
Submitted:
22 November 2024
Posted:
25 November 2024
You are already at the latest version
Abstract
Nowadays, the consequence of quick access to information has lead to the spread of fake news, which has a strong damaging impact on democracy, justice, and public trust. Thus, it is crucial to analyze and evaluate detection methods of fake news. This paper focuses on the detection of Romanian fake news. In this study, we made a comparative analysis of machine learning algorithms and transformer-based models on Romanian fake news detection using three datasets – FakeRom, New, and both FakeRom + New. The NEW dataset was build using a scrapping algorithm applied on the Veridica platform. Our approach uses for detection machine learning models: Native Bayes (NB,) Logistic regression (LR) and Support Vector Machine (SVM). We also used two transformer based models – BERT based multilingual based and RoBERTaLarge. The performance of the models was evaluated using various metrics: accuracy, precision, recall and F1-score. The results revealed that BERT model trained on NEW dataset consistently achieved the highest performance metrics across all test sets. Also, Support Vector Machine trained on NEW was another top performer, reaching a very good accuracy on the combined test set.
Keywords:
fake news detection
; machine learning
; transformer-based
1. Introduction
In today’s world, rapid access to vast information has become essential, but it also brings challenges like the spread of fake news. Fake news consists of inaccurate or misleading information presented as facts, with serious societal consequences, such as influencing public opinion and undermining democratic processes.
The rise of fake news, especially on social media, has sparked interest in finding effective methods for detection. Artificial intelligence (AI), particularly Machine Learning and Deep Learning, plays a crucial role by developing models that can analyze and classify text based on its truthfulness.
In Romania, the phenomenon of fake news has grown significantly in recent years, impacting various sectors such as politics, health, economy, and culture. Therefore, there is a strong need to develop local solutions tailored to the specific linguistic and cultural context for the effective detection of fake news.
Fake news refers to articles, images, videos, or other forms of media that contain false, misleading, or out-of-context information, created to deceive the public [1].
Fake news can be classified as: satire/parody which include false content created for humor - not deception, disinformation which is intentionally false content to manipulate opinion, propaganda that refers to misleading information used to promote ideologies, clickbait which are sensationalized headlines to attract clicks, distorted news that are true information presented in a misleading way, fabricated content that refers to completely false information with no basis in reality and conspiracy theories that represent unfounded claims of secret plots behind events [1].
Paper [2] addresses ambiguities around "fake news" and re-frames it as "false messages" within a digital context. It critiques current terminology and uses the ontology of digital objects to define false messages by attributes like editability and interactivity. The study highlights overlooked research areas by placing these messages within broader networks of digital actors.
Fake news significantly affects society, influencing politics, the economy, public health, and trust in institutions. Key consequences include:
- Influencing public opinion and elections: Fake news can distort public perception, affecting election outcomes and political decisions through disinformation campaigns [3];
- Eroding trust in media and institutions: The spread of fake news reduces public trust in traditional media and government, complicating informed participation in democratic processes;
- Creating panic during crises: In crises like pandemics, fake news exacerbates confusion by spreading false or alarming information, leading to dangerous public reactions;
- Impact on public health: Health-related disinformation can lead to vaccine refusal, inappropriate treatments, and disease spread;
- Affecting social cohesion: Fake news can divide communities, inciting radical ideas and interpersonal conflicts;
- Economic impact: Disinformation can destabilize markets by spreading false information about companies or economic events, causing financial losses [4].
Understanding the profound impact of fake news on society highlights the importance of developing effective solutions for its detection and mitigation. In the following chapters, we will explore the methods and technologies employed to address this complex issue, with a particular focus on the use of artificial intelligence in fake news detection.
This research aims to compare AI models used for detecting fake news, focusing on:
- Data collection and preprocessing: Building a new dataset of fake and real news for Romanian language and applying necessary preprocessing for model training;
- Model training: Implementing and training several AI models to assess their ability to detect fake news. Classical models used in our research for fake news detection include Logistic Regression, Support Vector Machines (SVM) and Naive Bayes. Also we investigated two transformer-based models BERT (Bidirectional Encoder Representations from Transformers) and RoBERTa-large (Pretrained BERT model for Romanian);
- Performance evaluation: Comparing models using metrics like accuracy, precision, recall, and F1 score;
- Results analysis: Identifying strengths, limitations, and future improvements for each model.
This paper is organized as follows: Section 2 presents the state of the art in fake news detection, Section 3 includes the used materials and methods, including Used technologies, Dataset collection, Dataset preprocessing, Machine Learning and Transformer-based models, Performance evaluation, Models implementation and training and the application implemented to detect fake news using the best performing AI model that resulted from our research. Section 4 presents the obtained results and section 5 highlights the main key findings from the results. Finally, section 6 includes the conclusions for this research.
2. State of the Art
In the last years fake news detection has become increasingly important due to the widespread dissemination of misleading information across social media and news platforms. Artificial Intelligence (AI) has proven to be a key enabler in identifying and mitigating the spread of such content, using various machine learning (ML) and natural language processing (NLP) techniques.
The study presented in [5] provides an overview of traditional machine learning models, including Naive Bayes and Logistic Regression, applied to fake news detection, discussing their strengths and weaknesses. Paper [6] categorizes fake news and discusses the use of traditional models like Logistic Regression and Naive Bayes for linguistic feature-based deception detection. The research presented in [7] investigates the use of traditional machine learning models, such as SVM and Naive Bayes, for fake news detection, focusing on n-gram linguistic features.
Utilizing ML classification models offers an effective solution to combat the spread of fake news. However, the development of fake news detection models has been hindered by the lack of comprehensive datasets. Existing datasets are limited in their scope, often missing multimodal text and image data, metadata, comments, and detailed fake news categorization. In response, in [8] is introduced Fakeddit, a novel multimodal dataset containing over 1 million samples across various fake news categories. After undergoing multiple review stages, the samples are labeled for 2-way, 3-way, and 6-way classification using distant supervision. Hybrid text and image models are developed by the authors and extensive experiments were conducted, showcasing the value of multimodality and fine-grained classification that are unique to Fakeddit.
The paper in [9] presents an extensive review of deep learning-based fake news detection (FND) methods, highlighting critical features like news content, social context, and external knowledge. The methods are grouped into supervised, weakly supervised, and unsupervised categories, with a detailed evaluation of representative approaches. The study also introduces commonly used FND datasets and provides a quantitative performance analysis of these methods across the datasets. Finally, it addresses the limitations of current techniques and proposes promising directions for future research.
Transformers, built on attention mechanisms, are powerful models for natural language processing tasks like text generation and language understanding. Pre-trained models like BERT and GPT (Generative Pre-trained Transformers ) have achieved state-of-the-art results in AI competitions and practical applications [10].
These advanced deep learning models have revolutionized AI, pushing the boundaries in fields like computer vision, natural language processing, and more. Each model has unique features and is chosen based on specific problem requirements.
The study presented in [11] introduces the Transformer model, which has since become crucial in NLP tasks, including fake news detection. In [12], BERT is introduced as a new language representation model. BERT is designed to pre-train deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. BERT model is conceptually simple and powerful, and the pre-trained BERT model have the huge advantage of being fine-tuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, including fake news detection.
Social networking platforms have become major hubs for global users to share views, news, and information. The rise of fake and spam profiles spreading disinformation has become a growing concern. While efforts have been made to distinguish real news from fake campaigns, manual verification of the vast amount of social media content is impractical.
A detailed survey of fake news detection approaches, focusing on both content-based methods and social-context-based models is given in [13].
The study [14] tackles this issue by proposing a framework that employs emotion-based sentiment analysis to analyze news, posts, and opinions on social media. The model computes sentiment scores to detect fake or spam content and identify both accounts, achieving an accuracy of 99.68%, surpassing other methods.
In [15] is proposed a new solution for fake news detection which incorporates sentiment as an important feature to improve the accuracy, trained on two datasets LIAR and ISOT [16]. The study develops key feature words using sentiment analysis with a lexicon-based scoring algorithm. A multiple imputation strategy, based on Multiple Imputation Chain Equation (MICE), addresses missing variables in the dataset. Term Frequency-Inverse Document Frequency (TF-IDF) is used to extract long-term features, and classifiers such as Naïve Bayes, passive-aggressive, and Deep Neural Networks (DNN) are employed to categorize data. The method achieved 99.8% accuracy in detecting fake news, outperforming existing methods when evaluated on statements ranging from true to false.
Although previous research on automatic fake news detection has been conducted for other languages, work in this area for Romanian is still in its early stages.
Paper [17] presents an automated analysis of political statements in Romanian using state-of-the-art Natural Language Processing techniques, focusing on the role of context in determining veracity. The dataset is based on entries from Factual, a Romanian fact-checking initiative, which includes public statements along with contextual information. The results are comparable to experiments on the PolitiFact dataset and serve as a solid baseline for studies in low-resource languages like Romanian.
The research presented in [18] discusses state-of-the-art techniques for text classification and evaluates the performance of different neural networks on a Romanian news article corpus. Both classical machine learning methods and more advanced Transformer-based models were considered, with RoBERTa and CNN achieving a weighted F1-score of 75%. Multi-task learning experiments, while promising, did not improve performance, reaching an F1-score of 74%. Additionally, the paper introduces a prototype web application and explores use cases for automated fake news detection systems.
The work in [19] focuses on the automatic detection of fake news in the Romanian language, aiming to improve accuracy in identifying deceptive content. It introduces a new available dataset for fake news detection, consisting of two subsets containing 977 and 29,154 Romanian news articles, categorized based on labeling and collection methods. The study explores various text-based approaches using artificial intelligence and machine learning, achieving an accuracy of 93%.
Paper [20] introduces a supervised machine learning system designed to detect fake news in Romanian online sources. It compares the performance of various models, including recurrent neural networks (LSTM - Long short-term memory and GRU - Gated recurrent units cells), a convolutional neural network (CNN), and the RoBERT model, a pre-trained BERT variant for Romanian. These deep learning models are evaluated against traditional classifiers like Naïve Bayes and Support Vector Machine (SVM) using a dataset with 25,841 true and 13,064 fake news items. CNN achieved the best performance, with over 98.20% accuracy, surpassing both classical methods and BERT models. Additionally, the study explores irony detection and sentiment analysis to address fake news challenges.
In [21] authors employ three key approaches for attaining smaller and more efficient NLP models. The technique implies training a Transformer-based neural network to detect offensive language. Data augmentation and knowledge distillation techniques are used in order to increase performance. Also multi-task learning with knowledge distillation and teacher annealing is incorporated.
The study in [22] demonstrates that Back Translation (BT) using transformer-based models, like mBART, improves fake news detection in Romanian. Models trained with BT-augmented data outperformed those using original data, with Extra Trees and Random Forest classifiers yielding the best results. The research highlights BT’s potential to enhance detection accuracy, especially when using mBART over Google Translate.
3. Materials and Methods
In this section we present the steps followed in our research. These include the used technologies, dataset collection, dataset description and dataset preprocessing, machine learning techniques, transformers implementation for fake news based on Romanian language. Also, we present performance evaluation of the implemented models.
3.1. Used Technologies
In the development and implementation of AI-based fake news detection systems, selecting the right libraries and technologies is crucial for achieving accurate and efficient results. This section discusses the importance of using Python3 and details the libraries and technologies employed for data scraping, preprocessing, and model training.
Python3 is a high-level programming language known for its simplicity and versatility, popular in data science and AI for several reasons, having an easy-to-learn and read syntax, facilitating quick and efficient coding. It offers a vast ecosystem of specialized libraries and packages for natural language processing (NLP), machine learning (ML), and deep learning (DL),
Libraries we used for Data Scraping and Preprocessing include:
- requests: A simple and elegant library for making HTTP requests, ideal for scraping data from websites and handling responses in HTML, JSON, or other formats;
- BeautifulSoup: Used for parsing HTML and XML documents, this library helps in extracting data from web pages and navigating complex HTML structures;
- json: Facilitates working with JSON (JavaScript Object Notation) data, useful for serializing and deserializing data from APIs or other sources;
- concurrent.futures: Allows parallel execution of code, making data scraping more efficient by enabling simultaneous HTTP requests or page analysis.
For AI Model Training we used the following libraries:
- pandas: Essential for data manipulation and analysis in Python, offering efficient data structures like DataFrame for preprocessing datasets before model training;
- logging: Provides functionalities for logging debugging, info, warning, and error messages, crucial for monitoring and troubleshooting during model development;
- psutil: Monitors and manages system resources such as CPU and memory usage, important for optimizing performance and preventing resource overload during model training;
- scikit-learn (sklearn): A comprehensive library for machine learning, offering a range of algorithms for classification, regression, clustering, and dimensionality reduction;
- TfidfVectorizer: Transforms raw text into numerical features based on term frequency-inverse document frequency (TF-IDF);
- GridSearchCV: Used for hyperparameter tuning by performing grid searches to optimize model performance.
These libraries and technologies form the foundation for developing and implementing fake news detection models. The following sections will detail the process of dataset collection and preprocessing, model implementation and training, performance evaluation, and result comparison.
3.2. Dataset Collection
Data collection is a crucial step in developing any AI model. For this project, a dataset was created by combining articles collected from Veridica [23], a platform that monitors and identifies fake news and misinformation, with the open-source FAKEROM dataset [24]. Custom datasets were created for use with PyTorch, randomly combining the elements of the FAKEROM dataset and another 1000+ items obtained from the scraping of the Veridica platform.
For this phase, a combination of web scraping techniques and Python libraries was used to extract the necessary data. The main libraries used for data collection are requests and BeautifulSoup.
Stages of the Data Collection Process include:
- Defining Scraping Functions: Functions were created to extract article metadata, obtain article content, and save the collected data in a JSON file. We used a function to extract relevant metadata, such as publication date, from the HTML structure of each article.
- Scraping Article Content: The implemented function extracts the content of articles by identifying relevant paragraphs and adding them to the article content.
- Scraping Article Details: We implemented a function that combines the title, content, and metadata of articles into a dictionary, which is then saved as a JSON file. This data is later combined with the FAKEROM dataset [25], improving it with current articles.
- Collecting Articles from Multiple Pages: Since the article source is organized by pagination, a method was built to navigate through this structure and access the corresponding article URLs.
- Main Program Execution: The main function initializes the scraping process, prompting the user to enter the URL, number of pages to scrape, and the file name for saving the data.
These steps ensure efficient and organized data collection for building AI models.
Part of the dataset was created using the web scraping algorithm detailed above (see Figure 1). This algorithm accesses pages on the Veridica platform, extracts article content, and stores it in a structured JSON format. This ensures that all articles are properly collected and labeled for training and evaluating AI models. The dataset was then randomly combined with the FAKEROM dataset.
The obtained, combined dataset includes a variety of information, with each article tagged to indicate its content type, such as fake_news for false news and misinformation for misleading information. Each record from the dataset includes the following fields:
- Content: The full text of the article;
- Tag: A label indicating the nature of the article (e.g. fake_news, misinformation, propaganda, real_news, satire).
Figure 2 shows an example from our dataset.
3.3. Dataset Preprocessing
Data preprocessing [26,27] is crucial for preparing the dataset for training AI models. In this project, several preprocessing techniques were applied to ensure the data is in an optimal format for training and evaluation.
In our project, data cleaning involves removing elements that could introduce noise into the model training process. The techniques applied include:
- Lowercase conversion: All text was converted to lowercase to eliminate variations caused by capitalization and ensure data consistency;
- Removal of non-letter characters: All characters that were not letters or spaces were removed using regular expressions, while retaining specific Romanian characters (e.g., ă, â, ș, ț);
- Removal of isolated letters: Single letters appearing between spaces were removed, as they may represent errors or offer little semantic value;
- Standardization of spaces: Multiple spaces were replaced with a single space to streamline the text and facilitate further processing;
- Trimming text edges: Leading and trailing spaces were removed to prevent issues during subsequent analysis.
Text was transformed into numerical representations using TfidfVectorizer, which reduces the text to a set of significant features for the models to identify and differentiate between content types.
The data was loaded by importing the dataset from a JSON file and transforming it into a DataFrame structure, which facilitates further manipulation and processing.
To address class imbalance in the dataset, data augmentation techniques were applied, focusing on underrepresented categories. Synonym replacement using pre-trained embeddings was chosen for its computational efficiency, being less resource-intensive than methods like back-translation.
The Romanian language embeddings were loaded using pre-trained fastText embeddings, which capture the semantic relationships between words. To optimize memory and resource usage, the number of loaded words was limited to the most frequent and relevant ones in the language.
The synonym replacement procedure involves selecting unique words from each text that could be replaced with synonyms, identifying possible synonyms based on similarity in the embedding vector space, controlling the replacement by limiting the number of words changed in each text to preserve original meaning and coherence and randomizing the replacements to introduce data diversity and avoid repetitive patterns.
Exception handling and quality assurance mechanisms were implemented to manage cases where a word lacked available synonyms or was absent from the embeddings, ensuring continuity without compromising data quality. The augmented dataset was then combined with the original, resulting in an expanded dataset that included both the initial examples and those generated through augmentation.
Class balancing through oversampling involved using the RandomOverSampler technique to equalize the number of examples in each class by randomly replicating data from the minority classes. This approach helps prevent bias in machine learning models toward majority classes and enhances their generalization ability.
Additionally, the following steps were taken: the balanced and preprocessed dataset was exported in a format that preserves Romanian diacritics and language specifics, ensuring its usability for future training and validation stages and the processed data is now prepared for machine learning algorithms, providing a solid foundation for achieving optimal performance. Figure 3 presents the Fakerom and NEW datasets after processing.
3.4. Machine Learning Techniques
Machine Learning (ML) encompasses various algorithms used to learn from data and make predictions, forming the basis of many AI applications. Key classical algorithms used in our project for fake detection include:
- Logistic Regression: A classification algorithm for binary problems, logistic regression predicts the probability of an observation belonging to one of two categories. It uses the logistic function to convert a linear combination of predictors into probabilities, applying a threshold (usually 0.5) to classify the observation [10];
- Support Vector Machines (SVM): SVMs are classification algorithms that separate data using an optimal hyperplane. The goal is to maximize the margin between the closest data points from different classes. For non-linearly separable data, SVMs use kernel functions to project data into higher-dimensional spaces where a hyperplane can separate the classes [10];
- Naive Bayes: A classification algorithm based on Bayes’ theorem, assuming feature independence. Despite this unrealistic assumption, Naive Bayes performs well in many real-world applications, especially text classification. It calculates probabilities for each class and selects the class with the highest likelihood [10];
Logistic Regression, Naive Bayes, Support Vector Machines (SVM) are classical models that have been used for detecting fake news based on linguistic features such as word frequency, sentiment analysis, or part-of-speech tagging. While these models are computationally efficient and interpretable, their performance often lags behind deep learning models. Paper [28] is a comprehensive survey that discusses the use of classical machine learning models, such as Logistic Regression, SVM, and Naive Bayes, highlighting their advantages and limitations in fake news detection. LIAR dataset is introduced in [29], that evaluates various machine learning models, including Logistic Regression and SVM, showing their performance on fake news detection tasks.
3.5. Transformer-Based Models
Advanced deep learning models are frequently used to address complex classification problems, including fake news detection. These models can learn complex data representations due to their deep architectures and ability to model nonlinear relationships [10].
A transformer model is a type of deep learning model that was first described in a 2017 paper called "Attention is All You Need" by Ashish Vaswani, a team at Google Brain, and a group from the University of Toronto [11]. These models have quickly become fundamental in natural language processing (NLP) and have been applied to a wide range of tasks in machine learning and artificial intelligence.
Transformers are a type of neural network architecture that transforms or changes an input sequence into an output sequence. They do this by learning context and tracking relationships between sequence components. The transformer model uses an internal mathematical representation that identifies the relevance and relationship between the words. It uses that knowledge to generate output.
Transformer models use an encoder-decoder architecture. The encoder has various layers, with each layer generating encodings about relevant input data before passing on the input data to the next encoder layer.
The encoders tag each data element, with attention units creating an algebraic map of how each element relates to others. A multi-head attention set of equations calculates all attention queries in parallel. This allows the transformer model to detect patterns just like humans [12].
Transformer-based models have become fundamental in the field of artificial intelligence and natural language processing due to their ability to handle data sequences in an efficient and scalable way. Transformers have revolutionized the field, being used not only for natural language but also in areas such as computer vision and image generation. Transformer models have brought about a fundamental change in artificial intelligence, providing a highly efficient way to model data sequences and the complex relationships between their elements.
The two transformer-based models used in our approach are:
3.6. Performance Evaluation
In this section, we briefly overview each metric used to measure performance. Model evaluation metrics play a crucial role in analyzing performance, providing an objective basis for measuring model efficiency and accuracy in text classification tasks. Metrics such as accuracy, precision, recall, and F1-score help determine how well models distinguish between correct classes and minimize errors. These metrics not only facilitate comparison between different models but also enable continuous optimization to ensure the best solution for the specific application.
Machine learning models are evaluated using various metrics, with accuracy, precision, recall, and F1-score being among the most commonly used. These metrics provide a detailed assessment of a model’s ability to make correct predictions while minimizing errors [31]:
- Accuracy: Accuracy represents the proportion of correct predictions out of the total predictions made by the model. It is suitable when dataset classes are balanced but may be misleading in cases of significant class imbalance.
- Precision: Precision measures the proportion of correctly predicted positive instances out of all positive predictions. It is particularly important when the cost of false positives is high, such as in fraud detection systems.
- Recall: Recall, or sensitivity, measures the proportion of correctly predicted positive instances out of the total actual positive instances. This is critical when it is important to identify all positive cases, as in medical diagnoses.
- F1-Score: The F1-score is the harmonic mean of precision and recall, providing a balanced measure, especially useful when there is class imbalance.
Cross-validation is a fundamental technique for evaluating a machine learning model’s performance. The most common method is k-fold cross-validation, where the dataset is divided into k subsets, and the model is trained and validated on various combinations of folds. This process helps reduce variance in performance estimates and provides a more robust evaluation [32].
3.7. Models Implementation and Training
A variety of models were experimented with, including traditional machine learning approaches and transformer models: RoBERTa -large and BERT-base-multilingual-cased.
The dataset described in Section 3.2 was used for implementation and evaluation.
The process began with loading the JSON dataset into a Pandas DataFrame for easier manipulation. The text was split into training and test sets using Scikit-learn’s train_test_split, with an 80% training and 20% test ratio. Labels were binarized for accurate performance measurement.
The machine learning models used in our implementation are the ones presented in Section 3.4. Also, we implemented two transformer-based models, described in Section 3.5.
Performance metrics calculated and saved included Accuracy, Precision, Recall, F1 Score, Log Loss, and ROC AUC.
Training parameters for BERT and RoBERTa were set using TrainingArgumentsfrom the transformers library, with configurations for epochs, batch size, warmup steps, weight decay, logging, and evaluation strategy.
The specifications for these parameters are as follows:
- output_dir: ../results - The directory where the results and the trained model will be saved.
- num_train_epochs: 3 - The model was trained for a total of 3 epochs.
- per_device_train_batch_size: 8 - The batch size for training data was set to 8.
- per_device_eval_batch_size: 8 - The batch size for evaluation was set to 8.
- warmup_steps: 500 warm-up steps were performed to stabilize the learning rate.
- weight_decay: 0.01 - Regularization penalty through weight decay was applied, set to 0.01.
- logging_dir: ./logs - Training logs were saved in the ./logs directory.
- logging_steps: 10 - Information was logged every 10 training steps.
- evaluation_strategy: "steps" - Model evaluation was performed based on steps rather than full epochs.
The BERT model implementation was done using the pre-trained BertTokenizerFast on the bert-base-multilingual-cased version. The dataset was tokenized with the parameters padding=True, truncation=True, and max_length=128, ensuring a constant sequence length and truncating overly long texts. Training and test datasets were created using custom classes of type FakeNewsDataset, which integrated the tokens and labels (transformed and encoded with LabelEncoder) to be compatible with the model.
Similarly, for the implementation of the RoBERTa-large model, a nearly identical process was followed, using the RobertaTokenizerFast tokenizer and setting the same values for tokenization parameters: padding=True, truncation=True, and max_length=128. In terms of training, the same techniques and strategies were applied as in the case of BERT, including configuring the training batch, number of epochs, and evaluation strategy. However, specific hyperparameters were adjusted to optimize the performance of the RoBERTa model.
These were set as follows:
- output_dir: ../results - Output directory for saving the model and results.
- num_train_epochs: 4 - The number of epochs was increased to 4 to ensure adequate model convergence.
- per_device_train_batch_size: 8 - The batch size per device for training remained at 8.
- per_device_eval_batch_size: 8 - The batch size per device for evaluation remained at 8.
- warmup_steps: 1000 - The number of warm-up steps was increased to 1000 to allow a better stabilization of the learning rate at the start of training.
- weight_decay: 0.01 - The weight decay was set to 0.01 to prevent over fitting.
- logging_dir: ./logs - Training logs were saved in the ./logs directory.
- logging_steps: 10 - Information was logged every 10 training steps.
- evaluation_strategy: "steps" - Evaluation was performed based on steps, ensuring constant monitoring of model performance.
Training was performed using the GPU of the Apple M1 Max processor, which offers up to 32 GPU cores and unified memory architecture, facilitating efficient data processing and model training.
3.8. Our Application
The application is designed to detect fake news using the best performing AI model that resulted from the research. Built with a modern tech stack, the application leverages the power of Next.js for server-side rendering, React for building user interfaces, and Prisma for database management. The project provides an intuitive and interactive platform for users to analyze and visualize the performance of machine learning models tested in our research in detecting fake news. The application can be accessed at https://ai-fake-news-ro.vercel.app/.
Key Features of our implementation include:
- Fake News Detection: The core functionality of the application is to detect fake news using multiple machine learning models. Users can input text or URLs, and the application will classify the content;
- Model Evaluation: The application provides detailed evaluations of different machine learning models, including metrics such as accuracy, precision, recall, F1 score, and log loss. These metrics help users understand the performance of each model tested during the research;
- Data Visualization: The application includes rich data visualization features, allowing users to compare the performance of different models through charts and tables. This is implemented using the Recharts library;
- Interactive UI: The user interface is built with Radix UI and Tailwind CSS, providing a responsive and accessible design. Users can easily navigate through different tabs to view model evaluations and dataset statistics;
- Authentication: The application uses NextAuth.js for secure user authentication, ensuring that only authorized users can access certain features;
- Database Management: Prisma is used for database management, providing a robust and scalable solution for handling dataset entries.
Technologies used to implement the application include: Next.js - A React framework for server-side rendering and static site generation; React - A JavaScript library for building user interfaces; TypeScript - A typed superset of JavaScript that enhances code quality and maintainability; Prisma - An ORM for Node.js and TypeScript, used for database management; Radix UI - A set of accessible UI components for building design systems; Recharts - A charting library built on React components for data visualization; Tailwind CSS - A utility-first CSS framework for rapidly building custom user interfaces; NextAuth.js - Authentication for Next.js applications; Zod - A TypeScript-first schema declaration and validation library; Lucide Icons - A collection of simple and customizable SVG icons; React Hook Form - A library for managing form state and validation in React applications; TanStack Table - A headless UI library for building powerful tables and datagrids, React Code Blocks - A library for rendering code blocks with syntax highlighting.
In the input process, users can add text or URLs to be analyzed by the AI models. Then, the input is processed by the selected machine learning model, which classifies the content as real or fake. The results are displayed to the user, along with detailed metrics and visualizations of the model’s performance.
4. Results
In this chapter, we analyzed and compared the performance of the different implemented models using several relevant metrics for text classification.
In order to demonstrate the validity of the results obtained based on the enriched data set, in the end we evaluated the performance of the models obtained based on the two data sets and made a comparison of the results obtained.
The NEW dataset (enhanced with new articles, before preprocessing) is available at: https://huggingface.co/datasets/mihalca/Fakerom_updated_original. The NEW dataset (enhanced with new articles, after preprocessing) is available at: https://huggingface.co/datasets/mihalca/FakeRO_updated.
In results folder we have collected:
- results_models_trained_on_original_fake_ro.json - includs the performance results of the models trained on the original FAKEROM dataset, without applying any of the previously mentioned preprocessing techniques, and the testing of the trained models was performed on a subset of 20% of the dataset used for training (original fakerom);
- results_models_trained_on_original_NEW.json - includes the performance results of the models trained on the original NEW data set, without applying any of the previously mentioned preprocessing techniques, and testing the trained models was performed on a subset of 20% of the data set used for training (original NEW);
- 1_results_all_models.json - includes the performance results of individually trained models on both the FAKEROM and NEW datasets, but after applying preprocessing techniques to both datasets.
Each trained model was tested on a subset of data from each dataset, as well as on a subset made with data from both datasets to eliminate the possibility of BIAS resulting from testing with data from the same dataset with which the model was trained.
For example:
-
SVM model - trained on NEW
- –
- Tested on subset of FAKEROM
- –
- Tested on subset of NEW
- –
- Tested on combination of data from both FAKEROM and NEW
The results obtained from a comparative perspective are accessible at: https://ai-fake-news-ro.vercel.app/about#model_evaluation.
4.1. Machine Learning Results
Figure 4 illustrates the performance of the tested machine learning algorithms for Romanina fake news detection, trained on NEW and FakeRom datasets and tested on data from FakeRom, New and FakeRom+New datasets. The obtained values for the performances show notable differences between the tested models. The Support Vector Machine (SVM) achieved the highest accuracy of 94.6%, for the model trained on NEW and tested on FakeRom+NEW, along with the highest precision, recall, and F1 score. This indicates its best performance among the machine learning models tested. The Logistic Regression (LR) also performed well, with the best accuracy of 90.90% for model trained on NEW and tested on FakeRom + NEW and high precision and recall values. Multinomial Naive Bayes (MNB) showed the lowest performance with an accuracy of 82.90% for the model trained on NEW and tested on FakeRom+NEW, and reasonable precision and recall. Also for other cases of datasets used for training and for different test sets the best-performing model was the SVM. Results show that models trained on NEW dataset outperformed models trained on FakeRom dataset, for all cases. On the whole, SVM performed the best, followed by LR, with MNB having the smallest accuracy.
4.2. Transformer-Based Results
The training of two different Transformer-based models for Romanian fake news detection demonstrates various tendencies in accuracy and log loss, as shown in Figure 5, Figure 6 and Figure 7.
The performance of various transformer-based models for Romanian fake news detection using FakeRom and NEW datasets for training and FakeRom, NEW, and FakeRom+NEW datasets for tests, illustrates another set of results, as shown in Figure 6. BERT achieved the highest accuracy at 96.50%, in the case of the NEW dataset used for training and the FakeRom+NEW dataset used for tests, and the highest precision and F1 score, showing its strong capability for the detection of Romanian fake news. RoBERTaLarge performed well with an accuracy of 94.40%. On the whole, the best-performing transformer-based model was BERT in terms of accuracy, irrespective of the dataset used for training and for testing.
4.3. Machine Learning vs. Transformed-Based Results
Figure 8 shows the accuracy metrics for the best ML and transformed-based models using different datasets for training and testing. The results demonstrate that the SVM model frequently achieves comparable accuracy to the BERT model, with particularly notable performance gains observed in the case of models trained on the NEW dataset and tested on the FakeRom+NEW dataset. Also, it can be seen, that in the case of precision, recall and F1 score SVM closely matches the performance values obtained for the BERT model.
4.4. Performance Evaluation Results
Table 1, Table 2, Table 3, Table 4 and Table 5 presents a comprehensive overview of the testing performance of the machine learning and transformer-based models on the FakeRom, on NEW and both FakeRom+NEW datasets. The performance metrics, accuracy, precision, recall, F1 score, points out the differences in the models’ effectiveness for the Romanian fake news detection.
Comparing the metrics from Table 1, Table 2, Table 3, Table 4 and Table 5 among the different implemented models (Naive Bayes, Logistic Regression, Support Vector Machine, BERT, RoBERTa-large), the following characteristics are observed:
- Naive Bayes shows relatively low performance in accuracy and F1 Score but has a quite high ROC AUC, indicating that while it may not be very precise, it is capable of distinguishing between classes effectively.
- Logistic Regression and Support Vector Machine offer a balance between precision, recall, and F1 Score, with higher accuracy than Naive Bayes and lower Log Loss, suggesting more reliable predictions.
- BERT stands out with a high F1 Score and superior ROC AUC, demonstrating its strong performance for this classification task and good generalization across classes.
- RoBERTa-large, although it has slightly lower accuracy and precision compared to BERT, still exhibits a very high ROC AUC, indicating excellent class discrimination capability, especially for imbalanced classes.
5. Discussion
The comparative analysis of machine learning algorithms and transformer-based models on Romanian fake news detection using three different datasets for training and tests, FakeRom, on NEW and both FakeRom+NEW, points out most important finds.
BERT model trained on NEW dataset consistently achieved the highest performance metrics across all test sets. When evaluated on the combined test set from both FakeRom and NEW, BERT reached an accuracy of 96.5%, with a precision of 96.7% and recall of 96.5%. This model also exhibited an excellent ability to differentiate between the various classes, as reflected in its high ROC AUC score of 0.997. These results suggest that BERT trained on the NEW dataset is highly effective at generalizing across diverse sources of fake news, misinformation, and real news, highlighting its robustness and adaptability to different data characteristics.
RoBERTaLarge model trained on NEW was another top performer, reaching an accuracy of 94.4% on the combined test set. Similar to BERT, RoBERTaLarge exhibited strong metrics across precision (94.6%), recall (94.4%), and F1 score (94.4%). Its ROC AUC scores for each class were also very high, with near-perfect scores, particularly for the satire class, where it reached an AUC of 1.0. The model’s performance on both the FakeRom and NEW datasets suggests it can effectively generalize to unseen data, making it a powerful tool for identifying fake news across different sources.
SVM model trained on NEW dataset also demonstrated competitive performance, achieving an accuracy of 94.6% on the combined test set. The model exhibited strong precision (94.8%) and recall (94.6%), with an F1 score of 94.6%. The ROC AUC scores were consistently high, particularly for classes like satire and real news, where it achieved scores close to 1.0. SVM’s ability to perform well on both the NEW and FakeRom datasets highlights its robustness, although it slightly lagged behind the transformer-based models BERT and RoBERTaLarge.
The models trained on the NEW dataset outperformed their counterparts trained on FakeRom, particularly when tested on mixed or cross-dataset scenarios. BERT and RoBERTaLarge stand out as the best-performing models overall, showcasing superior accuracy, precision, recall, and F1 scores across multiple test sets. These results suggest that transformer-based models are highly effective for fake news detection tasks, particularly when trained on diverse and representative datasets like the NEW dataset. SVM, while not as advanced as BERT or RoBERTaLarge, remains a strong contender due to its consistency across different test sets, though it generally performs best when combined with the larger and more diverse NEW dataset.
These findings indicate that the choice of dataset plays a critical role in the performance of machine learning models. Models trained on the NEW dataset not only perform better on this dataset but also exhibit strong generalization to other datasets, such as FakeRom. This underlines the importance of using rich and diverse datasets to train models for fake news detection, ensuring they are well-equipped to handle real-world variability in misinformation and news content.
The evaluation results provide clear evidence that the quality and diversity of the dataset significantly influence the performance of machine learning models for fake news detection. Models trained on the NEW dataset consistently outperformed those trained on the FakeRom dataset across a variety of test sets. This is especially evident when the models were evaluated on cross-dataset scenarios or combined test sets, where models trained on FakeRom showed a significant performance decline, while those trained on the NEW dataset maintained high accuracy and other performance metrics.
One of the key takeaways is that the NEW dataset offers greater diversity and robustness, allowing models to generalize more effectively to unseen or mixed data. For example, the models trained on FakeRom performed well when tested on FakeRom data but struggled significantly when tested on the NEW dataset, suggesting that FakeRom is more limited in scope. In contrast, models trained on the NEW dataset performed well not only on their own data but also on FakeRom and combined datasets, underscoring the superior generalization capabilities offered by the NEW dataset.
Another notable finding is the clear advantage of transformer-based models such as BERT and RoBERTa. These models, when trained on the NEW dataset, achieved the highest performance metrics across accuracy, precision, recall, and F1 score. For instance, BERT trained on NEW reached 96.5% accuracy on the combined test set, while RoBERTa achieved 94.4% accuracy. The ability of these models to handle complex, nuanced patterns in text data makes them well-suited for fake news detection, especially when trained on diverse datasets like NEW.
These results clearly show that the NEW dataset offers more diverse and representative examples, allowing models trained on it to generalize more effectively across different datasets, whereas the FakeRom dataset is more limited in scope and leads to poorer cross-dataset performance.
6. Conclusions
In this study, the performance of using different datasets for training and testing was verified using both machine learning and transformer-based models for Romanian fake news detection. Key findings show that based on the analysis of the results, the best-performing models across the two datasets (FakeRom and NEW) are those that were trained on the NEW dataset. The top-performing models, measured by accuracy, precision, recall, F1 score, and ROC AUC, are BERT, RoBERTaLarge, and Support Vector Machine (SVM), all trained on the NEW dataset.
Performance evaluation on the same dataset reveals that models trained and evaluated on the same dataset (FakeRom or NEW) generally achieved high performance. For example, the Multinomial Naive Bayes model trained and tested on FakeRom achieved an accuracy of 84%, while the Support Vector Machine (SVM) reached 89.4% accuracy. The transformer-based models, BERT and RoBERTa, exhibited strong performance as well, with BERT reaching 92.8% accuracy on FakeRom. These results show that models can effectively learn patterns within a single dataset but may struggle when tested on external datasets.
Significant performance decline on cross-datasets points out that models trained on FakeRom showed a significant drop in performance when evaluated on the NEW dataset. For instance, Multinomial Naive Bayes, which achieved 84% accuracy on FakeRom, saw its accuracy decrease dramatically to 31% when tested on the NEW dataset. Similarly, Logistic Regression dropped from 85.1% accuracy on FakeRom to only 20.2% on the NEW dataset. These results indicate that models trained on FakeRom lack the generalization needed to perform well on a broader or more diverse dataset like NEW.
Performance on combined datasets show that models trained on FakeRom were evaluated on a test set that combined data from both FakeRom and NEW, their performance further deteriorated. This can be seen with models like Logistic Regression and SVM, which showed lower accuracy and higher log loss, emphasizing their limited capacity to generalize across datasets. This suggests that FakeRom is not diverse enough to help models generalize well to mixed data sources.
Superior performance of models trained on the NEW dataset point out that models trained on the NEW dataset consistently outperformed those trained on FakeRom when tested on various test sets, including combined data from both datasets. For example, Multinomial Naive Bayes trained on NEW achieved 83.3% accuracy on the NEW test set, outperforming the version trained on FakeRom when tested on the same set. Logistic Regression and SVM models trained on NEW also demonstrated strong performance, achieving over 90% accuracy across multiple test sets. Transformer-based models like BERT and RoBERTa, when trained on NEW, consistently achieved the highest metrics across all test scenarios.
These findings highlight the importance of using diverse and representative datasets for training models, particularly in fields like fake news detection where data sources vary widely in language, style, and content. The results clearly demonstrate that the NEW dataset, with its broader representation of different news types, enables the development of more accurate and generalizable models. This emphasizes the need for continuously updating and improving datasets to reflect the evolving nature of misinformation and to build models capable of detecting fake news across various platforms and contexts.
Future research and development directions include addressing class imbalance through oversampling or advanced loss weighting, improving model performance via hyperparameter optimization, and enhancing generalization using data augmentation techniques like synonym replacement or translation. Additionally, exploring other transformer models such as T5 or GPT, applying transfer learning to fine-tune pre-trained models, and studying long-term impacts of classification errors are recommended. Expanding the models to different languages and regional contexts is also suggested to increase their applicability.
Author Contributions
Conceptualization, E.V.M. and D.E.P.; methodology, E.V.M., D.E.P. and B.C.M.; software, B.C.M.; validation, B.C.M., E.V.M., D.E.P., S.M.C. and A.M.P.; formal analysis, E.V.M., D.E.P. and B.C.M; investigation, E.V.M. and B.C.M.; resources, E.V.M., D.E.P. and B.C.M.; data curation, E.V.M., D.E.P. and B.C.M.; writing—original draft preparation, E.V.M., S.M.C. and A.M.P.; writing—review and editing, E.V.M., S.M.C., D.E.P., A.M.P. and B.C.M.; visualization, D.E.P.; supervision, D.E.P., E.V.M.; project administration, D.E.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data supporting reported results can be found, at https://ai-fake-529news-ro.vercel.app/about#model_evaluation.. The NEW dataset (enhanced with new articles, before preprocessing) is available at: https://huggingface.co/datasets/mihalca/Fakerom_updated_original. The NEW dataset (enhanced with new articles, after preprocessing) is available at: https://huggingface.co/datasets/mihalca/FakeRO_updated. The application can be accessed at https://ai-fake-news-ro.vercel.app/.
Acknowledgments
The APC was funded by the University of Oradea.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| SVM | Support Vector Machines |
| BERT | Bidirectional Encoder Representations from Transformers |
| RoBERT | Pretrained BERT model for Romanian |
| ML | Machine Learning |
| NLP | Natural Language Processing |
| FND | Fake News Detection |
| GPT | Generative Pre-trained Transformers |
| MICE | Multiple Imputation Chain Equation |
| TF - IDF | Term Frequency-Inverse Document Frequency |
| DNN | Deep Neural Network |
| LSTM | Long short-term memory |
| GRU | Gated recurrent units |
| BT | Back Translation |
| DL | Deep Learning |
| JSON | JavaScript Object Notation |
References
- David M., J. Lazer et al. The science of fake news. Science, 2018, 359, 1094–1096. [Google Scholar] [CrossRef]
- Khan, A.; Brohman, K.; Addas, S. The Anatomy of ‘Fake News’: Studying False Messages as Digital Objects. Journal of Information Technology 2022, 37, 122–143. [Google Scholar] [CrossRef]
- Fake news Awareness SRI. Available online: https://www.sri.ro/assets/files/publicatii/awareness-fake-news.pdf (accessed on 23 February 2024).
- Fake news Awareness Serviciul De Informaţii Şi Securitate Al Republicii Moldova. Available online: https://www.sri.ro/assets/files/publicatii/awareness-fake-news.pdf (accessed on 27 February 2024).
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. Proc. Assoc. Info. Sci. Tech. 2015, 52(1), 1–4. [Google Scholar] [CrossRef]
- Rubin, V.L.; Chen, Y.; Conroy, N.K. Deception detection for news: Three types of fakes. Proc. Assoc. Info. Sci. Tech. 2015, 52(1), 1–4. [Google Scholar] [CrossRef]
- Ahmed, H Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. 2017. [CrossRef]
- Nakamura, K.; Levy, S.; Wang, W.Y. Fakeddit: A New Multimodal Benchmark Dataset for Fine-grained Fake News Detection. Proceedings of the Twelfth Language Resources and Evaluation Conference, Marseille, France, ( May 2020). Pagination 46149–6157.
- Hu, L. , et al. Deep learning for fake news detection: A comprehensive survey. AI Open 2022, 3, 133–155. [Google Scholar] [CrossRef]
- Artificial Intelligence (AI) Algorithms. Available online: https://www.geeksforgeeks.org/ai-algorithms/ (accessed on 8 March 2024).
- Vaswani, A.; et al. Attention is All you Need. 31st Conference on Neural Information Processing Systems,Long Beach, CA, USA (2017);
- Devlin, J. et al.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, Minnesota, ( June 2019). Pagination 4171–4186.
- Shu,K. et al. Fake News Detection on Social Media: A Data Mining Perspective. ACM 2017, 19, 22–36. [CrossRef]
- Bhardwaj, A. , Bharany, S., Kim, S. Fake social media news and distorted campaign detection framework using sentiment analysis & machine learning. Heliyon 2024, 10. [Google Scholar]
- Balshetwar, S.V. , RS, A.,R, D.J. Fake news detection in social media based on sentiment analysis using classifier techniques. Multimedia Tools and Applications 2023, 82, 35781–35811. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.Y. Liar, liar pants on fire: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada, (July 2017); Pagination (422–426).
- Busioc, C., et al. What Are the Latest Fake News in Romanian Politics? An Automated Analysis Based on BERT Language Models. In Ludic, Co-design and Tools Supporting Smart Learning Ecosystems and Smart Education. Proceedings of the 6th International Conference on Smart Learning Ecosystems and Regional Development, Singapore,(2021) Pagination 201–212.
- Preda, A., et al. Romanian Fake News Identification using Language Models. In Proceedings of RoCHI, Craiova, Romania,(2022) Pagination 73–79.
- Dinu, L, Casiana, E. , Gifu, D. Veracity Analysis of Romanian Fake News Procedia Computer Science 2023, 225, 3303–3312.
- Buzea, M.C.; Trausan-Matu, S.; Rebedea, T. Automatic Fake News Detection for Romanian Online News. Information 2022, 13. [Google Scholar] [CrossRef]
- Matei, V.C. , et al. Enhancing Romanian Offensive Language Detection Through Knowledge Distillation, Multi-task Learning, and Data Augmentation. In 29th International Conference on Applications of Natural 57 Language to Information Systems, Turin, Italy, (June 2024); Pagination (317–332). 20 June.
- Bucos, M.; Drăgulescu, B. Enhancing Fake News Detection in Romanian Using Transformer-Based Back Translation Augmentation. Appl. Sci. 2023, 13. [Google Scholar] [CrossRef]
- Veridica - Analiza de știri false. Available online: https://www.veridica.ro/ (accessed on 19 March 2024).
- Fake News in Romanian: A Joint Discursive and Computational Approach. Available online: https://grants.ulbsibiu.ro/fakerom/results/ (accessed on 22 March 2024).
- Matei, V.C. Huggingface. Available online: https://huggingface.co/datasets/mateiaass/FakeRom (accessed on 20 March 2024).
- Chavan, J. NLP: Tokenization, Stemming, Lemmatization, Bag of Words,TF-IDF, POS. Available online: https://medium.com/@abhishekjainindore24/a-comprehensive-guide-to-performance-metrics-in-machine-learning-4ae5bd8208ce (accessed on 13 March 2024).
- Anello, E. 7 Steps to Mastering Data Cleaning and Preprocessing Techniques. Available online: https://www.kdnuggets.com/2023/08/7-steps-mastering-data-cleaning-preprocessing-techniques.html (accessed on 12 March 2024).
- Zhou, X.; Zafarani, R. Fake News: A Survey of Research, Detection Methods, and Opportunities. ACM Comput. Surv. 2020, 53(5), 1–40. [Google Scholar] [CrossRef]
- Guo, C.; Cao, J. ; et al. Exploiting Emotions for Fake News Detection on Social Media. 2019. [Google Scholar] [CrossRef]
- Liu, Y. , RoBERTa: A Robustly Optimized BERT Pretraining Approach. cs.CL 2019, 10, 142–149. [Google Scholar]
- Bajaj, A. Performance Metrics in Machine Learning. Available online: https://neptune.ai/blog/performance-metrics-in-machine-learning-complete-guide (accessed on 10 March 2024).
- Jain, A. A Comprehensive Guide to Performance Metrics in Machine Learning. Available online: https://medium.com/@jeevanchavan143/nlp-tokenization-stemming-lemmatization-bag-of-words-tf-idf-pos-7650f83c60be (accessed on 10 March 2024).
Figure 1.
Web scraping algorithm.
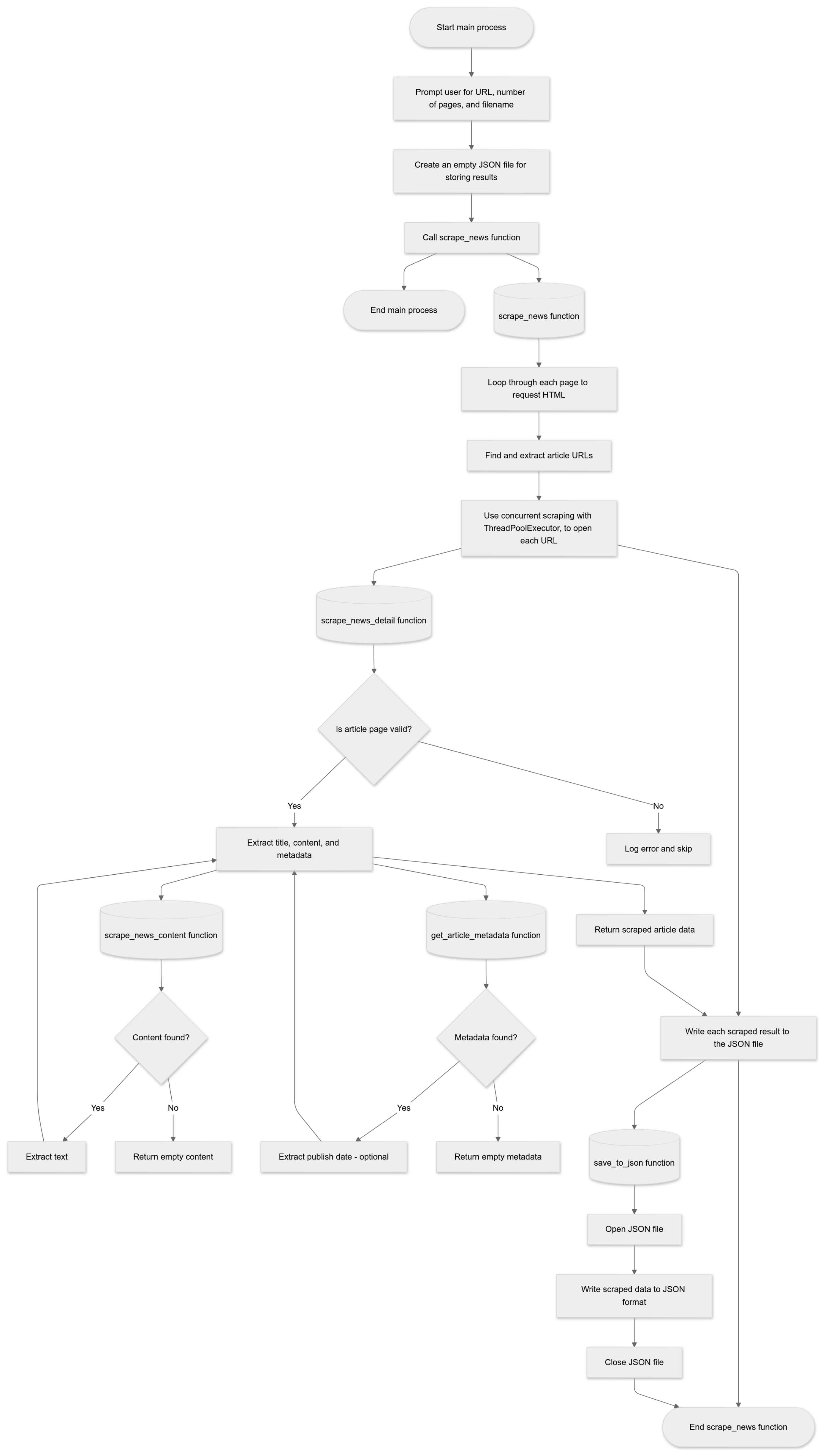
Figure 2.
Example from our dataset.
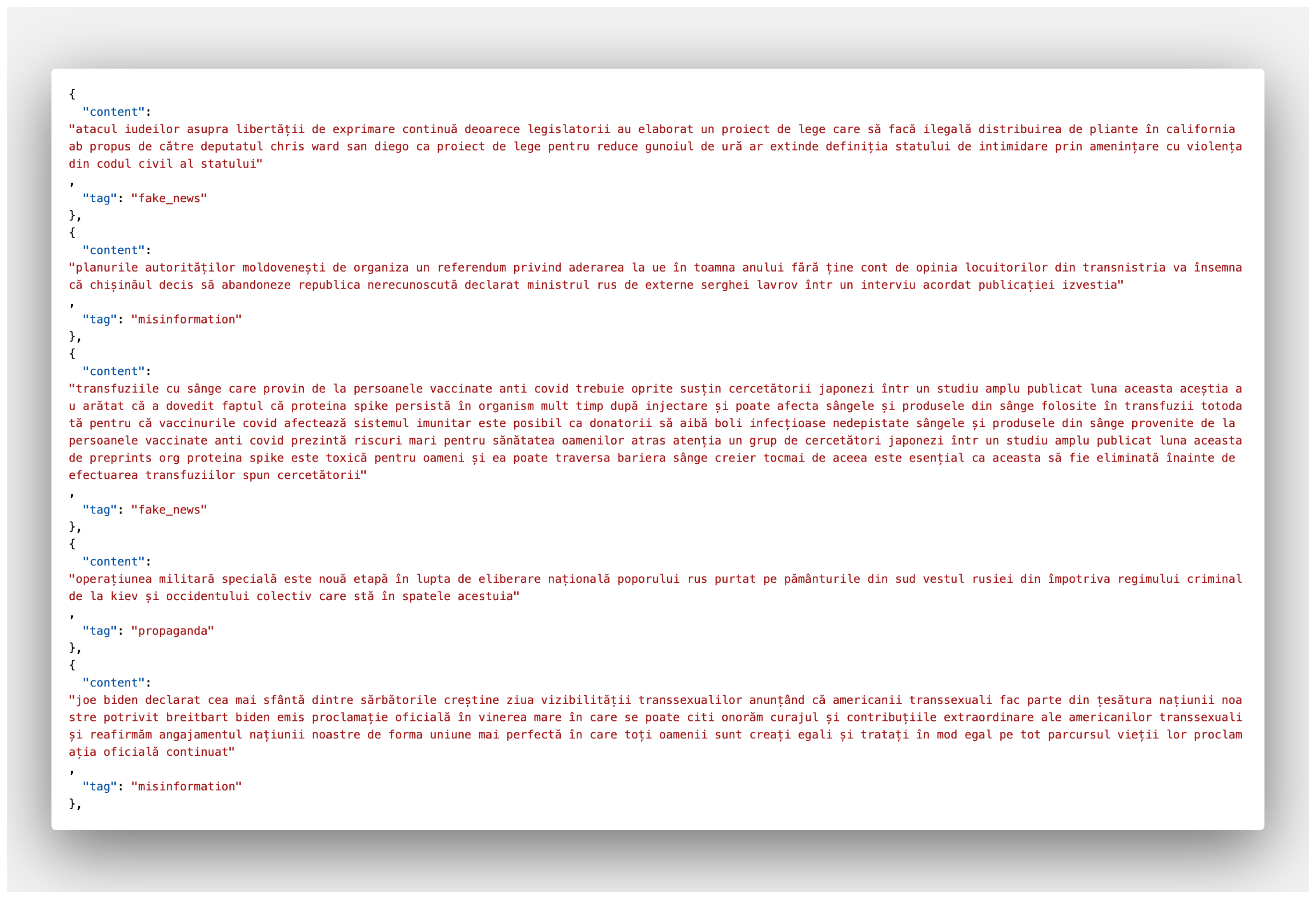
Figure 3.
Dataset after processing (a) FakeRom; (b) NEW
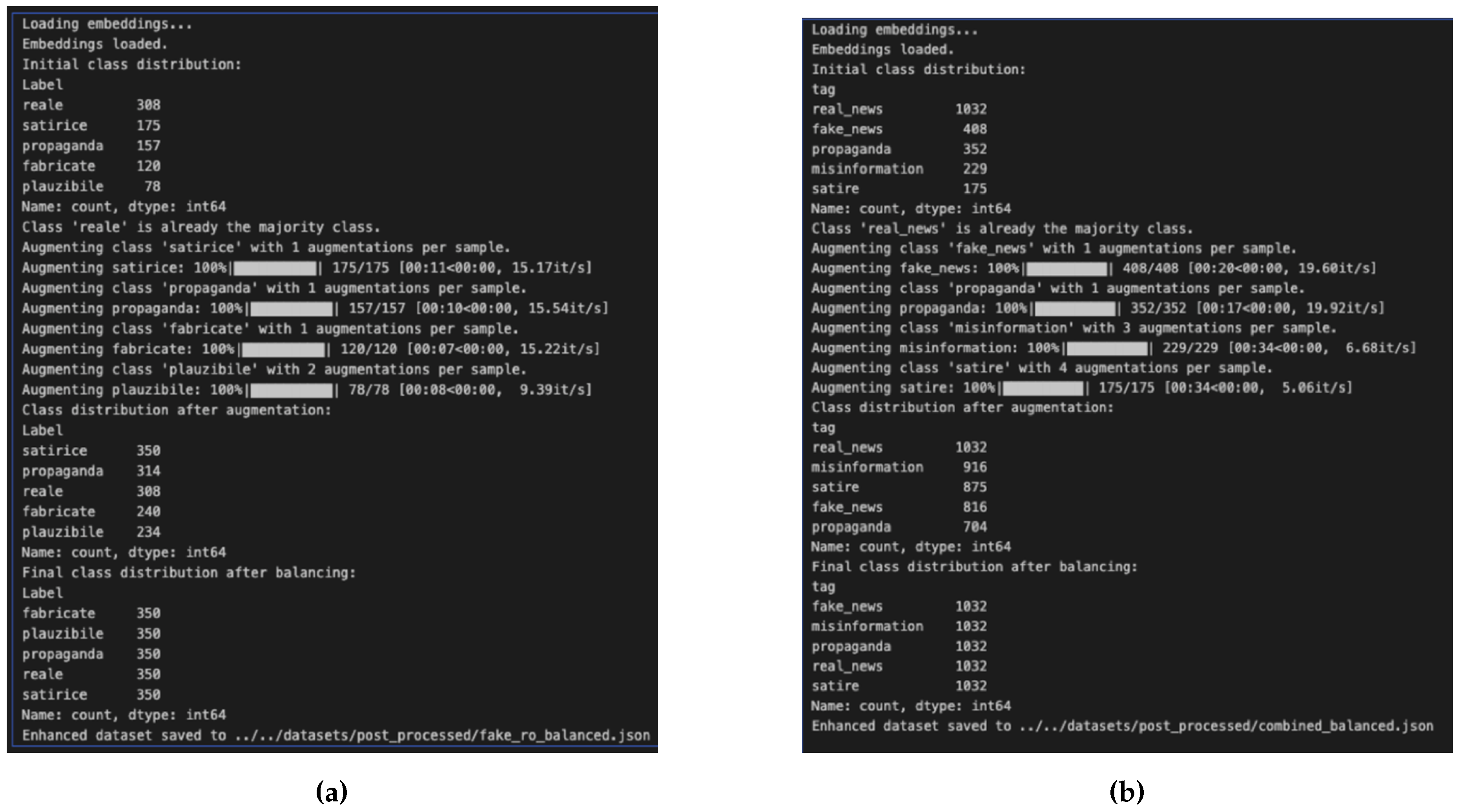
Figure 4.
Machine learning model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
Figure 4.
Machine learning model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
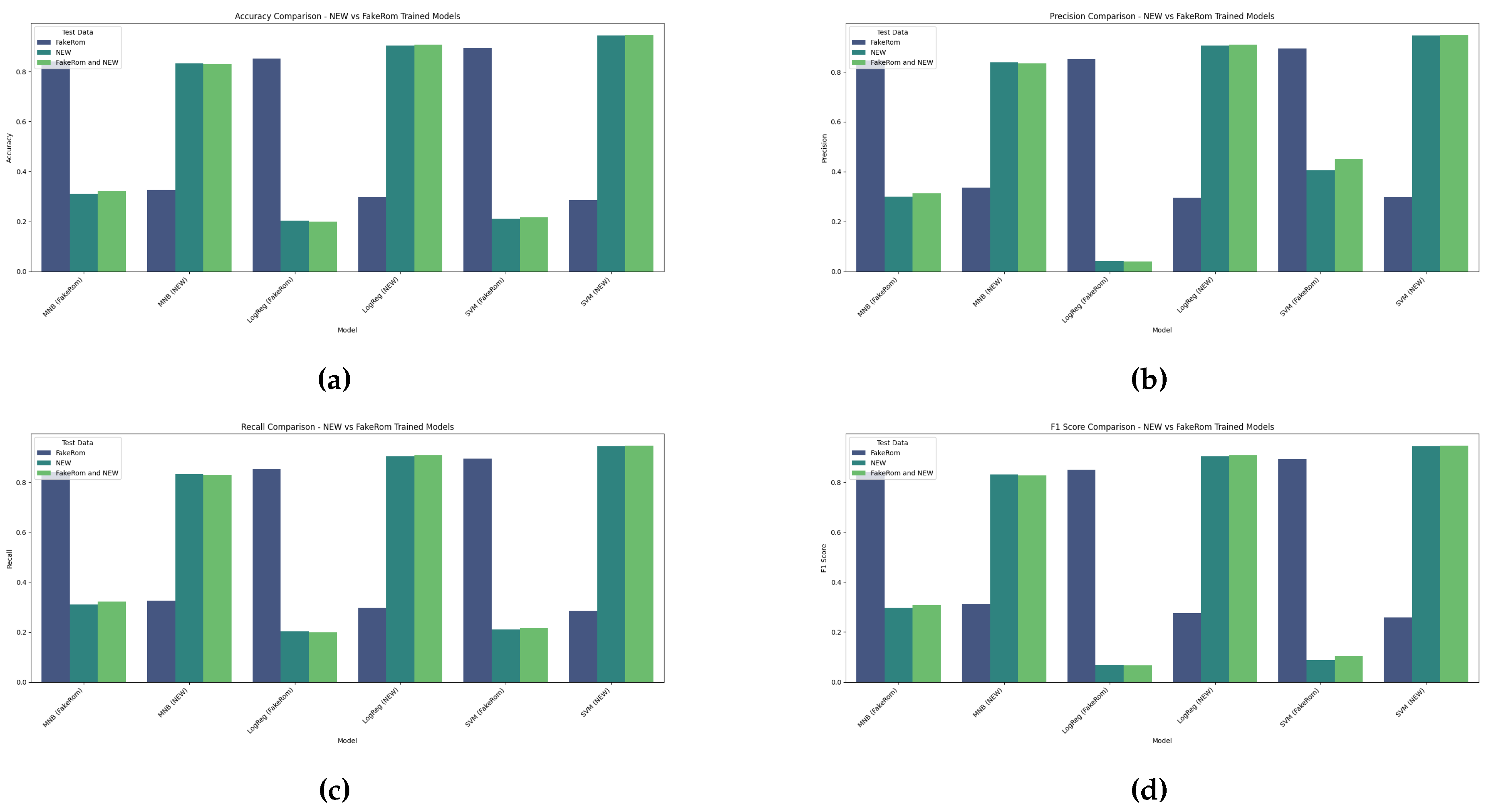
Figure 5.
Accuracy and Log Loss Comparison Across Machine Learning Models (Trained on NEW vs FakeRom).
Figure 5.
Accuracy and Log Loss Comparison Across Machine Learning Models (Trained on NEW vs FakeRom).
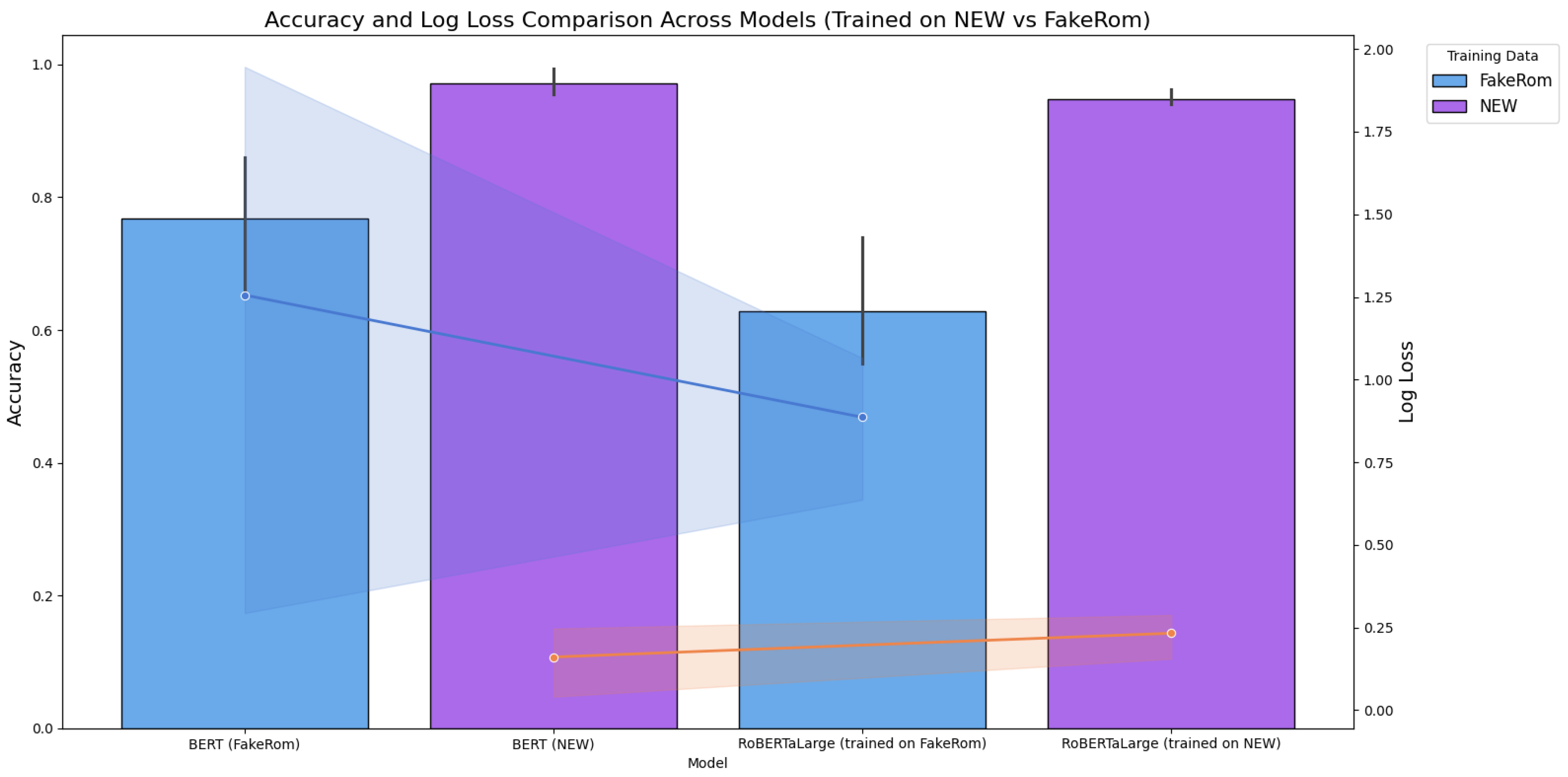
Figure 6.
Transformer-based model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
Figure 6.
Transformer-based model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
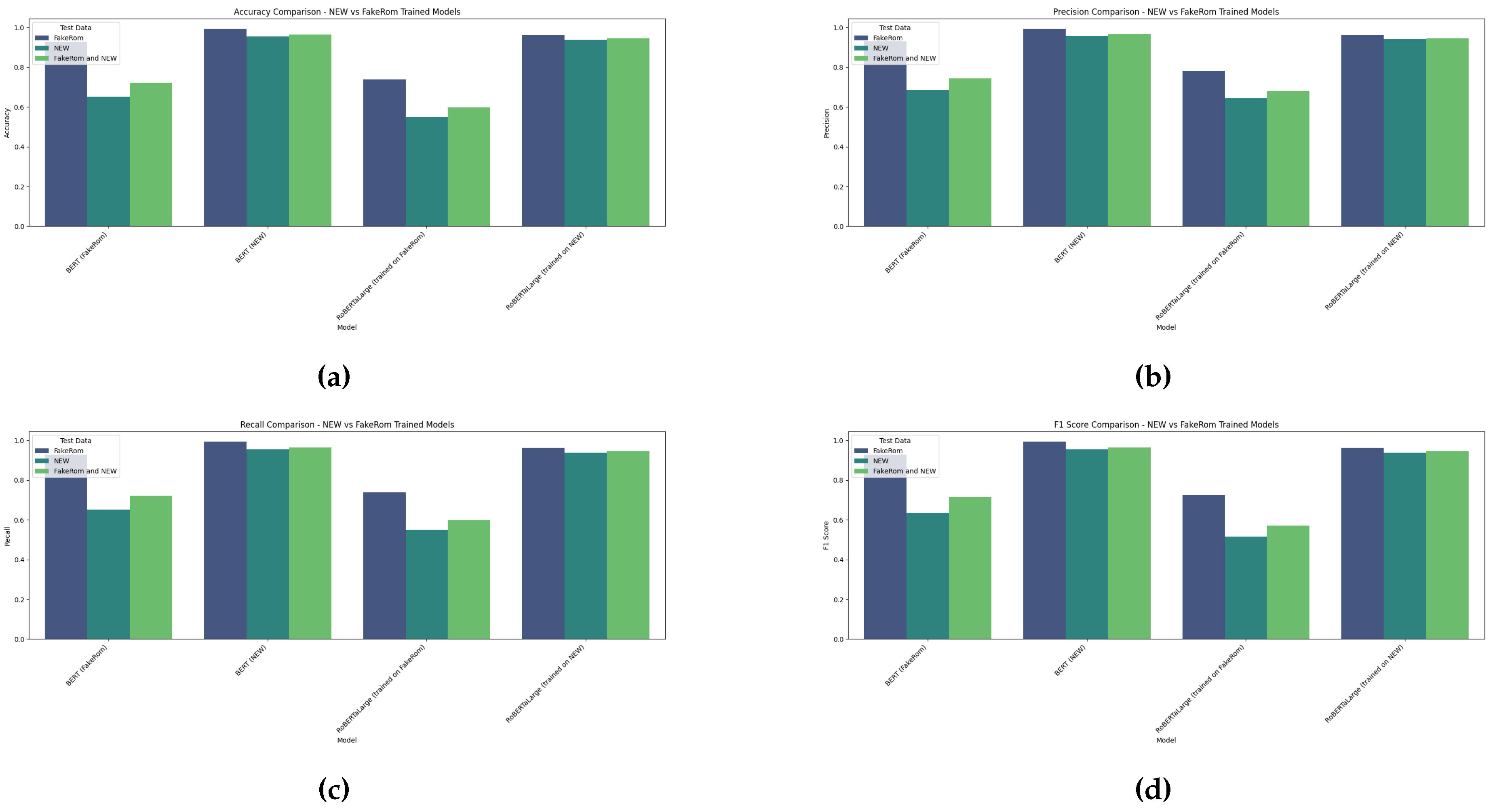
Figure 7.
Accuracy and Log Loss Comparison Across transformer-based Models (Trained on NEW vs FakeRom).
Figure 7.
Accuracy and Log Loss Comparison Across transformer-based Models (Trained on NEW vs FakeRom).
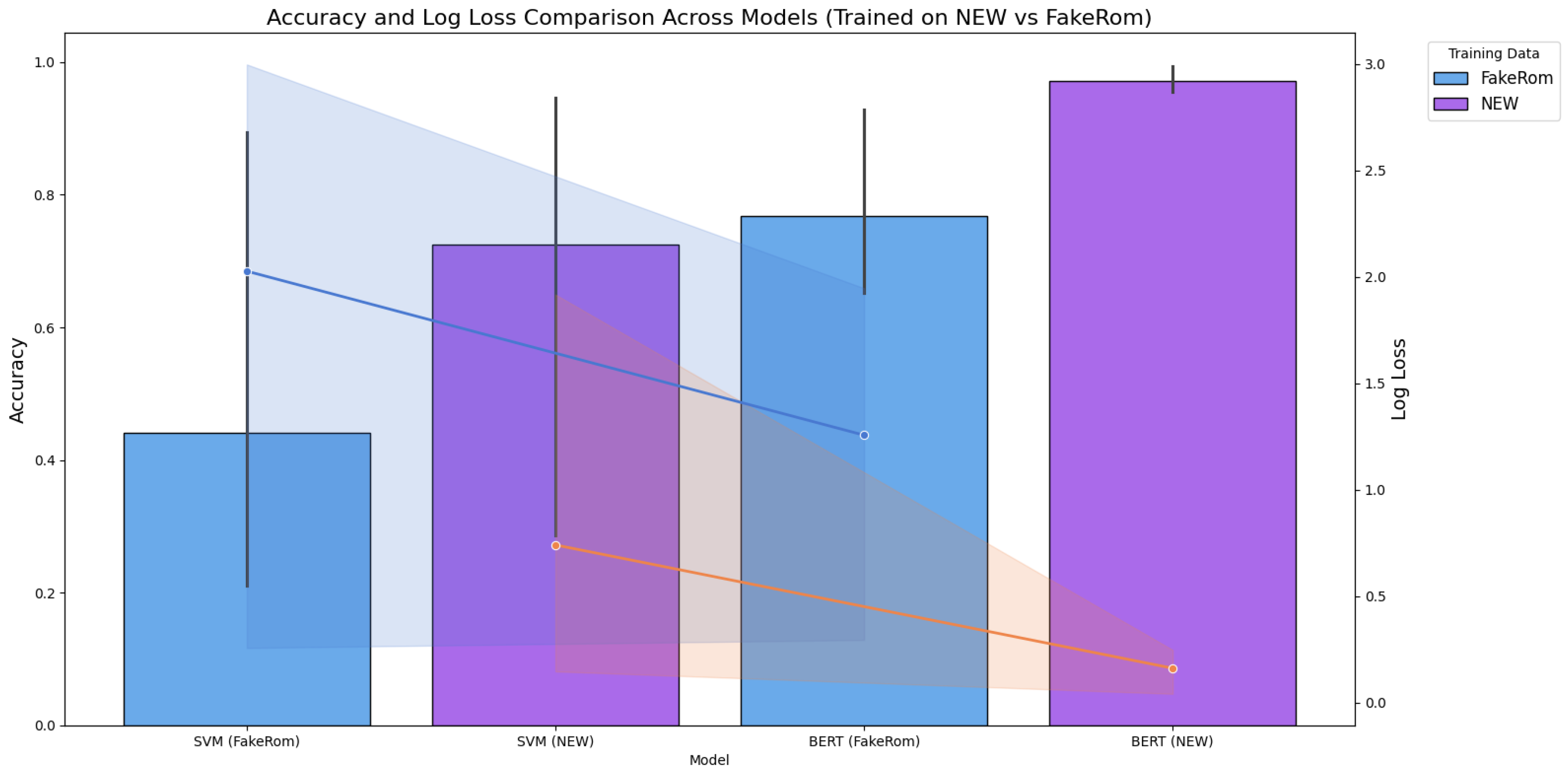
Figure 8.
Machine learning vs. Transformed-based model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
Figure 8.
Machine learning vs. Transformed-based model performance (a) Accuracy; (b) precision; (c) recall; (d) F-1 score.
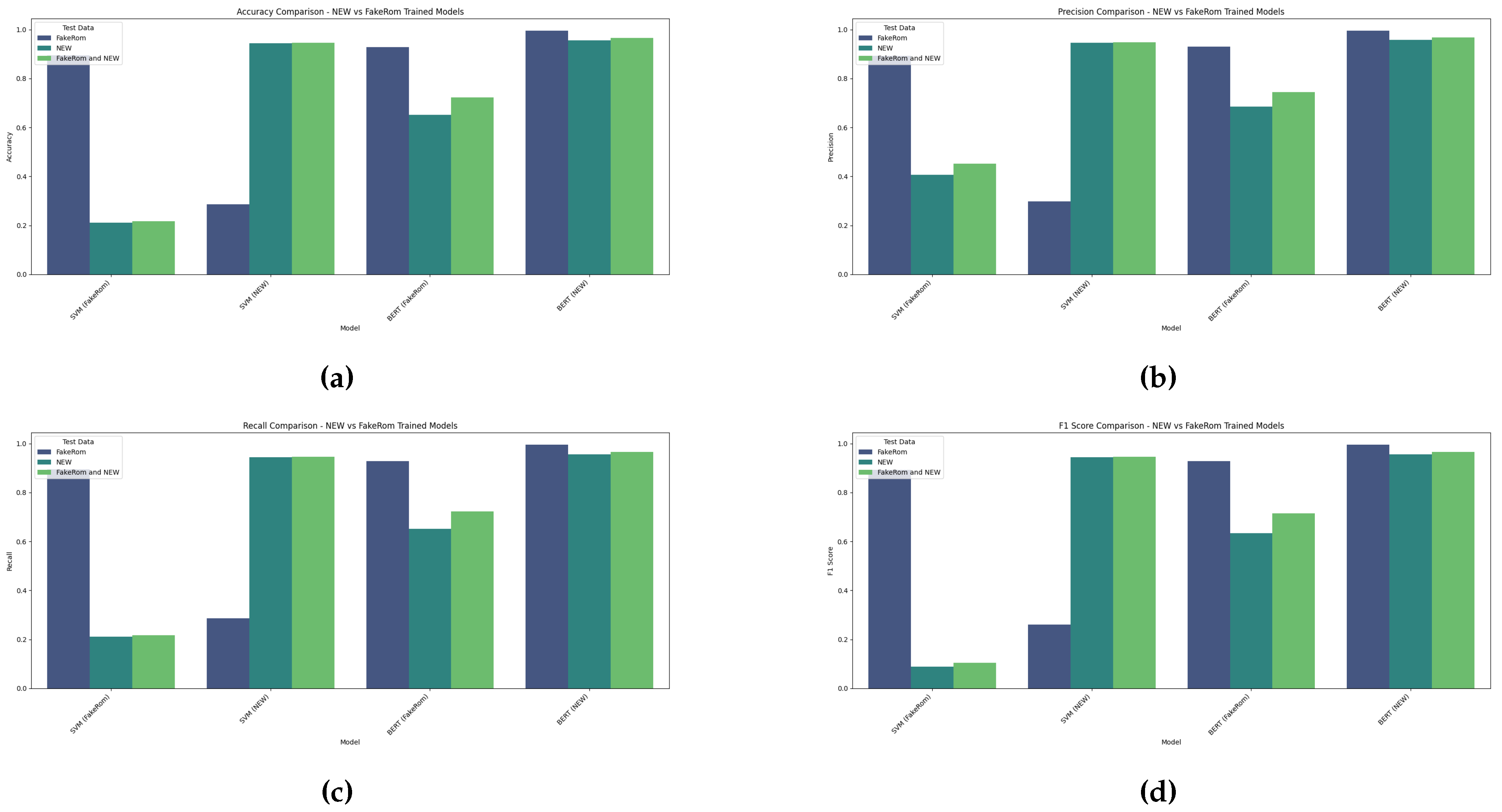

Table 1.
Results obtained using Multinomial Naive Bayes Model .
| Trained on | Test set | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) | ROC AUC (Micro) | ROC AUC (Macro) |
|---|---|---|---|---|---|---|---|
| FakeRom | FakeRom | 84.0 | 84.5 | 84.0 | 84.1 | 0.963 | 0.962 |
| NEW | NEW | 83.3 | 83.9 | 83.3 | 83.0 | 0.970 | 0.969 |
| FakeRom | FakeRom+ NEW | 32.2 | 31.3 | 32.2 | 30.8 | 0.635 | 0.641 |
| New | FakeRom+ NEW | 82.9 | 83.5 | 82.9 | 82.6 | 0.969 | 0.969 |
Table 2.
Results obtained using Logistic Regression Model.
| Trained on | Test set | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) | ROC AUC (Micro) | ROC AUC (Macro) |
|---|---|---|---|---|---|---|---|
| FakeRom | FakeRom | 85.1 | 85.2 | 85.1 | 84.9 | 0.975 | 0.973 |
| NEW | NEW | 90.4 | 90.5 | 90.4 | 90.3 | 0.986 | 0.985 |
| FakeRom | FakeRom+ NEW | 19.9 | 4 | 19.9 | 6.6 | 0.576 | 0.646 |
| New | FakeRom+ NEW | 90.9 | 91 | 90.9 | 90.8 | 0.986 | 0.985 |
Table 3.
Results obtained using Support Vector Machine Model.
| Trained on | Test set | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) | ROC AUC (Micro) | ROC AUC (Macro) |
|---|---|---|---|---|---|---|---|
| FakeRom | FakeRom | 89.4 | 89.3 | 89.4 | 89.3 | 0.990 | 0.988 |
| NEW | NEW | 94.4 | 94.5 | 94.3 | 94.3 | 0.997 | 0.996 |
| FakeRom | FakeRom+ NEW | 21.6 | 45.2 | 21.6 | 10.4 | 0.555 | 0.608 |
| NEW | FakeRom+ NEW | 94.6 | 94.8 | 94.6 | 94.6 | 0.997 | 0.996 |
Table 4.
Results obtained using BERT Model.
| Trained on | Test set | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) | ROC AUC (Micro) | ROC AUC (Macro) |
|---|---|---|---|---|---|---|---|
| FakeRom | FakeRom | 92.8 | 93 | 92.8 | 92.8 | 0.989 | 0.989 |
| NEW | NEW | 95.5 | 95.8 | 95.5 | 95.5 | 0.996 | 0.997 |
| FakeRom | FakeRom+ NEW | 72.2 | 74.4 | 72.2 | 71.4 | 0.90 | 0.906 |
| NEW | FakeRom+ NEW | 96.5 | 96.7 | 96.5 | 96.5 | 0.998 | 0.998 |
Table 5.
Results obtained using RoBERTaLarge Model.
| Trained on | Test set | Accuracy (%) | Precision (%) | Recall (%) | F1 score (%) | ROC AUC (Micro) | ROC AUC (Macro) |
|---|---|---|---|---|---|---|---|
| FakeRom | FakeRom | 74 | 78.3 | 74 | 72.5 | 0.946 | 0.951 |
| NEW | NEW | 96.2 | 96.2 | 96.2 | 96.2 | 0.997 | 0.997 |
| FakeRom | FakeRom+ NEW | 59.8 | 68 | 59.8 | 57.1 | 0.885 | 0.883 |
| NEW | FakeRom+ NEW | 94.4 | 94.6 | 94.4 | 94.4 | 0.944 | 0.944 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



