
Submitted:
13 July 2024
Posted:
18 July 2024
You are already at the latest version
Abstract
Color distortion in an image poses a challenge for classification and regression when the input data consists of pictures. Because of that, a new algorithm for color standardization of photos is proposed, which serves as a base for a deep neural network regression model. This approach utilizes a custom color template, which was developed based on an initial series of studies and digital imaging. Using the equalized histogram of R, G, B channels from the digital template and its photo, a color mapping strategy is computed. By applying this approach, the histograms are adjusted, and the colors of photos taken with a smartphone are standardized. The proposed algorithm has been developed for a series of photos where the entire surface roughly maintains a uniform color, and the differences in color between the photographs of individual objects are minor. The optimized approach was validated in the colorimetric determination procedure of vitamin C. The dataset for deep neural network in the regression variant was formed from photos of samples under two separate lighting conditions. For the concentration range of vitamin C from 0 to 87.72 µg·mL-1, the RMSE for the test set ranged between 0.75 and 1.95 µg·mL-1, in comparison to the non-standardized variant, where this indicator was at the level of 1.48-2.29 µg·mL-1. The consistency of the predicted concentration results with actual data expressed using R2 was between 0.9956 and 0.9999, for each of the standardized variants. This approach allows for the removal of light reflections on the shiny surface of solutions, which is a common problem in liquid samples. The color matching algorithm has a universal character, and its application scope is not limited.
Keywords:
color standardization
; color template matching
; RGB histogram fitting
; deep learning
; vitamin C colorimetric determination
1. Introduction
There is a close connection between the development of measurement methods and research strategies in various fields of science and technology, and the potential to support these tasks through the use of machine learning (ML) and deep learning (DL) methods. If information in the problem being solved is communicated through images, drawings, sketches or photographs, the use of DL in data modelling is often the optimal approach. The application of neural networks in typical supervised learning requires access to large data sets, which makes the method of obtaining and labelling data a significant limitation. Today’s technology provides many electronic devices, such as cameras or scanners, which can be used to obtain data for constructing models quickly and without special qualifications. Information can often be encoded simply in the form of objects, the relationship between objects in the analyzed area, texture, the quantity of small components, and colors.
If color is the main, decisive criterion in image analysis that codes the information we are looking for, it is crucial to take photos in such a way as to maintain the appropriate quality of this parameter. The true color of the image allows for the correct interpretation of various features of the photographed objects. Undesirable variability may arise from using multiple devices to capture images or from the method of acquiring images with a single device under uncontrolled or changing conditions. Significant factors include changes in lighting conditions, reflections on shiny surfaces, and variations such as the time of day. These elements may not directly impact the photo’s quality but can influence its informational value. Therefore, the importance of color standardization as a crucial step in data preprocessing should be considered. Various computational approaches for preserving or restoring the true color of images within a dataset for deep learning are described in numerous works, offering solutions to this problem.
This study presents an original algorithm for standardizing the colors of photos captured with a single smartphone camera under various lighting conditions. It also considers variability stemming from incidental factors associated with the photography process and the inherent lack of perfect repeatability of the camera. The research focused on a homogeneous liquid exhibiting minimal color variation among the tested objects. The entirety of the photo, used in the modeling process shared the same color, although with a certain level of random variability that could not be entirely eliminated. In this context, even slight changes in color held significant information value, emphasizing the importance of accurate color interpretation for enhancing the quality of the deep learning regression model and minimizing prediction errors.
A standardization algorithm was proposed that used the histogram of a specially designed template photographed under controlled conditions together with the tested object in relation to the histogram of the template prepared using a graphic application and its photograph. This study also presents the verification of the proposed approach for colorimetric determination of vitamin C using a regression model defined by DNN (Deep Neural Networks).
2. Related Works
2.1. Color Standardization
There are numerous categories of color calibration problems, with two fundamental groups pertaining to either the use of different devices within a series of photos or variations in the lighting conditions affecting the photographed subjects. Hardware color compensation can be achieved by employing camera sensors that automatically adjust settings based on the lighting of the scene being captured. The alternative approach involves numerical processing of photos using various strategies that ultimately aim to achieve consistent color tones across multiple images. To accomplish this, calibration charts are initially employed, which correlate and map the individual pixels of captured photos with the standardized values of the corresponding color patches on the chart [1,2]. A standard color calibration chart serves as a reference tool in photography, film creation, video recording or graphic design, ensuring accurate and consistent color reproduction in images. Typically, it comprises a grid of colored patches with known and standardized colors. These charts are applied in calibrating equipment and adjusting during post-processing, thereby ensuring consistency in color representation across various devices and conditions. Commercially, several calibration charts are available, ranging from those with 6 to 100 color patches. However, the 24-color patch calibration chart found widespread use in numerous applications. Additionally, the development of customized calibration charts plays an important role in standardizing image colors.
Color standardization plays an important role in many fields of science and technology, including medical diagnostics, bioanalysis, agriculture, analysis of evidence in forensic sciences, analytical chemistry, etc. In agricultural image processing, the focus lies in linking alterations in images color, in designated areas of interest, with particular quality attributes such as plant health, crop stress, and maturity level. In [3], a technique was proposed to calibrate digital images, ensuring their uniformity and enhancing phenological comparisons in agriculture. The color transformation of images was achieved through the utilization of a standard 24-color calibration chart. Calibration delivers typical and expected results by adjusting the RGB values of the color patches in the input image to standard RGB values. In [4], a digital shade-matching device was developed for determining tooth color, as accurate shade assessment is crucial in dental restoration procedures. Image recordings made with an intraoral camera served as the foundation for calculations and transformations. The support vector machine (SVM) algorithm and the CIEL*a*b* color space were employed to evaluate tooth color. Color correction was based on calculating the Euclidean distance between shades. The authors created a dedicated template, distinct from the typical one with a broad spectrum of colors, specifically adapted to the range of tooth color variations addressed in the study. The next proposition concerns improving the accuracy of color reproduction in digital cameras and smartphones. The first method uses white balance correction followed by a color space transformation. The second approach, applicable to images processed off-line, is based on performing full color balance instead of white balance and requires the use of machine learning to predict the color balance matrix [5]. The review paper [6] discusses the use of various histopathological image recognition algorithms. Differences in color in histopathology result from the use of various equipment or tissue staining techniques. Typically, color normalization involves transferring the average color of the target image to the source image and separating the stain present in the source image. The article describes an extensive set of color standardization methods that have been verified using histopathological images, including obtained in the diagnosis of breast and colon cancer.
2.2. Vitamin C Determination
Color standardization techniques are crucial in analytical chemistry, especially in colorimetric determination of different substances. This is particularly evident in methods where solutions of tested compounds are photographed, and concentration information is derived from these photos using various statistical tools and multivariate analysis. An illustration of such a methodology is the colorimetric determination of vitamin C.
Ascorbic acid (AA), i.e. vitamin C, is a natural, highly water-soluble compound, which plays a dominant role in human health and is essential for a range of metabolic reactions and biological processes, with strong antioxidant activity, limiting free radical damage. Insufficient concentration of vitamin C in the body, among others, causes scurvy, anemia and is associated with some psychological abnormalities, for example depression. Overconsumption of vitamin C can have negative consequences, such as hindering the absorption of vitamin B12 and potentially causing gastrointestinal issues or kidney stones. [7,8]. As humans are unable to produce vitamin C internally, it’s essential to supplement a regulated amount of AA, typically from fresh fruits and vegetables [9,10].
Analytical chemistry provides many strategies to determine AA in food products and vitamin C supplements. Traditionally, instrumental analysis techniques have been utilized to measure ascorbic acid levels, offering a broad concentration range with a low detection limit. These methods include direct titration [11], ultraperformance liquid chromatography (UPLC) and high performance liquid chromatography (HPLC) [12,13], Fourier transform infrared spectrometry (FT-IR) [14], chemiluminescence [15], Raman spectroscopy [16], near infrared (NIR), FT-Raman spectroscopy [17] or capillary electrophoresis [18]. Furthermore, a variety of electrochemical methods have been employed to determine AA, offering extremely high sensitivity, selectivity, reproducibility, and reliability [19,20,21]. However, the mentioned methods of chemical instrumental analysis require specialized laboratory rooms, expensive instrumentation, many auxiliary reagents, time-consuming extraction steps, and use complicated measurement procedures that necessitate highly skilled staff for tasks such as preparing reagents and samples, conducting research or interpreting the results.
The development of novel methodologies that either substitute or support traditional laboratory strategies with cost-effective instruments, fulfills the need for highly efficient and adaptable approaches in food, pharmaceutical or environmental analysis. Popular and widely available smartphones offer a promising analytical platform characterized by full automation, large local memory capacity, access to external cloud storage, and especially high-quality cameras, making them suitable for wide use as portable measuring devices. Compared with conventional methods, smartphone-based measurements use digital imaging, offering many applications in various fields and significant advantages. These are low cost, simple operation, possibility of installing various dedicated sensors, precise measurements in real time, non-destructive nature of testing in many cases, fast analysis, and portability to other similar devices. Such commonly available devices as cameras, webcams, scanners, and smartphones are applied in analytical chemistry to register images from colorimetric reactions, in which the intensity of the resulting color is directly correlated to the concentration of the analyte. The literature provides various descriptions of the use of digital imaging methods for determining AA. The work [22] presents a straightforward, rapid, and cost-effective technique employing smartphone image analysis to quantify AA in aqueous solution. The study is based on the assessment of the disturbing effect of AA in the enzymatic colorimetric detection of glucose. Another approach has been suggested, employing digital image colorimetry for determining the vitamin C content in natural fruit juices. This method involves measuring the color of the iron(II) - o-phenanthroline complex [23]. In the next article the authors developed a new circular dichroism spectrometer based on smartphones for highly sensitive and ultra-portable colorimetric analysis, offering the advantages of cost-effectiveness and simplicity. This spectrometer utilized an HSV color model and determined absorbance by summing the V value of adjacent positions to calculate overall intensity. The TMB-MnO2 nanosheet reaction was also used and, in the effect, a high sensitive and specific system for the detection of vitamin C was proposed [24]. In [25] a point of care sensor was developed, consisting of a fluorescent paper chip, 3D printed parts, and a smartphone. This system enabled quantitative and highly sensitive real-time visual detection of AA. The design of this device involved placing a fluorescent sensor in a portable sensing platform connected to a smartphone.
The analytical measurement method used in this work was based on the reducing properties of vitamin C. AA reduces Fe(III) to Fe(II) and then forms a complex with o-phenanthroline. The strong red complex of Fe(II) and o-phenanthroline is widely used for colorimetric determination and as an indicator [26]. This reaction is characterized by high speed, stability, and reproducibility. Utilizing this camera-based approach coupled with digital imaging of colored compounds enhances accuracy and reduces the cost of measuring vitamin C content.
2.3. Multivariate Regression Algorithms
Regression techniques are extensively employed as a supervised learning method, involving modeling the relationship between features and the target variable to address tasks aimed at predicting continuous values. The typical algorithms used for this purpose are PCR (Principal Component Regression) [27], PLSR (Partial Least Squares Regression) [28,29] and SVR (Support Vector Regression) [30]. DNN, with various architectures that map the nonlinear structure of the multivariate data, can also be applied for regression problems [31,32]. Convolutional neural networks (CNNs) are a type of deep learning algorithm, whose operation is based on a mathematical operation called convolution. They consist of multiple layers of convolutional filters that automatically learn hierarchical representations of features directly from the raw pixel data, making them highly effective for tasks such as image classification or segmentation, and object detection. Typically, the evaluation of fitting quality in regression models is conducted using the mean squares of errors between real values and predictions (MSE) or the mean of absolute error (MAE):
where n is the number of observations, yi is the actual value for the i-th observation and is the predicted value for the i-th observation. MSE and MAE are different error metrics used to evaluate the performance of predictive models. MSE is more sensitive to large errors because they are squared, while MAE provides a more intuitive understanding of the average error and is expressed in the unit of the target variable. These scores used as loss functions during neural network training minimize the mean difference between the predicted and the actual values. The training and prediction performance of the calibration model is also evaluated based on the following scores: the root mean square error of calibration (RMSEC), and prediction (RMSEP), coefficient of determination R2 for calibration and prediction [33]. Since the prediction result is expected to match the actual value, the points with coordinates (actual, predicted) should ideally lie on the line y = x. However, due to random variability and imperfect model fit to the data, it is sufficient for two conditions to be met: a value of 1 should belong to the confidence interval of the slope, and a value of 0 should belong to the confidence interval of the intercept [34].
3. Proposed Method
3.1. Color Matching Algorithm
In this work, the main objective was to develop an approach for determining vitamin C based on the color change of the solution influenced by its concentration. Therefore, a crucial step in achieving a high-quality regression model was performing the color standardization procedure of the photographed vitamin C samples. The proposed color standardization algorithm was divided into two parts. In the first step, the standard histogram matching was performed between a digital color template and a photography of a printed template obtained in a given lighting condition. In the second step, the histogram matching between a photo of the solution (tested sample) taken in the same illumination as the pattern and the reference template was realized. In the end, 512 smaller random squares were cut from the reconstructed image, to obtain a sufficiently large dataset for the subsequent training of the regression neural network. However, in order to do so, the additional step of adaptation of a reference template to the correct range of values was realized. This operation resulted in the development of an adapted histogram matching algorithm.
Histogram matching is an operation in which the pixels of an input image are manipulated in a way that allows its histogram to match the histogram of the reference image. In the case of color images each channel (RGB) is considered independently. In the context of image processing, this is a normalization task, associated for example with changing illumination (example: Figure 1).
In mathematical terms, histogram matching can be represented as an image transformation such that the cumulative distribution function (CDF) of the values in each band corresponds to the CDF of bands in another image.
To match histograms of two images, it is necessary to equalize their histograms. After that, each pixel of the first image is modified and mapped to the second picture. Such an operation was performed for each of the channels (R, G, B) of a photographed template under a given lightning condition (natural light and artificial light) and channels of a digital template. The whole process of picture colors transformation was represented in Figure 2.
In order to standardize the images of the tested chemical solutions, the correct range of RGB values was selected from the histograms of the photo of the tested sample. If the histogram value for a sample was greater than or equal to 1% of the maximum value of the chemical solution histogram, the value of the histogram was not modified, otherwise it was set to 0. The discrepancy in number of pixels was neutralized by their uniform random distribution across the range of values. The final step in the standardization algorithm was to match the histograms of an image of a solution with the adapted template histograms. This was done in the same way as described in Figure 3, followed by the reconstruction of an image from the R, G, and B channels.
3.2. Software
All calculations were performed in Python 3.10.0. The following libraries and packages were used: opencv 4.8.1, scikit-image 0.22.0, numpy 1.26.1, matplotlib 3.5.3, scikit-learn 1.0.2, tensorflow 2.9.1, keras 2.10.0.
4. Results and Discussion
4.1. Reagents, Laboratory Equipment and Measurement Procedure
In this work, the colorimetric reaction used to determine ascorbic acid (AA) was based on the reduction of Fe(III) to Fe(II) by AA, which forms a red color complex with orthophenanthroline. In this experiment, L( +)-ascorbic acid pure p.a., CAS: 50-81-7 (POCH, Poland), 1,10 phenanthroline p.a., CAS: 66-71-7 (POCH, Poland), ammonium iron(III) sulphate dodecahydrate pure p.a., CAS: 7783-83-7 (POCH, Poland) were used. The 1M acetate buffer was prepared in our laboratory by mixing sodium acetate and acetic acid i.e. 1.0 mol·L− 1 CH3COOH with 1.0 mol·L−1 CH3COONa (both reagents purchased from Avantor Performance Materials, Poland) and adjusting to the desired pH using 10N HCl. All solutions, ie, AA with a concentration of 2.5 gL-1, phenanthroline with a concentration of 4.0 gL-1, ammonium iron(III) sulphate with a concentration of 2.5 gL-1, and 1M acetate buffer (pH 4.6) used were prepared with double distilled water. Small laboratory equipment was applied in the experiments: precise analytical balance (RADWAG, model AS 60/220.XS, Poland), magnetic stirrer (WIGO, Poland), automatic pipettes of various volumes (Eppendorf, Germany), as well as glass, i.e., beakers and Petri dishes. To adjust the pH values of the buffer solution, the SevenCompact S210 laboratory pH meter (Mettler Toledo, Switzerland) was applied. All experiments were performed at room temperature.
Solutions with different concentrations of vitamin C for direct color assessment were prepared by first adding 9 mL of distilled water to the beakers, then 1 mL of acetate buffer, next the appropriate volume of ascorbic acid and 0.5 mL of ammonium iron(III) sulfate. After waiting 3 minutes, 0.5 mL of phenanthroline was finally added. The additions of AA were 0, 20, 50, 80, 100, 150 200, 300, 400 µL. Figure 3 shows photos of samples prepared for further testing. Parameters studied for optimization were reagent concentration, volume and the time between the individual stages (influence of chemical kinetics). After waiting about 20 minutes, 10 mL of each colored solution was poured into Petri dishes with a flat bottom and photos were taken with a smartphone camera.
4.2. Preparation of a Color Template and Picture Acquisition
The experiment was divided into several steps and the procedure is shown in Figure 4.
The first step was the preparation of the template for color standardization. To determine which colors should be used as a reference, a series of vitamin C solutions covering the concentration range considered in this study was prepared. This was done to estimate the range of RGB values significant for these calculations. The pictures of tested solutions were taken and using dedicated home-made software, 12 configurations of RGB values (colors) were chosen to be used on the template. The averaged RGB values formed the basis for determining the color range in the template dedicated to the solved issue. In order to slightly expand the color palette, the additional upper and lower values were estimated and the template was created to contain 12 colors. The template, where each color was represented by one square, was printed in several copies with one printer. The size of each square was 180x180 pixels and the total size of the template equaled 600x790 pixels.
The process of taking the pictures consisted of putting 10 ml of the solution in the Petri dish on the white background (highlighting the contrast between background and the Petri dish with solution), next to the template (which served as a color control set) on the black surface. There were two conditions in which the pictures were taken, natural lighting and light from the torch of the smartphone. In the second variant, the box completely isolating the photographed objects from the surroundings was put onto the experimental setup to cut off the access of the natural light. Differences in the colors of solutions and photographed color charts were observed under these two illuminations (Figure 5). The process was repeated 11 times for each sample with a different concentration of vitamin C. All of the pictures were taken with Xiaomi smartphone (Xiaomi Redmi Note 9) with the camera specs 48MP with f/1.79 aperture and the resolution of the pictures was 3984x1840px.
To histogram match the templates to be used in standardization additional pictures were taken of the template in both conditions. The templates were cut from the images and the histogram matching was performed between the achieved templates and the original one. The process with the results can be seen in Figure 6. Each template is presented as an RGB image and its histograms for each of the channels R, G and B. This figure clearly illustrates the operation of our algorithm. The first column shows the ideal histogram of the digital color template, designed for this task. The color histograms of the template photos are expected to match the ideal characteristics. However, in real conditions, there are significant differences (second and fourth columns) between the histograms of the photos and the digital version. Nonetheless, after applying the algorithm proposed in this work, the expected shape of the color histogram for all three components R, G, and B can be reproduced. The graphs in the third and fifth columns match those in the first column.
The cumulative histograms of matched images are the same as a cumulative histogram of the digital template (which serves as a reference) for each channel. Each spike on a given histogram corresponds to one component of a certain color on the template. The less discrete look of histograms of original images of a template are caused by variance due to the printing and different variables causing a camera to perceive the object with certain changes (e.g. shadows, highlights).
The data set for calculations was prepared in this way, that for 9 concentrations of vitamin C and 2 different lighting conditions, 198 pictures were taken. Which means that for a given solution for each of the conditions 11 pictures were taken. Each of the images underwent the process of standardization described in Section 3.1. The exemplary effect can be seen in Figure 7. In Figure 8, the effect of applying the algorithm to various images of the vitamin C solution with concentration 33.63 µg/mL was presented. This resulted in the generation of datasets for two lighting conditions. The combination of both sets resulted in preparation of mixed condition set, which consisted of:
- training set: 60416 images
- validation set: 20480 images
- test set: 20480 images.
The prepared image datasets served as input data for training a regression neural network to obtain a model for determining AA concentration based on the taken photos.
4.3. Network Architecture
A multivariate regression model was defined using deep neural networks with an unconventional architecture, specifically dedicated to this task. The network design considered essential information such as color-based modeling, very similar colors corresponding to successive values of the target variable, and the approximately uniform color of each photo.
The neural network’s input layer accepts images of dimensions 50x50 with three color channels (RGB), randomly selected from each photo. Subsequently, Conv2D convolutional layers with small 1x1 filters, L2 regularization, and the GELU (Gaussian Error Linear Unit) activation function after each convolutional layer were applied. A normalization layer was also used, operating along the feature axis for each sample to stabilize and improve the learning process. The architecture also includes pooling layers that reduce the spatial size of the feature map, including AveragePooling2D and GlobalMaxPooling2D, which reduce the spatial dimension to one value per feature map. The combination of global pooling and flattening is a standard technique for dimension reduction before fully connected layers. In the next stage, the data is flattened to a 1D vector, which is passed to fully connected dense layers with GELU activation and L2 regularization, while the addition of a Dropout layer prevents overfitting. The output was a value corresponding to the predicted concentration of the solution on the image. A detailed description of the network architecture is provided in Table 1. The total number of parameters is 23,879, and the training in a single cycle takes a few to several seconds (depending on the computation variant).
In a convolutional layer such as Conv2D, the applied L2 regularization works on the convolutional filters (kernels). These filters are responsible for extracting features from the input images. Adding L2 regularization means that during the optimization process, the loss function the model tries to minimize includes an additional term that penalizes large weight values of the filters. Adding L2 regularization to the convolutional layer helps prevent overfitting, stabilizes the optimization process, and promotes more uniform and stable solutions, leading to better model generalization.
The kernel size of 1x1 in the convolutional layer has specific and useful properties in neural networks. 1x1 filters are typically used to reduce the spatial dimensions without spatial aggregation, which can be useful in reducing the number of feature channels or introducing nonlinearity without changing the spatial size. This configuration is often called “pointwise convolution”. The 1x1 kernel changes the number of output channels (depth) without changing the width and height of the input image, allowing for the combination of information contained in different input channels without integrating spatial information. Each output point is a linear combination of the input channel values at a given spatial point. For example, if at a given input point (x, y) we have values in the channels (w1, w2, w3), the 1x1 kernel applies different weights to these values and combines them, creating new output channels. Such a kernel has fewer parameters compared to larger convolutional kernels, resulting in fewer computational operations. This is efficient in terms of memory and computation time. In modeling based on RGB components, using a 1x1 kernel means we examine the relationships between individual color components, rather than the neighborhood of each pixel. In our task, there is no need to detect small and then larger details, as is the case in shape recognition.
The GELU activation function [35], applied as an alternative to ReLU (Rectified Linear Unit) and other activation functions in neural networks, ensures better gradient behavior and more efficient learning in deep neural networks (Figure 9). Its continuity, differentiability, and ability to preserve nonlinear data characteristics make it a valuable tool in deep learning model design. Unlike ReLU, which can suffer from gradient flow issues during training (known as the vanishing gradient problem), GELU provides better gradient throughput due to its structure. GELU preserves nonlinear features that are crucial for learning data representations, helping models better capture complex dependencies in training data.
In the LayerNormalization layer, normalization is performed along the feature axis for each sample, meaning normalization is independent of other samples in the batch. Each feature vector (e.g., channels in an image) is normalized separately, considering only the values within that vector, not the entire batch. Unlike BatchNormalization, which operates dependent on batch size, LayerNormalization remains stable even with small batches or a batch size of 1. Normalization can help prevent issues like vanishing or exploding gradients and accelerate convergence. Normalizing activations helps maintain values within a reasonable range, stabilizing the learning process. When activations are normalized, the optimizer (learning algorithm) finds it easier to adjust network weights, speeding up convergence to optimal weight values.
GlobalMaxPool2D is a layer used in neural networks to reduce spatial data dimensions after applying convolutional layers or other layers processing spatial data, such as pooling layers [36,37]. GlobalMaxPool2D operates by selecting the maximum value from each feature channel across the entire spatial area (all points) of the input feature tensor. GlobalMaxPool2D is an effective tool for spatial dimensionality reduction, retaining only the most significant features (highest values) from each feature channel. This reduces the number of model parameters, which can help in reducing overfitting and computational complexity. GlobalMaxPool2D has no trainable parameters; its sole purpose is to select the maximum value from each feature channel across the entire feature map. For each feature channel, the GlobalMaxPool2D layer selects the highest value across the entire spatial area (height and width). The result of GlobalMaxPool2D is a tensor with reduced dimensions, containing only the maximum values for each feature channel. After applying GlobalMaxPool2D, the resulting tensor can be passed to fully connected layers or other types of layers that process one-dimensional data vectors.
In this study, the model was compiled using the Adam optimizer with customized beta parameters and a defined loss function, which was the sum of MSE and MAE. When the loss function is a combination of MSE and MAE, it affects how the model learns to minimize errors. MSE penalizes large errors more severely (due to the squares of differences), whereas MAE treats all errors equally. Combining these loss functions means the model will aim to reduce both large and small errors. The gradient of MSE is steeper for larger errors, causing the model to learn faster from significant errors. The gradient of MAE is constant, leading to a more consistent learning rate across all errors. MAE is more resistant to outliers than MSE because it does not involve squared differences. A loss function that combines MSE and MAE can lead to faster convergence in some cases by leveraging the strengths of both methods. MSE can accelerate the reduction of large errors, while MAE can provide stability and a consistent learning pace.
During training, a modification of the learning rate was applied after reaching a stable val_loss level for five epochs. The initial value was 0.001. Details regarding the learning parameters are provided in Table 2.
The input dataset consisted of images with dimensions of 400x400 and was divided into three parts: training, validation, and test sets in a 60/20/20 ratio. During training, 50x50 squares were dynamically cropped from the images and these squares served as the direct input to the first layer of the network.
There were six different variations of testing in deep learning, to train a regression algorithm to determine vitamin C based on images: original images for artificial lighting, matched images for artificial lighting, original images for natural lighting, matched images for artificial lighting, original images for mixed dataset, matched images for mixed dataset. For each one of them, the model was trained (Section 3.2.) and the predictions were made. Training and validation loss for calculations for artificial light data for both original and histogram matched images are presented in Figure 10. The range is similar in both cases; however, the values fluctuations are smaller in the case of matched images and in that condition validation and training losses are more similar to each other.
Figure 11 presents the results of the prediction made with the presented neural network. There are three sets of pairs of outcomes: artificial lightning, natural lightning, and mixed data each of which is repeated for both original images and processed one. There is an improvement for higher values of concentration for each of the conditions (Table 3). The standard deviation of predictions is lower in case of applying the proposed standardization method. The highest difference can be seen in the case of artificial light, which could be caused by the uniformization of light reflexes visible for original images.
Values of numerical model evaluation and fitting factors are presented in Table 3. R2 score resulted in a really high value (above 0.99) for all of the cases, however, in every instance, the R2 score received was higher when standardization was performed. As for root mean squared error values – they were lower for matched images in comparison to original ones. Depending on the lightning conditions, learning rate changes from an initial value of 10-3 up to 10-5.
4.4. Ablation Study
In this study, we also analyzed how different modifications to the network architecture affect the quality of the regression model. In the first stage, we considered a network that did not account for the specifics of the problem. The model contained six layers: one convolution, one pooling, one flatten and three dense. It was trained under identical conditions as earlier. The detailed quantitative results are presented in Table 4. The use of a more conventional architecture worsened the model’s ability to fit the data and its predictive capabilities. However, improvements in modeling quality were still observed after applying the color standardization algorithm.
Moreover, several various changes in the architecture were introduced before the final version was chosen. Some of them, with the comparison to the final version, can be evaluated in Table 5.
5. Conclusions
This work presents a new color standardization algorithm, in which the main stages consist in preparing a template based on an initial series of photos, developing a color mapping principle using equalized digital RGB histograms of an ideal pattern and its photo, color conversion of photographs of the examined object involving the use of information about mapping template histograms and image reconstruction based on the transformed histogram. The algorithm was developed for the case when the examined objects differ little in color and the color of each photographed object is almost uniform. The operation of the proposed procedure was demonstrated and verified in an analytical chemistry task, which involved the colorimetric determination of vitamin C. Photographs of AA solutions taken under controlled conditions did not differ much in color in the considered concentration range. The research was performed in daylight and artificial lighting in order to combine them into one dataset and obtain a model that will enable the determination of vitamin C regardless of the lighting conditions when taking photos. Sets of standardized images were the basis for deep machine learning using the architecture of neural networks in the regression variant.
For the concentration range of vitamin C from 0 to 87.72 µg·mL-1, the RMSE for the test set ranged between 0.75 and 1.95 µg·mL-1, in comparison to the non-standardized variant, where this score was at the level of 1.35-2.29 µg·mL-1. The compatibility of the concentration prediction results to actual data expressed using R2 was more than 0.99 for each of the standardized variants. Highest improvement was noted in case of artificial light, which can be explained by the elimination of reflexes on images of the surface of the solutions after standardization process. Further study is needed in order to determine the usefulness of the algorithm in different scenarios (e.g. colorimetric prediction of concentration of different compounds). This new approach may contribute to the development of a new field for chemical analysis, which includes quantitative evaluation of a broad spectrum of chemical analytes based on the use of mobile phones and image analysis. The presented study shows promise to be used in several fields of science and technology, such as: biomedical engineering, chemical engineering, or food industry.
Author Contributions
Patrycja Kwiek: Conceptualization; Methodology; Data curation; Formal analysis; Investigation; Software; Resources; Visualization; Writing - original draft. Małgorzata Jakubowska: Conceptualization; Formal analysis; Funding acquisition; Investigation; Methodology; Project administration; Supervision; Validation; Writing - original draft.
Funding
Research project supported by program „Excellence initiative – research university” for the AGH University of Krakow.
Data Availability Statement
The algorithms implemented in Python and the sample of the data for calculations are available on the Github platform at: https://github.com/pwkwiek/vitaminC
Acknowledgments
The authors thank dr inż. Filip Ciepiela (AGH University of Krakow) for the valuable guidance during the project implementation.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Minz, P.S.; Saini, C.S. Evaluation of RGB Cube Calibration Framework and Effect of Calibration Charts on Color Measurement of Mozzarella Cheese. J. Food Meas. Charact. 2019, 13, 1537–1546. [Google Scholar] [CrossRef]
- Ernst, A.; Papst, A.; Ruf, T.; Garbas, J.U. Check My Chart: A Robust Color Chart Tracker for Colorimetric Camera Calibration. In Proceedings of the ACM International Conference Proceeding Series; 2013.
- Sunoj, S.; Igathinathane, C.; Saliendra, N.; Hendrickson, J.; Archer, D. Color Calibration of Digital Images for Agriculture and Other Applications. ISPRS J. Photogramm. Remote Sens. 2018, 146, 221–234. [Google Scholar] [CrossRef]
- Kim, M.; Kim, B.; Park, B.; Lee, M.; Won, Y.; Kim, C.Y.; Lee, S. A Digital Shade-Matching Device for Dental Color Determination Using the Support Vector Machine Algorithm. Sensors (Switzerland) 2018, 18, 3051. [Google Scholar] [CrossRef] [PubMed]
- Karaimer, H.C.; Brown, M.S. Improving Color Reproduction Accuracy on Cameras. In Proceedings of the Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition; 2018; pp. 6440–6449.
- Roy, S.; kumar Jain, A.; Lal, S.; Kini, J. A Study about Color Normalization Methods for Histopathology Images. Micron 2018, 114, 42–61. [Google Scholar] [CrossRef]
- Food and Agriculture Organization, World Health Organization, Vitamin and Mineral Requirements in Human Nutrition Second Edition. FAO/WHO Rep. 1998, 1–20. doi:92 4 154612 3.
- Food and Agriculture Organization, World Health Organization, Human Vitamin and Mineral Requirements. FAO/WHO Rep. 2001.
- Lykkesfeldt, J. On the Effect of Vitamin C Intake on Human Health: How to (Mis)Interprete the Clinical Evidence. Redox Biol. 2020, 34, 101532. [Google Scholar] [CrossRef] [PubMed]
- Dosed, M.; Jirkovsk, E.; Kujovsk, L.; Javorsk, L.; Pourov, J.; Mercolini, L.; Remi, F. Vitamin C—Sources, Physiological Role, Kinetics, Deficiency, Use, Toxicity, and Determination. Nutrients 2021, 615, 1–34. [Google Scholar] [CrossRef]
- Suntornsuk, L.; Gritsanapun, W.; Nilkamhank, S.; Paochom, A. Quantitation of Vitamin C Content in Herbal Juice Using Direct Titration. J. Pharm. Biomed. Anal. 2002, 28, 849–855. [Google Scholar] [CrossRef]
- Klimczak, I.; Gliszczyńska-Świgło, A. Comparison of UPLC and HPLC Methods for Determination of Vitamin C. Food Chem. 2015, 175, 100–105. [Google Scholar] [CrossRef]
- Gazdik, Z.; Zitka, O.; Petrlova, J.; Adam, V.; Zehnalek, J.; Horna, A.; Reznicek, V.; Beklova, M.; Kizek, R. Determination of Vitamin C (Ascorbic Acid) Using High Performance Liquid Chromatography Coupled with Electrochemical Detection. Sensors 2008, 8, 7097–7112. [Google Scholar] [CrossRef]
- Bunaciu, A.A.; Bacalum, E.; Aboul-Enein, H.Y.; Udristioiu, G.E.; Fleschin, Ş. FT-IR Spectrophotometric Analysis of Ascorbic Acid and Biotin and Their Pharmaceutical Formulations. Anal. Lett. 2009, 42, 1321–1327. [Google Scholar] [CrossRef]
- Zhu, Q.; Dong, D.; Zheng, X.; Song, H.; Zhao, X.; Chen, H.; Chen, X. Chemiluminescence Determination of Ascorbic Acid Using Graphene Oxide@copper-Based Metal-Organic Frameworks as a Catalyst. RSC Adv. 2016, 6, 25047–25055. [Google Scholar] [CrossRef]
- Berg, R.W. Investigation of L (+)-Ascorbic Acid with Raman Spectroscopy in Visible and UV Light. Appl. Spectrosc. Rev. 2015, 50, 193–239. [Google Scholar] [CrossRef]
- Yang, H.; Irudayaraj, J. Rapid Determination of Vitamin C by NIR, MIR and FT-Raman Techniques. J. Pharm. Pharmacol. 2010, 54, 1247–1255. [Google Scholar] [CrossRef]
- Zykova, E.V.; Sandetskaya, N.G.; Ostrovskii, O.V.; Verovskii, V.E. Methods of Analysis and Process Control Determining Ascorbic Acid in Medicinal Preparations By Capillary Zone Electrophoresis and Micellar. Pharm. Chem. J. 2010, 44, 463–465. [Google Scholar] [CrossRef]
- Dodevska, T.; Hadzhiev, D.; Shterev, I. A Review on Electrochemical Microsensors for Ascorbic Acid Detection: Clinical, Pharmaceutical, and Food Safety Applications. Micromachines 2023, 14, 41. [Google Scholar] [CrossRef]
- Huang, L.; Tian, S.; Zhao, W.; Liu, K.; Guo, J. Electrochemical Vitamin Sensors: A Critical Review. Talanta 2021, 222, 121645. [Google Scholar] [CrossRef] [PubMed]
- Broncová, G.; Prokopec, V.; Shishkanova, T.V. Potentiometric Electronic Tongue for Pharmaceutical Analytics: Determination of Ascorbic Acid Based on Electropolymerized Films. Chemosensors 2021, 9, 110. [Google Scholar] [CrossRef]
- Coutinho, M.S.; Morais, C.L.M.; Neves, A.C.O.; Menezes, F.G.; Lima, K.M.G. Colorimetric Determination of Ascorbic Acid Based on Its Interfering Effect in the Enzymatic Analysis of Glucose: An Approach Using Smartphone Image Analysis. J. Braz. Chem. Soc. 2017, 28, 2500–2505. [Google Scholar] [CrossRef]
- Porto, I.S.A.; Santos Neto, J.H.; dos Santos, L.O.; Gomes, A.A.; Ferreira, S.L.C. Determination of Ascorbic Acid in Natural Fruit Juices Using Digital Image Colorimetry. Microchem. J. 2019, 149, 104031. [Google Scholar] [CrossRef]
- Kong, L.; Gan, Y.; Liang, T.; Zhong, L.; Pan, Y.; Kirsanov, D.; Legin, A.; Wan, H.; Wang, P. A Novel Smartphone-Based CD-Spectrometer for High Sensitive and Cost-Effective Colorimetric Detection of Ascorbic Acid. Anal. Chim. Acta 2020, 1093, 150–159. [Google Scholar] [CrossRef]
- Li, C.; Xu, X.; Wang, F.; Zhao, Y.; Shi, Y.; Zhao, X.; Liu, J. Portable Smartphone Platform Integrated with Paper Strip-Assisted Fluorescence Sensor for Ultrasensitive and Visual Quantitation of Ascorbic Acid. Food Chem. 2023, 402, 134222. [Google Scholar] [CrossRef]
- Zhaoa, W.; Caoa, P.; Zhua, Y.; Liua, S.; Gaob, H.-W.; Huang, C. Rapid Detection of Vitamin C Content in Fruits and Vegetables Using a Digital Camera and Color Reaction. Quim. Nov. 2020, 43, 1421–1430. [Google Scholar] [CrossRef]
- Dumancas, G.G.; Ramasahayam, S.; Bello, G.; Hughes, J.; Kramer, R. Chemometric Regression Techniques as Emerging, Powerful Tools in Genetic Association Studies. TrAC - Trends Anal. Chem. 2015, 74, 79–88. [Google Scholar] [CrossRef]
- Wold, S.; Sjöström, M.; Eriksson, L. PLS-Regression: A Basic Tool of Chemometrics. Chemom. Intell. Lab. Syst. 2001, 58, 109–130. [Google Scholar] [CrossRef]
- Li, B.; Morris, J.; Martin, E.B. Model Selection for Partial Least Squares Regression. Chemom. Intell. Lab. Syst. 2002, 64, 79–89. [Google Scholar] [CrossRef]
- Smola, A.J.; Schokopf, B. A Tutorial on Support Vector Regression. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press, 2016; ISBN 9780262035613.
- Lathuiliere, S.; Mesejo, P.; Alameda-Pineda, X.; Horaud, R. A Comprehensive Analysis of Deep Regression. In Proceedings of the IEEE Transactions on Pattern Analysis and Machine Intelligence; IEEE, 2020; Vol. 42, pp. 2065–2081.
- Pascual, L.; Gras, M.; Vidal-Brotóns, D.; Alcañiz, M.; Martínez-Máñez, R.; Ros-Lis, J.V. A Voltammetric E-Tongue Tool for the Emulation of the Sensorial Analysis and the Discrimination of Vegetal Milks. Sensors Actuators B Chem. 2018, 270, 231–238. [Google Scholar] [CrossRef]
- Wójcik, S.; Ciepiela, F.; Jakubowska, M. Computer Vision Analysis of Sample Colors versus Quadruple-Disk Iridium-Platinum Voltammetric e-Tongue for Recognition of Natural Honey Adulteration. Meas. J. Int. Meas. Confed. 2023, 209, 112514. [Google Scholar] [CrossRef]
- Lee, M. Mathematical Analysis and Performance Evaluation of the GELU Activation Function in Deep Learning. J. Math. 2023, 2023, Article. [Google Scholar] [CrossRef]
- Sikandar, S.; Mahum, R.; Alsalman, A.M. A Novel Hybrid Approach for a Content-Based Image Retrieval Using Feature Fusion. Appl. Sci. 2023, 13, 4581. [Google Scholar] [CrossRef]
- Hasan, M.A.; Haque, F.; Sabuj, S.R.; Sarker, H.; Goni, M.O.F.; Rahman, F.; Rashid, M.M. An End-to-End Lightweight Multi-Scale CNN for the Classification of Lung and Colon Cancer with XAI Integration. Technologies 2024, 12, 56. [Google Scholar] [CrossRef]
Figure 1.
Example of histogram matching for illustrative purposes.

Figure 2.
Diagram of the color matching algorithm.
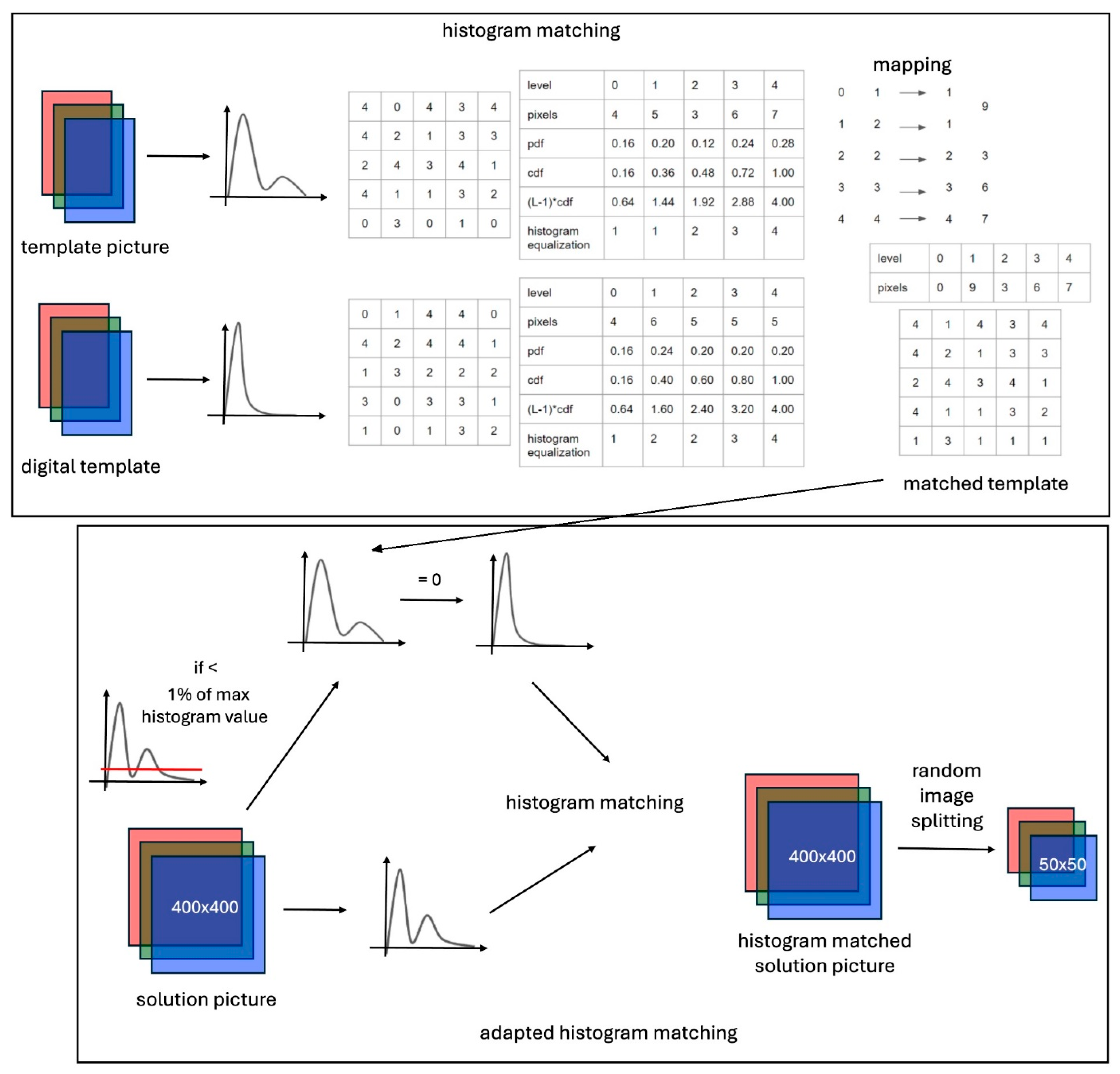
Figure 3.
Vitamin C solutions (0, 4.54, 11.31, 18.05, 22.52, 33.63, 44.64, 66.37, 87.72 µg·mL-1) in the presence of double-distilled water, acetate buffer, ammonium iron(III) sulfate and orthophenanthroline.
Figure 3.
Vitamin C solutions (0, 4.54, 11.31, 18.05, 22.52, 33.63, 44.64, 66.37, 87.72 µg·mL-1) in the presence of double-distilled water, acetate buffer, ammonium iron(III) sulfate and orthophenanthroline.

Figure 4.
Scheme of conducted experiments and calculations: preparation of AA solutions with varying concentrations; application of solutions onto Petri dishes; image capture under different lighting conditions (AA solutions with color templates); image preprocessing - color standardization; training and evaluation of the regression network.
Figure 4.
Scheme of conducted experiments and calculations: preparation of AA solutions with varying concentrations; application of solutions onto Petri dishes; image capture under different lighting conditions (AA solutions with color templates); image preprocessing - color standardization; training and evaluation of the regression network.
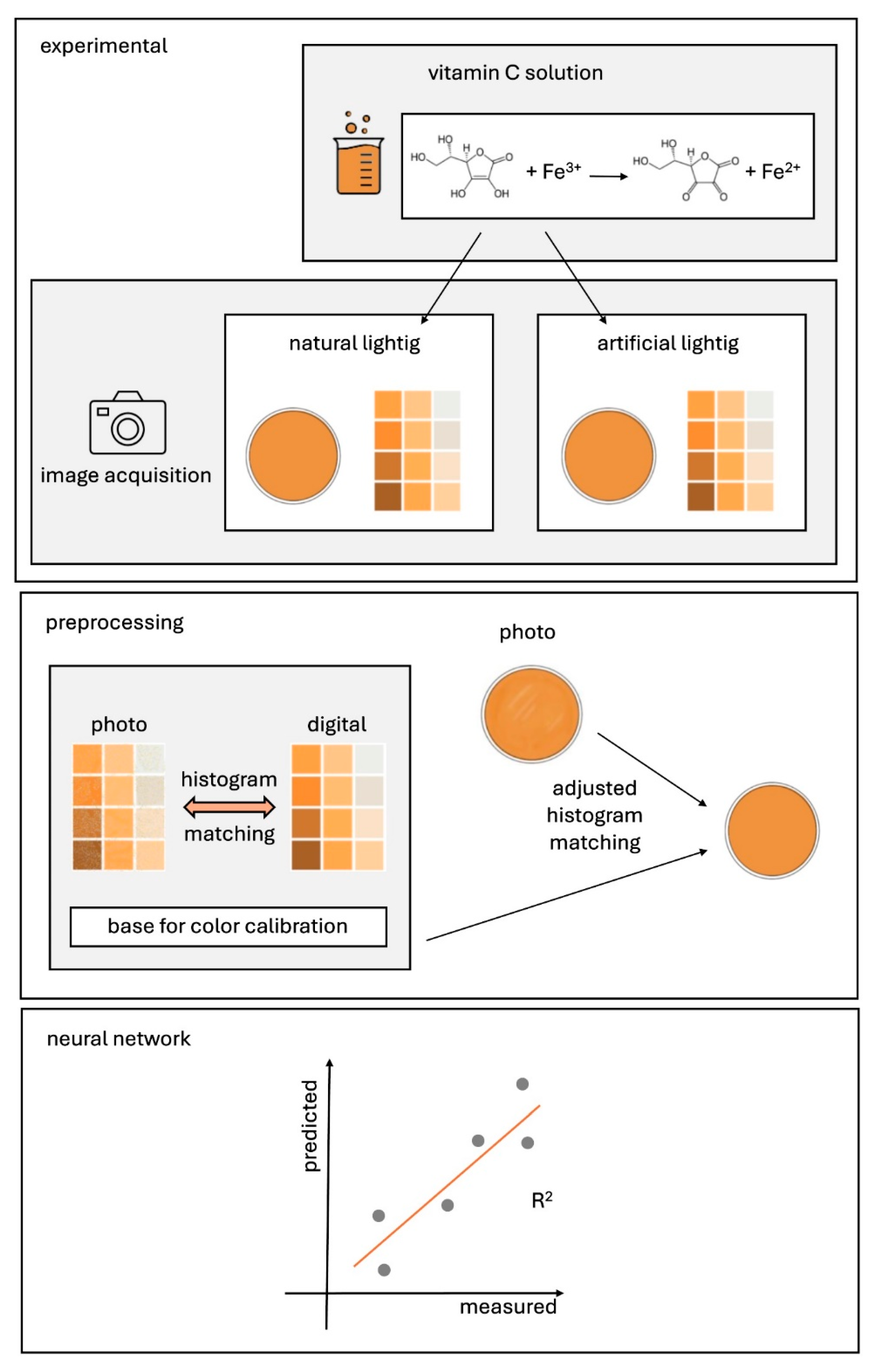
Figure 5.
Control of lighting conditions - two approaches: natural light (top) and smartphone lamp lighting (bottom). Right side of an image – digital template used in histogram matching; arrows indicate the lightning condition under which the images were taken.
Figure 5.
Control of lighting conditions - two approaches: natural light (top) and smartphone lamp lighting (bottom). Right side of an image – digital template used in histogram matching; arrows indicate the lightning condition under which the images were taken.

Figure 6.
Templates and their histograms for RGB channels: (i) original digital template (ii) image of a template under natural lighting (iii) image of a matched template under natural lighting (iv) image of a template under artificial lighting (v) image of a matched template under artificial lighting.
Figure 6.
Templates and their histograms for RGB channels: (i) original digital template (ii) image of a template under natural lighting (iii) image of a matched template under natural lighting (iv) image of a template under artificial lighting (v) image of a matched template under artificial lighting.
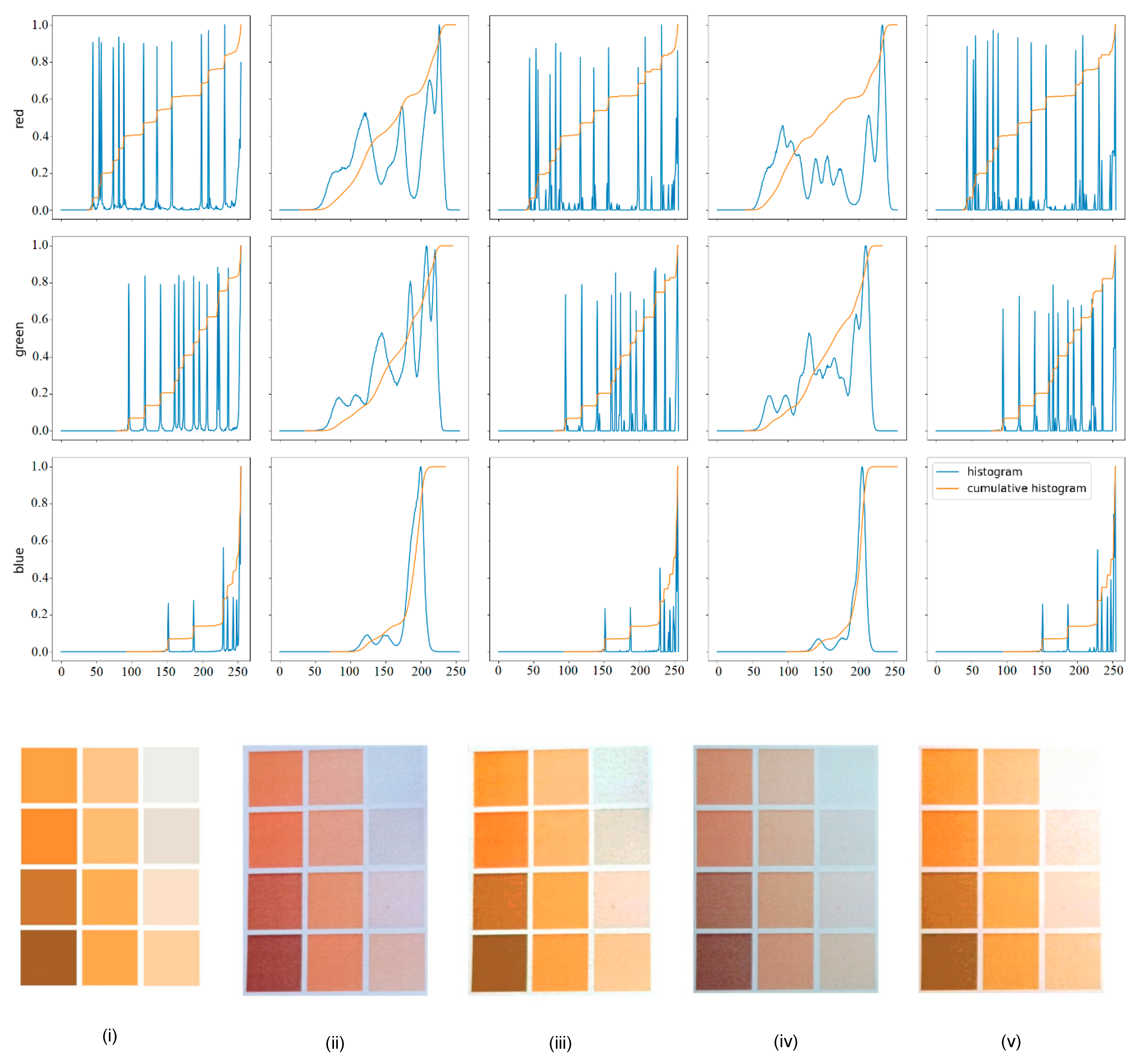
Figure 7.
Images of the solution (33.63 µg/mL) under artificial lightning condition before (source) and after (matched) application of the standardization algorithm and corresponding histograms of RGB channels.
Figure 7.
Images of the solution (33.63 µg/mL) under artificial lightning condition before (source) and after (matched) application of the standardization algorithm and corresponding histograms of RGB channels.
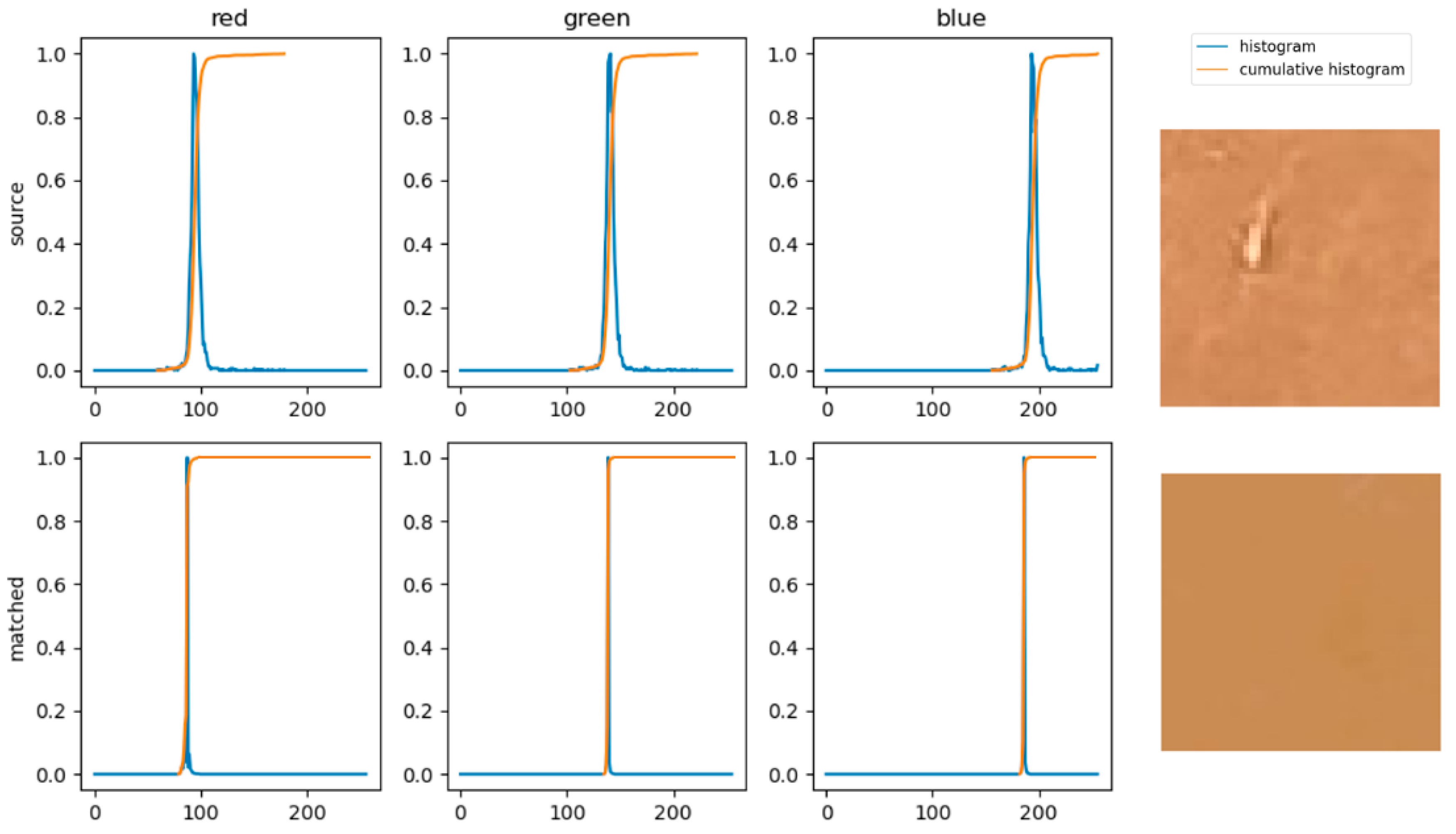
Figure 8.
Various exemplary images of the solution (33.63 µg/mL) under artificial lightning condition before (top) and after (bottom) application of the standardization algorithm.
Figure 8.
Various exemplary images of the solution (33.63 µg/mL) under artificial lightning condition before (top) and after (bottom) application of the standardization algorithm.

Figure 9.
ReLU and GELU activation functions.
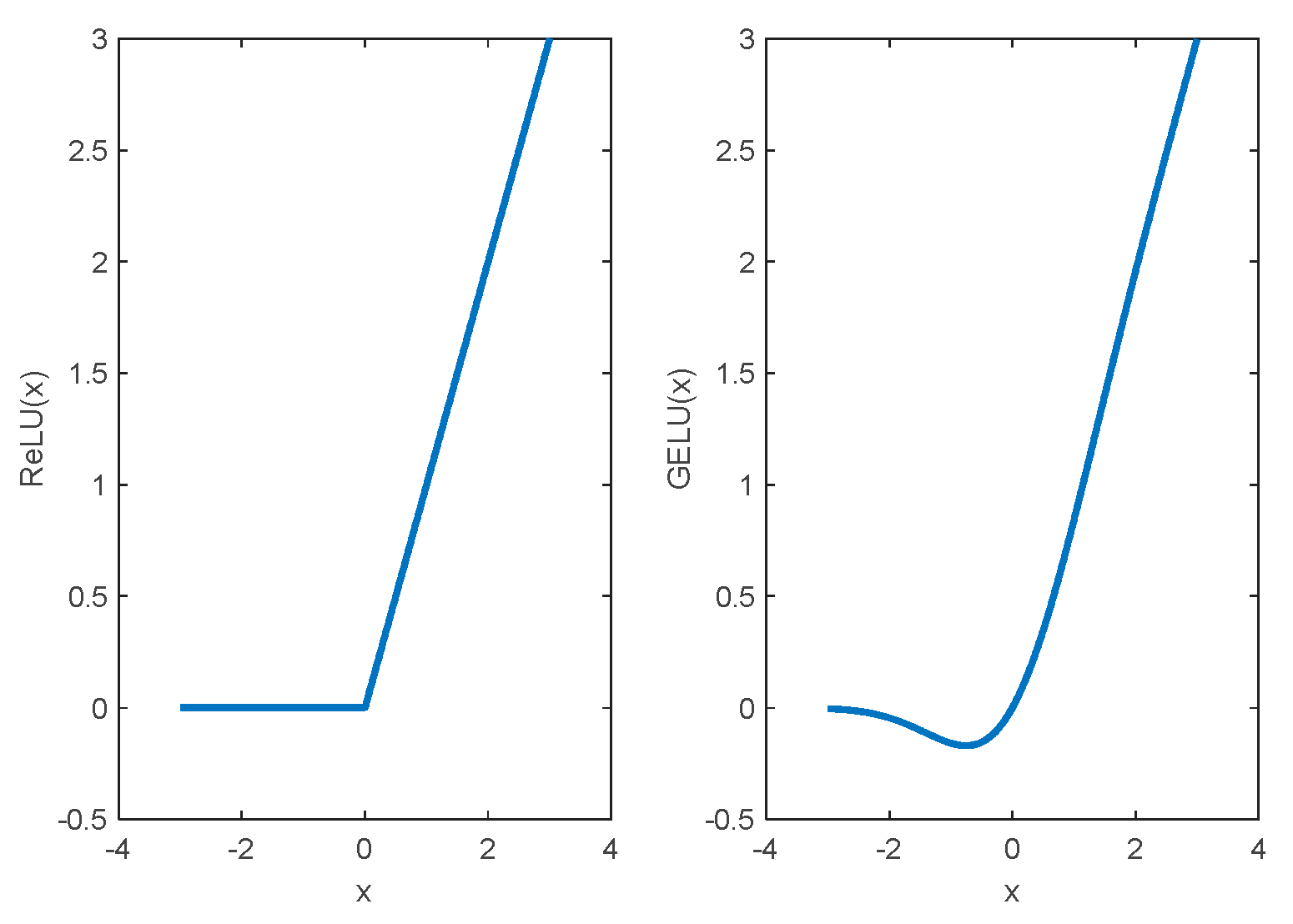
Figure 10.
Training and validation loss for calculations for artificial lightning condition for both original (i) and histogram matched (ii) images.
Figure 10.
Training and validation loss for calculations for artificial lightning condition for both original (i) and histogram matched (ii) images.
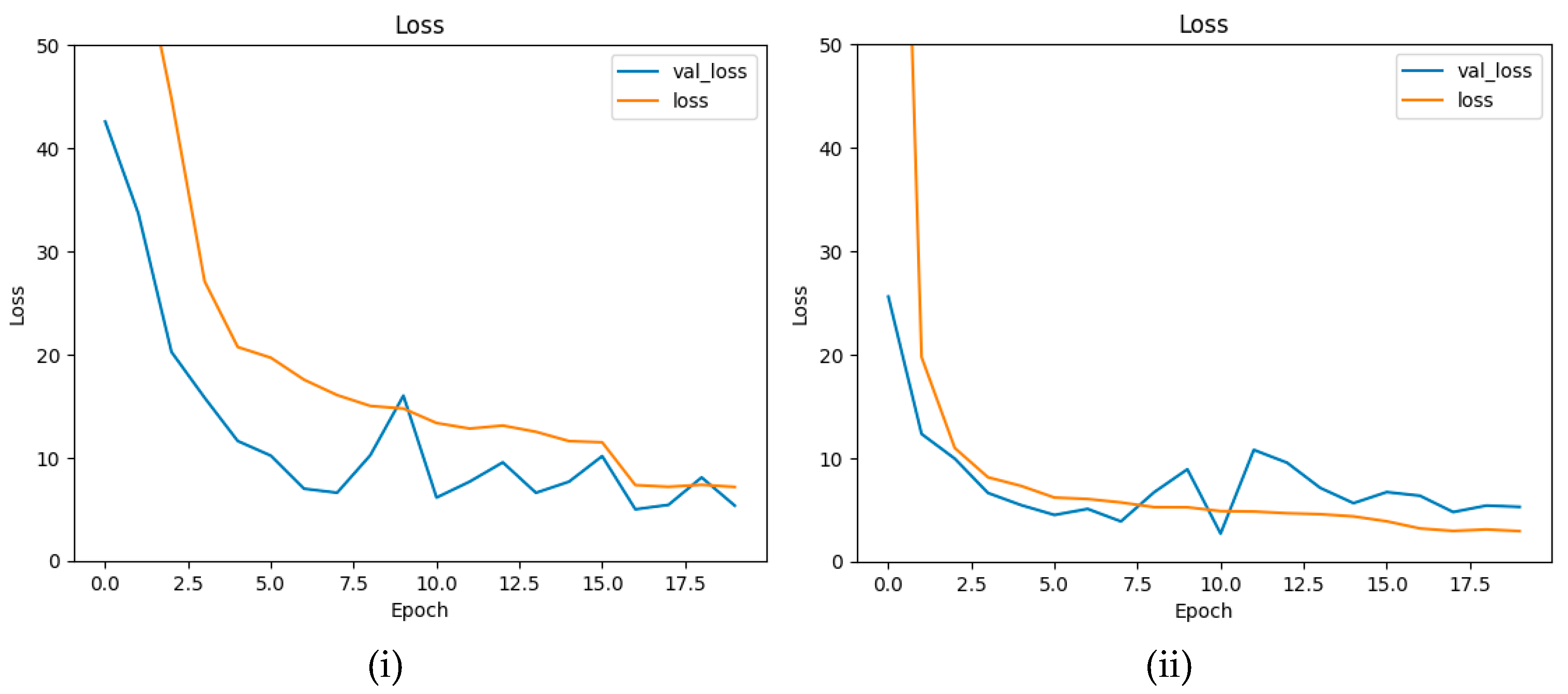
Figure 11.
Evaluation of the DL regression models for 6 different variations of testing, before (first column) and after color matching (second column).
Figure 11.
Evaluation of the DL regression models for 6 different variations of testing, before (first column) and after color matching (second column).
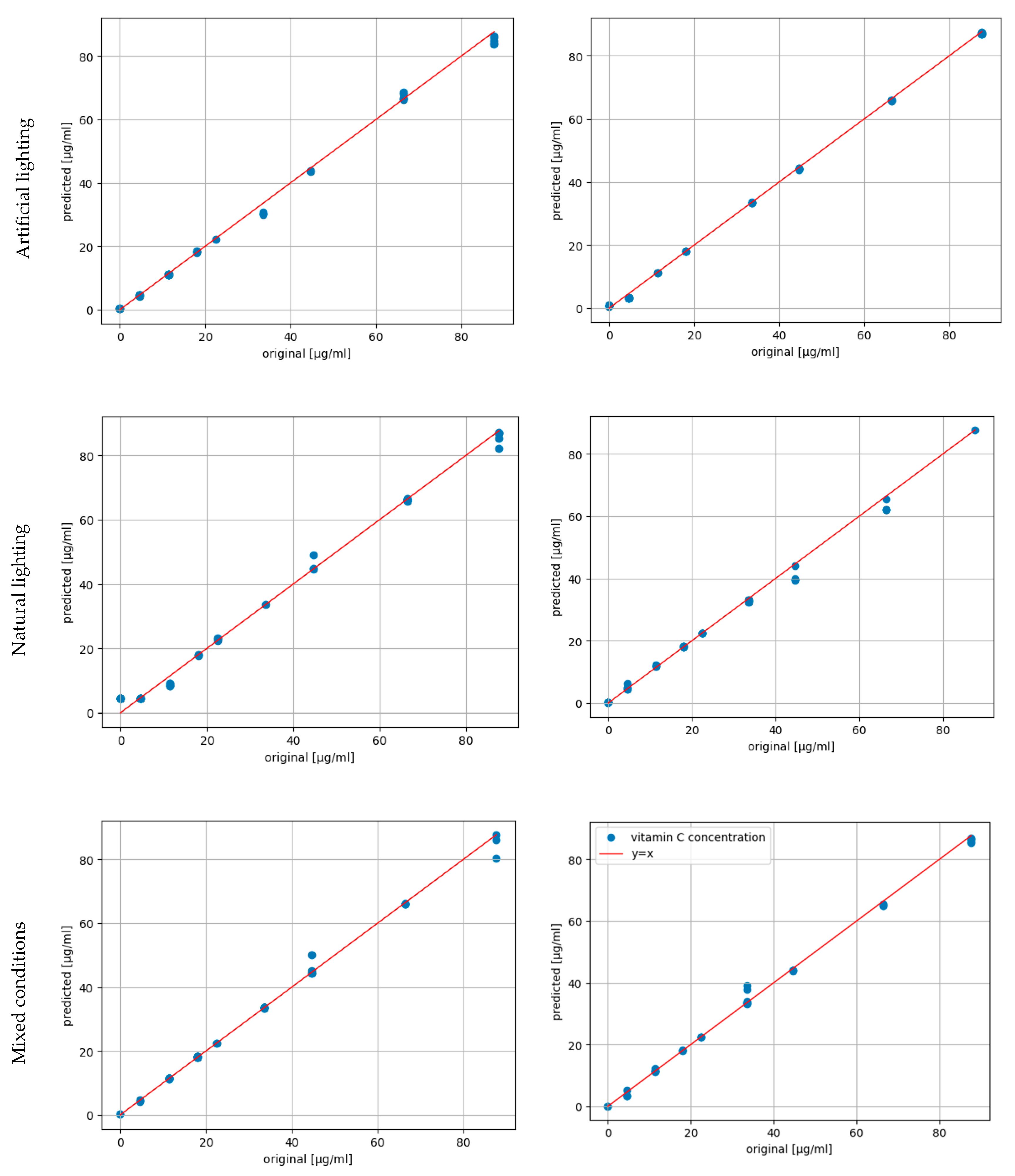

Table 1.
The total parameters used in this study.
| Layer (type) | Output shape | Param # |
|---|---|---|
| Input layer | (None, 50, 50, 3) | 0 |
| Conv2D | (None, 50, 50,3 2) | 128 |
| Activation | (None, 50, 50, 32) | 0 |
| Conv2D | (None, 50, 50, 64) | 2112 |
| Activation | (None, 50, 50, 64) | 0 |
| AveragePooling2D | (None, 46, 46, 64) | 0 |
| LayerNormalization | (None, 46, 46, 64) | 128 |
| Conv2D | (None, 46, 46, 64) | 4160 |
| Activation | (None, 46, 46, 64) | 0 |
| AveragePooling2D | (None, 44, 44, 64) | 0 |
| GlobalMaxPooling2D | (None, 64) | 0 |
| Flatten | (None, 64) | 0 |
| Dense | (None, 150) | 9750 |
| Dropout | (None, 150) | 0 |
| Dense | (None, 50) | 7550 |
| Dense | (None, 1) | 51 |
| Total params: 23879 (93.28 KB) Trainable params: 23879 (93.28 KB) Non-trainable params: 0 (0.00 Byte) | ||
Table 2.
Parameters of network training.
| Parameter | Setting |
|---|---|
| Image size | 50 x 50 x 3 |
| Loss function | MSE + MAE |
| Optimizer | Adam |
| Initial learning rate | 0.001 |
| Metric | RMSE |
| Batch size | 30 |
| Epoch | 20 |
| Shuffle | Every epoch |
Table 3.
Evaluation of the DL regression models with the best results for 6 different variations of testing.
Table 3.
Evaluation of the DL regression models with the best results for 6 different variations of testing.
| Artificial lighting, original | Artificial lighting, matched | Natural lighting, original | Natural lighting, matched | Mixed lighting, original | Mixed lighting, matched | |
|---|---|---|---|---|---|---|
| slope | 0.9799 | 0.9961 | 0.9706 | 0.9452 | 0.9784 | 0.9825 |
| intercept | -0.0036 | -0.2091 | 1.1888 | 0.6051 | 0.5832 | 0.4086 |
| RMSE / µg·mL-1 | 1.5769 | 0.7525 | 2.2900 | 1.9542 | 1.4828 | 1.3510 |
| R2 score | 0.9979 | 0.9999 | 0.9953 | 0.9956 | 0.9966 | 0.9968 |
Table 4.
Evaluation of the DL regression models considered in ablation study, for 6 different variations of testing, depending on the lighting conditions and the chosen dataset.
Table 4.
Evaluation of the DL regression models considered in ablation study, for 6 different variations of testing, depending on the lighting conditions and the chosen dataset.
| Artificial lighting, original | Artificial lighting, matched | Natural lighting, original | Natural lighting, matched | Mixed lighting, original | Mixed lighting, matched | |
|---|---|---|---|---|---|---|
| Slope | 0.9058 | 1.0138 | 0.9538 | 1.0071 | 1.0005 | 1.0112 |
| Intercept | 0.6891 | -0.3598 | -0.8347 | 0.2263 | 0.8747 | 0.0203 |
| RMSE / µg·mL-1 | 5.8415 | 1.7077 | 3.9504 | 2.5151 | 4.3488 | 2.8211 |
| R2 score | 0.9557 | 0.9962 | 0.9798 | 0.9918 | 0.9755 | 0.9897 |
Table 5.
Evaluation of the DL regression models considered in ablation study, for mixed lighting, matched condition of testing, depending on the changes in the model.
Table 5.
Evaluation of the DL regression models considered in ablation study, for mixed lighting, matched condition of testing, depending on the changes in the model.
| Change in architecture | RMSE / µg·mL-1 | R2 score | Comparison |
|---|---|---|---|
| Batch size = 120 | 2.3535 | 0.9947 | Decrease of R2 score and increase of RMSE in comparison to final model. |
| Image size = 16 | 4.0146 | 0.9825 | Significant decrease of R2 score and increase of RMSE in comparison to final model. Lower decline of initial rate in comparison to final version. |
| Loss function modification | 3.8203 | 0.9856 | Decrease of R2 score and significant increase of RMSE in comparison to final model. Minimized differences between training and validation loss during training. |
| Optimizer = Adagrad | 3.1625 | 0.9877 | Decrease of R2 score and increase of RMSE in comparison to final model. |
| Optimizer = SGD | - | - | There was no change in loss value between the epochs. The model did not learn to predict the concentration of vitamin C solutions. |
| Initial learning rate = 0.01 or 0.0001 | - | - | No significant change in the results was detected. The results achieved did not vary significantly in comparison to final model results. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



