
Submitted:
24 July 2024
Posted:
25 July 2024
You are already at the latest version
Abstract
Ensuring banking stability is essential for economic resilience and the prevention of financial crises. Financial Stability Reports (FSRs) provide critical data on the financial system. This study advocates for the use of text mining tools to enhance the analysis of FSRs. Text mining offers a systematic method for extracting insights from unstructured data, allowing analysts to uncover detailed information on capital adequacy, risk management, and regulatory compliance. Additionally, this approach identifies emerging trends and vulnerabilities that may not be apparent through traditional analysis methods. The paper examines the application of text mining techniques to FSR analysis within the Republic of Armenia.
Keywords:
financial stability reports
; finance
; central bank
; financial stability
1. Introduction
Ensuring the stability of banking institutions is fundamental for maintaining economic resilience and mitigating financial crises. Financial Stability Reports (FSRs) provide crucial data on the robustness and potential vulnerabilities within banking systems. However, manual analysis of these comprehensive reports is often labor-intensive and time-consuming. This paper promotes the adoption of text mining tools to enhance the efficiency and effectiveness of FSR analysis.
Text mining represents a valuable investment for central banks due to its ability to process diverse data sources that are critical for evaluating monetary and financial stability, which are otherwise challenging to quantify. Essential textual data for central banks encompass news articles, financial contracts, social media content, supervisory and market intelligence, and various written reports [1].
As a subset of data mining, text mining provides a structured approach to processing and analyzing unstructured textual data. By applying text mining techniques to FSRs, analysts can uncover nuanced insights related to capital adequacy, asset quality, risk management, and regulatory compliance. Moreover, text mining facilitates the identification of emerging trends, risks, and vulnerabilities that are not readily discernible through traditional methods.
This paper explores the text mining methodology applied to FSRs and elucidates its advantages in bolstering banking stability analysis. Utilizing natural language processing algorithms, sentiment analysis, and topic modeling, text mining automates the extraction of key indicators and sentiments from FSR narratives. Additionally, machine learning algorithms enable predictive analytics, empowering stakeholders to proactively anticipate threats to banking stability.
By harnessing text mining capabilities, regulators, policymakers, and financial institutions can enhance their ability to monitor, assess, and mitigate systemic risks effectively.
2. Literature Review
The literature review explores the use of natural language processing (NLP) techniques in financial text analysis, presenting a range of methodologies and case studies from different countries. These studies illustrate how sophisticated text mining tools can derive valuable insights from unstructured data, supporting sentiment analysis, risk identification, and financial stability assessment.
Bernal and Pedraz introduces a text mining method designed to extract and utilize information from financial texts to generate sentiment indices. The study specifically examines the Banco de España’s Financial Stability Reports from 2002 to 2019, focusing on the Spanish versions of these reports and the subsequent media reactions. The approach outlined in Bernal and Pedraz involves creating a Spanish dictionary categorizing words as positive, negative, or neutral, which, to our knowledge, is the first of its kind in the context of financial stability. The robustness of these sentiment indices is evaluated through their application to various sections of the Report, using different dictionary versions and index definitions [2]. Additionally, sentiment is assessed for press reports released in the days following the Report’s publication. The findings indicate that the reference dictionary provides a robust basis for estimating sentiment in these texts, offering a valuable methodology for analyzing the impact of financial stability reports and objectively quantifying the sentiment they convey.
Recent research by Kanelis and Siklos employed FinBERT, a large language model, to analyze the sentiment expressed by the European Central Bank (ECB) president in introductory remarks. Their study introduces new sentiment indicators for the euro area, revealing that ECB’s monetary policy sentiment, influenced by economic projections and macroeconomic conditions, significantly impacts the content of post-governing council press conferences. However, sentiment related to financial stability in speeches does not notably influence initial statements [3].
Mirjana Pejić Bach et al. explored the application of text mining techniques in the financial sector, focusing on extracting insights from extensive unstructured data sources. They highlighted the growing use of text analytics in areas such as customer analytics and risk detection, utilizing data from social media and emails to enhance operational strategies and mitigate fraudulent activities [4].
Klevak et al. demonstrated a practical framework for analyzing unstructured financial data, particularly in assessing sentiment and identifying significant textual events. Their approach, involving sentiment scoring of earnings conference call transcripts, suggests that changes in tone during such calls weakly correlate with earnings surprises and short-term returns, underscoring the potential of text mining to supplement traditional financial analyses [5].
Chan and Chong addressed the analytical challenges posed by the proliferation of financial texts by introducing a sentiment analysis engine (SAE) that extends sentiment analysis beyond individual words to incorporate grammatical structures. Their evaluation, using datasets from English movie reviews and financial text streams aligned with stock market indices, demonstrated superior performance over traditional bag-of-words methods, highlighting the strong correlation between sentiment trends in textual data and financial market outcomes [6]. Mishev et al. underscored the importance of promptly extracting sentiment from financial news to inform investment decisions. Their evaluation platform assessed various sentiment analysis approaches, indicating that contextual embeddings enhance efficiency compared to lexicon-based methods, with smaller NLP transformer models proving viable for practical applications in financial environments [7].
Suzuki et al. explored the adaptation of transformer-based models like BERT to financial texts, focusing on pre-training and vocabulary adaptation using specialized financial corpora in Japanese. Their findings suggest that customizing pre-training data and tokenizers to financial terminology enhances model effectiveness across diverse financial tasks, underscoring the utility of domain-specific language models in financial analysis [8].
Bernal and Pedraz developed a text mining framework to construct sentiment indices from Banco de España’s Financial Stability Reports, analyzing the sentiment conveyed in response to these reports. Their study highlights the efficacy of sentiment dictionaries in estimating the sentiment of financial stability reports, offering a robust methodology for evaluating the impact of such reports [2].
Kurowski and Smaga investigated the role of central bank analyses and communication in maintaining monetary credibility and predicting financial crises. Their novel approach, combining text mining techniques with receiver operating characteristic curves, explored linguistic indicators in financial stability reports (FSRs), revealing limited predictive value across most central banks except for specific cases such as the Central Bank of Iceland [9].
This review synthesizes various methodologies for analyzing financial texts using NLP techniques, highlighting their applications in different contexts and regions. Collectively, these studies underscore the growing significance of text mining and sentiment analysis in augmenting traditional financial analyses and informing policy decisions.
El-Haj et al. provide a critical evaluation of conventional accounting and finance research through the application of computational linguistics (CL) methods to examine financial discourse. Their review encompasses prevalent themes and innovations in the field, assessing the additional contributions of CL methods compared to manual content analysis [10]. The primary conclusions from their analysis are: (a) accounting and finance research lags in the adoption of CL methods, particularly in word sense disambiguation; (b) the anticipated benefits of CL are often diminished due to implementation challenges; (c) structural issues limit practical applicability; and (d) CL methods and high-quality manual analysis are complementary in analyzing financial discourse. They highlight four promising CL tools for mainstream accounting and finance research: named entity recognition (NER), summarization, semantics, and corpus linguistics.
Park et al. emphasize the importance of analyzing central bankers’ statements to understand economic conditions and predict market trends. They critique the predominant method of qualitative monitoring and evaluation (QME) for its reliance on expensive and subjective domain expert input. While text mining techniques have been proposed as alternatives, most have focused on correlating textual data with macroeconomic indicators rather than directly extracting keywords. Their study aims to automatically detect potential financial risk factors by applying text mining to speeches by Federal Reserve chairs. They propose a framework using a simple, effective unsupervised keyword-scoring method that treats bigrams as keywords and evaluates their temporal importance. Extensive experiments comparing eight existing methods, including statistical and pretrained language model approaches, show that their proposed method effectively identifies risk factors. Applying this framework to speeches from 1997 to 2019, they found terms like “east asia,” “information technology,” and “subprime mortgage” could have been detected before their respective crises. Quantitative evaluation revealed a significant increase in the frequency of “subprime mortgage” in 2007 speeches, preceding its rise in media articles. Their results demonstrate that central bankers’ speeches are valuable for early identification of market risk factors, contributing to a deeper understanding of financial market trends and aiding in the development of preemptive response strategies [11].
In recent research, Kanelis and Siklos employed FinBERT, a Large Language Model, to analyze the sentiment expressed by the ECB president in introductory remarks. Their study introduces new sentiment indicators for the euro area, revealing that ECB’s monetary policy sentiment, shaped by economic projections and macroeconomic conditions, significantly influences the content of post-governing council press conferences. However, they found that sentiment related to financial stability in speeches does not exert a notable influence on initial statements [3].
Mirjana Pejić Bach et al. explored the utilization of text mining techniques in the financial sector, focusing on extracting insights from extensive unstructured data sources. They underscored the growing application of text analytics in areas such as customer analytics and risk detection, leveraging data from diverse sources like social media and emails to enhance operational strategies and mitigate fraudulent activities [4].
Meanwhile, Klevak et al. demonstrated a practical framework for analyzing unstructured financial data, particularly in assessing sentiment and identifying significant textual events. Their approach, which involves sentiment scoring of earnings conference call transcripts, suggests that changes in tone during such calls weakly correlate with earnings surprises and short-term returns, highlighting the potential of text mining for supplementing traditional financial analyses [5].
Addressing the analytical challenges posed by the proliferation of financial texts, Chan and Chong introduced a sentiment analysis engine (SAE) that extends sentiment analysis beyond individual words to incorporate grammatical structures. Their evaluation, involving datasets from English movie reviews and financial text streams aligned with stock market indices, demonstrated superior performance over traditional bag-of-words methods, emphasizing the strong correlation between sentiment trends in textual data and financial market outcomes [6].
Furthermore, Mishev et al. underscored the importance of promptly extracting sentiment from financial news to inform investment decisions. Their evaluation platform assessed various sentiment analysis approaches, indicating that contextual embeddings enhance efficiency compared to lexicon-based methods, with smaller NLP transformer models proving viable for practical applications in financial environments [7].
In adapting transformer-based models like BERT to financial texts, Suzuki et al. explored methods for pre-training and vocabulary adaptation using specialized financial corpora in Japanese. Their findings suggest that customizing pre-training data and tokenizers to financial terminology enhances model effectiveness across diverse financial tasks, underscoring the utility of domain-specific language models in financial analysis [8].
Moreover, Bernal and Pedraz developed a text mining framework to construct sentiment indices from Banco de España’s Financial Stability Reports, analyzing the sentiment conveyed in response to these reports. Their study highlights the efficacy of sentiment dictionaries in estimating the sentiment of financial stability reports, offering a robust methodology for evaluating the impact of such reports [2].
Finally, Kurowski and Smaga investigated the role of central bank analyses and communication in maintaining monetary credibility and predicting financial crises. Their novel approach, combining text mining techniques with receiver operating characteristic curves, explored linguistic indicators in financial stability reports (FSRs), revealing limited predictive value across most central banks except for specific cases such as the Central Bank of Iceland [9].
The literature review examines the application of natural language processing (NLP) techniques in analyzing financial texts, highlighting diverse methodologies and case studies from various countries. These studies demonstrate how advanced text mining tools can extract valuable insights from unstructured data, aiding in areas such as sentiment analysis, risk identification, and financial stability assessment.
This review synthesizes various methodologies for analyzing financial texts using NLP techniques, highlighting their applications in different contexts and regions. These studies collectively underscore the growing significance of text mining and sentiment analysis in augmenting traditional financial analyses and informing policy decisions.
3. Data and Methodology
I use data (texts) of Financial Stability Reports of Central Bank of Armenia from 2007-20221.
The Central Bank of Armenia presents the results of review of financial stability in its Financial Stability Report (FSR). The Central Bank has been publishing the report annually since 2007, and also semi-annually, since 2010.
The main goal of FSR is description of potential risks to the country’s financial stability in the short-term horizon in the context of past and expected developments in real and financial sectors of the economy. FSR provides the assessment of the Central Bank on financial stability for a certain period of time, the current risks, and the measures aimed at preventing or absorbing these risks.
TextualArc is a visualization of the terms in a document that includes a weighted centroid of terms and an arc that follows the terms in document order.
TextualArc is heavily inspired by W. Bradford Paley’s TextArc. The concept has been adapted for use in Voyant and for performance considerations in the browser [12,13]. The concept has been adapted for use in Voyant and for performance considerations in the browser [14].
The current text is represented on the perimeter of the circle, starting at the top and looping around clockwise. Each occurrence of a term pulls the term toward its location on the perimeter and the position of the term label is the mean of these forces (or wighted centroid). The text is "read" from start to finish, with repeating, non-stopword terms, visited by the animated arc. The occurrences of the currently read term are shown by lines to the perimeter. Also over any term to see its occurrences on the perimeter.
For analyzing negative and positive words, keyword trends, and sentiment, R text mining packages have been used.
The word cloud visualizes the most frequent words in the text. For the merged Financial Stability Reports from 2007-2022, it is demonstrated in Figure 1.
4. Results
4.1. Key Observations
- “Bank”: The occurrence of the term “bank” shows significant peaks around 2010 and 2020, suggesting periods of heightened focus on banking activities or issues related to the banking sector.
- “Loans”: The term “loans” also peaks around 2010 and 2020, potentially reflecting periods of increased attention to lending practices or credit availability.
- “Stability” and “Risk”: These terms display notable fluctuations, which could represent shifts in the focus on financial stability and associated risks over time.
- “Credit” and “Exchange”: Trends for these terms vary, with observed peaks suggesting moments of heightened emphasis on credit conditions and foreign exchange matters.
The trend analysis of key terms provides valuable insights into the thematic focus of the Central Bank’s communications over the years (Figure 2). Peaks in terms like “bank”, “loans”, and “risk” around 2010 may be related to the aftermath of the 2008 global financial crisis, a period characterized by significant concerns about banking stability and credit availability. Similarly, the recurring peaks around 2020 likely correspond to the economic ramifications of the COVID-19 pandemic, which intensified attention on financial stability, lending practices, and economic development.
4.2. Interpretation of Term Frequency and Sentiment Score Plot
Figure 2. The line chart displays the trends of positive and negative words throughout the financial stability report. Figure 3. shows the relationship between term frequency and sentiment score for various terms in financial stability reports. Here’s a detailed interpretation:
- X-axis (Term Frequency - log scale): This represents the frequency of each term in the text, plotted on a logarithmic scale. Terms on the right side of the plot are more frequently mentioned in the reports.
- Y-axis (Sentiment Score - Positive minus Negative): This represents the sentiment score of each term. Positive values indicate a more positive sentiment, while negative values indicate a more negative sentiment.
- High Frequency, Negative Sentiment: Terms like "risk," "risks," "stress," "crisis," "loss," "debt," and "losses" appear frequently and have highly negative sentiment scores. This indicates that these terms are commonly associated with negative contexts in the financial stability reports.
- High Frequency, Positive Sentiment: The term "stability" stands out with a very high positive sentiment score and moderate frequency. This suggests that when discussing stability, the context is predominantly positive.
- Moderate Frequency, Mixed Sentiment: Terms like "positive," "recovery," "significant," "effective," "maturity," "inflationary," "negative," "gross," and "decline" have moderate frequencies and mixed sentiment scores, indicating a balanced discussion around these topics.
- Low Frequency, Neutral Sentiment: Most terms cluster around the origin (0,0), indicating they are mentioned infrequently and do not have a strong sentiment association.
Key Insights
- Stability: The term "stability" is uniquely positioned with a high positive sentiment score, reinforcing its positive connotation in financial stability reports.
- Risks and Negative Terms: The terms related to risks and financial stress dominate the negative sentiment side, highlighting concerns and issues discussed in these reports.
- Balanced Discussion: The terms with moderate frequency and mixed sentiment suggest a balanced approach in discussing various aspects of financial stability.
This plot effectively visualizes the sentiment and frequency of terms used in financial stability reports, providing insights into the positive and negative themes prevalent in the text.
4.3. Textualarc
By using TextArc as an innovative idea that translates complex financial stability reports into visually comprehensible representations. The plot of TextArc revolves around the visualization of intricate data contained within these reports, offering insights into economic trends, risks, and indicators.
In TextArc, financial data is transformed into dynamic visual displays where key terms, concepts, and data points are plotted along axes, often representing time and relevance. As the plot unfolds, clusters of data points emerge, forming patterns that highlight significant trends, correlations, and risks within the financial stability report.
Through the visualization, users can interactively explore the report, gaining a deeper understanding of the interconnectedness of various economic factors and their impact on stability. The plot dynamically adjusts as users delve into different sections of the report, revealing new insights and relationships. TextArc provides a unique perspective on financial stability, allowing analysts and policymakers to grasp complex information more intuitively and make informed decisions.
Its visual representation enhances comprehension and facilitates the identification of critical issues, contributing to more effective risk management and policy formulation.
Figure 5). appears to be a term co-occurrence network, created using text mining and visualization tools like TextualArc, specifically applied to financial stability reports. Here’s a detailed interpretation:
Key Elements
- Nodes (Terms): Each word or phrase represents a node. The size of the node indicates the frequency of the term in the text corpus. Larger nodes are more frequently mentioned.
- Edges (Connections): Lines connecting the nodes represent co-occurrences of terms within the same context. The thickness or color of the edges may indicate the strength or frequency of co-occurrence.
Central Terms
- "Stability" and "Financial": These terms are central and prominently featured, indicating their primary importance in financial stability reports. The size and central location suggest frequent and widespread use across the documents.
Co-occurrences
-
Positive and Negative Associations: The color coding (green for positive and red for negative) of the edges indicates the sentiment or nature of the relationship between terms.
- Positive Terms: "Growth," "development," and "increase" are associated with positive sentiments, as indicated by green lines connecting to central terms like "financial."
- Negative Terms: "Risk," "stress," "crisis," and "losses" are associated with negative sentiments, as shown by red lines.
Specific Connections
- "Financial" and "Growth": The term "financial" is connected to "growth" and related terms through positive (green) edges, suggesting discussions about financial growth and positive developments.
- "Stability" and "Risk": The term "stability" is connected to "risk" and similar terms with negative (red) edges, indicating a focus on stability challenges and associated risks.
- "Household" and "Debt": Terms like "household" and "debt" are connected through blue lines, highlighting specific discussions around household debt and financial burdens.
Sentiment and Focus
- Positive Sentiment: Positive sentiment terms like "growth," "development," and "increase" are closely linked with "financial," showing a focus on positive financial outcomes.
- Negative Sentiment: Negative sentiment terms like "risk," "stress," and "crisis" are connected to both "stability" and "financial," reflecting the concerns and challenges highlighted in the reports.
Other Observations
- Term Variety: The network shows a wide variety of terms, indicating a comprehensive analysis covering multiple aspects of financial stability.
- Key Themes: The visual emphasis on terms related to growth, risk, and household debt suggests these are key themes in the reports.
This term co-occurrence network effectively visualizes the complex relationships between key terms in financial stability reports. It highlights the central themes and sentiments, revealing the emphasis on stability, financial growth, and associated risks. The analysis shows a balanced discussion with attention to both positive developments and potential challenges in the financial stability landscape.
Interpretation of Top Terms in Topics from LDA Model
Figure 6). shows the top terms in different topics identified using a Latent Dirichlet Allocation (LDA) model applied to financial stability reports. Each subplot represents a topic, and the bars indicate the most significant terms within that topic based on their beta values. Here’s a detailed interpretation:
Topic 1
- Key Terms: The most significant terms are "stability," "percent," "total," "and," "central," "with," "bank," "financial," "and," and "the."
- Interpretation: This topic appears to focus on general discussions about financial stability, percentages, totals, and central banking activities. The prominence of common words like "and" and "the" suggests the need for further preprocessing to remove stop words.
Topic 2
- Key Terms: The most significant terms are "central," "previous," "loans," "risk," "growth," "credit," "financial," "for," "and," and "the."
- Interpretation: This topic seems to concentrate on financial risk management, loan performance, and economic growth. The inclusion of "central" suggests a focus on central bank policies or previous financial periods.
Topic 3
- Key Terms: The most significant terms are "source," "share," "loans," "which," "growth," "was," "system," "has," "and," and "the."
- Interpretation: This topic likely discusses the sources and shares of loans, the growth of financial systems, and historical analyses. The terms indicate an examination of the origins and distribution of financial activities.
Topic 4
- Key Terms: The most significant terms are "total," "risk," "growth," "was," "credit," "system," "economic," "for," "and," and "the."
- Interpretation: This topic appears to be related to total financial risk, economic growth, credit systems, and economic analysis. The focus on risk and credit highlights concerns about financial stability and economic performance.
General Observations
- Common Words: The presence of common words like "and," "the," "for," and "with" in all topics suggests that additional stop word removal may be necessary to improve topic clarity.
- Topic Diversity: The topics cover a range of themes, including general financial stability, risk management, loan performance, and economic growth. This indicates a comprehensive analysis of financial stability reports.
This plot effectively visualizes the key terms associated with different topics in financial stability reports, providing insights into the main themes and areas of focus within the text.
5. Summary
These insights are crucial for regulatory supervision, risk management, and investment decisions, enabling proactive risk mitigation. This paper concludes by advocating for the use of text mining in comprehensive Financial Stability Reports (FSR) analysis (Figure 7). By leveraging text mining, stakeholders can achieve a deeper understanding of banking stability dynamics, fostering a resilient financial system amidst increasing complexity and uncertainty.
This research delves into the application of unstructured data analysis within the financial sector, with a particular emphasis on sentiment analysis and event identification in text documents. It underscores the added value that sentiment analysis brings to earnings conference call transcripts, complementing traditional financial metrics. The potential of text mining to furnish investors with supplementary information is thoroughly examined.
The paper explores the pivotal role of text mining in the financial sector, highlighting its significance in extracting valuable insights from unstructured data. The ability to decode collective sentiments embedded in financial texts is emphasized as crucial for informed decision-making. The SAE’s linguistic analysis capabilities, extracting sentiments at both word and phrase levels, are presented, with evaluations demonstrating its effectiveness in various scenarios, including alignment with stock market indices.
Investigating the practical application of unstructured data analysis, the research focuses on the necessity and challenges of interpreting textual data within finance. The SAE, which extends sentiment analysis beyond individual word tokens to include phrases, is introduced and its effectiveness is validated across different datasets. The potential correlation between sentiment in text streams and stock market indices is showcased, highlighting the engine’s innovative approach.
These texts collectively emphasize the growing importance of text mining and sentiment analysis in the financial sector, particularly in deriving insights from unstructured data sources such as financial texts. They present advanced sentiment analysis engines that outperform traditional methods and demonstrate their effectiveness through various evaluations. This research indicates their potential to offer valuable supplementary information to investors and challenge conventional beliefs regarding the correlation between sentiments in text streams and stock market indices.
Conflicts of Interest
Any opinions, errors and omissions are the author’s responsibility alone. The views expressed in this paper are those of the author and do not necessarily represent those of the Central Bank of Armenia.
References
- Bholat, D.; Hansen, S.; Santos, P.; Schonhardt-Bailey, C. Text mining for central banks. Available at SSRN 2624811 2015.
- Bernal, Á.I.M.; Pedraz, C.G. Sentiment analysis of the Spanish financial stability Report. International Review of Economics & Finance 2024, 89, 913–939.
- Kanelis, D.; Siklos, P.L. The ECB press conference statement: deriving a new sentiment indicator for the euro area. International Journal of Finance & Economics 2024.
- Pejić Bach, M.; Krstić, Ž.; Seljan, S.; Turulja, L. Text mining for big data analysis in financial sector: A literature review. Sustainability 2019, 11, 1277.
- Klevak, J.; Livnat, J.; Suslava, K. A practical approach to advanced text mining in finance. The Journal of Financial Data Science 2019, 1, 122–129. [Google Scholar] [CrossRef]
- Chan, S.W.; Chong, M.W. Sentiment analysis in financial texts. Decision Support Systems 2017, 94, 53–64. [Google Scholar] [CrossRef]
- Mishev, K.; Gjorgjevikj, A.; Vodenska, I.; Chitkushev, L.T.; Trajanov, D. Evaluation of sentiment analysis in finance: from lexicons to transformers. IEEE access 2020, 8, 131662–131682. [Google Scholar] [CrossRef]
- Suzuki, M.; Sakaji, H.; Hirano, M.; Izumi, K. Constructing and analyzing domain-specific language model for financial text mining. Information Processing & Management 2023, 60, 103194. [Google Scholar]
- Kurowski, .; Smaga, P. Analysing financial stability reports as crisis predictors with the use of text-mining. The Journal of Economic Asymmetries 2023, 28, e00322.
- El-Haj, M.; Rayson, P.; Walker, M.; Young, S.; Simaki, V. In search of meaning: Lessons, resources and next steps for computational analysis of financial discourse. Journal of Business Finance & Accounting 2019, 46, 265–306. [Google Scholar]
- Park, J.; Lee, H.J.; Cho, S. Hot topic detection in central bankers’ speeches. Expert Systems with Applications 2023, p. 120563.
- Paley, W.B. Textarc: Showing word frequency and distribution in text. Poster presented at IEEE Symposium on Information Visualization, 2002, Vol. 2002.
- Paley, W.B. TextArc: An alternate way to view a text, 2002.
- Sinclair, S.; Rockwell, G. Voyant tools. URL: http://voyant-tools. org. September 2016, 8, 2018.
| 1 | Financial Stability Reports, Available on https://www.cba.am/en/sitepages/fsreport.aspx
|
Figure 1.
Word Cloud of Financial Stability Reports, 2007-2022.

Figure 2.
Key words.
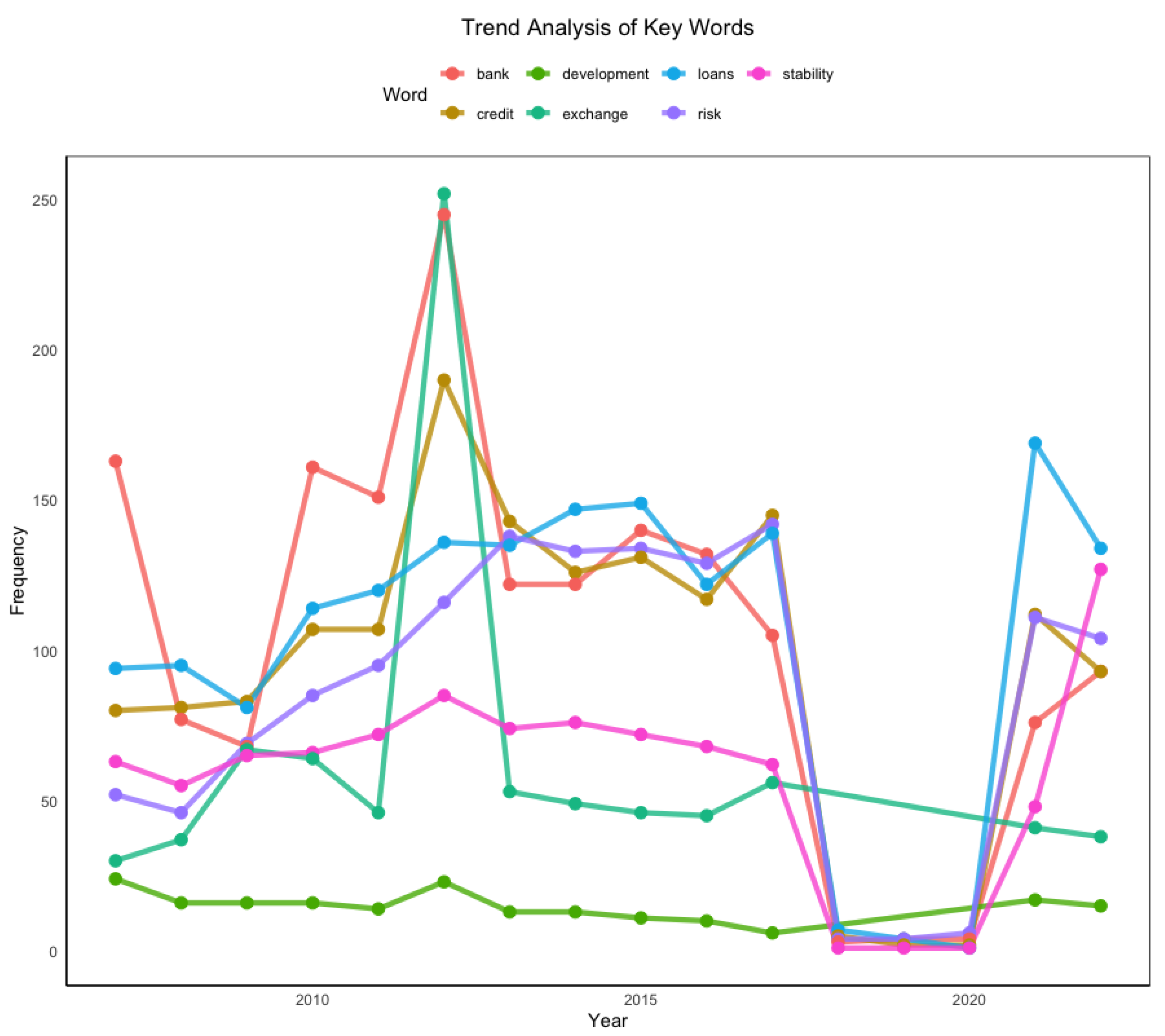
Figure 3.
Positive and negative words in financial stability reports, 2007-2022.
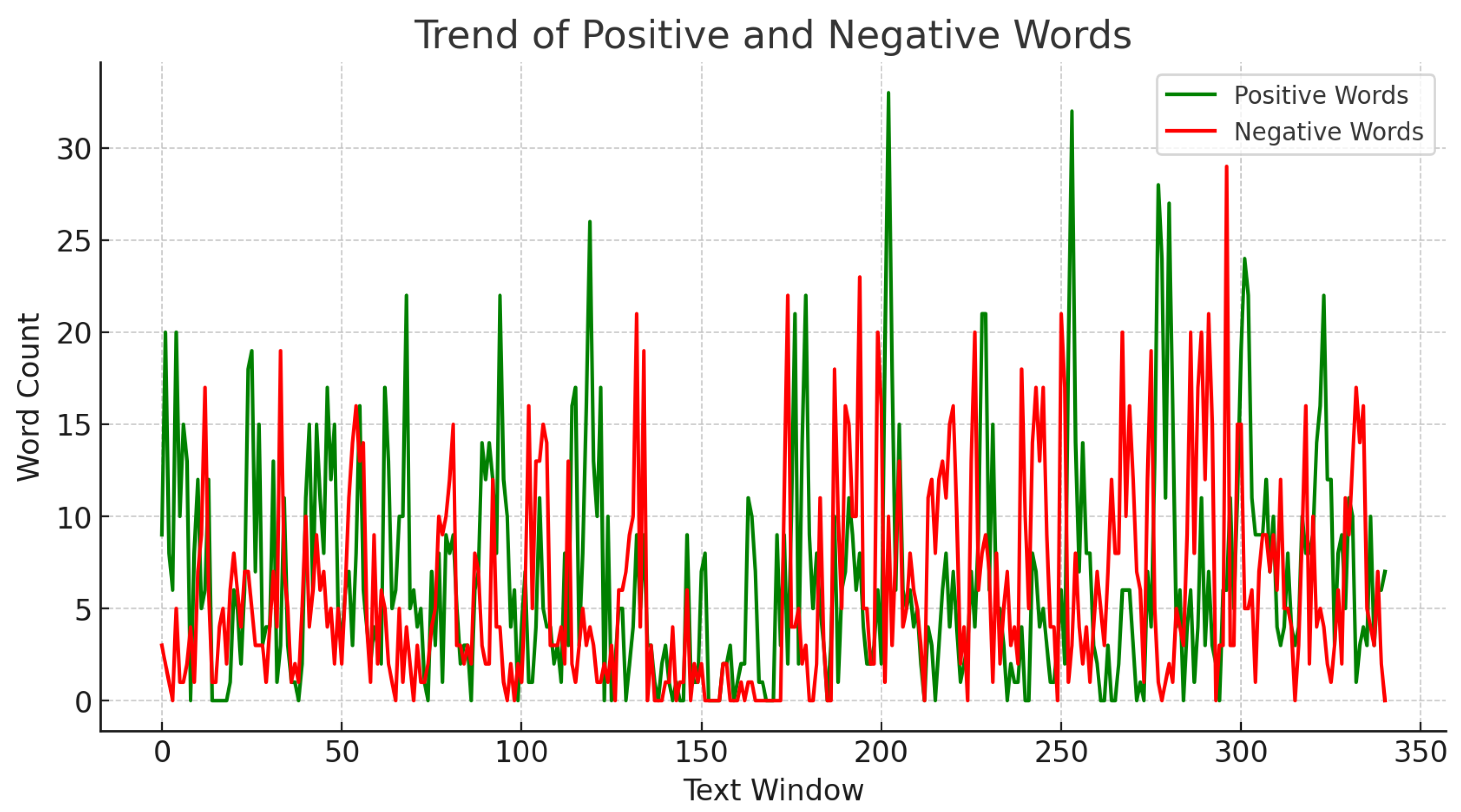
Figure 4.
Sentiment vs. Frequency: Positive and negative words in financial stability reports, 2007-2022.
Figure 4.
Sentiment vs. Frequency: Positive and negative words in financial stability reports, 2007-2022.
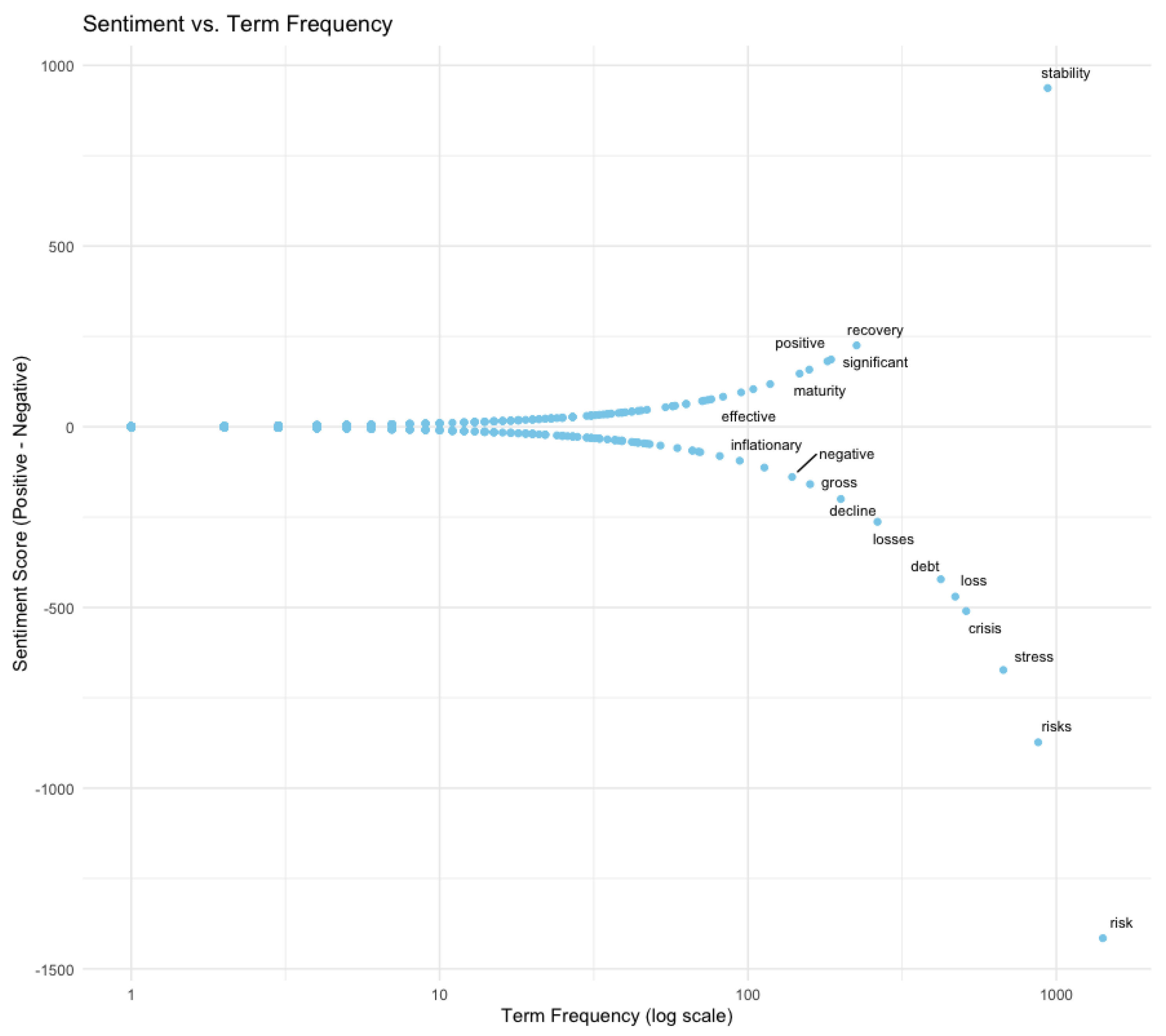
Figure 5.
TextualArc of stability and financial plot.
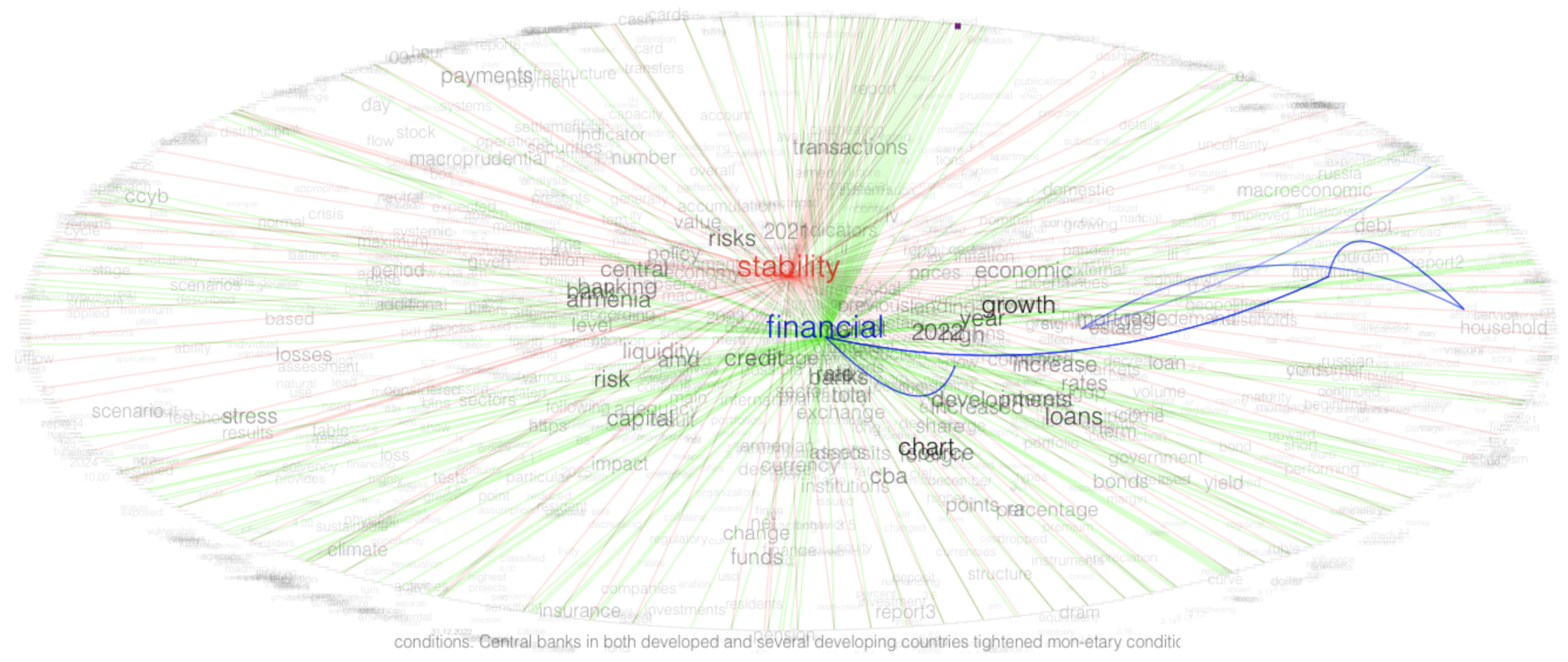
Figure 6.
Sentiment scores across Financial Stability Reports, 2007-2022.
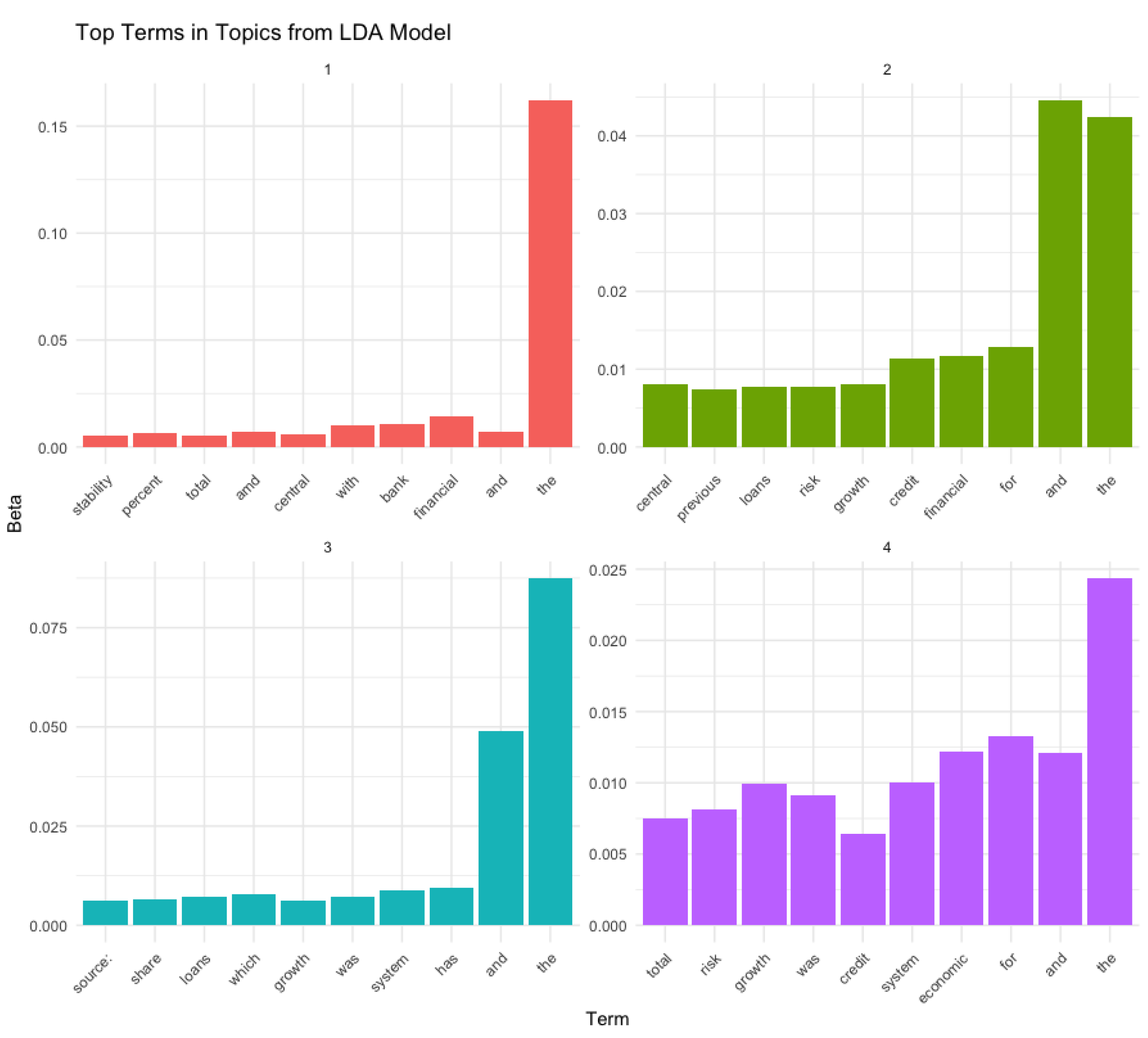
Figure 7.
Top 10 words, Financial Stability Reports, 2007-2022.
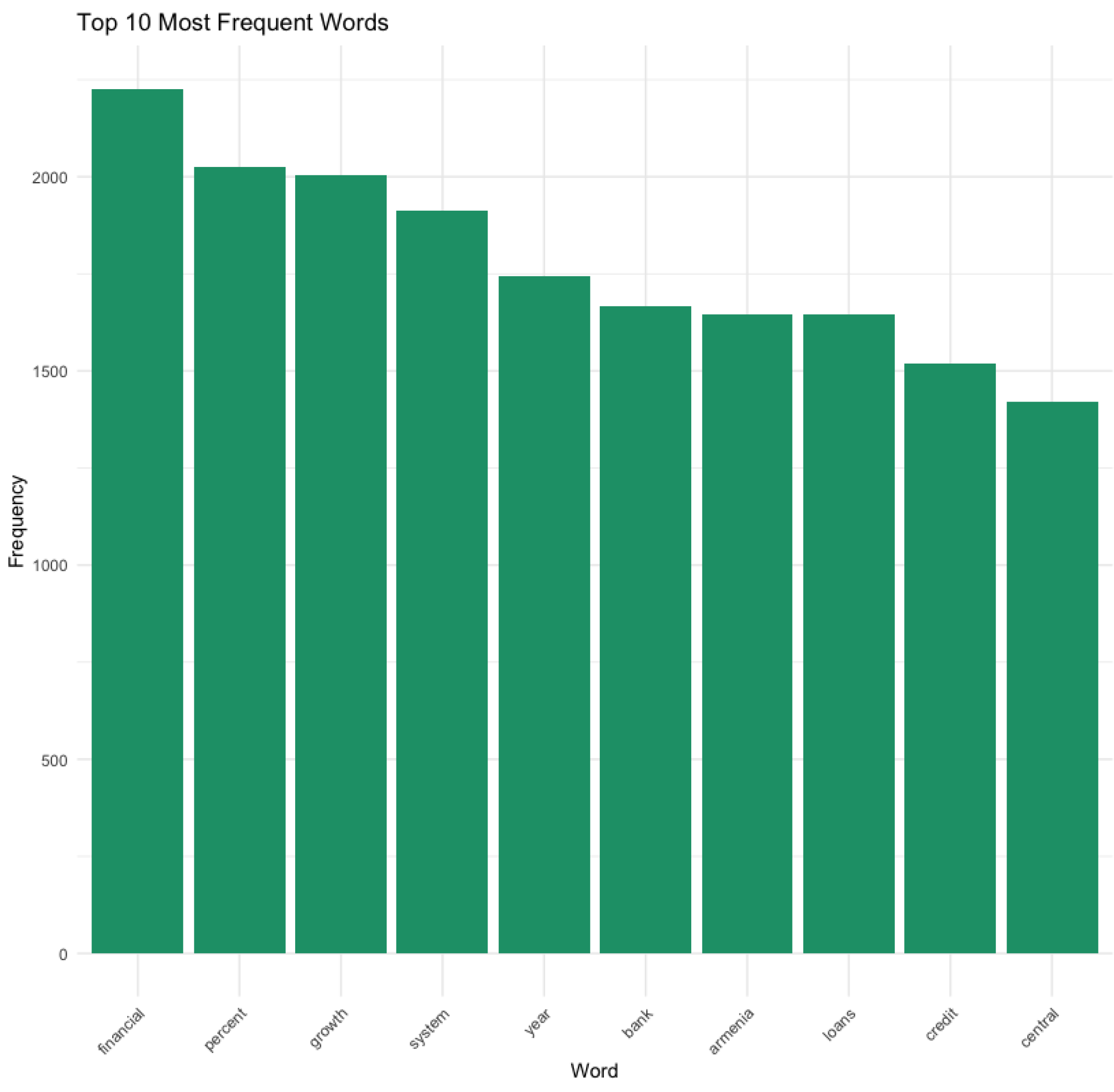
Figure 8.
Sentiment scores across Financial stability reports, 2007-2022.
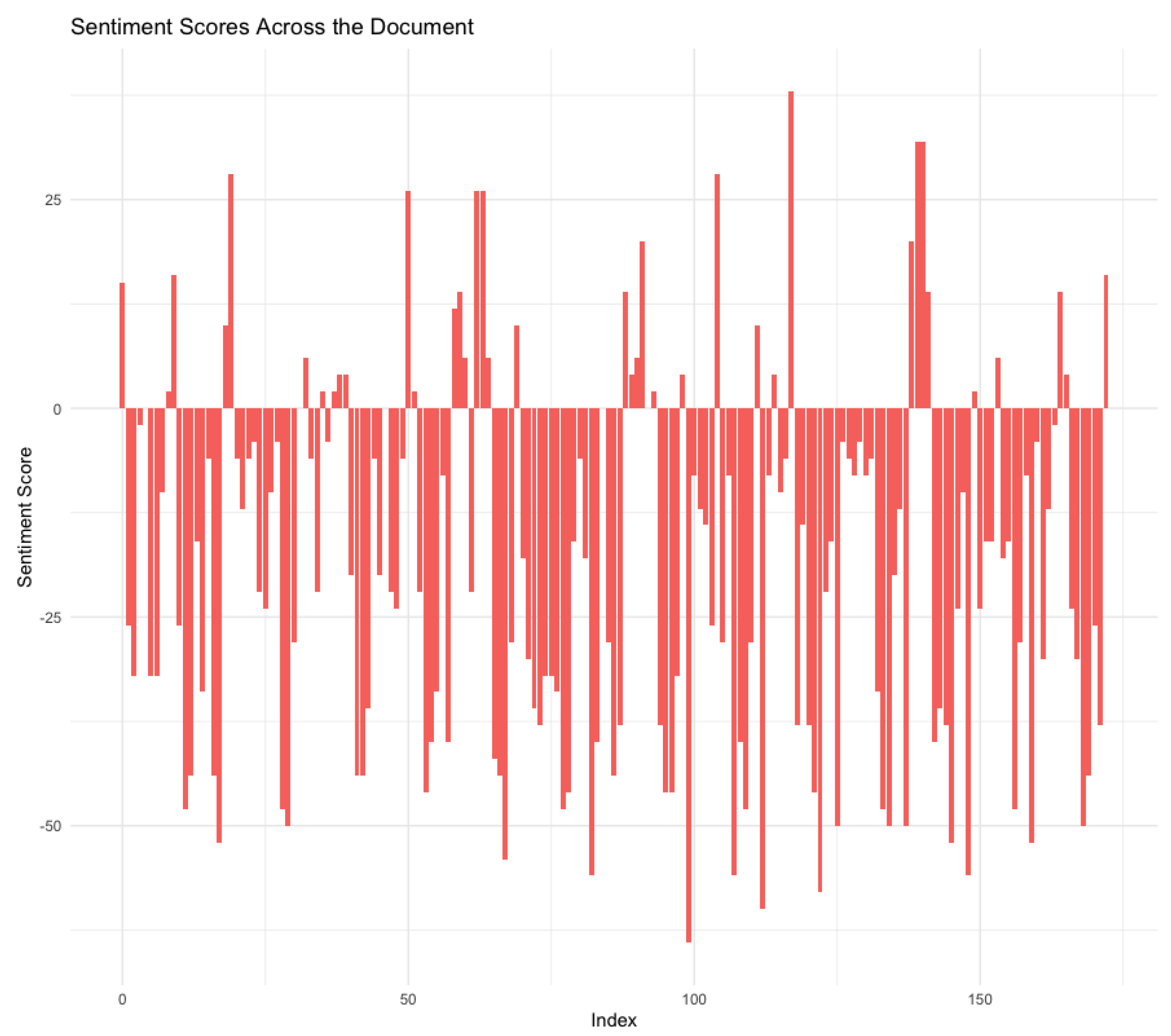
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



