
Submitted:
29 August 2024
Posted:
30 August 2024
You are already at the latest version
Abstract
The manuscript deals with a new two-parameter unit stochastic distribution, obtained by transforming the Gumbel distribution, using generalized logistic mapping, into a unit interval. The distribution thus obtained is called the Gumbel–Logistic Unit (abbr. GLU) distribution, and its key stochastic properties have been investigated in detail. Among others, it is shown that the GLU distribution, unlike the Gumbel one which is always positively asymmetric, can take both asymmetric forms. Also, the procedure for estimating parameters based on quantiles, along with the asymptotic properties of the obtained estimators and the study of their numerical simulation, is presented. Finally, the application of the GLU distribution in modeling some real–world data related to telecommunications is considered.
Keywords:
Unit distributions
; Gumbel distribution
; generalized logistic map
; asymmetry
; parameter estimation
; quantiles
; telecommunications
MSC: 60E05; 62E10; 62F10
1. Introduction
One of the most attractive areas of contemporary probability theory are certainly unit stochastic distributions, defined on the interval and commonly used as stochastic models that describe so-called proportional (percentage) variables. Thus, they represent theoretical models that can explain the behavior of some real phenomena (see as some more recent ones, e.g., [1,2,3,4,5,6,7,8,9]). Still, it is worth pointing out that modeling with unit distributions is very specific, primarily due to the limitation of the data within the interval. Although the procedure for creating unit distributions can be given in a rather general form [10], the most common approach is based on continuous transformations of distributions defined on infinite intervals into a unit interval (see as some recent results, e.g., [11,12,13,14,15,16,17]). Motivated with procedures similar as in Stojanović et al. [18,19], here is presented a novel unit distribution, called the Gumbel–logistic unit (GLU) distribution.
This distribution is based on a general logistic mapping of the Gumbel distribution into a unit interval, which gives it flexibility and convenience for describing various kind of empirical distributions. The definition of the GLU distribution as well as its basic stochastic properties, related to its modality, asymmetry, moments, etc. are described in the next Section 2. In addition, the hazard rate and quantile functions of the GLU distribution are also discussed in this section. After that, Section 3 considers the procedure for estimating the parameters of the GLU distribution based on the sample quantiles. The asymptotic properties of thus obtained estimators were also examinated, along with an appropriate Monte Carlo numerical study. Section 4 presents the application of the GLU distribution in fitting some real–world data, related to telecommunications and machine learning. Finally, Section 5 provides some concluding highlights.
2. The GLU Distribution
In the first part of this section, the concept of GLU distribution is given as well as some of its basic stochastic properties. Then the hazard rate and quantile function are described, which are used to explore some other properties of the GLU distribution.
2.1. Definition and Key Properties
Let us start from a random variable (RV) Y with a zero–centered Gumbel distribution, whose probability density function (PDF) is:
where and is the scale parameter. As is known, the Gumbel distribution is a special case of the so-called generalized distribution of extreme values (of the first order) and as such is often used to model the distribution of maxima of a large number of samples from various distributions. Therefore, the basic idea here is to transform this distribution into a unit interval, where a similar application to the newly created distribution can be found. For this purpose, the so-called general logistics map (of the first kind) is used, defined as follows:
wherein is . Notice that the logistic map is the bijective and continuous function , with limits:
According to Equation (1) and the inverse function , the novel RV , defined on the unit interval is obtained. After some computations, the PDF of the RV X can be expressed as follows:
where and . Thus, the RV X, with the PDF given by Equation (2), has a Gumbel–logistic unit (GLU) distribution, with the parameters , which will be further denoted as . Notice that GLU distribution is a two-parameter distribution, where, in addition to the scale parameter , there is also a shape parameter . Also, it is worth noting that the GLU distribution has similar properties to the Gumbel distribution. However, as is known, the Gumbel distribution is unimodal and positively asymmetric, while the GLU distribution has some other special characteristics. We first describe some of them with the following statement.
Theorem 1.
Let be the RV with the GLU distribution, whose PDF is given by Equation (2). Then, the following statements hold:
- When , the RV X is unimodal and both-sides vanishing, that is,
-
When and the functionhas at least one positive root , the RV X is unimodal, left-tailed and right-side vanishing, that is,
- Otherwise, the PDF of the RV X strictly decreases on , with boundary properties as in Equation (4).
Proof.
We use a procedure similar as in Stojanović et al. [19]. First, after some algebraic computation, the first partial derivative of the function , with respect to , is as follows:
Thus, it is obvious that the equation is equivalent to , where:
After substitution and some rearrangement, the previous equation is easily transformed into the equivalent one , i.e.,
Based on it, by applying Descartes’ rules of signs, the following cases can be observed:
When , there exists exactly one solution of Equation (5). Therefore, it obviously represents the unique mode of GLU distribution.
When , Equation (5) can have 0 or 2 different solutions and the other two cases mentioned in the theorem are then obtained.
Remark 1.
The preceding theorem describes three basic forms of the PDFs of the GLU distribution, which can also be seen in Figure 1(a). As can be easily noticed, the GLU distribution can have various shapes, where in addition to the typical one with a "peak", which is similar to the Gumbel distribution, it can also have a decreasing one. Let us also note that the shape of the GLU distribution depends on the number of solutions to Equation (5). Thus, for the standard Gumbel distribution with , this equation becomes quadratic one and a mode exists if and only if its discriminant satisfies , i.e, . Still, a more precise examination of the modality of GLU distribution will be further presented below.
According to Equation (2), the cumulative distribution function (CDF) of the GLU distribution can be obtained as:
where . Figure 1(b) shows the plots of this function for some parameter values . Obviously, the function is well defined at the ends of the unit interval, because is valid:
for all . Using the CDF , one can simply prove the following statement regarding the asymmetry conditions for the GLU distribution:
Theorem 2.
Let is the RV with the GLU distribution, and
the function on , where . Then, the GLU distribution is positively asymmetric when , and vice versa, it is negatively asymmetric when .
Proof.
Note that the CDF of the GLU distribution, given by Equation (6), is a strictly increasing function on the interval . Therefore, the median can be easily obtained as solutions of the equation:
Consequently, the RV will be positively asymmetric if and only if is valid that is, . After some algebraic calculation it is easy to see that the last inequality indeed gives , and the corresponding inequality for the negatively asymmetric GLU distribution is obtained in a similar way. □
Remark 2.
The previous theorem gives the parameter dependence under which the GLU distribution has different skewness. It is shown in Figure 2(a), along with the dependence , mentioned in Theorem 1, which indicating different shapes of the GLU distribution. Thereby, the point which represents the solution of the equation is clearly visible. It should be emphasized that the dependence does not indicate the symmetry of the GLU distribution. As an illustration, Figure 2(b) shows graphs of PDFs for which this dependence is applied, that is, for which the median is equal to . Note that the "true" symmetry of the GLU distributed RV X does not exist, which also confirms its PDF given by Equation (2). In this way, asymmetry represents one of the essential characteristics of this distribution.
We now describe the procedure for obtaining the moments of the GLU distribution:
where . Note that it is valid:
so the moments exist, but they cannot be expressed in a closed form. To this end, it is convenient to perform the series expansion for , given by the following statement.
Theorem 3.
The moment of the RV X with GLU distribution can be expressed as follows:
where and are the lower and upper incomplete gamma functions, respectively.
Proof.
According to definition of the moment, given by Equation (8), and by applying integration by parts, one obtains:
where and
Obviously, both integrals in (11) are absolutely convergent, and applying the generalized binomial formula in them, it follows:
Remark 3.
As already mentioned, Equation (9) can be suitable for numerical (approximate) calculation of the moments of GLU distribution, first of all its mean value and the variance . For instance, when and their approximate values (calculated by summing terms in Equation (9)) are, respectively, and . In a similar way one can calculate the other statistical measures of the GLU distribution. Thus, the skewness coefficient and the kurtosis are, respectively,
2.2. Hazard Rate and Quantile Functions
In this part, we consider two important functions which additionally characterize the GLU distribution. First, the hazard rate function (HRF) of the GLU distribution can be easily obtained according to Equations (2) and (6), as follows:
Obviously, the function strictly increases when , which means that in that case the probability of failure of the designed system increases. On the other hand, when , this HRF has two asymptotic points at and , i.e., it is a bath-tube shaped. Then, there is a so-called declining failure rate (DFR) that describes a phenomenon where the probability of failure decreases in some interval. Both of these situations can be obtained from the GLU distribution, for certain values of its parameters, as can be also seen in Figure 3(a). Similar to some previous results on unit distributions (see, e.g., Bakouch et al. [4] or Biçer et al. [15]), one typical characterization of the HRF of the GLU distribution can be given by the following statement:
Theorem 4.
The RV X has the GLU distribution , with the HRF defined by Equation (13), if and only if this HRF satisfies differential equation:
Proof.
We have use the procedure similar as in Bakouch et al. [4], and first assume that RV X has the GLU distribution . Thus, the logarithm of its PDF, given by Equation (2), is as follows:
By differentiating both sides of the previous equality on x, one obtains:
Therefore, according to the well-known property of HRF (see, e.g., Salinas et al. [21]), and using Equation (13), it follows:
Otherwise, let us assume that Equation (14) holds, which after integration becomes:
and the HRF is obtained as in Equation (13). Furthermore, by replacing this function into Equation (15) and after integration, one obtains:
that is
After another integration, it follows:
so according to the conditions and it is easy to obtain that and . Thus, the function is indeed the CDF of RV , and theorem is completely proved. □
In the following, the so-called quantile function (QF) of the GLU distribution is considered, obtained as inverse function of its CDF:
Herein is and plots of the QF for some parameter values are shown in Figure 3(b). The QF provides a useful tool for further investigating the properties of the GLU distribution, as given in the following statement.
Theorem 5.
Let is the GLU distributed RV, whose QF is defined by Equation (16). Then, the RV X is unimodal if and only if its parameters satisfy the equality:
where , and is the mode of the GLU distribution. Otherwise, the PDF of X is a strictly decreasing function.
Proof.
Applying the derivative rule of the inverse function, the derivatives of QF up to the third order are as follows:
where . At the same time, if the value is the mode for the RV X, it is the critical point of its PDF , that is, the value satisfies:
Remark 4.
Note that Theorems 1 and 5 provide complete insight into the modality property of the GLU distribution. It is explicit described by the functional dependence in Equation (17), which is close to logarithmic spirals, as shown in Figure 4. Here are presented, with two different “views", polar plots of parameter dependences that give unimodal GLU distribution, for different but fixed values . In addition, the QF can also describes the asymmetry conditions of the GLU distribution. The positive and negative asymmetry conditions are easily obtained by solving the inequalities and , respectively, and it can simply be proved that they are the same as in Theorem 2.
3. Parameters Estimation & Numerical Simulation Study
In this Section the estimation of the unknown parameters of the GLU-distributed RV X is described, based on its observed random sample of length n. Let us note first that according to the aforementioned properties of the GLU distribution, some common procedures for estimating its parameters are not appropriate here. For instance, according to Equation (9), it follows that the moments of the GLU distribution cannot be expressed in a closed form, and thus the method of moments cannot be successfully applied. Similarly, the maximum likelihood (ML) estimation method is also associated with certain difficulties, related to numerically finding solutions that maximize the likelihood function:
For these reasons, and similar as in Stojanović et al. [18], Stojanović et al. [19], here we consider parameter estimation methods based on the quantiles of the GLU distribution. These estimators (we will call them Q-estimators) are explicitly given and also have some convenient asymptotic properties, which will be shown below.
In that aim, for a random sample of the length n, let us define the appropriate order statistics . Then the PDF of the i-th order statistic , as is known, can be expressed as follows:
where . On the other hand, by replacing in the QF , given by Equation (16), the quantile is obtained. Therefore, the appropriate sample quantile can be obtained according to the equality:
where is the integer part of . Thus, sample quantiles are actually the order statistics, so their distribution is determined by Equation (20).
In order to determine the Q-estimators of the parameters of the GLU-distributed RV X, notice first that for is obtained the quantile . Hence, by equating this quantile with sample one , the estimator of the shape parameter is simply obtained as follows:
Furthermore, by substituting into the QF , it is obtained the median of the GLU distribution:
Thus, by equating median with the sample one , and using the estimator , for the estimator of the scale parameter one obtains:
In the following, some asymptotic properties of the proposed estimators are examined:
Theorem 6.
Statistics are consistent and asymptotic normal (AN) estimators of the true parameters .
Proof.
To prove the consistency of the proposed estimators, we apply some general results of sample quantile theory. Let us first note that the CDF is a differentiable and increasing function on . Therefore, the quantiles are uniquely determined by Equation (16), while the sample quantiles are uniquely determined by Equation (21). Now, according to Bahadur’s representation of sample quantiles (see, e.g., Theorem 1 in [22], or Serfling [23], pp. 91-92), it follows:
where is the empirical CDF of the GLU-distributed RV X. It is well known that for arbitrary , the empirical CDF almost surely and uniformly converges to the CDF , when . Applying this convergence on Equation (25), when , one obtains:
i.e., the sample quantiles are consistent estimators of the theoretical ones. At the same time, the estimators are continuous functions of the sample quantile , where , as well as the sample median . Thus, applying the continuity property of almost sure convergence (see, e.g., Serfling [23], p. 24), it follows:
i.e., are indeed consistent estimators of .
We now prove the AN properties of the proposed estimators. To this end, note that under the above assumptions, Equation (25) implies the following convergence in the distribution:
By using Equation (26), for the sample quantile , where , one obtains:
where, according to Equation (2) and after some calculations, we get:
Hence, applying the continuity of convergence in the distribution (see, e.g., Serfling [23], p. 118), for the estimator , defined by Equation (22), it is obtained:
where:
In a similar way, the AN property of the estimator , given by Equation (24), is proved. To that end, let us first notice that Equation (26), applying on the sample median , gives the following convergence:
In the following, a numerical study examing the efficiency of the proposed Q-estimators is presented, based on independent Monte Carlo simulations of samples drawn from the GLU distribution. In other words, various samples and parameter values from the GLU distribution were considered, according to which the Q-estimators were calculated, and their statistical analysis was also performed. To that aim, three different samples from the GLU-distribution are examined (also shown in Figure 5, below):
Sample I is taken from a decreasing GLU distribution, with parameters and , which satisfies the inequality .
Sample II is taken from a unimodal, positively skewed GLU distribution, with parameters and , so the equality holds.
Sample III is taken from a unimodal, negatively skewed GLU distribution, with parameters and , which satisfies the inequality .
Note that the simulated sample values are generated by the R-package "distr" [24], and thereafter the Q-estimates and are calculated using the procedure described above. To additionally check the efficiency of proposed estimators, realizations of samples of different lengths were considered, so that they are close to the lengths of some of the real-world data that will be analyzed below. In addition, for each of the samples, independent simulations were conducted, on which an appropriate statistical analysis of the obtained estimates was then performed. The results of this analysis are presented in the following Table 1, Table 2 and Table 3.
More specifically, the above Tables contain summary statistics of the calculated estimates, that is, their minimums (Min.), mean values (Mean) and maximums (Max.). In addition, some error statistics are also shown, i.e., the standard deviations (SD), the mean square errors of estimation (MSEE) and fractional errors of estimation (FEE). Finally, the results of the Anderson-Darling and Shapiro-Wilk normality tests are also given. Based on the results obtained in this way, it can be noted that the proposed estimators are efficient, because the bias, the sample range (Max.–Min.), as well as the values of SD, MSEE and FEE decrease with the increase in the sample size. At the same time, it can be noted that stability and efficiency are more significant at the estimates , especially in the first sample. This obviously follows from the fact that the estimate is calculated by a two-stage procedure, i.e., by using the previously obtained estimate .
Similar conclusions can be made according to the results of AN testing of these estimates. As previously mentioned, AN testing was conducted using Anderson–Darling and Shapiro–Wilk normality tests, whose statistics, labelled by AD and W respectively, as well as the appropriate p-values were calculated using the R-package "nortest " [25]. According to the results obtained in this way, also presented in Table 1, Table 2 and Table 3, it can be noted that estimates have a pronounced AN feature, which applies to all observed samples. On the other hand, estimates have a less pronounced AN feature, primarily in the case of smaller samples. Nevertheless, the AN property is clearly confirmed in most cases with them as well. Some confirmations of these facts can be also seen in Figure 5, where the realizations of the samples, as well as their empirical and theoretical distributions, are shown.
4. Applications of the GLU Distribution
As mentioned earlier, the Gumbel distribution can be used to model the extremes of some sample values. In more detail, in his original work Gumbel [26] has proved that the maximum of a sample taken from a population with an exponential distribution, after a simple transformation, approaches the Gumbel distribution with increasing sample size. This procedure can also be applied in some practical cases, such as in Burke et al. [27], where the Gumbel distribution is used to analyze maximum rainfall. In a similar way, the maximum load on the telecommunications system, which allows administrators to optimize network capacity and minimize the occurrence of overloads can be modeled with the Gumbel distribution. It is worth pointing that some other application can be in risk analysis related to the ICT technology, which enables companies to better understand and prepare for extreme scenarios that can significantly affect the business by developing methods for the development and introduction of new technologies and concepts, as is shown in Pažun Langović [28].
For those reasons, this section considers some possible applications of the GLU distribution in real-world data modeling, primarily in the domains of telecommunications and machine learning. The datasets observed here were downloaded from the website “Kaggle.com" [29], a platform focused on analysing and sharing datasets related to machine learning and online data science. Thereby, the observed data represent parts of the training data related to network and telecommunication traffic in India, i.e., describe the satisfaction and participation of end users, as well as the adaptability and extensibility of the corresponding network transport. More specifically, the three real-world datasets analyzed below can be briefly described as follows:
The first data set, named Series A, consists of data representing the percentage of service usage time of end users. The data was collected by Mirza [30] and as already mentioned, it is a part of the training data intended for machine learning and online coding and modeling.
The second one (Series B), are also part of the same training data as above, and consistes of monthly end user fees (in Indian Rupees). In doing so, these data are normalized in relation to their maximum and minimum values, and in this way a set of data in a unit interval is obtained.
Finally, the third set of data, designated as Series C, is obtained from training data authored by Mnassri [31], intended for the development of appropriate predictive models, i.e., training, cross-validation and performance testing of machine learning models. Therefore, Series C consists of data, which represent the total daily call length of end users (expressed in minutes), whereby the normalized values are obtained as the ratio of the call duration to the maximum call length.
Realizations of these series are shown in Figure 6(a), while Figure 6(b) shows the values of their corresponding autocorrelation functions (ACFs). As can be easily seen, the ACF values of all series are realatively low, so they can be considered as independent realizations of some unit RV, that is, they can obviously be modeled by one of the unit stochastic distributions.
In order to additionally verify the effectiveness of such modeling, in addition to the proposed GLU distribution, some other existing, well-known unit distributions were used to fit the empirical distributions of observed data. In more detail, the GLU distribution is compared with two well-known unit distributions, namely the Beta and Kumaraswamy distributions. Their PDFs are, respectively,
where , as are distribution parameters, and is the beta function. To obtain the estimated parameter values of the Beta distribution, the method of moments (MM) is used here (see, e.g., [32]). According to this, the MM estimates are as follows:
where and are the sample mean and variance, respectively, and the inequality holds. On the other hand, the maximum likelihood (ML) estimation method is used for the Kumaraswamy distribution, according to which estimators are obtained as solutions of coupled equations (see, e.g., Dey et al. [33]):
As is known, the proposed estimators for both of the above distributions have the properties of stability and asymptotic normality. In this way, one of the reasons for choosing them is the comparison not only with respect to their distribution, but also with respect to different estimation procedures.
The results of the previously described estimation procedures can be seen in Figure 6(c), where the empirical distributions of the observed data (given by histograms) are shown, along with the corresponding fitted PDFs. As can be easily seen, the empirical distribution of Series A is significantly positively skewed and it is fitted with decreasing theoretical PDFs. On the other side, Series B and Series C have negatively skewed unimodal distributions, with the distribution of Series C being "approximately symmetric" to some extent. This can also be confirmed by the estimated parameter values for each series and for all competing models, which are shown in Table 4 below.
Based on them, independent Monte Carlo simulations of the corresponding theoretical distributions were performed and the agreement between the empirical and fitted distributions was checked in several different ways. Namely, the mean square estimation error (MSEE) statistics, the Akaike information criterion (AIC), as well as the Bayesian information criterion (BIC) for model selection were used for this purpose. In addition, the Kolmogorov–Smirnov (KS) test of equivalence of the asymptotic distribution of the two samples was also performed, and all these values are also shown in Table 4.
According to the results obtained in this way, it is noticeable, for instance, that in the case of Series A all three theoretical distributions can be adequate for fitting. On the contrary, for the other two series, the values of MSEE, AIC and BIC are generally lower in cases where GLU and Beta distribution are applied as appropriate fitting models. Nevertheless, it is clear that the GLU distribution has better fitting characteristics than both other theoretical distributions, even in the case of Series C, which has an "approximately symmetric" distribution. Moreover, only with the GLU distribution, the KS test statistics do not reject, with a significant level , the hypothesis of the equivalence of the theoretical and the observed empirical distribution.
5. Conclusion
A novel, the so-called GLU distribution is presented here, along with its basic stochastic properties, where, among others, the asymmetry of the proposed distribution was shown. In addition, a quantile-based procedure was performed to estimate the parameters of the GLU distribution. The consistency and AN properties of the Q-estimators obtained in this way were considered, as well as a Monte-Carlo study of their efficiency. In order to further verify the effectiveness of the proposed model, it was applied in fitting the distributions of three real data sets, where it was compared with the Beta and Kumaraswamy distributions, thus demonstrating its higher efficiency. It is worth pointing out that the application of the GLU distribution shown here to training datasets intended for machine learning can also be the basis for some further research. Namely, as is known, logistic regressions are often used in machine learning and data science in general. Therefore, one of the guidelines for some potential further research can be the application of unit distributions based on logistic maps in this area.
Author Contributions
Conceptualization, V.S. and M.J; methodology, V.S. and M.J.; software, V.S., M.J. and B.P.; validation, V.S., M.J and B.P.; formal analysis, V.S. and M.J.; data curation, V.S., M.J. and Z.L.; writing—original draft preparation, V.S., M.J. and Z.L.; writing—review and editing, B.P. and Z.L.; visualization, V.S. and B.P.; supervision, B.P. and Z.L.; project administration, B.P. and Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original data presented in the study are openly available on the “Kaggle" website: https://www.kaggle.com.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Afify, A.Z.; Nassar, M. , Kumar, D.; Cordeiro, G.M. A New Unit Distribution: Properties and Applications. Electron. J. Appl. Stat. 2022, 15, 460–484. [Google Scholar]
- Nasiru, S.; Abubakari, A.G.; Chesneau, C. New Lifetime Distribution for Modeling Data on the Unit Interval: Properties, Applications and Quantile Regression. Math. Comput. Appl. 2022, 27, Article. [Google Scholar] [CrossRef]
- Martínez-Flórez, G.; Azevedo-Farias, R.B.; Tovar-Falón, R. New Class of Unit-Power-Skew-Normal Distribution and Its Associated Regression Model for Bounded Responses. Mathematics 2022, 10, Article. [Google Scholar] [CrossRef]
- Bakouch, H.S.; Hussain, T.; Tošić, M.; Stojanović, V.S.; Qarmalah, N. , Unit Exponential Probability Distribution: Characterization and Applications in Environmental and Engineering Data Modeling, Mathematics 2023, 11(19), Article No. 4207. [CrossRef]
- Korkmaz, M. Ç.; Korkmaz, Z. S. The Unit Log–log Distribution: A New Unit Distribution With Alternative Quantile Regression Modeling and Educational Measurements Applications. J. Appl. Stat. 2023, 50(4), 889–908. [Google Scholar] [CrossRef] [PubMed]
- Nasiru, S.; Abubakari, A.G.; Chesneau, C. The Arctan Power Distribution: Properties, Quantile and Modal Regressions with Applications to Biomedical Data. Math. Comput. Appl. 2023, 28, Article. [Google Scholar] [CrossRef]
- Shakhatreh, M.K.; Aljarrah, M.A. Bayesian Analysis of Unit Log-Logistic Distribution Using Non-Informative Priors. Mathematics 2023, 11, Article. [Google Scholar] [CrossRef]
- Fayomi, A.; Hassan, A.S.; Baaqeel, H.; Almetwally, E.M. Bayesian Inference and Data Analysis of the Unit–Power Burr X Distribution. Axioms 2023, 12, Article. [Google Scholar] [CrossRef]
- Alomair, G.; Akdoğan, Y.; Bakouch, H.S.; Erbayram, T. On the Maximum Likelihood Estimators’ Uniqueness and Existence for Two Unitary Distributions: Analytically and Graphically, with Application. Symmetry 2024, 16, Article. [Google Scholar] [CrossRef]
- Condino, F.; Domma, F. ; Unit Distributions: A General Framework, Some Special Cases, and the Regression Unit-Dagum Models. Mathematics, 2888. [Google Scholar] [CrossRef]
- Krishna, A.; Maya, R.; Chesneau, C.; Irshad, M.R. The Unit Teissier Distribution and Its Applications. Math. Comput. Appl. 2022, 27, Article. [Google Scholar] [CrossRef]
- Ramadan, A.T.; Tolba, A.H.; El-Desouky, B.S. A Unit Half-Logistic Geometric Distribution and Its Application in Insurance. Axioms 2022, 11, Article. [Google Scholar] [CrossRef]
- Mustafa, Ç.; Korkmaz, Z; Korkmaz, S. The Unit Log–log Distribution: A New Unit Distribution With Alternative Quantile Regression Modeling and Educational Measurements Applications, J. Appl. Stat. 2023, 50(4), 889–908,. [CrossRef]
- Nasiru, S.; Chesneau, C.; Abubakari, A.G.; Angbing, I.D. Generalized Unit Half-Logistic Geometric Distribution: Properties and Regression with Applications to Insurance. Analytics 2023, 2, 438–462. [Google Scholar] [CrossRef]
- Biçer, C.; Bakouch, H.S.; Biçer, H.D.; Alomair, G.; Hussain, T.; Almohisen, A. Unit Maxwell-Boltzmann Distribution and Its Application to Concentrations PoGLUtant Data. Axioms. [CrossRef]
- Nasiru, S.; Chesneau, C.; Ocloo, S.K. , The Log-Cosine-Power Unit Distribution: A New Unit Distribution for Proportion Data Analysis. Decis. Anal. J. 2024, 10, Article. [Google Scholar] [CrossRef]
- Alsadat, N.; Taniş, C.; Sapkota, L.P.; Kumar, A.; Marzouk, W.; Gemeay, A.M. Inverse Unit Exponential Probability Distribution: Classical and Bayesian Inference With Applications. AIP Advances 2024, 14, Article. [Google Scholar] [CrossRef]
- Stojanović, V.S.; Jovanović Spasojević, T.; Jovanović, M. Laplace-Logistic Unit Distribution with Application in Dynamic and Regression Analysis. Mathematics 2024, 12, Article. [Google Scholar] [CrossRef]
- Stojanović, V.S.; Bojičić, R.; Pažun, B.; Langović, Z. Quasi-Lindley Unit Distribution: Properties and Applications in Stochastic Data Modeling, U.P.B. Sci. Bull., Series A, submitted manuscript.
- Rudin, W. Real and complex analysis (3rd ed.), McGraw-Hill International Edition, New York, 1987.
- Salinas, H.S.; Bakouch, H.S.; Almuhayfith, F.E.; Caimanque, W.E.; Barrios-Blanco, L.; Albalawi, O. Statistical Advancement of a Flexible Unitary Distribution and Its Applications. Axioms 2024, 13, Article. [Google Scholar] [CrossRef]
- Dudek, D.; Kuczmaszewska, A. Some Practical and Theoretical Issues Related to the Quantile Estimators, Stat. Papers 2024, in press. [Google Scholar] [CrossRef]
- Serfling, R.J. Approximation Theorems of Mathematical Statistics, 2nd edition; John Wiley & Sons: New York, NY, USA, 2002. [Google Scholar]
- Ruckdeschel, P.; Kohl, M.; Stabla, T.; Camphausen, F.; S4 Classes for Distributions. R News, 2006, 6:(2–6). Available online: https://CRAN.R-project.org/doc/Rnews (accessed on 01 August, 2024).
- Gross, L. Tests for Normality. R package version 1.0-2. http://CRAN.R-project.org/package=nortest, 2013. http://CRAN.R-project.org/package=nortest (accessed on 1 August, 2024).
- Gumbel, E.J. Statistical theory of extreme values and some practical applications, Appl. Math. Ser. 1954, 33. [Google Scholar]
- Burke, E.J.; Perry, R.H.J.; Brown, S.J. An extreme value analysis of UK drought and projections of change in the future. J. Hydrol. 2010, 388 (1–2), 131–143. [CrossRef]
- Pažun, B., Langović, Z. Contemporary Information System Development Methodologies in Tourism Organizations, 4th International Scientific Conference, Tourism in Function of Development of the Republic of Serbia, Spa Tourism in Serbia and Experiences of Other Countries, 2019, Vrnjačka Banja, Serbia, 467-481. https://www.tisc.rs/proceedings/index.php/hitmc/article/view/267.
- Kaggle.com https://www.kaggle.com (accessed on 2 August, 2024).
- Mirza, M.H. "telecom_churn_dataset" (dataset), 2023. https://www.kaggle.com/datasets/mirzahasnine/telecom-churn-dataset (accessed on 2 August, 2024).
- Mnassri, B. "Telecom Churn Dataset" (dataset), 2023. https://www.kaggle.com/datasets/mirzahasnine/telecom-churn-dataset (accessed on 2 August, 2024).
- Kachiashvili, K.J.; Melikdzhanjan, D.I. Estimators of the Parameters of Beta Distribution. Sankhya B 2019, 81, 350–373. [Google Scholar] [CrossRef]
- Dey, S.; Mazucheli, J.; Nadarajah, S. Kumaraswamy Distribution: Different Methods of Estimation. Comp. Appl. Math. 2018, 37, 2094–2111. [Google Scholar] [CrossRef]
Figure 1.
Plots of the PDFs (a) and CDFs (b) of the GLU distribution for different values of parameters .
Figure 1.
Plots of the PDFs (a) and CDFs (b) of the GLU distribution for different values of parameters .
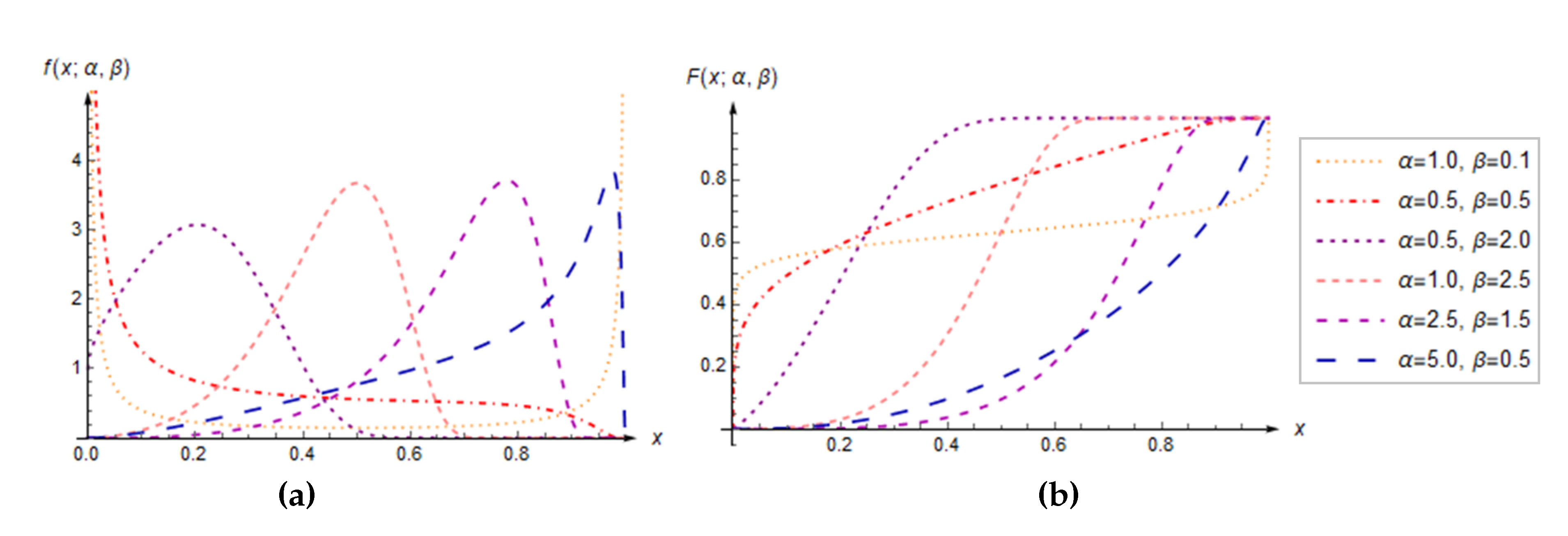
Figure 2.
(a) Parameter areas with different shapes and asymmetry of the GLU distribution. (b) Some PDFs of the GLU distributed RV X, where the dependence holds.
Figure 2.
(a) Parameter areas with different shapes and asymmetry of the GLU distribution. (b) Some PDFs of the GLU distributed RV X, where the dependence holds.
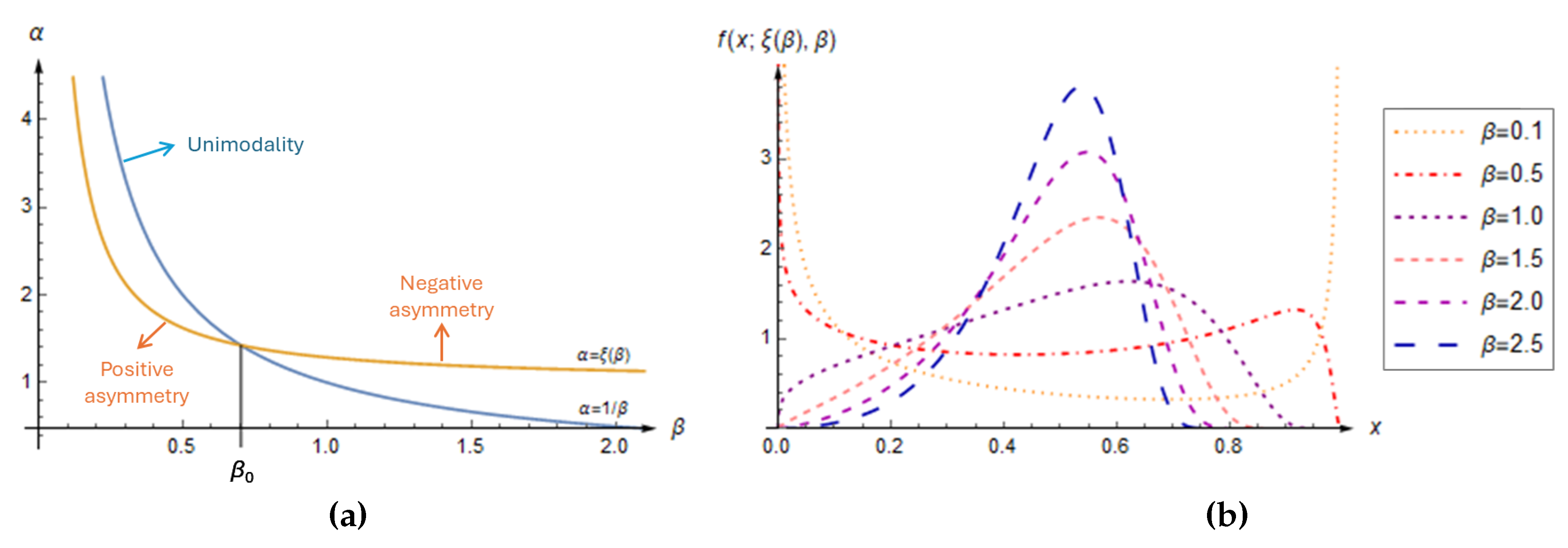
Figure 3.
Plots of the HRF (a) and QF (b) of the GLU distribution, obtained for some parameters values .
Figure 3.
Plots of the HRF (a) and QF (b) of the GLU distribution, obtained for some parameters values .
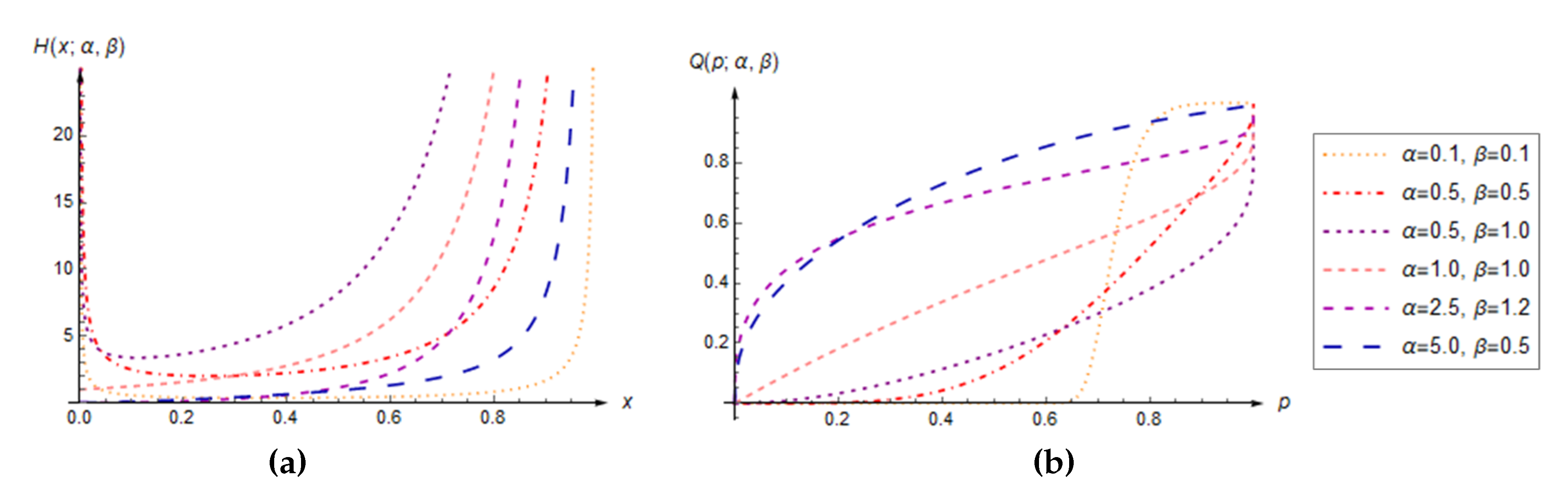
Figure 4.
Polar plots of parameter dependences yielding a unimodal GLU distribution, with some fixed values of and two different angular intervals: (a); (b).
Figure 4.
Polar plots of parameter dependences yielding a unimodal GLU distribution, with some fixed values of and two different angular intervals: (a); (b).
Figure 5.
Left plots: Observations of various samples drawn from the GLU-distribution. Right plots: Empirical and fitted PDFs of the RV .
Figure 5.
Left plots: Observations of various samples drawn from the GLU-distribution. Right plots: Empirical and fitted PDFs of the RV .
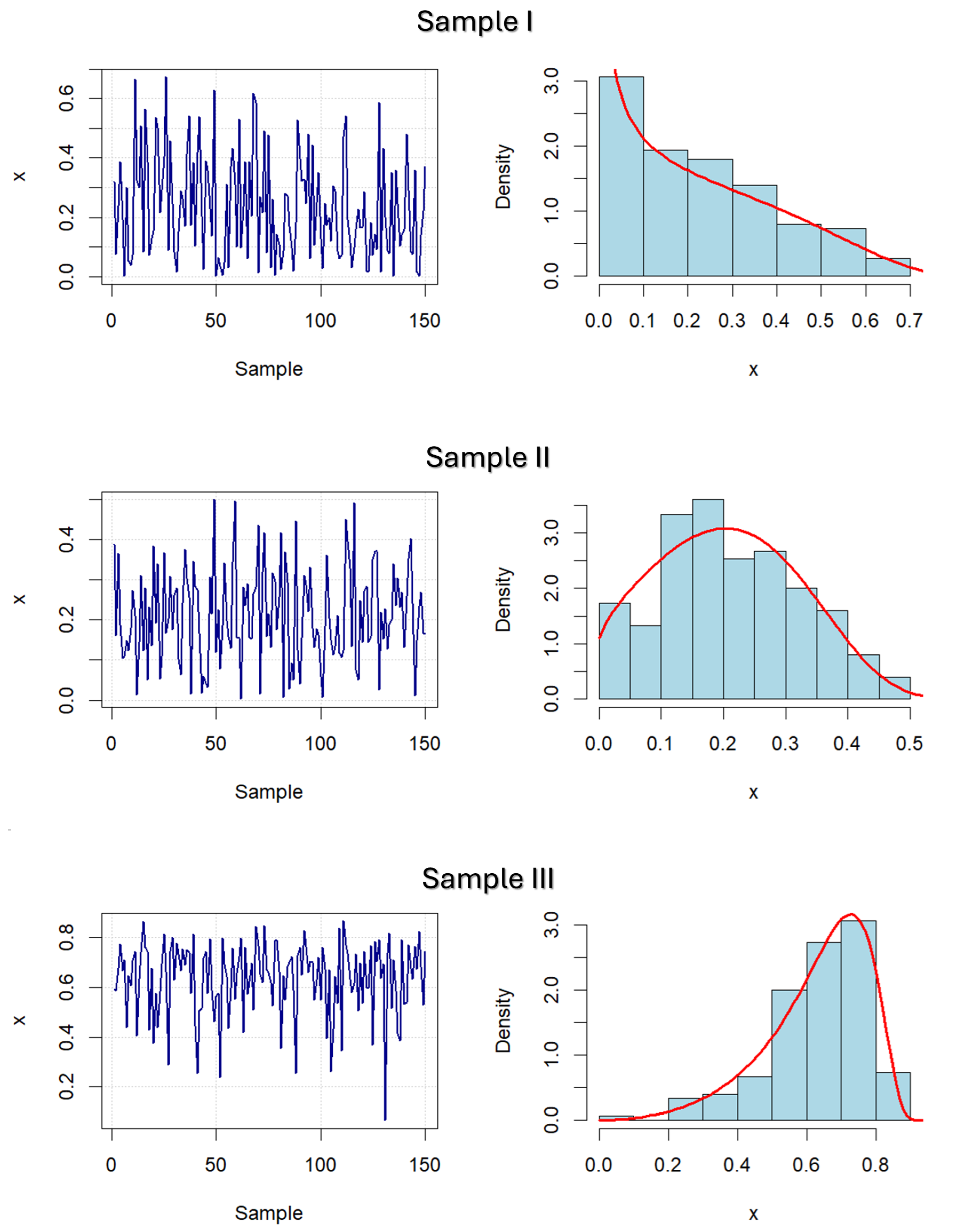
Figure 6.
(a): Observed sample values of three real-world data. (b): Estimated ACFs of observed samples (data series). (c): Empirical and fitted PDFs, obtained using the GLU, Beta and Kumaraswamy distributions.
Figure 6.
(a): Observed sample values of three real-world data. (b): Estimated ACFs of observed samples (data series). (c): Empirical and fitted PDFs, obtained using the GLU, Beta and Kumaraswamy distributions.
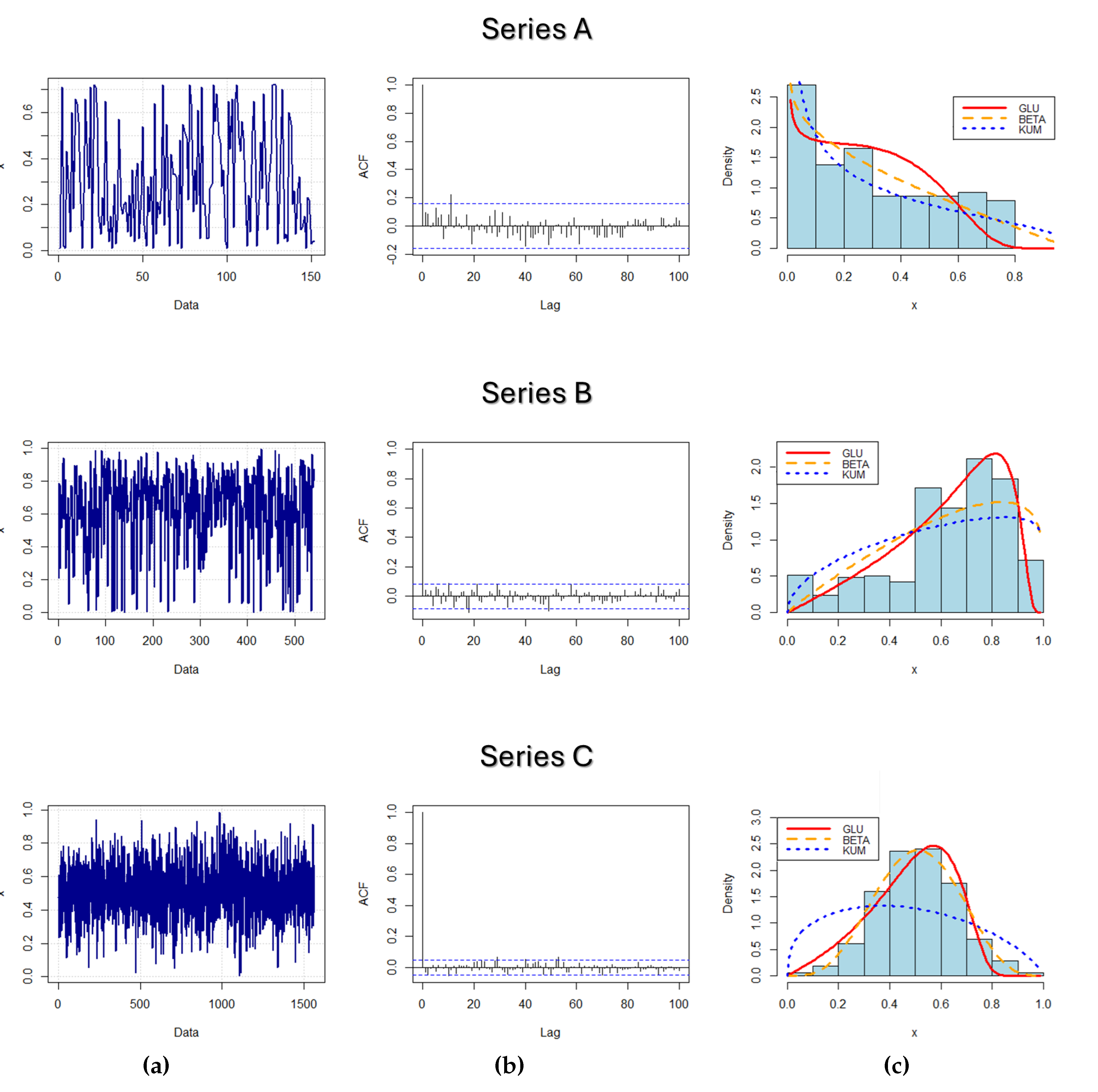

Table 1.
Summary statistics, estimation errors, and AN testing of parameter estimates of the GLU distribution: Sample I with the true parameter values and .
Table 1.
Summary statistics, estimation errors, and AN testing of parameter estimates of the GLU distribution: Sample I with the true parameter values and .
| Statistics | ||||||
|---|---|---|---|---|---|---|
| Min. | 0.4015 | 0.5716 | 0.4237 | 0.6739 | 0.4660 | 0.8195 |
| Mean | 0.5122 | 1.1906 | 0.5111 | 1.1519 | 0.5020 | 1.0488 |
| Max. | 0.6101 | 1.8720 | 0.5807 | 1.7959 | 0.5515 | 1.2252 |
| SD | 0.0388 | 0.9769 | 0.0221 | 0.2341 | 0.0122 | 0.0439 |
| MSEE | 0.0403 | 0.3218 | 0.0252 | 0.1906 | 0.0168 | 0.0519 |
| FEE (%) | 8.0623 | 32.177 | 5.0333 | 19.062 | 3.3707 | 5.1930 |
| 0.2933 | 0.5094 | 0.3035 | 0.6068 | 0.2930 | 0.4860 | |
| (p-value) | (0.5997) | (0.1962) | (0.5704) | (0.1137) | (0.6004) | (0.2240) |
| W | 0.9929 | 0.9876 * | 0.9946 | 0.9884 * | 0.9957 | 0.9902 |
| (p-value) | (0.2815) | (0.0299) | (0.5138) | (0.0414) | (0.7109) | (0.0890) |
.
Table 2.
Summary statistics, estimation errors, and AN testing of parameters estimates of the GLU distribution: Sample II with the true parameter values and .
Table 2.
Summary statistics, estimation errors, and AN testing of parameters estimates of the GLU distribution: Sample II with the true parameter values and .
| Statistics | ||||||
|---|---|---|---|---|---|---|
| Min. | 0.4299 | 1.2050 | 0.4731 | 1.3330 | 0.4821 | 1.5590 |
| Mean | 0.4993 | 2.1085 | 0.4995 | 2.0420 | 0.5000 | 2.0206 |
| Max. | 0.5615 | 2.6790 | 0.5194 | 2.2570 | 0.5155 | 2.1400 |
| SD | 0.0212 | 1.0480 | 9.26 | 0.3665 | 5.58 | 0.2013 |
| MSEE | 0.0181 | 0.3746 | 0.0105 | 0.0862 | 6.22 | 0.0356 |
| FEE (%) | 3.6132 | 18.728 | 2.0931 | 4.3068 | 1.2481 | 1.7883 |
| 0.3802 | 1.0201 | 0.2678 | 0.4337 | 0.2090 | 0.3384 | |
| (p-value) | (0.4005) | (0.0108) | (0.6826) | (0.2998) | (0.8621) | (0.5021) |
| W | 0.9914 | 0.9888 | 0.9939 | 0.9900 | 0.9956 | 0.99031 |
| (p-value) | (0.1504) | (0.0489) | (0.4049) | (0.0834) | (0.7032) | (0.0949) |
.
Table 3.
Summary statistics, estimation errors, and AN testing of parameters estimates of the GLU distribution: Sample III with the parameter values and .
Table 3.
Summary statistics, estimation errors, and AN testing of parameters estimates of the GLU distribution: Sample III with the parameter values and .
| Statistics | ||||||
|---|---|---|---|---|---|---|
| Min. | 1.6710 | 1.0773 | 1.8330 | 1.1057 | 1.8621 | 1.1950 |
| Mean | 1.9952 | 1.4901 | 1.9978 | 1.5052 | 2.0010 | 1.4970 |
| Max. | 2.2941 | 1.9122 | 2.1605 | 1.7935 | 2.1072 | 1.7245 |
| SD | 0.0949 | 0.6647 | 0.0606 | 0.2910 | 0.0326 | 0.1534 |
| MSEE | 0.0949 | 0.1901 | 0.0523 | 0.0796 | 0.0327 | 0.0482 |
| FEE (%) | 4.7450 | 12.675 | 2.6488 | 5.3096 | 1.6375 | 3.2158 |
| 0.3238 | 2.0687 | 0.2153 | 0.5059 | 0.3041 | 0.5160 | |
| (p-value) | (0.5235) | (2.83 ) | (0.8460) | (0.2001) | (0.5686) | (0.1889) |
| W | 0.99376 | 0.9806 | 0.9950 | 0.9903 | 0.9952 | 0.9908 |
| (p-value) | (0.3865) | (1.74 ) | (0.5840) | (0.0949) | (0.6194) | (0.1189) |
.
Table 4.
Estimated parameters of the LLU, beta, and Kumaraswamy distributions, along with the corresponding estimation errors and fit statistics.
Table 4.
Estimated parameters of the LLU, beta, and Kumaraswamy distributions, along with the corresponding estimation errors and fit statistics.
| Parameter/ | Series A | Series B | Series C | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Statistic | GLU | BETA | KUM | GLU | BETA | KUM | GLU | BETA | KUM |
| 0.6603 | 0.8939 | 0.5989 | 2.3400 | 1.9597 | 1.5018 | 1.2055 | 4.7587 | 1.3589 | |
| 1.1541 | 1.9902 | 1.3840 | 0.8773 | 1.1883 | 1.0948 | 1.5639 | 4.6025 | 1.7445 | |
| MSEE | 0.0118 | 0.0153 | 0.0215 | 5.54 | 7.98 | 0.0426 | 2.86 | 3.15 | 0.0573 |
| AIC | −116.0 | −69.18 | −83.81 | −310.9 | −145.5 | −65.37 | −1423.5 | −1419.7 | −218.0 |
| BIC | −110.0 | −63.13 | −77.76 | −294.3 | −128.9 | −48.78 | −1404.8 | −1401.0 | −199.3 |
| 0.0921 | 0.0987 | 0.1316 | 0.0623 | 0.0886 | 0.1495 | 0.0392 | 0.0403 | 0.2398 | |
| (p-value) | (0.5393) | (0.4498) | (0.1439) | (0.1654) | (0.0285) | (1.11 ) | (0.1858) | (0.1580) | (0.00) |
; .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



