
Submitted:
18 August 2024
Posted:
19 August 2024
Read the latest preprint version here
Abstract
Countless disasters have resulted from climate change, causing severe damage to infrastructure and the economy. These disasters have significant societal impacts, necessitating mental health services for the millions affected. To prepare for and respond effectively to such events, it is crucial to understand people's emotions and the life incidents they experience both before and after a disaster strikes. In this case study, we mined the emotions and life incidents expressed on Twitter during the 2017 Hurricane Harvey. Between August 20 and August 30, we collected a dataset of approximately 400,000 public tweets related to the storm. Using a BERT-based model, we predicted the emotions associated with each tweet. Following emotion prediction, we applied various natural language processing techniques to analyze the content of the tweets, aiming to uncover the 'topics' discussed alongside specific 'emotions.' To efficiently identify these topics, we utilized the Latent Dirichlet Allocation (LDA) technique for topic modeling, which allowed us to bypass manual content analysis and extract meaningful patterns from the data. However, rather than stopping at topic identification, we further refined our analysis by integrating Graph Neural Networks (GNN) and Large Language Models (LLM). The GNN was employed to generate embeddings and construct a similarity graph of the tweets, which was then used to optimize clustering. This step ensured that related tweets were accurately grouped together based on their content and context. Subsequently, we used an LLM to automatically generate descriptive names for each event cluster. This advanced approach allowed us to identify and label life incidents automatically, providing a nuanced understanding of the key issues faced by the community during the hurricane. The results revealed significant emotional shifts as the hurricane reached its most devastating phase. These shifts coincided with pressing concerns and demands from the population, such as evacuation plans, animal safety, safety updates, public policy, help requests, flood impacts, and the spread of fake news. By combining GNN and LLM for automatic event name prediction, our study not only mapped out the emotions but also accurately categorized the specific life incidents that were most relevant during the disaster, offering critical insights for disaster preparedness and response strategies.
Keywords:
emotional health
; climate change
; Large Language Model
; Graph Neural Network
; natural language processing
; topic modeling
; social media
1. Introduction
Climate change has caused many serious natural disasters around the world, like strong hurricanes, long droughts, higher temperatures, and heavy snowstorms. These extreme weather events damage buildings and the economy, affecting society deeply. Hurricanes, in particular, have become more frequent and severe. For example, Hurricane Harvey in 2017 brought massive amounts of rain to Texas and Louisiana, causing record-breaking floods. The National Hurricane Center estimated the damage at $125 billion. Also, 738,000 people asked for help from the Federal Emergency Management Agency (FEMA), and at least 3,900 homes lost electricity [1]. The huge number of 911 calls overwhelmed emergency services, leading many people to use social media to share their problems, worries, and requests for help.
Research by Cooper et al. demonstrated a strong connection between environmental conditions and emotional health through group discussions and interviews. Their study revealed that water shortages caused significant worry and fatigue among participants [2]. These findings were corroborated by other research, which showed that negative emotions are directly linked to immediate environmental conditions such as water shortages [3,4], food shortages [5], and environmental changes [6]. Hickman et al. conducted a study that highlighted the anxiety felt by many young people (aged 16-25 years) worldwide regarding climate change, with many participants expressing negative emotions towards their governments’ inaction on climate issues [7]. These studies employed various methodologies, including large surveys and group studies, to minimize bias. Despite providing valuable insights into the impact of climate change on daily life, these studies face several challenges. Primarily, such research is often costly and time-consuming, requiring significant resources for data collection and analysis. This process involves recruiting participants, organizing data collection sessions, and compensating participants, particularly in group studies. Furthermore, these studies are limited by the amount of data they can collect, which may not fully represent the broader population’s experiences.
In today’s world of fast technological progress and growing environmental concerns, social media platforms have become a powerful tool for investigating and understanding the different impacts of climate change. This research aims to use the vast real-time data available on social media during hurricanes to understand the complex relationship between these natural disasters and public reactions when they occur. By analyzing the digital traces left during Hurricane Harvey, this study seeks to find valuable insights into how society sees, responds, and how information spreads during hurricanes. The findings of this research could help improve disaster management communication strategies and contribute to the global conversation on climate change resilience.
We picked this approach for a few key reasons. First, we’re focusing on emotions and specific life incidents instead of just general mental health, which helps us see how environmental factors impact people’s feelings during disasters. Second, we use a BERT model to predict emotions and LDA to identify life incidents, combining the power of modern NLP models and topic modeling to get accurate results. Third, we ensure our findings are reliable by automatically grouping and accurately naming the incident topics using (GNN+LLM) Graph Neural Network [8,9] and Large language Model [10,11,12]. Lastly, real-time social media data lets us capture public reactions and feelings immediately, giving us timely insights that are important for managing disasters and public health. While [13] focuses on stressors related to climate change with the use of manual topic name prediction which could be human-biased, we accurately concentrate on immediate emotional reactions and specific life incidents during disasters by leveraging the use of graph neural networks and large language model. This approach allows us to provide more detailed insights into how specific incidents affect emotional health during disasters.
In this study, we leverage social media data from Hurricane Harvey to analyze emotional health and identify significant life incidents during this disaster. To accomplish this, we employ a combination of natural language processing (NLP), transfer learning, and graph neural networks (GNNs), enhanced with large language models (LLMs) for event prediction. The collected tweets undergo an extensive data cleaning process, where URLs, special characters, and irrelevant terms are removed. We also apply stop word removal, including an expanded list to filter out common disaster-related terms that do not contribute meaningfully to our analysis. Following the cleaning process, the tweets are transformed into embeddings using a pre-trained BERT model. These embeddings are then fed into a GNN, which is trained to refine the embeddings by capturing the underlying graph structure of the data. To determine the optimal number of clusters, we employ the silhouette score, a metric that evaluates how well each tweet fits within its assigned cluster compared to other clusters. This method ensures that the tweets are accurately grouped based on their content. Once the clustering is completed, we utilize a GPT-2-based LLM to generate meaningful event names for each cluster. This step involves synthesizing the content of tweets within a cluster to predict a concise event name that encapsulates the central theme of the cluster. Our approach offers several key contributions. First, it demonstrates the effective integration of GNNs with transformer models for refining tweet embeddings, leading to more accurate clustering. Second, by using an LLM for event name generation, we move beyond traditional topic modeling, providing a more human-like interpretation of the data. Finally, our analysis of emotional health during Hurricane Harvey highlights the potential of combining advanced machine learning techniques to gain deeper insights into the impact of disasters on public sentiment and mental health. This research not only advances the methodological framework for disaster analysis using social media data but also provides practical insights that can inform policymakers in developing comprehensive disaster management strategies that address both physical and emotional well-being.
2. Related Work
In this section, we review recent studies related to addressing climate change and public health. These studies are categorized into two main scientific areas: topic modeling for public health and the use of social media for disaster relief.
2.1. Topic Modeling for Public Health
Topic modeling helps find patterns and make sense of unstructured collections of documents [14]. This technique connects social and computational sciences. Topic models use probabilistic methods to uncover the hidden semantic structures of a group of texts through hierarchical Bayesian analysis. These texts can include emails, scientific papers, and newspaper articles. For example, Grassia et al. [15] used non-negative matrix factorization (NMF) to identify main themes in newspaper articles, pinpointing topics used for propaganda. Grootendorst [16] used BERTopic to create document embeddings with pre-trained transformer-based language models, clustering these embeddings and generating topic representations with a class-based TF-IDF procedure to build neural networks. Karas et al. [17] applied the Top2Vec model with doc2vec as the embedding model to extract topics from the subreddit "r/CysticFibrosis." Many studies use Latent Dirichlet Allocation (LDA) because it is popular and simple. For instance, Man et al. [18] used LDA to adapt an HPV transmission model to data on sexual behavior, HPV prevalence, and cervical cancer incidence. They predicted the effects of HPV vaccination on HPV and cancer incidence and the lifetime risk of cervical cancer over 100 years after vaccination. Asmundson et al. [19] replicated a study to examine the factor structure, reliability, and validity of the COVID-19 Incident Scales, showing how topic modeling can reveal fear and anxiety-related distress responses during pandemics. Mental health is a particular area where the importance of emotional and practical support, as well as self-disclosure, has been increasingly acknowledged. Manikonda et al. [20] aimed to understand the language features, content characterization, driving factors, and types of online disinhibition seen in social media, focusing on mental health.
2.2. Social Media for Disaster Relief
Social media, as explained by Kaplan, includes Internet-based applications that are built on the foundations of Web 2.0, allowing the creation and sharing of user-generated content [21]. This term covers platforms like Reddit, Twitter, Flickr, Facebook, and YouTube, which let users communicate and share information and resources. These tools are being used more and more for disaster relief efforts. For example, Gao et al. suggested using social media to create a crowdsourcing platform for emergency services during the 2010 Haiti earthquake [22]. Social media can also be combined with crisis maps to help organizations find places where supplies are needed the most. A 2011 study by the American National Government looked into using social media for disaster recovery, discussing how it can be used, future possibilities, and policy considerations [23]. Twitter, a popular social media platform, works as both a social network and a microblogging service, allowing users to post short messages called tweets. Du et al. suggested a social media-based system to analyze people’s concerns, see how important they are, and track how they change over time [24]. Their study compared the flow of concerns between Twitter and news outlets during the California mountain fires. Other studies have also used social media to engage communities in water resource management [25], coordinate volunteer rescue efforts [26], and predict people’s needs for better extreme weather planning [27]. Lu et al. visualized social media sentiment during extreme weather incidents, exploring trends in positive and negative feelings and their geographical distribution using Twitter data [28]. Additionally, social media can quickly assess damage from extreme weather incidents. Kryvasheyeu et al. developed a multiscale analysis of Twitter activity before, during, and after Hurricane Sandy to monitor and assess the disaster through the spatiotemporal distribution of disaster-related messages [29]. Our work focuses on using social media to understand emotions and incidents extractions, helping policymakers create better plans for disaster management and mitigation.
2.3. Graph Neural Networks
Graph Neural Networks (GNNs) have emerged as a powerful tool for modeling relationships and dependencies in data that can be naturally represented as graphs. GNNs extend neural networks to graph-structured data, enabling the learning of representations that consider both node features and the graph structure. Kipf and Welling [8] introduced the concept of semi-supervised learning with GNNs, demonstrating their effectiveness in classifying nodes in a graph. This method has since been adapted to various applications, including social media analysis where relationships between users or content can be modeled as graphs. Zhuang et al. [9] proposed a dual graph convolutional network model, which integrates local and global graph structures to improve classification accuracy in semi-supervised settings. These advancements in GNNs have laid the foundation for their application in event prediction, where the goal is to identify and name events based on their graph-structured representations in social media data.
2.4. Large Language Models for Topic Naming
Large Language Models (LLMs) like GPT-2 have revolutionized natural language processing by enabling the generation of coherent and contextually appropriate text. These models are pre-trained on vast corpora and can be fine-tuned for specific tasks, including topic naming and event prediction. Radford et al. [10] demonstrated the capability of GPT-2 to generate text that closely mirrors human language, making it a suitable tool for creating descriptive names for clusters of events or topics. Wei et al. [11] further explored the adaptability of LLMs, showing that fine-tuned language models could perform well even with limited data, a common scenario in real-time social media analysis. Brown et al. [12] introduced the concept of few-shot learning with LLMs, where the model requires minimal examples to accurately generate relevant and specific text. These capabilities make LLMs a valuable component in the pipeline for event name generation, particularly when combined with the structural insights provided by GNNs.
2.5. Combining GNNs and LLMs for Event Prediction
The integration of GNNs and LLMs offers a promising approach to event prediction and topic naming in social media data. By leveraging GNNs to model the relational structure of data and LLMs to generate meaningful textual representations, this hybrid approach can effectively identify and label events in a manner that reflects both the underlying data structure and the nuances of human language. This combination addresses the limitations of traditional clustering techniques by providing both a robust framework for grouping related data and a sophisticated method for interpreting and naming these groups. The work of combining GNNs and LLMs represents a significant step forward in the application of machine learning to disaster management and public health, enabling more accurate and insightful analysis of social media data.
3. Methods
3.1. Study Design
4. Methodology
To analyze t he emotional responses to Hurricane Harvey and predict life incident names, we meticulously processed our collected tweet data through several stages, as outlined in Figure 1. The initial step involved data cleaning, where we removed emojis, hexadecimal characters, images, special characters, hyperlinks, and irrelevant words to prepare the text for analysis. Next, the cleaned data was passed through an emotion classification model that categorized tweets into positive, negative, or neutral sentiments. This classification allowed us to focus on tweets relevant to the emotional and incident-based analysis. To further standardize the text, we applied lemmatization to ensure that words with similar meanings but different forms (e.g., "be," "being," "been") were unified. Additionally, we removed common English stopwords (e.g., "a," "an," "the") to eliminate non-informative words from the dataset. The text data was then transformed into token features using Term Frequency-Inverse Document Frequency (TF-IDF). With these features, we constructed an initial Latent Dirichlet Allocation (LDA) model to identify preliminary topics within the tweets. During this stage, we continuously refined our stopwords list, filtering out prevalent and unwanted tokens such as common disaster-related terms ("hurricane," "Harvey," "storm") and location names ("Texas," "Houston," "Antonio"). Following the preliminary topic extraction, the data underwent a more rigorous processing phase, incorporating Graph Neural Network (GNN) embeddings. We performed dimension reduction on these embeddings and constructed a similarity graph, which was then used to train a GNN model. The trained GNN model provided optimized clustering, identifying groups of related tweets. Finally, using a fine-tuned LDA model alongside the GNN-based clustering results, we employed a Large Language Model (LLM) to automatically generate descriptive names for each predicted event group. This approach allowed us to accurately predict life incident names and categorize tweets into meaningful clusters, reflecting the community’s response to the disaster. The refinement process, involving hyperparameter tuning of the number of topics, ensured that the extracted life incidents were specific and relevant to the context of Hurricane Harvey.
4.1. Data Pre-Processing and Feature Engineering
Our Hurricane Harvey dataset includes tweets collected from January 11, 2017, to August 29, 2017, and is publicly available on Kaggle [30]. The original dataset contains approximately 400,000 tweets about Hurricane Harvey. After initial filtering, we identified around 98,000 tweets expressing negative emotions. These extracted tweets then underwent data cleaning and text preprocessing to reduce redundancy and remove unwanted keywords for the topic modeling process. Specifically, we eliminated Twitter-specific characters from a defined range of Unicode characters, URLs, and hyperlinks by removing tokens containing "http." This standardization process also involved removing icons such as emojis and hex-images. Lastly, we excluded all single-character tokens from the tweets.
To classify the tweets into three distinct emotion categories, we used a BERT-based model, a Bidirectional Encoder Representations from Transformers (BERT) model with a state-of-the-art pre-built emotion detection capability. This approach resulted in 28 tags, each representing a specific emotion, then later grouping each tweet as positive, negative, or neutral.
4.2. Emotion Prediction and Life Incident Extraction
4.2.1. Text Vectorization
To expedite data processing, we employ Term Frequency-Inverse Document Frequency (TF-IDF). TF-IDF is a widely used text vectorization algorithm that creates a word frequency vector. The term frequency, inverse document frequency, and their product are computed as follows:
Here, denotes the frequency of the word t in document d, and D represents the entire collection of documents. In this study, each document corresponds to a tweet. D is a corpus with a size of N. To princident division by zero when t is absent in d, a value of one is added to the denominator in the formula.
4.2.2. LDA Topic Modeling based Life Incident Extraction
[31] demonstrates the technique of Latent Semantic Indexing (LSI) for indexing and retrieval, which helps understand the document’s content by finding the relationship between words and documents. [32] introduced the improvement of LSI, called probabilistic LSI (pLSI), which uses the likelihood method (e.g., Bayes method). The nature of pLSI is to help with finding the words’ models in a document where each word belongs to a specific topic. Both techniques ignore the words’ order in a document. In addition, the problem with time complexity occurs in both techniques, leading to overfitting, which Latent Dirichlet Allocation addressed well [33].
In the details of LDA, we assume that we have a document (d) that contains a set of words. In addition, we have a topic (z) that has several significant keywords (w). Knowing that each word can relate to many topics with various probabilities and that the amount of topics is the LDA parameter.
By estimating the confidential variables (, , ) by calculating the allocation in documents, LDA discovers the topics (Z) of each document and the significant words of each topic.
We define N as the words’ number in document d. Dirichlet prior parameters at the corpus level parameters are and . In addition, we choose the topic of each word from multinomial distribution for each word . We represent as below a word from :
Furthermore, we represent the probability of a corpus as below:
Topics identification for optimal number:
In order to examine the optimal amount of topics for the LDA model, we use Umass coherence score, [34]. This technique estimates the frequency of two words, which are and :
In this equation, denotes the frequency with which and co-occur in the same document, while indicates the number of documents that contain the word . To avoid division by zero, we add a value of 1 to the denominator. The UMass coherence value is calculated as the sum of the top N pre-determined terms. Typically, is much smaller than , which results in a negative UMass score. The quality of the LDA model improves as the UMass score approaches zero. However, adding more topics can increase the score, which leads to topics with very few documents. To mitigate this, we use the elbow method [35], which helps determine the optimal number of topics by identifying the point where the rate of improvement in the UMass coherence score diminishes. After defining the topics, we manually extract the life incidents from the representative terms of each topic.
Life incident extraction from the identified topics:
After establishing the optimal number of topics for the LDA model, we use a Python-based LDA visualization tool to illustrate each topic and identify the key terms that influence them. This visualization helps us interpret the topics through their distinct sets of keywords.
Automatic Group Topic Naming:
After determining the optimal number of clusters using the silhouette score, we employ a Graph Neural Network (GNN) to group related topics and a Large Language Model (LLM) to automatically generate meaningful names for each topic. The GNN processes the embeddings generated from the textual data, capturing both the content and the relational structure between topics. This approach ensures that the identified topics are cohesively grouped based on their underlying patterns. Once the topics are grouped, the LLM is used to predict descriptive names for each topic cluster. Our analysis focuses on life incidents specifically related to climate change. The GNN and LLM combination allows us to efficiently identify and name the most prominent incidents within these topics, facilitating a more detailed analysis of their impact. This method not only improves accuracy but also enhances the interpretability of the extracted incidents, making it easier to understand the specific events influencing public sentiment during disasters.
5. Results
5.1. Emotion Prediction Results
To categorize tweets with emotion tags, we ran the EmoRoBERTa model on a system featuring an Intel i7-11700 processor, 32 GB of RAM, and an NVIDIA RTX 2060 Super. For each tweet, we selected the highest-scoring emotion tag. The whole procedure, encompassing processing and annotation, exceeded 14 hours. In the results, about 280,000 tweets were marked as "neutral." This was expected, as many tweets likely provided updates on Hurricane Harvey’s progress or issued safety warnings. The emotion distribution of the tweets is illustrated in Figure 2.
Negative sentiments, such as "grief," "nervousness," "sadness," and "confusion," were prevalent, reflecting the anxiety and sorrow caused by the hurricane’s devastation. Neutral sentiments, dominated by terms like "realization" and "curiosity," indicate the role of social media in critical updates and factual information. Positive sentiments, including "joy," "gratitude," and "relief," highlight moments of community support, successful rescues, and appreciation for aid efforts.
5.2. Tweets Summary by Emotions
Figure 3.
Overview of all tweets and emotions tweets through out hurricane Harvey.
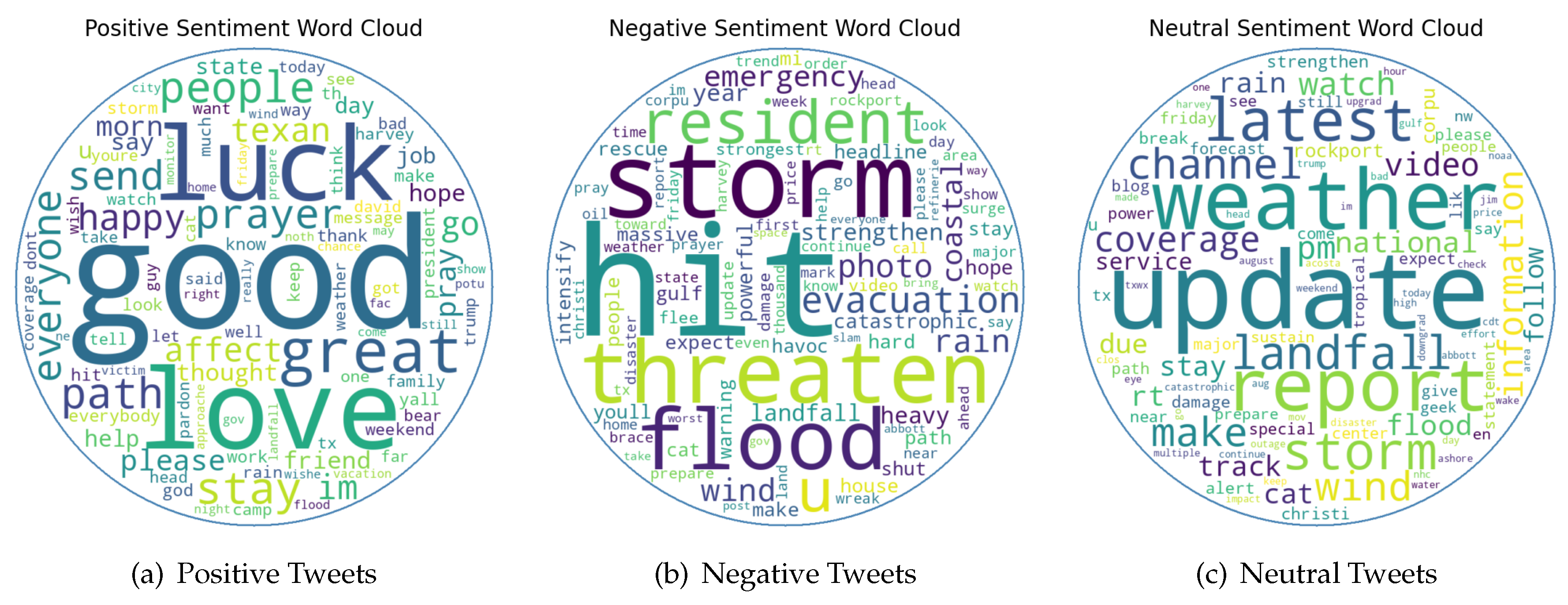

Table 1.
Top 20 Words for Each Sentiment Category in Hurricane Harvey Tweets based on their frequency and relevance in the tweets
Table 1.
Top 20 Words for Each Sentiment Category in Hurricane Harvey Tweets based on their frequency and relevance in the tweets
| Positive | Neutral | Negative |
|---|---|---|
| good | update | hit |
| love | weather | storm |
| luck | report | threaten |
| great | latest | flood |
| stay | storm | resident |
| people | landfall | u |
| path | channel | evacuation |
| prayer | wind | photo |
| send | make | rain |
| everyone | information | wind |
| happy | coverage | emergency |
| im | watch | coastal |
| texan | pm | strengthen |
| go | video | year |
| affect | national | heavy |
| safe | hurricane | warning |
| wonderful | track | horrible |
| blessed | system | damage |
| joy | gov | destruction |
| support | cnn | disaster |
The positive sentiment word cloud prominently features words such as “love,” “great,” “happy,” “good,” “wonderful,” “blessed,” “safe,” and “joy.” These words reflect a general sense of optimism and positivity among Twitter users. The presence of “love” and “happy” suggests expressions of care, solidarity, and relief, possibly directed toward successful rescue operations or the safety of loved ones. These words indicate that amidst the challenges posed by the hurricane, people found moments of emotional support and happiness. The terms “great” and “good” highlight commendations and satisfaction for the effective response by emergency services or the supportive actions taken by the community. In addition, this suggests that users acknowledged and appreciated the efforts made to mitigate the disaster’s impact and ensure public safety. The word “wonderful” conveys a strong sense of positivity, which might be related to successful evacuations, community support, or the resilience shown by individuals during the crisis. The appearance of “blessed” reflects a deep sense of gratitude and thankfulness, which might be in response to avoided dangers, received help, or the overall sense of being protected during the storm. This sentiment is crucial as it underscores the human aspect of the disaster response which helps with highlighting moments of kindness and support that were experienced. “Safe” and “joy” further emphasize the positive outcomes and feelings of security that were felt despite the adverse conditions. These words suggest that people were able to find comfort and happiness in the safety of their surroundings or in the knowledge that their loved ones were unharmed. In general, the positive sentiment word cloud reveals a prevailing sentiment of appreciation, relief, and encouragement, reflecting the community’s resilience and the successful measures taken to ensure safety and support. The positive emotions captured in these tweets highlight the human capacity to find light even in the darkest times, celebrating the small victories and the collective strength of the community.
In contrast, the primary negative words appearing in the negative sentiment word cloud were “storm,” “hit,” “resident,” “threaten,” “flood,” “wind,” “emergency,” “evacuation,” “intensify,” “photo,” “heavy,” “havoc,” “massive,” “coastal,” and “warning.” This suggests a widespread anxiety among Twitter users regarding the impending danger of the storm striking residential zones, the significant flooding, and the fierce winds anticipated to cause extensive damage. Words like “emergency” and “evacuation” highlight the urgency and need for prompt measures to ensure safety. Additionally, terms such as “intensify” and “heavy” underscore the severe conditions linked to the storm, which relates the potential for chaos and destruction. The use of “photo” indicates that users were likely sharing images depicting the damage or seeking vital information to assist in rescue and safety efforts. The word “resident” underscores the focus on individuals affected by the storm, emphasizing the human impact and the community’s reaction. Recurrent words like “coastal” and “warning” point to an increased awareness of the most vulnerable areas and the necessary precautions to lessen damage. This sentiment highlights the public’s concern about the storm’s effects on property, infrastructure, and the welfare of those impacted.In general, the negative sentiment word cloud reflects the serious and potentially hazardous nature of the storm, emphasizing the need for preparedness and effective action from emergency responders.
The neutral sentiment word cloud includes frequently mentioned words such as “update,” “news,” “information,” “report,” and “weather.” These terms indicate a strong focus on the reception of factual updates related to the hurricane. Words like “update” and “news” highlight the continuous flow of information being shared, possibly regarding the storm’s progress, safety advisories, or logistical details about relief efforts. This suggests that users were keen on staying informed and ensuring that others were kept up-to-date with the latest developments. “Information” and “report” suggest a reliance on structured communication and official sources to provide clarity and accuracy about the situation. These terms indicate that the public valued credible information to understand the unfolding incidents and make informed decisions. The prominence of these words shows that during the hurricane, there was a high demand for reliable data and transparent reporting to navigate the crisis effectively. The word “weather” underscores the central topic of interest, which reflects the discussions around meteorological conditions, forecasts, and the impact of the hurricane. This term likely encompassed a range of updates from weather forecasts to real-time reports on the storm’s intensity and path. The focus on weather indicates that people were closely monitoring the environmental conditions to prepare and respond appropriately. Additionally, the neutral sentiment word cloud may include words like “map,” “location,” “update,” “timeline,” “details,” and “status,” which further emphasizing the need for precise information. These words show that users were interested in the spatial aspects of the hurricane to understand its trajectory to better protect themselves and their communities. The neutral sentiment word cloud indicates that the primary focus among users was on receiving and sharing objective updates and essential information. The neutral sentiments captured in these tweets highlight the critical role of communication and information dissemination during a disaster. By staying informed, people were able to make timely decisions, coordinate their responses, and support each other through the crisis. The emphasis on neutrality and factual information underscores the importance of clarity and accuracy in managing public perception and response during emergencies.
5.3. Emotions Distribution and Evolution
5.4. Life incident Extraction Results
To find the best number of topics for our Latent Dirichlet Allocation (LDA) model, we used the scikit-learn library with a learning rate of 0.7 [36]. We created several LDA models, changing the number of topics from 20 to 70 in steps of 5. Then, evaluation is done via comparing UMass coherence score [34] for selection of optimal number of topics in datasets. Figure 4 shows an example of selection of optimal number of topics for positive sentiment. We notice that at 20 topics, the coherence score starts to decline rapidly. Thus, we chose 20 topics for the final version of our LDA model. Similarly, we get 30 topics for neutral sentiments and 55 topics for negative sentiments.
6. Analysis of Optimal k Selection for Sentiment Groups
The selection of the optimal number of clusters k for each sentiment group—negative, neutral, and positive—is informed by the silhouette score that we use to measure the quality of clustering by evaluating how similar an object is to its own cluster compared to other clusters.
About negative sentient group, as illustrated in Figure , the silhouette score reaches its peak at . This suggests that the negative sentiment data is best divided into two clusters. These clusters likely represent distinct thematic groups within the negative sentiment, showing the most significant variations in the data.
About neutral sentiment group, Figure shows that the highest silhouette score occurs at , indicating that the neutral sentiment data is optimally partitioned into three clusters. This finding suggests that there are three predominant topic groups within the neutral sentiment that are sufficiently distinct from one another to be considered separate clusters.
About positive sentiment group, for the positive sentiment group, as depicted in Figure , the silhouette score is highest at . This implies that the positive sentiment data is best categorized into two clusters, effectively capturing the key variations in positive emotions and themes expressed in the data.
Having determined these optimal topic numbers and to ensure consistency and accuracy, we employ the Silhouette Score technique to automatically cluster similar groups of topics. Thanks to leveraging Graph Neural Networks (GNNs) and the use of (LLM) large language models, we can accurately generate topic names.
Life Incidents Insight Analysis
The extracted life incidents and their associated terms are listed in Table 2, Table 3, and Table 4, representing negative, neutral, and positive sentiments, respectively. These tables present the predicted event names for life incidents grouped by a GNN-based approach and named using a large language model (LLM).
Table 2 captures negative sentiment life incidents, reflecting community challenges and emotional responses during Hurricane Harvey. The predicted event names such as "Troll and Non-Real Person" and "Trend in the Media" illustrate the societal disruptions and the media trends observed during the disaster. Representative tweets in the "Troll and Non-Real Person" category include terms related to emergency shelters, rescues, and aid, emphasizing the severe nature of the incidents, while "Trend in the Media" reflects the evolving public discourse and media focus on climate change and the disaster’s aftermath.
Table 3 lists neutral sentiment life incidents, primarily centered on factual reporting and updates. The event names such as "The Weather Channel" and "Best of Weather Reports (Last Week of Aug)" highlight the objective nature of the information shared during the event. The representative terms in these categories focus on updates, weather forecasts, and media reporting, emphasizing the importance of accurate information dissemination during a disaster.
Table 4 showcases positive sentiment life incidents, which emphasize community resilience and positive interactions. The predicted event names like "The Best of the Best" and "A ’Good’ Weather Event" capture the optimism and support within the community. These incidents include terms related to well-wishes, supportive actions, and positive outlooks, reflecting the community’s efforts to uplift morale during challenging times.
6.1. Limitations
We acknowledge several limitations in our study. Firstly, the information analyzed is derived from self-reported data on Twitter, which may introduce biases towards socially desirable responses or may not fully represent the true emotional state of individuals during the disaster. Secondly, our analysis is limited to Twitter data, which may not capture the emotional well-being and life incidents of people across other online platforms or in real-life scenarios, thus limiting the generalizability of our results. While our approach using GNN for clustering and LLM for naming event topics demonstrates the potential for extracting meaningful insights from social media data, it relies on the quality and scope of the dataset. The dataset used in this study is specific to Hurricane Harvey, and future work will involve applying these techniques to larger, more diverse datasets covering a broader range of climate change-related life incidents. This will help address the current limitation of focusing on a single disaster event and improve the robustness of our findings across different contexts. Additionally, while the use of GNN helps automate the grouping of related incidents, and LLM aids in generating event names, there is still a risk of bias in the model’s outputs, particularly if the training data reflects certain biases. Moreover, our method of relying on the silhouette score to determine the optimal number of clusters, while effective, may not always capture less frequently discussed but significant life incidents. This highlights the need for more extensive disaster datasets and the development of more objective, data-driven methods for incident extraction. Finally, future research should include further validation of our findings through interviews or surveys, which can provide additional context and confirm the accuracy of the extracted incidents. Additionally, the demographic composition of Twitter users, such as the tendency of younger people to use the platform more frequently than older adults, may introduce bias into our results. Moreover, our study focuses solely on hurricanes, and the findings may vary across different types of disasters, such as earthquakes or heatwaves. To address these issues, broader disaster datasets and cross-platform analyses are necessary to ensure that our methods and findings are applicable to a wider range of contexts.
7. Conclusions
This paper presents a case study on predicting public emotions and identifying life incidents during Hurricane Harvey using social media data. We employed a Graph Neural Network (GNN) to automatically group related incidents, combined with a Large Language Model (LLM) to generate meaningful event names. Unlike previous studies that broadly examine the mental health impacts of climate change using NLP techniques, our study specifically targets emotions and life incidents during a disaster event, offering a more focused analysis of how such incidents influence public sentiment. Our findings demonstrate that various life incidents, as grouped and named by the GNN-LLM approach, significantly impact the emotions expressed by individuals during the hurricane. This research highlights the potential of combining GNNs and LLMs with readily available social media data to gain insights into emotional health and the specific life incidents that occur during disasters. These insights are invaluable for healthcare professionals and policymakers in formulating comprehensive disaster management strategies that address both emotional well-being and life incident needs. Looking ahead, we plan to extend our algorithm to cover a broader range of disasters, thereby developing a comprehensive lexicon for the automatic identification of life incidents across different contexts. This will help overcome the limitations of manual extraction and enable the automated monitoring of disaster impacts on daily life and emotional health. By broadening the scope of our analysis, we aim to provide a more versatile tool for disaster response and mental health assessment, ensuring that our approach remains robust and applicable across various disaster scenarios.
Author Contributions
Thomas Hoang: Methodology, formal analysis, software, project administration, writing, and editing. Quynh Anh Nguyen: Software, formal analysis, writing and editing. Long Nguyen: Conceptualization, writing review, editing, supervision, funding acquisition, and project administration. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by NSF - USA CNS-2219614 and CNS-2302274.
Data Availability Statement
Source code and data is available at https://github.com/litpuvn/event-extraction-disaster (Accessed Date: August 16th, 2024).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Amadeo, K. Hurricane Harvey facts, damage and costs. The Balance 2018. [Google Scholar]
- Cooper, S.; Hutchings, P.; Butterworth, J.; Joseph, S.; Kebede, A.; Parker, A.; Terefe, B.; Van Koppen, B. Environmental associated emotional distress and the dangers of climate change for pastoralist mental health. Global Environmental Change 2019, 59, 101994. [Google Scholar]
- Aihara, Y.; Shrestha, S.; Sharma, J. Household water insecurity, depression and quality of life among postnatal women living in urban Nepal. Journal of water and health 2016, 14, 317–324. [Google Scholar] [PubMed]
- Stevenson, E.G.; Greene, L.E.; Maes, K.C.; Ambelu, A.; Tesfaye, Y.A.; Rheingans, R.; Hadley, C. Water insecurity in 3 dimensions: an anthropological perspective on water and women’s psychosocial distress in Ethiopia. Social science & medicine 2012, 75, 392–400. [Google Scholar]
- Ojala, M. Young people and global climate change: Emotions, coping, and engagement in everyday life. Geographies of global issues: Change and threat 2016, 8, 1–19. [Google Scholar]
- Friedrich, E.; Wüstenhagen, R. Leading organizations through the stages of grief: The development of negative emotions over environmental change. Business & society 2017, 56, 186–213. [Google Scholar]
- Hickman, C.; Marks, E.; Pihkala, P.; Clayton, S.; Lewandowski, R.E.; Mayall, E.E.; Wray, B.; Mellor, C.; van Susteren, L. Climate anxiety in children and young people and their beliefs about government responses to climate change: A global survey. The Lancet Planetary Health 2021, 5. [Google Scholar] [CrossRef]
- Kipf, T.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. ArXiv, 2016; abs/1609.02907. [Google Scholar]
- Zhuang, C.; Ma, Q. Dual Graph Convolutional Networks for Graph-Based Semi-Supervised Classification. Proceedings of the 2018 World Wide Web Conference 2018. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language Models are Unsupervised Multitask Learners. 2019.
- Wei, J.; Bosma, M.; Zhao, V.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned Language Models Are Zero-Shot Learners. ArXiv, 2021; abs/2109.01652. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. ArXiv, 2005. [Google Scholar]
- Bui, T.; Hannah, A.; Madria, S.; Nabaweesi, R.; Levin, E.; Wilson, M.; Nguyen, L. Emotional Health and Climate-Change-Related Stressor Extraction from Social Media: A Case Study Using Hurricane Harvey. Mathematics 2023, 11. [Google Scholar] [CrossRef]
- Blei, D.M.; Lafferty, J.D. Topic models. Text mining: classification, clustering, and applications 2009, 10, 34. [Google Scholar]
- Grassia, M.G.; Marino, M.; Mazza, R.; Misuraca, M.; Stavolo, A. Topic modeling for analysing the Russian propaganda in the conflict with Ukraine. ASA 2022.
- Grootendorst, M. BERTopic, Topic Modeling with a class-base for TF-IDF procedure. Frontiers in Sociology 2022. [Google Scholar]
- Karas, B.; Qu, S.; Xu, Y.; Zhu, Q. Experiments with LDA and Top2Vec for embedded topic discovery on social media data—A case study of cystic fibrosis. Frontiers in Artificial Intelligence 2022, 5, 948313. [Google Scholar] [PubMed]
- Man, I.; Georges, D.; de Carvalho, T.M.; Saraswati, L.R.; Bhandari, P.; Kataria, I.; Siddiqui, M.; Muwonge, R.; Lucas, E.; Berkhof, J.; et al. Evidence-based impact projections of single-dose human papillomavirus vaccination in India: a modelling study. The Lancet Oncology 2022, 23, 1419–1429. [Google Scholar] [PubMed]
- Asmundson, G.J.; Taylor, S. Coronaphobia: Fear and the 2019-nCoV outbreak. Journal of anxiety disorders 2020, 70, 102196. [Google Scholar]
- Manikonda, L. Analysis and Decision-Making with Social Media; Arizona State University, 2019.
- Kaplan, A.M. , Definition, and History. In Encyclopedia of Social Network Analysis and Mining; Alhajj, R., Rokne, J., Eds.; Springer New York: New York, NY, 2018; pp. 2662–2665. [Google Scholar] [CrossRef]
- Gao, H.; Barbier, G.; Goolsby, R. Harnessing the crowdsourcing power of social media for disaster relief. IEEE intelligent systems 2011, 26, 10–14. [Google Scholar]
- Lindsay, B.R. Social Media and Disasters: Current Uses, Future Options, and Policy Considerations. Technical report, Library of Congress. Congressional Research Service, 2011.
- Du, H.; Nguyen, L.; Yang, Z.; Abu-Gellban, H.; Zhou, X.; Xing, W.; Cao, G.; Jin, F. Twitter vs news: Concern analysis of the 2018 california wildfire event. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC). IEEE, Vol. 2; 2019; pp. 207–212. [Google Scholar]
- Nguyen, L.H.; Hewett, R.; Namin, A.S.; Alvarez, N.; Bradatan, C.; Jin, F. Smart and connected water resource management via social media and community engagement. In Proceedings of the 2018 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE; 2018; pp. 613–616. [Google Scholar]
- Yang, Z.; Nguyen, L.; Zhu, J.; Pan, Z.; Li, J.; Jin, F. Coordinating disaster emergency response with heuristic reinforcement learning. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM). IEEE; 2020; pp. 565–572. [Google Scholar]
- Nguyen, L.; Yang, Z.; Li, J.; Pan, Z.; Cao, G.; Jin, F. Forecasting people’s needs in hurricane events from social network. IEEE Transactions on Big Data 2019, 8, 229–240. [Google Scholar]
- Lu, Y.; Hu, X.; Wang, F.; Kumar, S.; Liu, H.; Maciejewski, R. Visualizing social media sentiment in disaster scenarios. In Proceedings of the Proceedings of the 24th international conference on world wide web, 2015, pp.; pp. 1211–1215.
- Kryvasheyeu, Y.; Chen, H.; Obradovich, N.; Moro, E.; Van Hentenryck, P.; Fowler, J.; Cebrian, M. Rapid assessment of disaster damage using social media activity. Science advances 2016, 2, e1500779. [Google Scholar]
- Hurricane Harvey Tweets. https://www.kaggle.com/datasets/dan195/hurricaneharvey, 2017 (Accessed Aug 06, 2023).
- Chen, T.H.; Thomas, S.W.; Hassan, A.E. A survey on the use of topic models when mining software repositories. Empirical Software Engineering 2016, 21, 1843–1919. [Google Scholar]
- Hofmann, T. Probabilistic latent semantic indexing. In Proceedings of the Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, 1999, pp.; pp. 50–57.
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. Journal of machine Learning research 2003, 3, 993–1022. [Google Scholar]
- Mimno, D.; Wallach, H.M.; Talley, E.; Leenders, M.; McCallum, A. Optimizing Semantic Coherence in Topic Models. In Proceedings of the Proceedings of the Conference on Empirical Methods in Natural Language Processing; Association for Computational Linguistics: USA, 2011; EMNLP ’11; pp. 262–272.
- Thorndike, R. Who belongs in the family? Psychometrika 1953, 18, 267–276. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. Journal of Machine Learning Research 2011, 12, 2825–2830. [Google Scholar]
Figure 1.
Overview of the research framework for climate change-related life incidents name prediction.
Figure 1.
Overview of the research framework for climate change-related life incidents name prediction.
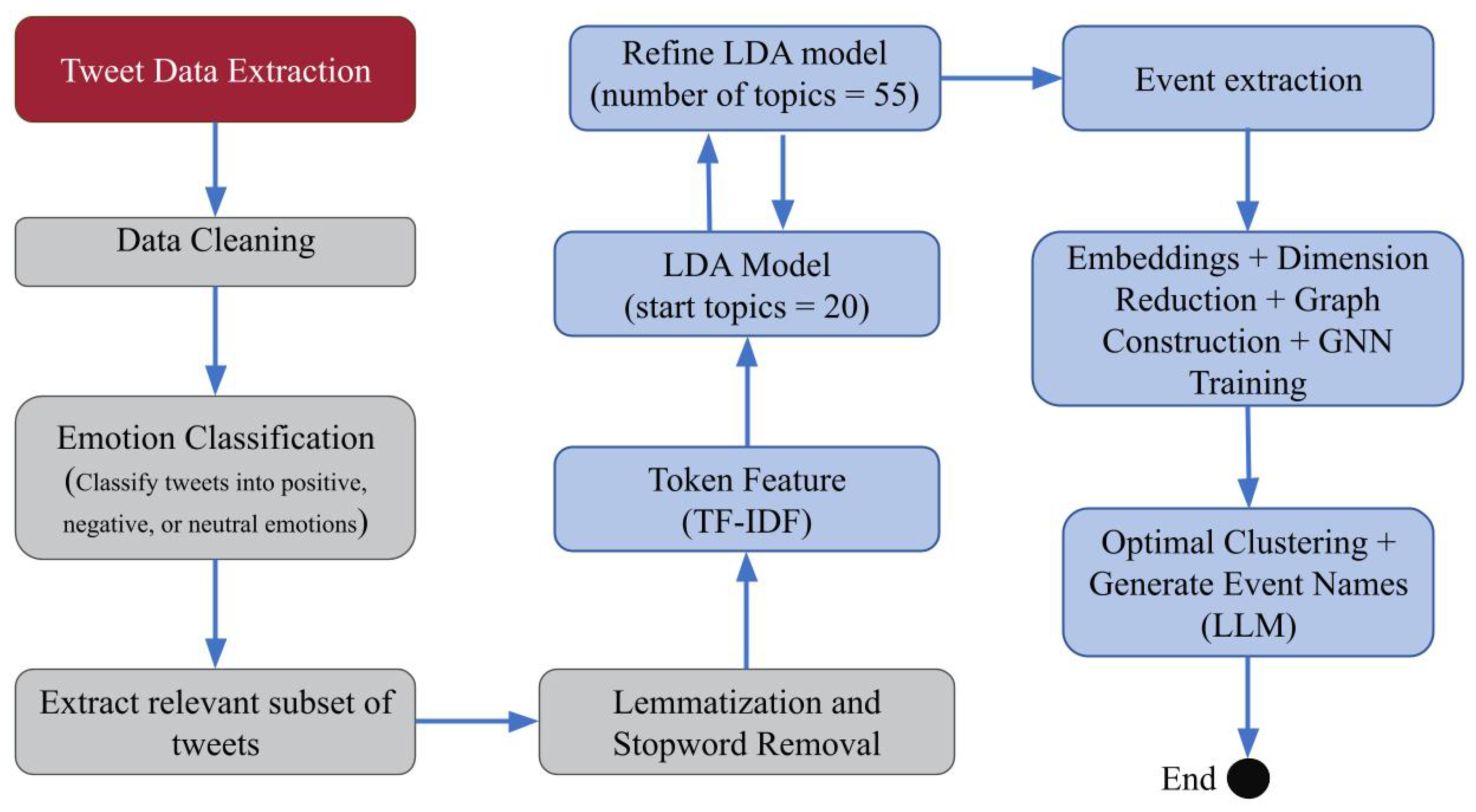
Figure 2.
Distribution of predicted emotion tags in the hurricane Harvey dataset.
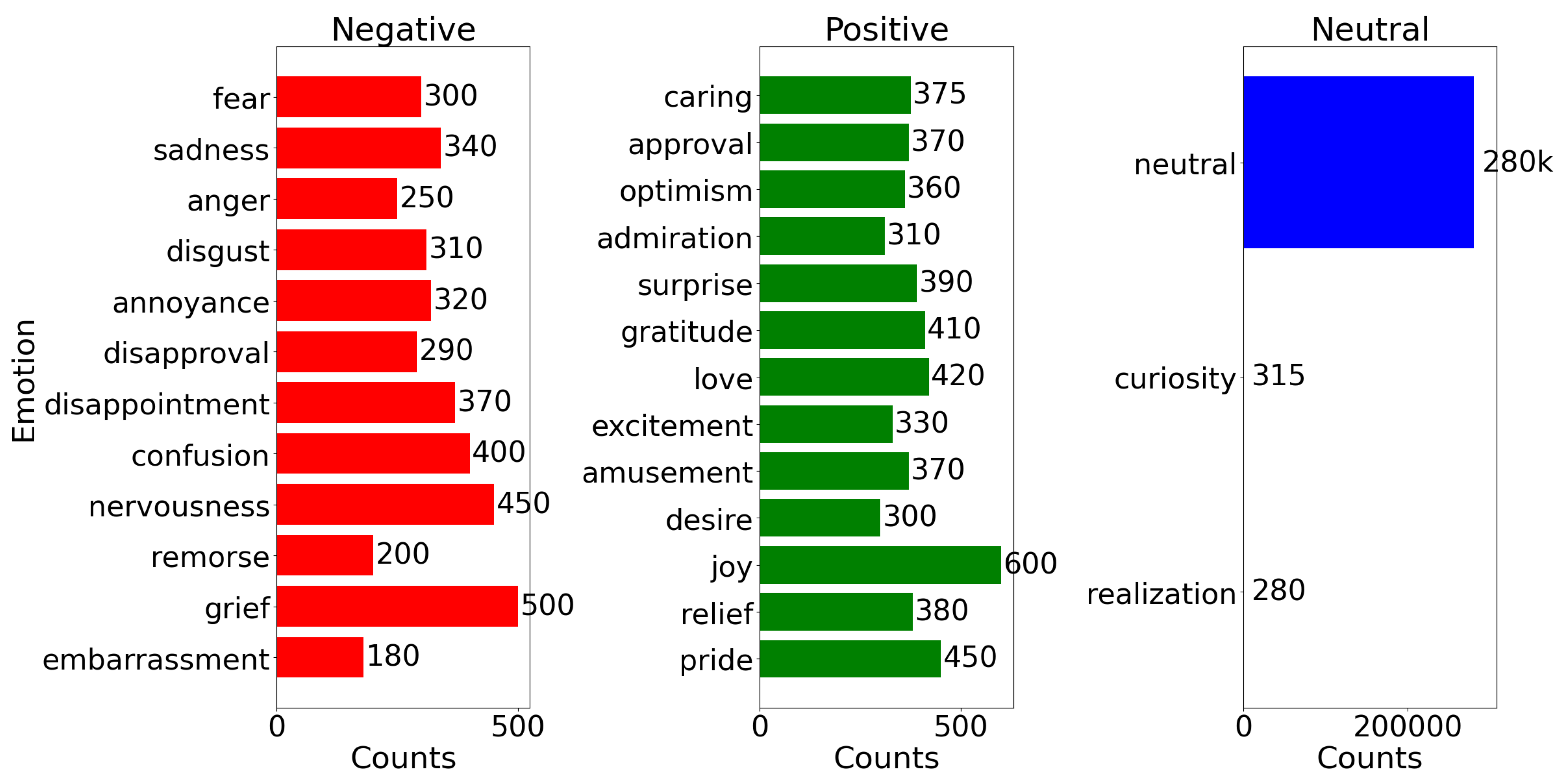
Figure 4.
Number of Topics for LDA topic modeling and life incidents extraction for positive sentiments.
Figure 4.
Number of Topics for LDA topic modeling and life incidents extraction for positive sentiments.
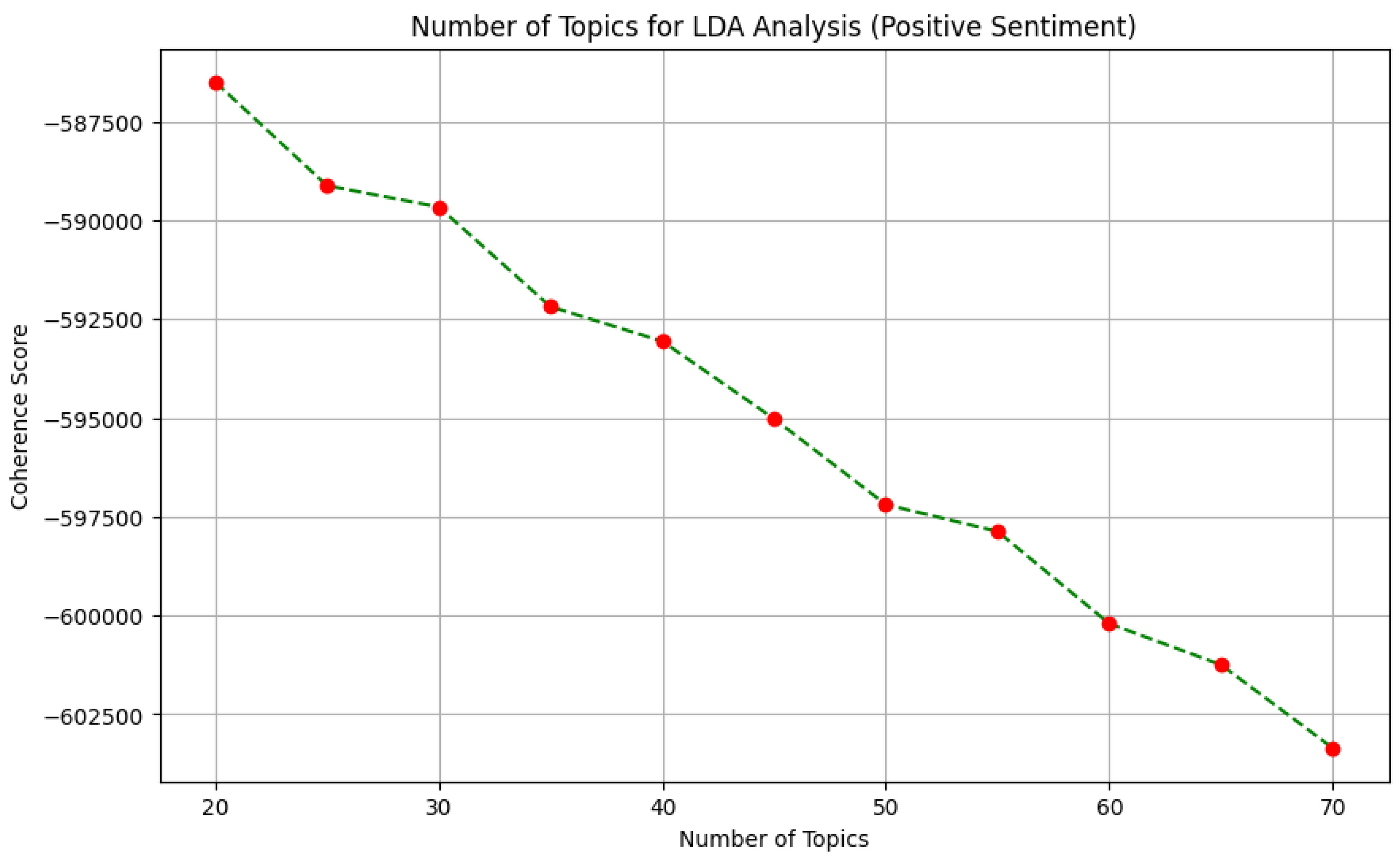
Figure 5.
Comparison of Silhouette Scores for Determining Optimal k in Different Sentiment Groups
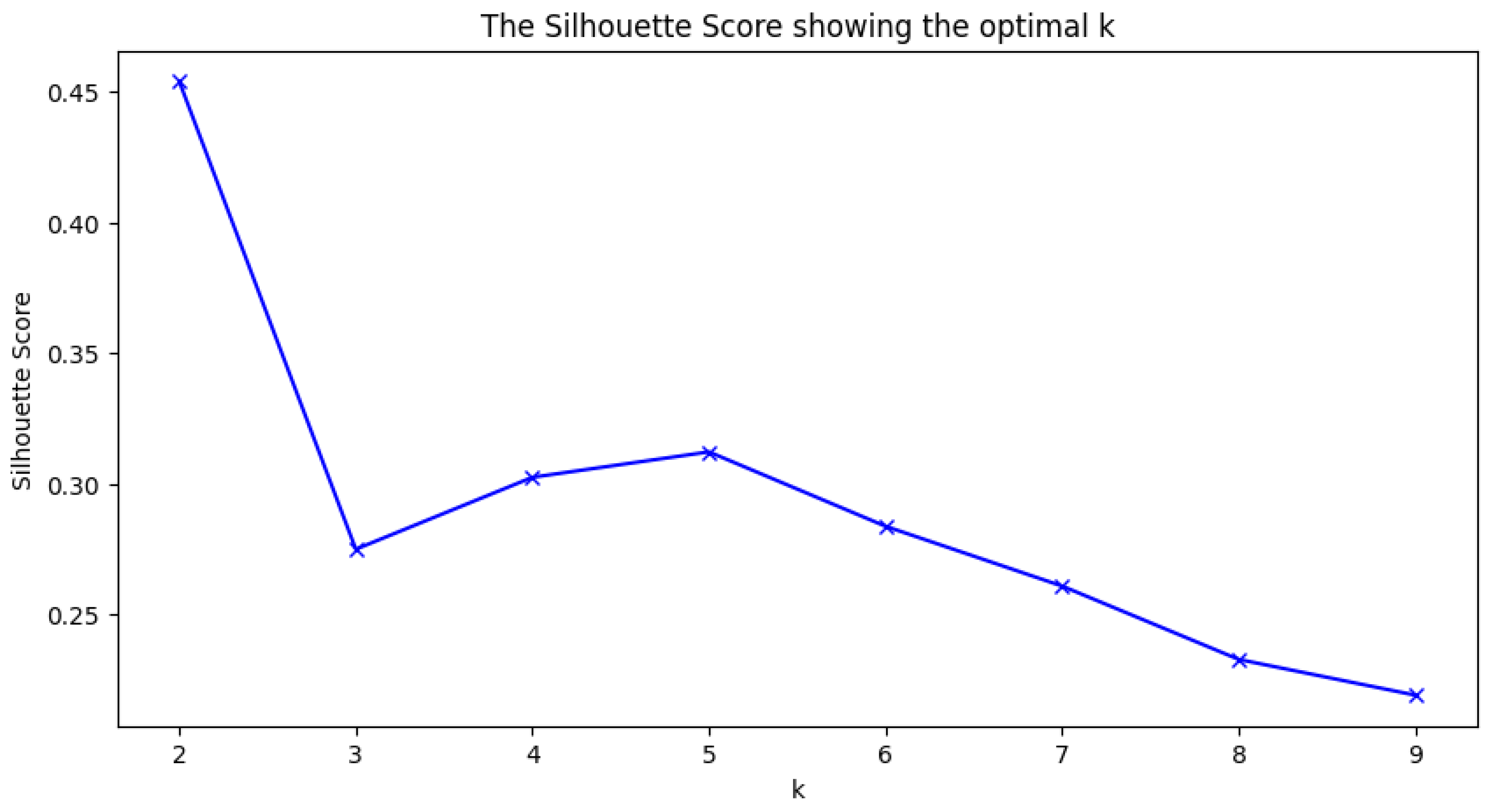
Table 2.
Predicted Event Names for Negative Life Incidents Grouped by GNN and Named by LLM
| Predicted Event Name | Representative Tweets and Terms |
|---|---|
| Troll and Non-Real Person | shelter, emergency, evacuee, free, offer, flood, help, continue, rescue, order; help, dog, relief, food, donate, cros, bag, support, away, affect; update, latest, report, president, disaster, city, head, wake, great, state; jeffpiotrowski, wind, periscope, gust, day, damag, crazy, got, last, cat; power, track, follow, story, top, without, bear, potential, map, update; disaster, gulf, open, border, first, patrol, brace, major, face, natural; rain, watch, tx, eye, rockport, water, bring, wind, barrel, wall; price, prepare, ga, oil, damage, major, san, governor, rise, cause; space, station, seen, nasa, international, cupola, victim, help, view, donation; path, look, like, monitor, david, camp, closely, fake, reporter, arriv; flood, hit, coverage, weather, house, week, channel, mis, hope, next; prayer, pray, affect, path, thought, everyone, people, god, go, know; im, get, go, hit, com, call, wait, gonna, like, cant; landfall, make, corpu, storm, christi, near, made, hit, could, southeast; people, pardon, dont, arpaio, evacuate, think, racist, good, would, coldplay |
| Trend in the Media | video, lik, change, climate, show, twitter, en, satellite, stream, approach; stay, everyone, please, hope, friend, good, path, ready, family, roar; flood, catastrophic, post, due, flee, thousand, storm, rainfall, intensifie, upgrade; center, national, say, pm, forecast, dog, number, one, threat, evacuate; storm, wind, strengthen, cat, break, toward, threaten, downgrade, year, high |
Table 3.
Predicted Event Names for Neutral Life Incidents Grouped by GNN and Named by LLM
| Predicted Event Name | Representative Tweets and Terms |
|---|---|
| The Weather Channel | report, update, video, track, special, alert, lik, price, satellite, watch; weather, channel, coverage, blog, geek, video, lik, due, condition, severe; power, en, weather, update, outage, report, wake, el, statement, atlntico; weather, report, stay, channel, people, watch, go, pray, due, reporter; update, report, follow, latest, catastrophic, flood, rockport, expect, damage, due; update, report, txwx, periscope, center, add, weather, jeffpiotrowski, national, mb; update, latest, statement, pm, watch, report, day, gulf, et, make; update, latest, major, please, water, damage, stay, br, wind, weather; update, come, center, storm, ashore, upgrade, weather, noaa, safety, statement |
| Best of Weather Reports (Last Week of Aug) | weather, information, forecast, best, aug, update, know, last, predict, beach; update, wind, weather, report, cat, kt, stay, mov, tonight, without; report, corpu, information, christi, near, update, tx, landfall, latest, make; update, landfall, latest, make, weather, service, national, storm, expect, made; wind, weather, sustain, report, update, storm, maximum, eye, max, cat; update, give, friday, abbott, break, greg, school, alert, august, gov |
| Trend in the News Cycle | weather, see, update, bad, report, could, story, rain, top, latest; report, weather, storm, hurricane, damage, rain, southeast, lash, help, wind; report, prepare, effort, jim, multiple, acosta, apparently, ignore, update, continue; update, strengthen, pm, storm, cdt, cat, track, aug, wind, information; update, storm, downgrade, tropical, latest, saturday, flood, head, toward, made |
Table 4.
Predicted Event Names for Positive Life Incidents Grouped by GNN and Named by LLM
| Predicted Event Name | Representative Tweets and Terms |
|---|---|
| The Best of the Best | good, day, pardon, friday, happy, great, arpaio, real, im, though; good, morn, luck, gulf, people, wish, cat, storm, love, rain; love, job, great, good, director, handle, bug, laud, agency, help; good, luck, love, help, victim, better, dont, deserve, near, go; love, prayer, stay, send, path, everyone, thought, affect, good, people |
| A "Good" Weather Event | good, weather, great, dog, show, food, day, side, many, bag; great, would, love, help, could, relief, storm, change, climate, like; good, far, im, happy, coverage, great, watch, power, get, keep; good, luck, everybody, bear, wish, like, love, hit, bad, im; head, good, vacation, fac, luck, great, yell, crassly, love, stay; great, state, work, city, noth, gov, monitor, chance, federal, closely; good, luck, great, tell, camp, david, way, president, watch, doesnt; good, luck, path, message, people, everybody, approach, say, said, word; god, love, great, good, hit, bless, help, thank, die, pray; happy, love, thank, birthday, take, keep, great, ill, wait, away; good, luck, get, corpu, go, th, look, people, like, say; weekend, great, good, im, love, happy, let, go, cover, look; good, great, make, landfall, go, love, impact, still, morn, wind; pray, good, everyone, love, affect, hop, first, day, great, night |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



