Submitted:
12 August 2024
Posted:
14 August 2024
You are already at the latest version
Abstract
In recent years, with the development of the Internet of Things and distributed computing, the "server-edge device" architecture has been widely deployed. This study focuses on leveraging autoencoder technology to address the binary classification problem in network intrusion detection, aiming to develop a lightweight model suitable for edge devices. Traditional intrusion detection models face two main challenges when directly ported to edge devices: inadequate computational resources to support large-scale models and the need to improve the accuracy of simpler models. To tackle these issues, this research utilizes Extreme Learning Machine for its efficient training speed and compact model size to implement autoencoders. Two improvements over the latest related work are proposed: First, to improve data purity and ultimately enhance detection performance, this study partitions the data into multiple regions based on the prediction results of these autoencoders. Second, leveraging autoencoder characteristics to investigate further the data within each region. We used the public dataset NSL-KDD to test the behavior of the proposed mechanism. The experimental results show that when dealing with multi-class attacks, the model's performance was significantly improved, the accuracy and the F1-score are improved by 3.5% and 2.9%, respectively maintaining its lightweight nature.
Keywords:
autoencoder
; network intrusion detection
; model accuracy improvement
; Extreme Learning Machine
1. Introduction
1.1. Background and Motivation
IoT (Internet of Things) refers to a network of interconnected devices facilitating communication between devices themselves and with the cloud. With advancements in computer hardware and increasing communication bandwidth, IoT has permeated our daily life. IoT technology enables smart applications across various domains, significantly enhancing productivity. Examples include integrated digital infrastructure in smart cities, vehicle traffic monitoring in intelligent transportation systems, and automated control of household devices in smart homes, among others [1]. Although often unnoticed, IoT has indeed infiltrated various fields.
Despite its ubiquitous presence, IoT development has not always been benign. According to Gartner, approximately 20% of enterprises or related entities experienced at least one IoT-based attack between 2015 and 2017 [2]. Some of these attacks had significant impact, such as the Mirai botnet, predominantly comprising embedded and IoT devices, which launched large-scale attacks in September 2016, crippling several prominent websites. Within the first 20 hours, the above-mentioned Mirai botnet infected nearly 65,000 IoT devices, stabilizing at 200,000 to 300,000 infected devices, marking one of the largest recorded attacks [3]. Additionally, incidents like the BlackEnergy attack on Ukraine's power grid [4], the Stuxnet attack on centrifuges in Iran's nuclear facilities [5], and the exploitation of baby monitors for household surveillance [6] underscore ongoing security challenges.
To bolster IoT device security, reliable Intrusion Detection Systems (IDS) are essential. IDS generally fall into two categories: 1) signature-based IDS, and 2) anomaly-based IDS. Signature-based IDS use predefined signatures or patterns to detect known attack types, triggering alerts when network traffic or behavior matches these signatures. Anomaly-based IDS, on the other hand, establish baselines of normal behavior and detect deviations indicative of potential attacks, often leveraging machine learning to identify anomalous behavior.
Compared to anomaly-based IDS, signature-based IDS typically offer higher detection accuracy but are limited to known attacks, rendering them ineffective against unknown threats. Moreover, signature-based IDS require continual updates to their signature databases to combat new threats, which can lead to system bloat and increased response times. Lastly, the manual intervention required for signature-based IDS is impractical in IoT contexts [7]. Therefore, this study opts for an anomaly-based IDS approach using machine learning to detect attacks.
The next challenge is selecting appropriate machine learning models for intrusion detection, considering the constraints of IoT edge devices [8]: limited memory and computational resources make complex model execution difficult. Additionally, IoT devices generate sparse network traffic compared to common devices, often triggered by infrequent user interactions, and bandwidth constraints are common. Furthermore, some IoT applications require rapid response times. Hence, lightweight yet accurate models are crucial for deployment on IoT devices.
1.2. Related Work
1.2.1. Autoencoder and Its Application to Intrusion Detection
An autoencoder is a neural network with the learning objective of making the output identical to the input. Its structure is divided into two parts: the encoder and the decoder. As shown in Figure 1, the encoder compresses the data into a low-dimensional space, and the decoder restores it to reconstruct the original data. Because the autoencoder can effectively extract features from the data during this process, early autoencoders were often used for data compression and feature learning. After the Backpropagation (BP) algorithm was proposed [9], the autoencoder algorithm, as one of the implementations of BP, also gained attention. The formal introduction of autoencoders as a type of neural network structure came from Yann LeCun's research published in 1987 [10]. Since then, autoencoders have continuously evolved and have spawned many variants. Today, one of the uses of autoencoders is for unsupervised learning, handling binary classification tasks.
The steps for using an autoencoder for attack detection are as follows: First, train the autoencoder using normal data. Then, input the data to be detected and calculate the reconstruction error. Generally, for normal data, the reconstruction error is small, while for attack data, the reconstruction error is large. Based on this reconstruction error, if it exceeds a pre-set threshold, the data is identified as attack data. For instance, Hyunseung Choi et al. utilized four models—basic autoencoder, denoising autoencoder, stacked autoencoder, and variational autoencoder—to train the training data and classify normal and abnormal data by setting thresholds [11]. Autoencoders can also be combined with other models. For example, Cosimo Ieracitano et al. proposed a deep classifier based on autoencoders [12], where the low-dimensional feature vectors obtained from the encoding stage are fed into a dense fully connected layer, and the Softmax activation function is used to classify the data as normal or abnormal. It is evident that autoencoders play a significant role in the field of attack detection.
1.2.2. On-Device Learning Anomaly Detector
ONLAD(On-Device Learning Anomaly Detector) [13] is an autoencoder model for detecting network intrusions that employs ELM (Extreme Learning Machine) as its main component.
ELM is a machine learning algorithm for single-hidden layer feedforward neural networks, proposed by Guang-Bin Huang et al. in 2004 [14]. Unlike traditional gradient descent methods that iteratively update all weight parameters, ELM randomly selects input weights and analytically determines output weights using matrix inversion. This approach avoids issues such as overfitting and local minima associated with gradient descent methods, significantly improving learning speed and generalization performance. Additionally, since ELM has only one hidden layer, the model is relatively small in scale. It can be said that ELM is a lightweight machine learning model in terms of both time and space efficiency.
Figure 2 illustrates the basic architecture of ONLAD. In the figure, α represents the input weights, β the output weights, b the bias vector, and G the activation function. The objective of ONLAD is to generate the output y from the input x through the model and make y as close as possible to the target t. Since ONLAD operates as an autoencoder, t is the same as x. The process of generating y can be represented by the following formula:
After α and b are randomly initialized, they are not changed. The parameter β is continuously updated. Let H denote the output of the hidden layer, which is G(xα + b). The optimal output weights β̂ are calculated as follows:
Here, is the pseudoinverse of H.
In the -th round of the learning process, the calculation of βi for updating the model parameters is as follows:
Specifically, at the very beginning, and .
1.2.3. Multiple Autoencoders Joint Decision-Making
In the above ONLAD scheme, researchers trained an autoencoder using normal data and used this autoencoder for intrusion detection. However, different types of attacks have different sensitivities to different features. For example, feature a contains a lot of information about DoS attacks but almost no information about Probe attacks. In this case, if the same features are used to train the model indiscriminately, the model's generalization ability will be poor. The solution is to train a separate autoencoder model for each type of attack. This way, each autoencoder can focus on detecting a specific type of attack and be trained based on the best features for that type of attack.
Therefore, in the paper [15], faced with the NSL-KDD dataset [16] (which includes normal data and four types of attacks: DDoS, Probe, R2L, and U2R), four corresponding autoencoders were trained for each type of attack. Each autoencoder was trained using the same normal data but with different features. The specific features used by each autoencoder are shown in Table 1.
When all four autoencoders determine the data to be normal, the detection result is normal. If any one of the autoencoders determines the data to be abnormal, the data is classified as abnormal, triggering an alert.
This tailored improvement makes the model more adept at handling complex, non-single type attacks in network traffic.
1.3. Challenges in This Study
To develop a network intrusion detection system suitable for an IoT environments, we propose two key requirements: first, the model should be as lightweight as possible; second, the model's detection accuracy should be maximized. The first requirement can be achieved using the Extreme Learning Machine mentioned earlier, as long as no significant additional load is added to the model that would drastically increase time or space complexity. However, the previous research [15] mentioned in Section 1.2 has shown shortcomings in addressing the second requirement. Ideally, the distribution of data in the feature space should have clearly defined boundaries between normal and attack data. However, due to the complexity of network traffic, in most scenarios, different types of data often overlap, making it difficult to accurately detect the anomalies. Therefore, this study focuses on reducing the complexity of data distribution in the feature space, aiming to improve the final detection performance of the model.
1.4. Our Contributions
The main contributions of this work can be briefly summarized as follows:
- The concept of paired autoencoders is introduced, where an autoencoder trained on attack data is paired with another trained on normal data.
- The data is partitioned into multiple regions to reduce the complexity of data distribution in each region and finally to improve the detection performance. For this purpose, multiple autoencoders are used for initial data prediction, and based on the prediction results, the data is partitioned.
- The threshold characteristics of the autoencoders are leveraged to precisely detect data types within each region.
- Even when dealing with traffic that contains a mix of different types of attacks, our proposal performs well, as has been validated on the public dataset (NSL-KDD).
2. Literature Review
Before formally introducing the content of this research, this section will elaborate on some relevant studies concerning network intrusion detection systems in IoT environments that have been investigated in recent years.
Intrusion detection systems (IDS) can generally be classified into two types: signature-based and anomaly-based. In traditional network security, signature-based IDS are more common, such as firewalls on personal PCs. Naturally, they also have their applications in IoT environments. In a paper by Philokypros P. Ioulianou et al. [17], a novel signature-based IDS is proposed. This system consists of IDS sensors deployed near the sensor end and IDS routers responsible for running detection modules and firewalls. The IDS sensors monitor and report suspicious activities to the IDS routers, which match the forwarded packets with malicious signatures and establish firewall rules based on the matching results.
Considering the possibility of internal attacks in collaborative intrusion detection systems (CIDS) in IoT environments, Li et al. proposed a consensus framework combining blockchain technology and signature-based IDS, called CBSigIDS (Collaborative Blockchained Signature-based Intrusion Detection System) [18]. They assume that in this scenario, attackers have the opportunity to control one or more nodes in the CIDS. To address this, each IDS node identifies attacks and periodically shares a set of signatures encrypted with its private key with other nodes. Before accepting these signatures, other nodes verify them against their local databases. Thus, by using blockchain technology, CBSigIDS provides a verifiable signature-sharing method for CIDS without the need for a trusted intermediary.
Nazim Uddin Sheikh et al. proposed a pattern matching algorithm to compare the DNA sequences of data to be detected with signatures in the signature database [19]. Simply put, this algorithm compares the session DNA sequences with signatures, calculating a similarity score. If the similarity exceeds a preset threshold, the session is marked as an attack.
The above are all signature-based IDS, but this type of IDS has its own drawbacks: firstly, it cannot detect unknown attacks; secondly, IoT edge devices may not be able to support large signature databases. Therefore, more people choose anomaly-based IDS as a solution for IoT environments, with machine learning being widely studied as an implementation method. Wai Weng Lo et al. proposed a novel network intrusion detection system called E-GraphSAGE [20], which is based on GNN(Graph Neural Networks). The GraphSAGE method can capture edge features and topological information of the graph, achieving edge classification to detect malicious network traffic. This method has achieved good results on four NIDS benchmark datasets such as BoT-IoT.
For GNN-based IDS in IoT environments, Zhou et al. proposed a new hierarchical adversarial attack generation method [21]. This method uses salient graph technology to identify key elements in the feature space and generates adversarial samples by minimally perturbing these key elements. Additionally, they use a hierarchical node selection algorithm based on random walks to find the most vulnerable nodes in IoT as attack targets. The combination of these two algorithms reduces the detection accuracy of two state-of-the-art GNN models by 30%.
Muder Almiani et al. proposed a network intrusion detection model in a fog computing environment [22]. This model adopts a two-layer detection structure, each layer using deep recurrent neural networks with different internal structures and parameter settings. The first layer mainly detects DoS attacks, while the second layer filters out hard-to-detect attacks such as R2L and U2R.
In the context of smart homes, Wang et al. proposed an intrusion detection system based on Transformer [23]. The method used by this system utilizes a self-attention mechanism to learn contextual embeddings of network features, capable of handling both continuous and categorical features simultaneously. It achieved good results on the ToN IoT dataset, with 97.95% accuracy for binary classification and 95.78% for multi-class classification.
Salam Fraihat et al. compared four feature selection algorithms—AOA, WSO, GWO, and BAT—in their paper [24], and combined them with various machine learning models such as RF, NB, and DT. They ultimately selected the optimal combination to build an IDS suitable for large-scale IoT networks.
Most of the machine learning models used in the above studies are supervised learning models. However, the preliminary research for this study, which is based on unsupervised learning models—autoencoders, is described in papers [13,15]. The research in these two papers has been thoroughly discussed in Section 1.2.
3. Our Proposal
3.1. Overviews
As shown in Figure 3, the overall process of our propal is as follows: First, multiple autoencoders are trained using attack data and combined with the original autoencoders trained with normal data for joint decision-making. Based on the decision results, the data to be detected is partitioned into four regions: quasi-normal region, quasi-attack region, divergence region, and undetermined region. The data in the divergence region can be further divided into multiple sub-regions which will be explained in detail later. For a specific region, the best-performing autoencoder from all previously trained autoencoders is selected as the classifier for that region, determining whether the data is normal or an attack.
Next, we will provide a detailed introduction to each stage.
3.2. Training Multiple Autoencoders Using Attack Data and Normal Data, Respectively
Typically, autoencoders used for attack detection are trained only on normal (negative) data. However, because the classification results of autoencoders are based on thresholds and proper thresholds are very difficult to be predefined. Thus, there will always be some anomalous data below the threshold since we don’t want to make the false positive rate very high. This leads to situations where intrusion data is present but no alert is triggered, which is fatal for an Intrusion Detection System (IDS). To minimize this issue, in this study, we additionally trained multiple autoencoders, each with a training set consisting of various types of attack data paired with the best features for that type of attack. In other words, these autoencoders are trained on positive data. Unlike traditional autoencoders, the new autoencoder indicates an attack has been detected when the reconstruction error is less than the threshold.
Now, we train multiple autoencoders using both normal and attack data distributions. For example, for a dataset containing normal data and three types of attacks (denoted as Attack1, Attack2, and Attack3), a total of six autoencoders need to be trained, including four models trained on normal data and four models trained on attack data. We name these autoencoders as Attack1_neg, Attack2_neg, Attack3_neg, Attack1_pos, Attack2_pos, and Attack3_pos. The part before the underscore in the names represents the type of attack that the model is particularly good at detecting, and the part after the underscore indicates whether the data used for training is negative or positive. This naming convention shows that the models exist in pairs, so we refer to such pairs of models as "paired autoencoders" (e.g., Attack1_neg and Attack2_pos).
3.3. First Layer — Data Partitioning
This section corresponds to the top right part of Figure 3, where the data to be detected is divided into the following four regions. As shown in Figure 4, based on the joint decision-making of these autoencoders, the data space can be divided into four regions: quasi-normal region, quasi-attack region, divergence region, and undetermined region. We use a Venn diagram to describe the behavior of a pair of autoencoders: consider the left ellipse as representing the autoencoder trained on attack data and the right ellipse as representing the autoencoder trained on normal data. If data points are distributed inside the circle, it means their reconstruction error on the corresponding autoencoder is less than the threshold of that autoencoder; conversely, if they are distributed outside the circle, their reconstruction error is greater than the threshold. In this way, the left difference set in the Venn diagram in Figure 4 represents the data that both autoencoders classify as attacks, while the right difference set represents the data that both autoencoders classify as normal. The intersection represents the data that the _neg autoencoder classifies as normal and the _pos autoencoder classifies as an attack, while the external complement set represents the data that the _neg autoencoder classifies as an attack and the _pos autoencoder classifies as normal. By observing the distribution of data in the Venn diagram, we can divide the data which need to be detected into different regions according to the following method (Data can be inputted one by one or collected in sufficient quantity and then inputted all at once (offline).):
- If all paired autoencoders classify the data as normal, then the data is classified into the quasi-normal region.
- If any paired autoencoder determines the data to be abnormal (i.e., both the autoencoder trained with normal data and the autoencoder trained with attack data classify the data as abnormal), then the data is classified into the quasi-attack region.
- Otherwise, If the performance of the data on any paired autoencoder is in the intersection, then the data is classified into the divergence region.
- In all other cases, the data is classified into the undetermined region. For example, when there is a pair of autoencoders, where the one trained on normal data classifies the data as an attack, and the one trained on attack data classifies the data as non-attack.
In regions other than the divergence regions, the distribution of data in the feature space is relatively simple, but the distribution of data in the divergence regions remains chaotic. There is often a significant overlap in the distribution ranges of different types of data in the feature space. Therefore, in the divergence regions, the data can be further divided into multiple areas according to the following rules:
- Data falls within the intersection only in one paired autoencoders for one kind of attack;
- Data falls within the intersection in multiple paired autoencoders.
This classification method serves as an initial processing step for the detected data, so we refer to it as the "data partitioning in the 1st layer". This approach has several advantages: first, it essentially performs a rough classification of the data, with some partitions already having high data purity. For example, the data in the quasi-normal region is classified as normal by all autoencoders, making it highly likely that the data in this region is indeed normal; second, partitioning the data reduces the complexity of the data in each region, making it more conducive to detection in the second layer.
3.4. Second Layer — Precise Detection
After partitioning the data, the next step is to make precise predictions for the data in each region. Previously, we obtained multiple autoencoders. Now, for a specific region, we can select the autoencoder that has the best classification performance for that region's data as the classifier for that region (classification performance is evaluated based on the accuracy on the validation set). This "optimal classifier" may be trained on negative data or positive data. For example, in the case of three types of attacks—Attack1, Attack2, and Attack3—the optimal classifier for a certain region is the one which selected from Attack1_neg, Attack2_neg, Attack3_neg, Attack1_pos, Attack2_pos, and Attack3_pos. The final prediction for each region, determined by the "optimal classifier," is what I refer to as "precise detection in the second layer." It is important to note that due to the different ranges of data samples, even if the same autoencoder is used, the thresholds for partitioning the data in the first layer and the second layer should be different.
4. Experiments
4.1. Dataset
The dataset used in this study is the NSL-KDD dataset [16]. The NSL-KDD dataset is an improved version of the KDD Cup 99 dataset [25], addressing issues such as redundant records and imbalanced data in the original dataset. This dataset is widely used in the field of network intrusion detection and aims to provide a more representative and usable dataset.
The NSL-KDD dataset is widely used not only in machine learning model evaluation and feature selection but also in testing and validating new network intrusion detection methods. Its improvements include the removal of redundant records, making the training and testing sets more balanced and representative [26].
Additionally, the NSL-KDD dataset includes multiple training and testing subsets of varying difficulty, such as KDDTrain+ and KDDTest+, which provide samples of different quantities and complexities to help researchers more comprehensively evaluate the performance of intrusion detection systems.
The records in the dataset are divided into normal and attack categories, with the attack types further divided into four major categories: Probe, DoS, U2R, and R2L. Each data sample contains 41 features, which are mainly divided into the following categories:
- Basic features: Describe the basic attributes of a single TCP connection, such as duration, protocol type, service type, etc. These features are derived from basic information at the IP and TCP layers.
- Content features: Describe features related to the contents of the data packets, such as the number of failed login attempts, number of access control files, etc. These features are mainly used to detect U2R and R2L attacks, as these attacks often involve spoofing or abnormal login behaviors.
- Time-based traffic features: Traffic features calculated based on a time window, such as the time interval between connections, the number of connections to the same service within a time window, etc. These features help detect DoS and Probe attacks, as these attacks often manifest as a large number of connection requests in a short period.
- Host-based traffic features: Statistical features based on the host, such as the number of connections to the same host, the number of connections to the same host within a specific time window, etc. These features are used to identify attack behaviors targeting a single host.
4.2. Data Preprocessing
Firstly, it is important to clarify that in order to determine the threshold for the autoencoder and select the best-performing classifier in each region, we need a validation set for parameter tuning. For this purpose, we randomly select 20% of the data from KDDTrain+.txt as the validation set, leaving the remaining 80% of the data to train the model. The data in KDDTest+.txt will be used as the test set for final model evaluation.
Next, to partition the training data, we first divide the training set into two parts based on the label: normal data and attack data. The attack data is further divided into four types of attacks according to their labels. Before the data is fed into the training process, feature selection is performed according to Table 1. Additionally, string feature values are encoded using one-hot encoding. It should be noted that the validation set and test set data should undergo feature selection and encoding before being input into the model. However, to ensure the consistency of the one-hot encoding results, we will perform this encoding simultaneously with the training set.
4.3. Model Training and Selecting
First, train eight autoencoders (four pairs) using the training set data and adjust the thresholds of each autoencoder based on their performance on the validation set. Compare the reconstruction error of the validation set data on each autoencoder with the thresholds, and divide the data into different regions accordingly.
For each region, use different autoencoders for classification. The autoencoder with the highest accuracy is selected as the classifier for that region. The classifiers selected for each region are shown in Table 2. As an example, the division of the validation set data for the quasi-normal region of DoS_pos are illustrated in Figure 5. We used MSE(Mean Squared Error) as the reconstruction error, and by continuously adjusting the threshold, we found that when the threshold is at the position of the blue dashed line, it can better separate the normal data from the attack data. This achieves a better detection effect than simply judging the data in this region as normal.
4.4. Evaluation Metrics
1) Overall Accuracy & Overall F1-Score: Accuracy is used to measure the overall correctness of a model's classifications, suitable for datasets with balanced class distributions. F1-Score is useful for evaluating model performance on imbalanced datasets, particularly when balancing precision and recall is important. They can be calculated using the following formulas:
where is the number of samples correctly predicted as positive among all the data. is the number of samples correctly predicted as negative among all the data. F is the number of samples incorrectly predicted as positive among all the data. F is the number of samples incorrectly predicted as negative among all the data.
2) Within-Region Accuracy: Assume that after the first layer of data partitioning, no precise detection is performed, and data in the quasi-normal region, divergence region, and indeterminate region are all predicted as normal (because these regions contain more normal labels than attack labels), while data in the quasi-attack region are all predicted as attacks. Record the accuracy within each region under this assumption (the ratio of correctly predicted data to the total data in the region), and compare it with the accuracy within each region after introducing precise detection to demonstrate the improvement brought by precise detection. The calculation formula is shown as follows:
where is the number of samples correctly predicted as positive among all the data. is the number of samples correctly predicted as negative among all the data. F is the number of samples incorrectly predicted as positive among all the data. F is the number of samples incorrectly predicted as negative among all the data.
3) Training Duration and Model Size: Compare the training duration and model size in this study with several commonly used machine learning models to demonstrate the lightweight nature of the proposed model.
4.5. Experiment Result: Overall Accuracy and Overall F1-Score
Through experiments, we obtained the confusion matrices of the original model, the original model with "precise detection" added, and the method proposed in this paper, as shown in Table 3. From these three confusion matrices, we can derive the overall accuracy and overall F1-Score for each model.
The overall accuracy and overall F1-Score of our proposed method are shown in Figure 6. Figure 6a) compares the accuracy of different models, while Figure 6b) compares the F1-Scores of these models. In Figure 6a), the left vertical bar (blue) represents the accuracy of the original method [15], the middle vertical bar (green) represents the accuracy after simply adding 'precise detection' to the second layer of the original method (i.e., based on predictions from four autoencoders trained on normal data, the data is divided into quasi-normal and quasi-attack regions, and the best classifier is selected for each region to predict the final result), and the right vertical bar (purple) shows the accuracy of our proposed method, which first trains paired autoencoders and then performs precise detection within the four regions. Similarly, in Figure 6b), the blue bars represent the F1-Score of the original method [15], the green bars represent the F1-Score of the 'precise detection' method, and the purple bars show the F1-Score of our proposed method. From both figures, we can observe the following points:
1) The original method has already achieved 90.49% accuracy and 91.89% F1-Score;
2) Simply adding precise detection only brings a slight improvement;
3) By combining data partitioning from the first layer with precise detection from the second layer, the model's performance is significantly improved.
Model Accuracy Comparison
Model F1-Score Comparison
Discussion: this experiment result can be understood as follows: if precise detection is performed solely based on the original method, the distribution of data in the quasi-normal and quasi-attack regions in the feature space remains complex, making it difficult for a single autoencoder to perform the classification. The advantages of combining data partitioning with precise detection are as follows:
1) It provides more selectable autoencoders to serve as classifiers for precise detection;
2) The distribution of data in each region in the feature space becomes simpler, making classification easier.
4.6. Experiment Result: Within-Region Accuracy
The experimental results of the accuracy within each region are shown in Table 4, where each row represents the accuracy with and without precise detection in a specific region, as well as the difference between them.
From Table 4, it can be seen that the accuracy in each region has increased to varying degrees after adopting precise detection, with the accuracy in the divergence region increasing by approximately 20%. In the worst-case scenario, even if the classifier in the second layer does not function effectively, it will not reduce the accuracy in that region. It can be said that the introduction of precise detection does not negatively impact the model's accuracy. As for the additional time brought by precise detection, since the classifier uses existing models and does not require retraining, it is negligible.
4.7. Training Time and Model Size Analysis
As shown in Table 5, the model proposed in this study is compared with the SVM model, the random forest model, and the model from previous research.
It can be seen that the proposed model has a significant advantage in terms of model size compared to the SVM and random forest. In terms of training time, its performance is also superior to that of the SVM and is on the same order of magnitude as that of the random forest. And, compared to previous research, although the model size is twice that of the previous model, it is still relatively small, and such an increase does not cause a significant burden. Moreover, since training is not performed continuously, a slight increase in training time is acceptable. Considering the significant improvement in model accuracy, this level of sacrifice does not pose a serious problem.
5. Conclusion and Future Work
In this study, we introduced an efficient classifier model for intrusion detection, leveraging autoencoders specifically designed for deployment on edge devices within IoT networks. Recognizing the limitations of traditional intrusion detection models on edge devices, such as insufficient computational resources and the need for enhanced accuracy, we proposed a lightweight model utilizing Extreme Learning Machine (ELM) for its swift training and compact size.
Our approach involved training multiple autoencoders using different types of attack data, as well as normal data paired with varying feature sets. These autoencoders collectively performed initial data prediction, partitioning data based on prediction results, and subsequently leveraging their characteristics for precise detection within each classification region. This method not only maintained the lightweight nature of the model but also improved its accuracy and F1-Score by 3.5% and 2.9% compared to the original approach on the NSL-KDD dataset while maintaining a lightweight advantage over traditional models like Random Forest and Support Vector Machine.
We evaluated the proposed model using the NSL-KDD dataset, which contains both normal and various attack types (DoS, Probe, U2R, R2L). Our experimental setup involved training eight autoencoders, including both normal and attack data, leading to the creation of "paired autoencoders." These paired autoencoders facilitated the initial data partitioning into quasi-normal, quasi-attack, divergence, and undetermined regions. The subsequent precise detection within these regions further enhanced the model's performance.
The experimental results demonstrated that our model achieved superior overall accuracy, particularly in the divergence region where accuracy improved by approximately 20%. Furthermore, the proposed model exhibited significant advantages in terms of model size and training duration, making it highly suitable for edge device deployment.
In summary, the binary classifier model based on autoencoders and ELM presented in this study effectively addresses the challenges faced by traditional IDS models in IoT environments. By combining data partitioning and precise detection, our approach not only ensures high detection accuracy but also maintains a lightweight profile, crucial for practical implementation on edge devices.
In the future, we will use more datasets to validate our model. Additionally, we will simulate a distributed IoT environment and apply methods like federated learning to aggregate the model. Regarding the model, we will balance accuracy and model size, appropriately reducing the number of autoencoders in data spaces where the impact on detection accuracy is minimal, to ensure further lightweight optimization.
References
- Abdul-Qawy A S, Pramod P J, Magesh E, et al. The internet of things (iot): An overview[J]. International Journal of Engineering Research and Applications 2015, 5, 71–82. [Google Scholar]
- Gartner Says Worldwide IoT Security Spending Will Reach $1.5 Billion in 2018 (https://www.gartner.com/en/newsroom/press-releases/2018-03-21-gartner-says-worldwide-iot-security-spending-will-reach-1-point-5-billion-in-2018.
- Antonakakis M, April T, Bailey M, et al. Understanding the mirai botnet[C]//26th USENIX security symposium (USENIX Security 17). 2017, 1093-1110.
- Khan R, Maynard P, McLaughlin K, et al. Threat analysis of blackenergy malware for synchrophasor based real-time control and monitoring in smart grid[C]//4th International Symposium for ICS & SCADA Cyber Security Research 2016. BCS, 2016: 53-63.
- Farwell J P, Rohozinski R. Stuxnet and the future of cyber war[J]. Survival 2011, 53, 23–40. [Google Scholar] [CrossRef]
- Stanislav M, Beardsley T. Hacking iot: A case study on baby monitor exposures and vulnerabilities[J]. Rapid7 Report, 2015.
- Eskandari M, Janjua Z H, Vecchio M, et al. Passban IDS: An intelligent anomaly-based intrusion detection system for IoT edge devices[J]. IEEE Internet of Things Journal 2020, 7, 6882–6897. [Google Scholar] [CrossRef]
- Nguyen T D, Marchal S, Miettinen M, et al. DÏoT: A federated self-learning anomaly detection system for IoT[C]//2019 IEEE 39th International conference on distributed computing systems (ICDCS). IEEE. 2019; 756–767.
- Rumelhart D E, Hinton G E, Williams R J. Learning representations by back-propagating errors[J]. nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Le Cun Y, Fogelman-Soulié F. Modèles connexionnistes de l'apprentissage[J]. Intellectica 1987, 2, 114–143. [Google Scholar]
- Choi H, Kim M, Lee G, et al. Unsupervised learning approach for network intrusion detection system using autoencoders[J]. The Journal of Supercomputing 2019, 75, 5597–5621. [Google Scholar] [CrossRef]
- Ieracitano C, Adeel A, Morabito F C, et al. A novel statistical analysis and autoencoder driven intelligent intrusion detection approach[J]. Neurocomputing 2020, 387, 51–62. [Google Scholar] [CrossRef]
- Tsukada M, Kondo M, Matsutani H. A neural network-based on-device learning anomaly detector for edge devices[J]. IEEE Transactions on Computers 2020, 69, 1027–1044. [Google Scholar] [CrossRef]
- Huang G B, Zhu Q Y, Siew C K. Extreme learning machine: a new learning scheme of feedforward neural networks[C]//2004 IEEE international joint conference on neural networks (IEEE Cat. No. 04CH37541). Ieee. 2004, 2, 985–990. [CrossRef]
- Yang Qin, Masaaki Kondo,”Federated Learning-Based Network Intrusion Detection with a Feature Selection Approach”,IPSJ SIG Technical Report (in Japanese), Vol.2021-EMB-56 No.24, Pages 1-7, 2021. [CrossRef]
- NSL_KDD dataset: http://nsl.cs.unb.ca/NSL-KDD/.
- Ioulianou P, Vasilakis V, Moscholios I, et al. A signature-based intrusion detection system for the internet of things[J]. Information and Communication Technology Form, 2018.
- Li W, Tug S, Meng W, et al. Designing collaborative blockchained signature-based intrusion detection in IoT environments[J]. Future Generation Computer Systems 2019, 96, 481–489. [Google Scholar] [CrossRef]
- Sheikh N U, Rahman H, Vikram S, et al. A lightweight signature-based IDS for IoT environment[J]. arXiv, 2018; arXiv:1811.04582.
- Lo W W, Layeghy S, Sarhan M, et al. E-graphsage: A graph neural network based intrusion detection system for iot[C]//NOMS 2022-2022 IEEE/IFIP Network Operations and Management Symposium. IEEE, 2022: 1-9. [CrossRef]
- Zhou X, Liang W, Li W, et al. Hierarchical adversarial attacks against graph-neural-network-based IoT network intrusion detection system[J]. IEEE Internet of Things Journal 2021, 9, 9310–9319. [Google Scholar] [CrossRef]
- Almiani M, AbuGhazleh A, Al-Rahayfeh A, et al. Deep recurrent neural network for IoT intrusion detection system[J]. Simulation Modelling Practice and Theory 2020, 101, 102031. [Google Scholar] [CrossRef]
- Wang M, Yang N, Weng N. Securing a smart home with a transformer-based iot intrusion detection system[J]. Electronics 2023, 12, 2100. [Google Scholar] [CrossRef]
- Fraihat S, Makhadmeh S, Awad M, et al. Intrusion detection system for large-scale IoT NetFlow networks using machine learning with modified Arithmetic Optimization Algorithm[J]. Internet of Things 2023, 22, 100819. [Google Scholar] [CrossRef]
- KDD Cup dataset: https://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html.
- Bala R, Nagpal R. A review on kdd cup99 and nsl nsl-kdd dataset[J]. International Journal of Advanced Research in Computer Science 2019, 10. [Google Scholar]
Figure 1.
Schematic Diagram of the Autoencoder.
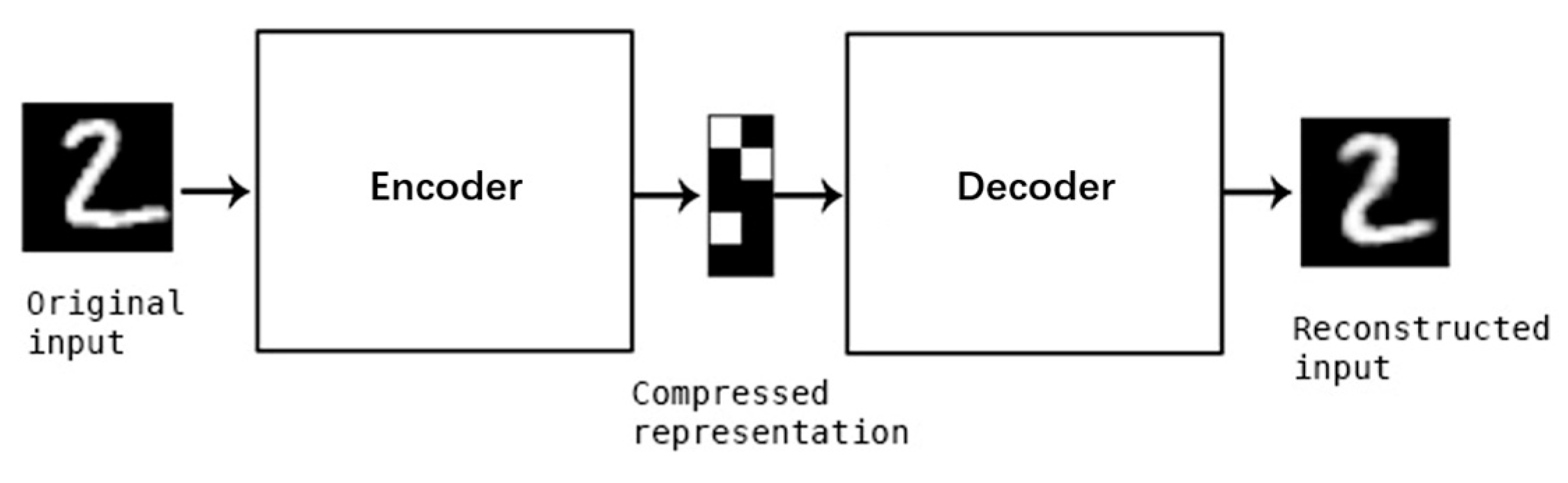
Figure 2.
ELM Architecture Diagram.
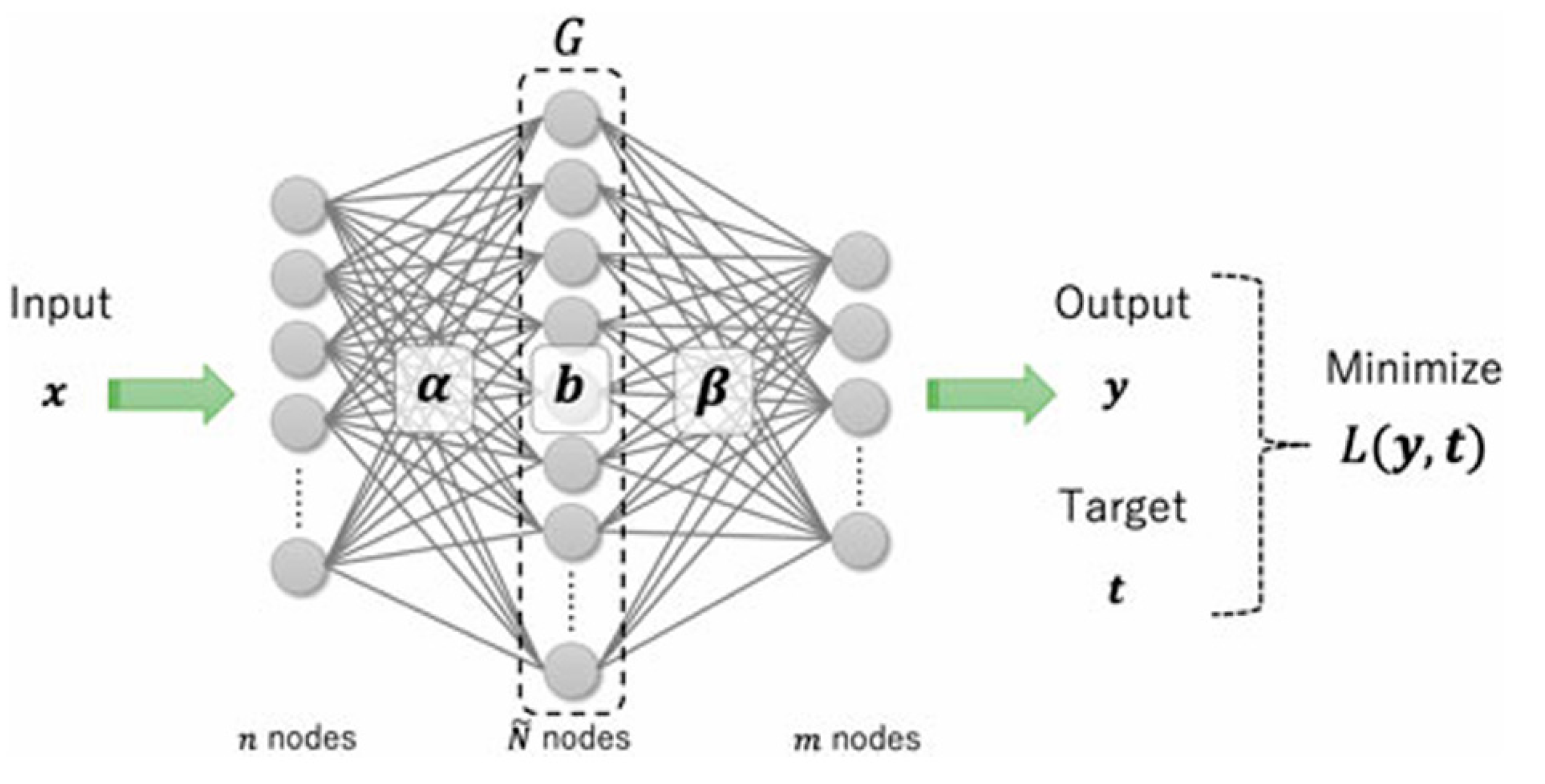
Figure 3.
Proposed Architecture Diagram.
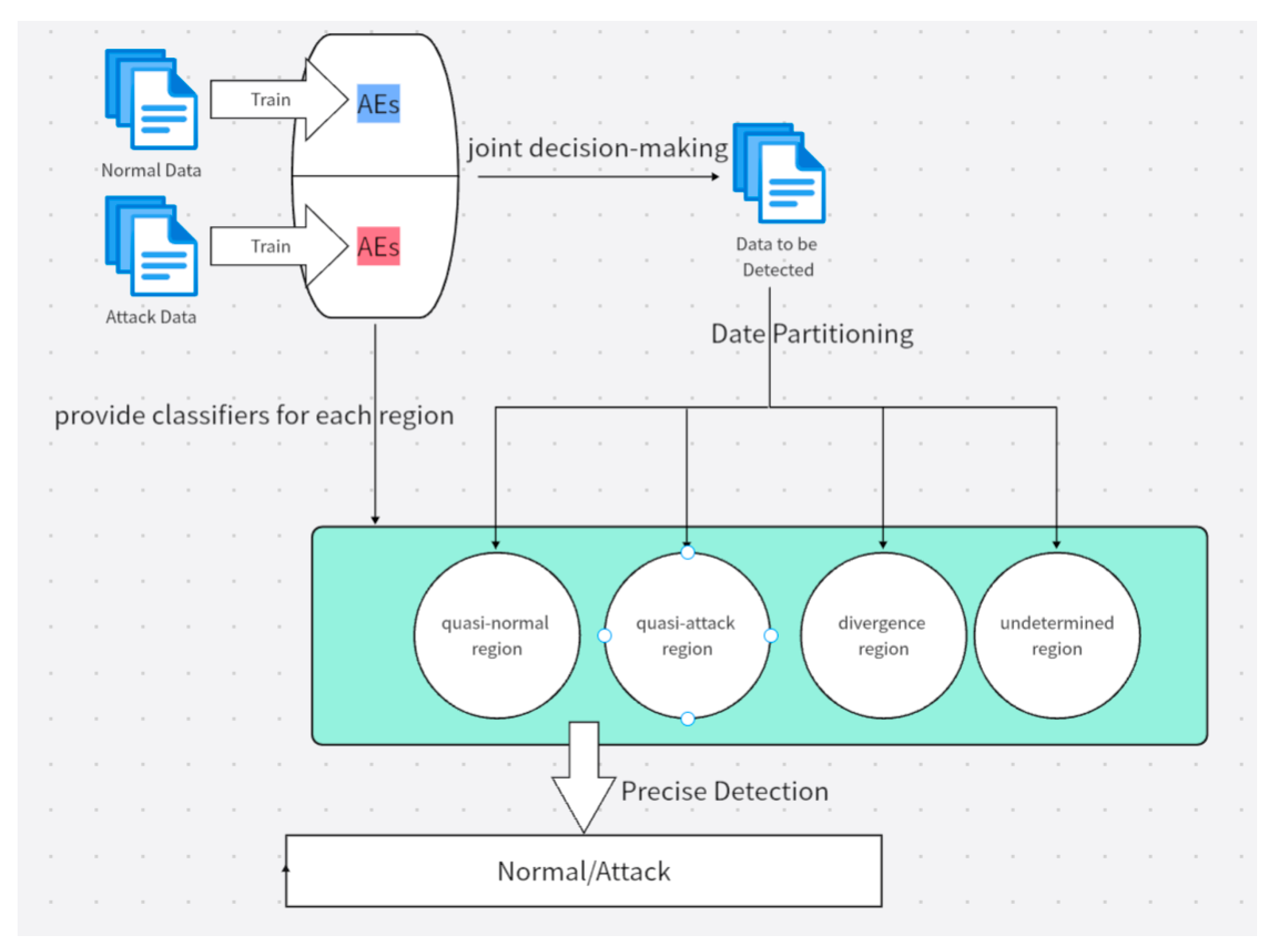
Figure 4.
Four Regions of Data Partitioning.
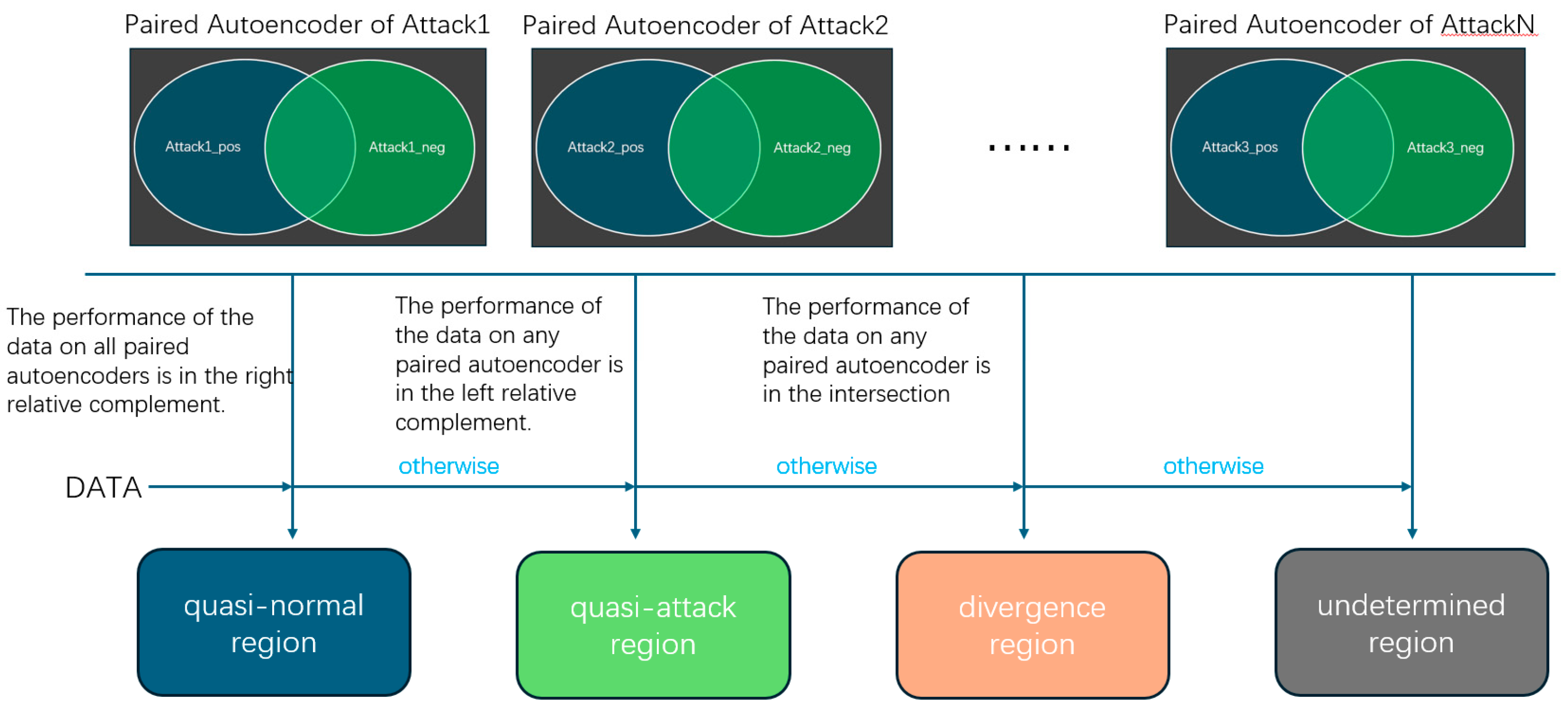
Figure 5.
Precise Detection in the Quasi-Attack Region.
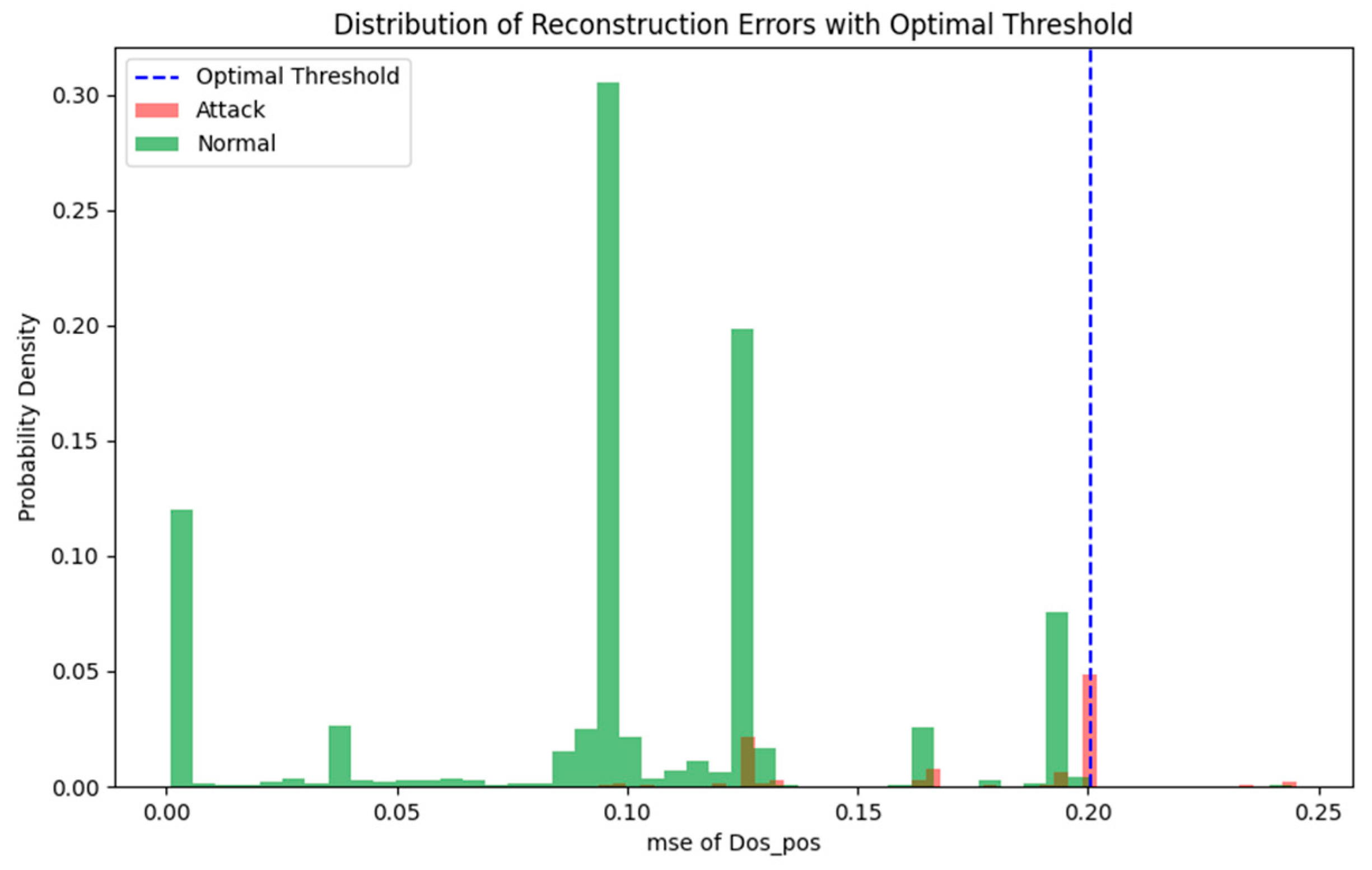
Figure 6.
Model Accuracy & F1-Score Comparison.
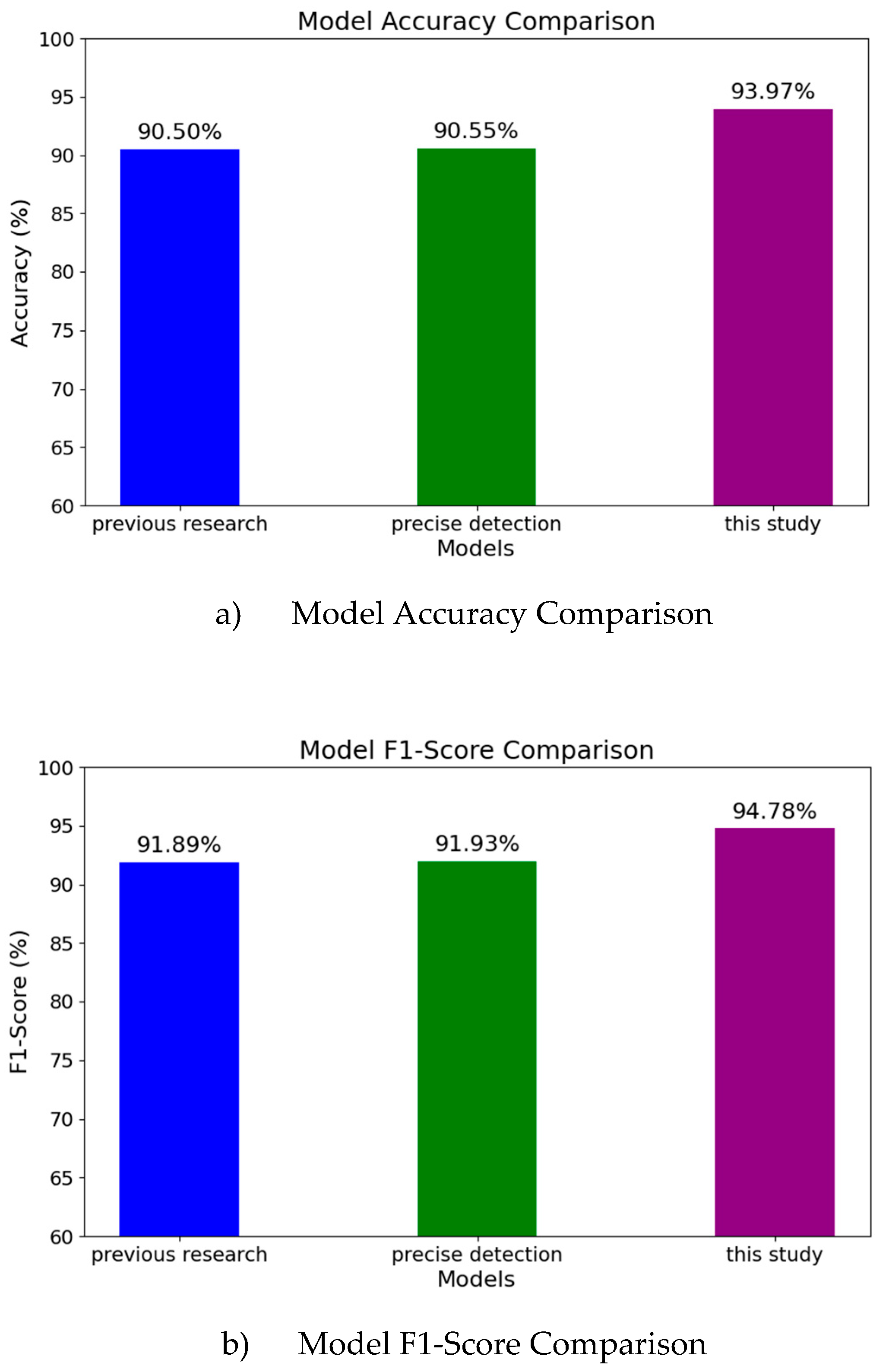

Table 1.
Feature Selection for Each Type of Attack Data.
| Type of Attack Data | Selected Feature |
|---|---|
| DoS | protocol_type, flag, wrong_fragment, num_compromised, root_shell, num_shells, same_srv_rate |
| Probe | logged_in, num_root, num_shells, in_host_login, srv_rerror_rate, srv_serror_rate, srv_diff_host_rate |
| R2L | service, urgent, num_root, num_shells, num_access_files, is_guest_login, srv_serror_rate |
| U2R | flag, land, hot, num_failed_login, logged_in, num_compromised, su_attempted, num_root, num_file_creations, num_outbound_cmds, is_guest_login, same_srv_rate, dst_host_srv_count |
Table 2.
Selected Classifiers for Each Region.
| Region | Selected autoencoder | |
| Quasi-normal region | DoS_pos | |
| Quasi-attack region | DoS_pos | |
| Undetermined region | U2R_neg | |
| Divergence region | Region1 | R2L_neg |
| Region2 | U2R_neg | |
| Region3 | DoS_pos | |
| Region4 | R2L_neg | |
| Region5 | R2L_neg | |
Table 3.
Confusion Matrix of Models.
| a) Confusion Matrix of previous research | ||
| Attack(Predicted) | Normal(Predicted) | |
| Attack(Actual) | 12136 | 696 |
| Normal(Actual) | 1446 | 8265 |
| b) Confusion Matrix of precise detection models | ||
| Attack(Predicted) | Normal(Predicted) | |
| Attack(Actual) | 12143 | 689 |
| Normal(Actual) | 1442 | 8269 |
| c) Confusion Matrix of precise this study | ||
| Attack(Predicted) | Normal(Predicted) | |
| Attack(Actual) | 12350 | 482 |
| Normal(Actual) | 878 | 8833 |
Table 4.
Comparison of Accuracy Within Regions.
| Region | Without Precise Detection | With Precise Detection | Increase Magnitude |
|---|---|---|---|
| Quasi-Normal Region | 93.18% | 96.31% | 3.13% |
| Quasi-Attack Region | 89.84% | 94.66% | 4.82% |
| Divergence Region | 68.37% | 89.05% | 20.68% |
| Undertermined Region | 96.48% | 96.48% | 0 |
Table 5.
Comparison of Training Time and Model Size.
| Model | Without Precise Detection | Model Size |
|---|---|---|
| RF | 12.6s | 2.29MB |
| SVM(kernel = linear) | 20min+ | |
| This Study | 42.3s | 484KB |
| Previous Research | 29.5s | 242KB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



