Submitted:
05 September 2024
Posted:
09 September 2024
You are already at the latest version
Abstract
This paper investigates the applicability of deep learning models for predicting the severity of forest wildfires, utilizing an innovative benchmark dataset called EO4WildFires. EO4WildFires integrates multispectral imagery from Sentinel-2, SAR data from Sentinel-1 and meteorological data from NASA Power annotated with EFFIS data for forest fire detection and size estimation. Resulting in a coverage of 45 countries (Figure \ref{Figure1-events}) with a total of 31730 wildfire events from 2018 to 2022. All these various sources of data are archived into data cubes, with the intention of assessing wildfire severity by considering both current and historical forest conditions, utilizing a broad range of data including temperature, precipitation, and soil moisture.
The experimental setup has been arranged to test different deep learning architectures’ effectiveness in predicting the size and shape of wildfire burned areas. The study incorporates both Image Segmentation networks and Visual Transformers, employing a consistent experimental design across various models to ensure comparability of results. Adjustments were made to the training data, such as the exclusion of empty labels and very small events, to refine the focus on more significant wildfire events and potentially improve prediction accuracy.
The models’ performance was evaluated using metrics like F1 Score, IoU Score, and Average Percentage Difference (aPD). These metrics offer a multi-faceted view of model performance, assessing aspects such as precision, sensitivity, and the accuracy of the burned area estimation. Through extensive testing with Image Segmentation networks and Visual Transformers, the research not only aims at enhancing the accuracy of estimating the burned area but also underscores the significance of quality training data and the comparative effectiveness of traditional segmentation methods over transformer-based models for this specific application.
The dataset is published with an Open Access license and is hosted at: \url{10.5281/zenodo.7762564}.
Keywords:
forest wildfires
; earth observation
; remote sensing
; machine learning
; deep learning
; training dataset
; multi-sensor data
1. Introduction
Forest wildfires present a significant global challenge, resulting in extensive harm to the environment, economy, and communities. The growing occurrence and severity of these wildfires has been linked [1] to climate change, deforestation, and anthropogenic factors. Precisely predicting the extent of areas than can be affected by wildfires is vital for efficient disaster response, allocation of resources, and preventative strategies. The utilization of remote sensing data from satellites like Sentinel-1 and Sentinel-2, along with meteorological data from entities such as NASA Power or the European Centre for Medium-Range Weather Forecasts (ECMWF), offers invaluable insights for creating machine learning and deep learning models to estimate wildfire severity.
In this study, we present and utilize the EO4WildFires dataset, a unique benchmark collection combining multispectral data (Sentinel-2), Synthetic-Aperture Radar (SAR) data (Sentinel-1), and meteorological information from 45 countries. This extensive, multi-sensor time-series dataset, annotated with the European Forest Fire Information System (EFFIS) for wildfire detection and area estimation, encompasses 31730 wildfire incidents from 2018 to 2022. By integrating Sentinel-2, Sentinel-1, and meteorological data into a unified data cube for each wildfire event, EO4WildFires facilitates a detailed examination of the variables influencing wildfire severity.
Our research seeks to predict the severity of forest wildfires before they occur, specifically focusing on the potential extent of fire damage in a given area, considering the current and historical forest conditions. We conduct three distinct experiments using the EO4WildFires dataset to investigate the impact of various factors on wildfire size prediction. These experiments explore different combinations of meteorological, multispectral, and SAR data, evaluating the performance of machine learning models derived from these data sets. Our objective is to contribute to the development of more precise and reliable models for forecasting wildfire severity, ultimately aiding policymakers and enhancing global wildfire management strategies.
The EO4WildFires [2] dataset addresses the scientific challenge of creating a model or a suite of models to predict the severity of imminent wildfire events in specific locations. This prediction is based on a combination of current and historical (30 days) meteorological data, along with multispectral and SAR imagery, to accurately represent the forest condition before a wildfire. The primary objective is not to predict the occurrence of wildfires (i.e., whether a forest wildfire might ignite) but to forecast their severity (size and shape), especially the extent of the area likely to be affected. Developing models that can effectively assimilate these diverse data types is crucial for generating precise severity forecasts. Successfully addressing this problem could significantly aid forest protection agencies and other relevant stakeholders in preparing for and mitigating the impacts of wildfires on the environment and communities. The research question posed is: “Can remote sensing data in combination with deep learning models be used to efficiently predict wildfire severity (in terms of burned area size)?” Moreover, : “How effective is the designed Eo4WildFires dataset, comprising meteorological data, multispectral, and SAR images, in predicting the severity (extent of area affected) of future wildfire events, considering the current and recent forest conditions?” In addition, using this dataset, “Which deep learning architecture delivers the best results in wildfire severity prediction?”.
2. Related Work
In this section, we explore the current research related to the EO4WildFires dataset and its applications, with a particular focus on feature extraction, machine learning, and image segmentation in satellite imagery. As part of the related work similar to our research question papers were included, like modeling burn severity/intensity, spread. The reason behind this inclusion is two fold. First in every case earth observation and weather/climate data are used to predict an aspect of a wildfire result (size, shape, intensity, spread etc). Second, our work focuses specifically on predicting the potential size and shape of a wildfire if it occurs. The current state of art does not focus specifically on this aspect of the problem, rather to the intensity, ignition and spread, which are different but still related works. Our work specifically focuses on estimating the size and shape of a wildfire if that occurs, thus this is not necessarily correlated with probability of occurrence (ignition) or spread or intensity.
2.1. Deep Learning Architectures
Deep learning technologies are rapidly evolving, particularly in their application to large-scale visual data, such as remote sensing data. This sub-section briefly overviews some recent significant deep learning architectures in this field.
In their study, Yu et al. [3] introduce the Contrastive Captioner (CoCa), an image-text encoder-decoder foundation model. CoCa blends contrastive loss with captioning loss, incorporating elements from CLIP and SimVLM. It focuses initially on unimodal text representations before tackling multimodal image-text representations. The model, pre-trained on extensive web-scale alt-text data and annotated images, excels in various tasks like visual recognition and image captioning, achieving a remarkable 91.0% top-1 accuracy on ImageNet with a finetuned encoder.
Liu et al. [4] delve into the challenges of large-scale models in computer vision, addressing issues like training instability, resolution gaps, and dependence on labeled data. They propose three innovative techniques: a residual-post-norm method with cosine attention, a log-spaced continuous position bias method, and SimMIM, a self-supervised pretraining method. Their approach leads to the successful training of a 3 billion-parameter Swin Transformer V2 model, setting new performance records on various benchmarks while being 40 times more data and time-efficient than similar-scale models by Google.
Dosovitskiy et al. [5] demonstrate the effectiveness of the Transformer architecture, a staple in natural language processing, in the realm of computer vision. Their Vision Transformer (ViT) applies the transformer directly to image patches. This model, when pre-trained on large datasets, outperforms traditional convolutional networks in various image recognition benchmarks, with significantly lower training resource requirements.
Chen et al. [6] present a novel approach for discovering algorithms aimed at optimizing deep neural network training. Their technique, termed Evolved Sign Momentum and codenamed Lion, is a memory-efficient optimizer surpassing popular optimizers like Adam [7] and Adafactor [8] across multiple tasks. Lion [6] enhances ViT’s accuracy on ImageNet by up to 2%, reduces pre-training compute on JFT datasets by up to 5x, and outperforms Adam in diffusion models and other learning tasks. It demonstrates better efficiency and accuracy, particularly with larger training batch sizes and reduced learning rates.
Advances in feature extraction from satellite imagery have been propelled by deep learning models. A notable development in this area is the introduction of Deep Residual Learning by He et al. [9]. Their ResNet model is a foundational tool in feature extraction, known for its ability to effectively learn from extensive data without encountering the vanishing gradient problem.
The application of EfficientNet, as developed by Tan and Le [10], has proven beneficial in satellite imagery analysis. This scalable network is designed to optimize accuracy and efficiency, making it well-suited for handling the varying scales and complexities of satellite data. It achieves this by balancing the network’s depth, width, and resolution. Lin et al. [11] conducted a significant study on image segmentation, focusing on the Microsoft COCO dataset. Their work offers valuable insights into segmenting complex images, a method that can be applied to satellite imagery to improve the identification and analysis of geographical features.
Qingmin Meng and Ross K. Meentemeyer’s study [12] showcases the application of Landsat TM data in modeling forest fire severity across different strata. This research underscores the utility of satellite imagery in evaluating forest fire severity, laying the groundwork for further investigations with machine learning methods.
2.2. Wildfires and Earth Observation
Wildfires, as natural disasters, result in the destruction of property, the loss of lives and significant harm to natural resources, including biodiversity, soil and therefore wildlife [13]. Satellites play a crucial role in detecting, monitoring, and characterizing wildfires [14]. This sub-section overviews significant recent research efforts that generate or leverage Earth Observation data for wildfire detection purposes (including intensity, spread, size, ignition etc). To our knowledge only a handful of research similar to ours exists.
A similar data-oriented approach is purposed by Víctor Fernández-García et al. [14], which leverages EFFIS, Sentinel data and Worldclim climatic data in order to asses the intensity of a wildfire (burn severity). Their methodology evaluates burn severity utilizing Normalized Burn Ration (NBR) [15] both for the pre and after fire data from Sentinel2’s Level 2 A bands 8a and 12. They observe that burn severity is highly related to indices that depict fuel load signature in time (i.e NDWI), likewise topographic and climatic features are also important for more robust classification results. Similary, Moressi et. al [16], also utilize NBR index for pre and post fire wildfire burn severity in Piednmont Region Italy (2017). They notice that temporal constraints when selecting paired images is crucial. Furthermore, they provide a compositing algorithm that is not dependant on specific optical sensor and/or multisensor data, as it can easily be transferred to other sensors.
In their study, Ying et al. [17] analyze the effectiveness of MODIS fire products compared to ground wildfire records in Yunnan Province, Southwest China, from December 2002 to November 2015. Their aim is to understand the disparities in the spatial and temporal patterns of wildfires identified by these two methods, evaluate the omission error in MODIS fire products, and examine the impact of local environmental factors on the probability of MODIS detecting wildfires. Their findings indicate that MODIS detects over double the number of wildfires than ground records, yet the patterns vary significantly. Only 11.10% of 5,145 verified ground records were identified by multiple MODIS fire products. The research identifies wildfire size as a key limitation in MODIS’s detection capability, with a 50% likelihood of detecting fires of at least 18 hectares. Other influencing factors include daily relative humidity, wind speed, and the altitude at which wildfires occur. The study underscores the necessity of integrating local conditions and ground inspections into wildfire monitoring and simulation efforts globally.
Oulad Sayad et al. [18] introduce a method that synergizes Big Data, Remote Sensing, and Data Mining algorithms (specifically Artificial Neural Networks and Support Vector Machines) to predict the occurrence (i.e. ignition) of wildfires using satellite imagery. They develop a dataset from Remote Sensing data, encompassing crop conditions (NDVI), meteorological conditions (LST), and the fire indicator "Thermal Anomalies" from MODIS instruments on Terra and Aqua satellites. This dataset, available on GitHub, was tested on the Databricks big data platform, achieving a high prediction accuracy of 98.32%. The results underwent various validation processes and were benchmarked against existing wildfire early warning systems.
Huot et al. [19] introduce "Next Day Wildfire Spread", a comprehensive, multivariate historical wildfire dataset from the United States. This dataset, which covers nearly a decade of remote-sensing data, is unique as it merges 2-D fire data with multiple explanatory variables like topography, vegetation, weather conditions, drought index, and population density. The authors use this dataset to develop a neural network that predicts wildfire spread with a one-day lead time, and they compare its performance with logistic regression and random forest models.
Yang et al. [20] propose an affordable, machine-learning-driven method that combines CNN and LSTM networks for predicting the chances (0-1) of forest fires that may occur (i.e. ignition) in Indonesia using MODIS data. This approach is particularly significant for developing countries that may lack the resources for expensive ground-based prediction systems. The model achieves 0.81 (ROC) curve, significantly surpassing the baseline method’s maximum of 0.7. Importantly, the model maintains its effectiveness even with limited data, showcasing the potential of machine-learning-based methods in establishing efficient and cost-effective forest fire prediction systems.
Double-Step U-Net [21] is a “double” CNN network, which combines Regression and Semantic Segmentation, to enchance accurate detection of the affected areas. It is trained using Copernicus EMS manually annotated data. The model is trained to estimate the final severity level of the wildfire; there are 4 levels spanning from 0 - No damage up to 4 - Completely destroyed. Their findings suggest that BCE-MSE loss can, in most cases, outperform state-of-the-art in RMSE scores.
F. Ahmad et. al [22] examines the use of machine learning algorithms for forest fire prediction. While its primary focus is on prediction, the methodologies discussed could be adapted for severity assessment using Earth Observation data.
Dedi Rosadi, Deasy Arisanty, and Dina Agustina’s study [23] utilizes neural networks with backpropagation learning and an extreme learning machine approach, incorporating meteorological and weather index variables. This methodology highlights the significance of integrating diverse data types, including Earth Observation data, for effective forest fire severity prediction.
In a recent study, Marjani et. al [24] utilize a combination of VIIRS Dataset and meteorological data (temperature, soil moisture, land cover, etc) for assessing wildfires in Australia. Their methodology merges CNN and biLSTM based architectures into a single model, which is later trained to predict the spread of potential wildfires.
ALLConvNet [25] is a convolutional model that is able to provide a 7 day wildfire burn forecast with the corresponding probability maps. This model is trained using features extracted from various datasets for Victoria and Austalia between years 2006 and 2017. According to the authors Lightning flash density, total precipitation and land surface temperature tend to be the most contributing features across all their testing, while wind, distance from the power grid and terrain affecting models’ performance the least. Zhang et. al [26], by evaluating different models, likewise suggest that features such as temperature, soil moisture indices (NDVI) and accumulative precipitation have a major impact on models’ performance throughout the year.
3. Dataset
The purpose of creating the EO4Wildfires dataset is to firstly structure in an AI ready format features (satellite images and weather data) that correlate with the result of wildfires. Secondly having this AI ready format, the purpose is to model how well the size and shape of wildfires can be predicted. This can server as a risk planning tool that identifies areas of high risk in wildfire seasons. EO4WildFires dataset [2], which incorporates data from the European Forest Fire Information System (EFFIS), Copernicus Sentinel-1 & 2, and NASA Power is utilized. Spatial resolution for all pixels is 10 meters, with an exception for the meteorological data, which hover the whole event region. Each event corresponds to a single data cube (netcdf file) that follows a common data loading routine and then is funneled into the various deep learning models. The following sections describe the data components and structure of the EO4WildFires dataset, along an exploratory analysis section.
3.1. European Forest Fire Information System
EFFIS [27,28] is a key platform providing current and historical data on forest fires in Europe, operated by the European Commission Joint Research Centre (JRC). It offers a wealth of information, including maps, data on fire locations, sizes, intensities, affected vegetation types, and land use. Additionally, EFFIS delivers daily wildfire danger forecasts and a fire danger rating system, all based on meteorological data. This platform is an indispensable tool for forest protection services, researchers, and policymakers who rely on precise and timely wildfire information for monitoring and management purposes in Europe.
3.2. Copernicus Sentinel 1 & 2
Sentinel-1, part of the Copernicus Programme developed by the European Space Agency (ESA), is a mission involving two polar-orbiting satellites that consistently gather Synthetic Aperture Radar (SAR) imagery in high resolution over terrestrial and coastal regions. Its C-band frequency SAR sensor provides all-weather, day-and-night imaging capabilities, useful for various applications like land and ocean monitoring, disaster response, and maritime surveillance. Sentinel-1’s data, accessible for free through the Sentinel Data Hub or third-party providers, is vital for long-term, global environmental and natural resource management.
Similarly, Sentinel-2, also from the Copernicus Programme and developed by ESA, comprises two satellites that capture optical imagery in high resolution. The onboard sensor records data across 13 spectral bands, facilitating the observation and monitoring of various phenomena such as vegetation, land use, natural disasters, and urban growth. Like Sentinel-1, Sentinel-2’s data is freely accessible and is pivotal for environmental monitoring, land use mapping, and disaster management due to its global coverage and high revisit frequency.
Sentinel 2 Level 1C data provides top-of-atmosphere (TOA) reflectance values, which are closer to the raw sensor data, instead of Sentinel 2 Level 2A which provide atmospherically corrected bottom-of-atmosphere (BOA) reflectance values. This allows researchers to apply their own correction and preprocessing techniques, potentially leading to more control over the quality and characteristics of the final dataset. In some cases, using S2L1C data can ensure a standard baseline for comparison across different studies and algorithms. Since S2L2A data already includes atmospheric correction, the preprocessing steps can vary depending on the algorithms and parameters used by different data providers. By starting with L1C data, researchers can standardize the preprocessing steps, ensuring that comparisons are fair and reproducible.
3.3. NASA Power
NASA Power [29,30] is a scientific initiative offering solar and meteorological data sets for applications in renewable energy, building energy efficiency, and agriculture. It aims to make these data sets more accessible and applicable for a diverse range of users, including researchers, policymakers, and practitioners. The project focuses on developing reliable and precise methods for measuring and forecasting solar and meteorological parameters like solar radiation, temperature, precipitation, and wind speed. NASA Power equips users with a variety of data sets, tools, and services to aid research and decision-making in energy, agriculture, and other sectors, contributing to sustainable and resilient future planning based on up-to-date and accurate solar and meteorological information.
3.4. Structure
EO4WildFires [2] comprises a blend of meteorological data, multispectral and SAR satellite imagery, along with wildfire event information sourced from the EFFIS system. EFFIS is tasked with delivering current and dependable data on wildland fires across Europe, aiding forest protection efforts.
This dataset was developed utilizing the Sentinel-hub API and the NASA Power API. The Sentinel-hub API facilitates Web Map Service (WMS) and Web Coverage Service (WCS) requests, enabling the downloading and processing of satellite imagery from various sources. Meanwhile, the NASA Power API offers access to solar and meteorological data compiled from NASA’s research, which is instrumental in sectors like renewable energy, building energy efficiency, and agriculture.
In the EO4WildFires dataset, each of the 31730 wildfire events is encapsulated as a datacube in NetCDF format. The process of data collection for each event involves several steps:
- Bounding box coordinates and the event date serve as the initial inputs.
- Meteorological parameters are derived using the central point of the area, collected from the day before the event to 30 days prior.
- Sentinel-2 imagery is cropped according to the bounding box coordinates. To address cloud cover issues, a mosaicking process https://custom-scripts.sentinel-hub.com/sentinel-2/monthly_composite/# is employed, selecting the optimal pixels from the last 30 days before the event.
- Sentinel-1 images are similarly cropped using the bounding box. Due to SAR images not being affected by cloud cover, only the most recent image before the event is used. Both ascending and descending images are included.
- A burned area mask is provided, representing the burned area as a boolean mask based on EFFIS vector data rasterized onto the Sentinel-2 grid.
The EO4WildFires dataset, as presented in Table 1, offers a comprehensive range of features suitable for wildfire severity prediction. This includes a fusion of meteorological data and satellite imagery, which sheds light on environmental conditions conducive to wildfires. The EFFIS-provided wildfire event labels are instrumental for training models to predict and respond to such events.
The mosaicking process for Sentinel-2 images creates a monthly composite, selecting the best pixel for each day in the preceding 31 days. This selection, based on band ratios, aims to minimize cloud cover. Depending on the level of blue in the image, different criteria are applied for pixel selection, with adjustments for water or snow presence. The resulting composite offers a clear representation of the last 31 days in the selected area.
The dataset encompasses 31730 wildfire events from 2018 to 2022 across 45 countries, affecting 8707 level-4 administrative areas. It integrates the GDAM database to align detected EFFIS events with administrative boundaries. Analysis of the data reveals that the median wildfire size is 31 hectares, with an average of 128.77 hectares. The largest recorded wildfire was 54,769 hectares in Antalya, Turkey (2021), followed by a 51,245 hectares fire in Evoia, Greece (2021). The dataset is publicly accessible at: 10.5281/zenodo.7762564
Figure 1 maps the level-4 administrative boundaries of the wildfires recorded in the dataset from 2018-2022, highlighting areas like the Mediterranean with high wildfire concentrations. Figure 2 aggregates the 5 most contributing countries to wildfires per year (for years 2018-2022) in the dataset. As seen Ukraine (UA) and Turkey (TR) account for approximately of total fires in the dataset. Adding Algeria (DZ), Spain (SP), Romania (RO) and Syria (SY) increases the total fire percentage to .
3.5. Explanatory Analysis
This section presents a comprehensive analysis of the EO4WildFires dataset, presenting key metrics and statistical figures to better understand the characteristics and quality of the data. The full dataset, including training, validation, and test sets, comprises 31,740 samples.
Each samples is resized to match a 224x224 pixel size. Samples that contain less than 10 burned pixels, which is equivalent to less than 1 km2 of burned area, have been excluded from certain experiments for a more focused analysis.
- The Median Value of Burned Pixels metric is calculated to provide insights into the typical extent of fire damage per event.
- Average Fire Area: An average measure of the area affected by fire in the dataset.
- Percentage of Unaffected Pixels: Indicates the proportion of pixels in each sample that were not impacted by fire, offering a perspective on the spatial extent of wildfires.
The dataset records a total burned area of . The Median Percentage of Burned Pixels in all events is . The Percentage of Total Burned Pixels represents of the total pixels across all events, offering a perspective on the overall impact of wildfires in the dataset.
Furthermore, the dataset includes a considerable number of NaN (Not a Number) values across various variables, particularly in the burned_mask, which has a total of 478.047.563 (56%) NaN values. These represent pixels unaffected by fire and are replaced with zeros to maintain consistency. Moreover, Sentinel 1 products for both Ascending and Descending orbit directions, have a 1.8% percentage of NaN values in total pixels. These values are likewise replaced with zeroes.
where group size, s total size, n number of groups and group median value.
An analysis using a weighted mean across different channels (Table 2), enables a more detailed understanding of central values in the dataset. Note that median is used instead of mean, due to its significantly biased mean value, possibly resulting from anomalies in data collection or processing.

Table 2.
Weighted mean of Median Values (See Equation (1)).
Table 2.
Weighted mean of Median Values (See Equation (1)).
| Channel | S1GRDA | S1GRDD | S2L2A |
|---|---|---|---|
| 1 | 0.09 | 0.08 | 0.05 |
| 2 | 0.02 | 0.02 | 0.07 |
| 3 | 0.61 | 0.63 | 0.09 |
| 4 | - | - | 0.13 |
| 5 | - | - | 0.23 |
| 6 | - | - | 0.23 |
| RH2M | T2M | PRECTOTCORR | WS2M | FRSNO |
|---|---|---|---|---|
| 70.82 | 11.97 | 0.24 | 2.2 | 0.01 |
| GWETROOT | SNODP | FRECSNOLAND | GWETTOP |
|---|---|---|---|
| 0.43 | 2.16 | 0 | 0.4 |
In addition to the aforementioned metrics, the average standard deviation using the Equation (2) is calculated. This measure provides insights into the variability within the dataset, considering different sample sizes and standard deviations for each channel.
where group size, s total size, n number of groups, and group std value.
3.6. Data Loading
The EO4WildFires dataset consists of distinct NetCDF (.nc) files, each representing a unique wildfire event. The dataset structure is designed to facilitate comprehensive analysis and be a standalone structure:
-
Dataset Composition: Every file in the dataset encapsulates a comprehensive datacube, representing a single wildfire event. This datacube is comprised of multiple channels:
- -
- Sentinel 2 Level 2A Product: Six channels from Sentinel 2, providing detailed multispectral imagery.
- -
- Sentinel 1 Product: Six channels, including VV, VH, and the ratio (VV-VH)/(VV+VH), split evenly between ascending and descending products. This accounts for a total of twelve unique channels from both Sentinel 1 and Sentinel 2.
- -
- Weather Metrics: Nine meteorological variables covering the 31 days leading up to the event, offering a holistic view of the environmental conditions prior to each wildfire.
- Binary Classification Mask: An integral part of each file is the binary mask that delineates the wildfire’s footprint. This mask is crucial for the classification and severity analysis of the event.
- Geospatial Encoding: Drawing inspiration from the work of Prapas et al. [31], we employ longitude and latitude information for pixel positional encoding. A sine and cosine transformation is applied, resulting in a four-channel encoding. Consequently, each loaded sample in the dataset is a 16-channel datacube, with varying dimensions due to the differing widths and heights of individual samples.
Figure 3.
EO 4Wildfires Datacube structure.
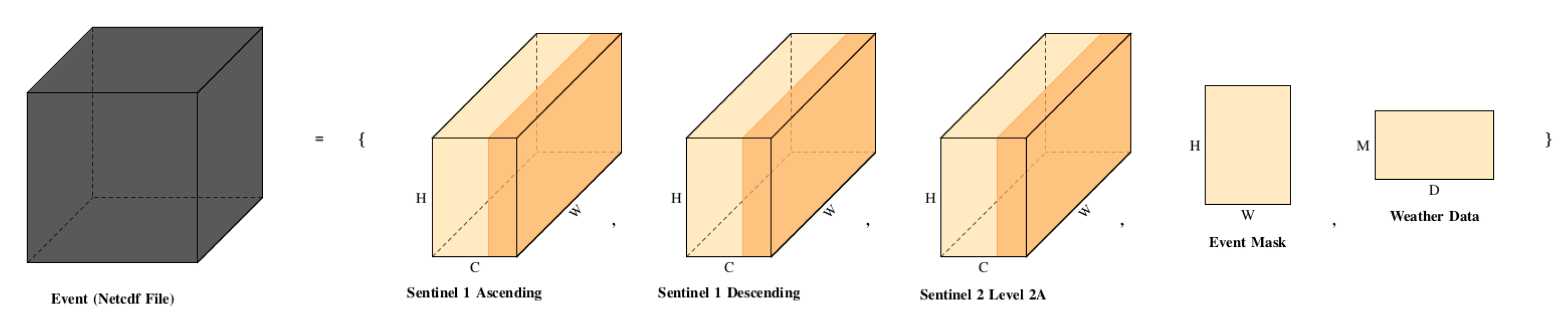
To accommodate state-of-the-art architectural requirements, each datacube (CxHxW, where C is channels, H is height, and W is width) undergoes a process of padding or segmentation to conform to a standard resolution of 224x224 pixels. This ensures uniformity across all input samples, with each one being a 16x224x224 data cube, accompanied by a 31x9 weather data matrix. During the data loading process, any missing values are substituted with zeros. This approach is also applied to the padding process, ensuring data integrity and consistency. The dataset does not employ data augmentation techniques, maintaining the authenticity of the original satellite and meteorological data. The dataset, when adjusted to the 224x224 resolution, includes 24794 samples with fewer than 10 burned pixels (equivalent to less than 1 km2 of burned area). To refine the dataset for more effective experiments, these samples are excluded from the analysis.
4. Experiments
In this section, we present the experiments performed using different deep learning architectures. In every experiment, the target is the same, i.e. to maximize the accuracy of the estimation of the burned area. Two main types of network architectures (with varying parameters) are examined:
- Image Segmentation Networks
- Visual Transformers
4.1. Data Processing and Machine Learning Pipeline
Figure 4 presents the dataflow for training and evaluating the models in each experiment. The Input Data Streams are initialized: Sentinel-1 Ascending and Descending, Sentinel-2 Level 2A, Event Metadata (Latitude & Longitude), Weather Data. The event metadata is encoded, to transform the latitude and longitude into a format that is usable by machine learning models. The encoded metadata and the Sentinel-2 imagery are concatenated (joined together) with the Sentinel-1 data to create an aggregated input. This combines all the different types of data into a single, cohesive dataset. Weather data is also prepared, to be fed into a Fully Connected (FC) network, a type of neural network used to process structured data. The aggregated input is then passed through various deep learning architectures. The FC network processes the weather data in parallel to the image data processing. The deep learning models output a "Prediction Mask", which is a binary mask predicting the burned area. This predicted output is then compared against the "Event Mask", which is the ground truth/actual observed data of the burned area. The results of the comparison (how close the prediction is to the event mask) are monitored, and various metrics are calculated to evaluate the performance of the models. These metrics include F1 Score, IOU Score, and aPD.
In a nutshell, Figure 4 describes the complex machine learning workflow that takes in satellite imagery, event metadata, and weather data to predict the extent of wildfire events. We emphasize data integration and transformation before applying machine learning models for prediction and subsequent performance evaluation.
The original EO4WildFires dataset is split into training, validation, and testing subsets, with 20307 events in the training set, 5077 events in the validation set, and 6346 events in the test set. The division of the dataset is the same for all three experiments to ensure comparability of results. The goal of the experiments is to determine which input features provide the best prediction performance for the size of a wildfire event. Heavily inspired by popular datasets like coco [11], three index files (train/val/test) are created that operate as literal file catalogues. Each row in the index files refers to a specific file in the disk.
4.2. Image Segmentation
Central to the architecture of every image segmentation model is the encoder, a component typically built upon well-known deep convolutional networks, such as ResNet and EfficientNet. The encoder’s primary function is to extract features from the input data, a critical step in the segmentation process. Although transfer learning is frequently employed to leverage pre-trained weights on three-dimensional images—thereby retaining knowledge from extensive prior training—this approach often falters when applied to satellite imagery. To counteract this issue, we have retrained the encoders’ weights from scratch for each experiment within our study.
Alongside re-initializing the weights, we have standardized the training approach across experiments. A consistent optimizer schedule was applied, and CrossEntropy loss was selected as the training criterion. This decision was made despite initial trials with Dice loss, which was quickly abandoned due to its subpar performance, likely aggravated by class imbalance within the dataset. Dice loss tends to under-perform when class imbalances are significant [32]. The models were built using the segmentation models library https://github.com/qubvel/segmentation_models.pytorch, chosen for its robustness and ease of use. The library provided a solid foundation upon which we could construct and evaluate our models. Our segmentation task is binary: determining whether a pixel will be impacted by fire or remain unaffected. This classification allows us to calculate True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN). From these values, we derive several metrics:
- F1 Score: A measure combining precision and sensitivity.
- IoU Score: The Intersection over Union (IoU), or Jaccard Index, computed using the formula .
- Average Percentage Difference (aPD): Metric indicating the model’s deviation from the actual observed data, derived from the percentage difference between the ground truth and predicted values.
For experiments utilizing direct models from the segmentation models library, an additional layer is incorporated into the architecture. This layer transforms the weather data matrix into an extra channel, facilitating the combination of meteorological data with the Sentinel datacube. The resultant input size of 13x224x224 provides a comprehensive view of each wildfire event, integrating satellite and weather data.
4.3. Visual Transformers
Building on the work of Prapas et al. [31], our experiments explore the adaptation of Visual Transformers (ViT) for the task of image segmentation within the context of satellite imagery. The architecture under consideration, TeleViT, presents a novel approach specifically tailored to satellite data. To utilize their model effectively, we meticulously followed the guidelines set forth in their publication, making necessary adjustments to accommodate our dataset.
The encoding channel was implemented as delineated in their code repository, ensuring that our model retains the intended data format throughout training. Consistent with previous steps that anticipated input sizes of 224 by 224, we maintained this dimensionality to guarantee that the data fed into the network would be evenly divisible by 224. Consequently, we opted for a patch size of 56, thereby subdividing each 224x224 sample into smaller segments of 56x56. This process effectively augmented the dataset size by a factor of 16.
A notable deviation from the TeleViT model is the requirement for weather data. Their model is configured to process 10 metrics spanning 10 months, which differs from our dataset’s structure of 9 metrics across the last 31 days. To reconcile this discrepancy, we appended a dedicated fully connected network to the model architecture. This ancillary network’s sole purpose is to transform our unique weather data dimensions into a compatible format for the TeleViT model. The transformed vector is then reshaped to align with the model’s channel size and integrated into the model’s input, akin to the methodology applied in segmentation model experiments.
For training, we employ CrossEntropy loss in conjunction with the Adam optimizer. A learning rate scheduler on plateau is utilized to modulate the learning rate based on the validation loss, ensuring that the model’s learning is both effective and efficient.
5. Results
Table 3 serves as a benchmark, presenting the initial results from applying various Image Segmentation networks and a Visual Transformer model to the EO4WildFires dataset. It lists different configurations of ResNet encoders paired with segmentation models like Unet++ and LinkNet. The table also includes metrics that evaluate the models’ performance in predicting the burned area, namely F1 Score, Intersection over Union (IoU) Score, and Average Percentage Difference (aPD).
Table 4 refines the experimental approach by removing samples with empty labels (full zeros) or below a certain size threshold (e.g., 1 ) from both the training and testing phases. This aims to focus the model training on more substantial and relevant data points. The same models and metrics are used as in Table 3, allowing for a direct comparison to evaluate the impact of removing these less informative samples on model performance.
Table 5 further iterates on the experimentation by removing samples with empty labels or below the threshold size (e.g., 1 ) only from the training set while keeping the full dataset for testing. This approach tests whether models trained on more significant events generalize better to all types of events, including those with minimal or no burned areas. The same models and performance metrics are used to assess the impact of training on a curated dataset while maintaining a comprehensive testing scenario.
The inclusion of the Visual Transformer model, referred to as TeleViT (global), allows for a comparison between more traditional segmentation networks and newer transformer-based approaches.
The F1 and IoU scores are relatively consistent across the different encoder and model combinations. This suggests that all the models tested have a comparable ability to predict the burned area in wildfire events. The performance seems to slightly improve when the models are trained without empty labels or very small events (Table 4), as compared to the baseline models (Table 3). This indicates that filtering out less informative data can lead to more accurate predictions by focusing on more substantial wildfire events. ViT model tends to perform better in APD metric, because it tends to predict the non dominant class, which is non-burned pixels. This is better understood when accessing F1 and IoU scores.
Table 5 shows that when models are trained without the empty labels but tested on the entire dataset, the performance metrics (F1 and IoU) do not significantly deteriorate, suggesting that the models are capable of generalizing well from more substantial to less substantial events. The Visual Transformer (TeleViT) model’s performance, as indicated by the F1 and IoU scores, is marginally lower than that of the image segmentation networks, implying that, while Visual Transformers are promising, the segmentation networks are currently more effective for this specific task of wildfire analysis. The aPD values are not consistently better or worse across the experiments, which suggests that the models’ ability to estimate the actual size of the burned area varies. This metric could be influenced by factors such as the complexity of the event or the quality of the input data.
The Image Segmentation networks seem to slightly outperform the Visual Transformer architecture in this context. Moreover, the practice of filtering training data to remove noise (empty labels or very small events) appears to enhance model performance, indicating the importance of high-quality training data for machine learning tasks in satellite imagery analysis. The results provide a strong basis for further refining the models and data preprocessing techniques to improve wildfire severity prediction using deep learning.
6. Discussion
In this section, a number of example case studies are presented to demonstrate the usability and potential of forecasting wildfire size in a more qualitative manner. The case studies are based on the Copernicus Emergency Management Service (EMS) - Mapping service, specifically its Rapid Mapping Portfolio and the EFFIS dataset.
EMS offers quick geospatial information in response to emergencies, utilizing satellite imagery and other data. It aims to support emergency management activities by providing standardized products, such as pre-event and post-event analysis, including fast impact assessment and detailed damage grading. The service operates under two production modes to cater to urgent and less urgent needs, ensuring timely delivery of critical information for disaster response efforts. Among the geospatial products of the EMS are the burned areas, which are produced using very high resolution satellite images () with high quality procedures that involve manual digitization and corrections to produce the final maps. For this purpose we utilized:
- EMSN077: Post-disaster mapping of forest fires in De Meinweg National Park, Germany-Netherlands border.
- EMSN090: Wildfires in Piedmont region, Italy.
Figure 5 shows the location of the case studies on a map. North’s Italy case and Netherland’s case are based on EMSN090 and EMSN077 correspondingly, while the rest rely on the EFFIS.
Table 6 and Figure 6 and Figure 8 depict the number of pixels predicted versus the ground truth for wildfire areas, while providing a detailed comparison of the predictive capabilities of the models used in the study against actual observed wildfire impacts. Table 6 and Figure 6 and Figure 8 compare the predicted area affected by wildfires (in terms of pixel count) to the actual (ground truth) area impacted. For each case study, the table shows a percentage difference between the model’s predictions and the actual observed data. The percentage differences range from very close estimations of the ground truth to larger underestimations, illustrating the challenges in accurately predicting the extent of wildfire damage using satellite imagery and machine learning models. The accompanying figure visually represents the data provided in Table 6 and Figure 6 and Figure 8, plotting the predicted pixel counts against the ground truth for each case study.
Key takeaway from the case studies examination is that the developed methodology can be used to forecast wildfire size if it actually ignites. From the Table 6 it is shown that although there errors will be in the range of 20-25%, this is a constant underestimation of the predictor. Thus, this gives a minimum baseline for evaluating upcoming risks during the fire season. Our proposed methodology is not intended to be used as a precision wildfire spread model, rather as a tool to forecast the potential size and shape of the wildfire if it occurs, so as to act as a utility tool that helps in the planning phase. Although shape is not the explicit optimization parameter, the models as they are trained learn the relevant pattern to predict the shape, since they are image segmentation models.
7. Conclusions
This study has presented an approach to use the potential of deep learning architectures in the domain of wildfire severity (size and shape) analysis using the EO4WildFires dataset. The EO4WildFires dataset is a comprehensive collection that includes Sentinel-1 and Sentinel-2 satellite imagery, event metadata (geolocated burned mask), and weather data. This multi-source data has been structured into a unified format, with event metadata encoded to be machine learning compatible and all data streams aggregated into a cohesive dataset for input into various deep learning models.
Through rigorous experimentation with Image Segmentation networks and Visual Transformers, we have pursued the goal of maximizing the accuracy of burned area size estimation. Our approach can be used to predict the size and shape of a wildfire if it ignites, but it does not estimate the probability of its ignition, nor it’s spread. Moreover, the severity is measured in terms of burned area surface and not in terms of potentially incurred costs (socio-economic, environmental, or other, i.e. due to human losses and injuries, or damages in properties, infrastructures and ecosystems).
Traditional Image Segmentation networks, that rely on convolution encoders; such as ResNet and EfficientNet, have demonstrated a slight edge over the Visual Transformer architecture in predicting wildfire affected areas. This suggests that, at least in the context of this dataset, conventional segmentation approaches are currently more effective than transformer-based counterparts.
Filtering the training data to exclude noise, such as empty labels or events below a certain threshold, has been found to improve model performance across all evaluation metrics. This emphasizes the importance of high-quality training data in machine learning, particularly in the field of satellite imagery analysis, where the vast presence of non-burned areas can pose a significant challenge.
The robustness of the models is reflected in the consistency of F1 and IoU scores across different encoder and model combinations, indicating a reliable ability to predict the burned area across a variety of deep learning approaches. When models trained without empty labels were tested on the full dataset, the performance metrics did not deteriorate significantly. This suggests that the models are able to generalize from larger to smaller events effectively.
The decision to abandon Dice loss due to poor performance suggests the models may struggle with class imbalance, a common issue in satellite imagery, where areas not affected by fire far outnumber those that are affected. The results form a solid foundation for further refining the models and data preprocessing techniques to improve the prediction of wildfire severity using deep learning techniques.
Author Contributions
Conceptualization, D.S. and K.D.; methodology, D.S, D.Z; software, D.Z; validation, D.S, D.Z, K.D; formal analysis, D.S; resources, K.D; data curation, D.S, D.Z; writing—original draft preparation, D.S, D.Z; writing–review and editing, D.S, K.D; visualization, D.S, D.Z; supervision, D.S, K.D; project administration, K.D; funding acquisition, K.D. All authors have read and agreed to the published version of the manuscript.
Funding
This study has been conducted in the framework of the SILVANUS project. This project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No 101037247. The contents of this publication are the sole responsibility of the authors and can in no way be taken to reflect the views of the European Commission.
Data Availability Statement
Data utilized in this paper can be found at: 10.5281/zenodo.7762564.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Flannigan, M.D.; Wagner, C.E.V. Climate change and wildfire in Canada. Canadian Journal of Forest Research 1991, 21, 66–72. [Google Scholar] [CrossRef]
- Sykas, D.; Zografakis, D.; Demestichas, K.; Costopoulou, C.; Kosmidis, P. EO4WildFires: an Earth observation multi-sensor, time-series machine-learning-ready benchmark dataset for wildfire impact prediction. Ninth International Conference on Remote Sensing and Geoinformation of the Environment (RSCy2023); Themistocleous, K.; Hadjimitsis, D.G.; Michaelides, S.; Papadavid, G., Eds. International Society for Optics and Photonics, SPIE, 2023, Vol. 12786, p. 1278603. [CrossRef]
- Yu, J.; Wang, Z.; Vasudevan, V.; Yeung, L.; Seyedhosseini, M.; Wu, Y. CoCa: Contrastive Captioners are Image-Text Foundation Models. 2022; arXiv:cs.CV/2205.01917. [Google Scholar]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; Wei, F.; Guo, B. Swin Transformer V2: Scaling Up Capacity and Resolution. 2022; arXiv:cs.CV/2111.09883. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; Uszkoreit, J.; Houlsby, N. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2021; arXiv:cs.CV/2010.11929. [Google Scholar]
- Chen, X.; Liang, C.; Huang, D.; Real, E.; Wang, K.; Liu, Y.; Pham, H.; Dong, X.; Luong, T.; Hsieh, C.J.; Lu, Y.; Le, Q.V. Symbolic Discovery of Optimization Algorithms. 2023; arXiv:cs.LG/2302.06675. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. 2017; arXiv:cs.LG/1412.6980. [Google Scholar]
- Shazeer, N.; Stern, M. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. 2018; arXiv:cs.LG/1804.04235. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. 2015; arXiv:cs.CV/1512.03385. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. 2020; arXiv:cs.LG/1905.11946. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. 2015; arXiv:cs.CV/1405.0312. [Google Scholar]
- Meng, Q.; Meentemeyer, R.K. Modeling of multi-strata forest fire severity using Landsat TM Data. International Journal of Applied Earth Observation and Geoinformation 2011, 13, 120–126. [Google Scholar] [CrossRef]
- Ghali, R.; Akhloufi, M.A. Deep Learning Approaches for Wildland Fires Using Satellite Remote Sensing Data: Detection, Mapping, and Prediction. Fire 2023, 6. [Google Scholar] [CrossRef]
- Fernández-García, V.; Beltrán-Marcos, D.; Fernández-Guisuraga, J.M.; Marcos, E.; Calvo, L. Predicting potential wildfire severity across Southern Europe with global data sources. Science of The Total Environment 2022, 829, 154729. [Google Scholar] [CrossRef]
- López García, M.J.; Caselles, V. Mapping burns and natural reforestation using Thematic Mapper data. Geocarto International 1991, 6, 31–37. [Google Scholar] [CrossRef]
- Morresi, D.; Marzano, R.; Lingua, E.; Motta, R.; Garbarino, M. Mapping burn severity in the western Italian Alps through phenologically coherent reflectance composites derived from Sentinel-2 imagery. Remote Sensing of Environment 2022, 269, 112800. [Google Scholar] [CrossRef]
- Ying, L.; Shen, Z.; Yang, M.; Piao, S. Wildfire Detection Probability of MODIS Fire Products under the Constraint of Environmental Factors: A Study Based on Confirmed Ground Wildfire Records. Remote Sensing 2019, 11. [Google Scholar] [CrossRef]
- Sayad, Y.O.; Mousannif, H.; Al Moatassime, H. Predictive modeling of wildfires: A new dataset and machine learning approach. Fire Safety Journal 2019, 104, 130–146. [Google Scholar] [CrossRef]
- Huot, F.; Hu, R.L.; Goyal, N.; Sankar, T.; Ihme, M.; Chen, Y.F. Next Day Wildfire Spread: A Machine Learning Dataset to Predict Wildfire Spreading From Remote-Sensing Data. IEEE Transactions on Geoscience and Remote Sensing 2022, 60, 1–13. [Google Scholar] [CrossRef]
- Yang, S.; Lupascu, M.; Meel, K.S. Predicting Forest Fire Using Remote Sensing Data And Machine Learning. 2021; arXiv:cs.CV/2101.01975. [Google Scholar]
- Monaco, S.; Pasini, A.; Apiletti, D.; Colomba, L.; Garza, P.; Baralis, E. Improving Wildfire Severity Classification of Deep Learning U-Nets from Satellite Images. 2020 IEEE International Conference on Big Data (Big Data), 2020, pp. 5786–5788. [CrossRef]
- Ahmad, F.; Waseem, Z.; Ahmad, M.; Ansari, M.Z. Forest Fire Prediction Using Machine Learning Techniques. 2023 International Conference on Recent Advances in Electrical, Electronics & Digital Healthcare Technologies (REEDCON), 2023, pp. 705–708. [CrossRef]
- Rosadi, D.; Arisanty, D.; Agustina, D. PREDICTION OF FOREST FIRE USING NEURAL NETWORKS WITH BACKPROPAGATION LEARNING AND EXREME LEARNING MACHINE APPROACH USING METEOROLOGICAL AND WEATHER INDEX VARIABLES. MEDIA STATISTIKA 2022, 14, 118–124. [Google Scholar] [CrossRef]
- Marjani, M.; Mahdianpari, M.; Mohammadimanesh, F. CNN-BiLSTM: A Novel Deep Learning Model for Near-Real-Time Daily Wildfire Spread Prediction. Remote Sensing 2024, 16. [Google Scholar] [CrossRef]
- Bergado, J.R.; Persello, C.; Reinke, K.; Stein, A. Predicting wildfire burns from big geodata using deep learning. Safety Science 2021, 140, 105276. [Google Scholar] [CrossRef]
- Zhang, G.; Wang, M.; Liu, K. Deep neural networks for global wildfire susceptibility modelling. Ecological Indicators 2021, 127, 107735. [Google Scholar] [CrossRef]
- Centre, J.R.; for Environment, I.; Sustainability.; San-Miguel-Ayanz, J.; Durrant, T.; Camia, A. The European fire database – Technical specifications and data submission – Executive report; Publications Office; 2014. [Google Scholar]
- Commission, E.; Centre, J.R.; Schulte, E.; Maianti, P.; Boca, R.; De Rigo, D.; Ferrari, D.; Durrant, T.; Loffler, P.; San-Miguel-Ayanz, J.; Branco, A.; Vivancos, T.; Libertà, G. Forest fires in Europe, Middle East and North Africa 2016; Publications Office, 2017.
- The data was obtained from the National Aeronautics and Space Administration (NASA) Langley Research Center (LaRC) Prediction of Worldwide Energy Resource (POWER) Project funded through the NASA Earth Science/Applied Science Program. https://power.larc.nasa.gov/, 2023.
- The data was obtained from the POWER Project’s Daily 2.4.2 version on 2023/03. https://power.larc.nasa.gov/, 2023.
- Prapas, I.; Bountos, N.I.; Kondylatos, S.; Michail, D.; Camps-Valls, G.; Papoutsis, I. TeleViT: Teleconnection-driven Transformers Improve Subseasonal to Seasonal Wildfire Forecasting. 2023; arXiv:cs.CV/2306.10940. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.K.M.; Ourselin, S.; Cardoso, M.J. Generalised Dice overlap as a deep learning loss function for highly unbalanced segmentations. Deep learning in medical image analysis and multimodal learning for clinical decision support : Third International Workshop, DLMIA 2017, and 7th International Workshop, ML-CDS 2017, held in conjunction with MICCAI 2017 Quebec City, QC,... 2017, 2017, 240–248. [Google Scholar] [PubMed]
Figure 1.
Wildfires events (2018-2022) with the corresponding affected level-4 administration boundaries - yellow polygons: administrative boundaries (level 4) of affected areas, red points: locations of wildfires events.
Figure 1.
Wildfires events (2018-2022) with the corresponding affected level-4 administration boundaries - yellow polygons: administrative boundaries (level 4) of affected areas, red points: locations of wildfires events.
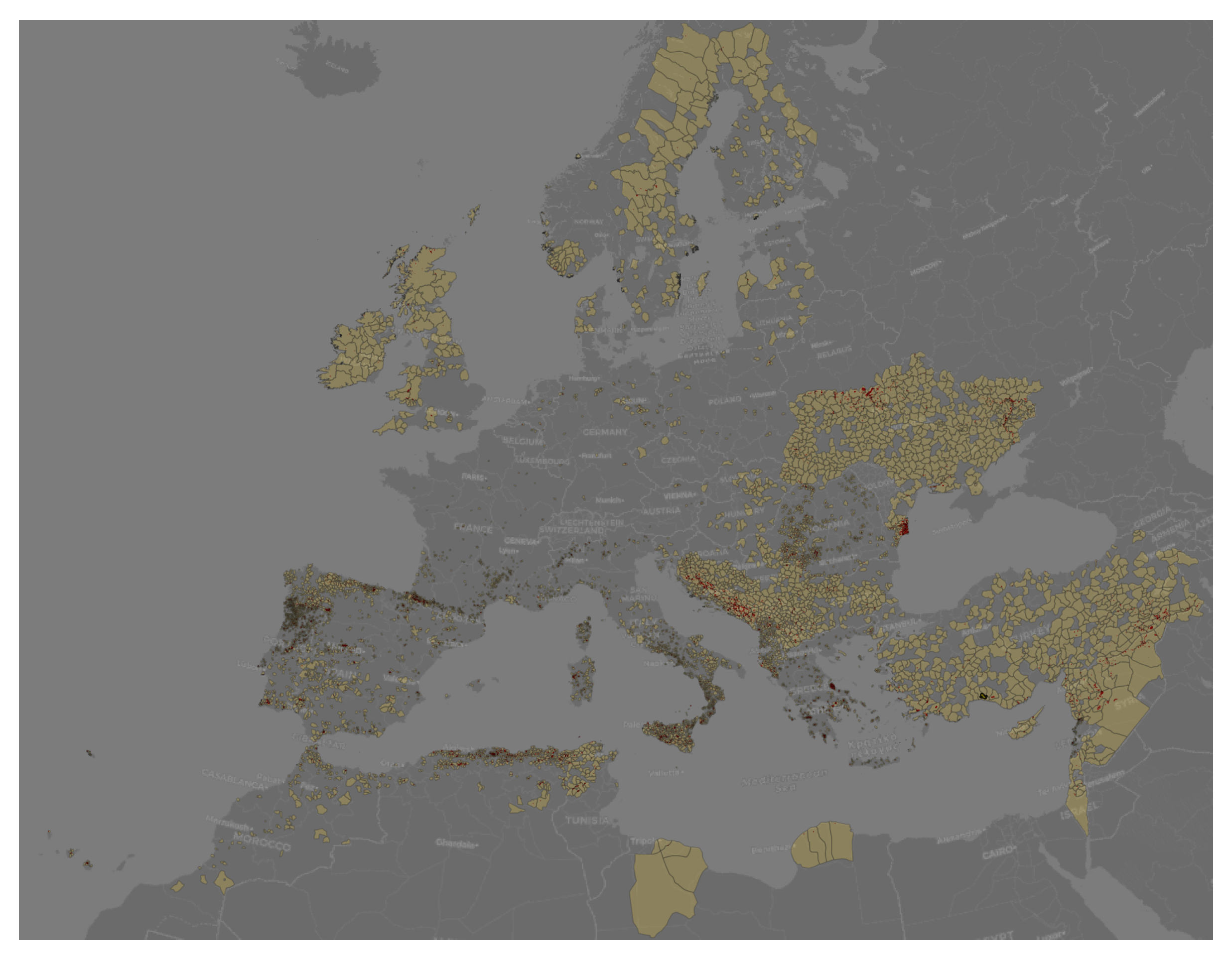
Figure 2.
Top 5 contributing countries to wildfires annually.
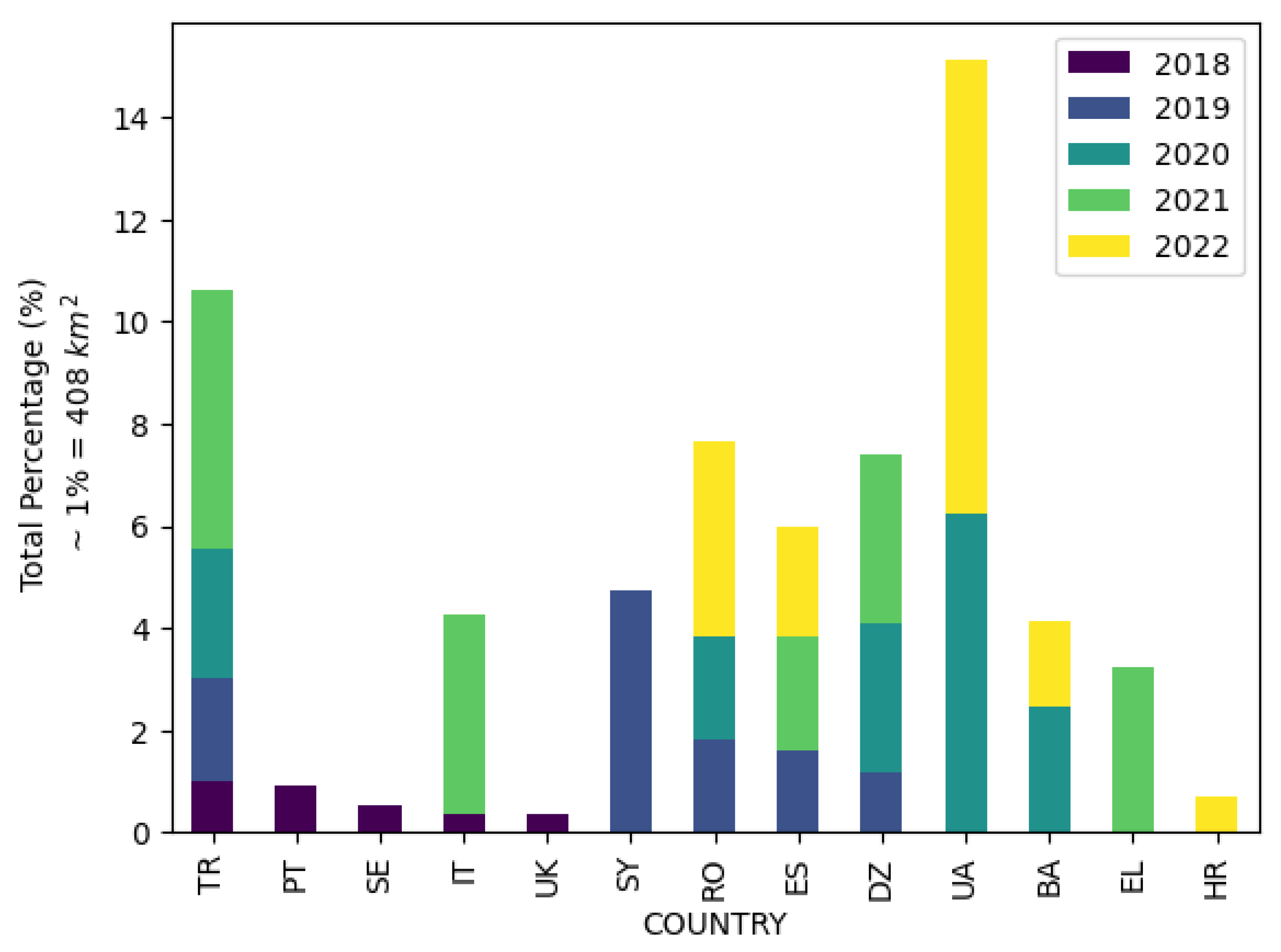
Figure 4.
Schematic representation of the data processing and machine learning pipeline for wildfire event analysis using the EO4WildFires dataset.
Figure 4.
Schematic representation of the data processing and machine learning pipeline for wildfire event analysis using the EO4WildFires dataset.
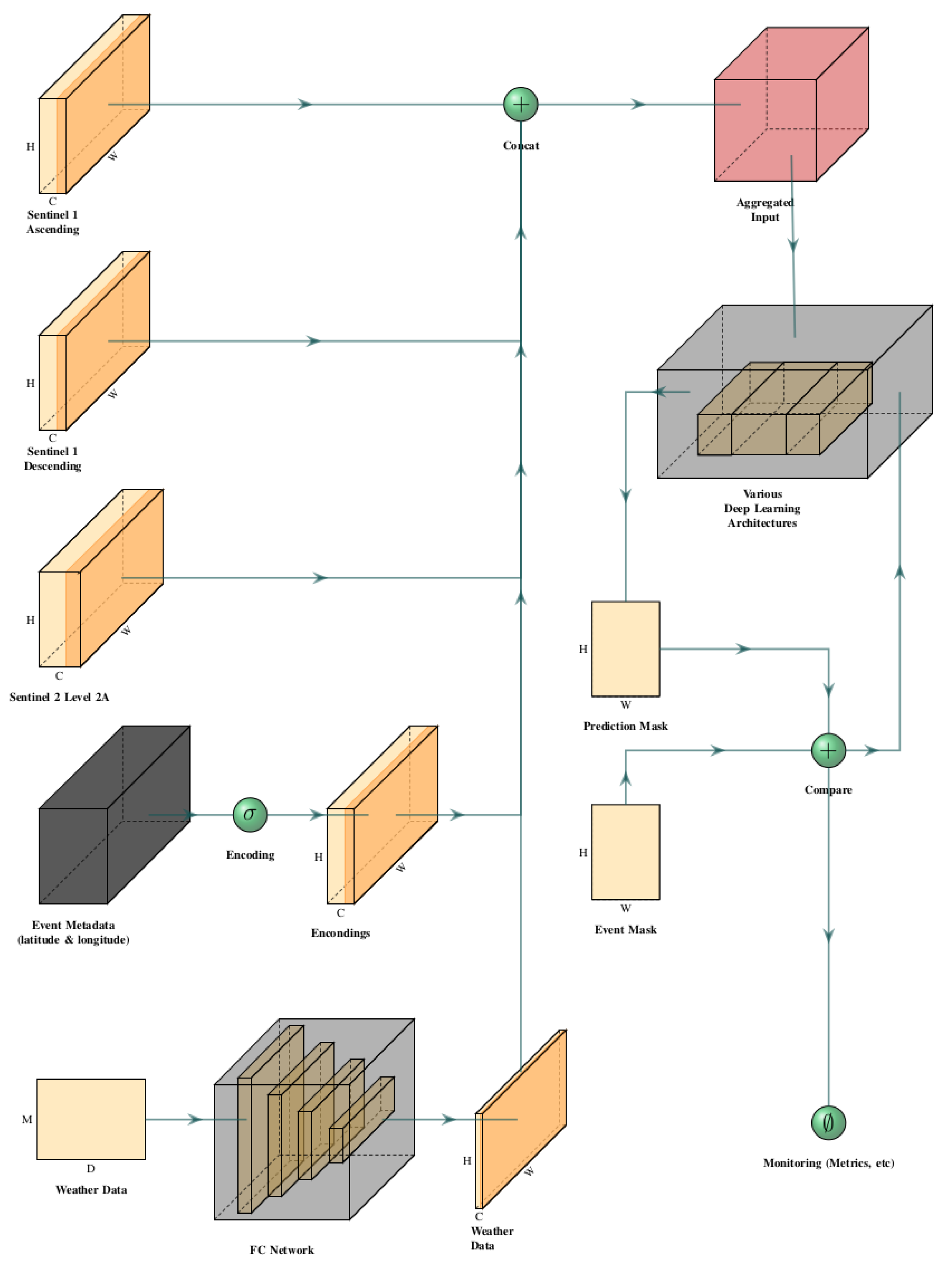
Figure 5.
Use case map overview.
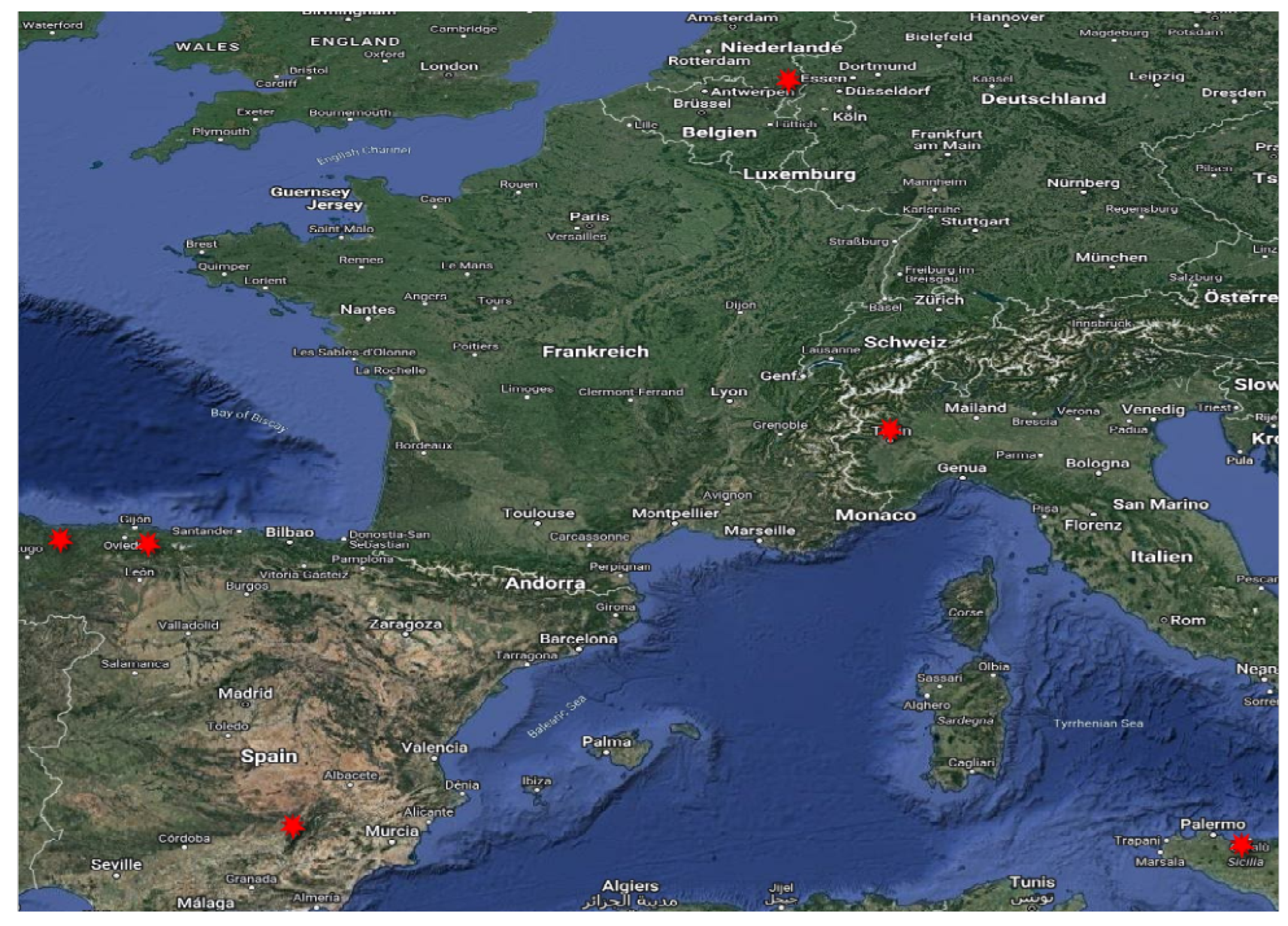
Figure 6.
Cases: #46933, #46848, #24600.
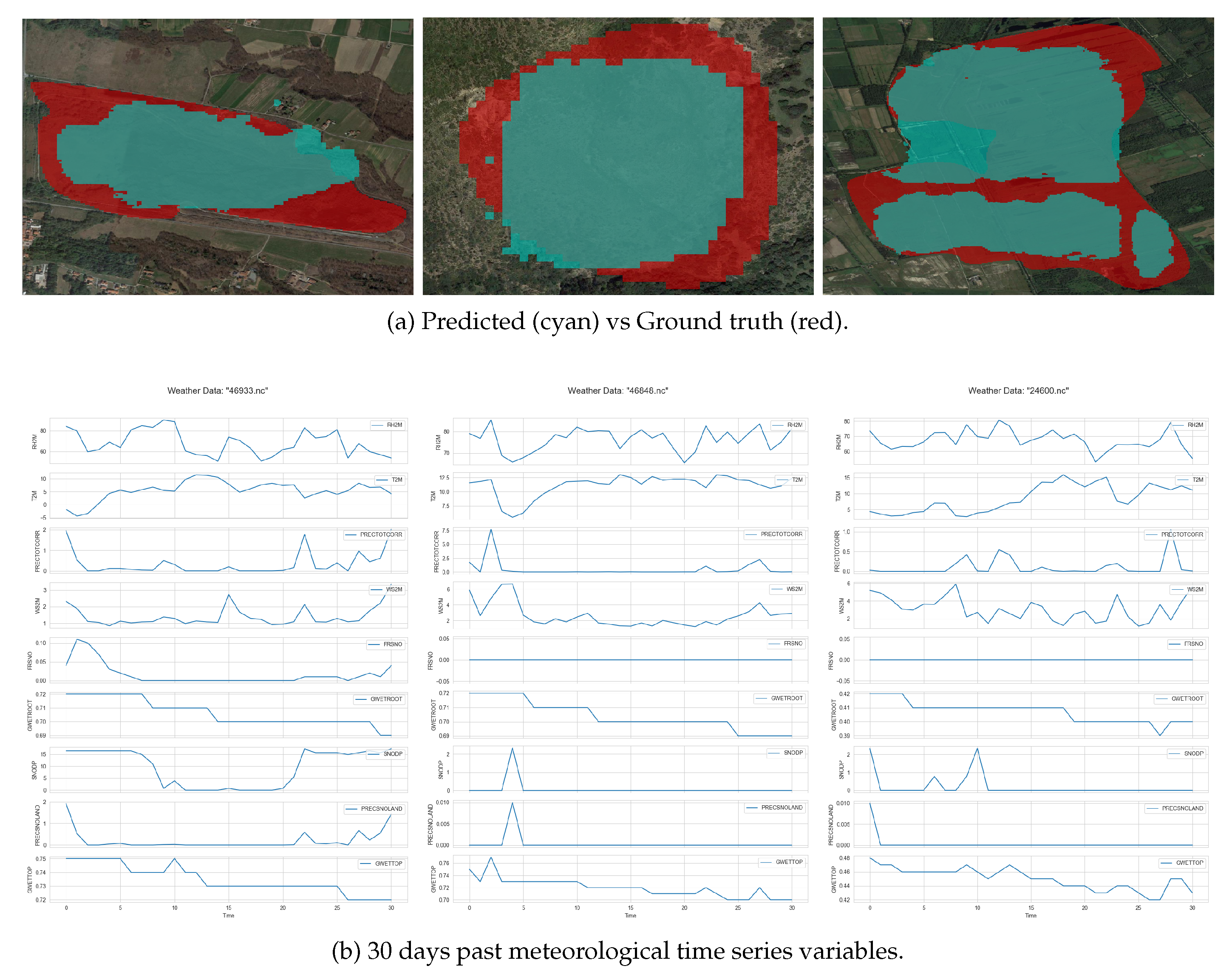
Figure 7.
Regression of Predicted vs Ground Truth.
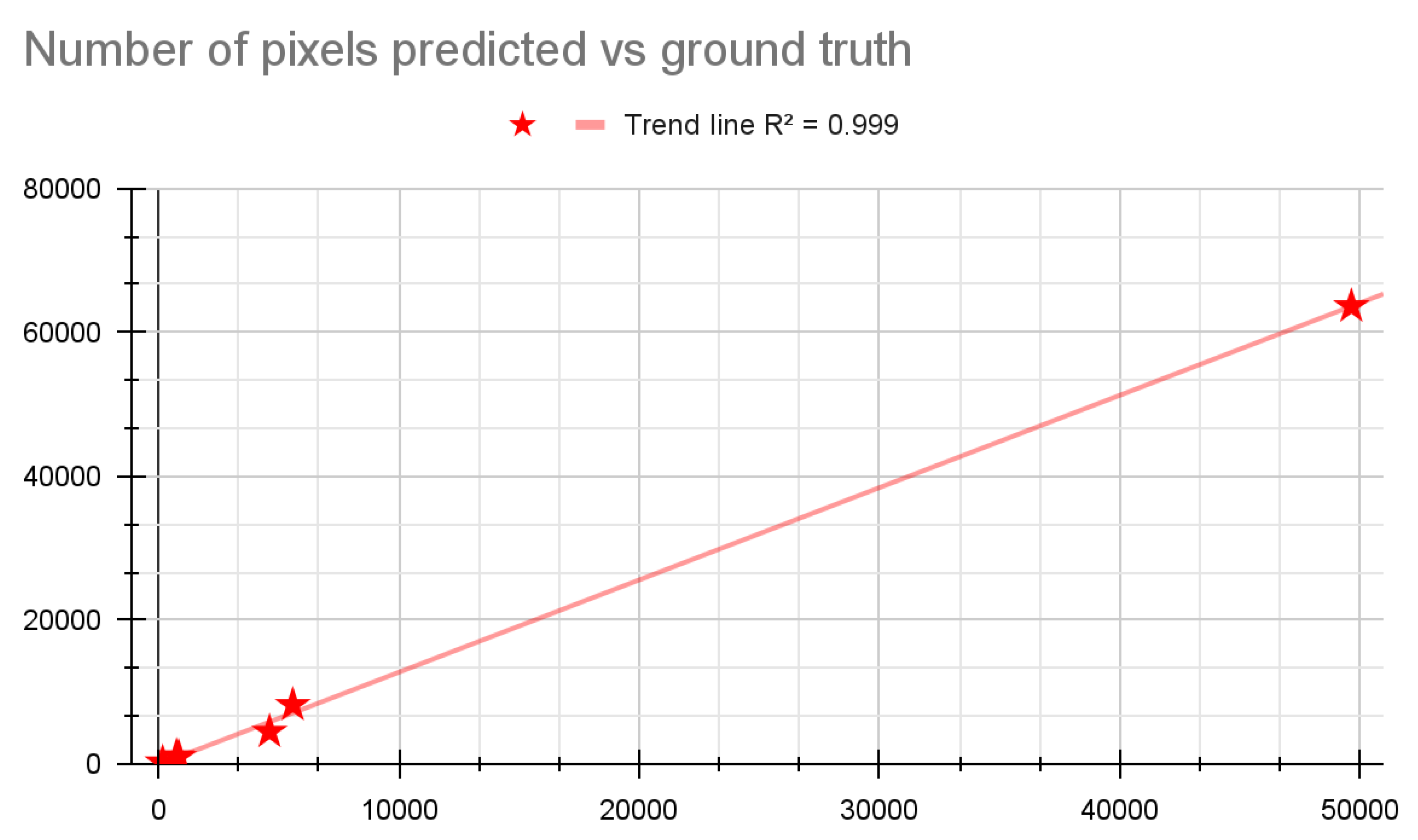
Figure 8.
Cases: #55463, #54455, #54278.
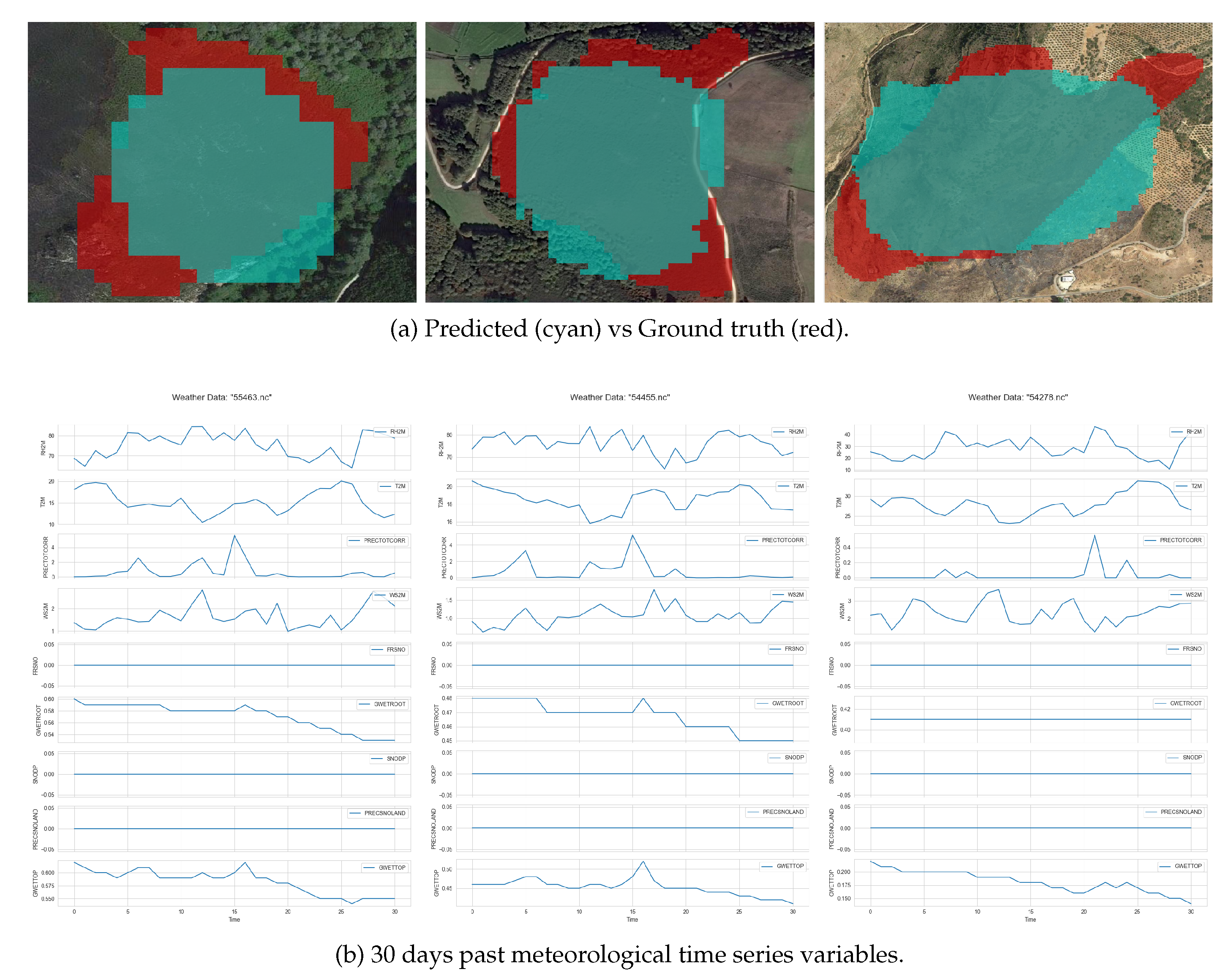
Table 1.
Parameters included in each wildfire event for each data source.
| Channel | Meteorological Data | Sentinel-1 | Sentinel-2 |
|---|---|---|---|
| 1 | Ratio of actual partial pressure of water vapor to the partial pressure at saturation (RH2M) |
VV | Band 02 |
| 2 | Average Temperature (T2M) |
VH | Band 03 |
| 3 | Bias corrected average total precipitation (PRECTOTCORR) |
Band 04 | |
| 4 | Average Wind Speed (WS2M) |
- | Band 05 |
| 5 | Fraction of Land Covered by Snowfall (PRECSNOLAND) |
- | Band 08 |
| 6 | Percent of Root Zone Soil Wetness (GWETROOT) |
- | Band 11 |
| 7 | Snow Depth (SNODP) |
- | - |
| 8 | Snow Precipitation (FRSNO) |
- | - |
| 9 | Soil Moisture (GWETTOP) |
- | - |
Table 3.
Baseline Models.
| Encoder | Model | F1 Score | IOU Score | aPD |
|---|---|---|---|---|
| ResNet18 | Unet++ | 0.85 | 0.74 | 56.2 |
| ResNet34 | Unet++ | 0.86 | 0.76 | 64.2 |
| ResNet50 | Unet++ | 0.85 | 0.75 | 77.8 |
| ResNet18 | LinkNet | 0.87 | 0.76 | 66.3 |
| ResNet34 | LinkNet | 0.86 | 0.75 | 70 |
| ResNet50 | LinkNet | 0.86 | 0.75 | 69 |
| - | TeleVIT (global) | 0.84 | 0.72 | 14.9 |
Table 4.
Baseline Models trained and tested without empty labels.
| Encoder | Model | F1 Score | IOU Score | aPD |
|---|---|---|---|---|
| ResNet18 | Unet++ | 0.87 | 0.77 | 50.4 |
| ResNet34 | Unet++ | 0.87 | 0.76 | 52.1 |
| ResNet50 | Unet++ | 0.87 | 0.76 | 44.9 |
| ResNet18 | LinkNet | 0.87 | 0.77 | 48.6 |
| ResNet34 | LinkNet | 0.87 | 0.77 | 44.8 |
| ResNet50 | LinkNet | 0.86 | 0.76 | 55.1 |
| - | TeleVIT (global) | 0.83 | 0.71 | 58.3 |
Table 5.
Baseline Models trained without empty labels.
| Encoder | Model | F1 Score | IOU Score | aPD |
|---|---|---|---|---|
| ResNet18 | Unet++ | 0.86 | 0.76 | 96.5 |
| ResNet34 | Unet++ | 0.86 | 0.75 | 97.6 |
| ResNet50 | Unet++ | 0.86 | 0.76 | 86.5 |
| ResNet18 | LinkNet | 0.86 | 0.76 | 91.8 |
| ResNet34 | LinkNet | 0.87 | 0.76 | 85.9 |
| ResNet50 | LinkNet | 0.87 | 0.75 | 103 |
| - | TeleVIT (global) | 0.84 | 0.72 | 79.4 |
Table 6.
Number of pixels predicted, ground truth and corresponding % difference.
| Case Study # | Predicted | Ground truth | % Difference |
|---|---|---|---|
| 54278 | 4620 | 4486 | 2.99 |
| 24600 | 49641 | 63619 | -21.97 |
| 46848 | 750 | 1075 | -30.23 |
| 46933 | 5589 | 8211 | -31.93 |
| 54455 | 844 | 974 | -13.35 |
| 55463 | 172 | 217 | -20.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



