
Submitted:
31 October 2024
Posted:
01 November 2024
You are already at the latest version
Abstract
As an extension of the (univariate) Birnbaum-Saunders distribution, the Type II generalized crack (GCR2) distribution, built on an appropriate base density, provides a sufficient level of flexibility to fit various distributional shapes including heavy-tailed ones. In this paper, we develop a bivariate extension of the Type-II generalized crack distribution and study its dependency structure. For practical applications, several specific distributions, GCR2-Generalized Gaussian, GCR2-Student’s t and GCR2-Logistic, are constructed. The expectation-maximization algorithm is implemented to estimate the parameters in the bivariate GCR2 models. The model fitting results on the catastrophic loss dataset show that the bivariate GCR2 distribution base on the generalized Gaussian density fits the data significantly better than other alternative models.
Keywords:
heavy-tailed distribution
; type II generalized crack distribution
; Spearman’s rho
; Kendall’s tau
; EM algorithm
; catastrophic loss
1. Introduction
Researchers have examined diverse classes of distributions to study various facets of problems. Most loss datasets in the context of actuarial loss modelling, share some common characteristics, such as being skewed to the right, unimodal in form (multimodal in certain situations), and having a thin left tail and a moderate to extremely thick right tail. In recent years, various classes of heavy-tailed distributions including the subexponential distribution class, have been studied for modelling heavy-tailed (or extreme) data ([1,2,3]). On the other hand, a different stream of problems, like the periodic vibrations in commercial aircraft, motivated the introduction of the Birnbaum-Saunders (BS) distribution ([4]). The BS distribution models the total time elapsed until a critical threshold is exceeded by fatigue accumulated on a subject of interest (material), causing the failure event of the material to occur. The BS distribution is a two-parameter lifespan distribution derived for material fatigue data modelling. Due to its ability to fit right-skewed data, it is highly effective for modelling numerous scenarios. For example, in situations where there is an accumulation of a certain factor that drives a quantifiable characteristic to surpass a critical threshold ([5]).
Various classes of extension of the BS distribution have been discussed in the literature. In [6], a type of generalized Birnbaum-Saunders distribution family that replaced the standard normal with elliptically contoured density functions is introduced. The extreme value version of the generalized Birnbaum-Saunders (GBS) distribution, which proved that the tail thickness of the auxiliary distribution (i.e., standard elliptically symmetric distribution) determines that of the GBS distribution, has been discussed in [7]. Some applications of the extreme value BS models can be found in [5,8].
Another important extension of the BS distribution is the three-parameter (Gaussian) crack distribution ([9]). The constructed distribution is a two-component mixture of inverse Gaussian and length-biased inverse Gaussian distributions with a weight parameter p. The Gaussian crack distribution features increased flexibility to fit various datasets due to the additional the mixture weight parameter. However, the thin-tailedness of standard normal base density imposes restrictions on the Gaussian crack distribution when it comes to modelling heavy-tailed data. Due to the importance of the heavy-tailed distributions and extension to various applications beyond reliability theory and survival analysis, researchers looked for new statistical distributions. The introduction of heavy-tailed distributions with additional parameters addresses the shortcomings of the traditional distributions. A notable extension by [10] results in a large class of generalized crack (GCR) distributions, which contains the three-parameter Gaussian crack (lifetime) distribution as a specific member. Each member of the generalized crack distribution class is built on a specific choice of a base density function that determines the tail characteristics of the resulting GCR distribution. In [10,11], applications of GCR distributions built on the Student’s t and the generalized Gaussian base density functions to catastrophic losses and heavy-tailed precipitation time series, respectively, are given. The GCR distribution class has recently been further extended to the class of Type II generalized crack (GCR2) distribution ([12]) in which an additional shape parameter is included to increase flexibility over the GCR class. The tail characteristics of the base density function and the new shape parameter in the GCR2 model determine the right tail properties of the GCR2 class.
Regarding applications for bivariate data with heavy-tailed marginals, a bivariate GCR distribution with a form of four-component mixture of independent models, has been constructed in [13]. The authors demonstrate that bivariate GCR models can exhibit various dependence structures and serve as valuable models for various real-world situations.
This paper aims to extend the univariate GCR2 models to bivariate cases by employing the mixture model structure used in [13]. This study considers three specific examples of GCR2 distributions, a newly constructed GCR2 model based on the logistic density in addition to the two GCR2 models introduced in [12], to effectively fit insurance and catastrophic losses. This paper studies some theoretical properties of the constructed model such as conditional distribution and the measures of dependency (e.g., Spearman’s rho and Kendall’s tau), a method for model parameter estimation through the Expectation-Maximization (EM) algorithm, and fitting the model to natural disasters datasets to demonstrate its applicability.
The rest of this paper is organized as follows. Section 2 gives a brief review of the origin, definition, examples, and key properties of the univariate Type II generalized crack distributions for the reader’s convenience. In Section 3, the bivariate Type-II generalized crack distribution is introduced with some detailed discussions on its theoretical properties. A method of model estimation and its application on a real catastrophic loss dataset are presented in Section 4 and Section 5, respectively. Finally Section 6 provides some concluding comments.
2. Type-II Generalized Crack Distribution
2.1. Birnbaum-Saunders Distribution
Birnbaum-Saunders (BS) distribution (also known as the fatigue-life distribution) was motivated by the problem of periodic vibration in aircraft that caused the materials to fatigue [4]. The Birnbaum-Saunders distribution is a well-known distribution for modelling the time of a crack (or a failure) happening when a material specimen is used repeatedly and experiences material fatigue due to gradual accumulation of stress/damages. The failure event occurs when the accumulated stress on the material specimen hits a critical threshold and the failure time T is the first hitting time of the accumulated stress to the critical threshold. Details of the Birnbaum-Saunders setting based on Brownian motion can be found in [12]. The Birnbaum-Saunders distribution is known to be a two-point mixture of the inverse Gaussian (IG) and the length-biased inverse Gaussian (LB-IG) distributions with equal mixture weights. Specifically the cumulative distribution function (cdf) and probability density function (pdf) of the BS distribution are as follows respectively:
where
Here and are the scale and shape parameters, respectively. and denote the cdf and pdf of the standard normal distribution, whereas and denotes the cdf and pdf of the two-parameter IG and the LB-IG distributions, respectively.
2.2. Gaussian Crack (CR) Distribution
The Gaussian crack distribution ([9]) is an extension of BS distribution by introducing the weight parameter in place of the fixed weight of 1/2 in the BS distribution. Naturally the CR distribution allows for higher flexibility compared to the classical BS distribution. The pdf of the Gaussian crack (CR) distribution is given as follows:
where , and are the scale, shape and mixture weight parameters, respectively, and .
Despite the fact that the right tail of the CR distribution thickens as p decreases, the tail maintains the shape of an exponential distribution. It is easy to see that the limit of the hazard rate function of the crack distribution converges to a constant that is greater than zero, i.e.,
which suggests that the Gaussian crack distribution does not belong to heavy-tailed distribution class ([3,14]).
2.3. Generalized Crack Distribution
In [10], the Gaussian CR distribution family has been extended to a large class of generalized crack (GCR) distribution whose members depend on the specification of base density function , where is a base (or auxiliary) density function which is symmetric about zero. The base density function replaces the standard normal density function used for the Gaussian crack density.
Specifically, a random variable T has the generalized crack(GCR) distribution with base density g, denoted as where the parameters , and the mixture weight , if its pdf is given as: PDF of GCR:
where
Here, and are referred to as the pdfs of the inverse symmetric (IS) and the length-biased inverse symmetric (LB-IS) distribution, respectively, on the base density function . The cdf of the distribution is given as:
where , is the distribution function of base density function , and .
A general expression for the nth raw moments of the IS and LB-IS random variable along with details on the tail behaviour of the GCR distribution is provided in [10]. Their findings demonstrated that, with an appropriate choice of base density function, the heavy-tailed generalized crack distribution performs better than many well-known parametric distributions, such as Log-normal, Pareto type II, and Weibull distributions, which are frequently used in modelling positively skewed and heavy-tailed extreme data sets.
2.4. Type-II Birnbaum-Saunders (BS2) Distribution
The type-II Birnbaum-Saunders distribution extends the BS distribution by introducing another shape parameter . Applying the inverse transform method to Eq. 1, it can easily be verified that the following stochastic relationship holds. Let us define a random variable T as
where X is a standard normal random variable. The Type-II Birnbaum-Saunders (BS2) distribution introduces an additional shape parameter to the expression above, defined formally as
The pdf of the Type-II Birnbaum-Saunders (BS2) distribution is
where are model parameters, and
The cdf is given as
Like the BS distribution, the BS2 distribution is a two-point mixture of densities and having equal weights. However, with the extra shape parameter , the BS2 distribution provides more flexibility over the BS distribution. The BS2 distribution reduces to the Birnbaum-Saunders distribution when .
2.5. Type-II Generalized Crack Distribution
The Type-II generalized crack distribution class can be seen as a natural extension of the Type-II Birnbaum-Saunders distribution by replacing the standard normal density with a symmetric base density and including the mixture weight parameter p ([12]). Specifically the pdf of GCR2 distribution with base density g is given as follows:
where
Respectively the cdf of GCR2 distribution with base density g is given as
where
and .
2.6. Specific Examples of GCR2 Distributions
The specification of the base density function on which GCR2 distribution is built may depend on some key distributional features (such as tail characteristics) that are required for each specific application. Two practical examples, the GCR2-t and the GCR2-GG distributions whose base densities are the Student’s t and the generalized Gaussian (normal) distributions, respectively, are given in [12]. In this paper we also consider the GCR2 distribution with the logistic base density, referred to as the GCR2-LG distribution, as another member of the GCR2 distribution class.
Example 2.1.(GCR2-t distribution).
The Student’s t distribution has a regular varying tail and its density function is given as
The corresponding density of the GCR2-t can be easily expressed as
The Student’s t distribution belongs to the Maximum Domain of Attraction (MDA) of the Fréchet distribution with index , which means that the distribution of a properly normalized maximum of independent and identically distributed (i.i.d.) Student’s t random variables converge to a Fréchet distribution asymptotically. Bae and Volodin[12] show that the tail of the GCR2-t distribution is regular varying with index , and thus it also belongs to the MDA of the Fréchet distribution. Comparing with the tail of the GCR-t distribution that has the index , the tail of GCR2-t becomes heavier than that of the GCR-t when gets smaller than . Figure 1, Figure 2 and Figure 3 illustrate the shapes of the GCR2-t density function for a few prescribed parameter sets.
Example 2.2. (GCR2-GG distribution).
The GCR2-GG is a large distribution family which encompasses both thin to moderately heavy-tailed ones, and it can be useful for various practical applications. In particular when , the generalized Gaussian model is subexponential ([3]). The pdf of the Generalized Gaussian (GG) is given as
For symmetry, we set and, for the identification of parameters, we set . The density function of the resulting GCR2-GG distribution has the following expression:
Example 2.3. (GCR2-LG distribution).
The Logistic (LG) distribution has the density function
For the identification of parameters, we set . The resulting GCR2-LG distribution has the density function as follows:
The GCR2-LG distribution can be an effective model to fit thin to moderate-tailed datasets for financial and insurance applications and, with one less paramter, it is simpler than the GCR2-t and GCR2-GG distributions.
As seen from these figures, various distribution forms can be constructed depending on the distributional features of the base density function and the related shape parameters. For a GCR2 distribution family with a specific base density, the right tail of the distribution becomes heavier as the mixture weight parameter p gets smaller. The larger the shape parameter is, the heavier the tail becomes, and the opposite is true for the shape parameter . For details of tail properties of the GCR2 distribution, see Theorem 1 and Theorem 2 in Bae and Volodin[12].
3. Bivaraite GCR2 Distribution
We introduce a bivariate extension of the Type II generalized crack distribution and study some properties like the conditional distribution and measures of association. Let g be a probability density function symmetric about zero. For two positive random variables, we define the bivariate Type-II generalized crack distribution as follows.
Definition 1.
A pair of random variables with base density g and parameters =(), = (), = () and (), has a bivariate Type-II generalized crack distribution, denoted as BVGCR2(,,,p;g), if and only if its joint pdf is given as follows:
where the mixture weight parameters satisfy , , , and, for each
and
BVGCR2(,,,p;g) is a mixture of four combinations of independent bivariate distributions. It is easy to see that the marginal distributions of and are GCR2 and GCR2 , respectively. Note that, for simplicity, we assume that the marginal distributions are built based on the same base density function g whose model parameter can be distinct for each marginal.
We provide the conditional distribution which is an essential property for the simulation of the pair of random variables. Following the relationship between the two mixture components of the GCR2 distribution, , the conditional density of given is expressed as follows. For notational convenience, we drop subscript and the parameters in the functions and write as;
Hence, the conditional distribution of given is also GCR2 where,
Using the conditional distribution, one can in sequence simulate the pairs of random variates for the BVGCR2 models, by first simulating from the GCR2 using the acceptance-rejection method as shown in Bae and Chen[10] and then, simulate from the conditional distribution GCR2 .
3.1. Dependence Measures
In this section we derive expressions for Spearman’s rho and Kendall’s tau of BVGCR2 random variables.
3.1.1. Spearman’s Rho
Spearman’s rho is a commonly used measure of association between two random variables. Due to the invariance under monotone transformations, Spearman’s rho provides a broad interpretation of the dependence structure for any bivariate distributions. With marginal densities, and for the random variables and , respectively, and the joint distribution on , the (population version) Spearman’s rho is defined as;
where and are uniform random variables. That is, Spearman’s rho is Pearson’s correlation between transformations of the variables into uniformly distributed ones. The following proposition provides an expression for Spearman’s rho of random variables having a BVGCR2 distribution.
Proposition 1.
Suppose BVGCR2(,,,p;g). Then, Spearman’s rho between and is given by
where
Proof. See Appendix A.
3.1.2. Kendall’s Tau
Kendall’s tau is a measure of concordance between two random variables. Formally, for the random variables and with the joint distribution on , the (population-version) Kendall’s tau is defined as
where the pair has the joint distribution F and is independent to .
The following proposition provides an expression for Kendall’s tau of random variables having a BVGCR2 distribution.
Proposition 2.
Suppose BVGCR2(,,,p;g). Then , Kendall’s tau between and is given by
where
Proof. See Appendix B.
Remark 3.1.
It is important to note that,
This inequalities can be proven by using the symmetry of , and integration by parts. Specifically,
For , , , and applying integration by parts,
With this and by Eqs. (1) and (2), we obtain the following bounds for and :
Note that and get the maximum when ==0.5 and attains its maximum of 1/4.
Also remark that, if , and thus , the joint density of the BVGCR2 model can be expressed as a product of two GCR2 marginals, i.e., the two random variables are independent.
3.2. Tail Independence
As remarked in the previous section, the dependency measures of the proposed BVGCR2 model are bounded, and thus the model may not be suitable for the cases where the extreme dependency is required, i.e., market turmoils. Here we further investigate the tail dependence of the BVGCR2 model in terms of the upper tail dependence which is defined as
where the last equality holds by the L’hospital’s rule. In fact,
Since , , and , we have
Therefore,
Then, by Eq. (9), we have . That is, the BVGCR2 model does not have tail dependence.
4. Model Parameter Estimation
In this section, we discuss parameter estimation of the bivariate Type-II generalized crack distribution using the expectation-maximization algorithm. We briefly review the EM algorithm in a general setting and provide a specific application to the BVGCR2 model.
4.1. Maximum Likelihood Estimation
Suppose is an independent and identically distributed random sample drawn from a density . Likelihood function is given as
The maximum likelihood estimation (MLE) aims to find the parameter estimate that maximizes the likelihood function, or equivalently, the log-likelihood function:
In the presence of latent (hidden/unobserved) values, however, the direct maximization method often does not provide reliable estimates; hence, other alternative methods are usually considered, and one of such methods is the expectation-maximization algorithm.
4.2. Expectation-Maximization Algorithm
For simple mixture models with a small number of mixture components, the direct optimization of the log-likelihood function may be used to obtain the maximum likelihood estimates of the model parameters. However, the direct optimization often fail to converge when the number of mixture components is large relative to the sample size.
The expectation maximization (EM) algorithm ([15]) is an efficient iterative procedure used to compute the maximum likelihood estimates in the presence of missing or hidden data. When applied to finite mixture model settings, the expectation step renders the separation of the mixture weight parameters from other model parameters for optimization, and the maximization step gives an explicit solution for updating the mixture weights. Due to this, the algorithm is the most widely used maximum likelihood estimation technique for finite mixture models.
Here we briefly review the general form of the EM algorithm. Suppose we have observed data with density and some latent (hidden/unobserved data) with density . The density of the complete data is denoted by . The goal of the EM algorithm is to find the MLE, that is, the maximum of the observed data likelihood function,
The EM algorithm proceeds by iterating between the following two steps;
- E-Step: This step calculates the expectation of the likelihood with respect to the conditional distribution of given and the initial parameter estimate , that is,
- M-Step: Choose
Lemma 4.1.
The EM algorithm improves , if then .
Proof. See Appendix C.
We now provide the EM algorithm for the estimation of the parameters in the BVGCR2 model. Let be a random sample drawn from a BVGCR2() distribution, where is a pair of observations for each , and the base density g may have its own parameter(s) such as involved in the Student’s t density. We denote the vector of parameters involved in the base densities by . Letting be the vector of all model parameters, the likelihood function based on the incomplete data is
where is the set of indexes and
On the other hand, letting be a set of latent variables where Pr for each , the likelihood function based on the (augmented) complete data is
where denotes the indicator function.
Let denote the current estimate of after m-th iteration of the EM algorithm. Then, by Bayes’ theorem, we have
The expectation step (E-step) of the EM algorithm follows.
The maximization step (M-step) finds the updated parameter estimates that maximize the objective function Equation (Section 4.2) which separates and the other parameters (). The update of can be dealt with separately by applying the method of Lagrange multiplier. The updated estimate is
The updated estimates and are the maximizers of the objective function
where
and
That is, the maximization for can be proceeded separately from that for and thus, the dimensionality of the optimization problem is reduced significantly.
5. Applications
In [12] the authors demonstrate the usefulness of the univariate GCR2 distribution for modelling heavy-tailed loss severity data. Here, we fit some bivariate Type-II generalized crack distributions on real catastrophic loss data compiled from the International Disaster Database (EM-DAT, www.emdat.be). Particularly, we consider a set of observations composed of two variables, losses from meteorological (Meteo) and hydrological (Hydro) disasters spanning from 1950 to 2022 in Asia. For the purpose of bivariate model fitting, we remove the pairs with missing observations, resulting in a bivariate dataset with 166 observations. The bivariate data is composed of quarterly times series of (estimated) damage due to meteorological disasters such as storms and extreme temperatures, and hydrologic disasters such as floods and landslides. The loss values are inflation-adjusted to be equivalent to the US dollar value in 2021 with a unit of 100 million USD.
Table 1 presents summary statistics of losses due to the hydrological and meteorological disasters in Asia. The descriptive statistics together with the histogram and normal Q-Q plots (Figure 10 and Figure 11) suggest that the two datasets are both positively skewed and heavy-tailed. To isolate the deterministic components, the quarterly time series are decomposed under the multiplicative model assumption. Figure 12 presents the datasets decomposition which shows the presence of strong seasonal components in both variables and some evidence of weak long-term trends. Since the proposed model does not assume any deterministic seasonality, we deseasonalize by dividing each time series with its estimated seasonal component.
Figure 13 gives the scatter plots of the two deseasonalized variables and their log-transformed versions. The figure shows some evidence of a dependent relationship between the two variables. The sample Spearman’s rho and Kendall’s tau are 0.425 and 0.291, respectively.
We apply the EM algorithm described in Section 4.2 to fit the data using six specific bivariate models: GCR-GG, GCR-t, GCR-LG, GCR2-GG, GCR2-t, and GCR2-LG. For each model fitting, the EM algorithm requires the initialization of the parameter values. To obtain a reliable result, we first fit the marginal models separately using the estimation method given in [12], and the fitted values of the marginal parameters, i.e., for GCR models and , for the GCR2 models, are used for the initialization of the BVGCR (or BVGCR2) model parameters. For the mixture weight parameter initialization, we use a large set of possible parameter values satisfying and , where and are the mixture weight parameter estimates for the marginal models. The log-likelihood function values of the EM fits under the set of initializations are compared and the one gives the largest log-likelihood value is selected for the final fit.
Since the number of estimated model parameters differs by model, we compare the fits of candidate BVGCR2 models in terms of the Akaike information criterion (AIC) and the Bayesian information criterion (BIC), defined as
respectively, where k is the number of estimated parameters and n is the sample size. Amongst candidate models, the preferred model is the one with the smallest value of either of these criteria. From Table 2, we see that the fitted BVGCR2-GG model outperforms all the other alternative models based on the Akaike information criterion. However, the BVGCR-LG model is preferred in terms of the Bayesian information criterion which heavily penalizes complex models. Comparing the BVGCR-GG to the BVGCR2-GG, one can see the BVGCR2-GG significantly improves model fitting due to the additional shape parameter.
Table 3 gives parameter estimates of the marginal distributions and the bivariate model of the fitted GCR2-GG model.
Note that the values of and based on the fitted BVGCR2-GG model are larger than the corresponding estimates of and . Spearman’s rho and Kendall’s tau under the fitted BVGCR2-GG model are 0.173 and 0.115, respectively, which are lower than the empirical counterparts. This may be because the empirical data contains spurious dependence due to the deterministic trend.
To test the statistical significance of the parameter estimates of the BVGCR2-GG model, we construct the bootstrap confidence intervals by computing the 2.5th and the 97.5th percentiles of the estimates based on the 100 bootstrap samples. Table 4 shows that all the parameter estimates on the original dataset fall in the corresponding 95% bootstrap confidence intervals.
Figure 14 gives the contour plots of the fitted BVGCR2-GG model and that of the log-transformed random variables and Figure 15 presents the scatter plots of the simulated random variables from the BVGCR2-GG model and their log-transformations. Comparing these plots with Figure 13, we can see that the fitted model explains the dependence structure of the empirical data well.
6. Conclusions
In this paper, we constructed a bivariate extension of the Type-II generalized crack distribution and studied a few specific examples of the bivariate GCR2 distributions base on the generalized Gaussian, Student’s t and logistic densities to demonstrate the applicability of the constructed model. Specifically, our main theoretical finding is that the level of dependence of the constructed BVGCR2 model in terms of Kendall’s tau and Spearman’s rho is a weak to medium association. The model fitting to a catastrophic loss data showed that the fitted BVGCR2-GG model outperformed all the other alternative models based on the Akaike information criterion. Especially when compared to the BVGCR-GG model, the BVGCR2-GG model has shown a significant improvement due to the increased flexibility. With an appropriate choice of base density function, the propose BVGCR2 model can be effectively used for various applications that requires a weak to moderate level of dependence.
Author Contributions
Conceptualization, T. Bae; methodology, T.B., H.Q.; software, H.Q.; validation, T.B.; formal analysis, T.B, H.Q.; investigation, T.B.; resources, T.B.; data curation, H.Q.; writing—original draft preparation, T.B., H.Q.; writing—review and editing, T.B.; visualization, H.Q.; supervision, T.B.; project administration, T.B.; funding acquisition, T.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research is supported by the Discovery Grant program of the Natural Science and Engineering Research Council of Canada (NSERC) with a funding reference number RGPIN-2022-03428
Data Availability Statement
The data used in this research is available upon request.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A. Proof of Proposition 1
We drop parameters in the expressions of the functions for notational convenience and write and By the joint distribution of having BVGCR2(,,,p;g), is
and the marginal density of is
also, the cdf of GCR2 distribution can be written as
where , is the cdf of g and
By expanding the integrand in Equation 6 using these expressions and taking the double integration, we have
where, for each
That is, the evaluating the double integral in Equation 6 reduces to the following two integrals: and . Due to the expression and
and changing the order of integrations, we obtain
Similarly, due to the expression , we obtain
The combination and some simplifications of these results give the expression Equation 7.
Appendix B. Proof of Proposition 2
As in the proof of proposition 1, expanding the integrand in 8 using the joint cdf and pdf of the BVGCR2 and taking double integrals, gives
As given the proof of Proposition 1, and for each . With these and after some simplification, the above integral can be expressed as
Appendix C. Proof of Lemma 4.1
The log-likelihood function of the observed data is given as . By the law of total probability,
Multiplying and dividing by a constant , which is the probability of hidden data given the observed data and initial guess parameter. Since this is a probability function, then and . Then, the log-likelihood is;
Therefore, gives the lower bound on the log-likelihood, which is the only term that depends on . is true for all including the situation where . We show the relationship is still true for ,
If we have for which , then
Therefore, as Q increases, it implies also increases. We conclude that, if is the MLE, then always holds.
References
- Bingham, N.H.; Goldie, C.M.; Teugels, J.L. Regular Variation; Cambridge University Press, 1987.
- Embrechts, P.; Klüppelberg, C.; Mikosch, T. Modelling Extremal Events for Insurance and Finance; Springer-Verlag: Berlin, 1997. [Google Scholar]
- Foss, S.; Korshunov, D.; Zachary, S. An Introduction to Heavy-Tailed and Subexponential Distributions; Springer Science+Business Media, 2013.
- Birnbaum, Z.W.; Saunders, S.C. A new family of life distributions. Journal of applied probability 1969, 6, 319–327. [Google Scholar] [CrossRef]
- Leiva, V. The Birnbaum-Saunders Distribution 2015.
- Díaz-García, J.A.; Leiva-Sánchez, V. A new family of life distributions based on the elliptically contoured distributions. Journal of Statistical Planning and Inference 2005, 128, 445–457. [Google Scholar] [CrossRef]
- Gomes, M.I.; Ferreira, M.; Leiva, V. The extreme value Birnbaum-Saunders model, its moments and an application in biometry. Biometrical Letters 2012, 49, 81–94. [Google Scholar] [CrossRef]
- Ferreira, M.; Gomes, M.I.; Leiva, V. On an extreme value version of the Birnbaum–Saunders distribution. REVSTAT-Statistical Journal 2012, 10, 181–210. [Google Scholar]
- Volodin, I.N.; Dzhungurova, O.A. On limit distributions emerging in the generalized Birnbaum-Saunders model. Journal of Mathematical Sciences 2000, 99, 1348–1366. [Google Scholar] [CrossRef]
- Bae, T.; Chen, J. On heavy-tailed crack distribution for loss severity modeling. International Journal of Statistics and Probability 2017, 6, 92–110. [Google Scholar] [CrossRef]
- Mazjini, M.; Bae, T. Statistical modelling of precipitation data in Canadian Prairies with a dynamic mixture structure. Theoretical and Applied Climatology 2023, 153, 173–192. [Google Scholar] [CrossRef]
- Bae, T.; Volodin, A. Type-II Generalized Crack Distribution with Application to Heavy-Tailed Data Modeling. Journal of Statistical Theory and Practice 2022, 16, 1–23. [Google Scholar] [CrossRef]
- Bae, T.; Choi, Y.H. A bivariate extension of three-parameter generalized crack distribution for loss severity modelling. Journal of the Korean Statistical Society 2022, 51, 378–402. [Google Scholar] [CrossRef]
- Klugman, S.A.; Panjer, H.H.; Willmot, G.E. Loss models: from data to decisions; Vol. 715, John Wiley & Sons, 2012.
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood from incomplete data via the EM algorithm. Journal of the royal statistical society: series B (methodological) 1977, 39, 1–22. [Google Scholar] [CrossRef]
Figure 1.
Density functions of GCR2-t distribution with = 0.5, = 5 , , p = 0.5, and = 3.
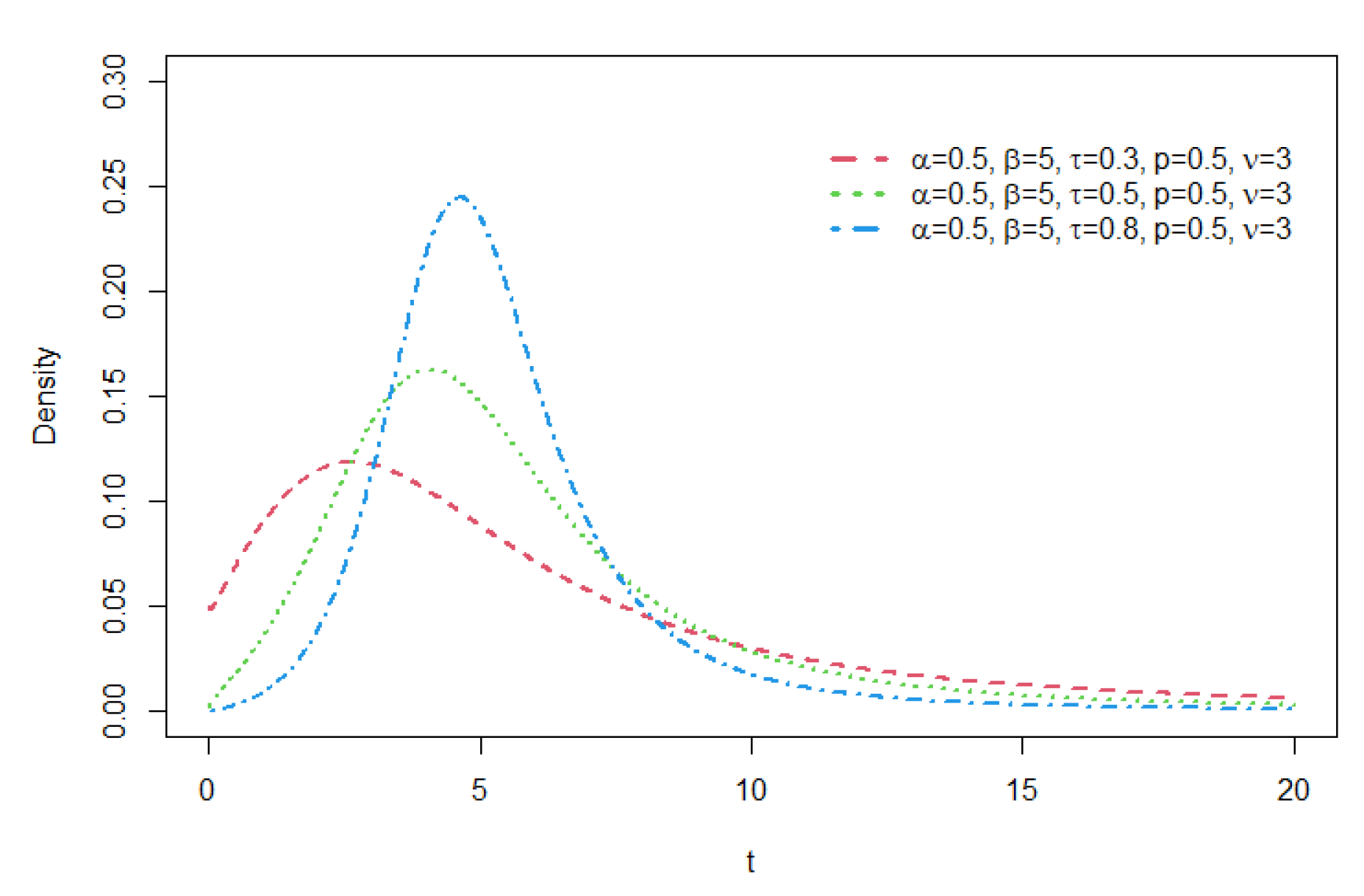
Figure 2.
Density functions of GCR2-t distribution with , = 5 , , p = 0.5, and = 5.
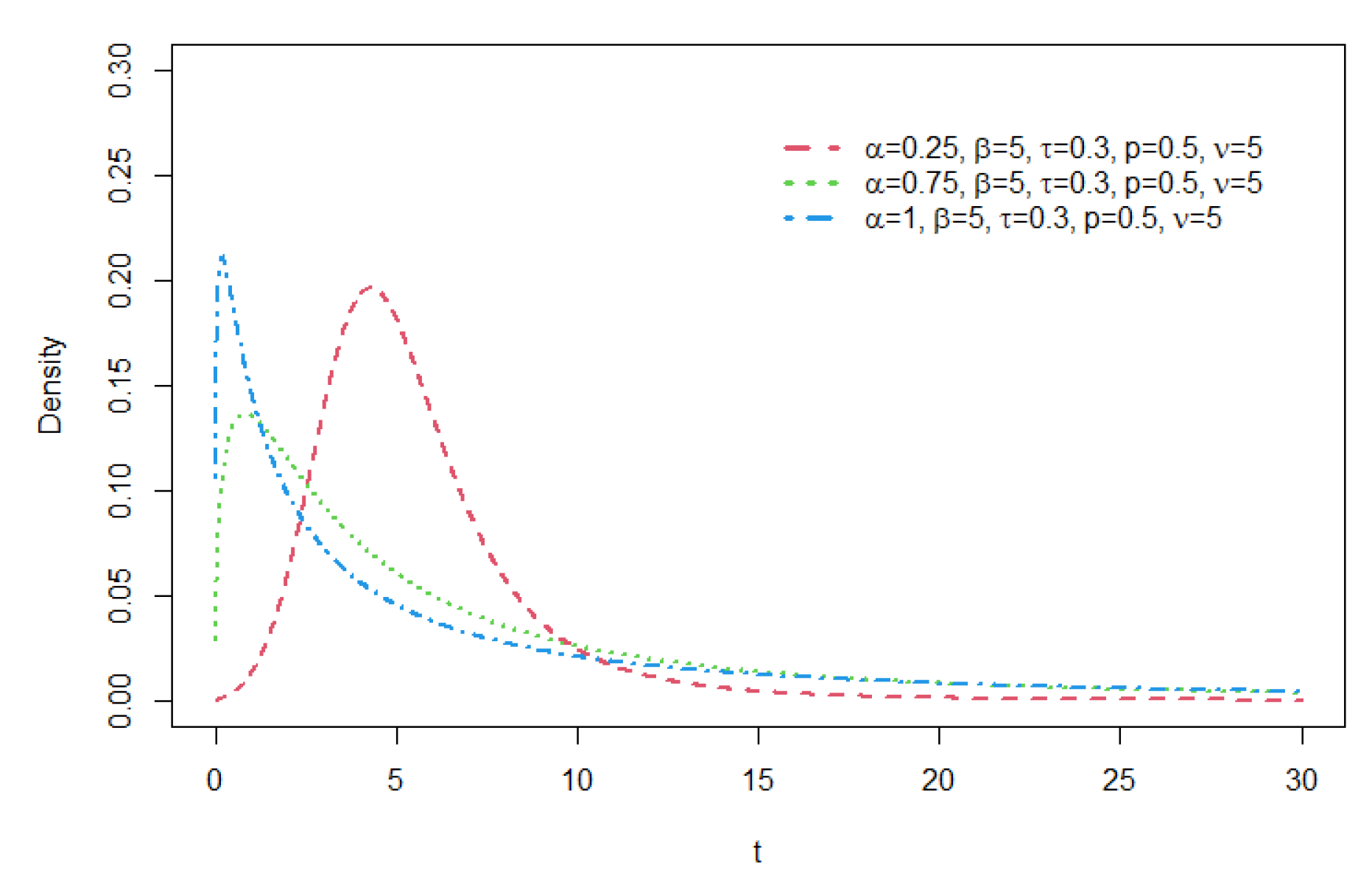
Figure 3.
Density functions of GCR2-t distribution with = 0.75, = 5 , = 0.5, p and = 5.
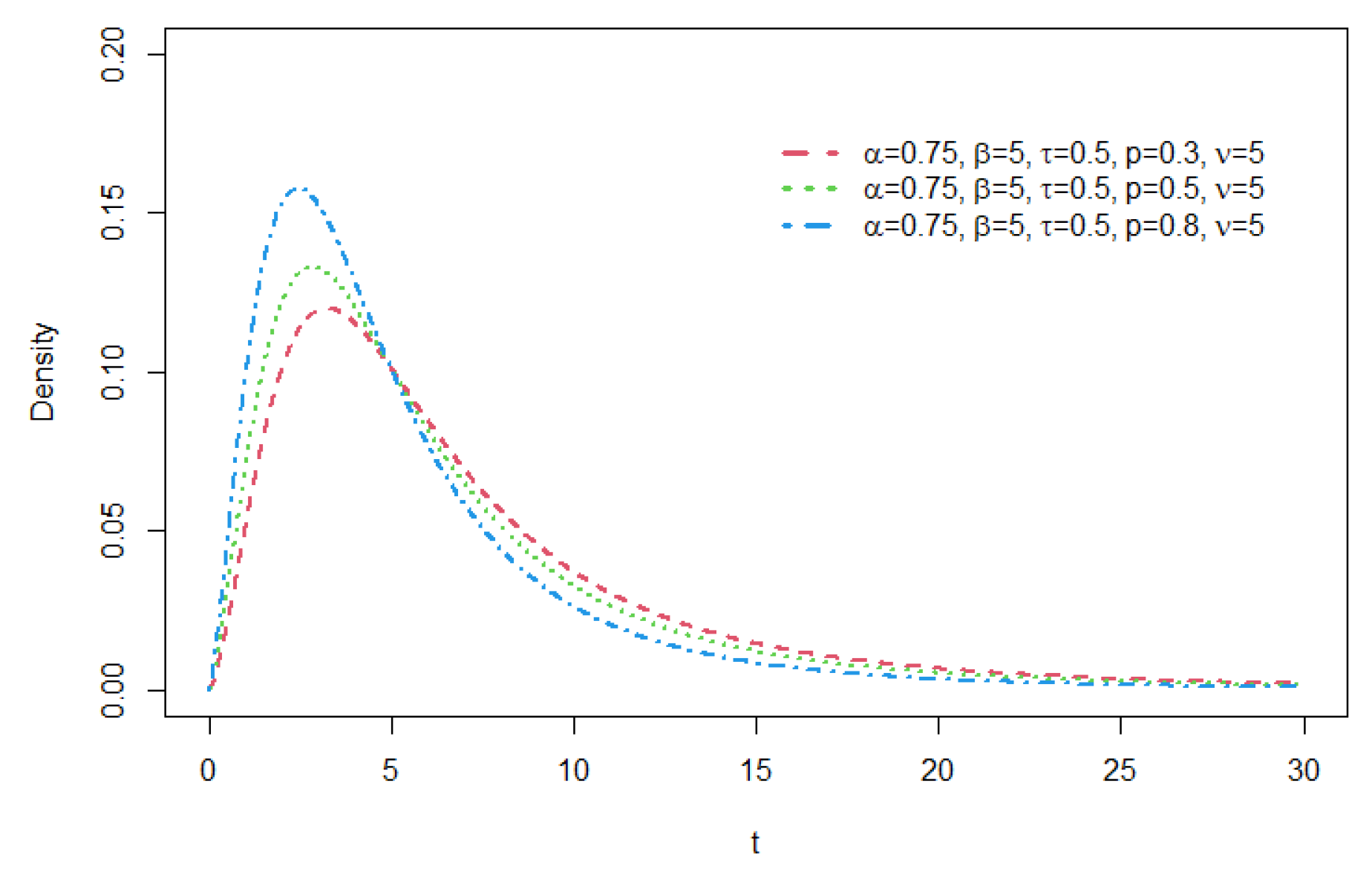
Figure 4.
Density functions of GCR2-GG distribution with , = 5 , , p = 0.5, and = 0.8.
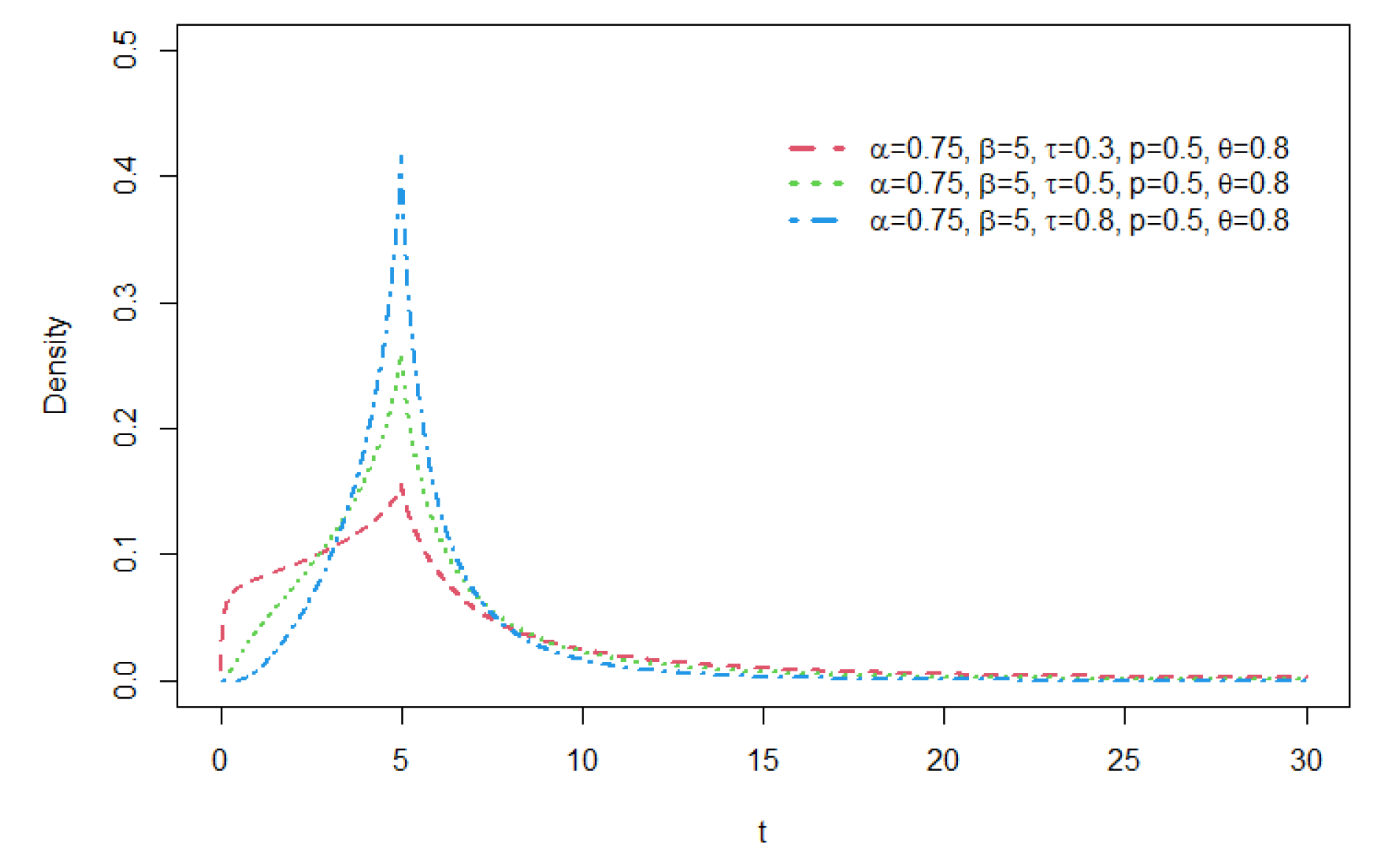
Figure 5.
Density functions of GCR2-GG distribution with , = 5 , , p, and = 1.
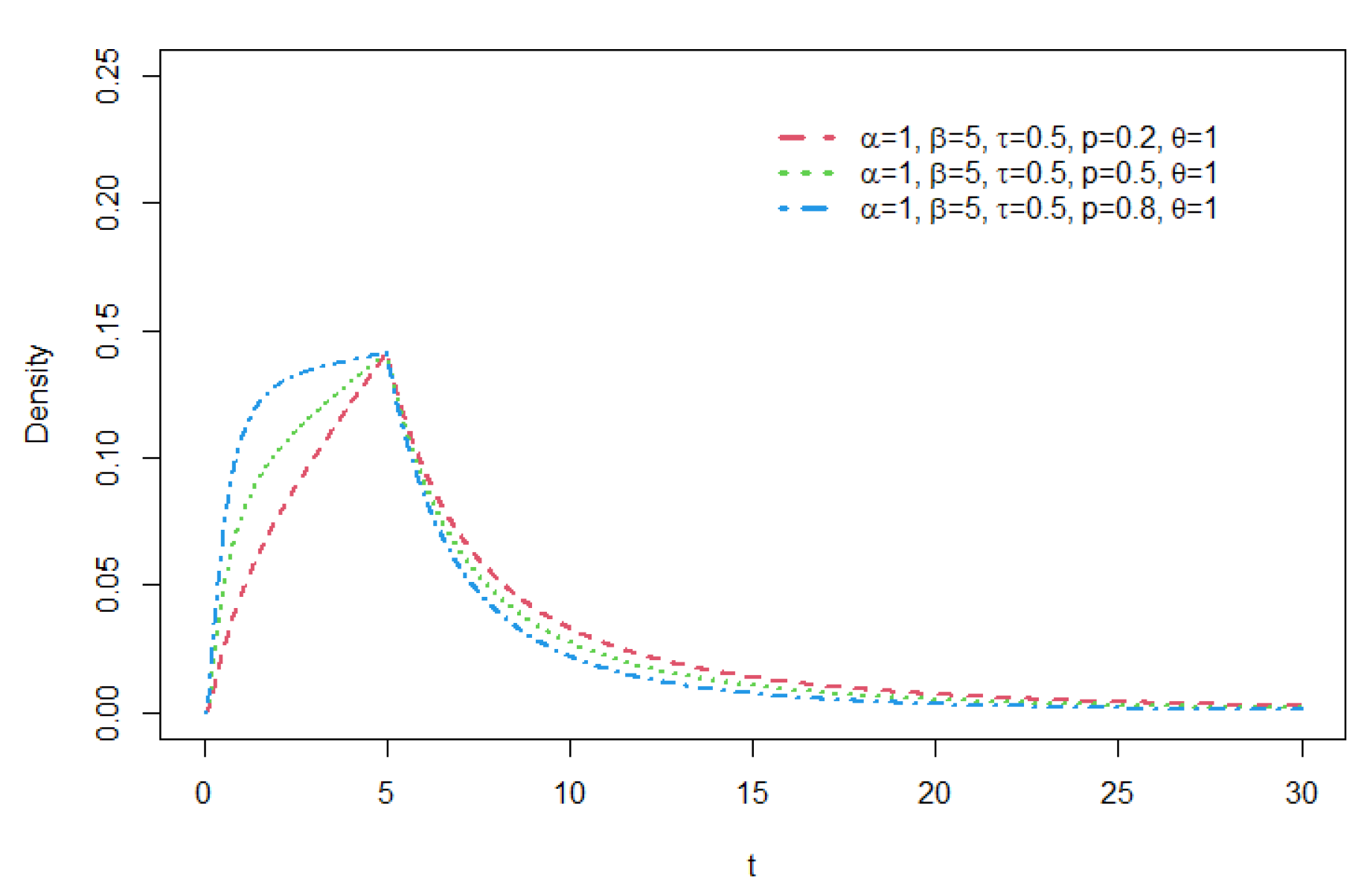
Figure 6.
Density functions of GCR2-GG distribution with , = 5 , , p = 0.5, and = 1.2.
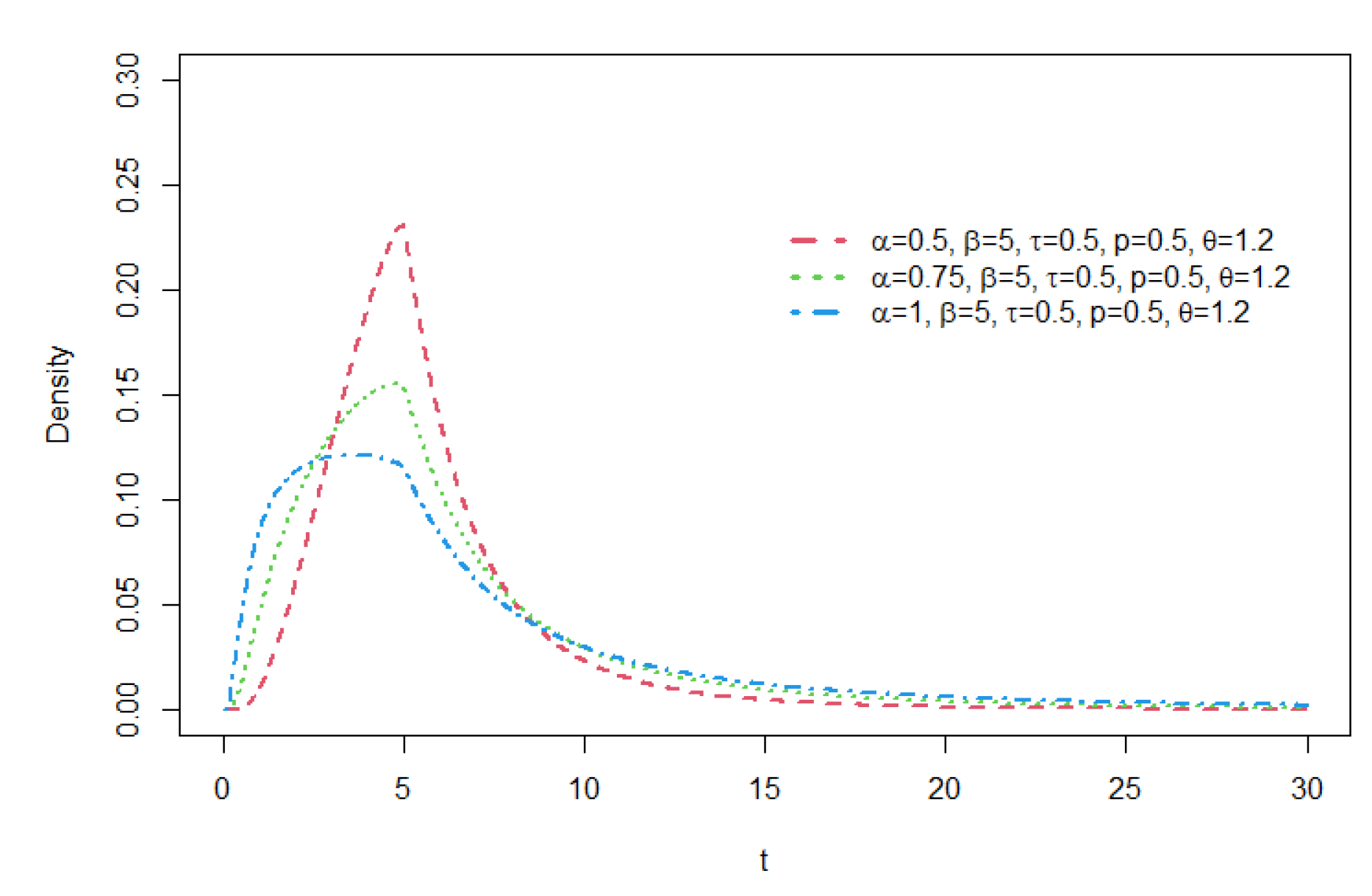
Figure 7.
Density functions of GCR2-LG distribution with = 1, = 5 , and p.
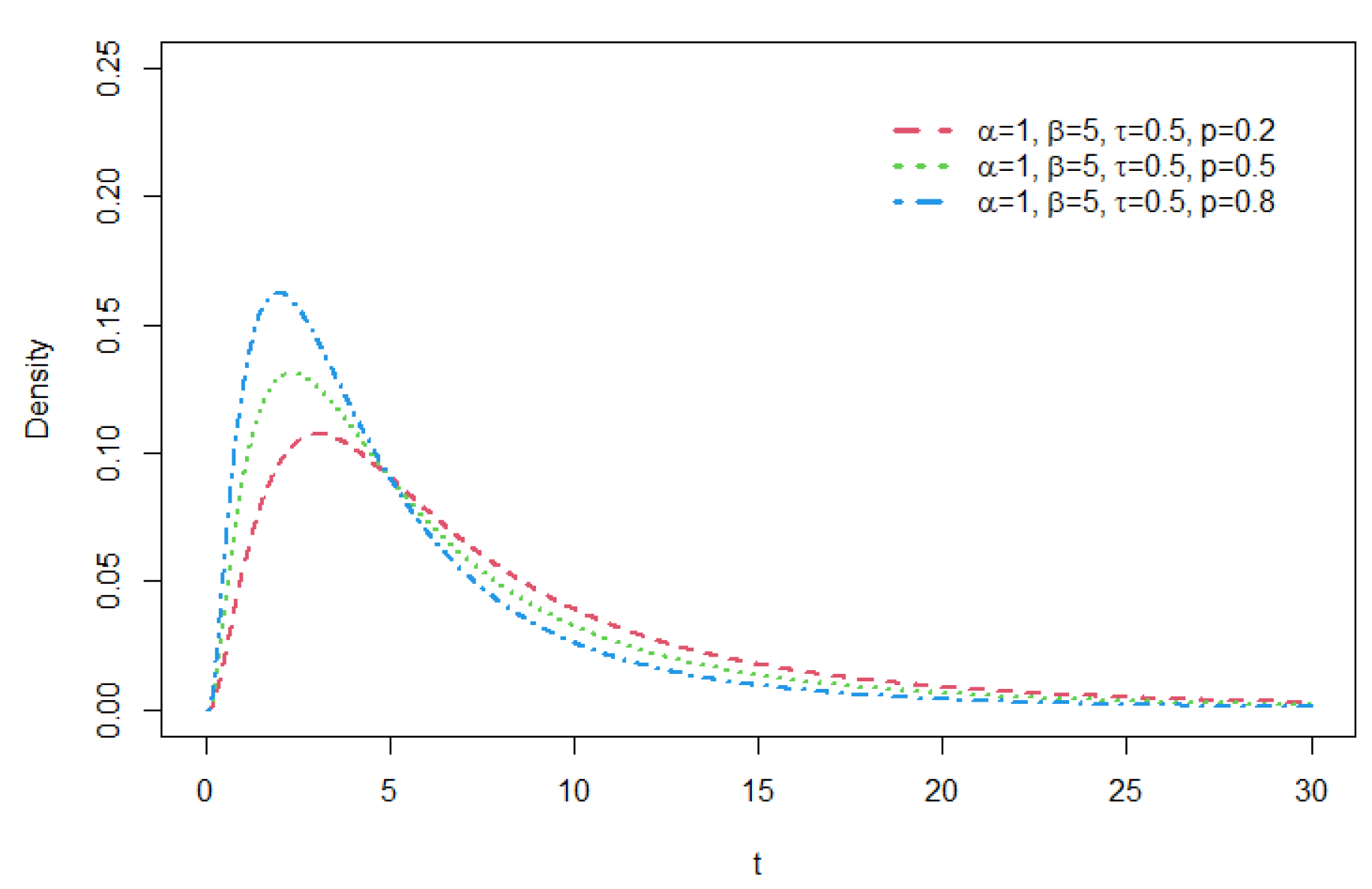
Figure 8.
Density functions of GCR2-LG distribution with =0.75 , = 5 , and p = 0.5.
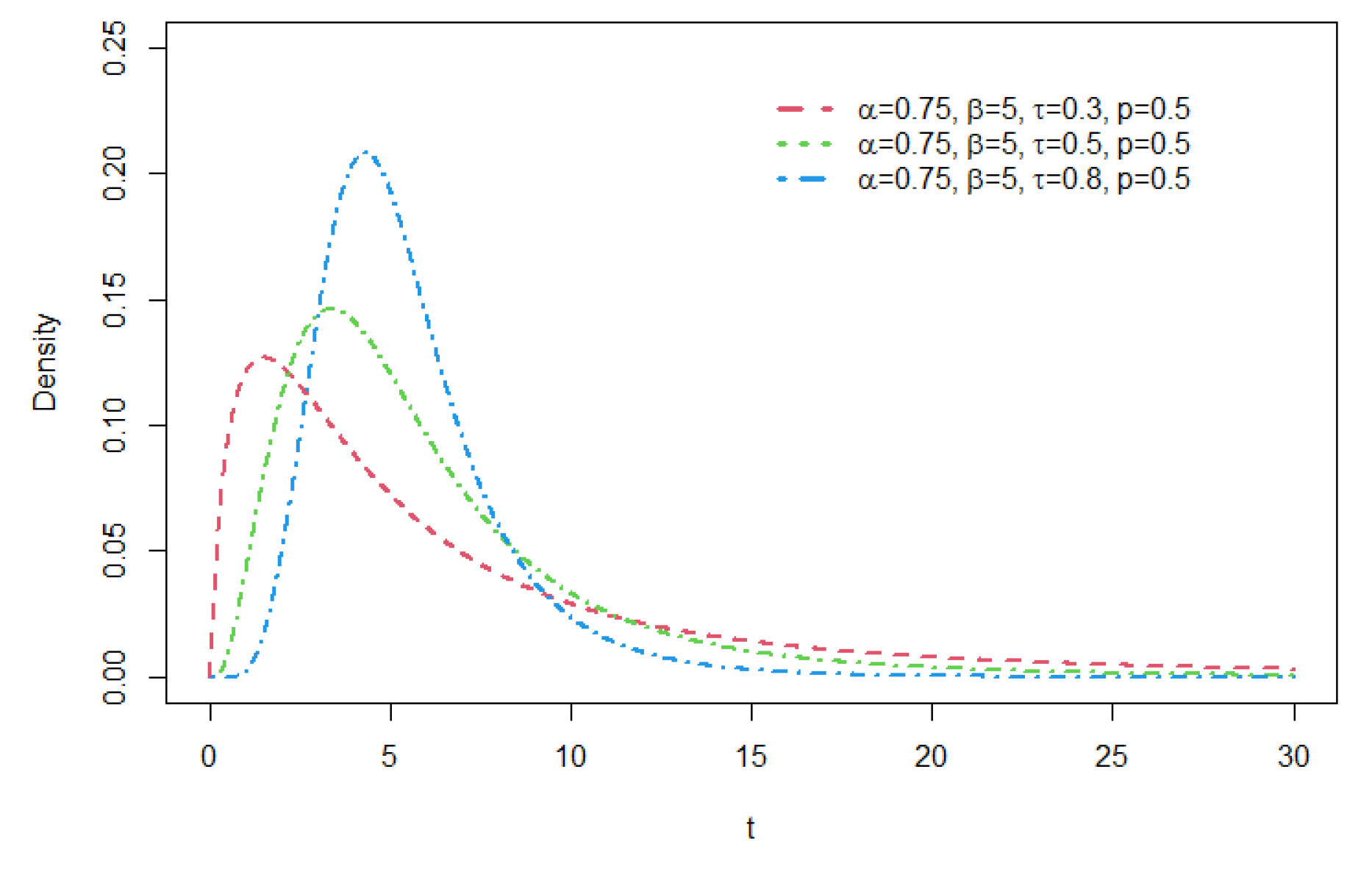
Figure 9.
Density functions of GCR2-LG distribution with , = 5 , and p = 0.5.
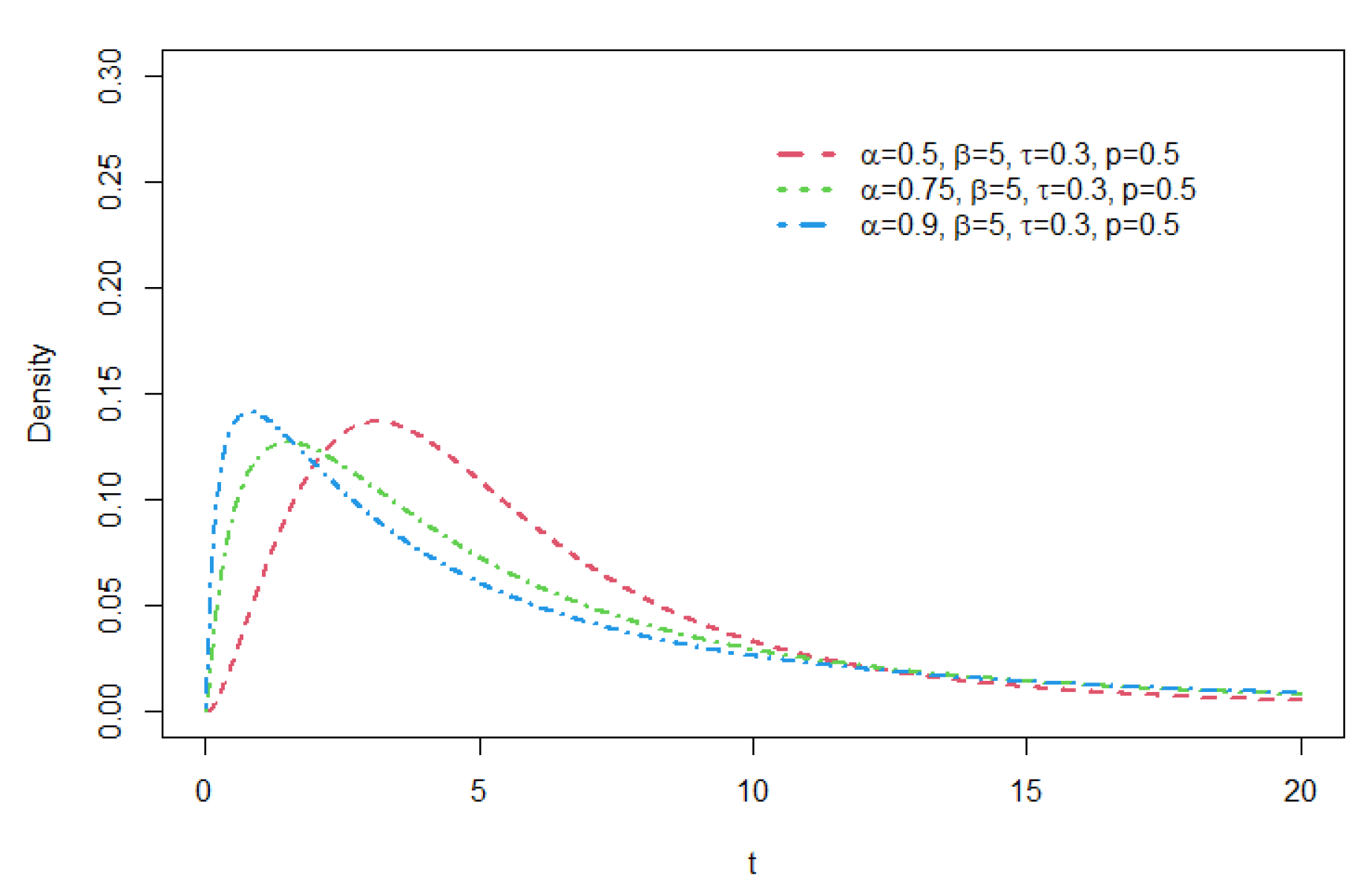
Figure 10.
Histogram of Meteo loss dataset and its normal Q-Q plot.
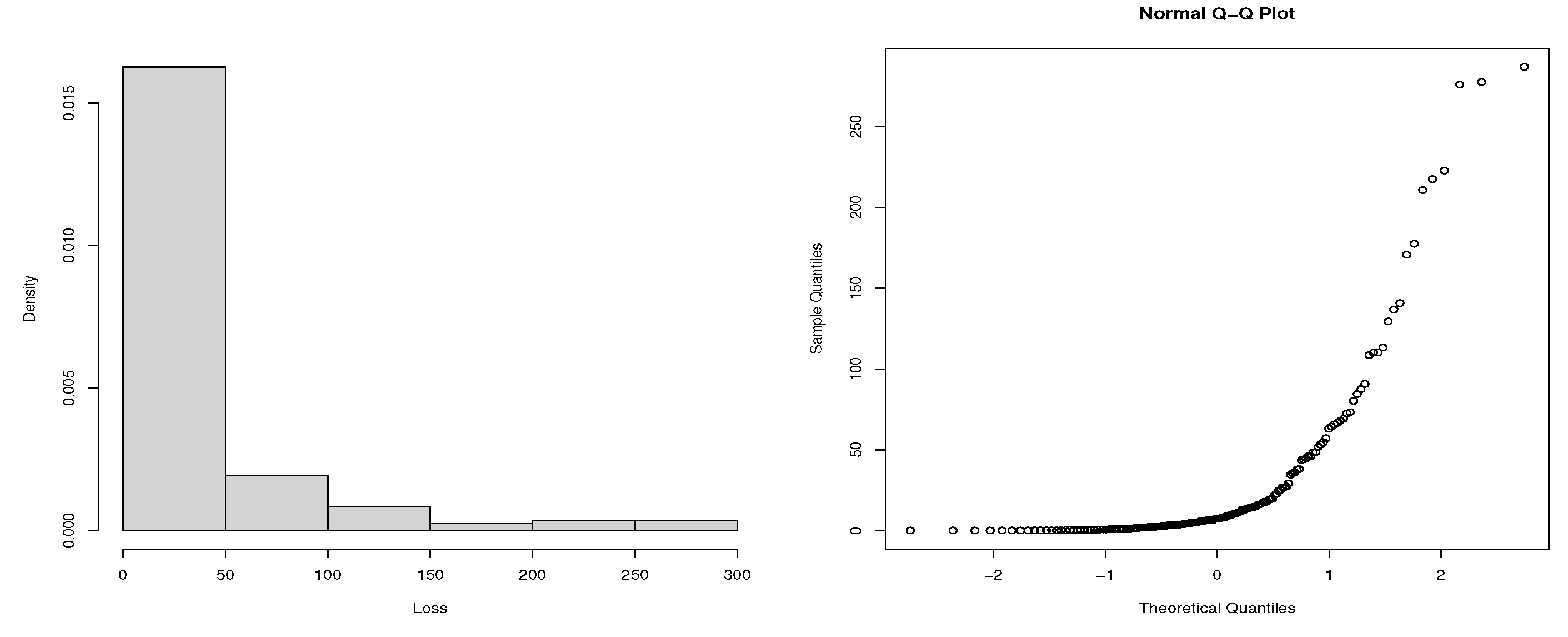
Figure 11.
Histogram of Hydro loss dataset and its normal Q-Q plot.
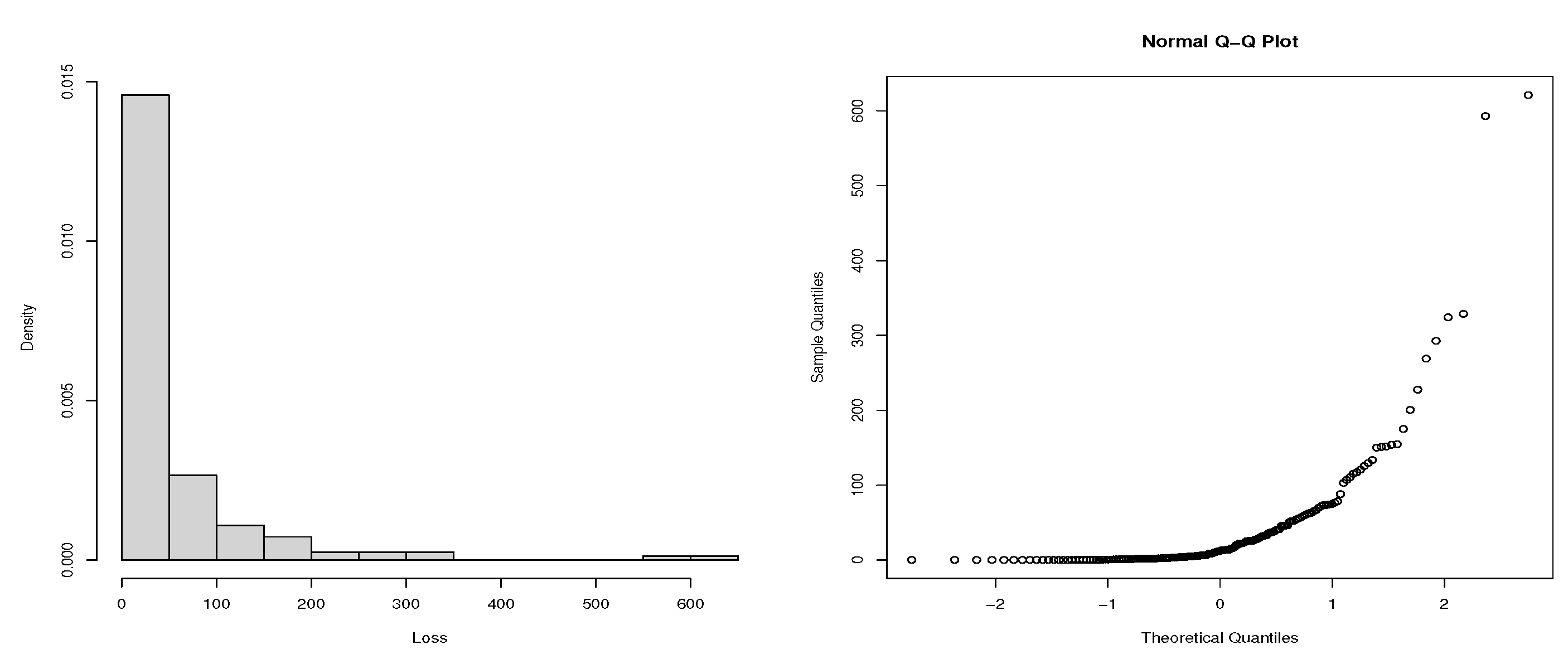
Figure 12.
Multiplicative decompositions of Meteo and Hydro time series.
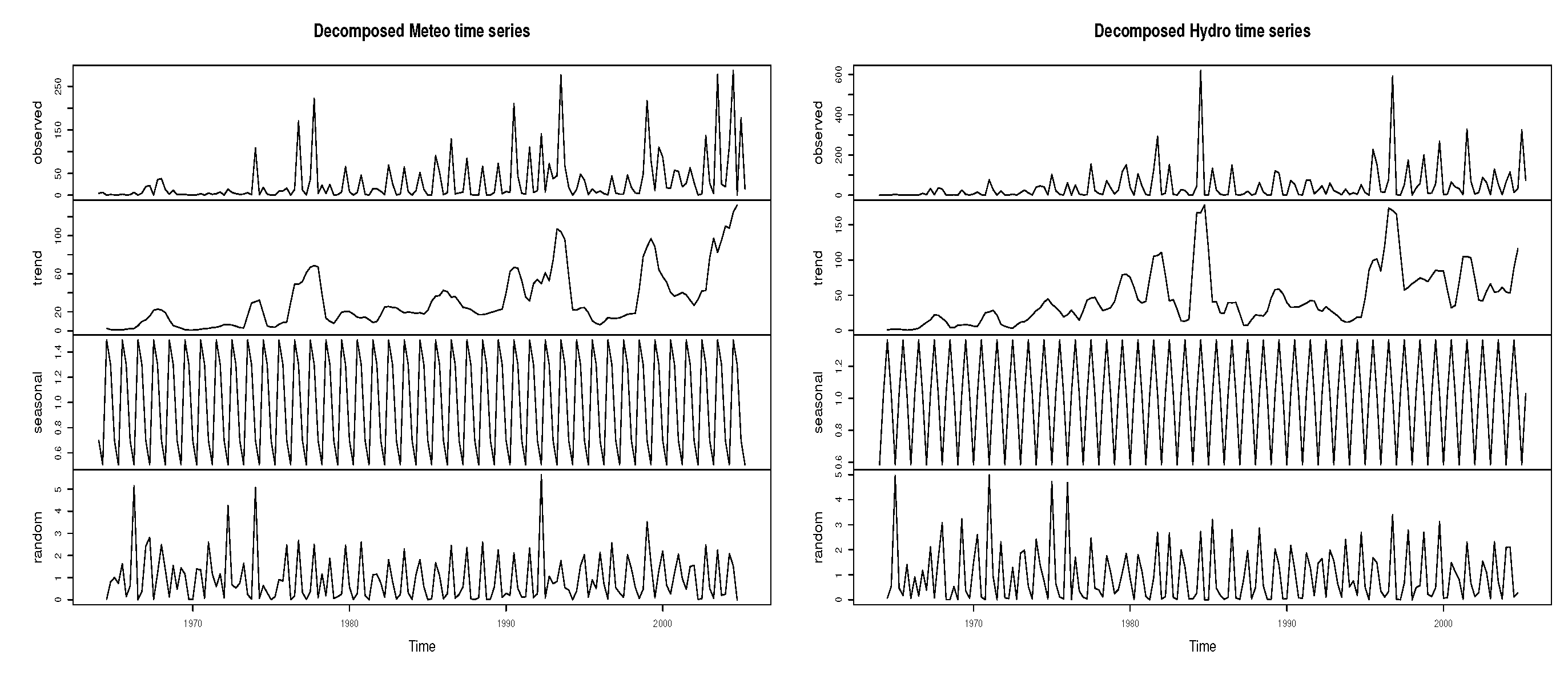
Figure 13.
Scatter plots of the deseasonalized data and their log-transformations.
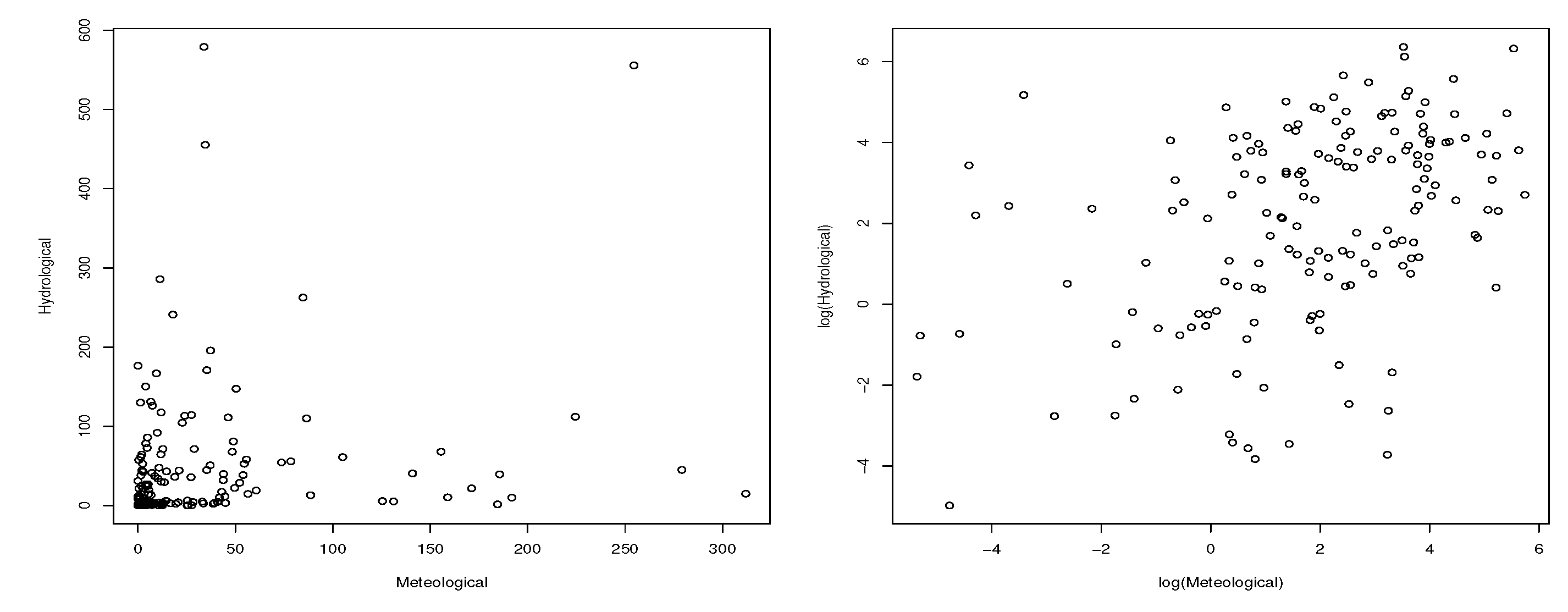
Figure 14.
Contour plots of the fitted BVGCR2-GG density and the density of the log-transformed random variables.
Figure 14.
Contour plots of the fitted BVGCR2-GG density and the density of the log-transformed random variables.
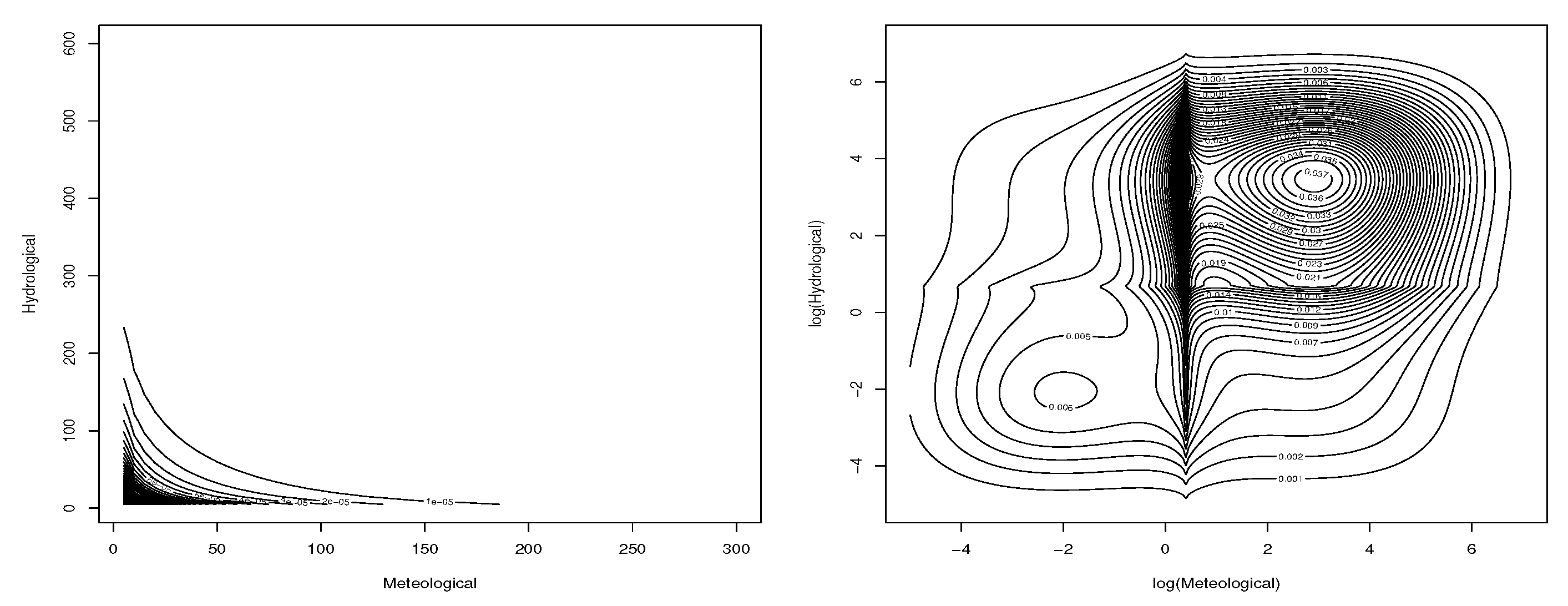
Figure 15.
Scatter plots of simulated random variables from the fitted BVGCR2-GG model and their log-transformations.
Figure 15.
Scatter plots of simulated random variables from the fitted BVGCR2-GG model and their log-transformations.
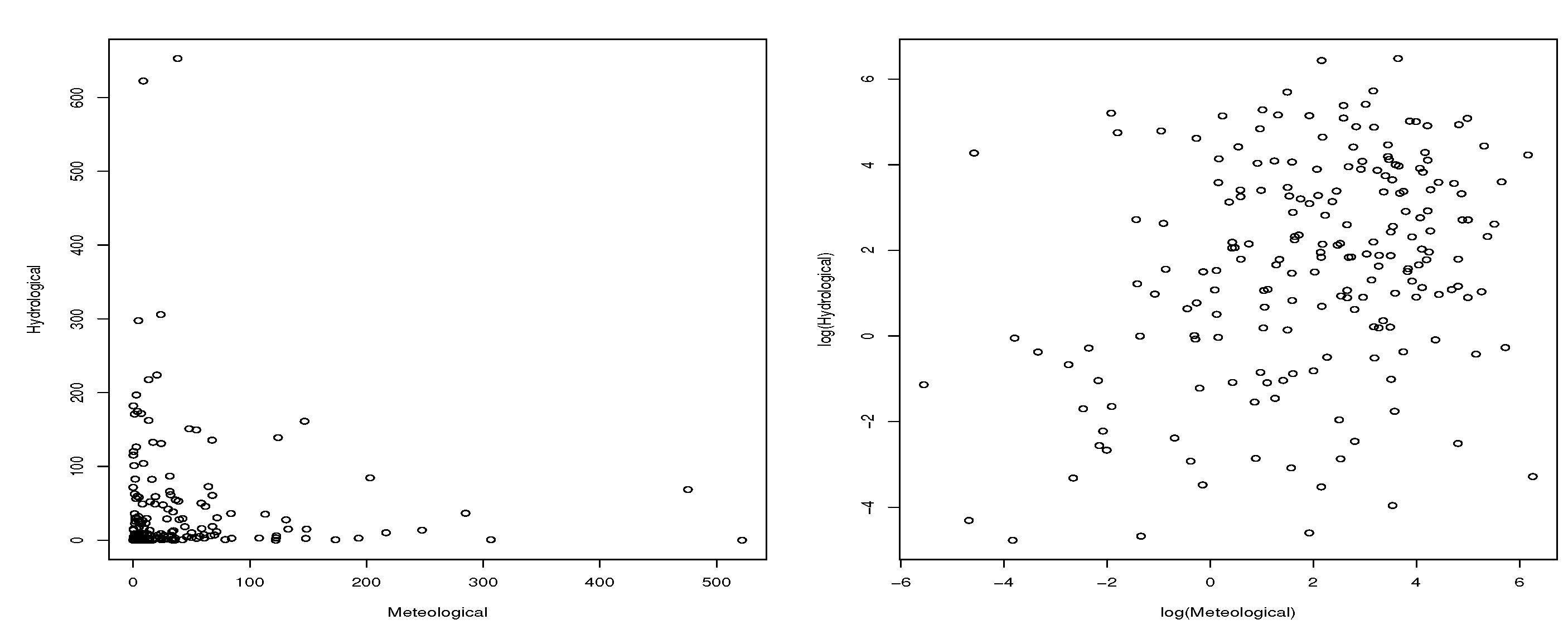

Table 1.
Descriptive summary statistics of the dataset (Unit: 100 million USD).
| Data | n | Min | 1st Qu. | Median | Mean | 3rd Qu. | Max | Skewness | Kurtosis |
| Meteo | 166 | 0.003 | 2.005 | 7.275 | 30.799 | 35.282 | 287.090 | 2.820 | 11.304 |
| Hydro | 166 | 0.007 | 1.692 | 12.172 | 45.538 | 53.330 | 621.207 | 4.014 | 23.188 |
Table 2.
Model comparison with AIC and BIC.
| Model | Log-likelihood | AIC | BIC |
| BVGCR-GG | -1370.332 | 2758.664 | 2786.672 |
| BVGCR-t | -1372.381 | 2762.762 | 2790.770 |
| BVGCR-LG | -1372.066 | 2758.132 | 2779.916 |
| BVGCR2-GG | -1367.346 | 2756.692 | 2790.924 |
| BVGCR2-t | -1371.782 | 2765.564 | 2799.796 |
| BVGCR2-LG | -1371.707 | 2761.414 | 2789.422 |
Table 3.
Parameter estimates of marginals and Bivariate GCR2-GG models.
| Meteo | 20.075 | 0.915 | 0.737 | 0.623 | 0.094 | |||||||||
| Hydro | 11.152 | 1.964 | 0.669 | 0.809 | 0.189 | |||||||||
| Bivariate | 22.644 | 1.494 | 0.791 | 0.477 | 11.442 | 1.964 | 0.675 | 0.798 | 0.124 | 0.040 | 0.072 | 0.764 |
Table 4.
The 95% bootstrap confidence intervals for the parameters in Bivariate GCR2-GG model
| Original estimate | 22.644 | 1.494 | 0.791 | 0.477 | 11.442 | 1.964 | 0.675 | 0.798 | 0.124 | 0.040 | 0.072 | 0.764 |
| Bootstrap mean | 27.673 | 1.524 | 0.735 | 0.583 | 14.189 | 2.065 | 0.680 | 0.988 | 0.131 | 0.037 | 0.067 | 0.766 |
| 2.5th percentile | 7.031 | 0.762 | 0.542 | 0.347 | 2.356 | 1.500 | 0.322 | 0.418 | 0.059 | 0.000 | 0.000 | 0.687 |
| 97.5th percentile | 52.149 | 2.252 | 0.951 | 1.013 | 42.898 | 2.803 | 0.913 | 3.027 | 0.192 | 0.080 | 0.147 | 0.843 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



