Submitted:
16 August 2024
Posted:
19 August 2024
You are already at the latest version
Abstract
In the context of global climate change, the frequency of sudden natural disasters is increasing. Assessing traffic road damage post-disaster is crucial for emergency decision-making and disaster management. Traditional ground observation methods for evaluating traffic road damage are limited by the timeliness and coverage of data updates. Relying solely on these methods does not adequately support rapid assessment and emergency management during extreme natural disasters. Social media, a major source of big data, can effectively address these limitations by providing more timely and comprehensive disaster information. Motivated by this, we utilized multi-source heterogeneous data to assess the damage to traffic roads under extreme conditions and established a new framework for evaluating traffic roads in cities prone to flood disasters caused by rainstorms. The approach involves several steps: First, extracting the surface area affected by precipitation using a threshold method constrained by confidence intervals derived from microwave remote sensing images; Second, collecting disaster information from the Sina Weibo platform, where social media information is screened and cleaned. A quantification table for road traffic loss assessment was defined, and a social media disaster information classification model combining text convolutional neural networks and attention mechanisms was proposed (TextCNN-Attention Disaster Classification); Finally, matching traffic road information on social media with basic geographic data, visualizing the classification of traffic road disaster risk levels, and completing the assessment of traffic road disaster levels based on multi-source heterogeneous data. Using the "7.20" rainstorm event in Henan Province as an example, this study categorizes the disaster impact on traffic roads into five levels: particularly severe, severe, moderate, mild, and affected, as interpreted from remote sensing images. The evaluation framework for flood disaster traffic roads based on multi-source heterogeneous data provides important data support and methodological support for enhancing disaster management capabilities and systems.
Keywords:
Multi-source heterogeneity
; Flood disaster
; Social media information
; TextCNN-Attention
; Transportation roads
; Loss assessment
1. Introduction
The intensification of global climate change has led to the widespread, frequent, recurrent, and concurrent occurrence of extreme weather disasters in various regions [1,2,3]. In recent years, the losses and impacts of natural disasters caused by extreme weather events have also intensified [4,5,6]. According to the "2023 Asian Climate Status" report released by the World Meteorological Organization, Asia experienced the highest incidence of disasters worldwide in 2023, primarily due to weather, climate, and hydrological factors. Floods and storms accounted for over 80% of these incidents, with floods and rainstorms causing the highest number of casualties and economic losses. Specifically, more than 60% of all disaster-related fatalities were caused by flooding. Urban areas, in particular, suffer significant disruptions from sudden, extreme rainstorms, leading to waterlogging, and severely impacting road traffic. Rapid and precise identification of the spatial location, extent, and severity of the damage is crucial for enhancing the efficiency of post-disaster recovery efforts. Such measures are vitally important for establishing lifelines during disasters and reducing their overall impact [7,8]. As critical components of regional economic infrastructure, transportation roads play a pivotal role in the spread of disaster impacts. Consequently, the timely dissemination of traffic and road disaster assessment results is essential for effective emergency response and robust disaster risk management [9,10].
With the rapid advancement of remote sensing technology, remote sensing methods now enable the large-scale and rapid extraction of disaster-related information, characterized by low costs and dynamic detection capabilities [11,12]. Recent studies have focused on delineating flood inundation extents, primarily utilizing optical remote sensing images and Synthetic Aperture Radar (SAR) images for flood feature extraction [13,14,15]. Optical remote sensing offers direct imaging, better image quality, and abundant spectral data. Using spectral indices to identify areas affected by flooding and sediment deposition has yielded notable results [16,17,18]. However, optical remote sensing data is highly vulnerable to cloud cover and adverse weather conditions, which compromise the accurate extraction of disaster information. Frequently existing cloud cover can also introduce significant errors in delineating inundation extents [19,20]. Microwave remote sensing, operable under all weather conditions, can penetrate clouds, snow, and fog, unaffected by meteorological factors. Flood information extraction methods using SAR imagery are typically categorized into traditional and deep learning approaches [21,22]. Traditional methods are notably rapid, catering to the urgent needs following disasters but are less effective in complex terrains, often hampered by mountain shadows and sensor noise. Conversely, deep learning methods have significantly enhanced extraction accuracy, offering improvements over issues associated with spectral interference from terrain and sensor anomalies. Nonetheless, the performance of deep learning models is largely dependent on ample sample sizes, requiring further refinement and optimization, especially for models utilizing remote sensing data from diverse sources. The application of existing deep learning models for rapid flood information extraction following brief, extreme weather-induced rainfall remains a subject for detailed investigation. Therefore, developing a rapid flood information extraction system using SAR image data is a primary objective of this study.
In the era of digital intelligence, leveraging remote sensing for urban natural disaster emergency response no longer suffices for comprehensive collection and rapid analysis of extreme natural disaster information. The advent of big data has revolutionized disaster management approaches and paradigms, introducing new research methodologies and strategies for urban flood prevention and governance. Social media crowdsourcing data, serving as an additional data source, offers a communication channel for reporting extreme natural disaster events. Its volume and spatial density often surpass that of traditional sensors [23,24]. Social media can rapidly aggregate information about sudden natural disasters in near real-time, eliminating the need for deploying reconnaissance equipment or personnel. It provides timely disaster and geographic distribution information, enhancing the monitoring capabilities of Earth observation satellites. On one hand, it monitors social media users’ attention and emotional responses to sudden natural disasters, providing valuable insights for emergency decision-making and public opinion management. On the other hand, the immediacy of social media data allows for a real-time understanding of conditions in disaster-affected areas, supporting emergency assessments and aiding disaster response decision-making. However, despite these advantages, the accuracy of risk assessment for sudden natural disasters using social media data still presents significant challenges compared to the processing of Earth observation data.
Current studies on the application of Natural Language Processing (NLP) to natural disasters primarily focus on emotional analysis, sensitivity mapping, post-disaster recovery, and loss assessment. Previous studies [25] have demonstrated the key role of social media in earthquake damage assessment and have defined a text-based damage assessment scale to underscore the rapid assessment capabilities of social media data. Researchers frequently employ text mining techniques to derive actionable insights during disasters. For instance, Yuan et al. (2018) created an index dictionary through semantic analysis to pinpoint damage-related tweets during Hurricane Matthew in Florida, illustrating the feasibility of using social media data to identify severely affected areas at the county level [26]. Another example is which utilized social media data for disaster loss evaluation, encompassing data preprocessing, fine-grained topic extraction, and quantitative damage estimation, and conducted correlation analysis at the urban level to link various themes with disaster losses [27]. Inspired by these findings, researchers have identified a strong correlation between social media activities and disaster damage [25,26,27]. Moreover, disaster loss assessment using social media information primarily involves text cleaning and processing of big data. Unlike news information classification, text classification methods in a disaster context face challenges due to the small amount of effective information, imbalanced sample data, and unclear differentiation scales between loss levels [8,30,31]. Motivated by these insights, this paper aims to assess emergency flood traffic road damage by integrating analyses of social media data, remote sensing, and geographic information. By leveraging multi-source heterogeneous data, this approach aims to improve the accuracy of traffic road loss assessments in sudden natural disasters, enabling emergency personnel to devise more effective disaster relief strategies. In this study, damage assessment of the transportation network is completed using social media data, remote sensing image data, and basic geographic information. The main technical process is illustrated in Figure 1. This work contributes in two major ways:
(1) Flood impact scope identification of SAR images Based on Confidence Interval is proposed, the establishment of this threshold provides a scientific and reliable technique, enhancing the credibility of the model's predictions and results.
(2) A quantitative table for assessing road traffic loss based on social media disaster information was established. Then, a road traffic risk classification model using social media data was developed. This model adds attention mechanisms and improves prediction performance, accuracy, and stability by optimizing the size of convolutional kernels and the number of layers.
2. Study Case and Data Collection
From 08:00 on July 20, 2021, to 06:00 on July 21, 2021, a severe rainstorm occurred in the north-central part of Henan Province, with extremely heavy rainfall recorded in areas of Zhengzhou, Xinxiang, Kaifeng, and others. Between 16:00 and 17:00 on July 20, the maximum hourly rainfall in the urban area of Zhengzhou reached 120-201.9 mm. The daily rainfall recorded at ten national meteorological observation stations in Zhengzhou, Xinxiang, and Kaifeng surpassed historical records. The intense rainfall affected approximately 13.9128 million people in Henan Province, resulting in 302 deaths and 50 individuals missing due to the disaster.
This study utilizes the Sina Weibo social platform to extract information on the rainstorm disaster in Henan. It allows users to access information through various mediums including web, email, apps, instant messaging, SMS, PCs, and mobile devices, facilitating real-time sharing and transmission of information in text, images, videos, and other multimedia formats. Social media platforms, characterized by their rapid response, extensive coverage, and significant impact, are critical in managing large-scale sudden natural disasters. Scientific analysis of post-disaster social media data can effectively mitigate losses and social hazards, providing essential data for emergency management departments to understand the needs of affected areas. The data collection period spanned from July 19, 2021, to July 24, 2021, across Weibo and other platforms, yielding a total of 83,030 valid entries, including basic geographic information from Henan Province, as illustrated in Figure 2.
3. Methodology
3.1. Flood Impact Scope Identification of SAR Images Based on Confidence Interval
For remote sensing image data, this study employed Sentinel-1 synthetic aperture radar (SAR) satellite imagery from the European Space Agency to identify areas affected by waterlogging. The analysis utilized VH polarized SAR images in IW mode GRD type HR, capturing data before the disaster from July 1, 2021, to July 19, 2021, and during the disaster from July 20, 2021, to August 10, 2021. Under the GEE platform, the extent of waterlogging was extracted using Sentinel-1 GRD image data, following preprocessing steps including orbit correction, ARD boundary noise removal, thermal noise removal, radiometric correction, terrain correction, and dB conversion. The study applied smoothing filters to SAR images to minimize speckle effects and differentiate post-disaster images from pre-disaster ones, creating a differential image that highlights changes due to flooding. The flood threshold was determined by manual selection of sample points within the constraints of confidence intervals.
A confidence interval is a commonly used method of interval estimation. For a dataset, where Ω is defined as the observation object, W is all possible observation results, and X is the actual observation value, X is essentially a random variable defined on Ω with values ranging over W. The confidence interval is defined by the functions u(.) and v(.), signifying that for an observation value X=x, its confidence interval is (u(x), v(x)). If the true value is w, then the confidence level is the probability c, expressed mathematically as:
Where U=u(X) and V=v(X) are statistics, making the confidence interval a random interval: (U, V). For instance, constructing a value interval with 95% confidence implies that, in 100 parameter estimates, 95 are expected to fall within this interval. Confidence is typically denoted as 1- α. Thus, if p<0.05, α represents statistical significance, and the confidence level is 0.95, equating to 95%. This is mathematically expressed as:
Here, μ represents the estimated true value, and P(μ∈[low, high]) denotes the probability that the true value falls within the specified interval.
Assuming that the data follows a normal distribution, due to the symmetric nature of the distribution, the confidence interval can be expressed as , where is the sample mean and c is the critical value to be calculated. This is applied in formula (2) as:
In the formula, is the sample mean, δ is the sample standard deviation, n is the sample size, α represents the confidence level, and P is the proportion value in the statistical sample.
3.2. Rapid Loss Assessment of Road Traffic in Flood Disasters Based on Social Media Data
3.2.1. Social Media Information Preprocessing
In the task of disaster loss analysis using social media data, data cleaning and purification are essential components of data preprocessing, significantly influencing both efficiency and outcomes. Initially, the original text often includes numerous non-essential characters (such as punctuation and spaces), which need to be removed, retaining only Chinese characters. After eliminating these characters, the text was segmented using Jieba's precise mode. In this mode, Jieba accurately divides the text into optimal word units, facilitating further analysis. To enhance text analysis quality, a stop word list was employed to filter the segmentation results. This list includes common conjunctions and particles that add little analytical value, such as "we", "de", and "ma". The processed segments were then concatenated into a single string, separated by spaces, forming the preliminary disaster assessment text corpus. Furthermore, deduplication of the initial dataset is necessary. Assuming two texts, S1 and S2, are provided, Word2Vec is used to encode feature vectors. Using these encodings, the MinHash algorithm was used to perform a deduplication on social media text data. This method can measure the similarity between texts and efficiently purifies a large volume of collected social media data, thereby enhancing the accuracy of disaster data analysis.
Disaster loss analysis via social media is essentially a multi-class text classification task, often challenged by small sample sizes and data imbalance between classes. To ensure balanced data across categories and maintain model classification accuracy, the study applied data augmentation. However, due to the specific nature of disaster information on social media, using random deletion methods may remove critical information, such as specific road names. Similarly, backtranslation for data augmentation might introduce semantic biases and compromise subsequent road information matching. To address these issues, this study designated road names as stop words to preserve essential road network information. The purpose of this operation is to avoid replacing road names with synonyms during data augmentation. On this basis, synonym substitution method was used for data augmentation. The synonym library used is the Harbin Institute of Technology Synonym Word Forest. Additionally, random extraction enhancement was performed on each category of the original text. If the same text is selected multiple times, synonyms are used to prevent redundancy in the augmented data. Ultimately, the augmented text was integrated with the original corpus to create the final social media disaster information dataset.
3.2.2. Damage Scales and Text Labeling
To construct a rapid loss assessment model for road traffic in flood disasters using social media data, the initial step involves defining the classification of loss levels derived from social media data. This study references emergency response plans for highway traffic emergencies to create a quantitative assessment table for road traffic losses based on social media information, as depicted in Table 1. The disaster levels of road networks are categorized into four grades: very serious, severe, relatively serious, and minor. Considering that some road disaster situations may not be reported by social media, remote sensing images identifying areas affected by waterlogging are used to enhance the assessment of the road network disaster status. The classifications are detailed as follows:
Level 0: Represents cases of significant impact, such as roads that have been submerged and require closure.
Level 1: Denotes heavy damage, characterized by deep water accumulation and resulting traffic congestion.
Level 2: Corresponds to moderate damage, for instance, partial waterlogging that leads to reduced driving speeds.
Level 3: Indicates slight damage, where there is virtually no standing water, and traffic flows normally.
Level 4: Represents a submerged state as identified in remote sensing images.
3.2.3. Traffic Risk Classification Method Based on Social Media Information Data
In this study, the domain of traffic road classification using social media information encompasses four categories: Level 0, Level 1, Level 2, and Level 3. This study introduces a text classification model that integrates convolutional neural networks with attention mechanisms, termed the TextCNN-Attention Disaster Classification model. This model is designed to optimize the utilization of both local features and global correlation information of text data, enhancing the efficiency and generalization capabilities of text classification tasks. Upon converting each word in social media information into a vector, the TextCNN-Attention Disaster Classification network classifies traffic damage information. This network comprises an embedding layer, a convolutional neural network module, an attention mechanism module, and a fully connected layer. The structure of the network is illustrated in Figure 3:
Word Embedding Layer: Each word in the input text is transformed into a vector through spatial mapping, creating low-dimensional representations for each word. These vector representations are connected to form a two-dimensional matrix. Assuming the word vector representing the ith word in the sentence, the mathematical description is as follows:
Where represents concatenation, a represents concatenation, and usually xi:i+j can be expressed as concatenation of words xi, xi+1, xi+j.
Convolutional module: This module extracts local features from the text. Each convolutional block includes a one-dimensional convolutional layer, a ReLU activation function, and a maximum pooling layer. The size and number of convolution kernels are adjusted to control the receptive field and the number of features extracted by the convolutional block. Convolutional layers are utilized to extract features between words, representing local sentence features. The ReLU activation function is employed to effectively capture and learn complex relationships and features in the input data, while the max pooling layer reduces feature dimensionality and highlights the most significant features. The mathematical description of a convolution operation includes a convolution kernel w∈Rh×k, which uses a window size of h×k (which h is the number of words and k is the encoding dimension) to generate a new feature. For example, feature ci is generated by the words within the window from xi:i+h-1, as shown in the following formula:
Where b ∈ R is the bias term, and f is a nonlinear function. This convolutional kernel traverses the entire sentence's words {x1:h, x2:h+1, xn-h+1:n} to generate a feature map c=[c1,c2,…,cn-h+1], where c∈Rn-h+1. The pooling layer employs maximum pooling, with the pooling size matching the dimensions of the feature map. The feature map is processed to extract the maximum value, resulting in the pooled feature map C. This map is then permuted, i.e. F=Permute (C).
Attention mechanism module: Following the convolution module, an attention mechanism is introduced, enhancing the model’s performance and interpretability by dynamically focusing on critical text segments. The attention module includes a learnable parameter matrix to compute the attention weights for each feature. The weighted feature representation, which incorporates global correlation information, is derived by calculating the weighted average of the feature and attention weights. Its mathematical description is as follows:
In the formula, et is the attention score, W is the weight matrix, α t is the attention weight, and V represents the weighted feature.
Finally, these weighted feature representations are fed into a linear classifier to determine the text's category probabilities. The model's accuracy is enhanced using a cross-entropy loss function to gauge the discrepancy between the model output and actual labels, and model parameters are refined via the backpropagation algorithm to minimize loss. The entire training regimen is conducted using an optimizer, specifically the AdamW optimizer, which updates model parameters and boosts the model's convergence speed and performance by fine-tuning the learning rate and other hyperparameters.
3.3. Accuracy Evaluation
Here, Accuracy, Precision, Recall, and F1 Score are metrics used to evaluate the accuracy of remote sensing image inundation range recognition classification and the performance of traffic risk level classification based on social media information. Here, TP represents the number of true positives, TN the number of true negatives, FP the number of false positives, and FN the number of false negatives.
Accuracy is the ratio of correctly classified samples to the total number of samples, serving as a statistical measure applicable to all samples. It is expressed mathematically as shown in formula (6):
Precision is a metric that assesses the accuracy of prediction results, specifically the ratio of correctly classified positive samples to the number of samples classified as positive by the model. Precision focuses on the accuracy of positive data identifications by the classifier. It is defined as in formula (7):
Recall measures the ratio of correctly classified positive samples to the actual positive samples. Recall rate is also a specific statistical measure, emphasizing the accuracy within the real positive samples. It is defined as formula (8):
F1 Score is the harmonic mean of Precision and Recall, incorporating both metrics to assess the overall efficacy of classification models. It is a statistical indicator for evaluating the precision of classification models. An F1 Score ranges from 0 to 1, with higher values indicating superior model performance. The formula is shown in (9):
4. Experimental Results and Analysis
4.1. Short-Term Rainstorm Flood Disaster Information Extraction and Analysis
This study extracted the surface area affected by short-term rainstorms based on confidence intervals to address the rapid emergency response needs for urban waterlogging resulting from such events. To further verify the recognition accuracy of SAR images affected by rainstorms based on confidence intervals, 525 flood points and 300 non-flood points were identified by selecting sample point data through visual interpretation, as depicted in Figure 4. The flood point sample data were distributed in a ratio of approximately 6:4, with 60% of the flood point data used in threshold determination based on confidence intervals. The average value of the sample point data was 1.18, the standard deviation was 0.08, and the final threshold was set at 1.19. This threshold was utilized to identify areas affected by short-term rainstorm-induced urban waterlogging, as illustrated in Figure 4. The main area impacted by the flooding is in the northeast of Henan Province (specifically Xinxiang City and Hebi City), where the flood impact concentrated in densely populated urban communities, resulting in significant economic and property losses and posing threats to human life safety. The experiment evaluated the performance of the proposed flood impact range recognition using Precision, Recall, F1 Score, and Accuracy metrics. The calculated results for Precision, Recall, F1 Score, and Accuracy were 0.89, 0.86, 0.88, and 0.87, respectively. These evaluation results indicate that the extraction accuracy of the flood impact range is satisfactory, suitable for rapid emergency response following short-term rainstorm disasters, and provides data support and methodological backing for enhancing post-disaster governance capabilities.
4.2. Processing and Analysis of Social Media Data
The study collected 83030 pieces of social media information regarding the July 20, 2021, flood and rainstorm disaster in Henan Province. After preprocessing, purification, and cleaning, 826 pieces of social media information related to road network damage were identified. To address the potential underfitting due to small sample sizes in multi-classification tasks, the sample data were augmented, increasing the original count of 826 to 2,004, thus achieving 1,178 data augmentations. Specifically, the augmentation included 447 pieces for level 1, representing 38% of the total augmentations; 345 for level 2, accounting for 29%; and 386 for level 3, making up 33%. Based on the damage level, manual classification was conducted, and the sample data are detailed in Table 2.

Table 2.
Example of Social Media Data Preprocessing Results and Labeling Situation.
| Social media information original text | Pre_processed results | Label |
| #The rainstorm in Zhengzhou this summer # Audience feedback: there is serious water accumulation near Shangding Road, East Fourth Ring Road, Zhengzhou, almost no roof# Rainstorm Screens in Henan # # Microblog Video of rainstorm in Henan Province # LMyRadio. | There is severe waterlogging near Shangding Road in the East Fourth Ring Road of Zhengzhou, with almost no water passing through the roof. | 0 |
| #The rainstorm in Zhengzhou this summer # Audience feedback: the north ring bridge of Huayuan Road in Zhengzhou is impassable# Rainstorm Screens in Henan # # Microblog Video of rainstorm in Henan Province # LMyRadio. | Unable to pass under the North Ring Bridge of Huayuan Road in Zhengzhou | 0 |
| #Rainstorm in Zhengzhou this summer # Audience feedback, the depth of non-motorized vehicle lane of Zhengzhou Agricultural Road via No. 5 Road is deep# Rainstorm Screens in Henan # # Henan Province Faces rainstorm # LMyRadio Weibo Video | Zhengzhou Agricultural Road passes through the water depth of the fifth non-motorized lane. | 1 |
| #Henan rainstorm # # Zhengzhou rainstorm # There is deep ponding at the future intersection of Zhengzhou Jinshui Road, please pay attention to passing vehicles! Xiaohui's Weibo video on the road | There will be deep water accumulation at the future intersection of Jinshui Road. Vehicles should pay attention. | 1 |
| [# Zhengzhou # One section of the road has accumulated water above the knee of a man] # rainstorm in Henan # On July 19, a reporter found that the Jindai Road in Zhengzhou was one kilometer away from the South Fourth Ring Road. There was a serious accumulation of water on the driveway of Jindai Road. There was nearly one kilometer of water on the north-south two-way six lanes, and the deepest part could submerge half of the wheels. The outer lane of the two-way road had deeper water. If the motor vehicle ran a little faster, it would stir up water spray twice higher than the body. At present, the water accumulation situation is still ongoing, and the on-site reporter did not see the pumping operation. Why is the water accumulation in this section so severe? Why is there no drainage operation? Journalists from Henan Traffic Radio will also continue to pay attention. Weibo Video of Henan Traffic Radio | The one-kilometer section of Jindai Road in Zhengzhou is flooded with water, and the deepest point can submerge half of the wheels. | 2 |
| #Pay attention to the heavy rainstorm in Henan # [Zhengzhou South Third Ring Road and other water accumulation points have been opened up] At 6:40 this morning, the water accumulation points in the South Third Ring Road jointly pumped and drained by Wuhan Water Group, the East Lake High tech Zone and the Huangpi District Water Affairs Department completed the task of pumping and draining, and handed it over to the local government for cleaning up as required by the local government. Following the opening of the waterlogging points on the South Third Ring Road, the Wuhan drainage rescue team has completed a total of 7 important waterlogging point drainage tasks, ensuring the restoration of urban main road traffic. | Zhengzhou South Third Ring Road and other waterlogging points have been gradually connected | 3 |
In the analysis of traffic road risk assessment based on social media data, the target domain comprises four categories: level 0, level 1, level 2, and level 3. After encoding feature vectors using Word2Vec, the TextCNN-Attention model was employed to classify social media information pertaining to flood disasters, and its performance was compared with various machine learning classifiers. The comparative classifiers used in this study include Nearest Neighbor (KNN), Logistic Regression (LR), Naïve Bayesian (NB), Decision Tree (DT), Support Vector Machine (SVM), Random Forest (RF), Adaboost algorithm, and TextCNN. The classification results are summarized in Table 3.
The experimental results indicate that the classification performance of KNN on the original dataset is moderate, with similar metrics but a low F1 score, suggesting that the model may underperform in certain categories. Logistic Regression (LR) also exhibits average performance on the original dataset, with relatively low F1 score and Precision, indicating difficulties in managing category imbalance. Naive Bayes shows notably low Precision, potentially due to poor prediction accuracy or overfitting to specific categories. The Decision Tree model performs well on the original dataset, particularly in terms of higher Precision and F1 score. Support Vector Machine (SVM) displays balanced performance across all metrics on the original dataset, demonstrating robust classification capabilities. Random Forest (RF) has slightly lower classification accuracy compared to SVM and Decision Tree across various metrics. AdaBoost's performance on the augmented dataset has deteriorated, especially in terms of Recall and F1 score, likely due to overfitting or issues stemming from data augmentation. The lower F1 score of the TextCNN model may result from imbalanced data and suboptimal parameter settings. TextCNN-Attention exhibits the strongest performance on both the original and augmented datasets, with metrics surpassing 96% following data augmentation. Overall, data augmentation has improved the performance of most models, underscoring its significance in enhancing model generalization and effectiveness, particularly for traditional machine learning models. Future efforts should concentrate on refining data augmentation techniques for models such as AdaBoost and investigating the interplay between different data augmentation methods and various machine learning algorithms.
The TextCNN-Attention Disaster Classification network analyzes the damage to traffic roads following a short-term rainstorm, with a specific focus on 720 traffic road networks in Henan Province affected by the event. The road network in Henan Province encompasses four categories: railway, expressway, highway, and subway. The total length of traffic roads impacted by the rainstorm is approximately 10272.47 km. Of this, railways affected based on social media information cover about 181.47 km, accounting for 1.39% of the total railway length. Similarly, microwave remote sensing data indicate that railways were affected over a length of 181.38 km, also representing 1.39% of the total. For expressways, social media data show that about 149.01 km were impacted, constituting 0.66% of their total length, with 62.02 km classified as severely affected. Remote sensing data suggest a total affected expressway length of 86.99 km, accounting for 0.39% of the total expressway length. The affected highway length, based on social media, stands at approximately 9,688.04 km, making up 3.9920% of the total, with severely affected sections totaling 2,570.97 km or 1.0594% of the overall highway length. Remote sensing data show that affected highways extend to 1888.77 km, or 0.78% of the total highway length. The subway system was significantly impacted, with social media information revealing that about 253.95 km, or 42.10% of the total subway length, was affected by the rainstorm. The severely affected subway sections covered 102.41 km, accounting for 16.98% of the total subway length. The visualization of these results is displayed in Figure 5.
5. Discussion
5.1. Theoretical Contributions and Implications for Practice
Integrating multi-source data and multi-disciplinary theoretical methods to address traffic road damage caused by short-term urban rainstorms and waterlogging holds significant theoretical importance and practical value for enhancing disaster management capabilities and post-disaster emergency response. Firstly, microwave remote sensing images employ a confidence interval-constrained threshold to extract the surface area affected by precipitation. This method accounts for the uncertainty inherent in the data, offering a more robust approach than relying solely on estimated sample values. Utilizing confidence intervals allows for a more effective management and interpretation of sample data fluctuations. The establishment of this threshold provides a scientific and reliable technique, enhancing the credibility of the model's predictions and results. Secondly, disaster information is collected from Sina Weibo, where social media data is screened and cleaned. A quantitative table for assessing road traffic loss based on this information was established. Building on this, a road traffic risk classification model using social media data (TextCNN-Attention Disaster Classification) was developed. This model integrates convolutional neural networks with attention mechanisms and improves prediction performance, accuracy, and stability by optimizing the size of convolutional kernels and the number of layers.
The essence of recognizing areas affected by short-term urban waterlogging involves identifying water bodies in remote sensing images. The proposed method for recognizing surface areas in SAR images affected by waterlogging, based on confidence intervals, offers simplicity, rapid processing, and independence from data-driven constraints. However, the main challenge lies in the precise determination of thresholds, which depends on the number and distribution of sample points. To reduce the reliance on sample point selection for threshold accuracy, this experiment establishes a threshold range based on confidence intervals, thereby enhancing threshold reliability to meet the urgent needs posed by short-term urban rainstorm disasters. Social media data can swiftly collect information about sudden natural disasters in near-real-time, complementing Earth observation satellite monitoring. Nonetheless, the preprocessing of such extensive big data requires further enhancement. The efficient and precise filtering and cleaning of vast amounts of social media information are crucial for determining the accuracy of text classification models. Improvements in deduplication and condensation of social media information can boost the efficiency of text classification models. Additionally, to maintain the accuracy of road network information, this study processes social media data with stop words during data augmentation to prevent alterations in road network names, which could impact disaster assessment accuracy. Building on sample enhancement, a text classification model that combines convolutional neural networks with attention mechanisms (TextCNN-Attention) is introduced to increase the accuracy of addressing small sample multi-classification issues. The text information is utilized to analyze the damage to traffic roads under short-term rainstorm conditions. The experiment validates the reliability of using social media data to assess the extent of road traffic damage from both temporal and spatial perspectives. This rapid assessment can facilitate swift decision-making following urban waterlogging due to short-term rainstorms, playing a crucial role in mobilizing rescue resources.
5.2. Limitations and Future Research
This experiment has shifted the approach of disaster data collection and mining, enabling a vast amount of "blind data" to assert its "data sovereignty." This transition aids in gaining crucial buffer time for disaster risk response, transforming from remote sensing big data to multi-source heterogeneous disaster data, and applying disaster big data to facilitate timely and rapid loss assessments post short-term rainstorms. In this experiment, the SAR radiation values of the sample data were relatively concentrated, with minimal variation in threshold determination based on the confidence interval. Additionally, a semi-automatic interpretation method was employed to address the inherent band problem in SAR data. Future research will consider using adaptive thresholds to enhance the accuracy of water body recognition. Compared to Earth observation data, the robustness and accuracy of integrating Internet social media data in sudden natural disaster risk assessments remain central to further in-depth studies. This study uniformly processed stop words for social media data. However, due to the wide variety of social media data sources and formats, applying this processing method uniformly to subsequent disaster events may not be feasible. Monitoring updates to the stop word database for disaster public opinion information will be a foundational task moving forward. This study primarily visualized the damage in affected areas based on location feedback from text content, which differs from the user’s posting location, home location, or registration location, ensuring the reliability of spatial distribution in disaster damage information. The overall evaluation depends on the dataset's quantity and quality; insufficient data or inadequate data cleaning may introduce biases into the final assessment. Ongoing efforts will focus on improving text classification models to better handle the challenges of small sample data and high-precision classification in social media information. Future research will also emphasize the development of multimodal large language models, which excel in text generation, semantic understanding, and are effective in cross-modal information fusion and human-computer interaction. A key future challenge will be selecting appropriate models based on actual needs in specific disaster assessment scenarios.
6. Conclusions
The flood disaster caused by short-term severe precipitation has inflicted significant losses on social and economic development. This study, focusing on the extreme rainstorm in Henan Province from July 17-23, 2021, applied multi-source heterogeneous data to thoroughly assess the risk to traffic roads from short-term urban flood disasters. This approach can provide valuable insights for utilizing multi-source heterogeneous data to analyze damage to urban waterlogged traffic roads from short-term rainstorms and offers a new perspective on the potential of using social media to assess expressway damage.
(1) This study used a confidence interval-based threshold algorithm to identify the scope of flood impact, enabling rapid responses to sudden disasters. The evaluation metrics, including Precision, Recall, F1 score, and Accuracy, were recorded at 0.89, 0.86, 0.88, and 0.87, respectively. This method allows for swift and targeted analysis of the impact range of short-term flood disasters, providing essential data support for disaster emergency response and post-disaster rescue efforts.
(2) This study can improve the accuracy of addressing small sample multi-classification problems by filtering and cleaning social media data and integrating a convolutional neural networks and attention mechanism-based text classification model (TextCNN-Attention) following sample enhancement. The traffic road risk grades for short-term rainstorm flood disasters are categorized into four levels, completing the definition of a quantitative table for road traffic loss assessment based on social media information. The accuracy of the TextCNN-Attention model in classifying traffic road risk grades is 96%. The assessment method proposed by the TextCNN-Attention model demonstrates high transferability for traffic road risk assessment in various disaster contexts, offering a robust tool for estimating traffic road risk in other regions affected by short-term rainstorm floods.
Author Contributions
H.Z. proposed the methodology and wrote the manuscript. J.M. and J.Y. contributed to improving the methodology and were the corresponding author. N.X. helped edit and improve the manuscript. All authors have read and agreed to the published version of the manuscript.
Funding
This research was jointly supported by Hebei Key Laboratory of Resource and Environmental Disaster Mechanism and Risk Monitoring (Grant No.FZ248204); the Hebei Natural Science Foundation (Grant No.D2020512001);by the National Natural Science Foundation of China (Grant No.42101343);by the National Natural Science Foundation of China (Grant No. 5047803); the National natural disaster risk remote sensing monitoring prewarning and emergency application platform construction (Grant No. 2021YFB3901204); the Science technology research and development plan self-fund program of Langfang (Grant No. 2022011020); the Hebei Province Science and Technology Research Project (Grant No. Z2020119); the Fundamental Research Funds for the Central Universities (Grant No. ZY20200202).
Data Availability Statement
The data are not publicly available due to restrictions privacy.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, T.; Wang, H.; Wang, Z.; et al. Dynamic risk assessment of urban flood disasters based on functional area division—A case study in Shenzhen, China. Journal of environmental management 2023, 345, 118787. [Google Scholar] [CrossRef]
- Fang, J.; Hu, J.; Shi, X.; et al. Assessing disaster impacts and response using social media data in China: A case study of 2016 Wuhan rainstorm. International journal of disaster risk reduction 2019, 34, 275–282. [Google Scholar] [CrossRef]
- Zhu, H.; Yao, J.; Meng, J.; et al. A Method to Construct an Environmental Vulnerability Model Based on Multi-Source Data to Evaluate the Hazard of Short-Term Precipitation-Induced Flooding. Remote Sensing 2023, 15, 1609. [Google Scholar] [CrossRef]
- Rodell, M.; Li, B. Changing intensity of hydroclimatic extreme events revealed by GRACE and GRACE-FO. Nature Water 2023, 1, 241–248. [Google Scholar] [CrossRef]
- Lan, H.; Zhao, Z.; Li, L. ,et al. Climate change drives flooding risk increases in the Yellow River Basin. Geography and Sustainability 2024, 5, 193–199. [Google Scholar] [CrossRef]
- Dottori, F.; Szewczyk, W.; Ciscar, J.; et al. Increased human and economic losses from river flooding with anthropogenic warming. Nat. Clim. Change 2018, 8, 781–786. [Google Scholar] [CrossRef]
- Roy, K.C.; Hasan, S.; Culotta, A.; et al. Predicting traffic demand during hurricane evacuation using Real-time data from transportation systems and social media. Transportation research part C: emerging technologies 2021, 131, 103339. [Google Scholar] [CrossRef]
- Chen, Y.; Ji, W. Enhancing situational assessment of critical infrastructure following disasters using social media. Journal of Management in Engineering 2021, 37, 04021058. [Google Scholar] [CrossRef]
- He, H.; Li, R.; Pei, J.; et al. Current overview of impact analysis and risk assessment of urban pluvial flood on road traffic. Sustainable Cities and Society 2023, 104993. [Google Scholar] [CrossRef]
- Cartes, P.; Navarro, T.E.; Giné, A.C.; et al. A cost-benefit approach to recover the performance of roads affected by natural disasters. International Journal of Disaster Risk Reduction 2021, 53, 102014. [Google Scholar] [CrossRef]
- Zhang, X.; Song, Y.; Nam, W.H.; et al. Data fusion of satellite imagery and downscaling for generating highly fine-scale precipitation. Journal of Hydrology 2024, 631, 130665. [Google Scholar] [CrossRef]
- Kazemi Garajeh, M.; Haji, F.; Tohidfar, M.; et al. Spatiotemporal monitoring of climate change impacts on water resources using an integrated approach of remote sensing and Google Earth Engine. Scientific reports 2024, 14, 5469. [Google Scholar] [CrossRef]
- Shen, X.; Wang, D.; Mao, K.; et al. Inundation extent mapping by synthetic aperture radar: A review. Remote Sensing 2019, 11, 879. [Google Scholar] [CrossRef]
- Jiang, X.; Liang, S.; He, X.; et al. Rapid and large-scale mapping of flood inundation via integrating spaceborne synthetic aperture radar imagery with unsupervised deep learning. ISPRS journal of photogrammetry and remote sensing 2021, 178, 36–50. [Google Scholar] [CrossRef]
- Serpico, S.B.; Dellepiane, S.; Boni, G.; et al. Information extraction from remote sensing images for flood monitoring and damage evaluation. Proceedings of the IEEE 2012, 100, 2946–2970. [Google Scholar] [CrossRef]
- Li, Y.; Dang, B.; Zhang, Y.; et al. Water body classification from high-resolution optical remote sensing imagery: Achievements and perspectives. ISPRS Journal of Photogrammetry and Remote Sensing 2022, 187, 306–327. [Google Scholar] [CrossRef]
- Kang, J.; Guan, H.; Ma, L.; et al. WaterFormer: A coupled transformer and CNN network for waterbody detection in optical remotely-sensed imagery. ISPRS Journal of Photogrammetry and Remote Sensing 2023, 206, 222–241. [Google Scholar] [CrossRef]
- Yao, J.; Sun, S.; Zhai, H.; et al. Dynamic monitoring of the largest reservoir in North China based on multi-source satellite remote sensing from 2013 to 2022: Water area, water level, water storage and water quality. Ecological Indicators 2022, 144, 109470. [Google Scholar] [CrossRef]
- Mohseni, F.; Saba, F.; Mirmazloumi, S.M.; et al. Ocean water quality monitoring using remote sensing techniques: A review. Marine Environmental Research 2022, 105701. [Google Scholar] [CrossRef]
- Mayer, T.; Poortinga, A.; Bhandari, B.; et al. Deep learning approach for Sentinel-1 surface water mapping leveraging Google Earth Engine. ISPRS Open Journal of Photogrammetry and Remote Sensing 2021, 2, 100005. [Google Scholar] [CrossRef]
- Mcfeeters, S.K. The use of the Normalized Difference Water Index (NDWI) in the delineation of open water features. International Journal of Remote Sensing 1996, 17, 1425–1432. [Google Scholar] [CrossRef]
- Li, H.; Xu, Z.; Zhou, Y.; et al. Flood Monitoring Using Sentinel-1 SAR for Agricultural Disaster Assessment in Poyang Lake Region. Remote Sensing 2023, 15, 5247. [Google Scholar] [CrossRef]
- Ghouri, A.Y.; Khan, A.; Raoof, H.; et al. Flood Mapping Using the Sentinel-1 SAR Dataset and Application of the Change Detection Approach Technique (CDAT) to the Google Earth Engine In Sindh Province, Pakistan. Ecological Questions 2024, 35, 1–18. [Google Scholar] [CrossRef]
- Yang, T.; Xie, J.; Li, G.; et al. Extracting Disaster-Related Location Information through Social Media to Assist Remote Sensing for Disaster Analysis: The Case of the Flood Disaster in the Yangtze River Basin in China in 2020. Remote Sens. 2022, 14, 1199. [Google Scholar] [CrossRef]
- Li, L.; Bensi, M.; Cui, Q.; et al. Social media crowdsourcing for rapid damage assessment following a sudden-onset natural hazard event. International Journal of Information Management 2021, 60, 102378. [Google Scholar] [CrossRef]
- Yuan, F.; Liu, R. Feasibility study of using crowdsourcing to identify critical affected areas for rapid damage assessment: Hurricane Matthew case study. International journal of disaster risk reduction 2018, 28, 758–767. [Google Scholar] [CrossRef]
- Dou, M.; Wang, Y.; Gu, Y.; et al. Disaster damage assessment based on fine-grained topics in social media. Computers & Geosciences 2021, 156, 104893. [Google Scholar]
- Hao, H.; Wang, Y. Leveraging multimodal social media data for rapid disaster damage assessment. International Journal of Disaster Risk Reduction 2020, 51, 101760. [Google Scholar] [CrossRef]
- Yang, T.; Xie, J.; Li, G.; et al. Extracting disaster-related location information through social media to assist remote sensing for disaster analysis: The case of the flood disaster in the Yangtze River Basin in China in 2020. Remote Sensing 2022, 14, 1199. [Google Scholar] [CrossRef]
- Lozano, J.M.; Tien, I. Data collection tools for post-disaster damage assessment of building and lifeline infrastructure systems. International journal of disaster risk reduction 2023, 94, 103819. [Google Scholar] [CrossRef]
- Li, L.; Bensi, M.; Baecher, G. Exploring the potential of social media crowdsourcing for post-earthquake damage assessment. International Journal of Disaster Risk Reduction 2023, 98, 104062. [Google Scholar] [CrossRef]
Figure 1.
Leveraging multisource data for emergency flood traffic road damage assessment flow.
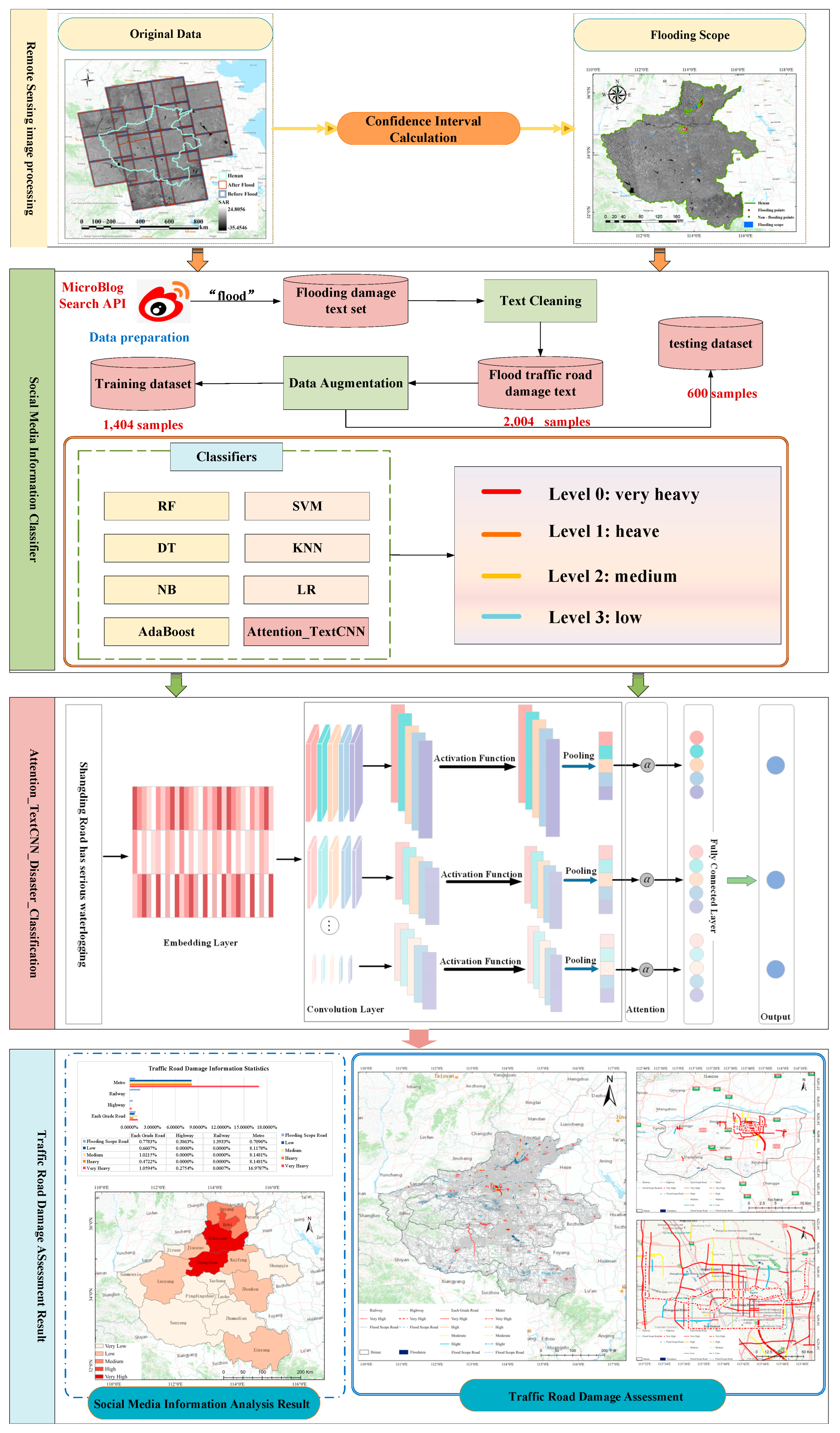
Figure 2.
Study area information. (a) is Geographic Location, (b) is Digital Elevation Model, (c) is the Road Network of Henan Province.
Figure 2.
Study area information. (a) is Geographic Location, (b) is Digital Elevation Model, (c) is the Road Network of Henan Province.
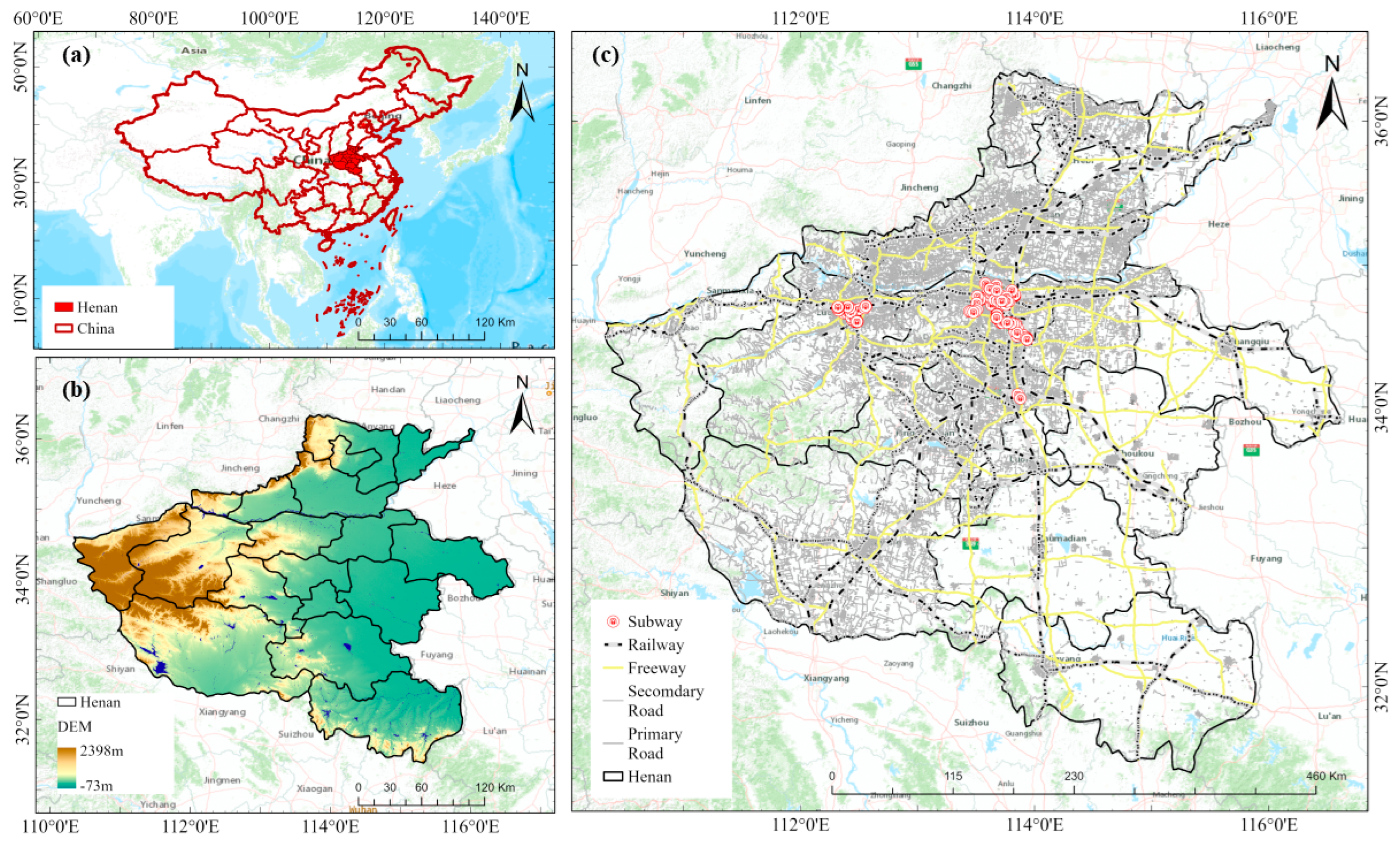
Figure 3.
TextCNN-Attention Disaster Classification Flow.
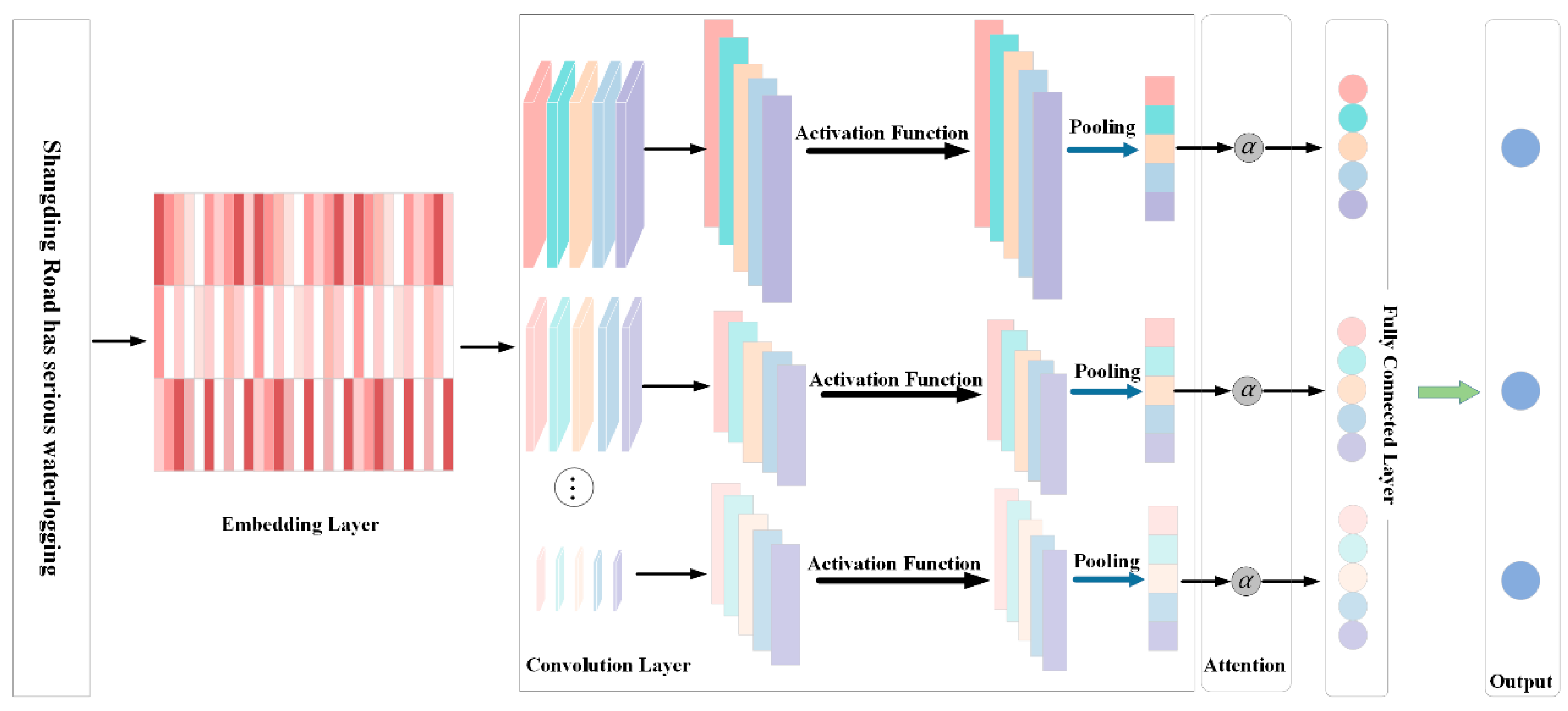
Figure 4.
Flood Impact Scope Identification Result and Accuracy Evaluation. (a) is Flood Impact Scope Identification Result and Distribution of Sample Points. (b) is a partial enlargement of Figure.4 (a), (c) is the Accuracy Evaluation of Flood Impact Scope Identification.
Figure 4.
Flood Impact Scope Identification Result and Accuracy Evaluation. (a) is Flood Impact Scope Identification Result and Distribution of Sample Points. (b) is a partial enlargement of Figure.4 (a), (c) is the Accuracy Evaluation of Flood Impact Scope Identification.
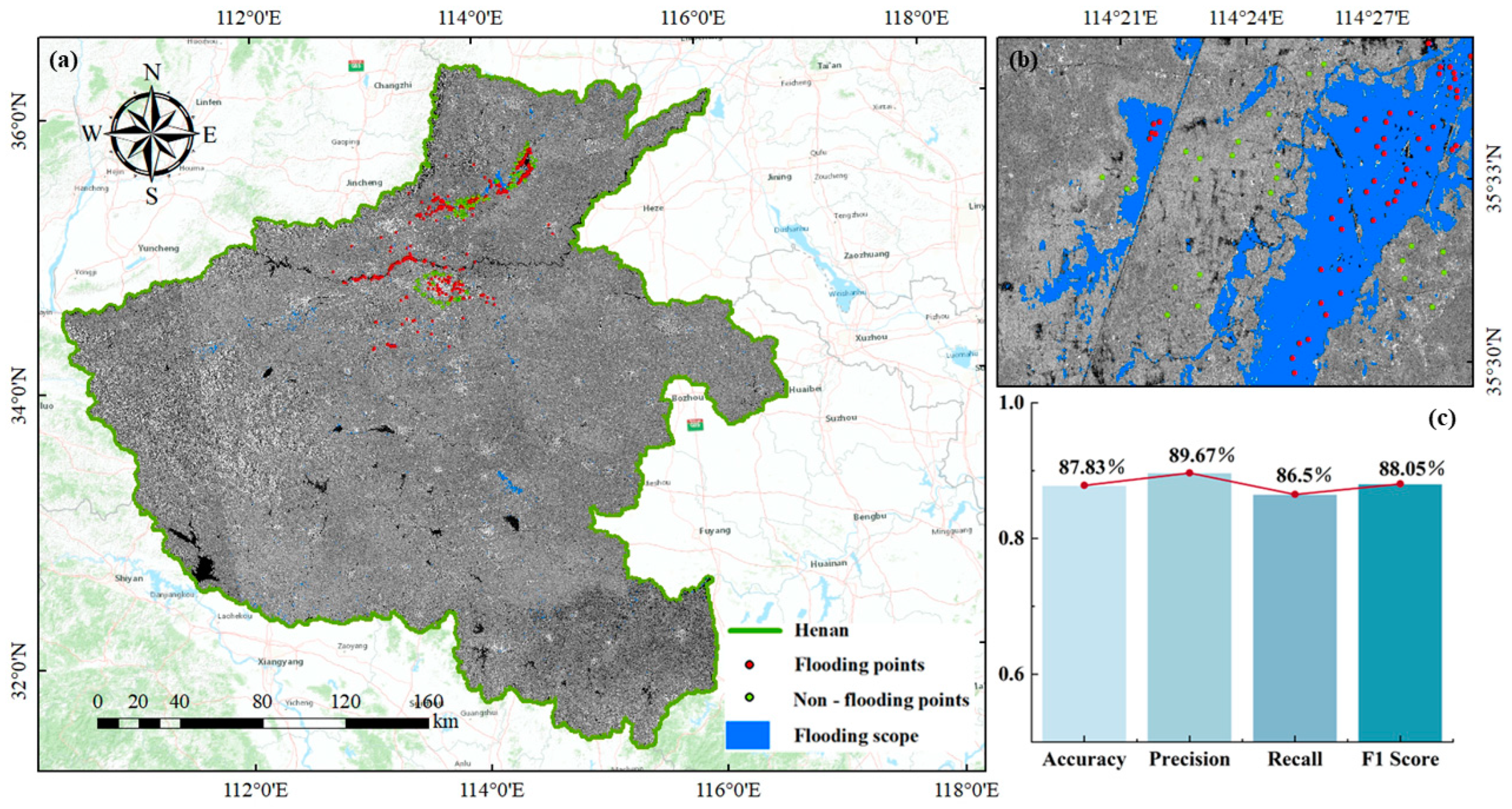
Figure 5.
Visualization Results of the Disaster Situation in the Road Network of Henan Province. (a) is the Traffic Road Damage Assessment of Henan Province, (b) is the Traffic Road Damage Assessment Statistical Results of Henan Province, (c) is Social media information posting popularity statistics, (d) is the Traffic Road Damage Assessment of Zhengzhou City, (e) is Localized Amplification Result of Traffic Road Damage Assessment of Zhengzhou City.
Figure 5.
Visualization Results of the Disaster Situation in the Road Network of Henan Province. (a) is the Traffic Road Damage Assessment of Henan Province, (b) is the Traffic Road Damage Assessment Statistical Results of Henan Province, (c) is Social media information posting popularity statistics, (d) is the Traffic Road Damage Assessment of Zhengzhou City, (e) is Localized Amplification Result of Traffic Road Damage Assessment of Zhengzhou City.
Table 1.
Description and Quantification of Rapid Assessment Events for Road Traffic Losses under Flood Disasters.
Table 1.
Description and Quantification of Rapid Assessment Events for Road Traffic Losses under Flood Disasters.
| Damage Level | Event description | Typical descriptive words | Case Description |
| Level 0—very heavy | Due to sudden disaster events, traffic damage, interruption, blockage, or many vehicles backlog, personnel retention, trapped, or death, houses are submerged, collapsed, or tilted, and the estimated repair and disposal time is more than 24 hours. When landslides, mudslides, or collapses occur, many people are stranded, and the resumption of operation and personnel evacuation are expected to take more than 48 hours | Serious/Major/Substantive/Damage, Serious Injury, Death of Personnel, Trapped, Drowning, Flooding, Traffic Paralysis, Inability to Pass, Damage, Collapse/Collapse/Collapse, Landslide, Mudslide Flow, Washout, Urgent/Urgent, Severe Disaster Area, Heavy Injury, Closure, Flood Discharge, Embankment Burst | Severe flooding in Mihe Town, Gongyi, Henan Province.
|
| Level 1—heavy | Due to unexpected events that may cause traffic damage, interruption, congestion, or a large backlog of vehicles, inconvenient transportation, and personnel retention, the repair and disposal time is expected to be more than 12 hours, resulting in a large amount of personnel retention. The resumption of operation and personnel evacuation are expected to take more than 24 hours | Some/extensive damage, multiple people injured, obstructed/damaged, congested, inconvenient transportation, deep mud/water accumulation, affected, requiring rescue | Zhengzhou Zhongyuan Road West Fourth Ring Road is flooded with water. Traffic police have completed vehicle rescue and advised to avoid driving in the water。
|
| Level 2—medium | When a sudden disaster occurs, the road traffic is smooth, slow, slightly muddy, slippery, and there is slight injury to personnel. Slow and slippery traffic | Mild/minor/water accumulation, minor/minor/minor injury, walking slowly, slightly muddy, slippery, with small potholes, etc. | The one-kilometer section of Jindai Road in Zhengzhou is flooded with water, and the deepest point can submerge half of the wheels.
|
| Level 3—low | In the event of a sudden disaster, there were no casualties, and there was no damage to the roads or houses. Rest areas and shelters were provided | No/zero damage, no death, no damage, provide a venue/rest area/shelter/shelter, recover | Zhengzhou Science and Technology Museum Parking Lot Refuge
|
Table 3.
Classification Performance.
| Dataset | Method | Precision | Recall | F1-score | Accuracy |
|
Original dataset |
KNN | 0.76 | 0.75 | 0.70 | 0.75 |
| LR | 0.66 | 0.68 | 0.59 | 0.68 | |
| NB | 0/57 | 0.66 | 0.55 | 0.66 | |
| DT | 0.79 | 0.71 | 0.73 | 0.71 | |
| SVM | 0.76 | 0.76 | 0.74 | 0.76 | |
| RF | 0.71 | 0.73 | 0.69 | 0.73 | |
| AdaBoost | 0.75 | 0.69 | 0.70 | 0.69 | |
| TextCNN | 0.80 | 0.54 | 0.56 | 0.73 | |
| TextCNN- Attention | 0.95 | 0.95 | 0.95 | 0.94 | |
|
Augmented dataset |
KNN | 0.79 | 0.79 | 0.79 | 0.79 |
| LR | 0.88 | 0.88 | 0.88 | 0.88 | |
| NB | 0.84 | 0.84 | 0.83 | 0.84 | |
| DT | 0.86 | 0.86 | 0.86 | 0.86 | |
| SVM | 0.91 | 0.91 | 0.91 | 0.91 | |
| RF | 0.89 | 0.88 | 0.88 | 0.88 | |
| AdaBoost | 0.75 | 0.62 | 0.62 | 0.62 | |
| TextCNN | 0.82 | 0.60 | 0.61 | 0.76 | |
| TextCNN-Attention | 0.97 | 0.97 | 0.97 | 0.96 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



