Submitted:
12 September 2024
Posted:
12 September 2024
You are already at the latest version
Abstract
Accurate forecasting and efficient management of commodities are crucial for stakeholders in the industry, given the volatile nature of these markets. This study addresses these needs by leveraging advanced forecasting techniques and machine learning models to predict prices and enhance supply chain efficiency. TThe focus is on utilizing ARIMA, SARIMAX, and LSTM models to analyze historical trading data for commodities such as cocoa, coffee, and sugar sourced from Kaggle’s comprehensive dataset. The research applies ARIMA and SARIMAX models to forecast price trends, overcoming initial challenges related to data index frequency and seasonality. LSTM models are employed for more nuanced demand forecasting, particularly for random-length lumber, demonstrating the model's capability to predict future market trends accurately. The study highlights significant improvements in prediction accuracy and supply chain management through meticulous feature engineering and model optimization, offering valuable insights for strategic decision-making in the supply chain sector.
Keywords:
Time Series Analysis
; Machine Learning Models
; Deep Learning Forecasting
; Supply Chain
; LSTM
I. Introduction
With the deepening of the integration of science and technology and industry in a new round, new quality productivity is accelerating the integration of new technologies such as cloud computing, big data, and artificial intelligence, enabling enterprises to form a new development pattern of efficient collaboration, resilient growth, and transformation from chain development to complex network structure. The supply chain digital intelligence platform has gradually developed into a new cloud platform in this environment. Building a service system based on mass data collection, aggregation, and analysis supports the ubiquitous connection, flexible supply, and efficient allocation of manufacturing resources. [1,2,3] The application of artificial intelligence technology makes the supply chain ecology present multi-dimensional characteristics, and the e-commerce platform can be used as the core node of the supply chain upgrade to build a platform ecology of symbiosis and shared prosperity to shape the core competitive advantage of enterprises.
The platform upgrade of the supply chain requires a dynamic response of the supply chain, that is, building a stable supply chain network to deal with uncertainty[4]. Establish a supply chain multi-cooperation system to optimize production efficiency and circulation efficiency. Based on supply chain demand forecasting, this paper will combine the artificial intelligence forecasting Model and use the SARIMAX and LSTM Models to analyze the supply chain demand of commodities in each season and provide appropriate supply chain management and optimisation strategies.
II. Related Work
A. Traditional Supply Chain Forecasting and Management
Martin Kristof, winner of the Outstanding Contribution Award of the American Supply Chain Management Association, pointed out that competition in the 21st century is no longer between enterprises but between supply chains. [5] This collaborative supply chain operation mode emphasises not only the integration of business flow, logistics, information flow, and capital flow but also the supply chain process management, which is the core task of modern supply chain management. 2012 "Logistics Terminology" national standard, the supply chain is the production and circulation process to provide products and services to the end user by the upstream and downstream enterprises jointly established network chain organization. Using technology, supply chain management has become more straightforward, and supply chain services have become more human.
Digital transformation and upgrading of supply chain management are significant issues in current social development. [6,7,8] Digital transformation is no longer a choice question for traditional enterprises but an urgent must-answer. It mainly uses IoT, intelligent order, and other digital technologies. It accesses any equipment based on AI and IoT technology to achieve the digital upgrade of the complete supply chain link, such as warehousing, transportation, and distribution. It promotes the upgrade of enterprise supply chain management.
B. Supply Chain Management Architecture
Most enterprises are on the road to upgrading their digital supply chain, continuously accumulating corporate data through scientific and technological means, feeding these data back to serve the supply chain, and upgrading supply chain management. [9]In the face of complex and diverse supply chain management scenarios, we launched the industry-leading JusLink solution to keep up with the pace of supply chain upgrading. [10,11]In the E-commerce supply chain management model, thanks to multiple information technologies and the Internet, customers can track the whereabouts of goods along the supply chain at any given time.
The operation mode of the supply chain is different: the traditional supply chain is a typical push operation. To overcome the obstacles in the space and time of commodity transfer, manufacturers use logistics to send goods to the market or customers, pushing both business flow and logistics. The process is a two-way interaction, as customers can customize, monitor, and even modify their inventory and orders. [12] As manufacturers, distributors can also adjust inventory and orders at any time according to the needs of customers, to maximize the performance of supply chain operation.
Supply chain management requirements are inconsistent. Traditional supply chain management emphasizes the stability and consistency of the logistics process. [13,14] Otherwise, there will be chaos in the logistics activities, and any fluctuation and variation in the logistics operation process may cause enormous losses for upstream and downstream enterprises. E-commerce supply chain management is different because the logistics demand itself is differentiated; logistics is a value-added activity based on highly information management.
C. Supply Chain Demand Based on Neural Network
Supply chain management generates large amounts of big data that can be used to support decision making. As a result, predicting supply chain processes is almost impossible without first clarifying supply chain visibility. In 2020, only 9% of supply chain managers will have insight into upstream and downstream networks and emphasize sharing data with partners. When forecasting demand, most supply chain managers rely on historical transaction data and direct data from consumer research. [15] The best example is New Year's resolutions. More than 75 per cent of people give up on their resolutions within 30 days, while only 8 per cent succeed in keeping them. When demand planning in the supply chain is based solely on self-reported data and managers' judgment, the likelihood of operational accidents is also high [16,17] Prior to entering the mass market, Pore Shoes of Prey conducted a series of market surveys to anticipate the demand for custom shoes and to prepare its production facilities for shorter lead times.
D. Supply Chains Need Predictive Models
LSTM model-Long short-term memory network [18](LSTM) is a deep learning model commonly used to process sequential data. LSTM implements this function through recurrent neural network (RNN) [19]units with gating mechanisms, including input gates, forget gates, and output gates, which control the flow and retention of information. In the field of meteorology and hydrology, LSTM can be used to deal with the phenomenon of missing data.
This makes LSTM ideal for managing inventory, optimizing logistics, and improving the overall efficiency of the supply chain. Many enterprises have begun applying LSTM to real-time data analysis and demand forecasting to respond to dynamic changes in market demand and reduce inventory costs. [20,21,22]In addition, as technology advances, the application of LSTM in supply chain management has gradually expanded, including predicting anomalies, improving supply chain resilience, and enhancing decision support capabilities.
The application of LSTM in supply chain demand forecasting is mainly reflected in its deep learning ability of time series data. The specific implementation process usually includes the following steps:
First, data preprocessing is key. Raw sales data, inventory levels, and other relevant factors are collected and collated into a time series format. Next, the data needs to be normalized to ensure the stability and efficiency of the model training. In this way, LSTM can not only improve the accuracy of forecasts but also help supply chain managers make more data-driven decisions, reduce inventory costs, and improve the overall operational efficiency of the supply chain.
c) ARIMA model
ARIMA (Autoregressive Composite Moving Average) is a widely used statistical method for analyzing time series data and predicting future values. ARIMA models model trends, seasonality, and noise (random fluctuations) in time series data.
The RIMA[23] (Residual-based Interpolation and Multi-step Analysis) model shows significant advantages in supply chain management and demand forecasting. Firstly, the model improves prediction accuracy by interpolating and analyzing the residual of time series data in multiple steps. ARIMA models can effectively capture complex fluctuations and trends in demand, thereby reducing forecasting errors and enhancing resilience to seasonal changes and trends. Second, the model's flexibility allows it to handle different data types and characteristic variables, adapting to multiple supply chain scenarios, including product categories and market conditions. In addition, RIMA models improve the stability and reliability of predictions by reducing sensitivity to outliers and data noise.
III. Methodology
While the owner presents this dataset for analysis and insights, he emphasises the importance of ethical sourcing and consumption, especially in commodities like cocoa and coffee with known ethical concerns in their supply chains[23,24,25,26]. This dataset delivers an extensive and current assortment of futures related to soft commodities. Futures are financial contracts obligating the buyer to purchase and the seller to sell a specified amount of a particular commodity at a predetermined price on a set date in the future.
Price Forecasting: Harness machine learning to predict the price dynamics of commodities, aiding stakeholders in their decision-making. Supply Chain Analysis: Evaluate the correlation between futures prices and global events, offering insights into potential supply chain disruptions.Demand Projections: Utilize deep learning techniques to correlate historical consumption patterns with price movements, projecting future demand.
A. Data Set
This experiment uses data sets from the Kaggle platform of the product futures market data set (data set ID: / Kaggle/input/product futures). The dataset contains historical trading data for several commodities (such as cocoa, coffee, sugar, etc.) from January 3, 2000, to December 11, 2023. Data fields include trading date, opening price, high price, low price, closing price, and volume. In the process of data pre-processing, we first confirmed the integrity and accuracy of the data, then carried out outlier processing, identified and removed the outliers through the box plot, and finally screened 18,951 valid records. Data analysis uses Pandas, Matplotlib and Seaborn libraries in Python to explore the sales of different products and their statistical characteristics.
This table shows the product futures market trading data from 2000 to 2023, including the opening, high, low, closing and volume of various commodities such as cocoa, coffee and sugar. The main columns in the data table are the commodity code, commodity name, trading date, opening price, high price, low price, closing price, and volume. A sample table is as follows:

Table 1.
SAMPLE data set of product futures mark.
| Index | Ticker | Commodity | Date | Open | High | Low | Close | Volume |
|---|---|---|---|---|---|---|---|---|
| 0 | CC=F | Cocoa | 2000/1/3 | 840 | 846 | 820 | 830 | 2426 |
| 1 | CC=F | Cocoa | 2000/1/4 | 830 | 841 | 823 | 836 | 1957 |
| 2 | CC=F | Cocoa | 2000/1/5 | 840 | 850 | 828 | 831 | 3975 |
| 3 | CC=F | Cocoa | 2000/1/6 | 830 | 847 | 824 | 841 | 3454 |
| 4 | CC=F | Cocoa | 2000/1/7 | 848 | 855 | 836 | 853 | 5008 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 30261 | SB=F | Sugar | 2023/12/5 | 25.9 | 25.9 | 24.81 | 24.96 | 107293 |
| 30262 | SB=F | Sugar | 2023/12/6 | 24.92 | 24.92 | 22.94 | 23 | 177202 |
| 30263 | SB=F | Sugar | 2023/12/7 | 23.39 | 23.93 | 22.8 | 23.03 | 132480 |
| 30264 | SB=F | Sugar | 2023/12/8 | 23.1 | 23.6 | 23.1 | 23.36 | 88278 |
| 30265 | SB=F | Sugar | 2023/12/11 | 23.44 | 23.49 | 22.17 | 22.56 | 0 |
B. Price Forecasting with ARIMA, SARIMAX and LSTM
When using the ARIMA model for time series prediction, the data is first preprocessed, including converting the date columns to 'datetime' format and setting them as indexes. Hysteresis features are created in the data to enhance the model's predictive power, and the data set is divided into a training set and a test set. After making the forecast, the mean square error (MSE)[27] was calculated and the initial MSE was 53,738.74. For further optimization, the data was resamped to monthly frequencies and re-engineered and trained for features, resulting in a significantly reduced mean square error of 1926.81. Finally, by drawing the comparison between the actual price and the predicted price, the prediction effect of the model can be clearly demonstrated.
Figure 1.
Forecast results of ARIMA's initial data commodity prices.
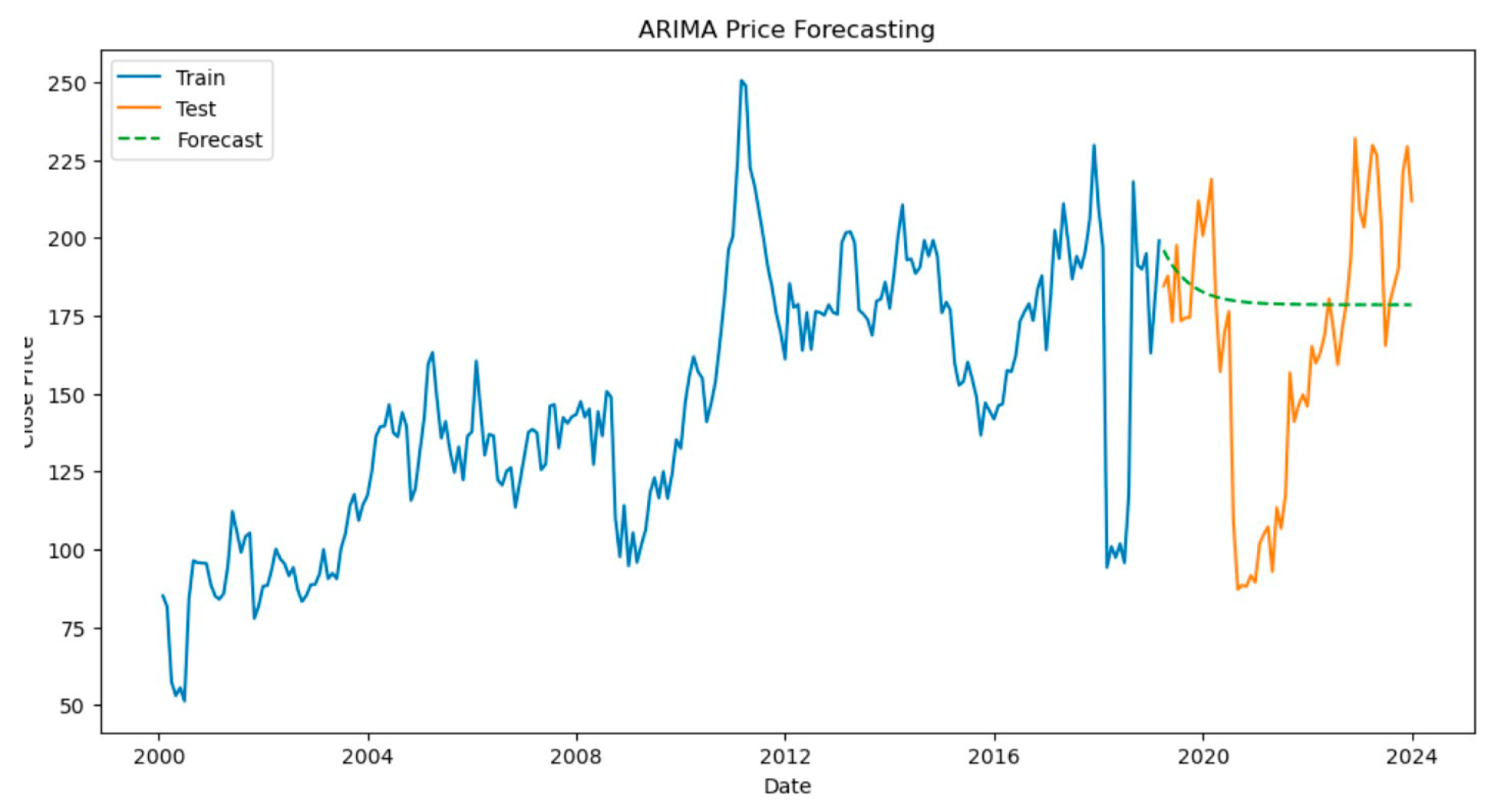
The original data set is first tested when evaluating the stationarity of time series using the extended Dickey-Fuller (ADF) test. The results of the ADF[28] test show that the ADF test statistic is -3.07, the P-value is 0.028, the lag uses 42 observations, and a total of 18,908 observations are used. This suggests strong evidence against the null hypothesis (Ho) that the time series has no unit root and is stationary. The data were seasonally differential processed for further verification and then re-ADF tested. [21] The ADF test results after processing showed that the ADF test statistic was significantly reduced to -20.32 with a P-value of 0.0, 44 observations were used with a lag, and a total of 18,894 observations were used, reconfirming the stationarity of the time series.
C. Supply Chain Analysis
To conduct a supply chain needs analysis, we conduct a correlation matrix analysis on the relationship between the price and characteristics of each commodity. Firstly, the correlation between the features is evaluated by calculating the correlation coefficient matrix of each commodity. These analyses can reveal patterns of feature associations across different commodities and provide valuable insights for further supply chain optimization.
In addition, to perform the seasonal decomposition of each commodity, we employ an addition model, which expresses the time series as the sum of trend, seasonality, and residual. In the case of "coffee," we break down its closing price data to extract and visualize these ingredients. [29]By using the seasonal_decompose function, we plotted the raw time series, trend component, seasonal component, and residual component. The additive decomposition applies when the magnitude of seasonality does not change with the overall change in the time series, helping us to understand the internal structure of the time series more clearly.
Figure 2.
Time series data for four commodities (coffee, cotton, sugar, and orange juice).
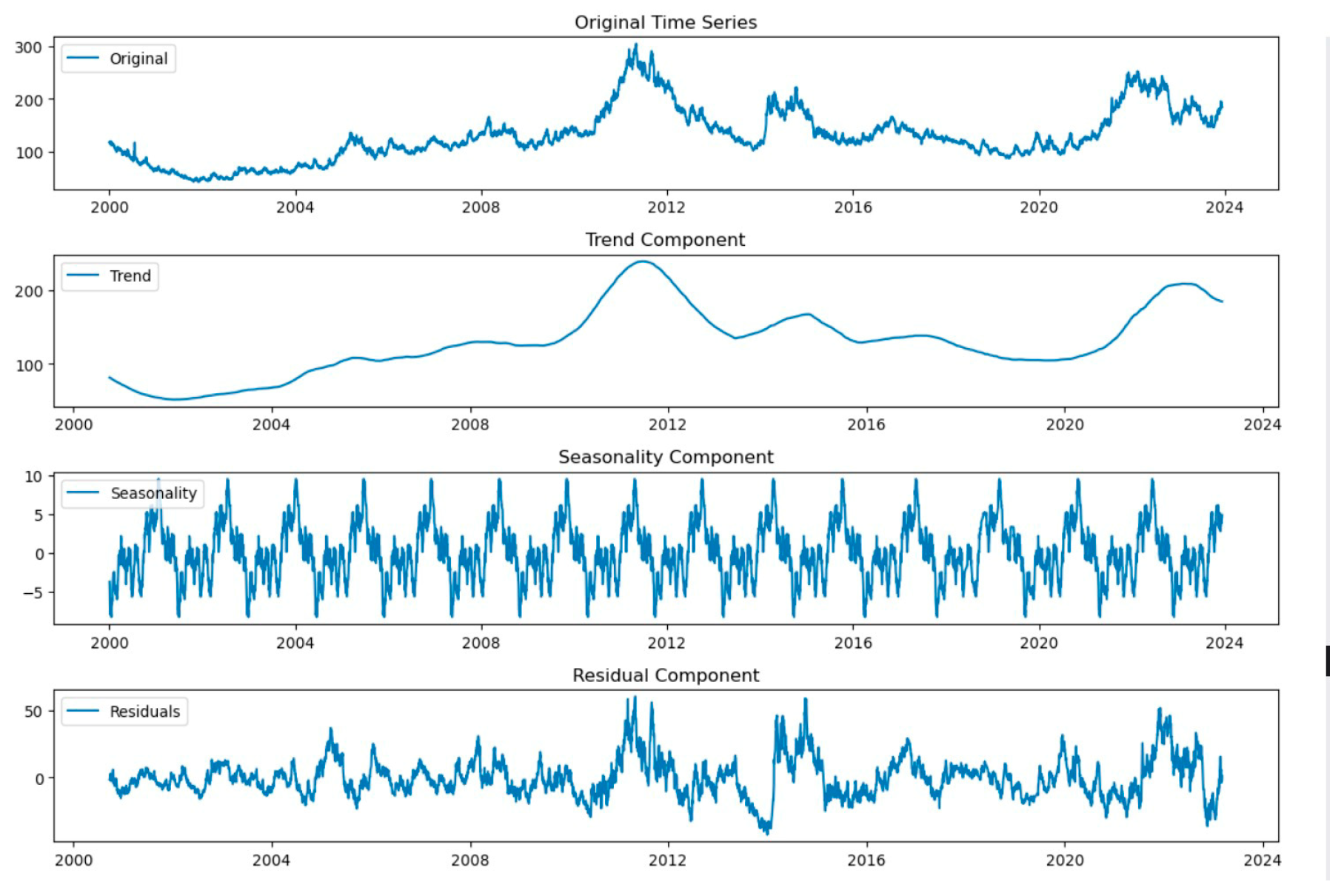
Time series data for four commodities (coffee, cotton, sugar, and orange juice) are decomposed seasonally by addition and their components are visualized. [30,31]First, the code breaks down the closing price data for each item using the seasonal_decompose function, dividing the time series into trend components, seasonal components and residual components. For each commodity, the decomposition results are plotted into four subplots: the original time series, the trend component, the seasonal component, and the residual component. These charts help users intuitively understand long-term trends, seasonal changes, and random noise in the data to better analyze and interpret the different components of time series data.
D. SARIMAX Model for Future Forecasting
Plotting each commodity's graph with SARIMAX and with setting a confidence interval
Confidence intervals (sometimes called prediction intervals when used in forecasting) tell us, for a certain level of confidence, a reasonable range of values in which the parameter of interest should fall.
Figure 3.
SARIMAX model predicts supply chain demand of goods.
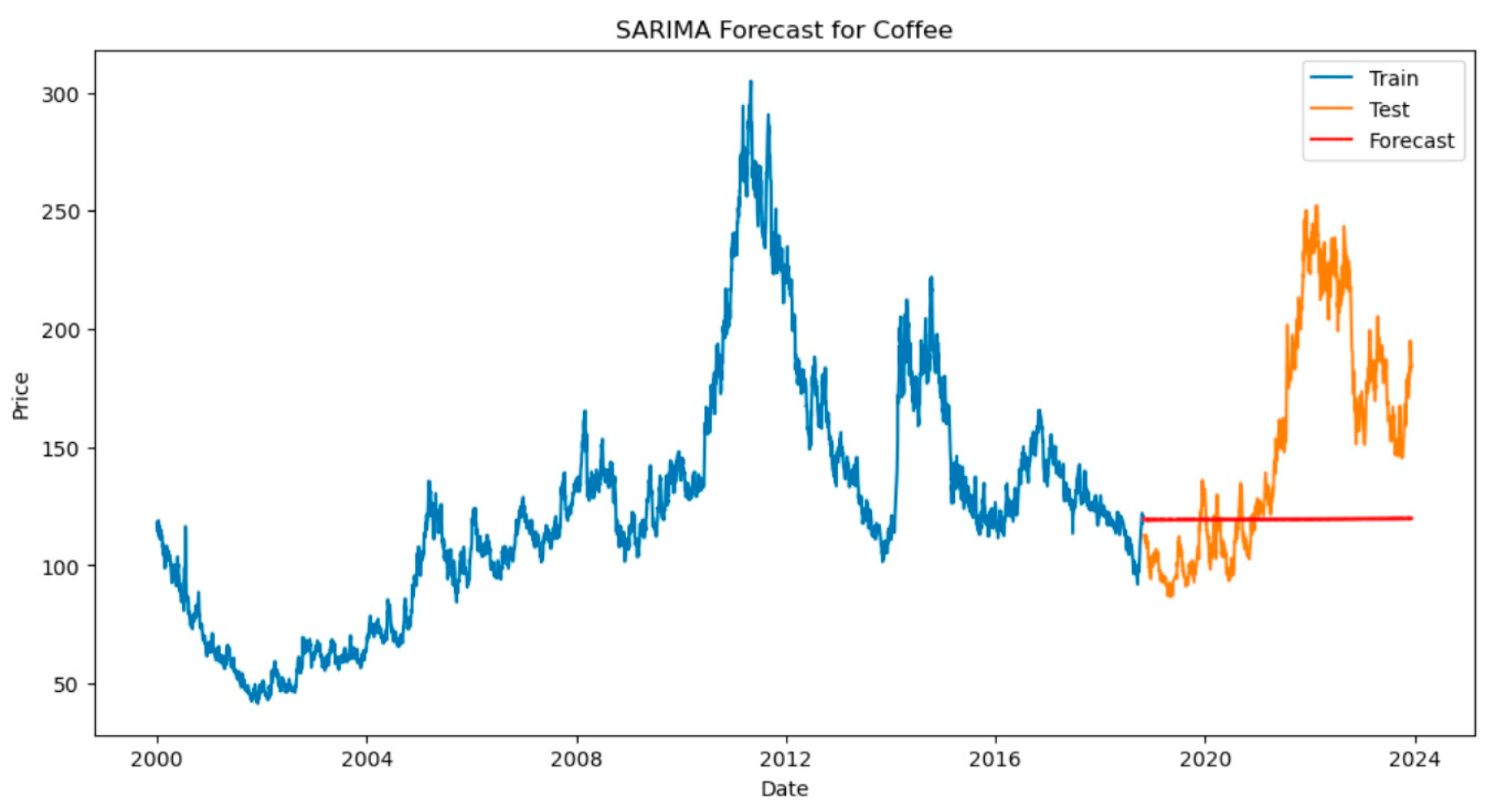
According to the above prediction model results, the SARIMAX model is used to predict the time series of the closed market price of the "coffee" commodity. The data is first divided into a training set and a test set, with 80% of the data used for training and the remaining 20% for testing. The parameter Settings of the model include the ARIMA or SARIMA and the seasonal order. The warning message indicates that the lack of frequency information in the date index may cause the model optimization not to converge or the prediction results to be problematic.
In addition, to ensure the accuracy and practicality of the model predictions, we use the features and target variables of the current data set to make predictions of future data. In the prediction process, Finally, by inverting the predicted value of the model output back to the original scale, we obtain the predicted result of future demand. These results help us understand future market trends and provide strong data support for formulating appropriate inventory management strategies.
E. Discussion
In this experiment, we gain important insights into demand patterns through time series analysis of historical consumption patterns of product commodities. We can achieve accurate demand forecasting using advanced models such as SARIMAX[32] and LSTM, which is essential for effective supply chain planning. In addition, the LSTM model, along with appropriate feature scaling and hyperparameter tuning, ensures the robustness and stability of the model, especially in the dynamic product market. These efforts will further improve the overall performance of the supply chain. The combination of time series analysis and optimization models demonstrated in this project provides stakeholders in the product sector with powerful tools to make more informed decisions, reduce costs, and improve the overall efficiency of the supply chain.
IV. Conclusion
This study underscores the critical importance of scientific forecasting and data-driven decision-making in modern supply chain management, particularly within the product futures market. By leveraging advanced time series analysis methods such as ARIMA and SARIMAX, alongside deep learning techniques like LSTM, we have effectively captured market price dynamics and demand patterns. These methodologies enable businesses to identify potential supply chain risks, optimize management strategies, and enhance overall operational efficiency. The in-depth analysis of historical data has allowed us to pinpoint key factors influencing prices and demand, thereby facilitating the development of more robust strategies to navigate market uncertainties. This data-driven approach not only benefits agribusinesses but also serves as a valuable reference for policymakers and market analysts.
However, the study is not without its limitations. Firstly, while ARIMA and SARIMAX models are effective for capturing linear dependencies, they may not fully address the complexities and non-linearity present in market data. The LSTM models, though powerful in handling sequential data, require extensive computational resources and may still struggle with overfitting in certain scenarios. Additionally, the scope of feature engineering was limited, and further exploration of additional factors and external variables could provide more comprehensive insights.
Future research should aim to address these limitations by incorporating more sophisticated feature engineering techniques, optimizing existing models, and exploring new technologies. This includes experimenting with hybrid models that combine various machine learning approaches and refining algorithms to adapt to evolving market conditions. Continuous advancements in these areas will not only improve forecasting accuracy but also broaden the applicability of these models across different sectors. Such improvements will enhance market understanding and provide more reliable decision support for stakeholders, driving further development and innovation in the industry.
References
- Hugos, M.H. Essentials of Supply Chain Management; John Wiley & Sons, 2024. [Google Scholar]
- Singh, S. P.; et al. "Application of AI in SCM or Supply Chain 4.0." Artificial Intelligence in Industrial Applications: Approaches to Solve the Intrinsic Industrial Optimization Problems (2022): 51-66.
- Zhao, F.; Zhang, M.; Zhou, S.; Lou, Q. Detection of Network Security Traffic Anomalies Based on Machine Learning KNN Method. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 1, 209–218. [Google Scholar] [CrossRef]
- Yang, M.; Huang, D.; Zhang, H.; Zheng, W. AI-Enabled Precision Medicine: Optimizing Treatment Strategies Through Genomic Data Analysis. J. Comput. Technol. Appl. Math. 2024, 1, 73–84. [Google Scholar]
- Wen, X.; Shen, Q.; Zheng, W.; Zhang, H. AI-Driven Solar Energy Generation and Smart Grid Integration A Holistic Approach to Enhancing Renewable Energy Efficiency. Int. J. Innov. Res. Eng. Manag. 2024, 11, 55–55. [Google Scholar] [CrossRef]
- Lou, Q. New Development of Administrative Prosecutorial Supervision with Chinese Characteristics in the New Era. J. Econ. Theory Bus. Manag. 2024, 1, 79–88. [Google Scholar]
- Zhou, S.; Yuan, B.; Xu, K.; Zhang, M.; Zheng, W. The impact of pricing schemes on cloud computing and distributed sysTEMS. J. Knowl. Learn. Sci. Technol. 2024, 3, 193–205. [Google Scholar] [CrossRef]
- Sun, J.; Wen, X.; Ping, G.; Zhang, M. Application of News Analysis Based on Large Language Models in Supply Chain Risk Prediction. J. Comput. Technol. Appl. Math. 2024, 1, 55–65. [Google Scholar]
- Huang, D.; Yang, M.; Wen, X.; Xia, S.; Yuan, B. AI-Driven Drug Discovery: Accelerating the Development of Novel Therapeutics in Biopharmaceuticals. J. Knowl. Learn. Sci. Technol. 2024, 3, 206–224. [Google Scholar] [CrossRef]
- Liu, Y.; Tan, H.; Cao, G.; Xu, Y. Enhancing User Engagement through Adaptive UI/UX Design: A Study on Personalized Mobile App Interfaces. 2024.
- Xu, H.; Li, S.; Niu, K.; Ping, G. Utilizing Deep Learning to Detect Fraud in Financial Transactions and Tax Reporting. J. Econ. Theory Bus. Manag. 2024, 1, 61–71. [Google Scholar]
- Li, P.; Hua, Y.; Cao, Q.; Zhang, M. Improving the Restore Performance via Physical-Locality Middleware for Backup Systems. In Proceedings of the 21st International Middleware Conference (pp. 341-355). 2020.
- Zhou, S.; Yuan, B.; Xu, K.; Zhang, M.; Zheng, W. The impact of pricing schemes on cloud computing and distributed systems. J. Knowl. Learn. Sci. Technol. 2024, 3, 193–205. [Google Scholar] [CrossRef]
- Shang, F.; Zhao, F.; Zhang, M.; Sun, J.; Shi, J. Personalized Recommendation Systems Powered By Large Language Models: Integrating Semantic Understanding and User Preferences. Int. J. Innov. Res. Eng. Manag. 2024, 11, 39–49. [Google Scholar] [CrossRef]
- Li, S.; Xu, H.; Lu, T.; Cao, G.; Zhang, X. Emerging Technologies in Finance: Revolutionizing Investment Strategies and Tax Management in the Digital Era. Manag. J. Adv. Res. 2024, 4, 35–49. [Google Scholar]
- Shi, J.; Shang, F.; Zhou, S.; et al. Applications of Quantum Machine Learning in Large-Scale E-commerce Recommendation Systems: Enhancing Efficiency and Accuracy. J. Ind. Eng. Appl. Sci. 2024, 2, 90–103. [Google Scholar]
- Wang, S.; Zheng, H.; Wen, X.; Fu, S. Distributed high-performance computing methods for accelerating deep learning training. J. Knowl. Learn. Sci. Technol. 2024, 3, 108–126. [Google Scholar] [CrossRef]
- Zhang, J.; Cao, J.; Chang, J.; Li, X.; Liu, H.; Li, Z. Research on the Application of Computer Vision Based on Deep Learning in Autonomous Driving Technology. arXiv 2024, arXiv:2406.00490. [Google Scholar]
- Zhang, M.; Yuan, B.; Li, H.; Xu, K. LLM-Cloud Complete: Leveraging Cloud Computing for Efficient Large Language Model-based Code Completion. J. Artif. Intell. Gen. Sci. (JAIGS) 2024, 5, 295–326. [Google Scholar] [CrossRef]
- Lei, H.; Wang, B.; Shui, Z.; Yang, P.; Liang, P. Automated Lane Change Behavior Prediction and Environmental Perception Based on SLAM Technology. arXiv 2024, arXiv:2404.04492. [Google Scholar] [CrossRef]
- Wang, B.; Zheng, H.; Qian, K.; Zhan, X.; Wang, J. Edge computing and AI-driven intelligent traffic monitoring and optimization. Appl. Comput. Eng. 2024, 77, 225–230. [Google Scholar] [CrossRef]
- Xu, Y.; Liu, Y.; Xu, H.; Tan, H. AI-Driven UX/UI Design: Empirical Research and Applications in FinTech. Int. J. Innov. Res. Comput. Sci. Technol. 2024, 12, 99–109. [Google Scholar] [CrossRef]
- Liu, Y.; Xu, Y.; Song, R. Transforming User Experience (UX) through Artificial Intelligence (AI) in interactive media design. Eng. Sci. Technol. J. 2024, 5, 2273–2283. [Google Scholar]
- Li, H.; Wang, S.X.; Shang, F.; Niu, K.; Song, R. Applications of Large Language Models in Cloud Computing: An Empirical Study Using Real-world Data. Int. J. Innov. Res. Comput. Sci. Technol. 2024, 12, 59–69. [Google Scholar] [CrossRef]
- Ping, G.; Wang, S.X.; Zhao, F.; Wang, Z.; Zhang, X. Blockchain Based Reverse Logistics Data Tracking: An Innovative Approach to Enhance E-Waste Recycling Efficiency. 2024.
- Xu, H.; Niu, K.; Lu, T.; Li, S. Leveraging artificial intelligence for enhanced risk management in financial services: Current applications and future prospects. Eng. Sci. Technol. J. 2024, 5, 2402–2426. [Google Scholar]
- Li, J.; Wang, Y.; Xu, C.; Liu, S.; Dai, J.; Lan, K. Bioplastic derived from corn stover: Life cycle assessment and artificial intelligence-based analysis of uncertainty and variability. Sci. Total Environ. 2024, 174349. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Shang, F.; Xu, Z.; Zhou, S. Emotion-Driven Deep Learning Recommendation Systems: Mining Preferences from User Reviews and Predicting Scores. J. Artif. Intell. Dev. 2024, 3, 40–46. [Google Scholar]
- Xiao, J.; Wang, J.; Bao, W.; Deng, T.; Bi, S. Application progress of natural language processing technology in financial research. Financ. Eng. Risk Manag. 2024, 7, 155–161. [Google Scholar]
- Wang, S.; Xu, K.; Ling, Z. Deep Learning-Based Chip Power Prediction and Optimization: An Intelligent EDA Approach. Int. J. Innov. Res. Comput. Sci. Technol. 2024, 12, 77–87. [Google Scholar] [CrossRef]
- Ping, G.; Zhu, M.; Ling, Z.; Niu, K. Research on Optimizing Logistics Transportation Routes Using AI Large Models. Appl. Sci. Eng. J. Adv. Res. 2024, 3, 14–27. [Google Scholar]
- Shang, F.; Shi, J.; Shi, Y.; Zhou, S. Enhancing E-Commerce Recommendation Systems with Deep Learning-based Sentiment Analysis of User Reviews. Int. J. Eng. Manag. Res. 2024, 14, 19–34. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



