
Submitted:
26 August 2024
Posted:
27 August 2024
You are already at the latest version
Preprints on COVID-19 and SARS-CoV-2
Abstract
This study harnesses the potential of artificial intelligence (AI) focusing on machine learning (ML) to improve decision-making in advanced engineering education. The onset of the COVID-19 pandemic compelled a swift transformation in higher education methodologies, particularly in the domain of course modality. This study aims to align institutional decisions with student and faculty preferences in the face of rapid changes in instructional approaches, particularly learning styles, theoretical, practical, and theoretical-practical, prompted by the COVID-19 pandemic. To ascertain the preferences of students and instructors regarding class modalities across various courses, we utilized the Cognitive Process-Embedded Systems and E-learning conceptual framework. This framework effectively delineates the task execution process within the scope of technology-enhanced learning environments for both students and instructors. This study was conducted in seven Iranian universities and their STEM departments, examining their preferences for different learning styles. After analyzing the variables by different feature selection methods, we used three ML methods—decision trees (DT), support vector machines (SVM), and random forest (RF)—for comparative analysis. The results demonstrated the high performance of the RF model in predicting curriculum style preferences, making it a powerful decision-making tool in the evolving post-COVID educational landscape. This study not only demonstrates the effectiveness of ML in predicting educational preferences but also contributes to understanding the role of self-regulated learning in educational policy and decision-making in higher education.
Keywords:
online learning
; technology-enhanced learning
; educational machine learning
; educational artificial intelligence
; feature selection methods
; random forest
; SVM
; decision tree
1. Introduction
The COVID-19 outbreak revealed the complex decision-making processes universities must undertake when prompt and judicious actions are required, and decisions must be made under time pressure. At the same time, the transition to remote instruction during the pandemic provided opportunities to expand the use of online learning. This decision-making process involves trade-offs between safeguarding students while maintaining high-quality, transformative learning experiences [1,2]. The swift transition from in-person to online classes due to COVID-19 highlights the importance of decision-making that considers the preferences of both instructors and students, given that the ability to incorporate students into the decision-making enhances the likelihood of successful school reform and student learning outcomes [3].
One benefit of the increase in online learning is the opportunity to leverage artificial intelligence’s (AI) ability to process large amounts of data to make timely decisions without the need to delay decision-making for human-controlled data analysis [4]. For instance, the decision to move instruction online or in-person must be made quickly and should consider instructors’ and students’ preferences [5]. The affordances provided by AI can enable administrators to make well-informed decisions that align with the needs of instructors and students while also optimizing the learning experience [6]. Through the utilization of AI, academic institutions can tailor course design and instructional modalities by using students’ and faculty preferences in real-time, significantly enhancing educational equity within the university ecosystem [7,8].
Incorporating technological advancements within the educational milieu necessitates the establishment of robust and adaptive quality assurance protocols, aptly tailored to the nuanced needs of students and instructors within dynamically changing contexts [9,10]. Achieving equilibrium between individual preferences and optimal pedagogical outcomes demands the conceptualization and implementation of a theory-driven framework for decision-making and fortifying the quality and efficacy of technological integrations into the course fabric [9,11].
This paper aims to emphasize the potential of an AI tool that utilizes machine learning (ML) techniques to address challenges associated with decision-making involving large data sets. We ground this discussion by describing a study that developed an AI tool that predicts preferences for course modality (e.g., online or in-person) within seven Iranian Universities. The findings of this study can inform decision-making processes in higher education institutions and contribute to understanding the factors influencing students’ preferences for online learning. By identifying preferences related to course modality, decision-makers can maximize the benefits of technology-enhanced learning by selecting course modality by a theory-driven data collection approach. This paper describes such an ML approach that addresses the research questions:
RQ1: To what extent can Machine Learning predict student and instructor preferences for course modality in a post-Corona learning context?
RQ2: To what extent can psychological constructs associated with self-regulated learning predict student and instructors’ preferences for course modality?
Given our research aim, we require AI approaches to follow suitable prediction strategies, as well as educational structures that investigate instructor and student preferences [12].
2. Literature Review
2.1. Machine Learning in Education
Within education, Machine Learning (ML) methodologies play a pivotal role in the comprehensive examination of student performance [13], facilitation of learning processes, provision of nuanced feedback, and personalized recommendations [14,15], as well as educational administration and decision-making [16]. A wide variety of approaches have been proposed for how to employ ML in educational settings.
2.1.1. Machine Learning Methods
Within educational studies, most Machine Learning (ML) techniques applied for clustering and prediction purposes contain Artificial Neural Networks (ANN), Decision Trees (DT), Random Forests (RF), and Support Vector Machines (SVM) [17]. Most articles compare the accuracy of some of these methods to control the accuracy and interpretability of the model [15,18,19]. The appropriate model for improving prediction accuracy with categorical items depends on factors such as sample size, the number of variables, and theoretical context in handling the data regarding the variables [20,21,22,23]. Studies have shown that SVM and RFs are accurate for clustering purposes with multidimensional and large data, such as predicting performance through activities and quarterly tests [15,24]. Conversely, DTs (CRAT, RF, and C4.5) are effective for clustering small and noisy data sets. For instance, [25] used DTs to predict student performance to help teachers provide adapted instructional approaches and supplementary practice for students likely to have difficulty understanding the content.
2.1.2. Variable Selection in Machine Learning
In Machine Learning (ML), the learning model requires the inclusion of relevant variables and excluding the unhelpful variables to identify the most relevant variables that contribute to accurate predictions [26,27]. In this context, wrapper methods, such as Recursive Feature Elimination (RFE) and Boruta, have proven to be effective by considering the intricate interactions between variables and predictive models [28], while filter methods, such as chi-square and mutual information, focus on evaluating the individual relevance of predictors, shedding light on their independent contributions, as pointed out by [29]. This capability makes these methods ideal for capturing and simplification of complex relationships and interactions [30]. Employing a combination of filter and wrapper methods in variable selection is essential for leveraging diverse ML approaches [31], often using a strategic approach like majority voting identified by multiple selection methods [32].
2.2. Related Works
[10] extensively investigated faculty readiness for online teaching, emphasizing the specific challenges faced by those unaccustomed to this format. They notably focused on integrating laboratory components, distinct from other types of classes, within e-learning systems frameworks during the COVID-19 pandemic. In a subsequent work, [33,34] investigated the impact of various course modalities on different aspects of learning, highlighting the importance of educational environment decisions. [35] applied K-dependence Bayesian classifiers in machine learning to facilitate resource selection tailored to an individual student’s prior knowledge, showcasing the integration of data-driven decision-making into teaching approaches and teacher preferences. Conversely, [36] pursued a methodological approach involving decision trees and neural networks. Their primary goal was to predict students’ educational material preferences through designed surveys by considering student preferences. [37] used gradient-boosting tree methods with great precision to bridge the gap between expected and actual data about predicting students’ success in Massive Open Online Courses (MOOCs), aiming for a cohesive approach to improve the reliability and accuracy of their research findings. Remarkably, no existing literature has yet harnessed the potential of Machine Learning (ML) techniques to predict student and instructor preferences within the context of course modality using theory-driven approaches. [38] delved into the theoretical foundations of classroom-level data-based decision-making while also examining the impact of teacher support on this process. Through latent mediation analyses on longitudinal data from teachers and students, the study explores the connections between instructional decision-making based on pedagogical approaches and students’ reading progress.
2.3. Theory-Driven ML in Educational Research
Two main threats that reduce the repeatability and reliability of Machine Learning (ML) are overfitting and underfitting of models due to limited sample sizes for training and largely defined variables [39]. Theory-driven ML approaches have been proposed to overcome the problem of inappropriate model fitting [7]. Theory-driven ML leverages existing theoretical frameworks like self-regulated learning to scaffold models and collect relevant and objective data [7,40]. Theory-driven ML models use theories of learning to define variables (or features) to include in predictive models. Variable selection methods assist theory-driven ML in determining whether to reduce the problem’s variables based on their importance for model predictability and their interdependence with other variables [30,40].
3. Theoretical Framework
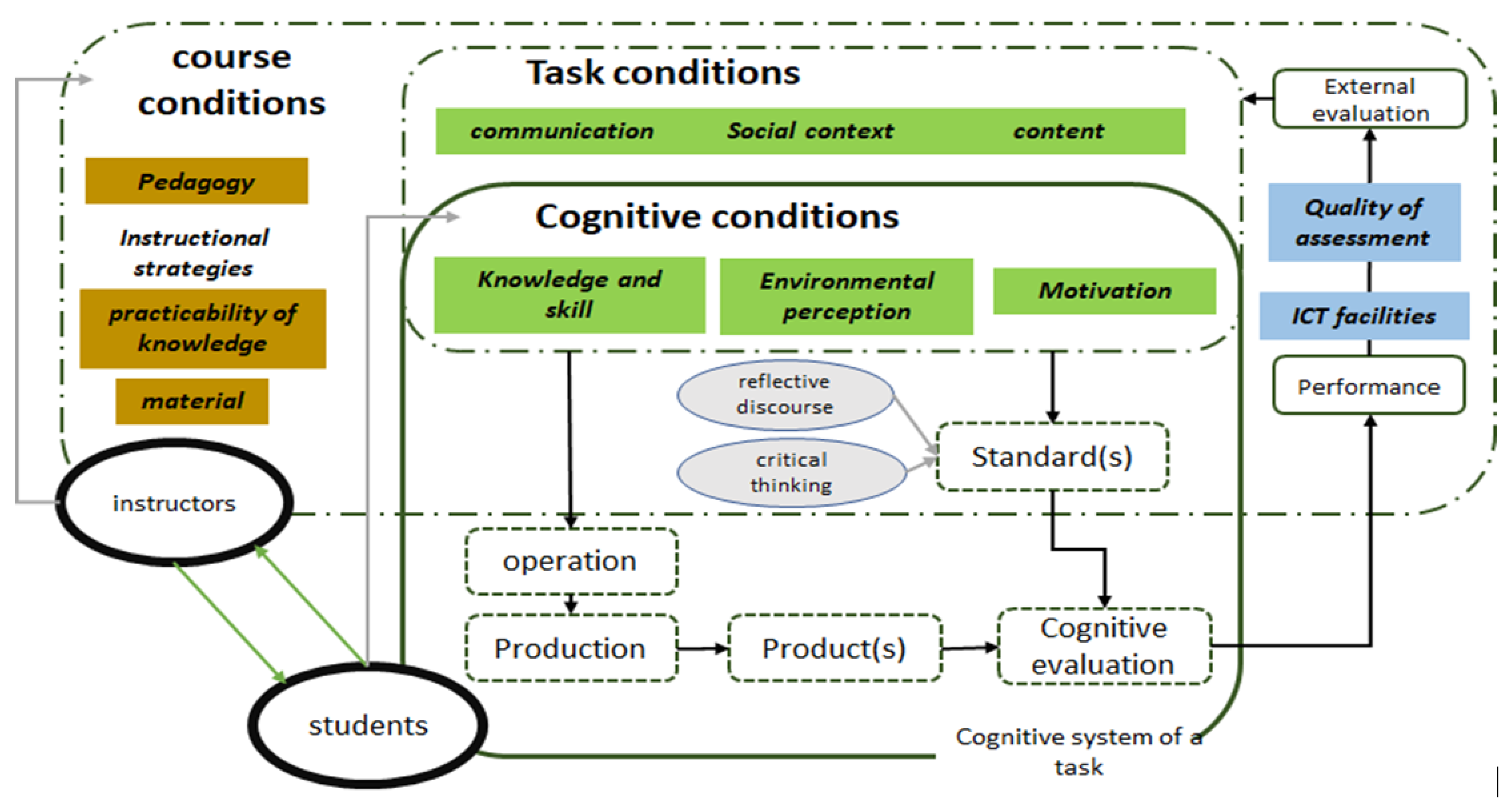
Within a course, the conditions related to the student are overshadowed by the course-related conditions set by the instructor. E-learning systems have enhanced educational accessibility and introduced diverse avenues through which learners can interact with educational materials, thereby contributing substantively to the advancement of educational equity among a broad spectrum of students [41,42]. So, it is necessary to increase the scope of investigation in Technology-Enhanced Learning (TEL) as a requirement. E-learning systems provide a framework for how an E-learning system meets the requirements of TEL stakeholders, technology, and service [43]. People engage with e-learning systems, while e-learning technologies facilitate both direct and indirect interactions among various user groups that affect learning. E-learning systems encompass all activities aligned with pedagogical models and instructional strategies. In the context of the Course, E-learning, and Pedagogy Evaluation Framework (COPES), the course conditions can be seen as part of the e-learning services component, which encompasses all activities aligned with pedagogical models and instructional strategies and controls the task and cognitive condition [41,44]. The external evaluation part of COPES can be seen as part of the people component, as it involves learners engaging with the e-learning system, and the quality of the E-learning system affects their evaluation. By adding the conditions of the E-learning systems framework like pedagogy, instructional strategies, and the quality of Information Communication Technology (ICT) as a condition of COEPS, we can investigate most factors related to the course modality [41].
3.1. Self-Regulated Learning
The concept of self-regulated learning involves perceiving learning as a dynamic process that entails the adaptive adjustment of cognition, behavior, and motivation to the content and the educational environment [45]. [46,47] proposed the Self-Regulation Learning (SRL) theory as a guiding framework in different learning environments for preferences of course modality, considering different conditions like students and instructors. One widely used theoretical model for investigating learning within self-regulated contexts is the Cognitive Process-Embedded Systems (COPES) model [41]. The COPES model investigates the process of learning during a task, considering the conditions that shape the satisfaction of tasks according to the learning goal and standards [41,48]. Conditions encompass both internal factors, such as the learner’s characteristics and knowledge about the topic, and external factors, including environmental variables that are believed to impact task-related internal conditions [41]. Conditions like the skill and knowledge of students, motivation models, and task content are inputs in information processing and decision-making, and the outcomes will be used to evaluate task success based on predefined standards and individual goals [41,45]. Given the success of the COEPS model in explaining student behavior in self-regulated learning contexts, the conditions from the COEPS model serve as useful variables to aid prediction in an ML model [41,45].
3.2. Course Modality as a Part of Technology-Enhanced Learning
Technology-enhanced learning (TEL) is the incorporation of technology in learning environments to promote the process of teaching and learning [49]. Any tool that aids in improving decision-making and learning experiences or adds value to educational environments by aligning the environment, tools, and content together can be classified as TEL [50]. Therefore, the preference for different course modalities is related to individual beliefs, experience with, and preferences for the integration of technology within the classroom [50,51]. As such, AI-based preference prediction tools should be investigated as a part of improving TEL [50,51].
3.3. E-Learning Systems
Within a course, the conditions related to the student are overshadowed by the course-related conditions set by the instructor. E-learning systems have enhanced educational accessibility and introduced diverse avenues through which learners can interact with educational materials, thereby contributing substantively to the advancement of educational equity among a broad spectrum of students [52]. So, it is necessary to increase the scope of investigation in Technology-Enhanced Learning (TEL) as a requirement. E-learning systems provide a framework for how an E-learning system meets the requirements of TEL stakeholders, technology, and service [43]. People engage with e-learning systems, while e-learning technologies facilitate both direct and indirect interactions among various user groups that affect learning. E-learning systems encompass all activities aligned with pedagogical models and instructional strategies. In the context of the COPES, the course conditions can be seen as part of the e-learning services component, which encompasses all activities aligned with pedagogical models and instructional strategies and controls the task and cognitive condition [43,48]. The external evaluation part of COPES can be seen as part of the people component, as it involves learners engaging with the e-learning system, and the quality of the E-learning system affects their evaluation. By adding the conditions of the E-learning systems framework, such as pedagogy, instructional strategies, and the quality of Information Communication Technology (ICT), as conditions of COEPS, we can investigate most factors related to the course modality [43].
4. Research Design
4.1. Participants
The research was carried out among 140 instructors and 379 students in engineering departments of seven Iranian universities, namely the University of Tehran, Sharif University of Technology, Isfahan University of Technology, Shiraz University, Sistan and Balouchestan University, Imam International University, and Ahvaz Shahid Chamran University. Participants were recruited via email from the seven universities in Iran. There were no restrictions based on age or other demographic factors, and participants did not receive any incentives or rewards for their involvement. For this study, two parallel surveys were developed and used to collect data from instructors and students. The surveys consisted of 50 and 49 questions, respectively, about the six dimensions of our theoretical framework of self-regulated learning and E-Learning systems Theory. Items were written to capture a variety of beliefs across six subscales, including Theory and Practice, Motivation, Pedagogy, Knowledge, Insight, and Skills, working life orientation, Quality of Assessment, and Information Communication Technology (Appendix A 17, Table A 21). In addition, participants were asked to indicate the type of course in which they were enrolled or taught (i.e., theoretical-practical, theoretical, and practical) and assess their preferences situation in each type of course in Likert type (Appendix Table A1). The lack of an established standardized survey called for the generation of pertinent survey items corresponding to distinct components of the framework. A pilot study of the surveys was conducted with ten students and five instructors to identify potential issues with item clarity. Prior to analysis, data cleaning procedures were implemented to ensure the suitability and accuracy of the collected data [19,42,53,54]. This procedure consists of identifying and addressing any inconsistencies, errors, outliers, or missing values in the dataset. For the student survey, the items of F2 and F3 for less than 50 students were empty, and we put the value of the response variable instead of them. Only 160 students responded to the I4 response variable, as they didn’t have experience with practical types of classes (R code and libraries are in Appendix A 17 and Table A 21).
4.2. Validity and Reliability Analysis
To examine the reliability of the survey items, Cronbach’s alpha coefficient was used to assess the internal consistency of the items [55], while discriminant validity was assessed using the Heterotrait-Monotrait Ratio of Correlations (HTMT) method [56], which examines the correlations of indicators across constructs and within the same construct [57]. The HTMT correlation ratio is an approach to examine the extent to which latent constructs are independent of each other [58,59]. Acceptable values of composite reliability/Cronbach alpha range from 0.60 to 0.70, while the acceptable range of HTMT is less than 0.9 [58,59] (methodology in Appendix A 8; results in Table A8 and A9).
Cronbach’s alpha for instructors’ surveys has a reliable value with a 0.95 confidence interval (). However, for students’ surveys, there are a couple of subscales with few items, which causes a reduction in Cronbach’s alpha. For the students’ survey, the 0.95 confidence interval has also a reliable value (). This is consistent with the findings of Rempel et al. [58,60] who found that Cronbach’s alpha can be reduced by subscales with few items. The result of Cronbach’s alpha for each subscale for both surveys is presented in Table A22 of Appendix A 18. Tables A8 and A9 show the HTMT values for all subscales of both surveys. The highest HTMT value observed for instructors is 0.6 and for students 0.532, which indicates that there is sufficient distinction between any two subscales in both surveys [58,61].
5. Methodology
5.0.1. Machine Learning Process
The first step in the machine learning (ML) process is variable selection, followed by modeling the problem using ML models, as illustrated in Figure 2. In this study, both surveys featured a relatively large number of questions (variables) and a relatively limited number of responses. Given our interest in the most relevant variables and the varied accuracy of different variable selection methods, considering the contribution to accurate predictions and imbalanced data (where one class in some variables has significantly fewer instances compared to another class), we employed four interpretable variable selection methods with a significance level of . To enhance the precision of variable selection and subsequent ML model implementation, a refined approach was adopted, as outlined in [62,63,64]. This approach involved retaining questions that exhibited similarity or analogous distinctive response classes to those found in Likert scale questions, excluding binary (Yes/No) inquiries, and questions with unrestricted response options [65]. Additionally, questions related to a specific learning management system, socioeconomic indicators, or personal identifying details such as the name of the university and age were excluded. Consequently, 38 questions were retained from the student survey, while 34 questions were preserved from the instructors’ survey for variable selection [63].
The chi-square test, a filter method, computes the chi-square statistic for each variable about the target item and compares it to a critical value or p-value determined by the chosen significance level, indicating a significant association between categorical variables [65,66,67]. Variables with chi-square statistics exceeding the critical value or p-values below the significance level are selected [66,68]. The Maximum Relevance Minimum Redundancy (MRMR) method, another filtering method, aims to identify a subset of variables that have high relevance to the target variable while minimizing redundancy among the selected variables [69]. Wrapper methods employ a specific ML model to assess subsets of variables and identify the optimal subset that maximizes the model’s performance [70,71,72,73]. Boruta, a wrapper method, employs a random forest model to evaluate variable importance, adding randomly generated variables and comparing their significance to original variables [74]. Recursive Feature Elimination (RFE), an embedded method, involves training a model on the full variable set, ranking variables based on their importance, eliminating the least important variables, and repeating this process [75,76].
Six response variables (Table A12) representing theoretical, practical, and theoretical-practical class types were analyzed using supervised ML models. The majority voting method was utilized to integrate outcomes and find the best sets of variables for each response variable [75,76]. This integration not only enhances the precision and reliability of the predictive model but also addresses challenges such as overfitting, noise, and the curse of dimensionality [75,76]. The REF method incorporates the population of the primary sample of variables entering the ML model. Moreover, the chi-square method lacks a definitive boundary for variable exclusion [31,62]. A threshold for the chi-square test was imposed, and the top variables according to REF criteria were selected from the chi-square test. The variable selection rule for majority voting to enter the ML stage is as follows: If an item has been eliminated by two or more variable selection methods, the item will be removed (Table A6). Tables A2 to A5 in the appendix indicate the variables selected by each of the chi-square, MRMR, Boruta, and RFE methods, describing the situation of each variable concerning the response variables. For REF and Boruta, 70% of the data was used for training ML models and 30% for testing, with the DT (CRAT) model used for Boruta and RF for the REF with 500 trees [19,31,53,62]. Table A7 indicates the variables that remained for ML.
5.0.2. Machine Learning Models
After selecting the variables, the next step in the Machine Learning (ML) process is to model the problem using ML models. In this study, according to [7], three ML models were utilized, including Decision Trees (DT), Support Vector Machines (SVM), and Random Forests (RF).
The DT (CRAN model in specific) method constructs a tree-like model of decisions and their possible consequences. Each variable in each tree predicts the response variable, and the leaf of DT represents the prediction. The construction of the tree involves recursively partitioning the data based on the most informative variable, aiming to maximize the separation of the target variable. This process continues until a stopping criterion is met, such as reaching a maximum depth in variable searching or a minimum number of samples of data for each variable per leaf [77] (methodology in Appendix A 13; results in Table A15 and A16).
The RF model constructs an ensemble of decision trees, where each tree is trained on a different subset of the data using a random selection of variables. During prediction, the model aggregates the predictions of individual trees to make the final prediction, resulting in a robust and reliable model. Additionally, RF identifies the key factors influencing the outcome. The cross-validation procedure for RF involved partitioning the dataset into 70% for training and 30% for testing, adhering to a significance level of [78] (methodology in Appendix A 12; results in Table A13 and A14).
As the response variable has multiple dimensions, the multiclass SVM was used to find an optimal hyperplane that separates different classes. Train data lie closest to the hyperplane that separates the classes in a binary classification problem. This hyperplane is determined by identifying a subset of data according to each variable called support vectors. The SVM model identifies these support vectors during the training phase and uses them to compute the optimal hyperplane. After we select the variables, the ML model by separating the test and train starts, and we need to learn. In this study, 60% of the data was used for training the ML models, and 40% of the data was used to test the models [79] (methodology in Appendix A 14; results in Table A17 and A18).
5.1. Accuracy of ML Models
Accuracy in machine learning refers to the measure of how often a classification model correctly predicts the true class of an instance, typically expressed as a ratio of correct predictions to the total number of predictions.
Equation (1). Formulation of accuracy in ML
The explication of True Positives (TP) as the quantification of instances accurately designated as positive, True Negatives (TN) as the quantification of instances accurately designated as negative, False Positives (FP) as the quantification of instances inaccurately designated as positive, and False Negatives (FN) as the quantification of instances inaccurately designated as negative, contained within the framework, provides a lucid exposition of the pivotal constituents that underlie the accuracy metric [19,53].
6. Results
6.1. Prediction Using Classification Techniques
The outcomes derived from ML prediction methodologies concerning the application of five-point Likert scale responses to anticipate the six designated response categories reveal an elevated level of precision attributed to Random Forest (RF) models (Table 1; the results summary of Table A13, A15, and A17), which is consistent with prior scholarly investigations [80]. According to Table 1, SVM and DT have less accuracy in comparison to RF. However, in all of them, the accuracy is not at an acceptable level.
To address the imbalance of responses in the population, a merging approach was utilized to reduce the classes in Likert. This approach reduces the students’ and instructors’ bias in responses, merges "strongly agree" and "agree" responses, and "strongly disagree" and "disagree" classes [81]. After merging the response classes, the implementation of ML changed to Table 2.
Results in Table 2 demonstrate a significant improvement in prediction accuracy (Table A11; Appendix A 10), particularly for the RF model, which remained more accurate than the DT and SVM methods. The change from a 5-point Likert scale to a 3-point Likert scale was particularly beneficial for the analysis of instructors’ survey responses by an increase in the accuracy of prediction for three response variables of the instructor. Unlike the RF model for the instructors, results indicated that DT and SVM cannot make accurate predictions within the 3-point Likert scale for the instructors (specifically the H4 and H6 response variables), which could be the result of a small sample, while this is not true for the students’ variables.
Despite the observed accuracy levels within the five-point Likert scale, discernible discrepancies surfaced in the "strongly agree," "strongly disagree," and "Neutral" classifications (Tables 1 and 2). Regardless of the employed Likert scale, it is evident (Appendix A 17) that the "Neutral" class consistently manifests the highest error rates. This phenomenon can be attributed to the imbalance in the population of the "Neutral" class according to the population of this class in comparison to other classes. According to Tables A 13-A 18, the random forest method demonstrated superior accuracy levels concerning the "Neutral" category in comparison to the remaining classification methods, regardless of the employed Likert scale. While the DT model has acceptable accuracy in ranges of agree and disagree for 3-point Likert, their effectiveness decreases within the "Neutral" class of 3-point Likert in comparison with the 5-point Likert (Appendix A 17). Within the class reduction process from five-point Likert to three-point Likert, the "Neutral" class remained constant in quantity, unlike the other two categories that experienced augmentation which increased the imbalance of this class. This merging of imbalanced classes subsequently heightened the likelihood of errors within the Neutral class. Meanwhile, the SVM model demonstrates greater accuracy upon the transition from a five-point to a three-point Likert scale. This enhancement in accuracy can be an output of merging two imbalanced classes. Despite the smaller number of data records from instructors, their predictions demonstrated higher accuracy and a unanimous opinion in comparison to students. This can be attributed to the defined theoretical framework and strong variable selection, which is aligned with instructors’ preferences and lets their responses be more predictable.
6.2. Subscales’ Ranking and Framework
Given the results above, the determination of subscale rankings in predicting student and instructor preferences (RQ2) was undertaken by leveraging the advanced classification capabilities of the RF. The Mean Decrease in Impurity methodology, which assesses the significance of variables, was harnessed for this purpose (Appendix A 15; the most important variables of RF and DT are in Table A19). For both instructors and students, pedagogy and motivation are the most important subscales to increase the predictability of the response variables (course modality); however, the ’theory and practice’ subscale indicated comparably diminished predictability. This diminished predictability might be related to the population of "Neutral" responses in related items in the survey as seen in the appendix (A 12 to A 14). The subscale of ’Knowledge, insight, and skill’ also provides less information for predictability for the instructors when compared to the students. The subscale of ’working-life orientation’ also is a prominent subscale for both students’ and instructors’ theoretical-practical response variables. Determinative subscales such as motivation, pedagogy, Insight, and Skills, Working-Life orientation, Quality of Assessment, and ICT, assume pivotal roles in shaping preferences. It should be noted that the correlation of the theory and practice subscale with the responses is not high (appendix A 12 to A 14).
7. Discussion
The results of the study indicate the superior predictive capabilities of the RF model in comparison to alternative models such as DT and SVM. Indeed, RF can handle high-dimensional response classes, imbalances, and multivariable situations. This study corroborates other studies where RF has been compared to other ML models, such as SVM and Logistic Regression [82,83]. A notable finding from this study is the predictive efficacy of RF models for "Neutral" responses which is in an acceptable range of accuracy for both the 3-point and 5-point Likert scales, the SVM also provided accuracy in an acceptable range however DT made a lower accuracy in comparison to SVM for most of the response variables. Consequently, the DT model tends towards divergent classifications with more clear distinct classes, thereby decreasing its suitability for high-level classification undertakings. This observation aligns with prior research [84,85]. However, the discriminatory boundaries between response classes like "agree" and "strongly agree" are not always the indicator of non-biased selection.
The COEPS and E-learning systems theoretical frameworks were used to define the subscales and subsequently the variables. Utilizing four different variable selection methods helped to simplify the ML model and select the most relevant variables which makes the prediction more robust [84,85]. This means that some of the variables were fully aligned with the response variables and could help us to predict the course modality. Indeed, the defined subscales and variables from the theoretical framework with a high level of confidence can explain the course modality preferences for both instructors and students [84,85,86,87].
The subscales were defined according to three conditions in the theoretical framework, after that the ML ranked the subscales according to the responses (Table 3 and Fig 1). Motivation and pedagogy are categorized under course and cognition conditions. Alignment between pedagogy and motivation is the most prevalent amongst all other subscales. This result does not mean that other subscales like those related to task condition are not important, but it means that for any decision-making about the course modality, the pedagogical approach of the instructor and how to motivate students should be prioritized and studied in any environment that is aligned with the result of studies like [84,85,86,87,88,89].
The findings from this study demonstrate the potential for ML to accurately classify student and instructor course modality preferences based on theoretical frameworks. So, the answer to the first research question is positive because the ML models with good accuracy can explain the multidimensional data and predict the preferences of students and instructors regarding the class modality.
The answer to the second research question is also yes. By considering the COEPS and E-learning systems as the frameworks and studying the preferences about course modality in the context of course, task, and cognitive condition, we have a tool that predicts the preferences of students and instructors in higher education. Indeed, while these theories separately do not directly explain the course modality situation, the course modality is explainable by adding the course conditions that come from the E-learning framework to the COEPS framework.
8. Conclusions
The necessity for adaptable instructional modalities is paramount to uphold educational standards and ensure accessibility in accurately predicting course modality preferences, which is critical for universities as they address the intricacies of education in the post-pandemic landscape. The alignment of pedagogical strategies with motivational factors emerged as a significant predictor, emphasizing the importance of considering both instructional design and student engagement when selecting course modalities. This finding is instrumental for educational institutions aiming to optimize learning experiences, where the flexibility and adaptability of course delivery methods are crucial. Aligning educational strategies and course designs with the preferences revealed through ML analysis promises to create more stimulating and efficacious learning environments, thereby enhancing student engagement and achieving superior educational outcomes [84,85,87,88,90]. The results of this study are highly applicable to universities and educational institutions that have large amounts of high-dimensional data with lots of different subscales. As the type of data in access universities varies, in situations where survey data is not available, behavior data or historical preference records can be used to implement machine learning, specifically RF as the most robust model according to our result, to make decisions about the educational policies and activities like course modality based on students’ and instructors’ preferences [84,85,87,88]. The research further elucidates the significance of incorporating psychological constructs related to self-regulated learning within the decision-making paradigm. This underscores the merit of a data-informed approach in crafting educational experiences that are both personalized and attuned to the evolving dynamics of student and instructor needs. Such an approach is instrumental in fostering educational strategies that are responsive and tailored, reflecting the contemporary demands of the academic community. The investigation showcases artificial intelligence’s (AI) pivotal role in transforming higher education by facilitating a harmonious balance between the quality of instruction and the multifaceted needs of the academic populace. This endeavor is crucial not only for augmenting the flexibility and robustness of educational frameworks but also for ensuring their continued relevance and efficacy in addressing the exigencies of forthcoming educational paradigms.
9. Future Research Directions
The development of predictive models for student and faculty preferences through this research marks a pivotal advancement in comprehending and accommodating the needs of the academic community, thereby providing a critical instrument for administrators striving to deliver educational experiences that are high in quality, equity, and effectiveness. Future research endeavors should aim to refine these predictive models, with a particular focus on elucidating the roles of motivation and pedagogy or exploring alternative models that more acutely incorporate these dimensions. Such efforts necessitate comprehensive data collection strategies within educational settings, encompassing a variety of sources to amass data conducive to the application of advanced AI Big Data methodologies. This approach will facilitate educational institutions in making more informed, confident, and precise decisions regarding course modality selections, leveraging the rich tapestry of data at their disposal.
Supplementary Materials
The following supporting information can be downloaded at the website of this paper posted on Preprints.org.
Author Contributions
Conceptualization, Amirreza Mehrabi, Jason W. Morphew, Hossein Memarian, and Negar Memarian; Methodology, Amirreza Mehrabi and Jason W. Morphew; Software, Babak Nadjar Araabi and Amirreza Mehrabi ; Validation, Amirreza Mehrabi, Babak Nadjar Araabi, and Jason W. Morphew; Formal Analysis, Amirreza Mehrabi; Investigation, Amirreza Mehrabi, Babak Nadjar Araabi, and Jason W. Morphew; Resources, Amirreza Mehrabi; Data Curation, Babak Nadjar Araabi, Amirreza Mehrabi, Hossein Memarian, and Negar Memarian; Writing – Original Draft Preparation, Amirreza Mehrabi, Jason W. Morphew, Babak Nadjar Araabi, Hossein Memarian, and Negar Memarian; Writing – Review & Editing, Amirreza Mehrabi, Jason W. Morphew, Babak Nadjar Araabi, Hossein Memarian, and Negar Memarian; Visualization, Amirreza Mehrabi; Supervision, Jason W. Morphew; Project Administration, Amirreza Mehrabi.
Funding
We wish to acknowledge that this work received no external funding and was not part of any government activities. All research and writing efforts were self-supported by the authors.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Acknowledgments
The primary contributor to this undertaking, serving as the principal author, embarked on this journey initially as a researcher within the Erasmus Plus project at Sharif University of Technology. Insights and ideas for designing the survey for this study were garnered from the experience of working within the Erasmus Plus project. This phase involved collaborative efforts with fellow students and esteemed professors, collectively dedicated to designing and implementing the project’s survey. We would like to extend our heartfelt gratitude to the individuals whose invaluable contributions supported me in this area of study and also in the Erasmus Plus project which shaped my mind about this interesting topic. This acknowledgment encompasses Sama Ghoreyshi, Dr. Arafe Bigdeli, the former Deputy Director of International Affairs at Sharif University and an active researcher within the field; Dr. Monica Fasciani of Sapienza Università di Roma; Dr. Timo Halttunen and Dr. Matti Lappalainen, both esteemed members of Turku University of Applied Sciences; and Breejha S. Quezada, a PhD student at Purdue University.
Conflicts of Interest
The authors declare no conflict of interest. The funding sponsors had no role in the design of the study; in the collection, analysis, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Krismanto, W.; Tahmidaten, L. Self-Regulated Learning in Online-Based Teacher Education And Training Programs. Aksara: Jurnal Ilmu Pendidikan Nonformal 2022, 8, 413. [Google Scholar] [CrossRef]
- Skar, G.B.U.; Graham, S.; Huebner, A. Learning loss during the COVID-19 pandemic and the impact of emergency remote instruction on first grade students’ writing: A natural experiment. Journal of Educational Psychology 2022, 114, 1553. [Google Scholar] [CrossRef]
- Pekrul, S.; Levin, B. Building Student Voice for School Improvement. In International Handbook of Student Experience in Elementary and Secondary School; D. Thiessen, A.S., Ed.; Springer Netherlands, 2007; chapter 27, pp. 711–726. [CrossRef]
- Winne, P.H. Cognition and Metacognition within Self-Regulated Learning. In Handbook of Self-Regulation of Learning and Performance, Second ed.; Shunk, D.S.; Greene, J.A., Eds.; Taylor and Francis, 2017; pp. 36–48. [CrossRef]
- Lima, R.M.; Villas-Boas, V.; Soares, F.; Carneiro, O.S.; Ribeiro, P.; Mesquita, D. Mapping the implementation of active learning approaches in a school of engineering–the positive effect of teacher training. European Journal of Engineering Education, 2024; 1–20. [Google Scholar] [CrossRef]
- Alpaydin, E. Machine Learning: The New AI; The MIT Press, 2016.
- Macarini, L.A.B.; Cechinel, C.; Machado, M.F.B.; Ramos, V.F.C.; Munoz, R. Predicting Students Success in Blended Learning—Evaluating Different Interactions Inside Learning Management Systems. Applied Sciences 2019, 9, 5523. [Google Scholar] [CrossRef]
- Johri, A.; Katz, A.S.; Qadir, J.; Hingle, A. Generative artificial intelligence and engineering education. Journal of Engineering Education 2023. [Google Scholar] [CrossRef]
- Hilbert, S.; Coors, S.; Kraus, E.; Bischl, B.; Lindl, A.; Frei, M.; Wild, J.; Krauss, S.; Goretzko, D.; Stachl, C. Machine learning for the educational sciences. Review of Education 2021, 9. [Google Scholar] [CrossRef]
- Singh, J.; Steele, K.; Singh, L. Combining the Best of Online and Face-to-Face Learning: Hybrid and Blended Learning Approach for COVID-19, Post Vaccine, & Post-Pandemic World. Journal of Educational Technology Systems 2021, 50, 140–171. [Google Scholar] [CrossRef]
- Koretsky, M.D.; Nolen, S.B.; Galisky, J.; Auby, H.; Grundy, L.S. Progression from the mean: Cultivating instructors’ unique trajectories of practice using educational technology. Journal of Engineering Education 2024. [Google Scholar] [CrossRef]
- Meyer, G.; Adomavicius, G.; Johnson, P.E.; Elidrisi, M.; Rush, W.A.; Sperl-Hillen, J.M.; O’Connor, P.J. A machine learning approach to improving dynamic decision making. Information Systems Research 2014, 25, 239–263. [Google Scholar] [CrossRef]
- Talib, N.I.M.; Majid, N.A.A.; Sahran, S. Identification of Student Behavioral Patterns in Higher Education Using K-Means Clustering and Support Vector Machine. Applied Sciences 2023, 13, 3267. [Google Scholar] [CrossRef]
- Martin, F.; Wang, C.; Sadaf, A. Student perception of helpfulness of facilitation strategies that enhance instructor presence, connectedness, engagement and learning in online courses. Internet and Higher Education 2018, 37, 52–65. [Google Scholar] [CrossRef]
- Psyridou, M.; Koponen, T.; Tolvanen, A.; Aunola, K.; Lerkkanen, M.K.; Poikkeus, A.M.; Torppa, M. Early prediction of math difficulties with the use of a neural networks model. Journal of Educational Psychology 2023. [Google Scholar] [CrossRef]
- Inusah, F.; Missah, Y.M.; Najim, U.; Twum, F. Data Mining and Visualisation of Basic Educational Resources for Quality Education. International Journal of Engineering Trends and Technology 2022, 70, 296–307. [Google Scholar] [CrossRef]
- Safaei, M.; Sundararajan, E.A.; Driss, M.; Boulila, W.; Shapi’i, A. A systematic literature review on obesity: Understanding the causes & consequences of obesity and reviewing various machine learning approaches used to predict obesity. Computers in Biology and Medicine 2021, 136, 104754. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.; Sanchez-Castillo, M.; Chica-Olmo, M.; Chica-Rivas, M. Machine learning predictive models for mineral prospectivity: An evaluation of neural networks, random forest, regression trees and support vector machines. Ore Geology Reviews 2015, 71, 804–818. [Google Scholar] [CrossRef]
- Bayirli, E.G.; Kaygun, A.; Öz, E. An Analysis of PISA 2018 Mathematics Assessment for Asia-Pacific Countries Using Educational Data Mining. Mathematics 2023, 11, 1318. [Google Scholar] [CrossRef]
- Alghamdi, M.I. Assessing Factors Affecting Intention to Adopt AI and ML: The Case of the Jordanian Retail Industry. MENDEL 2020. [Google Scholar] [CrossRef]
- Li, F.Q.; Wang, S.L.; Liew, A.W.C.; Ding, W.; Liu, G.S. Large-Scale Malicious Software Classification With Fuzzified Features and Boosted Fuzzy Random Forest. IEEE Transactions on Fuzzy Systems 2021, 29, 3205–3218. [Google Scholar] [CrossRef]
- Liu-Yi, W.; Li-Gu, Z.H.U. Research and application of credit risk of small and medium-sized enterprises based on random forest model. 2021 IEEE International Conference on Consumer Electronics and Computer Engineering (ICCECE), 2021, pp. 371–374. [CrossRef]
- Park, C.G. Implementing alternative estimation methods to test the construct validity of Likert-scale instruments. Korean Journal of Women Health Nursing 2023, 29, 85–90. [Google Scholar] [CrossRef]
- Abdelmagid, A.S.; Qahmash, A.I.M. Utilizing the Educational Data Mining Techniques ‘Orange Technology’ for Detecting Patterns and Predicting Academic Performance of University Students. Information Sciences Letters 2023, 12, 1415–1431. [Google Scholar] [CrossRef]
- Sengupta, S. Towards Finding a Minimal Set of Features for Predicting Students’ Performance Using Educational Data Mining. International Journal of Modern Education and Computer Science 2023, 15, 44–54. [Google Scholar] [CrossRef]
- Osanaiye, O.; Cai, H.; Choo, K.K.R.; Dehghantanha, A.; Xu, Z.; Dlodlo, M. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing. EURASIP Journal on Wireless Communications and Networking 2016, 2016, 130. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: a hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 dataset. Journal of Big Data 2023, 10, 15. [Google Scholar] [CrossRef]
- Saeed, A.; Zaffar, M.; Abbas, M.A.; Quraishi, K.S.; Shahrose, A.; Irfan, M.; Huneif, M.A.; Abdulwahab, A.; Alduraibi, S.K.; Alshehri, F.; others. A Turf-Based Feature Selection Technique for Predicting Factors Affecting Human Health during Pandemic. Life 2022, 12. [Google Scholar] [CrossRef] [PubMed]
- Zaffar, M.; Hashmani, M.A.; Savita, K.; Rizvi, S.S.H.; Rehman, M. Role of FCBF Feature Selection in Educational Data Mining. Mehran University Research Journal of Engineering and Technology 2020, 39, 772–779. [Google Scholar] [CrossRef]
- Tadist, K.; Najah, S.; Nikolov, N.S.; Mrabti, F.; Zahi, A. Feature selection methods and genomicbig data: a systematic review. Journal of Big Data 2019, 6, 79. [Google Scholar] [CrossRef]
- Vommi, A.M.; Battula, T.K. A hybrid filter-wrapper feature selection using Fuzzy KNN based on Bonferroni mean for medical datasets classification: A COVID-19 case study. Expert Systems with Applications 2023, 218, 119612. [Google Scholar] [CrossRef]
- Zhou, X.; Li, Y.; Song, X.; Jin, L.; Wang, X. Thin Reservoir Identification Based on Logging Interpretation by Using the Support Vector Machine Method. Energies 2023, 16, 1638. [Google Scholar] [CrossRef]
- Singh, J.; Steele, K.; Singh, L. Combining the Best of Online and Face-to-Face Learning: Hybrid and Blended Learning Approach for COVID-19, Post Vaccine, & Post-Pandemic World. Journal of Educational Technology Systems 2021, 50, 140–171. [Google Scholar] [CrossRef]
- Singh, J.; Evans, E.; Reed, A.; Karch, L.; Qualey, K.; Singh, L.; Wiersma, H. Online, Hybrid, and Face-to-Face Learning Through the Eyes of Faculty, Students, Administrators, and Instructional Designers: Lessons Learned and Directions for the Post-Vaccine and Post-Pandemic/COVID-19 World. Journal of Educational Technology Systems 2022, 50, 301–326. [Google Scholar] [CrossRef]
- Carmona, C.; Castillo, G.; Millán, E. Discovering Student Preferences in E-Learning. Proceedings of the International Workshop on Applying Data Mining in E-Learning, 2007, pp. 33–42.
- Kotsiantis, S.B.; Zaharakis, I.D.; Pintelas, P.E. Assessing Supervised Machine Learning Techniques for Predicting Student Learning Preferences. Proceedings of 3rd Congress on Information and Communication Technologies in Education; Dimitracopoulou, A., Ed.; University of Aegean,, 2002. [CrossRef]
- Hew, K.F.; Hu, X.; Qiao, C.; Tang, Y. What predicts student satisfaction with MOOCs: A gradient boosting trees supervised machine learning and sentiment analysis approach. Computers & Education 2020, 145, 103724. [Google Scholar] [CrossRef]
- Hebbecker, K.; Förster, N.; Forthmann, B.; Souvignier, E. Data-based decision-making in schools: Examining the process and effects of teacher support. Journal of Educational Psychology 2022, 114, 1695. [Google Scholar] [CrossRef]
- Turgut, Y.; Bozdag, C.E. A framework proposal for machine learning-driven agent-based models through a case study analysis. Simulation Modelling Practice and Theory 2023, 123, 102707. [Google Scholar] [CrossRef]
- Ouyang, F.; Wu, M.; Zheng, L.; Zhang, L.; Jiao, P. Integration of artificial intelligence performance prediction and learning analytics to improve student learning in online engineering course. International Journal of Educational Technology in Higher Education 2023, 20, 1–23. [Google Scholar] [CrossRef]
- Muis, K.R.; Chevrier, M.; Singh, C.A. The Role of Epistemic Emotions in Personal Epistemology and Self-Regulated Learning. Educational Psychology 2018, 53, 165–184. [Google Scholar] [CrossRef]
- Kumar, R.; Sexena, A.; Gehlot, A. Artificial Intelligence in Smart Education and Futuristic Challenges. 2023 International Conference on Disruptive Technologies (ICDT). IEEE, 2023, pp. 432–435. [CrossRef]
- Aparicio, M.; Bacao, F.; Oliveira, T. An e-Learning Theoretical Framework | Enhanced Reader. Educational Technology & Society 2016, 19, 293–307. [Google Scholar]
- Schrumpf, J. On the Effectiveness of an AI-Driven Educational Resource Recommendation System for Higher Education. International Association for Development of the Information Society 2022. [Google Scholar]
- Zimmerman, B.J.; Campillo, M. Motivating Self-Regulated Problem Solvers. In The Psychology of Problem Solving; Cambridge University Press, 2003; pp. 233–262. [CrossRef]
- Whiteside, A.L.; Dikkers, A.G.; Lewis, S. More Confident Going into College’: Lessons Learned from Multiple Stakeholders in a New Blended Learning Initiative. Online Learning 2016, 20, 136–156. [Google Scholar] [CrossRef]
- Sitzmann, T.; Ely, K. A Meta-Analysis of Self-Regulated Learning in Work-Related Training and Educational Attainment: What We Know and Where We Need to Go. Psychological Bulletin 2011, 137, 421–442. [Google Scholar] [CrossRef]
- Balid, W.; Alrouh, I.; Hussian, A.; Abdulwahed, M. Systems engineering design of engineering education: A case of an embedded systems course. Proceedings of IEEE International Conference on Teaching, Assessment, and Learning for Engineering (TALE) 2012. IEEE, 2012, pp. W1D–7. [CrossRef]
- Passey, D. Technology-enhanced learning: Rethinking the term, the concept and its theoretical background. British Journal of Educational Technology 2019, 50, 972–986. [Google Scholar] [CrossRef]
- Duval, E.; Sharples, M.; Sutherland, R. Research themes in technology enhanced learning. In Technology Enhanced Learning: Research Themes; 2017; pp. 1–10. [CrossRef]
- Jackson, C.K. The full measure of a teacher: Using value-added to assess effects on student behavior. Education Next 2019, 19, 62–69. [Google Scholar]
- Gunawardena, M.; Dhanapala, K.V. Barriers to Removing Barriers of Online Learning. Communications of the Association for Information Systems 2023, 52, 264–280. [Google Scholar] [CrossRef]
- Rabbi, J.; Fuad, M.T.H.; Awal, M.A. Human Activity Analysis and Recognition from Smartphones using Machine Learning Techniques. https://arxiv.org/abs/2103.16490, 2021. [CrossRef]
- Sánchez-Ruiz, L.; López-Alfonso, S.; Moll-López, S.; Moraño-Fernández, J.; Vega-Fleitas, E. Educational Digital Escape Rooms Footprint on Students’ Feelings: A Case Study within Aerospace Engineering. Information 2022, 13, 478. [Google Scholar] [CrossRef]
- Bland, J.M.; Altman, D.G. Statistics notes: Cronbach’s alpha. BMJ 1997, 314, 572. [Google Scholar] [CrossRef] [PubMed]
- Afthanorhan, A.; Ghazali, P.L.; Rashid, N. Discriminant Validity: A Comparison of CBSEM and Consistent PLS using Fornell & Larcker and HTMT Approaches. Journal of Physics: Conference Series, 2021, Vol. 1874, p. 012085. [Google Scholar] [CrossRef]
- Henseler, J.; Ringle, C.M.; Sarstedt, M. A new criterion for assessing discriminant validity in variance-based structural equation modeling. Journal of Academic Marketing Science 2015, 43, 115–135. [Google Scholar] [CrossRef]
- Yusoff, A.S.M.; Peng, F.S.; Abd Razak, F.Z.; Mustafa, W.A. Discriminant validity assessment of religious teacher acceptance: The use of HTMT criterion. Journal of Physics: Conference Series. IOP Publishing, 2020, Vol. 1529, p. 042045. [CrossRef]
- Ab Hamid, M.R.; Sami, W.; Sidek, M.M. Discriminant Validity Assessment: Use of Fornell & Larcker criterion versus HTMT Criterion. Journal of Physics: Conference Series 2017, 890, 012163. [Google Scholar] [CrossRef]
- Rempel, J.K.; Holmes, J.G.; Zanna, M.P. Trust in close relationships. Journal of Personality and Social Psychology 1985, 49, 95–112. [Google Scholar] [CrossRef]
- Hamid, M.R.A.; Sami, W.; Sidek, M.H.M. Discriminant Validity Assessment: Use of Fornell & Larcker criterion versus HTMT Criterion. Journal of Physics: Conference Series 2017, 890, 012163. [Google Scholar] [CrossRef]
- Remeseiro, B.; Bolon-Canedo, V. A review of feature selection methods in medical applications. Computers in biology and medicine 2019, 112, 103375. [Google Scholar] [CrossRef]
- Buenaño-Fernández, D.; Gil, D.; Luján-Mora, S. Application of machine learning in predicting performance for computer engineering students: A case study. Sustainability 2019, 11, 2833. [Google Scholar] [CrossRef]
- Singh, J.; Perera, V.; Magana, A.J.; Newell, B.; Wei-Kocsis, J.; Seah, Y.Y.; Strimel, G.J.; Xie, C. Using machine learning to predict engineering technology students’ success with computer-aided design. Computer Applications in Engineering Education 2022, 30, 852–862. [Google Scholar] [CrossRef]
- Chopade, S.; Chopade, S.; Gawade, S. Multimedia teaching learning methodology and result prediction system using machine learning. Journal of Engineering Education Transformations 2022, 35, 135–142. [Google Scholar] [CrossRef]
- Campbell, I. Chi-squared and Fisher–Irwin tests of two-by-two tables with small sample recommendations. Stat Med 2007, 26, 3661–3675. [Google Scholar] [CrossRef] [PubMed]
- Borrego, M.; Froyd, J.E.; Hall, T.S. Diffusion of engineering education innovations: A survey of awareness and adoption rates in US engineering departments. Journal of Engineering Education 2010, 99, 185–207. [Google Scholar] [CrossRef]
- Masood, H. Breast cancer detection using machine learning algorithm. International Research Journal of Engineering and Technology (IRJET) 2021, 8. [Google Scholar]
- Rachburee, N.; Punlumjeak, W. A comparison of feature selection approach between greedy, IG-ratio, Chi-square, and mRMR in educational mining. 2015 7th international conference on information technology and electrical engineering (ICITEE). IEEE, 2015, pp. 420–424. [CrossRef]
- Chen, R.C.; Dewi, C.; Huang, S.W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. Journal of Big Data 2020, 7, 1–26. [Google Scholar] [CrossRef]
- Jia, W.; Sun, M.; Lian, J.; Hou, S. Feature dimensionality reduction: a review. Complex & Intelligent Systems 2022, 8, 2663–2693. [Google Scholar] [CrossRef]
- Kursa, M.B.; Jankowski, A.; Rudnicki, W.R. Boruta – A System for Feature Selection. Fundamenta Informaticae 2010, 101, 271–285. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Applied Sciences 2021, 3, 1–12. [Google Scholar] [CrossRef]
- Yan, K.; Zhang, D. Feature selection and analysis on correlated gas sensor data with recursive feature elimination. Sensors and Actuators B: Chemical 2015, 212, 353–363. [Google Scholar] [CrossRef]
- Alotaibi, B.; Alotaibi, M. Consensus and majority vote feature selection methods and a detection technique for web phishing. Journal of Ambient Intelligence and Humanized Computing 2021, 12, 717–727. [Google Scholar] [CrossRef]
- Borandag, E.; Ozcift, A.; Kilinc, D.; Yucalar, F. Majority vote feature selection algorithm in software fault prediction. Computer Science and Information Systems 2019, 16, 515–539. [Google Scholar] [CrossRef]
- Jindal, A.; Dua, A.; Kaur, K.; Singh, M.; Kumar, N.; Mishra, S. Decision Tree and SVM-Based Data Analytics for Theft Detection in Smart Grid. IEEE Transactions on Industrial Informatics 2016, 12, 1005–1016. [Google Scholar] [CrossRef]
- Teo, S.G.; Han, S.; Lee, V.C.S. Privacy Preserving Support Vector Machine Using Non-linear Kernels on Hadoop Mahout. 2013 IEEE 16th International Conference on Computational Science and Engineering, 2013, pp. 941–948. [CrossRef]
- Sikder, J.; Datta, N.; Tripura, S.; Das, U.K. Emotion, Age and Gender Recognition using SURF, BRISK, M-SVM and Modified CNN. 2022 International Conference on Electrical, Computer and Energy Technologies (ICECET), 2022, pp. 1–6. [CrossRef]
- Kuo, K.M.; Talley, P.C.; Chang, C.S. The accuracy of machine learning approaches using non-image data for the prediction of COVID-19: A meta-analysis. International Journal of Medical Informatics 2022, 164, 104791. [Google Scholar] [CrossRef] [PubMed]
- Beuthner, C.; Friedrich, M.; Herbes, C.; Ramme, I. Examining survey response styles in cross-cultural marketing research: A comparison between Mexican and South Korean respondents. International Journal of Market Research 2018, 60, 257–267. [Google Scholar] [CrossRef]
- Vora, D.R.; Iyer, K.R. Deep Learning in Engineering Education: Implementing a Deep Learning Approach for the Performance Prediction in Educational Information Systems. In Deep Learning Applications and Intelligent Decision Making in Engineering; IGI Global, 2021; pp. 222–255. [CrossRef]
- Vora, D.R.; Iyer, K.R. Deep Learning in Engineering Education: Performance Prediction Using Cuckoo-Based Hybrid Classification. In Machine Learning and Deep Learning in Real-Time Applications; IGI Global, 2020; pp. 187–218. [CrossRef]
- Saputra, N.A.; Hamidah, I.; Setiawan, A. A bibliometric analysis of deep learning for education research. Journal of Engineering Science and Technology 2023, 18, 1258–1276. [Google Scholar]
- Davis, L.; Sun, Q.; Lone, T.; Levi, A.; Xu, P. In the Storm of COVID-19: College Students’ Perceived Challenges with Virtual Learning. Journal of Higher Education Theory and Practice 2022, 22, 66–82. [Google Scholar]
- Li, H. The Influence of Online Learning Behavior on Learning Performance. Applied Science and Innovative Research 2023, 7, p69. [Google Scholar] [CrossRef]
- Kanetaki, Z.; Stergiou, C.; Bekas, G.; Troussas, C.; Sgouropoulou, C. A hybrid machine learning model for grade prediction in online engineering education. Int. J. Eng. Pedagog 2022, 12, 4–23. [Google Scholar] [CrossRef]
- Onan, A. Mining opinions from instructor evaluation reviews: a deep learning approach. Computer Applications in Engineering Education 2020, 28, 117–138. [Google Scholar] [CrossRef]
- Yogeshwaran, S.; Kaur, M.J.; Maheshwari, P. Project based learning: predicting bitcoin prices using deep learning. 2019 IEEE global engineering education conference (EDUCON). IEEE, 2019, pp. 1449–1454. [CrossRef]
- Lameras, P.; Arnab, S. Power to the Teachers: An Exploratory Review on Artificial Intelligence in Education. Information 2022, 13. [Google Scholar] [CrossRef]
Figure 2.
Process of ML
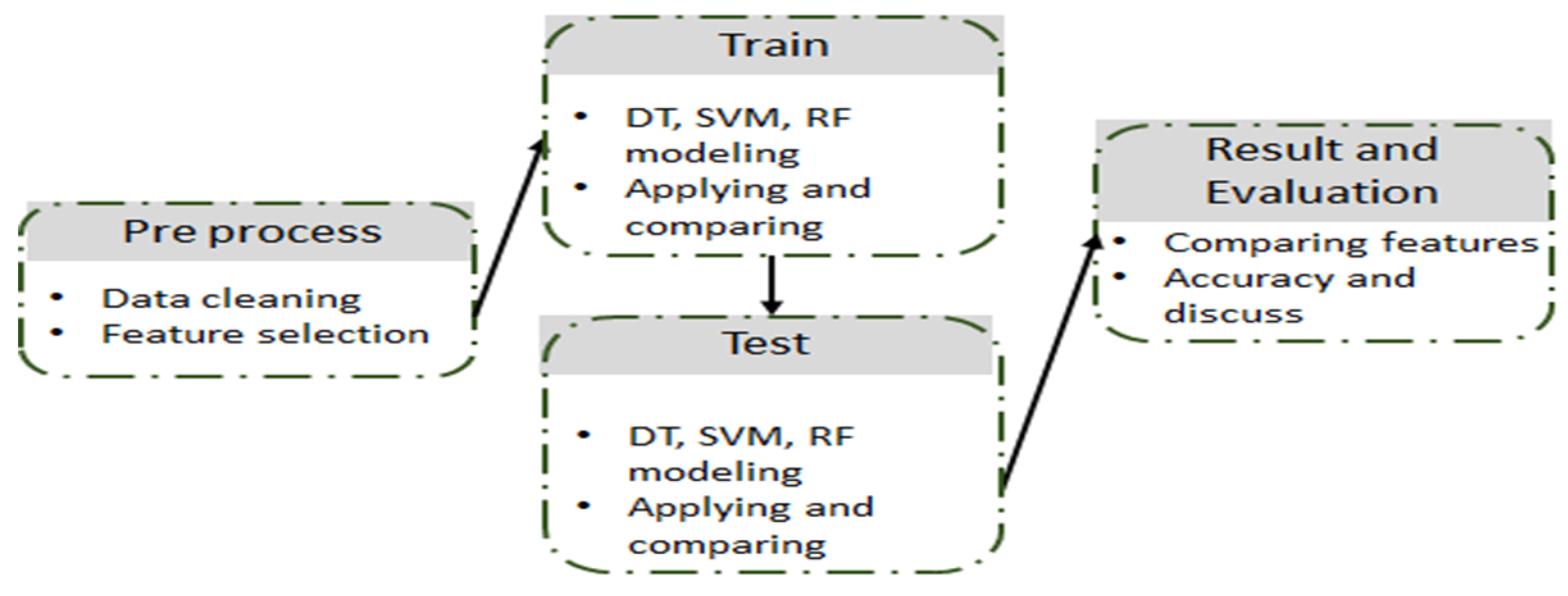

Table 1.
The accuracy results of ML models based on test results for a five-point Likert spectrum for students and instructors (the results’ summary of Table A14, A16, and A18).
Table 1.
The accuracy results of ML models based on test results for a five-point Likert spectrum for students and instructors (the results’ summary of Table A14, A16, and A18).
| Models | Students | Instructors | |||||
|---|---|---|---|---|---|---|---|
| I2 Theoretical | I4 Practical | I6 Theor.-Pract. | H2 Theoretical | H4 Practical | H6 Theor.-Pract. | ||
| SVM | 0.45 | 0.43 | 0.56 | 0.48 | 0.53 | 0.42 | |
| DT | 0.39 | 0.40 | 0.45 | 0.41 | 0.53 | 0.35 | |
| RF | 0.45 | 0.43 | 0.58 | 0.49 | 0.62 | 0.37 | |
Table 2.
Accuracy averages of models for students and instructors.
| Models | Students | Instructors | |||||
|---|---|---|---|---|---|---|---|
| I2 Theoretical | I4 Practical | I6 Theor.-Pract. | H2 Theoretical | H4 Practical | H6 Theor.-Pract. | ||
| SVM | 0.70 | 0.75 | 0.80 | 0.50 | 0.65 | 0.55 | |
| DT | 0.71 | 0.72 | 0.71 | 0.53 | 0.65 | 0.48 | |
| RF | 0.78 | 0.81 | 0.94 | 0.69 | 0.72 | 0.79 | |
Table 3.
Ranking of different dimensions based on the average reduction in impurity of each group of items in Appendix A 15 and Table A 19.
Table 3.
Ranking of different dimensions based on the average reduction in impurity of each group of items in Appendix A 15 and Table A 19.
| Groups | ||||||
|---|---|---|---|---|---|---|
| Students | Instructors | |||||
| Rank | I2 Theo. | I4 Prac. | I6 T-P | H2 Theo. | H4 Prac. | H6 T-P |
| Likert type (5-scale) | ||||||
| 1 | Ped. | Ped. | Ped. | Ped. | Ped. | Work-life Ori. |
| 2 | Motiv. | Motiv. | Work-life Ori. | Motiv. | Motiv. | Ped. |
| 3 | Qual. of Assess. & ICT | Know., Ins. & Skill | Motiv. | Work-life Ori. | Work-life Ori. | Motiv. |
| 4 | Know., Ins. & Skill | Theory & Pract. | Qual. of Assess. & ICT | Qual. of Assess. & ICT | Qual. of Assess. & ICT | Theory & Pract. |
| 5 | Work-life Ori. | Work-life Ori. | Know., Ins. & Skill | Know., Ins. & Skill | Theory & Pract. | Qual. of Assess. & ICT |
| 6 | Theory & Pract. | Qual. of Assess. & ICT | Theory & Pract. | Theory & Pract. | Know., Ins. & Skill | Know., Ins. & Skill |
| Likert type (3-scale) | ||||||
| 1 | Ped. | Ped. | Ped. | Ped. | Ped. | Motiv. |
| 2 | Motiv. | Motiv. | Motiv. | Motiv. | Motiv. | Ped. |
| 3 | Qual. of Assess. & ICT | Know., Ins. & Skill | Qual. of Assess. & ICT | Know., Ins. & Skill | Work-life Ori. | Work-life Ori. |
| 4 | Know., Ins. & Skill | Theory & Pract. | Know., Ins. & Skill | Work-life Ori. | Qual. of Assess. & ICT | Theory & Pract. |
| 5 | Work-life Ori. | Work-life Ori. | Work-life Ori. | Theory & Pract. | Theory & Pract. | Qual. of Assess. & ICT |
| 6 | Theory & Pract. | Qual. of Assess. & ICT | Theory & Pract. | Qual. of Assess. & ICT | Know., Ins. & Skill | Know., Ins. & Skill |
14.1cmNote: Abbreviations represent the following - Ped.: Pedagogy, Motiv.: Motivation, Qual. of Assess. & ICT: Quality of Assessment & ICT, Know., Ins. & Skill: Knowledge, Insight, & Skill, Theory & Pract.: Theory & Practice, Work-life Ori.: Working-life Orientation.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



