Submitted:
14 October 2024
Posted:
15 October 2024
You are already at the latest version
Abstract
Due to the influence of factors such as user consumption habits and manufacturer service quality, e-commerce platforms cannot push personalized product information to any consumer. This project studies the push of product information on e-commerce platforms based on deep neural networks. It mines the data of users' online shopping behaviors such as browsing, collecting, and adding to cart on e-commerce platforms, and pre-processes the mined user behavior data by cleaning, integrating, and normalizing them. It builds a deep bidirectional Transformer model to learn users' historical behavior data and predict the most probable products that meet users' behavior needs, thereby realizing the automatic push of product information on e-commerce platforms. The experimental results show that the F1 value of the push result of product information on e-commerce platforms under the method designed by this algorithm is 0.97, which confirms the effectiveness and superiority of this method.
Keywords:
Deep neural network
; E-commerce platform
; Personalization
; Product information push
1. Introduction
With the popularization of the Internet and mobile Internet, online shopping has become a popular way for modern young people to shop. Therefore, e-commerce platforms play an increasingly important role in people's lives. People can complete the purchase of goods conveniently and quickly through e-commerce platforms. However, with the continuous development of e-commerce platforms, the problem of product information push has become increasingly prominent. Product information push refers to the e-commerce platform pushing product information to users in various ways to attract users' attention and promote sales. Literature [1] considers the individual differences and information needs of different users and pushes personalized shopping information resources, making the one-stop information push service more personalized; Literature [2] introduced the BERT model for information mining of biological entities, solving the problems of complex content of biomedical entities and difficulty in extracting professional terminology features; Literature [3] builds modeling based on the collection and analysis of user behaviors and interests, achieves accurate push notifications, and improves the click-through rate of advertisements. To realize the personalized push of product information on e-commerce platforms, the key lies in the acquisition and push of user behavior data. Therefore, based on the above information push research, this paper will design a product information push method for e-commerce platforms based on deep neural networks.
This project proposes a method for pushing product information on e-commerce platforms based on deep neural networks. This method mines user behavior data on e-commerce platforms, classifies users using the K-means clustering algorithm, and combines the Transformer model to learn user historical behaviors and preferences, and achieves accurate prediction of user interests, thereby achieving the purpose of personalized product recommendations. The core process is listed as follows.
Figure 1.
Data mining to prediction process.
2. Mining Consumer Behavior Data on E-Commerce Platforms
When mining consumer behavior data on e-commerce platforms, this paper first needs to obtain the original data. Since the consumer behavior data on e-commerce platforms in most countries are private data, this paper mainly uses the consumer behavior data on e-commerce platforms given in a big data competition as the original data [4]. Then, a simple classification is performed on the original e-commerce platform consumer behavior data. Here, this paper mainly uses the K-means clustering algorithm for data classification. The specific process is as follows: first, an initial value is determined according to the actual characteristics of the e-commerce platform consumer behavior data, that is, the number of clusters; then, data points are randomly selected from the original data set as the centroid of the initial cluster, and the data is divided according to the distance between the remaining points in the data set and the centroid. After all the data are divided, classified sets of e-commerce platform user behavior data can be obtained, and then a second division is performed according to the distance between the new centroid in each set and the remaining data points. This process is repeated until the clustering result reaches the expected result, and the -means clustering algorithm is terminated to obtain the initial mining result of the e-commerce platform consumer behavior data. On this basis, this paper uses the DB index to evaluate the initial mining results of user behavior data on e-commerce platforms. The calculation formula is as follows:
In the formula: represents the index used to evaluate the optimal number of clusters of user behavior data on the e-commerce platform; represents the distance between the center point of cluster Si and the center point of cluster in the user behavior data of the e-commerce platform; and represent the average distance between samples of cluster and in the cluster division data , , …, , …, of the clustering results of the original e-commerce platform user behavior data, respectively. The specific calculation formula is as follows:
In the formula: represents the distance between sample data and in the corresponding cluster . In practice, the smaller the index obtained by formula (1), the better the clustering result of the e-commerce platform user behavior data, which means that the e-commerce platform user behavior data mined in this paper is more accurate. Therefore, according to the above steps, relatively accurate e-commerce platform user behavior data mining can be completed.
3. Preprocessing the consumer behavior data on e-commerce platforms
Assuming that the two different attribute values of the user behavior data of the e-commerce platform are and , the correlation between the two can be calculated according to the following formula:
In the formula: , represent the mean; represents the number of user behavior data on the e-commerce platform; , represent the standard deviation of the data source. After measuring the correlation between the original e-commerce platform user behavior data according to formula (3), the data can be integrated according to the relevant threshold. Finally, for those e-commerce platform user information behavior data with different dimensions and dimensions, in order to eliminate the impact of such data on the product information push results, this paper uses the following formula to perform minimum-maximum normalization on the data:
In the formula, and respectively represent the user behavior data of the e-commerce platform before and after normalization; and respectively represent the minimum and maximum values of the original user behavior data of the e-commerce platform. After preprocessing the original e-commerce user behavior data using the above content in the article, it is suitable for training deep neural networks, thereby providing a data basis for the subsequent automatic push of product information.
4. Automatic Push of Product Information Based on Deep Neural Network
The traditional push method is not only prone to misjudgment caused by human subjective factors, but also wastes a lot of time and affects the efficiency of product information push on the e-commerce platform. Therefore, this article introduces a deep neural network to automatically push product information on the e-commerce platform [5]. In recent years, deep learning technology has achieved remarkable results in many fields, especially in the medical field. It can not only be used for feature extraction [6,7] and analysis of medical examination images, furthermore, Bo [8] et al. have also tried to use it for snoring sound analysis, showing great potential in detecting and managing nocturnal breathing disorders. Literatures [9,10] even proposed the application of this model in deception detection prediction and cardiovascular disease (CVD) prediction. Therefore, this article introduces deep learning technology to build a deep two-way Transformer model, and uses this deep neural network model to learn the historical behaviors and preferences of e-commerce platform users, predict the user's interest in unknown products, thereby achieving accurate personalized recommendations [11]. In the deep bidirectional Transformer model constructed in this article, it mainly includes the global feature extraction module and the Transformers module. Among them, the global feature extraction module is mainly implemented through the BiLSTM network. Generally speaking, the LSTM network consists of a forgetting gate and a memory gate. And the output gate consists of three gate functions. The expression is as follows:
In the formula: , , represent the information in the forget gate, memory gate and output gate at time respectively; sigmoid represents the activation function; , , represent the weights of the gate functions respectively; represents the input information of the three gate functions at time ; , , represent the output information of the three gate functions at time t respectively; represents the information in the hidden layer at the previous time. When the LSTM network composed of the above three different gate functions is used to train and learn the time series information of the user behavior data of the e-commerce platform from the forward and reverse directions, the global features of the user behavior data can be extracted. Then the global feature information is input into the Transformers module for learning and prediction, thereby outputting the prediction results of the relevant product information. The Transformers module is a data processing module composed of many deep learning architectures. When the module receives the global feature information, it can perform parallel calculations on the information. In order to speed up the calculation speed of the module, this paper sets the function shown in the following formula:
In the formula: represents the predicted value of the probability that the product information on the e-commerce platform meets the user's needs; represents the linear mapping function; represents the activation function; represents the global feature information of the user behavior data on the e-commerce platform. After the operation of formula (6), the user's favorite probability corresponding to each product information can be obtained, and the product information with the maximum probability is output. In summary, this paper combines deep learning technology with neural networks to construct a deep bidirectional Transformer model. By inputting the mined and preprocessed user behavior historical data of the e-commerce platform into the model, the product information with the maximum probability that meets the user's behavior needs can be predicted, and the automatic push of product information can be completed.
5. Simulation Experiment
5.1. Experimental Preparation
In the above content, this paper introduces in detail the implementation process of the e-commerce platform information push method based on deep neural network. According to the characteristics of the push method designed in this paper, the e-commerce platform information push method based on collaborative filtering and the e-commerce platform information push method based on association rules are selected as the control group, and the simulation experiment is carried out to verify the feasibility and reliability of the push method designed in this paper.
First, the experimental environment shown in Table 1 is configured in MATLAB software. Then, user behavior data on a certain e-commerce platform is collected as experimental data. In order to better verify the product information recommendation effect under different methods, 50,000 user behavior data are obtained after mining and preprocessing in this simulation experiment. These data contain five user behaviors: browsing, collecting, adding to cart, repurchasing and commenting. The experimental data are divided into training data set and test data set according to the ratio of 6:4, which are 20,000 and 30,000 data respectively. Finally, the above push method is installed on the simulation platform, and the user behavior data is input for corresponding calculations to obtain different e-commerce platform product information push results. By comparing the experimental results, the push performance of different methods can be determined.
5.2. Computational Cost Evaluation
In order to evaluate the computational cost of this model in practical applications, this paper conducts a detailed evaluation of the following indicators:
1. Training time: Under the same hardware environment (such as GPU or CPU), record the time required for different push models to complete training. According to literature [12], training time is a key indicator to measure model complexity and computing resource usage. Especially for large-scale data sets, the training time of the model directly affects the cost of practical applications.
2. Inference time: Evaluate the inference time of each model when processing a single user behavior data, that is, the time required from input data to generating recommendation results. This indicator is particularly important for the real-time performance of the recommendation system. Literature [13] shows that the optimization of inference time can significantly improve the user experience.
3. Memory usage: This paper uses a memory monitoring tool to track the memory usage of the model in real time during the training and inference stages to ensure that the model can run stably under limited resource environments. Memory usage is an important factor to consider when deploying a model, especially when running on embedded devices or mobile devices.
The evaluation of the above indicators can more comprehensively compare the computational costs of different push methods under the same hardware environment in order to evaluate the actual feasibility. Finally, these push methods are installed on the simulation platform, and user behavior data is input for calculation to obtain the push results of product information on different e-commerce platforms.
5.3. Experimental Results
Since this simulation experiment uses different methods to push product information on e-commerce platforms, relevant indicators are needed to measure the performance of each method. The general evaluation indicators of information push performance include accuracy, recall rate, etc. The evaluation results obtained by this indicator are relatively one-sided, so this article selects the F1 evaluation indicator to measure the actual performance of each push method. The calculation formula of this indicator is shown as follows:
In the formula: represents the recall rate of the push results of the e-commerce platform product information, that is, the proportion of product information that users like and are pushed among all the products on the e-commerce platform that users like; represents the accuracy of the push results of the e-commerce platform product information, that is, the proportion of product information that users like and are recommended among all the product information pushed by the e-commerce platform to users. According to the above formula, the evaluation index can be regarded as the harmonic mean of the accuracy rate and the recall rate, so this paper uses this index to comprehensively measure the push results of the e-commerce platform product information. Generally, the larger the value, the better the recommendation effect of the product information. In this simulation experiment, the user behavior data is divided into 6 groups for the push experiment of the control variable. Simply put, under different lengths of the recommended product list, the value changes of the product information recommendation results obtained by the experimental group method and the control group method are evaluated. The specific results are shown in Figure 2.
From the experimental results in Figure 2, it can be seen that as the length of the recommended product list of the e-commerce platform gradually increases, the value of the e-commerce platform product information push results obtained by the control group method shows an overall upward trend, which means that the more product information is pushed, the greater the probability that the product in the push result is liked by the user. However, no matter how the length of the recommended product list increases, the value of the e-commerce platform product information push results obtained by the design method in this paper has always been at a high level, and is much higher than the control group method, indicating that this method can achieve personalized recommendation of e-commerce platform product information. The average value of the e-commerce platform product information push results under the design method is 0.97, which is 0.262 and 0.218 higher than the control group method. Therefore, for the push of e-commerce platform product information, the design method in this paper has greater advantages in accuracy, recall rate and value. The simulation experiment results also further verify the feasibility and reliability of the design method, which meets the actual needs of my country's e-commerce recommendation field.
6. Conclusions
Various e-commerce websites or e-commerce apps provide a convenient way for people to communicate online, but a significant volume of user activity and product information data makes it challenging to deliver product recommendations on e-commerce platforms. Therefore, based on the mining and preprocessing of e-commerce platform user behavior data, this paper uses deep neural networks to push product information on e-commerce platforms, and conducts experimental verification. The experimental results show that the design method in this paper can effectively improve the accuracy and recall rate of product information push on e-commerce platforms. In the future, this paper will further optimize the model structure and push strategy, improve the real-time performance of recommendation services, and provide e-commerce platforms with better product information push services. Li [14] preprocessed the public data on the Internet to form related data, which provides valuable accessibility real-time services for the society. Inspired by this, there is potential in the future to conduct e-commerce related research or model training based on the public e-commerce data such as Kaggle, especially in product recommendation, sales forecasting, user behavior analysis, etc.
References
- Boss, S. C. , & Nelson, M. L. (2013). Federated search tools: The next step in the quest for one-stop-shopping. In The Reference Collection (pp. 139-160). Routledge.
- Lee, Y. , Son, J., & Song, M. BertSRC: Transformer-based semantic relation classification. BMC Medical Informatics and Decision Making 2022, 22, 234. [Google Scholar]
- Al-Mashraie, M. , Chung, S. H., & Jeon, H. W. Customer switching behavior analysis in the telecommunication industry via push-pull-mooring framework: A machine learning approach. Computers & Industrial Engineering 2020, 144, 106476. [Google Scholar]
- MIN Tian, SUN Tao, LAI Furao, HOU Xiang. Application of persona to precise pushing of WeChat official accounts of scientific journals[J]. Chinese Journal of Scientific and Technical Periodicals 2021, 32, 1549–1555. [Google Scholar]
- Zhou, L. Product advertising recommendation in e-commerce based on deep learning and distributed expression. Electronic Commerce Research 2020, 20, 321–342. [Google Scholar] [CrossRef]
- Weimin, W. A. N. G. , Yufeng, L. I., Xu, Y. A. N., Mingxuan, X. I. A. O., & Min, G. A. O. Enhancing liver segmentation: A deep learning approach with eas feature extraction and multi-scale fusion. International Journal of Innovative Research in Computer Science & Technology 2024, 12, 26–34. [Google Scholar]
- Xiao, M., Li, Y., Yan, X., Gao, M., & Wang, W. (2024, March). Convolutional neural network classification of cancer cytopathology images: Taking breast cancer as an example. In Proceedings of the 2024 7th International Conference on Machine Vision and Applications (pp. 145-149).
- Dang, B. , Ma, D., Li, S., Qi, Z., & Zhu, E. Y. Deep Learning-Based Snore Sound Analysis for the Detection of Night-time Breathing Disorders.
- Li, P. , Abouelenien, M., Mihalcea, R., Ding, Z., Yang, Q., & Zhou, Y. (2024, May). Deception detection from linguistic and physiological data streams using bimodal convolutional neural networks. In 2024 5th International Conference on Information Science, Parallel and Distributed Systems (ISPDS) (pp. 263-267). IEEE.
- Ni, H. , Meng, S., Geng, X., Li, P., Li, Z., Chen, X.,... & Zhang, S. (2024). Time Series Modeling for Heart Rate Prediction: From ARIMA to Transformers. arXiv:2406.12199.
- Chandra, A. , Tünnermann, L., Löfstedt, T., & Gratz, R. Transformer-based deep learning for predicting protein properties in the life sciences. Elife 2023, 12, e82819. [Google Scholar] [PubMed]
- Strubell, E., Ganesh, A., & McCallum, A. (2020, April). Energy and policy considerations for modern deep learning research. In Proceedings of the AAAI conference on artificial intelligence (Vol. 34, No. 09, pp. 13693–13696).
- Han, S. , Pool, J., Tran, J., & Dally, W. Learning both weights and connections for efficient neural network. Advances in neural information processing systems 2015, 28. [Google Scholar]
- Li, Y., Yan, X., Xiao, M., Wang, W., & Zhang, F. (2023, December). Investigation of creating accessibility linked data based on publicly available accessibility datasets. In Proceedings of the 2023 13th International Conference on Communication and Network Security (pp. 77-81).
Figure 2.
Comparison of e-commerce platform information push results.
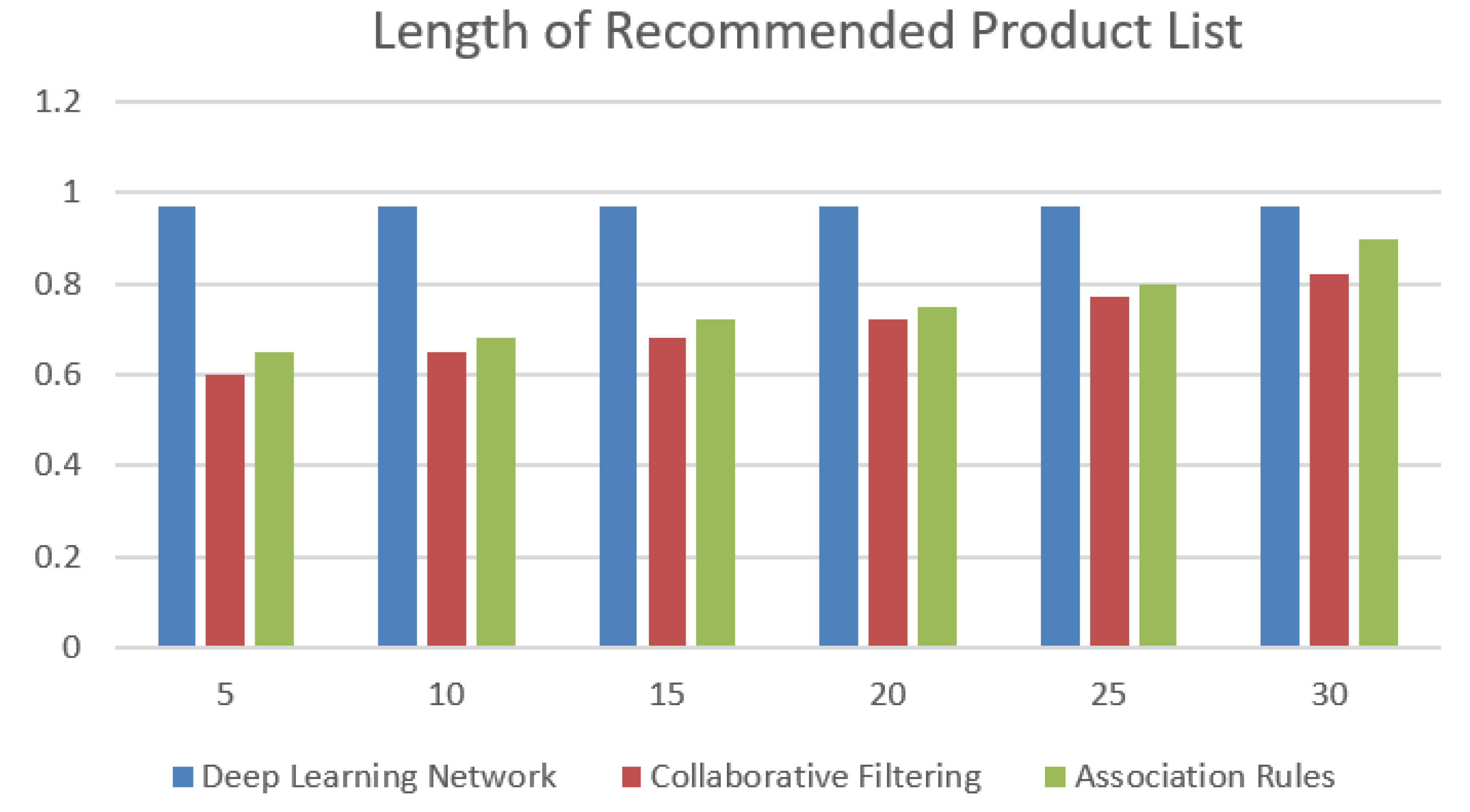

Table 1.
Simulation experiment environment parameter configuration.
| Project | Parameters | ||
| Operating system | Windows 10 | ||
| CPU | Intel(R)Core™i5-4590@3.30GHz | ||
| Graphics card | NVIDIA GeForce RTX 4060 | ||
| Memory | 64GB | ||
| Deep learning framework | tensorflow-gpu1.4.0 | ||
| Language | Python2.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



