
Submitted:
07 October 2024
Posted:
07 October 2024
You are already at the latest version
Abstract
Implementing machine learning technologies in manufacturing environment relies heavily on human expertise in terms of domain and machine learning knowledge. Yet, the required machine learning knowledge is often not available in manufacturing companies. A possible solution to overcome this competence gap and let domain experts with limited machine learning programming skills build viable applications are digital assistance systems that support the implementation. At the present, there is no comprehensive overview over corresponding assistance systems. Thus, within this study a systematic literature review was conducted. Twenty-nine papers were identified and analyzed in depth regarding machine learning use case, required resources and research outlook. Six key findings as well as requirements for future developments are derived from the investigation. As such, the existing assistance systems basically focus on technical aspects whereas the integration of the users as well as validation in industrial environments lack behind. Future assistance systems should put more emphasis on the users and integrate them both in development and validation.
Keywords:
machine learning
; systematic literature review
; manufacturing
; digital assistance systems
; work-based learning
1. Introduction and Background
Caused by latest innovations such as a strong decrease of computing times of processors as well as advances in algorithms, Machine Learning (ML) applications yield high potentials for manufacturing companies [1,2]. Yet, a survey by the World Economic Forum identifies a mismatch between AI capabilities and operational needs as well as insufficient skills at the intersection of AI and operations leading to a poor dissemination in practice [3]. Indeed, most initiated ML projects fail due to unstructured project management and a lack of prerequisites such as ML knowledge, infrastructure and data [4,5]. Despite all technical advances, implementing such applications still relies strongly on the expertise of different specialists like domain experts, software engineers and data scientists [6,7] – as well as external experts not familiar with specific processes [3]. Nevertheless, recent publications show that data scientists and their required AI expertise are missing in many companies, especially in small and medium enterprises (SMEs) [8,9,10]. Although SMEs usually have a high level of manufacturing knowledge, the lack of programming skills hinders the implementation of ML applications [9,11,12]. However, employees think in causal chains and make connections from existing knowledge and experiences [13]. The ability to abstract and transfer them to new situations underlines their importance for successful implementation of ML.
In their literature review, Aggogeri et al. [14] identify various possible applications of ML in manufacturing processes. They finally state that ML models are currently used to determine vibrations on equipment, roughness estimation and prediction, quality assurance, modeling the behavior of machine tool components and parts, and machine and tool condition monitoring. Mypati et al. [15] investigate approaches to specific production processes (casting, machining, molding, welding, etc.). They also arrive at similar use cases. In the context of assembly, ML applications are suitable for predicting overall equipment effectiveness [16], for supporting employees in identifying the right components [17] and for process planning [18]. Other production-related approaches use ML to simplify root cause analysis [19], for human-machine interaction [15], for robot control [20], to ramp up production [21] or to monitor energy consumption [22].
A large number of process models have been developed in recent years to support project management. Probably the best known is the CRISP-DM [23]. The KDD [24], SEMMA, DMME [25] and the CRISP-ML(Q) [26] have also become popular.
Beyond that, authors addressed the gap between potentials and actual distribution by developing easy-to-use software-based digital assistance systems (DAS), which assist domain experts in implementing ML applications without demanding programming knowledge. Those assistance systems exhibit the following properties [27]:
- They provide an end-to-end ML pipeline in a generic and structured way.
- They contain technical details and application scenarios and thereby allow use in arbitrary ML tasks.
- They provide performance measurements indicating the models’ performance.
Such DAS have already been developed and diffused in other domains than manufacturing. For example, Wöstmann et al. [28] created an architecture for the process industry by which data collection from several databases and the subsequent performing of machine learning tasks are simplified without having to write program code. Several models are trained and evaluated automatically. Diamantis and Iakovidis [27] developed a framework based on Deep Learning for obstacle recognition in images in several health use cases. The application simplifies the ML pipeline by pretrained models whereby coding tasks are externalized from the user. Martín et al. [29] described an architecture called Kafka-ML that manages the pipeline of ML applications through data streams. By writing few lines of source code in a graphical user interface, users can create an ML model and control the ML pipeline, create configurations to evaluate different ML models, train, validate, and deploy them. Likewise, numerous commercial systems such as KNIME [30], WEKA [31], or Orange [32] have been launched previously. Rosemeyer et al. [33] provide a detailed description of published applications of communal use, including a classification of strengths and weaknesses.
Notwithstanding their potential in supporting manufacturing managers and workers during the implementation of machine learning on the shop floor by providing a step-by-step guide and support in numerous decisions [34,35], examples of DAS are still limited. Therefore, for researchers and manufacturing managers interested in this topic and willing to increase the spread of ML applications in manufacturing, it is of paramount importance to gain an overview over software-based DAS existing in literature. However, to the best of the authors’ knowledge, no systematic review exists that parses the current state of research regarding corresponding DAS and analyzes them in depth. Hence, this publication aims to shed light over the research landscape by conducting a systematic literature review (SLR). Based on the findings, requirements for the development of future DAS are derived. This publication thereby allows researchers to easily identify research gaps in the description of existing DAS and serves as baseline for future research.
The remainder of this paper is thus structured as follows. In section 2, the research methodology including research questions, search term and investigation criteria is described in depth. The findings of the SLR are then outlined in section 3. In section 4, the findings are discussed as well as requirements for future research derived. Section 5 finally summarizes the contribution of the paper.
2. Systematic Literature Review Methodology
An SLR was considered an adequate method to provide the intended overview of the current state of research and to identify existing gaps. The guidelines proposed by Kitchenham [36] and Page et al. [37] were applied. For the sake of ensuring reliability within the SLR, all conducted steps including search term, inclusion and exclusion criteria and interim results for reaching the overview are described in the following paragraphs [38]. Given the aim of the study, a bibliometric analysis and a content analysis were performed. In terms of bibliometric analysis, publication year, region of origin of the authors, author keywords and publication medium (e.g., conference proceedings or journal) were analyzed. As for the content analysis, the ML use cases regard in existing DAS were investigated. Besides, three further research questions (RQs) were posed, which are named in the following and briefly described thereupon.
RQ1: Which ML use cases are addressed by the identified DAS?
In a first step, the ML use case addressed in the identified DAS were analyzed and thereupon classified in a previously published scheme. Thus, it was explored whether the articles take monitoring, quality prediction or anomaly detection into consideration. Following, the use cases were categorized into the classes given by Nti et al. [39].
RQ 2: To what extend are shortcomings of SMEs considered in identified DAS?
Second, it was investigated whether the shortcomings described in Section 1, namely lack of ML knowledge, lack of IT infrastructure and lack of data are targeted in the papers. In this context, it is of question, whether those hurdles as well as other prerequisites are addressed or whether observed articles solely concentrate on the infrastructure of described DAS. In order to deliver an adequate answer, the five factors for organizational artificial intelligence (AI) readiness first proposed by Pumplun et al. [40] and later outlined by Jöhnk et al. [41] and their respective sub-factors were adopted and extended with two factors proposed by Hamm and Klesel [42]. A brief explanation of each factor is presented in the following.
Strategic alignment: The factor describes the condition that the use of AI technologies is in line with the business goals of a company and that one’s customers are also prepared for product-integrated applications. Corresponding sub-categories are AI-business potentials, Customer AI readiness, Top management support, AI process fit and Data-driven decision-making.
Since the factor Strategic alignment is outside of the scope of this paper, it was dropped.
Resources: The factor comprises all resources that have to be considered when implementing AI technologies: Financial budget, AI personnel (meaning domain experts with basic understanding of AI serving as translators) and IT infrastructure.
Knowledge: The factor describes any knowledge about AI that employees in different positions need to have encompassing AI awareness (awareness of prerequisites for AI applications like high-quality data), Upskilling (upskilling of existing employees), AI ethics (adherence to ethical standards like gender bias).
Culture: The factor relates to any influence on company’s culture dealing with Innovativeness (ability to taking risky decisions), Collaborative Work (capability to collaborate in teams from several departments) and Change management (competence to deal with fears of employees).
Data: The factor encompasses all aspects that are related to data that are needed to train and test the AI application focusing on Data availability (quantity of data), Data quality (high-quality data), Data accessibility (access management to several data sources) and Data flow (pipeline to move data from source to application).
Industrial validation: This aspect investigates whether authors validate their models in real industrial validation. Optionally, they might either use an open-source data set, focus on learning factories or have no validation at all.
Target group validation: This factor focuses on a validation with the target group, e.g., manufacturing employees with decision-making competency but no deep programming knowledge.
RQ3: Which focal points for next development steps can be outlined in the publications?
Lastly, emphasis was laid on the research outlook that is presented in the articles. In order to present the results compactly, they were classified into the three categories Human, Technology and Organization by Strohm and Escher [43].
The research was conducted on the Web of Science in February 2024. The following keywords were searched in abstract, title and author keywords for finding proper publications: ((AI OR "artificial intelligence" OR ML OR "machine learning" OR "data science" OR "data analytics") AND (production OR manufacturing) AND ("digital assistan*" OR "cognitive assistan*" OR tool* OR guide*)).
In the following, a description is delivered how articles for deeper investigation were selected. An overview over inclusion and exclusion criteria is applicable in Table 1, whereas their description is delivered thereupon. Besides, the selection process according to PRISMA-P [37] is displayed in Figure 1 at the end of the description.
3. Results of the Review
Firstly, this section provides an overview over the bibliometric information of the identified articles. Subsequently, a report about the findings of the content analysis by answering the three research questions posed in section 2 is given.
3.1. Descriptive Analysis
To gain an overview over the state of the art on the subject, the publication year, continent, and country of the authors were analyzed in a first step. In case of cross-continental work, the continent of the corresponding author was considered. It is apparent, that no relevant publication was found in 2015 and 2016 and that no year-related trend is applicable (see Distribution by publication year). Moreover, it can be seen that most publications are originated in Europe (20 papers, and here especially from Germany (8 publications)) followed by Asia (four papers) and North America (three papers). An overview over the results shows Figure 3. As applicable in Figure 4, 16 papers were published in a journal, 11 presented during a conference and two are book chapters.
In order to investigate most relevant mediums, a more detailed analysis of the single journals and conferences was performed. As such, cited authors published their articles in 18 different books, conferences, or journals. Thereby, the most frequently used ones are the Journal of Manufacturing Systems, Procedia CIRP and The International Journal of Advanced Manufacturing Technology. Other citing media can be seen in Table 2.
Additionally, an examination of author keywords was undertaken using VOS viewer. The findings of the co-occurrence network analysis are depicted in Figure 5, with temporal trends illustrated in Figure 6. Figure 5 highlights that “Industry 4.0” and “machine learning” form the primary clusters, followed by “artificial intelligence” and “cyber-physical systems”. Meanwhile, Figure 6 demonstrates a growing research focus on the development and integration of AI systems in manufacturing over time. Furthermore, recent years have witnessed the emergence of keywords related to skills, human-centered approaches, and assistive systems, signalling the need of incorporating human in the AI loop and a growing interest in supporting industrial stakeholders – managers, professionals, and operators – in leveraging the advantages offered by AI.
3.2. Content Analysis
Results of RQ1
In the context of the first research question, the ML use case addressed in each paper was analyzed. They were then categorized into the classification scheme provided by Nti et al. [39]. The analysis reveals that most of the articles focused on manufacturing monitoring, cost and power consumption (although costs are not of importance) as well as wear and tear monitoring (seven publications each). Slightly less important were anomaly detection and predictive maintenance (five papers). This was followed by machine vision and fault diagnostics (two papers each). In five of the papers the use case could not be classified into the framework or remains unclear. The results are also displayed in Figure 7.
Results of RQ2
To answer the second research question, the factors for AI adoption as described in section 2 were considered within the articles. For this, each paper was ranked regarding its extend against the single criteria. A summary is reported in Table 3. Unless otherwise stated, a paper is assigned an empty space if the respective factor is not mentioned at all. In case of naming without deeper description of a fact, papers are given a semi-filled circle. If a detailed description over several sentences can be found, papers are ranked with a filled circle. In case of the latter situation, a brief introduction about the realization within the respective paper is presented thereupon.
First, the extent of needed Personnel was regarded. Eleven papers did not mention required employees and competencies. Only technical requirements and functionalities were described. Eleven authors briefly introduced the work of affected employees, and seven papers describe affected roles and their tasks in more detail. As such, Villanueva Zacarias et al. [46] introduce a framework where domain experts are responsible for the problem definition, whereas data engineer and data scientist take over algorithm-related tasks. Kranzer et al. [53] follow a different approach. They describe the user’s interaction with the system which is realized by a tablet PC and augmented reality. Senna et al. [54] sub-divide their development steps into three pillars, out of which human-machine interaction is one of them. Indeed, the authors aim to display relevant information to decision-makers in a human-centered way. Yet, its realization is not outlined. Bocklisch et al. [62] put strong focus on the later user by testing his interaction with the developed system and subsequently collect his feedback. Neunzig et al. [35] introduce an assistance system aiming at employees from development and planning departments. To address user requirements’ they develop three different interaction modes that are based on different skill levels. Angulo et al. [68] describe the development of a cognitive assistance system that interacts with its user. To achieve appropriate interaction, the authors additionally collect user’s feedback by empirical methods and respective scales. Wellsandt [67] develop a DAS that is able to interact with its users by text-to-speech methods. The user is thereby equipped through additional information.
The next aspect deals with the IT infrastructure on the shop floor and connectivity towards the presented assistance systems. It should be noted that the aim here is not to show the extent of IT within the systems, but the connection to IT systems on the production floor. From the results, it is apparent that 31% of the authors did not mention the IT infrastructure needed by a company interested in the developed system. 48% of the publications at least named requirements or described them in few words. Another 21% of the papers gave further descriptions about how to connect the developed model to existing IT infrastructure. For example, Rousopoulo et al. [57] make use of a data acquisition module that is connected to factory machines and cloud services using an open-source hardware system as well as a Message Queuing Telemetry Transport (MQTT) broker. Liu et al. [51] integrate several industrial ethernet, fieldbus and serial communication protocols as well different communication protocols which allows data collection from numerous sensors directly implemented in a machining process. Wu et al. [45] list a number of communication protocols that is used in their application to interact with physical devices in the production hall. As such, several wireless communication technologies (e.g., Wi-Fi, and 4G LTE) enable network connectivity whereas MTConnect ensures interoperability. Likewise, Deshpande, et al. [58] also make use of MTConnect and use Hypertext Transfer Protocol (HTTP) for data transport. A similar approach follow Woo et al. [60] who connect their platform to a manufacturing execution system (MES) using MTConnect. Heimes et al. [66] connect their platform to several open source and commercial databases, such as Hadoop, Open Shift, Microsoft Azure or Amazon Web Services.
As described by Jöhnk et al. [41], a basic requirement for successful adoption is the AI awareness of its functionalities. Hence, the third factor analyzes the amount of knowledge about ML that affected employees need to have. The review reveals that in six of the papers high knowledge is needed, especially about several algorithms, metrices, among others. 17 articles present a model that requires some basic knowledge about ML or statistics, deeper knowledge is taken over by the framework. The remaining six papers describe easy-to-use models in terms of required background knowledge. As such, the system developed by Villanueva Zacarias et al. [46] allows users to give instructions in a language they are familiar with. ML-based tasks are then overtaken by respective experts. The model described by Senna et al. [54] requires little ML-knowledge due to an expert system that deals with numerous steps of the ML-pipeline and therefore simplifies its use. As the system described by Kranzer et al. [53] requires little interaction with the user, it is also assigned a full circle. Data is collected via an interface from the Supervisory Control and Data Acquisition (SCADA) system and output given to users finally. Fischbach et al. [55] develop a model where many steps from the ML-pipeline is transferred to the assistance system. The user is basically responsible for data generation and result evaluation. Users of the model presented by Garouani et al. [70] require little previous ML knowledge due to the high number of automated tasks such as data ingestion, algorithm selection and tuning as well as provision of recommendations based on a knowledge-base. Due to the focus on visual inspection, the DAS by Deshpande et al. [58] allows users to perform ML applications more easily and intuitively. Theoretically, the system developed by Neunzig et al. [35] has to be attributed different ratings to as it integrates three different skill modes (beginner, advanced and expert). Those user modes thereby differ in the scope of the instructions and in the variety of functions. Given the beginner mode, within this publication, a full circle indicating little required ML knowledge was considered most appropriate.
Jöhnk et al. [41] furthermore state that “upskilling enables employees to learn and develop AI or AI-related skills”. In this context, papers within the review at hand were investigated regarding its ability to function for a so-called work-integrated learning. Papers were rated with a full circle if a detailed description of procedures and background knowledge and thereby methods for non-formal learning were provided, with a semi-filled circle in case of a brief explanation and an empty one otherwise. Precisely, one paper contains an in-depth knowledge support, four articles provide at least some ideas and 24 publications do not contain any deeper knowledge description at all. Other than described above, also papers with a half-filled circle are to be described here. Angulo et al. [68] make use of a cognitive module that analyzes its environment and extracts information. This information is provided to the user for learning reasons. Another possible method for realization of upskilling deliver Garouani et al. [70] by the integration of explainable AI, whereby facilitating the interpretability of algorithms. Likewise, Terziyan et al. [65] transfer human knowledge to their system and use this to support the decision-making in later steps. As described earlier, Senna et al. [54] aim to enhance users’ cognitive abilities by their assistance system. However, they do not describe a realization of this goal. As described before, Neunzig et al. [35] make use of different user modes depending on the previous experience of the users. They describe that, i.e., the length of instructions varies in this context. Thus, beginners are given longer text to introduce them in the subject and explain in more detail what to do and what will happen in the DAS.
Not only an explanation of stakeholder was under examination, but also their Collaborative work. The analysis demonstrates that 22 of the articles do not provide a description of different functions/departments (e.g., manufacturing operators, information technology or human resources). Six of the papers at least briefly mention or describe the role of several stakeholders. Only in one paper, a detailed description with roles and integrative work is explained. As already introduced above, Villanueva Zacarias et al. [46] indicate that domain experts are responsible for the problem definition and model evaluation in terms of applicability in manufacturing, whereas data engineer and data scientist are in charge for algorithm-related tasks. Hence, a delimitation of tasks is described.
An essential prerequisite for ML models is the Data availability. Thus, both the quantity and quality were investigated. The review demonstrates that six papers do not address at all in what way data was used. Some of them neither validate their models. 22 of the articles validate the model by either using open-source data or by using a complete data set from learning factories or industrial partner. Only one publication generates data when using the model developed and demonstrate practical applicability in that context. As such, Woo et al. [60] use their framework for energy prediction on a milling machine. In the context of the prototype implementation, they record data with a given set of work piece, machine tool and operation.
Also, Data Quality can be considered to be crucial for ML implementation. Nevertheless, 55% of the articles do not outline in what way data quality is ensured. 24% of the publications briefly describe methods to improve data within their model. Six articles extensively ensure that data quality is considered and improved. The model described by Villanueva Zacarias et al. [46] consists of four sub-modules out of which one is meant for increasing data quality. It also allows to summarize a profile of the later to be used in later steps. Zhang et al. [47] describe in detail and over several paragraphs necessary steps for ensuring high data quality and how it realized in their assistance system. Similarly, Rousopoulou et al. [57] included data cleaning with i.e., missing value handling and normalization as well as remove low variance features as both decrease the model performance. Equal steps are taken by Garouani et al. [70] who also conduct a robustness test in order to ensure the applicability of the model in the long-term. Lechevalier et al. [49] include a data pre-processing module in their system aiming to clean, reduce and transform data as necessary. Heimes et al. [66] place a filter to maintain data quality at the beginning of their DAS. In this way, they ensure that only high-quality data is used and that, in case of doubt, adjustments are made to the data set at an early stage. To achieve this, they rely on various visualization tools.
As stated by Jöhnk et al. [41] Data accessibility should also be considered. It can be outlined that slightly half of the papers (15) do not provide information about access to data. Further eleven articles only mention accessibility, while three articles elucidate in detail the access to data that they used within their model. In the validation of those papers listed here with a full circle, data must be collected directly from a machine. Otherwise, the accessibility cannot be proven. Liu et al. [51] describe several sensors and connectors to allocate data directly from machines. In consequence, their system allows data analytics in real-time. Wu et al. [45] make use of MTConnect and Open Platform Communications Unified Architecture (OPC UA) to gather data directly from the shop floor and then store it in a local data base. As previously shown, Heimes et al. [66] link their assistance system with various cloud platforms and can therefore easily access data. They then divide the data into different categories so that their DAS can analyze it precisely.
In addition, a focus was laid on the validation in industrial environment. Papers were rated with a full circle if the validation was indeed conducted in manufacturing environment and with semi-filled if the validation took either place on an open-source data set or in a learning factory. In case that there was no validation at all, papers were rated with an empty circle. The research reveals that five research ideas were validated in the manufacturing environment of partner enterprises. Another nineteen of the articles validated their models on open-source data sets and learning factories, respectively, and five developments were not validated at all. Frye et al. [61] perform wear and tear monitoring and vibration prediction in a milling process of a real product. After conducting necessary steps, they outline next steps for long-term deployment. Terziyan et al. [65] use their assistance system to facilitate decision-making in the absence of actual decision-makers at a company site in Ukraine. It simplifies the decision-making process for non-experts. Rousopoulou et al. [57] perform anomaly detection on six injection molding machines of an anonymous company site and extract relevant information for a high-quality machining process. Jun et al. [56] conduct condition monitoring in an injection company. They extract data from an MES and feed it into their assistance system. González Rodríguez et al. [52] solve a hybrid flow shop problem in an industrial production planning process. There, they aim to control the stocks at a tactical level. Heimes et al. [66] validate their solution in two use cases of an automotive battery production for electric vehicles. In this context, they record data from several sensors and try to investigate whether there exists a correlation.
Lastly, it was investigated whether the validation was carried out only by the authors of the papers or whether the target group was actively involved. Deviating from the previously described classification, a paper reporting a validation with non-ML experts was rated with a full circle, an empty one otherwise. From the findings, it can be seen that the target group was directly involved in four of the 29 papers. In the other 25 publications, only the work of the developers was described. González Rodríguez et al. [52] for example assign specific tasks to several users that are relevant for the validation in practice. Yet, from their description, it can be concluded that the authors themselves still strongly support the users during execution. As described above, Bocklisch et al. [62] test their assistance system with one user, observe him while execution and thereupon collect his feedback. Terziyan et al. [65] point out that three employees from a targeted company were involved in the validation. Nevertheless, it remains unclear what their specific tasks were. Angulo et al. [68] describe how an operator can collaboratively work with the system, especially what his tasks are and in what way he can overrule the proposals made by the assistance system. Garouani et al. [70] perform interviews with the target group after execution for collecting feedback when working with their system. A detailed description of the feedback is given subsequently.
Finally, it can be highlighted that the sub-factors Financial budget, AI ethics, Innovativeness, Change management and Data flow were not considered in the papers.
Results of RQ3
Within the frame of RQ3, the outlook for future research presented in the papers were investigated and categorized into the classes Human, Technology and Organization [43]. It must be noted that the classification is not disjoint, as authors might present more than one outlook. The research reveals that seven publications describe improvements and necessary adjustments for the users. Here, emphasis is mostly laid on collecting users’ feedback as well as improving the user interface for better interaction. Most effort is attributed to the technology, as 23 papers contain respective delineations. The respective articles either describe improvements regarding the algorithms selected as well as extensions to other algorithms or outline adjustments in the assistance system infrastructure. Ten publications contain specifications for organizational aspects, most often indicating the need to transfer the model developed to other manufacturing use cases, and to industrial implementation, respectively. Two articles provide no outlook at all. In sum, it can be concluded that future effort is mostly assigned to technical improvements of developed DAS, whereas the impact on the users as well as the organization usage in manufacturing environments are poorly regarded.
4. Discussion of the Results and Research Outlook
In this section, the previously obtained and described findings are first further discussed. This is followed by recommendations for future research.
The review shows that increasing effort has been put on the development of DAS supporting users with little programming knowledge in designing ML use cases for manufacturing environments especially in the last seven years. In return, no relevant publication could be found in 2015 and 2016. This finding is not unexpected as research on ML technologies is conducted in particular in recent years [72]. Especially authors from Europe concentrate their effort on the design of such applications, which leads to a European bias in the publications.
In addition, six key findings (KF) can be derived from the results of RQ2 (extend of AI readiness) and RQ3 (focal points in research outlook), which will be outlined here and discussed in more detail subsequently:
As displayed in KF1 most emphasis is laid on technical aspects and technical improvements. In fact, almost 80% of the articles describe future advances in additional algorithms or improvements of ML-common performance indicators (e.g., accuracy). The focus on technical aspects and technical improvements can be attributed to the novelty of the research field and to the fact that technical developments are of high importance in the peer-review process of high-ranked journals and conferences.

Despite the previously described focus on technical developments, regarded articles only roughly concentrate on data generation, quality and access (KF2). In contrast, it is often supposed that sufficient data are already available and only need to be loaded into the respective system. It can be assumed that this behavior is due to the difficulty of accessing data sets by researchers. As a result, in many cases either public data sets from learning factories or synthetically generated data sets have to be used.
Although the integration of users is considered a success factor [73,74] only few publications also focus on them (KF3). Firstly, the targeted personnel is marginally described and the validation is mostly not performed with the target group. Secondly, only few articles describe future human-centric development plans. In fact, special attention to the users is only given by Villanueva Zacarias [46], Garouani et al. [70], Senna et al. [54], Bocklisch et al. [62], Wellsandt et al. [67], Neunzig et al. [35], Kranzer, et al. [53] and Angulo et al. [68]. Notably, many of the articles point out in their introduction that solutions for non-experts are needed. Nevertheless, only five papers also include the target group in the final validation. Besides, the low consideration of possibilities for non-formal learning leaves the question unanswered as to whether domain experts can operate independently with the models in a comparable situation in the future (KF4). Corresponding approaches are only very briefly described by Senna et al. [54], Terziyan et al. [65], Angulo et al. [68] and Garouani et al. [70]. However, a more detailed description is pending.
A consideration of consecutive Change management with respect to the use of ML is therefore difficult to implement. Moreover, the deployment of models is rarely regarded (KF5). Indeed, a technology readiness level (TRL) of five can be attributed to most applications, meaning that models were tested in laboratory settings and not in real production environments and are therefore in particular not deployed. The investigation allows to conclude that most papers perform a support evaluation and possibly application evaluation [75]. A success evaluation is hardly evident and can only be attributed to those five articles that carry out the validation with the target group. Rather, the validation is carried out by the authors themselves. This observation can be attributed to the fact that the development of corresponding assistance systems is a novel topic and thus few real industrial applications are expected but more industrial pilots or industry-related environments such as learning factories. However, the marginal validation in industrial practice also hinders the consideration of AI ethics.
Considering the key findings, it can be concluded that the answer to RQ2 is that SMEs’ shortcomings (lack of ML knowledge, lack of (high quality) data and lack of IT infrastructure) as described at the beginning of this article are barely addressed (KF6). It remains open to what extend employees from SMEs can use the DAS analyzed in this paper.
However, this publication cannot provide an in-depth analysis of the systems themselves as software code was barely accessible. Likewise, an evaluation of the applicability in industrial environments from the user's point of view was outside of the research frame. Thus, only the descriptions within the publications were considered in this work and not the assistance systems themselves. This limitation may result in individual DAS being more usable than described by the authors. For example, they could be intuitive for users to operate. This applies all the more to the learnability of the systems, which, as shown, was only marginally described. Further research is necessary in this regard.
Subsequently, requirements for future research projects are pointed out. These follow an ideal situation in which all the criteria described above are integrated completely. The corresponding key findings are referenced at the appropriate points to simplify understanding. Consequently, the shortcomings for ML in SMEs are regarded in particular and employees from SMEs are enabled to use the systems. At this point, the discussion and recommendations are enriched leveraging on the available (extended) literature and the experience of the authors. Here again, four requirements, which can be derived from the analysis, are listed first, explained in more detail thereupon and finally summarized in Figure 9.

Just as the DAS described in this article, newly developed assistance systems contain a detailed description about functionalities and sub-systems. But it becomes necessary that they put the actual target group and their requirements in the center of development (KF3) [73,74]. Due to the criticality of users’ acceptance [76], they should be regarded in detail. To this end, researchers can take advantage of several methodologies that have been proposed for integrating human factors in engineering design [77], user-centered design and human-centered design elements [78,79]. From the descriptions, technical requirements on the side of the shop floor become evident. Thus, readers can extract which data protocols and data storage systems are necessary to use the respective DAS. To increase practical relevance, it should be indicated, which data is of relevance, and which is not, how data quality can be increased and how access to data is realized (KF2). It should be noted that in complex ML systems, data quality should be monitored throughout the entire life cycle. This applies to data preparation, training and testing as well as the validation of ML models. [80] Besides, legal and ethical requirements need to be elicited and addressed to improve transparency, fairness, and trustworthiness of ML applications throughout the entire lifecycle [81,82,83].
The DAS itself then contains as many steps of the ML pipeline as possible and, according to possibility, encompasses a cognitive module from which explanations about results can be drawn. For the sake of simplified use of such assistance systems as well as for independent future applicability, the background knowledge and other non-formal learning opportunities are to be integrated (KF4). For instance, Clement et al. [84] and Naqvi et al. [85] provide an overview of Explainable Artificial Intelligence techniques that have been implemented in the manufacturing domain. Furthermore, if applicable, coaches or social learning can be considered, such that the systems can be integrated into competence development. Since ML-projects require company-wide collaboration and change management efforts [86], support in the construction of an interdisciplinary and innovative team is of advantage. Thus, not only the main target group should be analyzed and involved, but also other affected stakeholders such as IT and HR units. When it comes to the validation phase, use cases with respective data from industry are considered (KF5). The systems should not be validated by the authors themselves or colleagues of theirs but by the considered target group. This allows a success evaluation, in which it can be finally stated whether the original goal, i.e., the development of an assistance system on the topic of ML for non-experts, has been achieved.
5. Conclusions and Outlook
In this publication, 29 software-based digital assistance systems focusing on the implementation of ML applications in manufacturing environment and targeting non-ML-experts with limited programming knowledge were reviewed and analyzed in depth. A special emphasis was thereby laid on an examination of the systems regarding organizational AI readiness previously defined in literature [40,41].
The review shows that this topic is especially addressed in European countries. Within development steps, articles focus on technical aspects. Algorithm improvements, performance improvements, among others are considered in detail and represent the essential focus for future improvement. In contrast, human-centered matters lack behind – despite the relevance described by most of the authors themselves. Besides, many assistance systems have not been validated in industrial practice and even if they were, validation was carried out in most cases by the developers themselves. The most frequently considered ML use cases are manufacturing monitoring, cost and power consumption as well as wear and tear monitoring.
The conducted research provides a summary and points out future research directions to researchers interested in this field and companies interested in assisted implementation and use of ML in their manufacturing environment. In consequence, suggestions for future research projects were provided in detail. They are designed in such a way that also SMEs with their lack of ML specialists can profit from them.
In addition to the integration of the described requirements in newly developed systems, future research is necessary on the effects of such digital assistance systems on the users. As such, a more detailed analysis of user requirements has to be performed and the described DAS rated against them. For this, an in-depth investigation using the systems is necessary.
Author Contributions
Conceptualization: JR, MP; methodology: JR, MP; formal analysis: MP; investigation: JR; resources: JR, MP; data curation: JR; writing—original draft preparation: JR, MP; writing—review and editing: JR, MP, JM; visualization: JR, MP; supervision: JM; project administration: JR; funding acquisition: MP. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Italian Ministry of University and Research (MUR), grant number L. 232/2016.
Conflicts of Interests
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
References
- Papadopoulos, T.; Sivarajah, U.; Spanaki, K.; Despoudi, S.; Gunasekaran, A. Editorial: Artificial Intelligence (AI) and data sharing in manufacturing, production and operations management research. Int. J. Prod. Res. 2022, 60, 4361–4364. [Google Scholar] [CrossRef]
- Rai, R. , Tiwari, M.K., Ivanov, D., Dolgui, A., 2021. Machine learning in manufacturing and industry 4.0 applications. International Journal of Production Research 59 (16), 4773–4778.
- Armutak, E.A. , Fendri, M., 2022. Unlocking Value from Artificial Intelligence in Manufacturing. Centre for the Fourth Industrial Revolution Turkey; World Economic Forum’s Platform for Shaping. https://www3.weforum.org/docs/WEF_AI_in_Manufacturing_2022.pdf. Accessed 6 March 2024.
- Ermakova, T. , Blume, J., Fabian, B., Fomenko, E., Berlin, M., Hauswirth, M., 2021. Beyond the Hype: Why Do Data-Driven Projects Fail?, in: Proceedings of the 54th Hawaii International Conference on System Sciences, pp. 5081–5090.
- Metternich, J. , Biegel, T., Bretones Cassoli, B., Hoffmann, F., Jourdan, N., Rosemeyer, J., Stanula, P., Ziegenbein, A., 2021. Künstliche Intelligenz zur Umsetzung von Industrie 4.0 im Mittelstand: Leitfaden zur Expertise des Forschungsbeirats der Plattform Industrie 4.0. https://www.acatech.de/publikation/fb4-0-ki-in-kmu/download-pdf/?lang=wildcard. Accessed 6 March 2024.
- Biegel, T. , Bretones Cassoli, B., Hoffmann, F., Jourdan, N., Metternich, J., 2021. An AI Management Model for the Manufacturing Industry - AIMM. https://hds.hebis.de/ulbda/Record/HEB48543220X. Accessed 6 March 2024.
- Krauß, J.; Pacheco, B.M.; Zang, H.M.; Schmitt, R.H. Automated machine learning for predictive quality in production. Procedia CIRP 2020, 93, 443–448. [Google Scholar] [CrossRef]
- Bauer, M. , van Dinther, C., Kiefer, D., 2020. Machine learning in SME: an empirical study on enablers and success factors, in: AMCIS 2020 proceedings - Advancings in information systems research. 26th Americas Conference on Information Systems. August 10-14 2020. Association for Information Systems (AIS), Atlanta, pp. 1–10.
- Bettoni, A.; Matteri, D.; Montini, E.; Gładysz, B.; Carpanzano, E. An AI adoption model for SMEs: a conceptual framework. IFAC-PapersOnLine 2021, 54, 702–708. [Google Scholar] [CrossRef]
- Pinzone, M. , Fantini, P., Fiasché, M., Taisch, M., 2016. A Multi-horizon, Multi-objective Training Planner: Building the Skills for Manufacturing, in: Bassis, S., Esposito, A., Morabito, F.C., Pasero, E. (Eds.), Advances in Neural Networks. Computational Intelligence for ICT, vol. 54. Springer International Publishing Switzerland, pp. 517–526.
- Fantini, P. , Pinzone, M., Sella, F., Taisch, M., 2018. Collaborative Robots and New Product Introduction: Capturing and Transferring Human Expert Knowledge to the Operators, in: Trzcielinski, S. (Ed.), Advances in Ergonomics of Manufacturing: Managing the Enterprise of the Future. Springer International Publishing AG, pp. 259–268.
- Pinzone, M.; Fantini, P.; Taisch, M. Skills for Industry 4.0: a structured repository grounded on a generalized enterprise reference architecture and methodology-based framework. Int. J. Comput. Integr. Manuf. 2023, 37, 952–971. [Google Scholar] [CrossRef]
- Pfaff-Kastner, M.M.-L.; Wenzel, K.; Ihlenfeldt, S. Concept Paper for a Digital Expert: Systematic Derivation of (Causal) Bayesian Networks Based on Ontologies for Knowledge-Based Production Steps. Mach. Learn. Knowl. Extr. 2024, 6, 898–916. [Google Scholar] [CrossRef]
- Aggogeri, F.; Pellegrini, N.; Tagliani, F.L. Recent Advances on Machine Learning Applications in Machining Processes. Appl. Sci. 2021, 11, 8764. [Google Scholar] [CrossRef]
- Mypati, O.; Mukherjee, A.; Mishra, D.; Pal, S.K.; Chakrabarti, P.P.; Pal, A. A critical review on applications of artificial intelligence in manufacturing. Artif. Intell. Rev. 2023, 56, 661–768. [Google Scholar] [CrossRef]
- Dobra, P.; Jósvai, J. Overall Equipment Effectiveness-related Assembly Pattern Catalogue based on Machine Learning. Manuf. Technol. 2023, 23, 276–283. [Google Scholar] [CrossRef]
- Andrianakos, G.; Dimitropoulos, N.; Michalos, G.; Makris, S. An approach for monitoring the execution of human based assembly operations using machine learning. Procedia CIRP 2019, 86, 198–203. [Google Scholar] [CrossRef]
- Zhang, S.-W.; Wang, Z.; Cheng, D.-J.; Fang, X.-F. An intelligent decision-making system for assembly process planning based on machine learning considering the variety of assembly unit and assembly process. Int. J. Adv. Manuf. Technol. 2022, 121, 805–825. [Google Scholar] [CrossRef]
- Weichert, D.; Link, P.; Stoll, A.; Rüping, S.; Ihlenfeldt, S.; Wrobel, S. A review of machine learning for the optimization of production processes. Int. J. Adv. Manuf. Technol. 2019, 104, 1889–1902. [Google Scholar] [CrossRef]
- Mazzei, D.; Ramjattan, R. Machine Learning for Industry 4.0: A Systematic Review Using Deep Learning-Based Topic Modelling. Sensors 2022, 22, 8641. [Google Scholar] [CrossRef]
- Doltsinis, S.; Ferreira, P.; Lohse, N. A Symbiotic Human–Machine Learning Approach for Production Ramp-up. IEEE Trans. Human-Machine Syst. 2017, 48, 229–240. [Google Scholar] [CrossRef]
- Mhlanga, D. Artificial Intelligence and Machine Learning for Energy Consumption and Production in Emerging Markets: A Review. Energies 2023, 16, 745. [Google Scholar] [CrossRef]
- Wirth, R. , Hipp, J., 2000. CRISP-DM: Towards a Standard Process Model for Data Mining. http://www.cs.unibo.it/~montesi/CBD/Beatriz/10.1.1.198.5133.pdf. Accessed 6 March 2024.
- Azevedo, A. , Santos, M., 2008. KDD, SEMMA and CRISP-DM: a parallel overview. IADIS European Conference on Data Mining.
- Huber, S.; Wiemer, H.; Schneider, D.; Ihlenfeldt, S. DMME: Data mining methodology for engineering applications – a holistic extension to the CRISP-DM model. Procedia CIRP 2019, 79, 403–408. [Google Scholar] [CrossRef]
- Studer, S.; Bui, T.B.; Drescher, C.; Hanuschkin, A.; Winkler, L.; Peters, S.; Müller, K.-R. Towards CRISP-ML(Q): A Machine Learning Process Model with Quality Assurance Methodology. Mach. Learn. Knowl. Extr. 2021, 3, 392–413. [Google Scholar] [CrossRef]
- Diamantis, D.E.; Iakovidis, D.K. ASML: Algorithm-Agnostic Architecture for Scalable Machine Learning. IEEE Access 2020, 9, 51970–51982. [Google Scholar] [CrossRef]
- Wostmann, R.; Schlunder, P.; Temme, F.; Klinkenberg, R.; Kimberger, J.; Spichtinger, A.; Goldhacker, M.; Deuse, J. Conception of a Reference Architecture for Machine Learning in the Process Industry. 2020 IEEE International Conference on Big Data (Big Data). IEEE, Piscataway, NJ; pp. 1726–1735.
- Martín, C.; Langendoerfer, P.; Zarrin, P.S.; Díaz, M.; Rubio, B. Kafka-ML: Connecting the data stream with ML/AI frameworks. Futur. Gener. Comput. Syst. 2022, 126, 15–33. [Google Scholar] [CrossRef]
- Berthold, M.R. , Cebron, N., Dill, F., Gabriel, T.R., Kötter, T., Meinl, T., Ohl, P., Sieb, C., Thiel, K., Wiswedel, B., 2008. KNIME: The Konstanz Information Miner, in: Data Analysis, Machine Learning and Applications. Springer Berlin Heidelberg, Berlin, Heidelberg, pp. 319–326.
- Garner, S.R. , 1995. WEKA: The Waikato Environment for Knowledge Analysis. https://www.cs.waikato.ac.nz/~ml/publications/1995/Garner95-WEKA.pdf. Accessed 6 March 2024.
- Demšar, J. , Curk, T., Erjavec, A., Gorup, Č., Hočevar, T., Milutinovič, M., Možina, M., Polajnar, M., Toplak, M., Starič, A., Štajdohar, M., Umek, L., Žagar, L., Žbontar, J., Žitnik, M., Zupan, B., 2013. Orange: Data Mining Toolbox in Python. Journal of Machine Learning Research 14 (71), 2349–2353.
- Rosemeyer, J. , Neunzig, C., Akbal, C., Metternich, J., Kuhlenkötter, B., 2024. A maturity model for digital ML tools to be used in manufacturing environments, Darmstadt. https://tuprints.ulb.tu-darmstadt.de/26519/1/Rosemeyer%20et%20al._2024_A%20maturity%20model%20for%20digital%20ML%20tools%20to%20be%20used%20in%20manufacturing%20environments.pdf. Accessed 10 July 2024.
- Apt, W. , Schubert, M., Wischmann, S., 2018. Digitale Assistenzsysteme: Perspektiven und Herausforderungen für den Einsatz in Industrie und Dienstleistungen. https://www.iit-berlin.de/iit-docs/fd2aa38ad4474e6cb53720e7878ffd4a_2018_02_01_Digitale_Assistenzsysteme_Perspektiven_und_Herausforderungen.pdf. Accessed 6 March 2024.
- Neunzig, C.; Möllensiep, D.; Kuhlenkötter, B.; Möller, M. ML Pro: digital assistance system for interactive machine learning in production. J. Intell. Manuf. 2023, 1–21. [Google Scholar] [CrossRef]
- Kitchenham, B. , 2004. Procedures for Performing Systematic Reviews. http://artemisa.unicauca.edu.co/~ecaldon/docs/spi/kitchenham_2004.pdf. Accessed 6 March 2024.
- Page, M.J. , McKenzie, J.E., Bossuyt, P.M., Boutron, I., Hoffmann, T.C., Mulrow, C.D., Shamseer, L., Tetzlaff, J.M., Akl, E.A., Brennan, S.E., Chou, R., Glanville, J., Grimshaw, J.M., Hróbjartsson, A., Lalu, M.M., Li, T., Loder, E.W., Mayo-Wilson, E., McDonald, S., McGuinness, L.A., Stewart, L.A., Thomas, J., Tricco, A.C., Welch, V.A., Whiting, P., Moher, D., 2021. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ (Clinical research ed.) 372, n71.
- Gibbert, M. , Ruigrok, W., Wicki, B., 2008. What passes as a rigorous case study? Strategic Management Journal 29 (13), 1465–1474.
- Nti, I.K.; Adekoya, A.F.; Weyori, B.A.; Nyarko-Boateng, O. Applications of artificial intelligence in engineering and manufacturing: a systematic review. J. Intell. Manuf. 2021, 33, 1581–1601. [Google Scholar] [CrossRef]
- Pumplun, L. , Tauchert, C., Heidt, M., 2019. A new organizational chassis for artifical intelligence: Exploring organizational readiness factors, in:, Proceedings of the 27th European Conference on Information Systems (ECIS), Uppsala & Stockholm, Sweden.
- Jöhnk, J. , Weißert, M., Wyrtki, K., 2021. Ready or Not, AI Comes— An Interview Study of Organizational AI Readiness Factors. Business & Information Systems Engineering 63 (1), 5–20.
- Hamm, P. , Klesel, M., 2021. Success Factors for the Adoption of Artiticial Intelligence in Organizations: A Literature Review, in: AMCIS 2021 proceedings - Advancings in information systems research. 27th Americas Conference on Information Systems. Association for Information Systems (AIS), pp. 1–10.
- Strohm, O. , Escher, O.P., 1997. Unternehmen arbeitspsychologisch bewerten: Ein Mehr-Ebenen-Ansatz unter besonderer Berücksichtigung von Mensch, Technik und Organisation. vdf Hochschulverlag an der ETH Zürich, Zürich, 448 pp.
- Zhu, K.; Zhang, Y. A Cyber-Physical Production System Framework of Smart CNC Machining Monitoring System. IEEE/ASME Trans. Mechatronics 2018, 23, 2579–2586. [Google Scholar] [CrossRef]
- Wu, D.; Liu, S.; Zhang, L.; Terpenny, J.; Gao, R.X.; Kurfess, T.; Guzzo, J.A. A fog computing-based framework for process monitoring and prognosis in cyber-manufacturing. J. Manuf. Syst. 2017, 43, 25–34. [Google Scholar] [CrossRef]
- Zacarias, A.G.V.; Reimann, P.; Mitschang, B. A framework to guide the selection and configuration of machine-learning-based data analytics solutions in manufacturing. Procedia CIRP 2018, 72, 153–158. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, H.; Li, J.; Gao, H. A generic data analytics system for manufacturing production. Big Data Min. Anal. 2018, 1, 160–171. [Google Scholar] [CrossRef]
- Cho, S. , May, G., Tourkogiorgis, I., Perez, R., Lazaro, O., La Maza, B. de, Kiritsis, D., 2018. A Hybrid Machine Learning Approach for Predictive Maintenance in Smart Factories of the Future, in: Moon, I., Lee, G.M., Park, J., Kiritsis, D., Cieminski, G. von (Eds.), Advances in Production Management Systems. Smart Manufacturing for Industry 4.0. IFIP WG 5.7 International Conference, APMS 2018, Proceedings Part II, vol. 536. Springer International Publishing, pp. 311–317.
- Lechevalier, D.; Narayanan, A.; Rachuri, S.; Foufou, S. A methodology for the semi-automatic generation of analytical models in manufacturing. Comput. Ind. 2018, 95, 54–67. [Google Scholar] [CrossRef]
- Cinar, E.; Kalay, S.; Saricicek, I. A Predictive Maintenance System Design and Implementation for Intelligent Manufacturing. Machines 2022, 10, 1006. [Google Scholar] [CrossRef]
- Liu, C.; Vengayil, H.; Zhong, R.Y.; Xu, X. A systematic development method for cyber-physical machine tools. J. Manuf. Syst. 2018, 48, 13–24. [Google Scholar] [CrossRef]
- Rodríguez, G.G.; Gonzalez-Cava, J.M.; Pérez, J.A.M. An intelligent decision support system for production planning based on machine learning. J. Intell. Manuf. 2019, 31, 1257–1273. [Google Scholar] [CrossRef]
- Kranzer, S.; Prill, D.; Aghajanpour, D.; Merz, R.; Strasser, R.; Mayr, R.; Zoerrer, H.; Plasch, M.; Steringer, R. An intelligent maintenance planning framework prototype for production systems. 2017 IEEE International Conference on Industrial Technology (ICIT). LOCATION OF CONFERENCE, COUNTRYDATE OF CONFERENCE; pp. 1124–1129.
- Senna, P.P.; Almeida, A.H.; Barros, A.C.; Bessa, R.J.; Azevedo, A.L. Architecture Model for a Holistic and Interoperable Digital Energy Management Platform. Procedia Manuf. 2020, 51, 1117–1124. [Google Scholar] [CrossRef]
- Fischbach, A.; Strohschein, J.; Bunte, A.; Stork, J.; Faeskorn-Woyke, H.; Moriz, N.; Bartz-Beielstein, T. CAAI—a cognitive architecture to introduce artificial intelligence in cyber-physical production systems. Int. J. Adv. Manuf. Technol. 2020, 111, 609–626. [Google Scholar] [CrossRef]
- Jun, C.; Lee, J.Y.; Kim, B.H. Cloud-based big data analytics platform using algorithm templates for the manufacturing industry. Int. J. Comput. Integr. Manuf. 2019, 32, 723–738. [Google Scholar] [CrossRef]
- Rousopoulou, V.; Vafeiadis, T.; Nizamis, A.; Iakovidis, I.; Samaras, L.; Kirtsoglou, A.; Georgiadis, K.; Ioannidis, D.; Tzovaras, D. Cognitive analytics platform with AI solutions for anomaly detection. Comput. Ind. 2022, 134, 103555. [Google Scholar] [CrossRef]
- Deshpande, A.M.; Telikicherla, A.K.; Jakkali, V.; Wickelhaus, D.A.; Kumar, M.; Anand, S. Computer Vision Toolkit for Non-invasive Monitoring of Factory Floor Artifacts. Procedia Manuf. 2020, 48, 1020–1028. [Google Scholar] [CrossRef]
- Vafeiadis, T.; Kalatzis, D.; Nizamis, A.; Ioannidis, D.; Apostolou, K.; Metaxa, I.; Charisi, V.; Beecks, C.; Insolvibile, G.; Pardi, M.; et al. Data analysis and visualization framework in the manufacturing decision support system of COMPOSITION project. Procedia Manuf. 2019, 28, 57–62. [Google Scholar] [CrossRef]
- Woo, J.; Shin, S.-J.; Seo, W.; Meilanitasari, P. Developing a big data analytics platform for manufacturing systems: architecture, method, and implementation. Int. J. Adv. Manuf. Technol. 2018, 99, 2193–2217. [Google Scholar] [CrossRef]
- Frye, M.; Krauß, J.; Schmitt, R. Expert System for the Machine Learning Pipeline in Manufacturing. IFAC-PapersOnLine 2021, 54, 128–133. [Google Scholar] [CrossRef]
- Bocklisch, F.; Paczkowski, G.; Zimmermann, S.; Lampke, T. Integrating human cognition in cyber-physical systems: A multidimensional fuzzy pattern model with application to thermal spraying. J. Manuf. Syst. 2022, 63, 162–176. [Google Scholar] [CrossRef]
- Richter, J. , Nau, J., Kirchhoff, M., Streitferdt, D., 2021. KOI: An Architecture and Framework for Industrial and Academic Machine Learning Applications, in: Simian, D., Stoica, L.F. (Eds.), Modelling and Development of Intelligent Systems, vol. 1341. Springer International Publishing, Cham, pp. 113–128.
- Magnotta, L. , Gagliardelli, L., Simonini, G., Orsini, M., Bergamaschi, S., 2018. MOMIS Dashboard: a powerful data analytics tool for Industry 4.0, in: Transdisciplinary engineering methods for social innovation of Industry 4.0. Proceedings of the 25th International Conference on Transdisciplinary Engineering. IOS Press, Washington DC, pp. 1074–1081.
- Terziyan, V.; Gryshko, S.; Golovianko, M. Patented intelligence: Cloning human decision models for Industry 4.0. J. Manuf. Syst. 2018, 48, 204–217. [Google Scholar] [CrossRef]
- Heimes, H. , Kampker, A., Buhrer, U., Steinberger, A., Eirich, J., Krotil, S., 2019. Scalable Data Analytics from Predevelopment to Large Scale Manufacturing, in: 2019 Asia Pacific Conference on Research in Industrial and Systems Engineering (APCoRISE), Depok, Indonesia. IEEE, Piscataway, NJ, pp. 1–6.
- Wellsandt, S. , Foosherian, M., Lepenioti, K., Fikardos, M., Mentzas, G., Thoben, K.-D. Supporting Data Analytics in Manufacturing with a Digital Assistant, in: Kim, D.Y., Cieminski, G. von, Romero, D. (Eds.), Advances in Production Management Systems. Smart Manufacturing and Logistics Systems: Turning Ideas into Action, vol. 664, 664 ed. IFIP Advances in Information and Communication Technology, pp. 511–518.
- Angulo, C.; Chacón, A.; Ponsa, P. Towards a cognitive assistant supporting human operators in the Artificial Intelligence of Things. Internet Things 2022, 21. [Google Scholar] [CrossRef]
- Gyulai, D.; Bergmann, J.; Gallina, V.; Gaal, A. Towards a connected factory: Shop-floor data analytics in cyber-physical environments. Procedia CIRP 2019, 86, 37–42. [Google Scholar] [CrossRef]
- Garouani, M.; Ahmad, A.; Bouneffa, M.; Hamlich, M.; Bourguin, G.; Lewandowski, A. Towards big industrial data mining through explainable automated machine learning. Int. J. Adv. Manuf. Technol. 2022, 120, 1169–1188. [Google Scholar] [CrossRef]
- Chakravorti, N.; Rahman, M.M.; Sidoumou, M.R.; Weinert, N.; Gosewehr, F.; Wermann, J. Validation of PERFoRM reference architecture demonstrating an application of data mining for predicting machine failure. Procedia CIRP 2018, 72, 1339–1344. [Google Scholar] [CrossRef]
- Web of Science, 2024. Analyze Results: AI OR "artificial intelligence" OR ML OR "machine learning". https://www.webofscience.com/wos/woscc/analyze-results/f935061a-0d6c-407c-ab02-017786b1d759-d204f0dc. Accessed 6 March 2024.
- Łapińska, J.; Escher, I.; Górka, J.; Sudolska, A.; Brzustewicz, P. Employees’ Trust in Artificial Intelligence in Companies: The Case of Energy and Chemical Industries in Poland. Energies 2021, 14, 1942. [Google Scholar] [CrossRef]
- Varsaluoma, J.; Väätäjä, H.; Heimonen, T.; Tiitinen, K.; Hakulinen, J.; Turunen, M.; Nieminen, H. Guidelines for Development and Evaluation of Usage Data Analytics Tools for Human-Machine Interactions with Industrial Manufacturing Systems. , in: Proceedings of the 22nd International Academic Mindtrek Conference. Mindtrek 2018: Academic Mindtrek 2018, Tampere Finland. ACM, New York, NY, USA; pp. 172–181.
- Blessing, L.T.M. , Chakrabarti, A., 2009. DRM, a design research methodology. Springer, Dordrecht, Heidelberg, 397 pp.
- van Oudenhoven, B. , van de Calseyde, P., Basten, R., Demerouti, E., 2022. Predictive maintenance for industry 5.0: behavioural inquiries from a work system perspective. International Journal of Production Research.
- Sun, X.; Houssin, R.; Renaud, J.; Gardoni, M. A review of methodologies for integrating human factors and ergonomics in engineering design. Int. J. Prod. Res. 2018, 57, 4961–4976. [Google Scholar] [CrossRef]
- International Organization for Standardization, 2020. Ergonomics of Human System Interaction: Part 110: Dialogue principles, Geneva, Switzerland.
- Ngoc, H.N.; Lasa, G.; Iriarte, I. Human-centred design in industry 4.0: case study review and opportunities for future research. J. Intell. Manuf. 2021, 33, 35–76. [Google Scholar] [CrossRef]
- Fischer, L.; Ehrlinger, L.; Geist, V.; Ramler, R.; Sobiezky, F.; Zellinger, W.; Brunner, D.; Kumar, M.; Moser, B. AI System Engineering—Key Challenges and Lessons Learned. Mach. Learn. Knowl. Extr. 2020, 3, 56–83. [Google Scholar] [CrossRef]
- Hooshyar, D.; Azevedo, R.; Yang, Y. Augmenting Deep Neural Networks with Symbolic Educational Knowledge: Towards Trustworthy and Interpretable AI for Education. Mach. Learn. Knowl. Extr. 2024, 6, 593–618. [Google Scholar] [CrossRef]
- Oliveira, M. , Arica, E., Pinzone, M., Fantini, P., Taisch, M., 2019. Human-Centered Manufacturing Challenges Affecting European Industry 4.0 Enabling Technologies, in: Stephanidis, C. (Ed.), HCI International 2019 – Late Breaking Papers. Springer Nature Switzerland, pp. 507–517.
- Rožanec, J.M.; Novalija, I.; Zajec, P.; Kenda, K.; Ghinani, H.T.; Suh, S.; Veliou, E.; Papamartzivanos, D.; Giannetsos, T.; Menesidou, S.A.; et al. Human-centric artificial intelligence architecture for industry 5.0 applications. Int. J. Prod. Res. 2022, 61, 6847–6872. [Google Scholar] [CrossRef]
- Clement, T.; Kemmerzell, N.; Abdelaal, M.; Amberg, M. XAIR: A Systematic Metareview of Explainable AI (XAI) Aligned to the Software Development Process. Mach. Learn. Knowl. Extr. 2023, 5, 78–108. [Google Scholar] [CrossRef]
- Naqvi, M.R.; Elmhadhbi, L.; Sarkar, A.; Archimede, B.; Karray, M.H. Survey on ontology-based explainable AI in manufacturing. J. Intell. Manuf. 2024, 1–23. [Google Scholar] [CrossRef]
- Moencks, M.; Roth, E.; Bohné, T.; Romero, D.; Stahre, J. Augmented Workforce Canvas: a management tool for guiding human-centric, value-driven human-technology integration in industry. Comput. Ind. Eng. 2021, 163, 107803. [Google Scholar] [CrossRef]
Figure 1.
Publication selection process; own illustration based on Page et al. [37].
Figure 1.
Publication selection process; own illustration based on Page et al. [37].
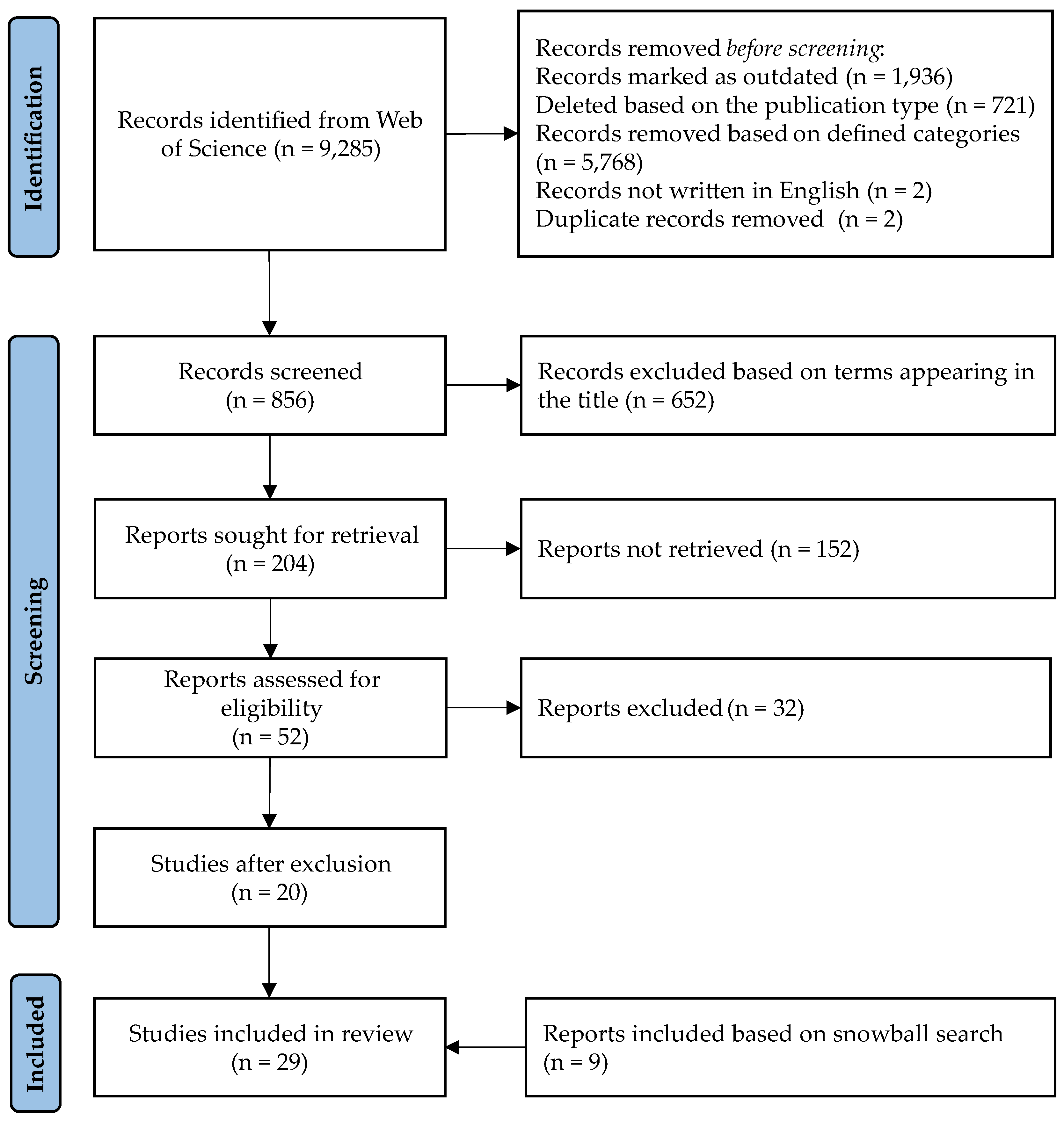
Figure 2.
Distribution by publication year.
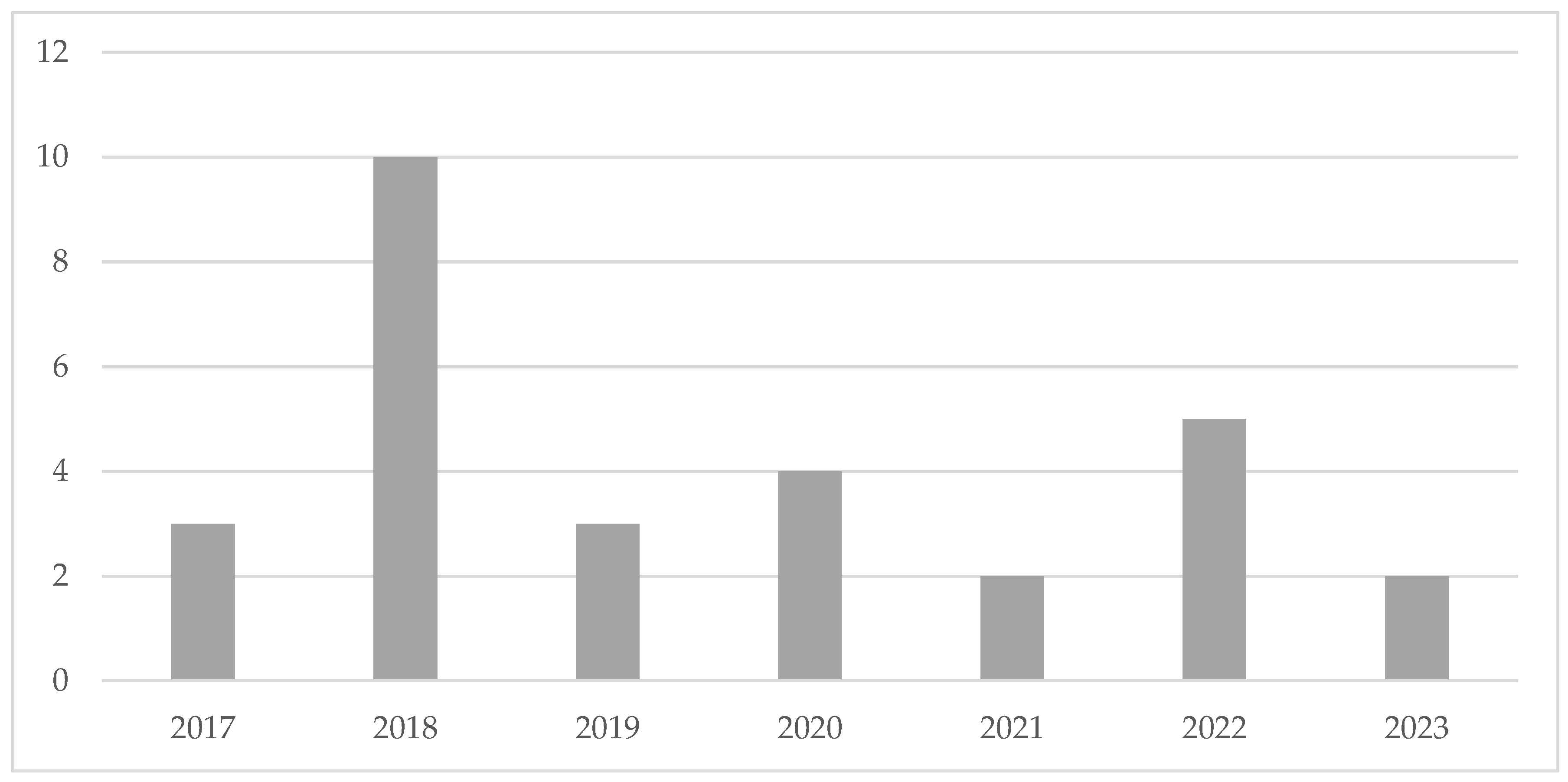
Figure 3.
Distribution by region.
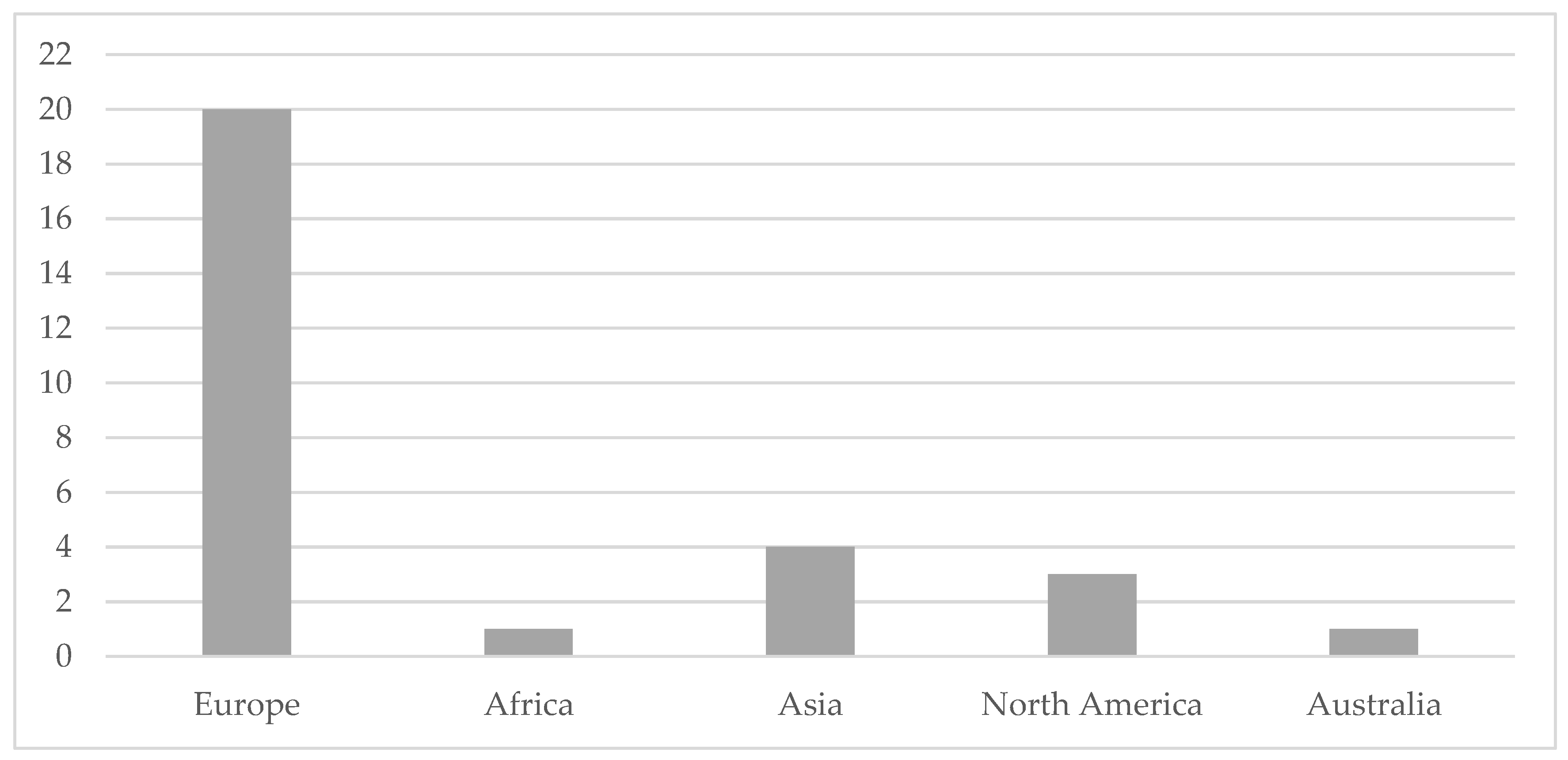
Figure 4.
Publication medium.
Figure 5.
Clustering of co-occurrence keywords network using VOSviewer.
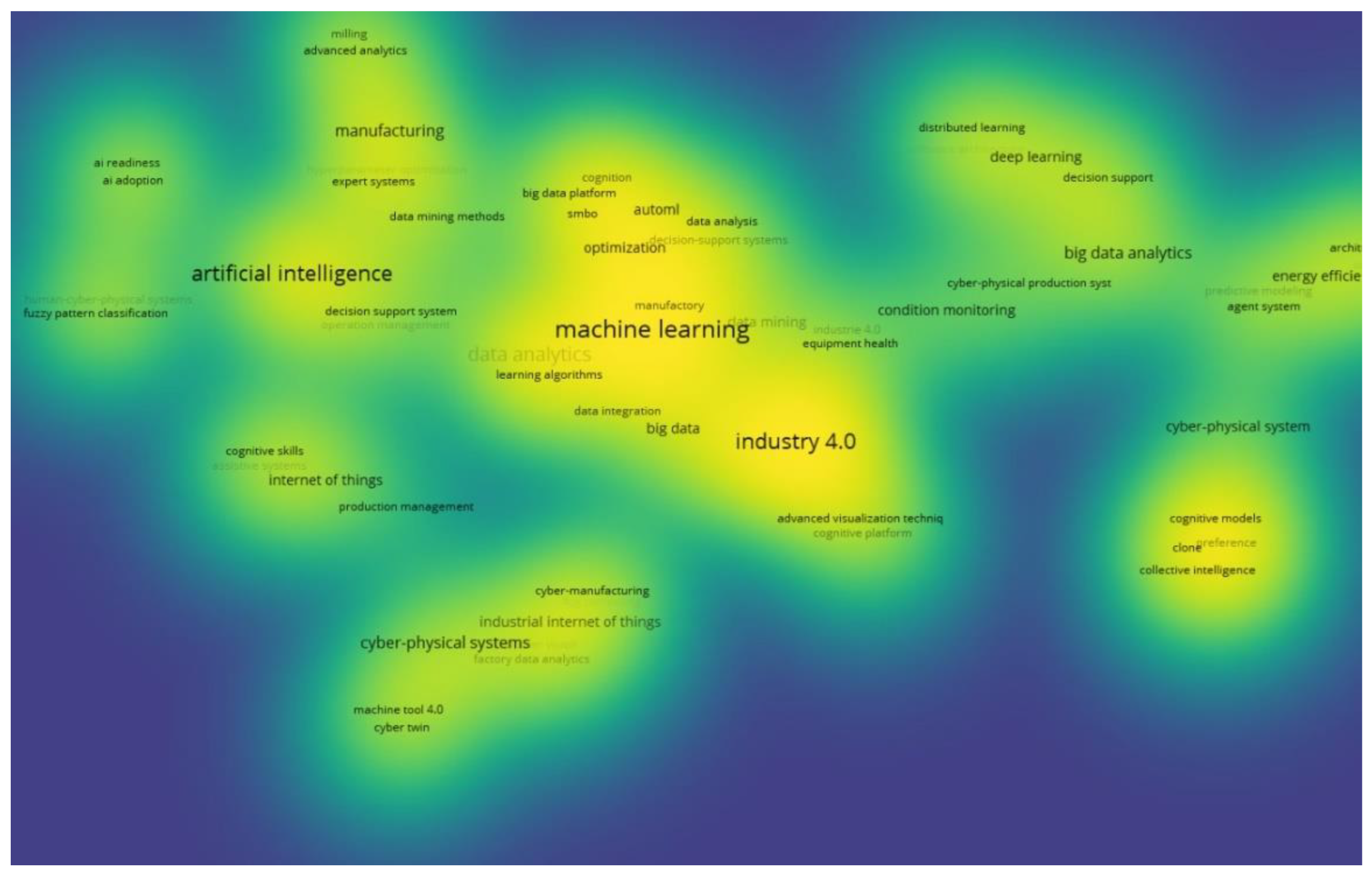
Figure 6.
Overlay visualization using VOSviewer.
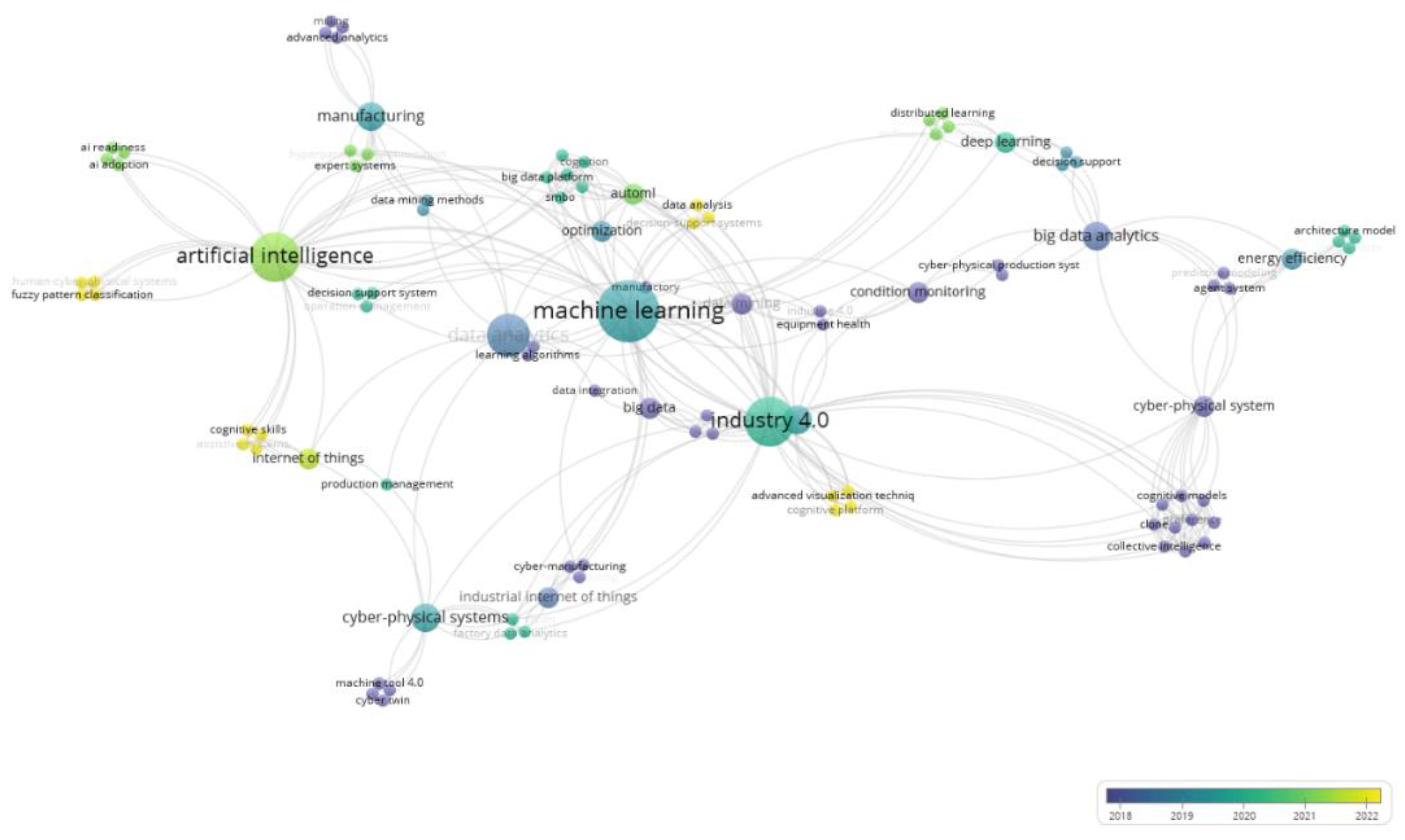
Figure 7.
ML use cases.
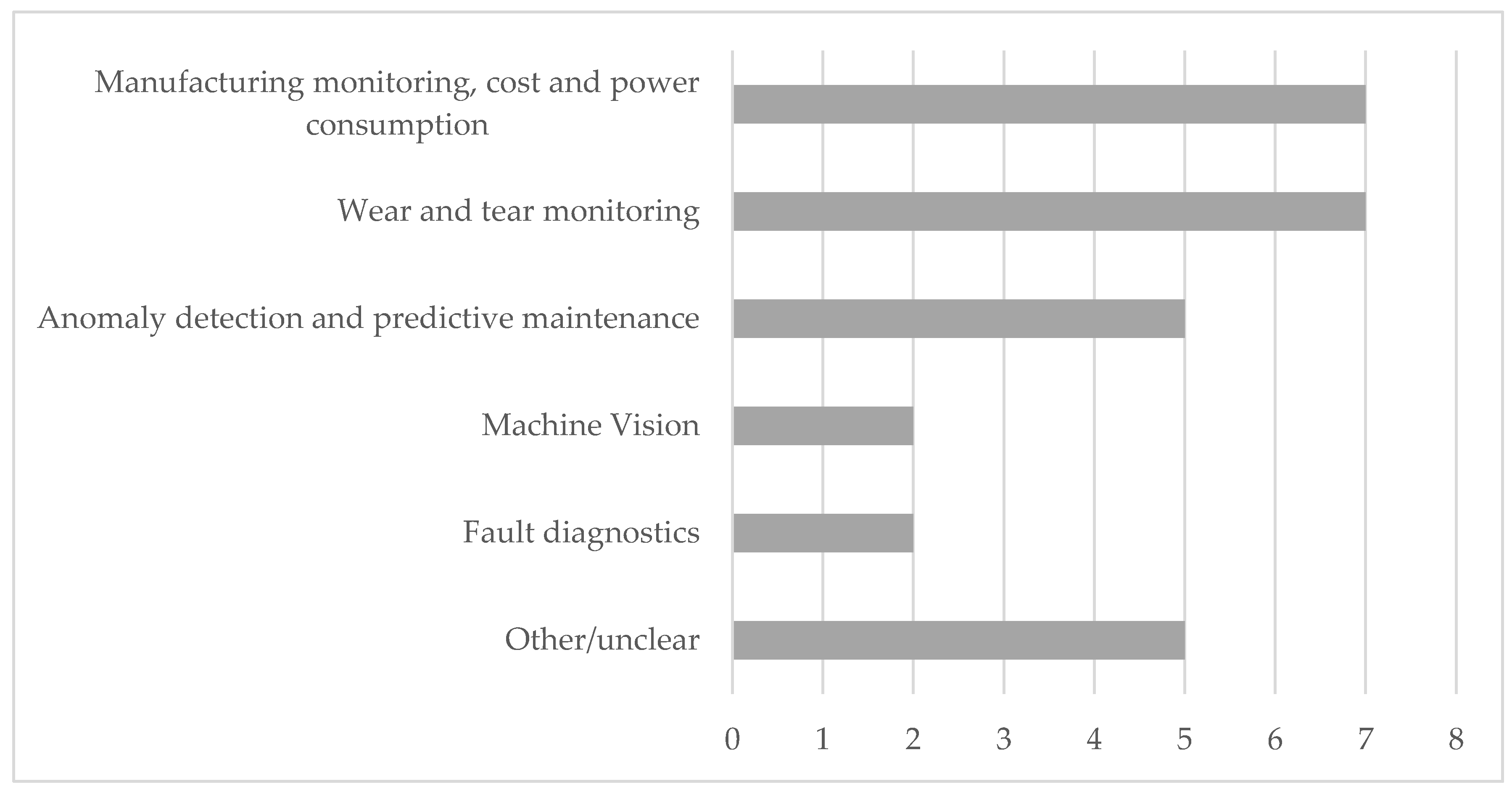
Figure 8.
Presented research outlook.
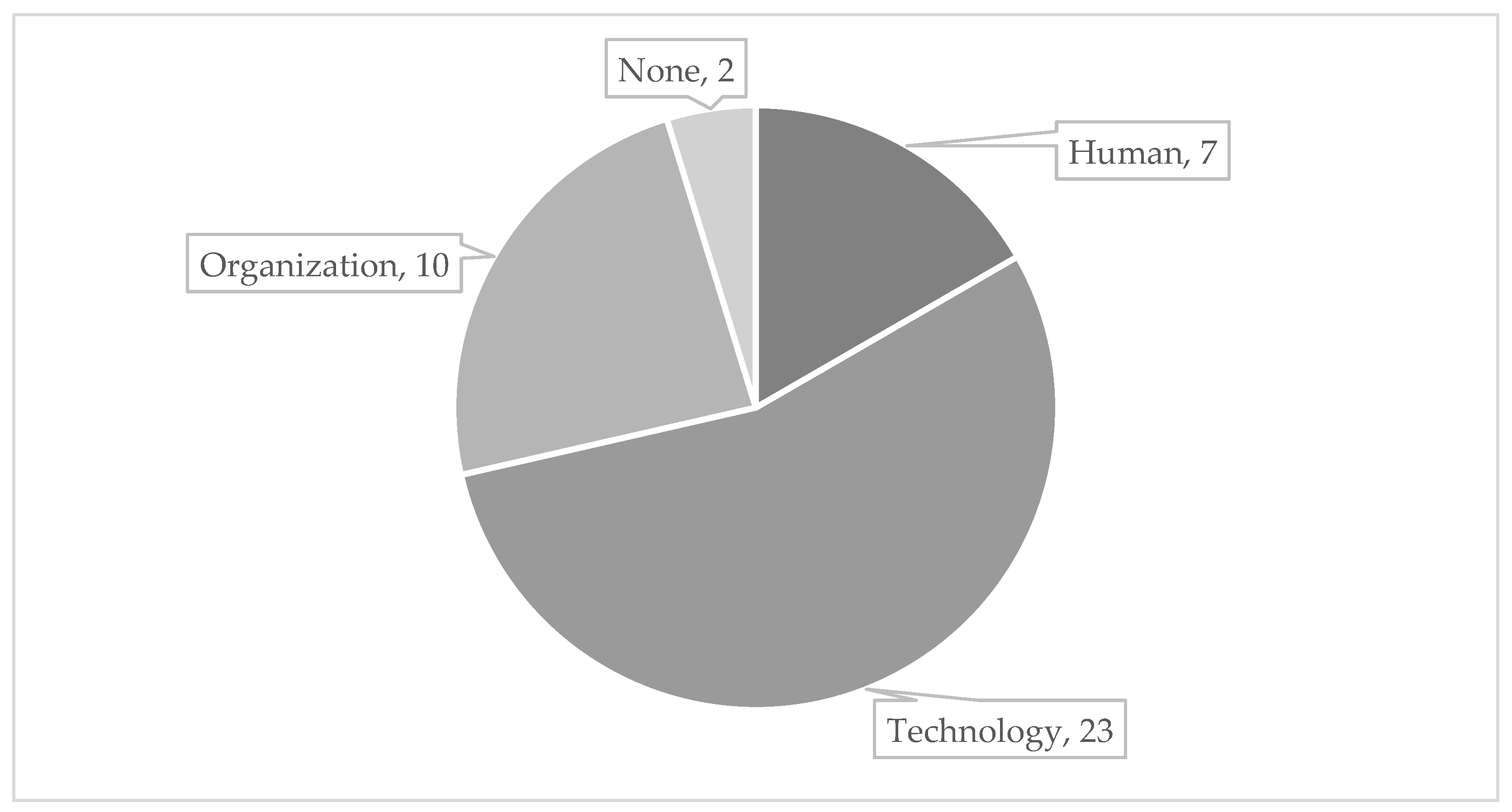
Figure 9.
Requirements for future DAS.
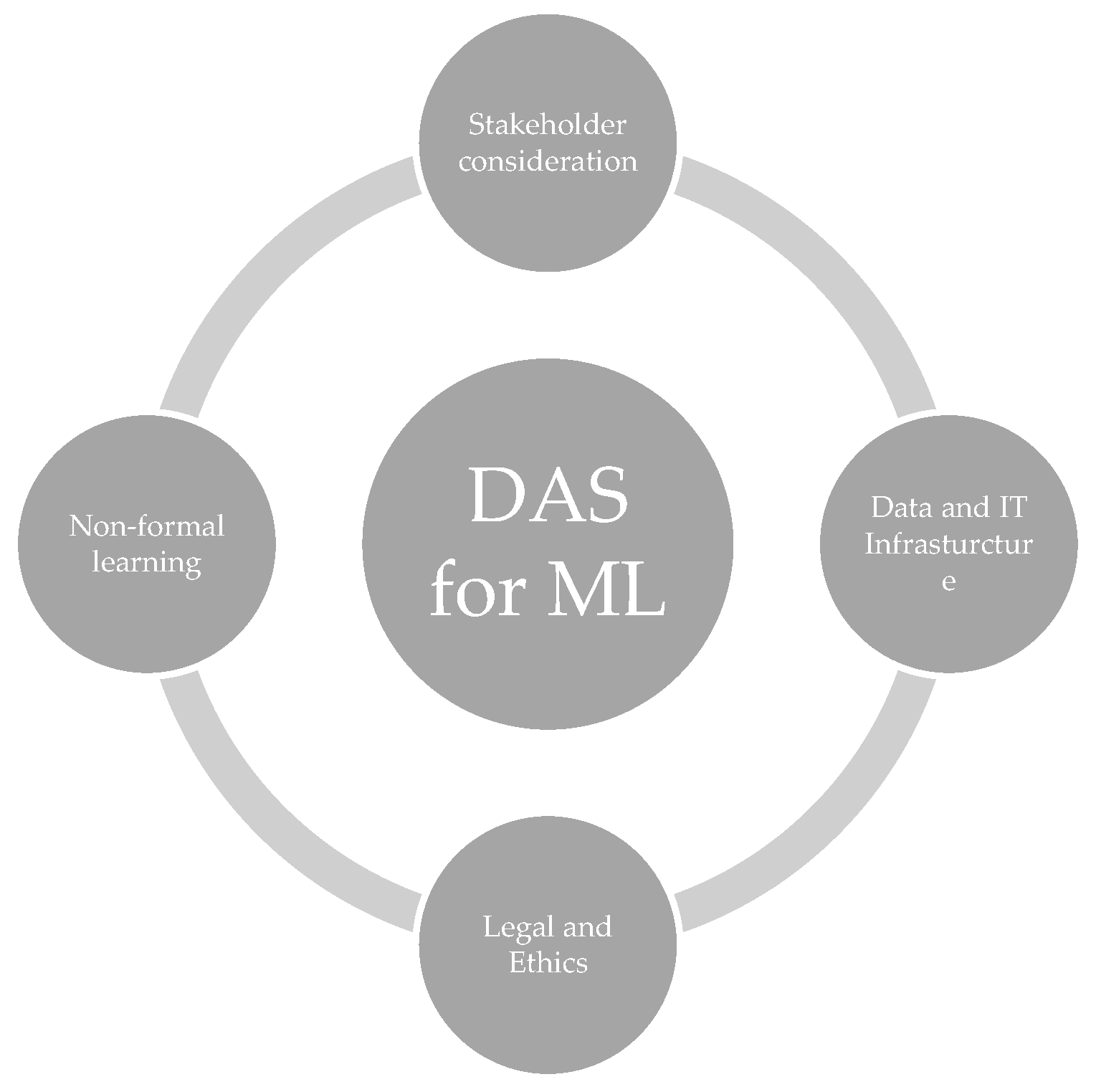

Table 1.
Inclusion and exclusion criteria.
| Inclusion criteria | Exclusion criteria |
|---|---|
|
|
Table 2.
Most relevant journals and conferences.
| Publication medium | Number |
|---|---|
| Journal of Manufacturing Systems | 4 |
| The International Journal of Advanced Manufacturing Technology | 3 |
| Procedia CIRP | 3 |
| Computers in Industry | 2 |
| Journal of Intelligent Manufacturing | 2 |
| IFIP Advances in Information and Communication Technology | 2 |
| Procedia Manufacturing | 2 |
Table 3.
Overview over the publications in alphabetical order of the titles.


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



