Submitted:
28 July 2024
Posted:
31 July 2024
You are already at the latest version
Abstract
Recommender Systems (RecSys) are crucial in managing information overload and enhancing user satisfaction across various digital platforms, including e-commerce and entertainment. Evolving from traditional models to Deep Neural Networks (DNNs) and, more recently, Large Language Models (LLMs), these systems leverage sophisticated algorithms to analyze user behaviors and preferences. LLMs, such as GPT-4, are trained on extensive datasets to comprehend and generate natural language, significantly advancing their ability to deliver personalized recommendations. This tutorial explores the transformative impact of LLMs on RecSys, discussing their development, application in handling complex datasets, and the integration of contextual insights. Real-world examples illustrate how LLMs enhance recommendation accuracy and user experience, highlighting challenges and future directions in the field.
Keywords:
Recommender Systems (RecSys)
; Large Language Models (LLMs)
; Personalized Recommendations
; Deep Neural Networks (DNNs)
1. Introduction
Recommender Systems (RecSys) are essential in navigating the vast digital landscape, addressing information overload, and enhancing user satisfaction across diverse sectors like e-commerce, entertainment, and personalized content delivery. [1]These systems utilize sophisticated algorithms to analyze user behaviors and preferences, enabling them to deliver tailored recommendations that align with individual tastes and needs. The evolution from traditional recommendation models to Deep Neural Networks (DNNs) has significantly enhanced their capabilities by integrating complex datasets and contextual insights.
For instance, consider a leading e-commerce platform that leverages DNN-based RecSys to personalize product recommendations. [2]These systems can accurately predict consumer preferences by processing vast amounts of historical user interaction data, including browsing behaviors, purchase histories, and demographic information. This capability enhances user experience by suggesting relevant products, increasing conversion rates and customer satisfaction.
In recent years, the emergence of Large Language Models (LLMs) has revolutionized how recommendation tasks are approached. [3,4,5]These models, such as GPT-4, are trained on massive datasets to understand and generate natural language text. In the context of recommender systems, LLMs can interpret nuanced user queries, comprehend product descriptions, and incorporate contextual information such as current trends or user sentiment from reviews. This advanced natural language processing (NLP) capability allows LLMs to provide more nuanced and effective recommendations, further improving user engagement and satisfaction.
This tutorial aims to delve into the transformative impact of LLMs on recommender systems, offering insights into their development, practical application, and the challenges they present. By exploring real-world examples and case studies, we aim to illustrate how LLMs can be harnessed to enhance recommendation accuracy, personalization, and the overall user experience across various domains.
1. Background and Related Work
2.1. Large Language Model (LLM)
Recent advancements in natural language processing have been pivotal, especially with the rise of Large Language Models (LLMs) equipped with billions of parameters. These transformer-based models are trained on extensive textual data from diverse sources, enabling them to effectively comprehend and generate human-like language responses. [6]LLMs exhibit remarkable language understanding, generation, and reasoning capabilities, which significantly enhance their adaptability to various recommendation tasks. Unlike traditional models, LLMs demonstrate impressive generalization skills, requiring minimal fine-tuning to excel in new tasks by leveraging their learned knowledge and reasoning abilities. Techniques like in-context learning further bolster their performance in complex decision-making processes, making them invaluable for next-generation recommender systems.
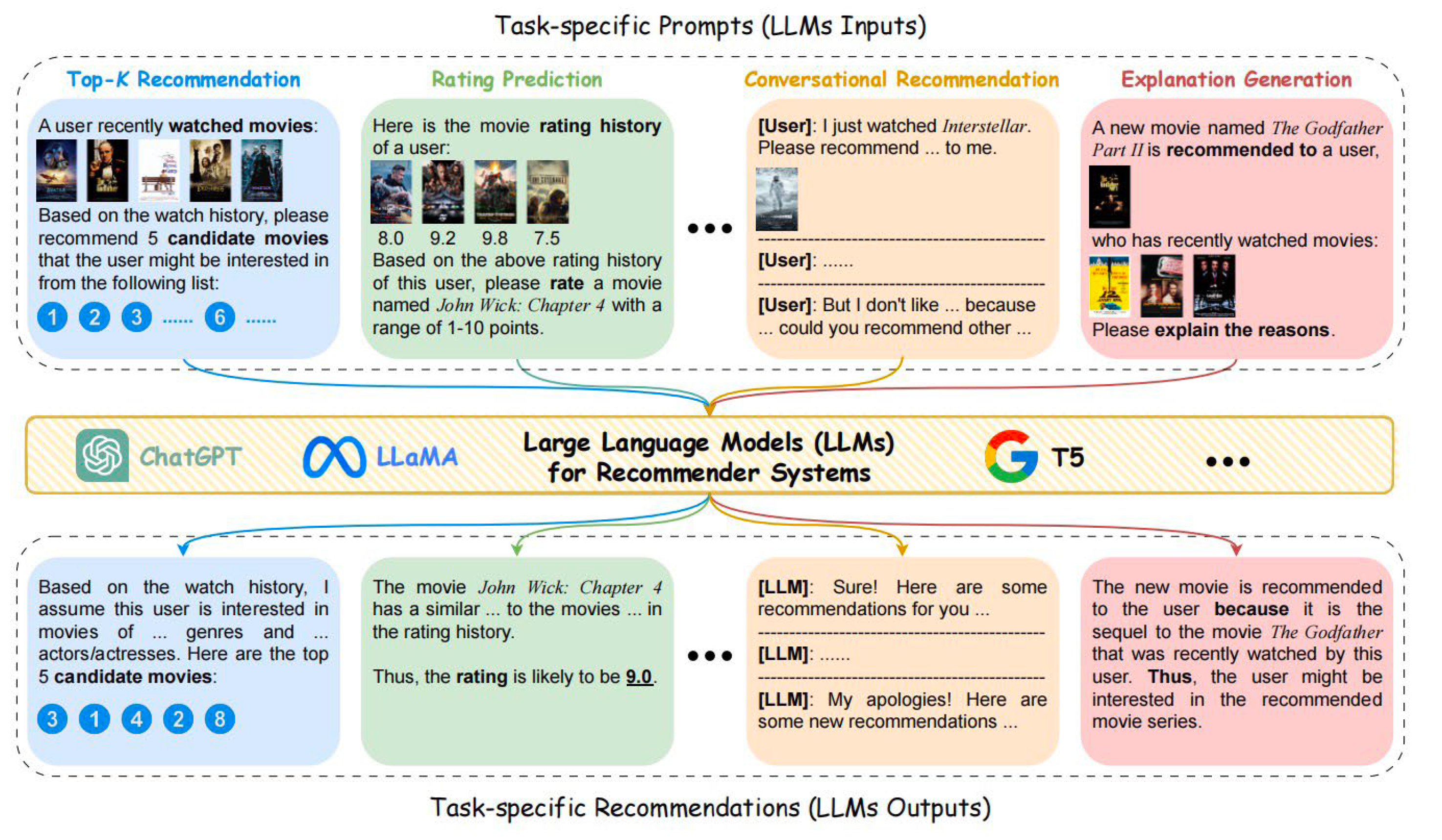
Recent advancements in natural language processing have been pivotal, especially with the rise of Large Language Models (LLMs) equipped with billions of parameters. [7,8,9]These transformer-based models are trained on extensive textual data from diverse sources, enabling them to effectively comprehend and generate human-like language responses. LLMs exhibit remarkable language understanding, generation, and reasoning capabilities, which significantly enhance their adaptability to various recommendation tasks. Unlike traditional models, LLMs demonstrate impressive generalization skills, requiring minimal fine-tuning to excel in new tasks by leveraging their learned knowledge and reasoning abilities. Techniques like in-context learning further bolster their performance in complex decision-making processes, making them invaluable for next-generation recommender systems.
2.2. Limitations of Existing Recommender Systems
Despite their successes, advanced recommender systems face intrinsic limitations that hinder their performance across various scenarios. [10]Firstly, traditional DNN-based models like CNNs, LSTMs, and pre-trained language models such as BERT often struggle to capture nuanced textual knowledge about users and items. This limitation results in suboptimal prediction performance in recommendation tasks that require sophisticated natural language understanding. Additionally, these systems are typically tailored to specific tasks, such as movie rating predictions, and often lack generalization abilities to unseen recommendation scenarios like top-k recommendations with explanations. [11]Moreover, current DNN-based methods excel in simple decision-making tasks but must improve in complex, multi-step decision processes that necessitate extensive reasoning, such as trip-planning recommendations.
2.3. Recommender Systems (RecSys)
To address the challenge of information overload, recommender systems have become essential tools in various online applications by providing personalized content and services to individual users. These systems typically employ two primary approaches [12,13]: Collaborative Filtering (CF) and Content-based recommendation.
Collaborative Filtering (CF) methods analyse user behavior patterns to predict future interactions based on historical data such as purchase history or ratings[14,15,16,17]. Matrix Factorization (MF), a popular CF technique, learns user and item representations from user-item interactions. It encodes discrete user and item IDs into embedding vectors, enabling efficient computation of matching scores for recommendations.
Content-based recommendation methods leverage additional information about users or items, such as demographics or item descriptions, to enhance user and item representations and improve recommendation accuracy. [18]Textual information is particularly valuable in this context as it enriches understanding of user preferences and item characteristics.
Deep learning techniques have significantly advanced recommender systems by enhancing representation learning capabilities. For example, models like Neural Matrix Factorization (NeuMF) use deep neural networks to capture nonlinear interactions between users and items, surpassing traditional linear models[19,20,21]. Additionally, Graph Neural Networks (GNNs) have emerged as powerful tools for learning meaningful representations of nodes (users and items) in graph-structured data, utilizing message propagation strategies tailored for recommender systems.

Examples and Applications: 1) Streaming Services: Platforms like Netflix use collaborative filtering to recommend movies and TV shows based on user viewing history. 2) E-commerce Platforms: Websites like Amazon integrate content-based recommendations to suggest products based on user preferences and item descriptions[22]. 3) Music Streaming: Services like Spotify utilize deep learning models to recommend music based on user listening patterns and preferences, providing personalized playlists and recommendations.
Deep Representation Learning for LLM-Based Recommender Systems
In the domain of recommender systems, effectively managing information overload is crucial. Recommender systems leverage sophisticated algorithms to tailor content and services to individual users, thereby enhancing user satisfaction and engagement across various online applications.
3.1. Atomic Units in Recommender Systems
Users and items are the bedrock of recommender systems, pivotal in tailoring content and services to individual preferences across various digital platforms. [23]Traditionally, these entities are identified and managed through unique indices, or discrete IDs, which streamline capturing user interactions with items. These interactions, from clicks and likes to purchases and ratings, form the basis for predicting user preferences and recommending relevant content. Matrix Factorization techniques exemplify this approach by decomposing the user-item interaction matrix into latent factors, effectively learning representations that optimize recommendation accuracy based on historical behaviors.
In recent years, however, the limitations of ID-based systems have become apparent, particularly in handling sparse interaction data and incorporating richer contextual information. [24]To address these challenges, recommender systems have embraced textual side information integration, leveraging advancements in natural language processing (NLP)[25,26,27]. By encoding textual descriptions, reviews, or metadata associated with users and items into dense embeddings using models like BERT[28] or GPT[29], recommender systems can capture semantic relationships and nuanced preferences more effectively. This hybrid approach enhances recommendation accuracy and enriches user experiences by offering more contextually relevant suggestions. Techniques such as Unisec and text-based collaborative filtering (TCF)[30 illustrate this evolution, demonstrating how textual embeddings can complement traditional ID-based representations to improve recommendation quality across diverse application domains.
These advancements underscore a shift towards more sophisticated recommender systems capable of leveraging both structured ID-based data and unstructured textual information[31]. By integrating these approaches, recommender systems can better adapt to user preferences and deliver personalized recommendations that enhance user engagement and satisfaction in today's digital landscape.
3.2. ID-Based Recommender Systems
ID-based recommender systems model user-item interactions by learning embedding vectors for users and items. In [32]LLM-based systems, users and items are represented as "[prefix] [ID]", where the prefix signifies the type (user or item) and the ID uniquely identifies the entity. For instance, the [33,34]P5 framework integrates various recommendation data formats into natural language sequences using a pre-trained T5 backbone with personalized prompts.
Hua et al. propose several indexing strategies within P5, such as sequential, collaborative, semantic (content-based), and hybrid indexing, emphasizing the importance of effective indexing methods for recommendation tasks. Semantic IDs, utilizing codewords with semantic meanings for each user or item, offer a hierarchical approach to enhance representation learning.
3.3. Textual Side Information-Enhanced Recommender Systems
While ID-based methods are robust, they face challenges in capturing semantic information essential for effective recommendations, especially with sparse user-item interactions. [35,36]Textual side information, including user profiles and item descriptions, enriches the representation of users and items. Language models like BERT encode this textual information, enabling fine-grained analysis of user interests and item characteristics.
Approaches like Unisec utilize item descriptions to develop universal item representations, employing techniques such as parametric whitening and mixture-of-experts (MoE) [37] enhanced adaptors. Text-based collaborative filtering (TCF), leveraging LLMs like GPT-3, outperforms traditional ID-based methods by effectively utilizing textual side information.
VQ-Rec introduces vector-quantized item representations to mitigate over-reliance on text features, mapping item descriptions into discrete indices for efficient retrieval. Zero-Shot Item-based Recommendation (ZSIR) incorporates Product Knowledge Graphs (PKG) [38,39]to refine item features, while Shopper BERT pre-trains user embeddings based on purchase history for personalized recommendations.
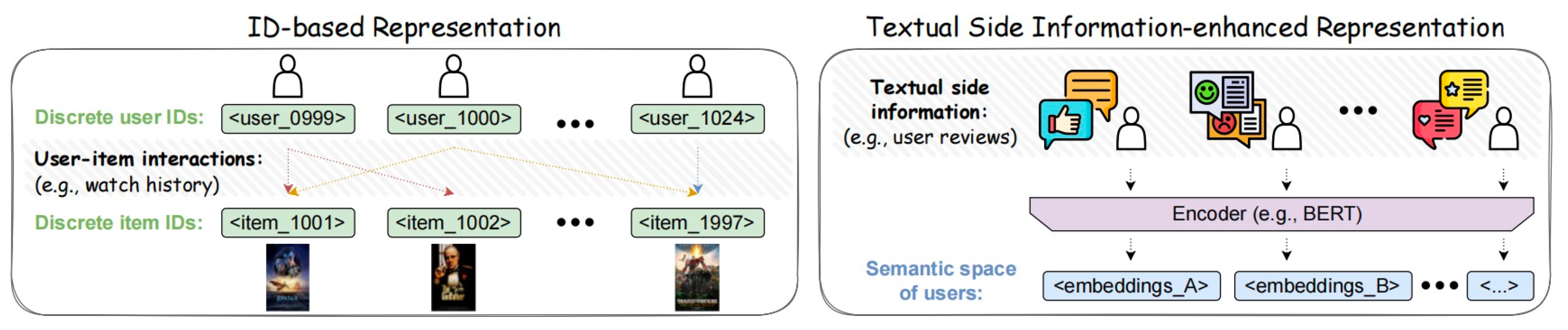
IDA-SR, an ID-Agnostic User Behavior Pre-training framework, utilizes pre-trained [40]LLMs to extract representations from item descriptions directly, enhancing sequential recommendation tasks without relying solely on ID-based indices.
Integrated with LLMs, deep representation learning enhances recommender systems' sophistication by leveraging both ID-based and textual side information approaches. These advancements aim to provide more accurate and personalized recommendations, addressing the dynamic needs of users in diverse online applications. As research progresses, further innovations in representation learning are expected to refine recommendation algorithms, ensuring optimal user experience and engagement.
Conclusions
In conclusion, Large Language Models (LLMs) represent a cutting-edge AI technology that has demonstrated remarkable success across diverse applications, including molecule discovery and finance. Their capabilities in language understanding, generation, generalization, and adaptation to new tasks have positioned them as pivotal tools in revolutionizing recommender systems (RecSys). This survey has provided a comprehensive overview of LLM-empowered RecSys, focusing on methodologies such as pre-training, fine-tuning, and prompting paradigms. Despite the rapid evolution observed in LLM applications within RecSys, the current research landscape remains relatively nascent. Moving forward, there is a critical need for more systematic and comprehensive studies to harness the full potential of LLMs in enhancing recommendation quality and personalization. Addressing these challenges will pave the way for future advancements in this dynamic field.
Furthermore, the survey identifies several promising avenues for future research in LLM-empowered RecSys. These include exploring advanced techniques in pre-training and fine-tuning LLMs specific to recommendation tasks, integrating multi-modal data for more affluent user and item representations, and developing novel evaluation metrics to assess the efficacy of LLM-based recommendation systems comprehensively. By addressing these areas, researchers and practitioners can further advance the state-of-the-art in personalised recommendation services, meeting the increasing demands for high-quality, context-aware suggestions across various domains.
Acknowledgments
Acknowledgments are extended to Zhan, X., Shi, C., Li, L., Xu, K., & Zheng, H. (2024) for their contributions to the paper titled [1]"Aspect Category Sentiment Analysis Based on Multiple Attention Mechanisms and Pre-trained Models," published in Applied and Computational Engineering. Their research has significantly advanced the field of sentiment analysis by integrating multiple attention mechanisms and pre-trained models for aspect category sentiment analysis. Their work has provided valuable insights and methodologies that enhance the accuracy and efficiency of sentiment analysis applications, contributing to both theoretical advancements and practical implementations in computational engineering. Acknowledgments are extended to Zhan, T., Shi, C., Shi, Y., Li, H., & Lin, Y. (2024) for their contributions to the paper titled [2]"Optimization Techniques for Sentiment Analysis Based on LLM (GPT-3)," published as an arXiv preprint (arXiv:2405.09770). Their research has significantly advanced sentiment analysis techniques by optimizing methodologies based on Large Language Models (LLMs) like GPT-3. Their work has provided valuable insights and technical innovations that improve the accuracy and efficiency of sentiment analysis applications, contributing to both theoretical advancements and practical implementations in natural language processing.
References
- Zhan, X.; Shi, C.; Li, L.; Xu, K.; Zheng, H. (2024). Aspect category sentiment analysis based on multiple attention mechanisms and pre-trained models. Applied and Computational Engineering, 71, 21-26.
- Zhan, T.; Shi, C.; Shi, Y.; Li, H.; Lin, Y. (2024). Optimization Techniques for Sentiment Analysis Based on LLM (GPT-3). arXiv:2405.09770.
- Guo, Lingfeng, et al. "Bank Credit Risk Early Warning Model Based on Machine Learning Decision Trees." Journal of Economic Theory and Business Management 1.3 (2024): 24-30.
- Zhan, X.; Ling, Z.; Xu, Z.; Guo, L.; Zhuang, S. (2024). Driving Efficiency and Risk Management in Finance through AI and RPA. Unique Endeavor in Business & Social Sciences, 3(1), 189-197.
- Zheng, H.; Wu, J.; Song, R.; Guo, L.; Xu, Z. (2024). Predicting Financial Enterprise Stocks and Economic Data Trends Using Machine Learning Time Series Analysis.
- Song, R.; Wang, Z.; Guo, L.; Zhao, F.; Xu, Z. (2024). Deep Belief Networks (DBN) for Financial Time Series Analysis and Market Trends Prediction.
- Shi, Y.; Yuan, J.; Yang, P.; Wang, Y.; Chen, Z. Implementing Intelligent Predictive Models for Patient Disease Risk in Cloud Data Warehousing.
- Lin, Y.; Li, A.; Li, H.; Shi, Y.; Zhan, X. (2024). GPU-Optimized Image Processing and Generation Based on Deep Learning and Computer Vision. Journal of Artificial Intelligence General science (JAIGS) ISSN: 3006-4023, 5(1), 39-49.
- Chen, Zhou, et al. "Application of Cloud-Driven Intelligent Medical Imaging Analysis in Disease Detection." Journal of Theory and Practice of Engineering Science 4.05 (2024): 64-71.
- Wang, B.; Lei, H.; Shui, Z.; Chen, Z.; Yang, P. (2024). Current State of Autonomous Driving Applications Based on Distributed Perception and Decision-Making.
- Yang, T.; Xin, Q.; Zhan, X.; Zhuang, S.; Li, H. (2024). ENHANCING FINANCIAL SERVICES THROUGH BIG DATA AND AI-DRIVEN CUSTOMER INSIGHTS AND RISK ANALYSIS. Journal of Knowledge Learning and Science Technology ISSN: 2959-6386 (online), 3(3), 53-62.
- Zhan, X.; Ling, Z.; Xu, Z.; Guo, L.; Zhuang, S. (2024). Driving Efficiency and Risk Management in Finance through AI and RPA. Unique Endeavor in Business & Social Sciences, 3(1), 189-197.
- Li, Zihan, et al. "Robot Navigation and Map Construction Based on SLAM Technology." (2024).
- Fan, C.; Ding, W.; Qian, K.; Tan, H.; Li, Z. (2024). Cueing Flight Object Trajectory and Safety Prediction Based on SLAM Technology. Journal of Theory and Practice of Engineering Science, 4(05), 1-8.
- Ding, W.; Tan, H.; Zhou, H.; Li, Z.; Fan, C. Immediate Traffic Flow Monitoring and Management Based on Multimodal Data in Cloud Computing.
- Zhou, Y.; Zhan, T.; Wu, Y.; Song, B.; Shi, C. (2024). RNA Secondary Structure Prediction Using Transformer-Based Deep Learning Models. arXiv:2405.06655.
- Liu, B.; Cai, G.; Ling, Z.; Qian, J.; Zhang, Q. (2024). Precise Positioning and Prediction System for Autonomous Driving Based on Generative Artificial Intelligence. Applied and Computational Engineering, 64, 42-49.
- Cui, Z.; Lin, L.; Zong, Y.; Chen, Y.; Wang, S. (2024). Precision Gene Editing Using Deep Learning: A Case Study of the CRISPR-Cas9 Editor. Applied and Computational Engineering, 64, 134-141.
- Wang, B.; He, Y.; Shui, Z.; Xin, Q.; Lei, H. (2024). Predictive Optimization of DDoS Attack Mitigation in Distributed Systems using Machine Learning. Applied and Computational Engineering, 64, 95-100.
- Song, R.; Wang, Z.; Guo, L.; Zhao, F.; Xu, Z. (2024). Deep Belief Networks (DBN) for Financial Time Series Analysis and Market Trends Prediction.
- Xu, Z.; Guo, L.; Zhou, S.; Song, R.; Niu, K. (2024). Enterprise Supply Chain Risk Management and Decision Support Driven by Large Language Models. Applied Science and Engineering Journal for Advanced Research, 3(4), 1-7.
- Bai, X.; Zhuang, S.; Xie, H.; Guo, L. (2024). Leveraging Generative Artificial Intelligence for Financial Market Trading Data Management and Prediction.
- Sha, X. (2024). Research on financial fraud algorithm based on federal learning and big data technology. arXiv preprint . arXiv:2405.03992.
- Guo, L.; Song, R.; Wu, J.; Xu, Z.; Zhao, F. (2024). Integrating a Machine Learning-Driven Fraud Detection System Based on a Risk Management Framework.
- Xin, Q.; Song, R.; Wang, Z.; Xu, Z.; Zhao, F. (2024). Enhancing Bank Credit Risk Management Using the C5. 0 Decision Tree Algorithm. Journal Environmental Sciences And Technology, 3(1), 960-967.
- Srivastava, S.; Huang, C.; Fan, W.; Yao, Z. (2023). Instance Needs More Care: Rewriting Prompts for Instances Yields Better Zero-Shot Performance. arXiv preprint . arXiv:2310.02107.
- Yang, T.; Xin, Q.; Zhan, X.; Zhuang, S.; Li, H. (2024). ENHANCING FINANCIAL SERVICES THROUGH BIG DATA AND AI-DRIVEN CUSTOMER INSIGHTS AND RISK ANALYSIS. Journal of Knowledge Learning and Science Technology ISSN: 2959-6386 (online), 3(3), 53-62.
- Bai, X.; Zhuang, S.; Xie, H.; Guo, L. (2024). Leveraging Generative Artificial Intelligence for Financial Market Trading Data Management and Prediction.
- Zhan, X.; Ling, Z.; Xu, Z.; Guo, L.; Zhuang, S. (2024). Driving Efficiency and Risk Management in Finance through AI and RPA. Unique Endeavor in Business & Social Sciences, 3(1), 189-197.
- Sun, Y. (2024). TransTARec: Time-Adaptive Translating Embedding Model for Next POI Recommendation. arXiv preprint . arXiv:2404.07096.
- Xu, Z.; Guo, L.; Zhou, S.; Song, R.; Niu, K. (2024). Enterprise Supply Chain Risk Management and Decision Support Driven by Large Language Models. Applied Science and Engineering Journal for Advanced Research, 3(4), 1-7.
- Ma, H. (2021, September). Automatic positioning system of medical service robot based on binocular vision. In 2021 3rd International Symposium on Robotics & Intelligent Manufacturing Technology (ISRIMT) (pp. 52-55). IEEE.
- Zhan, X.; Shi, C.; Li, L.; Xu, K.; Zheng, H. (2024). Aspect category sentiment analysis based on multiple attention mechanisms and pre-trained models. Applied and Computational Engineering, 71, 21-26.
- Wu, B.; Xu, J.; Zhang, Y.; Liu, B.; Gong, Y.; Huang, J. (2024). Integration of computer networks and artificial neural networks for an AI-based network operator. arXiv preprint . arXiv:2407.01541.
- Liang, P.; Song, B.; Zhan, X.; Chen, Z.; Yuan, J. (2024). Automating the training and deployment of models in MLOps by integrating systems with machine learning. Applied and Computational Engineering, 67, 1-7.
- Xiao, Jue, et al. "Application progress of natural language processing technology in financial research." Financial Engineering and Risk Management 7.3 (2024): 155-161.
- Zhang, Y.; Liu, B.; Gong, Y.; Huang, J.; Xu, J.; Wan, W. (2024). Application of machine learning optimization in cloud computing resource scheduling and management. Applied and Computational Engineering, 64, 9-14.
- Li, J.; Wang, Y.; Xu, C.; Liu, S.; Dai, J.; Lan, K. (2024). Bioplastic derived from corn stover: Life cycle assessment and artificial intelligence-based analysis of uncertainty and variability. Science of The Total Environment, 174349.
- Haowei, M. A.; et al. "Employing Sisko non-Newtonian model to investigate the thermal behavior of blood flow in a stenosis artery: Effects of heat flux, different severities of stenosis, and different radii of the artery." Alexandria Engineering Journal 68 (2023): 291-300.
- Huang, J.; Zhang, Y.; Xu, J.; Wu, B.; Liu, B.; Gong, Y. Implementation of Seamless Assistance with Google Assistant Leveraging Cloud Computing.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



