak data points. ⑦ Output peak data for each spectrum data. |
3.4. Network Training Methodology
(1) Optimizer:
The optimizer is a method for finding the optimal solution of a model. Commonly used optimizers include gradient descent and adaptive learning rate optimization algorithms. The former includes standard gradient descent (GD), stochastic gradient descent (SGD) and batch gradient descent (BGD). The disadvantage of GD method is slow training speed and sensitivity to local optimal values. The latter includes the Adaptive Gradient (AdaGrad), Root Mean Square Propagation (RMSProp), Adaptive Moment Estimation (Adam) and Adaptive Delta (AdaDelta). Among them, the RMSProp optimizer with adaptive learning rate adjustment has been chosen for this paper.
RMSProp [34] is an optimization algorithm that adjusts the learning rate adaptively based on the moving average of the gradient square, providing different learning rates for each parameter and solving the problem of overly large or small learning rates in SGD algorithm effectively. It uses exponential decay average of historical gradients to adaptively adjust the learning rate.
The second-order momentum of RMSProp Vt is calculated as follows:
where is a time step, is the second order momentum of the current time step, is the second order momentum of the previous time step. is the decay rate of historical second-order momentum, it is generally set to 0.9 and used to control the decay rate of historical information, while is the gradient. pays more attention to the recent gradient, and does not superimpose to infinity.
The learning rate of each element in the objective function argument is re-adjusted by the element operation, and then the formula of is updated
where is learning rate, is a constant added to maintain numerical stability and the value is usually set to10-6, and stands for the product of elements, the calculation method is .
RMSProp excels in handling large-scale non-convex optimization and deep learning problems by adaptively adjusting the learning rate to prevent it from vanishing. However, it suffers from hyperparameter dependence, as the choice of attenuation factor and other parameters can significantly impact its performance.
(2) Loss function and classification accuracy
When using SCNN for data comparison, the model’s predicted value needs to be compared with the true label. During training, positive samples should exhibit higher similarity, while negative samples should have as low a similarity as possible. The contrastive loss function [33] is commonly used in Siamese networks to guide meaningful feature representation learning by comparing similarities between positive and negative sample pairs. The can be expressed as:
where represents the true label (positive sample pair labeled as 1, negative sample pair as 0), denotes the predicted distance. Meanwhile is a constant determining the separation between different classes of elements, usually set to 1, and stands for the number of samples.
When the true label represents a positive sample, the loss function is , signifying the square of the predicted distance. The loss function promotes similarity by minimizing the distance between their feature representations. When true label , namely negative samples, loss function is , namely when predicting small at , loss of , otherwise the loss is 0. Contrastive loss promotes the reduction of similarity by minimizing the square of their distance from the .
Subsequently, the classification accuracy rate is establish to be utilized in conjunction with the contrastive loss function.:
where is the number of samples, is the actual label of i sample, is the prediction probability label for i sample, the function maps the probability to the nearest integer (0 or 1).
(3) Similarity score function
The similarity score function is determined by the Euclidean distance metric.:
where represents the Euclidean distance between the true label and the model’s prediction. is the parameter that controls the slope, usually set to 1. is the maximum distance value and is used for normalization, is a normalized distance. When two data pieces are closer, the normalization distance is closer to 0, and the similarity score is closer to 0.5. This function is a monotonically decreasing function, so we can use the maximum similarity score as the criterion for the similarity of two data pieces.
4. Experiment and Result
Section 4 encompasses the execution of experiments and evaluation of results. Initially, the performance measures for the classification algorithm and the experimental results from classifying the network designed in this paper using the spectrum dataset are presented. Subsequently, we discuss the experiment results of CO2 feature vector-based classifier method and direct input of mid-infrared spectrum into SCNN. Finally, ablation experiments are provided to compare effectiveness of peak features, SCNN model, optimizer selection, learning rate selection, and running time.
4.1. Performance Measures and Experiment Results
Based on the evaluation criteria for data classification tasks, the performance measures of PF-SCNN for aero-engine hot jet includes Accuracy, Precision, Recall, F1-score and Confusion matrix. An instance is classified as a positive class and predicted to be positive, resulting in a True Positive (TP); if it is classified as negative but predicted as positive, it becomes a False Negative (FN); conversely, if the instance is a negative class and predicted to be positive, it results in a False Positive (FP), while predicting negative correctly leads to True Negative (TN). Based on these assumptions, evaluation criteria such as accuracy rate, recall rate, F1 value and confusion matrix are defined:
Accuracy: The accuracy is the ratio of correctly classified samples to the total number of samples.
Precision: The precision is the ratio of correctly predicted positive samples to all predicted positive samples.
Recall: The recall is the ratio of the number of samples correctly predicted to be positive to the number of samples that are actually positive.
F1-score: The F1-score is a composite measure of precision and recall, which considers both aspects to evaluate the overall performance of the model.
where the stands for ,while the stands for .
Confusion Matrix: The confusion matrix presents the classification results of various categories by the classifier, encompassing TP, FP, TN and FN. It visually demonstrates the disparity between actual and predicted values, with the diagonal elements indicating the number of accurate predictions for each category made by the classifier. Table 4 offers a detailed breakdown of each component in the confusion matrix.
To validate the algorithm’s effectiveness, training and prediction experiments were conducted on a dataset comprising six types of aero-engine spectra. The experiments took place on a Windows 10 workstation equipped with 32 GB of RAM, an Intel Core i7-8750H processor, and a GeForce RTX 2070 graphics card.
Table 5 provides detailed parameters for PF-SCNN:
According to the Table 5 parameters, we conducted training and label prediction on the data set, and obtained experimental results as shown in Table 6:
Figure 5.
PF-SCNN spectrum matching classification experiment results, where the left figure is the loss function transformation curve, the right figure is the correct rate transformation curve, the blue line is the training data, orange is the verification data.
Figure 5.
PF-SCNN spectrum matching classification experiment results, where the left figure is the loss function transformation curve, the right figure is the correct rate transformation curve, the blue line is the training data, orange is the verification data.
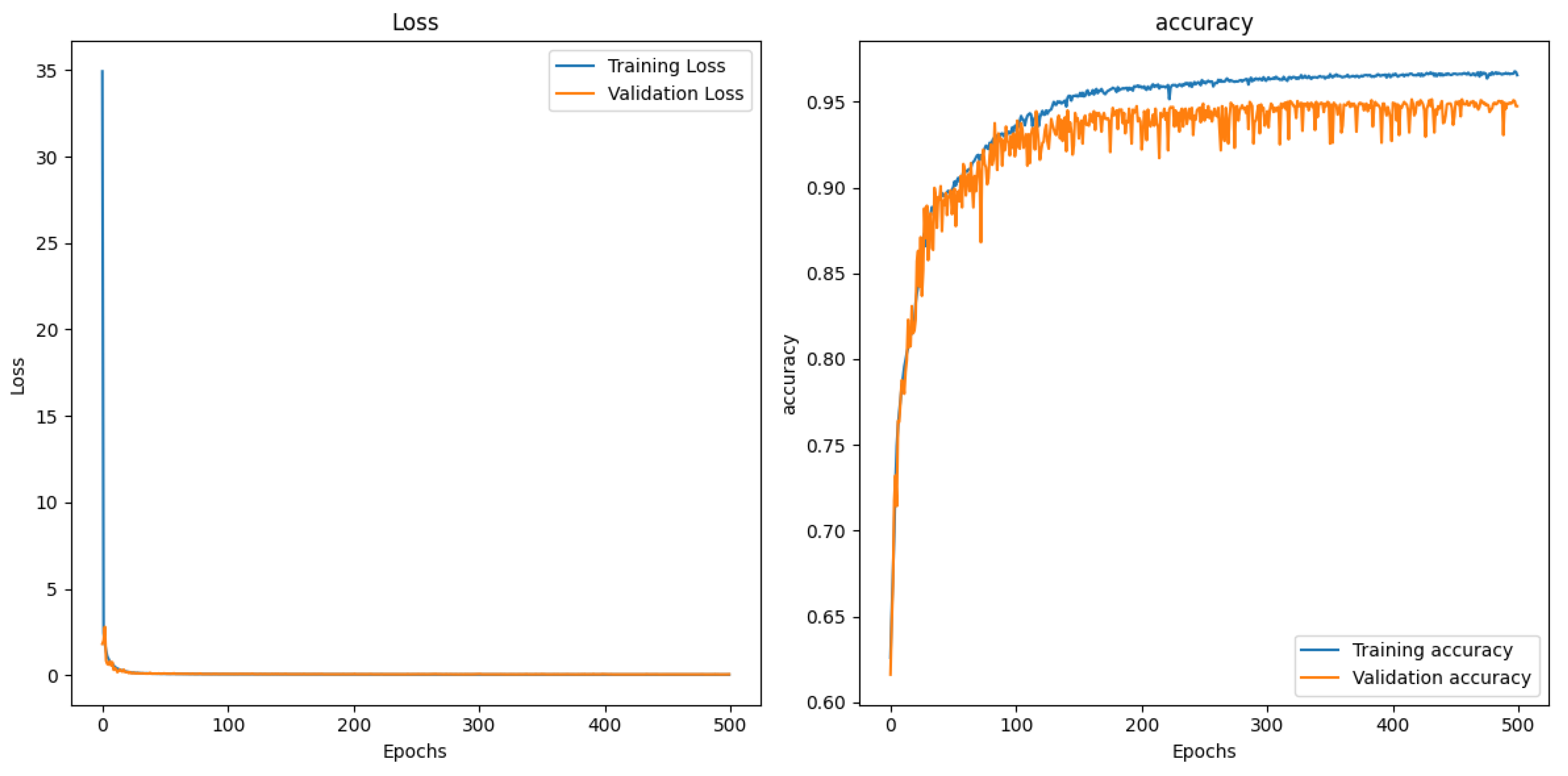
The PF-SCNN, as designed in this paper, effectively classifies the six types of aero-engine hot jet spectrum dataset with 99.46% accuracy. The model demonstrates high precision (99.77%) and recall (99.56%), accurately predicting both positive classes and actual positive samples. The confusion matrix provides insights into prediction performance for each class. Analysis of the F1 score (99.66%) shows a strong balance between accuracy and recall, while Loss and accuracy converge rapidly within 500 training sessions—taking 2757.8s for training and 71s for label prediction per data.
Despite encountering special cases such as aero-engine failure during experiment, our PF-SCNN demonstrates robustness with minimal impact on overall classification accuracy when handling error data within spectrum data set.
4.2. The Traditional Method Classifies and Compares Experimental Results
The hot jet comprises mixed gases such as oxygen (O2), nitrogen (N2), carbon dioxide (CO2), steam (H2O), carbon monoxide (CO), among others. To facilitate comparison with classical classifier methods, the main components of the aero-engine hot jet were analyzed, and a CO2 feature vector was designed. In the experiment, four characteristic peaks in the mid-wave infrared region of the BTS from the aero-engine hot jet were selected to construct the spectrum feature vector. These peaks corresponded to wave numbers 2350cm-1, 2390cm-1, 720cm-1, and 667cm-1 respectively; their positions are illustrated in Figure 6:
The peak differences between 2390cm-1 and 2350cm-1, as well as between 719cm-1 and 667cm-1, form a single spectral feature vector :
Due to environmental influences, the peak positions of the selected characteristic peaks may shift. The experimentally measured infrared spectrum data’s maximum and minimum peaks at 2350cm-1, 2390cm-1, 720cm-1 and 667cm-1 are extracted within a specified region to form the spectrum feature vector. The specific threshold range is detailed in Table 7:
The feature vector needs to be combined with the classifier to test the classification effect. We select the commonly used classifier such as SVM, XGBoost, CatBoost, AdaBoost, Random Forest, LightGBM, Neural Network algorithm to combine with CO2 feature vector for the aero-engine hot jet spectrum classification task.
Table 8 provides the parameter settings of the classifier algorithms:
In order to compare with the deep learning method, we combine training set with validation set, set the training set and the prediction set with the ratio of 9:1, and obtain the experiment results in Table 9:
Based on the analysis of experimental results for CO2 feature vector classifier methods, it is observed that the overall performance of SVM algorithm in classification is suboptimal. AdaBoost exhibits poor prediction performance with consistently low indices while Neural Networks also underperform. Conversely, XGBoost, CatBoost, Random Forest and LightGBM demonstrate strong classification capabilities with excellent predictive accuracy, positive instance capture, balanced accuracy rate and recall rate. However, they still have some distance from our high-precision recognition. This distance is reflected in the limitation of a single feature vector to the feature representation of data. In complex experimental scenarios, it is not enough to use CO2 as a single spectrum feature to represent the spectrum characteristics, and more features should be explored to describe our spectrum data.
4.3. Ablation Experiment Analysis
(1) Peak Feature Effectiveness: Integrating peak features with traditional classifiers validates their impact on algorithm enhancement for classification. We identified peaks in our data set and obtained experimental results, as depicted in Figure 7:
In Figure (a), the red points represent the peak positions identified by the peak finding algorithm; in (b), the blue histogram illustrates the distribution of these peak positions within the data set; and in (c), the red line indicates the locations of points with higher frequency in the spectrum data set. Following a comprehensive statistical analysis of these peak positions, a total of 56 peaks were identified. Subsequently, data corresponding to these 56 peak positions from each dataset were computed, and a classification experiment was conducted using SVM and XGBoost classifier methods as part of our previous study, resulting in detailed classification results presented in Table 10:
Based on the experimental results, the extracted peak data demonstrates significant efficacy. When compared with CO2 feature vector classifiers, all indices exhibit notable enhancements. The experimental findings suggest that feature extraction using the peak finding algorithm is highly effective for classification tasks.
(2) SCNN model
We use the same parameters of the PF-SCNN model to input data in the mid-infrared region into SCNN for training and prediction, and obtain Table 11:
Figure 8.
SCNN spectrum matching classification experiment results, where the left figure is the loss function transformation curve, the right figure is the correct rate transformation curve, the blue line is the training data, the orange line is the verification data.
Figure 8.
SCNN spectrum matching classification experiment results, where the left figure is the loss function transformation curve, the right figure is the correct rate transformation curve, the blue line is the training data, the orange line is the verification data.
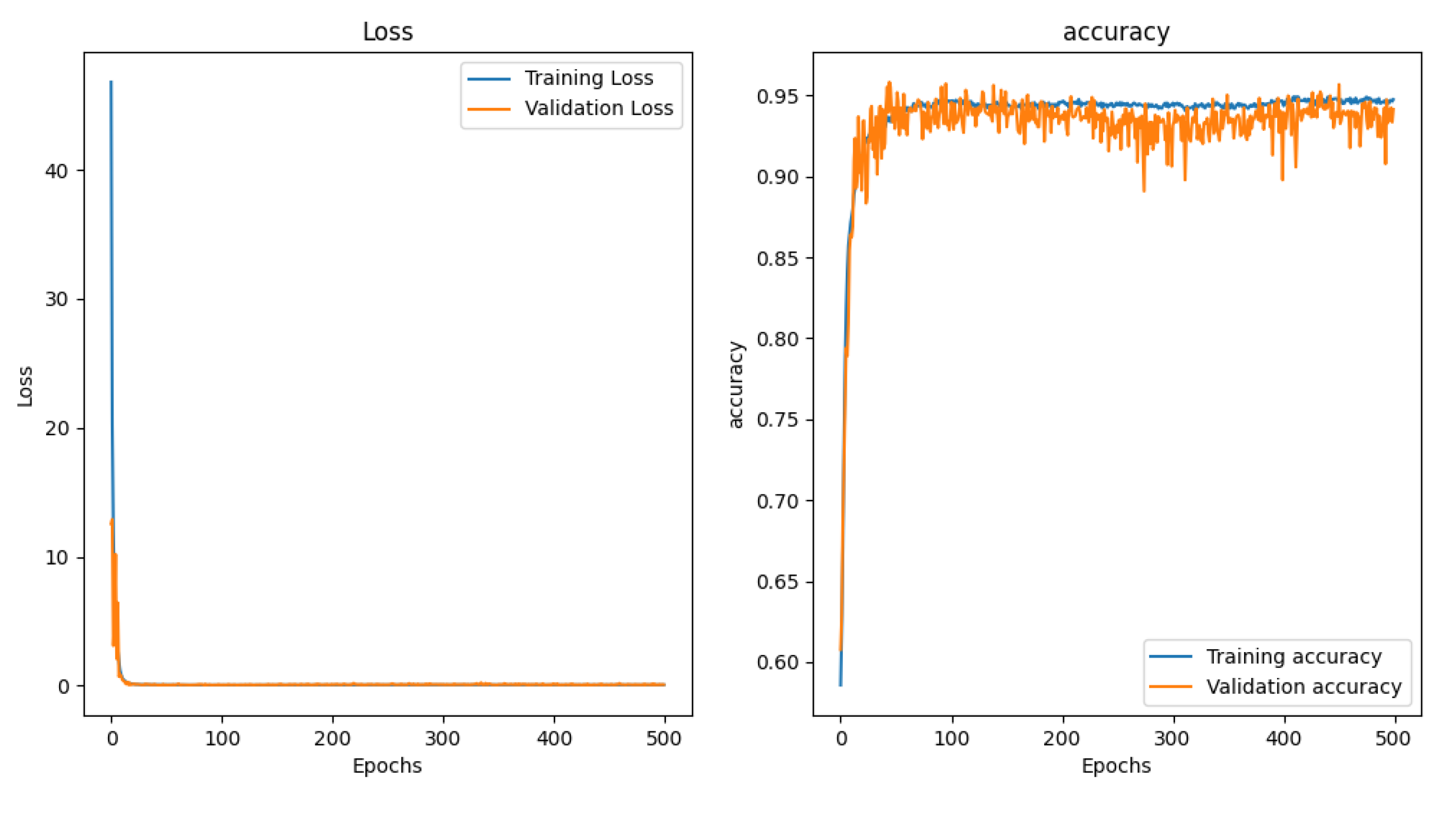
When the entire mid-infrared spectrum was used as input, the training time amounted to 19103.60 seconds. It is evident that the SCNN model can achieve commendable accuracy in both training and prediction. However, owing to data quantity issues, the SCNN model demands substantial computing resources and time.
(3) Optimizer selection:
In deep learning network training, we input commonly used optimizers such as RMSProp, Adam, Nadam, SGD, Adagrad, and Adadelta into the base network model for comparison on the spectrum data used in this paper to determine the most suitable optimizer. The optimizer parameters are shown in Table 12:
We conducted 200 training tests on the peak data of the spectrum dataset using various optimizers on the base network, resulting in Table 13:
Figure 9.
Network training and validation of Loss function and Accuarcy variation curves on spectrum data set by different optimizers: RMSProp in blue, Adam in orange, Nadam in green, SGD in red, Adagrad in purple, and Adadelta in brown.
Figure 9.
Network training and validation of Loss function and Accuarcy variation curves on spectrum data set by different optimizers: RMSProp in blue, Adam in orange, Nadam in green, SGD in red, Adagrad in purple, and Adadelta in brown.
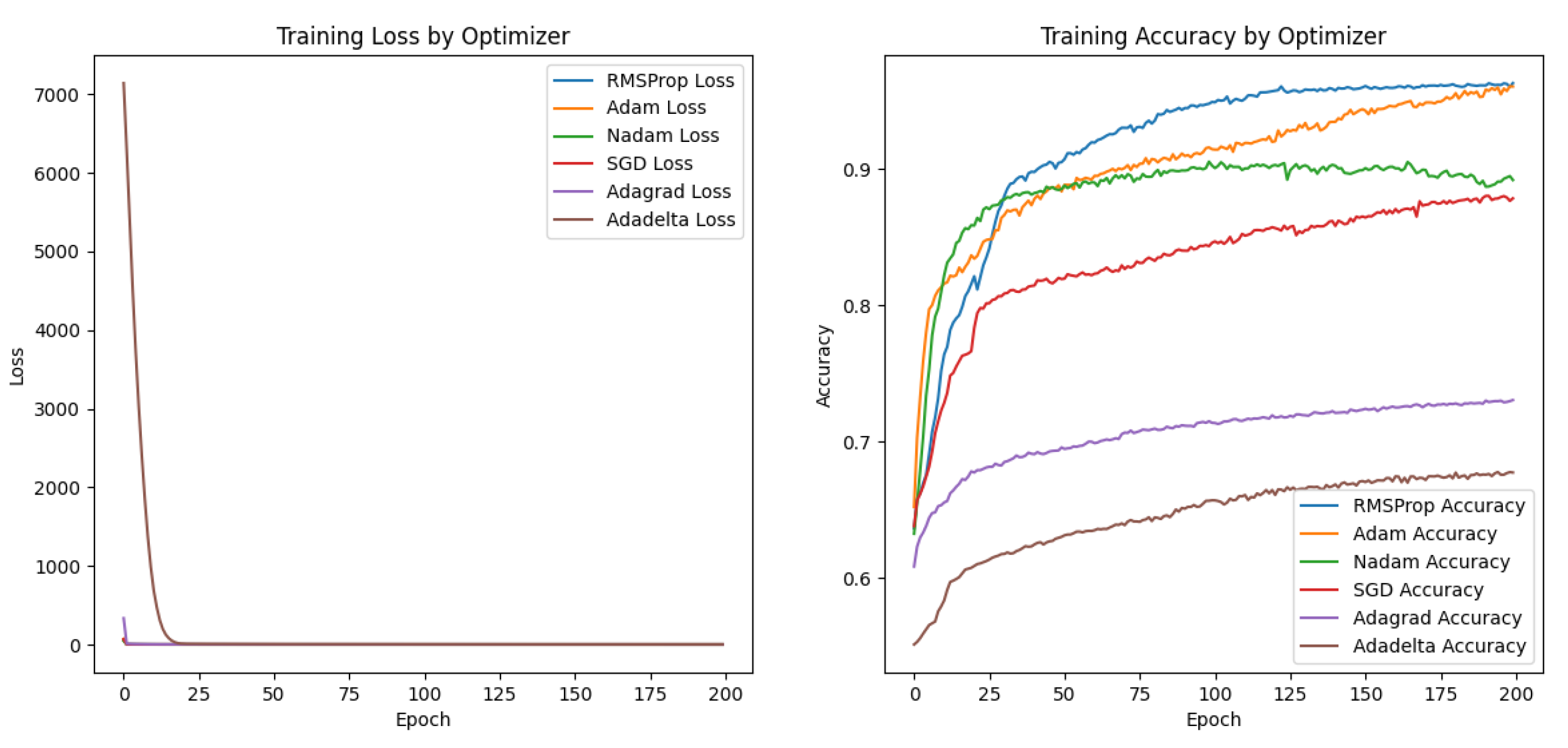
As depicted in the graph, both RMSProp and Adam exhibit rapid convergence on the loss function curve and accuracy curve after 200 iterations of model training, leading to high prediction accuracy.
(4) Learning rate selection:
The choice of learning rate is a crucial step in training a neural network. In our experiments, we tried different learning rate values and observed their impact on the model’s performance. Starting from 0.001, we gradually increased the learning rate using a power of 10. In this way, we obtained a series of results and summarized them in Table 14 for detailed comparison and analysis. This helps us find the optimal learning rate value that best fits the data set and model architecture, thereby improving training efficiency and model performance:
Figure 10.
Network training and validation of RMSProp with different learning rates on spectrum data sets loss function and accuarcy change curve: Among them, blue represents the learning rate of 0.001, orange represents the learning rate of 0.0001, green represents the learning rate of 0.00001, and red represents the learning rate of 0.000001.
Figure 10.
Network training and validation of RMSProp with different learning rates on spectrum data sets loss function and accuarcy change curve: Among them, blue represents the learning rate of 0.001, orange represents the learning rate of 0.0001, green represents the learning rate of 0.00001, and red represents the learning rate of 0.000001.
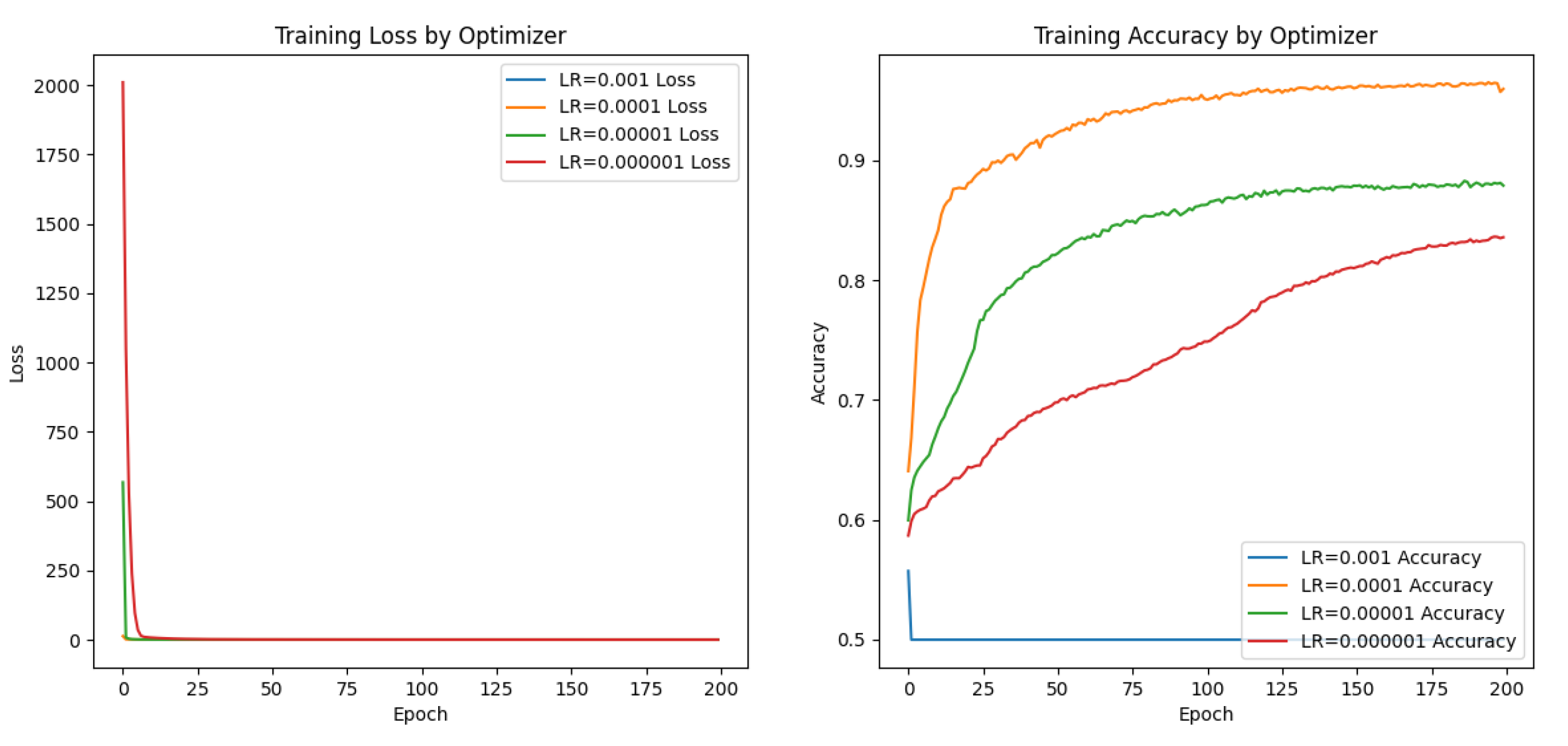
Based on the variations in the loss function and accuracy curves for a given optimizer under different learning rates, as well as considering the final accuracy value, it is apparent that RMSProp demonstrates optimal performance on the spectrum data set when utilizing a learning rate of 0.0001. It is consistent with the learning rate we have adopted.
(5) Running time:
Deep learning methods necessitate longer model training times due to their typical utilization of large datasets and complex network structures. In contrast to traditional classifier methods, deep learning algorithms require more iterations for parameter adjustment and model optimization in order to achieve higher accuracy and generalization capability. In practical applications, we conducted a detailed comparison of prediction times for different methods on datasets and compiled the results into a test time comparison table Table 15. These data clearly illustrate the differences in prediction times required by various algorithms when processing the same dataset, providing valuable references for further analysis and evaluation:
The data in Table 15 indicates that CO2 feature vector classifiers exhibit fast running times. However, the PF-SCNN does not offer significant advantages in terms of running time, as it requires matching prediction data with trained data during the network’s prediction stage, resulting in substantial consumption of computing time and memory. Although introducing peak values significantly enhances algorithmic speed compared to using only the SCNN model for prediction, the one-to-one matching method still demands considerable computing time. Based on these findings regarding running times, our future research will focus on extracting stable and distinct features from each type of aero engine’s hot jet spectrum to reduce predicted data volume and prediction time.
5. Summary
The PF-SCNN with a dual-branch structure proposed in this paper is designed for matching and classifying spectrum data. It utilizes the peak finding algorithm to extract spectrum peak values, which are then input to the SCNN for spectrum feature extraction and distance similarity calculation. The experimental results demonstrate a high prediction accuracy of 99%, validating the effectiveness of PF-SCNN in achieving good matching with the spectrum data set and its successful application in classifying hot jet spectra of aero-engines. However, the method’s approach of individually matching each test data with all trained data during the prediction stage leads to significant time and computational costs. Future iterations of this algorithm should prioritize extracting representative characteristic peaks from each type of aero-engine’s hot jet spectrum data and identifying prominent features within each category. Subsequently, PF-SCNN can be employed to compare predicted data with representative characteristic peak data, thereby enhancing classification accuracy and matching rates.
Author Contributions
Formal analysis, Y.L.; investigation, S.D. and Z.L.; software, Z.K. and F.L.; validation, W.H. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by National Natural Science Foundation of China, grant number 62005320.
Data Availability Statement
The data presented in this study are available upon request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- ROZENSTEIN O, PUCKRIN E, ADAMOWSKI J. Development of a new approach based on midwave infrared spectroscopy for post-consumer black plastic waste sorting in the recycling industry. Waste Management, 2017, 68: 38-44. [CrossRef]
- HOU X, LV S, CHEN Z, et al. Applications of Fourier transform infrared spectroscopy technologies on asphalt materials. Measurement, 2018: 304-316. [CrossRef]
- OZAKI Y. Infrared Spectroscopy—Mid-infrared, Near-infrared, and Far-infrared/Terahertz Spectroscopy. Analytical Sciences,2021: 1193-1212. [CrossRef]
- Jang, H.-D.; Kwon, S.; Nam, H.; Chang, D.E. Semi-Supervised Autoencoder for Chemical Gas Classification with FTIR Spectrum. Sensors,2024,24, 3601. [CrossRef]
- UDDIN Md P, MAMUN Md A, HOSSAIN Md A. PCA-based Feature Reduction for Hyperspectral Remote Sensing Image Classification. IETE Technical Review, 2021: 377-396.
- XIA J, BOMBRUN L, ADALI T, et al. Spectral–Spatial Classification of Hyperspectral Images Using ICA and Edge-Preserving Filter via an Ensemble Strategy. IEEE Transactions on Geoscience and Remote Sensing, 2016: 4971-4982. [CrossRef]
- JIA S, ZHAO Q, ZHUANG J, et al. Flexible Gabor-Based Superpixel-Level Unsupervised LDA for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing, 2021: 10394-10409. [CrossRef]
- Zhang Y, Li T. Three different SVM classification models in Tea Oil FTIR Application Research in Adulteration Detection//Journal of Physics: Conference Series. IOP Publishing, 2021, 1748(2): 022037.
- Chen T, Guestrin C. XGBoost: A scalable tree boosting system//Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining. 2016: 785-794.
- Breiman L. Random Forests. Machine learning, 2001, 45: 5-32.
- Kumaravel ArulRaj,Muthu Karthikeyan,Deenadayalan Narmatha.A View of Artificial Neural Network Models in Different Application Areas.E3S Web of Conferences,2021,287(a).
- LI X, LI Z, QIU H, et al. An overview of hyperspectral image feature extraction, classification methods and the methods based on small samples. Applied Spectroscopy Reviews, 2021: 1-34. [CrossRef]
- CHEN Y, LIN Z, ZHAO X, et al. Deep Learning-Based Classification of Hyperspectral Data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2014: 2094-2107.
- ZHOU W, KAMATA S I, WANG H, et al. Multiscanning-Based RNN-Transformer for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing, 2023: 1-19. [CrossRef]
- Hu, H.; Xu, Z.; Wei, Y.; Wang, T.; Zhao, Y.; Xu, H.; Mao, X.; Huang, L. The Identification of Fritillaria Species Using Hyperspectral Imaging with Enhanced One-Dimensional Convolutional Neural Networks via Attention Mechanism. Foods 2023, 12, 4153. [CrossRef]
- Ma, Y.; Lan, Y.; Xie, Y.; Yu, L.; Chen, C.; Wu, Y.; Dai, X. A Spatial–Spectral Transformer for Hyperspectral Image Classification Based on Global Dependencies of Multi-Scale Features. Remote Sens. 2024, 16, 404. [CrossRef]
- JIA S, JIANG S, LIN Z, et al. A Semisupervised Siamese network for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing, 2022: 1-17. [CrossRef]
- ONDRASOVIC M, TARABEK P. Siamese Visual Object Tracking: A Survey. IEEE Access, 2021: 110149-110172. [CrossRef]
- XU T, FENG Z, WU X J, et al. Toward Robust Visual Object Tracking With Independent Target-Agnostic Detection and Effective Siamese Cross-Task Interaction. vol. 32, pp. 1541-1554, 2023. [CrossRef]
- WANG L, WANG L, WANG Q, et al. SSA-SiamNet: Spectral–Spatial-Wise Attention-Based Siamese network for Hyperspectral Image Change Detection. IEEE Transactions on Geoscience and Remote Sensing, 2022: 1-18.
- MELEKHOV I, KANNALA J, RAHTU E. Siamese network features for image matching//2016 23rd International Conference on Pattern Recognition (ICPR), Cancun. 2016.
- LI Y, CHEN C L P, ZHANG T. A Survey on Siamese network: Methodologies, Applications, and Opportunities. IEEE Transactions on Artificial Intelligence, 2022: 994-1014.
- HUANG L, CHEN Y. Dual-Path Siamese CNN for Hyperspectral Image Classification With Limited Training Samples. IEEE Geoscience and Remote Sensing Letters, 2021: 518-522. [CrossRef]
- MIAO J, WANG B, WU X, et al. Deep Feature Extraction Based on Siamese network and Auto-Encoder for Hyperspectral Image Classification. IEEE Conference Proceedings,IEEE Conference Proceedings, 2019.
- NANNI L, MINCHIO G, BRAHNAM S, et al. Experiments of Image Classification Using Dissimilarity Spaces Built with Siamese networks. Sensors, 2021, 21(5): 1573. [CrossRef]
- LIU B, YU X, ZHANG P, et al. Supervised Deep Feature Extraction for Hyperspectral Image Classification. IEEE Transactions on Geoscience and Remote Sensing, 2018: 1909-1921. [CrossRef]
- LI X, LI Z, QIU H, et al. An overview of hyperspectral image feature extraction, classification methods and the methods based on small samples. Applied Spectroscopy Reviews, 2021: 1-34. [CrossRef]
- KRUSE FredA, KIEREIN-YOUNG K S, BOARDMAN JosephW. Mineral mapping at Cuprite, Nevada with a 63-channel imaging spectrometer. Photogrammetric Engineering and Remote Sensing,Photogrammetric Engineering and Remote Sensing, 1990.
- BROMLEY J, BENTZ J W, BOTTOU L, et al. SIGNATURE VERIFICATION USING A “SIAMESE” TIME DELAY NEURAL NETWORK//Series in Machine Perception and Artificial Intelligence,Advances in Pattern Recognition Systems Using Neural Network Technologies. 1994: 25-44.
- THENKABAIL PrasadS, KRISHNA M, TURRAL H. Spectral Matching Techniques to Determine Historical Land-use/Land-cover (LULC) and Irrigated Areas Using Time-series 0.1-degree AVHRR Pathfinder Datasets. Photogrammetric Engineering and Remote Sensing,Photogrammetric Engineering and Remote Sensing, 2007.
- SOHN K. Improved deep metric learning with multi-class N-pair loss objective. Neural Information Processing Systems,Neural Information Processing Systems, 2016.
- Homan D C, Cohen M H, Hovatta T, et al. MOJAVE. XIX. Brightness Temperatures and Intrinsic Properties of Blazar Jets. The Astrophysical Journal, 2021, 923(1): 67. [CrossRef]
- ZHOU W, ZHANG J, JIE D. The research of near infrared spectral peak detection methods in big data era//2016 ASABE International Meeting. 2016.
- Tieleman, T., & Hinton, G. (2012). Lecture 6.5-rmsprop: divide the gradient by a running average of its recent magnitude. COURSERA: Neural networks for machine learning, 4(2), 26–31.
Figure 1.
Aero-engine hot jet infrared spectrum measurement experiment site layout diagram.
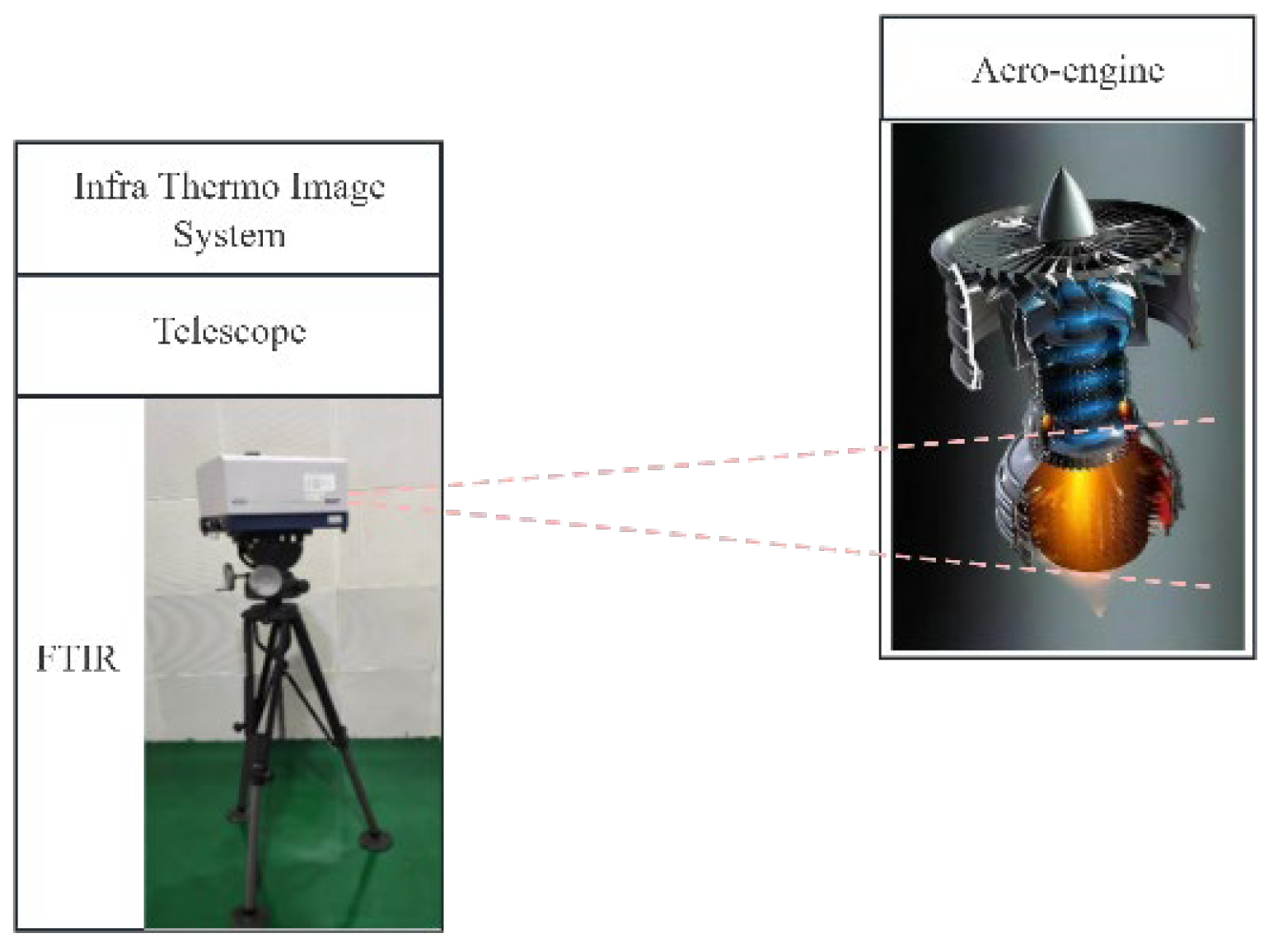
Figure 2.
Experiment measurement of infrared spectra of aero-engine hot jets.
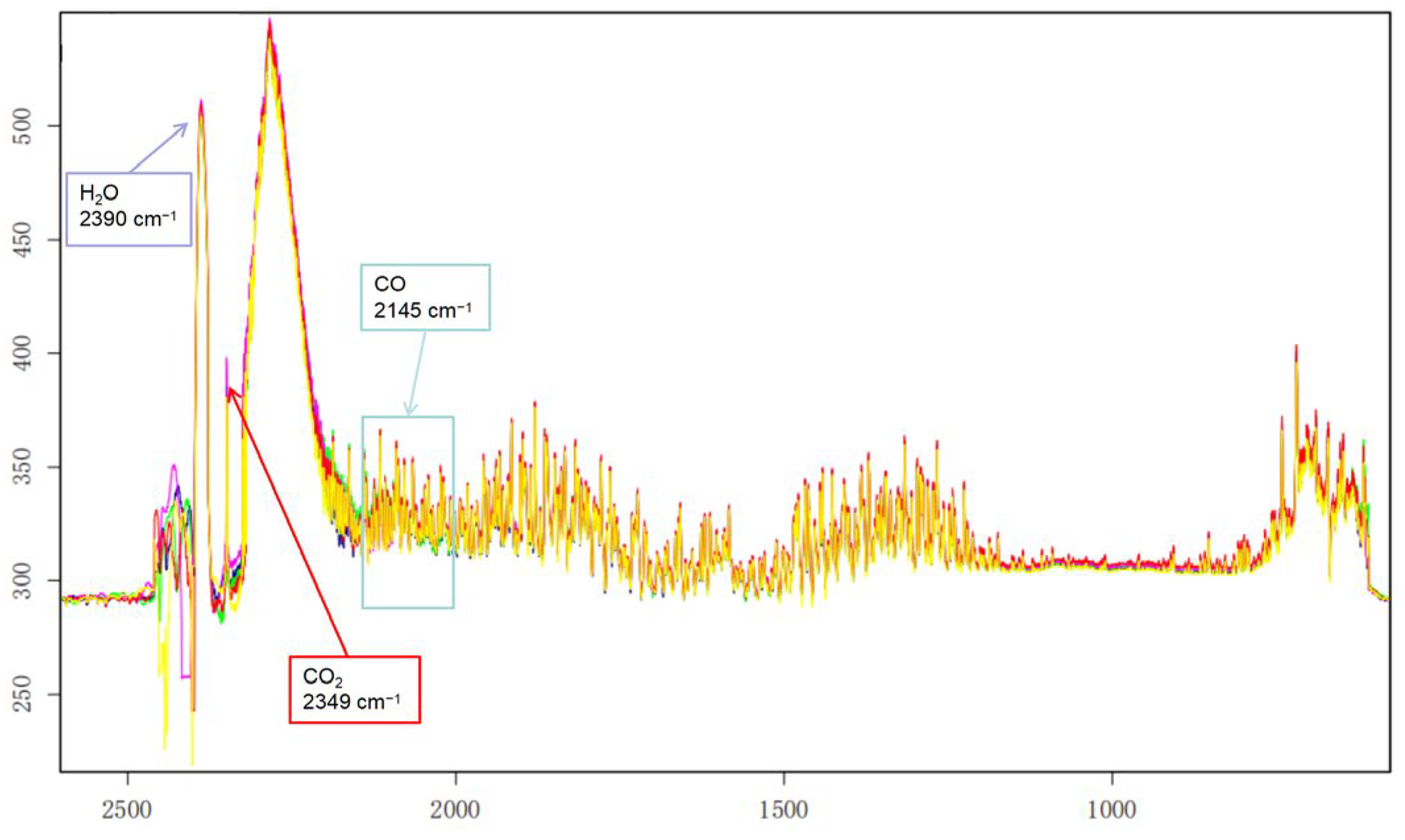
Figure 3.
Spectral classification Siamese network infrastructure.
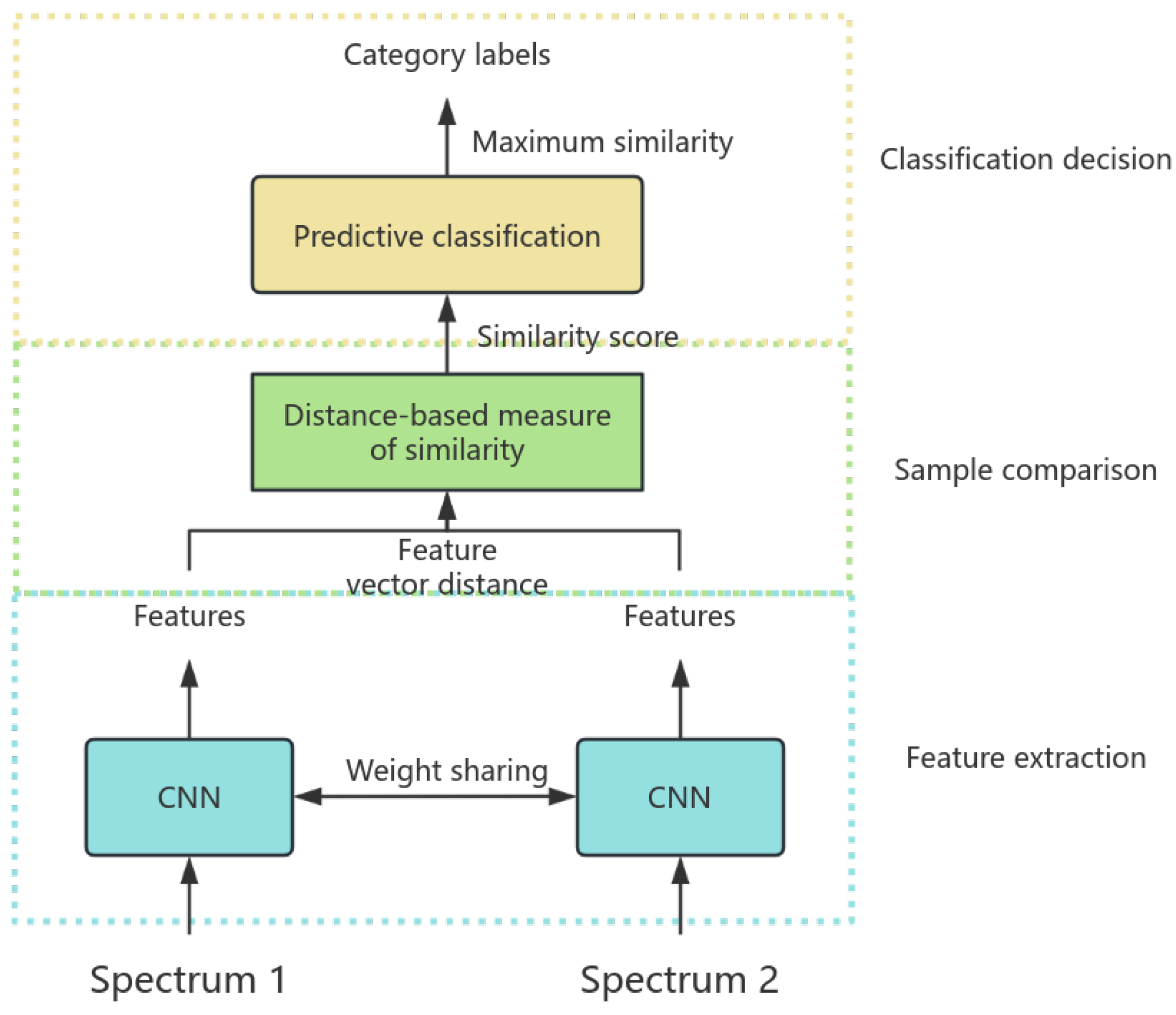
Figure 4.
Detail drawing of the aero-engine hot jet infrared spectrum classification network PF-SCNN.
Figure 4.
Detail drawing of the aero-engine hot jet infrared spectrum classification network PF-SCNN.
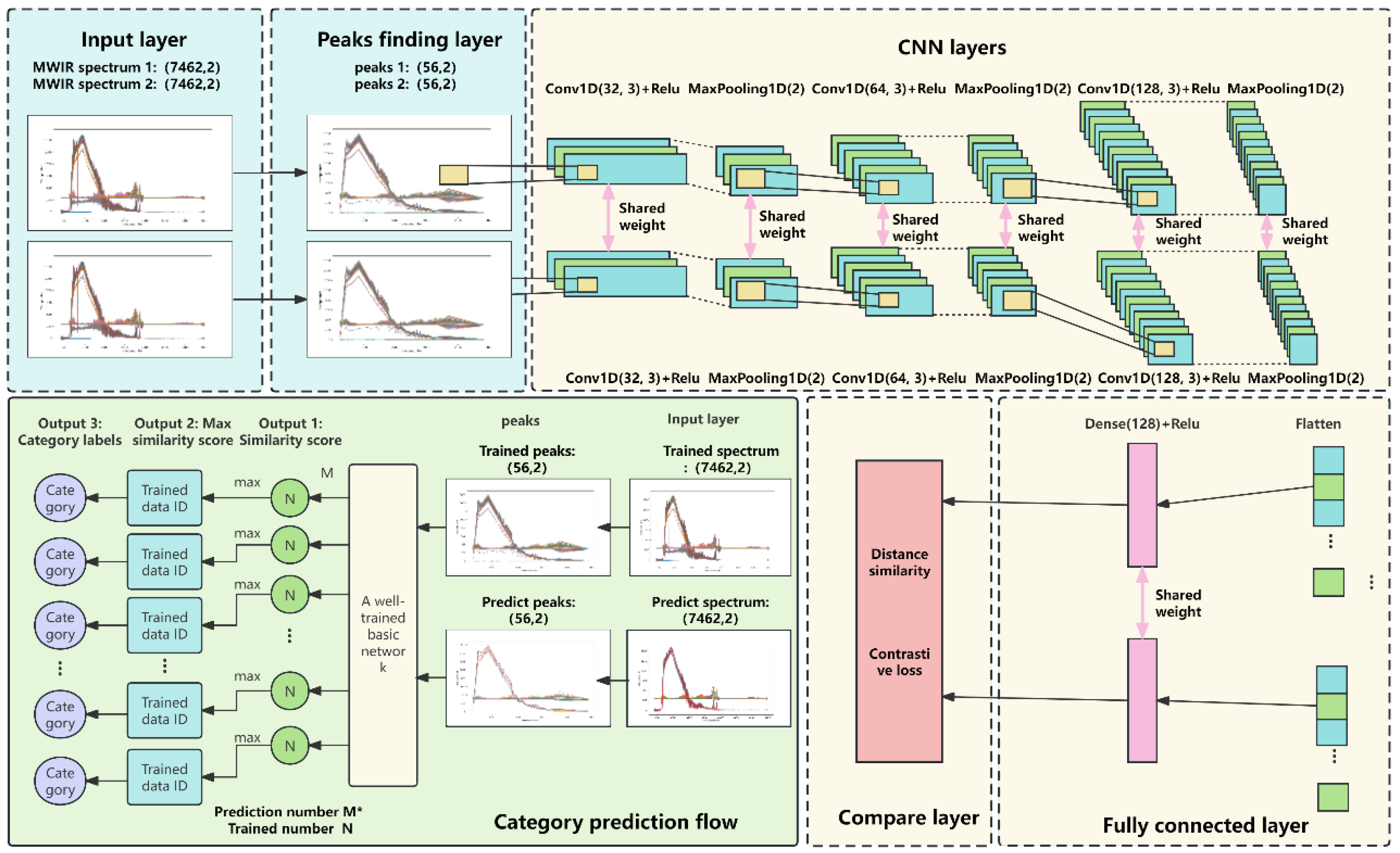
Figure 6.
The position diagram of the four characteristic peaks of the measured aero-engine.
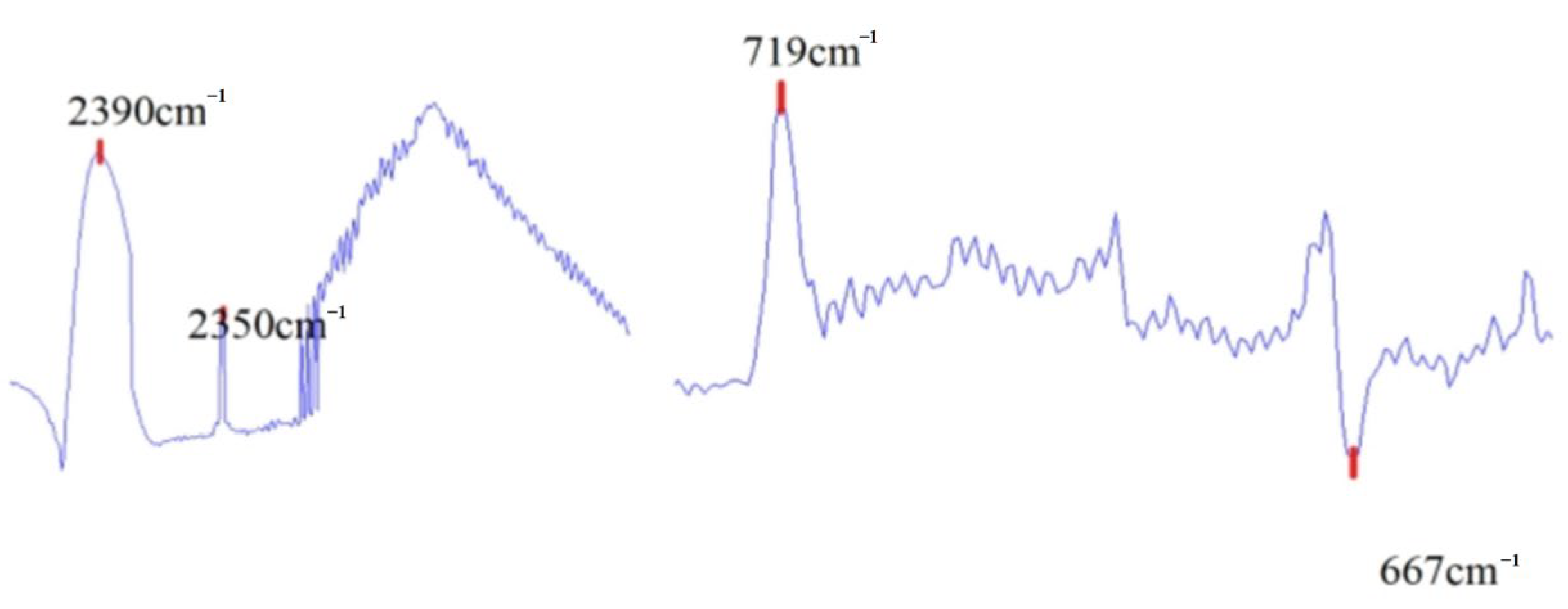
Figure 7.
Experimental results of peak finding and high frequency peak statistics: (a) visualization of peak finding, (b) statistics of peak frequency, and (c) visualization of peak position.
Figure 7.
Experimental results of peak finding and high frequency peak statistics: (a) visualization of peak finding, (b) statistics of peak frequency, and (c) visualization of peak position.
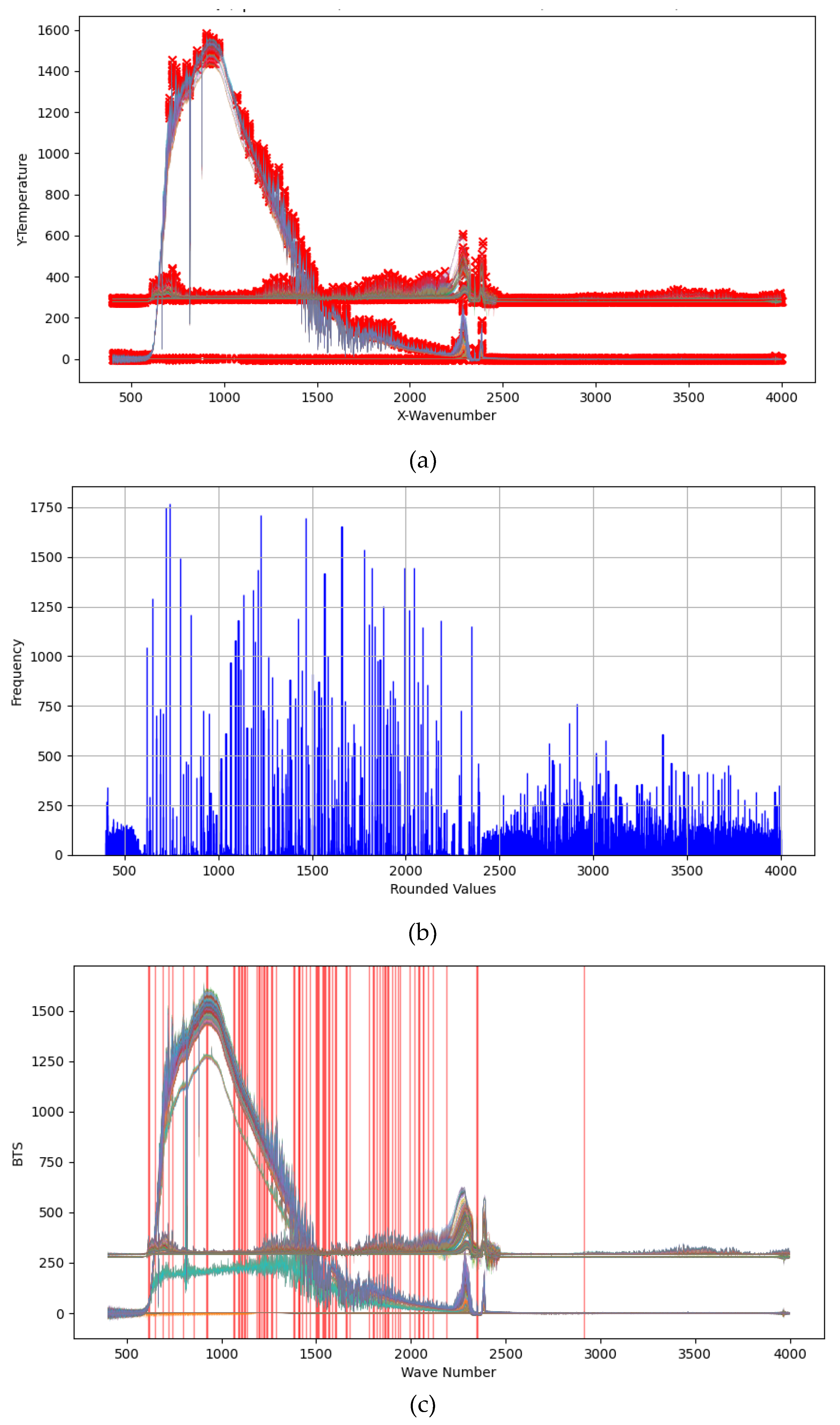

Table 1.
Parameters of the FT-IR spectrometers used for the aero-engine hot jet measurement outfield experiment.
Table 1.
Parameters of the FT-IR spectrometers used for the aero-engine hot jet measurement outfield experiment.
| Name | Measurement Pattern | Spectral Resolution (cm−1) | Spectral Measurement Range (µm) | Full Field of View Angle |
|---|---|---|---|---|
| EM27 | Active/Passive | Active: 0.5/1 Passive: 0.5/1/4 | 2.5~12 | 30 mrad (no telescope) (1.7°) |
| Telemetry Fourier Transform Infrared Spectrometer | Passive | 1 | 2.5~12 | 1.5° |
Table 2.
Environmental parameters of the aero-engine hot jet measurement outfield experiment.
| Aero-Engine Serial Number | Environmental Temperature | Environmental Humidity | Detection Distance |
|---|---|---|---|
| Engine 1 (Turbofan) | 19℃ | 58.5%Rh | 5m |
| Engine 2 (Turbofan) | 16℃ | 67%Rh | 5m |
| Engine 3 (Turbojet) | 14℃ | 40%Rh | 5m |
| Engine 4 (Turbojet UAV) | 30℃ | 43.5%Rh | 11.8m |
| Engine 5 (Turbojet UAV with propeller at tail) | 20℃ | 71.5%Rh | 5m |
| Engine 5 (Turbojet) | 19℃ | 73.5%Rh | 10m |
Table 3.
Data set of hot jet BTS from six types of aero-engines.
| Dataset | Type | Number of data pieces | Number of error data | Full band data volume | Medium wave range data volume |
|---|---|---|---|---|---|
| 1 | Engine 1 (Turbojet UAV) | 193 | 0 | 16384 | 7464 |
| 2 | Engine 2 (Turbojet UAV with propeller at tail) | 48 | 0 | 16384 | 7464 |
| 3 | Engine 3 (Turbojet) | 202 | 3 | 16384 | 7464 |
| 4 | Engine 4 (Turbofan) | 792 | 17 | 16384 | 7464 |
| 5 | Engine 5 (Turbofan) | 258 | 2 | 16384 | 7464 |
| 6 | Engine6 (Turbojet) | 384 | 4 | 16384 | 7464 |
Table 4.
Confusion matrix.
| Forecast results | |||
|---|---|---|---|
| Positive samples | Negative samples | ||
| Real results | Positive samples | TP | TN |
| Negative samples | FP | FN | |
Table 5.
PF-SCNN model parameter information table.
| Methods | Parameter Settings |
|---|---|
| PF-SCNN | Conv1D(32, 3), Conv1D(64, 3), Conv1D(128, 3), activation=‘relu’ |
| MaxPooling1D(2)(x) | |
| Dense(128, activation=‘relu’) | |
| Optimizers= RMSProp,(learning_rate=0.0001) | |
| loss=contrastive_loss, metrics=[accuracy] | |
| epochs=500 |
Table 6.
Experiment results of the spectrum matching classification network PF-SCNN.
| Evaluation criterion | Accuracy | Precision | Recall | Confusion matrix |
F1-score |
|---|---|---|---|---|---|
| Dataset | 99.46% | 99.77% | 99.56% | [27 0 0 0 0 0] [ 0 72 0 0 0 0] [ 0 0 21 0 0 0] [ 0 1 0 37 0 0] [ 0 0 0 0 20 0] [ 0 0 0 0 0 6] |
99.66% |
Table 7.
Value range of the characteristic peak threshold.
| Characteristic peak type | Emission peak (cm-1) | Absorption peak (cm-1) | ||
|---|---|---|---|---|
| Standard feature peak value | 2350 | 2390 | 720 | 667 |
| Feature peak range value | 2350.5-2348 | 2377-2392 | 722-718 | 666.7-670.5 |
Table 8.
Parameters of CO2 feature vector classifier methods.
| Methods | Parameter Settings |
|---|---|
| SVM | decision_function_shape = ‘ovr’, kernel = ‘rbf’ |
| XGBoost | objective = ‘multi:softmax’, num_classes = num_classes |
| CatBoost | loss_function = ‘MultiClass’ |
| Adaboost | n_estimators = 200 |
| Random Forest | n_estimators = 300 |
| LightGBM | objective’: ‘multiclass’, ‘num_class’: num_classes |
| Neural Network | hidden_layer_sizes = (100), activation = ‘relu’, solver = ‘adam’, max_iter = 200 |
Table 9.
Experiment results of CO2 feature vector classifier methods on spectrum data set.
| Evaluation criterion | Accuracy | Precision score | Recall | Confusion matrix | F1-score | |
|---|---|---|---|---|---|---|
| Classification methods | ||||||
| CO2 feature vector + SVM | 59.78% | 44.15% | 47.67% | [ 8 0 3 0 0 0] [ 0 3 0 0 0 0] [ 9 1 12 0 0 0] [ 0 3 1 84 22 33] [ 0 0 0 0 0 0] [ 0 0 0 0 0 0] |
42.38% | |
| CO2 feature vector + XGBoost | 94.97% | 92.44% | 93.59% | [15 0 3 0 0 0] [ 0 7 0 0 0 0] [ 2 0 13 0 0 0] [ 0 0 0 83 3 0] [ 0 0 0 1 19 0] [ 0 0 0 0 0 33] |
92.95% | |
| CO2 feature vector + CatBoost | 94.41% | 90.35% | 93.52% | [15 0 2 0 0 0] [ 0 6 0 0 0 0] [ 2 0 14 0 0 0] [ 0 0 0 83 4 0] [ 0 1 0 1 18 0] [ 0 0 0 0 0 33] |
91.81% | |
| CO2 feature vector + AdaBoost | 79.89% | 63.66% | 71.49% | [17 5 6 0 0 0] [ 0 2 0 0 0 0] [ 0 0 10 0 0 0] [ 0 0 0 84 18 3] [ 0 0 0 0 0 0] [ 0 0 0 0 4 30] |
62.56% | |
| CO2 feature vector + Random Forest | 94.41% | 91.40% | 92.70% | [15 0 4 0 0 0] [ 0 7 0 0 0 0] [ 2 0 12 0 0 0] [ 0 0 0 83 3 0] [ 0 0 0 1 19 0] [ 0 0 0 0 0 33] |
91.91% | |
| CO2 feature vector + LightGBM | 94.41% | 90.68% | 92.40% | [14 0 2 0 0 0] [ 0 6 0 0 0 0] [ 3 0 14 0 0 0] [ 0 0 0 82 2 0] [ 0 1 0 2 20 0] [ 0 0 0 0 0 33] |
91.42% | |
| CO2 feature vector + Neural Networks | 84.92% | 76.79% | 76.57% | [17 0 2 0 0 0] [ 0 6 0 0 0 0] [ 0 0 12 0 0 0] [ 0 0 2 84 18 0] [ 0 1 0 0 0 0] [ 0 0 0 0 4 33] |
76.02% | |
Table 10.
Experiment results of peak-seeking classifier on spectral data set.
| Accuracy | Precision | Recall | Confusion Matrix | F1-score | Running time | |
|---|---|---|---|---|---|---|
| Peaks+SVM | 58.15 | 48.09 | 43.58 | [ 0 0 0 0 0 0] [13 42 0 0 0 0] [ 0 0 20 0 13 6] [14 30 0 38 0 0] [ 0 0 1 0 7 0] [ 0 0 0 0 0 0] |
41.02 | 0.54 |
| Accuracy | Precision | Recall | Confusion Matrix | F1-score | Running time | |
| Peaks+XGBoost | 98.91 | 96.78 | 99.01 | [27 0 0 0 0 0] [ 0 72 0 1 0 0] [ 0 0 21 0 0 1] [ 0 0 0 37 0 0] [ 0 0 0 0 20 0] [ 0 0 0 0 0 5] |
97.76 | 1.27 |
Table 11.
Experiment results of spectrum matching classification SCNN model.
| Evaluation criterion | Accuracy | Precision score | Recall | Confusion matrix |
F1-score |
|---|---|---|---|---|---|
| Dataset | 99.46% | 99.24% | 99.56% | [27 0 0 0 0 0] [ 0 72 0 0 0 0] [ 0 0 21 0 0 0] [ 0 0 1 37 0 0] [ 0 0 0 0 20 0] [ 0 0 0 0 0 6] |
99.39% |
Table 12.
Optimizer parameters information.
| Methods | Parameter Settings |
|---|---|
| RMSProp | learning rate=0.0001, clipvalue=1.0 |
| Adam | learning rate=0.0001, clipvalue=1.0 |
| Nadam | learning rate=0.0001, clipvalue=1.0 |
| SGD | learning rate=0.0001, clipvalue=1.0 |
| Adagrad | learning rate=0.0001, clipvalue=1.0 |
| Adadelta | learning rate=0.0001, clipvalue=1.0 |
Table 13.
Experiment results of different optimizers.
| Optimizers | Prediction accuracy | Training time/s | Title 3 |
|---|---|---|---|
| RMSProp | 96% | 1180.96 | data |
| Adam | 96% | 1014.82 | data 1 |
| Nadam | 89% | 1523.14 | |
| SGD | 88% | 1101.65 | |
| Adagrad | 73% | 1021.90 | |
| Adadelta | 68% | 991.90 |
Table 14.
Experiment results of RMSProp optimizer in different learning rate.
| Learning rate | Prediction accuracy | Training time/s |
|---|---|---|
| 0.001 | 0.50 | 1283.49 |
| 0.0001 | 0.96 | 1252.83 |
| 0.00001 | 0.88 | 1171.39 |
| 0.000001 | 0.84 | 1193.72 |
Table 15.
Prediction time comparison.
| Methods | Prediction time |
|---|---|
| PF-SCNN | 71s Each data ; 3:44:17 total |
| SCNN | 79s Each data; 4:30:45.78 total |
| CO2 feature vector +SVM | 0.12 s |
| CO2 feature vector +XGBoost | 0.30 s |
| CO2 feature vector+CatBoost | 4.74 s |
| CO2 feature vector +AdaBoost | 0.39 s |
| CO2 feature vector +Random Forest | 0.56 s |
| CO2 feature vector +LightGBM | 0.44 s |
| CO2 feature vector +Neural Networks | 0.85 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



