
Submitted:
26 September 2024
Posted:
27 September 2024
You are already at the latest version
Abstract
A basic limitation of the periodogram as frequency estimator is that any of its significant peaks may be produced by a diffuse (or spread) frequency component instead of a pure one. Diffuse components are common in applications such as channel estimation in which a given periodogram peak reveals the presence of a complex multipath distribution (unresolvable propagation paths or diffuse scattering, for example). We present a method to detect the presence of a diffuse component in a given peak based on analyzing the projection of the data vector onto the span of the signature’s derivatives up to a given order. Fundamentally, a diffuse component is detected if the energy in the derivatives’ subspace is too high at the peak’s frequency, and its spread is estimated as the ratio between this last energy and the peak’s energy. The method is based on exploiting the signature’s Vandermonde structure through the properties of discrete Chebyshev polynomials. We also present an efficient numerical procedure for computing the data component in the derivatives’ span based on barycentric interpolation. The paper contains a numerical assessment of the proposed estimator and detector.
Keywords:
Periodogram
; beamformer
; Maximum Likelihood estimation
; diffuse components
; discrete Chebyshev polynomials
; frequency estimation
; channel estimation
1. Introduction
The periodogram of a finite data sequence consists of the square absolute value of its Discrete-Time Fourier Transform (DTFT) and is one of the most versatile tools in Signal Processing. Just to recall a few of its uses, it is a well-known power spectral-density estimator and the basis of more elaborate estimators of the same type [1], (Ch.6). It allows one to implement the Maximum Likelihood (ML) estimator of a single frequency and a good quality estimator for multiple well-separated frequencies [2], (Sec.13.3.2), [3,4]. Besides, it is also applicable to delays and angles of arrivals, given that these parameter types can be turned into frequencies either by means of the Fourier transform or by exploiting a uniform and linear array geometry respectively [5,6]. Finally, it also provides channel impulse-response estimates [7,8].
The periodogram can be efficiently sampled using the Fast Fourier Transform (FFT), a fact that seems to be the main factor behind its popularity. Actually, this sampling just involves operations, where N is the data sequence length. There exists an extensive literature on methods for estimating multiple frequencies that complement this FFT sampling with other operations such as the computation of additional DTFT samples or the evaluation of interpolators, [9,10,11,12,13,14,15,16,17]. These additional operations have complexity where K is the number of frequency estimates, except for the method in [12,15] in which their complexity is ; (see also [18] for the interpolation method used in these last references).
In most cases, frequency estimation using the periodogram is done assuming well-separated pure components, i.e, the data is assumed to consist of as sum of components in white noise. However, in channel estimation, this assumption is often inadequate, given that physical phenomena such as reflections on rough surfaces or multiple closely-spaced specular reflections produce diffuse or spread components that appear as a single peak in the periodogram [8,19,20,21,22]. Intuitively, we may expect the shape of a given periodogram peak to reveal, in some way, whether it is produced by a diffuse or a pure component. In this paper, we specify this intuition by presenting a method to detect whether a given periodogram peak is diffuse and to estimate its “spreadness”, i.e, the degree to which it is diffuse. The method is based on analyzing the subspace spanned by the signature’s derivatives (up to a given order) at the peak’s frequency.
The paper has been organized as follows. In the next section, we present the signal models for a pure and a diffuse component, the periodogram function, and sketch the proposed method for detection and estimation of diffuse components. Then, in Section 3, we derive the Gram-Schmidt basis associated with the frequency signature and its derivatives which is the main analytical tool in subsequent sections. After that, we obtain the statistical distribution of the projection of the data vector onto the span of the signature’s derivatives in Section 4, and we present the proposed estimator and detector in Section 5. Section 6 is dedicated to an efficient computation method for the correlation samples required by the method which is based on barycentric interpolation. Finally, we assess the proposed detector and estimator in Section 7 numerically.
1.1. Notation
The notation is the paper is the following:
- We denote column vectors in bold and lower case (, ).
- denotes the identity matrix.
- denotes the nth component of vector .
- and are the transpose and Hermitian of vector respectively.
- New symbols or functions are introduced using the symbol “≡”.
- is the discrete Dirac delta, i.e, and for integer .
- denotes a column vector of zeroes whose length can be determined from the context.
- For a function , denotes the total derivative of at the value , i.e, is the best linear approximation to at .
2. Signal Models for a Pure and a Diffuse Component. Sketch of the Proposed Method
Consider a data vector consisting of a single undamped exponential of frequency in noise,
where
is a complex amplitude, and an complex zero-mean circularly-symmetric white noise vector of variance . The Deterministic Maximum Likelihood (DML) estimate of in (1) is the abscissa at which the global maximum of the periodogram function
is attained, that is,
(See [3], (Sec3.B)). This frequency estimator is popular due to its statistical efficiency and because it can be efficiently computed through an FFT algorithm followed by a numerical method; [9,15].
(1) is often a simplified model for a situation in which there is actually some frequency spread along a short band . For instance, in channel sounding, the periodogram’s peak may be produced by an imperfect specular reflection, i.e, a reflection on an irregular surface, and a more realistic model would be
for a function . Here, is completely unknown and hardly estimable in practice. It can be, for example, a sum of components, i.e,
for complex coefficients and frequencies , ; a continuous function in ; or any distribution we can think of in .
Assume now that the periodogram has a significant peak at frequency for which both (1) and (5) seem plausible. The question is whether there is a detector that allows us to select either (1) or (5). In this detector, (1) would be hypothesis H0 and (5) hypothesis H1. To sketch a possible detector, consider (1) and (5) without noise (). In this case, the periodogram estimate is exact assuming (1), that is , and lies in the span of given that
However, assuming (5), turns out to be a frequency in and fails to lie in the span of . But since is short, a truncated Taylor expansion of small order P such as
is accurate in and, therefore, approximately lies in the span of , , given that
Thus, if we decompose in two components
where lies in the span of and lies in the orthogonal complement of relative to the span of , then we have that a diffuse component can be detected by a non-zero vector .
In order to carry over this idea to the noisy case (), we would need to find out the statistical distribution of under model (1), and then select a threshold such that implies that model (1) must be discarded and (5) accepted with a given false-alarm probability . We can simplify this task significantly if we start by describing the span of in terms of a Gram-Schmidt basis. More precisely, let , , denote a set of signatures such that
- ; , .
- has the same span as for , P.
In terms of this basis, can be written as
and the test’s inequality would be
We carry out this plan in the next three sections:
Finally, regarding the case of a periodogram with significant peaks, it is straight-forward that (1) and (5) can be extended to the models
and
where are separate frequencies and disjoint intervals containing the diffuse components, . The argument just presented for (5) is applicable to any of the K periodogram peaks, say the kth, if its corresponding interval is sufficiently separated from the other peaks’ intervals. However, if the separation with, say, component is small then there can be a significant contribution of component to the orthogonal component of the kth peak. We do not discuss this more complex case in this paper though we can envisage two possible strategies for dealing with it: we can increase the threshold in (12) in terms of the separation between and any adjacent peak interval, or we can apply some kind of windowing in order to select just one periodogram peak. This second possibility appears naturally in the proposed method as shown in Section 3.3.
3. Gram-Schmidt Basis of the Span of the Signature and Its Derivatives
In the sequel, we present the Gram-Schmidt basis in three separate sub-sections. In the first, we define it in terms of the so-called discrete Chebyshev polynomials. Then, in Section 3.2, we derive a key property of this basis, namely, the fact that the derivative of any belongs to the span of three consecutive signatures at most. This property is fundamental in the results presented in Section 4. Finally, we show in Section 3.3 that we can select or “filter” the signatures with frequencies inside a range of variable length by truncating the basis. This feature is useful given that it allows us to employ the model in (5) for one diffuse peak even if there are several significant periodogram peaks.
3.1. Definition of the Gram-Schmidt Basis in Terms of Discrete Chebyshev Polynomials
In order to derive the ortho-normal basis , , , consider the following formula for the derivatives of ,
where is the Vandermonde vector
In (15), since is a constant and a unitary transformation, we have that any ortho-normal basis , , of the span of , , produces an ortho-normal basis of the span of given by the signatures
A basis , , can be obtained through the Gram-Schmidt process and, besides, its vectors can be expressed in closed form if they are related with the so-called discrete Chebyshev polynomials [24], (p.58).
Let denote the set of real polynomials of order at most equipped with the inner product
Given a polynomial , the sampling operator defined by
assigns to z its vector of samples at . Besides, has an inverse which is the interpolation operator that assigns to any vector the unique polynomial such that , . It can be readily checked that is an isomorphism mapping onto . This implies that the problem of ortho-normalizing is equivalent to that of ortho-normalizing the image of these vectors in which is the set of monomials , . The discrete Chebyshev polynomials provide an orthogonal basis for this last set for any P. Specifically, the p-th order polynomial of this kind is defined by the recurrence
If the first polynomials form an orthogonal basis of the span of , . Thus, if we define from them a normalized set of polynomials given by
where for any it is , we have that the polynomials form an ortho-normal basis of the span of , . Besides, has order p, i.e, there is a set of coefficients such that
3.2. Three-Term Relationship for Basis Signature Derivatives
Let us take (27) as the definition of the ortho-normal basis of the span of , , . This basis has a property, stemming from the three-term recurrence formula (20), that is key in the next sections. The property is that the derivative of any of the basis vectors lies in the span of at most the three signatures , and , (excluding if and if ). Specifically, since the set , forms an ortho-normal basis of , can be expressed in this last basis using a set of coefficients , i.e, it is
We prove in Appendix A that the coefficients are real, constant in f, and equal to zero if . Besides, the non-zero coefficients are symmetric in p and q, i.e, , and given by
This result allows us to write as
3.3. Selection of a Frequency Range Using Basis Signatures
For a given truncation index P, the span of is the same as the span of . Besides, given a frequency increment , the signature can be approximated by the Pth-order truncated Taylor expansion of at , i.e,
and the accuracy of this formula increases with P. These facts imply that projecting onto the span of acts as a filter that selects a range around frequency f, i.e, we have that the approximation
is accurate in a range whose length increases with P. Besides, if we exclude in (32) then the projection selects a punctured range with a null at frequency f. To test this filtering effect numerically, let denote the energy of the projection of onto the span of . can be readily expressed in terms of the real vectors in (17):
Figure 1 shows for several values of P and . Note that has a null at , i.e, the projection cancels but, if , it keeps most of the energy of for between, roughly, and a higher value of that increases with P. For example, this higher value is, roughly, for and for . We can see that we can reduce the energy of for significant values of by selecting a small P. This filtering effect is useful whenever the periodogram has several peaks of significant amplitude, given that it allows us to separate them by employing a small P, i.e, it allows us to process each of them as if it were the only significant peak in the periodogram.
4. Statistical Distribution of Correlations with Ortho-Normal Signatures
Consider the single-frequency model in (1) and the corresponding periodogram estimator in (4). Since is the frequency at which attains a maximum, it follows that
Computing this differential from (3), noting that , we have that fulfills the implicit equation
In (1), if we view and as fixed values and as a vector of free parameters, we have that is a function of ,
and the same occurs to functions of such as the periodogram estimate and the correlations
Besides, these functions have known values at , namely, , , and , . In Appendix B, we derive the first-order Taylor expansions of and of the correlations for but in the phase-corrected form given by
where
If we define , the resulting expansions are the following:
For the model in (1), these expansions imply the following approximate distributions:
-
is a real Gaussian variable of mean and varianceNote that this variance is equal to the Cramer-Rao (CR) bound for single-frequency estimation; (see Eq. (17) in [3]).
- The correlations , , are statistically independent.
- is a real Gaussian variable of zero mean and variance .
- , , is a complex circularly-symmetric Gaussian variable of zero mean and variance .
5. Detection of a Diffuse Component. Spread Factor
The data vector can be written in terms of the correlations as
where, for short, we write and as and respectively. We consider that the first summation may be affected by a diffuse signal component while the second is mostly produced by noise. The choice of P depends on the assumptions on the frequency distribution in (5) and also on the filtering effect discussed in Section 3.3. The detection task consists of deciding between the single component model in (1) (H0 hypothesis) and the diffuse component model in (5) (H1 hypothesis). Under H0, the distribution of the correlations , is that derived in the previous section and from it we can deduce that the sum
follows a Chi-Square distribution of order . Besides, we can determine a threshold for which the condition
implies the presence of a signal component for a given false-alarm probability . Finally, if H1 is accepted then a measure of the “diffuseness” of the periodogram peak is the ratio between the estimated signal components energies in the spans of and , i.e,
We call the spread factor. Additionally, we define if H1 is rejected.
6. Computation of Correlations from DFT Samples
The periodogram estimate and the proposed detector and estimator require in their computation the value of one or more correlations of either the form or at arbitrary frequencies f. These correlations involve summations with a large number of summands N, namely,
for , P. Thus, we may expect a large computational burden if the summations in either (48) or (49) are directly evaluated for any p, . However, the fact is that all the correlations in (48)-(49) can be obtained with small complexity from just of a few of the DFT samples in (13). Actually, as we show in the sequel, it is possible to obtain them from samples of the DFT using a so-called barycentric interpolator [18], where is an integer that controls the interpolation accuracy. Specifically, the interpolation error decreases exponentially with Q and, in practice, a small Q is sufficient; (typically, Q ranges from 3 to 6.) The method for doing this is based on the following ideas:
1) Note that the correlations can be computed from the correlations due to (27), i.e,
So, it is only necessary to compute the correlations of the first type , , P.
2) The initial correlation can be written as
where
Additionally, any derivative can be obtained form the derivatives of of orders 0 to P through Leibnitz’s formula for the pth derivative of a product; i.e, the pth order derivative of (51) is
Therefore, the computation of the correlations can be reduced to the computation of the derivatives for arbitrary u and .
3) is a band-limited signal in u of two-sided bandwidth and, as a consequence, it can be computed from its samples with spacing 1 using the sinc series. More precisely, let n and v be defined by the modulo-1 decomposition of u given by
The sinc series in v for the signal is
Note that is equal to which is one of the DFT samples in (13). Therefore, all the samples appearing in (54) are already available.
4) Since there is oversampling in (54), this series is also valid for a product where is a fixed signal whose two-sided bandwidth is below the limit . So we have
Now, if where is a fixed pulse whose tails are negligible outside the v range for a given truncation index Q, then we may truncate (55) at and extract the function implicit in , i.e,
Additionally, (55) and (56) also hold if is replaced by 1 (which has zero bandwidth). So, we also have the approximation
Dividing (56) by (57), we obtain an approximation for ,
This is a so-called barycentric interpolation formula and we can readily see that it only involves arithmetic operations, given that the values are constant in u and can be pre-computed. Besides, (58) can be extremely accurate, as shown in [18], for a proper choice of . Actually, for Knab’s pulse [25] given by
the error in (58) is bounded by
where A is the maximum of for u in . Note that this last bound implies that the error decreases as and, therefore, a small Q ensures high accuracy. Besides, the derivative of (58) up to any order can be computed using the Horner-like scheme described in [18], (Sec.IV). The complexity of obtaining for is , i.e, independent of the correlation length N.
From these ideas, we can readily deduce a method to interpolate (48)-(49) consisting of the following steps:
7. Numerical Assessment
We consider the periodogram with and scenarios of one of the following two types:
- Type 1. Scenario with two frequency components of unequal power. Its distribution in (5) iswhere and .
- Type 2. Scenario with main frequency and a diffuse component. Its distribution iswhere the summation models the diffuse component and lie in a range , .
For both types, the power of the second component is set 5 dB below that of the first component. The signal-to-noise ratio (SNR) is defined as the ratio between the first component’s power and . In scenarios in which the SNR is not variable it is set to 0 dB.
The specific scenarios in the numerical assessment are the following:
- Delta. Type-1 scenario with , , and uniformly distributed in .
- Delta-. The same as Delta but viewing the phase of relative to as a variable .
- Delta-. The same as Delta but with variable .
- Diffuse. Type-2 scenario with and amplitudes, phases, and frequencies in summation following uniform distributions in , , and respectively.
- Diffuse-. The same as Diffuse but with variable .
We consider the following two detectors:
- Secondary peak (SP). The second signal component is detected if the residual periodogram given byhas a peak above a detection threshold with false-alarm probability.
- Proposed (Prop-). Detector in Section 5 with a given truncation order P and 0.05 false-alarm probability.
7.1. Performance Versus Signal-To-Noise Ratio
Figure 2 and Figure 3 shows the detection probability versus the SNR in the Delta and Diffuse scenarios respectively. In both figures, Prop-2 to Prop-7 have similar performance and outperform SP by, roughly, 6 dB in SNR. Prop-1 has a intermediate performance between that of SP and Prop-2 to Prop-7.
In order to assess the behavior of Prop-1, Figure 4 shows the detection probability of Prop-1 versus the relative phase in Delta-. Note that the detection performance of Prop-1 drops at , i.e, Prop-1 is unable to detect the second component for these phases. This seems to be a consequence of the fact that is real.
7.2. Detection Performance Versus Frequency Spread
Figure 5 and Figure 6 show the detection probability in the Delta- and Diffuse- scenarios versus . Note that Prop-1 fails in Delta-2 scenario at . This is due to the zero at that position in , (Figure 1). However, this is not an issue if given that then has no nulls for . The null in seems to be the cause for the sub-optimal detection probability in Diffuse- for high .
7.3. Spread Factor
8. Conclusions
We have presented a detector for a diffuse component in any periodogram peak of significant amplitude and an estimator of the spread of such component. Basically, the detector tests whether the power in the span of a number of the signature’s derivatives is too high for a noise realization, where the derivatives are evaluated at the peak’s frequency. Then, the “spreadness” of the diffuse component is estimated through the so-called spread factor which is the ratio between the estimated signal power in the span of the signature and the estimated signal power in the derivatives’ span. Both the detector and the estimator exploit the Vandermonde structure of the frequency signature through the properties of discrete Chebyshev polynomials. We have assessed their performance numerically.
Appendix A. Proof of (29)
Define the diagonal matrix , . and let the subscript denote multiplication by n on any polynomial , i.e, .
Recalling (17), we have that can be written as
Next, left multiply (28) by and use (17), the last formula, and (21):
So we have that is a real constant . can be directly computed using the inner product definition in (18). The result is
Next, to determine the rest of coefficients , let us write the last inner product in (A2) in terms of the recurrence formula in (20). If we replace p with in (20) and then solve for , we obtain, after some operations,
And forming the inner product with , we obtain
We may derive from this formula several results. First, it is if . Second, taking and substituting the result into (A2), we obtain
Third, note that we may exchange p and q in given that
Therefore, for any . And fourth, exchange p and q on the right-hand side of (A5) and then write any expression multiplying a Dirac delta in terms of q only:
Equating the coefficient of in (A5) and (A8), we obtain
which can be written as
So, from (A2), (A5) and (A10) with , we have
Appendix B. Perturbation Analysis of the Periodogram Estimator
To simplify the derivations in this appendix, we let y denote any of the real or imaginary parts of the components of , i.e, the parts
In the sub-sections that follow, we first compute the derivatives in y and then identify y with each of the parts in (A12) in order to obtain total derivatives. We additionally adopt the following simplified notation:
- , and denote , and respectively.
- stands for .
- The subscript “y” stands for the derivative in y.
- Sub-script “0” denotes evaluation at ; for example is the derivative in y of at .
Appendix B.1. Total Derivative of Periodogram Estimate (ϵ)
Substituting the first formula in (30) into (35), taking into account that and are real and , we have
Let us differentiate this equation in y. We have
Next, let us set . Then, , , , and . So we have
And solving for , we obtain
This expression is linear in the parts specified in (A12) and, therefore, identifying y with each of them, we obtain the total derivative of at ,
This formula directly gives (40).
Appendix B.2. Total Derivatives of Correlations (ϵ)
References
- Percival, D.B.; Walden, A.T. Spectral analysis for univariate time series; Cambridge University Press, 2020; Vol. 51. [Google Scholar]
- Kay, S.M. Modern spectral estimation, 1st ed.; Signal Processing, Prentice Hall, 1988. [Google Scholar]
- Rife, D.; Boorstyn, R. Single tone parameter estimation from discrete-time observations. IEEE Transactions on Information Theory 1974, 20, 591–598. [Google Scholar] [CrossRef]
- Rife, D.C.; Boorstyn, R.R. Multiple tone parameter estimation from discrete-time observations. Bell System Technical Journal 1976, 55, 1389–1410. [Google Scholar] [CrossRef]
- Selva, J. Interpolation of bounded band-limited signals and applications. IEEE Transactions on Signal Processing 2006, 54, 4244–4260. [Google Scholar] [CrossRef]
- Selva, J. An efficient Newton-type method for the computation of ML estimators in a Uniform Linear Array. IEEE Transactions on Signal Processing 2005, 53, 2036–2045. [Google Scholar] [CrossRef]
- Molisch, A.F.; Tufvesson, F.; Karedal, J.; Mecklenbrauker, C.F. A survey on vehicle-to-vehicle propagation channels. IEEE Wireless Communications 2009, 16, 12–22. [Google Scholar] [CrossRef]
- Richter, A. Estimation of Radio Channel Parameters: Models and Algorithms. Faculty for Electrical Engineering and Information Technology, University of Ilmenau, 2005. [Google Scholar]
- Quinn, B.G. Estimating Frequency by Interpolation Using Fourier Coefficients. IEEE Transactions on Signal Processing 1994, 42, 1264–1268. [Google Scholar] [CrossRef]
- Mcleod, M. Fast Nearly ML Estimation of the Parameters of Real or Complex Single Tones or Resolved Multiple Tones. IEEE Transactions on Signal Processing 1998, 46, 141–148. [Google Scholar] [CrossRef]
- Aboutanios, E.; Mulgrew, B. Iterative Frequency Estimation by Interpolation on Fourier Coefficients. IEEE Transactions on Signal Processing 2005, 53, 1237–1242. [Google Scholar] [CrossRef]
- Selva, J. Efficient maximum likelihood estimation of a 2-D complex sinusoidal based on barycentric interpolation. International Conference on Acoustics Speech, and Signal Processing, 2011, pp. 4212–4215.
- Candan, C. A method for fine resolution frequency estimation from three DFT samples. IEEE Signal processing letters 2011, 18, 351–354. [Google Scholar] [CrossRef]
- Orguner, U.; Candan, Ç. A fine-resolution frequency estimator using an arbitrary number of DFT coefficients. Signal processing 2014, 105, 17–21. [Google Scholar] [CrossRef]
- Selva, J. ML Estimation and Detection of Multiple Frequencies Through Periodogram Estimate Refinement. IEEE Signal Processing Letters 2017, 24, 249–253. [Google Scholar] [CrossRef]
- Serbes, A. Fast and Efficient Estimation of Frequencies. IEEE Transactions on Communications 2021, 69, 4054–4066. [Google Scholar] [CrossRef]
- D’Amico, A.A.; Morelli, M.; Moretti, M. Frequency estimation by interpolation of two Fourier coefficients: Cramér-Rao bound and maximum likelihood solution. IEEE Transactions on Communications 2022, 70, 6819–6831. [Google Scholar] [CrossRef]
- Selva, J. Design of Barycentric Interpolators for Uniform and Nonuniform Sampling Grids. IEEE Transactions on Signal Processing 2010, 58, 1618–1627. [Google Scholar] [CrossRef]
- Fleury, B. First- and second-order characterization of direction dispersion and space selectivity in the radio channel. IEEE Transactions on Information Theory 2000, 46, 2027–2044. [Google Scholar] [CrossRef]
- Akdeniz, M.R.; Liu, Y.; Samimi, M.K.; Sun, S.; Rangan, S.; Rappaport, T.S.; Erkip, E. Millimeter Wave Channel Modeling and Cellular Capacity Evaluation. IEEE Journal on Selected Areas in Communications 2014, 32, 1164–1179. [Google Scholar] [CrossRef]
- Wang, Q.; Yuan, X.; Xu, C.; Wang, X. A Bayesian Approach to Communication-Driven SLAM Based on Diffuse Reflection Model. IEEE Wireless Communications Letters 2023, 12, 1279–1283. [Google Scholar] [CrossRef]
- Wen, F.; Wymeersch, H. 5G Synchronization, Positioning, and Mapping From Diffuse Multipath. IEEE Wireless Communications Letters 2021, 10, 43–47. [Google Scholar] [CrossRef]
- Szego, G. Orthogonal polynomials; American Mathematical Society, 1939; Vol. 23. [Google Scholar]
- Hirvensalo, M. Studies on Boolean functions related to Quantum Computing; Citeseer, 2003. [Google Scholar]
- Knab, J.J. Interpolation of band-limited functions using the Approximate Prolate series. IEEE Transactions on Information Theory 1979, IT-25, 717–720. [Google Scholar] [CrossRef]
Figure 1.
FF1 Magnitude of the component of signature in the span of as defined in (32).
Figure 1.
FF1 Magnitude of the component of signature in the span of as defined in (32).

Figure 2.
FF2 Detection probability in Delta-2 scenario versus SNR for the SP and Prop-1 to Prop-7 detectors.
Figure 2.
FF2 Detection probability in Delta-2 scenario versus SNR for the SP and Prop-1 to Prop-7 detectors.
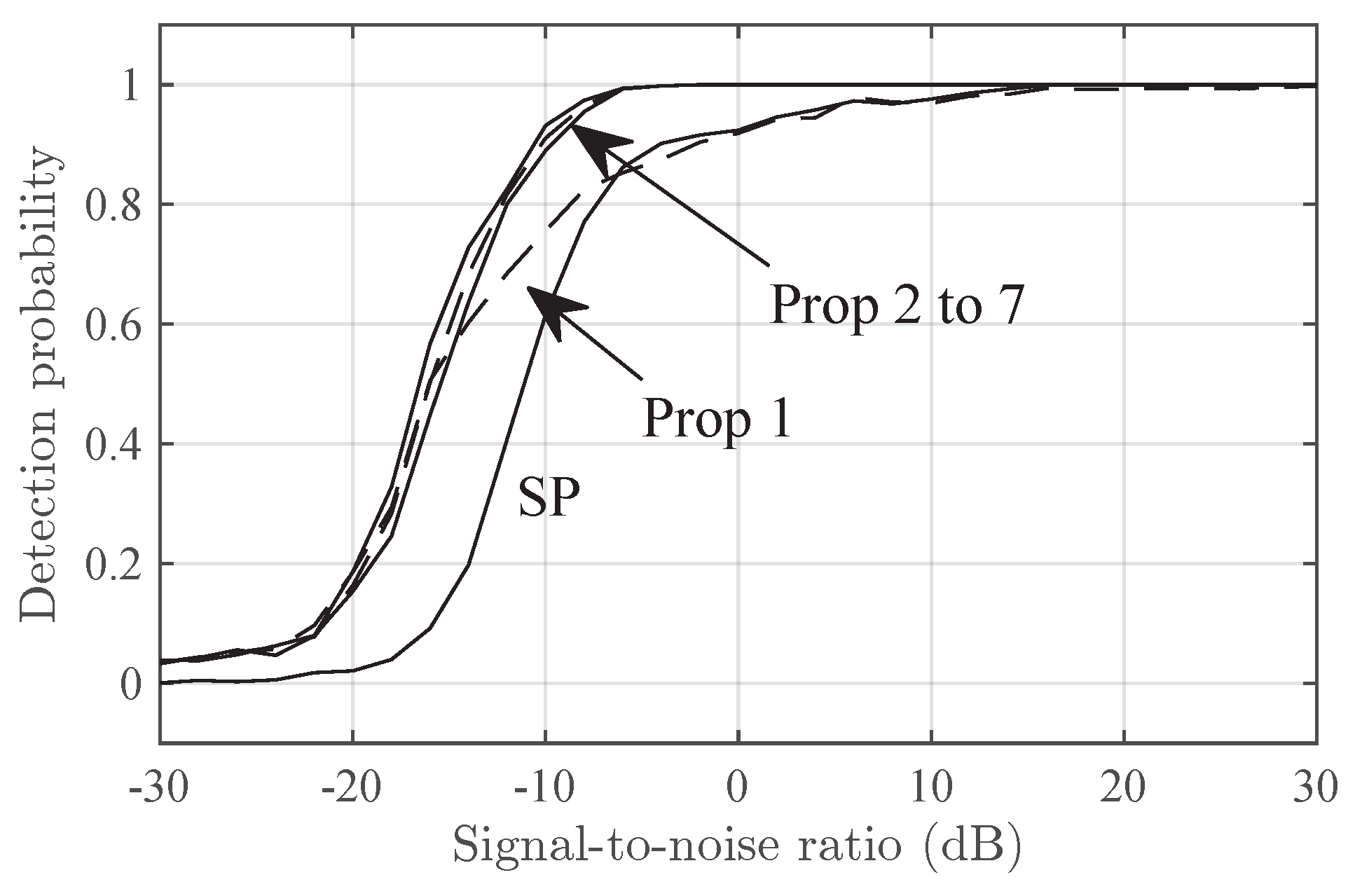
Figure 3.
FF3 Detection probability in Diffuse-2 scenario versus SNR for the SP and Prop-1 to Prop-7 detectors.
Figure 3.
FF3 Detection probability in Diffuse-2 scenario versus SNR for the SP and Prop-1 to Prop-7 detectors.
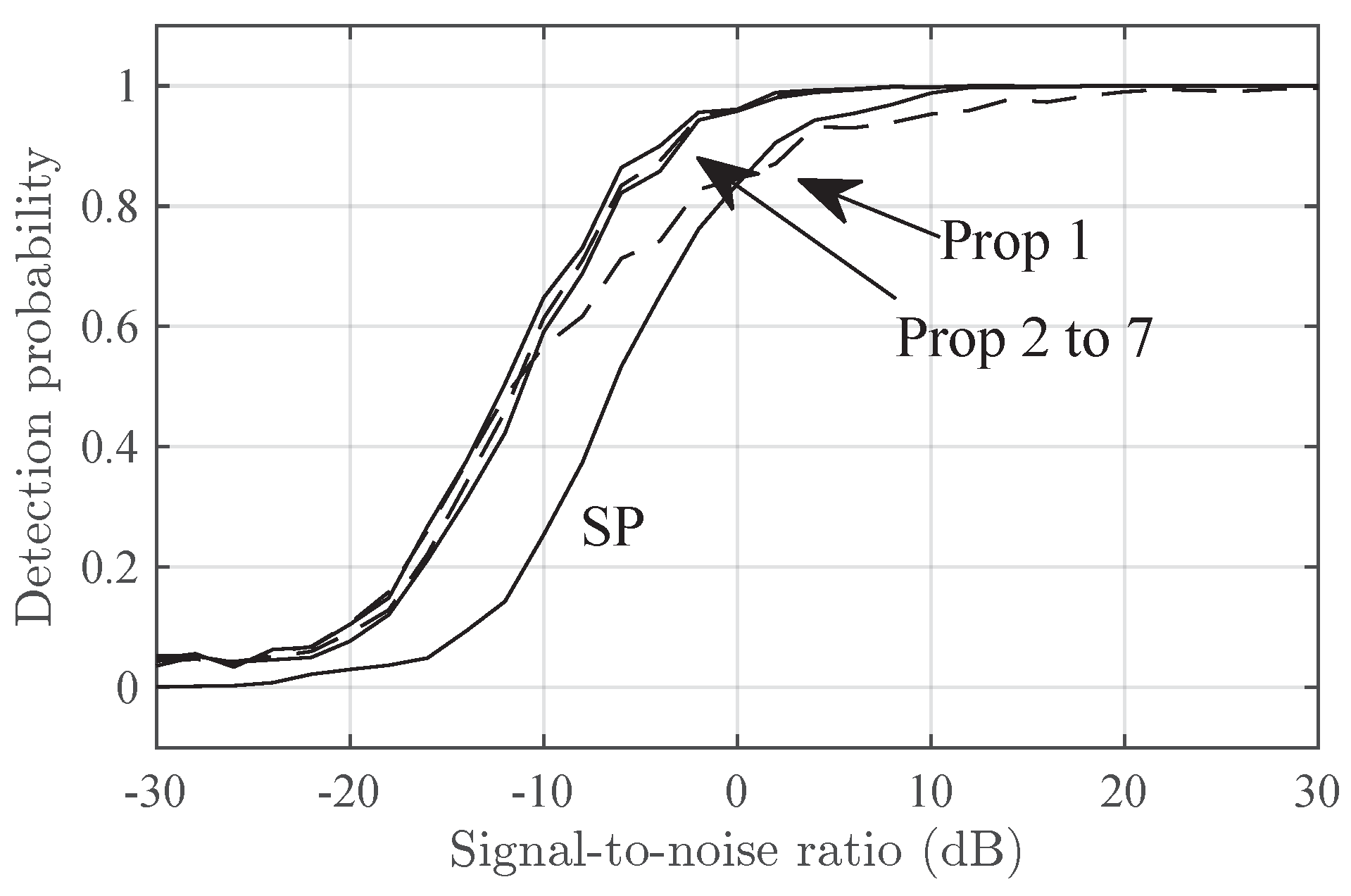
Figure 4.
FF13 Detection probability of Prop-1 detector in the Delta- scenario versus the relative phase .
Figure 4.
FF13 Detection probability of Prop-1 detector in the Delta- scenario versus the relative phase .
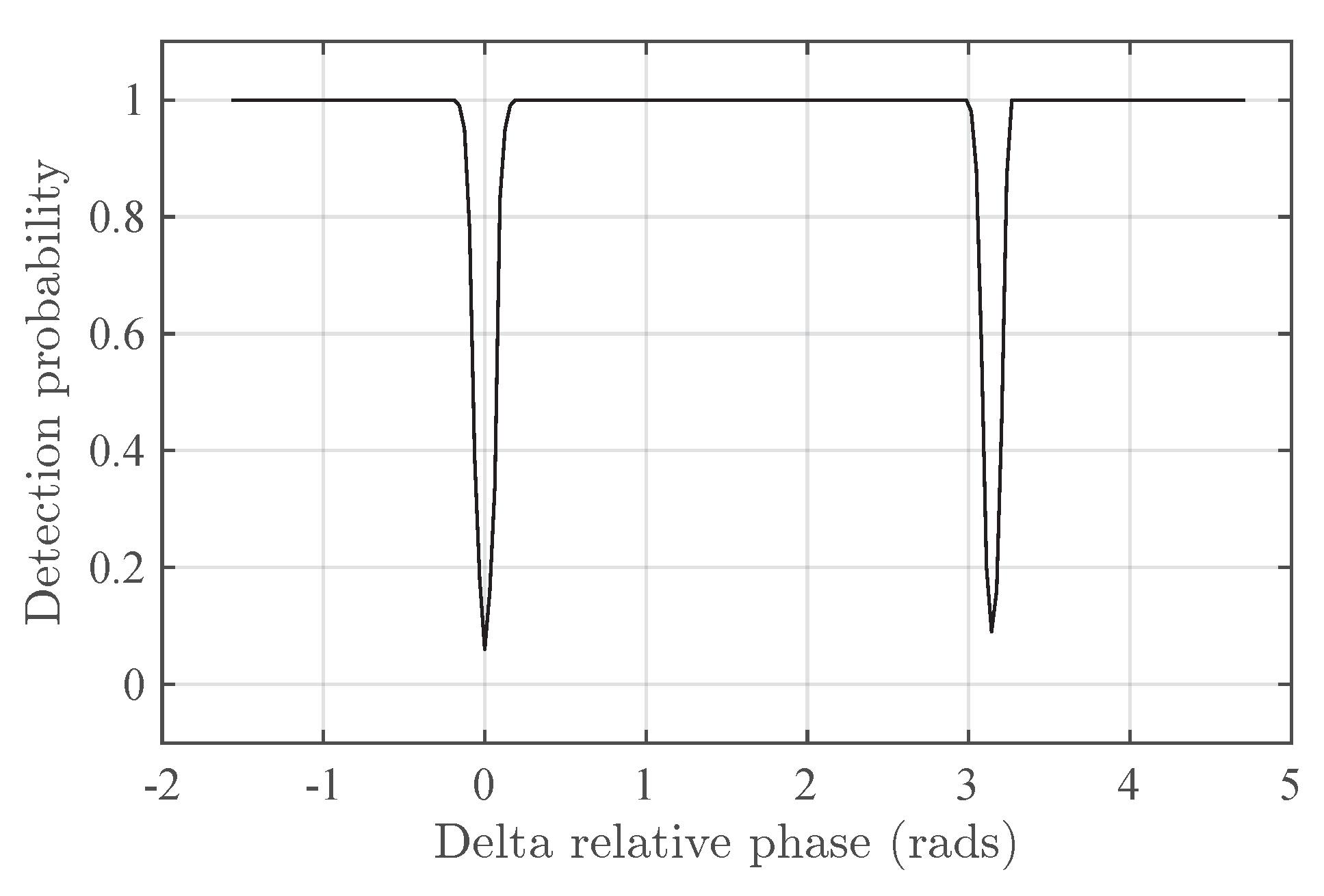
Figure 5.
FF8 Detection probability for the SP and Prop 1 to 7 detectors in the Delta- scenario versus .
Figure 5.
FF8 Detection probability for the SP and Prop 1 to 7 detectors in the Delta- scenario versus .
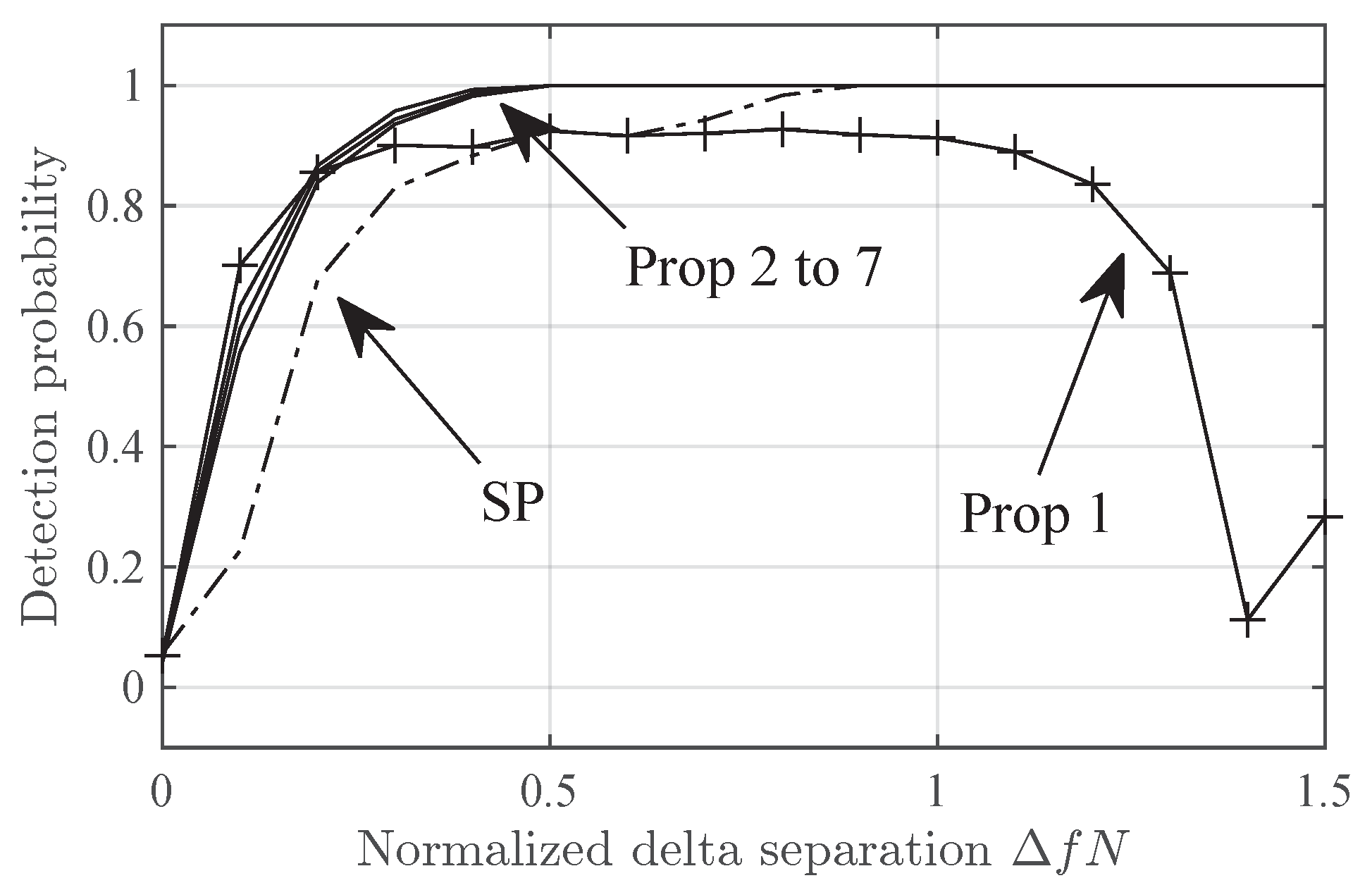
Figure 6.
FF7 Detection probability for the SP and Prop 1 to 7 detectors in the Diffuse- scenario versus the frequency separation.
Figure 6.
FF7 Detection probability for the SP and Prop 1 to 7 detectors in the Diffuse- scenario versus the frequency separation.
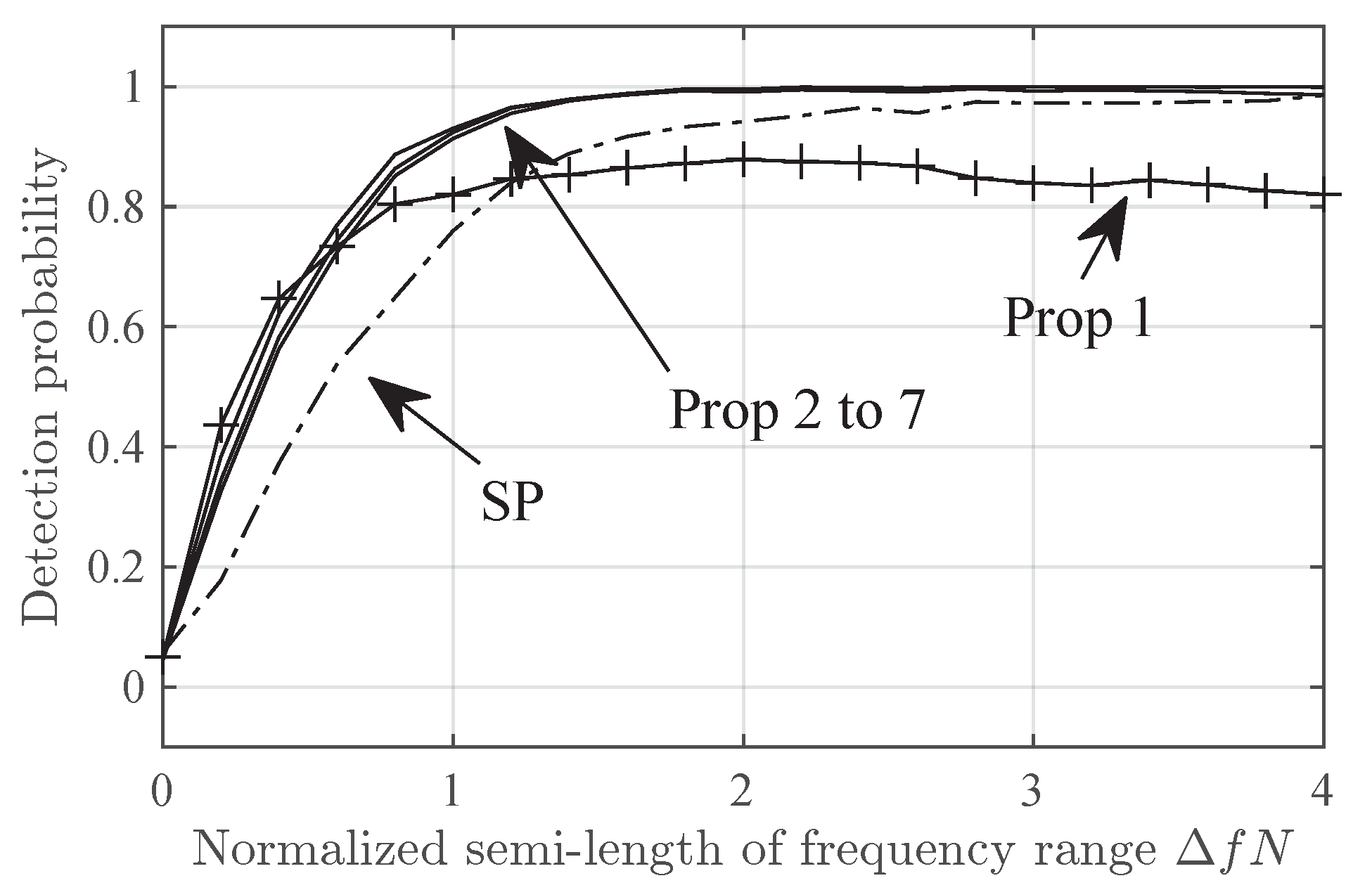
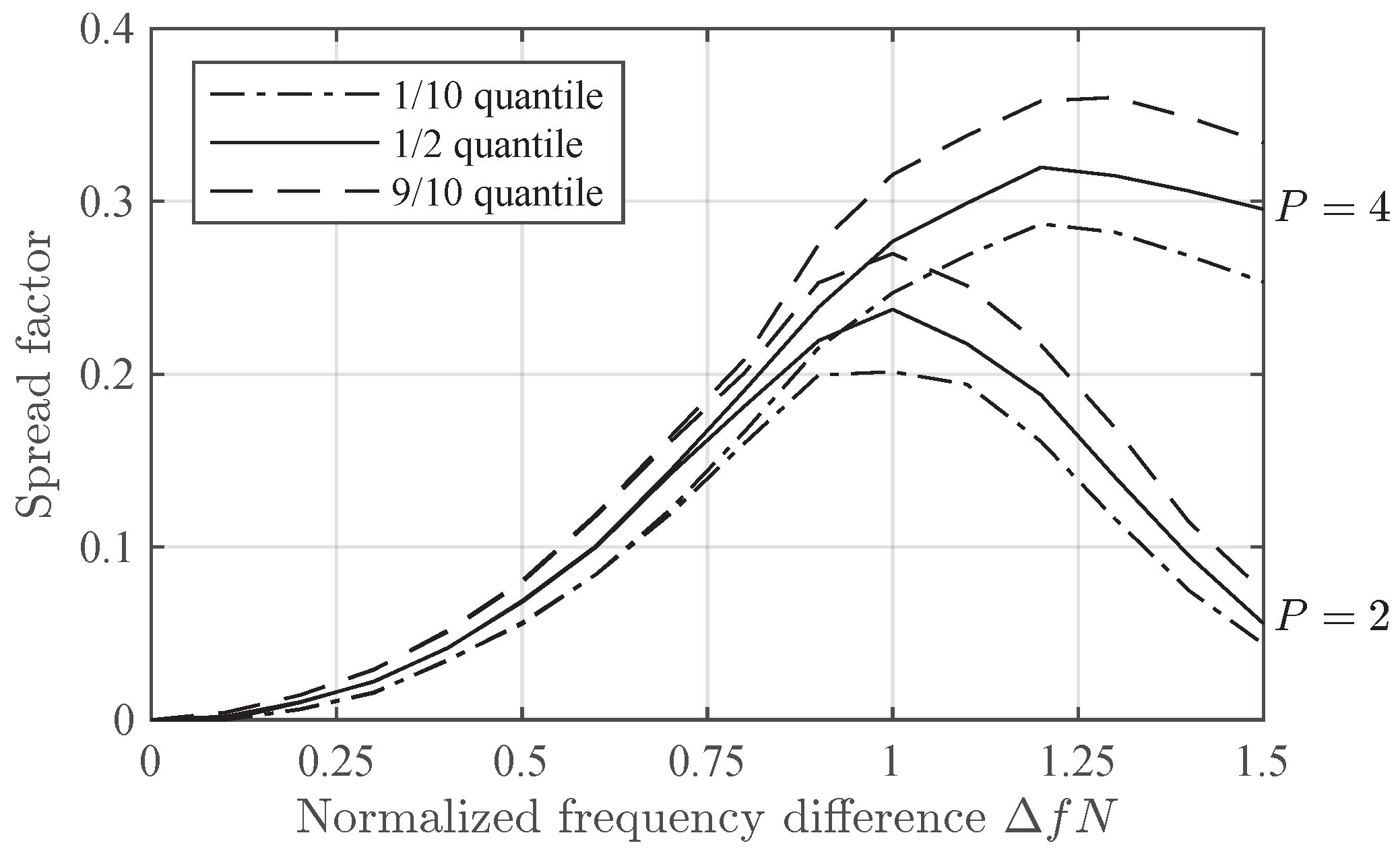
Figure 7.
FF14 Spread factor for and in Delta- scenario, expressed using the 1/10, 1/2 and 9/10 quantiles, versus .
Figure 7.
FF14 Spread factor for and in Delta- scenario, expressed using the 1/10, 1/2 and 9/10 quantiles, versus .
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



