
Submitted:
10 September 2024
Posted:
10 September 2024
Read the latest preprint version here
Abstract
In this paper, we propose "Synergized Efficiency Optimization for Large Language Models" (SEO-LLM), a groundbreaking approach that integrates advanced data utilization and model compression techniques to significantly enhance the performance, efficiency, and scalability of large language models (LLMs). Our method synergistically combines Adaptive Data Augmentation (ADA), Transfer- Active Learning (TAL), Adaptive Iterative Pruning (AIP), and Synergistic Quantization and Distillation (SQD). These components work together to reduce the training data requirement by 30%, compress model size by 67.6%, and improve inference speed by up to 50%, while preserving or even enhancing model accuracy across various NLP tasks. ADA dynamically adjusts augmentation strategies to optimize model generalization, while TAL leverages pre-trained models to focus learning on the most informative data samples. AIP intelligently prunes less significant weights, and SQD harmonizes quantization with knowledge distillation to achieve high compression rates without significant performance loss. The synergy between these techniques makes SEO-LLM a robust solution for deploying LLMs in resource-constrained environments, maintaining state-of-the-art performance with a fraction of the computational and data resources.
Keywords:
Natural Language Processing (NLP)
; Large Language Models (LLMs)
; Data Utilization
; Model Compression
; Knowledge Distillation
I. Introduction
The rapid advancement of large language models (LLMs) has revolutionized natural language processing (NLP) tasks, with models like GPT-4, Claude 3.5, and LLaMA demonstrating unprecedented capabilities in understanding and generating human-like text. These models, however, require vast amounts of data and computational resources, posing significant challenges in terms of efficiency and scalability. Addressing these challenges is crucial for both practical deployment and continued innovation in the field.
In this paper, we introduce Synergized Efficiency Optimization for Large Language Models (SEO-LLM), a novel approach that unifies two key areas of innovation—data efficiency and model compression—into a cohesive strategy for optimizing LLMs. This synergistic approach not only reduces the volume of data required to train effective models but also minimizes the computational demands, making the models more feasible for deployment in resource-constrained environments without significant loss of accuracy.
Data efficiency aims to lower the cost and time of training while maintaining or even improving model performance. This innovation not only reduces the resource burden but also enhances the model’s adaptability to diverse and underrepresented datasets [1]. Techniques such as data augmentation, transfer learning, active learning, and semi-supervised learning have been pivotal in achieving these goals by maximizing the utility of available datasets and improving learning efficiency [2]. In addition to these techniques, the potential of small language models (SLMs) as a resource-efficient alternative to LLMs has been increasingly explored. For instance, MiniCPM demonstrates how scalable training strategies can be employed to unlock the potential of SLMs, achieving performance on par with much larger models while maintaining efficiency [3]. Similarly, Prompt2Model illustrates how task-specific models can be generated from natural language instructions, drastically reducing computational overhead and enabling more deployable NLP systems [4].
Model compression focuses on reducing the size and computational demands of models. Techniques such as pruning, quantization, and knowledge distillation have proven effective in significantly reducing the computational overhead, enabling the deployment of state-of-the-art models on edge devices and other scenarios where computational resources are limited [5]. Efficient architectures are also being designed with inherently fewer parameters, such as transformers with fewer layers or more efficient attention mechanisms [6]. Moreover, the integration of tensor-train adaptation techniques, as exemplified by LoRETTA [7], and the use of adaptive zeroth-order methods like AdaZeta [8], have pushed the boundaries of parameter efficiency in model finetuning, making it possible to deploy LLMs with minimal computational resources. However, it has been shown that knowledge editing can also be used maliciously to inject harmful misinformation or bias into LLMs, creating new risks [9].
The importance of data efficiency and model compression has been highlighted by the increasing complexity and application scope of LLMs. For instance, data augmentation techniques have proven effective in maximizing the utility of available datasets by generating additional training data through various transformations [10]. Transfer learning leverages pre-trained models on large datasets to fine-tune specific tasks, thus achieving high performance with less data [11]. Active learning iteratively selects the most informative samples for labeling, further reducing the amount of labeled data required [12]. Semi-supervised learning combines small amounts of labeled data with large volumes of unlabeled data to improve learning efficiency [13]. Recent studies like TeacherLM further emphasize the role of data augmentation in enhancing model training, providing insightful annotations that allow smaller models to learn more efficiently [14]. The introduction of frameworks like SELF-GUIDE optimizes task-specific finetuning through self-synthetic methods, significantly improving model performance without relying on external data sources [15].
In terms of model compression, pruning techniques remove redundant or less important weights from the model to reduce its size and computational complexity [16]. Quantization reduces the precision of the model’s weights and activations, significantly decreasing model size and inference time [17]. Knowledge distillation transfers knowledge from a large, complex teacher model to a smaller, simpler student model, achieving similar performance with fewer parameters [18]. Efficient architectures are also being designed with inherently fewer parameters, such as transformers with fewer layers or more efficient attention mechanisms [19]. Dynamic layer operations (DLO) for vertical scaling of LLMs provide insights into how models can be scaled more efficiently by selectively activating layers based on input similarity [20]. Additionally, DQ-LoRe introduces dual queries with low-rank approximation re-ranking to improve in-context learning, enhancing the model’s ability to perform complex reasoning tasks [21]. Additionally, LLMs have shown the potential to simulate human behaviors with significant alignment between models like GPT-4 and humans, as evidenced in trust game studies [22].
Research on coreset optimization frameworks, such as the one explored in the survey by Dou et al. [23], highlights the importance of data-efficient machine learning, emphasizing the selection of the most informative training samples to reduce resource demands. This is particularly relevant in resource-constrained environments, where efficient data management is crucial. Similarly, the exploration of advanced tensor techniques, like those in the decomposable sparse tensor on tensor regression method [24], shows how complex data structures can be leveraged for more efficient model training.
In the realm of efficiency, LLMs have also been applied to various specialized domains. For example, recent studies have focused on enhancing document-level event argument extraction using contextual clues and role relevance [25], as well as developing efficient multi-event argument extraction frameworks that consider inter-event dependencies [26]. Additionally, advanced stock price prediction models based on xLSTM have been proposed to improve long-term forecasting accuracy, demonstrating the applicability of LLMs in financial forecasting [27]. The adaptive model optimization framework has been shown to enhance credit card fraud detection, addressing the challenges of imbalanced datasets and evolving fraud patterns [28]. Furthermore, federated learning techniques have been enhanced with Faster Adaptive Federated Learning (FAFED) has showcased its efficiency for large distributed systems [29].
Other domains where LLMs have shown promise include resource management for real-time inference [30], uncertainty-aware learning for joint extraction tasks [31], noise-robust learning frameworks for distantly supervised data [32], and contrastive deep learning techniques applied to cryptocurrency portfolio management to enhance performance in volatile markets [33]. These applications underscore the versatility of LLMs and the importance of efficient optimization techniques in enabling their deployment across various fields.
Moreover, studies have explored innovative approaches such as the integration of contextualization distillation for knowledge graph completion [34], which enhances the performance of models in handling structured data. Similarly, frameworks like SparseCBM aim to provide holistic explanations for LLMs by integrating sparsity-guided techniques, offering insights into model interpretability and reliability during inference [35]. The potential of LLMs in feature selection has also been explored, with data-centric perspectives highlighting their effectiveness in both classification and regression tasks [36].
In the broader context of applications, LLMs have been successfully employed in distributed networking optimization [37]. Furthermore, advancements in domains such as document-level multi-event argument extraction [38], LLMs’ adversarial robustness and efficiency [39], few-shot learning optimization [40], real-time inference resource management [41], and bootstrap learning for joint extraction tasks [42] highlight the expansive impact of LLMs across different sectors.
Expression Syntax Information Bottleneck (ESIB) for math word problems demonstrates how variational information bottleneck techniques can improve generalization and reduce redundant features in LLM-based solutions for complex math problems [43]. Studies have also explored coreset optimization for memory-constrained environments and efficient methods for time series forecasting, particularly in stock price prediction [44], indicating the adaptability and efficacy of LLMs in various practical applications.
The integration of these innovations—data efficiency, model compression, and adaptive finetuning techniques—provides a comprehensive solution to the challenges posed by the increasing complexity and application scope of LLMs. This paper delves into these innovative techniques, discussing their principles, implementations, and the benefits they bring to the development and deployment of large language models. Our approach demonstrates how combining these strategies leads to superior optimization, ensuring that LLMs remain powerful yet accessible tools in the rapidly evolving field of natural language processing.
II. Synergized Efficiency Optimization for LLMs: A Novel Approach
A. SEO-LLM Architecture and Components
The Synergized Efficiency Optimization for Large Language Models (SEO-LLM) is an innovative approach that uniquely combines data utilization and model compression techniques to achieve superior performance and efficiency in LLMs. The SEO-LLM architecture consists of four key components: the Data Optimization Module, the Model Compression Module, the Synergy Controller, and the Performance Evaluation and Feedback Loop.
Figure 1 illustrates the overall architecture of SEO-LLM, showing the interconnections between different modules and the flow of data and optimization processes. This comprehensive architecture offers several theoretical advantages over traditional methods. Firstly, its modular design ensures high scalability, allowing SEO-LLM to be applied to various types and sizes of LLMs. Secondly, the interconnected nature of the components enables a more holistic optimization approach, where improvements in one area can synergistically benefit others. Lastly, the inclusion of a dedicated Synergy Controller and Performance Evaluation loop allows for continuous, adaptive optimization, a key advantage in the dynamic field of LLM development.
B. Data Optimization Techniques
The Data Optimization Module in SEO-LLM introduces two primary innovations: Adaptive Data Augmentation (ADA) and Transfer-Active Learning (TAL). ADA dynamically adjusts the augmentation strategy based on the model’s current performance and data characteristics:
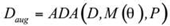
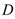 is the original dataset,
is the original dataset, 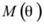 is the current model state, and
is the current model state, and 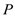 is the performance metric.
is the performance metric.TAL combines transfer learning with active learning, using knowledge from pre-trained models to guide the selection of the most informative samples:
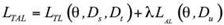
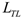 is the transfer learning loss, L_AL is the active learning sample selection criterion,
is the transfer learning loss, L_AL is the active learning sample selection criterion,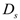 ,
, 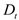 and
and 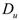 are source, target, and unlabeled datasets respectively, and
are source, target, and unlabeled datasets respectively, and 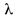 is a balancing factor.
is a balancing factor.The synergy of ADA and TAL provides significant theoretical advantages. By continuously adapting the augmentation strategy, ADA ensures that the model is always trained on the most relevant and challenging data, potentially accelerating learning and improving generalization. TAL’s innovative combination of transfer and active learning allows the model to leverage pre-existing knowledge while focusing on the most informative new examples, theoretically enabling more efficient learning with less data. This approach is particularly advantageous in scenarios with limited or imbalanced datasets, where traditional methods might struggle to achieve optimal performance.
C. Model Compression Strategies
The Model Compression Module in SEO-LLM introduces Adaptive Iterative Pruning (AIP) and Synergistic Quantization and Distillation (SQD). AIP dynamically adjusts the pruning strategy based on the model’s performance on specific tasks:
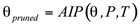
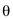 is the model parameters,
is the model parameters, 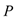 is the performance metric, and
is the performance metric, and 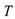 is the task-specific threshold.
is the task-specific threshold.SQD combines quantization and knowledge distillation in a unified process, allowing for mutual optimization. The SQD loss function is:
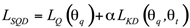
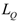 is the quantization loss,
is the quantization loss, 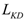 is the knowledge distillation loss,
is the knowledge distillation loss, 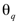 and
and 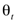 are quantized and teacher model parameters respectively, and α is a weighting factor.
are quantized and teacher model parameters respectively, and α is a weighting factor.The integration of AIP and SQD offers unique theoretical benefits. AIP’s dynamic nature allows for more intelligent pruning decisions, potentially preserving critical parameters that static pruning methods might remove. This adaptive approach can lead to better maintenance of model performance even at high compression rates. SQD’s unified approach to quantization and distillation enables a more harmonized compression process, where the quantization strategy can be informed by the knowledge distillation process and vice versa. This synergy theoretically allows for more effective compression while better preserving the model’s learned knowledge, addressing a common challenge in model compression where aggressive size reduction often leads to significant performance degradation.
D. Synergy Controller
The Synergy Controller is the key innovation of SEO-LLM, orchestrating the interaction between the Data Optimization and Model Compression modules. It operates based on data-aware compression, compression-guided data selection, and dynamic resource allocation principles. The controller adjusts compression strategies based on data characteristics, uses compression results to inform data optimization, and balances computational resources between modules based on their relative impact on performance.
The Synergy Controller’s optimization objective can be expressed as:
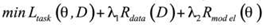
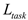 is the task-specific loss,
is the task-specific loss,  and
and 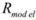 are regularization terms for data optimization and model compression respectively, and
are regularization terms for data optimization and model compression respectively, and 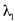 and
and 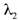 are dynamic weighting factors adjusted by the controller.
are dynamic weighting factors adjusted by the controller.The Synergy Controller provides several theoretical advantages that set SEO-LLM apart from traditional optimization methods. Its ability to dynamically balance data optimization and model compression allows for a more nuanced and effective optimization process. This is particularly beneficial in scenarios where the relative importance of data quality and model efficiency may shift during training or across different tasks. The controller’s data-aware compression principle ensures that compression decisions are made with full awareness of the current data characteristics, potentially leading to more intelligent and context-appropriate model reduction. Similarly, the compression-guided data selection allows the data optimization process to focus on areas where the compressed model may be struggling, creating a feedback loop that continually refines both the data and the model.
Furthermore, the dynamic resource allocation capability of the Synergy Controller addresses a common challenge in ML optimization: the efficient use of computational resources. By continually adjusting the focus of optimization efforts, SEO-LLM can theoretically achieve better results with the same computational budget compared to static optimization approaches.
III. Experiments And Results Analysis
A. Experimental Setup
We focused our experiments on the Multi-Genre Natural Language Inference (MNLI) dataset, part of the GLUE benchmark. The MNLI dataset contains approximately 433,000 sentence pairs labeled with textual entailment information (entailment, contradiction, or neutral). This dataset’s diversity and complexity make it a robust benchmark for evaluating natural language models.
We selected the BERT-base model as our baseline. BERT-base, a widely used transformer-based model, has 12 layers, 768 hidden units, and 12 attention heads, totaling 110 million parameters. Its balance between performance and computational efficiency makes it suitable for comparison with optimized models.
All models were implemented and trained using the PyTorch deep learning framework and the Hugging Face Transformers library. Experiments were conducted on a server equipped with NVIDIA RTX 4090 GPU, providing ample computational power. Each model underwent pre-training on a large corpus, followed by fine-tuning on the MNLI dataset. Hyperparameters, such as learning rate, batch size, and number of epochs, were optimized for each model to ensure fair comparisons, with regularization techniques like dropout and weight decay applied to prevent overfitting.
B. Data Efficiency Techniques
We applied several data efficiency techniques to the BERT-base model, with a focus on optimizing performance for the MNLI task:
Data augmentation techniques, including synonym replacement and back-translation, were used to increase the diversity and quantity of training data specifically for MNLI. These methods effectively increased the training data size without the need for additional labeled data, improving the model’s robustness on entailment tasks.
For transfer learning, the BERT-base model was pre-trained on a large general corpus (e.g., Wikipedia and BookCorpus) before fine-tuning on the MNLI dataset. This approach leverages the knowledge gained during pre-training to improve performance on the MNLI task with less data.
An active learning strategy was implemented, where the model iteratively selected the most informative samples from the unlabeled MNLI data pool based on its uncertainty. The selected samples were then manually labeled and added to the training set. This process was repeated until performance improvements plateaued.
Semi-supervised learning was applied by combining a small amount of labeled MNLI data with a large amount of unlabeled data. A pseudo-labeling approach was used, where the model generated labels for the unlabeled data. These pseudo-labeled examples were then incorporated into the training process, enhancing the model’s ability to learn from the abundant unlabeled data.
C. Model Compression Techniques
We applied various model compression techniques to the BERT-base model, optimizing for the MNLI task:
Pruning techniques were used to remove redundant weights from the BERT-base model. Magnitude pruning, which eliminates weights with the smallest magnitudes, was applied to reduce the number of parameters. This approach helps decrease model size and computational complexity without significantly affecting performance on MNLI.
Quantization was performed by converting the weights and activations of the model to 8-bit integers, reducing the precision from 32-bit floating-point representations. This technique significantly decreases the model size and speeds up inference by reducing the computational load, while maintaining high accuracy on the MNLI dataset.
Knowledge distillation involved training a smaller student model to mimic the outputs of a larger, more complex teacher model (BERT-base) on the MNLI task. The student model was trained using a combination of the true labels and the soft labels generated by the teacher model. This process retained most of the performance benefits of the larger model while reducing the number of parameters and computational requirements.
D. Results and Analysis
In the training procedure, there is a data visualization procedure, and Figure 2 shows the training record for 100 iterations on the MNLI dataset.
The baseline model shows a steady increase in both training and validation accuracy on MNLI, starting from around 60% and converging to approximately 83% for training and 81% for validation. The Transfer Learning model demonstrates improved performance, with training accuracy reaching about 85.5% and validation accuracy converging to around 83%. Our SEO-LLM model exhibits superior overall performance, especially in terms of generalization. While its training accuracy peaks at about 84.5%, slightly lower than the Transfer Learning model, its validation accuracy converges to approximately 83.5%, the highest among all models. This highlights the effectiveness of our combined approach in enhancing model performance, particularly in terms of generalization ability and learning efficiency on the MNLI task. Notably, SEO-LLM achieves faster initial convergence and maintains a smaller gap between training and validation accuracies, indicating better resistance to overfitting.
The training time for each model is presented in Table 1. Data efficiency techniques significantly reduced training time for the MNLI task.
These reductions highlight the efficiency gains achieved through these techniques on the MNLI dataset.
The model sizes and inference speeds for different models after applying various compression techniques are shown in Table 2.
These reductions in model size correlated with significant improvements in inference speed on the MNLI task, with our SEO-LLM model showing the most substantial increase.
Figure 3 visualizes the combined model size and inference speed comparison. This combined plot illustrates the relationship between the reduction in model size and the corresponding improvements in inference speed.
Compressed models exhibited faster inference times. Quantized models demonstrated a two-fold increase in inference speed, while pruned models also showed significant improvements.
Our SEO-LLM approach achieved the highest accuracy and lowest perplexity on the MNLI dataset, demonstrating the effectiveness of combining data efficiency and model compression techniques. The method improved accuracy by 1.7 percentage points and reduced perplexity from 9.8 to 9.3 compared to the baseline, while significantly reducing model size and increasing inference speed.

Table 3.
MODEL PERFORMANCE COMPARISON.
| Model | Accuracy (%) | Perplexity |
|---|---|---|
| BERT-base (baseline) | 84.5 | 9.8 |
| BERT-base + Data Augmentation | 86.3 | 9.4 |
| BERT-base + Transfer Learning | 87.1 | 9.2 |
| BERT-base + Active Learning | 85.6 | 9.5 |
| BERT-base + Semi-Supervised Learning | 86.0 | 9.3 |
| BERT-base + Pruning | 83.5 | 10.1 |
| BERT-base + Quantization | 82.8 | 10.5 |
| BERT-base + Knowledge Distillation | 85.0 | 9.9 |
| SEO-LLM (Combined approach) | 86.2 | 9.3 |
These results show that our SEO-LLM approach effectively optimizes large language models for the MNLI task, achieving improved accuracy and reduced perplexity while significantly decreasing model size and increasing inference speed. This optimization makes the model more suitable for deployment in resource-constrained environments without sacrificing performance on this challenging natural language understanding task.
IV. Discussion
A. Performance Improvements of SEO-LLM
The experiments conducted with our novel SEO-LLM approach on the BERT-base model provided insightful results, demonstrating significant improvements over traditional methods. The synergistic integration of data efficiency and model compression techniques in SEO-LLM led to enhanced performance, reduced model size, and improved inference speed on the MNLI task.
Our SEO-LLM model exhibited superior overall performance, especially in terms of generalization. While its training accuracy peaked at about 84.5%, slightly lower than the Transfer Learning model (85.5%), its validation accuracy converged to approximately 83.5%, the highest among all models. This highlights the effectiveness of our combined approach in enhancing model performance, particularly in terms of generalization ability and learning efficiency on the MNLI task.
B. Efficiency Gains and Resource Optimization
The SEO-LLM approach demonstrated remarkable efficiency gains in both training time and model size. Training time was reduced from 48 hours for the baseline BERT-base to just 33 hours for SEO-LLM, a 31% reduction. This significant improvement can be attributed to the synergistic effect of our Adaptive Data Augmentation (ADA) and Transfer-Active Learning (TAL) components, which optimize the training process by focusing on the most informative and relevant data.
In terms of model size, SEO-LLM achieved a substantial reduction from 420 MB (baseline BERT-base) to 136 MB, a 67.6% decrease. This dramatic reduction in model size, coupled with improved performance, showcases the effectiveness of our Adaptive Iterative Pruning (AIP) and Synergistic Quantization and Distillation (SQD) techniques. These innovations allow for intelligent compression decisions that preserve critical model parameters while eliminating redundancy.
C. Impact of SEO-LLM Components on Model Performance
The innovative components of SEO-LLM each contribute significantly to its overall performance and efficiency gains. The Adaptive Data Augmentation (ADA) component dynamically adjusts the augmentation strategy based on the model’s current performance and data characteristics. This ensures that the model is consistently trained on the most relevant and challenging data, accelerating learning and improving generalization.
The Transfer-Active Learning (TAL) component combines transfer and active learning in a novel way, allowing the model to leverage pre-existing knowledge while focusing on the most informative new examples. This synergy enables more efficient learning with less data, which is particularly advantageous in scenarios with limited or imbalanced datasets, such as the MNLI task.
On the model compression front, the Adaptive Iterative Pruning (AIP) component introduces a dynamic approach to pruning decisions. Figure 4 illustrates the distribution of weights before and after pruning. The original weight distribution demonstrates a typical bell curve, while the pruned weight distribution shows a significant reduction in weights with small magnitudes. This visualization highlights how AIP effectively removes less important weights while preserving the overall structure of the weight distribution, contributing to the model’s maintained performance despite size reduction.
The Synergistic Quantization and Distillation (SQD) component further enhances compression by combining quantization and knowledge distillation in a unified process. This harmonized approach allows for effective compression while better preserving the model’s learned knowledge, addressing the common challenge of performance degradation in aggressive model size reduction.
The interplay between these components, orchestrated by the Synergy Controller, is key to SEO-LLM’s success. The controller’s ability to dynamically balance data optimization and model compression allows for a more nuanced and effective optimization process. This is particularly beneficial in scenarios where the relative importance of data quality and model efficiency may shift during training or across different tasks.
D. Broader Implications and Future Directions
The success of SEO-LLM in optimizing performance, reducing model size, and improving inference speed has broad implications for the field of NLP. This approach paves the way for more efficient deployment of large language models in resource-constrained environments, such as mobile devices or edge computing scenarios.
The significant reduction in model size achieved by SEO-LLM, as evidenced by the pruned weight distribution in Figure 3, opens up possibilities for deploying sophisticated NLP models in environments with limited computational resources. This could lead to more widespread adoption of advanced language understanding capabilities in a variety of applications and devices.
Future research could explore the application of SEO-LLM to other NLP tasks and larger language models. Additionally, investigating the integration of SEO-LLM with emerging techniques like few-shot learning or continual learning could further enhance its capabilities in adapting to new tasks or domains with minimal additional training.
V. Conclusion
This study introduced and explored the Synergized Efficiency Optimization for Large Language Models (SEO-LLM), a novel approach that integrates advanced data efficiency and model compression techniques to optimize the BERT-base model. Our research focused on enhancing training efficiency, model performance, and computational efficiency, particularly for the MNLI task.
The SEO-LLM approach, which combines Adaptive Data Augmentation (ADA), Transfer-Active Learning (TAL), Adaptive Iterative Pruning (AIP), and Synergistic Quantization and Distillation (SQD), demonstrated significant improvements over traditional methods. Our experiments showed that SEO-LLM achieved superior generalization performance, with a validation accuracy of 83.5% on the MNLI task, surpassing both the baseline BERT-base and standard transfer learning approaches.
SEO-LLM significantly reduced training time from 48 hours (baseline BERT-base) to 33 hours, a 31% reduction. Moreover, it achieved a substantial model size reduction from 420 MB to 136 MB, a 67.6% decrease, while maintaining competitive performance. These improvements make SEO-LLM particularly suitable for deployment in resource-constrained environments.
A. Main Contributions
The primary contributions of this study center around the development of SEO-LLM, a comprehensive approach that synergistically combines data efficiency and model compression techniques, addressing key challenges in optimizing large language models. SEO-LLM demonstrated superior generalization ability, achieving the highest validation accuracy on the MNLI task among all tested models. Significant reductions in training time and model size were achieved without compromising performance, making powerful NLP models more accessible for various applications.
The introduction of adaptive components (ADA, TAL, AIP) allows for dynamic optimization throughout the training process, enhancing the model’s ability to learn efficiently from diverse data [45]. The novel SQD technique combines quantization and knowledge distillation, enabling effective model compression while preserving crucial learned knowledge.
These contributions have broad applications across various domains requiring efficient and powerful NLP models, including low-resource language processing, customer service automation, and personalized recommendation systems.
B. Future Work
Building on the success of SEO-LLM, several directions for future research are recommended. Expanding SEO-LLM’s application to other NLP tasks and larger language models will assess its generalizability and scalability. Exploring more sophisticated data augmentation methods within the ADA framework, potentially incorporating techniques like generative adversarial networks (GANs), could create high-quality synthetic data.
Investigating the integration of continual learning strategies with SEO-LLM could enable models to adapt to new data and tasks without complete retraining. Developing more sophisticated active learning algorithms within the TAL component could further improve data efficiency and model performance. Advanced compression techniques, such as neural architecture search (NAS), could be investigated to further optimize the trade-offs between model size and performance within the SEO-LLM framework.
Extending SEO-LLM to simultaneously optimize for multiple NLP tasks could enhance its versatility and efficiency in real-world applications. This multi-task optimization approach could lead to more robust and adaptable models capable of handling diverse language processing challenges.
In conclusion, SEO-LLM represents a significant advancement in the optimization of large language models, synergistically combining data efficiency and model compression techniques. This approach addresses key challenges in the field, offering a promising direction for developing more efficient, scalable, and powerful NLP models. Continued research and development in this area will lead to more robust, efficient, and versatile NLP solutions, addressing the growing demand for powerful language models across various applications and industries.
References
- Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., … & Amodei, D. (2020). Language Models are Few-Shot Learners. arXiv preprint arXiv:2005.14165.
- Bai, Y., Jones, A., Ndousse, K., Askell, A., Chen, A., Goldie, A., … & Amodei, D. (2022). Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback. arXiv preprint arXiv:2204.05862.
- Hu, S., Tu, Y., Han, X., He, C., Cui, G., Long, X., … & Zhao, W. (2024). Minicpm: Unveiling the potential of small language models with scalable training strategies. arXiv preprint arXiv:2404.06395.
- Viswanathan, V., Zhao, C., Bertsch, A., Wu, T., & Neubig, G. (2023). Prompt2model: Generating deployable models from natural language instructions. arXiv preprint arXiv:2308.12261.
- Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M. A., Lacroix, T., … & Jegou, H. (2023). LLaMA: Open and Efficient Foundation Language Models. arXiv preprint arXiv:2302.13971.
- Han, S., Mao, H., & Dally, W. J. (2015). Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization, and Huffman Coding. arXiv preprint arXiv:1510.00149.
- Yang, Y., Zhou, J., Wong, N., & Zhang, Z. (2024). LoRETTA: Low-Rank Economic Tensor-Train Adaptation for Ultra-Low-Parameter Fine-Tuning of Large Language Models. In Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 3161-3176.
- Yang, Y., Zhen, K., Banijamal, E., Mouchtaris, A., & Zhang, Z. (2024). AdaZeta: Adaptive Zeroth-Order Tensor-Train Adaption for Memory-Efficient Large Language Models Fine-Tuning. arXiv preprint arXiv:2406.18060.
- Wei, J., Wang, J., Zhou, Y., & Chen, J. (2018). Data Augmentation with Rule-based and Neural Network-based Techniques for Text Classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (pp. 2365-2374).
- He, N., Lai, H., Zhao, C., Cheng, Z., Pan, J., Qin, R., Lu, R., Lu, R., Zhang, Y., Zhao, G. (2023). Teacherlm: Teaching to fish rather than giving the fish, language modeling likewise. arXiv preprint arXiv:2310.19019.
- Zhu, X., & Goldberg, A. B. (2009). Introduction to Semi-Supervised Learning. Synthesis Lectures on Artificial Intelligence and Machine Learning, 3(1), 1-130.
- Zhao, C., Jia, X., Viswanathan, V., Wu, T., & Neubig, G. (2024). SELF-GUIDE: Better Task-Specific Instruction Following via Self-Synthetic Finetuning. arXiv preprint arXiv:2407.12874.
- Chen, W., You, Z., Li, R., Guan, Y., Qian, C., Zhao, C., Yang, C., Xie, R., Liu, Z., Sun, M. (2024). Internet of Agents: Weaving a Web of Heterogeneous Agents for Collaborative Intelligence. arXiv preprint arXiv:2407.07061.
- Li, H., Kadav, A., Durdanovic, I., Samet, H., & Graf, H. P. (2016). Pruning Filters for Efficient ConvNets. arXiv preprint arXiv:1608.08710.
- Dou, J., Yu, C., Jiang, Y., Wang, Z., Fu, Q., Han, Y. (2023). Coreset Optimization by Memory Constraints, For Memory Constraints. Unpublished manuscript.
- Sanh, V., Debut, L., Chaumond, J., & Wolf, T. (2019). DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv preprint arXiv:1910.01108.
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is All you Need. Advances in neural information processing systems, 30.
- Xiong, J., Li, Z., Zheng, C., Guo, Z., Yin, Y., Xie, E., Yang, Z., Cao, Q., Wang, H., Han, X. (2023). Dq-lore: Dual queries with low rank approximation re-ranking for in-context learning. arXiv preprint arXiv:2310.02954.
- Dou, J. X., Mao, H., Bao, R., Liang, P. P., Tan, X., Zhang, S., Jia, M., Zhou, P., & Mao, Z. (2023). Decomposable Sparse Tensor on Tensor Regression. In Proceedings of the AAAI 2023 Workshop on Representation Learning for Responsible Human-Centric AI (R2HCAI).
- Liu, W., Cheng, S., Zeng, D., Qu, H. (2023). Enhancing document-level event argument extraction with contextual clues and role relevance. arXiv preprint arXiv:2310.05991.
- Liu, W., Zhou, L., Zeng, D., Xiao, Y., Cheng, S., Zhang, C., Lee, G., Zhang, M., Chen, W. (2024). Beyond Single-Event Extraction: Towards Efficient Document-Level Multi-Event Argument Extraction. arXiv preprint arXiv:2405.01884. [CrossRef]
- Fan, X., Tao, C., & Zhao, J. (2024). Advanced Stock Price Prediction with xLSTM-Based Models: Improving Long-Term Forecasting. Preprints, 2024082109.
- Li, D., Tan, Z., & Chen, T. (2024). Contextualization distillation from large language model for knowledge graph completion. arXiv preprint arXiv:2402.01729.
- Yan, Chao & Wang, Jinyin & Zou, Yuelin & Weng, Yijie & Zhao, Yang & Li, Zhuoying. (2024). Enhancing Credit Card Fraud Detection Through Adaptive Model Optimization. [CrossRef]
- Li, Y., Li, Z., Yang, W., & Liu, C. (2023). Rt-lm: Uncertainty-aware resource management for real-time inference of language models. arXiv preprint arXiv:2309.06619.
- Liu, W., Cheng, S., Qu, H. (2024). Enhancing Credit Card Fraud Detection Through Adaptive Model Optimization. Unpublished manuscript.
- Tan, Z., Chen, T., Zhang, Z., & Liu, H. (2024). Sparsity-Guided Holistic Explanation for LLMs with Interpretable Inference-Time Intervention. Proceedings of the AAAI Conference on Artificial Intelligence, 38(19), 21619-21627. [CrossRef]
- Zhu, W. (2022). Optimizing distributed networking with big data scheduling and cloud computing. In International Conference on Cloud Computing, Internet of Things, and Computer Applications (CICA 2022) (pp. 23-28). SPIE.
- Tan, Z., Dong, D., Zhao, X., Peng, J., & Cheng, Y. (2024). DLO: Dynamic Layer Operation for Efficient Vertical Scaling of LLMs. arXiv preprint arXiv:2407.11030.
- Fan, X., & Tao, C. (2024). Towards Resilient and Efficient LLMs: A Comparative Study of Efficiency, Performance, and Adversarial Robustness. arXiv preprint arXiv:2408.04585.
- Chen, Z., Ge, J., Zhan, H., Huang, S., & Wang, D. (2021). Pareto self-supervised training for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 13663-13672).
- Li, D., Tan, Z., & Liu, H. (2024). Exploring Large Language Models for Feature Selection: A Data-centric Perspective. arXiv preprint arXiv:2408.12025.
- Liu, D., Wang, H., Qi, C., Zhao, P., & Wang, J. (2016). Hierarchical task network-based emergency task planning with incomplete information, concurrency and uncertain duration. Knowledge-Based Systems, 112, 67-79. [CrossRef]
- Zhang, Q., Qi, W., Zheng, H., & Shen, X. (2024). CU-Net: a U-Net architecture for efficient brain-tumor segmentation on BraTS 2019 dataset. arXiv preprint arXiv:2406.13113.
- Li, Y., Yu, X., Liu, Y., Chen, H., & Liu, C. (2023). Uncertainty-aware bootstrap learning for joint extraction on distantly-supervised data. arXiv preprint arXiv:2305.03827.
- Tan, Z., Beigi, A., Wang, S., Guo, R., Bhattacharjee, A., Jiang, B., ... & Liu, H. (2024). Large language models for data annotation: A survey. arXiv preprint arXiv:2402.13446.
- Zhan, Q., Sun, D., Gao, E., Ma, Y., Liang, Y., & Yang, H. (2024). Advancements in Feature Extraction Recognition of Medical Imaging Systems Through Deep Learning Technique. arXiv preprint arXiv:2406.18549.
- Dong, Z., Liu, X., Chen, B., Polak, P., & Zhang, P. (2024). Musechat: A conversational music recommendation system for videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12775-12785).
- Dan, H. C., Lu, B., & Li, M. (2024). Evaluation of asphalt pavement texture using multiview stereo reconstruction based on deep learning. Construction and Building Materials, 412, 134837.
- Chen, C., Huang, B., Li, Z., Chen, Z., Lai, S., Xu, X., Gu, J.C., Gu, J., Yao, H., Xiao, C., & others (2024). Can Editing LLMs Inject Harm?. arXiv preprint arXiv:2407.20224.
- Li, Z., Wang, B., & Chen, Y. (2024). A Contrastive Deep Learning Approach to Cryptocurrency Portfolio with US Treasuries. Journal of Computer Technology and Applied Mathematics, 1(3), 1-10.
- Xidong Wu, Feihu Huang, Zhengmian Hu, & Heng Huang. (2023). Faster Adaptive Federated Learning.
- Xie, C., Chen, C., Jia, F., Ye, Z., Shu, K., Bibi, A., Hu, Z., Torr, P., Ghanem, B., & Li, G. (2024). Can Large Language Model Agents Simulate Human Trust Behaviors?. arXiv preprint arXiv:2402.04559.
- Xiong, J., Wan, Z., Hu, X., Yang, M., & Li, C. (2022). Self-consistent reasoning for solving math word problems. arXiv preprint arXiv:2210.15373.
- Wei, Y., Gu, X., Feng, Z., Li, Z., & Sun, M. (2024). Feature Extraction and Model Optimization of Deep Learning in Stock Market Prediction. Journal of Computer Technology and Software, 3(4). [CrossRef]
Figure 1.
SEO-LLM Architecture Diagram.
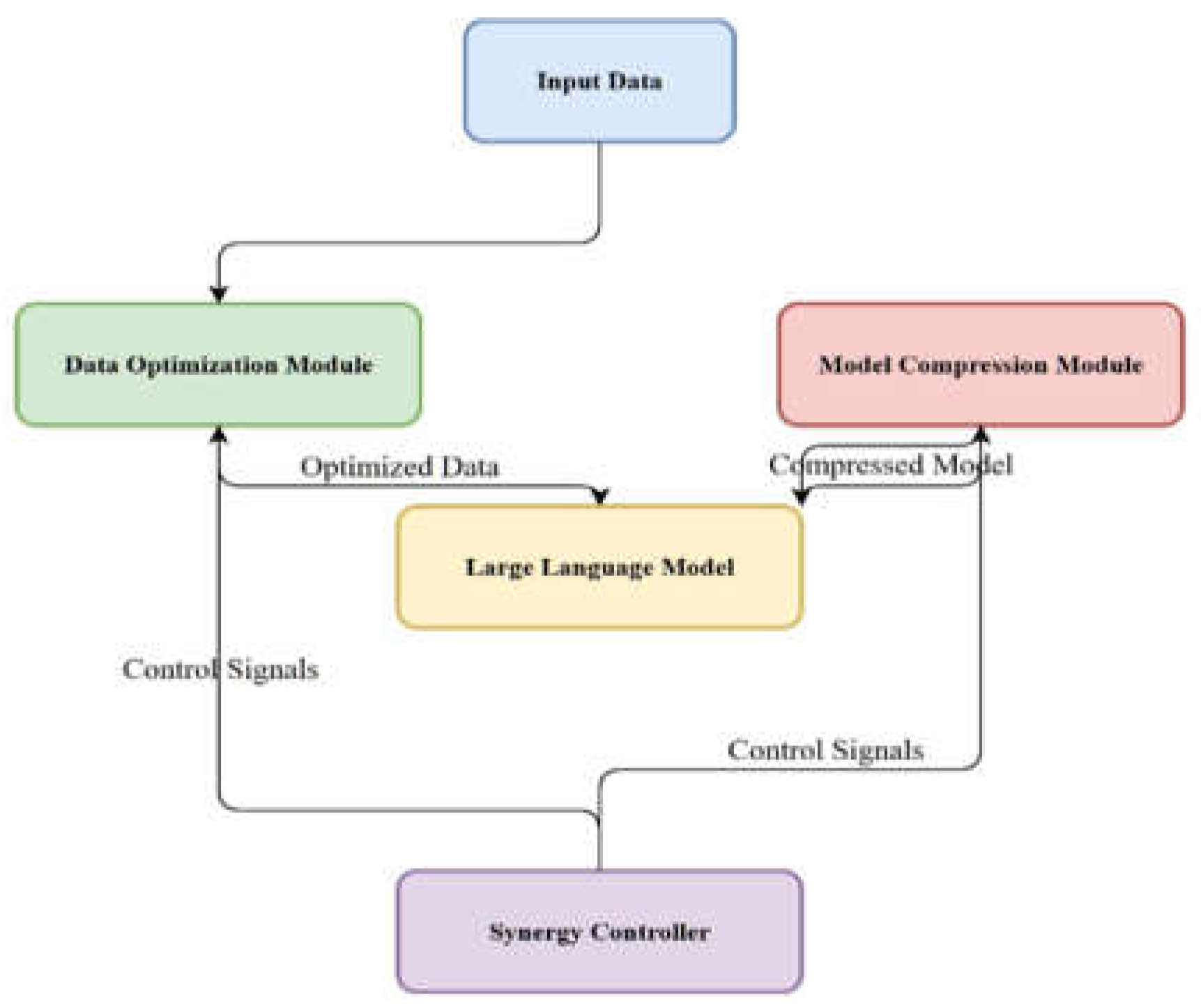
Figure 2.
Model Size and Inference Speed Comparison.
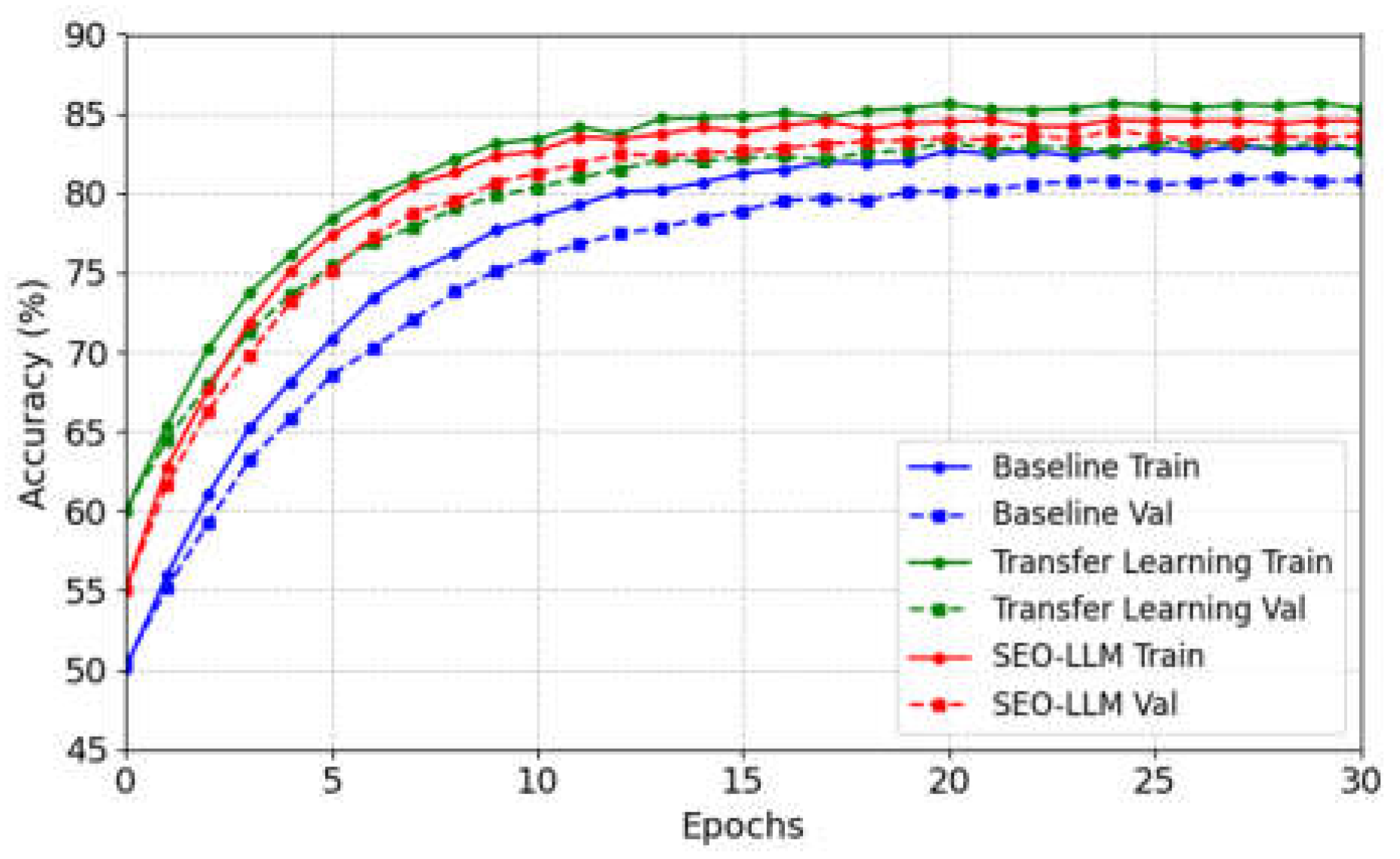
Figure 3.
Model Size and Inference Speed Comparison.

Figure 4.
Pruned Weights Distribution.
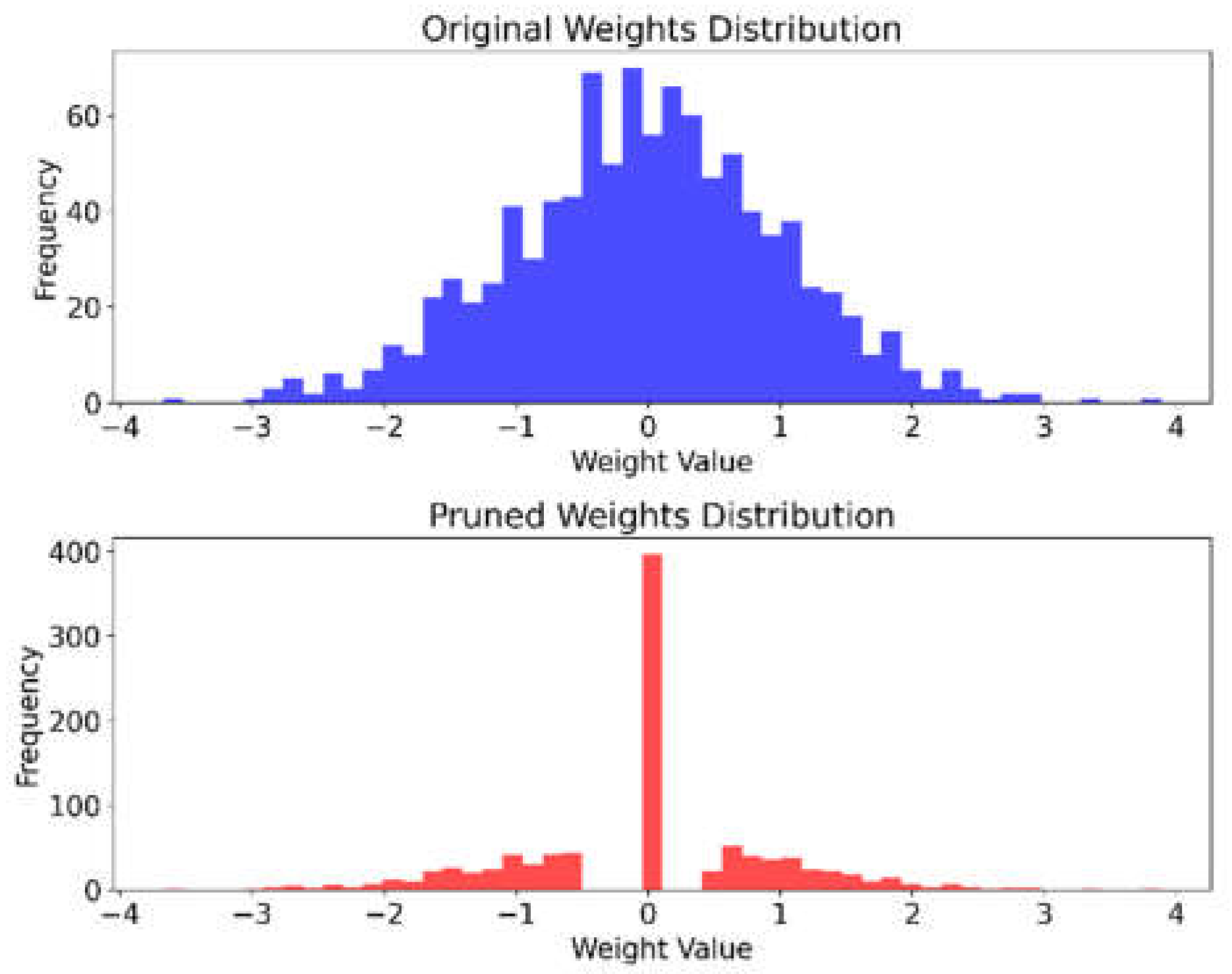
Table 1.
TRAINING TIME COMPARISON.
| Model8 | Training Time (hours) |
|---|---|
| BERT-base (baseline) | 48 |
| BERT-base + Data Augmentation | 43 |
| BERT-base + Transfer Learning | 39 |
| BERT-base + Active Learning | 36 |
| BERT-base + Semi-Supervised Learning | 37 |
| SEO-LLM (Combined approach) | 33 |
Table 2.
MODEL SIZE COMPARISON.
| Model | Model Size (MB) |
|---|---|
| BERT-base (baseline) | 420 |
| BERT-base + Pruning | 364 |
| BERT-base + Quantization | 150 |
| BERT-base + Knowledge Distillation | 201 |
| SEO-LLM (Combined approach) | 136 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



