Submitted:
14 August 2024
Posted:
16 August 2024
You are already at the latest version
Abstract
Assembly theory provides a promising framework to explain the complexity of systems such as molecular structures and the origins of life, with broad applicability across various disciplines. In this study, we explore and consolidate different aspects of assembly theory by introducing a simplified toy model to simulate the autocatalytic formation of complex structures. This model abstracts the molecular formation process, focusing on the probabilistic control of catalysis rather than the intricate interactions found in organic chemistry. We establish a connection between probabilistic catalysis events and key principles of assembly theory, particularly the probability of a possible construction path in the formation of a complex object, and examine how the assembly of complex objects is impacted by the presence of autocatalysis. Our findings suggest that autocatalysis tends to favor longer consecutive construction sequences in environments with low catalysis probability, while this bias diminishes in environments with higher catalysis probabilities, highlighting the significant influence of environmental factors on the assembly of complex structures.
Keywords:
Assembly Theory
; Autocatalytic Sets
; Complexity
; Formation of Molecules
; Origin of Life
; Autocatalysis
1. Introduction
The search for a comprehensive framework to discuss and describe complexity remains ongoing, despite the development of numerous theories over the years. Complexity science, which seeks to understand the behaviors and properties of complex systems, has introduced various concepts such as emergence, self-organization, and non-linearity. These have been instrumental in fields ranging from biology to economics. However, contemporary challenges—such as modeling global climate change, understanding large-scale social dynamics, and managing highly interconnected technological systems—continue to test the limits of existing frameworks, [1,2]. This ongoing evolution of ideas underscores that our quest to understand complexity is far from complete.
Among the myriad theories that serve to describe the formation of complex structures, are assembly theory and the theory of autocatalysis, which are the focus of this work. We must disclaim at this point that although the following discussion is framed within the context of chemistry, as was the original context of these frameworks, this article addresses these concepts on a more abstract level.
Assembly theory provides a quantitative measure of molecular complexity through the Molecular Assembly (MA) index, which can be experimentally verified using mass spectrometry. This framework is crucial for identifying complex molecules that signify life, both on Earth and potentially on other planets. It posits that living systems produce complex molecules in abundance, which are highly unlikely to be created randomly or abiotically [3]. This MA index differentiates between biological and non-biological molecules, offering a robust, experimentally tractable measure of complexity that does not rely on specific biochemical pathways [3,4].
On the other hand, autocatalytic sets are fundamental in understanding biochemical networks and the origin of life. These sets consist of chemical reactions where the catalysts for the reactions are produced by the reactions within the set itself, creating a self-sustaining system. Introduced by Stuart Kauffman in the early 1970s, autocatalytic sets have been pivotal in exploring the emergence and evolution of complex biochemical systems [5]. Further developments by researchers like Eigen and Schuster have emphasized the robustness and evolutionary potential of these networks [6].
The motivation for integrating assembly theory and autocatalysis lies in their complementary approaches to understanding complexity. Assembly theory discusses pathway probabilities, while autocatalytic sets highlight the necessity for increased pathway probabilities to sustain certain biochemical processes. By merging these concepts, we aim to explore whether the principles of autocatalysis influence the fundamental pathways proposed by assembly theory. This integration is essential for a deeper understanding of how complex structures form and evolve.
This work aims to merge these two concepts and discuss their interplay using a simplified toy model. We demonstrate that autocatalysis impacts even the basic foundations of the connections that constitute complex structures. Our results illustrate that the likelihood of autocatalytic processes affects the pathways through which complex structures are formed. We achieve this by constructing a simplified toy model, analyzing its fundamental properties, and providing arguments on how and where our findings can be applied to real-life complexity. Our approach and the most significant result are presented in Figure 1. Specifically, we analyze multiple ways to form a complex object and find that in environments where the probability of catalyzing necessary processes is low, autocatalysis favors more consecutive rather than parallel builds of complex objects.
This article is structured as follows. Section 2 provides a brief review of historical sources on autocatalytic sets and assembly theory in chronological order for readers to get an overview of key developments. Section 3 describes the employed concepts and tools from both assembly theory and autocatalytic sets. Section 4 introduces the developed toy model and discusses the involved assumptions and technical details. Next, we discuss our numerical experiments and results in Section 5, followed by an in-depth discussion in Section 6 and a final conclusion in Section 7.
2. Related Work
This section is a collection of past research that we consider as key developments and/or neat resources for the interested reader to get an overview of both assembly theory and the implications of autocatalysis.
2.1. Assembly Theory
Assembly theory, as a framework for understanding the formation and complexity of systems, has gotten significant attention across various scientific disciplines, from biological to chemical and even abstract mathematical contexts.
The foundational concept of assembly theory is detailed in [7], where the authors introduce the notion of pathway assembly. This graph-based approach quantifies the number of steps required to assemble an object based on its hypothetical formation history, estimating the likelihood of its formation without biological processes. This early work provides a novel measure to distinguish randomly occurring objects from biologically assembled ones, setting the stage for later developments in assembly theory.
Building upon these early theoretical constructs, [4] discuss how assembly theory quantifies selection and evolution, particularly in biological systems. This work provides the theoretical underpinning for understanding how complexity can arise and be quantified in various contexts, establishing a foundation for subsequent research. Further, [8], introduce a probabilistic framework for identifying biosignatures using pathway complexity. This approach allows for a more nuanced understanding of complex structure formation and identification, adding depth to deterministic views.
Theoretical advancements have significantly expanded the framework of assembly theory. [3] provide a comprehensive mathematical framework, focusing on constructing objects from basic elements within defined assembly spaces. This innovative method differentiates between objects formed by random processes and those resulting from directed biological or technological actions, offering a novel metric for assessing complexity and origin. Complementing this,[3] introduce the concept of assembly spaces, providing a formalized approach to understanding the pathways leading to life’s formation, emphasizing the predictive power of assembly theory. [9] explores the chemical space with molecular assembly trees, providing tools to map and navigate the vast possibilities within chemical spaces. This paper is crucial for extending the utility of assembly theory beyond biological contexts, demonstrating its relevance in chemistry and materials science. Finally, [10] delve into the assembly pathways of binary messages, showcasing the versatility of assembly theory in abstract mathematical contexts. This study provides a mathematical basis for understanding information assembly and hints at potential applications in computational sciences and information theory.
On the experimental front, several studies have applied assembly theory to practical scenarios. [11] introduce a novel approach for detecting extraterrestrial life by using mass spectrometry to measure molecular complexity through the molecular assembly index (MA). They validate this method on several million molecules, aiming to establish a universal criterion for identifying biosignatures, which is essential for both space missions and synthetic biology experiments on Earth. [12] present an experimental framework for quantifying molecular complexity, making significant strides in the direct measurement of MA using spectroscopic techniques. This approach not only enhances our understanding of molecular evolution but also holds potential for broad applications in drug development and origin of life research. [11] apply assembly theory to mass spectrometry, providing a practical framework for identifying molecules as biosignatures, thus bridging theoretical constructs and practical applications. Their study showcases how assembly theory can identify complex molecular structures that might indicate the presence of life. Additionally, [4] provides empirical evidence and quantitative metrics for selection and evolution across biological and physical systems. They introduce a refined method for calculating the assembly index, demonstrating its practical application in distinguishing between random and directed processes. This work underscores the theory’s utility in experimentally measurable contexts, highlighting its relevance for both theoretical exploration and practical applications in understanding complex system formation.
Notably, the theoretical advancements, such as those presented by [3], complement the experimental insights provided by [11]. These studies collectively emphasize the predictive power of assembly theory and its structured approach to exploring the theoretical spaces within which complex structures can form. Together, these papers form a comprehensive overview of assembly theory’s applicability across multiple domains. They collectively highlight the theory’s potential to explain and predict complex structures in both natural and artificial systems, making a significant contribution to our understanding of complexity and the processes leading to the formation of life and other complex entities.
2.2. Autocatalysis
Autocatalysis, a concept central to the origin of life, has been extensively studied and developed over the years. Initially, the idea was independently introduced several times in the context of early life models [5,13,14]. The foundational work of Manfred Eigen and Peter Schuster on the hypercycle in the late 1970s introduced the idea of self-replication in molecules, a process crucial for biological systems. Although primarily biological, the hypercycle concept provides insights into general principles of complex systems that extend to other domains [14,15]. Building on this, Stuart Kauffman explored the formation of autocatalytic sets. He posited that life emerges as a phase transition, suggesting that given a sufficiently diverse mix of molecules, the formation of an autocatalytic system, which is self-maintaining and self-reproducing, becomes almost inevitable [16]. The core principle involves chemical reaction systems (CRS) where a set of molecule types and reactions form self-sustaining networks that can grow and evolve. This is formally captured in the Reflexively Autocatalytic and Food-generated (RAF) theory, which defines an autocatalytic set as a subset of reactions where every reaction is catalyzed by molecules produced within the set, and all reactants can be generated from a basic food set through these reactions [17,18].
A significant milestone in the development of RAF theory was the introduction of the binary polymer model by Kauffman [5], where molecule types are represented as bit strings, and reactions involve ligation and cleavage of these strings. This model helped demonstrate that autocatalytic sets can emerge with high probability under realistic levels of catalysis [5,19]. Subsequent work by Hordijk and Steel further refined the mathematical framework, proving that a linear growth rate in catalysis suffices to form RAF sets, and developing efficient algorithms to detect such sets within CRSs [19,20]. Empirical studies have shown that RAF sets are not necessarily large; they often consist of smaller, interdependent subsets called subRAFs, which can themselves be autocatalytic. This structural decomposability has profound implications for the evolvability and robustness of these systems. For example, an autocatalytic set can potentially be broken down into irreducible RAFs (irrRAFs), each capable of sustaining autocatalysis independently. This hierarchical organization allows for complex behaviors such as inheritance, mutation, and competition, akin to biological evolution [18,21,21]. The notion of RAF sets has expanded beyond origin-of-life studies to other fields like ecology and economics, where systems can be seen as networks of interdependent entities catalyzing each other’s production and survival [17,18]. For instance, in economics, production processes involving raw materials, intermediates, and catalysts (such as machinery) form autocatalytic-like networks, highlighting the universality and broad applicability of RAF theory [19]. Similarly, Lorenzo Napolitano’s analysis of technological networks reveals that innovation and patenting dynamics are shaped by autocatalytic structures. These structures grow as interconnected technological fields mutually benefit from their connections, reflecting a self-reinforcing pattern of innovation, [22]. Also Wim Hordijk’s work on the emergence of autocatalytic sets in models of technological evolution shows that these sets can form in simple models, providing insights into economic models and innovation dynamics [23]. Mike Steel’s concept of the adjacent possible complements these ideas by describing how human creativity involves combining existing items in new ways to generate further growth. This combinatorial approach is fundamental to innovation and can explain the accelerating pace of innovations. Steel’s model suggests that the adjacent possible refers to new opportunities that arise given the current state of existence, [24].
The recent work by Kauffman and Roli further extends this by proposing that the emergence of life is an expected phase transition in the evolving universe. This theory unites the concepts of Collectively Autocatalytic Sets (CAS) and the Theory of the Adjacent Possible (TAP). In this context, TAP theory suggests that as the diversity and complexity of molecules increase, a phase transition occurs, leading to the spontaneous formation of molecular reproduction systems [25]. This integration provides a comprehensive view of how life can emerge from non-living matter through a predictable and inevitable process driven by increasing molecular complexity and catalytic interactions. The concept of catalytic closure, where every reaction in the system is catalyzed by at least one molecule within the system, is central to this theory and aligns with the principles outlined in RAF theory. This work not only reinforces the importance of autocatalysis in the origin of life but also suggests new avenues for research in astrobiology and the search for life on exoplanets by identifying potential catalytic networks [21,25].
Overall, the development of autocatalytic sets and RAF theory represents a significant leap in understanding the emergence and evolvability of complex systems, offering insights into the fundamental processes that underpin life’s origin and its diverse manifestations.
3. Methodology
Assembly Theory provides a framework for quantifying the complexity of molecular structures by measuring the information required to assemble them. On the other hand, the concept of autocatalysis often arises when dealing with chemical reactions in organic matter, leading to the formation of complex structures. This section introduces the mathematical tools from Assembly Theory, focusing on the Assembly Index and pathway probability. Additionally, we briefly introduce the concept of autocatalysis.
3.1. Assembly Index (AI)
The Assembly Index is a measure of the complexity of a molecular structure, defined as the minimum number of steps required to construct the molecule’s graph by recursively combining simpler substructures. To illustrate this, consider the example of constructing the word “” from its constituent letters.
- The word “ABRACADABRA” consists of 11 characters but only 5 unique letters: .
- Begin with the letter “A”. Combine “A” with “B” to form “”. This is the first step. I.e. we allow only for the following operation where two objects, not necessarily unique letters, are joined: , where and can be “A”, “”, “”, “”, or any other combination of unique letters of arbitrary length.
- Repeat this process to form “” in subsequent steps.
- The structure “” can then be reused to complete the word in fewer steps than starting from scratch each time.
We took this example from the assembly theory homepage, [26]. The fewest number of steps, required to assemble “” by combining two components is thus 7, as detailed below:
The assembly process involves constructing an object by sequentially joining a finite set of basic components. In this process, once an object is constructed, it can be reused in subsequent steps to form more complex structures. This process occurs within a defined framework known as the assembly space. The assembly space provides a formal structure in which all possible assembly pathways can be explored. It defines the relationships between basic components and the more complex structures they can form. The assembly space is essentially a map of all potential ways an object can be assembled, starting from its simplest components and leading to the final complex structure.
3.2. Linking Assembly Space, Molecular Assembly Index, and Pathway Probability
The concept of an assembly space is directly connected to the molecular assembly index and pathway probability. The molecular assembly index quantifies the complexity of a structure by determining the minimum number of steps needed to assemble it from basic components within the assembly space. This index reflects how “simple” or “complex” it is to build the structure, with a higher index indicating a more complex assembly process. Pathway probability comes into play when considering the likelihood of a specific assembly pathway being followed in the assembly space. Not all pathways are equally likely; some are favored due to factors like autocatalysis, as discussed in this article, which can bias the assembly process towards certain sequences of steps. A higher pathway probability suggests that a particular sequence of assembly steps is more likely, potentially indicating a non-random or biological origin for the structure, [3]. In summary, the assembly space provides the foundational framework for understanding the construction of complex objects. The molecular assembly index quantifies the complexity of this construction process, while pathway probability evaluates the likelihood of different assembly pathways within the space, helping to distinguish between abiotic and biotic origins of complex molecules, [3].
3.3. Autocatalytic Sets
The concept of autocatalysis is frequently discussed in the expanding body of literature modeling the emergence of self-sustaining biochemical systems essential for life [18]. It directly ties into the origin of life and the possibility of life forming by chance, given specific environmental conditions that catalyze chemical reactions, leading to the production of increasingly complex molecules and interactions. A formal definition of autocatalysis is often given in terms of RAF sets. Given a catalytic reaction system (CRS)—a network of molecule types and catalyzed chemical reactions—a (sub)set R of such reactions (plus the molecules involved in the reactions in R) is called:
- Reflexively autocatalytic (RA) if every reaction in R is catalyzed by at least one molecule involved in any of the reactions in R;
- F-generated (F) if every reactant in R can be constructed from a small “food set” F by successive applications of reactions from R;
- Reflexively autocatalytic and F-generated (RAF) if it is both RA and F.
The food set F contains molecules assumed to be freely available in the environment. Therefore, an RAF set formally captures the notion of “catalytic closure,” i.e., a self-sustaining set supported by a steady supply of (simple) molecules from some food set [18]. A simple example of such a RAF set is provided in Figure 2.
Summed up, Autocatalysis refers to a process where a chemical reaction is catalyzed by one of its own products, enabling a self-sustaining chain or network of reactions. This concept is central to understanding the origin of life, as it suggests that under the right conditions, simple molecules can catalyze the formation of increasingly complex systems, leading to the emergence of life. SR:DONE
4. A Toy Model for Autocatalytic Sets
We developed a toy model to discuss aspects of assembly theory and autocatalytic sets within one framework. Building upon the earlier example from Section 3.1, i.e., the "" construction, we simplify the model by avoiding repetitions. This means we build words of only unique letters. For example, we consider a word of length 6, "," and explore its various constructions by always merging two constituents. This is illustrated in Figure 3. However, this conflicts to some degree with previous research and corresponding foundations on assembly theory, as in order to assemble a complex object, one is allowed to use already existing objects at each step of the construction, [3,27,28,29]. For example, adding the already existing "" to the consecutive construction to form "" in Step 7 in Equation (1). We avoid using already existing elements in the chain, allowing only unique constituents of an object. This simplification is necessary for our toy model to gain an initial understanding of the problem at the most fundamental level, in the most sterile scenario, and to determine if a connection between assembly theory and autocatalytic sets exists at this level. Our approach should be expanded in future work, for example, to include cases similar to Step 7 from Equation (1), allowing for greater complexity and variety among the covered symbolic reactions.
Next, we assign catalysts to our reactions/events, as shown in Figure 4. This assignment is governed by probability, meaning we randomly determine whether a catalyst is assigned to a reaction with a probability from the set . After determining if a reaction is catalyzed, we choose the catalyst from all elements involved in the reaction. We consider two methods for selecting the catalyst:
- We choose an all-equally random catalyst. Further, we do not allow this catalyst to be used again.
- We choose a catalyst with a weighted probability, and allow catalysts to be used more than once.
The outcome of building a tree of reactions and randomly assigning a catalyst is shown in Figure 5. This figure is a direct output from our python code. Summed up, we are creating random construction schemes/trees/constructions for an object/final product, e.g., "", from it’s unique building blocks "A", "B", "C", "D", "E" and "F", and all interactions are always sorted in alphabetical order to further simplify the model. All possible constructions are the assembly space of our object/final product. Thus, we formally describe our model in the following way: For each final product X, which consists of unique elements/letters and a corresponding construction , with reactions, and intermediate products building up the final product X from the unique elements. Next, for each final product X, we can find the minimum depth, i.e., the corresponding depth for a maximal parallel distribution in the manner of 1 from Figure 3, via the following relation, which is independent of the construction , analogous to binary search trees, [30,31] :
where again is the number of unique elements of X. Thus, this minimal depth of each final product X is similar to the assembly index of a complex molecule as discussed by assembly theory [3,11]. In this construction , we find a set of constituents and a set of products. The products
contain the final product X and all elements created up to the final product , but not the unique elements . In contrast, the constituents
contain everything but the final product. Together, they form the set of all elements:
containing a total of elements. All catalysts are then chosen randomly, from this set of all elements and form the set of catalysts K, with a maximum possible number of catalysts equal to the number of reactions . We use two ways to choose the catalysts randomly, first, equally random without using one catalyst twice, and second with allowing to use catalysts more than once but with a weighted probability such that longer catalysts are more probable to be chosen such that:
where is the length of an element e, or a set of lengths for all elements .
We define a construction for a final product to be autocatalytic if all catalysts are within the set of all elements, , which is always the case if at least one catalyst is assigned. A possible construction for a given final product "" is depicted in Figure 5.
However, within each construction , we find a construction for each intermediate product , and corresponding sets, , and , which contain all products, constituents, elements in general, and catalysts, respectively for each intermediate product. For example, in the case of the intermediate product "" from Figure 5, this would correspond to:
Here, the same definition for autocatalysis holds for every subconstruction , i.e., all catalysts must be contained within the set of all elements for a subconstruction to be autocatalytic, which is obviously not the case for the above example. This is also illustrated in Figure 6
4.1. Assembly Theory and Autocatalysis within the Toy Model
Next we need to discuss the proposed model in an Assembly Theory context. This means we want to assess the assembly index, or assembly properties of the regarded objects and consider the pathway probability of each possible construction. However, the assembly index of each possible construction of a set of letters, e.g., "ABCDEF," is trivial since the number of interactions/reactions/events necessary to construct this assembly of letters is always its length minus one, i.e., the steps it takes to construct this object. Thus, the assembly index of different words is:
Still, there are different ways to build our objects, which are not captured by this rather strictly defined assembly index or by counting the number of interactions it takes to build an object but rather (just in our toy model) by a proxy for it, i.e., the depth of the set of reactions building up the final product "X". I.e. we analyze the distribution of these depths for a particular element and obtain the minimum depth, as a resemblance of the assembly index via Equation (2). We depict these differences in depth in Figure 3. The first object, denoted ➀, depicts a balanced structure where two strands, "" and "," are constructed in parallel, corresponding to the minimal depth, Equation (2). The other chain of events is more consecutive, denoted as ➁. Both chains of reactions have the same number of reactions, but the second chain (➁) has an increased depth compared to ➀. Comparing these two chains of events to our initial example of how to build "" (Equation (1)), we see that ➀ can be interpreted as a chain of events where, as in the "" case, a larger object joins at a later point in the reaction chain, i.e., "" and "" join to build "." In contrast, ➁ depicts a more consecutive chain of events where no two larger objects are joining. Thus, we use the depth to characterize a construction and, consequently, the minimal depth as a proxy for the assembly index. Here ➀ has a depth of 3 and ➁ a depth of 5. Thus, we differentiate between the individual constructions by assessing the depth of a chain of reactions. The proxied "assembly index", i.e., the minimal depth of this object is 3, as you cannot construct this object without using a minimal depth of 3.
We also want to account for the pathway probability of each possible construction, and we do this by assessing the autocatalytic properties of a given catalyzed construction of an object. This means that each catalyzed construction of a given final product is autocatalytic such that all catalysts need to be part of the set of products and constituents, if at least one catalyst is set. Constituents are all elements that produce another one in a merging process, and products are all elements that are constructed by merging two constituents. Given our previous example from Figure 4, the set of all products is and the set of all constituents is . We then count for each construction the number of sub-autocatalytic sets, meaning that we look at each sub-reaction/event and check if all used catalysts are contained within this set of products and constituents. This process is depicted in Figure 6. We deconstruct a catalyzed construction of an object into sub-objects and analyze the subsequent construction for being autocatalytic. For each final product and a particular construction, we increase the pathway probability of a particular construction based on its autocatalytic subset count. this is based on the intuition that if a certain process is autocatalytic, it is more likely to happen, as the particular set of reactions sort of amplifies itself. We implemented this in a way that adds multiples of the observed depth of a construction to our distribution of Depths for all possible constructions . First, we obtain the depth of a construction for each , i.e., . This forms our initial case for building a distribution and a corresponding baseline—we collect all depths of a set of random constructions of a final product X. Next, we alter this distribution to account for autocatalysis by including each depth of a construction times, where is determined such that:
We refer to this as exponential autocatalytic amplification in the following.
Summed up, we analyze four distributions of depths across all constructions for each final product X:
-
Equally randomly chosen catalysts, no weighting, no reuse;No autocatalytic amplification.This serves as our baseline distribution.
-
Equally randomly chosen catalysts, no weighting, no reuse;Exponential autocatalytic amplification.
-
Weighted randomly chosen catalysts, reuse allowed;No autocatalytic amplification.
-
Weighted randomly chosen catalysts, reuse allowed;Exponential autocatalytic amplification.
5. Numerical Experiments
Based on the previous description of our toy model and the corresponding assumptions in Section 4, we built an experimental setup to observe the influence of different catalyst probabilities and the presence of autocatalysis on the depth of a reaction chain leading to the formation of a particular object, and thus the final product. Specifically, we analyzed the distribution of different constructions that form a particular object within a sample assembly space consisting of 10,000 random constructions of that object, confined to the boundaries of the previously discussed toy model. We further modified the assembly space to include several copies of the construction in the presence of autocatalysis, according to Equation (9).
We tested different probabilities of catalysis, i.e., , to observe how they influence the formation of different objects with and without autocatalytic amplification of a particular construction scheme. For our experiments, we selected objects within a range of unique elements, starting from 6 unique elements "" up to 20 unique elements "". We tested the formation of these objects under various conditions and observed the average depth within the collected distributions of the assembly spaces to assess whether there is a bias in the construction of these objects and how this bias changes under different conditions.
5.1. Results
We obtained results for a range of different catalysis probabilities and a range of different object lengths consisting of unique letters, where and .
We further tested these conditions with and without amplification for autocatalysis, and with and without a weighted catalyst assignment. This means we obtained a sample distribution of the assembly space for each probability (11), each length l (15), with and without catalysis amplification (2), and with and without catalyst weighting (2). Thus, distributions were analyzed for their average construction depth, and we searched for biases within these distributions, particularly focusing on whether autocatalytic amplification influences these distributions and favors certain constructions over others.
We show the average depths in the sample assembly spaces for probabilities 0.0, 0.1, 0.5, 1.0, for all catalysis and autocatalysis configurations in Figure 7. Additional plots are collected in Appendix A. These graphics show that we do not observe a separation, and thus no bias, for autocatalysis or weighted catalysts when the catalysis probability is 0.0 or 1.0. Furthermore, across all plots, we do not see a difference or bias in how the catalysts are chosen—whether weighted or not. However, in the cases with probabilities 0.1 and 0.5, we observe a separation and thus a bias towards longer reaction depths for all cases with autocatalytic amplification, with the greatest separation observed for a catalysis probability of 0.1.
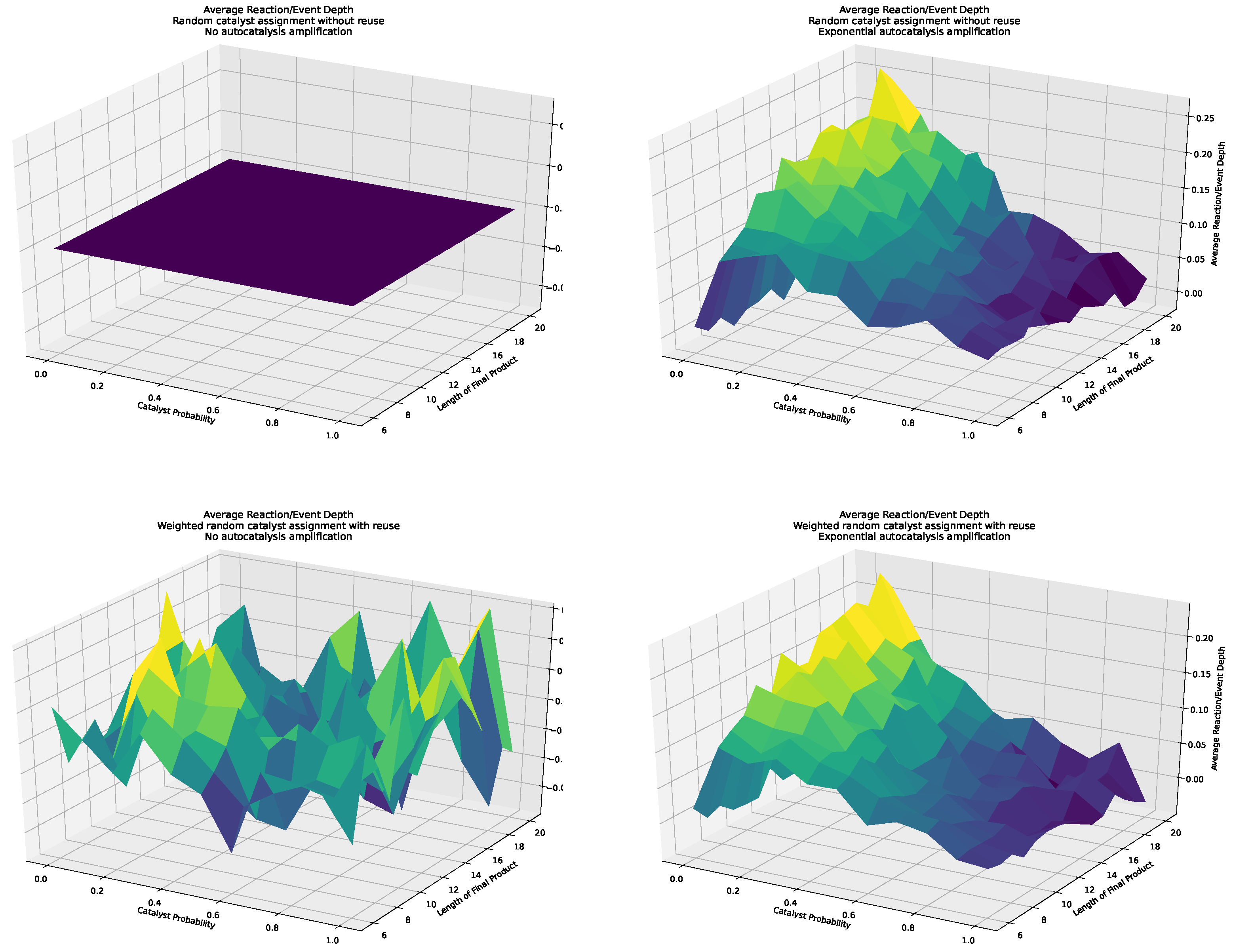
We also depicted the results for all analyzed distributions in 3D surface plots. Here, we used the case without weighted catalysts and no autocatalytic amplification as a baseline, which we subtracted from all three other cases; i.e., weighted catalysis and no autocatalytic amplification, weighted catalysts and autocatalytic amplification, and non-weighted catalysts with autocatalytic amplification. These 3D surface plots are depicted in Figure 8. First, as a proof of concept, we see that the baseline is zero, clearly indicating which case is used as a baseline. Next, we observe a strong separation, with the strongest separation occurring for a probability of 0.1, and increasing separation for increasing object lengths, in both cases with and without weighted catalysts and autocatalytic amplification. However, the case with non-weighted catalysts shows slightly more separation. Furthermore, we do not observe any interpretable trends for the case without autocatalytic amplification.
- The autocatalytic amplification, which alters the distribution in the sampled assembly space for certain constructions/pathways, causes a bias toward longer chains of reactions/events, and thus greater depths of the observed constructions.
- We cannot conclude that the weighting of the catalysts has any impact on the distribution of pathways in the observed sample assembly spaces.
- We observe an increasing separation of the average depths between cases with and without autocatalytic amplification in our sampled assembly spaces for lower probabilities of catalysis (i.e., highest for ) and increasing object lengths .
6. Discussion
Our results showed that autocatalysis can favor longer consecutive reaction chains, indicated by a bias towards increased average depths, rather than reaction chains occurring in parallel. This is somewhat evident from our definition of autocatalysis used in our model (Section 4). Specifically, if all catalysts are part of all reactions within the model, we consider it autocatalytic. This implies that organizing events into a longer consecutive chain increases the probability of incorporating all autocatalysts, as the cascading sequence encompasses most events. However, this bias disappears at different probabilities of catalysis. When the probability of catalysis is increased, this bias diminishes, allowing more distributed and less consecutive chains to be equally prevalent among our possible reactions.
To explain further: In environments with a low probability of catalysis, the preferred way of building complex, catalyzed objects is through a consecutive chain of events (e.g., A + B → AB, AB + C → ABC, etc.). In contrast, environments with a higher probability of catalysis favor more parallel or interconnected catalyzed reaction chains.
In terms of Assembly Theory, this suggests that the pathway probability of forming complex objects is closely tied to their environment. Analyzing a complex object without considering its environment might give a distorted view of the probability of a particular pathway. Though this study does not directly deal with an interpretable assembly index, we conclude that the dependency of pathways on environmental conditions (i.e., the probability of catalysis) could mean that the shortest or longest assembly index for a particular object might never be realized in certain environments. Thus, sampled assembly spaces and the statistics thereof might suffer from a bias toward more consecutive, and thus longer, chains of reactions and events in environments with a lower probability of catalysis. On the other hand, we might only observe the shortest chains of reactions and events in environments with a high probability of catalysis, e.g., biological environments developed to produce complex molecules. We thus conclude that the statistics of sampled assembly spaces are indicative of a certain environment, as these sampled assembly spaces might suffer from a bias toward longer reaction chains in environments with a low catalysis probability. Given certain edge cases, this might obscure the actual assembly index of the construction of a complex object by only slightly increasing constructions. Furthermore, this might enable the detection of autocatalysis indirectly by analyzing the statistics of different sampled assembly spaces of the same process/construction in different environments. This, of course, applies to the original use-case of Assembly Theory, i.e., the analysis of molecular structures [3]. However, we also want to provide an example in terms of software development:
Given an environment of a small team of software developers within a small company with very limited infrastructure, this team will have to build everything step by step themselves and cannot draw on results from other teams within the company. Such a team might, for example, build an initial implementation, then build a server structure to test it on, and so on. This corresponds to an environment with a low probability of catalysis, i.e., the team cannot draw on infrastructure (catalysts) from other teams or products; they need to build the catalysts themselves, which only become available to earlier steps afterward. Thus, in such an environment, a team of developers needs to follow a more consecutive chain of events/reactions. In a bigger company where a lot of infrastructure and other resources are available, a team aiming to build the same product might draw on infrastructure, e.g., available servers, at every step of the way to the final product, i.e., draw on more catalysts. Though not all processes are autocatalyzed, they are catalyzed within the company environment, and thus an environment like this can run more parallel builds, as products from a variety of teams are always available to each team.
Overall, we believe the presented work is a reasonable contribution to the growing body of both Assembly Theory and autocatalysis. However, to connect our results, or more precisely our ideas, with a more realistic scenario, one might apply our ideas, e.g., of increased pathway probabilities, to RAF and TAP models and similar use-cases ([18,23]) and observe the distribution of the length of assemblies or another proxy for this within the generated networks—i.e., analyze sampled assembly spaces of, e.g., RAF and TAP models and conclude, e.g., pathway probabilities from these approaches.
In a more complex build, we need to find out which pathways in the assembly are connected to autocatalysis and thus analyze the statistics of the assembly space, taking into account pathway probabilities to make pathways associated with autocatalysis visible.
Further, we want to mention a very speculative guess that Assembly Theory, and particularly this statistical analysis of sampled assembly spaces with corresponding pathway probabilities and assembly indices, might help in showing phase transitions for the emergence of life in unions of TAP and RAF models, as proposed by a recent work of Stuart Kauffman [25].
7. Conclusions
This article aims to find a connection between autocatalytic sets, or autocatalysis in general, and assembly theory, a relatively recent theory developed to characterize the complexity of objects, particularly molecules. We discuss both key concepts, i.e., assembly theory and autocatalysis, and, based on the basic principles of these frameworks, develop a toy model that explores how certain objects of different complexity form based on autocatalysis. Additionally, we investigate how assembly theory can integrate the presence of autocatalysis and further characterize it in the formation of complex objects.
The developed toy model takes into account varying probabilities of catalysis in the construction of objects of different complexities, exemplified by sequences such as "ABCDEF." It examines how the presence of autocatalysis in the construction of these objects influences the construction process by affecting the probability of different constructions or reaction/event chains leading to a certain object. We further assess the differences in individual construction schemata by using the depth of a given construction. The minimal depth of these reaction chains serves as a proxy for the assembly index, a key concept from assembly theory. After creating and analyzing a multitude of different objects and their constructions, i.e., a sampled assembly space, we observe that autocatalysis introduces a bias toward a more sequential construction of complex objects.
This bias is somewhat evident because sequential construction naturally aligns with the concept of autocatalysis, where the elements necessary for building a certain object, along with the object itself, have an increased probability of catalyzing their own formation. In a sequential construction, each step in the chain directly builds upon the previous one, making it easier for autocatalysis to occur as the sequence progresses. Conversely, in a parallel construction, multiple strands of reactions may proceed simultaneously, with each strand potentially catalyzing others rather than catalyzing within its own sequence. This can result in fewer autocatalytic subsets within each individual strand, as the focus shifts away from self-catalysis toward mutual catalysis between parallel strands. However, this bias vanishes for increasing probabilities of catalysis, indicating that while sequential constructions of complex objects are favored by autocatalysis in environments with scarce catalysis, this is not the case in environments with higher catalysis probabilities. We ultimately derive from our results that while sequential constructions of complex objects are favorable for initiating formation in simple environments, in more complex environments with abundant catalysis, this bias is less prominent, allowing for a more parallel assembly of complex objects.
In conclusion, our study demonstrates that autocatalysis can favor longer consecutive reaction chains over parallel chains, particularly in low-catalysis environments. This finding is crucial for understanding how the complexity of objects can be influenced by the probability of catalysis in their environment. It suggests that the pathway probability of forming complex objects is closely tied to its environment, and analyzing a complex object without considering its environmental conditions might provide a distorted view of the pathway’s probability and ultimately obscure the associated assembly index. We propose that analyzing the statistics of sampled assembly spaces could add information to the representation of the pathways forming complex objects, emphasizing the significance of autocatalytic connections within the environment.
Acknowledgments
The authors acknowledge the funding by TU Wien Bibliothek for financial support through its Open Access Funding Program.
The full program code will be made available upon acceptance in an open GitHub repository and linked within the article.
Appendix A. Additiona Plots
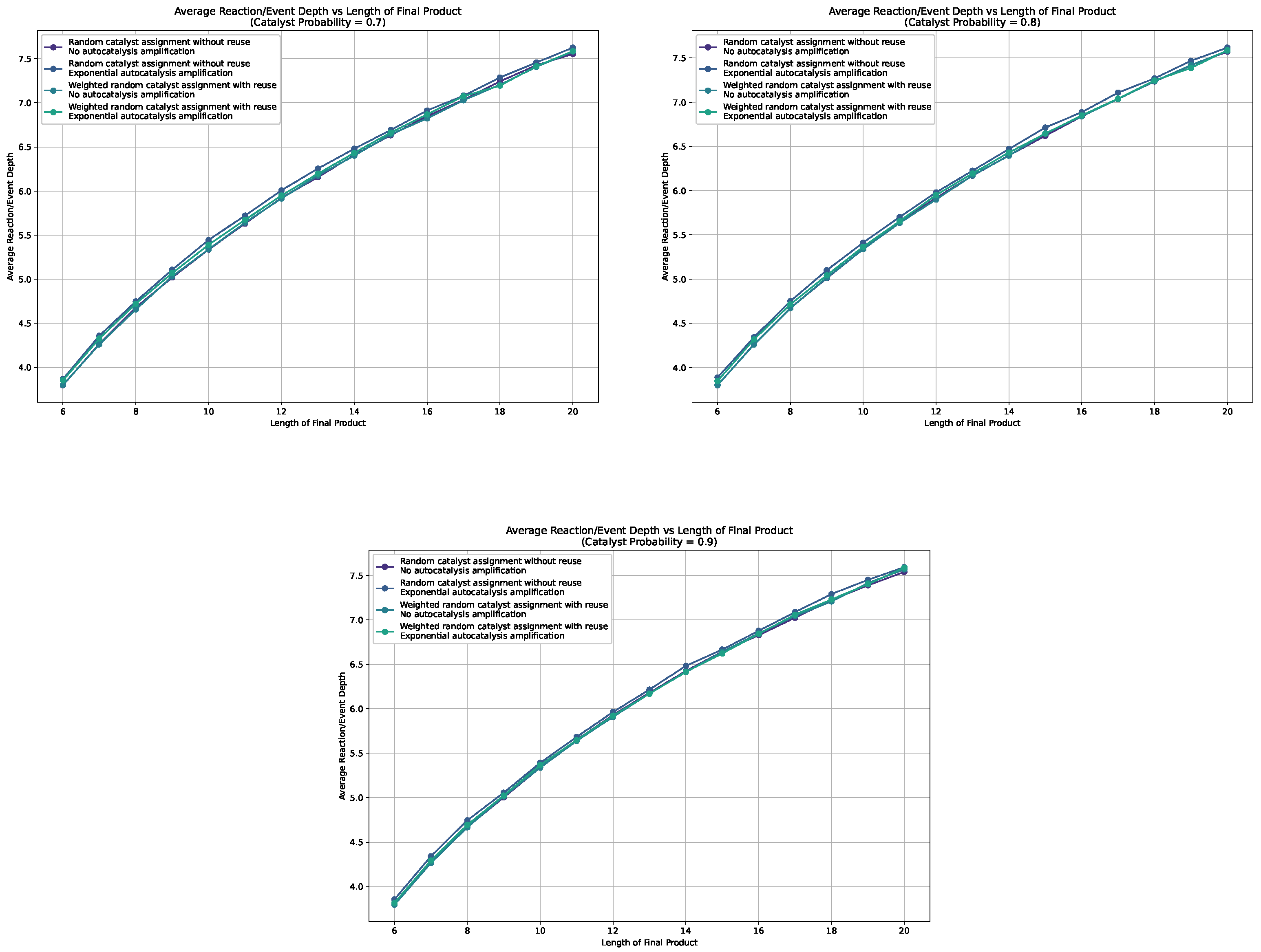
This Appendix collects the missing line plots from Section 5.1 for probabilities .
Figure A1.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
Figure A1.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
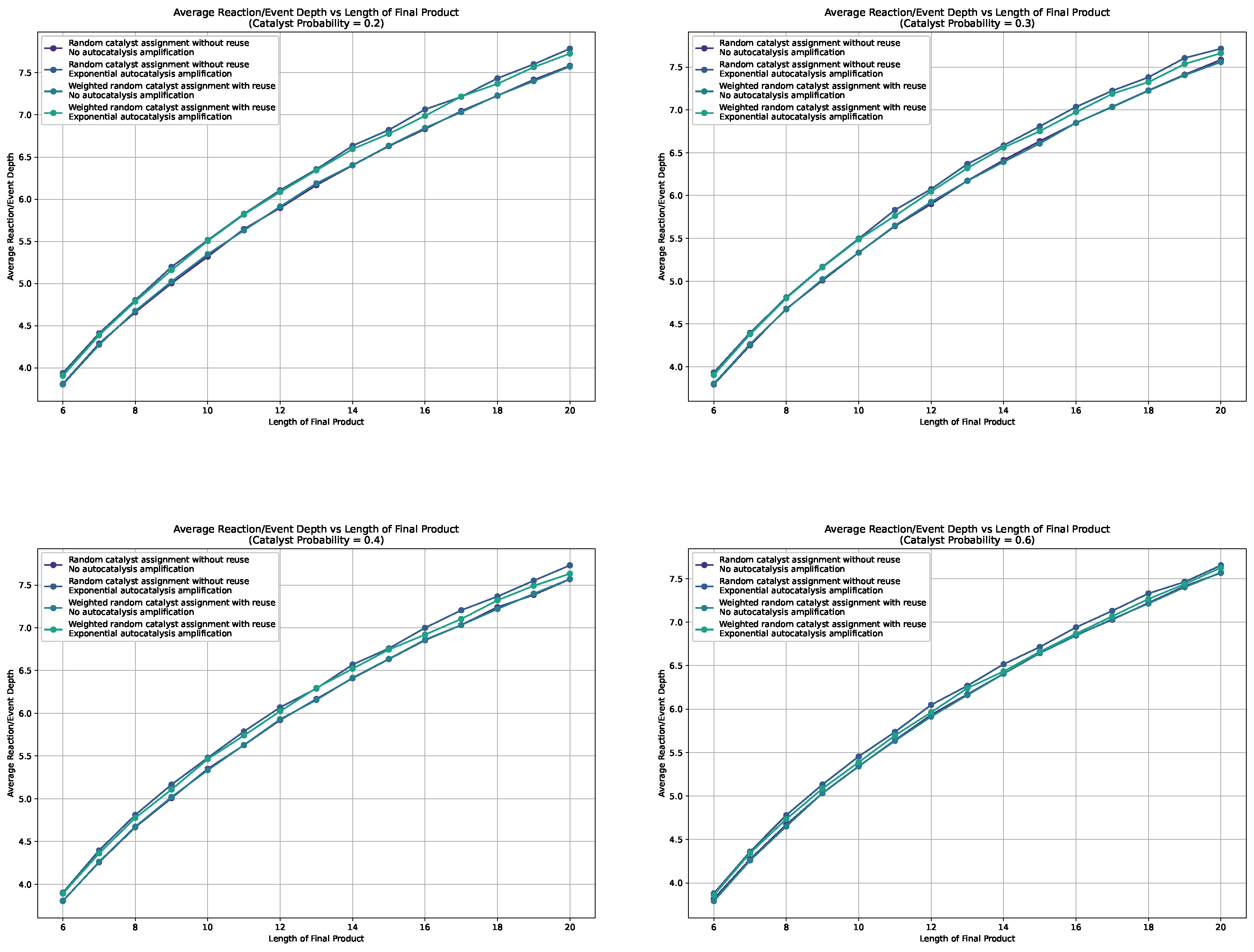
Figure A2.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
Figure A2.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
References
- Mitchell, M. Complexity A Guided Tour; Oxford University Press, 2009. [CrossRef]
- Ladyman, J.; Lambert, J.; Wiesner, K. What is a Complex System? European Journal for Philosophy of Science 2013, 3, 33–67. [Google Scholar] [CrossRef]
- Marshall, S.M.; Moore, D.G.; Murray, A.R.G.; Walker, S.I.; Cronin, L. Formalising the Pathways to Life Using Assembly Spaces. Entropy 2022, 24. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Czégel, D.; Lachmann, M.; Kempes, C.P.; Walker, S.I.; Cronin, L. Assembly theory explains and quantifies selection and evolution. Nature 2023, 622, 321–328. [Google Scholar] [CrossRef] [PubMed]
- Kauffman, S.A. Cellular Homeostasis, Epigenesis and Replication in Randomly Aggregated Macromolecular Systems. Journal of Cybernetics 1971, 1, 71–96. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. The hypercycle: A principle of natural self-organization. Part A: Emergence of the hypercycle. Naturwissenschaften 1977, 64, 541–565. [Google Scholar] [CrossRef] [PubMed]
- Murray, A.; Marshall, S.; Cronin, L. Defining Pathway Assembly and Exploring its Applications, 2018, [arXiv:cs.IT/1804.06972].
- Marshall, S.M.; Murray, A.R.G.; Cronin, L. A probabilistic framework for identifying biosignatures using Pathway Complexity. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 2017, 375, 20160342. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Mathis, C.; Bajczyk, M.D.; Marshall, S.M.; Wilbraham, L.; Cronin, L. Exploring and mapping chemical space with molecular assembly trees. Science Advances 2021, 7, eabj2465. [Google Scholar] [CrossRef] [PubMed]
- Åukaszyk, S.; Bieniawski, W. Assembly Theory of Binary Messages. Mathematics 2024, 12. [Google Scholar] [CrossRef]
- Marshall, S.; Mathis, C.; Carrick, E.; Keenan, G.; Cooper, G.; Graham, H.; Craven, M.; Gromski, P.; Moore, D.; Walker, S.; Cronin, L. Identifying molecules as biosignatures with assembly theory and mass spectrometry. Nature communications 2021, 12. [Google Scholar] [CrossRef]
- Jirasek, M.; Sharma, A.; Bame, J.R.; Mehr, S.H.M.; Bell, N.; Marshall, S.M.; Mathis, C.; MacLeod, A.; Cooper, G.J.T.; Swart, M.; Mollfulleda, R.; Cronin, L. Investigating and Quantifying Molecular Complexity Using Assembly Theory and Spectroscopy. ACS Central Science 2024, 10, 1054–1064. [Google Scholar] [CrossRef]
- Dyson, F.J. A model for the origin of life. Journal of Molecular Evolution 1982, 18, 344–350. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. The Hypercycle: A Principle of Natural Self-Organization; Springer-Verlag Berlin, Heidelberg: Berlin, Heidelberg, 1979. Reprint of papers which were published in: Die Naturwissenschaften, issues 11/1977, 1/1978, and 7/1978. [Google Scholar] [CrossRef]
- Eigen, M.; Schuster, P. The Hypercycle: A principle of natural self-organization Part B: The abstract hypercycle. Die Naturwissenschaften 1978, 65, 7–41. [Google Scholar] [CrossRef]
- Kauffman, S.A. At Home in the Universe: The Search for Laws of Self-Organization and Complexity; Oxford University Press: New York, 1995. [Google Scholar]
- Hordijk, W.; Steel, M.; Kauffman, S. The Structure of Autocatalytic Sets: Evolvability, Enablement, and Emergence. Acta Biotheoretica 2012, 60, 379–392. [Google Scholar] [CrossRef]
- Hordijk, W.; Kauffman, S.A.; Steel, M. Required Levels of Catalysis for Emergence of Autocatalytic Sets in Models of Chemical Reaction Systems. International Journal of Molecular Sciences 2011, 12, 3085–3101. [Google Scholar] [CrossRef]
- Hordijk, W.; Steel, M. Predicting template-based catalysis rates in a simple catalytic reaction model. Journal of Theoretical Biology 2012, 295, 132–138. [Google Scholar] [CrossRef]
- Hordijk, W.; Steel, M. Detecting autocatalytic, self-sustaining sets in chemical reaction systems. Journal of Theoretical Biology 2004, 227, 451–461. [Google Scholar] [CrossRef]
- Hordijk, W.; Hein, J.; Steel, M. Autocatalytic Sets and the Origin of Life. Entropy 2010, 12, 1733–1742. [Google Scholar] [CrossRef]
- Napolitano, L.; Evangelou, E.; Pugliese, E.; Zeppini, P.; Room, G. Technology networks: the autocatalytic origins of innovation. Royal Society Open Science 2018, 5, 172445. [Google Scholar] [CrossRef] [PubMed]
- Hordijk, W.; Kauffman, S.; Koppl, R. Emergence of autocatalytic sets in a simple model of technological evolution. Journal of Evolutionary Economics 2023, 33, 1519–1535. [Google Scholar] [CrossRef]
- Steel, M.; Hordijk, W.; Kauffman, S.A. Dynamics of a birthâdeath process based on combinatorial innovation. Journal of Theoretical Biology 2020, 491, 110187. [Google Scholar] [CrossRef] [PubMed]
- Kauffman, S.; Roli, A. Is the Emergence of Life an Expected Phase Transition in the Evolving Universe?, 2024, [arXiv:q-bio.PE/2401.09514]. 2024.
- Mathis, C.; Patarroyo, K.Y.; Cronin, L.; Croninlab. Molecular Assembly - Learning Platform. http://www.molecular-assembly.com/learn/, 2024. Accessed: 2024-08-13.
- Lee, D.H.; Granja, J.R.; Martinez, J.A.; Severin, K.; Ghadiri, M.R. A self-replicating peptide. Nature 1996, 382, 525–528. [Google Scholar] [CrossRef] [PubMed]
- Pressé, S.; Ghosh, K.; Lee, J.; Dill, K.A. Principles of maximum entropy and maximum caliber in statistical physics. Rev. Mod. Phys. 2013, 85, 1115–1141. [Google Scholar] [CrossRef]
- Kolmogorov, A.N. Three approaches to the quantitative definition of information *. International Journal of Computer Mathematics 1968, 2, 157–168. [Google Scholar] [CrossRef]
- Cormen, T.H.; Leiserson, C.E.; Rivest, R.L.; Stein, C. Introduction to Algorithms, Fourth Edition, 4th ed.; The MIT Press: Cambridge, Massachusetts and London, England, 2022; p. 1312. [Google Scholar]
- Martínez, C.; Roura, S. Randomized binary search trees. J. ACM 1998, 45, 288–323. [Google Scholar] [CrossRef]
Figure 1.
This is a simplified preliminary depiction of our results. Autocatalysis favors more consecutive builds of complex objects in environments with low catalysis. The left side portrays possible ways to form a complex object "ABCDEF," and the right side shows the builds favored by autocatalysis.
Figure 1.
This is a simplified preliminary depiction of our results. Autocatalysis favors more consecutive builds of complex objects in environments with low catalysis. The left side portrays possible ways to form a complex object "ABCDEF," and the right side shows the builds favored by autocatalysis.

Figure 2.
This figure illustrates a catalytic reaction system (CRS) consisting of molecule types (solid nodes) and four reactions (open nodes). The food set is . Solid arrows represent reactants entering and products leaving a reaction, while dashed arrows represent catalysis. The subset (highlighted with bold arrows) forms a RAF set. This example is taken and adapted from [18].
Figure 2.
This figure illustrates a catalytic reaction system (CRS) consisting of molecule types (solid nodes) and four reactions (open nodes). The food set is . Solid arrows represent reactants entering and products leaving a reaction, while dashed arrows represent catalysis. The subset (highlighted with bold arrows) forms a RAF set. This example is taken and adapted from [18].
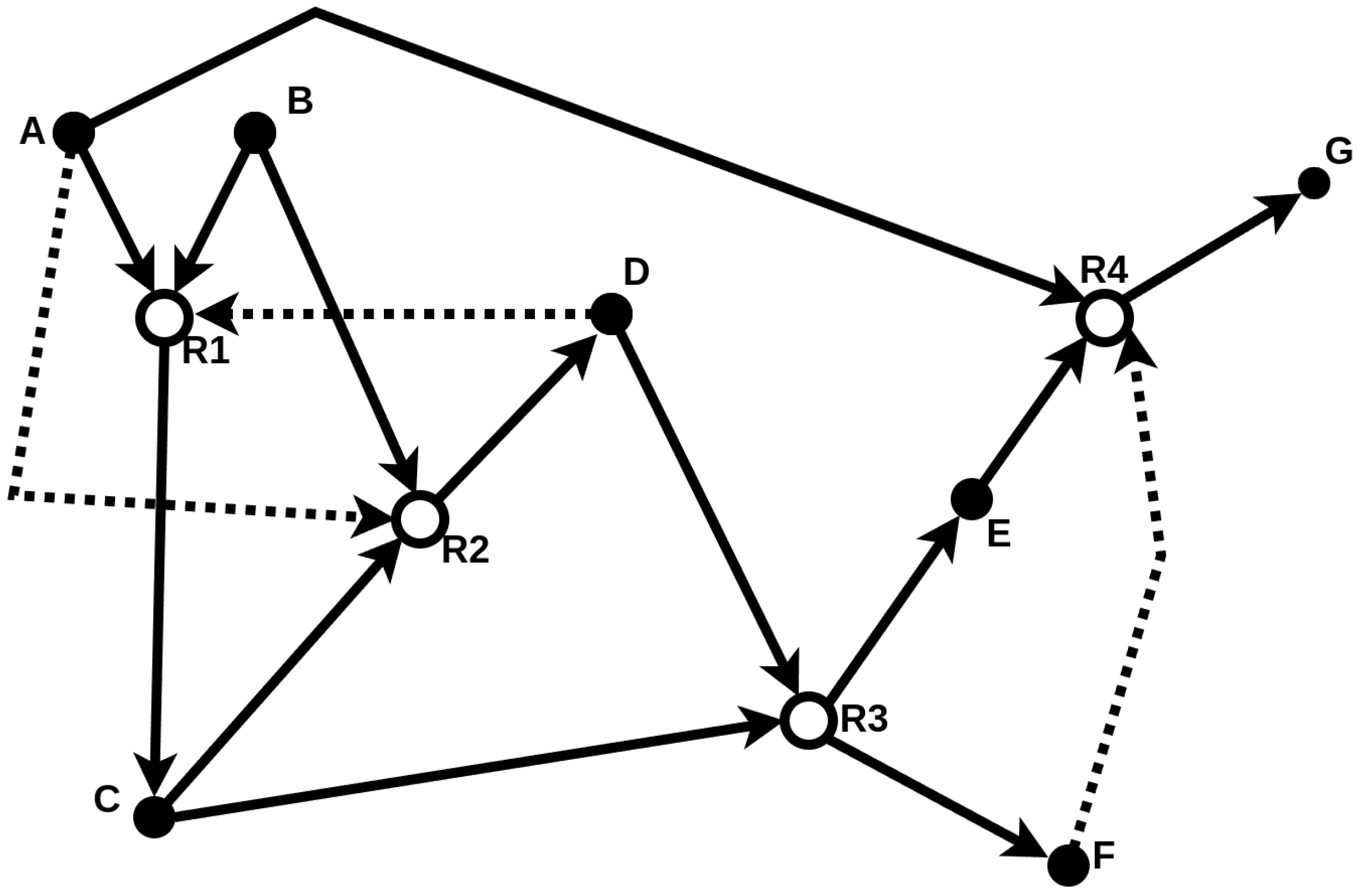
Figure 3.
Illustrating our Toy Model: The figure shows two possible pathways/constructions to create the object ’’ within the confines of our model. The left construction, ➀, depicts a more parallel construction, whereas the right one, ➁, illustrates a more consecutive construction of ’’.
Figure 3.
Illustrating our Toy Model: The figure shows two possible pathways/constructions to create the object ’’ within the confines of our model. The left construction, ➀, depicts a more parallel construction, whereas the right one, ➁, illustrates a more consecutive construction of ’’.
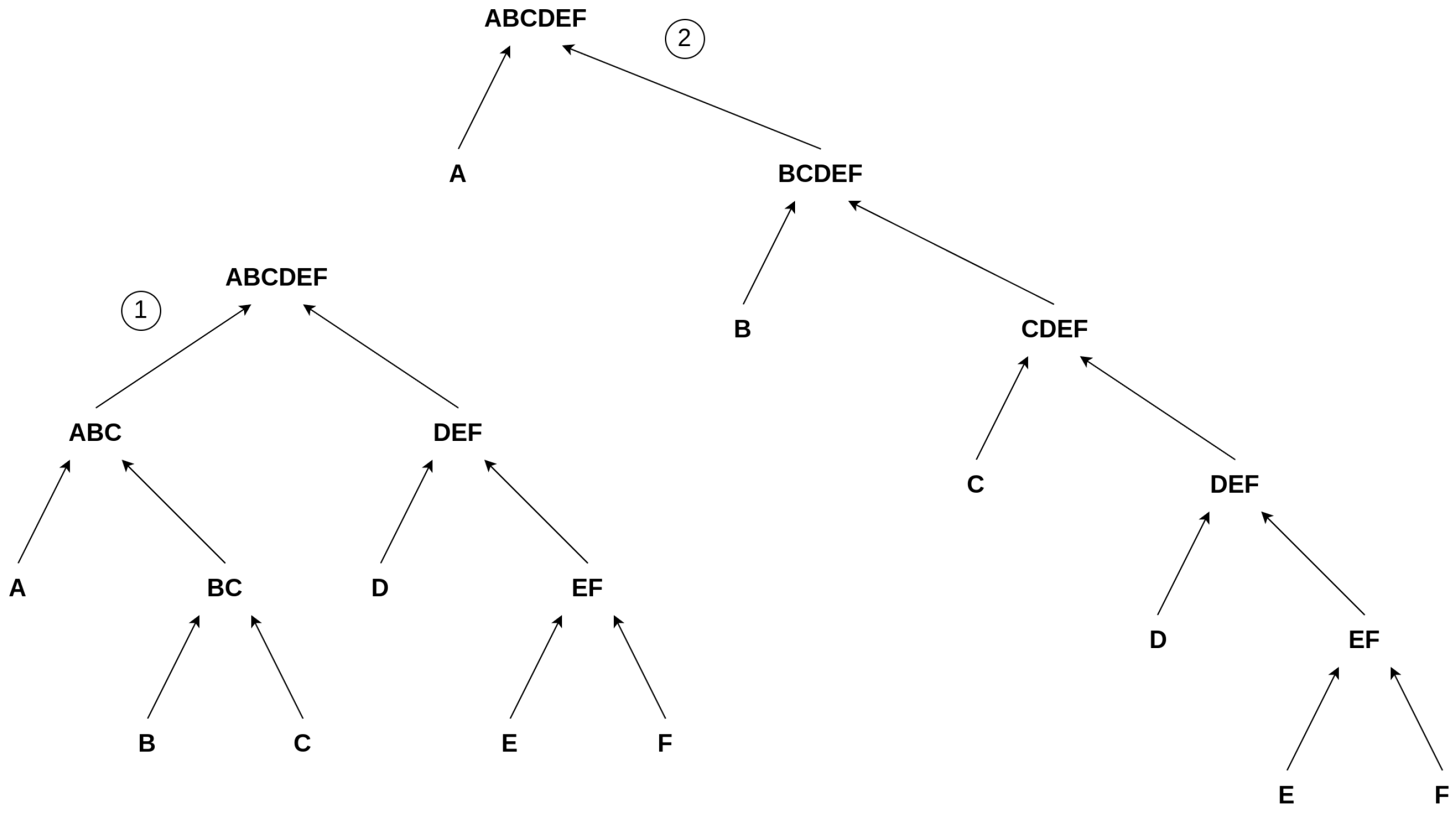
Figure 4.
Depiction of how different reactions within the toy model can be catalyzed. For example, we can choose catalysts for a reaction from all products and constituents available in the entire chain/tree of reactions. The dashed lines show which reactions are catalyzed by which element, with the arrows pointing to the catalyzed reactions and the dashed lines starting at the chosen catalyst.
Figure 4.
Depiction of how different reactions within the toy model can be catalyzed. For example, we can choose catalysts for a reaction from all products and constituents available in the entire chain/tree of reactions. The dashed lines show which reactions are catalyzed by which element, with the arrows pointing to the catalyzed reactions and the dashed lines starting at the chosen catalyst.
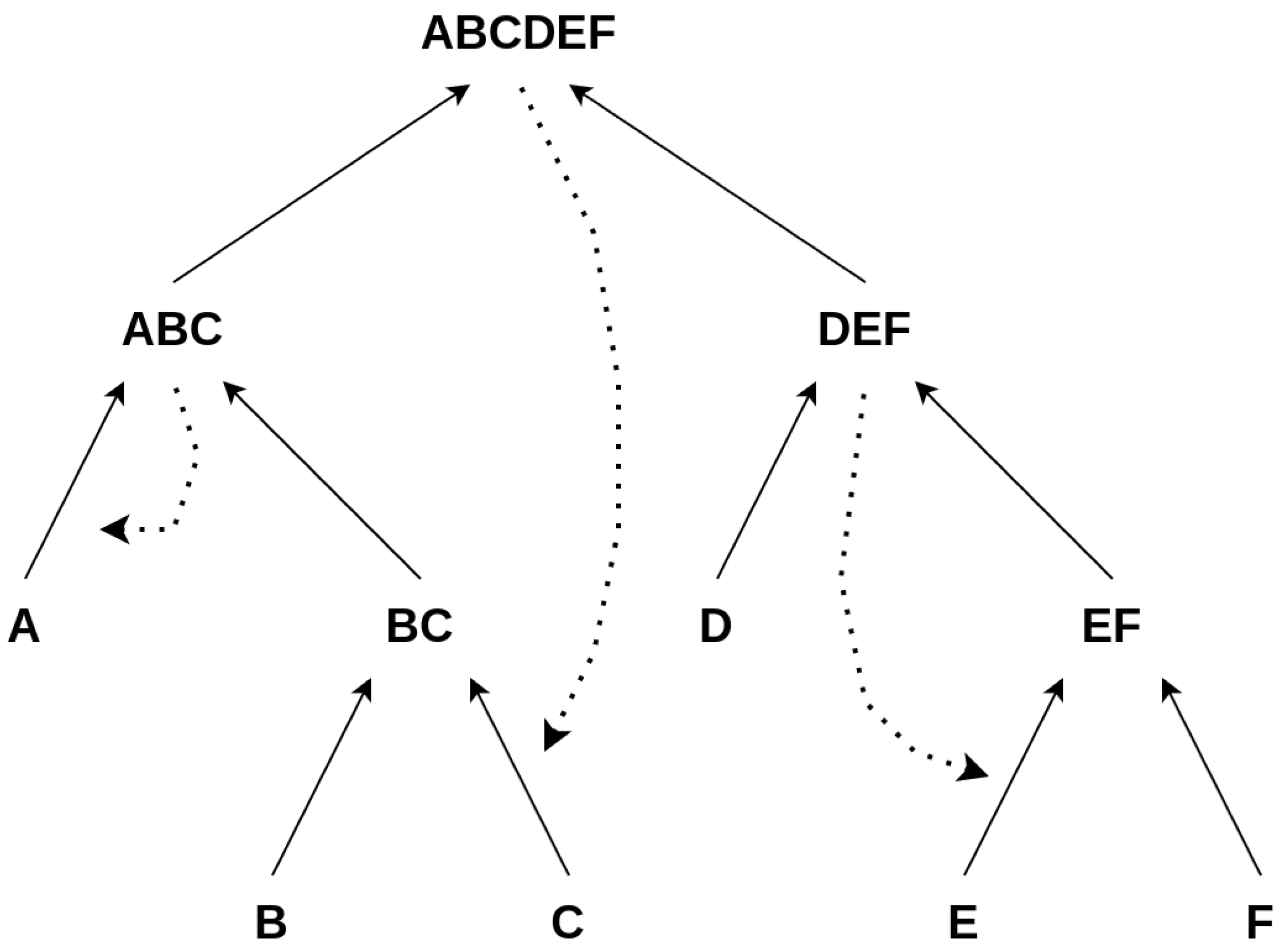
Figure 5.
This is one of many possible ways to assemble ’,’ i.e., one construction among all possible ones in the assembly space for ’.’ This figure is a direct output from the Python implementation of our toy model. Each product and constituent is assigned a unique color, and if this element is used as a catalyst, we also use this color for the arrows depicting the reaction.
Figure 5.
This is one of many possible ways to assemble ’,’ i.e., one construction among all possible ones in the assembly space for ’.’ This figure is a direct output from the Python implementation of our toy model. Each product and constituent is assigned a unique color, and if this element is used as a catalyst, we also use this color for the arrows depicting the reaction.
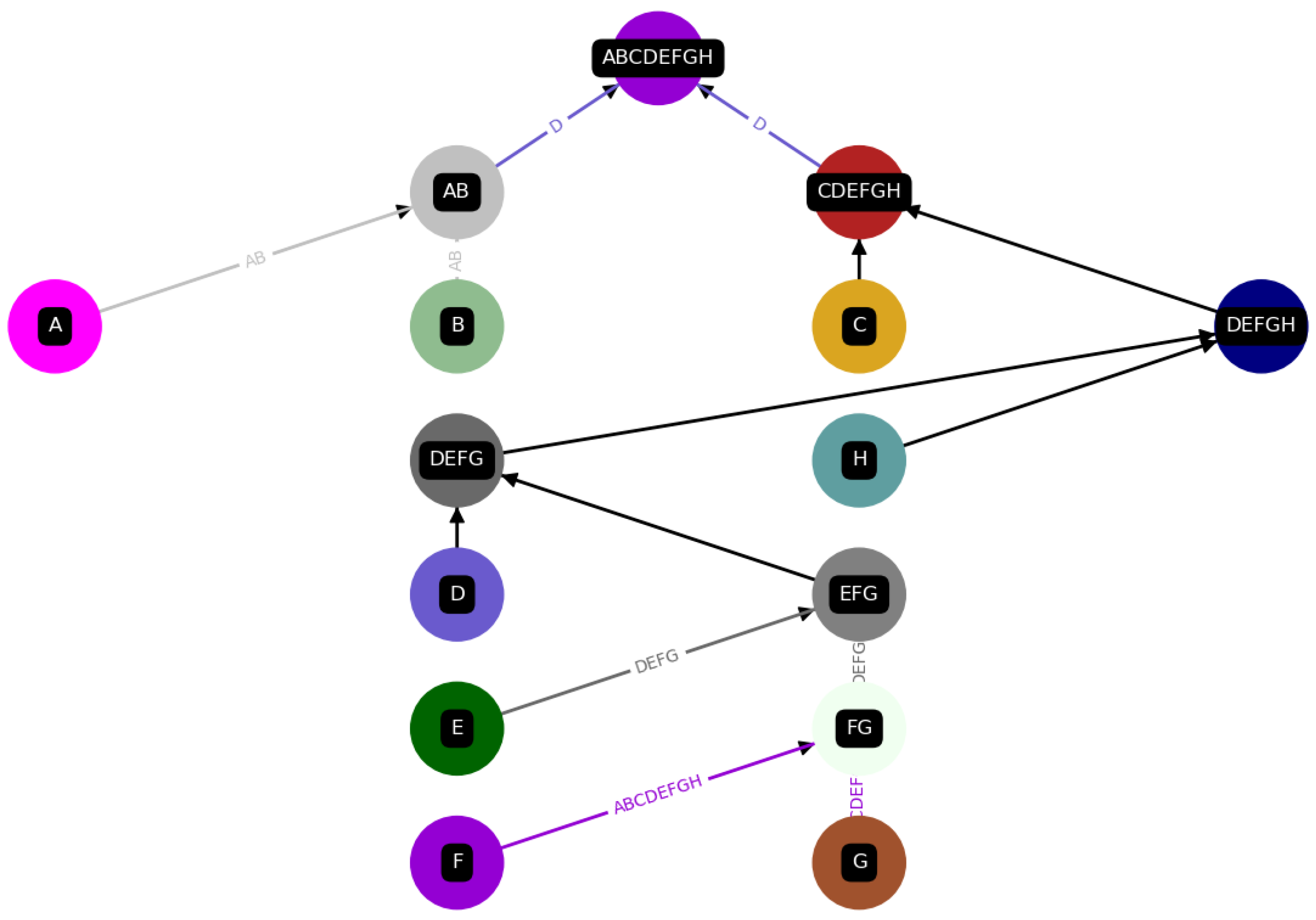
Figure 6.
Assessing autocatalysis of subnetworks: This scheme depicts how we assess whether a subnetwork/subconstruction of a construction is autocatalytic. Subconstructions with a purple shadow are not autocatalytic, as their catalysts are not contained within them. Conversely, subconstructions with a green shadow are autocatalytic, with all catalysts present among the products and constituents of the subconstruction.
Figure 6.
Assessing autocatalysis of subnetworks: This scheme depicts how we assess whether a subnetwork/subconstruction of a construction is autocatalytic. Subconstructions with a purple shadow are not autocatalytic, as their catalysts are not contained within them. Conversely, subconstructions with a green shadow are autocatalytic, with all catalysts present among the products and constituents of the subconstruction.
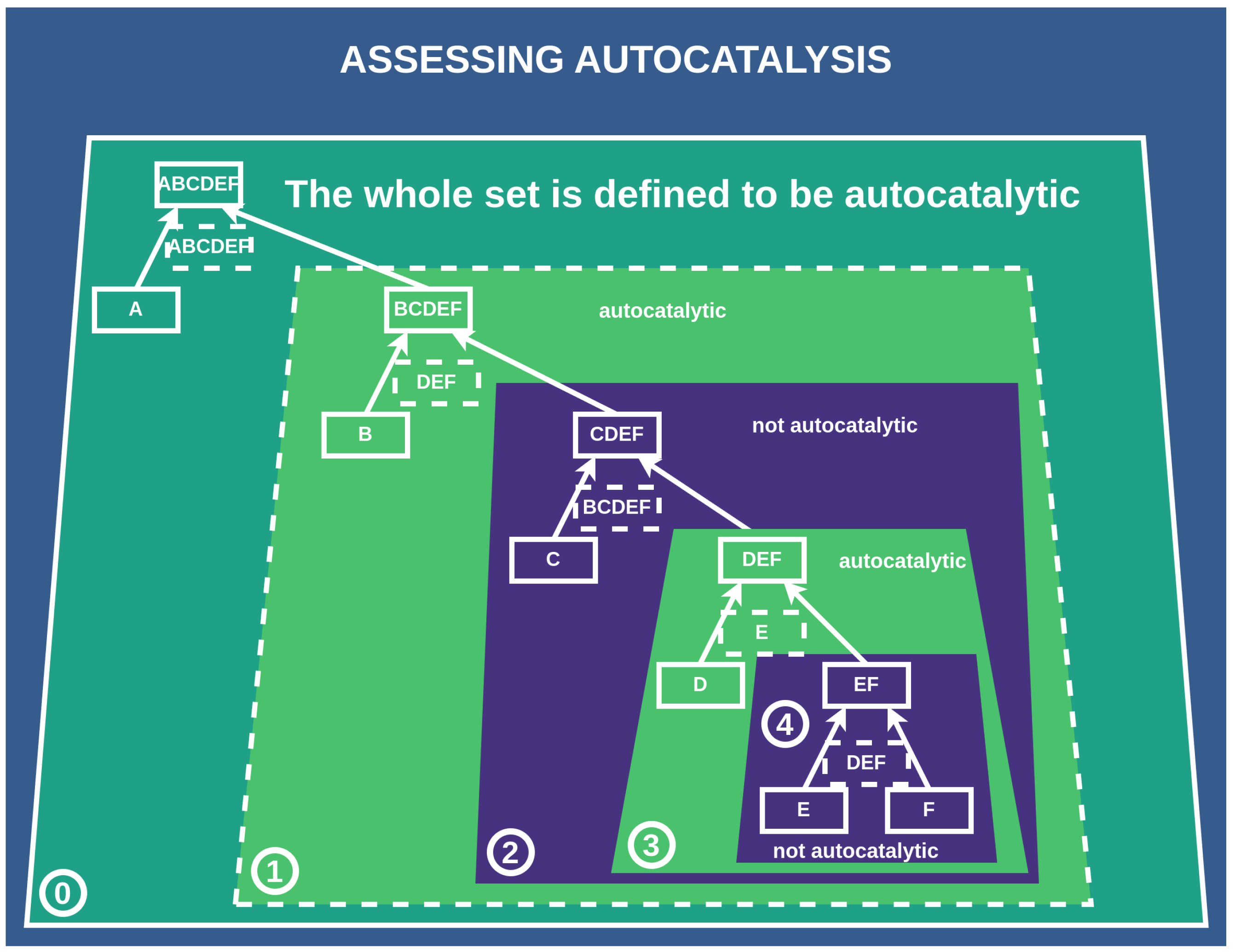
Figure 7.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
Figure 7.
Line plots for the average depth in the sampled assembly space for different settings, i.e., weighted, non-weighted, and with and without autocatalytic amplification, for different catalysis probabilities.
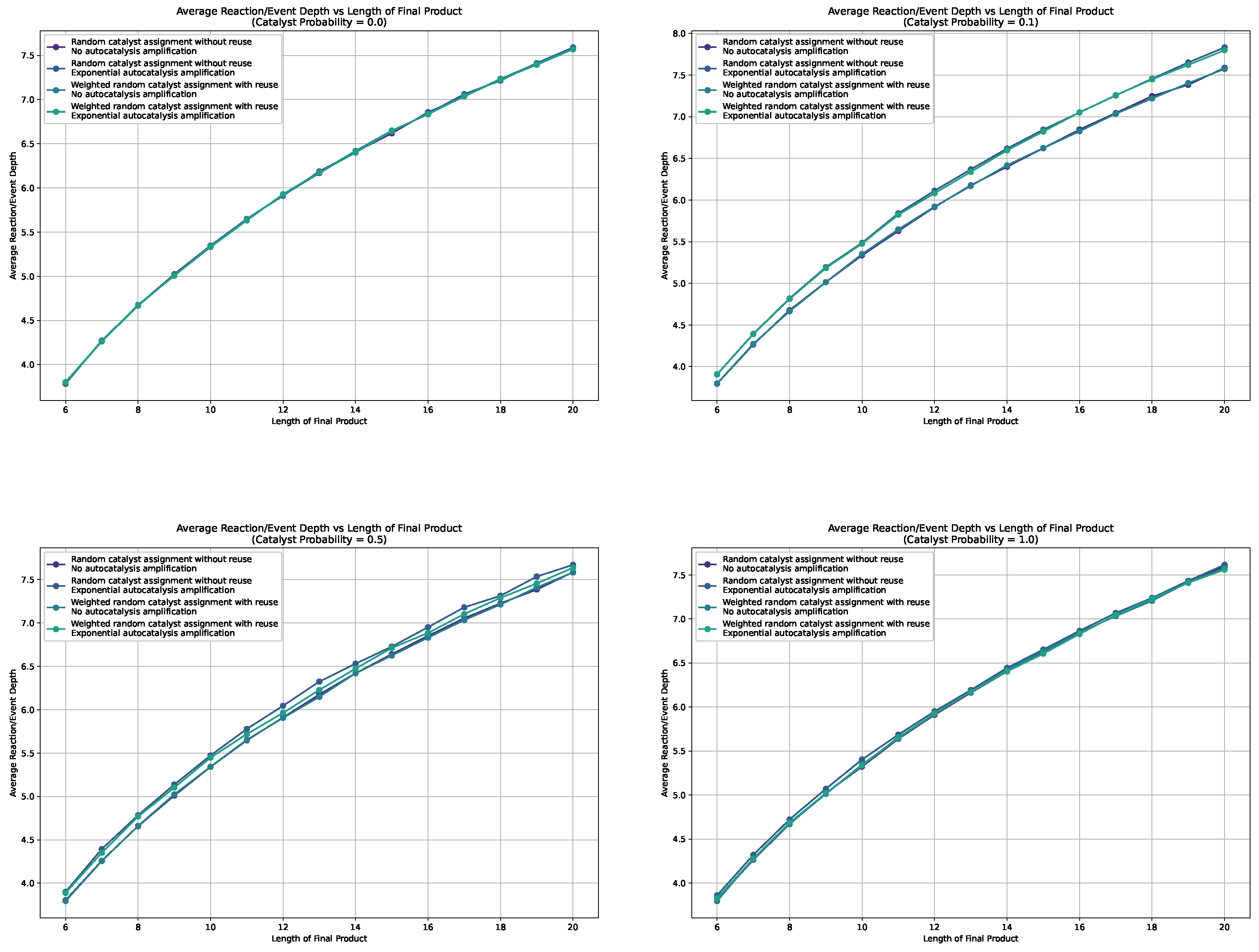
Figure 8.
3D surface plots for different scenarios: with and without autocatalytic amplification, and with weighted and non-weighted catalysts. The upper left plot is the baseline, which we subtracted from all other cases to make the differences, i.e., the separation from the baseline, visible. The remaining plots depict how different sampled assembly spaces differ in terms of the average reaction depth from each other.
Figure 8.
3D surface plots for different scenarios: with and without autocatalytic amplification, and with weighted and non-weighted catalysts. The upper left plot is the baseline, which we subtracted from all other cases to make the differences, i.e., the separation from the baseline, visible. The remaining plots depict how different sampled assembly spaces differ in terms of the average reaction depth from each other.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



