
Submitted:
16 August 2024
Posted:
19 August 2024
You are already at the latest version
Abstract
In this paper, a distributed algorithm for reaching average consensus is proposed for multi-agent systems with tree communication graph, when the edge weight distribution is unbalanced. First, the problem is introduced as a key topic of core algorithms for several modern scenarios. Then, the relative solution is proposed as a finite-time algorithm, which can be included in any application as a preliminary setup routine, and it is well-suited to be integrated with other adaptive setup routines, thus making the proposed solution useful in several practical applications. A special focus is devoted to the integration of the proposed method with a recent Laplacian eigenvalue allocation algorithm, and the implementation of the overall approach in a wireless sensor network framework. Finally, a worked example is provided, showing the significance of this approach for reaching a more precise average consensus in uncertain scenarios.
Keywords:
Laplacian eigenvectors
; Perron vector
; average consensus problems
1. Introduction
In the last decades, research on the collective behavior of a team of agents through iterative local interactions has been intense, due to the significance of applications in a wide range of fields, from computer science to social networks, from complex technological networks (e.g. electric smart grid), to biological ecosystems [1]. In each framework, a fundamental property to reach agreement among all agents through local interactions is the consensus condition, which happens when all agents recursively update a local variable using local information to asymptotically get a common value for all participants [2].
One special yet fundamental consensus condition regards the value of such agreement as a function of the initial conditions of all nodes, and, in particular, the average of all initial conditions of the agents is known in the literature as the average consensus [3,4]. This special condition is adopted in a large number of applications of distributed estimation, WSN algorithms, robotics, and many more [5].
Average consensus is the natural equilibrium condition for a multi-agent system whenever the communication graph is undirected and unweighted, or more in general, whenever it is weight-balanced, and this special condition allows solving several basic goals in a distributed fashion [1].
Unfortunately, one fundamental limitation when dealing with classical average consensus through the use of undirected communication graphs with the traditional symmetric edge weight assignment is a limited convergence rate, which significantly decreases when the number of participants grows [5]. This condition has the drawback of a large time span for convergence, and in turn, this makes consensus not even possible in practice when the unavoidable presence of communication delays, computation errors or agents’ faults over a large time span are accounted for [6].
However, the practical significance of this condition for the large number of the applications referenced above pushed the scientific community to a significant effort to derive sophisticated algorithms for general unbalanced graphs, as, for example, through the use of additional state variables [7], dedicated atomic transactions between pairs of neighbors [8], a chain of two integrators that are coupled with a distributed estimator [9] average tracking with incomplete measurement through a distributed averaging filter and a decentralized tracking controller [10], and recently considering also signed networks [11].
In the last few years, advances have been made in adopting the strategy of assigning asymmetric weights to neighbors’ edges [12]. Indeed, it was found that a proper choice of asymmetric weights can significantly improve the convergence rate, even over the symmetric optimal design [13], and it makes the convergence rate independent of the size of the graph with asymmetric weights, which is in striking contrast with the fundamental limitations of symmetric weights [1]. On the other hand, the choice of asymmetric weights makes the network converge to a different function of the nodes instead of the average of the initial conditions.
In general, there are several scenarios where edge weight asymmetry should be taken into account, other than a design choice. Indeed, empirical research clearly shows that real-world networks usually have a large heterogeneity in the intensity or capacity of the connections (and hence the weights of the links) [14]. These asymmetries are related to defects and uncertainties in the network, and they result in an inaccurate and biased consensus condition (namely, the asymptotic values of network nodes are only roughly close to each other). The technique proposed in this paper can be useful in these scenarios, as it would produce a much more precise consensus condition.
The approach proposed in this paper can be combined with an asymmetric design of the edge weights as in [15] to achieve the ambitious goal of average consensus with prescribed dynamics. Analogous techniques have been adopted to achieve prescribed-time consensus [16]. The opportunity of setting the Laplacian eigenvalues through an appropriate choice of edge weights has also a beneficial effect on security; indeed most of the algorithms designed to monitor network evolution to exclude the presence of edge faults [17] or malicious nodes [18] require the knowledge of eigenstructure of the network It is worth noting that malicious attacks can destabilize the entire system when there is access of at least one of its eigenvalues [19].
The theoretical backbone of the proposed approach is the distributed estimation of the Perron vector, which allows for a scaling of the initial conditions to reach average consensus, thus combining the beneficial effects of asymmetric edge weight assignment with the large practical applications of average consensus problems. It is worth remarking that the use of Perron vector to achieve a more precise average estimation is discussed in [20]. The results developed in this paper are inspired by [21], as described in detail in Section 3.
The paper is organized as follows. After a brief description of the notation hereafter, in Section 2 some motivating examples of the research pursued in this paper are described, and hence two facets of the problem are stated. In Section 3, the main theoretical results are provided for two graph topologies, namely path graphs and star graphs, which are prodromal for the inductive general solution, whose theoretical backbone is given in Section 4. These results are then exploited in Section 5, where the iterative algorithm is deduced through a worked example. A final simulation is provided in Section 6, where the application of the results to an uncertain WSN network, computing the average value of an environmental quantity, shows the effectiveness of the proposed results to achieve a more precise consensus value.
Notation
Here we briefly describe the notation adopted along the paper. We denote by , , , the set of natural, real numbers and non-negative real numbers, and positive real numbers. We denote by , , the d-dimensional vectors with components equal to 0 and by those vectors whose components are all 1. , , is the matrix made by all zero entries. Vector denotes the i-th canonical vector, e.g. . Vectors are denoted in bold letters. For a vector we denote the ith component of so that . The spectral radius of A is the maximum modulus of its eigenvalues, namely
A nonnegative (positive) matrix satisfies (). A permutation matrix P is a matrix obtained by permuting the rows of the identity matrix. A nonnegative matrix is reducible if there exist a permutation matrix P such that the matrix is in block triangular form, i.e.:
where , are square matrices. An irreducible matrix is a matrix that is not reducible. A nonnegative matrix is primitive if there exist a positive integer m such that .
A graph is made of a vertex set and an edge set. It is undirected if if and only if . The neighbors set of a node is defined as . A path connecting vertex with is a subset of nodes connected by graph edges . An undirected graph is connected if there is a path connecting i and j for every pair of vertices such that .
An undirected graph with no cycles is called a tree if it is connected, otherwise it is called forest. For a vertex w of a tree , denotes the forest obtained from by deleting w, and it is made of trees. For any v neighbor of w, , denotes the subtree of having v as a vertex. The center (or Jordan center) of a graph is the set of all vertices where the greatest distance to other vertices is minimal. Equivalently, it is the set of vertices with eccentricity equal to the graph’s radius. Every tree has a center consisting of one vertex or two adjacent vertices. The center is the middle vertex or middle two vertices in every longest path.
For a graph , the adjacency matrix is the matrix if and if , the weighted adjacency matrix as with if and if . The weighted Laplacian matrix is built upon the rule if , . By construction, , i.e. the Laplacian is a zero-row sum matrix. In the following, given a graph , denotes the set of all zero row-sum -structured square matrices. There are connections between the properties of nonnegative matrices and their related graphs explaining their zero-nonzero pattern, as the following result shows [1]:
Lemma 1.1.
A matrix is irreducible if and only if its relative graph encoding its zero-nonzero pattern is strongly connected.
2. Motivating Examples
In this Section, we introduce the abstract mathematical framework of our problem, namely average consensus for a multi-agent system running distributed iterative algorithm to accomplish a global task, which is usually in terms of network coordination or synchronization. After that, several applications in modern fields adopting the described framework are reported.
2.1. Multi-Agent Systems Running Consensus Algorithms
Here, we introduce the mathematical framework of multi-agent systems running consensus algorithm [1,2].
This setting is made of a set of N nodes, each holding a variable , updated as where is set by each node i to update its value. Some nodes of the team can communicate between themselves, and two neighbor nodes i, j are able to exchange their values. In this setting, each node i assigns as input where are set by node i. The resulting evolution of the team can be effectively computed using the aggregate vector chosen as and updating as , which gives rise to the Laplacian flow [1]:
for a in the set . Network evolution is dictated by the spectrum of [22]. It is worth mentioning that the design of asymmetric gains was recently proposed [13,23,24] as a key feature to improve the convergence rate, and it was recently explored also in [25,26,27].
Other multi-agent processes are better described by discrete updates of a local quantity, namely , where is called coupling factor and it should be chosen sufficiently small to keep the system stable [1], and analogously in this case one gets the following global evolution:
Both in case of of (1) and (2), matrix shows some interesting properties inherited from the properties of that , , namely [1]:
Moreover, even if the eigenvalues of matrix are related to those of according to for systems (1) and when dealing with (2), eigenvectors of (1) and (2) do coincide.
By direct consequence of (3), system (1) and (2) are called consensus networks, namely for every choice of the initial conditions there exists such that:
or, equivalently, . The constant is called the consensus value (or collective decision) [2] for system (1), corresponding to the given initial conditions. The consensus value is a key tool in many applications, indeed it encapsulates a global information, equal to:
where is a left eigenvector of associated to the unitary eigenvalue and satisfying the normal condition [28]. In a wide number of applications, it holds and Equation (5) simplifies to the average of the initial conditions of the whole network, i.e.:
and we refer to this condition as average consensus.
Average consensus became a very popular and significant tool in many applications as for example sensor fusion and data aggregation, distributed optimization and machine learning, collective motion, vehicle coordination, and more [1]. However, one main issue of multi-agent systems running standard consensus protocols is a low convergence rate, which is related to the algebraic connectivity of graph and it is often a key limiting feature of the original consensus protocol [1].
The fundamental mathematical background for our analysis is the renowned Perron-Frobenius Theorem [1]:
Theorem 2.1
(PerronâFrobenius). Let be an irreducible nonnegative matrix. Then:
- A has a positive eigenvalue equal to , and it is a simple eigenvalue of A.
- The left and right eigenvectors relative to the eigenvalue are positive.
It is worth remarking that, for any nonnegative matrix , is an eigenvalue of A and the right and left eigenvectors of can be selected non-negative. If A is additionally irreducible, then the multiplicity of is one and the relative left and right eigenvector are strictly positive and uniquely determined (up to a scalar factor).
In general, the positive left and right eigenvectors relative to the eigenvalue are called left and right Perron vectors. However, considering Equation (3), vector is always a right eigenvector of so that in the following, we refer to the left eigenvector of as the Perron vector of (e.g. vector in Equation (3)).
In the following of the paper, for a given Laplacian matrix related to a connected graph , we denote by its left eigenvector corresponding to . If matrix is the generator of a dynamical flow , then is the Perron vector of the positive matrix , and with a little abuse of notation we refer to as the Perron vector of .
The importance of the Perron vector in such applications is that it explains how the final distribution is [29], so it allows to detect aggregrations, clusters, or, conversely, the weight of each node influence on the asymptotic consensus value.
In the following, we provide some recent technological applications where the above framework has been exploited to design decentralized average consensus algorithms.
2.2. Some Examples of Modern Applications
The above setting is the abstract representation of several technological modern applications, where average consensus is the key methodology for distributed algorithm architectures, as described in the following.
In [5], the authors survey the scientific literature on distributed estimation and control applications using linear consensus algorithms. In the paper, there are interesting examples on how some classical estimation and control problems can be rephrased as the average value of some suitable quantities, thus allowing for being efficiently computed in a distributed fashion through average consensus algorithms.
Average consensus is the key strategy for sharing global information through local interactions. In the field of wireless sensor networks, clock synchronization is a fundamental problem and it can be efficiently solved through consensus [30]. In [31] the same synchronization problem is solved through average consensus in IoT applications. Within the above application scenarions, average consensus is adopted also for achieving the estimation of an environmental quantity [8].
In the field of Electric grid, Smart Power Grids and Renewable energies, average consensus-based algorithms are widely adopted for the following fundamental issues: (1) generators synchronization[32] (2) economic dispatch [33] (3) clock synchronization [34].
Finally, several tasks of great value in the area of robotic networks can be accomplished through the exploitment of average consensus. Among the others, it is worth mentioning the rendez-vous and, conversely, the deployment of a team of robots, which is fundamental for surveillance and, in general, for coverage purposes. Also attaining and keeping a formation can be executed through properly designed average consensus protocols, without recurring to a supervisory device [35]
2.3. Problem Statement
Inspired by the applications discussed in the previous Paragraph, we are now ready to state the Problem that we afford in the following of this paper.
Problem Statement 1. Given a weighted Laplacian matrix of a tree graph , compute the (left) Perron vector of the positive matrix , either in case of (1) or (2).
However, in view of the motivations discussed above and considering the applications described so far, Problem Statement 1 can be rephrased in a more application-oriented enginnering fashion, as follows.
Problem Statement 2. Given a weighted tree graph and a multi-agent system (either (1) or (2)) running consensus algorithm so that each node asymptotically reaches the value as in (4) with equal to (5), compute a set of scaling factors , such that the state vector defined as converges to with , thus solving the average consensus problem for the original problem.
The above two problems are indeed two facets of the same argument, the first being closer to a mathematical fashion while the second in an engineering style. It is worth noting that Statement 2 can be also effectively encapsulated into the Problem Statement of [15], which is related to the Laplacian eigenvalue allocation by a proper asymmetric edge weights assignment, so that the two problems can be integrated each other as follows:
Problem Statement 2-bis. Given a tree graph , and one node ℓ triggering the distributed algorithm in [36] to allocate the Laplace spectrum and grounded Laplacian to, resp., and (satisfying ), compute a set of scaling factors , such that the state vector defined as converges to with , thus solving the average consensus problem with prescribed dynamics adopting the asymmetric weight distribution.
Remark.
The connection and equivalence of the different Problem Statements stated above is clearly established by considering Equation (5) and (6). Namely, the asymptotic value of is with , so that, considering that and imposing:
one has that the system evolution seeks average consensus for any set of initial conditions if the scaling factors are set equal to
Remark.
Even if it is not explicitly stated in the above Problem Statement, a further feature of the proposed Algorithm is that it can be implemented distributedly, namely each component of the scaling vector can be computed through the use of local data.
3. Problem Solution
We start by seeking the solution of some special topologies, namely path graphs and star graphs, which constitute the topology of the most peripherical branches of any tree, as well as widely adopted graph topologies in general [1]. We further extend the solution to a generic n tree graphs.
In the case of path and star graph, we are able to provide the full characterization of the Perron vector by exploiting some recent mathematical results concerning structured matrix manipulation and inversion.
On the other hand, the general solution for tree graphs is inductive, and it can be implemented through an iterative algorithm.
3.1. Solution for Path Graphs
The Laplacian matrix of Path Graphs is a special case of tridiagonal matrix, so the theoretical background of the construction of the solution is based on [37] adapted to our special structure of matrices. The following statement is proved in [37], and it is our main mathematical tool to get the explicit solution of Path Graph.
Proposition 3.1
and assume that L is nonsigular. Build the two sequences:
and
then the inverse of matrix L can be computed using the following formula:
It is possible to exploit the above result for the computation of the Perron vector in the case of path graphs, as follows.
Proposition 3.2.
Let , and consider the Laplacian matrix:
with diagonal entries for . The corresponding (left) Perron vector is equal to:
Proof.
The proof is conducted by direct inspection on the relation with as in (13) for a nonzero . Consider the partition of as follows:
with , and
so that, taking with , , one has:
from the second relation it is possible to parametrize as:
3.2. Solution for Star Graphs
The explicit parametric structure of the Perron vector can be easily computed by direct inspection in the case of star graphs. Indeed,
Proposition 3.3.
Let be a star graph having n rays, and suppose that the central node is selected as first node. Let be its corresponding Laplacian matrix for any choice of edge weights, so that:
where
Then, the corresponding Perron vector is equal to:
4. A Recursive General Solution Tree Graphs
In this Section, we derive a solution for a general tree graph . The structure of the solution in such case is not in a closed form as for path and star graphs, but it is based on an inductive process over , so that the resulting algorithmic solution is recursive. The proposed approach is inspired by the subdivision of the computation of the Perron vector into smaller problems of [21], and it perfectly fits the eigenvalue allocation algorithm in [15], so it can be integrated into the final algorithmic solutiono, thus solving the ambitious problem of eigenvalue allocation for average consensus problems.
Proposition 4.1.
Consider a tree graph , its corresponding Laplacian, and let . , represent the subtrees of after remotion of node 1, each made of nodes, and finally the submatrix of being the Laplacian of .
If we denote by a Perron vector for , where and each then it holds that:
- Each is a Perron vector for each .
- The first component of each satisfies:
Proof.
Let , so that a convenient labeling allows to write the Laplacian matrix without loss of generality as:
where with being the weighted Laplacian of , and . Now take a vector partitioned conformably to the Laplacian (28), so that with dimension of each according to those of the related subtree and detailed in the above statement. By direct inspection of the relation one gets:
and considering that , Equation (29) can be rewritten as:
so that, assuming that each satisfies , one has:
and hence the statement follows. □
The previous result provides the main tools for setting an algorithm which solves Problem 1 iteratively, though some Remarks are needed to fully describe the proposed approach. In the next Section we exploit the results gained in this Section and we deduce an algorithm for the solution of Problem 1 and 2, thus achieving our main goal for this paper.
5. A Distributed Algorithm for the General Solution
The results of Section 4 are useful to establish an interative procedure for the distributed computation of the Perron vector. In the following, we solve Problem 1 for a worked example, which is taken from the Simulation Results of [36]. Then we provide the general algorithm, based on the experience gained through the example.
5.1. An Illustrative Example
Consider the weighted tree graph in Figure 1, and Node 1 be the reference node for the algorithm execution. Considering the notation adopted in this paper, which is reported in Fig. Figure 1 (b), we take a vector partitioned as:
where
and the first component of each subvector must satisfy:
Consider now that each subtree has the topology of either a path or a star graph, so that we can recur to the results of Section 3.1 and Section 3.2. Specifically, is either a path of two nodes or equiv. a star with one ray, is a path made of 3 nodes and finally is a three-node two-ray star, thus:
Combining (35) with (33), one has that the structure of is as follows:
for a nonzero . We now seek the value of to match the normal condition , which leads to:
so that (36) together with
solves Problem 1. It is worth noting here, in view of Problem 2 and a distributed implementation of the proposed approach, that coefficients are analogous coefficients related to each subtree, and indeed we can write
and each can be analogously be computed referring to the subgraphs of each , thus opening the path for a distributed implementation for its computation. Coefficients are reminiscent of the normalizing terms in [21] called coupling factors, and in the following if this paper we use the same name.
5.2. Algorithm Description
Starting from the experience gained from the example, we now generalize the iterative algorithm to retrieve the value of the scaling factors that allow for reaching average consensus, as stated in Problem Statement 2.
Considering the solution computed in the example, and in particular Equation (37), (38), (39), it is straight to see that a first stage of the computation of the coupling factors should flow from the peripherical nodes to the inner ones. Indeed, each coupling factor can be determined only following this order, since for leaf nodes while it is unknown in advance for the other nodes.
The first stage of the algorithm is as follows. Each leaf node starts the computation with , and sends it to its (only) neighbor v. At each time instant, each node should run the following algorithm:
- if v has received less than coefficients from its neighbors, node v must stay idle.
- if v has received coefficients from its neighbors, node v must computeand send it to the remaining neighbor.
The above computation is active until there is at least one node executing the second line, and it is easy to see that there exists an instant when a node, that we call it c in the following, receives all the coefficients from each one of its neighbors. When this condition happens, then node c triggers the second stage of the algorithm, as follows:
Then, this latter procedure propagates from node c back to the leaf nodes. At this stage, when any node, say node j, receives from one of its neighbors ℓ, then:
The above procedure prosecutes until there are more peripherical neighbor nodes, thus ending when it reaches the leaf nodes.
The above procedure allows to compute the scaling factors for average consensus in a distributed fashion. A final issue of the above procedure is the time instant when the leaf node should start running stage one. There are several possible strategies according to the specific setting, described in the foillowing. However, it is not an issue for the algorithm execution, but only for an estimation in advance of the time needed for execution.
If all the leaf nodes start synchronously at time , then the algorithm lasts until , where R is the radius of the graph, In this case, the ending node is the center of the tree. However, if the leaves are not synchronized and each node has its own starting time, then the algorithm still have a finite execution with a correct solution, though it cannot be computed in advancethe execution time nor the location of the last node(s) running the algorithm.
Finally, there are scenarios where one leader node is present and it can trigger the algorithm. In this latter case, our reference scenario is the Laplacian allocation algorithm in [15], where weights are set in a distributed fashion, starting from the leader node to leaf nodes. However, several different frameworks are possible, also adopting a virtual leader. In this latter setting, where a leader triggers the algorithm, the total algorithm time execution is equal to , where e represents the eccentricity of the leader within the network graph.
6. Simulation Results
In this Section, we show the results of the proposed approach in the consensus network described by the graph in Figure 2, where a parameter denotes an uncertainty term and it is a variation of the edge value with respect to the nominal one equal to 1.
Our reference scenario for this simulation is the WSN Implementation of the Average Consensus Algorithm as described in [38] Figure 3 , where the architecture of a wireless sensor node is sketched, allowing the scaling of the initial measurements in the preliminary initialization step (Stage I and II).
We assume to have a set of 9 sensor nodes connected as depicted in Figure 2, each holding a measured quantity, the initial values are set equal to
with average value equal to .
The first simulation shows the results of the evolution of the system when the uncertainty parameter . The evolution of the system is shown in Figure 3, solid lines.
A first notable point is the magnitude of the drift of the consensus value from the initial average value. Indeed, in such a case, the consensus value turns to , which is away from the nominal average value, even if the variation was only of magnitude .
The above phenomenon is even more evident for values of . Indeed, in such case the asymptotic value is equal to , so that it is more than far from the nominal one, and it is useless even as a rough estimation of the average value.
The reason for this phenomenon is related to the variation of the Perron vector. Even if each component has limited variation, the overall weighted sum results so far from the average. The Perron vector is equal to
so that a suitable rescaling of the initial values according to Equation (8) provides:
which restores the original consensus value to the average of (dashed lines).
7. Conclusions
In this paper, a distributed algorithm is derived for the computation of suitable scaling factors which allow reaching average consensus in unbalanced tree networks. The general algorithm is iterative and based on local data, and it is appropriate to be run as a preliminary routine. Simulation results show that the proposed algorithm can be effectively integrated with other set-up routines, and it gathers beneficial effects on the precision of the computed average value. Further research is oriented in different directions, e.g. the extension of the proposed approach to more general and time-varying graphs, considering more general dynamics of a single agent allowing for vehicle and mobile robot network applications, and testing the algorithm in experimental stages of WSN applications.
References
- Bullo, F. Lectures on Network Systems, 1 ed.; 2022.
- Olfati-Saber, R.; Fax, A.J.; Murray, R. Consensus and Cooperation in Networked Multi-Agent Systems. Proceedings of the IEEE 2007, 95, 215–233. [Google Scholar] [CrossRef]
- Rezaee, H.; Abdollahi, F. Average consensus over high-order multiagent systems. IEEE Transactions on Automatic Control 2015, 60, 3047–3052. [Google Scholar] [CrossRef]
- Kia, S.S.; Van Scoy, B.; Cortes, J.; Freeman, R.A.; Lynch, K.M.; Martinez, S. Tutorial on dynamic average consensus: The problem, its applications, and the algorithms. IEEE Control Systems Magazine 2019, 39, 40–72. [Google Scholar] [CrossRef]
- Garin, F.; Schenato, L. A survey on distributed estimation and control applications using linear consensus algorithms. In Networked control systems; Springer, 2010; pp. 75–107.
- Patterson, S.; Bamieh, B.; El Abbadi, A. Convergence rates of distributed average consensus with stochastic link failures. IEEE Transactions on Automatic Control 2010, 55, 880–892. [Google Scholar] [CrossRef]
- Cai, K.; Ishii, H. Average consensus on general digraphs. In Proceedings of the 2011 50th IEEE Conference on Decision and Control and European Control Conference. IEEE; 2011; pp. 1956–1961. [Google Scholar]
- Guyeux, C.; Haddad, M.; Hakem, M.; Lagacherie, M. Efficient distributed average consensus in wireless sensor networks. Computer Communications 2020, 150, 115–121. [Google Scholar] [CrossRef]
- Sun, S.; Chen, F.; Ren, W. Distributed average tracking in weight-unbalanced directed networks. IEEE Transactions on Automatic Control 2020, 66, 4436–4443. [Google Scholar] [CrossRef]
- Sen, A.; Sahoo, S.R.; Kothari, M. Distributed average tracking with incomplete measurement under a weight-unbalanced digraph. IEEE Transactions on Automatic Control 2022, 67, 6025–6037. [Google Scholar] [CrossRef]
- Du, M.; Meng, D.; Wu, Z.G. Distributed averaging problems over directed signed networks. IEEE Transactions on Control of Network Systems 2021, 8, 1442–1453. [Google Scholar] [CrossRef]
- Shafi, S.Y.; Arcak, M.; El Ghaoui, L. Graph weight allocation to meet Laplacian spectral constraints. IEEE Transactions on Automatic Control 2011, 57, 1872–1877. [Google Scholar] [CrossRef]
- Hao, H.; Barooah, P. Improving convergence rate of distributed consensus through asymmetric weights. In Proceedings of the 2012 American Control Conference (ACC). IEEE; 2012; pp. 787–792. [Google Scholar]
- Gao, L.; Zhao, J.; Di, Z.; Wang, D. Asymmetry between odd and even node weight in complex networks. Physica A: Statistical Mechanics and its Applications 2007, 376, 687–691. [Google Scholar] [CrossRef]
- Parlangeli, G. Laplacian Eigenvalue Allocation Through Asymmetric Weights in Acyclic Leader-Follower Networks. IEEE Access 2023, 11, 126409–126419. [Google Scholar] [CrossRef]
- Parlangeli, G. Prescribed-time average consensus through data-driven leader motion. IEEE Access 2024. [Google Scholar] [CrossRef]
- Valcher, M.E.; Parlangeli, G. On the effects of communication failures in a multi-agent consensus network. In Proceedings of the 2019 23rd International Conference on System Theory, Control and Computing (ICSTCC). IEEE; 2019; pp. 709–720. [Google Scholar]
- Parlangeli, G. A Supervisory Algorithm Against Intermittent and Temporary Faults in Consensus-Based Networks. IEEE Access 2020, 8, 98775–98786. [Google Scholar] [CrossRef]
- Dibaji, S.M.; Pirani, M.; Flamholz, D.B.; Annaswamy, A.M.; Johansson, K.H.; Chakrabortty, A. A systems and control perspective of CPS security. Annual reviews in control 2019, 47, 394–411. [Google Scholar] [CrossRef]
- Kenyeres, M.; Kenyeres, J. Average Consensus with Perron Matrix for Alleviating Inaccurate Sensor Readings Caused by Gaussian Noise in Wireless Sensor Networks. In Proceedings of the Software Engineering and Algorithms: Proceedings of 10th Computer Science On-line Conference 2021, Vol.; pp. 12021391–405.
- Meyer, C.D. Uncoupling the Perron eigenvector problem. Linear Algebra and its applications 1989, 114, 69–94. [Google Scholar] [CrossRef]
- Liu, Z.; Guo, L. Synchronization of multi-agent systems without connectivity assumptions. Automatica 2009, 45, 2744–2753. [Google Scholar] [CrossRef]
- Sardellitti, S.; Giona, M.; Barbarossa, S. Fast distributed average consensus algorithms based on advection-diffusion processes. IEEE Transactions on Signal Processing 2009, 58, 826–842. [Google Scholar] [CrossRef]
- Chen, Y.; Tron, R.; Terzis, A.; Vidal, R. Corrective consensus with asymmetric wireless links. In Proceedings of the 2011 50th IEEE Conference on Decision and Control and European Control Conference. IEEE; 2011; pp. 6660–6665. [Google Scholar]
- Song, Z.; Taylor, D. Asymmetric Coupling Optimizes Interconnected Consensus Systems. arXiv preprint arXiv:2106.13127, arXiv:2106.13127 2021.
- Parlangeli, G.; Valcher, M.E. Leader-controlled protocols to accelerate convergence in consensus networks. IEEE Transactions on Automatic Control 2018, 63, 3191–3205. [Google Scholar] [CrossRef]
- Parlangeli, G.; Valcher, M.E. Accelerating consensus in high-order leader-follower networks. IEEE Control Systems Letters 2018, 2, 381–386. [Google Scholar] [CrossRef]
- Mirzaev, I.; Gunawardena, J. Laplacian dynamics on general graphs. Bulletin of mathematical biology 2013, 75, 2118–2149. [Google Scholar] [CrossRef] [PubMed]
- Dietzenbacher, E. Aggregation in multisector models: using the Perron vector. Economic Systems Research 1992, 4, 3–24. [Google Scholar] [CrossRef]
- Schenato, L.; Fiorentin, F. Average TimeSynch: A consensus-based protocol for clock synchronization in wireless sensor networks. Automatica 2011, 47, 1878–1886. [Google Scholar] [CrossRef]
- Shi, F.; Yang, S.X.; Mukherjee, M.; Jiang, H.; da Costa, D.B.; Wong, W.K. Parameter-sharing-based average-consensus time synchronization in IoT networks. IEEE Internet of Things Journal 2022, 10, 8215–8227. [Google Scholar] [CrossRef]
- Wu, J.; Li, X. Collective synchronization of Kuramoto-oscillator networks. IEEE Circuits and Systems Magazine 2020, 20, 46–67. [Google Scholar] [CrossRef]
- Duan, Y.; He, X.; Zhao, Y. Distributed algorithm based on consensus control strategy for dynamic economic dispatch problem. International Journal of Electrical Power & Energy Systems 2021, 129, 106833. [Google Scholar]
- Macii, D.; Rinaldi, S. Time synchronization for smart grids applications: Requirements and uncertainty issues. IEEE Instrumentation & Measurement Magazine 2022, 25, 11–18. [Google Scholar]
- Bullo, F.; Cortés, J.; Martínez, S. Distributed Control of Robotic Networks; Princeton University Press, 2009. Applied Mathematics Series.
- Parlangeli, G. A distributed algorithm for the assignment of the Laplacian spectrum for path graphs. Mathematics 2023, 11, 2359. [Google Scholar] [CrossRef]
- Usmani, R.A. Inversion of a tridiagonal Jacobi matrix. Linear Algebra and its Applications 1994, 212, 413–414. [Google Scholar] [CrossRef]
- Kenyeres, J.; Kenyeres, M.; Rupp, M.; Farkas, P. WSN implementation of the average consensus algorithm. In Proceedings of the 17th European Wireless 2011-Sustainable Wireless Technologies. VDE; 2011; pp. 1–8. [Google Scholar]
Figure 1.
Worked Example from [36] : (a) Unbalanced tree graph (b) Subdivision of the graph according to the notation.
Figure 1.
Worked Example from [36] : (a) Unbalanced tree graph (b) Subdivision of the graph according to the notation.
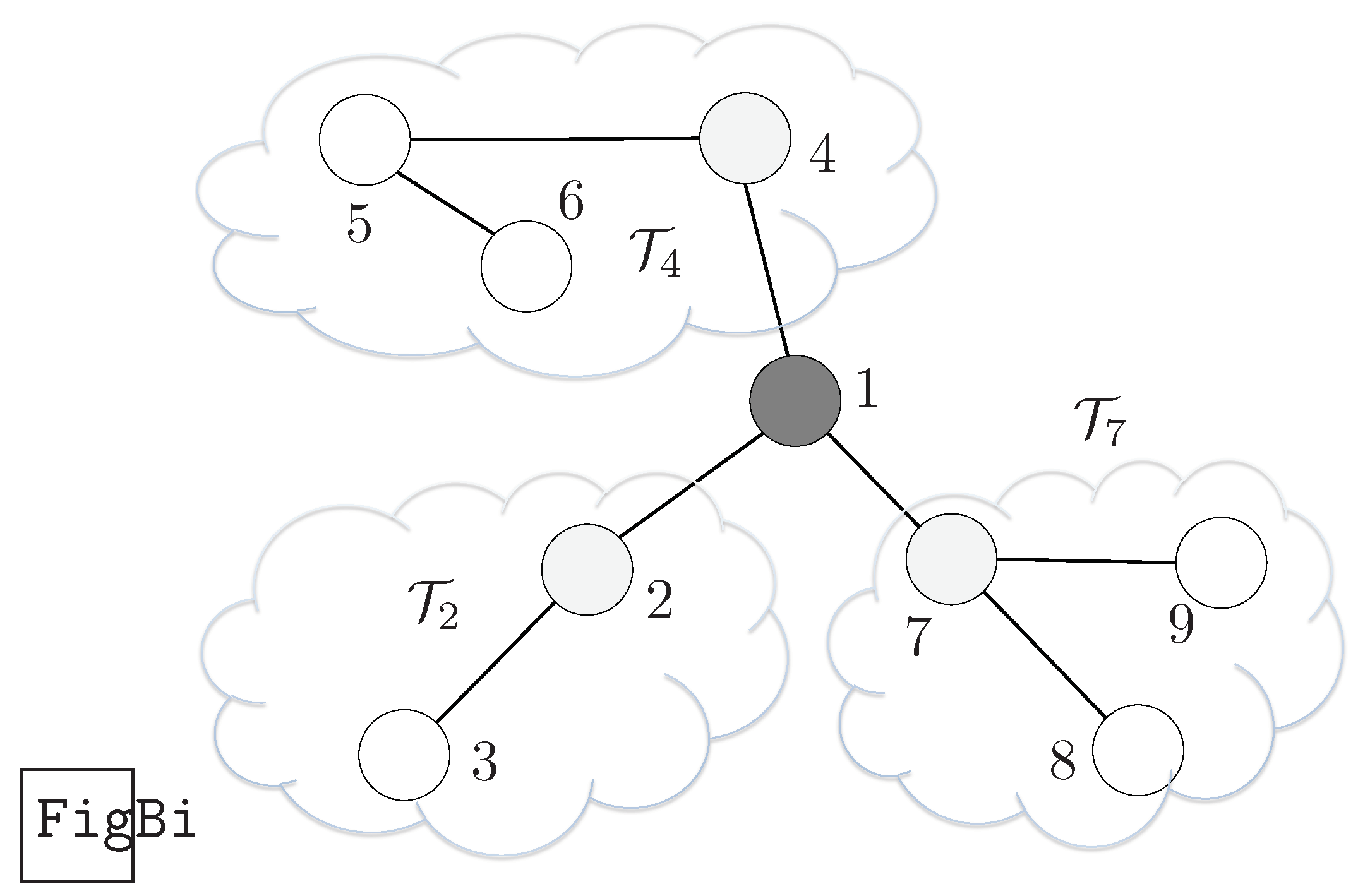
Figure 2.
Simulation results: perturbed consensus network topology adopted in the simulations.
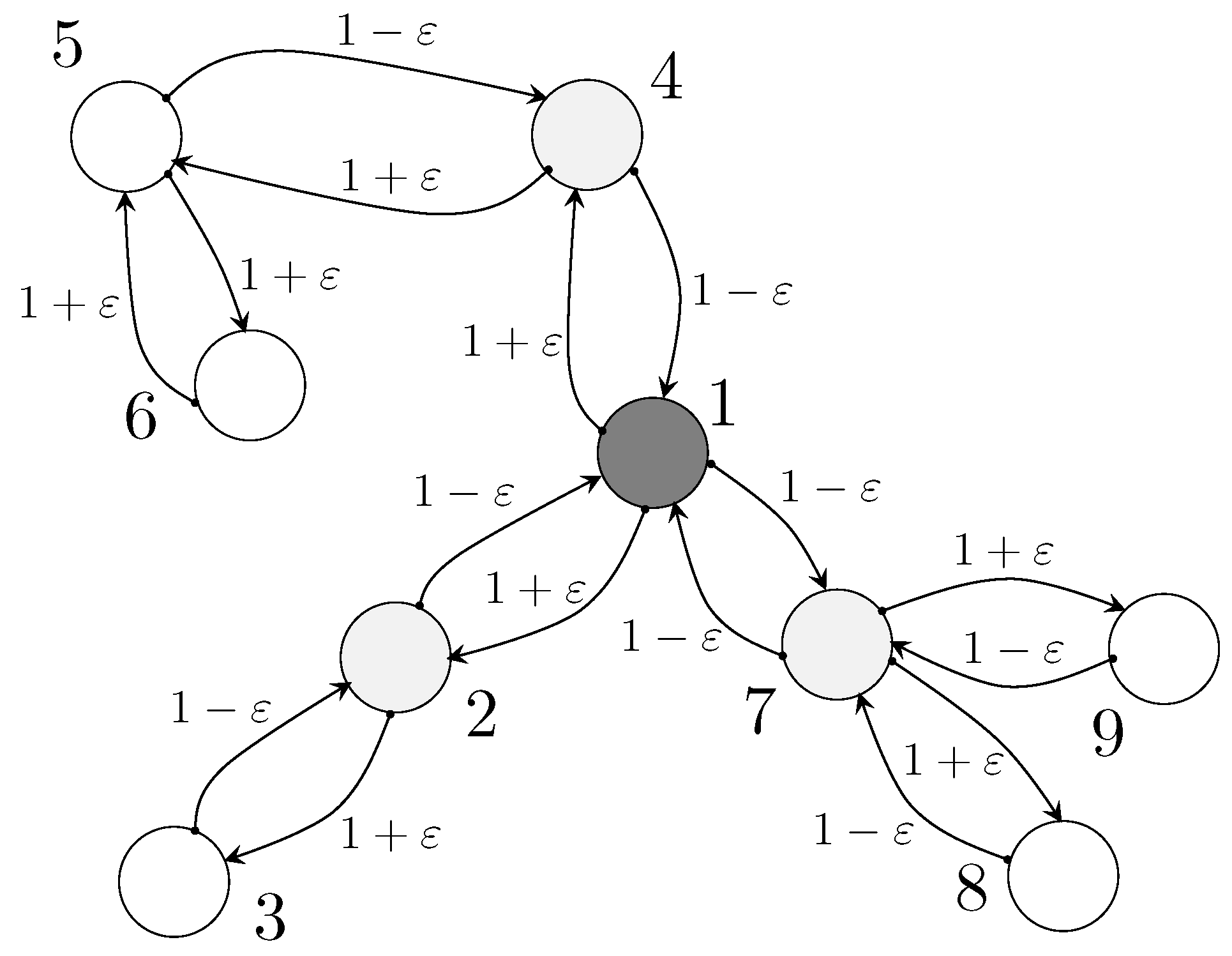
Figure 3.
Simulation results: perturbed consensus network. Case . Solid lines plots show uncompensated trajectories, dashed lines show the evolution with scaled initial conditions.
Figure 3.
Simulation results: perturbed consensus network. Case . Solid lines plots show uncompensated trajectories, dashed lines show the evolution with scaled initial conditions.
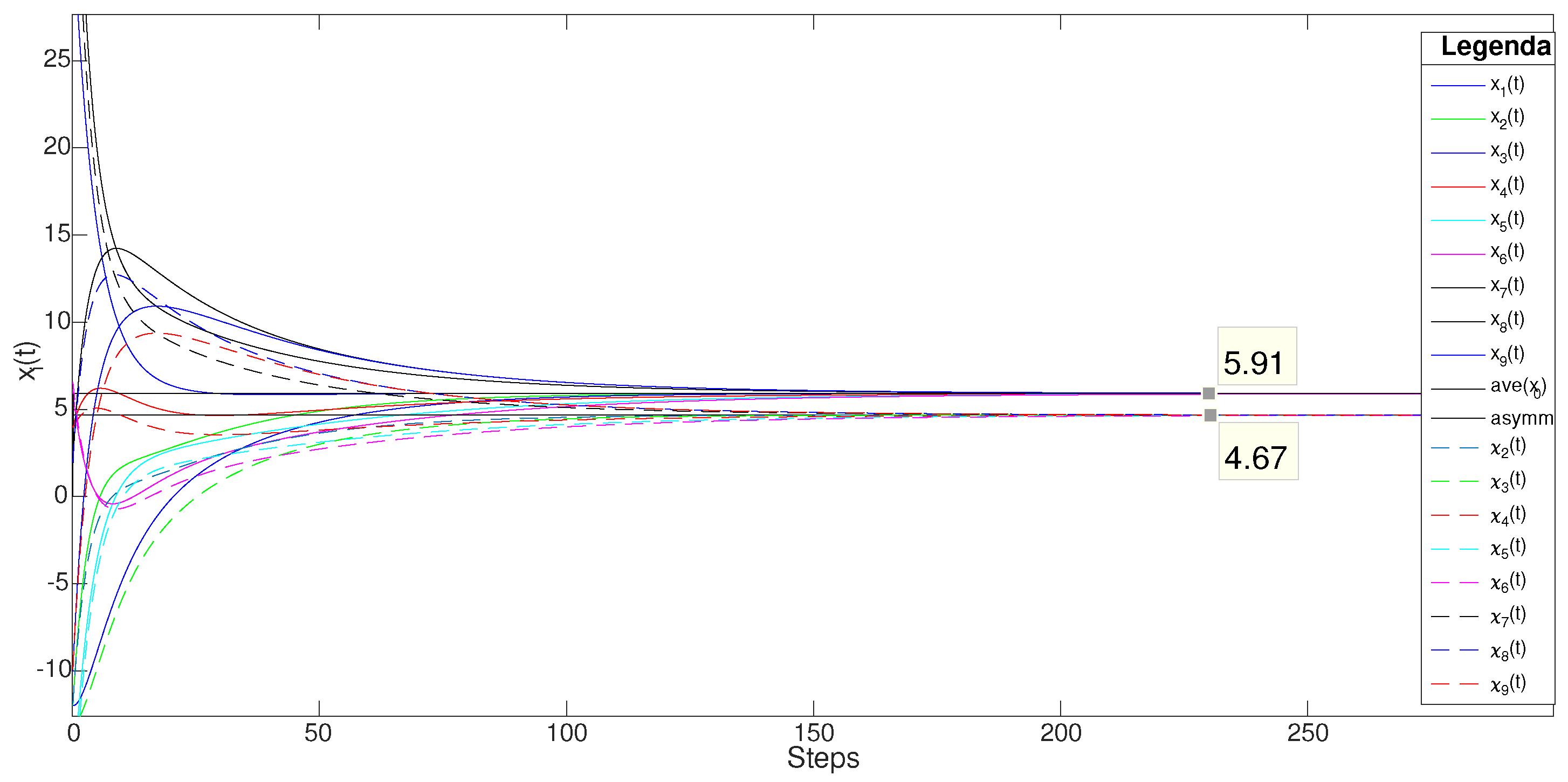
Figure 4.
Simulation results: perturbed consensus network. Case . Solid lines plots show uncompensated trajectories, dashed lines show the evolution with scaled initial conditions.
Figure 4.
Simulation results: perturbed consensus network. Case . Solid lines plots show uncompensated trajectories, dashed lines show the evolution with scaled initial conditions.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



