1. Introduction
Intensifying heat extremes, reflected in increasing numbers of record highs in temperature time series [
1], damage human health, welfare, and infrastructure, as well as ecosystems generally [
2,
3]. The impacts of heat increase nonlinearly with temperature and with other heat indices [
4]. Therefore, it is important to be able to accurately forecast the risk of heat extremes given information about current weather dynamics and ongoing climate change [
5].
Often, temperature extremes are modeled using statistical extreme value theory, which asymptotically can describe the distribution of the most extreme values in large enough sets of quantities drawn from any of a broad range of probability distributions [
6]. This is typically operationalized by working with the time series of annual maximum temperature (denoted TXx [
7]) from station observations or weather and climate model outputs. Based on extreme value theory, the TXx are assumed to be generated from the generalized extreme value distribution (GEVD) [
8]. After GEVD parameters are estimated from the TXx data using maximum likelihood or other suitable methods, the likelihood of temperatures exceeding any specified threshold in a future year can be estimated [
9,
10,
11,
12]. To account for the impact of climate change, the GEVD is typically taken to be non-stationary, with its location parameter a linear function of global mean temperature and potentially other covariates [
13].
Temperature extremes have been modeled using a similar approach for attribution studies, which seek to quantify the anthropogenic elevation of risk of observed recent extreme heat waves [
14,
15,
16,
17]. The standard approach for such attribution studies, as developed by the World Weather Attribution collaboration, is to estimate the probability of the observed extreme heat assuming that TXx or another temperature-based time series follows the GEVD with the location parameter a linear function of global mean temperature. Comparing this probability with that obtained from the same statistical model when the global mean temperature is set at a preindustrial baseline, the factor (probability ratio) by which anthropogenic warming has increased the likelihood of the observed extreme is obtained [
18,
19].
A complication that has been noted in attribution studies is that some observed heat extremes were so far above the historic distribution that, even allowing for global warming, the fitted GEVD implied that they were very unlikely (e.g., [
20,
21]). These implausible results from the GEVD have been explained in several ways, such as pointing to selection bias from only analyzing the most extreme heat waves and to difficulty in accurately estimating the GEVD’s right tail from short historic records [
22]. Here, the alternative considered is that the GEVD is not actually the most suitable distribution for modeling temperature extremes. In particular, the performance of the GEVD is compared here with that of a non-stationary normal distribution, which is widely used for modeling the entire temperature probability distribution (not limited to extreme values) [
23,
24,
25,
26].
The remainder of this paper is structured as follows. First, the TXx series analyzed (from station data as well as reanalysis), probabilistic forecast methodology based on either the GEVD or normal distribution, and evaluation metrics for forecast quality are all presented. Then, the results comparing the two distributions are shown, followed by discussion of their implications and possible directions for future research to improve forecasts of heat extremes further.
2. Methods
2.1. Temperature Data
Compared to station observations, reanalyses provide spatially and temporally complete weather data that may be less affected by location-specific human and measurement error. On the other hand, station observations have the advantage of being direct measurements, while reanalyses are subject to their own biases related to the setup of the underlying numerical weather model and inhomogeneity of the assimilated data streams, which may particularly affect the representation of extreme events [
27,
28]. Therefore, in order to robustly evaluate the probability distribution of temperature extremes, both reanalysis and station based temperature series are considered.
2.1.1. Reanalysis
Reanalysis TXx values are extracted from the hourly 2-m air temperature field of the state-of-the-art 5th Generation European Center for Medium Range Weather Forecasting Reanalysis (ERA5) [
29]. ERA5 data were obtained from the National Center for Atmospheric Research for 1940-2023 at a spatial resolution of 0.25 degrees [
30]. ERA5 data were previously used in many studies of extreme heat (e.g., [
31,
32,
33,
34,
35]).
TXx time series were evaluated for a globally distributed sample of grid cells in populated land areas. As described previously [
36], 100 ERA5 grid cells were selected in descending order of 2020 population density from Version 4 of the Gridded Population of the World product [
37,
38]. For broad spatial coverage and to minimize correlation between the time series, cells were only included if they were at least 10 degrees distant from all previously included cells.
In addition to this grid point based analysis, temperature extremes were also evaluated on the regional scale [
3,
39]. There is a hierarchical set of politically defined regions for analysis of climate extremes, with each level of the hierarchy having a characteristic areal extent [
40]. Grid-scale ERA5 TXx was averaged over each of the 231 Level 4 land regions, which each have a typical area of around half a million square km and collectively cover almost all land area.
2.1.2. Station Observations
Stations were selected for broad temporal and spatial coverage from the Global Historical Climatology Network (GHCN) Daily dataset, which compiles and quality-controls openly available observations in a uniform format [
41,
42,
43]. Stations were selected in descending order of the number of years from 1850 through 2023 for which they have complete temperature observations (needed for determining TXx). Stations were only included if they were at least 4 degrees distant from all previously included stations and had at least 31 complete years of observations, for a total of 310 selected stations with an average of 68 years of observations each (range: 31-158 years).
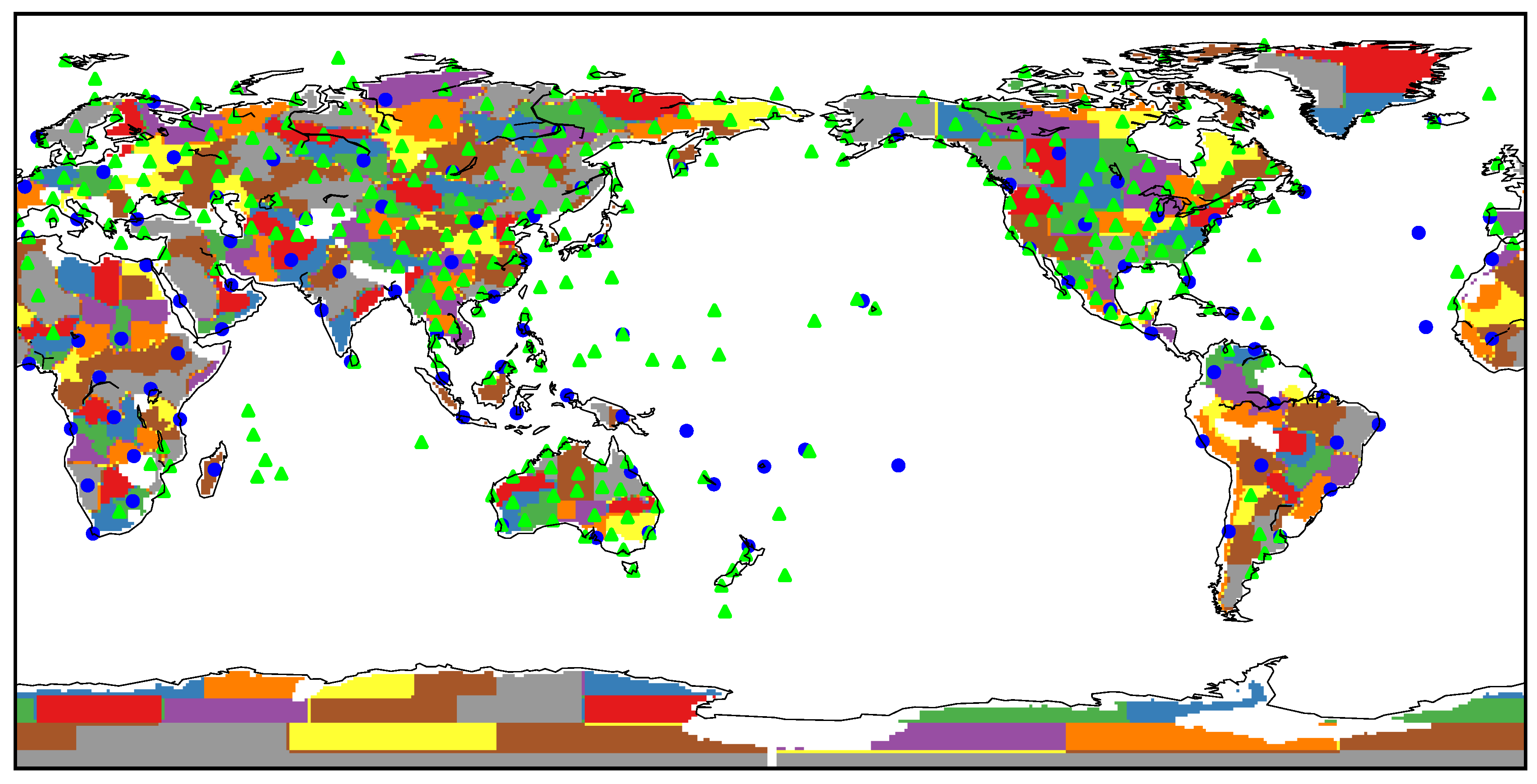
Figure 1 shows the locations of the selected GHCN-Daily stations, along with the selected ERA5 grid cells and regions.
2.2. Temperature Probabilistic Forecasts
For simplicity, only temperature forecasts for the next year are evaluated here using the station and reanalysis data. This may be extended to n years ahead for using similar methods.
For each TXx time series, a probability distribution (GEV or normal) is fitted to the first 30 years of data (for the stations, these were not necessarily consecutive years), and used to forecast the 31st year. This is repeated for each available year after the 31st, until the first years are used for fitting and to forecast the last year (where is the total number of years in the time series), for a total of 5400 ERA5 grid point year-ahead forecasts, 12798 ERA5 region forecasts, and 11677 station forecasts.
2.2.1. The Generalized Extreme Value Distribution
A variable
x distributed according to the GEVD with a real shape parameter ξ, real location parameter μ, and positive scale parameter σ follows the cumulative distribution function (CDF)
where
. Details about the GEVD and its derivation from extreme value theory are available in many references (e.g., [
6,
44,
45]). The case
is the Gumbel distribution (GEVD Type I), which has unbounded support. The case
is the Fréchet distribution (Type II), which is bounded below. The case
, which is usually the best fit for temperature data, is the reversed Weibull distribution (Type III), and is bounded above. Note that some sources reverse the sign for the shape parameter so that it is equivalent to
in the current notation.
As done by the World Weather Attribution collaboration and others, the GEVD fitted is one with a trend in the location parameter. That is, ξ and σ are taken to be the same across all years, but
, where
is the mean annual global temperature, either from ERA5 (for reanalysis TXx time series) or from the BEST global mean temperature anomaly time series [
46,
47] (for station TXx time series). The maximum-likelihood parameter values
were found using the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm and the analytic gradient of the likelihood with respect to the parameter vector. The starting point for the likelihood optimization was chosen using the method of moments [
48,
49] with the trend coefficient
set at 0. At times, maximum likelihood returned a degenerate set of parameters with very negative ξ and for which the gradient of the likelihood was not close to zero, which relates to the known nonregularity of likelihood as a function of GEVD parameters when
[
50,
51]; in such cases, the optimization was redone with a penalty term proportional to ξ
2 [
52,
53] that was progressively increased until the gradient indicated convergence to a likelihood maximum.
Probabilistic forecasts were obtained by considering not only the GEVD with maximum likelihood parameter values but the full posterior distribution of GEVD parameters [
54,
55], that is
assuming standard uninformative prior distributions of the parameters.
x is the temperature being forecast,
is the forecast year,
is the vector of distribution parameters (ξ, σ,
,
),
is the TXx time series from previous years used for fitting. The integration is performed over all admissible values of
, here a 4-dimensional space. Since for the GEVD this integral does not have an analytic solution, it was approximated by drawing 1000 parameter samples from the multivariate normal distribution centered at the maximum likelihood value and with covariance matrix given by the inverse of the analytic second derivative matrix of the likelihood at that point. These samples were then weighted following the importance sampling methodology [
56]. The resulting approximation for the posterior predictive density was
where was the number of samples (1000), refers to the GEVD density given each sampled set of parameter values, and are the non-negative importance-sampling weights, which sum to 1. In a few cases, the probability density of the observation was exactly zero under all 1000 samples; for those, sampling was repeated with a wider dispersion for the shape parameter than implied by the likelihood second derivative, in order to include unlikely parameter sets with less negative shape parameter under which the observation had nonzero probability.
2.2.2. The Normal Distribution
The normal distribution has one fewer parameter than the GEVD, since the shape is fixed. The location parameter is the distribution mean, and the scale parameter is the distribution standard deviation. As with the GEVD, the location parameter is assumed to linearly depend on temperature, while the scale parameter is time invariant. For the normal distribution with noninformative priors, the integral (
2) over all possible parameter combinations has an analytic solution, with the posterior
following a t distribution [
26,
57], so there was no need for numerical optimization or sampling parameter values from their posterior distribution.
2.2.3. Trend or Stationarity
To help evaluate the performance of the compared distributions (GEV or normal, both with trend in the location parameter) over a broader context, stationary versions of the GEV and normal distributions were also fitted and evaluated. These differ from the non-stationary ones only in that there is no trend, , and therefore one fewer parameter to be estimated from observations.
2.3. Forecast Performance Metric
The main performance metric for the probabilistic forecasts, used to compare the GEVD and normal distribution approaches, was mean negative log likelihood (NLL) of the actual next-year temperature in the forecast distribution. The expression for NLL is of the form
, where
is a forecast probability distribution and
is the actual maximum temperature during the forecast year. Lower NLL corresponds to greater forecast probability density at the observed value and therefore a better forecast. NLL is closely connected to the expected information gain from the forecast system [
58,
59] and is the unique probability metric satisfying certain desirable properties [
60]. Compared to other metrics used to evaluate probabilistic forecast performance, NLL is particularly sensitive to the probabilities assigned to the most unlikely observed values (here, typically the most extreme and impactful heat anomalies); in the extreme, assigning zero forecast probability to an event that was observed would result in infinite NLL [
61].
Supplementary metrics that were also calculated included the Kolmogorov-Smirnov statistic and mean return period of the observed TXx in the forecast CDF. For a well-calibrated forecast, the distribution of the actual maximum temperatures
in the forecast CDF should follow a uniform density between 0 and 1, with, e.g., close to 1% of observations found above the forecast 99th percentile, and 0.1% of observations should be above the forecast 99.9 percentile. The Kolmogorov-Smirnov statistic can be used to quantify overall closeness to the uniform distribution, with lower values suggesting better calibration [
26]. In addition to good performance over all cases, decision makers may well be especially interested in the calibration of predictions of the worst heat extremes. Thus, it is of particular importance to consider the frequency of observations at the highest quantiles, near 1, corresponding to heat extremes with long return periods (where return period is a function of quantile
q with
). The observations’ forecast RP has infinite expectation, since the integral for
q from 0 to 1 of
is infinite. However, it is possible to compare the mean value of some sublinear power
(
), which has the expected value of
for a well-calibrated forecast. A higher-than-expected value suggests that the observations have more extremely high values than forecast, while a lower-than-expected value suggests that the forecast makes extremes have greater probability than they actually do. Higher
k gives greater prominence to whether most extreme events. Therefore, the CDF across forecasts was computed and plotted, as well as the mean
subtracted from its ideal value of
for
k ranging from 0.1 to 0.9. Similar ideas have previously been used to evaluate probabilistic forecasts of temperature and precipitation extremes [
62,
63].
3. Results
Mean NLL was lower for the normal than the GEVD forecasts for all three datasets (GHCN stations, ERA5 grid cells, and ERA5 regions) (
Table 1), suggesting that overall, the normal distribution outperforms the GEVD for forecasting the annual maximum temperature TXx. NLL was higher for ERA5 grid cells than for ERA5 regions, and highest for individual stations, consistent with more erratic temperatures at smaller spatial scales.
Significance measures for the difference in mean NLL between GEVD and normal forecasts were estimated using 1000 bootstrap resamples [
64] from the 5400 ERA5 grid forecasts (this set of forecasts was chosen because the larger spacing between grid points minimized inter-forecast correlations, which were not accounted for in the bootstrap resampling). Based on these, the difference of 0.0195 nats in mean NLL between the two sets of forecasts (indicating that the normal distribution generated better forecasts on average than the GEVD) is greater than zero at the 0.999 confidence level, and has a 95% confidence interval of 0.0099 to 0.0311 nats.
The Kolmogorov-Smirnov statistic was not consistently different between the two forecasts: it was lower for GEVD forecasts for the stations and grid cells, but lower for normal distribution forecasts for the regions (
Table 1). This suggests that the reason for the normal forecasts outperforming the GEVD ones as measured by NLL is not their performance near the middle of the TXx probability distribution, to which the Kolmogorov–Smirnov statistic is most sensitive, but due to the normal distribution better forecasting the more extreme TXx values. Indeed, if we look at the mean
, especially at higher
k such as 0.9, there are large differences between the two forecast probability distributions, resulting from some observations being highly unlikely (very large RP) on the GEVD forecasts, whereas the normal distribution forecasts of the most extreme observations are relatively well calibrated.
The stationary normal and GEVD forecasts clearly performed worse in all respects compared with the non-stationary ones that were taken as the standards, consistent with the pronounced warming trend seen in all temperature datasets. As might be expected given this warming trend, the stationary forecasts particularly underestimate the likelihood of the hottest extremes observed in recent decades, as quantified by the large positive departures of RP moments from the values for a well-calibrated forecast. The stationary version of the GEVD tended to do slightly worse than the stationary version of the normal distribution (
Table 1).
Coming back to the non-stationary forecasts, even with the normal distribution,
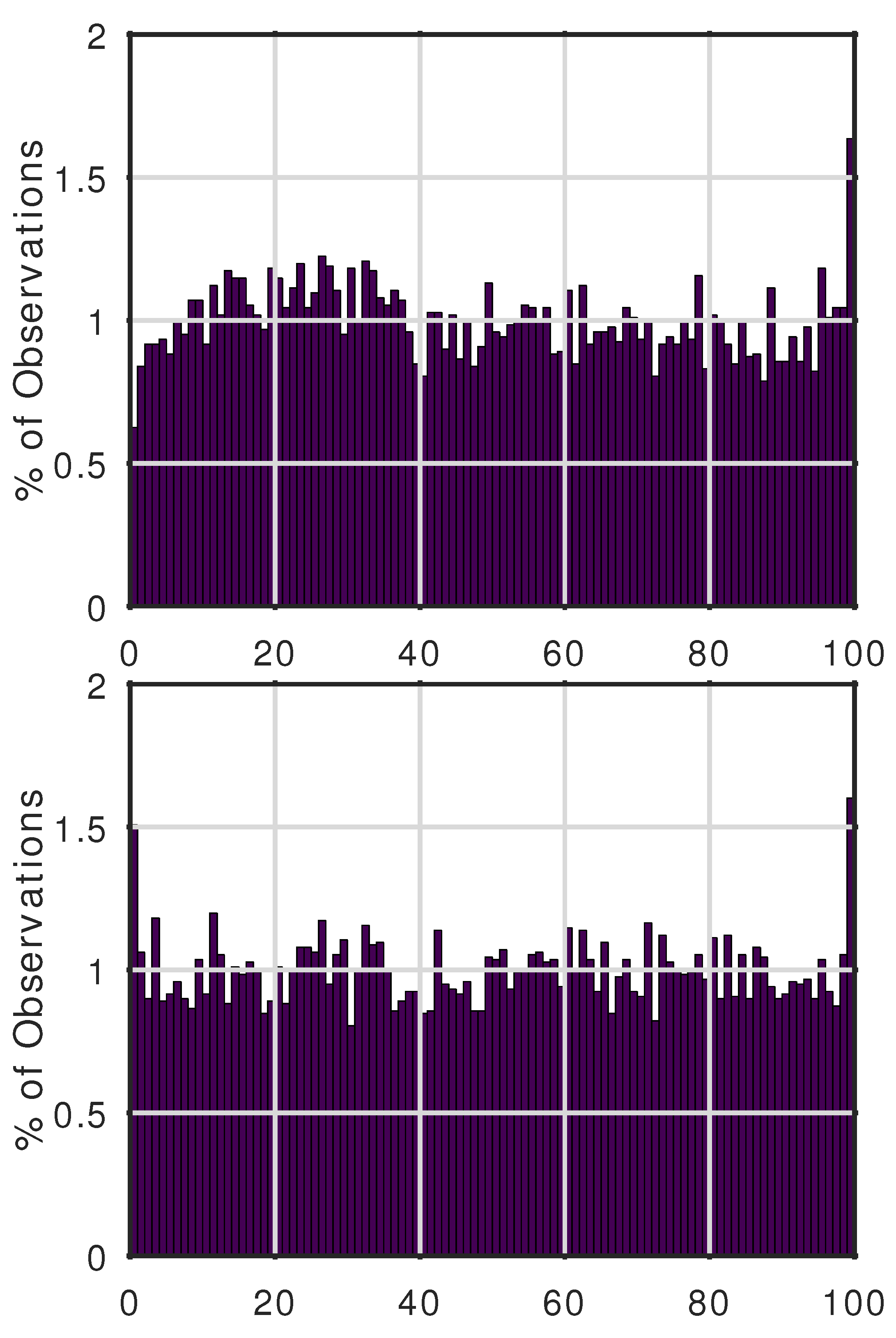
is considerably larger than expected for the station data (but not for reanalysis data), indicating that even this forecast does not completely account for the most extreme few station observations. In fact, out of 11677 station observations, 191 (1.64%) were above the 99th percentile of the normal forecast (100 year return period – compared with 1% expected under a perfectly calibrated forecast), and 29 (0.25%) were above the 99.9th percentile (100 year return period – compared with 0.1% expected under a perfectly calibrated forecast). For the GEVD forecasts, the number above the 99th percentile was about the same, 183, but the number above the 99.9th percentile was larger, 47 (
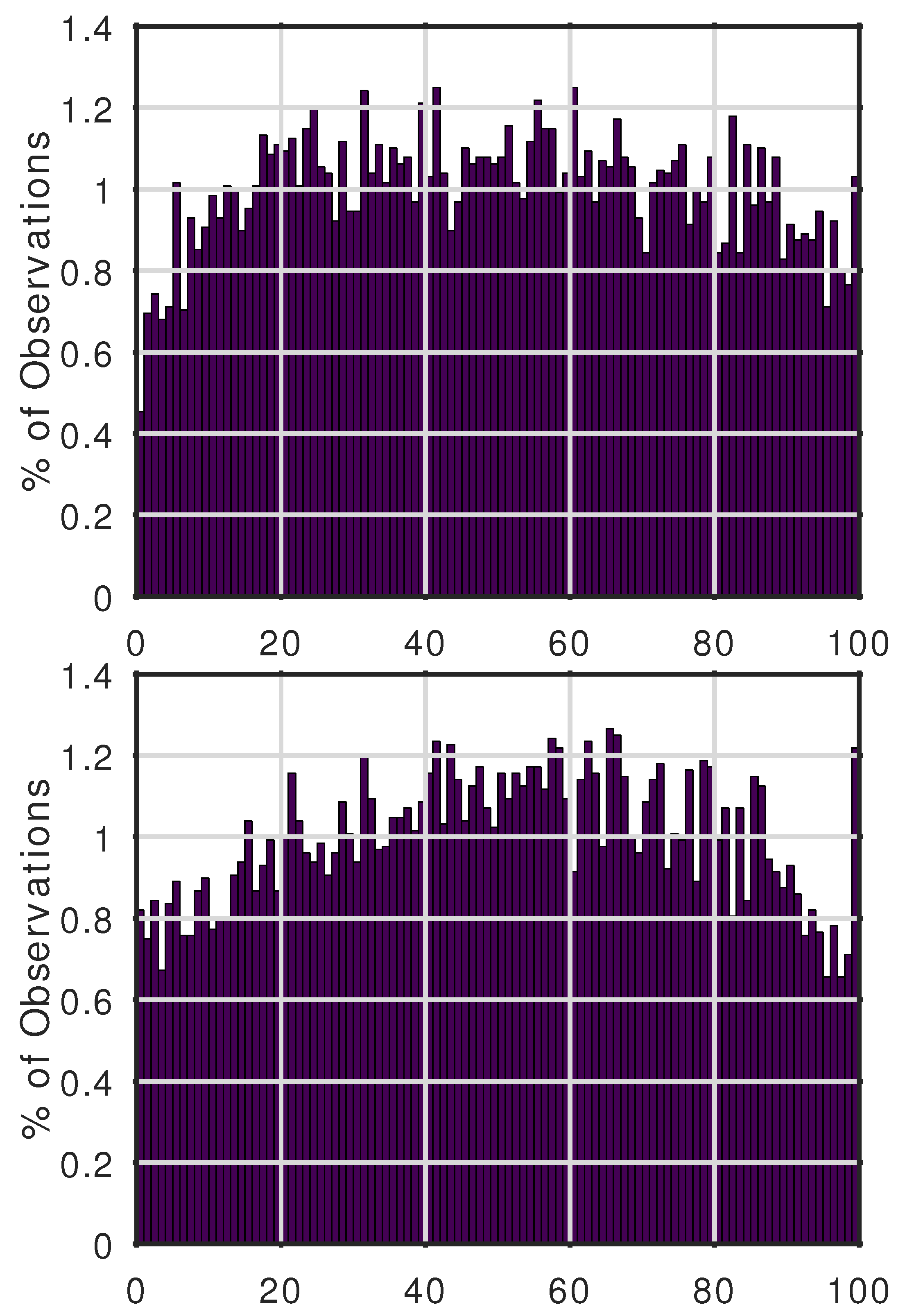
Figure 2). The GEVD forecasts for ERA5 regions also show more observations than expected in the top percentile (
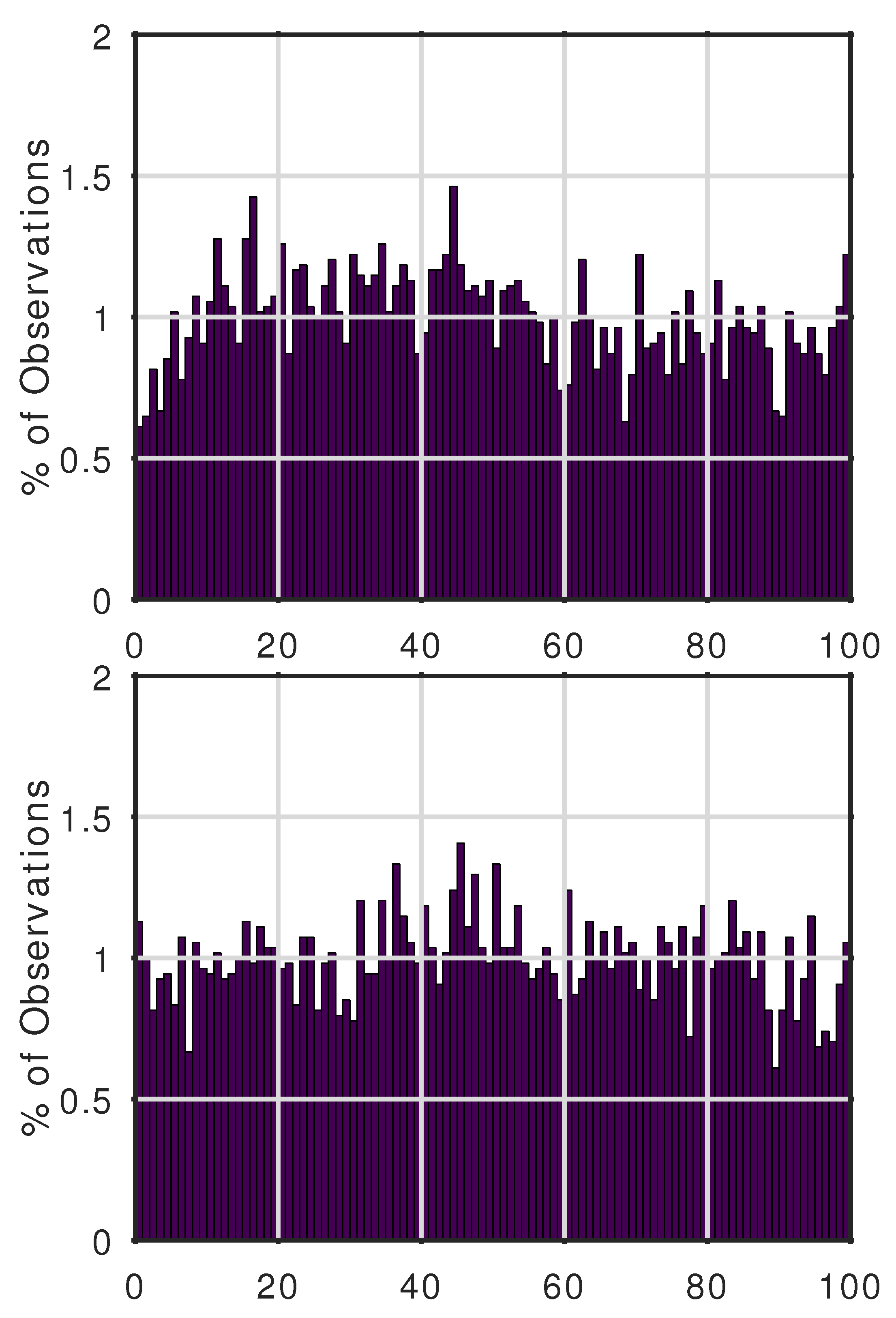
Figure 3), while for ERA5 grid cells, both forecasts were reasonably calibrated at the top percentile (
Figure 4). Thus, much of the outperformance of the normal distribution seems to be in the most extreme fraction of percent of observations, which the GEVD, despite its theoretical basis under extreme value theory, turned out to be worse at representing.
4. Discussion
4.1. Why Are Extreme Temperatures So Normal?
A key finding of this work is that for probabilistic forecasting of hot extremes in recent decades, the GEVD was outperformed by the simpler normal distribution. The GEVD particularly underestimated the probability of the most extremely high temperatures. It is recommended, therefore, that the World Weather Attribution collaboration and similar efforts replace or at least supplement the GEVD as their main tool for estimating the probability of extreme heat waves.
This poorer performance of the GEVD for the hottest extremes is unexpected, since the GEVD has theoretical justification as the asymptotic limit distribution of extremes from a wide variety of parent distributions. Indeed, the World Weather Attribution protocol notes that “If the event is not very extreme, a normal distribution can also be used. …Gaussian [=normal] distributions are often seen not to describe the tails well. …[The GEVD] is thus used for event definitions like the annual maximum temperature” [
18]. Even outside of climate science, it is commonly assumed that, unlike the GEVD and related distributions, normal distributions underestimate the likelihood of the most extreme and impactful events [
65,
66]. There are a number of possible reasons for the surprising overperformance, found in the current study, of the normal distribution as compared to the GEVD for annual maximum temperatures.
The finite available record length, of order 50-100 years, from observations and reanalyses may not be long enough for the GEVD to be a good approximation. As well, it can be considered that where there is a strong temperature seasonal cycle, TXx is really the maximum over a few dozen days and a few synoptic shifts in the hottest month or two, so may not be a sufficiently extreme block maximum for the GEVD to approximate well.
In general, the best probability distribution to fit to a given type of data depends on the length of the available record, with more complicated distributions (with more free parameters) often providing the better predictions when there is a very long record to fit to, while simpler distributions with few free parameters are likely to be better suited when there are fewer data points [
67]. For this perspective, the present analysis, with the test forecasts being based on 30-157 years of data, is directly applicable to typical efforts to estimate the risk of future temperature extremes using either station or reanalysis data, where the record length is of this order in most cases.
More concretely, the GEVD fitted to annual maximum temperature series generally has negative shape parameter ξ, which implies zero probability mass above some upper limit that may not be far above the record historical value. This does not fit the physics of even a stationary climate, since an unlikely but physically possible configuration of atmospheric circulation can generally push temperature substantially above a previous record at a given location. In a climate with different anthropogenic and natural perturbations over a range of timescales, a hard upper limit to next year’s temperature is even less plausible. The Bayesian approach adopted here of using the full posterior distribution of GEVD parameters to generate a forecast, which blurs the definite upper bound associated with each individual GEVD parameter combination, mitigates this conceptual discrepancy and improves the forecast NLL compared to using a point GEVD parameter estimate [
36], but evidently not enough to predict sufficient probabilities for the most extreme recently observed temperatures.
4.2. Extensions and Future Research Directions
Even the normal distribution underestimated the occurrence of the most extreme temperatures, particularly in station data. As described below, a number of approaches could be tried to generate better forecasts, beyond an empirical adjustment for this misfit [
68] in the form of a quantile correction for bias correction [
69]. The less good fit of forecasts for station temperature compared to reanalysis temperature could also have a component of observation errors and shifts in instruments and observation conditions, as well as aspects of microclimate that are not captured in reanalyses but could nevertheless be important for local heat impacts.
Temperatures in certain regions have been found to have nonzero skew or asymmetric tails, inconsistent with the normal distribution [
24,
70,
71]. In this context, generalized and skew normal distributions could be explored [
72,
73] to improve extreme temperature forecasts. Variants of the GEVD that may mitigate its underestimation of the likelihood of the most extreme temperatures can also be compared [
36]. The distribution scale (standard deviation) may be changing over time, as well as its location (mean) [
74,
75]. Covariates for local climate influences (beyond global mean temperature) could be added, ranging from teleconnections such as the Southern Oscillation to urbanization, land use, and air pollution [
76,
77,
78]. Spatial statistics methods could also refine forecasts of extreme heat risk and allow extension to unobserved areas by pooling information across nearby stations [
79].
It would be interesting to see to what extent the conclusions drawn for annual maximum temperature TXx are valid for other temperature extremes. Annual minimum temperature TNn has, like TXx, been warming, and understanding the evolving risk of cold extremes also has significance for agriculture and ecology as well as civic infrastructure [
80,
81,
82,
83]. Humid heat poses health risks beyond temperature alone, so the risk of extreme humid heat metrics such as wet bulb temperature could also be assessed [
33,
84,
85,
86].
5. Conclusions
In this work, a representative global station, grid, and regional temperature time series were used to compare the ability of the GEVD and normal distributions to accurately estimate the risk of the hot extremes observed in recent decades using only data from earlier years. A Bayesian approach was used to integrate across parametric uncertainty to produce probabilistic assessments of future temperature extremes. As measured by the negative log likelihood of observations in the forecast, year-ahead local and regional maximum temperature forecasts better follow the normal distribution compared with the GEVD. Selecting an appropriate probability distribution is valuable for generating well-calibrated assessments of the risk of high-impact heat extremes, which can be the target of mitigation and adaptation measures on local, national, and global scales. A number of possible directions for follow-up research are outlined to further improve probabilistic forecasts of the most extreme events, including exploration of other probability distributions and covariates beyond global mean temperature.
Funding
No funding to report.
Conflicts of Interest
The author declares no conflict of interest.
References
- Nerantzaki, S.D.; Papalexiou, S.M.; Rajulapati, C.R.; Clark, M.P. Nonstationarity in high and low-temperature extremes: insights from a global observational data set by merging extreme-value methods. Earth’s Future 2023, 11. [Google Scholar] [CrossRef]
- Stillman, J.H. Heat waves, the new normal: summertime temperature extremes will impact animals, ecosystems, and human communities. Physiology 2019, 34, 86–100. [Google Scholar] [CrossRef] [PubMed]
- Thompson, V.; Mitchell, D.; Hegerl, G.C.; Collins, M.; Leach, N.J.; Slingo, J.M. The most at-risk regions in the world for high-impact heatwaves. Nature Communications 2023, 14. [Google Scholar] [CrossRef] [PubMed]
- Matthews, T.K.R.; Wilby, R.L.; Murphy, C. Communicating the deadly consequences of global warming for human heat stress. Proceedings of the National Academy of Sciences 2017, 114, 3861–3866. [Google Scholar] [CrossRef]
- Oldenborgh, G.J.V.; Wehner, M.F.; Vautard, R.; Otto, F.E.L.; Seneviratne, S.I.; Stott, P.A.; Hegerl, G.C.; Philip, S.Y.; Kew, S.F. Attributing and projecting heatwaves is hard: we can do better. Earth’s Future 2022, 10. [Google Scholar] [CrossRef]
- de Haan, L.; Ferreira, A. Extreme Value Theory; Springer: New York, 2006. [Google Scholar] [CrossRef]
- Klein Tank, A.M.; Zwiers, F.W.; Zhang, X. Guidelines on analysis of extremes in a changing climate in support of informed decisions for adaptation; Technical report; World Meteorological Organization, 2009. [Google Scholar]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Quarterly Journal of the Royal Meteorological Society 81, 158–171. [CrossRef]
- Hall, P.; Tajvidi, N. Nonparametric analysis of temporal trend when fitting parametric models to extreme value data. Statistical Science 2000, 15, 153–167. [Google Scholar] [CrossRef]
- Slater, R.; Freychet, N.; Hegerl, G. Substantial changes in the probability of future annual temperature extremes. Atmospheric Science Letters 2021, 22. [Google Scholar] [CrossRef]
- Castillo-Mateo, J.; Asín, J.; Cebrián, A.C.; Mateo-Lázaro, J.; Abaurrea, J. Bayesian variable selection in generalized extreme value regression: modeling annual maximum temperature. Mathematics 2023, 11, 759. [Google Scholar] [CrossRef]
- Rai, S.; Hoffman, A.; Lahiri, S.; Nychka, D.W.; Sain, S.R.; Bandyopadhyay, S. Fast parameter estimation of generalized extreme value distribution using neural networks. Environmetrics 2024, 35. [Google Scholar] [CrossRef]
- Cannon, A.J. A flexible nonlinear modelling framework for nonstationary generalized extreme value analysis in hydroclimatology. Hydrological Processes 2009, 24, 673–685. [Google Scholar] [CrossRef]
- Otto, F.E.L.; Massey, N.; van Oldenborgh, G.J.; Jones, R.G.; Allen, M.R. Reconciling two approaches to attribution of the 2010 Russian heat wave. Geophysical Research Letters 2012, 39. [Google Scholar] [CrossRef]
- Fischer, E.M.; Knutti, R. Anthropogenic contribution to global occurrence of heavy-precipitation and high-temperature extremes. Nature Climate Change 2015, 5, 560–564. [Google Scholar] [CrossRef]
- Zhang, L.; Yu, X.; Zhou, T.; Zhang, W.; Hu, S.; Clark, R. Understanding and attribution of extreme heat and drought events in 2022: current situation and future challenges. Advances in Atmospheric Sciences 2023, 40, 1941–1951. [Google Scholar] [CrossRef]
- Tejedor, E.; Benito, G.; Serrano-Notivoli, R.; González-Rouco, F.; Esper, J.; Büntgen, U. Recent heatwaves as a prelude to climate extremes in the western Mediterranean region. npj Climate and Atmospheric Science 2024, 7. [Google Scholar] [CrossRef]
- Philip, S.; Kew, S.; van Oldenborgh, G.J.; Otto, F.; Vautard, R.; van der Wiel, K.; King, A.; Lott, F.; Arrighi, J.; Singh, R.; van Aalst, M. A protocol for probabilistic extreme event attribution analyses. Advances in Statistical Climatology, Meteorology and Oceanography 2020, 6, 177–203. [Google Scholar] [CrossRef]
- van Oldenborgh, G.J.; van der Wiel, K.; Kew, S.; Philip, S.; Otto, F.; Vautard, R.; King, A.; Lott, F.; Arrighi, J.; Singh, R.; van Aalst, M. Pathways and pitfalls in extreme event attribution. Climatic Change 2021, 166, 13. [Google Scholar] [CrossRef]
- Philip, S.Y.; Kew, S.F.; van Oldenborgh, G.J.; Anslow, F.S.; Seneviratne, S.I.; Vautard, R.; Coumou, D.; Ebi, K.L.; Arrighi, J.; Singh, R.; van Aalst, M.; Pereira Marghidan, C.; Wehner, M.; Yang, W.; Li, S.; Schumacher, D.L.; Hauser, M.; Bonnet, R.; Luu, L.N.; Lehner, F.; Gillett, N.; Tradowsky, J.S.; Vecchi, G.A.; Rodell, C.; Stull, R.B.; Howard, R.; Otto, F.E.L. Rapid attribution analysis of the extraordinary heat wave on the Pacific coast of the US and Canada in June 2021. Earth System Dynamics 2022, 13, 1689–1713. [Google Scholar] [CrossRef]
- Bercos-Hickey, E.; O’Brien, T.A.; Wehner, M.F.; Zhang, L.; Patricola, C.M.; Huang, H.; Risser, M.D. Anthropogenic contributions to the 2021 Pacific Northwest heatwave. Geophysical Research Letters 2022, 49. [Google Scholar] [CrossRef]
- Zeder, J.; Sippel, S.; Pasche, O.C.; Engelke, S.; Fischer, E.M. The effect of a short observational record on the statistics of temperature extremes. Geophysical Research Letters 2023, 50. [Google Scholar] [CrossRef]
- Bruhn, J.A.; Fry, W.E.; Fick, G.W. Simulation of daily weather data using theoretical probability distributions. Journal of Applied Meteorology 1980, 19, 1029–1036. [Google Scholar] [CrossRef]
- Harmel, R.D.; Richardson, C.W.; Hanson, C.L.; Johnson, G.L. Evaluating the adequacy of simulating maximum and minimum daily air temperature with the normal distribution. Journal of Applied Meteorology 2002, 41, 744–753. [Google Scholar] [CrossRef]
- Corobov, R.; Overcenco, A. To normality of air temperature distribution with an emphasis on extremes. In Academician Eugene Fiodorov–100 years: Collection of Scientific Articles; 2010; pp. 36–42. [Google Scholar]
- Krakauer, N.Y.; Devineni, N. Up-to-date probabilistic temperature climatologies. Environmental Research Letters 2015, 10, 024014. [Google Scholar] [CrossRef]
- Singh, T.; Saha, U.; Prasad, V.; Gupta, M.D. Assessment of newly-developed high resolution reanalyses (IMDAA, NGFS and ERA5) against rainfall observations for Indian region. Atmospheric Research 2021, 259, 105679. [Google Scholar] [CrossRef]
- Mistry, M.N.; Schneider, R.; Masselot, P.; Royé, D.; Armstrong, B.; Kyselý, J.; Orru, H.; Sera, F.; Tong, S.; Lavigne, É.; Urban, A.; Madureira, J.; García-León, D.; Ibarreta, D.; Ciscar, J.C.; Feyen, L.; de Schrijver, E.; de Sousa Zanotti Stagliorio Coelho, M.; Pascal, M.; Tobias, A.; Alahmad, B.; Abrutzky, R.; Saldiva, P.H.N.; Correa, P.M.; Orteg, N.V.; Kan, H.; Osorio, S.; Indermitte, E.; Jaakkola, J.J.K.; Ryti, N.; Schneider, A.; Huber, V.; Katsouyanni, K.; Analitis, A.; Entezari, A.; Mayvaneh, F.; Michelozzi, P.; de’Donato, F.; Hashizume, M.; Kim, Y.; Diaz, M.H.; la Cruz Valencia, C.D.; Overcenco, A.; Houthuijs, D.; Ameling, C.; Rao, S.; Seposo, X.; Nunes, B.; Holobaca, I.H.; Kim, H.; Lee, W.; Íñiguez, C.; Forsberg, B.; Åström, C.; Ragettli, M.S.; Guo, Y.L.L.; Chen, B.Y.; Colistro, V.; Zanobetti, A.; Schwartz, J.; Dang, T.N.; Dung, D.V.; Guo, Y.; Vicedo-Cabrera, A.M.; and, A.G. Comparison of weather station and climate reanalysis data for modelling temperature-related mortality. Scientific Reports 2022, 12. [Google Scholar] [CrossRef]
- Hersbach, H.; de Rosnay, P.; Bell, B.; Schepers, D.; Simmons, A.; Soci, C.; Abdalla, S.; Alonso-Balmaseda, M.; Balsamo, G.; Bechtold, P.; Berrisford, P.; Bidlot, J.R.; de Boisséson, E.; Bonavita, M.; Browne, P.; Buizza, R.; Dahlgren, P.; Dee, D.; Dragani, R.; Diamantakis, M.; Flemming, J.; Forbes, R.; Geer, A.J.; Haiden, T.; Hólm, E.; Haimberger, L.; Hogan, R.; Horányi, A.; Janiskova, M.; Laloyaux, P.; Lopez, P.; Munoz-Sabater, J.; Peubey, C.; Radu, R.; Richardson, D.; Thépaut, J.N.; Vitart, F.; Yang, X.; Zsótér, E.; Zuo, H. Operational global reanalysis: progress, future directions and synergies with NWP; Technical Report 27; ECMWF, 2018. [Google Scholar] [CrossRef]
- ERA5 Reanalysis (0.25 Degree Latitude-Longitude Grid). 2024. [CrossRef]
- Kennedy-Asser, A.T.; Andrews, O.; Mitchell, D.M.; Warren, R.F. Evaluating heat extremes in the UK Climate Projections (UKCP18). Environmental Research Letters 2020. [Google Scholar] [CrossRef]
- Rogers, C.D.W.; Ting, M.; Li, C.; Kornhuber, K.; Coffel, E.D.; Horton, R.M.; Raymond, C.; Singh, D. Recent increases in exposure to extreme humid-heat events disproportionately affect populated regions. Geophysical Research Letters 2021, 48. [Google Scholar] [CrossRef]
- Speizer, S.; Raymond, C.; Ivanovich, C.; Horton, R.M. Concentrated and intensifying humid heat extremes in the IPCC AR6 regions. Geophysical Research Letters 2022, 49. [Google Scholar] [CrossRef]
- Kong, Q.; Huber, M. Regimes of soil moisture-wet bulb temperature coupling with relevance to moist heat stress. Journal of Climate 2023, 1–45. [Google Scholar] [CrossRef]
- Krakauer, N.Y. Amplification of extreme hot temperatures over recent decades. Climate 2023, 11, 42. [Google Scholar] [CrossRef]
- Krakauer, N.Y. Extending the blended generalized extreme value distribution. Discover Civil Engineering 2024, 1. [Google Scholar] [CrossRef]
- Doxsey-Whitfield, E.; MacManus, K.; Adamo, S.B.; Pistolesi, L.; Squires, J.; Borkovska, O.; Baptista, S.R. Taking advantage of the improved availability of census data: a first look at the Gridded Population of the World, Version 4. Papers in Applied Geography 2015, 1, 226–234. [Google Scholar] [CrossRef]
- Center For International Earth Science Information Network-CIESIN-Columbia University. Gridded Population of the World, Version 4 (GPWv4): population count, Revision 11; 2018. [Google Scholar] [CrossRef]
- Cattiaux, J.; Ribes, A.; Thompson, V. Searching for the most extreme temperature events in recent history. Bulletin of the American Meteorological Society 2024, 105, E239–E256. [Google Scholar] [CrossRef]
- Stone, D.A. A hierarchical collection of political/economic regions for analysis of climate extremes. Climatic Change 2019, 155, 639–656. [Google Scholar] [CrossRef]
- Durre, I.; Menne, M.J.; Gleason, B.E.; Houston, T.G.; Vose, R.S. Comprehensive automated quality assurance of daily surface observations. Journal of Applied Meteorology and Climatology 2010, 49, 1615–1633. [Google Scholar] [CrossRef]
- Menne, M.; Durre, I.; Vose, R.; Gleason, B.; Houston, T. An overview of the Global Historical Climatology Network-Daily database. Journal of Atmospheric and Oceanic Technology 2012, 29, 897–910. [Google Scholar] [CrossRef]
- Jaffrés, J.B. GHCN-Daily: a treasure trove of climate data awaiting discovery. Computers & Geosciences 2019, 122, 35–44. [Google Scholar] [CrossRef]
- Kotz, S.; Nadarajah, S. Extreme Value Distributions: Theory and Applications; Imperial College Press, 2000. [Google Scholar]
- Beirlant, J.; Goegebeur, Y.; Teugels, J.; Segers, J. Statistics of Extremes: Theory and Applications; Wiley, 2004. [Google Scholar] [CrossRef]
- Rohde, R.; Muller, R.; Jacobsen, R.; Perlmutter, S.; Rosenfeld, A.; Wurtele, J.; Curry, J.; Wickham, C.; Mosher, S. Berkeley Earth temperature averaging process. Geoinformatics and Geostatistics: An Overview 2013, 1, 1000103. [Google Scholar] [CrossRef]
- Rohde, R.; Muller, R.A.; Jacobsen, R.; Muller, E.; Perlmutter, S.; Rosenfeld, A.; Wurtele, J.; Groom, D.; Wickham, C. A new estimate of the average Earth surface land temperature spanning 1753 to 2011. Geoinformatics and Geostatistics: An Overview 2013, 1, 1000101. [Google Scholar] [CrossRef]
- Martins, E.S.; Stedinger, J.R. Generalized maximum-likelihood generalized extreme-value quantile estimators for hydrologic data. Water Resources Research 2000, 36, 737. [Google Scholar] [CrossRef]
- Ailliot, P.; Thompson, C.; Thomson, P. Mixed methods for fitting the GEV distribution. Water Resources Research 2011, 47, W05551. [Google Scholar] [CrossRef]
- Smith, R.l. Maximum likelihood estimation in a class of nonregular cases. Biometrika 1985, 72, 67–90. [Google Scholar] [CrossRef]
- Castillo, E.; Hadi, A.S. Parameter and quantile estimation for the generalized extreme-value distribution. Environmetrics 1994, 5, 417–432. [Google Scholar] [CrossRef]
- Coles, S.G.; Dixon, M.J. Likelihood-based inference for extreme value models. Extremes 1999, 2, 5–23. [Google Scholar] [CrossRef]
- Lee, Y.; Shin, Y.; Park, J.S. A data-adaptive maximum penalized likelihood estimation for the generalized extreme value distribution. Communications for Statistical Applications and Methods 2017, 24, 493–505. [Google Scholar] [CrossRef]
- Gelman, A.; Hill, J. Data Analysis Using Regression and Multilevel/Hierarchical Models; Cambridge University Press, 2006; ISBN 052168689X. [Google Scholar]
- Yoon, S.; Cho, W.; Heo, J.H.; Kim, C.E. A full Bayesian approach to generalized maximum likelihood estimation of generalized extreme value distribution. Stochastic Environmental Research and Risk Assessment 2010, 24, 761–770. [Google Scholar] [CrossRef]
- Tokdar, S.T.; Kass, R.E. Importance sampling: a review. WIREs Computational Statistics 2009, 2, 54–60. [Google Scholar] [CrossRef]
- Koch, K.R. Introduction to Bayesian Statistics, second, updated and enlarged edition; Springer-Verlag; p. 250.
- Krakauer, N.Y.; Grossberg, M.D.; Gladkova, I.; Aizenman, H. Information content of seasonal forecasts in a changing climate. Advances in Meteorology 2013, 2013, 480210. [Google Scholar] [CrossRef]
- Aizenman, H.; Grossberg, M.D.; Krakauer, N.Y.; Gladkova, I. Ensemble forecasts: probabilistic seasonal forecasts based on a model ensemble. Climate 2016, 4, 19. [Google Scholar] [CrossRef]
- Benedetti, R. Scoring rules for forecast verification. Monthly Weather Review 2010, 138, 203–211. [Google Scholar] [CrossRef]
- Tödter, J. New Aspects of Information Theory in Probabilistic Forecast Verification. Master’s thesis 2011. [Google Scholar]
- Prates, F.; Buizza, R. PRET, the Probability of RETurn: a new probabilistic product based on generalized extreme-value theory. Quarterly Journal of the Royal Meteorological Society 2011, 137, 521–537. [Google Scholar] [CrossRef]
- Dong, Q. Calibration and quantitative forecast of extreme daily precipitation using the extreme forecast index (EFI). Journal of Geoscience and Environment Protection 2018, 06, 143–164. [Google Scholar] [CrossRef]
- Efron, B.; Gong, G. A leisurely look at the bootstrap, the jackknife, and cross-validation. American Statistician 1983, 37, 36–48. [Google Scholar] [CrossRef]
- Embrechts, P.; Resnick, S.I.; Samorodnitsky, G. Extreme value theory as a risk management tool. North American Actuarial Journal 1999, 3, 30–41. [Google Scholar] [CrossRef]
- Chen, W.; Zhao, X.; Zhou, M.; Chen, H.; Ji, Q.; Cheng, W. Statistical inference and application of asymmetrical generalized Pareto distribution based on peaks-over-threshold modela. Symmetry 2024, 16, 365. [Google Scholar] [CrossRef]
- Cherkassky, V.; Mulier, F. Learning From Data: Concepts, Theory, and Methods; Wiley, 2007. [Google Scholar]
- van den Dool, H.; Becker, E.; Chen, L.C.; Zhang, Q. The probability anomaly correlation and calibration of probabilistic forecasts. Weather and Forecasting 2017, 32, 199–206. [Google Scholar] [CrossRef]
- Singh, A.; Sahoo, R.K.; Nair, A.; Mohanty, U.C.; Rai, R.K. Assessing the performance of bias correction approaches for correcting monthly precipitation over India through coupled models. Meteorological Applications 2017, 24, 326–337. [Google Scholar] [CrossRef]
- Donat, M.G.; Alexander, L.V. The shifting probability distribution of global daytime and night-time temperatures. Geophysical Research Letters 2012, 39, L14707. [Google Scholar] [CrossRef]
- Ruff, T.W.; Neelin, J.D. Long tails in regional surface temperature probability distributions with implications for extremes under global warming. Geophysical Research Letters 2012, 39. [Google Scholar] [CrossRef]
- Nadarajah, S. A generalized normal distribution. Journal of Applied Statistics 2005, 32, 685–694. [Google Scholar] [CrossRef]
- Azzalini, A. The skew-normal distribution and related multivariate families. Scandinavian Journal of Statistics 2005, 32, 159–188. [Google Scholar] [CrossRef]
- McKinnon, K.A.; Rhines, A.; Tingley, M.P.; Huybers, P. The changing shape of Northern Hemisphere summer temperature distributions. Journal of Geophysical Research: Atmospheres 2016, 121, 8849–8868. [Google Scholar] [CrossRef]
- Tamarin-Brodsky, T.; Hodges, K.; Hoskins, B.J.; Shepherd, T.G. Changes in Northern Hemisphere temperature variability shaped by regional warming patterns. Nature Geoscience 2020, 13, 414–421. [Google Scholar] [CrossRef]
- Mishra, V.; Ganguly, A.R.; Nijssen, B.; Lettenmaier, D.P. Changes in observed climate extremes in global urban areas. Environmental Research Letters 2015, 10, 024005. [Google Scholar] [CrossRef]
- Belkhiri, L.; Kim, T.J. Individual influence of climate variability indices on annual maximum precipitation across the global scale. Water Resources Management 2021, 35, 2987–3003. [Google Scholar] [CrossRef]
- Wu, X.; Wang, L.; Yao, R.; Luo, M.; Li, X. Identifying the dominant driving factors of heat waves in the North China Plain. Atmospheric Research 2021, 252, 105458. [Google Scholar] [CrossRef]
- Zhong, P.; Huser, R.; Opitz, T. Modeling nonstationary temperature maxima based on extremal dependence changing with event magnitude. The Annals of Applied Statistics 2022, 16. [Google Scholar] [CrossRef]
- Magarey, R.D.; Borchert, D.M.; Schlegel, J.W. Global plant hardiness zones for phytosanitary risk analysis. Scientia Agricola 2008, 65, 54–59. [Google Scholar] [CrossRef]
- Krakauer, N.Y. Estimating climate trends: Application to United States plant hardiness zones. Advances in Meteorology 2012, 2012, 404876. [Google Scholar] [CrossRef]
- Krakauer, N.Y. Shifting hardiness zones: trends in annual minimum temperature. Climate 2018, 6, 15. [Google Scholar] [CrossRef]
- Suh, J.N.; Kang, Y.I.; Choi, Y.J.; Seo, K.H.; Kim, Y.H. Plant hardiness zone map in Korea and an analysis of the distribution of evergreen trees in Zone 7b. Journal of People, Plants, and Environment 2021, 24, 519–527. [Google Scholar] [CrossRef]
- Matthews, T. Humid heat and climate change. Progress in Physical Geography: Earth and Environment 2018, 42, 391–405. [Google Scholar] [CrossRef]
- Wang, P.; Yang, Y.; Jianping, T.; Leung, L.R.; Liao, H. Intensified humid heat events under global warming. Geophysical Research Letters 2020. [Google Scholar] [CrossRef]
- Willett, K.M. HadlSDH.extremes part II: exploring humid heat extremes using wet bulb temperature indices. Advances in Atmospheric Sciences 2023. [Google Scholar] [CrossRef]
|
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).