Submitted:
07 September 2024
Posted:
09 September 2024
You are already at the latest version
Abstract
Face recognition is a key computer vision task that focuses on identifying or verifying individuals using their facial features. This task becomes more difficult with low-resolution images, where the reduced pixel count and detail make it harder to extract and match features accurately. In this study, we assess the effectiveness of Multilinear Side-Information-based Discriminant Analysis (MSIDA) on low-resolution images, using the CelebA database as a reference. The system showed strong performance, achieving 90.60% accuracy on high-resolution and 88.23% on low-resolution images, highlighting the robustness and effectiveness of MSIDA.
Keywords:
Face recognitio
; Low-resolution
; MSIDA
; CelebA database
I. Introduction
Devices are utilized in a multitude of applications, ranging from simple to complex problem-solving methods. Among such contributions, face recognition technology has emerged as a useful tool to recognize features of faces through their inherent traits [1,2,3,4]. It has been one of the most researched areas in the field of pattern recognition and computer vision due to its wide use in many applications such as biometrics, information security, law enforcement, access control, surveillance systems, and smart cards. However, it presents many challenges for researchers that need to be addressed [5]. Recognizing a face as an object depends on various factors, including facial expressions, which constitute meaningful features. For instance, pose invariance, lighting conditions, and aging are critical areas that require further investigation beyond previous work. Research shows that facial expressions change with aging, making it difficult to permanently model faces for recognition. The face recognition problem can be categorized into two main phases: 1) face verification and 2) face identification [6,7,8,9,10,11,12]. These phases are crucial for developing more accurate and reliable face recognition systems [5].
In real-world face recognition deployment scenarios, particularly in surveillance applications, the pixel resolution of detected face images is often significantly reduced due to extreme long-range distances and wide viewing angles of the acquisition devices. These small regions of interest typically range from 16×16 to 32×32 pixels, resulting in poor pixel resolution. Additionally, they are affected by various types of noise, including poor illumination, non-frontal poses at extreme angles, unconstrained facial expressions, blurriness, and occlusions. It is important to note that these very low-resolution (VLR) face images can degrade the performance of face recognition models that are trained on high-resolution (HR) counterparts, leading to a lack of generalizability in addressing the VLR face recognition (VLRFR) challenge [13].
Given the challenges posed by emerging applications, there is an increasing demand for more efficient dimensionality reduction techniques to manage large-scale multidimensional data . Recently, there has been growing interest in multilinear subspace learning (MSL) [14,15,16,17,18,19,20], which has shown potential for generating more compact and informative representations. Linear subspace learning (LSL) remains important for its ability to simplify high-dimensional data into lower-dimensional spaces while preserving essential information. Techniques Multi-linear Side Information-based Discriminant Analysis (MSIDA) [9] in MSL and Side-Information based Linear Discriminant (SILD)[21] in LSL are anticipated to play crucial roles in advancing novel algorithms and addressing complex problems in applications that involve extensive multidimensional datasets [22].
In this study, we address the challenge of matching face pairs using tensor representation techniques, specifically MSIDA and SILD, with a particular emphasis on training data comprising low-resolution images.
- Multilinear Side-Information based Discriminant Analysis (MSIDA) is employed to reduce dimensionality and classify tensor data in cases where complete class labels are unavailable. MSIDA transforms the input face tensor into a new multilinear subspace, enhancing the separation between samples from different classes while minimizing the variance within samples of the same class. Furthermore, MSIDA reduces the dimensionality of each tensor mode [9].
- We empirically evaluate the proposed approach for face based identity verification on four challenging face benchmark CelebA. Comparisons against the state-of-the-art methods demonstrate the efficiency of our approach.
The remainder of this paper is structured as follows, Section 2 outlines the proposed Multilinear Side-Information based Discriminant Analysis for low-resolution images. Section 3 presents the experimental evaluation, along with the results and analysis. Finally, Section 4 provides the conclusion and discusses potential future work.
II. Multilinear Side-Information based Discriminant Analysis
This section presents the Multilinear Side-Information based Discriminant Analysis (MSIDA).
In many scenarios, obtaining the precise full class labels for data samples can be challenging. Instead, it is often more feasible to collect a form of weak labels for the samples. For instance, in face verification under unconstrained conditions, the only available information might be whether pairs of face images belong to the same individual or not. These weak labels, typically represented as pair match/non-match, are referred to as side information. In such cases, traditional Linear Discriminant Analysis (LDA) is not applicable, as it requires the class label, such as the identity of the person, for each sample to compute the scatter matrices. To address this limitation, Side-Information based Linear Discriminant Analysis (SILD) [21] has been introduced. SILD effectively utilizes weak label information, where positive pairs (matches) are employed to compute the within-class scatter matrix , and negative pairs (non-matches) are used to compute the between-class scatter matrix [9].
This section presents the extension of SILD to handle multilinear data. Let represent the tensor form of the training samples. The training data is organized into two sets: the match tensor pairs and the non-match tensor pairs , where l denotes the side information [9].
To enhance the discrimination between tensors of different classes, we introduce a Discriminant Tensor Criterion (DTC). The DTC is achieved by applying multiple interrelated projections of the tensor across its various modes. The DTC in our framework is defined as:
Equation 1 presents an optimization problem characterized by a high-order nonlinear constraint. As a result, obtaining a closed-form solution for this problem is a challenging task. An alternative approach is to employ iterative optimization, as suggested in [23], to estimate the interrelated projection matrices. Initially, by focusing on a single mode of the tensor, the optimization problem can be formulated as:
The optimization problem in Eq. (2) can be reformulated as follows:
where is the between-class scatter matrix for mode k, calculated using the vectors of the negative pairs as follows:
Similarly, in Eq. (3), represents the within-class scatter matrix for mode k, calculated using the corresponding vectors from the unfolded matrices of the positive sample pairs:
The iterative process of MSIDA terminates upon satisfying one of the following conditions: (i) the number of iterations reaches a predefined maximum; or (ii) the norm of the difference between the estimated projections in two successive iterations falls below a specified threshold,
where represents the dimension of mode k, and denotes the eigenvector matrix in mode k [9].
The complete procedure for the proposed Multilinear Side-Information-based Discriminant Analysis (MSIDA) can be found in [9].
II. Face Pair Matching Using MSIDA
A. Features Extraction
Feature extraction plays a crucial role in face verification systems, where it generates a feature vector or matrix for each database element, functioning as its biometric signature. Deep neural networks have recently outperformed state-of-the-art in various classification tasks, enhancing the accuracy and reliability of feature extraction methods [24,25]. Our work utilizes the VGG-face[26] network, originally trained on a large dataset of 2.6 million images of 2,622 individuals for face recognition. This network has shown remarkable performance in face verification tasks involving both image pairs and videos, surpassing other state-of-the-art methods[24].
The VGG-face [26] network takes an RGB face image of size 224 × 224 pixels as input. It consists of 13 convolutional layers, each followed by a non-linear rectification layer (ReLU). Some of these rectification layers are also followed by a max-pooling layer. The network further includes two fully connected layers, each producing a 4096-dimensional vector. At the top of the initial network, there is a fully connected layer with a size matching the number of classes to predict (2622), followed by a softmax layer that computes the class posterior probabilities [24].
B. Matching
To determine the similarity between a pair of faces, we use cosine similarity. The approach involves learning a transformation matrix from the training data and optimizing the cosine similarity’s performance within the transformed subspace. The effectiveness of this method is evaluated using cross-validation error[9,27].
IV. Experiments
To evaluate the effectiveness of our approach, we conducted a series of experiments using the CelebA datasets. First, we introduce the datasets used in our experiments. We then outline the parameter settings, followed by a detailed presentation and analysis of the experimental results. The performance of our proposed approach is specifically evaluated using the VGG-Face network. Finally, we compare our best results with those of state-of-the-art methods.
A. Datasets
The CelebFaces Attributes Dataset (CelebA) [28] is a large-scale face attributes dataset containing over 200,000 celebrity images, each annotated with 40 distinct attributes. This dataset features significant diversity, encompassing various poses and varied background clutter. CelebA is notable for its extensive diversity, volume, and detailed annotations, which include 10,177 unique identities, 202,599 face images, 5 landmark locations, and 40 binary attribute annotations per image[28].
B. Parameter Settings
The face images are initially aligned and then cropped to 16x16, 32x32, and 48x48 pixels for the CelebA dataset Figure 1. Each pair of images is processed using our proposed identity verification method to extract both handcrafted and deep features, essential for accurately describing the face images of size 224 × 224. For deep features, we use the VGG-Face network, extracting features from four specific layers: fc6, relu6, fc7, and relu7.
C. Results
The assessment results of the proposed MSIDA and SILD methods using low-resolution images, along with comparisons to state-of-the-art techniques, are presented in Table 1 and Table 2 for the CelebA datasets. These results emphasize the key observations, further detailed in the following sections.
1) Evaluation of Low-Resolution Images
Our study focused on utilizing low-resolution images to assess and demonstrate the robustness and effectiveness of our face verification system, MSIDA. As detailed in Table 1, the results highlight the significant performance of MSIDA compared to alternative systems. Our method achieved impressive accuracy across different resolutions, with 75.97%, 86.50%, and 88.23% at 16x16, 32x32, and 48x48, respectively. These findings underscore the effectiveness of MSIDA across various resolutions and its capability to maintain strong performance even with lower-resolution images. This demonstrates MSIDA’s robustness and practical applicability, making it a valuable tool for face verification in diverse and challenging conditions.
2) Evaluation of State-of-the-Art in High-Resolution (HR) and Low-Resolution (LR)
As for the comparison, I’ve included Table 2 showing the effectiveness of our MSIDA system compared to others. Our system outperformed 86.50% of the competing methods in low-resolution tasks, with an improvement of approximately 20%. Also, MSIDA achieved an accuracy of 90.60% in high-resolution tasks, demonstrating a significant difference of 19.4%. This substantial advantage is attributed to the robustness and adaptability of MSIDA, which excels in extracting and leveraging both handcrafted and deep features across various image resolutions. This capability allows MSIDA to maintain high accuracy even in challenging conditions, making it a superior choice for face verification tasks.
V. Conclusion
In conclusion, the robustness and efficacy of the proposed system have been conclusively demonstrated, especially when compared to alternative systems. The system achieved an accuracy of 90.60% on high-resolution images and 88.23% on low-resolution images, reflecting the significant performance improvements discussed in the previous section. These results affirm the system’s reliability, and future enhancements are expected to further advance its performance and accuracy.
References
- A. Chouchane, M. Belahcene, A. Ouamane, and S. Bourennane, “3d face recognition based on histograms of local descriptors,” in 2014 4th International Conference on Image Processing Theory, Tools and Applications (IPTA), pp. 1–5, IEEE, 2014.
- M. Belahcène, A. Ouamane, and A. T. Ahmed, “Fusion by combination of scores multi-biometric systems,” in 3rd European Workshop on Visual Information Processing, pp. 252–257, IEEE, 2011.
- R. Aliradi, A. Belkhir, A. Ouamane, and A. S. Elmaghraby, “Dieda: discriminative information based on exponential discriminant analysis combined with local features representation for face and kinship verification,” Multimedia Tools and Applications, pp. 1–18, 2018.
- A. Ouamane, E. Boutellaa, M. Bengherabi, A. Taleb-Ahmed, and A. Hadid, “A novel statistical and multiscale local binary feature for 2d and 3d face verification,” Computers & Electrical Engineering, vol. 62, pp. 68–80, 2017.
- M. Lal, K. Kumar, R. H. Arain, A. Maitlo, S. A. Ruk, and H. Shaikh, “Study of face recognition techniques: A survey,” International Journal of Advanced Computer Science and Applications, vol. 9, no. 6, 2018.
- O. Laiadi, A. Ouamane, E. Boutellaa, A. Benakcha, A. Taleb-Ahmed, and A. Hadid, “Kinship verification from face images in discriminative subspaces of color components,” Multimedia Tools and Applications, vol. 78, pp. 16465–16487, 2019.
- A. Chouchane, M. Bessaoudi, E. Boutellaa, and A. Ouamane, “A new multidimensional discriminant representation for robust person re-identification,” Pattern Analysis and Applications, vol. 26, no. 3, pp. 1191–1204, 2023.
- A. Ouamane, A. Chouchane, E. Boutellaa, M. Belahcene, S. Bourennane, and A. Hadid, “Efficient tensor-based 2d+ 3d face verification,” IEEE Transactions on Information Forensics and Security, vol. 12, no. 11, pp. 2751–2762, 2017.
- M. Bessaoudi, A. Ouamane, M. Belahcene, A. Chouchane, E. Boutellaa, and S. Bourennane, “Multilinear side-information based discriminant analysis for face and kinship verification in the wild,” Neurocomputing, vol. 329, pp. 267–278, 2019.
- A. Ouamane, M. Bengherabi, A. Hadid, and M. Cheriet, “Side-information based exponential discriminant analysis for face verification in the wild,” in 2015 11th IEEE international conference and workshops on automatic face and gesture recognition (FG), vol. 2, pp. 1–6, IEEE, 2015.
- A. Chouchane, A. Ouamane, E. Boutellaa, M. Belahcene, and S. Bourennane, “3d face verification across pose based on euler rotation and tensors,” Multimedia Tools and Applications, vol. 77, pp. 20697–20714, 2018.
- C. Ammar, B. Mebarka, O. Abdelmalik, and B. Salah, “Evaluation of histograms local features and dimensionality reduction for 3d face verification,” Journal of information processing systems, vol. 12, no. 3, pp. 468–488, 2016.
- J. C. L. Chai, T.-S. Ng, C.-Y. Low, J. Park, and A. B. J. Teoh, “Recognizability embedding enhancement for very low-resolution face recognition and quality estimation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9957–9967, 2023.
- M. Belahcene, M. Laid, A. Chouchane, A. Ouamane, and S. Bourennane, “Local descriptors and tensor local preserving projection in face recognition,” in 2016 6th European workshop on visual information processing (EUVIP), pp. 1–6, IEEE, 2016.
- A. Ouamane, A. Benakcha, M. Belahcene, and A. Taleb-Ahmed, “Multimodal depth and intensity face verification approach using lbp, slf, bsif, and lpq local features fusion,” Pattern Recognition and Image Analysis, vol. 25, pp. 603–620, 2015.
- M. Belahcene, A. Chouchane, and H. Ouamane, “3d face recognition in presence of expressions by fusion regions of interest,” in 2014 22nd Signal Processing and Communications Applications Conference (SIU), pp. 2269–2274, IEEE, 2014.
- I. Serraoui, O. Laiadi, A. Ouamane, F. Dornaika, and A. Taleb-Ahmed, “Knowledge-based tensor subspace analysis system for kinship verification,” Neural Networks, vol. 151, pp. 222–237, 2022.
- O. Guehairia, F. Dornaika, A. Ouamane, and A. Taleb-Ahmed, “Facial age estimation using tensor based subspace learning and deep random forests,” Information Sciences, vol. 609, pp. 1309–1317, 2022.
- M. Khammari, A. Chouchane, A. Ouamane, M. Bessaoudi, Y. Himeur, M. Hassaballah, et al., “High-order knowledge-based discriminant features for kinship verification,” Pattern Recognition Letters, vol. 175, pp. 30–37, 2023.
- A. A. Gharbi, A. Chouchane, A. Ouamane, Y. Himeur, S. Bourennane, et al., “A hybrid multilinear-linear subspace learning approach for enhanced person re-identification in camera networks,” Expert Systems with Applications, p. 125044, 2024.
- O. Laiadi, A. Ouamane, A. Benakcha, A. Taleb-Ahmed, and A. Hadid, “Learning multi-view deep and shallow features through new discriminative subspace for bi-subject and tri-subject kinship verification,” Applied Intelligence, vol. 49, no. 11, pp. 3894–3908, 2019.
- H. Lu, K. N. Plataniotis, and A. N. Venetsanopoulos, “A survey of multilinear subspace learning for tensor data,” Pattern Recognition, vol. 44, no. 7, pp. 1540–1551, 2011.
- M. Safayani and M. T. M. Shalmani, “Three-dimensional modular discriminant analysis (3dmda): a new feature extraction approach for face recognition,” Computers & Electrical Engineering, vol. 37, no. 5, pp. 811–823, 2011.
- E. Boutellaa, M. B. López, S. Ait-Aoudia, X. Feng, and A. Hadid, “Kinship verification from videos using spatio-temporal texture features and deep learning,” arXiv preprint arXiv:1708.04069, 2017.
- M. Bessaoudi, A. Chouchane, A. Ouamane, and E. Boutellaa, “Multilinear subspace learning using handcrafted and deep features for face kinship verification in the wild,” Applied Intelligence, vol. 51, pp. 3534–3547, 2021.
- O. Parkhi, A. Vedaldi, and A. Zisserman, “Deep face recognition,” in BMVC 2015-Proceedings of the British Machine Vision Conference 2015, British Machine Vision Association, 2015.
- H. V. Nguyen and L. Bai, “Cosine similarity metric learning for face verification,” in Asian conference on computer vision, pp. 709–720, Springer, 2010.
- Z. Liu, P. Luo, X. Wang, and X. Tang, “Deep learning face attributes in the wild,” in Proceedings of International Conference on Computer Vision (ICCV), December 2015.
- Q. Jiao, R. Li, W. Cao, J. Zhong, S. Wu, and H.-S. Wong, “Ddat: Dual domain adaptive translation for low-resolution face verification in the wild,” Pattern Recognition, vol. 120, p. 108107, 2021.
Figure 1.
Illustrate the low-resolution images from CelebA.
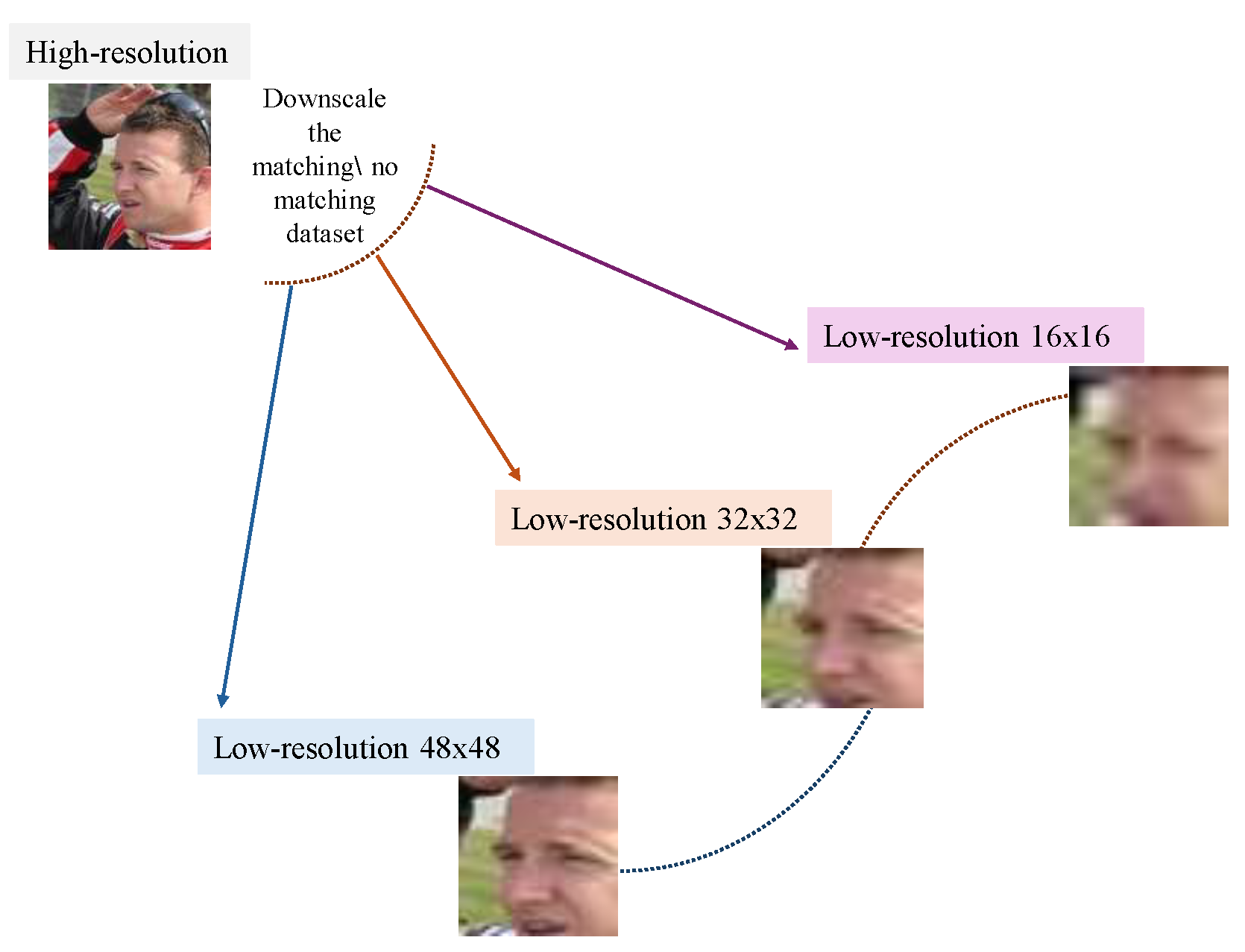

Table 1.
Results regarding the accuracy of face verification.
| MSIDA | SILD | |
|---|---|---|
| High-Resolution | 90.60 | 83.80 |
| LR 16x16 | 75.97 | 67.60 |
| LR 32x32 | 86.50 | 78.30 |
| LR 48x48 | 88.23 | 81.30 |
Table 2.
Results regarding the accuracy of face verification.
| HR | 32x32 | ||
|---|---|---|---|
| Jiao, Q . | |||
| (2021), [29] | CenterLoss | 56.2 | - |
| SphereConv w/ linear operator | 54.8 | - | |
| SphereConv w/ cosine operator | 53.6 | - | |
| SphereConv w/ sigmoid operator | 53.3 | - | |
| CosFace | - | 66.2 | |
| SphereFace | - | 66.5 | |
| Baseline | 57.5 | - | |
| CSRI | 61.2 | - | |
| DDAT | 70.6 | - | |
| DDAT w/ target domain labels | 71.2 | - | |
| MSIDA | 90.60 | 86.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



