
Submitted:
17 July 2024
Posted:
18 July 2024
You are already at the latest version
Abstract
In the Internet of Things (IoT) era, Mobile Edge Computing (MEC) significantly enhances the efficiency of smart devices but is limited by battery life issues. Wireless Power Transfer (WPT) addresses this issue by providing a stable energy supply. However, effectively managing overall energy consumption remains a critical and under-addressed aspect for ensuring the network’s sustainable operation and growth. In this paper, we consider a WPT-MEC network wit user cooperation to migrate the double near-far effect for the mobile node (MD) far from the base station. We formulate the problem of maximizing long-term computation rates under a power consumption constraint as a multi-stage stochastic optimization (MSSO) problem. This approach is tailored for a sustainable WPT-MEC network, considering the dynamic and varying MEC network environment, including randomness in task arrivals and fluctuating channels. We introduce a virtual queue to transform the time-average energy constraint into a queue stability problem. Using the Lyapunov optimization technique, we decouple the stochastic optimization problem into a deterministic problem for each time slot, which can be further transformed into a convex problem and solved efficiently. Our proposed algorithm works efficiently online without requiring further system information. Rigorous mathematical analysis shows that our algorithm achieves O(1/V),O(V) trade-off between computation rate and queues stability. Extensive simulation results demonstrate that our proposed algorithm outperforms baseline schemes, achieving approximately 4% enhancement while maintain the queues stability.
Keywords:
mobile edge computing (MEC)
; wireless power transfer (WPT)
; computation rate
; Lyapunov optimization
; convex optimization
1. Introduction
In the era of the Internet of Things (IoT) [1,2,3,4], the surge in the number of mobile devices and network traffic has created a high demand for data processing capabilities and response speeds. Mobile Edge Computing (MEC) technology effectively enhances the operational efficiency of smart devices by providing powerful computing resources at the network’s edge, particularly in delay-sensitive applications such as autonomous driving and AR/VR [5]. By offloading complex computational tasks to MEC servers [6,7,8,9,10,11], resource-constrained mobile devices (MDs) can significantly alleviate the pressure experienced when running high-demand applications and achieve a notable leap in performance. However, the limited battery capacity of mobile devices has become a bottleneck that restricts their further development [12]. This limitation is especially evident for devices that require continuous operation over long periods and are not easily recharged, such as in remote areas or emergency situations, where insufficient battery life can severely impact the functionality and reliability of the devices. Therefore, despite the significant advantages of MEC in enhancing network performance, the limitation of battery endurance remains a key issue that urgently needs to be addressed.
In addition to battery constraints, reducing the energy consumption of IoT devices during the data offloading process is equally important. Trillions of tiny smart sensors make up the Internet of Things, facing significant limitations in computational capabilities and energy supplied by batteries. Advancements in wireless energy harvesting technologies, including renewable energy harvesting and wireless power transfer (WPT) [13], can alleviate the challenges previously posed by battery capacity limitations. Renewable energy sources like solar, wind, and ocean energy can provide power to some extent, but they are significantly influenced by natural conditions such as weather and climate [14]. To address this issue, green wireless charging technology has emerged. This technology can offers stable energy to devices through radio frequency signals and store it in the batteries of IoT nodes for future use, extending battery life [15,16]. To ensure that nodes do not fail due to energy depletion, green wireless charging adheres to the principle of energy neutrality operation [17] state, ensuring that the energy consumed in any operation will never exceed the energy collected. Green Wireless Powered Mobile Edge Computing (WPMEC) combines the strengths of WPT and MEC, enhancing devices’ computational capabilities and energy self-sufficiency. In the upcoming 6G networks, green WPMEC will provide IoT devices with quick response and real-time experiences [18], while reducing operational costs and extending the lifespan of devices.
However, WPMEC networks face the challenge of the dual far-near effect [19] caused by positional differences, which has prompted the development of edge collaborative networks [20,21,22] to optimize application offloading performance. By introducing a user cooperation (UC) mechanism, where nearby users assist distant users in accelerating the processing of computational tasks while effectively offloading their own tasks, this collaborative approach leverages the superior channel conditions of nearby users to gain more energy during the WPT phase. This not only addresses the unfairness caused by geographical location but also enhances the efficiency of energy utilization. The dense deployment of smart IoT devices further facilitates the opportunity to utilize the unused computing resources of idle devices and wireless energy harvesting. These devices, by assisting in completing the computational tasks of distant users, contribute to improving the overall computational performance of the WPMEC network.
To demonstrate the effectiveness of UC, recent studies, such as references [23,24], have effectively addressed the dual far-near effect in WPMEC networks through UC. The D2D communication in reference [25] and the incentive mechanism in reference [26] are both designed to facilitate resource sharing and collaborative offloading. In references [20,24,27,28], authors have focused on studying the basic three-node WPMEC model, which involves a Far User (FU) being allowed to offload computational input data to a Near User (NU). In reference [29], researchers designed a Non-Orthogonal Multiple Access (NOMA) based computation offloading scheme aimed at enhancing the performance of multi-user MEC systems. Google has also developed federated learning technology, which enables multiple devices to collaborate on machine learning tasks. Despite this, these studies are often based on the assumption of determinism or predictability of future information, failing to fully integrate the dynamic changes of the network environment, which may affect the efficiency and success rate of task offloading and processing.
This paper investigates the basic three-node green WPMEC network shown in Figure 1, focusing on the use of collaborative communication technology to accomplish the computation-intensive and delay-sensitive tasks powered by the HAP. Our goal is to maximize the network’s data processing capability in a real-time dynamic offloading system, taking into account the randomness of data generation and the high dynamics of wireless channel conditions. The challenges we face in addressing this issue include the unpredictability of task arrivals and the dynamics of channel conditions, as well as the coupling of variables in resource allocation, which makes traditional convex optimization methods inapplicable. To tackle these challenges, we have designed an efficient dynamic task offloading algorithm, the User-Assisted Dynamic Resource Allocation Algorithm (UADRA). This algorithm employs Lyapunov optimization techniques to transform the problem into a simplified form that relies on current information, and performs dynamic resource allocation in each time slot to enhance the network’s data processing capability. Our primary contributions are summarized as follows:
• We propose a model for maximizing the long-term weighted computation rate in a green sustainable WPT-MEC network, subject to energy consumption constraints. Our model takes into account the randomness of task arrivals and the dynamic variations in wireless channel states. By extending the models in [28,30], we have effectively mitigated the double near-far effect and fostered collaboration among users. This is achieved by considering the different data weights of near and far nodes, which enhances data transmission efficiency, system flexibility, and alignment with real-world applications.
• We design a low-complexity dynamic control algorithm called UADRA, based on Lyapunov optimization theory, while providing rigorous mathematical theory analysis to demonstrate its performance. A virtual queue is introduced to transforms the time-average energy constraint to a queue stable requirement. Leveraging the drift-plus-penalty technique, we decouple the original multi-stage stochastic problem into a non-convex deterministic sub-problem for each time slot. Furthermore, by using variable substitution and convex optimization theory, we convert these sub-problems into convex problems with a minimal number of decisions , that can be solved efficiently. Our algorithm can work efficiently without depending on the prior knowledge of the system information.
• We have conducted extensive simulations to evaluate the effectiveness and practicality of our proposed algorithm, particularly examining how the control parameter V, network bandwidth, energy constraint, task arrival rate, and geographical distance affect the average computation rate and network stability. Experimental results demonstrate that the proposed algorithm not only shows superior performance over benchmark methods but also achieves this improvement while simultaneously ensuring the stability of the system queues, with an enhancement of up to 4% in overall performance. Moreover, our algorithm effectively achieves a trade-off between computation rate and stability, adhering to the theoretical bounds of .
The remainder of this paper is organized as follows. Section II we presents the system model of the user-assistance green WPMEC network and sets forth a MSSO problem. In Section III, we utilize the Lyapunov optimization approach to tackle the problem, putting forward an effective dynamic offloading algorithm with an accompanying theoretical analysis of its performance. Section IV evaluate the efficacy of the suggested algorithm via simulation outcomes. Conclusively, Section V concludes the paper.
1.1. Related Work
The integration of WPT technology with MEC networks provides an effective solution for IoT devices, enhancing their energy and computing capabilities with controllable power supply and low-latency services. Recent research has extensively explored the potential of these wirelessly powered MEC networks. For instance, in [31], researchers optimized charging time and data offloading rates for WPT-MEC IoT sensor networks to improve computational rates in scenarios. Furthermore, authors in [32] investigated a NOMA-assisted WPT-MEC network with a nonlinear EH model, successfully enhancing the system’s Computational Energy Efficiency (CEE) by fine-tuning key parameters within the network. Specifically, to meet the energy consumption requirements of devices, the authors in [33] proposed a Particle Swarm Optimization (PSO)-based algorithm. The goal was to reduce the latency of devices processing computational data streams by jointly optimizing charging and offloading strategies. Additionally, in [34], the authors focused on the computational latency issue in WPT-MEC networks. They found suitable offloading ratio strategies to achieve synchronized latency for all WDs, effectively reducing the duration of the overall computational task.
To tackle the dual far-near effect issue, researchers have begun to focus on user-assisted WPMEC networks and have confirmed their effectiveness in enhancing the computing performance of distant users. Specifically, in [35], the study analyzed a three-node system composed of distant users, nearby users, and the base station within a user-assisted MEC-NOMA network model, addressing the optimization problem of joint transmission time and power allocation for users. Furthermore, [36,37] respectively explored joint computing and communication collaboration schemes and the application of Device-to-Device (D2D) communication in MEC. The method proposed in [36] aims to maximize the total computing rate of the network with the assistance of nearby users, while [37] focuses on minimizing the overall network response delay and energy consumption through joint multi-user collaborative partial offloading, transmission scheduling, and computing allocation. [38] extended this research, expanding from a single collaboration pair to multiple collaboration pairs, proposing a scheme to achieve the minimization of the total energy consumption of the AP.
In user assistance networks, the online collaborative offloading method, which is highly adaptable and can promptly respond to changes in task arrivals, has garnered significant attention from the research community. For instance, in [39], to address the randomness of energy and data arrivals, a Lyapunov optimization-based method was proposed to maximize the long-term system throughput. Furthermore, in [40], the authors studied and proposed a Lyapunov-based Profit Maximization (LBPM) task offloading algorithm in the context of the Internet of Vehicles (IoV), which aims at maximizing the time-averaged profit as the optimization goal. Additionally, in [41], within the application of MEC in the industrial IoT, a Lyapunov-based privacy-aware framework was introduced, which not only addressed privacy and security issues but also achieved optimization effects by reducing energy consumption. In [42], focusing on a multi-device single MEC system, the energy-saving task offloading problem was formulated as a time-averaged energy minimization problem considering queue length and resource constraints.
Different from prior studies, this paper is dedicated to addressing the challenges of dynamic task offloading in a green sustainable WPMEC networks with user assistance. We take into account the total system’s energy consumption constraint, the dynamically arriving tasks in real-time scenarios, and the high dynamics of wireless channel conditions. Moreover, the temporal coupling between WPT and user collaborative communication, as well as the coupling of data offloading timing and transmission power in collaborative communication, impose significant challenge to the problem.
2. System Model
2.1. Communication Model
As depicted in Figure 1, we consider a WPMEC system that comprises two MDs and one HAP. The HAP is equipped with both an RF energy transmitter and an MEC server, offering wireless energy and computation offloading services to MDs within the base station’s coverage area. Both MDs work on the same frequency band and are tasked with completing computation-intensive, delay-sensitive operations. One MD, known as the Far User (FU), is situated at a considerable distance from the HAP. In contrast, the other MD, called the Near User (NU), is in closer proximity to the HAP and serves as a facilitator, aiding the FU by offloading a portion of its tasks to the HAP.
To minimize interference, each MD utilizes a Time Division Duplex (TDD) approach to switch between communication and energy harvesting phases. We implement a Time Division Multiple Access (TDMA) framework with each time slot lasting T seconds. At the start of each time slot, both MDs capture RF signals emitted by the HAP for energy harvesting. Given the suboptimal channel conditions between the FU and the HAP, along with the compounded near-far effect, the FU is capable of transferring some of its computational data to the NU. The NU then forwards this data to the HAP. Additionally, the NU is scheduled to offload its own computational tasks to the HAP. The primary symbols and definitions used are enumerated in Table 1.
2.2. Task Queue Model
Both FU and NU maintain a queue to buffer the randomly arriving tasks for awaiting processing. Let and denote the queue lengths at the FU and NU at slot t, respectively, which cab be observed at the beginning of time slot t. The backlog of task queue update according to the following equations:
where and represent the raw task data arriving at the FU and NU data queues during time slot t, respectively.
In reality, the data queue lengths and are always positive. Additionally, since the data processing amount by the MDs cannot exceed the current queue length, we have the following constraints:
Additionally, if the local computation of the MD is capable of processing the entire current queue, then local computation is given priority , which is also in line with practical requirements.
2.3. Computation Model
(1) Local Computation Mode: MDs are capable of performing continuous local computations. Let and denote the local CPU frequencies of the FU and NU, respectively. Additionally, let and represent the CPU cycles required to process one bit of data at the FU and NU, respectively. Consequently, the amount of raw data (in bits) processed locally by MDs within a time slot t and the corresponding energy expenditure over that period can be determined by the following threshold rules.
For the FU, the local data processing in bits is given by
At the begin of each time slot t, we obtain the queue length of the FU. If the queue length exceeds its local processing capacity, the FU will utilize a user collaboration mechanism to offload partial tasks; if the queue length is within the computing capacity, the FU will perform complete local computation (that is, ), and the corresponding energy consumed during this period, as combined with (where denotes the amount of data processed locally at slot t) [30], is:
Similarly, for the NU, the local data processing is
When the NU engages in complete local computation, , with the energy consumed being
Here, represents the computational energy efficiency coefficient of the processing chip [43].
(2) Offloading Mode: We adopt a partial task offloading strategy for both FU and NU. As illustrated in Figure 2. Initially, the FU transfers a portion of its task data to the NU during time , using a transmission power . Subsequently, the NU forwards the FU’s data to the HAP during time with a transmission power . Furthermore, the NU offloads its own data to the HAP during time using transmission power . Throughout this process, the NU consume the energy it has harvested. It is essential that the amount of data offloaded by the FU for remote computation at the HAP corresponds to the data initially offloaded to the NU.
In practical applications, the HAP possesses significantly greater computational capacity and transmission power compared to the MDs. As a result, the time required for data computation and feedback at the HAP is negligible. Therefore, the total time allocated for energy harvesting and task offloading by MDs must not exceed the time slot duration T, as represented by the following inequality:
We focus solely on the energy consumption of the MDs during the offloading process. The transmission power of the FU is constrained by . According to Shannon’s theorem, the amount of data offloaded from the FU to the NU is given by
The corresponding energy consumption for this process is
where W is the channel bandwidth, is the channel gain from the FU to the NU during time slot t, and represents the power of additive white Gaussian noise.
After the initial time , the NU has received the offloaded tasks from the FU. The NU must then determine the transmission powers for relaying the FU’s data to the HAP and for offloading its own data. The quantity of data relayed by the NU from the FU to the HAP is expressed as
with the associated energy consumption being
Similarly, the amount of data offloaded by the NU to the HAP is
and the corresponding energy consumption is
Here, denote the transmission power of the NU, and represents signifies the channel gain from the NU to the HAP during the respective time slot.
During each time slot t, the NU is required to process all offloading tasks received from the FU, adhering to the constraint that the amount of data offloaded by the FU does not exceed that of the NU’s capability to relay it
2.4. Energy Consumption Model
As illustrated in Figure 2, during the initial phase , the HAP disseminates radio frequency energy to the MDs. The energy harvested by each MD can be represented as
where and denote the energy harvested by the FU and NU from the HAP during time slot t, respectively. The coefficients and are defined as , , where , represents the energy conversion efficiency. signifies the RF energy transmission power of the HAP, and the channel power gains from the HAP to the FU and NU are represented by and , respectively. Assuming block fading, these gains remain consistent within a time slot but fluctuate independently between frames. It is important to note that the WPT from the HAP is the sole energy source for performing computational tasks.
In each time slot t, the energy consumption of the FU and NU must adhere to the following constraints:
For a sustainable wireless charging IoT network, all energy for the wireless nodes originates from the RF signals emitted remotely by the HAP. Therefore, controlling the energy consumption of the HAP is of significant importance to the development of the entire IoT network. Consequently, we assume that the time-average energy consumption of the HAP is subject to the following constraints.
where . is the energy consumption for HAP at the tth time slot, and is the energy threshold.
2.5. Problem Formulation
For a dynamically changing WPT-MEC network system, maintaining system stability is crucial due to the stochastic arrival of tasks and the dynamic changes in the channel environment [44] . Therefore, we first provide the definition of system queue stability as follows.
Definition 1. (Queue Stability): The task data queue is strong stable if it satisfies [44]
,
In this paper, we aim to design a dynamic offloading algorithm to maximize the long-term average weighted sum computation rate for all MDs, by making decision of time allocation , and the power allocation at each time slot t under the long term power consumption constraint of IoT network. Our proposed algorithm should ensure the stability of data queues and work without prior knowledge of random channel conditions and data arrival patterns, optimizing within each time slot. By denoting , , the maximization of weighted computation rate problem of WPT-MEC can be formulated as a MSSO problem (P1) as:
where , and denotes the fixed weight of the FU and NU, respectively. Constraint (22b) ensures the total time allocation does not exceed the time slot. Constraints (22c) and (22d) represent the energy constraints for the FU and Near NU, respectively. Constraint (22e) captures the average power constraints for the system. Constraints (22f) guarantee the stability of data queues. Constraints (22g) and (22h) denote the maximum data processing limits for the FU and NU within time slot t. Constraint (22i) ensures that the data offloaded from the FU can be processed within the same time slot. Problem (P1) poses a complex stochastic optimization challenge that conventional convex optimization methods cannot easily solve. To address this, we introduce a Lyapunov-based optimization algorithm that transforms the stochastic problem into a deterministic one within each time slot.
3. Algorithm Design
3.1. Lyapunov Optimization
To address the average power constraints, we introduce a virtual energy queue , where [44]. Here can be seen as a queue with random "energy arrivals" and a fixed "service rate" . Thus, we derive the following Lemma 1.
Lemma 1.
The long-term average power constraints will be met if the virtual queue satisfies average rate stability
Proof.
According to the above formula , we can conclude that
we can expand all the terms of , sum them up, and then take the average, yielding
Next, we simultaneously take the expectation on both sides and set K, obtaining:
By our assumption, it follows that , i.e., , the lemma is proven. □
By defining a network queue vector , which encompasses the queue lengths for the NU, FU, and the virtual queue, respectively, we can obtain the associated Lyapunov function and the Lyapunov drift as
Employing the Lyapunov optimization theory, we drive the drift-plus-penalty as
Here, signifies the penalty’s importance weight. The Lyapunov optimization method aims to minimize the upper bound of the drift plus penalty, thereby maximizing the objective function while ensuring queue stability. Optimizing the objective function across each time slot leads to long-term optimality. It’s important to note that a higher value of V prioritizes objective maximization, whereas a lower value emphasizes queue stability. To obtain the upper bound of , we derive the following Lemma 2.
Lemma 2.
At each time slot t, for any control strategy , the one-slot Lyapunov drift-plus-penaltyis bounded as per the following inequality
where B is a constant that satisfies the following
Proof.
For all , we have the inequality . By using the inequality, we have
Upon combining inequalities (31), (32), and (33), the resulting expression yields the upper bound of the Lyapunov drift-plus-penalty. □
By applying the drift-plus-penalty minimization technique, and eliminating the constant term observable at the start of time slot t in (29), we can obtain the optimal solution to problem (P1) by solving the following problem in each individual time slot.
Due to the the non-convex constraints (34b), (P2) remains a non-convex problem. We introduce auxiliary variables here. According to equation (22j), we have . We denote . To simplify the mathematical expressions, we omit t here. So (P2) can be equivalently substituted as
The coefficients are defined as and , where , and . Owing to the non-convex constraint (35e), problem (P3) remains non-convex. To address this, we introduce auxiliary variables and , defined such that . By making these definitions, problem (P3) can be reformulated in terms of these auxiliary variables as follows:
, when the problem (P4) reaches the optimal solution, it aligns with the original problem (P3). Specifically, for constraint (36e), is a concave function of since the perspective operation applied to preserves convexity [45] . Thus, constraint (36e) is convex, making problem (P4) a convex optimization problem. To further analyze the solution, we will employ convex optimization tools, such as CVX [46].
We introduce an efficient dynamic task offloading algorithm with user assistance to tackle Problem 4. Additionally, we apply the Lagrange method to gain meaningful insights into the optimal solution’s properties.
Theorem 1.
Given non-negative Lagrange multipliers , , the optimal power allocation must fulfill certain conditions
Proof.
Let for denote the Lagrange multipliers corresponding to the constraints. The Lagrangian function for problem (P4), constructed based on these multipliers, is as follow
We can use the first-order optimality conditions. Taking the derivative of the Lagrangian function yields
By examining the first-order derivatives, we can establish the necessary conditions for optimality. The relationship between the auxiliary variables and the original variables is leveraged to derive the theorem. □
According to this theorem, we can infer that during the process of radio frequency energy transfer, higher power leads to better results. As the value of W increases, both FU and NU entities are more motivated to offload data, which results in a reduction of the computational tasks performed locally. Furthermore, an increase in V prompts FU and NU to offload a larger portion of their tasks. This shift towards offloading is driven by the desire to enhance the computation rate, which in turn leads the MDS to increase the volume of data offloaded to meet its objectives.
The process of solving the original MSSO problem, denoted as (P1), is encapsulated within Algorithm 1.
| Algorithm 1: User-Assisted Dynamic Resource Allocation Algorithm |
 |
3.2. Algorithm Complexity Analysis
We have employed the Lyapunov algorithm, which not only ensures the stability of the system but also allows us to effectively decompose the complex overall problem into multiple sub-problems (P2). By implementing Algorithm 1, we are able to solve (P2) within each time slot. Therefore, the solution complexity at each time slot is crucial in determining the overall performance and responsiveness of the algorithm. When solving the problem (P4), we have utilized the interior-point method, which possesses a computational complexity of approximately .
In this context, n denotes the total of decision variables, and reflects the degree of precision in computation. In our algorithm, with , the number of decision variables is sufficiently small. This design not only ensures the efficiency of the algorithm but also enables us to complete the optimization of resource allocation within a reasonable time, thus meeting the performance requirements in practical applications.
3.3. Algorithm Performance Analysis
In this section, we demonstrate that the proposed scheme can achieve an optimal long-term time-average solution. First, we establish a key assumption as follows
Subsequently, we deduce that the expected value will also converge to the same set of solutions
Furthermore, we establish the existence of an optimal solution founded on the existing conditions of the queue as follows.
Lemma 3.
Should problem (P1) be solvable, there is a set of decisions that adhere to the conditions
Here, the asterisk * denotes the value associated with the optimal solution.
Proof.
Here we omit the proof details for brevity. See the parts 4 and 5 of [44]. □
Theorem 2.
The optimal long-term average weighted computation rate derived from (P1) is bounded below by a lower bound, which is independent of time and space. The algorithm is capable of achieving the following solutions:
- All queues , , are mean rate stable, thereby satisfying the constraints.
Proof.
For any , we consider the policy and queue state as defined in equations (40). Given that the values , are independent of the queue status , we can deduce that
By integrating these results into equation (29) and taking , we obtain
Utilizing the iterated expectation, and summing the aforementioned inequality over the time horizon , we derive the following result
By dividing both sides of equation (47a) by , applying Jensen’s inequality, and considering that , we obtain
Furthermore, letting , we have
From Equation (41), we have
Furthermore we obtain
□
Theorem 3.
A defined upper limit confines the time-averaged sum of queue lengths
Proof.
By employing the method of iterated expectations and applying telescoping sums iteratively for each , we can derive
Dividing both sides of (53) by , and considering , we rearrange the terms to obtain the desired result
Specifically
□
Theorems 2 and 3 underpin our proposed algorithm by establishing that as V increases, the computation rate improves at a rate of , whereas the queue length grows at a rate of . This suggests that by choosing an appropriately large value for V, we can achieve an optimal . Furthermore, the time-averaged queue length, denoted as , is shown to increase linearly with V. This linear relationship implies a trade-off between the optimized computation rate and the queue length, . In line with Little’s Law [47], which posits that delay is proportional to the time-averaged length of the data queue. In other words, our proposed algorithm enables a trade-off between and the average network latency.
4. Simulation Results
In this section, plenty of numerical simulations are performed to assess the efficiency of our proposed algorithm. Our experiments were conducted on a computational platform with an Intel(R) Xeon(R) Gold 6148 CPU 2.40 GHz, 20 cores and four GeForce RTX 3070 GPUs. In our simulations, we employed a free-space path-loss model to depict the wireless channel characteristics [48]. The averaged channel gain here is denoted as
where denotes the antenna gain, denotes the carrier frequency, denotes the path loss exponent, and in meters denotes the distance between two nodes. The time-varying WPT and task offloading channel gains are represented by the vector , adhering to the Rayleigh fading channel model. In this model, the random channel fading factors are characterized by an exponential distribution with a unit mean, capturing the variability inherent in wireless communication channels. For the sake of simplicity, we assume that the vector of fading factors is constant and equal to for any given time slot, implying that the channel gains are static within that slot. The interval between task arrivals at FU and NU both follow an exponential distribution with constant average rates and respectively. The parameters are all listed in Table 2.
4.1. Impact of System Parameters on Algorithm Performance
Figure 3 illustrates trend for the average task computation rate and the average task queue lengths of FU and NU over a 5000 time slots period. The the task arrival rates for FU and NU are set at 1.75 Mbps and 2 Mbps, respectively. Initially, is low, but it rapidly increases and eventually stabilizes as time progresses. This initial surge in is due to the system’s initial adjustment to the initial task queue fluctuations, which demands more intensive processing for FU tasks, resulting in increased energy consumption and a temporary reduction in the overall computation rate. Moreover, the average queue length decreases and stabilizes, reflecting the system’s ability to self-regulate and reach a steady state.
Figure 4 demonstrates the average task computation rate of our proposes algorithm under different control parameter .The results show that the average task computation rates converge similarly across different V. Notably, as V increases, there is a corresponding increase in the average task computation rates. This trend is attributed to the fact that a larger V compels the algorithm to prioritize computation rates over queue stability, which is consistent with theoretical analysis, which is corresponding to Theorems 2. Here, the parameter V serves as a balancing factor between the task computation rate and queue stability, reflecting a trade-off that is consistent with our theoretical predictions.
Figure 5 shows the trend of average task queue lengths of FU and NU after with different V. As V increases from 100 to 900, the task queue lengths of FU and HD declines from bits to bits and from bits to bits respectively. In the user-assisted offloading paradigm, processing a task from NU involves only a single offloading step, which is markedly more efficient than the two-step offloading data from FU. Consequently, with the increasing of V, indicating a shift in the algorithm’s focus towards prioritizing computation rates over queue stability, the algorithm will naturally prefer to offload tasks from NU, resulting in a more rapid decline in the NU’s task queue length. By tuning the value of V, an optimal balance in task processing between FU and HU can be effectively achieved, reflecting the algorithm’s adaptability to different operational priorities.
Figure 6 evaluates the impact of the average energy constraint on system performance with V fixed at 500. As increases from joule to joule, the average task computation rate rises from bits/s to bits/s, while the average task queue length of FU and NU decreases from bits to bits. This reduction in queue length and increase in computation rate are attributed to the higher energy availability for WPT, enabling FU and NU to offload tasks more effectively. Notably, after the average energy constraint reaching 2.1 joule, the variation of task computation rate and task queue is reduced. This observation suggests that there is an upper bound to the energy consumption of our algorithm. Beyond this threshold, additional energy has minimal impact on performance enhancement. Hence, energy constraint as a critical parameter, significantly influences both the data processing rates and the stability of task queues within the system. The findings underscore the importance of energy management in optimizing system performance.
Figure 7 presents the total system energy consumption of our proposed algorithm under different values of the parameter V, specifically and . Initially, the total energy consumption exhibits substantial fluctuations. However, with the progression of time, the system’s energy consumption stabilizes and hovers around the average energy constraint after approximately 2500 time slots. Notably, an elevated V value is correlated with higher average energy consumption, as the algorithm pay more attention to the system’s computation rate, consequently incurring greater energy costs. Figure 7 highlight the algorithm’s efficacy in managing average energy consumption, a critical feature for the sustainability of IoT networks.
In Figure 8, we evaluate the offloading power across varying bandwidths W, ranging from Hz to Hz. It is observed that all the offloading powers increases as bandwidth W escalates. Consistent with the results of the analysis in Theorem 1, the increase in bandwidth makes the system more inclined to perform task offloading, reflected in the increase in offloading power.
4.2. Comparison with Baseline Algorithms
To evaluate the performance of our propose algorithm, we choose the the following three representative benchmarks as the baseline algorithms.
(1) All offloading scheme: Both FU and NU do not perform local computing and consumes all the energy for task offloading.
(2) No cooperation scheme: FU offloads tasks directly to HAP without soliciting assistance from NU, similar to the method in [49].
(3) No lyapunov scheme: Disregarding the dynamics of task queues and the energy queue, this scheme focuses solely on maximizing the average task computation rate, similar to the Myopic method in [30]. To ensure a fair comparison, we constrain the energy consumption of each time slot by solving.
Figure 9 shows the average task computation rates under four schemes over a 5000 time-slots period, with the control parameter V set to 500. All schemes converge after 1000 time slots. Our proposed algorithm achieves the best task computation rate after convergence, outperforming the other three by 0.8%, 3.9%, and 4.1% respectively. Our algorithm’s key strengths lie not only in achieving the highest data processing rate but also in ensuring the stability of the system queues. This prevents excessively long queues that could lead to prolonged response times and a negative user experience. The no-Lyapunov scheme, while achieving the second-highest computation rate, neglects queue stability in its pursuit of maximizing computation speed. This oversight can lead to system instability, prolonged user service times, and potential system failure. The all-offloading scheme, relying solely on edge computing, consumes more energy and thus underperforms in energy-limited scenarios. In the no-cooperation scheme, the system initially benefits from a high computation rate due to the NU’s lack of assistance to the FU. But as the NU’s tasks are completed and its resources are no longer available, the average computation rate falls sharply. The FU’s communication with the HAP is further impeded by the dual proximity effect, causing a notable decline in the system’s long-term computation performance.
Figure 10 show the impact of varying network bandwidth W from Hz to Hz on the performance of different schemes. As W increase, task computation rates for all schemes rise, reflecting improved transmission efficiency for wireless power transfer and task offloading. This allows HAP to handle more offloaded tasks, highlighting the critical role of bandwidth in system performance. Notably, our proposed scheme consistently outperforms others across all bandwidth levels, showcasing its adaptability and robustness in varying network conditions.
Figure 11 evaluates how the distance between FU and NU affects the performance of all four schemes, with distances varying from 120 m to 160 m. We observe that as the distance increases, the computation rates for both our proposed scheme and the all-offloading scheme decrease. This suggests that proximity plays a crucial role in task offloading efficiency. In contrast, the no-cooperation scheme shows a stable computation rate, consistent with its design that excludes task offloading between FU and NU. Interestingly, the no-Lyapunov scheme performs best at a distance of about 140 meters. However, its performance drops as the distance decreases, contrary to the expectation that a shorter distance would enhance task offloading from FU to NU. This unexpected trend is likely due to instances where the FU’s task queue depletes faster than new tasks arrive, leading to lower computation rates for the no-Lyapunov scheme. This highlights the importance of balancing task computation rates with queue stability in system design.
In Figure 12, we evaluate the performance of four schemes as the task arrival rate of NU varies from bits/s to bits/s. Our proposed scheme’s task computation rate demonstrates a modest increase and maintains the highest computation rate as tasks arrive more rapidly. This trend underscores the scheme’s robustness across diverse scenarios. Correspondingly, the no cooperation scheme exhibits a more pronounced increase in task computation rate. This is attributable to its vigorous task processing capacity at the NU, which allows it to capitalize on the higher task arrival rates effectively.
5. Conclusions
The joint optimization of computation offloading and resource allocation in WPMEC systems poses a significant challenge due to the time-varying network environments and the time-coupling nature of energy consumption constraint. In this study, we aim at maximizing the average task computation rate in an MEC system with WPT and user collaboration. A task computation maximization problem was formulated considering uncertainty of load dynamics alongside energy consumption constraint. The complexity of this problem is amplified by the interplay of multiple coupled parameters. To surmount these difficulties, we introduce an innovative online algorithm, named UAORA. This algorithm leverages Lyapunov optimization theory to manage long-term task queue lengths and energy consumption, effectively transforming the sequential decision-making dilemma into a series of deterministic optimization problems for each time slot. Extensive simulation results substantiate the effectiveness of the proposed UAORA algorithm, demonstrating a significant enhancement in average task computation performance when compared with benchmark methods. Simulations also underscores the advantages of jointly consider the task computation rate and the task queues in our algorithm. An enticing avenue for future research is to account for dynamically changing local computation rates. Incorporating such variability could potentially augment the system’s flexibility and applicability within the complexities of real-world scenarios.
Author Contributions
Methodology, H.H.; Validation, Z.C. and H.F.; Formal analysis, H.H.; Investigation, H.H. and H.F.; Resources, H.H.; Data curation, H.H. and Y.Y.; Writing—original draft, H.H. and H.F.; Writing—review and editing, H.H.; Supervision, Y.Y. and S.H.; All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Science and Technology Planning Project of Guangdong Province, China (No.2021A0101180005).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
We thank all of the reviewers for their valuable comments.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Wu, W.; Zhou, F.; Hu, R.Q.; Wang, B. Energy-efficient resource allocation for secure NOMA-enabled mobile edge computing networks. IEEE Transactions on Communications 2019, 68, 493–505. [Google Scholar] [CrossRef]
- Na, Z.; Liu, Y.; Shi, J.; Liu, C.; Gao, Z. UAV-supported clustered NOMA for 6G-enabled Internet of Things: Trajectory planning and resource allocation. IEEE Internet of Things Journal 2020, 8, 15041–15048. [Google Scholar] [CrossRef]
- Zhao, R.; Zhu, F.; Tang, M.; He, L. Profit maximization in cache-aided intelligent computing networks. Physical Communication 2023, 58, 102065. [Google Scholar] [CrossRef]
- Liu, X.; Sun, Q.; Lu, W.; Wu, C.; Ding, H. Big-data-based intelligent spectrum sensing for heterogeneous spectrum communications in 5G. IEEE Wireless Communications 2020, 27, 67–73. [Google Scholar] [CrossRef]
- Mao, Y.; You, C.; Zhang, J.; Huang, K.; Letaief, K.B. A Survey on Mobile Edge Computing: The Communication Perspective. IEEE Communications Surveys & Tutorials 2017, 19, 2322–2358. [Google Scholar] [CrossRef]
- Chen, M.; Hao, Y. Task Offloading for Mobile Edge Computing in Software Defined Ultra-Dense Network. IEEE Journal on Selected Areas in Communications 2018, 36, 587–597. [Google Scholar] [CrossRef]
- Sun, C.; Zhou, J.; Liuliang, J.; Zhang, J.; Zhang, X.; Wang, W. Computation Offloading with Virtual Resources Management in Mobile Edge Networks. 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), 2018, pp. 1–5. [CrossRef]
- Guo, H.; Zhang, J.; Liu, J.; Zhang, H. Energy-Aware Computation Offloading and Transmit Power Allocation in Ultradense IoT Networks. IEEE Internet of Things Journal 2019, 6, 4317–4329. [Google Scholar] [CrossRef]
- Sun, H.; Zhou, F.; Hu, R.Q. Joint Offloading and Computation Energy Efficiency Maximization in a Mobile Edge Computing System. IEEE Transactions on Vehicular Technology 2019, 68, 3052–3056. [Google Scholar] [CrossRef]
- Anajemba, J.H.; Yue, T.; Iwendi, C.; Alenezi, M.; Mittal, M. Optimal Cooperative Offloading Scheme for Energy Efficient Multi-Access Edge Computation. IEEE Access 2020, 8, 53931–53941. [Google Scholar] [CrossRef]
- Zhu, X.; Luo, Y.; Liu, A.; Bhuiyan, M.Z.A.; Zhang, S. Multiagent Deep Reinforcement Learning for Vehicular Computation Offloading in IoT. IEEE Internet of Things Journal 2021, 8, 9763–9773. [Google Scholar] [CrossRef]
- Zhou, Z.; Chen, X.; Li, E.; Zeng, L.; Luo, K.; Zhang, J. Edge Intelligence: Paving the Last Mile of Artificial Intelligence With Edge Computing. Proceedings of the IEEE 2019, 107, 1738–1762. [Google Scholar] [CrossRef]
- Mao, S.; Leng, S.; Maharjan, S.; Zhang, Y. Energy Efficiency and Delay Tradeoff for Wireless Powered Mobile-Edge Computing Systems With Multi-Access Schemes. IEEE Transactions on Wireless Communications 2020, 19, 1855–1867. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic Computation Offloading for Mobile-Edge Computing With Energy Harvesting Devices. IEEE Journal on Selected Areas in Communications 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Huang, K.; Lau, V.K.N. Enabling Wireless Power Transfer in Cellular Networks: Architecture, Modeling and Deployment. IEEE Transactions on Wireless Communications 2014, 13, 902–912. [Google Scholar] [CrossRef]
- Mao, S.; Wu, J.; Liu, L.; Lan, D.; Taherkordi, A. Energy-Efficient Cooperative Communication and Computation for Wireless Powered Mobile-Edge Computing. IEEE Systems Journal 2022, 16, 287–298. [Google Scholar] [CrossRef]
- Margolies, R.; Gorlatova, M.; Sarik, J.; Stanje, G.; Zhu, J.; Miller, P.; Szczodrak, M.; Vigraham, B.; Carloni, L.; Kinget, P.; others. Energy-harvesting active networked tags (enhants) prototyping and experimentation. ACM Transactions on Sensor Networks (TOSN) 2015, 11, 1–27. [Google Scholar] [CrossRef]
- Tataria, H.; Shafi, M.; Molisch, A.F.; Dohler, M.; Sjöland, H.; Tufvesson, F. 6G Wireless Systems: Vision, Requirements, Challenges, Insights, and Opportunities. Proceedings of the IEEE 2021, 109, 1166–1199. [Google Scholar] [CrossRef]
- Ju, H.; Zhang, R. Throughput Maximization in Wireless Powered Communication Networks. IEEE Transactions on Wireless Communications 2014, 13, 418–428. [Google Scholar] [CrossRef]
- Ji, L.; Guo, S. Energy-Efficient Cooperative Resource Allocation in Wireless Powered Mobile Edge Computing. IEEE Internet of Things Journal 2019, 6, 4744–4754. [Google Scholar] [CrossRef]
- Li, M.; Zhou, X.; Qiu, T.; Zhao, Q.; Li, K. Multi-Relay Assisted Computation Offloading for Multi-Access Edge Computing Systems With Energy Harvesting. IEEE Transactions on Vehicular Technology 2021, 70, 10941–10956. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Device-to-Device Relaying: Optimization, Performance Perspectives, and Open Challenges Towards 6G Networks. IEEE Communications Surveys & Tutorials 2022, 24, 1336–1393. [Google Scholar] [CrossRef]
- Su, B.; Ni, Q.; Yu, W.; Pervaiz, H. Optimizing Computation Efficiency for NOMA-Assisted Mobile Edge Computing With User Cooperation. IEEE Transactions on Green Communications and Networking 2021, 5, 858–867. [Google Scholar] [CrossRef]
- Li, B.; Si, F.; Zhao, W.; Zhang, H. Wireless Powered Mobile Edge Computing With NOMA and User Cooperation. IEEE Transactions on Vehicular Technology 2021, 70, 1957–1961. [Google Scholar] [CrossRef]
- Sun, M.; Xu, X.; Huang, Y.; Wu, Q.; Tao, X.; Zhang, P. Resource Management for Computation Offloading in D2D-Aided Wireless Powered Mobile-Edge Computing Networks. Ieee Internet of Things Journal 2021, 8, 8005–8020. [Google Scholar] [CrossRef]
- Wang, X.; Chen, X.; Wu, W.; An, N.; Wang, L. Cooperative application execution in mobile cloud computing: A stackelberg game approach. IEEE Communications Letters 2015, 20, 946–949. [Google Scholar] [CrossRef]
- You, C.; Huang, K. Exploiting Non-Causal CPU-State Information for Energy-Efficient Mobile Cooperative Computing. IEEE Transactions on Wireless Communications 2018, 17, 4104–4117. [Google Scholar] [CrossRef]
- Hu, X.; Wong, K.K.; Yang, K. Wireless Powered Cooperation-Assisted Mobile Edge Computing. Ieee Transactions on Wireless Communications 2018, 17, 2375–2388. [Google Scholar] [CrossRef]
- Wang, F.; Xu, J.; Ding, Z. Optimized Multiuser Computation Offloading with Multi-Antenna NOMA. 2017 IEEE Globecom Workshops (GC Wkshps), 2017, pp. 1–7. [CrossRef]
- Bi, S.; Huang, L.; Wang, H.; Zhang, Y.J.A. Lyapunov-guided deep reinforcement learning for stable online computation offloading in mobile-edge computing networks. IEEE Transactions on Wireless Communications 2021, 20, 7519–7537. [Google Scholar] [CrossRef]
- Zhang, S.; Bao, S.; Chi, K.; Yu, K.; Mumtaz, S. DRL-based computation rate maximization for wireless powered multi-AP edge computing. IEEE Transactions on Communications 2023. [Google Scholar] [CrossRef]
- Shi, L.; Ye, Y.; Chu, X.; Lu, G. Computation Energy Efficiency Maximization for a NOMA-Based WPT-MEC Network. IEEE Internet of Things Journal 2021, 8, 10731–10744. [Google Scholar] [CrossRef]
- Zheng, X.; Zhu, F.; Xia, J.; Gao, C.; Cui, T.; Lai, S. Intelligent computing for WPT–MEC-aided multi-source data stream. EURASIP Journal on Advances in Signal Processing 2023, 2023, 52. [Google Scholar] [CrossRef]
- Zhu, B.; Chi, K.; Liu, J.; Yu, K.; Mumtaz, S. Efficient Offloading for Minimizing Task Computation Delay of NOMA-Based Multiaccess Edge Computing. IEEE Transactions on Communications 2022, 70, 3186–3203. [Google Scholar] [CrossRef]
- Wen, Y.; Zhou, X.; Fang, F.; Zhang, H.; Yuan, D. Joint time and power allocation for cooperative NOMA based MEC system. 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall). IEEE, 2020, pp. 1–5.
- He, B.; Bi, S.; Xing, H.; Lin, X. Collaborative Computation Offloading in Wireless Powered Mobile-Edge Computing Systems. 2019 IEEE Globecom Workshops (GC Wkshps), 2019, pp. 1–7. [CrossRef]
- Peng, J.; Qiu, H.; Cai, J.; Xu, W.; Wang, J. D2D-assisted multi-user cooperative partial offloading, transmission scheduling and computation allocating for MEC. IEEE Transactions on Wireless Communications 2021, 20, 4858–4873. [Google Scholar] [CrossRef]
- Mao, S.; Wu, J.; Liu, L.; Lan, D.; Taherkordi, A. Energy-efficient cooperative communication and computation for wireless powered mobile-edge computing. IEEE Systems Journal 2020, 16, 287–298. [Google Scholar] [CrossRef]
- Lin, X.H.; Bi, S.; Su, G.; Zhang, Y.J.A. A Lyapunov-Based Approach to Joint Optimization of Resource Allocation and 3D Trajectory for Solar-Powered UAV MEC Systems. IEEE Internet of Things Journal 2024. [Google Scholar] [CrossRef]
- Sun, G.; Wang, Z.; Su, H.; Yu, H.; Lei, B.; Guizani, M. Profit Maximization of Independent Task Offloading in MEC-Enabled 5G Internet of Vehicles. IEEE Transactions on Intelligent Transportation Systems 2024. [Google Scholar] [CrossRef]
- Shen, S.; Xie, L.; Zhang, Y.; Wu, G.; Zhang, H.; Yu, S. Joint differential game and double deep q–networks for suppressing malware spread in industrial internet of things. IEEE Transactions on Information Forensics and Security 2023. [Google Scholar] [CrossRef]
- Mei, J.; Dai, L.; Tong, Z.; Zhang, L.; Li, K. Lyapunov optimized energy-efficient dynamic offloading with queue length constraints. Journal of Systems Architecture 2023, 143, 102979. [Google Scholar] [CrossRef]
- Wang, Y.; Sheng, M.; Wang, X.; Wang, L.; Li, J. Mobile-edge computing: Partial computation offloading using dynamic voltage scaling. IEEE Transactions on Communications 2016, 64, 4268–4282. [Google Scholar] [CrossRef]
- Neely, M. Stochastic network optimization with application to communication and queueing systems; Springer Nature, 2022.
- Boyd, S.; Vandenberghe, L. Convex optimization; Cambridge university press, 2004.
- Grant, M.; Boyd, S. CVX: Matlab software for disciplined convex programming, version 2.1, 2014.
- Mao, S.; Leng, S.; Maharjan, S.; Zhang, Y. Energy efficiency and delay tradeoff for wireless powered mobile-edge computing systems with multi-access schemes. IEEE Transactions on Wireless Communications 2019, 19, 1855–1867. [Google Scholar] [CrossRef]
- Wu, T.; He, H.; Shen, H.; Tian, H. Energy Efficiency Maximization for Relay-aided Wireless Powered Mobile Edge Computing. IEEE Internet of Things Journal 2024. [Google Scholar] [CrossRef]
- Huang, Y.; Liu, Y.; Chen, F. NOMA-aided mobile edge computing via user cooperation. IEEE Transactions on Communications 2020, 68, 2221–2235. [Google Scholar] [CrossRef]
Figure 1.
System model of WPMEC network with user-assisted.
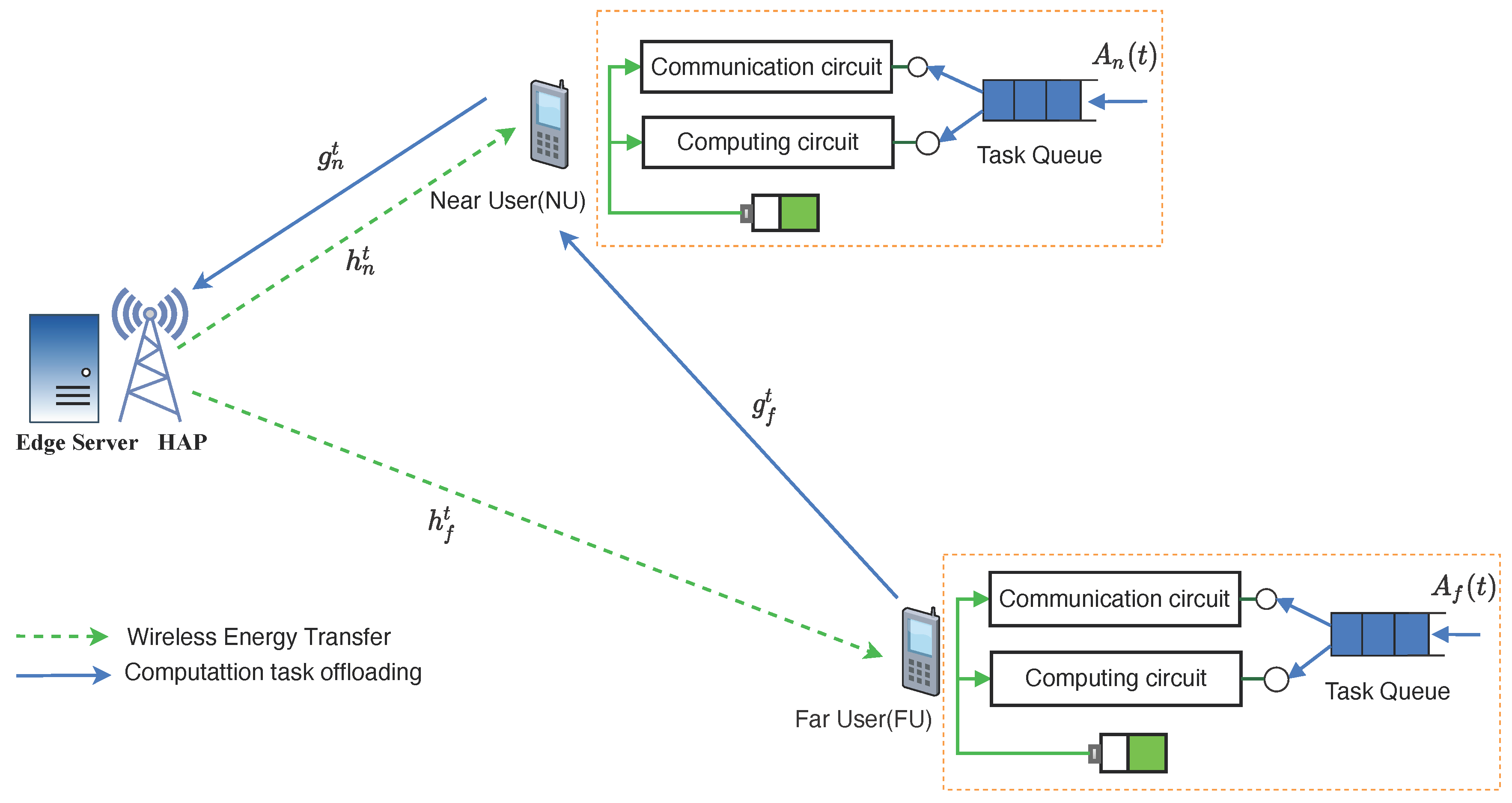
Figure 2.
An illustrative time division structure.
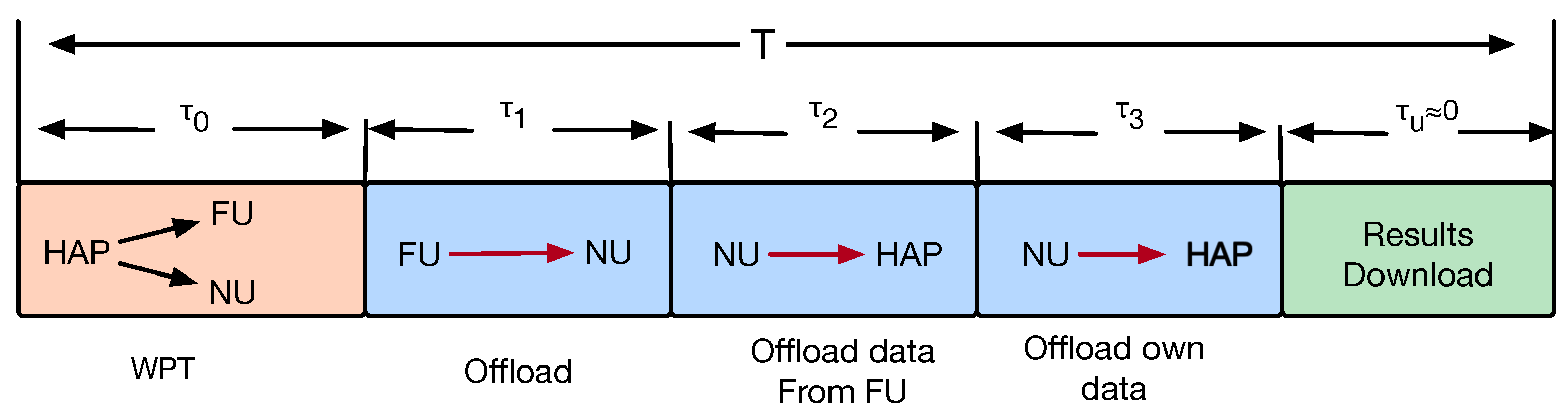
Figure 3.
Average task computation rate and average task queue length over time slots.
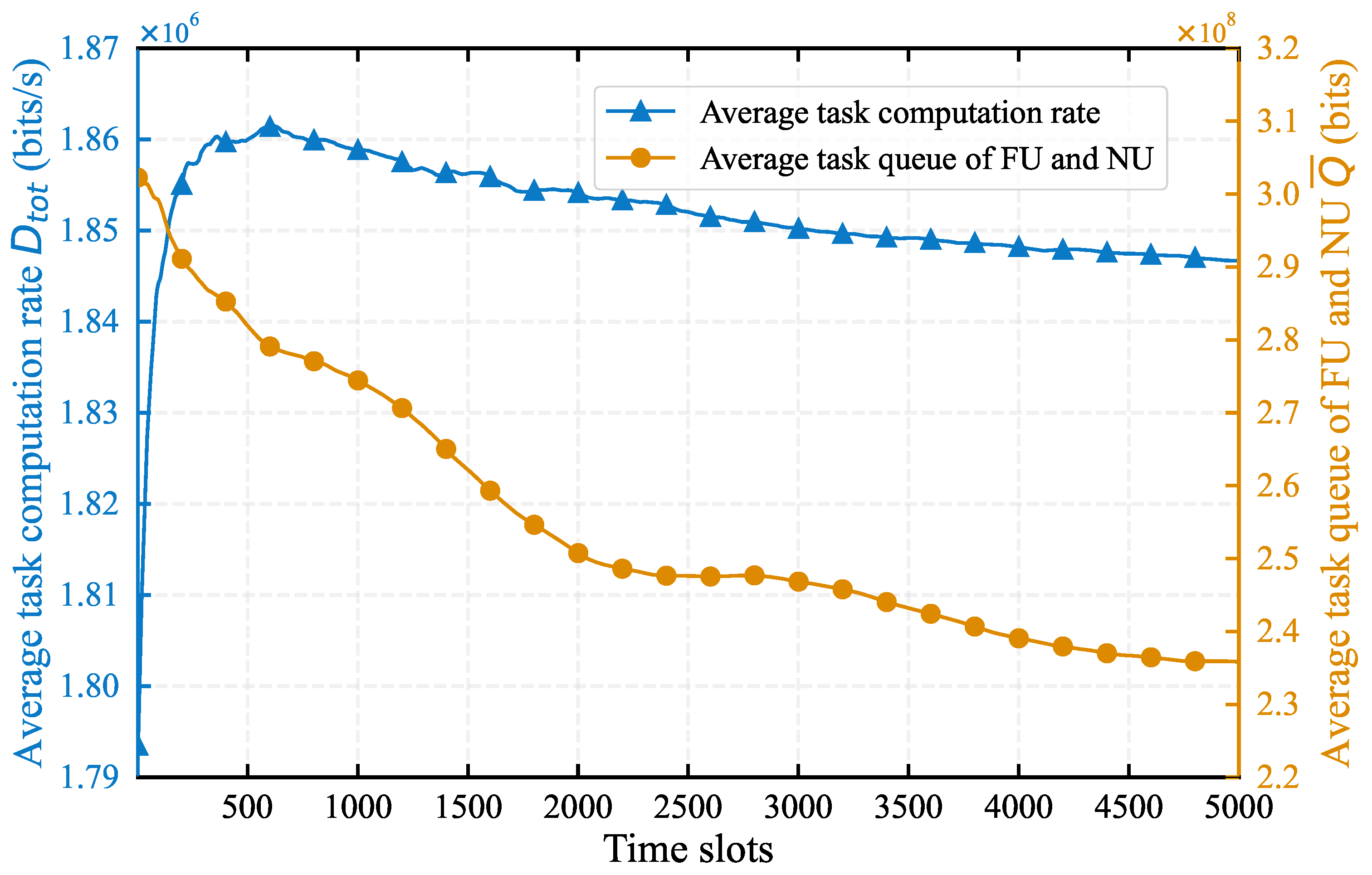
Figure 4.
Average task computation rates with different control parameter V.
Figure 5.
Task queue lengths with different control parameter V.
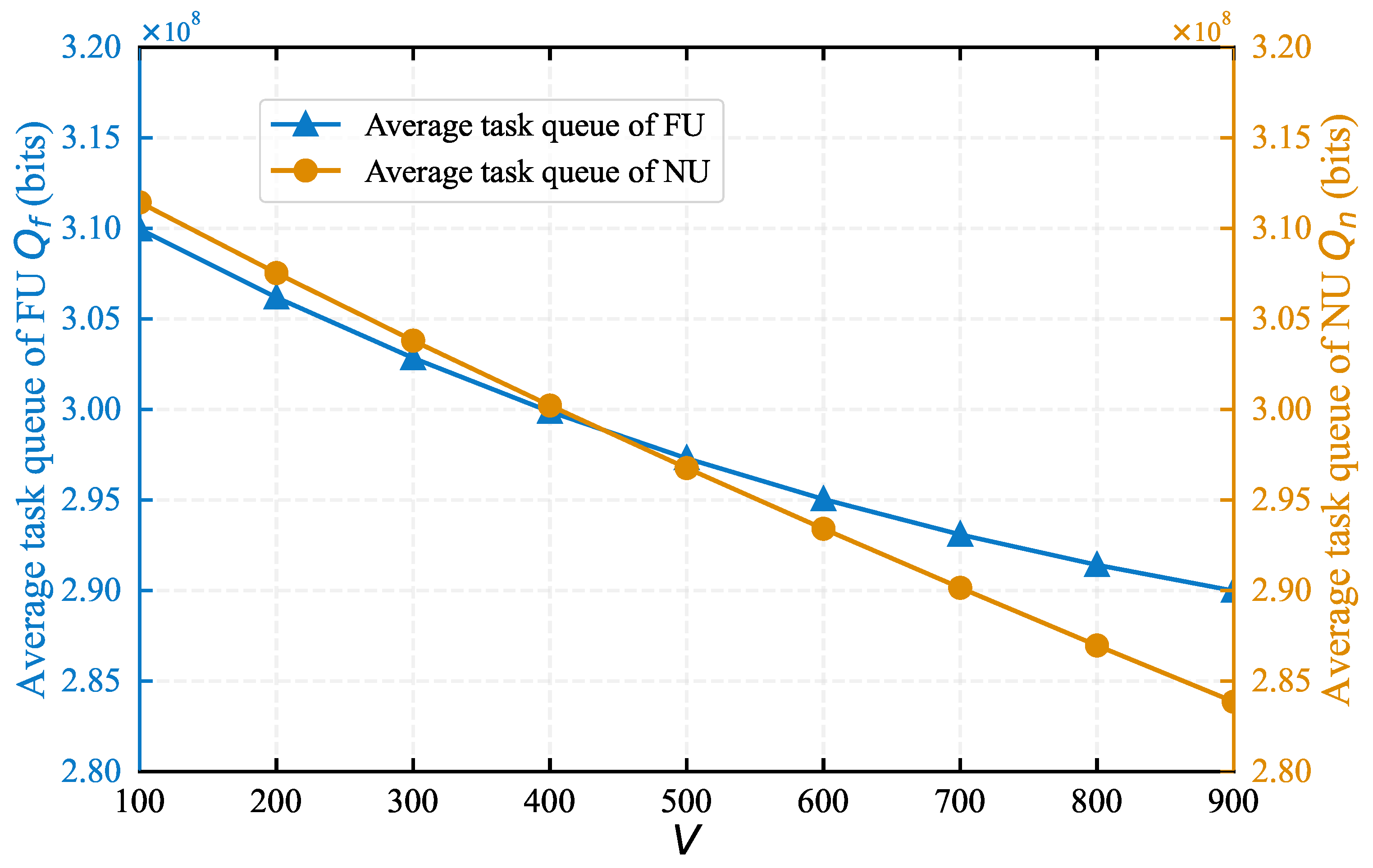
Figure 6.
Average task computation rate and task queue length with different energy constraint .
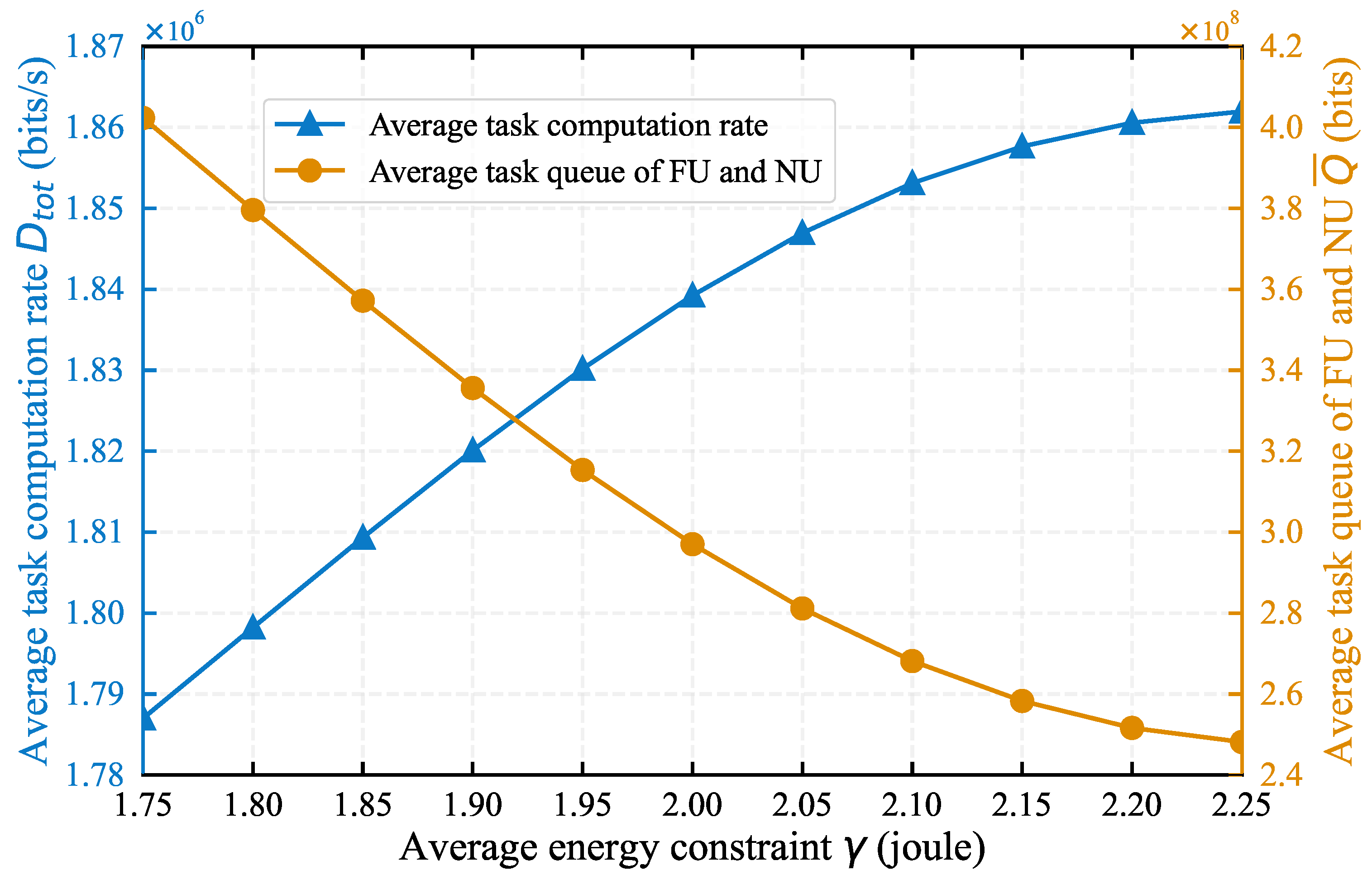
Figure 7.
Convergence performance of energy consumption with different parameter V.
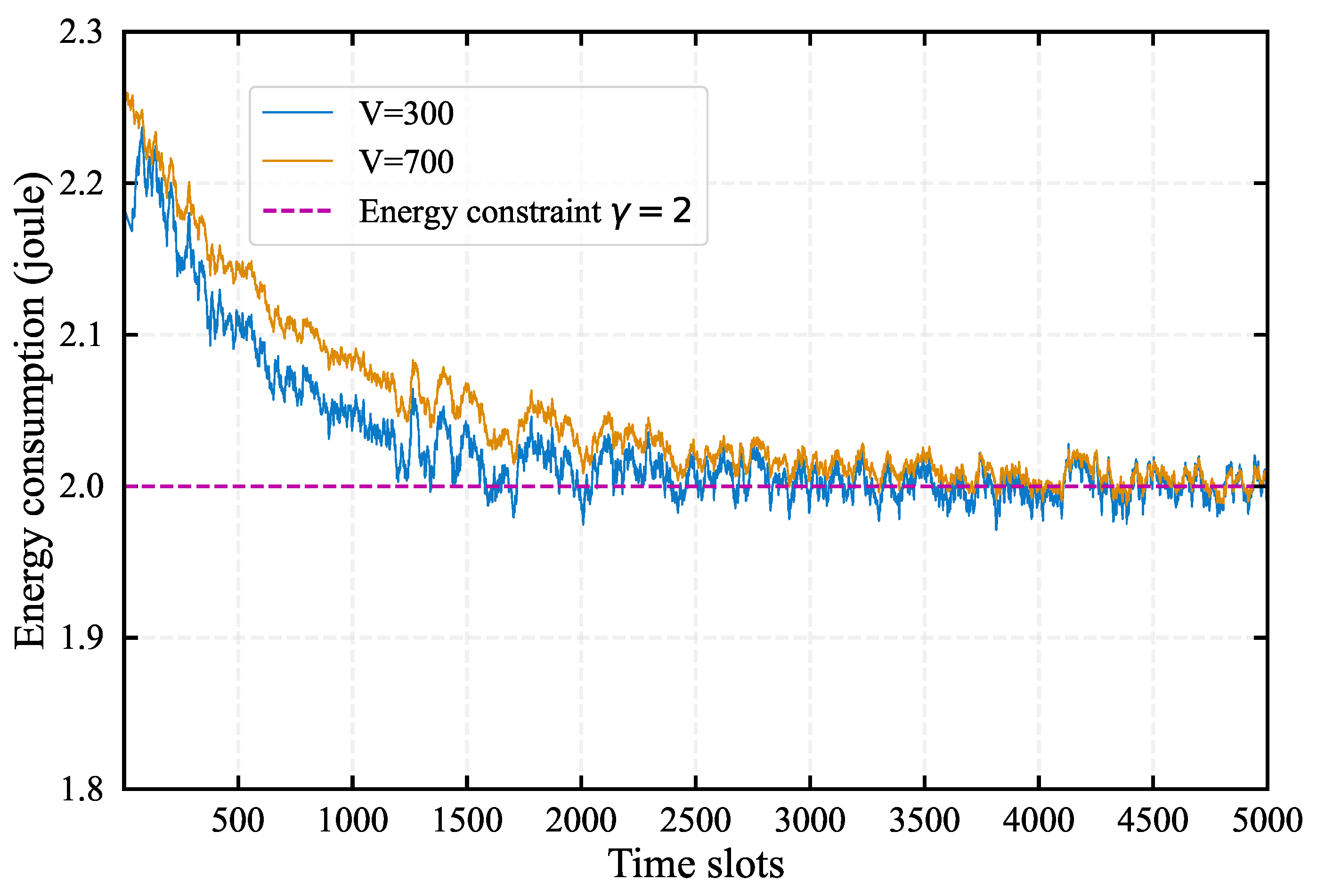
Figure 8.
Offloading power of FU and NU with different Bandwidth W.
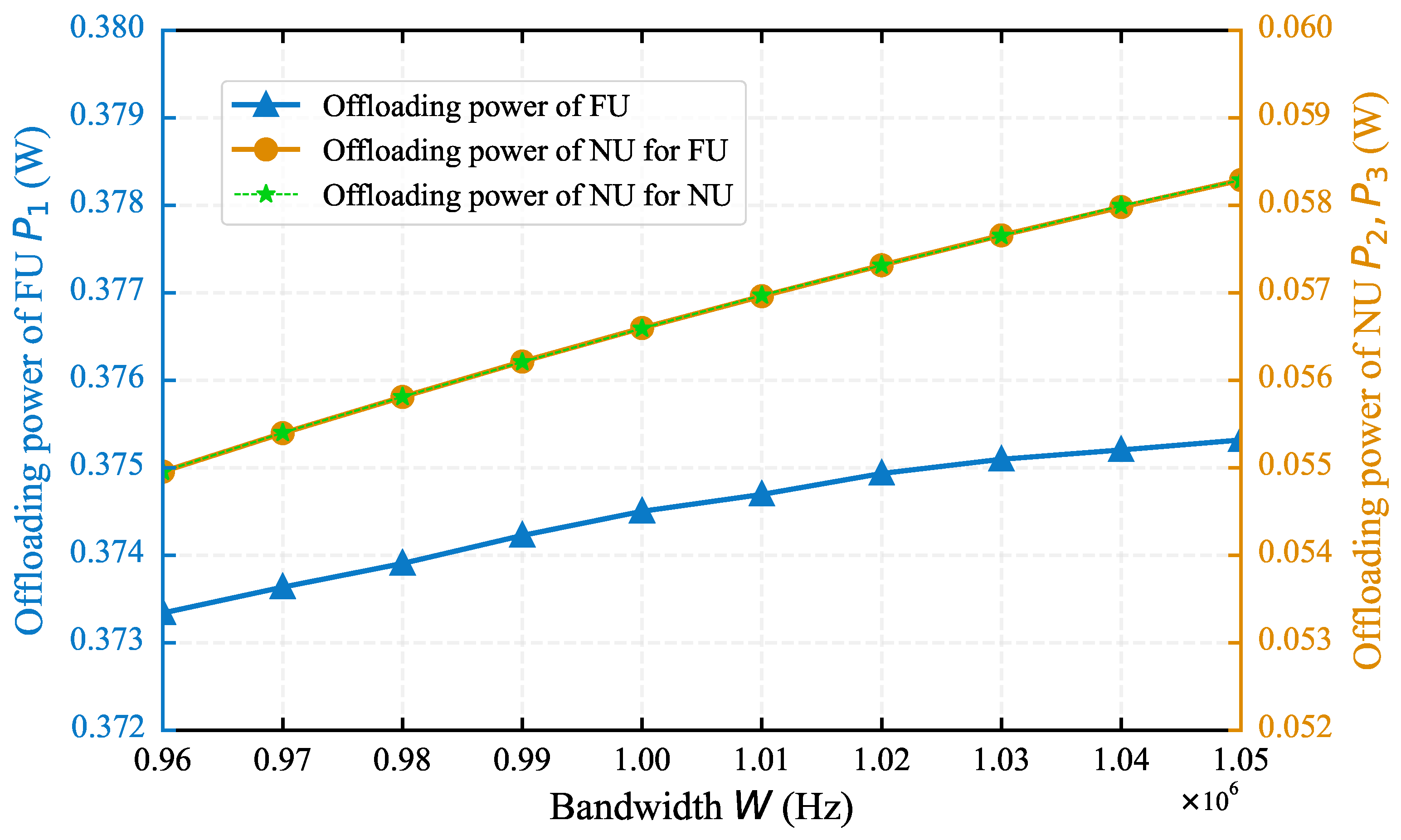
Figure 9.
Average task computation rates in different schemes over time slots.
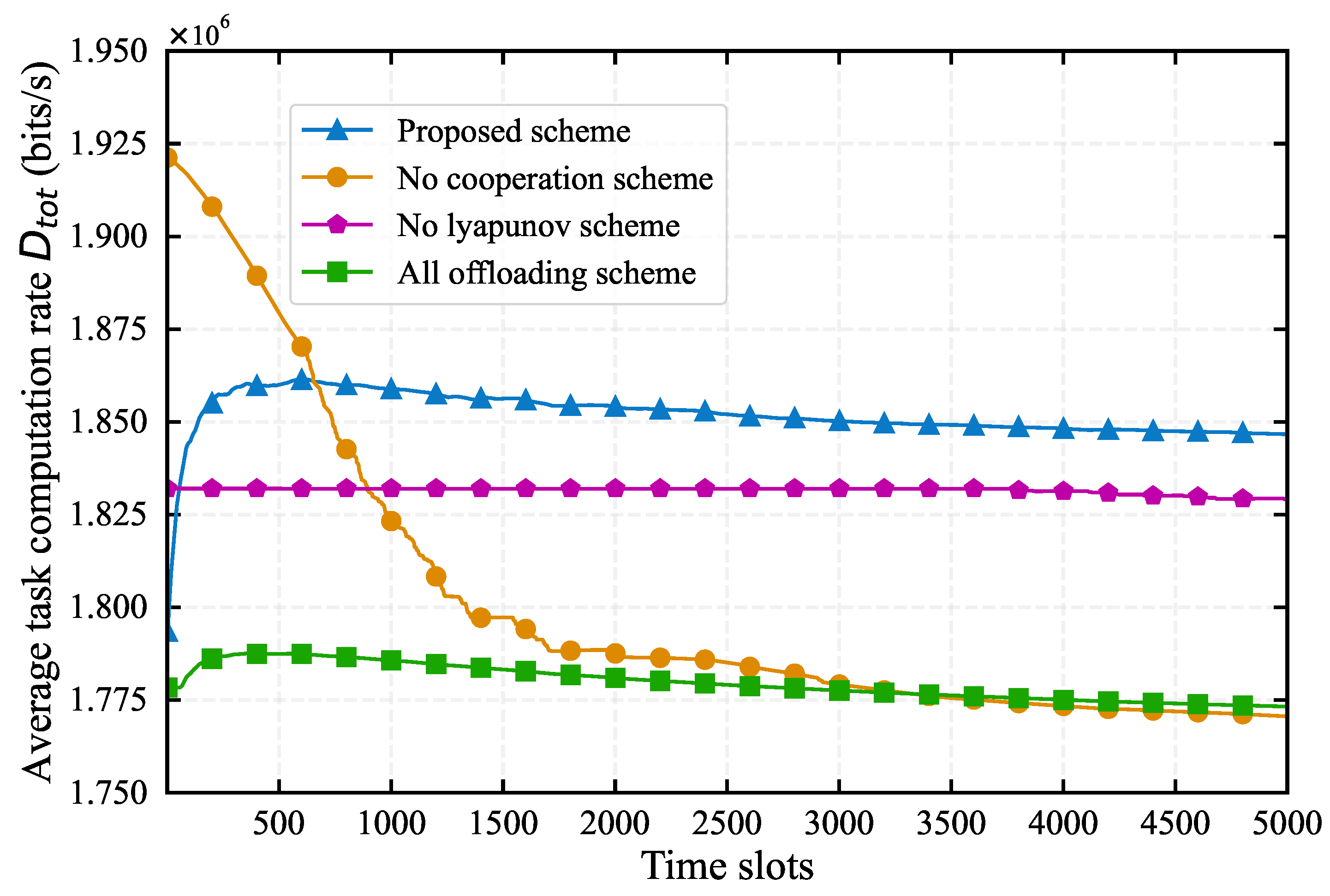
Figure 10.
Average computation rates in different schemes with different bandwidth W.
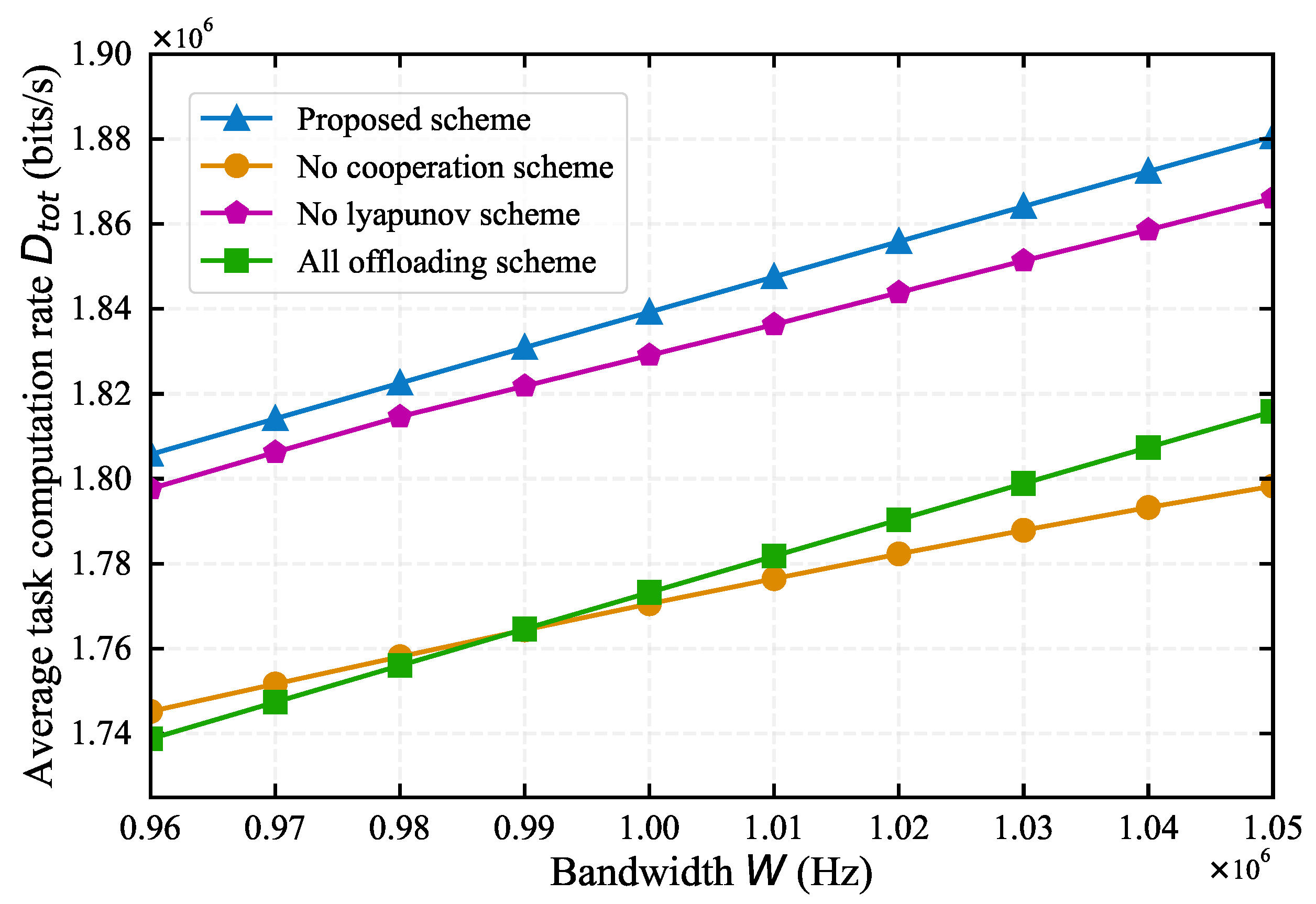
Figure 11.
Average computation rates in different schemes with different distances between FU and NU.
Figure 11.
Average computation rates in different schemes with different distances between FU and NU.
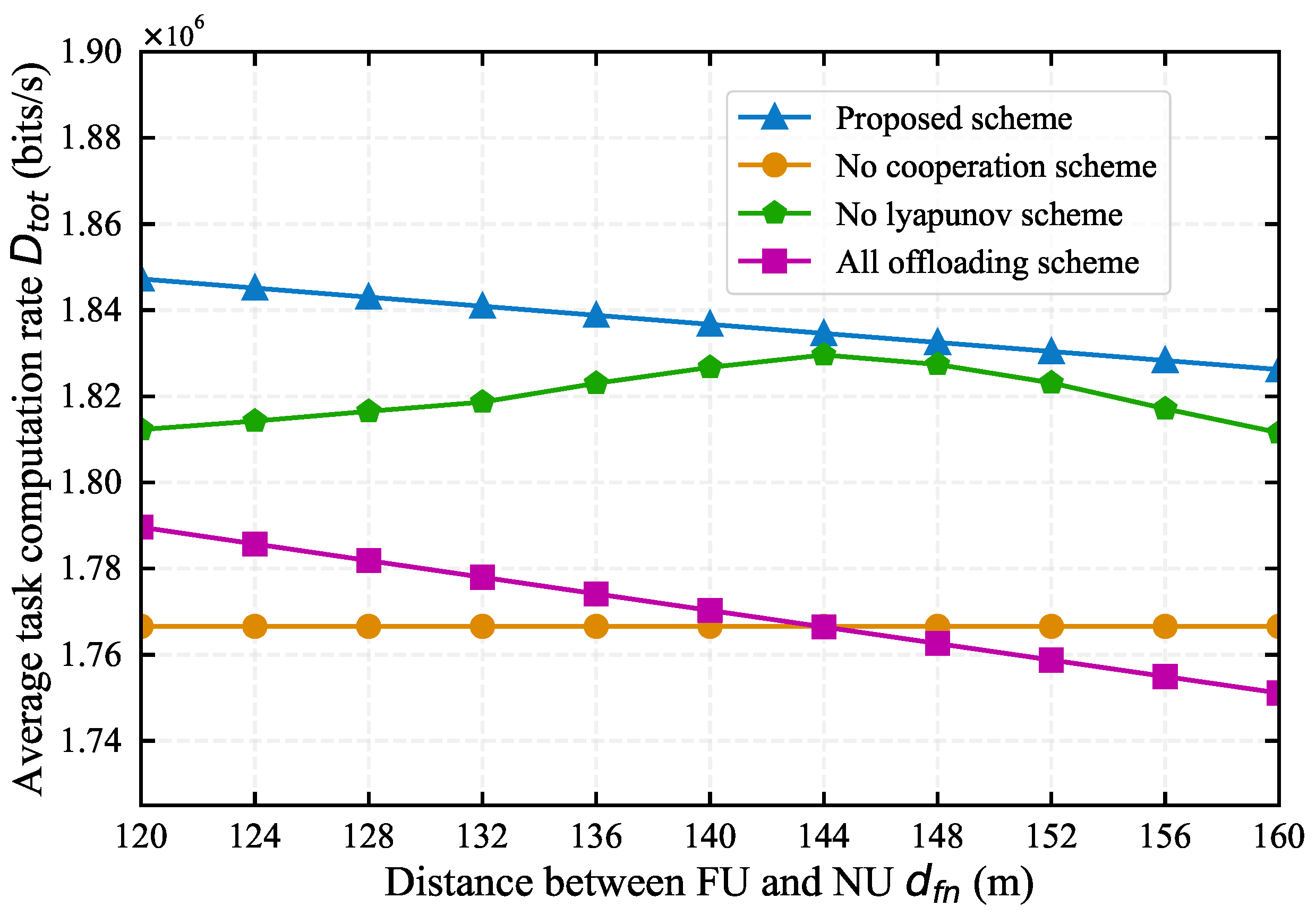
Figure 12.
Average computation rates in different schemes with different task arrival rates of FU

Table 1.
Key Notations and Definitions.
| Notation | Definition |
|---|---|
| T | The time block |
| The time for WPT | |
| The time for offloading of FU | |
| The time for NU to offload FU’s data | |
| The time for NU to offload its own data. | |
| , | The energy harvested by MD and helper in slot t |
| , | The WPT channel gain between FU and HAP, NU and HAP |
| , | The offloading channel gain between FU and NU, NU and HAP |
| ,,, | The transmit power for HAP, FU , NU to offload FU’s data |
| and NU to offload its own data in slot t | |
| The amount of tasks processed locally at FU in slot t | |
| The amount of tasks offloaded to NU at FU in slot t | |
| The amount of tasks processed locally at NU in slot t | |
| The amount of tasks that NU offloads to HAP from FU in slot t | |
| the amount of tasks that NU offloads to HAP from itself in slot t | |
| The energy consumed by processing tasks at FU in slot t | |
| The energy consumed by offloading tasks at FU in slot t | |
| The energy consumed by processing tasks at helper in slot t | |
| The energy consumed by NU to offload FU’s tasks in slot t | |
| the energy consumed by NU to offload its own tasks in slot t | |
| The amount of tasks processed in slot t | |
| , | The local CPU frequency at FU and NU |
| , | The CPU cycles required to compute one bit task at FU and NU |
| The energy conversion efficiency | |
| The computing energy efficiency | |
| W | The channel bandwidth |
| The additive white Gaussian noise |
Table 2.
Simulation Parameters.
| Symbol | Value |
|---|---|
| Time slot length | 1 s |
| Noise power | W |
| Distance between the HAP and the FU | 230 m |
| Distance between the FU and the NU | 140 m |
| Distance between the HAP and the NU | 200 m |
| CPU frequency of FU | 160 MHz |
| CPU frequency of NU | 220 MHz |
| CPU cycles to compute 1 bit task of FU | 180 cycles/bit |
| CPU cycles to compute 1 bit task of NU | 200 cycles/bit |
| Equal computing efficiency parameter | |
| Weight of the computation rate of FU | 0.55 |
| Weight of the computation rate of NU | 0.45 |
| the antenna gain in channel model | 3 |
| the carrier frequency in channel model | 915 MHz |
| the path loss exponent in channel model | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



