6.1. Quantitative Analysis
Table 6 demonstrates that BanglaBERT demonstrates the highest performance across all metrics, with an accuracy of 92.25%, precision of 92.23%, recall of 92.27%, and an F1-score of 92.19%. This indicates its strong performance in hate speech detection. Bangla BERT Base performs slightly lower, with accuracy, precision, recall, and F1-score around 91.29%, 91.30%, 91.24%, and 91.27%, respectively, showing it is a strong model, though not as effective as BanglaBERT. mBERT has an accuracy of 91.28% and precision of 91.30%, but it excels in recall (92.24%) and F1-score (92.19%), making it comparable to BanglaBERT. XLM-RoBERTa shows an accuracy of 91.22% and precision of 91.36%, but its F1-score drops to 90.27%, indicating a slight trade-off between precision and recall. sahajBERT has the lowest performance among the evaluated models, with an accuracy of 90.67%, precision of 90.88%, recall of 90.14%, and an F1-score of 90.39%. Despite performing well, sahajBERT is less effective compared to the other models listed. This analysis highlights BanglaBERT as the top-performing model for the BD-SHS dataset, followed closely by mBERT due to its high recall and F1-score.
Table 6.
Performance of Pretrained Language Models on the BD-SHS Dataset
Table 6.
Performance of Pretrained Language Models on the BD-SHS Dataset
| Model |
Accuracy |
Precision |
Recall |
F1-Score |
| BanglaBERT |
0.9225 |
0.9223 |
0.9227 |
0.9219 |
| Bangla BERT Base |
0.9129 |
0.9130 |
0.9124 |
0.9127 |
| mBERT |
0.9128 |
0.9130 |
0.9224 |
0.9219 |
| XLM-RoBERTa |
0.9122 |
0.9136 |
0.9128 |
0.9027 |
| sahajBERT |
0.9067 |
0.9088 |
0.9014 |
0.9039 |
Table 7 shows that BanglaBERT emerges as the top performer in Bengali hate speech detection, excelling across several key metrics. It achieves the highest accuracy at 89.21%, indicating that it correctly classifies 89.21% of the samples. Its recall is equally impressive at 89.21%, demonstrating its effectiveness in identifying actual positive samples. BanglaBERT also leads with an F1-Score of 89.20%, reflecting a balanced performance between precision and recall. However, its precision is slightly lower at 88.05%, which means that while it identifies most positive samples, a small proportion of its positive predictions are incorrect. In close competition, Bangla BERT Base exhibits an accuracy of 88.53% and shines with the highest precision among the models at 89.03%. This indicates that it has a high ratio of true positive predictions to total predicted positives. Its recall and F1-Score are 88.53% and 88.49%, respectively, showcasing its reliability and balanced performance, though marginally behind BanglaBERT in recall and F1-Score. Both mBERT and sahajBERT present similar results, each attaining an accuracy of 87.93%. Their precision and F1-Scores are closely matched, with mBERT achieving a precision of 88.14% and an F1-Score of 87.92%, while sahajBERT scores 88.21% in precision and 87.91% in F1-Score. These results suggest that both models are competent, with minor variations in their ability to balance precision and recall. XLM-RoBERTa, while still competitive, ranks lowest among the evaluated models. It achieves an accuracy of 87.23%, precision of 87.32%, recall of 87.23%, and an F1-Score of 87.23%. Despite being at the lower end of the performance spectrum in this comparison, XLM-RoBERTa still offers a robust performance, underscoring the overall competitive nature of these models in handling Bengali hate speech detection.
Table 7.
Performance of Pretrained Language Models on the Bengali Hate Speech Dataset v1.0 & v2.0
Table 7.
Performance of Pretrained Language Models on the Bengali Hate Speech Dataset v1.0 & v2.0
| Model |
Accuracy |
Precision |
Recall |
F1-Score |
| BanglaBERT |
0.8921 |
0.8814 |
0.8921 |
0.8920 |
| Bangla BERT Base |
0.8853 |
0.8903 |
0.8853 |
0.8849 |
| mBERT |
0.8793 |
0.8805 |
0.8793 |
0.8792 |
| XLM-RoBERTa |
0.8723 |
0.8732 |
0.8723 |
0.8723 |
| sahajBERT |
0.8793 |
0.8821 |
0.8793 |
0.8791 |
Table 8 provides a comprehensive evaluation of several models on the Bengali Hate Dataset, revealing that Bangla BERT Base achieved the highest accuracy at 91.34%, indicating it correctly classified approximately 91.34% of the instances. Following closely, BanglaBERT and mBERT performed well with accuracies of 90.42% and 90.21%, respectively, while sahajBERT and XLM-RoBERTa had lower accuracies of 85.63% and 85.52%. In terms of precision, mBERT stands out with the highest value of 91.43%, suggesting a high rate of correctly identified positive instances, followed by Bangla BERT Base and BanglaBERT with similar high precision values of 91.76% and 90.87%. SahajBERT and XLM-RoBERTa, however, have lower precision values of 78.07% and 77.68%, indicating more false positives. Bangla BERT Base again leads with a recall of 91.12%, closely followed by BanglaBERT at 90.25% and mBERT at 90.84%, whereas sahajBERT and XLM-RoBERTa have lower recall values of 84.81% and 81.84%, respectively, indicating they miss more positive instances. The highest F1-Score is achieved by Bangla BERT Base at 91.54%, reflecting a strong balance between precision and recall, with BanglaBERT and mBERT also performing well with F1-Scores of 90.63% and 91.26%, respectively. Conversely, sahajBERT and XLM-RoBERTa have lower F1-Scores of 80.14% and 78.92%, reflecting their lower precision and recall. Overall, Bangla BERT Base demonstrates the best performance across all metrics, making it the most effective model for the Bengali Hate Dataset, while BanglaBERT and mBERT also show strong performance, particularly in precision and recall, making them reliable choices for hate speech detection. In contrast, sahajBERT and XLM-RoBERTa show comparatively lower performance across all metrics, suggesting they are more prone to false positives and false negatives, respectively.
Table 8.
Performance of Pretrained Language Models on the Bengali Hate Dataset
Table 8.
Performance of Pretrained Language Models on the Bengali Hate Dataset
| Model |
Accuracy |
Precision |
Recall |
F1-Score |
| BanglaBERT |
0.9042 |
0.9087 |
0.9025 |
0.9063 |
| Bangla BERT Base |
0.9134 |
0.9176 |
0.9112 |
0.9154 |
| mBERT |
0.9021 |
0.9143 |
0.9084 |
0.9126 |
| XLM-RoBERTa |
0.8552 |
0.7768 |
0.8184 |
0.7892 |
| sahajBERT |
0.8563 |
0.7807 |
0.8481 |
0.8014 |
This
Table 9 presents a comparative analysis of the performance metrics of two language models, GPT 3.5 Turbo and Gemini 1.5 Pro, across three distinct datasets in a zero-shot learning setting. In Dataset 1, GPT 3.5 Turbo achieves an accuracy of 86.61%, with precision, recall, and F1-score values closely aligned at 86.69%, 86.71%, and 86.65%, respectively, while Gemini 1.5 Pro achieves 82.20% accuracy, with precision, recall, and F1-score values around 82.18%, 82.24%, and 82.19%, respectively. Moving to Dataset 2, GPT 3.5 Turbo demonstrates an accuracy of 80.29%, with precision, recall, and F1-score values of approximately 80.31%, 80.24%, and 80.27%, respectively, whereas Gemini 1.5 Pro shows a slightly higher accuracy of 81.30%, maintaining consistent precision, recall, and F1-score values of 81.30%. In Dataset 3, GPT 3.5 Turbo achieves an accuracy of 83.31%, with precision, recall, and F1-score values all hovering around 83.30% and 83.31%, respectively, while Gemini 1.5 Pro demonstrates superior performance with an accuracy of 87.76%, achieving precision, recall, and F1-score values of 87.82%, 87.69%, and 87.75%, respectively. Overall, both models show competitive performance metrics across datasets, with GPT 3.5 Turbo maintaining stable performance and Gemini 1.5 Pro exhibiting noticeable improvements, particularly in Dataset 3. However, it is important to note that these zero-shot results generally indicate worse performance compared to models fine-tuned on specific tasks, such as pre-trained language models, due to the lack of task-specific training and adaptation.
Table 9.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a Zero-Shot Learning Scenario
Table 9.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a Zero-Shot Learning Scenario
| Dataset |
Model |
Accuracy |
Precision |
Recall |
F1-Score |
| Dataset 1 |
GPT 3.5 Turbo |
0.8661 |
0.8669 |
0.8671 |
0.8665 |
| |
Gemini 1.5 Pro |
0.8220 |
0.8218 |
0.8224 |
0.8219 |
| Dataset 2 |
GPT 3.5 Turbo |
0.8029 |
0.8031 |
0.8024 |
0.8027 |
| |
Gemini 1.5 Pro |
0.8130 |
0.8130 |
0.8130 |
0.8130 |
| Dataset 3 |
GPT 3.5 Turbo |
0.8331 |
0.8330 |
0.8331 |
0.8331 |
| |
Gemini 1.5 Pro |
0.8776 |
0.8782 |
0.8769 |
0.8775 |
Table 10 showcases the performance of two large language models, GPT-3.5 Turbo and Gemini-1.5 Pro, across three datasets in a 5-shot learning scenario. GPT-3.5 Turbo consistently outperforms Gemini-1.5 Pro on all datasets, with the most pronounced difference in Dataset 1 (approximately 2.5 percentage points across all metrics) and the least in Dataset 2 (less than 0.2 percentage points). For Dataset 1, GPT-3.5 Turbo achieved 93.79% Accuracy, 93.85% Precision, 93.73% Recall, and 93.79% F1-Score, while Gemini-1.5 Pro scored 91.29%, 91.30%, 91.24%, and 91.27%, respectively. On Dataset 2, GPT-3.5 Turbo’s metrics remained strong and consistent with those of Dataset 1, whereas Gemini-1.5 Pro improved significantly to 93.65% Accuracy, 93.71% Precision, 93.79% Recall, and 93.64% F1-Score. For Dataset 3, GPT-3.5 Turbo demonstrated its best performance with metrics around 94.65%, compared to Gemini-1.5 Pro’s 92.29% Accuracy, 92.30% Precision, 92.24% Recall, and 92.27% F1-Score. Overall, GPT-3.5 Turbo showed higher consistency and robustness across datasets, while Gemini-1.5 Pro exhibited more variation, indicating potential sensitivity to dataset characteristics. Notably, the 5-shot learning approach consistently outperforms both zero-shot and pretrained language models due to its ability to leverage a small amount of task-specific training data, allowing for improved adaptation to the task at hand.
Table 10.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 5-Shot Learning Scenario
Table 10.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 5-Shot Learning Scenario
| Dataset |
Model |
Accuracy |
Precision |
Recall |
F1-Score |
| Dataset 1 |
GPT 3.5 Turbo |
0.9379 |
0.9385 |
0.9373 |
0.9379 |
| |
Gemini 1.5 Pro |
0.9129 |
0.9130 |
0.9124 |
0.9127 |
| Dataset 2 |
GPT 3.5 Turbo |
0.9378 |
0.9382 |
0.9374 |
0.9378 |
| |
Gemini 1.5 Pro |
0.9365 |
0.9371 |
0.9379 |
0.9364 |
| Dataset 3 |
GPT 3.5 Turbo |
0.9465 |
0.9463 |
0.9467 |
0.9465 |
| |
Gemini 1.5 Pro |
0.9229 |
0.9230 |
0.9224 |
0.9227 |
Table 11 provides a detailed performance comparison of two advanced large language models, GPT-3.5 Turbo and Gemini 1.5 Pro, across three different datasets in a 10-shot learning scenario using four key evaluation metrics: Accuracy, Precision, Recall, and F1-Score. For Dataset 1, GPT-3.5 Turbo demonstrates strong performance with an accuracy of 94.53%, precision of 94.48%, recall of 94.57%, and F1-Score of 94.52%, outperforming Gemini 1.5 Pro which has an accuracy of 93.75%, precision of 93.72%, recall of 93.78%, and F1-Score of 93.76%. On Dataset 2, GPT-3.5 Turbo maintains high performance with an accuracy of 95.67%, precision of 95.63%, recall of 95.69%, and F1-Score of 95.66%, but is surpassed by Gemini 1.5 Pro, which achieves an accuracy of 96.67%, precision of 96.63%, recall of 96.69%, and F1-Score of 96.66%. For Dataset 3, GPT-3.5 Turbo again shows strong performance with an accuracy of 95.67%, precision of 95.63%, recall of 95.69%, and F1-Score of 95.66%, whereas Gemini 1.5 Pro performs less well with an accuracy of 93.20%, precision of 93.18%, recall of 93.24%, and F1-Score of 93.19%. Overall, GPT-3.5 Turbo generally outperforms Gemini 1.5 Pro on Datasets 1 and 3, while Gemini 1.5 Pro shows superior performance on Dataset 2, with trends in precision, recall, and F1-Score following the accuracy trends. The 10-shot learning approach consistently demonstrates better performance compared to 5-shot learning, zero-shot, and pretrained language models. This improvement is attributed to the increased amount of task-specific training data, allowing the models to better adapt and generalize to the evaluation tasks, resulting in higher accuracy and more balanced precision-recall trade-offs.
Table 11.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 10-Shot Learning Scenario
Table 11.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 10-Shot Learning Scenario
| Dataset |
Model |
Accuracy |
Precision |
Recall |
F1-Score |
| Dataset 1 |
GPT 3.5 Turbo |
0.9453 |
0.9448 |
0.9457 |
0.9452 |
| |
Gemini 1.5 Pro |
0.9375 |
0.9372 |
0.9378 |
0.9376 |
| Dataset 2 |
GPT 3.5 Turbo |
0.9567 |
0.9563 |
0.9569 |
0.9566 |
| |
Gemini 1.5 Pro |
0.9667 |
0.9663 |
0.9669 |
0.9666 |
| Dataset 3 |
GPT 3.5 Turbo |
0.9567 |
0.9563 |
0.9569 |
0.9566 |
| |
Gemini 1.5 Pro |
0.9320 |
0.9318 |
0.9324 |
0.9319 |
In the comparative analysis presented in
Table 12, GPT 3.5 Turbo and Gemini 1.5 Pro were evaluated across three distinct datasets in a 15-shot learning scenario. Across Dataset 1, GPT 3.5 Turbo slightly outperformed Gemini 1.5 Pro with higher accuracy (97.33% compared to 97.11%), precision (97.31% compared to 97.02%), recall (97.35% compared to 97.15%), and F1-score (97.33% compared to 97.13%). Moving to Dataset 2 and Dataset 3, GPT 3.5 Turbo consistently demonstrated superior performance with noticeably higher accuracy, precision, recall, and F1-scores compared to Gemini 1.5 Pro. Specifically, in Dataset 2, GPT 3.5 Turbo achieved an accuracy and F1-score of 98.42%, while Gemini 1.5 Pro scored 97.23% and 97.23% respectively. In Dataset 3, GPT 3.5 Turbo maintained high metrics with 98.53% accuracy and 98.53% F1-score, whereas Gemini 1.5 Pro achieved 97.47% and 97.48%. This comprehensive analysis highlights GPT 3.5 Turbo’s consistent superiority over Gemini 1.5 Pro across diverse datasets in the 15-shot learning scenario. The 15-shot learning approach demonstrates superior performance compared to 5-shot and 10-shot learning methods, as well as zero-shot and pretrained language models. This improvement can be attributed to the increased availability of task-specific training data, allowing the models to refine their understanding and optimization for the evaluation tasks, resulting in higher accuracy and precision-recall balance. Additionally, the 15-shot learning scenario benefits from a larger sample of task-specific examples during training, facilitating deeper model adaptation and more accurate predictions.
Table 12.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 15-Shot Learning Scenario
Table 12.
Performance Comparison of GPT 3.5 Turbo and Gemini 1.5 Pro on Three Datasets in a 15-Shot Learning Scenario
| Dataset |
Model |
Accuracy |
Precision |
Recall |
F1-Score |
| Dataset 1 |
GPT 3.5 Turbo |
0.9733 |
0.9731 |
0.9735 |
0.9733 |
| |
Gemini 1.5 Pro |
0.9711 |
0.9702 |
0.9715 |
0.9713 |
| Dataset 2 |
GPT 3.5 Turbo |
0.9842 |
0.9840 |
0.9844 |
0.9842 |
| |
Gemini 1.5 Pro |
0.9723 |
0.9727 |
0.9726 |
0.9723 |
| Dataset 3 |
GPT 3.5 Turbo |
0.9853 |
0.9851 |
0.9855 |
0.9853 |
| |
Gemini 1.5 Pro |
0.9747 |
0.9743 |
0.9746 |
0.9748 |
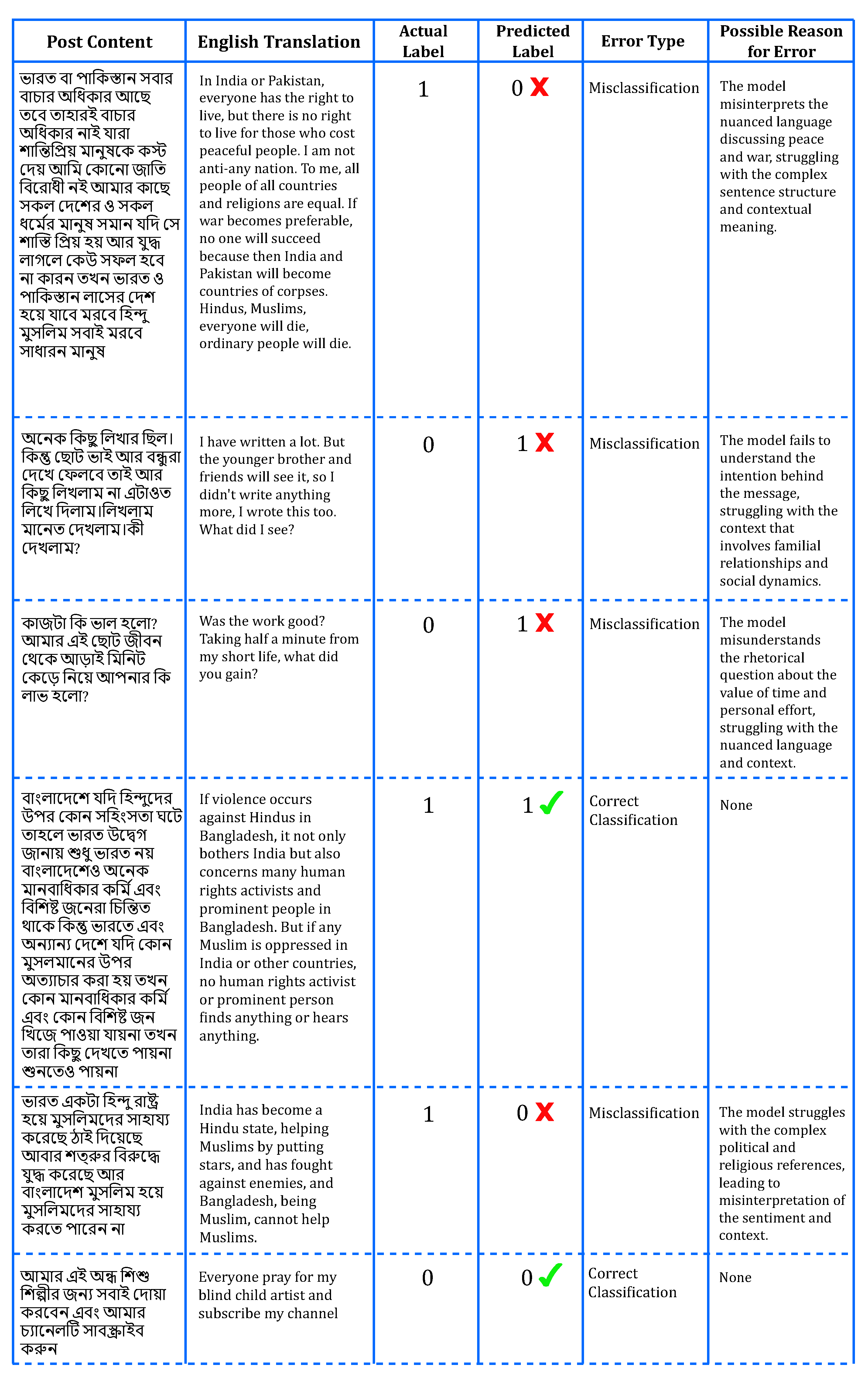
Figure 11 illustrates an error analysis of Bangla language social media posts evaluated by PLMs, emphasizing the critical role of error analysis in evaluating model performance. Firstly, it sheds light on the model’s proficiency in interpreting nuanced language, evident in its misclassification of sentiments related to war, equality, and peace in the first post. This highlights the necessity for the model to better comprehend complex socio-political discussions for accurate sentiment analysis and contextual understanding in sensitive topics. Secondly, error analysis identifies specific challenges faced by the model, such as its difficulty in distinguishing neutral or rhetorical statements from positive sentiments, as observed in the misclassifications of the second and third posts. Understanding these challenges is pivotal for refining model training strategies to enhance its performance in real-world applications where precise sentiment classification is crucial. Moreover, correct classifications, exemplified by the fourth and sixth posts, validate the model’s capability to accurately interpret sentiments concerning human rights issues and neutral content, respectively. These instances underscore areas where the model excels and provides reliable predictions, bolstering confidence in its performance. Conversely, the misclassification of the fifth post, which discusses intricate political and religious themes, exposes significant hurdles in the model’s comprehension of such culturally specific references. This insight underscores the need for targeted improvements to broaden the model’s understanding of diverse content, thereby enhancing its overall reliability in Bangla language processing tasks. Ultimately, conducting thorough error analysis yields actionable insights for enhancing PLMs’ proficiency in sentiment analysis and contextual understanding of Bangla social media discourse. By addressing identified challenges and leveraging strengths, these efforts aim to bolster the models’ accuracy and effectiveness in handling complex linguistic nuances and socio-cultural contexts.
Figure 13.
Error Analysis of Pre-Trained Language Models on Bangla Hate Speech Detection.
Figure 13.
Error Analysis of Pre-Trained Language Models on Bangla Hate Speech Detection.