
Submitted:
06 September 2024
Posted:
09 September 2024
Read the latest preprint version here
Abstract
In the paper, we suggest a method for calculating optimal time intervals in the queue analysis. The suggested method processes partitioning of the time interval and utilizes the epsilon-entropy and epsilon-capacity of the partition for finding an optimal partition. Optimality of the partition is specified based on its epsilon-information. The suggested method is illustrated by defining the intervals for histograms of differently distributed samples and demonstrated its effectiveness in comparison with the existing methods.
Keywords:
Arrival rate
; departure rate
; epsilon-entropy
; epsilon-capacity
; epsilon-information
; partition
MSC: 60K25; 90B22
1. Introduction
The use of queue models implies the knowledge of the arrival and departure rates, which in their turn require the well-defined time intervals [3].
For example, consider a clerk serving clients of some office during the day. Then, the arrival rate and the departure rate per day completely describe the state of the system at the end of the day but do not provide any information about the system during the day. On other hand, specification of the rates and , for example, per minute is also useless since both the clients and the clerk do not act with such rates.
The incorrect specification of the time intervals leads to incorrect consideration of the processes with unsteady arrivals or departures. In many cases, such situations are resolved using the queues with time dependent rates [5,8], but even in such considerations certain time intervals per which the rates are defined have to be specified.
Similar problem appears in statistics while plotting histograms of the data sample and it is required to define the lengths of the bins. Since there is no strictly proven formula, which defines the bin length with respect to the number of data counts or distribution over the sample, the heuristic formulas are used.
For example, the simplest heuristic defines the bin length as
The Sturges rule [15] defines the number of bins as . Then the bin length is
The Scott rule [12] defines the bin length
with respect to the standard deviation of the sample. Finally, the Freedman-Diaconis formula [2] uses the interquartile range instead of the standard deviation and defines the bin length
where is the third quartile and is the first quartile of the sample.
In general, this problem can be considered in the terms of discretization of stochastic processes [4], where it is required to build a discretization scheme, which is a sequence , , of stopping times such that and . But if is a random variable, then the length of the time intervals is also random and depend on the distribution of the considered process. Similarly, if the discretization scheme is regular with constant interval lengths , then the increments of the process at the times are random.
For example, let be a Wiener process at the time interval starting with . In such a process, the increments are independent and for any and the differences have normal distribution with the variance . Assume that the interval is divided to sub-intervals with the length . Then, the stopping times are , and the increments are normally distributed with .
In this paper, we seek the answer to the following question formulated by Yaakov Reis [9]. Given a total period, a sequence of clients arriving at the times to a service point, what is an optimal length of the time interval, on which the arrival rate and the service rate (which is a departure rate) have to be defined?
An immediate answer to this question follows the heuristics used for definition of the bin length in histogram. However, such heuristics cannot be considered as the best method and their result is not strictly proved approximation.
To find an optimal length we follow the line of the Schwarz information criterion [11] and apply well-known concepts of -entropy and -capacity, which were introduced by Kolmogorov and Tikhomirov [6]. The calculations of the optimal interval are also based on the concept of the entropy of partition introduced by Rokhlin [10].
Initially -entropy and -capacity were used for analysis of functions and functional spaces and then, as well as the entropy of partition, were applied to the studies of dynamical systems. For many examples of application of these concepts and their relationship with the Shannon entropy [13] see the paper by Dinaburg [1] and the books by Vitushkin [16] and by Sinai [14].
2. Problem Formulation
Let be a time interval of the length and assume that during this interval sequentially occur events . The times of occurrences of these events are , respectively.
The problem is to define a length of the time interval or, that is the same, the stopping times , , such that intervals cover the interval and such that they as better as possible represent the times , , when the considered events occurred.
To illustrate the problem, let us consider a simple example of a non-steady supply process. Assume that the mentioned above clerk serves the clients with the rate clients/hour. During the workday of hours arrive clients. Then, the arrival rate of the clients defined over a workday is clients/hour and the transition rate that should guarantee that at the end of the workday all clients will be served.
Additionally, assume that in the morning, during the first two hours of the day, arrive clients. Then during the next four hours the clients do not arrive and then, in the evening, during the last two hours of the day, arrive the last clients. Thus, in the morning and in the evening the arrival rate is clients/hour, that means that the first clients will wait in the queue and the last clients will not be served until the end of the workday.
Certainly, such phenomena are well-known; in the queue theory they are solved using the state-dependent and time-dependent arrival rates [3,5,8], and in practice are overcome by adding the clerks in the morning and in the evening and by stopping the service in the midday. However, a prior definition of the appropriate time intervals can simplify further analysis and even decrease the expected number of varying rates.
Finally, note that the considered problem is essentially discrete problem, where it is required to split the discrete dataset. Together with that, since it is closely related to the discretization problems dealing with the continuous functions, below we will make some remarks on such problems as well.
3. Methods
The suggested solution of the problem is based on the concepts of -entropy and -capacity, which were introduced by Kolmogorov and Tikhomirov in the middle of 1950-s and presented in detail in their paper [6]. In addition, it uses the multiplication of partitions as it was implemented by Rokhlin [10] and by Sinai [14] in the studies of dynamical systems.
3.1. -Entropy and -Capacity
Let be a non-empty bounded set of a metric space and let be a real number.
The set is called -covering of the set , if and the diameter of any is not greater than .
The set is said to be -distinguishable, if any two of its distinct points are located at distance greater than .
Given a bounded set , for any there exists a finite -covering of , and for any any -distinguishable set is finite.
Denote by the minimal number of the sets in -covering of the set , and by the maximal number of points in an -distinguishable subset of the set .
The value
is called the -entropy of the set , and the value
is called the -capacity of the set .
These values are interpreted as follows: -entropy is a minimal number of bits required to transmit the set with the precision , and -capacity is a maximal number of bits, which can be memorized by with the precision .
Among the properties of -entropy and -capacity we will use the following fact [6]: given the bounded set , both -entropy and -capacity as functions of are non-increasing with increasing .
3.2. ɛ-Entropy of Partition
Let be a partition of the set that is and for any two sets holds .
The entropy of partition is defined as follows [10,14]. Let be a non-negative measure on the set such that and . Then, for any . The value
is called the entropy of partition. If is the probability measure on , then the sets can be interpreted as events and the entropy is equivalent to the Shannon entropy [13].
Assume that the partition is finite and the number of the sets in is . Define the measure on the set as follows:
Then, the entropy of partition is reduced to the value
Finally, if the diameter of any set is not greater than , then the partition is an -covering and called -partition. Then, the entropy of partition is equivalent to the -entropy of the set defined by equation (5).
Let be -partition of the set with and be another -partition of the set with . Multiplication of the partitions and is the partition
Each set is a subset of some set and of some set . Then it is said that is a refinement of both and ; this fact is denoted by and . Hence, following the properties of the entropy of partition,
and
Moreover, the entropy of the multiplication of the partition and is the -entropy of the set with any .
4. Suggested Solution
Let , , be a time interval and let be the set of moments in which certain events occur. We assume that the moments have an increasing order such that , .
As it follows from the formulation of the problem, in the consideration below the interval plays a role of the set and the intervals , , are considered as the elements of -partitions of the interval .
Given , the minimal number of sets in the -covering of the set
Then, the -entropy of the set is
Let
be a minimal value of for the set . Then, the value
is maximal -entropy of the set .
Finally, assume that on the interval two sets and , and , of moments are defined. Denote by partition of the interval corresponding to the set and by partition of the interval corresponding to the set . The number of intervals in the partition is and the number of intervals in the partition is .
Then, since the multiplication is a refinement of each of the partitions and of the sets, the size of the partition is , and the entropy of the multiplication is not smaller than the entropies and of the partitions and .
Hence, if
then, following equation (11),
Following the line of the Schwarz information criterion [11], let us define -information of the set .
Let be a partition corresponding to the set and let be a partition corresponding to the set , and , in which , . In the partition all intervals except the last are of the length .
Denote by the set of moments corresponding to the multiplication of the partitions and . Then, -information of the set is defined as follows
In this formula, the first term represents the number of bits required to transmit the set with maximal precision, the second term represents the number of bits required to transmit the set with precision , and the last term represents the number of bits required to transmit the set with precision using additional set generated with precision . Thus, the value is the number of bits remained after the transmission of the set with the precision . In the other words, -information of the set characterizes the part of the set, which cannot be transmitted with the precision .
Using equations (13) and (15), formula (18) of -information can be simplified and written in the form
The value of the entropy depends on the distribution of time moments , , over the interval . If the moments are distributed evenly, then and
Note that in general case equation (20) does not hold and calculation of the entropy of multiplication of partitions is processed according to the algorithm presented by Function 1 (see section 5).
Similarly, the value of -capacity depends on the distribution of the time moments over the interval . If the moments are distributed evenly such that and for any , then
and
If the distribution of the moments is such that , which means that all the moments except are located between and , and , then
and
Finally, if , then the set does not contain -distinguishable subset, and we assume that
and
Calculation of -capacity in general case follows the algorithm of Function 2 (see section 5).
The length of the time interval, which defines the stopping times , , is defined as
where is such a value for which -information of the set is as close as possible to -capacity of this set.
Note that given the set , the entropy is constant and both entropies and as functions of are decreasing. Thus, -information increases with . Along with that, -capacity as function of decreases.
Hence, the problem of finding the length is formulated as follows: given the set , find the value of such that
To illustrate the calculation of the length , let us consider a simple example. Assume that the considered time interval is and the set consists of the evenly distributed moments such that for any . Then (here for simplicity we omit the notion of ceiling),
Hence, according to the criterion (28), it is required to specify the value such that
which is
and finally
For example, if and , then
For comparison, the indicated above methods (1)-(4) of specifying the bin length in the histograms result in the following values:
In the considered example, the interval length calculated using the suggested method is compatible with the lengths obtained using the methods of calculating the bin lengths, but for the other distributions the interval lengths can be strongly different.
Note again that in general case the interval lengths cannot be calculated using close formulas. In the next section we summarize the suggested methods in the form of an algorithm which is applicable to arbitrary data.
5. Algorithmic Implementation
We summarize the suggested solution in the form of an algorithm which can be directly implemented in any high-level programming language. In our trials we used the MATLAB® environment.
| Algorithm 1. Computing an optimal interval length |
|
|
The algorithm includes two functions, and which are defined as follows.
| Function 1. |
|
|
The function was implemented in MATLAB® by concatenation of the sets and using the function cat with further removing of the doubling elements by the function unique.
| Function 2. |
|
|
The function computes the number of -distinguishable elements in the set for given and then computes as of this number.
Time complexity of Algorithm 1 includes the following terms: – complexity of the lines 1-4; – complexity of the line 5; – complexity of the line 6; – complexity of the line 7; – complexity of the line 8 and – complexity of the lines 9-13. Then, time complexity of each iteration of the algorithm is . The maximal number of iterations is ; hence complexity of Algorithm 1 is
Convergence of Algorithm 1 is guaranteed by the indicated above fact that -information increases with increasing while -capacity decreases with increasing . Since the interval is bounded, the difference between increasing -information and decreasing -capacity has its minimum in , which is a terminating point of the algorithm.
Dependence of the functions and on the interval length is illustrated in Figure 1.
The computed interval is . For this interval and , the values of -information and -capacity are bit. Note that the accuracy of computing the interval increases with decreasing the step .
6. Examples
First, let us consider the examples of computing the interval lengths for different distributions of time intervals. In all considered cases we assume that the length of time interval is and .
The data were generated by the MATLAB® function random with respect to the distribution created by the MATLAB® function makedist. In the examples, we used uniform distribution with and , normal distribution with and , and exponential distribution with .
The obtained interval lengths were used as bin lengths in the histograms. For comparison, we present the histograms plotted with the bin lengths calculated using the Scott rule (see equation (3)), which is also used as a basis for a default method in MATLAB®. The resulting histograms are shown in Figure 2.
The values of the interval lengths are:
- -
- evenly distributed data:Δ = 14.21, δ1 = 9.90, δ2 = 12.95, δ3 = 21.81 and δ4 = 21.54,
- -
- uniform distribution with and :Δ = 14.11, δ1 = 9.83, δ2 = 12.87, δ3 = 22.69 and δ4 = 22.65,
- -
- normal distribution with and :Δ = 14.91, δ1 = 8.27, δ2 = 10.83, δ3 = 13.11 and δ4 = 10.38,
- -
- exponential distribution with :Δ = 1.20, δ1 = 1.07, δ2 = 1.41, δ3 = 1.35 and δ4 = 0.91.
The suggested method results in the interval lengths that are close to the interval lengths provided by the conventional methods with respect to the distribution of the data. In fact, for evenly and uniformly distributed data interval length is close to the interval length resulted by the Sturges method, for normal distribution and for exponential distribution .
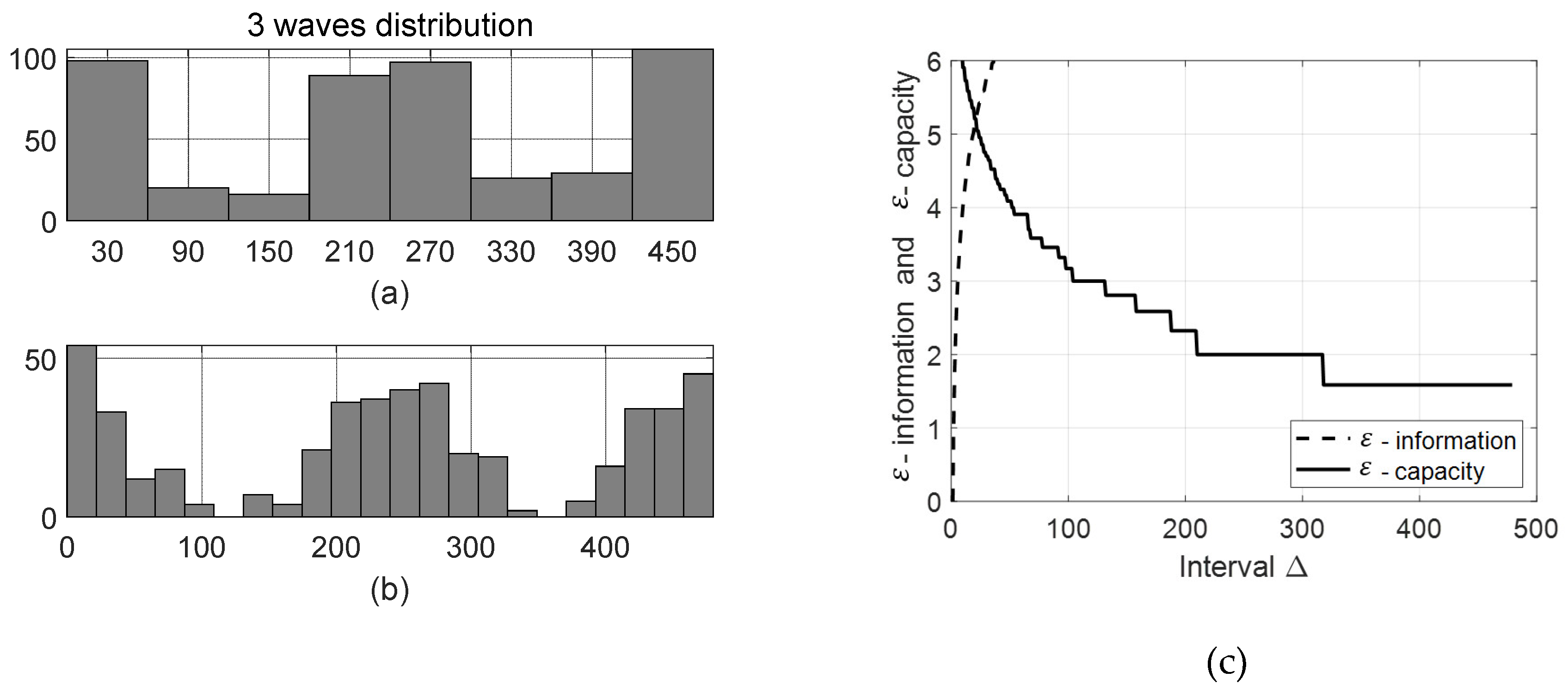
Now let us consider the use of the suggested algorithm for specification of the arrival rates and corresponding service rates . Assume that the office, where the mentioned above clerk works, serves clients hours during the day that is minutes. Also, assume that the clients arrive by three “waves” – in the morning, in the midday and in the evening. The histogram of the number of clients during the day is shown in Figure 3.a. In this histogram the bin length is computed by the Scott rule (value below).
The values of the interval lengths for this distribution are:
Δ = 22.0, δ1 = 21.91, δ2 = 48.45, δ3 = 67.99 and δ4 = 66.41.
Histogram of the number of clients during the day with the bin length computed by the suggested algorithm is shown in Figure 3.b. Dependence of the functions and on for this distribution is shown in Figure 3.c.
From the results of computations of the interval length and the bin lengths it follows that by the suggested algorithm the arrival rates during a day should be calculated each minutes, while by the Scott they should be calculated each minutes. Thus, for multimodal distribution the suggested algorithm results in shorter intervals that provides more exact representation of the data.
7. Conclusion
In the paper, we suggested the method of calculating optimal time intervals required for definition of arrival and departure rates. The method is useful for specification of the bin lengths in histograms, especially for the data with multimodal distributions.
The method utilizes the Kolmogorov and Tikhomirov -entropy and -capacity and the Rokhlin entropy of partition. Optimality of the partition is defined basing on the -information.
The procedure is presented in the form of a ready-to-use algorithm, which was compared with the known methods used for calculation of the interval lengths in histograms and demonstrated its robustness and correct sensitivity to the data.
Funding
This research has not received any grant from funding agencies in the public, commercial, or non-profit sectors.
Competing interests
The authors declare no competing interests.
References
- Dinaburg, E.I. On the relations among various entropy characteristics of dynamical systems. Math. USSR Izvestija 1971, 5, 337–378. [Google Scholar] [CrossRef]
- Freedman, D.; Diaconis, P. On the histogram as a density estimator: L2 theory. Zeit. Wahrscheinlichkeitstheorie und Verwandte Gebiete 1981, 57, 453–476. [Google Scholar] [CrossRef]
- Gross, D.; Shortle, J.F.; Thompson, J.M.; Harris, C.M. Fundamentals of Queueing Theory, 4th ed.; John Wiley & Sons: Hoboken, NJ, 2008. [Google Scholar]
- Jacod, J.; Protte, P. Discretization of Processes; Springer: Berlin, 2012. [Google Scholar]
- Keller, J.B. Time-dependent queues. SIAM Review 1982, 24, 401–412. [Google Scholar] [CrossRef]
- Kolmogorov, A.N.; Tikhomirov, V.M. ɛ-entropy and ɛs-capacity of sets in functional spaces. Amer. Mathematical Society Translations, Ser. 2 1961, 17, 277–364. [Google Scholar]
- Lawler, G.F. Introduction to Stochastic Processes; Chapman & Hall: New York, 1995. [Google Scholar]
- Newell, G.F. Queues with time-dependent arrival rates (I-III). J. Applied Probability, 1968, 5(2), 436-451 (I); 5(3), 579-590 (II); 5(3), 591-606 (III).
- Reis, Y. Private conversation. Ariel University, Ariel, March 2021. [Google Scholar]
- Rokhlin, V.A. New progress in the theory of transformations with invariant measure. Russian Mathematical Surveys 1960, 15, 1–22. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Annals of Statistics 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Scott, D.W. On optimal and data-based histograms. Biometrika 1979, 66, 605–610. [Google Scholar] [CrossRef]
- Shannon, C. A mathematical theory of communication. The Bell System Technical Journal 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Sinai, Y.G. Topics in Ergodic Theory.; Princeton University Press: Princeton, 1993. [Google Scholar]
- Sturges, H. The choice of a class-interval. J. Amer. Statistics Association 1926, 21, 65–66. [Google Scholar] [CrossRef]
- Vitushkin, A.G. Theory of Transmission and Processing of Information; Pergamon Press: New York, 1961. [Google Scholar]
Figure 1.
Dependence of -information and -capacity on the interval length for the set of evenly distributed time moments; , and .
Figure 1.
Dependence of -information and -capacity on the interval length for the set of evenly distributed time moments; , and .
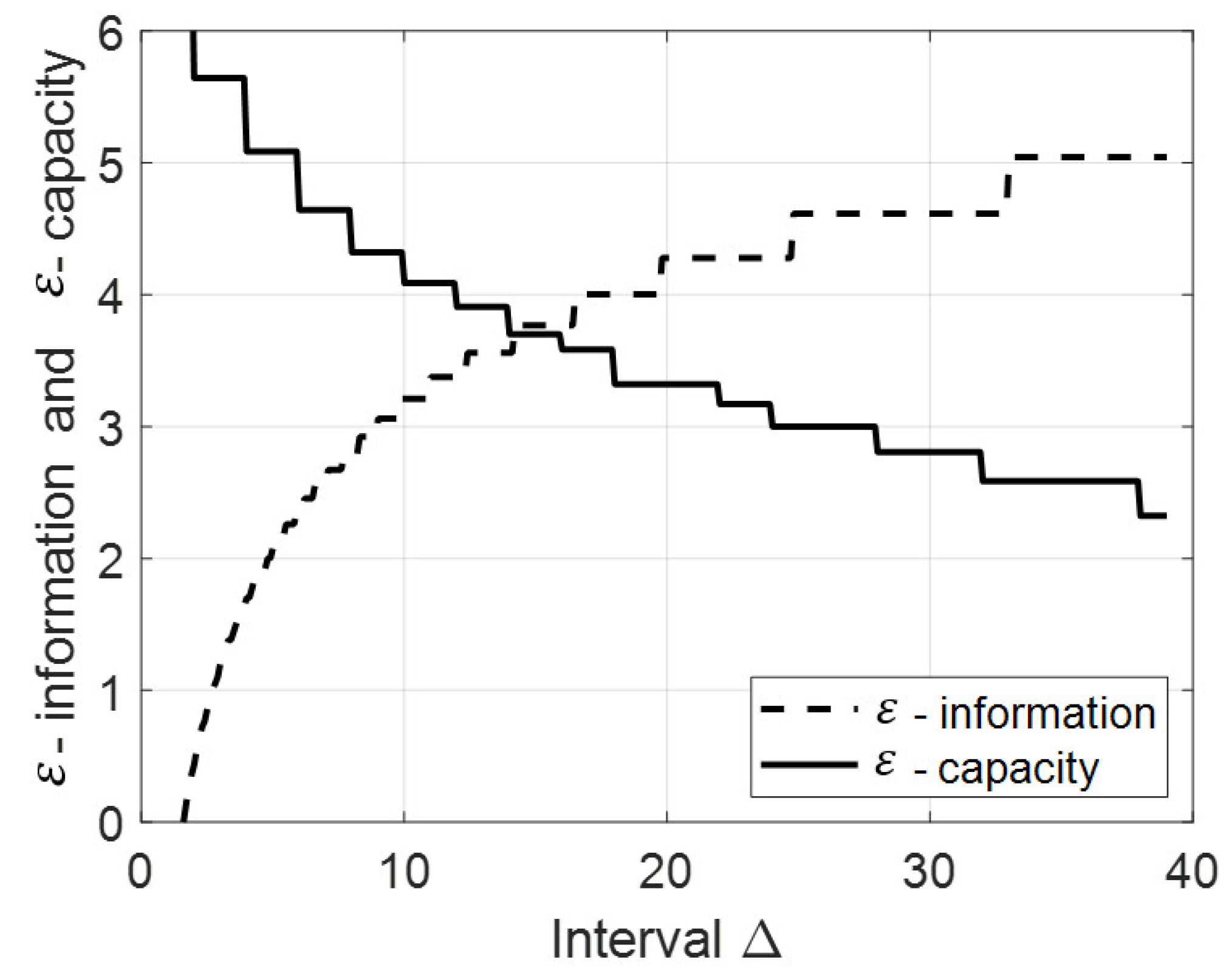
Figure 2.
Histograms of the data plotted using the bin lengths computed by the Scott rule (figures (a) for each distribution) and using the bin lengths computed by the suggested algorithm (figures (b) for each distribution).
Figure 2.
Histograms of the data plotted using the bin lengths computed by the Scott rule (figures (a) for each distribution) and using the bin lengths computed by the suggested algorithm (figures (b) for each distribution).
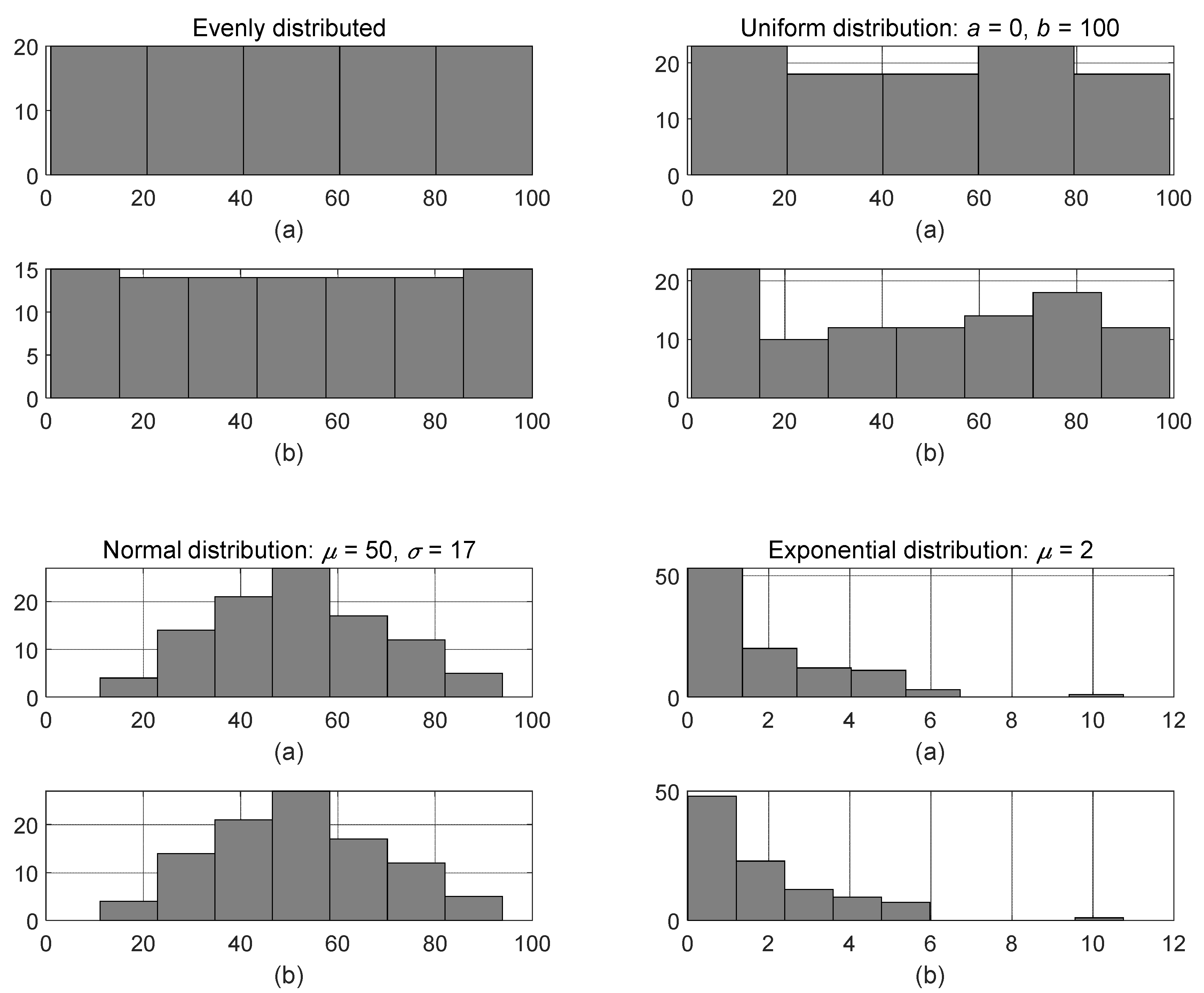
Figure 3.
Arrivals of the clients during a day: (a) histogram with the bin length computed by the Scott rule; (b) histogram with the bin length computed by the suggested algorithm; (c) dependences of -information and -capacity on for the set of arrival times.
Figure 3.
Arrivals of the clients during a day: (a) histogram with the bin length computed by the Scott rule; (b) histogram with the bin length computed by the suggested algorithm; (c) dependences of -information and -capacity on for the set of arrival times.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



