Submitted:
06 December 2024
Posted:
09 December 2024
You are already at the latest version
Abstract
The United States housing market has historically exhibited regional imbalances in housing supply and demand, which have contributed to reduced housing affordability and market volatility. The application of big data technology enables the utilisation of data to enhance comprehension of these imbalances, thereby informing the formulation of policy. We put forth a model for analyzing the housing supply and demand based on big data, which employs a comprehensive approach to examine both the demand and supply sides. With regard to the demand side, the model incorporates a multitude of data sources to ascertain and delineate the pivotal elements influencing housing demand. These include population growth rate, household income level, employment opportunity distribution, migration and flow trends, and cost of living. By constructing cubes, the model is capable of capturing the characteristics of dynamic demand changes in different regions. With regard to the supply side, the model assesses land use, building materials and labor costs, the timeliness of building permitting and approval processes, and the impact of regional policies and regulations. By means of a quantitative analysis of the aforementioned factors, the model is able to identify housing supply bottlenecks in different regions. The model's efficacy in identifying significant imbalances between supply and demand in the United States housing market was validated through experimental analysis of historical data.
Keywords:
1. Introduction
2. Related Work
3. Methodologies
3.1. Supply and Demand Models
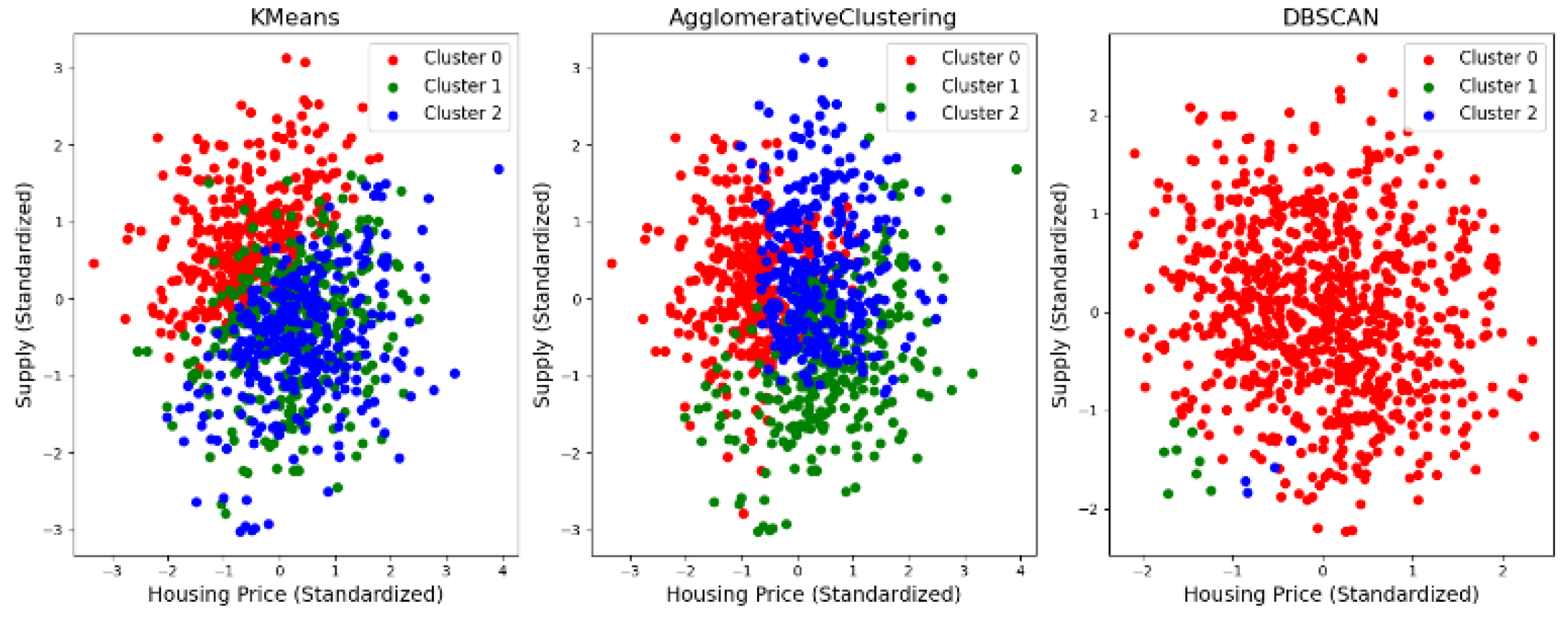
3.2. Cluster Analysis
4. Experiments
4.1. Experimental Setup
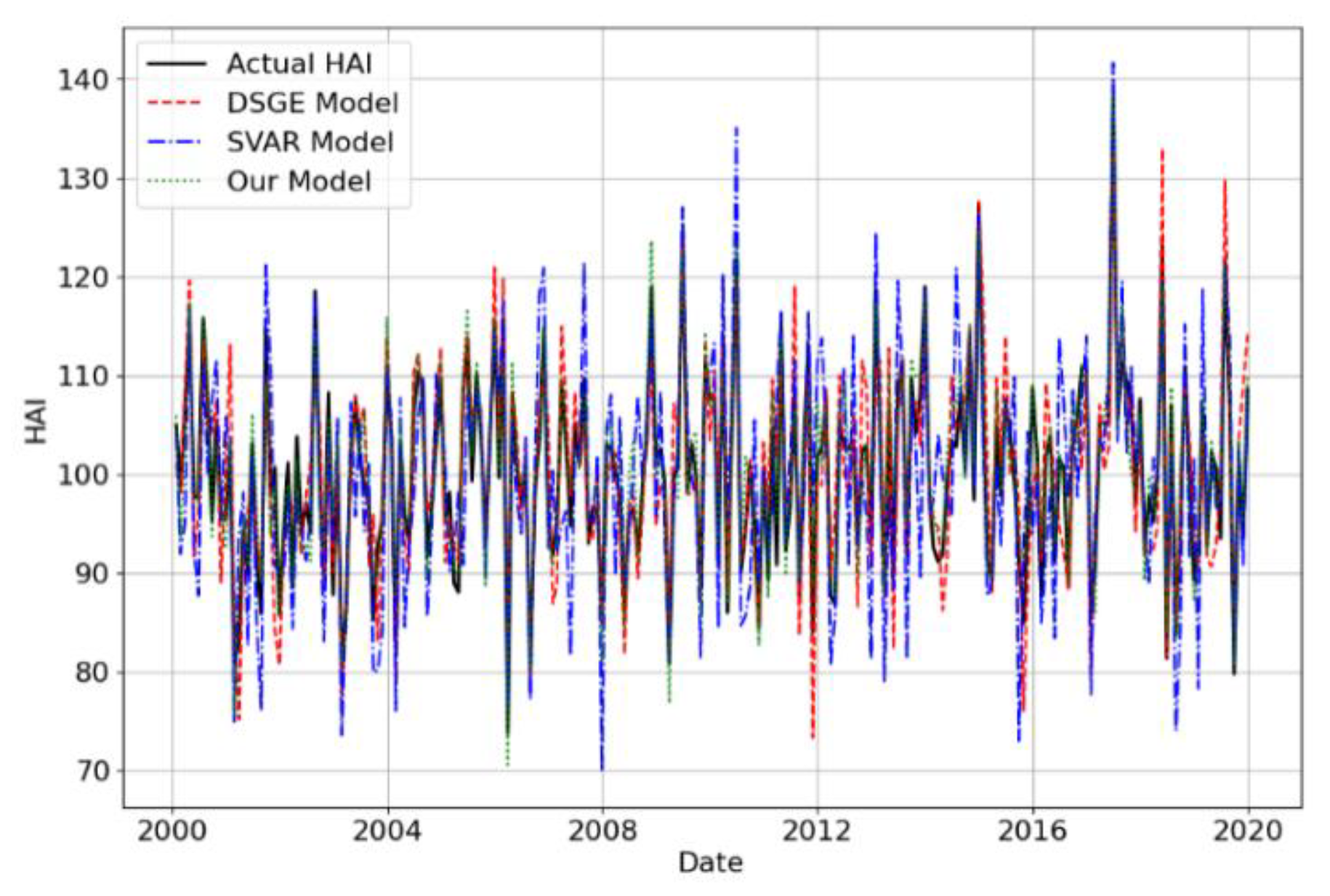
4.2. Experimental Analysis
5. Conclusions
References
- Xu, Zihan, et al. "Spatial correlation between the changes of ecosystem service supply and demand: An ecological zoning approach." Landscape and Urban Planning 217 (2022): 104258. [CrossRef]
- Adabre, Michael Atafo. "Developing a model for bridging the gap between sustainable housing and affordable housing (low-cost housing) in the Ghanaian housing market." (2021).
- Giusino, Davide, et al. "“We all held our own”: job demands and resources at individual, leader, group, and organizational levels during COVID-19 outbreak in health care. A multi-source qualitative study." Workplace health & safety 70.1 (2022): 6-16. [CrossRef]
- Humphreys, Helen, et al. "Long COVID and the role of physical activity: a qualitative study." BMJ open 11.3 (2021): e047632. [CrossRef]
- Li, Han, et al. "Energy flexibility of residential buildings: A systematic review of characterization and quantification methods and applications." Advances in Applied Energy 3 (2021): 100054. [CrossRef]
- Shirmohammadi, Melika, Wee Chan Au, and Mina Beigi. "Remote work and work-life balance: Lessons learned from the covid-19 pandemic and suggestions for HRD practitioners." Human Resource Development International 25.2 (2022): 163-181. [CrossRef]
- Hsieh, Chang-Tai, and Enrico Moretti. "Housing constraints and spatial misallocation." American economic journal: macroeconomics 11.2 (2019): 1-39. [CrossRef]
- Stacy, Christina, et al. "Land-use reforms and housing costs: Does allowing for increased density lead to greater affordability?." Urban Studies 60.14 (2023): 2919-2940. [CrossRef]
- Alig, Ralph. "Urbanization in the US: Land use trends, impacts on forest area, projections, and policy considerations." Journal of Resources, Energy and Development 7.2 (2010): 35-60. [CrossRef]
- Reifschneider, Dave, William Wascher, and David Wilcox. "Aggregate supply in the United States: recent developments and implications for the conduct of monetary policy." IMF Economic Review 63.1 (2015): 71-109. [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).



