Submitted:
03 September 2024
Posted:
05 September 2024
You are already at the latest version
Abstract
The Kennedy model offers a robust framework for modeling forward rates, leveraging Gaussian random fields to accommodate emerging phenomena such as negative rates. In our study, we employ maximum likelihood estimations to determine the parameters of the Kennedy field, utilizing Radon-Nikodym derivatives for enhanced accuracy. We introduce an efficient simulation method for the Kennedy field and develop a Black-Scholes-like analytical pricing formula for diverse financial assets. Additionally, we present a novel parameter estimation algorithm grounded in numerical extreme value optimization, enabling the recalibration of parameters based on observed financial product prices. To validate the efficacy of our approach, we assess its performance using real-world par swap rates in the latter part of this article.
Keywords:
Kennedy model
; calibration
; term structure model
; option pricing
; interest rate swap
; Gaussian random field
; Heath-Jarrow-Morton framework
; HJM model
1. Introduction
In the 2010s, a new phenomenon, the negative rates, appeared in the financial markets, which brought extreme uncertainty to the world, resulting in the mathematical models used to describe the dynamics of the interest rates being reconsidered. The model, defined by Kennedy in the 1990s, describes the dynamics of the forward rates with Gaussian random fields [1,2]. This approach contains several advantages; for example, it offers a solution to handle the negative rates naturally and can be connected to the industry standard Heath-Jarrow-Morton (HJM) framework [3]. Additionally, maximum likelihood estimations of the parameters and analytical Black-Scholes-like pricing formulas for different financial assets can be derived due to the standard distribution properties of the Gaussian random fields.
This article summarizes the most critical issues related to using the Kennedy model in the financial world. In Section 2, we present the term structure model for describing forward interest rates based on Gaussian random fields proposed by Kennedy. Among other things, we present the condition for the martingale property of the discounted bond price and show in which cases coincide with the Gaussian Heath-Jarrow-Morton framework. Section 3 introduces the theoretical background of the parameter estimations. The results of the Radon-Nikodym derivative of Gaussian measures with different means are shown. This section derives the maximum likelihood and probability one estimation for the parameters in the Kennedy field. Section 4 shows a practical, simple, and fast way to simulate the Kennedy field with the help of the Brownian sheet. The following section (5) contains the analytical, fair price of various financial products (caplet, floorlet, and swap). Section 6 summarizes the calibration method for different financial products, in our case, the optimization algorithm, which is based on numerical extreme value search to estimate the parameters of the field. Finally, the previously presented calibration algorithm on real swap par rate data can be found in Section 7.
2. Kennedy Model
The development of the forward rates in the model proposed by Kennedy is described in the upcoming equation.
where is a centered Gaussian random field with the covariance structure specified by
The function c is given and satisfies . Assume that the drift function is deterministic and continuous in and that the initial term structure of is specified, also . The covariance function is symmetric in and , and is nonnegative definite in and . The dependency of the ensures that the Gaussian random field has independent increments.
A sufficient condition on the drift surface is derived to ensure that the discounted bond prices of zero-coupon bonds are martingales. Therefore, the model can be used to price financial products in the future.
First, let us introduce the following notations, where .
where denotes the spot rate at time t, represents the price at time s of a bond paying one unit at time t. defines the discounted price of the previously defined bond at time 0, while the information available at time s is that contained in the -algebra, thereby implying that the whole yield curve is observed at each time point. We also introduce a new notation, , to the continuously compounded forward rate for the period ), which can be interpreted as an average of the forward rate for the current period, at time s.
An important theorem is emphasized in Kennedy’s article, which states the following [2].
Theorem 1
(Kennedy (1997)). In the independent-increments case the following statements are equivalent:
- (a)
- For each , the discounted bond-price process is a martingale;
- (b)
- , for all ; and
- (c)
- for all , .
The proof of the theorem is accessible in the original article written by Kennedy [1]. Furthermore, a different derivation of the theorem can be found in the appendices appendices A.1. To complete the proof, it was necessary to include an additional statement, which formulates an equivalent form of defining the drift term with the covariance function.
Remark 1.
The two statements for the drift term in the Kennedy model are equivalent. For all
Proof of Remark 1.
The proof is given by showing that both directions are correct.
□
2.1. Connection between HJM and the Kennedy-Model
The Heath-Jarrow-Morton framework is a widely used model considered an industry standard [3]. This is also a term structure model, which creates a connection between bonds with different maturities. The HJM model is an infinite-dimensional framework. Therefore, the whole yield curve evolves in forward time instead of at a specific point.
Kennedy has stated in his article that the Kennedy model includes the Heath-Jarrow-Morton framework in the case when the coefficients, and , in the underlying stochastic differential equations are not random and so the rates are Gaussian [2]. Therefore, in this section, we will show precisely in which cases the two models can correspond to each other.
The notations of the HJM model are written consistently with those found in the book by Shreve [6]. We first examine the case when a single Wiener process drives the forward interest rates; then, the dynamics can be written as follows:
where refers to the initial forward year curve known at time 0, is a Wiener process under the actual measure, and and are deterministic processes in the variable s. Let us denote which is independent from process and is a Gaussian process.
The expected value and the covariance function of the Heath-Jarrow-Morton framework and the key Kennedy field conditions can be written in the following form.
- The expected value function from the Heath-Jarrow-Morton model can be calculated in the following way.
-
Similarly to the previously calculated expected value function, the covariance function is calculated as follows. Let us denote the covariance function between withThe covariance function is specified as a function of . This ensures that the Gaussian random field has independent increments in time s, which is also fulfilled due to point 2 in the HJM framework. This confirms that all Gaussian HJM models (where the drift and the volatility terms are deterministic) are the well-known Kennedy model.
-
By adding the martingale property in the Kennedy model (like in point (c) in theorem 1), which guarantees that the conditional expected value of the discounted bond-price process is a martingale under the risk-neutral measure. As a result, the model is arbitrage-free. Then, by matching the equations of the expected values to each other, we get the famous condition of the HJM model, according to which the drift term can be obtained in the form below.where the last equation satisfies the famous HJM condition.
-
By adding the Markov property to the previous conditions, where the discounted bond price process is martingale, we get an even narrower class of models.Definition 1(first Markov property). The random field of instantaneous forward rates satisfies the first Markov property if for all , , we have .Definition 2(second Markov property). The random field of instantaneous forward rates satisfies the second Markov property if for all , , with we have .Definition 3(Markov property). The random field of instantaneous forward rates is Markov if it satisfies both the first and second Markov properties.Definition 4(Markov in t-direction). The random field of instantaneous forward rates is Markov in the t-direction , that is, in the maturity-time coordinate, if for all thenDefinition 5(strict Markov property). The random field of instantaneous forward rates strictly Markov if it is both Markov and Markov in the t-direction.Kennedy stated (in theorem 3.1 in [2]) that if a random field of forward rates is Markov and satisfies the independent-increments property, then the covariance function can be written in the following form.where f is a monotone increasing and g is a symmetric and positive semidefinit function. This property can be written as follows for the HJM model.By setting and equal to each other , we obtain the following equalityConsequentlywhere and . Therefore, it is shown that if the HJM model is Markovian, then the function appears in the form of Equation (26). We thus obtained that in the Markovian case, the volatility function must be separable in the time parameters. HenceFor Equation (23) can be written in the following formIf the function is constant, then we get the trivial case when for all . In the non-trivial case, we get from Equation (31) that is not constant. Therefore, we gotHence, we showed that if the HJM model is Markovian, then functions and r occur in the previously derived form. Now, we show the opposite direction: if our covariance function has this shape, then the HJM model will be Markovian.which is exactly the necessary condition (22).In 1992, Cheyette published an article in which a restriction was applied to the Heath-Jarrow-Morton model, which forms a subset of the original HJM models to make the model Markovian. This so-called Cheyette model is an arbitrage-free term structure model, which is Markovian in a finite number of state variables and consistent with an arbitrary initial term structure. Due to these favorable properties, the Cheyette model quickly spread throughout the industry and became widely used [7].In this case, the volatility function has to be separable into time and maturity-dependent factors given by the following structure [8].However, this condition is completely identical to the previously derived condition for the volatility term in the Markov case in the Kennedy model.
-
Kennedy further narrowed the model class by requiring stationarity in addition to the Markov property and the independent increments property (stated in theorem 3.2 in [2]).Definition 6(stationary). The random field is stationary if for each the joint distributions of are the same as those of for any fixed .Therefore, the covariance function takes the form below.:where and .For the HJM framework, it was shown that , hence according to point 5.For and it can be writtenNow substitutingReturning again to Equation (39) while substituting Equation (41)By deriving the integral equation according to the variable s, we get the following solutionTherefore, the covariance function of the forward rates , when the rates are stationary, strictly Markov, and satisfy the independent-increments property, can be described with the following set of four parameters and is of the formThe function of the expected value of the Gaussian random field can be easily derived from the covariance function.
3. Parameter Estimation
In finance, where uncertainty reigns supreme and decisions are often made under incomplete information, accurate modeling of interest rate dynamics is paramount. This is where parameter estimation comes into play as a fundamental aspect of financial modeling, particularly in the context of Kennedy-type term structure models. While calibration is a widely adopted practice in finance, parameter estimation also holds significant importance.
The central assumption of these models is that interest rates follow stochastic processes, the parameters of which govern their behavior over time. These parameters determine the shape of the yield curve and influence the pricing of various financial instruments, such as bonds, options, and derivatives. Therefore, obtaining reliable estimates of these parameters is essential for making informed investment decisions, managing risk, and pricing financial products accurately.
Parameter estimation techniques enable practitioners to calibrate these models to observed market data, such as bond prices or interest rate derivatives. Among the most commonly used methods are maximum likelihood estimation (MLE), estimation with probability 1 and Radon-Nikodym derivatives, which allow for determining parameter values that maximize the likelihood of observing the given market data under the model assumptions. Through rigorous statistical inference, these techniques provide a systematic framework for extracting information from observed market prices and estimating the underlying dynamics of interest rates.
3.1. Maximum Likelihood Estimations
In this section, the theoretical background of the maximum likelihood estimations, in the case of Gaussian functionals, is presented based on the work of Rozanov and Arató [4,5].
Definition 7
It is well known that two Gaussian measures are either equivalent or orthogonal.(Gaussian functional). Let be a probability space, and T is a parameter set. Then is a Gaussian functional, if for any and ,
is normally distributed. Then P is called a Gaussian measure in . For simplicity, we can assume that The expected value and the standard deviation of the Gaussian functional are marked as follows
3.1.1. The Case of Different Expected Values
Let be a Gaussian functional. Let the expected value of the Gaussian functional under the measure P be 0 and the expected value under the measure be m.
Let U denote the linear space of the variables of the following shape
Also, take the following scalar product
Finally, denotes the Hilbert space obtained by closing U.
Rozanov showed that for different expected values, the Radon-Nikodym derivative can be calculated as follows [5].
Theorem 2
A simple consequence of this theorem is the following statement by Arató. [4](Rozanov). The P and measures are equivalent if and only if there exists an for which
In the case of equivalence, the Radon-Nikodym derivative of the two measures are
Theorem 3
(Arató). Let be a Gaussian functional. Let the expected value of the Gaussian functional under the measure P be 0, and the expected value under the measure be . The P and measures are equivalent if and only if there exists an for which
In the case of equivalence, the Radon-Nikodym derivative of the two measures are
Theorem 4
(Maximum likelihood estimation). Let be a Gaussian functional. Then, using the notations of the previous statement, the maximum likelihood estimation of m is the following
The estimation is normally distributed and unbiased, and the standard deviation is
Proof of Theorem 4.
The shape of the estimation is derived immediately from the Radon-Nikodym derivative. To determine the expected value and standard deviation, calculate the next expected value if .
Calculating the first two moments, we get the following values
- if , then →
- if , then →
For the expected value, we obtain the following
Similarly to the first moment, we can derive the second moment.
The standard deviation can be deduced immediately from these derivations. Since these are Gaussian functionals, normality is evident. □
3.1.2. The Case of Constant Expected Value
If the expected value of our Gaussian process is constant, then for every . Let ), . Let us fix a point and let Let us assume that . Then the maximum likelihood estimation of m is
Proof.
The proof uses the law of total expectation and the statement.
Based on the previous derivations, the maximum likelihood estimation is the following
□
3.1.3. Some Simple Examples
The well-known results of various stochastic processes often used to model financial processes immediately follow from the previous statements.
For example, let us observe a Gaussian process with m expected value and the same covariance as the Wiener process on the interval , where and . In this case, the maximum likelihood estimation of the Wiener process is the value of the process at the starting
On the other hand, a stationary Ornstein-Uhlenbeck process in the interval can also be observed. We know the value of in advance and the expected value and the covariance matrix of the process
Therefore, the following covariances can be easily determined
Taking advantage of the fact that, in this case, the maximum likelihood estimation is unbiased, we get the well-known Grenander formula [11]:
3.2. Parameter Estimations of the Kennedy Field
From now on, we investigate the case when the random field of forward rates is stationary, strictly Markov, and it satisfies the independent-increments property. Then - as we have seen before - the covariance and expected value functions have the form (52) and (53) and these functions are defined by four parameters ( and ). Therefore, the expected initial forward curve is easily obtained.
Also, from the equation above, it can be straightforwardly seen that the parameter refers to the expected value of the spot curve.
We can notice that the field is an Ornstein-Uhlenbeck process in the variable s, therefore
This means that if we can observe the process on an interval according to s for some value t, then is determined with probability 1. If we can do this for two different t values, then and are defined with probability 1.
If we look at another covariance from the field
Which means that is defined with probability 1, therefore also and are defined with probability 1.
In the following, we observe the field on a region marked with T. The following auxiliary random field is introduced, where the expected value under the measure is .
where
We demonstrate that the following estimate is the maximum likelihood estimate of this parameter.
First, we get that gives the same value for every . On the other hand, . Thus, based on Theorems 2 and 3, is the maximum likelihood estimate.
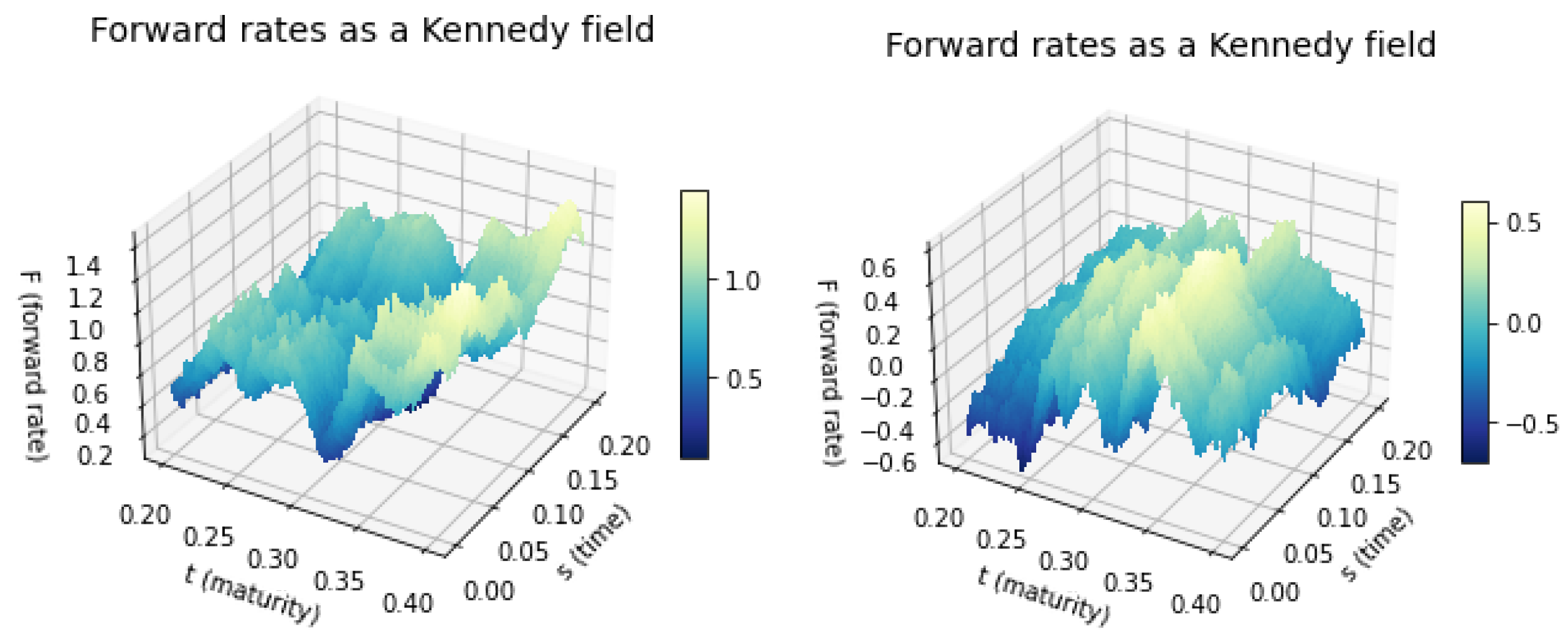
4. Simulation of the Kennedy Field
In this section, we aim to simulate the Kennedy field in points. We can consider this as an normally distributed vector whose expected value and covariance matrix are known. However, for sufficiently large n and m, simulating a multidimensional, normally distributed vector is extremely slow due to the size of the covariance matrix. A much more effective, simpler, and faster way is if we notice that if is a Brownian sheet, then is a Kennedy field with the appropriate covariance structure.
The question is how can we generate a Brownian sheet at the points the fastest way possible, where the division is not necessarily equidistant. Let us take independent random variables with distributions and denote them with . Accordingly, the Brownian sheet can be written in the following form
Hence, the upcoming matrix operation should be coded in the fastest way possible to achieve the desired results.
Fortunately, ready-made, fast algorithms exist for this double summation.
In Figure 1, we can see two different simulations where the number of simulated points is 10000.
5. Option Pricing
This section aims to show that the fair prices of various financial assets can be derived analytically if we assume that the forward rates evolve according to a Gaussian random field.
5.1. European Caplet
In the case of options, instead of using instantaneous forward rates, compounded forward rates are used. Consequently, it is necessary to transition from the instantaneous forward rate, described earlier by the Kennedy field, to a discrete forward rate for a given time period, often denoted as , with reference to the LIBOR rate. Consistently with the following discretization scheme, the discretized version of the HJM framework, which is considered the industry standard, is the LIBOR Market Model (LMM).
This derivation is equivalent to the one derived by Kennedy but uses a different approach. We would like to calculate the price of an interest rate caplet at strike K for the time period t to . This may be regarded as a European option on the forward rate which is exercised at time t if , yielding a payoff at time . The payoff function of this transaction is shown below.
The discount factor from time s to time t is defined as follows.
A cap normally consists of a string of such options for successive time periods, but it is sufficient here to consider only one time period. The discounted payoff of the option at time s is the following
The price of a financial asset is obtained by taking the expected value of the discounted payoff function. The definition of the drift term guarantees that the model is under a risk-neutral measure, just like in the Heath-Jarrow-Morton framework.
For the sake of simplicity, two additional variables are introduced ( and ) to denote the time range over which the forward rate is integrated.
Hence, in the case of caplet, we deal with the following special case of and .
Due to the properties of the Gaussian random field is following a multivariate normal distribution. Henceforth, except for necessary cases, we omit the corresponding time indices to indicate the expected value, standard deviation and correlation between and . Consequently let us denote them with the following notations , , and . From now on, the conditional normal distribution theorem can be used. As a result, the conditional distribution of given is the following
where . Therefore, the fair price of the European option can be calculated as follows.
During the derivations, the law of total expectation and the fact that is measurable for is used. As we can see, is normally distributed, therefore , where . Therefore . Since the conditional distribution of given is known, therefore can be calculated as the expectation of a lognormally distributed random variable.
Returning to the pricing formula
Finally, by subtracting the values of the two integrals from each other, we get the analytical pricing formula for the European call option in the case of the Kennedy fields.
5.1.1. Expected Values and Variances
Based on the calculations in Appendix A.2 for the pricing of the caplet, the expected value of and , their standard deviation, and the correlation between them are as follows.
5.2. European Floorlet
Similarly to the previously derived European caplet, the price of an interest rate floorlet is now derived. Thereby, using the put-call parity, the pricing formula of the swap can be easily calculated. The payoff function of this transaction is shown below.
The discount factor from time s to time t is defined just as previously: . A floorlet normally consists of a string of such options for successive time periods, but it is sufficient here to consider only one time period. The discounted payoff of the option at time s is the following
The price of a financial asset is obtained by taking the expected value of the discounted payoff function. The definition of the drift term guarantees that the model is under the risk-neutral measure, just like in the Heath-Jarrow-Morton framework.
The derivation is completely similar to the price of the caplet product presented earlier and can be found in Appendix A.3. Therefore, the analytical pricing formula for the European floorlet option in the case of Kennedy fields is as follows.
5.3. Swap
An interest rate swap is a forward contract exchanging a floating and fixed rate for a predetermined period. The special financial asset in which the floating versus fixed rate exchange only applies to one period is called a swaplet. In this section, the fair price, hence the conditional expected value of the discounted payoff function under the risk-neutral measure for one period, is derived. We first examine the simplest case, a one-period swap. In this case, the interest rate exchange takes place at only one point in time, T in the swap product. In this case, the swap is similar to a caplet with an extreme cap value, where the product is definitely worth calling. The price of the swaplet product at time s is as follows.
In this case, the previously introduced and are interpreted in the following time period.
As we can see, the definition of is unchanged; therefore, only the value of , and the covariance changes.
As we can see, in that case, the covariance of and equals to the variance of .
This calculation is easy to see if we use the previously introduced multidimensional normally distributed random variables (, and ) because in this case, and random variables are lognormally distributed. It is well-known that the quotient of two lognormally distributed random variables with correlation is also lognormally distributed with the following expected value and standard deviation.
Hence
Therefore, we easily got the previously calculated result back.
Furthermore, the price of a one-period long swap, the so-called swaplet at time s, can be easily obtained using the previously derived caplet and floorlet pricing formulas and the put-call parity. Therefore, the difference between the calculated fair price of the caplet and the floorlet option.
The fair price of a fixed vs floating swap for more time periods at time 0 can be found in the Appendix A.2.
5.4. Par Swap Rate
In the previous section, we could derive the fair price of a one-period swap, the so-called swaplet.
Therefore, let us first adjust the previously defined and variables to the following time periods.
The so-called swap quote can be easily expressed from that equality, which equals the par swap rate. The par rate is the value of the fixed rate that gives the swap a zero present value or the fixed rate that makes the value of both legs equal. The derivation of this rate is important because, in many cases, the financial data contains par swap rates instead of swap prices; in other words, this financial product is quoted using the par swap rate.
After that, we want to express the par swap rate with the original parameters of the Kennedy field.
From here, the par swap rate can be easily written with the original parameters of the Kennedy field.
Therefore, if the swap par rate can be observed for at least four different tenors, then three parameters of the original four (, and ) can be determined with a probability of 1. However, it is worth mentioning that the parameter is omitted from the description of the par swap rate.
6. Calibration on Simulated Data
Simulated financial caplet, floorlet, and swaplet prices were generated using the previously derived analytical pricing formulas with different maturities and strikes. Therefore, first of all, we just wanted to test the punctuality of the calibration engine.
Numerical calibration is an extreme value optimization problem. The method aims to find the parameter set that minimizes the squared deviation error between the previously generated financial caplet, floorlet, and swaplet data and the analytically calculated prices with the calibrated parameters. The calibration engine is based on the stochastic gradient descent method. The extreme value optimization is based on the article of Mikhaliov and Nögel, and the implementation in Python is based on the work of Emerick and Tatsat [9,10].
Figure 2.
Simulated Monte Carlo market prices (Mesh) vs Calibrated Kennedy model prices (Markers) for a caplet
Figure 2.
Simulated Monte Carlo market prices (Mesh) vs Calibrated Kennedy model prices (Markers) for a caplet
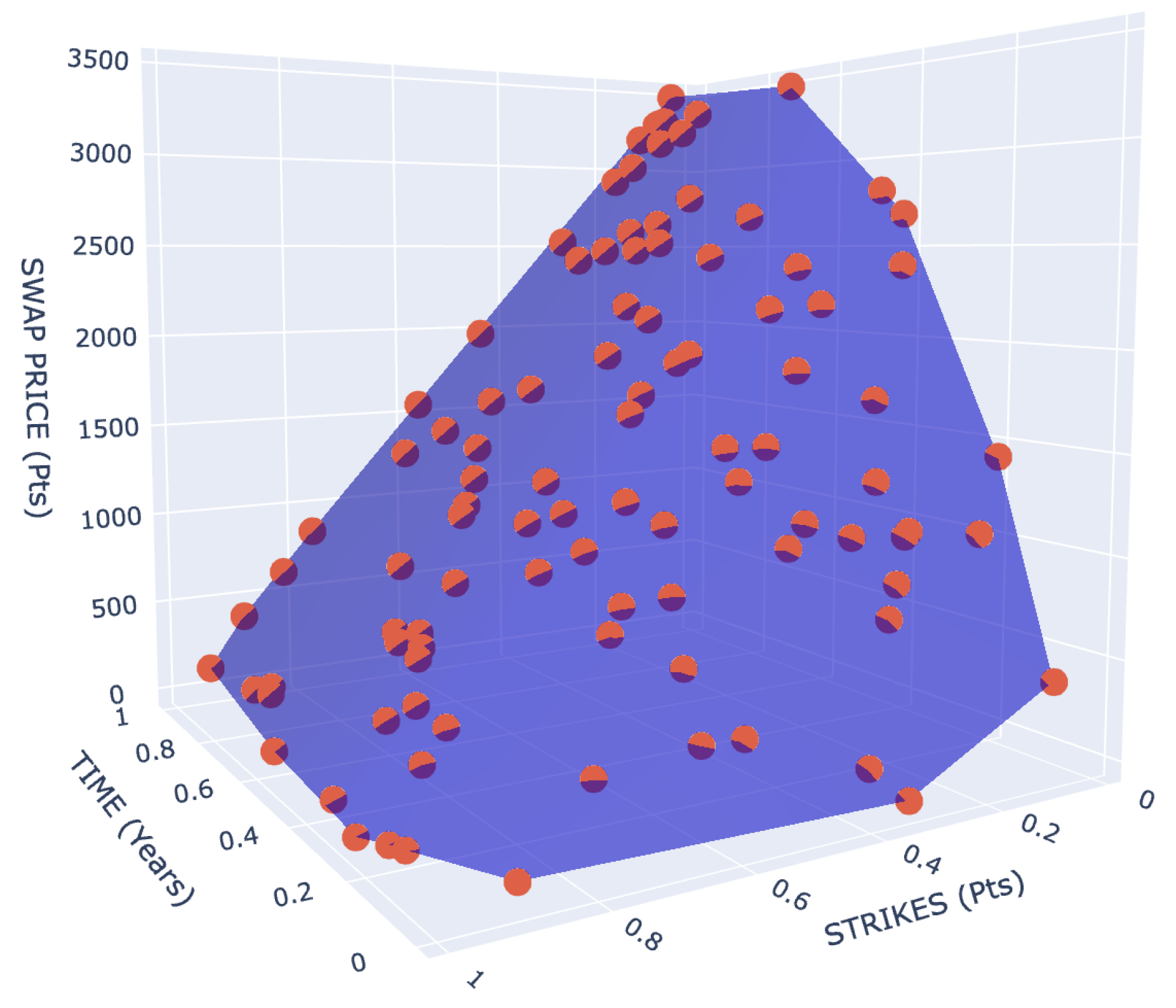
The figure shows that the prices calculated with the back-estimated parameters fit our synthetic dataset almost perfectly. The calibration returns the used parameters; the difference is negligible and can be considered a numerical error.
7. Calibration on Real Data
A time series of swap par rates was obtained with the help of the Bloomberg terminal. The financial dataset contains the par swap rates of the USD SOFR fixed versus floating interest rate swaplet from July 2018 to April 2023. The historical dataset includes par swap rates for 28 different maturities daily.
We calibrated the model daily for different maturities for par swap rates with the calibration algorithm 100 days back. As we can see, the Kennedy field fits the dataset nicely; however, it slightly overestimates the values for shorter maturities while slightly underestimating the par swap rates at long maturities.
Figure 3.
Par swap rate market prices (Mesh) vs Calibrated Kennedy model prices (Markers)
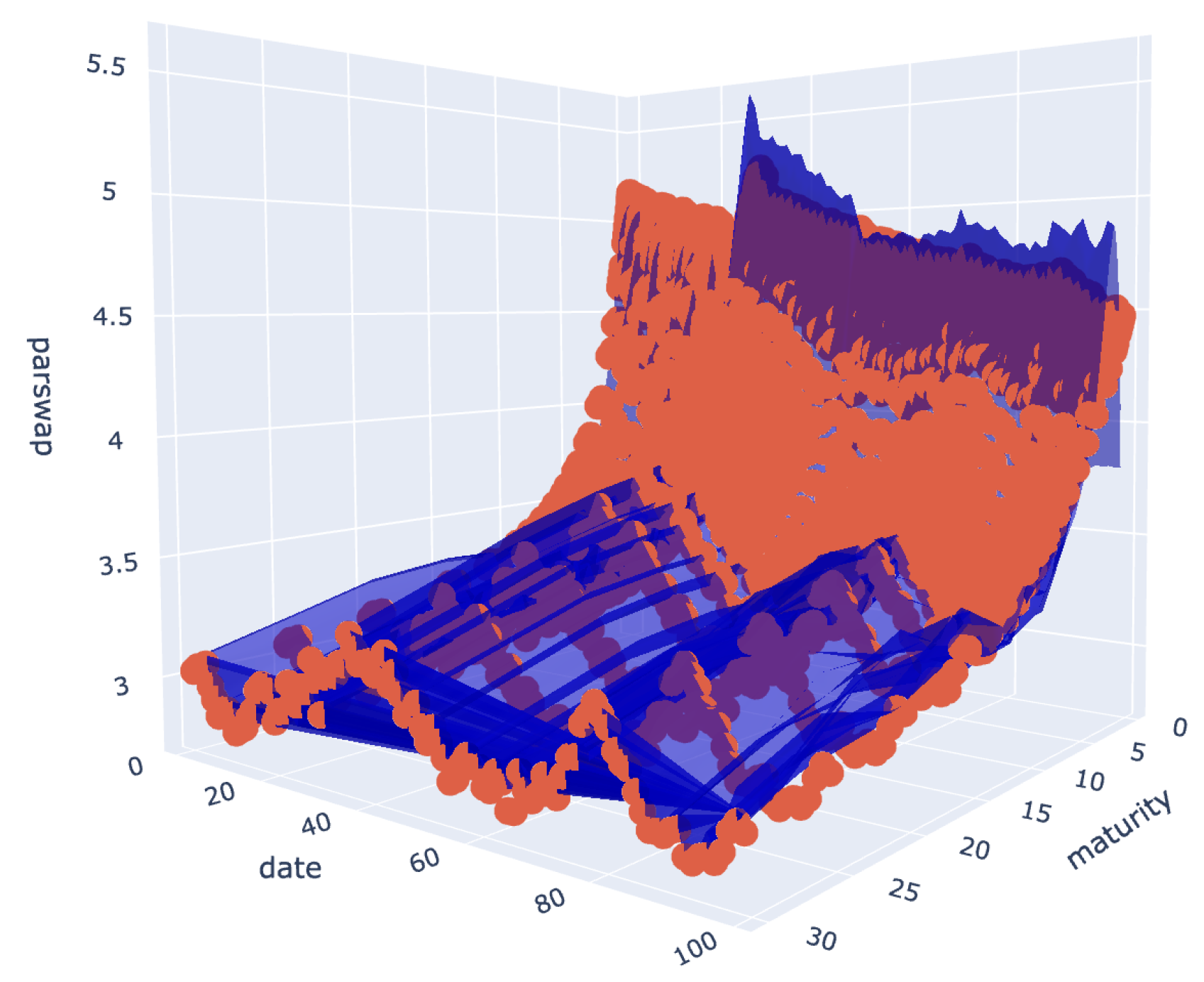
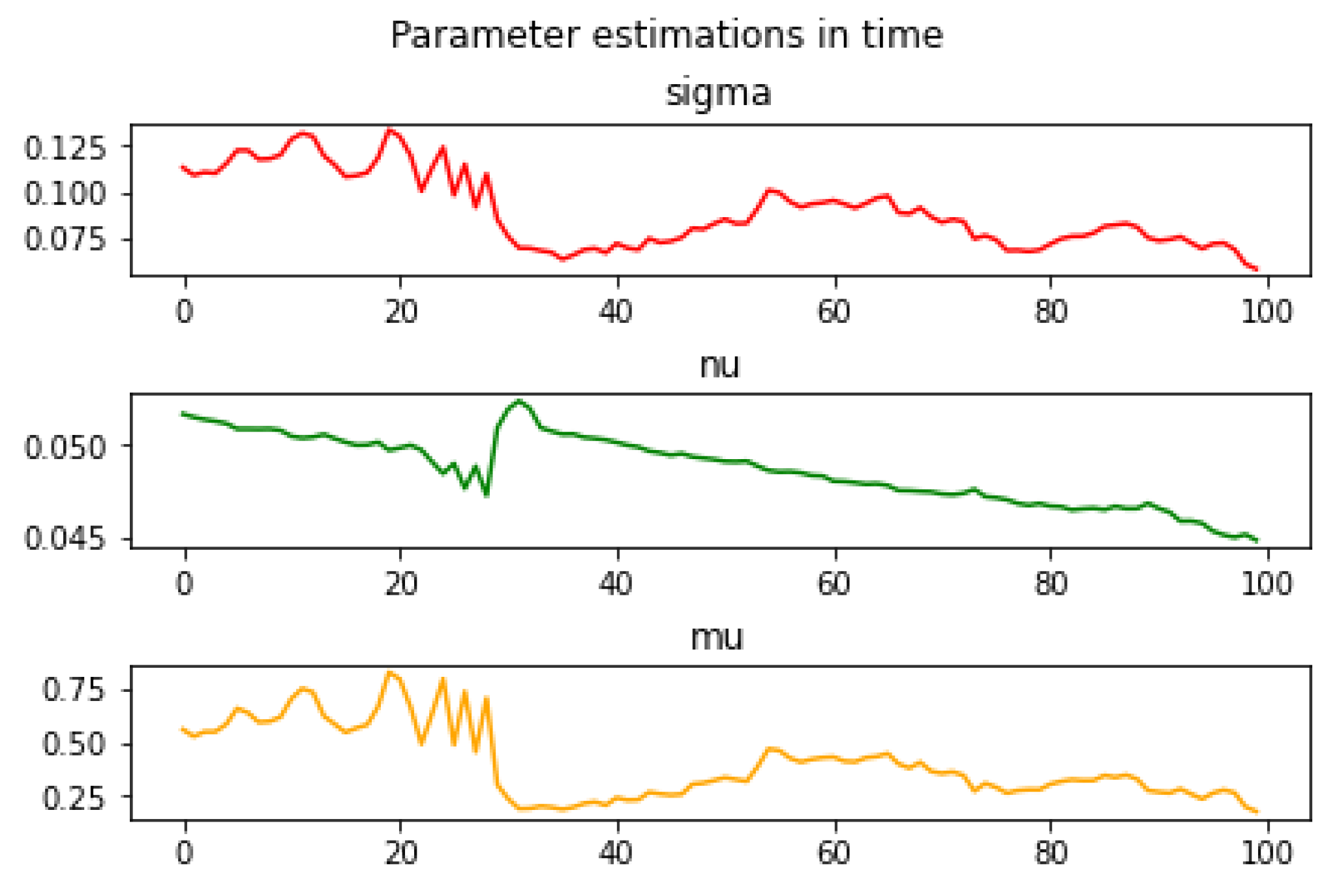
In addition to the analytical results, it can also be seen that does not play a role in the numerical implementation since this back-estimated parameter value is highly volatile. Meanwhile, the value of the other three parameters varies on a much smaller scale, and similar trends can be observed.
As a result, our guess is that the parameter, which is not included in the par swap rate, describes a temporal relationship; in other words, the term structure of the model; , greatly influences the standard deviation of the field; while is used to describe the level of the yield curves, since is the parameter that describes the expected value of the spot rate (.
Figure 4.
Historical parameter estimations in time
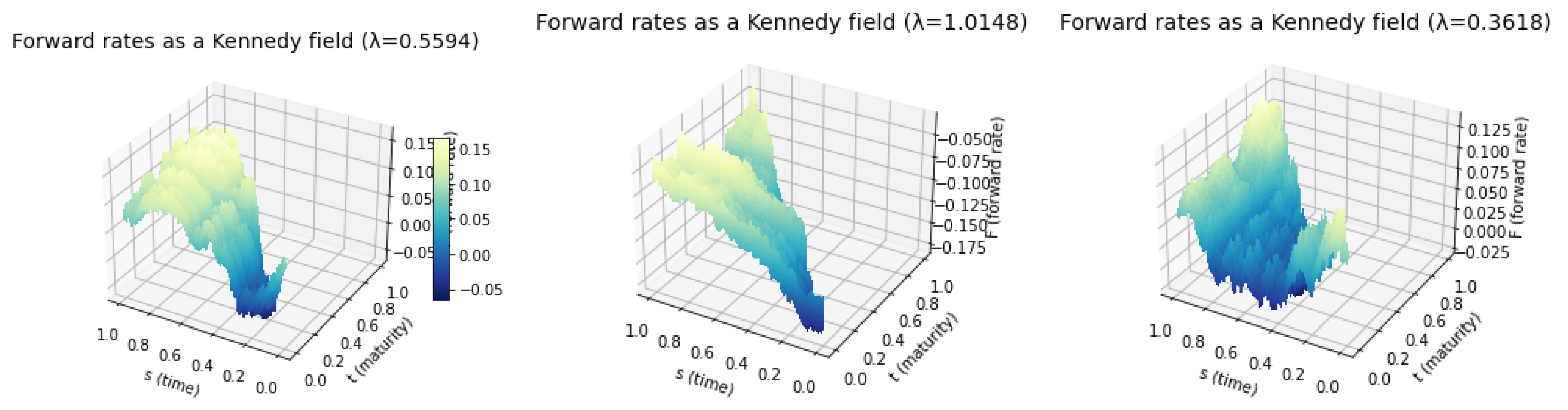
In the following, we plotted Kennedy fields for describing forward interest rates with the three parameters back-estimated from the par swap rate dataset (, and ) and three different values, to see what rates would be generated in a realistic case.
Figure 5.
Differently parameterized Kennedy fields for describing forward rates
8. Results
Our article focuses on a mathematical model based on Gaussian random fields introduced by Kennedy to describe forward interest rates. Among other things, we provided novel proof for the equivalence of conditions regarding the martingale property of the discounted bond prices. We demonstrated the relationship between the Kennedy model and the HJM framework in special cases (Markov property, stationarity). Additionally, utilizing Radon-Nikodym derivatives, we derived maximum likelihood estimates and estimates with probability one for the original parameters of the field. We presented a new, efficient method, based on Brownian sheets, to simulate the Kennedy field.
Subsequently, we derived analytical pricing formulas resembling Black-Scholes for various financial products, including caplets, floorlets, swaplets, and swaps. Finally, we calibrated the field using a numerical extreme value search algorithm based on stochastic gradient descent on a simulated synthetic dataset to recover the original parameters. We then calibrated it on actual par swap rates to examine how our model performs in a market environment.
9. Discussion
Kennedy introduced a model based on Gaussian random fields for modeling forward interest rates in the 1990s, which, due to its normal distribution, can generate negative interest rates. At that time, this scenario was not considered feasible; however, in the interest rate environment of the 2010s, negative interest rates emerged. Since this model naturally handles them, it underscores the relevance of the model. Calibration on actual par swap rates demonstrated that our model fits well with the current interest rate environment and effectively describes the market.
Moving forward, our primary objective is to go beyond analytical pricing formulas and utilize models based on artificial intelligence, including LSTM and neural networks, for parameter estimation. We aim to compare the accuracy of parameters recovered through calibration with these AI-based models. Additionally, we plan to investigate the temporal stability of parameters and compare them with industry-standard models such as SABR.
10. Conclusions
Overall, we can conclude that a new result has been achieved in estimating the parameters of the Kennedy field, and an excellent calibrator has been built. This can be a great starting step to investigate and compare it to other, more complicated models.
Our research also aims to calibrate the parameters of the negative interest rate models with machine learning algorithms to compare them with the previously derived analytical estimations.
Funding
This work is supported by the KDP-2021 program and the ELTE TKP 2021-NKTA-62 funding scheme of the Ministry of Innovation and Technology from the source of the National Research, Development and Innovation Fund.
Data Availability Statement
Data used in this study include historical par swap rates of the USD SOFR fixed vs. floating interest rate swaps (Bloomberg ticker: USOSFR1Z BGN Curncy), obtained from Bloomberg. The data spans from April 20, 2018, to April 20, 2023, with daily frequency in USD, sourced from BGN. Due to proprietary restrictions, these data are not publicly available. Access to the data is subject to Bloomberg’s terms and conditions and is not shared openly. For more information, please contact the authors.
Acknowledgments
We would like to take this opportunity to thank my business supervisor, Csaba Kőrössy, for his help and dedication to the research. Even though he joined the research later, he spent much time understanding it, and his comments and suggestions immensely helped this article. We want to thank dr Fáth Gábor, who involved us in Risklab and since then regularly consults, gives ideas, and helps on this topic, in which he also has great expertise. Finally, we would like to thank dr András Ványolos for his help, interest, and enthusiasm with which he joined our project, who is motivated simply by his love for mathematical research. We enjoy doing math with you.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Appendix A.1
The proof of Theorem 1 can be found in the original article by Kennedy. [1] However, we present an alternative derivation to prove the statement. To facilitate this, we first introduce an auxiliary lemma, which will be utilized in the proof of the theorem.
Lemma A1.
is a Gaussian system, where for every . Then the following statements are equivalent:
- (a)
- and
- (b)
- X and are independent for all and .
Proof of Lemma A1.
The equivalence is proven by deriving both directions from each other.
-
⟹First, we prove the (a) to (b) direction. If is true then it can be stated thatThusTherefore, we can conclude that and .
-
⟹Then we deduce that if (b) is fulfilled, then statement (a) is also true. If X and are independent for all and then
□
Proof of Theorem 1.
It is obvious that , where , and are measurable random variables, just as . Therefore, it can be stated that there is no problem with the existence of expected values. The equivalence of the statements is proved circularly.
-
⟹Let us start with the statement that the discounted bond price is a martingale. HenceFrom statement a, we quickly deduced that the discount factor occurs in the given form.
-
⟹Henceforth, we derive the drift term from the discount factorAccording to Lemma A1, this is equivalent to the fact that and are independent and , where . Since we are dealing with Gaussian variables, it is enough to examine the covariance.Since is equal to , therefore and are independent.The variance is a bit more complicated to calculate.Let us apply the Leibniz integral rule to the following function.from whichSince , thusfor all . Using Remark 1, we have established the implication from (b) to (c).
-
⟹First, we show that part (b) of the theorem is satisfied, by showing that the drift term has the form of (c) and this is sufficient because part (b) immediately demonstrates that is a regular martingale. It can be easily seen that in Lemma A1, using the previous notations, and are independent. During the derivations Remark 1 is used as well.
Let us apply the Leibniz rule again for the following function using the fact that the covariance function is symmetric in and .
Finally, the theorem is proved. □
Appendix A.2
This subsection calculates the expected value and standard deviation of the expressions previously marked with and and their correlation.
Now let us move on to the expected value of . The steps of the derivation are similar to what we have seen above.
After the derivation of the expected values, the standard deviation of the expressions marked with and are calculated.
At first, let us deal with the inner integral, then move on to the outer integral.
The variance of can be similarly derived.
Similarly to the previous calculation, the derivation starts by calculating the inner integral without the multiplier.
Now, let us move to the outer integral per term.
Therefore, by adding the multiplier, we got back the variance of .
The last variable to be calculated is , indicating the correlation between and . However, for all financial products used in the article, the values of and were equal, denoted by t. Furthermore, we can assume that , since represents the time to which we discount, the time at which we want the value of the financial product, while is the starting time of the transaction, which can start now or even later. So let us suppose that .
The two terms of the summation are calculated separately.
By adding the calculated two terms back together, we got the covariance between and .
Therefore, the correlation between and calculated as follows
Appendix A.3
In this subsection of the appendix, the analytical fair price of the European floorlet option is also derived, similarly to the previously derived European caplet option. As we have seen before, the fair price of the floorlet is the expected value of the payoff function under the risk-neutral measure.
We use the previously introduced variables: and .
Similarly to the previously derived pricing formula for the caplet, the conditional expected value of to follows a normal distribution. Hence, in this case, the conditional standard distribution theorem can also be used with the previously defined parameters. Therefore, the fair price of the European floorlet can be calculated as follows.
During the derivations, the law of total expectation and the fact that is measurable for is used.
As we can see is normally distributed, therefore , where . Therefore . Since the conditional distribution of given is known, therefore can be calculated as the expected value of a lognormal distribution.
The integral returns the expected value of a random variable that is lognormally distributed. Returning to the pricing formula
Therefore, the analytical pricing formula for the European floorlet option in the Kennedy fields is as follows:
Appendix A.4
The fair price of a fixed vs floating swap for several periods (k) at time s can be written using the formula below. Let us denote the time periods by and .
As we have done previously, more additional variables are introduced, and , the following way.
Referring to previous calculations, we know the expected value and standard deviation of and . Therefore, the expected values of the variables are the following
and the covariance is
Due to the properties of the Gaussian random field, always follows a multivariate normal distribution, with the covariance matrix shown before.
The correlation between and is the value of the covariance normalized with the standard deviation of and .
Because of the properties of the normal distribution, the distribution of is also normally distributed where the mean of the convolution is the sum of the means, and the variance is the following.
Therefore, the price of the interest rate swap can be easily calculated
References
- Kennedy, D. P. The term structure of interest rates as a Gaussian random field. Mathematical Finance 1994, 4, 247–258. [Google Scholar] [CrossRef]
- Kennedy, D. P. Characterizing Gaussian models of the term structure of interest rates. Mathematical Finance 1997, 7, 107–116. [Google Scholar] [CrossRef]
- Heath, D. C.; Jarrow, R. A.; Morton, A. Bond pricing and term structure of interest rates: a new methodology for contigent claims valuation. Econometrica 1992, 60, 77–105. [Google Scholar] [CrossRef]
- Arató, N. M. Mean estimation of Brownian sheet. Computers Mathematics with Applications 1997,, 33, 12–25. [Google Scholar] [CrossRef]
- Rozanov, Ju. Infinite-dimensional Gaussian distributions: Proceedings (Proceedings of the Steklov Institute of Mathematics number 108 (1968)), 3rd ed.; American Mathematical Society: Providence, Rhode Island, 1971. [Google Scholar]
- Shreve, S. E. Stochastic Calculus for Finance I-II., 1st ed; Springer Finance: Pittsburg, USA, 2004. [Google Scholar]
- Cheyette, O. Markov representation of the Heath-Jarrow-Morton model SSRN Electronic Journal 2001. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6073 (accessed on 13 October 2023).
- Beyna, I.; Wystup, U. On the calibration of the Cheyette interest rate model PQF Working Paper Series 2010. Available online: chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://mathfinance.com/wp-content/uploads/2017/06/beyna-wystup-calibrationofcheyette.pdf (accessed on 26 October 2023).
- Emerick, J.; Tatsat, H. Stochastic Volatility Models - Heston Model Calibration to option prices QuantPy 2022. Available online: https://quantpy.com.au/stochastic-volatility-models/heston-model-calibration-to-option-prices/ (accessed on 10 January 2023).
- Mikhailov, S.; Nögel, U. Heston’s Stochastic Volatility Model Implementation, Calibration and Some Extensions. Fraunhofer Institute for Industrial Mathematics 2003. [Google Scholar]
- Grenander, U. Stochastic processes and statistical inference. Ark. Mat. 1950, 1, 195–277. [Google Scholar] [CrossRef]
- Norros, I.; Valkeila, E.; Virtamo, J. An Elementary Approach to a Girsanov Formula and Other Analytical Results on Fractional Brownian Motions. Bernoulli 1999, 5, 571–587. [Google Scholar] [CrossRef]
Figure 1.
Simulated Kennedy-fields
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



