
Submitted:
18 August 2024
Posted:
21 August 2024
You are already at the latest version
Abstract
The continuous expansion of Large Language Models (LLMs) has significantly transformed the fields of artificial intelligence (AI) and natural language processing (NLP). This paper reviews the rapidly evolving domain of language models and introduces the concept of Extremely Large Language Models (XtremeLLMs), a new category defined for models exceeding one trillion parameters. These models are monumental in scale and engineered to enhance performance across a diverse range of language tasks. This study aims to establish a comprehensive framework that explores the significant opportunities and complex challenges presented by such extensive scaling and emphasises the implications for future advancements in the field.
Keywords:
Artificial intelligence
; deep learning
; LLM
; machine learning
; XtremeLLM
1. Introduction
Language models have fundamentally transformed the field of AI, driving innovations in different fields, ranging from digital assistants to advanced machine translation services [1,2,3]. Fundamentally, these models are designed to understand, generate, and manipulate human language, which is essential for applications requiring natural language understanding and generation. Initially based on simple statistical methods that calculate word occurrence probabilities, language models have evolved into sophisticated neural networks that can understand deeper semantic meanings across expansive text corpora [4]. These models are critical for a broad range of machine learning (ML) applications that involve human language interaction, such as speech recognition, sentiment analysis, and content recommendation systems [5].
The field of language models has experienced rapid growth, with the size of these models increasing significantly over the years [5,6]. Early models, such as the initial versions of GPT and BERT, had parameters in the hundreds of millions. As technology improved, these numbers increased to billions, as seen with models like GPT-3 [7]. This monumental growth has shattered previous conceptions about the practical limits of model sizes [8,9], laying the foundation for what we now define as "XtremeLLMs" to describe models that exceed one trillion parameters. These models represent a major advancement in their ability to process and understand language, setting a new benchmark in the capabilities of language models. A detailed evolution of LLMs is presented in Figure 1.
Meanwhile, XtremeLLM is a term coined to describe models that not only surpass the one trillion parameter milestone but also represent a significant advancement in the potential to handle and process language. These models push the boundaries of what machines can understand and achieve, leveraging the opportunities that such scale offers. XtremeLLMs are expected to handle a wide array of language-based tasks with minimal task-specific adjustments. This flexibility is crucial for AI systems that need to adapt efficiently to diverse operational demands. However, the increase in size and complexity of these models also brings about heightened computational demands and energy usage, as well as an increased potential for bias, all of which require careful management.
This paper makes several contributions to the field of AI research, including:
- Introducing the term “XtremeLLM” and defines it within the context of current advancements in language model technology.
- Examines the technological, ethical, and practical challenges associated with developing and deploying these models.
- Explores the potential applications and impacts of XtremeLLMs across various sectors, providing insights into how they can be harnessed to advance innovation and address complex challenges in the industry.
The rest of the paper is structured as follows: Section 2 reviews related works, and Section 3 presents an overview of large language models. Section 4 introduces the concept of XtremeLLMs, while Section 5 discusses the technological foundations for scaling up LLMs. Section 6 addresses the challenges in developing XtremeLLMs, and Section 7 highlights the ethical and societal considerations. Section 8 details the potential applications and impacts of XtremeLLMs. Section 9 discusses future research directions and prospects, and Section 10 concludes the paper.
2. Related Works
The development of language models has been a dynamic area of research within artificial intelligence, with significant contributions shaping the evolution of these technologies. Historically, language models began with simpler statistical methods, such as n-gram models, which have been widely used for basic text predictions [10]. The introduction of ML techniques, especially those involving neural networks, marked a significant advancement in the field [11]. Pioneering works by Bengio et al. [12] on neural probabilistic language models laid the foundation for subsequent innovations. The transition to more complex models was significantly influenced by the development of the Long Short-Term Memory (LSTM) networks by Hochreiter and Schmidhuber [13], which improved the ability of models to handle long-range dependencies in text.
The advent of transformer-based models, presented in Figure 2, introduced by Vaswani et al. [14], represented a fundamental change in language model architecture by utilizing self-attention mechanisms. This architecture contributed to the current generation of LLMs, including models like Generative Pre-trained Transformer (GPT) by OpenAI and Bidirectional Encoder Representations from Transformers (BERT) by Google. These models have set new standards for language understanding and generation capabilities and achieved remarkable performance in numerous language tasks.
More recent efforts have focused on scaling up these transformer models to create what we now define as XtremeLLMs. Research has shown a consistent trend: as the number of parameters in language models increases, their performance across diverse tasks improves significantly [6,15,16]. This scalability has been explored extensively in works such as GPT-3, which features several hundred billion parameters [17,18]. However, the exponential growth in model size has introduced new challenges, particularly in terms of computational efficiency, environmental impact, and the management of biases.
Therefore, our work introduces the concept of XtremeLLMs, defined specifically as models possessing over one trillion parameters. This classification not only captures the trend towards larger models but also emphasizes the necessity to innovate how these models are trained and utilized to manage their increasing complexity effectively. The term "XtremeLLM" highlights the extreme scale of these models and the corresponding challenges and opportunities they present.
Unlike previous studies that have primarily focused on the incremental benefits of scaling up LLMs, our research explores the implications of this scale, including computational demands, ethical considerations, and potential applications that could transform how AI interacts with human language, paving the way for future innovations in the field.
3. Overview of Large Language Models
The field of NLP has seen significant advancements through the development of LLMs, which include both the Generative Pre-trained Transformers (GPT) series by OpenAI and the Bidirectional Encoder Representations from Transformers (BERT) models by Google, along with their variants. These models have enhanced the capabilities of NLP systems, setting new benchmarks for a wide range of language tasks.
3.1. GPT Series
The GPT series by OpenAI shows the rapid advancement in language model development, bringing robust innovations in AI through each iteration. Beginning with GPT-1, this series has consistently pushed the boundaries of what language models can achieve. GPT-1, introduced in 2018, was a pioneering model that utilized the transformer architecture to emphasize unsupervised pre-training followed by supervised fine-tuning [5,19]. This approach helped improve language understanding significantly and set a new standard for subsequent models. Meanwhile, GPT-2, released in 2019, built on the foundations laid by GPT-1 by increasing the model size to 1.5 billion parameters and training on a much larger dataset [20,21,22]. This scale-up enabled GPT-2 to generate more coherent and contextually relevant text across a wide range of topics. GPT-3, with its 175 billion parameters, was introduced in 2020 and is a significant advancement in the series. It employs the self-attention mechanism, which is fundamental to the transformer architecture [5]:
where Q, K, and V represent the query, key, and value vectors, respectively, and denotes the dimensionality of the key. GPT-3’s capacity allows it to handle diverse and complex language tasks with excellent performance. GPT-3.5, released in 2022, is an intermediary update between GPT-3 and GPT-4 [23,24]. It maintained a parameter size close to that of GPT-3 and introduced refined training techniques and algorithmic improvements that enhance reasoning and text comprehension, further smoothing the text output quality and contextual relevance [25,26]. GPT-4, released in 2023, is a huge step forward with an estimated 1.7 Trillion parameters [5,27,28]. It extends GPT-3’s capabilities by improving performance in multilingual tasks and complex problem-solving scenarios. It excels at producing high-quality text, understanding and generating content across different languages, which makes it one of the most powerful models to date. From enhancing basic language understanding to solving complex, multidimensional problems, the GPT series continues to achieve excellent performance and contribute significantly to the advancement of AI.
3.2. BERT and Its Variants
Developed by Google, BERT uses a bidirectional training approach to process the entire sequence of words at once [29]. This approach greatly enhances its contextual understanding. It can be represented mathematically as:
where is the set of masked tokens, represents the sequence excluding the token , and denotes the model parameters.
BERT has inspired several notable variants, including the Robustly Optimized BERT Approach (RoBERTa) [30], which modifies BERT’s pre-training process to improve its performance, eliminating the next-sentence prediction and adjusting training strategies. Meanwhile, DistilBERT [31] optimizes BERT for greater efficiency by reducing the size of the model while retaining most of its effectiveness through techniques like knowledge distillation. A Lite BERT (ALBERT) [32] reduces the model’s size and increases training speed by sharing parameters across layers and reducing embedding sizes. Furthermore, Enhanced representation through knowledge integration (ERNIE) [33] by Baidu incorporates structured knowledge, such as entities from knowledge graphs, into training, thereby enhancing the model’s understanding by leveraging real-world context.
Despite their success, these models face several challenges, including high computational demands, environmental impacts, and potential biases. The future development of LLMs involves not only scaling these models to achieve greater performance but also refining them to address these issues. Innovations in model architecture, training procedures, and data handling are crucial for realizing the full potential of LLMs while ensuring they are developed in an ethical and sustainable manner. Both the GPT series and BERT have significantly pushed the boundaries of what AI can achieve with language. However, the continuous development of these models is crucial for further breakthroughs in AI, enhancing their ability to interact and understand human language in ways that closely mimic human cognitive abilities. Table 1 summarizes the different LLMs.
4. XtremeLLMs
Extremely large language models represent the next evolutionary step in language processing technologies, scaling up to trillions of parameters (). This significant increase in size, far exceeding that of conventional large language models such as GPT-3, places XtremeLLMs as a new benchmark in the field, aimed at achieving breakthroughs in natural language processing that were previously unattainable. The concept of XtremeLLMs is driven by the hypothesis that increases in the number of parameters lead to exponential improvements in model capabilities [34,35]. Unlike standard LLMs, which typically feature parameters in the billions, XtremeLLMs operate on a scale where parameters reach the trillion mark. This drastic scale-up is expected to enhance model robustness and generalization, allowing for a more detailed understanding and generation of human-like text. The potential for XtremeLLMs to process complex linguistic structures and semantics could be represented mathematically by the increase in the depth and width of neural network layers:
where P represents the total parameters. A logarithmic increase in depth and width with parameters suggests a more complex network architecture capable of more sophisticated functions. It is expected that XtremeLLMs will continue to utilize the transformer architecture, benefiting from its ability to scale with parameter size [36,37,38]. The advanced capabilities of XtremeLLMs could be partially attributed to improvements in parallel processing techniques and optimization algorithms, which are crucial for handling the extensive computational requirements of such models:
where Compute represents the total computational resources and Steps the number of training iterations required. As we project the capabilities of XtremeLLMs, it is anticipated that they will not only perform existing tasks more effectively but also unlock new applications in areas such as real-time multilingual translation, sophisticated sentiment analysis, and complex problem-solving across domains. However, the development of XtremeLLMs comes with significant challenges. For instance, the computational demands for training such models are immense, with associated increases in energy consumption and potential environmental impacts [39,40]. Moreover, the larger the model, the greater the risk of amplifying any biases present in the training data [41,42], necessitating advanced strategies for bias mitigation and ethical oversight.
5. Technological Foundations for Scaling Up
The development of XtremeLLMs depends heavily on cutting-edge technological foundations, including hardware, software, and data management. Each of these areas has seen significant innovations that have directly enabled the scaling up of model parameters into the trillions.
5.1. Hardware Innovations
Advancements in hardware, particularly in Graphics Processing Unit (GPU) and Tensor Processing Unit (TPU) technologies, have been critical in meeting the computational demands of XtremeLLMs [43,44]. GPUs, with their highly parallel structure, are well-suited for the matrix operations that dominate neural network computations. TPUs, designed specifically for tensor operations, offer even greater efficiency and have been instrumental in accelerating the training process of deep learning models [45,46,47]. The architecture of TPUs is optimized to handle large batches and high throughput, which significantly reduces the time required for training models with enormous parameter sets. Meanwhile, the use of TPUs in models like XtremeLLMs can be quantified by their ability to perform hundreds of petaflops per second:
This equation illustrates the scalability of TPUs, where represents the number of TPU units deployed, and indicates the floating-point operations per second that each unit can handle. By increasing the number of TPUs, one can linearly scale the computational power available, thereby enabling proportionally faster processing and shorter training times for models with trillions of parameters.
The direct impact of TPU scalability on the performance of large-scale models is substantial. For instance, if a single TPU can handle 100 petaflops per second, using 10 TPUs would increase the computational capability to 1000 petaflops per second. This massive scaling is essential for processing the large data sets and complex algorithms required by XtremeLLMs. It allows for more rapid iteration during model development and faster convergence of learning algorithms, which are critical when training models to perform tasks across vast datasets with complex linguistic features. Furthermore, the ability to scale up TPUs means that researchers and developers can experiment with larger batches and more complex model architectures. This flexibility is crucial for pushing the boundaries of what these models can learn and achieve, leading to better model accuracy and robustness when faced with real-world tasks.
5.2. Software and Algorithmic Developments
Significant enhancements in software and algorithms have enabled the scaling of language models to the scope of XtremeLLMs. One of the core advancements has been in the architectural domain, particularly with the evolution of the transformer architecture. Originally introduced by Vaswani et al. [14], transformers have undergone various modifications to support larger and more complex models. These architectures now often include techniques such as attention with sparsity or low-rank approximations, which allow for handling larger input sequences without a quadratic increase in computational requirements [48,49,50].
Additionally, the training techniques for these sophisticated models have seen substantial improvements. Parallel training algorithms have become a vital part of the field, enabling the distribution of model training across multiple GPUs or TPUs [43]. This is crucial for managing the huge computational load required by trillions of parameters. Other techniques, such as model pruning and quantization, further enhance training and inference efficiency [51,52,53]. Model pruning involves systematically removing parameters that contribute the least to model performance, effectively reducing the model’s size and computational overhead without significant loss in accuracy [54]. Meanwhile, quantization reduces the precision of the numerical parameters, thereby decreasing the model’s demand on memory and speeding up computation [55]. These advancements are often supported by sophisticated optimization algorithms that enhance the efficiency of parameter updates during the training process, such as gradient descent algorithm:
where represents the parameters at iteration t, is the learning rate, and is the gradient of the loss function with respect to the parameters. This equation is fundamental in algorithms such as stochastic gradient descent and its variants like adaptive moment estimation (Adam) and root mean square propagation (RMSprop), which are crucial for the training of neural networks [56]. Optimization not only focuses on the accuracy and speed of convergence but also incorporates strategies to overcome challenges such as vanishing gradients, which are more prevalent in larger networks [57,58]. Techniques such as gradient clipping and adaptive learning rate adjustments are used to maintain stability in the training process. Additionally, newer forms of regularization and batch normalization techniques have been developed to ensure that the models do not overfit the training data and generalize well to new, unseen data [59,60].
5.3. Data Requirements
The effectiveness of XtremeLLMs is critically dependent on the volume and quality of the data used during training [61]. XtremeLLMs require massive datasets to capture a wide range of linguistic patterns, which in turn enables the models to generalize across different types of language input and applications. The diversity and representativeness of the training data are essential for ensuring that the models do not simply perform well on benchmark tests but are truly capable of understanding and generating human-like language in varied real-world scenarios. This multifaceted nature of data quality essential for training XtremeLLMs can be represented as:
where Diversity refers to the range of linguistic variations covered by the data, including dialects, sociolects, and registers. Comprehensiveness involves the breadth of contexts and topics included, ensuring that the model can handle a wide spectrum of situations and subjects. Accuracy pertains to the correctness of the data, particularly in labelled datasets used for supervised learning, where precise annotations are crucial for effective model training. Managing such large datasets requires sophisticated data processing pipelines. These pipelines are designed to handle the ingestion, cleaning, standardization, and efficient retrieval of data [62,63]. The processing stages often involve:
- Data Ingestion: Integrating data from various sources into a single repository. This stage may involve dealing with different data formats and merging data while ensuring consistency.
- Data Cleaning: Removing inaccuracies and preparing the data by fixing or discarding incorrect records, filling missing values, and resolving inconsistencies.
- Data Standardization: Applying uniform formats and labels to ensure that data from various sources can be used interchangeably in training.
- Data Retrieval: Developing systems that can quickly access required data subsets during the training process, which is critical for efficient use of computational resources.
These tasks are not trivial and require advanced technologies in database management, software engineering, and computational infrastructure to execute efficiently. Furthermore, the handling of data at such a scale often raises ethical and privacy concerns, especially when personal information is involved. It is imperative that organizations developing XtremeLLMs implement robust data governance policies to address these concerns.
6. Challenges in Developing XtremeLLMs
Developing XtremeLLMs presents significant challenges that extend beyond technical feasibility and include economic, environmental, and efficiency-related issues. These challenges indicate the complexity of scaling up language models and necessitate careful consideration of the broader impacts of such advancements.
6.1. Computational and Financial Costs
The computational requirements for training and maintaining XtremeLLMs are monumental. These models require state-of-the-art hardware, often involving hundreds of advanced GPUs or TPUs running continuously for weeks or even months [64]. This leads to high computational costs and also incurs substantial financial investments. For instance, the cost of training a cutting-edge language model can run into millions of dollars [65,66], which includes expenses related to data centre operations, hardware maintenance, and electricity. These high costs limit the accessibility of XtremeLLMs to well-funded organizations and institutions, potentially widening the technological gap between entities with different resource availabilities.
6.2. Issues of Diminishing Returns
The concept of diminishing returns in the context of XtremeLLMs represents a significant challenge in AI, particularly concerning resource utilisation efficiency as models scale. As language models increase in size, adding each new parameter tends to contribute less to overall improvements in model performance [67,68,69]. This phenomenon is critical to understanding the limitations of current scaling strategies and has profound implications for the continued development of XtremeLLMs. Empirical studies have indicated that while early increments in model size yield substantial improvements in tasks such as language understanding, translation accuracy, and text generation, these benefits grow incrementally smaller as models reach an enormous scale. For instance, models moving from millions to billions of parameters often see marked improvements in performance metrics such as accuracy on standard benchmarks. However, when progressing from billions to trillions of parameters, the improvements in these metrics become less pronounced [61,70].
This trend can be partially explained by several factors:
- Overfitting Risk: Larger models, especially those that significantly outsize their training data, are at a higher risk of memorizing rather than generalizing from their training sets.
- Parameter Efficiency: There is an upper limit to how effectively additional parameters can be utilized due to inherent limitations in training data diversity and model architecture.
- Optimization Challenges: As models grow larger, they become increasingly difficult to tune and optimize. Advanced optimization techniques that work well for smaller models might not scale linearly with size, leading to suboptimal training outcomes.
Given these issues, the question of cost-effectiveness becomes paramount. Doubling the size of a language model, which might involve doubling the computational resources and associated costs, does not necessarily result in doubling the performance. The incremental gains decrease as the model size increases, posing a significant challenge in justifying the exponential increase in resources for only marginal improvements. This challenge necessitates a careful evaluation of the trade-offs involved:
where is the cost-effectiveness of the model at size P, measures the incremental improvement in model performance relative to the baseline, and encompasses the computational, financial, and environmental costs of scaling the model to size P. Lastly, the challenge posed by the issue of diminishing returns highlights the need for innovation in the design of larger models, as well as in developing more efficient architectures and training methods that can deliver significant improvements without proportionately large increases in resource consumption.
6.3. Environmental Impacts of Energy Consumption
The environmental impact of developing and deploying XtremeLLMs is another significant challenge. The energy consumption required to train and operate these models is substantial, contributing to carbon emissions and stressing power grids [71,72]. As the field of AI advances, the sustainability of AI practices comes into question, prompting researchers and developers to consider more energy-efficient algorithms and to invest in renewable energy sources to mitigate the environmental impact.
While the development of XtremeLLMs promises significant advancements in AI capabilities, it also brings to light a series of challenges. Addressing these challenges is essential for ensuring responsible and sustainable growth of AI technologies.
7. Ethical and Societal Considerations
As the capabilities and applications of XtremeLLMs expand, they bring with them a host of ethical and societal challenges that must be carefully managed. This section explores the critical issues of privacy and security, bias and fairness, and the evolving domain of regulatory and policy frameworks that are crucial for responsible development and deployment of these technologies.
7.1. Privacy and Security Concerns
The deployment of XtremeLLMs raises substantial privacy and security issues due to their capacity to process, store, and potentially expose vast amounts of personal and sensitive data [40,73]. The sheer volume of data combined with the complexity of these models increases the risk of data breaches and unintended data exposure, posing serious challenges in maintaining data confidentiality and integrity. Some of the concerns and possible solutions to mitigate them include:
7.1.1. Advanced Security Measures
To mitigate these risks, it is essential to implement advanced security protocols. Encryption of data at rest and in transit forms the foundation of protecting data from unauthorized access [74]. Advanced cryptographic techniques, such as homomorphic encryption, allow computations on encrypted data, offering another layer of security by ensuring that data remains encrypted even during processing.
7.1.2. Potential Vulnerabilities
XtremeLLMs, by their nature, require access to extensive datasets that often include personal information such as individual behaviours, preferences, and health records. This data is invaluable for training models to perform accurately but also makes them attractive targets for cyberattacks [40]. The risk is even worse when data is transmitted across networks or stored in cloud environments, where unauthorized access can lead to significant breaches. Furthermore, the complexity of XtremeLLMs can lead to "model inversion" attacks, where attackers input enough data into the model to effectively reverse-engineer sensitive information from the model’s responses [74,75].
7.1.3. Access Controls and Audits
Robust access controls must be enforced to ensure that only authorized personnel have access to sensitive data and AI models. These controls should be complemented by regular security audits and penetration testing to identify and rectify potential vulnerabilities before they can be exploited [76]. Automated monitoring systems can also be deployed to detect unusual activities that may indicate a security breach.
7.1.4. Federated Learning
Federated learning offers a promising approach to enhancing privacy. In this paradigm, XtremeLLMs are trained across multiple decentralized devices or servers without centralizing the data [77]. Each participant’s data remains on their device, and only the model updates are aggregated centrally. This significantly reduces the risk of central data exposure and is particularly useful for applications involving highly sensitive data, such as in healthcare and finance.
7.1.5. Transparency and User Control
Maintaining transparency with users about how their data is being used is not only a good ethical practice but also a regulatory requirement in many jurisdictions, such as under the General Data Protection Regulation (GDPR) in the EU [78]. Users should be given clear information about data collection, processing, and storage practices and control over their data. This includes options to opt out of data collection, access the data held about them, and request its deletion.
7.2. Regulatory and Policy Challenges
The rapid advancement and significant impacts of XtremeLLMs present serious challenges for regulators and policymakers. The scale and capabilities of these systems introduce new dimensions to already complex regulatory landscapes, necessitating a robust approach to governance that can keep pace with technological progress while safeguarding the public interest. This includes:
7.2.1. Adapting Legal Frameworks
Current legal frameworks often struggle to accommodate the unique challenges of advanced AI technologies, especially XtremeLLMs. Issues such as autonomy in decision-making, accountability for actions taken by AI systems, and the transparency of algorithms are critical areas that existing regulations may not fully address [79,80]. For example, the ability of XtremeLLMs to make decisions or generate content based on vast amounts of data raises questions about the responsibility for those decisions and the rights to data-derived content.
7.2.2. Enhancing Explainability and Accountability
There is an urgent need to develop mechanisms to ensure the explainability of decisions made by XtremeLLMs. Explainability enhances user trust and is crucial for accountability, particularly in healthcare, finance, and law enforcement sectors, where decisions significantly impact human lives [80,81,82]. For example, Anderljung et al. [83] tasked policymakers with creating standards that compel AI developers to incorporate explainability features without stifling innovation.
7.2.3. Developing Comprehensive Governance Frameworks
To effectively manage the broad implications of XtremeLLMs, comprehensive AI governance frameworks must be developed. These frameworks should ensure that AI systems are safe and reliable and operate within ethical boundaries [84]. Importantly, they should also consider the long-term societal impacts, addressing issues such as potential job displacement, privacy implications, and the digital divide. Engaging a diverse range of stakeholders, including AI developers, ethicists, legal experts, and the public, in the formulation of these frameworks is essential for their success and acceptance.
7.2.4. Fostering International Cooperation
Given the global nature of AI technologies and the data they process, international cooperation is crucial. XtremeLLMs often operate across borders, making unilateral regulatory approaches insufficient. Harmonizing regulatory frameworks internationally can help manage the risks associated with these technologies while supporting global research and commercialization efforts [85,86]. Initiatives such as the GDPR in Europe have set precedents for privacy and data protection that could serve as models for broader regulatory alignment.
7.2.5. Anticipating Future Challenges
As XtremeLLMs continue to evolve, so will the challenges they pose. Regulators and policymakers must remain agile, continuously updating and refining regulations to keep up with technological advancements. Scenario planning and foresight can help anticipate future developments in AI, allowing for proactive rather than reactive policymaking [86,87,88].
7.3. Bias and Fairness
One of the most pressing concerns in developing XtremeLLMs is the propagation of biases that these models may inherit from their training data [89,90]. Given the vast size of XtremeLLMs, they can process and generate content based on extensive datasets, which often include historical data that can reflect societal biases [91]. The effects of these biases are magnified when models are used in decision-making processes, such as in hiring, loan approvals, or law enforcement, where biased outputs can lead to unfair or discriminatory outcomes. To address this issue, it is essential to implement robust methods for detecting and mitigating bias within datasets and model outputs. This includes diversifying training data, employing fairness-aware algorithms, and continuous monitoring of model decisions for biased patterns [92,93]. Also, transparency in how models are trained and how decisions are made can help stakeholders understand and trust the fairness of these systems.
8. Potential Applications and Impacts of XtremeLLMs
The development of XtremeLLMs is poised to bring about significant transformations across various sectors. As these models evolve, they can enhance existing applications and enable new possibilities that were previously unfeasible due to technological constraints. This section explores the revolutionary uses of XtremeLLMs in technology and industry, their economic and social implications, and their comparative aspects to human cognitive capabilities.
8.1. Revolutionary Uses in Technology and Industry
XtremeLLMs are capable of transforming various sectors by enhancing language understanding and generation capabilities. This technological advancement is enhancing existing applications and also paving the way for new innovations across diverse fields. In the healthcare space, these models can assist in diagnostic processes by analyzing and synthesizing vast amounts of medical literature and patient data, often identifying subtle patterns and correlations that may elude even seasoned professionals [94]. XtremeLLMs could predict disease outbreaks by analyzing patterns in historical medical data combined with real-time health reports, thus enabling proactive healthcare measures. Moreover, they can be integrated into clinical decision support systems to give doctors second opinions on diagnoses and treatment plans [95,95].
In the legal domain, XtremeLLMs can be used to automate the review and generation of legal documents. By understanding and generating language at an expert level, these models can help legal professionals quickly draft and review complex documents such as contracts, wills, and legal briefs, reducing the time and cost associated with these tasks [96,97]. XtremeLLMs can also be trained to stay updated with new laws and regulations, ensuring that all generated documents comply with current legal standards. Additionally, XtremeLLMs power sophisticated chatbots and virtual assistants that provide support that is nearly indistinguishable from human interaction. These advanced systems can handle various inquiries, from simple questions to complex complaints, improving response times and customer satisfaction while reducing the workload on human employees [98,99].
Furthermore, XtremeLLMs can also make significant inroads into creative fields. In content creation, these models assist in writing scripts, composing music, and even generating artistic content [100,101]. They can analyze existing musical styles to compose new pieces or script narrative content for video games and movies, collaborating with human artists to enhance creativity. This collaboration between human creativity and machine intelligence can enable new forms of artistic expression and entertainment. Lastly, in scientific research, the capability of XtremeLLMs to process and analyze large datasets can lead to faster and more accurate scientific discoveries. They are particularly useful in fields like genomics, where they can help decipher complex genetic data, or in materials science, where they can predict new materials with desired properties by analyzing existing data [102].
8.2. Economic and Social Implications
The integration of XtremeLLMs into diverse sectors presents significant economic implications. These models promise to enhance productivity and efficiency, driving cost reductions across industries such as finance, healthcare, and manufacturing. For example, XtremeLLMs can automate real-time analysis of market data and customer service interactions, potentially saving billions in operational costs [103]. In healthcare, these models could process patient data and medical literature to support diagnostic and treatment processes, increasing accuracy while reducing the burden on healthcare professionals [20,104,105]. However, the acceleration of automation driven by XtremeLLMs also raises substantial concerns about job displacement.
As these models take over tasks traditionally performed by humans, from customer support to data analysis, the demand for certain job roles might decrease, leading to significant shifts in the labour market [106,107]. This displacement could increase economic inequalities if certain groups or regions are disproportionately affected. To mitigate these effects, there is a growing need for policies that support workforce reskilling and adaptation, ensuring that workers can transition to new roles that require more complex, creative, or supervisory skills, which are less likely to be automated. From a social perspective, XtremeLLMs could reshape communication dynamics significantly. In the media industry, these models could be used to generate personalized news articles, potentially enhancing user engagement and raising ethical concerns about creating echo chambers and manipulating public opinion [108,109]. The capacity of XtremeLLMs to produce content that is indistinguishable from that created by humans could influence political campaigns, advertising, and even interpersonal communications, altering the information dissemination domain.
8.3. Comparisons with Human Cognitive Capabilities
The comparison of XtremeLLMs with human cognitive capabilities presents a fascinating perspective on the intersection of AI and human intelligence. XtremeLLMs excel in tasks involving pattern recognition, data processing, and language understanding, often performing these tasks at a scale and speed far exceeding human capabilities. XtremeLLMs can analyze and generate predictions from large datasets almost instantaneously, which might take humans several hours or even days. However, despite these capabilities, XtremeLLMs lack fundamental aspects of human cognition such as consciousness, emotional depth, and ethical reasoning [40,110].
While XtremeLLMs can process language and generate coherent responses, their ’understanding’ of this information is based purely on statistical correlations and patterns in the data they have been trained on [106]. This fundamentally differs from human comprehension, which involves contextual awareness, emotional context, and ethical considerations. Therefore, the capabilities of XtremeLLMs should be used to enhance and support human decision-making rather than attempting to replace the full breadth of human cognitive functions. Understanding the limitations of these models is crucial for their ethical and effective integration into society. We can maximize the benefits of XtremeLLMs while minimizing the risks associated with their deployment by harnessing the strengths of both human and machine intelligence
9. Future Research Directions and Prospects
The exploration of XtremeLLMs opens numerous avenues for future research, each with the potential to significantly impact the field of AI. As we continue to push the boundaries of what these powerful models can achieve, several key areas can be considered as critical for further exploration and development, including:
9.1. Exploration of Alternative Architectures
The recent dominance of transformer-based architectures has established a robust standard for performance in natural language processing. However, this reliance also indicates a crucial opportunity to innovate with alternative neural network designs that may surpass existing models in computational efficiency, overall performance, or ease of interpretability. Such innovations are crucial for advancing the state-of-the-art and addressing specific limitations inherent in current transformer models, such as their substantial resource requirements and sometimes opaque decision-making processes [111,112].
Therefore, future research can develop novel architectures that depart from traditional frameworks. Interest is growing in designs inspired by biological neural networks, which could offer more naturalistic processing of information and lead to greater generalization capabilities [113]. These biologically inspired models often focus on aspects of human cognition that are poorly represented in current models, such as dynamic memory, continuous learning, and energy-efficient processing [114,115]. The development of such architectures can improve how machines understand and generate language and how they learn and adapt over time with minimal supervision. Additionally, the investigation into sparse and quantized neural networks is another area that can be explored. These architectures aim to reduce the computational load and memory usage without a substantial performance loss, making deploying advanced NLP models more feasible in resource-constrained environments [112,116,117]. Implementing these efficiently could significantly broaden the applicability and accessibility of high-performing NLP technologies across various sectors.
9.2. Energy Efficiency and Sustainability
The computational cost of training and maintaining XtremeLLMs is substantial, raising significant concerns about their energy consumption and environmental impact. These models require extensive computational resources, leading to high energy demands, which translate into large carbon footprints [118]. This situation demonstrates the urgency of developing more sustainable AI practices. To address these concerns, future research could focus on creating training algorithms that are inherently more energy efficient. This includes exploring advanced optimization techniques that can speed up convergence, thereby reducing the number of computations needed. Techniques such as model pruning, which reduces the model size during training, and the adoption of federated learning frameworks, where computations are distributed across multiple devices, could also play crucial roles in decreasing overall energy usage.
Alongside software innovations, there is a pressing need for hardware solutions designed to enhance energy efficiency. Utilizing hardware accelerators such as Field-Programmable Gate Arrays (FPGAs) or Application-Specific Integrated Circuits (ASICs), which are tailored for AI workloads, can offer significant reductions in power consumption [119,120]. These specialized hardware solutions are optimized to handle large-scale computations more efficiently than general-purpose processors. Thus, they are crucial for sustainable model development.
9.3. Mitigating Bias and Enhancing Fairness
As the size and complexity of language models such as XtremeLLMs increase, the risk of these models amplifying biases present in their vast training datasets also increases. These biases can skew AI behaviour in ways that perpetuate societal inequalities, often reflecting historical injustices found in the data sources [121]. Consequently, it is necessary to incorporate robust mechanisms to detect, mitigate, and correct biases to ensure these technologies contribute positively to society. To effectively address these issues, future research must focus on developing sophisticated methods for bias detection. This can involve using advanced analytics to examine model decisions across varied demographic groups and scenarios to identify patterns that may indicate biased outcomes [122]. Tools and metrics that quantify bias in model outputs are essential for this analysis, providing a standardized measure of fairness. Once biases are detected, the next step is to implement mitigation strategies. This can involve refining the model’s training process, such as by altering the data selection and preparation methods to ensure a more balanced and representative dataset. Techniques such as data augmentation, re-sampling, and employing fairness constraints during model training can also be effective [123,124]. Also, correcting biases in already deployed models is crucial for models in use. This can be done by continuously monitoring their outputs and integrating user feedback to adjust model parameters post-deployment. Additionally, employing algorithmic fairness approaches, such as equalizing odds and ensuring demographic parity, can help adjust decisions at the point of application.
Transparency in model development and decision-making processes also plays a critical role in enhancing fairness. Openly sharing details about the datasets used, the model’s decision-making frameworks, and the specific steps taken to address bias can help build trust and accountability. Engaging with diverse groups of stakeholders, including ethicists, sociologists, and representatives from affected communities, during the development and review processes ensures a broader perspective on what constitutes fairness and how it can be achieved.
9.4. Interdisciplinary Applications
The capabilities of XtremeLLMs extend beyond the confines of technology-focused industries, reaching into sectors such as healthcare, law, and education, among others. Their ability to process and analyze vast amounts of unstructured text data can substantially improve efficiency across these fields. XtremeLLMs can revolutionize diagnostic processes by analyzing patient data, medical texts, and research papers to suggest treatments or identify disease patterns [93]. Such models can also support medical professionals by providing up-to-date medical information synthesized from the latest studies, thus aiding in evidence-based medicine.
Also, XtremeLLMs can be used to personalize patient care by predicting individual treatment outcomes based on historical data, potentially transforming patient management and follow-up processes. XtremeLLMs can also impact areas like environmental science, where they could analyze climate data and model complex environmental systems, or in the arts, by aiding in creating new forms of artistic expression through content generation and analysis. In public policy, they could be used to analyze large volumes of public feedback on policy proposals, helping policymakers make informed decisions that reflect the preferences and needs of the populace. Future research can focus on these interdisciplinary applications, ensuring that XtremeLLMs are tailored to meet the specific challenges and requirements of these diverse fields. This involves not only the technological development of the models themselves but also addressing ethical, privacy, and implementation challenges that arise when deploying AI in sensitive and impactful areas.
9.5. Ethical Implications and AI Governance
As XtremeLLMs become more embedded in various sectors, their ethical implications and the governance frameworks that regulate their development and deployment become increasingly important. The expansive capabilities of these models mean that they can significantly influence public opinion, decision-making processes, and personal privacy. Concerns such as data privacy, algorithmic bias, and the broader societal impacts of automated decision-making systems require rigorous and continual examination. Firstly, data privacy concerns are paramount as these models often require massive amounts of data to train, which can include sensitive personal information. Ensuring that the data used is anonymous and secured against breaches is crucial for maintaining public trust.
Meanwhile, the societal implications of decisions made by autonomous systems are profound. As these systems can make or support decisions that affect people’s lives, ensuring that they do so fairly and transparently is essential. This includes the ability of individuals to understand and challenge decisions made about them by AI, a concept known as "algorithmic accountability". To address these challenges, it is imperative to establish comprehensive ethical frameworks and robust regulatory policies that govern the development and use of XtremeLLMs. These frameworks should ensure compliance with existing laws and evolve in response to new challenges and technologies. They should address the complete lifecycle of AI systems—from design and training to deployment.
9.6. Enhancing Human-AI Interaction
The practical effectiveness of XtremeLLMs in real-world applications relies on their interaction with human users. As these models are integrated into more complex and varied environments, the design of user interfaces that are both intuitive and accessible becomes increasingly important. This involves simplifying the user experience to reduce the barrier to entry for non-experts and enhancing the ability of all users to interact effectively with these systems. To improve these interactions, future research should focus on the development of user interface (UI) design principles tailored specifically for complex AI systems. This could include the use of NLP itself to facilitate more natural and conversational interfaces that allow users to interact with AI in a more human-like manner. For instance, enabling users to query an AI system using everyday language and receiving contextually aware and easily understandable responses can greatly enhance usability.
Furthermore, incorporating adaptive user interfaces that can learn and adjust to individual user preferences and styles over time is another promising avenue. These interfaces could dynamically modify their behaviour based on ongoing interaction patterns, making AI systems more personalized and effective for specific user needs. Additionally, incorporating robust feedback mechanisms is crucial. These mechanisms should allow users to provide real-time feedback on AI decisions, which can be used to continuously fine-tune and train the AI models. Such feedback loops can significantly improve the accuracy and reliability of AI systems by integrating human oversight into AI decision-making processes, thereby enhancing trust and transparency.
10. Conclusions
XtremeLLMs represent a monumental shift in the field of AI, pushing the boundaries of what machines can understand and achieve with human language. This paper presented the significant advancements and challenges associated with the development of XtremeLLMs, emphasizing their potential to transform different sectors, from healthcare and education to customer service and beyond. This study aims to assist researchers, developers, and policymakers to collaboratively explore the vast potentials of XtremeLLMs while navigating their complexities responsibly. Through strategic innovation and governance, XtremeLLMs can be leveraged to advance technological frontiers and enhance societal well-being.
References
- Zhang, B.; Haddow, B.; Birch, A. Prompting large language model for machine translation: A case study. International Conference on Machine Learning. PMLR, 2023, pp. 41092–41110.
- Piñeiro-Martín, A.; García-Mateo, C.; Docío-Fernández, L.; López-Pérez, M.d.C. Ethical challenges in the development of virtual assistants powered by large language models. Electronics 2023, 12, 3170. [Google Scholar] [CrossRef]
- Kasneci, E.; Seßler, K.; Küchemann, S.; Bannert, M.; Dementieva, D.; Fischer, F.; Gasser, U.; Groh, G.; Günnemann, S.; Hüllermeier, E.; others. ChatGPT for good? On opportunities and challenges of large language models for education. Learning and individual differences 2023, 103, 102274. [Google Scholar]
- Naseem, U.; Razzak, I.; Khan, S.K.; Prasad, M. A comprehensive survey on word representation models: From classical to state-of-the-art word representation language models. Transactions on Asian and Low-Resource Language Information Processing 2021, 20, 1–35. [Google Scholar]
- Raiaan, M.A.K.; Mukta, M.S.H.; Fatema, K.; Fahad, N.M.; Sakib, S.; Mim, M.M.J.; Ahmad, J.; Ali, M.E.; Azam, S. A review on large Language Models: Architectures, applications, taxonomies, open issues and challenges. IEEE Access 2024. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; others. Language models are few-shot learners. Advances in neural information processing systems 2020, 33, 1877–1901. [Google Scholar]
- Shoeybi, M.; Patwary, M.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-lm: Training multi-billion parameter language models using model parallelism. arXiv preprint arXiv:1909.08053, 2019; arXiv:1909.08053. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the dangers of stochastic parrots: Can language models be too big? Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, 2021, pp. 610–623.
- Zhang, M.; Li, J. A commentary of GPT-3 in MIT Technology Review 2021. Fundamental Research 2021, 1, 831–833. [Google Scholar]
- Federico, M.; Cettolo, M. Efficient handling of n-gram language models for statistical machine translation. Proceedings of the Second Workshop on Statistical Machine Translation, 2007, pp. 88–95.
- Doval, Y.; Gómez-Rodríguez, C. Comparing neural-and N-gram-based language models for word segmentation. Journal of the Association for Information Science and Technology 2019, 70, 187–197. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P. A neural probabilistic language model. Advances in neural information processing systems 2000, 13. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural computation 1997, 9, 1735–1780. [Google Scholar] [PubMed]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Advances in neural information processing systems 2017, 30. [Google Scholar]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Computing Surveys 2023, 56, 1–40. [Google Scholar]
- Kim, G.; Baldi, P.; McAleer, S. Language models can solve computer tasks. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Bongini, P.; Becattini, F.; Del Bimbo, A. Is GPT-3 all you need for visual question answering in cultural heritage? European Conference on Computer Vision. Springer, 2022, pp. 268–281.
- Chan, A. GPT-3 and InstructGPT: technological dystopianism, utopianism, and “Contextual” perspectives in AI ethics and industry. AI and Ethics 2023, 3, 53–64. [Google Scholar]
- Nassiri, K.; Akhloufi, M. Transformer models used for text-based question answering systems. Applied Intelligence 2023, 53, 10602–10635. [Google Scholar]
- Thirunavukarasu, A.J.; Ting, D.S.J.; Elangovan, K.; Gutierrez, L.; Tan, T.F.; Ting, D.S.W. Large language models in medicine. Nature medicine 2023, 29, 1930–1940. [Google Scholar]
- Nguyen-Mau, T.; Le, A.C.; Pham, D.H.; Huynh, V.N. An information fusion based approach to context-based fine-tuning of GPT models. Information Fusion 2024, 104, 102202. [Google Scholar]
- Aydın, N.; Erdem, O.A. A research on the new generation artificial intelligence technology generative pretraining transformer 3. 2022 3rd International Informatics and Software Engineering Conference (IISEC). IEEE, 2022, pp. 1–6.
- Kalyan, K.S. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Natural Language Processing Journal, 1000. [Google Scholar]
- Savelka, J.; Agarwal, A.; Bogart, C.; Sakr, M. From GPT-3 to GPT-4: On the Evolving Efficacy of LLMs to Answer Multiple-choice Questions for Programming Classes in Higher Education. International Conference on Computer Supported Education. Springer, 2023, pp. 160–182.
- Nazir, A.; Wang, Z. A comprehensive survey of ChatGPT: Advancements, applications, prospects, and challenges. Meta-radiology, 1000. [Google Scholar]
- Shahin, M.; Chen, F.F.; Hosseinzadeh, A. Harnessing customized AI to create voice of customer via GPT3. 5. Advanced Engineering Informatics 2024, 61, 102462. [Google Scholar]
- Yang, Z.G.; Laki, L.J.; Váradi, T.; Prószéky, G. Mono-and multilingual GPT-3 models for Hungarian. International Conference on Text, Speech, and Dialogue. Springer, 2023, pp. 94–104.
- Ding, X.; Chen, L.; Emani, M.; Liao, C.; Lin, P.H.; Vanderbruggen, T.; Xie, Z.; Cerpa, A.; Du, W. Hpc-gpt: Integrating large language model for high-performance computing. Proceedings of the SC’23 Workshops of The International Conference on High Performance Computing, Network, Storage, and Analysis, 2023, pp. 951–960.
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018; arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019; arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108, 2019; arXiv:1910.01108. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. Albert: A lite bert for self-supervised learning of language representations. arXiv preprint arXiv:1909.11942, 2019; arXiv:1909.11942. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. Ernie: Enhanced representation through knowledge integration. arXiv preprint arXiv:1904.09223, 2019; arXiv:1904.09223. [Google Scholar]
- Gruver, N.; Finzi, M.; Qiu, S.; Wilson, A.G. Large language models are zero-shot time series forecasters. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Fathullah, Y.; Wu, C.; Lakomkin, E.; Jia, J.; Shangguan, Y.; Li, K.; Guo, J.; Xiong, W.; Mahadeokar, J.; Kalinli, O.; others. Prompting large language models with speech recognition abilities. ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2024, pp. 13351–13355.
- Zhai, X.; Kolesnikov, A.; Houlsby, N.; Beyer, L. Scaling vision transformers. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 12104–12113.
- Pope, R.; Douglas, S.; Chowdhery, A.; Devlin, J.; Bradbury, J.; Heek, J.; Xiao, K.; Agrawal, S.; Dean, J. Efficiently scaling transformer inference. Proceedings of Machine Learning and Systems 2023, 5. [Google Scholar]
- Nie, X.; Chen, X.; Jin, H.; Zhu, Z.; Qi, D.; Yan, Y. ScopeViT: Scale-aware Vision Transformer. Pattern Recognition, 1104. [Google Scholar] [CrossRef]
- Jagannadharao, A.; Beckage, N.; Nafus, D.; Chamberlin, S. Timeshifting strategies for carbon-efficient long-running large language model training. Innovations in Systems and Software Engineering.
- Yao, Y.; Duan, J.; Xu, K.; Cai, Y.; Sun, Z.; Zhang, Y. A survey on large language model (llm) security and privacy: The good, the bad, and the ugly. High Confidence Computing, 1002. [Google Scholar]
- Jansen, B.J.; Jung, S.g.; Salminen, J. Employing large language models in survey research. Natural Language Processing Journal 2023, 4, 100020. [Google Scholar]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; others. Large language models encode clinical knowledge. arXiv preprint arXiv:2212.13138, 2022; arXiv:2212.13138. [Google Scholar]
- Brakel, F.; Odyurt, U.; Varbanescu, A.L. Model Parallelism on Distributed Infrastructure: A Literature Review from Theory to LLM Case-Studies. arXiv preprint arXiv:2403.03699, 2024; arXiv:2403.03699. [Google Scholar]
- Xu, M.; Yin, W.; Cai, D.; Yi, R.; Xu, D.; Wang, Q.; Wu, B.; Zhao, Y.; Yang, C.; Wang, S.; others. A survey of resource-efficient llm and multimodal foundation models. arXiv preprint arXiv:2401.08092, 2024; arXiv:2401.08092. [Google Scholar]
- Czymmek, V.; Möller, C.; Harders, L.O.; Hussmann, S. Deep learning approach for high energy efficient real-time detection of weeds in organic farming. 2021 IEEE International Instrumentation and Measurement Technology Conference (I2MTC). IEEE, 2021, pp. 1–6.
- Civit-Masot, J.; Luna-Perejón, F.; Corral, J.M.R.; Domínguez-Morales, M.; Morgado-Estévez, A.; Civit, A. A study on the use of Edge TPUs for eye fundus image segmentation. Engineering Applications of Artificial Intelligence 2021, 104, 104384. [Google Scholar]
- Shuvo, M.M.H.; Islam, S.K.; Cheng, J.; Morshed, B.I. Efficient acceleration of deep learning inference on resource-constrained edge devices: A review. Proceedings of the IEEE 2022, 111, 42–91. [Google Scholar]
- Ren, H.; Dai, H.; Dai, Z.; Yang, M.; Leskovec, J.; Schuurmans, D.; Dai, B. Combiner: Full attention transformer with sparse computation cost. Advances in Neural Information Processing Systems 2021, 34, 22470–22482. [Google Scholar]
- Choromanski, K.; Likhosherstov, V.; Dohan, D.; Song, X.; Gane, A.; Sarlos, T.; Hawkins, P.; Davis, J.; Mohiuddin, A.; Kaiser, L.; others. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020; arXiv:2009.14794. [Google Scholar]
- Dass, J.; Wu, S.; Shi, H.; Li, C.; Ye, Z.; Wang, Z.; Lin, Y. Vitality: Unifying low-rank and sparse approximation for vision transformer acceleration with a linear taylor attention. 2023 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2023, pp. 415–428.
- Ma, X.; Fang, G.; Wang, X. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems 2023, 36, 21702–21720. [Google Scholar]
- Kurtić, E.; Frantar, E.; Alistarh, D. ZipLM: Inference-Aware Structured Pruning of Language Models. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Huang, W.; Liu, Y.; Qin, H.; Li, Y.; Zhang, S.; Liu, X.; Magno, M.; Qi, X. BiLLM: Pushing the Limit of Post-Training Quantization for LLMs. arXiv preprint arXiv:2402.04291, arXiv:2402.04291 2024.
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A survey of model compression and acceleration for deep neural networks. arXiv preprint arXiv:1710.09282, arXiv:1710.09282 2017.
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized convolutional neural networks for mobile devices. Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 4820–4828.
- Peng, Y.L.; Lee, W.P. Practical guidelines for resolving the loss divergence caused by the root-mean-squared propagation optimizer. Applied Soft Computing 2024, 153, 111335. [Google Scholar]
- Hanin, B. Which neural net architectures give rise to exploding and vanishing gradients? Advances in neural information processing systems 2018, 31. [Google Scholar]
- Ravikumar, A.; Sriraman, H. Mitigating Vanishing Gradient in SGD Optimization in Neural Networks. International Conference on Information, Communication and Computing Technology. Springer, 2023, pp. 1–11.
- Moradi, R.; Berangi, R.; Minaei, B. A survey of regularization strategies for deep models. Artificial Intelligence Review 2020, 53, 3947–3986. [Google Scholar]
- Santos, C.F.G.D.; Papa, J.P. Avoiding overfitting: A survey on regularization methods for convolutional neural networks. ACM Computing Surveys (CSUR) 2022, 54, 1–25. [Google Scholar]
- Tirumala, K.; Simig, D.; Aghajanyan, A.; Morcos, A. D4: Improving llm pretraining via document de-duplication and diversification. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Guérin, J.; Nahid, A.; Tassy, L.; Deloger, M.; Bocquet, F.; Thézenas, S.; Desandes, E.; Le Deley, M.C.; Durando, X.; Jaffré, A.; others. Consore: A Powerful Federated Data Mining Tool Driving a French Research Network to Accelerate Cancer Research. International Journal of Environmental Research and Public Health 2024, 21, 189. [Google Scholar]
- Arora, S.; Yang, B.; Eyuboglu, S.; Narayan, A.; Hojel, A.; Trummer, I.; Ré, C. Language models enable simple systems for generating structured views of heterogeneous data lakes. arXiv preprint arXiv:2304.09433, 2023; arXiv:2304.09433. [Google Scholar]
- Candel, A.; McKinney, J.; Singer, P.; Pfeiffer, P.; Jeblick, M.; Prabhu, P.; Gambera, J.; Landry, M.; Bansal, S.; Chesler, R.; others. h2ogpt: Democratizing large language models. arXiv preprint arXiv:2306.08161, 2023; arXiv:2306.08161. [Google Scholar]
- Li, Y.; Wang, S.; Ding, H.; Chen, H. Large language models in finance: A survey. Proceedings of the Fourth ACM International Conference on AI in Finance, 2023, pp. 374–382.
- Chae, Y.; Davidson, T. Large language models for text classification: From zero-shot learning to fine-tuning. Open Science Foundation 2023. [Google Scholar]
- Muennighoff, N.; Rush, A.; Barak, B.; Le Scao, T.; Tazi, N.; Piktus, A.; Pyysalo, S.; Wolf, T.; Raffel, C.A. Scaling data-constrained language models. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Ho, A.; Besiroglu, T.; Erdil, E.; Owen, D.; Rahman, R.; Guo, Z.C.; Atkinson, D.; Thompson, N.; Sevilla, J. Algorithmic progress in language models. arXiv preprint arXiv:2403.05812, 2024; arXiv:2403.05812. [Google Scholar]
- Bai, G.; Chai, Z.; Ling, C.; Wang, S.; Lu, J.; Zhang, N.; Shi, T.; Yu, Z.; Zhu, M.; Zhang, Y.; others. Beyond efficiency: A systematic survey of resource-efficient large language models. arXiv preprint arXiv:2401.00625, 2024; arXiv:2401.00625. [Google Scholar]
- Wang, Y.; Chen, K.; Tan, H.; Guo, K. Tabi: An efficient multi-level inference system for large language models. Proceedings of the Eighteenth European Conference on Computer Systems, 2023, pp. 233–248.
- Doo, F.X.; Kulkarni, P.; Siegel, E.L.; Toland, M.; Paul, H.Y.; Carlos, R.C.; Parekh, V.S. Economic and Environmental Costs of Cloud Technologies for Medical Imaging and Radiology Artificial Intelligence. Journal of the American College of Radiology 2024, 21, 248–256. [Google Scholar]
- Hort, M.; Grishina, A.; Moonen, L. An exploratory literature study on sharing and energy use of language models for source code. 2023 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). IEEE, 2023, pp. 1–12.
- Sebastian, G. Privacy and data protection in chatgpt and other ai chatbots: Strategies for securing user information. International Journal of Security and Privacy in Pervasive Computing (IJSPPC) 2023, 15, 1–14. [Google Scholar]
- Huang, K.; Goertzel, B.; Wu, D.; Xie, A. GenAI Model Security. In Generative AI Security: Theories and Practices; Springer, 2024; pp. 163–198.
- Yan, B.; Li, K.; Xu, M.; Dong, Y.; Zhang, Y.; Ren, Z.; Cheng, X. On Protecting the Data Privacy of Large Language Models (LLMs): A Survey. arXiv preprint arXiv:2403.05156, 2024; arXiv:2403.05156. [Google Scholar]
- Alawida, M.; Abu Shawar, B.; Abiodun, O.I.; Mehmood, A.; Omolara, A.E.; Al Hwaitat, A.K. Unveiling the dark side of chatgpt: Exploring cyberattacks and enhancing user awareness. Information 2024, 15, 27. [Google Scholar] [CrossRef]
- Ali, R.; Zikria, Y.B.; Garg, S.; Bashir, A.K.; Obaidat, M.S.; Kim, H.S. A federated reinforcement learning framework for incumbent technologies in beyond 5G networks. IEEE network 2021, 35, 152–159. [Google Scholar]
- Albrecht, J.P. The EU’s new data protection law–how a directive evolved into a regulation. Computer Law Review International 2016, 17, 33–43. [Google Scholar]
- Rendón, L.G. An Introduction to the Principle of Transparency in Automated Decision-Making Systems. 2022 45th Jubilee International Convention on Information, Communication and Electronic Technology (MIPRO). IEEE, 2022, pp. 1245–1252.
- Mirghaderi, L.; Sziron, M.; Hildt, E. Ethics and transparency issues in digital platforms: An overview. AI 2023, 4, 831–843. [Google Scholar] [CrossRef]
- Kaur, D.; Uslu, S.; Durresi, M.; Durresi, A. LLM-Based Agents Utilized in a Trustworthy Artificial Conscience Model for Controlling AI in Medical Applications. International Conference on Advanced Information Networking and Applications. Springer, 2024, pp. 198–209.
- Chacko, N.; Chacko, V. Paradigm shift presented by Large Language Models (LLM) in Deep Learning. ADVANCES IN EMERGING COMPUTING TECHNOLOGIES 2023, 40. [Google Scholar]
- Anderljung, M.; Barnhart, J.; Leung, J.; Korinek, A.; O’Keefe, C.; Whittlestone, J.; Avin, S.; Brundage, M.; Bullock, J.; Cass-Beggs, D.; others. Frontier AI regulation: Managing emerging risks to public safety. arXiv preprint arXiv:2307.03718, 2023; arXiv:2307.03718. [Google Scholar]
- Mylrea, M.; Robinson, N. Artificial Intelligence (AI) trust framework and maturity model: applying an entropy lens to improve security, privacy, and ethical AI. Entropy 2023, 25, 1429. [Google Scholar] [CrossRef] [PubMed]
- Smuha, N.A. From a ‘race to AI’to a ‘race to AI regulation’: regulatory competition for artificial intelligence. Law, Innovation and Technology 2021, 13, 57–84. [Google Scholar]
- Huang, K.; Joshi, A.; Dun, S.; Hamilton, N. AI Regulations. In Generative AI Security: Theories and Practices; Springer, 2024; pp. 61–98.
- Huang, K.; Ponnapalli, J.; Tantsura, J.; Shin, K.T. Navigating the GenAI Security Landscape. In Generative AI Security: Theories and Practices; Springer, 2024; pp. 31–58.
- Gaske, M.R. Regulation Priorities for Artificial Intelligence Foundation Models. Vand. J. Ent. & Tech. L. 2023, 26, 1. [Google Scholar]
- Hou, Y.; Zhang, J.; Lin, Z.; Lu, H.; Xie, R.; McAuley, J.; Zhao, W.X. Large language models are zero-shot rankers for recommender systems. European Conference on Information Retrieval. Springer, 2024, pp. 364–381.
- Yang, J.; Jin, H.; Tang, R.; Han, X.; Feng, Q.; Jiang, H.; Zhong, S.; Yin, B.; Hu, X. Harnessing the power of llms in practice: A survey on chatgpt and beyond. ACM Transactions on Knowledge Discovery from Data 2023. [Google Scholar]
- Head, C.B.; Jasper, P.; McConnachie, M.; Raftree, L.; Higdon, G. Large language model applications for evaluation: Opportunities and ethical implications. New Directions for Evaluation 2023, 2023, 33–46. [Google Scholar]
- Yuan, L.; Chen, Y.; Cui, G.; Gao, H.; Zou, F.; Cheng, X.; Ji, H.; Liu, Z.; Sun, M. Revisiting Out-of-distribution Robustness in NLP: Benchmarks, Analysis, and LLMs Evaluations. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Ullah, E.; Parwani, A.; Baig, M.M.; Singh, R. Challenges and barriers of using large language models (LLM) such as ChatGPT for diagnostic medicine with a focus on digital pathology–a recent scoping review. Diagnostic Pathology 2024, 19, 1–9. [Google Scholar]
- Reddy, S. Generative AI in healthcare: an implementation science informed translational path on application, integration and governance. Implementation Science 2024, 19, 27. [Google Scholar]
- Fawzi, S. A Review of the Role of ChatGPT for Clinical Decision Support Systems. 2023 5th Novel Intelligent and Leading Emerging Sciences Conference (NILES). IEEE, 2023, pp. 439–442.
- Guha, N.; Nyarko, J.; Ho, D.; Ré, C.; Chilton, A.; Chohlas-Wood, A.; Peters, A.; Waldon, B.; Rockmore, D.; Zambrano, D.; others. Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models. Advances in Neural Information Processing Systems 2024, 36. [Google Scholar]
- Trozze, A.; Davies, T.; Kleinberg, B. Large language models in cryptocurrency securities cases: can a GPT model meaningfully assist lawyers? Artificial Intelligence and Law, 2024; 1–47. [Google Scholar]
- Haleem, A.; Javaid, M.; Singh, R.P. Exploring the competence of ChatGPT for customer and patient service management. Intelligent Pharmacy 2024. [Google Scholar] [CrossRef]
- Nazir, A.; Wang, Z. A comprehensive survey of ChatGPT: Advancements, applications, prospects, and challenges. Meta-Radiology 2023, 1, 100022. [Google Scholar] [CrossRef] [PubMed]
- Hämäläinen, P.; Tavast, M.; Kunnari, A. Evaluating Large Language Models in Generating Synthetic HCI Research Data: a Case Study. CHI ’23: CHI Conference on Human Factors in Computing Systems, ACM, 2023. [CrossRef]
- Cox, S.R.; Abdul, A.; Ooi, W.T. Prompting a Large Language Model to Generate Diverse Motivational Messages: A Comparison with Human-Written Messages. HAI ’23: International Conference on Human-Agent Interaction, ACM, 2023. [CrossRef]
- Xie, T.; Wan, Y.; Zhou, Y.; Huang, W.; Liu, Y.; Linghu, Q.; Wang, S.; Kit, C.; Grazian, C.; Zhang, W.; Hoex, B. Creation of a structured solar cell material dataset and performance prediction using large language models. Patterns, 1009. [Google Scholar] [CrossRef]
- Alt, R.; Fridgen, G.; Chang, Y. The future of fintech — Towards ubiquitous financial services. Electronic Markets 2024, 34. [Google Scholar] [CrossRef]
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.W.; Liu, N. Large language models in health care: Development, applications, and challenges. Health Care Science 2023, 2, 255–263. [Google Scholar]
- Law, S.; Oldfield, B.; Yang, W. ChatGPT/GPT-4 (large language models): Opportunities and challenges of perspective in bariatric healthcare professionals. Obesity Reviews 2024. [Google Scholar] [CrossRef]
- Eloundou, T.; Manning, S.; Mishkin, P.; Rock, D. GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models, 2023, [arXiv:econ.GN/2303.10130].
- Carvalho, I.; Ivanov, S. ChatGPT for tourism: applications, benefits and risks. Tourism Review 2023, 79, 290–303. [Google Scholar] [CrossRef]
- Gao, S.; Fang, J.; Tu, Q.; Yao, Z.; Chen, Z.; Ren, P.; Ren, Z. Generative News Recommendation, 2024, [arXiv:cs.IR/2403.03424].
- Sharma, N.; Liao, Q.V.; Xiao, Z. Generative Echo Chamber? Effects of LLM-Powered Search Systems on Diverse Information Seeking, 2024, [arXiv:cs.CL/2402.05880].
- Ke, L.; Tong, S.; Cheng, P.; Peng, K. Exploring the Frontiers of LLMs in Psychological Applications: A Comprehensive Review, 2024, [arXiv:cs.LG/2401.01519].
- Denecke, K.; May, R.; Rivera-Romero, O. Transformer Models in Healthcare: A Survey and Thematic Analysis of Potentials, Shortcomings and Risks. Journal of Medical Systems 2024, 48, 23. [Google Scholar]
- Farina, M.; Ahmad, U.; Taha, A.; Younes, H.; Mesbah, Y.; Yu, X.; Pedrycz, W. Sparsity in transformers: A systematic literature review. Neurocomputing 2024, 127468. [Google Scholar]
- Mohammad, A.F.; Clark, B.; Agarwal, R.; Summers, S. LLM GPT Generative AI and Artificial General Intelligence (AGI): The Next Frontier. 2023 Congress in Computer Science, Computer Engineering, and Applied Computing (CSCE), 2023, pp. 413–417.
- Bal, M.; Sengupta, A. Spikingbert: Distilling bert to train spiking language models using implicit differentiation. Proceedings of the AAAI Conference on Artificial Intelligence, 2024, Vol. 38, pp. 10998–11006.
- Zhang, H.; Yin, J.; Wang, H.; Xiang, Z. ITCMA: A Generative Agent Based on a Computational Consciousness Structure. arXiv preprint arXiv:2403.20097, 2024; arXiv:2403.20097. [Google Scholar]
- Roth, W.; Schindler, G.; Klein, B.; Peharz, R.; Tschiatschek, S.; Fröning, H.; Pernkopf, F.; Ghahramani, Z. Resource-efficient neural networks for embedded systems. Journal of Machine Learning Research 2024, 25, 1–51. [Google Scholar]
- Chitty-Venkata, K.T.; Mittal, S.; Emani, M.; Vishwanath, V.; Somani, A.K. A survey of techniques for optimizing transformer inference. Journal of Systems Architecture 2023, 102990. [Google Scholar]
- Luccioni, A.S.; Viguier, S.; Ligozat, A.L. Estimating the Carbon Footprint of BLOOM, a 176B Parameter Language Model. Journal of Machine Learning Research 2023, 24, 1–15. [Google Scholar]
- Mohaidat, T.; Khalil, K. A Survey on Neural Network Hardware Accelerators. IEEE Transactions on Artificial Intelligence 2024, 1–21. [Google Scholar] [CrossRef]
- Akkad, G.; Mansour, A.; Inaty, E. Embedded Deep Learning Accelerators: A Survey on Recent Advances. IEEE Transactions on Artificial Intelligence 2023, 1–19. [Google Scholar] [CrossRef]
- Timmons, A.C.; Duong, J.B.; Simo Fiallo, N.; Lee, T.; Vo, H.P.Q.; Ahle, M.W.; Comer, J.S.; Brewer, L.C.; Frazier, S.L.; Chaspari, T. A call to action on assessing and mitigating bias in artificial intelligence applications for mental health. Perspectives on Psychological Science 2023, 18, 1062–1096. [Google Scholar] [PubMed]
- Nezami, N.; Haghighat, P.; Gándara, D.; Anahideh, H. Assessing Disparities in Predictive Modeling Outcomes for College Student Success: The Impact of Imputation Techniques on Model Performance and Fairness. Education Sciences 2024, 14, 136. [Google Scholar]
- Wan, M.; Zha, D.; Liu, N.; Zou, N. In-processing modeling techniques for machine learning fairness: A survey. ACM Transactions on Knowledge Discovery from Data 2023, 17, 1–27. [Google Scholar]
- Ferrara, E. Fairness and bias in artificial intelligence: A brief survey of sources, impacts, and mitigation strategies. Sci 2023, 6, 3. [Google Scholar] [CrossRef]
Figure 1.
Evolution of LLMs.
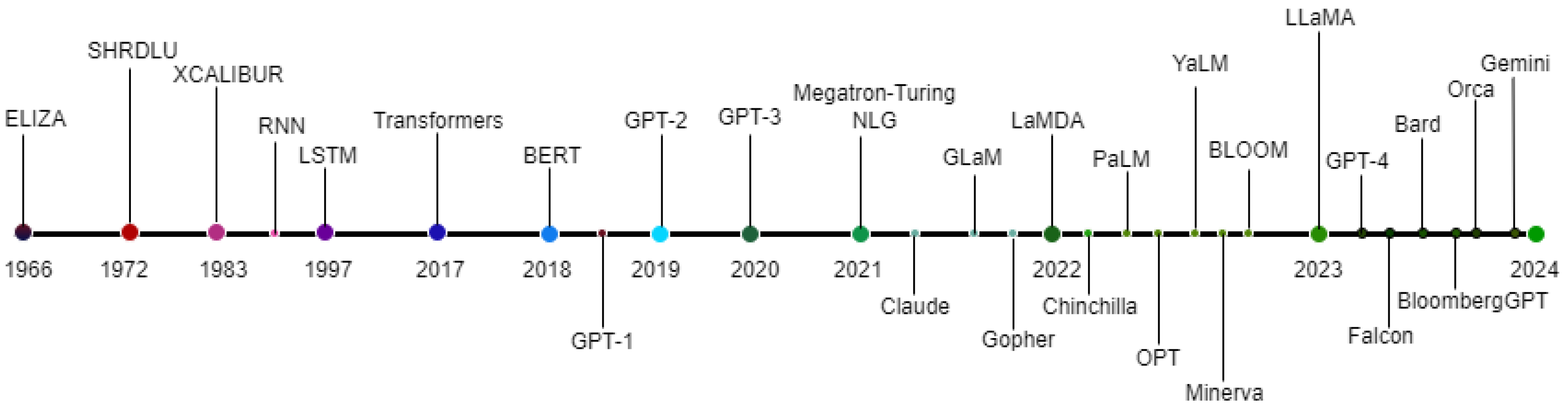
Figure 2.
The Transformer Architecture [14].
Figure 2.
The Transformer Architecture [14].
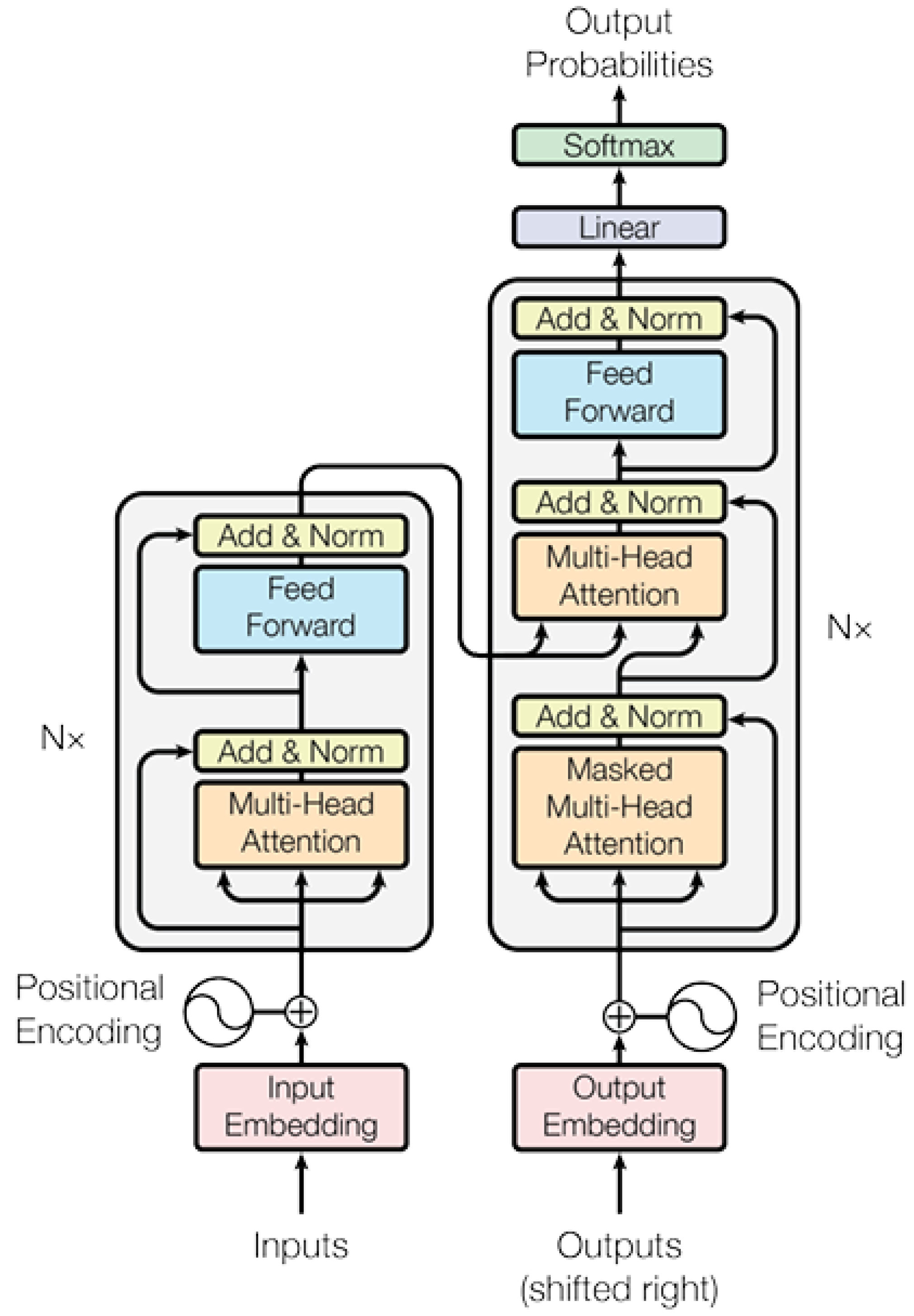

Table 1.
Summary of Large Language Models.
| Name | Year | Developer/Company | Method | Parameter Size | Unique Contribution |
|---|---|---|---|---|---|
| GPT-1 | 2018 | OpenAI | Transformer-based, unsupervised pre-training | 117M | Introduction of transformer model to NLP |
| BERT | 2018 | Transformer-based, bidirectional training | 110M (Base), 340M (Large) | Deep contextual understanding from bidirectional training | |
| GPT-2 | 2019 | OpenAI | Transformer-based, scaled-up GPT-1 | 1.5B | Scale-up in size and training data for greater generality |
| RoBERTa | 2019 | Facebook AI | Optimized BERT pre-training approach | 125M (Base), 355M (Large) | Removed BERT’s next-sentence prediction |
| DistilBERT | 2019 | Hugging Face | Knowledge distillation from BERT | 66M | Reduced size and preserved performance |
| ALBERT | 2019 | Parameter-reduction techniques | 12M (Base), 18M (Large) | Factorized embedding and cross-layer parameter sharing | |
| ERNIE | 2019 | Baidu | Integrating structured knowledge into pre-training | Similar to BERT | Leveraging real-world knowledge |
| GPT-3 | 2020 | OpenAI | Transformer-based, unsupervised learning | 175B | Scalability to a very large number of parameters |
| LaMDA | 2021 | Language model for dialog applications | 137B | Specialized in conversational understanding | |
| Bard | 2021 | Reinforcement learning from human feedback | 1.3B | Enhanced user interaction capabilities | |
| Gemini | 2021 | Microsoft | Hybrid transformer-CNN architecture | 2B | Integration of CNNs for enhanced spatial reasoning |
| GPT-3.5 | 2022 | OpenAI | Refinement of GPT-3 architecture | 175B | Improved training techniques and fine-tuning |
| Orca | 2022 | Multi-task learning approach | 500B | Advanced multitasking across diverse NLP applications | |
| PaLM | 2022 | Pathway language modeling | 540B | Pathways approach for simultaneous multiple tasks | |
| Falcon | 2022 | SpaceX AI | Streamlined architecture for low-resource environments | 850M | Optimized for rapid deployment in constrained settings |
| GPT-4 | 2023 | OpenAI | Further scaled and optimized GPT architecture | 800B | Extended capabilities in multilingual tasks and complex problem-solving |
| LLaMA | 2023 | Facebook AI | Advanced language model with minimal supervision | 65B | Efficient learning from fewer data |
| YaLM | 2023 | Yandex | Customizable modules for specific industries | 750B | Tailored solutions for sector-specific needs |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



