Submitted:
16 August 2024
Posted:
19 August 2024
You are already at the latest version
Abstract
The increasing rearrangement is a rewarding instrument in financial risk management. In practice, risk must be managed in different perspectives. A common example is portfolio risk which often can be seen from at least two perspectives: market value and book value. Different perspectives that is different distributions can be coupled by increasing rearrangement. One distribution is regarded as underlying, and the other distribution can be expressed as increasing rearrangement of the underlying distribution. Then, the risk measure for the latter can be expressed in terms of the underlying distribution. Our first objective is to introduce the increasing rearrangement for application in financial risk management and apply the increasing rearrangement to the class of distortion risk measures. We derive formulas to compute risk measures in terms of the underlying distribution. Afterwards, we apply our results to a series of special distortion risk measures, namely Value at Risk, Expected Shortfall, Range Value at Risk, Conditional Value at Risk, Wang's risk measure. Finally, we present the connection of increasing rearrangement to inverse transform sampling, Monte Carlo simulation, and cost-efficient strategies. Butterfly options serve as illustrative example for the method.
Keywords:
increasing rearrangement
; risk measure
; distortion risk measure
; expected shortfall
; value at risk
; range value at risk
; conditional value at risk
; Wang’s risk measure
; inverse transform sampling
; cost-efficient strategies
MSC: 62P05; 62P20; 91B05; 91G70
1. Introduction
Increasing rearrangements often appear in finance and risk management in a natural context. For example, consider the market value and book value of a portfolio, where the book value is reported according to some reporting standard. In many cases, the portfolio risk has to be managed based on market values as well as book values – both points of view may be important and there may be even more perspectives to be controlled. Mostly, the book value can be regarded as an increasing function of the market value. In this case, risk measures of book and market values are related in a special manner. Given that the distribution of the market values does not have atoms, distortion risk measures of book values can be written in terms of the corresponding market values. This gives insight and computational advance.
The class of distortion risk measures to which this idea applies is a rather general yet useful and handy class of risk measures. All distortion risk measures are coherent as defined by Artzner et al. [1], i.e. they are translation invariant, monotonous, sub-additive, and positively homogeneous. Distortion risk measures were introduced by Denneberg [8] and Wang [20]. Their roots lie in the dual utility theory of Yaari [21], where it is shown that there must exist a type of function such that a prospect is valued at its distorted expectation. In place of using the tail probabilities in order to quantify risk, the decision maker uses the distorted tail probabilities. A general overview of distortion risk measures and their relation with the orderings of risks and the concept of comonotonicity can be found in [6] and [7].
Distortion risk measures allow an asset manager to reflect a client’s attitude towards risk by choosing the appropriate distortion function. For instance, in insurance data analytics and actuarial practice, distortion risk measures are used to capture the riskiness of the distribution tail and then employed to price extreme events, to develop reserves, to design risk transfer strategies, and to allocate capital.
The example of book and market values generalizes to any two distributions when one of them does not have atoms, as in this case an increasing rearrangement exists that transforms the continuous distribution into the other. Hence, given any distribution, we may find the increasing rearrangement with respect to some continuous distribution of our choice (e.g. uniform or normal distribution) and compute the risk of the given distribution in terms of the continuous distribution we chose.
Inverse transform sampling is a special case of this setting. In this case, the continuous distribution is the uniform distribution on . Monte Carlo methods often use inverse transform sampling. Another example are cost-efficient portfolios as it turns out that the increasing and decreasing rearrangement yields explicit formulas for cost-efficient (and cost-inefficient) portfolios.
The article is organized as follows:
In Section 2 we introduce the increasing rearrangement in two versions called the “quantile version” and the “transport version”. While the quantile version is especially advantageous in finance – as it has the transformation property needed when applied to risk measures – the transport version is a little smoother in a way and for this reason preferred when applied to optimal transport, hence our naming.
The following Section 3 brings the application of increasing rearrangements (quantile version) to distortion risk measures. We derive formulas of how to compute the risk in terms of the underlying continuous distribution (“market values”).
This can be applied in Section 4 to a series of special distortion risk measures, namely Value at Risk, Expected Shortfall, Range Value at Risk, Conditional Value at Risk, and Wang’s risk measure.
We apply increasing rearrangement to inverse transform sampling and Monte Carlo simulation in Section 5. An example is the butterfly spread with R code provided in Appendix A. Finally, we point out the relation of increasing rearrangement to the theory of cost-efficient strategies.
2. The Increasing Rearrangement
The increasing rearrangement is related to the generalized inverse of distribution functions. Therefore we first introduce this concept. Here and in the following, increasing means
Definition 2.1.
Let be an increasing function. The generalized inverse of T is defined by
with .
Let F be any distribution function. For , we denote the corresponding quantile function with . It coincides with the generalized inverse and is given by
If X is a random variable with distribution function F, we write as well. To specify distribution functions, we write for the distribution function of X. If X and Y have the same distribution function, we write . If X has distribution , we write .
We assume all random variables to be elements of some domain of random variables with values in and be a convex cone, i.e. for all and .
Given any increasing function , the generalized inverse of T is increasing and left-continuous (cf. [14], p. 641 f.).
Proposition 2.2. [14], p. 642 If X is a random variable with distribution function and is increasing and left-continuous, then
In terms of the quantile function, this means
Definition 2.3.
Let be an increasing function. The right-continuous generalized inverse of T is defined by
with .
Definition 2.4.
Let X and Y be random variables with distribution functions and . The increasing rearrangement (quantile version) of Y with respect to X is given by
The increasing rearrangement (transport version) of Y with respect to X is given by
Lemma 2.5. [18], p. 19 f. Let X and Y be random variables. Let be the increasing rearrangement (transport version) of Y with respect to X. Then the following holds:
- 1.
- is increasing.
- 2.
- is right-continuous.
- 3.
- If X does not have atoms, then
Lemma 2.6.
Let X and Y be random variables. Let be the increasing rearrangement (quantile version) of Y with respect to X. Then the following holds:
- 1.
- is increasing.
- 2.
- If X does not have atoms, then is left-continuous.
- 3.
- If X does not have atoms, then .
Proof. (i) The functions and are increasing, and so is .
(ii) X does not have atoms iff is continuous. Moreover, is left-continuous. This implies (2).
(iii) The continuity of implies (uniformly distributed on ). Hence . (cf. [10], p. 429) □
While the quantile version of the increasing rearrangement seems to be a natural choice in terms of the generalized inverse and favorable in view of Proposition 2.2, the transport version of the increasing rearrangement is right-continuous without further assumptions on X. Villani praises the transport version of the increasing rearrangement: “This rearrangement is quite simple, explicit, as smooth as can be, and enjoys good geometric properties” [18], p. 20.
3. Risk measures of increasing rearrangements
Distortion risk measures are law-invariant risk measures and include Value at Risk and Expected Shortfall. They are defined in the following way:
Definition 3.1. [17]
- 1.
- A distortion function D is an increasing, right-continuous function on satisfying and .
- 2.
- The distortion risk measure associated with a distortion function D is defined by
Note that in our notation we regard X as loss function, i.e. positive values of X stand for losses, negative values of X stand for profits. If one uses a p&l-function with an opposite interpretation, the formulas here and in the following have to be altered accordingly.
In [14] the definition of distortion risk measures is given for the smaller class of convex, absolutely continuous distortion functions. With respect to these distortion functions, the corresponding distortion risk measures are coherent. However, this excludes Value at Risk from the class, which is why we prefer the more general Definition 3.1 of Tsukahara.
Let D be an absolutely continuous distortion function and be the right derivative of D. Then is a non-negative function, and
One defines
Definition 3.2.
Let be the right derivative of an absolutely continuous distortion function. The spectral risk measure with respect to is
One calls the spectrum of .
If is the right derivative of an absolutely continuous distortion function D, then holds by construction.
Lemma 3.3.
Let D be a distortion function and the risk measure associated with D. Then can be written in the form
Proof.
The proof given in [14], p. 287 for convex and absolutely continuous distortion function D applies literally. □
The chain rule, applied to (12), implies
Lemma 3.4.
Let D be an absolutely continuous distortion function, φ its spectrum and the risk measure associated with φ. Let X be a random variable with an absolutely continuous distribution function and let be the right-derivative of (density of X). Then can be written in the form
Theorem 3.5.
Let X and Y be random variables and X be atomless. Let be the quantile version of increasing rearrangement of Y with respect to X. Let D be a distortion function and the distortion risk measure associated with D. Then the following holds:
If D is absolutely continuous and φ is the corresponding spectrum, we have
Moreover, if X is absolutely continuous with density ,
Note that representation (17) cannot be written down in terms of , because is not supposed to be absolutely continuous (not even continuous).
Proof.
By Lemma 5.3., is an increasing, left-continuous function, and . Thus Proposition 2.2 applies and yields (14) and (16).
To show (15), we write and observe .1 Now
We introduce the random variable and obtain with (14)
This shows (15). Finally, applying the chain rule to (15) implies (17) and this finishes the proof. □
4. Application to Special Risk Measures
4.1. Application to Value at Risk
Value at Risk of a loss distribution is defined to be the quantile at some confidence level , we write
Value at Risk is a distortion risk measure with distortion function
(See [17] for more details.) Hence, Theorem 3.5 applied to VaR yields the well-known
Lemma 4.1.
Let X and Y be random variables and X does not have atoms. Let be the quantile version of increasing rearrangement of Y with respect to X. Then
Proof.
The assertion follows from equation (14) of Theorem 3.5. Also, it is a consequence of Lemma 5.3. (iii) in combination with Proposition 2.2, namely:
□
4.2. Application to Expected Shortfall
The Expected Shortfall of a random variable Y with and confidence level , e.g. , is the spectral risk measure defined as follows:
with specific spectrum
Alternatively, Expected Shortfall can be represented in terms of the distortion function of the form:
(This follows from Definition 3.2 of distortion risk measures.) For continuous random variables X, Expected Shortfall has an intuitive interpretation as conditional expectation, namely
For discontinous random variables though, one has to be careful and the proper definition in this general case amounts to [14], p. 283
Nevertheless, the theorem on increasing rearrangement and distortion risk measures allows to find a version of formula (27) for discontinuous random variables as follows:
Theorem 4.2.
Let X and Y be random variables and X be absolutely continuous. Let be the quantile version of increasing rearrangement of Y with respect to X. Let . Then
Proof.
As X is absolutely continuous there exists a density function . Consequently, the expected shortfall can be written in the form of equation (17) with the spectrum . We derive
as was to be shown. □
In case , X-a.s., Theorem 4.2. takes the striking form
The following theorem shows that this holds for any (not necessarily left-continuous) increasing transformation g with , X-a.s., as well.
Theorem 4.3.
Let X be an absolutely continuous random variable, and , X-a.s., where g is increasing. Let . Then
Proof.
We consider the sets
In the first place, , or, what is the same,
Indeed, for an arbitrary we obtain
which means . This implies (34). Moreover, we find that
This can be shown by contradiction. Indeed, let be arbitrary and assume . Then we obtain by the monotony of g and the absolute continuity of X
hence in contradiction to . Thus statement (36) holds.
Now we prove the theorem by showing
Representation (28) of Expected Shortfall is equivalent to
as follows from
The random variable X is assumed to be absolutely continuous and hence possesses a probability density function . We calculate with (39)
4.3. Application to Range-Value-at-Risk
Next, we highlight Range-Value-at-Risk introduced by [4]. It is a modified version of Expected Shortfall such that an average of VaR levels is calculated across a pre-defined range of loss probabilities. Let , , then
Range-Value-at-Risk has good statistical properties (“-robustness”) which carry over to Expected Shortfall in a certain sense as is discussed in [4]. In applying our main theorem 3.5, we derive a formula for the Range-Value-at-Risk of Y in terms of X:
Theorem 4.4.
Let X and Y be random variables and X be absolutely continuous. Let be the quantile version of increasing rearrangement of Y with respect to X. Let and , . Then
Proof.
The assumption of absolute continuity of X gives us the possibility to write the Range-Value-at-Risk in terms of the density function by (17), as follows:
as was to be shown. □
4.4. Application to Conditional Value at Risk
The distributional transform is defined as follows [3,15]: Let X be a real random variable with distribution function F and let be uniformly distributed on and independent of X. The modified distribution function is defined by
The (generalized) distributional transform of X is then defined by
An equivalent representation of the distributional transform is
An early source for this transform is the statistics book [11]. See [16, p. 21-28] for a range of applications of the distributional transform. By means of the distributional transform one can give a proper definition of Conditional Value at Risk, namely (see [3], [15])
The main theorem on conditional value at risk is that it actually coincides with expected shortfall. We prove this result of Burgert and Rüschendorf by applying Theorem 4.2.
Corollary 4.5.
Proof.
On , is the identity. Hence the increasing rearrangement of Y with respect to U equals on by (7). This implies a.s.
U posesses a density (namely, the density of the uniform distribution on ). That means that U is absolutely continuous and Theorem 4.2. applies. We obtain
Using a.s., this implies
as was to be shown. □
4.5. Application to Wang’s risk measure
For the pricing of financial and insurance risk, [19] has introduced a specific distortion function which is based on the standard normal distribution in combination with a shift parameter :
Formula (15) of Theorem 3.5 yields
Lemma 4.6.
Let X and Y be random variables and X be normal distributed with and . Let be the quantile version of increasing rearrangement of Y with respect to X. Let . Then
holds for .
Likewise, let X be log-normal distributed with and and be the quantile version of increasing rearrangement of Y with respect to X, . Then (53) holds for .
Proof.
We start with the definition of Wang’s risk measure and (15):
Let us assume that . We can equivalently write X in terms of the standard normal distribution, namely , and obtain for the integrator:
This implies (53) with .
The analogous argument holds for and the log-normal distribution function :
Thus equation (53) holds in both cases and the Lemma is proven. □
One may write the assertion of the lemma in terms of X rather than Z. Namely, in the notation of the lemma and in case , equation (53) amounts to
In case , (53) amounts to
5. Application to Numerical Simulation and Cost-Efficient Portfolios
5.1. Inverse Transform Sampling
Inverse transform sampling is related to the increasing rearrangement. The well-known inversion principle (or, inversion method) to random number generation reads:
Theorem 5.1.
Let F be a cumulative distribution function and X be uniformly distributed on . Then has cdf F.
Proof.
See e.g. [13], p. 87. □
In this setting, the increasing rearrangement of Y with respect to X is
In other words, as given in the theorem is the increasing rearrangement applied to X in special case . Hence, all assertions of the preceding section apply to inverse transform sampling.
5.2. Monte Carlo simulation
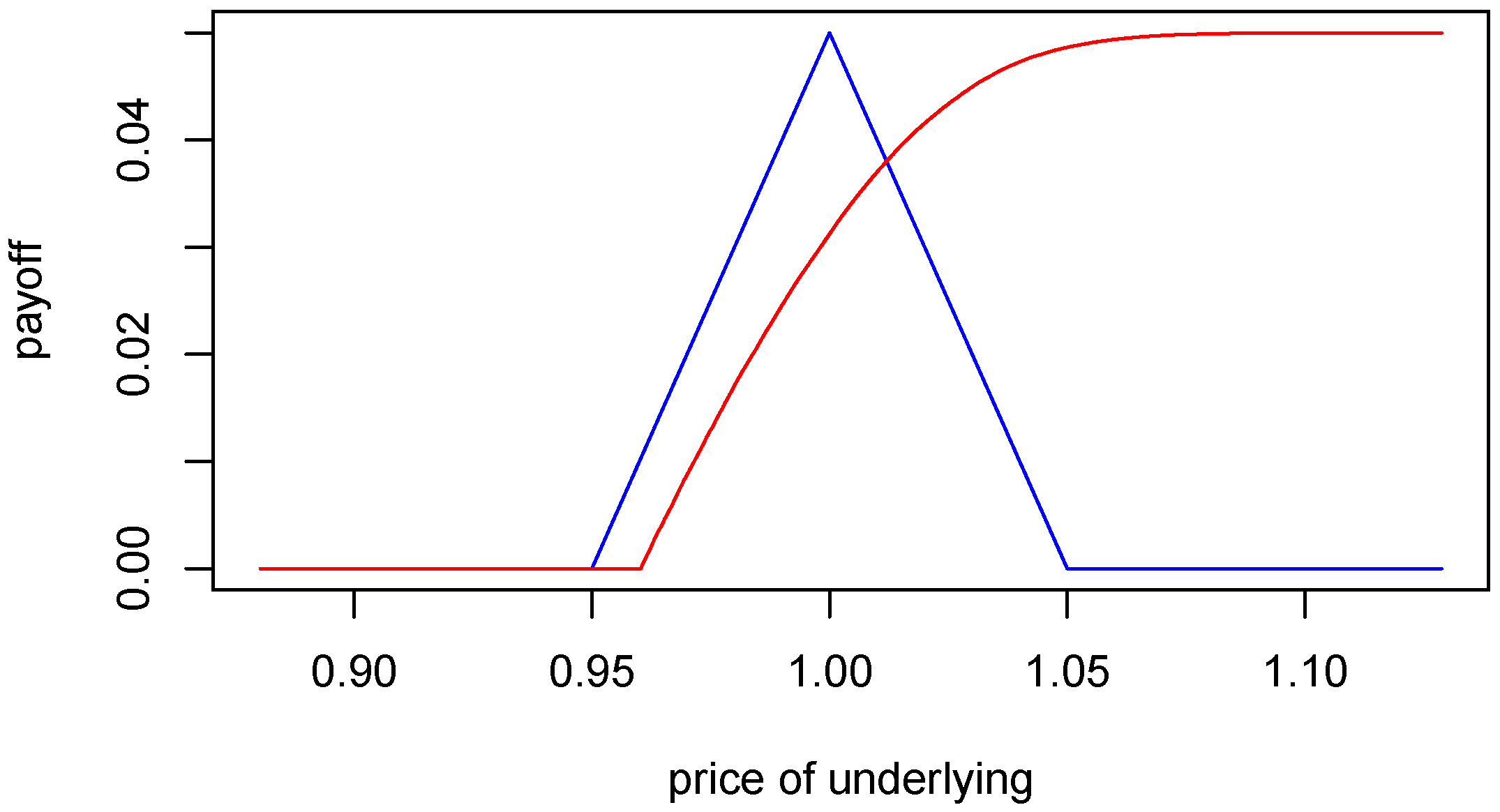
In general, with Monte Carlo simulation, simulated prices are not an increasing rearrangement of random numbers or underlying prices, respectively. Consider for example a butterfly spread [12], p. 190 ff. with payoff as displayed in Table 1. Notation:
- price of underlying at maturity T,
- strike prices, , .
The payoff of the butterfly spread reads as follows:

Table 1.
payoff of butterfly spread.
| stock price | payoff |
|---|---|
| 0 | |
| 0 |
The payoff is depicted in Figure 1 (blue line). Given the model for stock prices, the distribution of the butterfly payoff can be obtained by the increasing rearrangement. Let us denote the butterfly payoff with and the increasing rearrangement of Y with respect to by . Then by Lemma 5.3 we have:
This is easy to compute in the Monte Carlo simulation. One just has to sort Y. R code is provided in the appendix.
Assuming a lognormal distribution for with , and , we obtain Figure 1. The payoff Y is denoted with the blue line, with the red line. Note that is increasing while Y is not. However, both have the same distribution.
5.3. Cost-Efficient Strategies
A strategy (or a payoff) is said to be cost-efficient if any other strategy that generates the same distribution costs at least as much. Starting with Cox and Leland [5], Dybvig [9] pointed out that there are indeed inefficient strategies in the market. Examples like the so-called constant proportion portfolio insurance (CPPI), or the butterfly spread discussed in section 5.2 show, as Dybvig puts it, “how to throw away a million dollars in the stock market”.
It turns out that a payoff is cost-efficient if and only if it is non-increasing in the state-price almost surely, see [2] for an introduction into the topic, proofs and references. We will make this statement more explicit in Theorem 5.4 below.
In the words of Bernard et al.: “The cheapest way to achieve a lottery assigns outcomes of the lottery to the states in reverse order of the state-price density.” [2] So we define the decreasing rearrangement, as follows:
Definition 5.2.
Let X and Y be random variables with distribution functions and . The decreasing rearrangement (quantile version) of Y with respect to X is given by
Lemma 5.3.
Let X and Y be random variables. Let be the decreasing rearrangement (quantile version) of Y with respect to X. Then the following holds:
- 1.
- is decreasing.
- 2.
- If X does not have atoms, then is left-continuous.
- 3.
- If X does not have atoms, then .
Proof. (i) The function is decreasing while is increasing, so is a decreasing function.
(ii) X does not have atoms iff is continuous. Moreover, is left-continuous. This implies (2).
(iii) The continuity of implies (uniformly distributed on ), so as well. Hence (cf. [10, p.429]). □
We consider an arbitrage-free and complete market with an unique state-price density , and assume that is atomless for all . In such a market the price (or cost) of a strategy (or of a financial investment contract) with terminal payoff at is given by
where the expectation is taken under the physical measure. The Theorem on cost efficient strategies reads as follows.
Theorem 5.4.
[2] Let be a given payoff, i.e. any random variable. Let , be the state-price density and the decreasing rearrangement (quantile version) of with respect to . Then and is thecost-efficientstrategy to replicate : Given any other random variable with , it holds that
In the Black-Scholes model with positive expected return , stock prices and state prices at are non-increasing functions of each other. Hence Theorem 5.4 amounts to the payoff be increasing in the stock price, i.e. the increasing rearrangement of the payoff in terms of the price of the underlying stock yields the cost-efficient strategy that replicates the distribution of the payoff under consideration. An example is given by the butterfly spread discussed in the previous section. While the given payoff is not cost-efficient, its increasing rearrangement is.
Note that the assertion hinges (amongst the other assumptions) on the assumption that . Investors who do not believe that the drift of stock is positive will consequently not conclude that the payoff of the increasing rearrangement of the butterfly spread is cost-efficient.
6. Conclusions
We consider distortion risk measures of increasing rearrangements. The “pull through property” of the increasing rearrangement with respect to quantiles implies formulas for the risk measure of Y in terms of X, given that Y is the increasing rearrangement of X.
The special case of Value at Risk illustrates the principle by the well-known formula
where and is the increasing rearrangement.
Moreover, applied to Expected Shortfall, the principle allows to generalize the interpretation of Expected Shortfall as conditional expectation. Namely, let Y be an arbitrary random variable (“book values”), X be an arbitrary absolutely continuous random variable (“market values”) and be the increasing rearrangement of Y with respect to X. Then the Expected Shortfall of Y can be written as a conditional expectation on (which has the same distribution as Y) in terms of X. This applies to Range Value at Risk as well.
Next, the principle implies a Theorem of Burgert and Rüschendorf stating that Expected Shortfall equals Conditional Value at Risk. An application to Wang’s risk measure yields a representation of Wang’s risk measure as some expected value.
Finally, we highlight the connection of the principle to inverse transform sampling, Monte Carlo simulation, and cost-efficient strategies.
Acknowledgments
We thank Michael Diether, Gregor Fels, Dieter Kadelka, Julia Mehlitz, Thomas Plehn and Bruce Auchinleck for valuable discussions.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A R-code (butterfly example)
Figure 1 was drawn with the following R code:
N <- 100000
alpha <- 0.10 # conficence level 1 - alpha
sigma <- 0.2 # volatility
T <- 1 / 52 # time (week)
K1 <- 0.95
K3 <- 1.05
K2 <- (K1 + K3) / 2
X <- sort(rlnorm(N, sdlog = sigma * sqrt(T)))
Y <- pmax(X - K1, 0) + pmax(X - K3, 0) - 2 * pmax(X - K2, 0)
plot(X, Y, type = "l", col = "blue", xlab = "price of underlying",
ylab = "payoff")
# main ="numerical increasing rearrangement of butterfly"
lines(X, sort(Y), type = "l", col = "red")
In the last line, the increasing rearrangement is done by just sorting Y.
References
- Artzner, Philippe; Delbaen, Freddy; Eber, Jean-Marc; Heath, David. Coherent measures of risk. Mathematical finance 1999, 9.3, 203-228. [CrossRef]
- Bernard, Carole; Boyle, Phelim P.; Vanduffel, Steven. Explicit representation of cost-efficient strategies. Finance 2014, 35.2, 5-55. [CrossRef]
- Burgert, Christian; Rüschendorf, Ludger. On the optimal risk allocation problem. Statistics and Decisions—International Journal Stochastic Methods and Models 2006, 24.1, 153-172. [CrossRef]
- Cont, Rama; Deguest, Romain; Scandolo, Giacomo. Robustness and sensitivity analysis of risk measurement procedures. Quantitative Finance 2010, 10.6, 593-606. [CrossRef]
- Cox, J.C.; Leland, H. On Dynamic Investment Strategies. Journal of Economic Dynamics and Control 2000, 24.11-12, 1859-1880.
- Denuit, Michel; Dhaene, Jan; Goovaerts, Marc; Kaas, Rob. Actuarial theory for dependent risks: measures, orders and models. John Wiley: Chichester, 2005.
- Dhaene, Jan; Vanduffel, Steven; Tang, Qihe; Goovaerts, Marc J.; Kaas, Rob ; Vyncke, David. Risk measures and comonotonicity: a review. Stochastic Models 2006, 22, 573606. [CrossRef]
- Denneberg, Dieter. Distorted probabilities and insurance premiums. Methods of Operations Research 1990, 63, 3-5.
- Dybvig, Phillip H. Inefficient dynamic portfolio strategies or how to throw away a million dollars in the stock market. The Review of Financial Studies 1988, 1.1, 67-88. [CrossRef]
- Embrechts, Paul; Hofert, Marius. A note on generalized inverses. Mathematical Methods of Operations Research 2013, 77.3, 423-432. [CrossRef]
- Ferguson, Thomas S. Probability and mathematical statistics. Academic Press: 1967.
- Hull, John. Options, Futures, and Other Derivatives. Prentice Hall: 5th ed. 2003.
- Kolonko, Michael. Stochastische Simulation. Vieweg+Teubner:2008.
- McNeil, Alexander J.; Frey, Rüdiger; Embrechts, Paul. Quantitative risk management: concepts, techniques and tools—revised edition. Princeton university press: 2015.
- Rüschendorf, Ludger. On the distributional transform, Sklar’s theorem, and the empirical copula process. Journal of Statistical Planning and Inference 2009, 139.11, 3921-3927. [CrossRef]
- Rüschendorf, Ludger. Mathematical risk analysis. Springer: Heidelberg, 2013.
- Tsukahara, Hideatsu. One-Parameter Families of Distortion Risk Measures. Mathematical Finance 2009, 19.4, 691-705. [CrossRef]
- Villani, Cedric. Optimal transport: old and new. Springer: 2008.
- Wang, Shaun S. A Class Of Distortion Operators For Pricing Financial And Insurance Risks. The Journal of Risk and Insurance 2000, 67.1, 15-36. [CrossRef]
- Wang, Shaun S.; Young, Virginia R.; Panjer, Harry H. Axiomatic characterization of insurance prices. Insurance: Mathematics and Economics 1997, 21, 173-183. [CrossRef]
- Yaari, Menahem E. The dual theory of choice under risk. Econometrica 1987, 55, 95-116. [CrossRef]
| 1 | Cf. [14], p. 287 |
Figure 1.
Numerical increasing rearrangement of butterfly spread.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



