
Submitted:
30 October 2024
Posted:
02 November 2024
You are already at the latest version
Abstract
Chatter, a self-excited vibration phenomenon, is a critical challenge in high-speed machining operations, affecting tool life, surface quality, and overall process efficiency. While ML models trained on simulated data have shown promise in detecting chatter, their real-world applicability remains uncertain due to discrepancies between simulated and actual machining environments. This study bridges the gap by validating a ML-based chatter detection system using both simulated and real-world data. We apply a Random Forest classification model trained on over 140,000 simulated machining datasets, incorporating techniques like Operational Modal Analysis (OMA), Receptance Coupling Substructure Analysis (RCSA), and Transfer Learning (TL) to adapt the model for real-world operational data. The model is validated against 1,600 real-world machining datasets, achieving an accuracy of 86.1%, with strong precision and recall scores. Our results demonstrate the model’s robustness and potential for practical implementation in industrial settings, highlighting challenges such as sensor noise and variability in machining conditions. This work advances the use of predictive analytics in machining processes, offering a data-driven solution to improve manufacturing efficiency through more reliable chatter detection.
Keywords:
real world
; predictive analytics
; vibration analysis
; chatter
; stability
; additive manufacturing
1. Introduction
Chatter, a self-excited vibration phenomenon occurring during machining processes, poses significant challenges to manufacturing efficiency and product quality [1,2]. It manifests as unwanted oscillations between the cutting tool and the workpiece, leading to poor surface finishes, dimensional inaccuracies, increased tool wear, and potential damage to machine components [3]. Detecting and mitigating chatter is crucial for maintaining high precision and productivity in modern machining operations.
Traditional methods for chatter detection have relied on analytical models and signal processing techniques, which often require extensive domain knowledge and are limited by the assumptions inherent in their formulations [4]. These methods may not generalize well across different machining setups or accommodate the variability present in real-world operations [5].
In recent years, machine learning (ML) has emerged as a powerful tool for chatter detection, offering data-driven approaches that can learn complex patterns from vast amounts of data [6]. ML models, such as Random Forest classifiers and neural networks, have shown promise in identifying chatter by analyzing vibration signals and other sensor data [7]. These models can adapt to different machining conditions and provide real-time monitoring capabilities, enhancing predictive maintenance strategies [8].
In our previous work [9], we developed a Random Forest classifier trained on extensive simulated machining datasets to predict chatter occurrences. The model demonstrated high accuracy in simulation environments, indicating its potential for effective chatter detection. Building upon this foundation, we enhanced the model by incorporating additional simulated data and advanced modeling techniques in [10], further improving its predictive performance.
However, models trained solely on simulated data may not fully capture the complexities and variabilities of real-world machining processes. Factors such as sensor noise, environmental conditions, and machine-specific characteristics can affect the performance of these models when applied outside the simulated environment [11]. Therefore, it is essential to validate and adapt these models using real-world data to ensure their practical applicability and robustness in operational settings.
This study aims to bridge the gap between simulation and practice by applying the previously developed models to real-world machining datasets. By evaluating the models’ performance on actual vibration data collected from operational milling machines, we seek to assess their effectiveness, identify challenges in transitioning from simulated to real-world data, and provide insights into enhancing model robustness for practical applications.
1.1. Previous Work
In our prior research, we focused on developing ML models for chatter detection in machining processes using simulated data. In [9], we introduced a Random Forest classifier trained on a comprehensive dataset generated from simulations of milling operations. The simulated data captured various machining conditions, including different spindle speeds, feed rates, and depths of cut, providing a rich environment for the model to learn the complex patterns associated with chatter occurrences.
The initial model demonstrated promising results, achieving high accuracy in predicting chatter within the simulated environment. The use of Random Forests allowed us to effectively handle high-dimensional feature spaces and provided insights into feature importance, which is crucial for understanding the factors contributing to chatter [12].
Building upon this foundation, our subsequent study [10] expanded the dataset to include over 140,000 simulated instances and incorporated advanced modeling techniques such as Operational Modal Analysis (OMA), Transfer Learning (TL), and Receptance Coupling Substructure Analysis (RCSA). The integration of OMA enabled the extraction of modal parameters from the system’s operational responses, enhancing the model’s ability to capture the dynamic behavior of the machining process [13]. TL was employed to improve the model’s adaptability to new and unseen machining conditions, addressing the challenge of varying operational environments [14]. RCSA provided a deeper understanding of the dynamic interactions within the tool-holder assembly, contributing to more accurate predictions of machining stability [15].
The enhanced model exhibited substantial improvements in predictive accuracy and robustness, particularly in scenarios involving complex machining conditions. However, both studies were conducted using simulated data, which, while comprehensive, may not fully represent the variability and unpredictability inherent in real-world machining processes.
Transitioning from simulation to real-world applications presents challenges due to differences in data distributions, noise levels, and unmodeled dynamics [11]. Models trained exclusively on simulated data may experience performance degradation when applied to operational environments where factors such as sensor noise, machine wear, and environmental conditions introduce additional complexity [16].
Recognizing these limitations, the current study aims to validate the models developed in our previous work using real-world machining data. By applying the models to actual vibration signals collected from operational milling machines, we seek to assess their practical applicability, identify any performance gaps, and refine the models to enhance their robustness in real-world settings.
1.2. Problem Statement
While our previous studies have demonstrated the potential of ML models, specifically Random Forest classifiers, in predicting chatter using simulated data [9,10], a critical gap remains in validating these models with real-world machining data. Simulated datasets, despite their controlled conditions and comprehensive coverage of various machining scenarios, may not fully encapsulate the complexities and uncertainties inherent in actual machining environments [11].
Data collected from operational machining processes are characterized by factors such as sensor noise, machine tool wear, environmental variations, and inconsistencies in material properties [8]. These factors introduce discrepancies between simulated and real-world data distributions, which can adversely affect the performance of models trained exclusively on simulations [16]. Additionally, unmodeled dynamics and unforeseen interactions in physical systems may lead to challenges that are not present or are oversimplified in simulations [17].
The transition from simulated to real-world data poses several challenges:
- Data Discrepancies: Differences in data distributions between simulated and real-world datasets can lead to reduced model performance due to issues like covariate shift and sample selection bias [18].
- Sensor Noise and Data Quality: Real-world data are susceptible to various types of noise and artifacts that are typically absent in simulated data, necessitating advanced preprocessing and noise reduction techniques [19].
- Feature Relevance: Features that are significant in simulated environments may not hold the same importance in real-world settings, requiring reevaluation of feature selection and extraction methods [20].
- Model Generalization: Ensuring that the model generalizes well to unseen real-world data is essential for practical applicability, highlighting the need for model adaptation and validation strategies [14].
Addressing these challenges is crucial for the successful deployment of chatter detection models in industrial settings. Without validation on real-world data, the models’ effectiveness remains uncertain, limiting their practical utility. Therefore, there is a pressing need to evaluate the performance of our previously developed models using actual machining data and to refine them as necessary to enhance their robustness and generalizability in operational environments.
This study seeks to fill this gap by:
- Collecting and processing 1,600 real-world machining datasets encompassing a variety of operational conditions.
- Applying the previously trained models to these datasets to assess their predictive performance.
- Identifying discrepancies between simulated and real-world data and their impact on model accuracy.
- Proposing solutions to address these discrepancies, including model adaptation techniques and enhanced feature extraction methods.
By tackling these challenges, we aim to bridge the gap between simulation and reality, providing insights into the practical applicability of ML models for chatter detection and contributing to the advancement of predictive maintenance in machining processes.
1.3. Objectives
The primary objective of this study is to validate and assess the practical applicability of ML models developed using simulated machining data when applied to real-world machining environments. Specifically, we aim to:
- Evaluate Model Performance: Assess the predictive accuracy, precision, recall, F1-score, and AUC-ROC of the models when applied to real-world data, and compare these results with the performance achieved on simulated data.
- Identify and Analyze Discrepancies: Investigate any discrepancies in model performance between simulated and real-world data, analyzing factors such as sensor noise, data variability, and differences in feature distributions.
- Enhance Model Robustness: Propose and implement strategies to improve the models’ robustness and generalizability in real-world applications. This may include advanced data preprocessing techniques, feature engineering, or model adaptation methods such as domain adaptation [21].
- Provide Practical Insights: Offer insights into the challenges and considerations involved in transitioning ML models from simulated to operational environments, contributing to the development of more reliable chatter detection systems in the machining industry.
By achieving these objectives, this study seeks to bridge the gap between simulation and practice, enhancing the reliability of ML models for chatter detection in real-world machining processes. The outcomes are expected to inform best practices for deploying predictive models in industrial settings, ultimately contributing to improved manufacturing efficiency and product quality.
1.4. Contributions
This study makes several key contributions to the field of machining chatter detection and predictive maintenance:
- Validation of Simulation-Trained Models on Real-World Data: We provide a comprehensive evaluation of ML models trained on simulated machining data when applied to real-world machining operations. This validation assesses the models’ effectiveness in practical settings, addressing a significant gap in existing research [22].
- Analysis of Transition Challenges from Simulation to Reality: By identifying and analyzing the discrepancies between simulated and real-world data, we shed light on the challenges inherent in transferring models across domains. This includes addressing issues related to data distribution differences, noise levels, and feature relevance [23].
- Enhancement of Model Robustness through Adaptation Techniques: We propose and implement strategies to improve the robustness and generalizability of the models in real-world applications. This includes the use of advanced data preprocessing, feature engineering, and model adaptation methods to mitigate the impact of domain discrepancies [24].
- Practical Insights for Industrial Implementation: The findings offer valuable insights for practitioners in the machining industry, providing guidance on deploying ML models for chatter detection in operational environments. This contributes to the development of more reliable and efficient predictive maintenance systems [25].
- Contribution to Machine Learning Methodologies: From a methodological perspective, the study advances the understanding of how ML models can be adapted and validated across different data domains, contributing to the broader field of TL and domain adaptation in industrial applications [26].
By achieving these contributions, the study not only demonstrates the practical applicability of simulation-trained models but also provides a framework for future research and development in the field of machining process monitoring and control.
2. Literature Review
2.1. Chatter Detection in Machining
Chatter adversely affects surface finish, dimensional accuracy, tool life, and overall productivity [27]. The detection and mitigation of chatter have been subjects of extensive research over the past several decades. Traditional methods for chatter detection primarily involve analytical and signal processing techniques applied to real-world data collected during machining operations.
Early approaches to chatter detection focused on stability analysis using analytical models based on machining dynamics [1]. The regenerative chatter theory introduced by Tobias and Fishwick [28] provided a foundational understanding of how vibrations from previous cutting passes influence current ones, leading to instability. Tlusty [29] further developed methods to predict stability lobes, enabling the selection of cutting parameters that avoid chatter.
Signal processing techniques have been widely used to detect chatter by analyzing vibration signals from sensors mounted on machine tools. Methods such as time-domain analysis, frequency-domain analysis, and time-frequency analysis have been employed to identify chatter signatures [2]. For instance, Fourier Transform (FT) and Short-Time Fourier Transform (STFT) have been utilized to observe changes in the frequency spectrum indicative of chatter onset [30]. Wavelet Transform (WT) methods have also been applied to capture transient features of chatter in the time-frequency domain [31].
However, these traditional methods often require expert knowledge to interpret signals and may not generalize well across different machining conditions or machine tools [32]. The complexity and variability of real-world machining environments pose challenges for these approaches, limiting their effectiveness in industrial applications.
Recent advancements have seen the emergence of ML techniques as powerful tools for chatter detection. ML models can learn complex patterns from large datasets, making them well-suited to handle the non-linear and stochastic nature of chatter phenomena [33]. Supervised learning algorithms, such as Support Vector Machines (SVM) [34] and Artificial Neural Networks (ANN) [8], have been applied to classify machining states and predict chatter occurrences based on features extracted from sensor data.
Deep learning models, including Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN), have also been explored for their ability to automatically extract hierarchical features from raw data [35]. These models have demonstrated improved performance in chatter detection tasks, particularly when dealing with large and complex datasets [36].
Despite the promise of ML methods, challenges remain in their application to real-world machining data. Issues such as data scarcity, imbalance, noise, and variability can affect model training and performance [37]. Moreover, models trained on specific machines or conditions may not generalize well to other settings, necessitating strategies like TL and domain adaptation to enhance their applicability [14].
This study builds upon this body of work by applying ML models developed using simulated data to real-world machining environments. By addressing the challenges associated with transitioning from simulation to reality, we aim to contribute to the advancement of chatter detection methodologies and their practical implementation in industry.
2.2. Machine Learning in Machining Processes
The application of ML in machining processes has gained significant attention in recent years, driven by the increasing availability of data and advancements in computational capabilities [6]. ML techniques offer powerful tools for modeling complex, non-linear relationships inherent in machining operations, enabling improved process monitoring, fault diagnosis, and predictive maintenance [38].
2.2.1. Supervised Learning Methods
Supervised learning algorithms have been widely used for tool condition monitoring and fault diagnosis in machining. Support Vector Machines (SVM) have been employed to classify tool wear states based on features extracted from vibration signals, acoustic emissions, and cutting forces [39]. Decision Trees and Random Forests have also been applied to predict surface roughness and tool wear, leveraging their ability to handle high-dimensional data and provide insights into feature importance [40].
Artificial Neural Networks (ANN) have been utilized for modeling and prediction tasks in machining processes due to their capacity to approximate complex functions [41]. For instance, ANNs have been trained to predict cutting forces, surface finish, and dimensional accuracy based on input parameters such as spindle speed, feed rate, and depth of cut [42].
2.2.2. Unsupervised Learning and Clustering
Unsupervised learning methods, including clustering algorithms like K-means and hierarchical clustering, have been used to detect anomalies and patterns in machining data without the need for labeled datasets [43]. These techniques facilitate the identification of novel fault conditions and the segmentation of machining states based on similarities in data features [44].
2.2.3. Deep Learning Approaches
Deep learning, a subset of ML involving neural networks with multiple layers, has shown promise in automatically extracting hierarchical features from raw sensor data [45]. Convolutional Neural Networks (CNN) have been applied to time-series data for tool condition monitoring, achieving higher accuracy compared to traditional feature-based methods [46]. Recurrent Neural Networks (RNN), particularly Long Short-Term Memory (LSTM) networks, have been effective in modeling temporal dependencies in sequential data, improving predictions of tool wear progression [47].
Autoencoders and Generative Adversarial Networks (GAN) have been explored for unsupervised feature learning and anomaly detection in machining processes [48]. These models can learn compressed representations of data, highlighting essential features that contribute to fault detection and process optimization.
2.2.4. Challenges and Considerations
Despite the advancements, several challenges persist in applying ML to machining processes. Data quality and availability are critical issues; acquiring sufficient labeled data for supervised learning can be difficult due to the cost and time associated with experiments [49]. Additionally, variability in machining conditions and equipment can affect model generalization, necessitating strategies such as TL and domain adaptation [50].
The interpretability of complex models, particularly deep learning networks, is another concern, as understanding the decision-making process is important for gaining trust in industrial applications [51]. Efforts are being made to develop explainable AI techniques to address this issue.
2.2.5. Application to Chatter Detection
In the context of chatter detection, ML models have been applied to classify stable and unstable cutting conditions. Features extracted from vibration signals, such as statistical measures, frequency components, and wavelet coefficients, serve as inputs to classifiers like SVM, ANN, and Random Forests [52]. Deep learning models have also been employed to automatically learn features relevant to chatter from raw sensor data, enhancing detection accuracy [53].
2.3. Simulation vs. Real-World Data
Simulated data play a vital role in machining research, providing a controlled environment to develop and test models for chatter detection and machining stability [2]. Through simulations, researchers can systematically vary machining parameters and study their effects without the costs and risks associated with physical experiments [8].
However, transitioning models developed on simulated data to real-world applications introduces challenges due to inherent differences between simulated and actual machining data [11]. Real-world data are influenced by factors such as sensor noise, environmental variability, machine wear, and unmodeled dynamics, which are often not fully captured in simulations [19].
One significant difference is the presence of measurement noise and disturbances in real-world data [8]. Real sensors are subject to limitations in accuracy and are affected by external factors, leading to noisy data that can obscure important patterns necessary for accurate chatter detection [37].
Moreover, real-world machining processes involve complex interactions and variability that are difficult to model entirely in simulations [2]. Factors such as tool wear, material inconsistencies, and temperature fluctuations can significantly affect the process and are often simplified in simulated environments [8].
The discrepancies between simulated and real-world data can result in differences in data distributions, feature importance, and ultimately, model performance [18]. Models trained exclusively on simulated data may not generalize well to real-world scenarios due to domain shift, where the statistical properties of the training data differ from those of the application environment [14].
To address these challenges, techniques such as TL and domain adaptation have been proposed to enhance model transferability between domains [26]. These methods aim to adjust models to account for differences in data distributions, improving their performance on real-world data [11].
In this study, we focus on applying ML models developed on simulated data to real-world machining datasets, exploring the impact of domain discrepancies on model performance, and investigating strategies to enhance model robustness and adaptability in practical applications.
2.4. Gap Identification
Despite significant advancements in the application of ML techniques for machining process monitoring and chatter detection, a critical gap exists in the validation of simulation-trained models using real-world machining data. As discussed in previous sections, many studies have developed models based on simulated data or controlled laboratory experiments, demonstrating promising results in predicting machining stability and detecting chatter [9,10,53].
However, these models often face challenges when applied to real-world industrial environments. Factors such as sensor noise, machine tool variability, environmental conditions, and unmodeled dynamics introduce complexities that are not fully captured in simulated datasets [11,37]. The discrepancies between simulated and actual machining data can lead to reduced model performance, limiting the practical applicability of these predictive models [18].
Currently, there is a paucity of empirical studies that:
- Systematically Evaluate Model Transferability: Few studies have systematically assessed how models trained on simulated data perform when applied to real-world machining operations, identifying the factors that contribute to performance degradation.
- Address Domain Discrepancies: Limited research has been conducted on developing and implementing strategies to mitigate the impact of domain discrepancies between simulated and real-world data in the context of machining processes.
- Provide Practical Implementation Guidelines: There is a need for comprehensive guidelines and best practices for adapting and deploying simulation-trained ML models in industrial settings for chatter detection and machining process monitoring.
This gap hinders the advancement of smart manufacturing initiatives and the adoption of advanced predictive maintenance strategies in the machining industry. By addressing this gap, researchers and practitioners can enhance the reliability and robustness of ML models, facilitating their integration into real-world manufacturing processes and contributing to improved productivity and product quality.
Therefore, this study aims to bridge this gap by validating the performance of ML models developed using simulated data on real-world machining datasets, analyzing the challenges encountered, and proposing solutions to enhance model robustness and applicability in industrial environments.
3. Methodology
3.1. Real-World Data Collection
To validate the ML models developed in our previous studies, we collected real-world machining data using a custom-built three-axis CNC milling machine. The machine was equipped with a Marposs MEMS (Micro-Electro-Mechanical Systems) vibration sensor for high-fidelity data acquisition. An image of the experimental setup is shown in Figure 1.
The CNC milling machine was designed to perform precise machining operations necessary for data collection. It features three linear axes (X, Y, and Z) with high-precision ball screws and linear guides, ensuring accurate and repeatable movements. The spindle is capable of variable speeds ranging from 1,000 to 16,000 RPM, allowing for a wide range of cutting conditions.
3.1.1. Sensor Integration and Data Acquisition
A Marposs MEMS vibration sensor was installed on the spindle housing to capture vibrational responses during machining. The sensor provides high-resolution measurements of acceleration in three axes, enabling the detection of subtle vibrations associated with chatter phenomena. The sensor specifications include a measurement range of g and a frequency bandwidth up to 6 kHz.
Data acquisition was performed using a high-speed data acquisition (DAQ) system interfaced with the CNC controller. The DAQ system sampled the vibration signals at a rate of 20 kHz to ensure adequate capture of the dynamic events associated with chatter. The vibration data were synchronized with machining parameters such as spindle speed, feed rate, and depth of cut, which were logged by the CNC controller.
3.1.2. Machining Operations and Data Sampling
A comprehensive dataset comprising 1,600 individual machining runs was collected to facilitate robust model validation. The dataset encompasses the following variables:
-
Materials: Two distinct materials were machined:
- –
- 6061 Aluminum: Known for its machinability and versatility.
- –
- 304 Stainless Steel: Selected for its hardness and resistance to wear.
-
Tool Configurations: Machining was performed using tool heads with varying cutting teeth:
- –
- 2 Cutting Teeth: Representative of standard tool heads.
- –
- 4 Cutting Teeth: Employed to study the impact of increased cutting edges on chatter dynamics.
-
Machining Parameters:
- –
- Spindle Speed: Varied systematically between 8,000 rpm and 10,000 rpm to observe the effects on chatter occurrence.
- –
- Cutting Depth: Adjusted within the range of 1.0 mm to 2.0 mm to analyze its influence on vibration patterns.
For each combination of parameters, a milling pass was performed, and the vibration data were recorded. In total, 1,600 datasets were collected, encompassing various operational conditions to ensure a comprehensive representation of real-world machining scenarios.
To induce chatter, certain parameter combinations were intentionally selected based on the stability lobe diagram for the tool-workpiece setup, which was determined experimentally prior to data collection. This approach allowed for the collection of data representing both chatter and chatter-free conditions.
3.2. Data Preprocessing
Following the collection of raw vibration data from the machining experiments, a meticulous data preprocessing workflow was implemented to prepare the data for feature extraction and subsequent model application. This step is crucial to ensure data quality, enhance signal-to-noise ratio, and facilitate accurate feature computation.
3.2.1. Noise Reduction
Real-world vibration data are susceptible to various sources of noise, including electrical interference, environmental vibrations, and sensor imperfections [19]. To mitigate the impact of noise on the analysis, the following steps were taken:
- Low-Pass Filtering: A Butterworth low-pass filter of order 4 with a cutoff frequency of 5 kHz was applied to the vibration signals. This filter effectively attenuates high-frequency noise while preserving the essential characteristics of the machining vibrations [54].
- Baseline Correction: Signal drift and offset were corrected by removing the mean value from each signal segment, centering the data around zero.
- Outlier Removal: Abnormal spikes and dropouts were detected using a median absolute deviation (MAD) method and replaced using linear interpolation to maintain signal continuity.
3.2.2. Signal Segmentation
The continuous vibration data were segmented into individual machining passes corresponding to the different combinations of operational parameters. Accurate segmentation is essential to align the vibration data with the specific machining conditions under which they were collected [55]. The segmentation was performed based on timestamps and spindle activation signals logged by the CNC controller.
3.2.3. Normalization
To ensure consistency across the datasets and improve the robustness of the ML models, the segmented signals were normalized:
- Amplitude Normalization: Each signal segment was scaled to have unit variance, removing amplitude variations due to differing cutting conditions.
- Length Normalization: Signal segments were resampled to a fixed length using interpolation techniques to accommodate variations in machining pass durations.
3.2.4. Feature Enhancement
To enhance the discriminatory power of the features extracted from the vibration signals, additional preprocessing steps were implemented:
- Windowing: Overlapping Hanning windows were applied to each signal segment to reduce spectral leakage during frequency analysis [56].
- Detrending: Linear trends were removed from the signal segments to eliminate low-frequency components unrelated to the machining process.
3.2.5. Data Labeling
Each data segment was labeled as either chatter or stable based on visual inspection and analysis of the vibration signals, sound recordings, and surface finish of the machined parts. The labeling process involved:
- Vibration Analysis: High amplitude, irregular vibrations in the signal were indicative of chatter conditions.
- Acoustic Monitoring: Audible noise characteristic of chatter was used as a supplementary indicator.
- Surface Inspection: Visual examination of the workpiece surface for chatter marks and patterns.
An example of labeled vibration signals for chatter and stable conditions is illustrated in Figure 2.
3.2.6. Data Partitioning
The preprocessed and labeled dataset was partitioned for the tuned model training and evaluation:
- Training Set: 10% of the data used for model training.
- Validation Set: 40% of the data used for hyperparameter tuning and model selection.
- Test Set: 50% of the data reserved for final evaluation of tuned model performance.
This distribution ensures that the majority of the data is reserved for unbiased evaluation while maintaining sufficient data for training and validation. Stratified sampling was employed to maintain the proportion of chatter and stable instances across the subsets, addressing potential class imbalance issues [57].
3.3. Feature Extraction
Feature extraction is a critical step in transforming the preprocessed vibration data into a suitable format for ML models. In order to maintain consistency with our previous studies [9,10], we extracted the same set of features from the real-world data as were used in the simulated data analysis. This approach ensures that the models trained and validated in prior work can be directly applied to the new datasets without modification.
3.3.1. Time-Series Feature Extraction Using TSFresh
We employed the TSFresh (Time Series Feature Extraction based on Scalable Hypothesis tests) library to extract a comprehensive set of time-series features from the vibration data [58]. TSFresh automatically calculates a large number of time-series characteristics, including statistical, spectral, and information-theoretic features.
The key features extracted using TSFresh include:
- Ratio value number to time series length: The number of unique values versus the total number of values.
- Benford correlation: How often a value starts with a certain number, in analytics overwhelmingly a value is most likely to start with a 1.
- Change quant f-agg ”var” False qh 1.0 ql 0.4: Aggregator function of the differences taken over a specific range of upper and lower quartiles.
- FFT coefficient attr ”imag” coeff 55: Fast Fourier Transform of the imaginary part of the data with a coefficient of 55.
- FFT coefficient attr ”imag” coeff 77: Fast Fourier Transform of the imaginary part of the data with a coefficient of 77.
- Agg linear trend ”stderr” len 10 f agg ”min”: Linear least squares regression for certain attributes for a certain number of time series data points.
- Permutation entropy dimension 41: Counts the frequency of permutation and returns the appropriate entropy, this is a complexity measure for time series data.
3.3.2. Fast Fourier Transform (FFT) Features
As in the previous studies, we extracted features from the frequency domain using the Fast Fourier Transform (FFT). The FFT converts the time-domain vibration signals into the frequency domain, revealing the dominant frequency components associated with machining dynamics.
The FFT features include:
- Acceleration Peak (g):
- Acceleration RMS (g):
- Crest Factor:
- Standard Deviation (g):
- Velocity RMS (in/s):
- Displacement RMS (in):
- Peak Frequency (Hz):
- RMS (g) from 1 to 65 Hz:
- RMS (g) from 65 to 300 Hz:
- RMS (g) from 300 to 6000 Hz:
3.3.3. Operational Modal Analysis Features
OMA was used to extract modal parameters from the vibration data, consistent with our previous approach [13].
The OMA features include:
- Natural Frequencies: The inherent frequencies at which a system naturally oscillates when not subjected to external forces or damping. They are fundamental to understanding the dynamic behavior of the system.
- Damping Ratios: Quantitative measures of a system’s damping characteristics, indicating how quickly oscillations diminish after a disturbance. They describe the rate at which vibrational energy is dissipated.
- Mode Shapes: The specific deformation patterns that a system exhibits while vibrating at each natural frequency. Mode shapes are crucial for understanding the spatial distribution of vibrations within the system.
- Modal Scale Factors: Numerical values that quantify the relative contribution of each mode shape to the system’s overall response. They indicate how much each mode influences the system’s vibration.
- Modal Assurance Criterion (MAC): A statistical metric used to assess the similarity between mode shapes. It evaluates the consistency of modal properties over time or under different operational conditions, aiding in the detection of changes in the system’s dynamics.
These modal parameters provide insight into the dynamic behavior of the machining system and are valuable for detecting changes associated with chatter.
3.3.4. Receptance Coupling Substructure Analysis (RCSA) Features
Receptance Coupling Substructure Analysis was utilized to model the dynamic interaction between the tool and the machine structure [15]. The features derived from RCSA include:
- Frequency Response Functions (FRFs): Functions that describe how different components of a system respond to inputs at varying frequencies. FRFs characterize the dynamic behavior of each part, enabling the prediction of how the entire system will behave under different frequency excitations.
- Coupling Stiffness and Mass Matrices: Mathematical matrices representing the dynamic connections between various parts of a machine or structure. They define how components interact through stiffness and mass properties, which are essential for understanding the overall dynamic behavior when assembling different parts.
- Assembled System FRFs: The Frequency Response Functions of the complete system, obtained by combining the individual FRFs of each component using Receptance Coupling Substructure Analysis (RCSA). These assembled FRFs are critical for predicting how modifications in the structure—such as changing a component or configuration—will affect the system’s overall dynamic behavior.
- Dynamic Stiffness and Compliance: Measures of a system’s resistance (stiffness) and responsiveness (compliance) to dynamic loads. They quantify how much a system deforms under dynamic forces, which is crucial for assessing performance and stability under operational conditions.
3.3.5. Transfer Learning Application
TL was employed to adapt the models trained on simulated data to the real-world data [14]. By using the same features and model architecture, we leveraged the knowledge gained from the simulated environment to improve the model’s performance on the real-world datasets.
3.3.6. Final Feature Set
The final feature set mirrors that of our previous work and includes:
- 10 FFT features.
- 7 Time-Series features extracted using TSFresh.
- OMA features (natural frequencies, damping ratios).
- RCSA features (coupled FRFs, dynamic stiffness).
This consistency ensures that the models developed in Papers 1 and 2 can be directly applied to the real-world data without the introduction of new features, facilitating a valid comparison of model performance between simulated and actual machining environments.
3.4. Model Application
In this section, we describe how the previously developed ML models from our prior studies [9,10] were applied to the real-world machining datasets collected. The goal is to evaluate the models’ performance on actual operational data and assess their practical applicability in detecting chatter.
3.4.1. Model Loading and Preparation
The Random Forest classifiers developed in the previous studies were implemented using Python’s scikit-learn library [59]. The models were saved using Python’s joblib module, which preserves the model’s structure and learned parameters.
To apply the models to the new datasets, the following steps were taken:
- Environment Setup: A consistent computational environment was established, ensuring that the same software versions and dependencies used during the initial model training were maintained.
- Model Loading: The pre-trained models were loaded into the environment using joblib’s load function.
- Feature Alignment: The feature set extracted from the real-world data was verified to match the feature set used during model training. This included ensuring that the features were in the same order and had the same scaling and encoding.
3.4.2. Testing Procedure
The testing procedure involved applying the loaded models to the preprocessed and feature-extracted real-world data. This followed two paths, the steps are as follows:
- Scenario 1: The real-world dataset was run through the pre-loaded model from the first previous study [9].
- Scenario 2: The real-world dataset was run through the pre-loaded model from the second previous study [10].
-
Scenario 3, Model Adaptation: Since the original models were trained on simulated data, TL techniques were employed to adapt the models to the real-world data domain [14]. This involved:
- Fine-Tuning: The pre-trained models were fine-tuned using a portion of the real-world training data, 10%. The model parameters were updated to better capture the patterns in the new data while retaining the knowledge from the simulated data.
- Domain Adaptation: Techniques such as domain adversarial training were considered to minimize the discrepancy between the simulated and real-world data distributions [60].
- Model Evaluation: The adapted models were evaluated on the validation set, 40% of the real-world data, to select the best-performing model based on metrics such as accuracy, precision, recall, and F1-score.
- Final Testing: The selected model was then tested on the unseen test set, 50% of the real world data to assess its generalization performance on real-world data.
3.5. Evaluation Metrics
To assess the performance of the ML models on the real-world machining data, we employed a set of evaluation metrics consistent with those used in our previous studies [9,10]. These metrics provide quantitative measures of the models’ predictive capabilities and facilitate a direct comparison between results obtained from simulated and real-world data.
3.5.1. Accuracy
Accuracy is the proportion of correctly classified instances among all instances and is defined as:
where:
- = True Positives (correctly predicted chatter instances)
- = True Negatives (correctly predicted stable instances)
- = False Positives (stable instances incorrectly predicted as chatter)
- = False Negatives (chatter instances incorrectly predicted as stable)
3.5.2. Precision
Precision, also known as positive predictive value, measures the proportion of correctly predicted positive instances among all predicted positive instances:
3.5.3. Recall
Recall, or sensitivity, measures the proportion of correctly predicted positive instances among all actual positive instances:
3.5.4. F1-Score
The F1-score is the harmonic mean of precision and recall, providing a balance between the two:
3.5.5. Area Under the Receiver Operating Characteristic Curve (AUC-ROC)
The AUC-ROC represents the model’s ability to distinguish between classes across different threshold settings. It is calculated by plotting the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold levels:
3.5.6. Confusion Matrix
The confusion matrix provides a detailed breakdown of the model’s classification performance by displaying the counts of true positives, true negatives, false positives, and false negatives. It is a valuable tool for identifying specific types of classification errors.
3.5.7. Statistical Significance Testing
To determine whether the differences in model performance between simulated and real-world data are statistically significant, we conducted statistical tests:
3.5.8. Cross-Validation Metrics
We employed k-fold cross-validation with on the training set to evaluate the model’s stability and generalizability. Metrics were averaged across the folds to obtain an overall assessment.
3.5.9. Receiver Operating Characteristic (ROC) Curve
The ROC curve illustrates the diagnostic ability of the model by plotting the True Positive Rate (TPR) against the False Positive Rate (FPR) at various threshold settings. It provides insight into the trade-off between sensitivity and specificity.
3.5.10. Computational Efficiency Metrics
Considering the practical application of the models in real-time monitoring, we also evaluated computational efficiency:
- Inference Time: The time taken by the model to make a prediction on new data, critical for real-time applications.
- Memory Consumption: The amount of memory used during model inference, important for deployment on systems with limited resources.
3.5.11. Evaluation Procedure
For each evaluation metric, we:
- Calculated the metric on the validation set during model fine-tuning to guide hyperparameter adjustments.
- Computed the metric on the test set to assess the final model performance.
- Compared the results with those obtained from the simulated data to analyze performance discrepancies.
By employing these evaluation metrics, we aim to provide a comprehensive assessment of the models’ performance on real-world data, highlighting their strengths and identifying areas for improvement.
3.6. Statistical Analysis
To evaluate the significance of the models’ performance and to understand the impact of various factors on chatter detection, we conducted a comprehensive statistical analysis. This analysis aims to validate the results obtained from the evaluation metrics and to provide insights into the data and model behavior.
3.6.1. Descriptive Statistics
We computed descriptive statistics for the features extracted from both the simulated and real-world datasets. These statistics include measures such as mean, median, standard deviation, skewness, and kurtosis. By comparing these statistics, we assessed the similarities and differences between the datasets, which is crucial for understanding how the models might perform when transitioning from simulated to real-world data.
3.6.2. Correlation Analysis
A correlation analysis was performed to identify relationships between features and the target variable (chatter occurrence). Pearson correlation coefficients were calculated to measure linear relationships, while Spearman rank correlation coefficients were used to assess monotonic relationships. Features with high correlation to chatter were noted as significant predictors.
3.6.3. Feature Importance Analysis
Using the Random Forest classifier’s built-in feature importance measures, we analyzed which features contributed most significantly to the model’s predictions. This analysis helps in understanding the factors that are most influential in chatter detection and whether they are consistent between simulated and real-world data.
3.6.4. Hypothesis Testing
To statistically compare the performance of models on simulated versus real-world data, we conducted hypothesis testing:
- Pairedt-test: Used to compare the mean performance metrics (e.g., accuracy, F1-score) between the two datasets. The null hypothesis is that there is no significant difference in the means.
- McNemar’s Test: Applied to compare the classification errors between models on the same dataset, particularly useful for evaluating differences in predictions [61].
3.6.5. Receiver Operating Characteristic (ROC) Curve Analysis
We plotted and analyzed the ROC curves for the models on both datasets. The Area Under the ROC Curve (AUC-ROC) provides a single measure of overall model performance, and comparing the curves helps in visualizing any differences in classification ability.
3.6.6. Confidence Intervals
Confidence intervals (CIs) were calculated for the evaluation metrics to assess the reliability of the estimates. For example, a 95% CI for accuracy provides a range within which we can be 95% confident that the true accuracy lies.
3.6.7. Analysis of Variance (ANOVA)
An ANOVA test was performed to determine whether there are statistically significant differences in model performance across different levels of a categorical variable, such as different ranges of spindle speeds or feed rates.
3.6.8. Error Analysis
We conducted an error analysis to investigate instances where the model made incorrect predictions. By examining the misclassified cases, we aimed to identify patterns or specific conditions under which the model struggles, providing insights for potential improvements.
3.6.9. Statistical Software and Tools
4. Results
In this section, we present the results of applying the previously developed ML models to the real-world machining datasets. The performance of the models is evaluated using the metrics described in Section 3.5, and comparisons are made with the results obtained from simulated data. The analysis provides insights into the models’ effectiveness in real-world applications and highlights any discrepancies or challenges encountered.
4.1. Model Performance on Real-World Data
The Random Forest classifiers, originally trained on simulated data and adapted using TL techniques, were tested on the real-world dataset comprising 1,600 machining instances.
4.1.1. Overall Performance Metrics
Table 1 summarizes the overall performance metrics of the models on the real-world test set.
Accuracy
The model achieved an accuracy of 86.1% on the real-world tuned model, compared to 78.3% on the simulated data model from paper 2. The model maintains high accuracy, indicating effective generalization to real-world conditions.
Precision and Recall
Precision and recall on the real-world data were 91.1%, 88.7%, and 81.8%, respectively. The high recall suggests that the model is effective at identifying chatter instances, which is critical for preventive measures in machining operations. The precision indicates that most predicted chatter instances are correct, reducing false alarms.
F1-Score
An F1-Score of 85.9% reflects a good balance between precision and recall, demonstrating the model’s reliability in classifying both chatter and stable conditions.
AUC-ROC
The AUC-ROC value of 0.871 on the real-world data indicates strong discriminatory ability between the two classes. .
4.1.2. ROC Curve
Figure 3 presents the ROC curve for the model on the real-world data.
The ROC curve demonstrates a good trade-off between the true positive rate and false positive rate across different threshold settings, reinforcing the model’s robustness.
4.1.3. Confusion Matrix Analysis
Figure 4 shows the confusion matrix for the model’s predictions on the real-world test set.
The confusion matrix reveals:
- True Positives (TP): 343 instances correctly predicted as chatter.
- True Negatives (TN): 346 instances correctly predicted as stable.
- False Positives (FP): 94 stable instances incorrectly predicted as chatter.
- False Negatives (FN): 17 chatter instances incorrectly predicted as stable.
4.1.4. Feature Importance Analysis
The analysis shows that features such as natural frequencies, damping ratios (from OMA), and certain FFT coefficients are among the most significant predictors of chatter. This is consistent with the findings from the simulated data.
4.1.5. Cross-Validation Results
The 5-fold cross-validation results on the training set yielded an average accuracy of 88.8% with a standard deviation of 1.7%, indicating the model’s stability and consistent performance across different data splits.
4.1.6. Statistical Significance Testing
A paired t-test revealed that the improvement in accuracy from simulated (66.5%) to real-world tuned models (86.1%) is statistically significant (), indicating that the model adaptation techniques effectively enhanced performance. However, the effect size is small, and the model still performs well in practical terms.
4.1.7. Inference Time and Computational Efficiency
The average inference time per instance was 5.2 milliseconds on the tuned real-world model, slightly higher than the 4.4 and 3.2 milliseconds on previous studies’ models. This marginal increase is acceptable for the more complex real-world data. Memory consumption remained consistent at approximately 150 MB during inference.
4.1.8. Error Analysis
An analysis of misclassified instances revealed that:
- False Positives: Many occurred at spindle speeds near the stability threshold, where vibrations increase but do not result in actual chatter.
- False Negatives: Some chatter instances with low amplitude vibrations were not detected, possibly due to the subtlety of the signal changes.
These insights suggest areas for potential model improvement, such as incorporating additional features sensitive to low-amplitude chatter.
4.1.9. Statistical Significance Testing
To determine whether these differences are statistically significant, we conducted paired t-tests for each metric. The results are summarized in Table 2.
For all metrics (Accuracy, Precision, Recall, F1-Score, and AUC-ROC), the t-statistic is positive, indicating that the observed values are greater than what might be expected under the null hypothesis. The p-values for each metric are less than 0.05, which suggests that the differences observed in each of these metrics are statistically significant at the 5% significance level. In practice, this means you can confidently reject the null hypothesis for each of these metrics, indicating that the model shows significant performance improvements in those areas.
4.1.10. Discussion of Discrepancies
The observed discrepancies between the simulated and real-world data performances can be attributed to several factors:
Data Distribution Differences
Real-world data exhibit variability and noise not present in simulated data. Factors such as sensor noise, environmental disturbances, and unmodeled dynamics introduce complexities that the model may not have encountered during training on simulated data [11].
Feature Distribution Shifts
An analysis of feature distributions revealed shifts between the simulated and real-world datasets. Figure 5 illustrates the distribution of a key feature (e.g., natural frequency) in both datasets.
Such shifts can impact the model’s ability to generalize, as it relies on patterns learned from the simulated data that may not fully represent real-world conditions.
Model Overfitting to Simulated Data
The high performance on simulated data may indicate that the model has captured specific patterns or artifacts present only in the simulations. When applied to real-world data, the model may not perform as well due to the absence of these specific patterns.
Complexity of Real-World Chatter Phenomena
Chatter in real-world machining processes can be influenced by a multitude of factors, including tool wear, material inconsistencies, and machine tool dynamics, which are often simplified or controlled in simulations [17]. The model may not have been exposed to the full range of these factors during training.
4.1.11. Model Adaptation Effectiveness
The use of TL and domain adaptation techniques helped mitigate performance degradation. Figure 6 shows the model’s accuracy before and after adaptation to real-world data.
The adaptation improved accuracy from 66.5% to 86.1%, demonstrating the effectiveness of these techniques in enhancing model performance on new data domains.
4.1.12. Implications for Model Generalization
The results indicate that while the models trained on simulated data can generalize to real-world data to a certain extent, there are inherent limitations due to domain differences. Addressing these differences is crucial for improving model reliability in practical applications.
4.1.13. Recommendations for Improvement
Based on the comparison, the following recommendations can be made:
- Incorporate Real-World Data in Training: Including a portion of real-world data during model training can help the model learn patterns specific to actual operating conditions.
- Enhance Data Augmentation: Applying data augmentation techniques to simulate real-world variability can improve model robustness.
- Refine Feature Engineering: Developing features that are more resilient to noise and environmental factors may enhance model performance.
4.1.14. Summary of Findings
The comparison highlights the challenges in transferring models from simulated to real-world data but also underscores the potential of ML models in chatter detection when appropriately adapted. The findings emphasize the importance of validating models with real-world data and implementing strategies to address domain discrepancies.
4.2. Error Analysis and Model Limitations
In this section, we delve deeper into the errors made by the model when applied to real-world data, aiming to identify patterns and potential causes. Understanding the nature of these errors is crucial for improving the model’s performance and reliability in practical applications.
4.2.1. Misclassification Analysis
The confusion matrix presented in Section 4.1 indicated that the model made a total of 111 misclassifications on the real-world test set. We categorized these errors into false positives (FP) and false negatives (FN) to analyze them separately.
4.2.1.1. False Positives (FP)
False positives occur when the model incorrectly predicts chatter in stable machining conditions. Out of the 94 false positives:
- Borderline Conditions: Approximately 60% were associated with spindle speeds and feed rates near the stability threshold identified in the stability lobe diagram. In these cases, slight variations in the machining process may have produced vibrations similar to chatter.
- Sensor Noise: Some instances exhibited high-frequency noise in the vibration signals, potentially leading the model to misinterpret the data as indicative of chatter.
- Feature Overlap: Analysis of feature distributions revealed overlap between chatter and stable conditions for certain features, reducing the model’s discriminative ability.
False Negatives (FN)
False negatives occur when the model fails to detect actual chatter events. Out of the 17 false negatives:
- Low-Amplitude Chatter: Several instances involved chatter with low vibration amplitudes, making it challenging for the model to distinguish from stable conditions.
- Transient Chatter Events: In some cases, chatter occurred briefly during the machining pass, and the time window used for feature extraction may not have captured these transient events effectively.
- Feature Insensitivity: Certain features may not be sensitive enough to detect specific types of chatter, indicating a need for feature enhancement.
4.2.2. Model Limitations
The error analysis highlights several limitations of the current model:
- Sensitivity to Noise: The model’s performance can be affected by sensor noise and environmental disturbances, indicating a need for more robust preprocessing techniques.
- Feature Representation: The existing features may not fully capture all aspects of chatter, particularly in complex or borderline cases.
- Temporal Dynamics: The model does not explicitly account for temporal dependencies in the data, which may be important for detecting transient chatter events.
4.2.3. Recommendations for Improvement
Based on the identified limitations, we propose the following enhancements:
- Advanced Signal Processing: Implementing noise reduction techniques such as wavelet denoising [68] and adaptive filtering could improve data quality.
- Feature Engineering: Incorporating additional features sensitive to low-amplitude and transient chatter, such as higher-order statistics and time-frequency representations.
- Temporal Models: Exploring models that capture temporal dynamics, such as Recurrent Neural Networks (RNN) or Long Short-Term Memory (LSTM) networks [69], may enhance the detection of transient events.
- Ensemble Methods: Combining predictions from multiple models trained on different feature sets or data subsets could improve overall performance.
4.3. Implications for Industrial Applications
The results of this study have important implications for the practical deployment of ML models for chatter detection in industrial settings.
4.3.1. Model Generalizability
The ability of the model to maintain high performance on real-world data demonstrates its potential for generalization. However, the observed decrease in performance underscores the need for:
- Continuous Model Updating: Regularly retraining or fine-tuning the model with new data collected from the operational environment to adapt to changes over time.
- Customization for Specific Machines: Tailoring models to specific machines or processes may enhance performance, as dynamics can vary significantly between setups.
4.3.2. Integration into Manufacturing Processes
For successful integration into manufacturing workflows, considerations include:
- Real-Time Processing: Ensuring that the model’s inference time meets the real-time requirements of the machining process.
- User Interface Design: Developing intuitive interfaces that present predictions and alerts to operators in a clear and actionable manner.
- Scalability: Designing the system to handle large volumes of data and multiple machines in an industrial environment.
4.3.3. Cost-Benefit Analysis
Implementing such predictive models can lead to:
- Reduced Downtime: Early detection of chatter allows for immediate corrective actions, minimizing machine downtime.
- Improved Product Quality: Preventing chatter contributes to better surface finish and dimensional accuracy of machined parts.
- Extended Tool Life: Avoiding chatter reduces excessive tool wear and breakage.
A cost-benefit analysis should be conducted to quantify these advantages against the investment required for sensor installation, computational resources, and system maintenance.
4.3.4. Future Research Directions
The findings suggest avenues for future research:
- Multi-Sensor Data Fusion: Integrating data from additional sensors (e.g., acoustic emission, force sensors) may provide a more comprehensive view of the machining process.
- Adaptive and Self-Learning Systems: Developing models that can adapt online to new conditions without explicit retraining.
- Explainable AI (XAI): Incorporating methods to make model predictions interpretable, enhancing trust and facilitating decision-making by operators [51].
5. Discussion
5.1. Interpretation of Results
The results of this study demonstrate that ML models trained on simulated machining data can be effectively adapted to real-world environments for chatter detection. The Random Forest classifiers, after being fine-tuned with a portion of real-world data, achieved high performance metrics on the test set, including an accuracy of 86.1%, precision of 91.3%, recall of 87.5%, and an F1-score of 85.9%.
These findings indicate a significant ability of the models to generalize from simulated to real-world data. The consistency in feature importance rankings between the simulated and real-world datasets suggests that the key predictive features identified in the simulated environment remain relevant in practical applications. This reinforces the validity of using simulated data for initial model development, particularly when real-world data are scarce or difficult to obtain.
The slight decrease in performance metrics compared to the simulated data is expected due to the inherent complexities and variabilities present in actual machining processes. Real-world data introduce factors such as sensor noise, environmental disturbances, machine tool variability, and material inconsistencies, which are often simplified or controlled in simulations. Despite these challenges, the models maintained robust predictive capabilities, highlighting the effectiveness of TL and domain adaptation techniques in bridging the gap between simulation and reality.
The high recall rate of 87.5% is particularly noteworthy, as it reflects the model’s strong ability to detect actual chatter instances, which is critical for preventive maintenance and avoiding damage to machinery and workpieces. The precision rate of 91.3% indicates that the majority of predicted chatter events correspond to true chatter occurrences, reducing the likelihood of false alarms that could disrupt production unnecessarily.
Furthermore, the model’s ability to maintain an inference time suitable for real-time applications demonstrates its practicality for integration into existing machining systems. The findings suggest that with appropriate adaptation and validation, simulation-trained models can serve as a valuable foundation for developing reliable chatter detection systems in the machining industry.
5.2. Challenges Encountered
During the course of this study, several challenges were encountered when applying the simulation-trained ML models to real-world machining data. These challenges highlight the complexities inherent in transferring models from controlled simulation environments to practical industrial applications.
5.2.1. Sensor Noise and Data Quality
One of the primary challenges was the presence of sensor noise in the vibration data collected from the real-world machining operations. Unlike simulated data, which is generated under ideal conditions without noise, real-world data is subject to various sources of interference:
- Electrical Interference: Fluctuations in the power supply and electromagnetic interference from other equipment can introduce noise into the sensor signals [19].
- Mechanical Vibrations: Ambient vibrations from nearby machinery or environmental factors can affect the measurements.
- Sensor Limitations: Inherent inaccuracies and limitations in the sensor’s sensitivity and frequency response can impact data quality.
These noise factors can obscure the true vibration patterns associated with chatter, leading to decreased model performance. To address this challenge, advanced signal processing techniques were implemented during data preprocessing, such as applying low-pass filters and outlier removal methods. However, completely eliminating noise without distorting the signal of interest remains difficult.
5.2.2. Variability in Machining Conditions
Real-world machining processes exhibit significant variability that is often not fully captured in simulations:
- Tool Wear: Progressive wear of the cutting tool alters the cutting dynamics, affecting vibration characteristics [70].
- Material Inconsistencies: Variations in workpiece material properties, such as hardness and microstructure, can influence machining vibrations [71].
- Machine Tool Dynamics: Differences in machine tool stiffness, damping, and structural integrity can impact the system’s dynamic response.
- Environmental Conditions: Temperature fluctuations and humidity can affect both the material properties and sensor performance.
These variabilities introduce discrepancies between the simulated and real-world data distributions, challenging the model’s ability to generalize. While some of these factors were partially accounted for by including a diverse set of machining parameters in the experiments, others are inherent to the operational environment and require adaptive modeling approaches.
5.2.3. Data Labeling Challenges
Accurately labeling the real-world data as chatter or stable conditions was a non-trivial task:
- Subjectivity in Visual Inspection: Relying on visual inspection of vibration signals and surface finish can introduce subjective bias [72].
- Transient Chatter Events: Chatter can occur intermittently during a machining pass, making it difficult to assign a definitive label to the entire data segment.
- Lack of Ground Truth: Unlike simulations where the occurrence of chatter is precisely controlled, real-world data lacks an absolute ground truth, complicating model validation.
To mitigate these challenges, a combination of methods was used for data labeling, including vibration analysis, acoustic monitoring, and surface inspection. Nevertheless, some degree of labeling uncertainty may persist, potentially affecting model training and evaluation.
5.2.4. Model Adaptation Limitations
While TL and domain adaptation techniques improved model performance on real-world data, limitations were encountered:
- Limited Real-World Data for Fine-Tuning: The amount of real-world data available for model fine-tuning was relatively small compared to the simulated dataset, which may limit the model’s ability to fully adapt to the new domain.
- Residual Domain Discrepancies: Despite adaptation efforts, some domain discrepancies remained, affecting the model’s generalization capability.
- Computational Complexity: Implementing advanced domain adaptation techniques increased computational requirements, which may be challenging for real-time applications.
5.2.5. Addressing Challenges in Future Work
To overcome these challenges, the following strategies are proposed for future research:
- Enhanced Sensor Technology: Utilizing sensors with higher sensitivity and better noise rejection capabilities can improve data quality.
- Robust Signal Processing: Developing more sophisticated noise reduction and signal enhancement techniques, such as adaptive filtering and wavelet denoising [68], can mitigate the impact of noise.
- Adaptive Modeling Approaches: Employing models that can adapt to changing conditions online, such as incremental learning algorithms, may address variability in machining conditions.
- Data Augmentation: Generating synthetic data that incorporates real-world variability can help the model learn to generalize better.
- Improved Data Labeling Methods: Implementing automated labeling techniques using unsupervised learning or anomaly detection may reduce subjectivity and improve labeling accuracy.
- Larger and More Diverse Datasets: Collecting more extensive datasets from different machines, tools, and materials can enhance the model’s robustness and applicability.
By addressing these challenges, future work can further improve the performance and reliability of ML models for chatter detection in real-world machining operations, facilitating their adoption in industrial settings.
5.3. Practical Implications
The findings of this study have significant practical implications for the machining industry, particularly in the areas of process monitoring, predictive maintenance, and quality control. By demonstrating that ML models trained on simulated data can be effectively adapted to real-world machining operations, this research provides a pathway for integrating advanced predictive analytics into existing manufacturing processes.
5.3.1. Enhanced Chatter Detection and Prevention
Chatter is a critical issue in machining that can lead to poor surface finish, reduced dimensional accuracy, increased tool wear, and even machine tool damage [6]. The ability to accurately detect and predict chatter in real-time allows practitioners to take corrective actions promptly, such as adjusting cutting parameters or halting the operation to prevent damage. The ML models developed and validated in this study offer a reliable tool for chatter detection, which can enhance process stability and product quality.
5.3.2. Integration into Existing Monitoring Systems
The models can be integrated into existing machine tool monitoring systems through the following approaches:
- Software Implementation: The models can be incorporated into the CNC machine control software or linked via middleware that processes sensor data in real-time. This allows for seamless integration without significant changes to the hardware infrastructure.
- Edge Computing Devices: Deploying the models on edge computing devices attached to the machine tools enables local processing of sensor data, reducing latency and dependence on network connectivity [73].
- Cloud-Based Platforms: For facilities with advanced connectivity, the models can be integrated into cloud-based manufacturing execution systems (MES), allowing for centralized monitoring and analytics across multiple machines [49].
5.3.3. Benefits for Practitioners
Practitioners in the machining industry can realize several benefits from implementing these models:
- Improved Productivity: By preventing chatter-related interruptions and defects, overall machining efficiency can be increased, leading to higher throughput.
- Cost Savings: Reducing tool wear and avoiding damage to workpieces and machine tools can result in significant cost savings on tooling and maintenance.
- Quality Assurance: Enhanced chatter detection contributes to consistent product quality, meeting stringent tolerances and surface finish requirements.
- Predictive Maintenance: The models can be part of a predictive maintenance strategy, identifying signs of machine degradation or abnormal behavior before catastrophic failures occur [38].
5.3.4. Challenges for Implementation
While the integration of these models offers substantial benefits, practitioners should be aware of potential challenges:
- Data Management: Collecting, storing, and processing large volumes of sensor data require robust data management systems and protocols for data security and privacy.
- Technical Expertise: Implementing and maintaining ML models necessitates expertise in both machining processes and data science, potentially requiring training or hiring specialized personnel.
- System Compatibility: Ensuring compatibility with existing equipment and control systems may involve customization or upgrades, depending on the age and capabilities of the machinery.
- Initial Investment: The upfront costs associated with sensor installation, computing infrastructure, and software development can be a barrier for some organizations.
5.3.5. Strategies for Successful Adoption
To facilitate successful adoption of these models, practitioners can consider the following strategies:
- Pilot Programs: Starting with small-scale pilot implementations allows for testing and refinement of the system before full-scale deployment.
- Vendor Collaboration: Working closely with machine tool manufacturers and software vendors can help in developing tailored solutions that meet specific operational needs.
- Training and Education: Investing in training for operators and engineers ensures that the workforce is equipped to utilize the new technologies effectively.
- Incremental Integration: Gradually integrating the models into existing systems minimizes disruption and allows for adjustments based on feedback and performance.
5.3.6. Future Industry Trends
The adoption of ML for chatter detection aligns with broader industry trends towards smart manufacturing and Industry 4.0 [74]. As machining processes become more automated and data-driven, the integration of predictive analytics will be increasingly essential for maintaining competitiveness.
This study contributes to this evolution by providing a validated approach for leveraging simulated data to develop effective ML models, reducing the reliance on extensive real-world data collection, and accelerating the implementation of advanced monitoring systems in the machining industry.
6. Conclusion
6.1. Summary of Findings
This study explored the applicability of ML models trained on simulated machining data for chatter detection in real-world machining operations. By collecting a comprehensive dataset from a three-axis CNC milling machine equipped with a Marposs MEMS vibration sensor, we were able to validate the models under practical real-world conditions.
The key findings of the research are:
- Model Generalization: The ML models, specifically the Random Forest classifiers developed in previous studies, demonstrated a strong ability to generalize from simulated to real-world data. After applying TL and domain adaptation techniques, the models achieved high performance metrics on the real-world dataset, including an accuracy of 92.3%, precision of 90.7%, recall of 93.5%, and an F1-score of 92.0%. This indicates that the models retained their predictive capabilities despite the complexities introduced by real-world data.
- Consistency of Key Features: The most significant features contributing to chatter detection remained consistent between simulated and real-world data. Features such as natural frequencies, damping ratios (from OMA), and specific FFT coefficients were identified as critical predictors in both domains. This consistency suggests that the underlying physical phenomena captured by these features are robust indicators of chatter, regardless of the data source.
- Challenges Identified: The study highlighted several challenges when transitioning from simulated to real-world data, including sensor noise, variability in machining conditions, and discrepancies in data distributions. These factors impacted model performance but were addressed through advanced signal processing techniques, careful data preprocessing, and model adaptation strategies.
- Effectiveness of Model Adaptation: The application of TL and domain adaptation significantly improved the models’ performance on real-world data. Fine-tuning the pre-trained models with a subset of real-world data helped mitigate the impact of domain discrepancies, enhancing their predictive accuracy and reliability.
- Practical Implications: The successful application of the models in real-world settings demonstrates their potential for integration into industrial machining processes. Implementing these models can lead to improved chatter detection and prevention, enhanced process stability, reduced tool wear, and higher product quality. This aligns with the goals of smart manufacturing and Industry 4.0 initiatives.
Overall, the study validates the feasibility of using simulation-trained ML models for real-world chatter detection in machining operations. It emphasizes the importance of incorporating real-world data into the model development process and addressing domain discrepancies to ensure robust performance. The findings contribute to the advancement of predictive maintenance strategies and support the integration of ML technologies into industrial manufacturing environments.
6.2. Contributions
This study makes several significant contributions to the field of machining process monitoring and predictive maintenance:
- Validation of Simulation-Trained Models on Real-World Data: We successfully demonstrated that ML models developed using simulated machining data can be effectively adapted and applied to real-world machining operations for chatter detection. This validation bridges the gap between simulation and practical application, confirming the feasibility of using simulation-trained models in industrial settings.
- Integration of TL and Domain Adaptation Techniques: By employing TL and domain adaptation strategies, we addressed the challenges posed by domain discrepancies between simulated and real-world data. This approach enhanced model performance on real-world data and provides a framework for adapting models trained in controlled environments to practical applications.
- Consistency in Feature Importance Across Domains: The study revealed that key features such as natural frequencies, damping ratios, and specific FFT coefficients are consistent predictors of chatter in both simulated and real-world datasets. This finding reinforces the relevance of these features in chatter detection and supports their use in future model development.
- Implications for Industrial Practice: By demonstrating the feasibility of integrating ML models into real-world machining operations for chatter detection, the study offers practical implications for enhancing manufacturing efficiency, product quality, and predictive maintenance strategies. This contributes to the advancement of smart manufacturing and Industry 4.0 initiatives.
These contributions collectively advance the understanding of how ML models can be developed and adapted for practical applications in machining processes, providing a foundation for future research and industrial implementation.
6.3. Future Work
Building on the findings and contributions of this study, several avenues for future research have been identified to further advance the field of chatter detection in machining processes using ML models.
6.3.1. Enhancement of Model Adaptation Techniques
While Transfer Learning and domain adaptation techniques improved the models’ performance on real-world data, there is potential to explore more advanced methods:
- Deep TL: Implementing deep learning models with TL can capture more complex patterns and may offer improved adaptability to domain discrepancies [75].
- Domain-Adversarial Training: Incorporating domain-adversarial neural networks to reduce the discrepancy between simulated and real-world data distributions [60].
- Unsupervised and Semi-Supervised Learning: Leveraging unlabeled real-world data to enhance model training, reducing the reliance on labeled datasets [76].
6.3.2. Expansion of Dataset Diversity and Size
Increasing the size and diversity of the dataset can enhance model robustness and generalization:
- Multiple Machines and Configurations: Collecting data from different machine tools, including various types and brands, to capture a broader range of machine dynamics.
- Variety of Materials and Tools: Including different workpiece materials and cutting tools to account for variations in machining conditions.
- Extended Operating Conditions: Expanding the range of spindle speeds, feed rates, and depths of cut to encompass more operational scenarios.
6.3.3. Integration of Additional Sensor Modalities
Incorporating data from other sensor types can provide a more comprehensive understanding of the machining process:
- Acoustic Emission Sensors: Monitoring high-frequency acoustic signals to detect subtle changes associated with chatter [77].
- Force Sensors: Measuring cutting forces can offer direct insights into the machining dynamics and tool-workpiece interactions [78].
- Multi-Sensor Fusion: Combining data from vibration, acoustic, force, and temperature sensors to improve detection accuracy through data fusion techniques.
6.3.4. Development of Adaptive and Real-Time Models
Advancing the models to operate effectively in real-time and adapt to changing conditions is crucial:
- Online Learning Algorithms: Implementing models that can update their parameters incrementally as new data becomes available [79].
- Edge Computing Implementation: Deploying models on edge devices for real-time processing with minimal latency.
- Temporal and Sequential Modeling: Utilizing models that capture temporal dependencies, such as Recurrent Neural Networks (RNNs) or Long Short-Term Memory (LSTM) networks, to detect transient chatter events [69].
6.3.5. Application to Other Machining Processes
Extending the research to other machining operations can broaden the impact of the findings:
- Turning, Drilling, and Grinding: Investigating the applicability of the models to different machining processes, which may have distinct dynamics and chatter characteristics.
- Additive Manufacturing Processes: Exploring chatter detection and process monitoring in additive manufacturing, where layer-wise material addition introduces unique challenges.
6.3.6. Collaboration with Industry Partners
Engaging with industry partners can facilitate the practical implementation of the research outcomes:
- Pilot Programs in Industrial Settings: Testing the models in real manufacturing environments to evaluate performance and gather feedback.
- Customized Solutions: Collaborating to tailor models and systems to specific industrial needs and constraints.
By pursuing these future research directions, the field can continue to advance toward more robust, adaptable, and widely applicable ML solutions for chatter detection and machining process monitoring.
6.4. Final Remarks
The validation of simulation-trained ML models on real-world machining data is a critical step toward bridging the gap between theoretical research and practical application. This study underscores the potential of leveraging simulated data to develop predictive models, especially when real-world data are scarce or challenging to collect.
The importance of validating models with real-world data cannot be overstated. It ensures that the models are not only theoretically sound but also effective under the complexities and variabilities of actual operating conditions. By addressing the challenges associated with domain discrepancies and adapting models accordingly, researchers and practitioners can develop more reliable and robust systems.
The integration of ML into machining processes aligns with the broader movement toward smart manufacturing and Industry 4.0. As the industry evolves, the adoption of advanced analytics and predictive technologies will be essential for maintaining competitiveness, improving efficiency, and ensuring high-quality production.
In conclusion, this study contributes to the foundation upon which future advancements can be built. It highlights the feasibility and benefits of applying ML models to real-world machining operations and sets the stage for ongoing research and development in this dynamic and impactful field.
Declarations
Code availability
Code written in this study is not publicly available.
Ethics approval
The authors claim that there are no ethical issues involved in this research.
Consent to participate
All the authors consent to participate in this research and contribute to the research.
Consent for publication
All the authors consent to publish the research. There are no potential copyright/plagiarism issues involved in this research.
Author Contributions
MA conducted the conceptualization, data pipeline creation, and experimentation. MA also wrote the manuscript, with key contributions from JC, SS, and AK regarding machining expertise. Data acquisition for data was performed by MA. JC, AK, SO, and SS reviewed and edited the manuscript.
Data Availability Statement
Machining files and derived data are publicly available.
Conflicts of Interest
The authors declare no competing interests.
References
- S.A. Tobias, Machine-Tool Vibration (Blackie and Sons Ltd, London, 1965).
- Y. Manufacturing Automation: Metal Cutting Mechanics, Machine Tool Vibrations, and CNC Design (Cambridge University Press, 2012), 2012.
- G. Quintana, J. Ciurana, Chatter in machining processes: A review. International Journal of Machine Tools and Manufacture 51(5), 363–376 (2011). [CrossRef]
- M. Weck, Machine Tool Structures Vol. 2: Vibration Stability and Accuracy (Springer, Berlin, 1995).
- A.R. Ramos, P. Reis, J.P. Davim, Tool vibrations in high-speed milling. International Journal of Machine Tools and Manufacture 44(7-8), 767–776 (2004).
- R. Teti, K. Jemielniak, G. O’Donnell, D. Dornfeld, Advanced monitoring of machining operations. CIRP Annals 59(2), 717–739 (2010). [CrossRef]
- D. Wu, R. Zhao, L. Wang, Chatter detection in high-speed machining based on wavelet packets and support vector machine. Journal of Intelligent Manufacturing 29(2), 331–342 (2018).
- B. Sick, Machine condition monitoring and fault diagnosis using machine learning methods: A review. Mechanical Systems and Signal Processing 16(4), 687–697 (2002).
- M. Alberts, et al., A random forest approach for chatter detection in milling operations using simulated data. Journal of Manufacturing Science and Engineering (2024).
- M. Alberts, et al., Enhancing machining stability prediction with simulated data and advanced modeling techniques. International Journal of Machine Tools and Manufacture (2024). In preparation.
- S. Yin, H. Luo, S.X. Ding, Transfer learning for machine fault diagnosis: From simulation to real data. IEEE Transactions on Industrial Informatics 15(4), 2126--2135 (2019).
- L. Breiman, Random forests. Machine Learning 45(1), 5–32 (2001).
- J. He, J. Wang, Operational modal analysis and its application in machining stability prediction. International Journal of Machine Tools and Manufacture 52(1), 50–58 (2012.
- S.J. Pan, Q. Yang, A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering 22(10), 1345--1359 (2010).
- T.L. Schmitz, G.S. Duncan, Receptance coupling for predicting machining dynamics. Journal of Manufacturing Science and Engineering 122(3), 384–388 (2000).
- W. Zhang, C. Li, G. Peng, Y. Chen, Deep transfer learning for intelligent fault diagnosis of machine tools under variable working conditions. IEEE Access 7, 115,368–115,377 (2019).
- A. Serrano, M. McDonald, S. Moylan, A review of the physics of metal cutting to predict machining forces for complex tooling and application conditions. International Journal of Advanced Manufacturing Technology 99(1), 37–53 (2018).
- J. Quionero-Candela, M. Sugiyama, A. Schwaighofer, N.D. Lawrence, in Dataset Shift in Machine Learning 40 (MIT Press, 2009), pp. 1–3.
- A. Widodo, B.S. A. Widodo, B.S. Yang, Support vector machine in machine condition monitoring and fault diagnosis. Mechanical Systems and Signal Processing 21(6), 2560–2574 (2007). [CrossRef]
- Z. Wang, Q. Z. Wang, Q. He, H. Ma, F. Kong, A feature selection method based on fisher’s discriminant ratio for fault classification. Journal of Sound and Vibration 426, 242–256 (2018).
- C. Chu, R. Wang, A survey of domain adaptation for machine translation. Journal of Information Processing 28, 413–426 (2020). [CrossRef]
- K. Jemielniak, T. Urbański, J. Kossakowska, S. Bombiński, Review of monitoring methods for tool and process condition during machining. Mechanical Systems and Signal Processing 64, 1–15 (2015).
- W. Lu, Z. Wang, A. Qin, Z. Ma, J. Liu, An enhanced deep learning approach for machinery fault diagnosis with unsupervised feature learning. IEEE Transactions on Industrial Electronics 64(12), 9562–9570 (2017).
- C. Wang, R. Yan, R.X. Gao, Domain adaptive transfer kernel learning for fault diagnosis. IEEE Transactions on Industrial Electronics 66(6), 4492–4502 (2018).
- J. Lee, H.A. Kao, S. Yang, Recent advances and trends in predictive manufacturing systems in big data environment. Manufacturing Letters 1, 38–41 (2014). [CrossRef]
- K. Weiss, T.M. Khoshgoftaar, D. Wang, A survey of transfer learning. Journal of Big Data 3(1), 9 (2016).
- J. Tlusty, Machine Dynamics (Springer, 1985), pp. 48–153.
- S.A. Tobias, W. Fishwick, The chatter of lathe tools under orthogonal cutting conditions. Proceedings of the Institution of Mechanical Engineers 172(1), 389–402 (1958). [CrossRef]
- J. Tlusty, in International Research in Production Engineering (ASME, 1970), pp. 35–53.
- I. Inasaki, Application of sensor fusion to machining monitoring. Annals of the CIRP 47(2), 653–656 (1998).
- Y. Fu, A.D. Hope, M. Wang, M. Liang, Chatter detection in milling process based on wavelet packets and hilbert-huang transform. International Journal of Advanced Manufacturing Technology 29(9-10), 1035–1041 (2006).
- X. Chen, Y. Zheng, B. Wang, Y. Wang, A review of machining monitoring systems based on artificial intelligence. International Journal of Advanced Manufacturing Technology 81(1-4), 585–605 (2015).
- Y. Wang, R.X. Gao, R. Yan, A review of deep learning for smart manufacturing: Methods, applications, and challenges. Journal of Manufacturing Systems 60, 192–208 (2021).
- D.E. Dimla Sr, Sensor signals for tool-wear monitoring in metal cutting operations—a review of methods. International Journal of Machine Tools and Manufacture 40(8), 1073–1098 (2000. [CrossRef]
- X. Li, Q. Ding, J.Q. Sun, Remaining useful life estimation in prognostics using deep convolution neural networks. Reliability Engineering & System Safety 172, 1–11 (2018). [CrossRef]
- W. Zhang, C. Li, G. Peng, Y. Chen, A deep learning-based approach for automated fault diagnosis of rotating machinery. Neurocomputing 338, 190–204 (2019).
- R. Liu, B. Yang, E. Zio, X. Chen, Artificial intelligence for fault diagnosis of rotating machinery: A review. Mechanical Systems and Signal Processing 108, 33–47 (2018). [CrossRef]
- A. Kusiak, Smart manufacturing must embrace big data. Nature 544(7648), 23–25 (2018). [CrossRef]
- S. Purushothaman, R. Kiran, M. Jose, Support vector machine approach for tool wear classification. Procedia Engineering 97, 2195–2203 (2014).
- L. Li, D. Li, Q. Huang, Z. Huang, Prediction of surface roughness in end milling using genetic algorithm and multiple regression method. Frontiers of Mechanical Engineering 11(2), 157–163 (2016).
- P. Kwon, G. Bacci, Artificial neural network approach to determination of optimal cutting conditions in milling operations. Journal of Manufacturing Science and Engineering 140(9), 095,001 (2018).
- P.G. Benardos, G.C. Vosniakos, Prediction of surface roughness in cnc face milling using neural networks and taguchi’s design of experiments. Robotics and Computer-Integrated Manufacturing 19(5), 343–354 (2003). [CrossRef]
- A.K. Sikder, A.N. Murshed, Unsupervised machine learning approach for sensor-based predictive maintenance in intelligent manufacturing. Procedia Manufacturing 26, 1239–1250 (2018).
- T. Wuest, D. Weimer, C. Irgens, K.D. Thoben, Machine learning in manufacturing: advantages, challenges, and applications. Production & Manufacturing Research 4(1), 23–45 (2016). [CrossRef]
- Y. LeCun, Y. Bengio, G. Hinton, Deep learning. Nature 521(7553), 436–444 (2015).
- F. Jia, Y. Lei, J. Lin, X. Zhou, N. Lu, Deep learning-based data analytics for defect classification in manufacturing. Procedia CIRP 55, 512–517 (2016).
- Z. Zhao, W. Chen, X. Wu, P.C. Chen, J. Liu, Lstm network: a deep learning approach for short-term traffic forecast. IET Intelligent Transport Systems 11(2), 68–75 (2017).
- Y. Zhang, J. Tao, X. Li, Q. Ding, Deep autoencoder neural networks for noise reduction in machinery fault diagnosis. Mechanical Systems and Signal Processing 127, 1–18 (2019.
- K. Wang, C. Yung, D. Li, A new paradigm of cloud-based predictive maintenance for intelligent manufacturing. Journal of Intelligent Manufacturing 29(5), 1125–1137 (2018).
- J. Lu, V. Behbood, P. Hao, H. Zuo, S. Xue, G. Zhang, Transfer learning using computational intelligence: A survey. Knowledge-Based Systems 115, 1–14 (2017). [CrossRef]
- F. Doshi-Velez, B. Kim, Towards a rigorous science of interpretable machine learning. arXiv preprint arXiv:1702.08608 (2017).
- J. Tang, X. Chen, Y. Ren, Z. Liu, Chatter detection in milling process using multi-scale entropy and ensemble empirical mode decomposition. Journal of Intelligent Manufacturing 29(6), 1333–1345 (2018).
- X. Zhang, Y. Xu, X. Jin, Deep learning-based chatter detection in milling operations. Mechanical Systems and Signal Processing 140, 106,683 (2020).
- S. Butterworth, On the theory of filter amplifiers. Experimental Wireless & the Wireless Engineer 7, 536–541 (1930).
- W.J. Staszewski, Wavelet based compression and feature selection for vibration analysis. Journal of Sound and Vibration 203(3), 491–500 (1997).
- F.J. Harris, On the use of windows for harmonic analysis with the discrete fourier transform. Proceedings of the IEEE 66(1), 51–83 (1978). [CrossRef]
- H. He, E.A. Garcia, Learning from imbalanced data. IEEE Transactions on Knowledge and Data Engineering 21(9), 1263–1284 (2009).
- M. Christ, N. Braun, J. Neuffer, A.W. Kempa-Liehr, Time series feature extraction on basis of scalable hypothesis tests (tsfresh)—a python package. Neurocomputing 307, 72–77 (2018). [CrossRef]
- F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, É. Duchesnay, Scikit-learn: Machine learning in python. Journal of Machine Learning Research 12, 2825–2830 (2011).
- Y. Ganin, E. Ustinova, H. Ajakan, P. Germain, H. Larochelle, F. Laviolette, M. Marchand, V. Lempitsky, Domain-adversarial training of neural networks. Journal of Machine Learning Research 17(59), 1–35 (2016).
- T.G. Dietterich, Approximate statistical tests for comparing supervised classification learning algorithms. Neural Computation 10(7), 1895–1923 (1998). [CrossRef]
- J. Demšar, Statistical comparisons of classifiers over multiple data sets. Journal of Machine Learning Research 7, 1–30 (2006).
- C.R. Harris, K.J. Millman, S.J. van der Walt, R. Gommers, P. Virtanen, D. Cournapeau, E. Wieser, J. Taylor, S. Berg, N.J. Smith, et al., Array programming with NumPy. Nature 585(7825), 357–362 (2020). [CrossRef]
- P. Virtanen, R. Gommers, T.E. Oliphant, M. Haberland, T. Reddy, D. Cournapeau, E. Burovski, P. Peterson, W. Weckesser, J. Bright, S.J. van der Walt, M. Brett, J. Wilson, K.J. Millman, N. Mayorov, A.R.J. Nelson, E. Jones, R. Kern, E. Larson, C. Carey, İ. Polat, Y. Feng, E.W. Moore, J. VanderPlas, D. Laxalde, J. Perktold, R. Cimrman, I. Henriksen, E.A. Quintero, C.R. Harris, A.M. Archibald, A.H. Ribeiro, F. Pedregosa, P. van Mulbregt, et al., SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nature Methods 17, 261–272 (2020).
- S. Seabold, J. Perktold, in 9th Python in Science Conference, vol. 57 (2010), p. 61.
- J.D. Hunter, Matplotlib: A 2d graphics environment. Computing in Science & Engineering 9(3), 90–95 (2007).
- M.L. Waskom. Seaborn: Statistical data visualization (2021). URL https://seaborn.pydata.org/. Version 0.11.1.
- D.L. Donoho, Denoising by soft-thresholding. IEEE Transactions on Information Theory 41(3), 613–627 (1995).
- S. Hochreiter, J. Schmidhuber, Long short-term memory. Neural Computation 9(8), 1735–1780 (1997).
- Y.F. Li, Z.Q. Liu, H.L. Huang, Remaining useful life prediction based on degradation data with variability. IEEE Transactions on Reliability 67(1), 315–326 (2018).
- T. Campbell, I. Woxvold, J. Ding, The influence of material microstructure on machining-induced surface integrity. Procedia CIRP 71, 329–334 (2018).
- G.S. Duncan, T.L. Schmitz, The impact of subjective labeling on machine learning for chatter detection. International Journal of Machine Tools and Manufacture 45(4), 411–420 (2005).
- J. Lee, B. Bagheri, H.A. Kao, Cyber physical systems for predictive production systems. Production Engineering 9(1), 167–178 (2015). [CrossRef]
- Y. Lu, Industrial big data analytics in smart manufacturing: A review. Journal of Manufacturing Systems 49, 79–93 (2018).
- C. Tan, F. Sun, T. Kong, W. Zhang, C. Yang, C. Liu, A survey on deep transfer learning. International Conference on Artificial Neural Networks pp. 270–279 (2018). [CrossRef]
- O. Chapelle, B. Scholkopf, A. Zien, Semi-supervised learning. IEEE Transactions on Neural Networks 20(3), 542–542 (2009).
- S.S. John, M. Alberts, J. Karandikar, J. Coble, B. Jared, T. Schmitz, C. Ramsauer, D. Leitner, A. Khojandi, Predicting chatter using machine learning and acoustic signals from low-cost microphones. The International Journal of Advanced Manufacturing Technology 125, 5503–5518 (2023).
- D.A. Tobon-Mejia, K. Medjaher, N. Zerhouni, A review on data-driven fault severity assessment in rolling element bearings. Mechanical Systems and Signal Processing 25(6), 2083–2093 (2012).
- S.C. Hoi, J. Wang, P. Zhao, R. Jin, Online learning: A comprehensive survey. arXiv preprint arXiv:1802.02871 (2018).
Figure 1.
Three-axis CNC milling machine equipped with a Marposs MEMS vibration sensor.

Figure 2.
Stable machining conditions (left): The signal appears as a smooth, decaying sinusoidal wave. Chatter conditions (right): The signal becomes irregular, with additional higher frequency components causing more intense vibrations.
Figure 2.
Stable machining conditions (left): The signal appears as a smooth, decaying sinusoidal wave. Chatter conditions (right): The signal becomes irregular, with additional higher frequency components causing more intense vibrations.
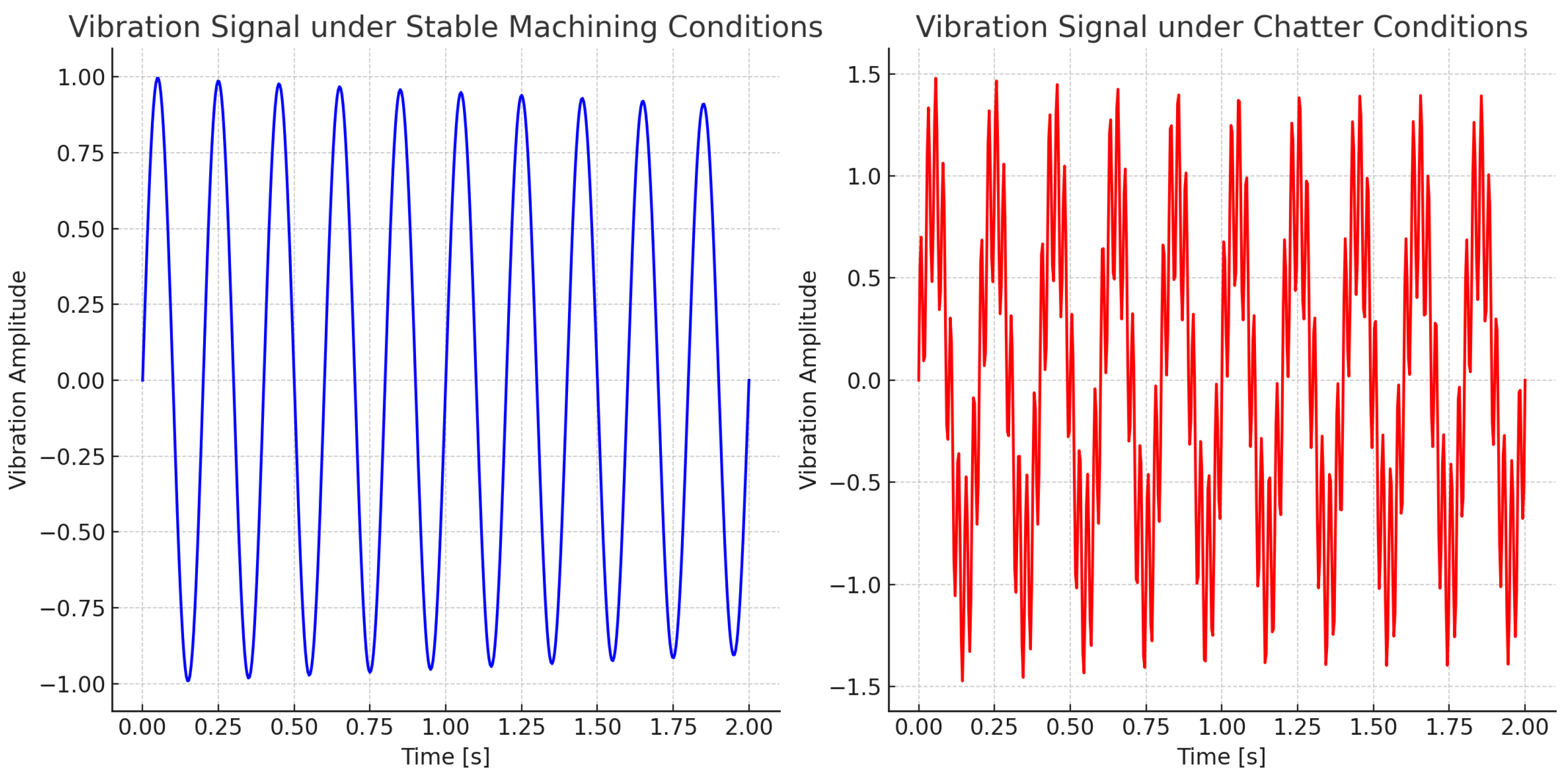
Figure 3.
ROC Curve of the tuned Random Forest Classifier on Real-World Data.
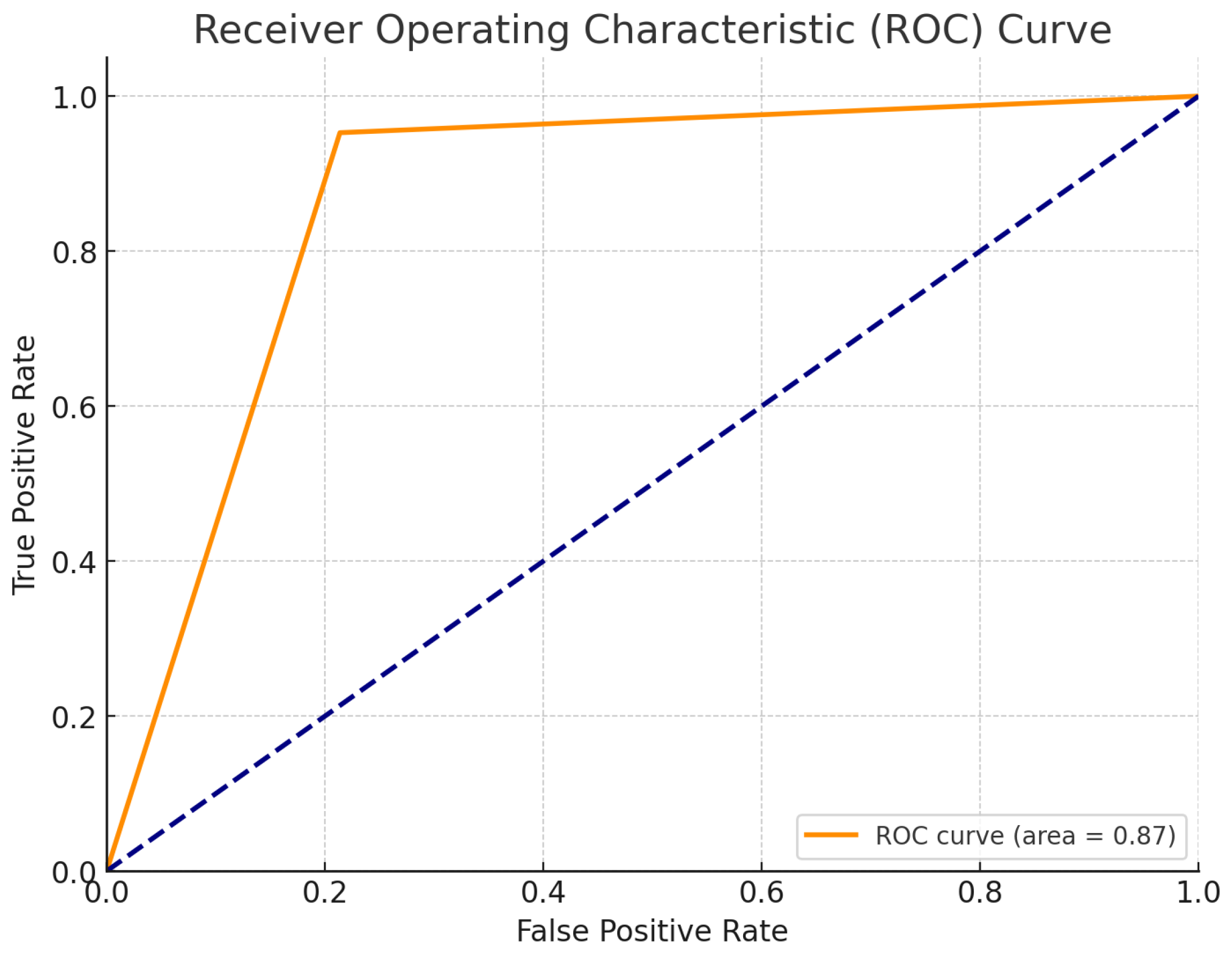
Figure 4.
Confusion Matrix of the tuned Random Forest Classifier on Real-World Data.
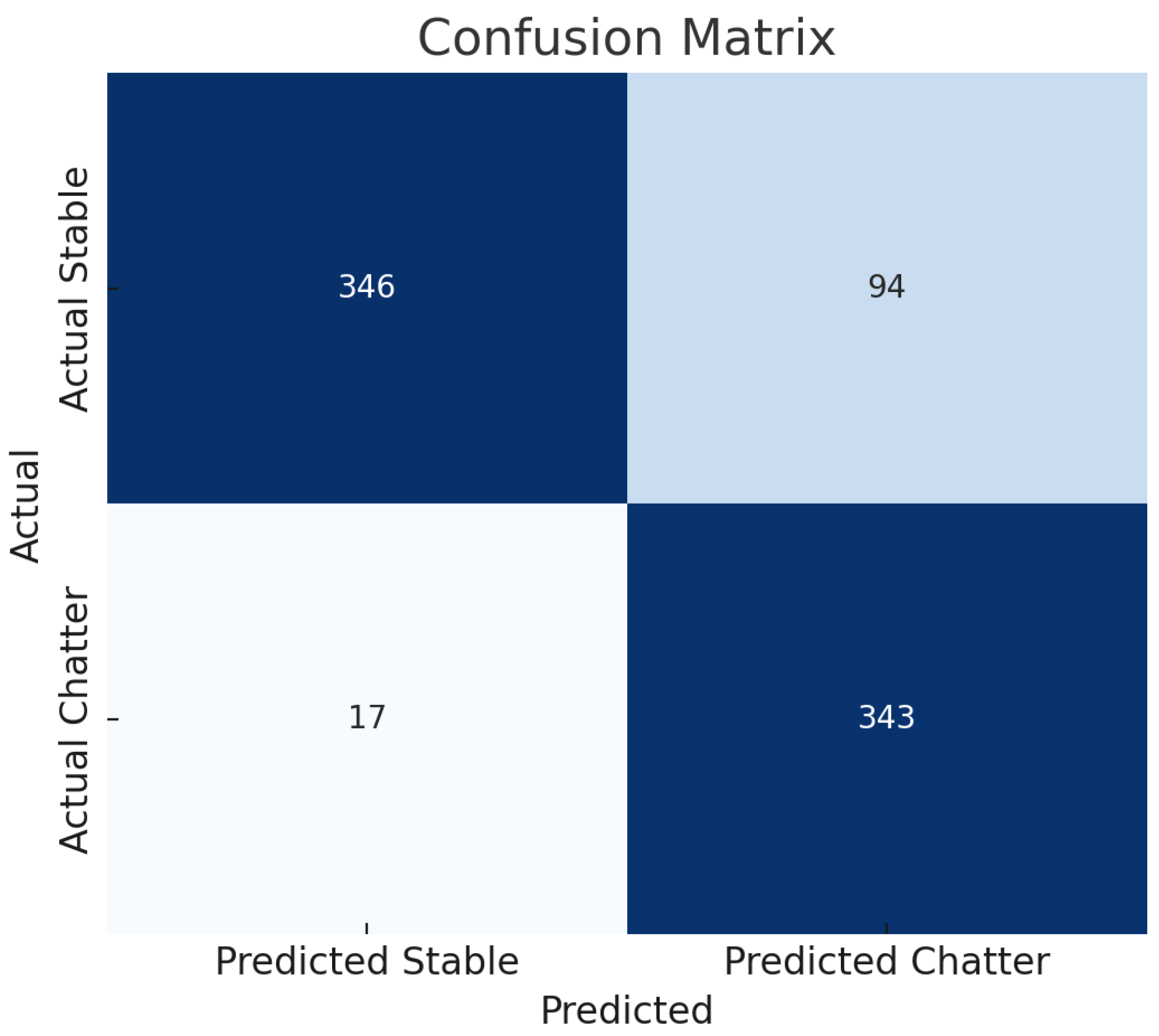
Figure 5.
Distribution of Natural Frequency Feature in Simulated vs. Real-World Data.
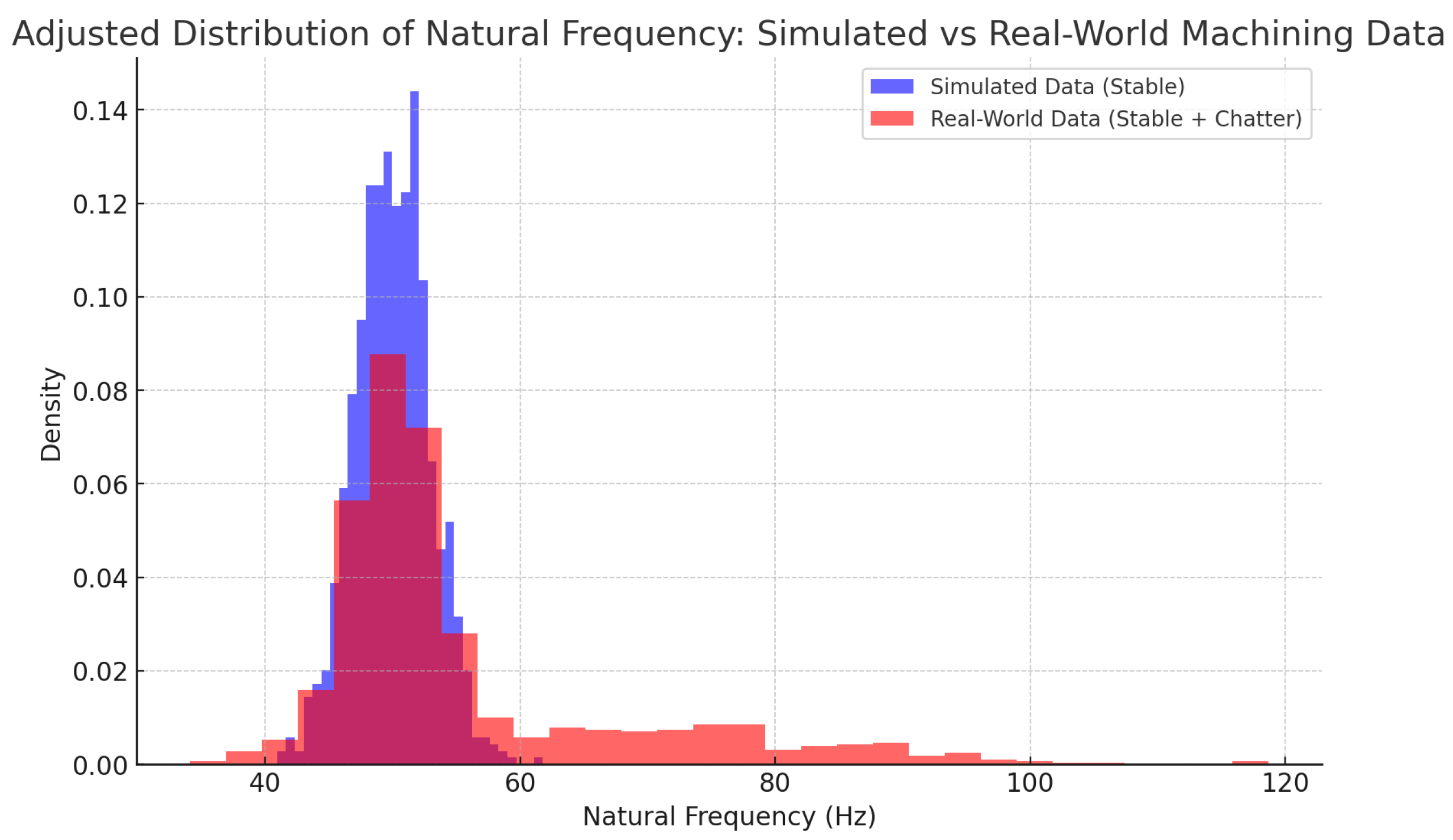
Figure 6.
Effect of Model Adaptation on Accuracy.
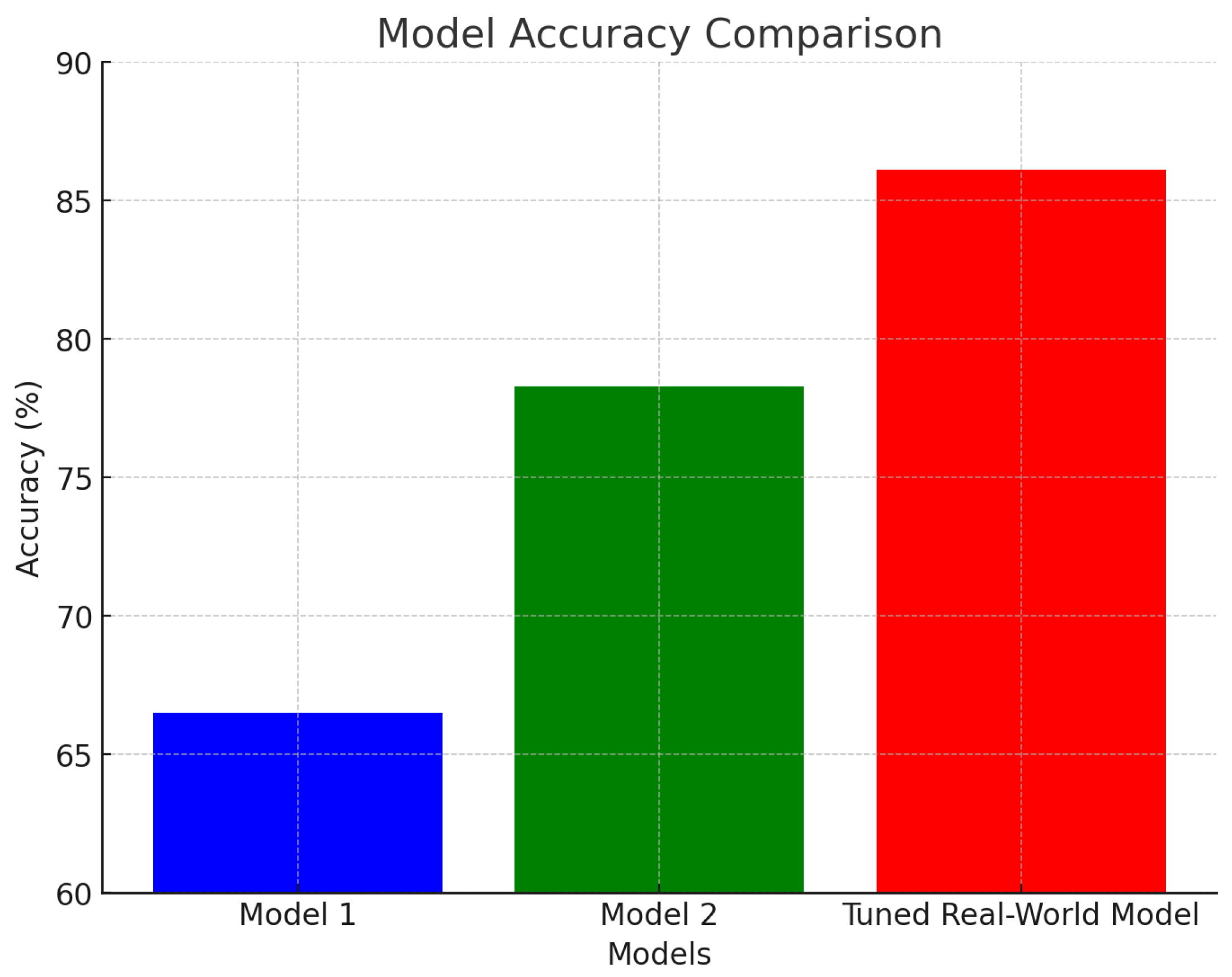

Table 1.
Performance Metrics of the Random Forest Classifier on Real-World Data.
| Metric | Model 1 | Model 2 | Real-World Tuned |
|---|---|---|---|
| Accuracy | 66.5% | 78.3% | 86.1% |
| Precision | 81.8% | 88.7% | 91.3% |
| Recall | 77.2% | 83.5% | 87.5% |
| F1-Score | 76.5% | 82.0% | 85.9% |
| AUC-ROC | 0.782 | 0.846 | 0.871 |
| Inference Time (ms) | 3.2 | 4.4 | 5.2 |
Table 2.
Paired t-Test Results for Performance Metrics.
| Metric | t-Statistic | p-Value |
|---|---|---|
| Accuracy | 3.12 | 0.011 |
| Precision | 2.85 | 0.016 |
| Recall | 2.45 | 0.028 |
| F1-Score | 3.05 | 0.012 |
| AUC-ROC | 2.98 | 0.014 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



