
Submitted:
17 December 2024
Posted:
18 December 2024
You are already at the latest version
Abstract
The ability of a molecule to self-replicate is the driving force behind the evolution of cellular life, and in the transition from RNA to DNA as genetic material. Thus the physicochemical properties of genome replication, such as the requirement for a terminal hydroxyl group for de novo DNA synthesis, are conserved in all three domains of life: Eukaryotes, Bacteria, and Archaea. Canonical DNA replication is initiated from specific chromosomal sequences termed origins. Early bacterial models of DNA replication proposed origins as regulatory points for spatiotemporal control, with replication factors acting on a single origin on the chromosome. In Eukaryotes and Archaea, however, replication initiation usually involves multiple origins, with complex spatio-temporal regulation in the former. An alternative replication initiation mechanism, recombination-dependent replication, is observed in every domain (and viruses); DNA synthesis is initiated instead from the 3’ end of a recombination intermediate. In the domain Archaea, species including Haloferax volcanii are not only capable of initiating DNA replication without origins, but grow faster without them. This raises questions on the necessity and nature of origins. Why have Archaea retained such alternative DNA replication initiation mechanisms? Might recombination-dependent replication be the ancestral mode of DNA synthesis that was used during evolution from the primordial RNA world? This review provides an historical overview of major advancements in the study of DNA replication, followed by a comparative analysis of replication initiation systems in the three domains of life. Our current knowledge of origin-dependent and recombination-dependent DNA replication in Archaea is summarised.
Keywords:
DNA replication
; replication initiation
; origins
; evolution
; recombination-dependent replication
; Archaea
1. Introduction: The Where, When, and How of DNA Replication
The core genetic information processing pathways and associated machinery – which promote cellular life and its propagation – are conserved across the three domains of life: Eukarya, Bacteria, and Archaea. It is now widely accepted that the genomic content of every organism is contained as DNA within the chromosomes of its cells. And before these cells can divide, the entire genome must undergo accurate and timely duplication in order to be distributed equally, and remaining identical to the original copy, into the daughter cells. Faithful duplication requires that the genome is replicated only once per cell division cycle. Errors in DNA replication present a threat to not only the viability of an individual cell (i.e., chromosome rearrangements and breakage leading to cell apoptosis), but also to the entire organism – where DNA lesions impede replication progression in the form of stalled or blocked replication forks. Eventually, accumulation of sustained DNA damage leads to genomic instability (i.e., global replication stress) – a hallmark of cancer aetiology [1]. Thus proper genome maintenance is dependent on the cooperation of several tightly linked processes termed the ‘Three Rs’: Replication, Recombination, and Repair.
Much scientific effort has been directed at understanding how the assembly of replication machinery is coordinated in space and time, and what safety mechanisms are activated should any errors arise. Given the prevalence of genomic instability in human disease, it is unsurprising that DNA replication constitutes one of the most active research areas in today’s field of molecular biology. Therefore, this section aims to provide a historical perspective on the period of uncertainty (i.e., the ‘Replication Problem’), and the subsequent burst of research (i.e., the ‘Molecular Revolution’), that has led us to the latest guiding paradigm – a theoretical framework – for DNA replication mechanisms.
1.1. The DNA Replication Problem
The breakthrough marking the beginning of molecular biology was when the ‘transforming principle’ from pneumococcal bacteria was discovered to be made of DNA, as opposed to of protein [2,3]. Avery and colleagues provided the initial evidence of the genetic material’s chemical composition. The implication of DNA playing a role in the transmission of genetic information – regarded as an axiom today – presented a theoretical challenge against the existing protein-centred hypothesis [4,5]. Despite the isolated substance being resistant to trypsin, chymotrypsin, and ribonuclease agents, Mirsky argued that there was a possibility of protein impurities in Avery’s samples, thus igniting a long debate on the true nature of the transforming principle. Because there was no counter evidence, the ability of DNA to transform all organisms was regarded as a working hypothesis for almost a decade.
The main obstacle to the acceptance of Avery’s work was that the DNA polymer was thought of as ‘too simple’: how can a single molecular entity consisting of a 4-base nucleotide sequence permit such diversity in genes across all kingdoms of life? As a response, Chargaff proposed that the amount of adenine was equal to thymine, and cytosine to guanine [6] – with the respective ratios differing across species – thereby overthrowing Levene’s tetranucleotide hypothesis [7]. Hershey-Chase’s experiments supporting DNA’s genetic role [8], were readily accepted despite the 25% of protein contamination [9], and provided an essential clue. The same year, genes previously seen as a hypothetical abstraction were ‘rediscovered’ as concrete, structural entities. Watson and Crick [10] had known that the key to understanding the biological processes of heredity was contained in the tertiary structure of DNA, so they applied the available crystallographic [11,12], and biochemical data [13] to assign a right-handed double helix model [14] to the enigmatic molecule. Assuming ‘form follows function’, they proposed that the complementary nucleotide bases between coiled helices were held by hydrogen bonds (eventually termed Watson-Crick interactions). Another important consequence of the model was that it implied a self-duplicating mechanism, whereby one strand of the helix acts as a template to direct the synthesis of the new strand through phosphodiester bond formation between the sugars and the nitrogenous bases, arranged in an antiparallel orientation. Their suggestion raised contention among other leaders in the field who noticed a problem with their model; namely, the mechanism of helical unwinding through hydrogen bond breaking before synthesis [15]. Delbrück drew attention to the plectonemic coiling of the helix, and argued against the semi-conservative replication by suggesting an alternative dispersive mode (see Figure 1). The replication debate was settled when Meselson and Stahl provided evidence of semi-conservative replication [16]. Watson concluded: “Nor does the need to untwist the DNA molecule to separate the two intertwined strands represent a real problem”(for review see [17] ).
1.2. The Polymerase Puzzle
The key evidence for DNA’s genetic role, and its semi-conservative mode of replication came from Kornberg’s lab, where the chemical process of DNA synthesis was reconstituted in vitro, followed by the purification of the “catalytic extracts” which contained the enzyme required for phosphodiester bond formation, and chain elongation – discovered as DNA polymerase I – in Escherichia coli [18,19]. Previous analyses have shown that the precursor to strand formation must be an activated nucleoside 5’-phosphate [20]. Analogously to glucose-1-phosphate being activated to uridine-diphosphate glucose in glycogen synthesis [21], Kornberg’s group generated four 32P labelled nucleotide bases – dATP,dCTP,dTTP, and dGTP – to serve as starting units for the synthetic DNA strand extension reaction. From that, they have formed their initial hypotheses regarding the enzymatic mechanisms, and the chemical composition of the replication products:
- (1)
- Is the synthesised DNA strand identical to its template?
Does DNA synthesis proceed in a template directed manner like Watson-Crick’s model would suggest, and is the newly synthesised DNA therefore a faithful copy of its template? The ‘nearest neighbour’ technique of 32P labelled nucleotides revealed that the frequency of nucleotide pairs, and the complementary base ratios between the ‘starting’, and the synthesised strand remained identical – serving as corroboratory evidence for the antiparallel orientation outlined in the double helix model. The authors were surprised to find that all four nucleotide bases, as well as DNA polymerase and Mg2+, were required; if the template substrate served as a simple primer, why were all four nucleotides a necessity? This has prompted further questioning:
- (2)
- Does replication proceed in a template directed manner as predicted by Watson and Crick, catalysed by DNA polymerase?
When “DNA primers” containing differing ratios (i.e., 0.5 to 1.9) of nucleotide base pairs were used – the synthesised product maintained the initial nucleotide pair ratios, and was independent of the concentrations of the individual bases thus indicating template-directed replication.
These conclusions have laid the foundation for DNA replication research using bacterial models that occupied scientists for the next 70 years and counting. During the Nobel Prize acceptance lecture, Kornberg compared DNA to a “tape recording” in that:
“exact copies can be made from it so that this information can be used again and elsewhere in time and space.”
But how are these copies during DNA polymerase directed synthesis made “exact”?
Considering that the nucleotide pool contains an unequal proportion of the four bases, what are regulatory mechanisms that ensure accurate nucleotide selectivity? At the base-pairing selection step, (1) the correct nucleotide must be selected for the polymerisation reaction through correct geometric pairing with the polymerase, and (2) the preceding nucleotide in the primer terminus is “proofread” for accurate base pairing before the addition of the second nucleotide (Figure 2). This highlights another universal hallmark of DNA (i.e., replicative) polymerases – that is, the inability of de novo synthesis. Replicative polymerases are incapable of performing the initial phosphodiester bond formation between two dNTPs – in contrast to RNA polymerases – thus they must add nucleotides to a pre-existing RNA primer site at the template, synthesised by a specialised RNA polymerase called primase, and extend it from 3’-OH end of the single-stranded DNA template strand (n.b., implications of the 3’ prime end requirement form a recurrent theme throughout this review, and is made relevant in various systems).
While preparing their second manuscript, Kornberg’s group faced a problem: they were unable to remove deoxyribonuclease activity from the polymerase. It was later found that the reason was the presence of 3’-5’ exonuclease domain [22] that carries proofreading, as well as mispaired nucleotide excision (i.e. editing) mechanisms. When the second replicative enzyme – called DNA polymerase III – was isolated from E. coli, it took on the role as the primary enzyme responsible for the elongation of the majority of the bacterial chromosome. Since then, sequence conservation [23] and biochemical [24] studies have led to the classification of DNA polymerases from all three domains of life into six families: A, B, C, D, X and Y – with the first four polymerases responsible for high fidelity DNA replication, while X and Y are more specialised forms of lesion bypass, and translesion synthesis polymerases involved in DNA Repair [25]. PolA, PolB, and PolC are homologous to PolI, PolII, and PolIII families in E. coli [26] respectively, with family B most commonly found in Eukaryotes, families A and C in Bacteria, and families B and D in Archaea.
Despite differences in function between polymerases, the archetypal DNA-dependent polymerase (Figure 2B) is composed of a core polymerisation catalytic site, which itself is composed of fingers, palm, and thumb subdomains, as well as a separate 3’-5’ exonuclease domain that proceeds in an opposing direction to DNA synthesis. In case of a mismatched base pair, the catalytic step is slowed down, and the nascent strand terminus is ‘shuttled’ from the polymerisation to the exonuclease active site of the DNA polymerase (Figure 2C) for the excision of the incorrect nucleotide through bond hydrolysis. Such structural distribution of enzymatic function is exemplified by the crystal structure of the multidomain E. coli Pol I Klenow fragment [27] which retains 3’-5’ exonuclease (proofreading), and 5’-3’ polymerisation activities, thereby contributing to replication fidelity through intrinsic proofreading and strand displacement synthesis abilities [28].
It is worthwhile to note that the polymerase is a molecular motor capable of translocation along the template strand which proceeds chiefly in terms of chemical thermodynamics. In other words, DNA polymerase acts as a “channel” for the copying of genetic information, by the “reading” of each nucleotide on the template strand, and “writing in” of the complementary nucleotide through a nucleotidyl transfer reaction, where the paired nucleotides are stabilised by hydrogen bonds and base stacking interactions. This ability to convert “information” through a physical reaction or “work” has led some authors to propose that the polymerase functions analogously to a Maxwell’s demon [29,30]. The “memory” of an organism’s genetic information is embedded within the DNA polymer’s structure, where DNA replication is the reversible process of “retrieving” and “storing” of this information – with information processing and assimilation being the defining features of a complex system or a living organism. The RNA-first scenario proposes that while modern genetic apparatus requires to be encoded by proteins, in the early pre-DNA environments (i.e., the RNA world), the ancient RNA-dependent RNA polymerase or the ribozyme harboured the ability to self-replicate, and thus played a major role in the RNA to DNA transition. The DNA molecule – due to its inherent stability – has replaced RNA as the main genetic material; however, the imposed directionality of 5’ triphosphate addition in DNA synthesis is itself an artefact of the RNA world metabolism. The structural similarities of polymerase families A and B, as well as viral RNA polymerases all suggest a common origin [31].
Following this reasoning, the polymerase is the earliest form of a self-reproducing system that has evolved from prebiotic conditions; whose ability to harbour both “information” and “function” has been the driving factor of evolution itself. Thus it can be assumed that the basic physicochemical forces underpinning DNA replication are both conserved and fundamental in all living systems. Various kinetic studies (for review see [32], and citations therein) using DNA polymerases have therefore led to a minimal model [33] of the polymerisation process; its mechanics are outlined in Figure 2A.
Figure 2.
(A) Universal mechanism of nucleotide incorporation during the polymerisation step in DNA replication. Among all studied replicative polymerases, phosphodiester bond formation occurs via a conserved stepwise mechanism. (B) The side chains of the ‘fingers’ domain (refer to diagram 2B; schematic of the polymerase multidomain organisation (left); crystal structure of E. coli Pol I Klenow fragment (right), adapted from [28] (PBD ID:1KFD)) bind the incoming dNTP, and position it in the conserved palm domain (i.e., the catalytic unit). The active site of the palm contains two essential aspartic acid residues which coordinate the two divalent ions necessary for the nucleotidyl transfer reaction: the activated 3’OH on the nascent strand terminus performs a nucleophilic attack on the α-phosphate of the dNTP thus resulting in phophodiester bond formation through a condensation reaction. The inorganic pyrophosphate group (PPi) bond is hydrolysed, and the free energy change ensures forward translocation of the polymerase along the template. (C) The dNTP substrate can only undergo activation in its 5’ position, which is what imposes the strict unidirectionality of DNA replication. What is the reason behind this universal requirement, if the 5’-OH is just as capable of a nucleophilic attack? The answer lies in the proofreading function of the polymerase; the addition of one nucleotide per synthesis step ensures fidelity, and polymerase repurposing for multiple enzymatic reactions without dissociating from the DNA is bioenergetically convenient. The thumb domain assists in the switching of the polymerase between polymerisation to editing modes (figure 2C; tertiary structure of the Pyrococcus furiosus PCNA-PolB-DNA complex switching from pol and exo states, taken from [34] ).
Figure 2.
(A) Universal mechanism of nucleotide incorporation during the polymerisation step in DNA replication. Among all studied replicative polymerases, phosphodiester bond formation occurs via a conserved stepwise mechanism. (B) The side chains of the ‘fingers’ domain (refer to diagram 2B; schematic of the polymerase multidomain organisation (left); crystal structure of E. coli Pol I Klenow fragment (right), adapted from [28] (PBD ID:1KFD)) bind the incoming dNTP, and position it in the conserved palm domain (i.e., the catalytic unit). The active site of the palm contains two essential aspartic acid residues which coordinate the two divalent ions necessary for the nucleotidyl transfer reaction: the activated 3’OH on the nascent strand terminus performs a nucleophilic attack on the α-phosphate of the dNTP thus resulting in phophodiester bond formation through a condensation reaction. The inorganic pyrophosphate group (PPi) bond is hydrolysed, and the free energy change ensures forward translocation of the polymerase along the template. (C) The dNTP substrate can only undergo activation in its 5’ position, which is what imposes the strict unidirectionality of DNA replication. What is the reason behind this universal requirement, if the 5’-OH is just as capable of a nucleophilic attack? The answer lies in the proofreading function of the polymerase; the addition of one nucleotide per synthesis step ensures fidelity, and polymerase repurposing for multiple enzymatic reactions without dissociating from the DNA is bioenergetically convenient. The thumb domain assists in the switching of the polymerase between polymerisation to editing modes (figure 2C; tertiary structure of the Pyrococcus furiosus PCNA-PolB-DNA complex switching from pol and exo states, taken from [34] ).
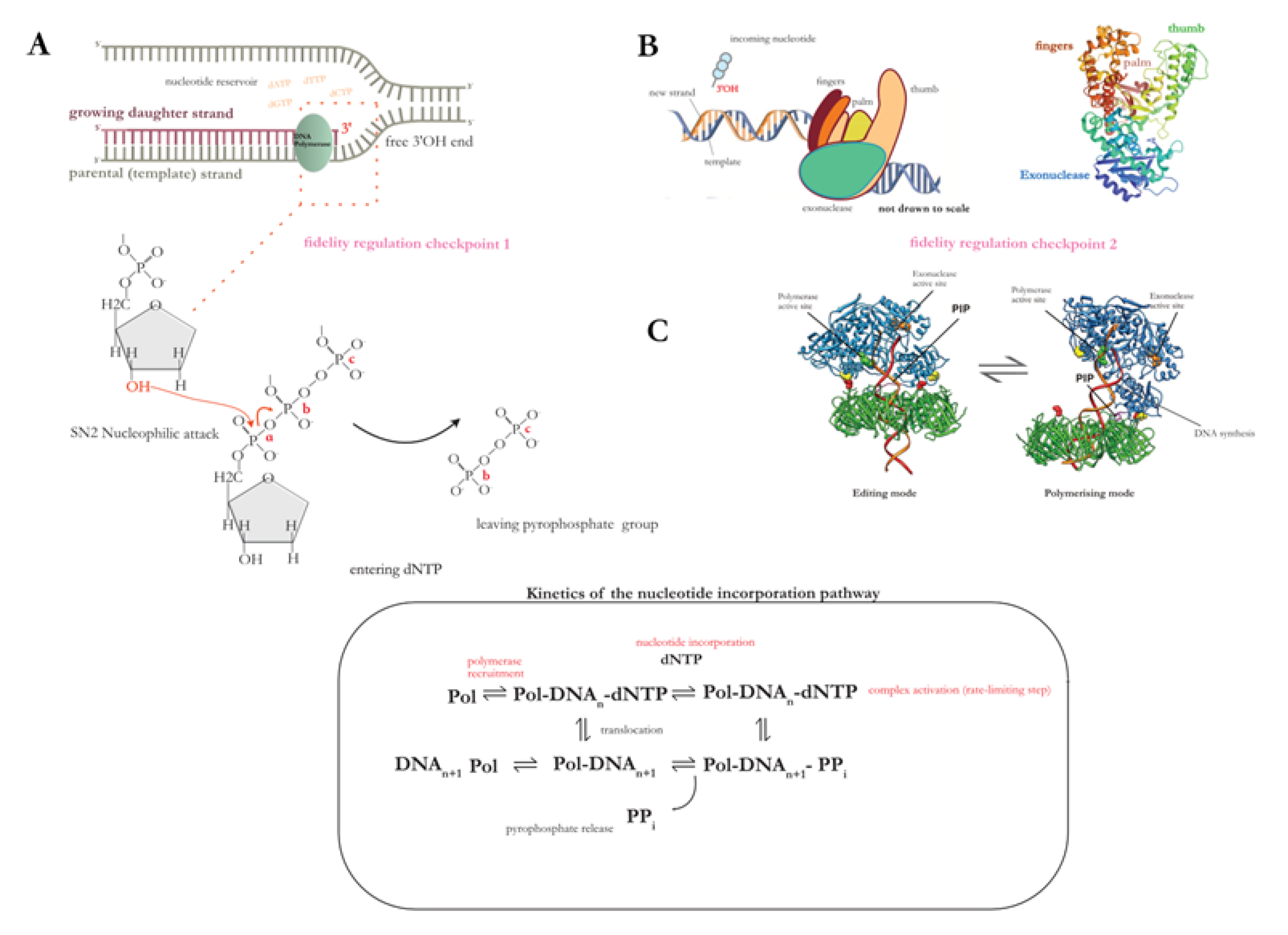
Polymerase selectivity is one of the major contributors to overall fidelity of replication, with the proofreading function increasing accuracy of copying by 102-103 fold at nucleotide level [34]. At a more global scale, however, the order of replication events must be regulated both temporally and spatially. The genome must be replicated during the synthesis (S-phase) stage before cell division, and at the same time must occur only once per cell division cycle to avoid over-replication. Aberrant replication initiation events can lead to chromosome copy number alterations (i.e., aneuploidy or polyploidy), and promote genomic instability through the accumulation of mutations. Thus the formation of the replication bubble must occur at a specific locus of the chromosome – dictated by the location of the replication origin – and proceed in a timely manner in accordance with the cell division cycle, as well as transcription and DNA repair events [35]. It is therefore unsurprising that the main regulatory step through which this is imposed is replication initiation.
2. The Replicon Model: Leading Paradigm for the Study of DNA Replication
It is helpful to think of initiation of any biological event as a result of the direct or combined action of regulatory elements; on specific substrates, as well as the negative or positive effects these elements elicit upon binding. Early models of gene expression control were centred around its repression – for example, the (lac) operon model of bacterial gene regulation, as proposed by Jacob and Monod [36], states that gene expression is controlled by a regulatory circuit formed through specific interaction between a trans-acting repressor factor and a cis-acting operator. The authors reached a – what may currently seem rather short-sighted – conclusion that these genetic control mechanisms operate solely through inhibition, and that the removal of these repressive effects is the main event that activates protein synthesis. With the lack of integrative approaches, progress in bacterial cell biology research had come to an impasse; there was a fundamental gap in knowledge on the integrative action of molecular mechanisms within the cell. Jacob and colleagues had expressed this growing sentiment at the 1969 Cold Spring Harbor symposium [37]:
“we still know very little about the general system which integrates cellular controls, the regulation of DNA replication, the formation of bacterial membrane, and the process of cellular division with its equipartition of the DNA copies”
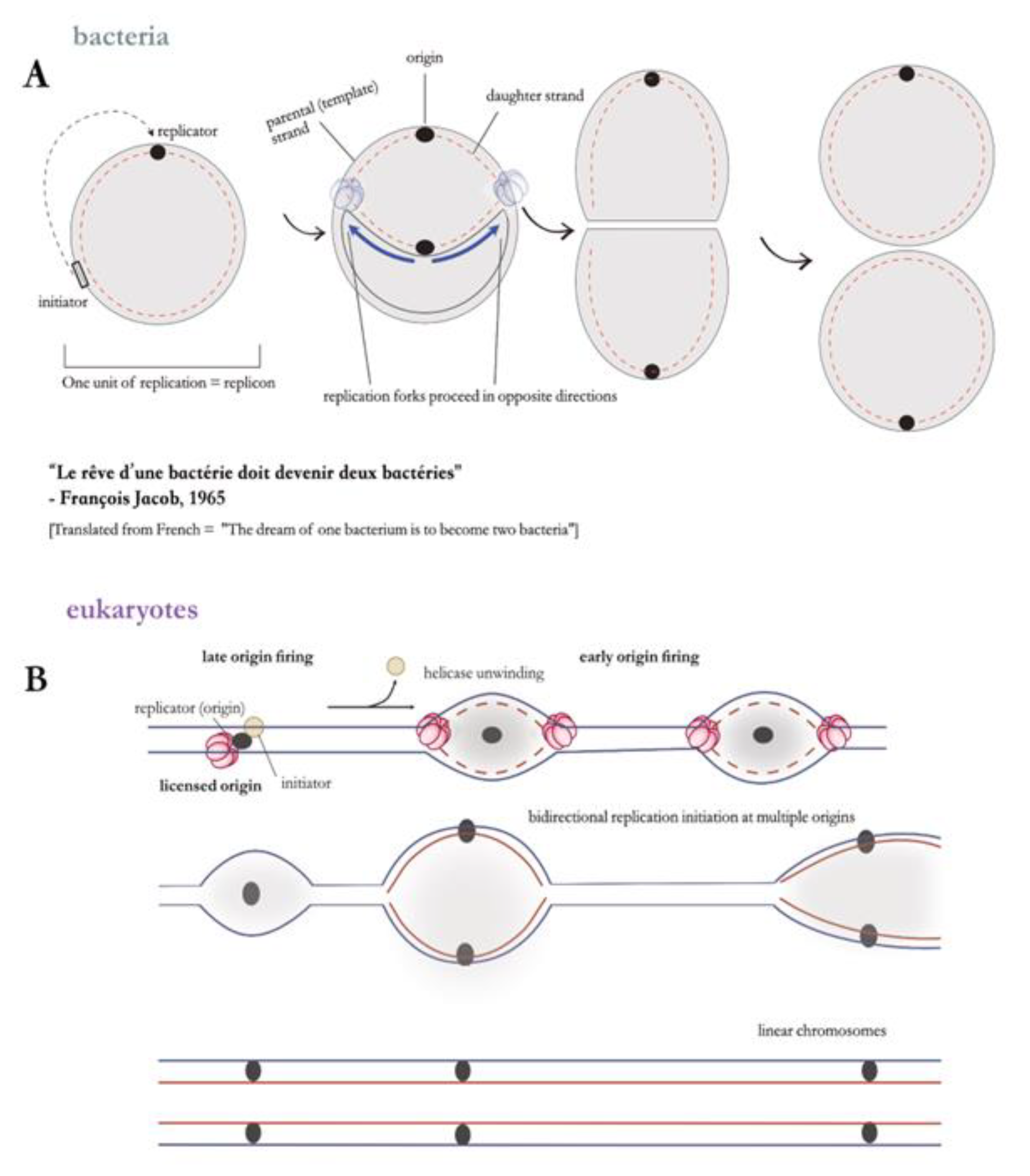
Following the discovery of extra-chromosomal, self-replicating genetic elements – called episomes: a term now used interchangeably with plasmids [38] – Jacob et al [39] proposed a simple replicon model for replication initiation in E. coli circular chromosome. In their model, an individual unit of replication – the replicon – is defined by the specific chromosomal sequence called a replicator (i.e., replication origin or ori ; ‘operator of replication’) [40], from which replication is initiated upon the interaction with the trans-acting, diffusible initiator protein (whose own structural gene is found frequently in proximity to the native origin) in a sequence-specific manner. This in turn triggers the recruitment of a helix unwinding element called helicase that acts as a stable platform for the assembly of replication machinery – collectively referred to as the replisome – in a concerted manner forming a replication bubble from the single strands for elongation to occur (see Figure 2A,B). A defining feature of the replicon unit is that it encodes specific determinants (that is, the replicator and the initiator) which allow it to process control signals allowing it to autonomously replicate as one whole. This is in contrast to other autonomously replicating sequences such as episomal plasmids. The replicon hypothesis provides an explanation for the phenomenon in E. coli called plasmid incompatibility which arises due to the competition of several plasmids for the same initiation factors, thus preventing stable inheritance [41]. An observant reader may notice that the replicon is a reworking of the earlier lac operon model, combined with the idea of a diffusible factor interacting with the membrane during bacterial conjugation [42] – the operon repressor is analogous to the initiator, and the operator to the replicator, with one critical distinction being that the initiator acts as an activator in a positive interaction with the origin. However, due to the nature of replication being inherently autocatalytic, regulation cannot be complete without the reciprocal actions of both activation and repression mechanisms that occur during distinct stages of the cell cycle. If the rate of replication is determined by the frequency of initiation events, what are the distinct factors that regulate origin firing in space and time?
3. The Divided Genome: Nature’s Riddle
The following section discusses the limitations of the single replicon model – the findings that stimulated its subsequent reworkings, and a revision of the commonly accepted terms such as replicon unit, origin of replication etc.,
3.1. The Diversity of Replication Factors
The replicon model was shown to be highly adaptable to most bacterial systems, with limitations arising when extended to more complex genomes, such as the ones of higher eukaryotes. Due to genetic simplicity (i.e., a circular chromosome with a single bidirectional origin) and ease of culture, E. coli served as the leading model for the identification of ARS (Autonomously Replicating Sequence) elements through the cloning of candidate replicator fragments into a marked plasmid vector, selected for their ability to self-replicate, and remain as a separate unit within the host cell. Using this simple ARS assay, the E. coli replicator OriC was identified [43] thus making the replicon model a guiding paradigm for the replication regulation and origin prediction [44] in bacterial systems. Supporting evidence for the replicon model came from the isolation of the E. coli initiator – a 473 amino acid protein called DnaA [41,42] was shown to bind with high affinity to DNA containing the sequence for OriC, in an ATP-dependent manner [45]. The DnaA initiator protein, which binds to the specific 9-aa consensus sequence called DnaA box (clustered within the 250-aa OriC region; the DnaA gene itself is usually found adjacent to the origin) which controls the replication of the entire chromosome was found to be highly conserved among bacterial species [46]. In eukaryotes, such as budding (Saccharomyces cerevisiae) and fission (Schizosaccharomyces pombe) yeast, the ARS technique developed through bacterial genetics led to the isolation [47] and sequence analysis [48] of yeast ARS elements – 100bp long, with a characteristic AT-rich consensus sequence (5′-[A/T]TTTAT[A/G]TTT[A/T]-3′) – that serve as putative replicators. From that, the eukaryotic initiator multiprotein complex ORC (Origin Recognition Complex) was purified from budding yeast in 1992 [49].
One may think of a replicator as a specific initiation site or control point for an individual event of bidirectional replication; the single origin model in bacteria served as a useful starting point for the identification of several initiator proteins under set physiological growth conditions. Under stressful growing conditions (e.g., arrested protein synthesis) the paradigm is flipped: both OriC (Origin of Chromosomal Replication) and DnaA are shown to be dispensable during SDR in thymine-starved E. coli cells. While the hetero-hexameric ORC initiator is conserved in eukaryotes, with orthologues found from yeast to humans [50], the cis-acting replicators or clusters of origins are highly diverse among different species. In the majority of bacteria, the dual DnaA-OriC interaction occurs in a sequence specific manner to replicate the single circular chromosome. This is in contrast to eukaryotic replication systems, which typically possess many linear chromosomes that are larger in size, on which there are clusters of origins – where one round of replication may initiate from hundreds to thousands of origins, as depicted in early autoradiography studies [51]. The way the replicon model falls short is that it fails to address spatial and temporal regulation of initiation which occurs in eukaryotes such as fission yeast with an excess of activation-capable origins, and more fluid control mechanisms [52].
Figure 3.
(A) Early model of the replicon hypothesis in bacterial systems. (B) Adaptation of the replicon model to eukaryotic genomes. The earlier model was reworked to accommodate the multiple origin organisation in eukaryotes, from studies in ARS elements in budding yeast. In eukaryotes, origins are fired asynchronously during S-phase. For an origin to be ‘activated’, it must first be licensed through the recruitment of various replication factors. Differential timing of origin activation – marked by early and late replication initiation events – prevents over-replication or aberrant re-replication events. Thus a single set of initiation factors activates hundreds-to-thousands of replication origins on a single eukaryotic linear chromosome.
Figure 3.
(A) Early model of the replicon hypothesis in bacterial systems. (B) Adaptation of the replicon model to eukaryotic genomes. The earlier model was reworked to accommodate the multiple origin organisation in eukaryotes, from studies in ARS elements in budding yeast. In eukaryotes, origins are fired asynchronously during S-phase. For an origin to be ‘activated’, it must first be licensed through the recruitment of various replication factors. Differential timing of origin activation – marked by early and late replication initiation events – prevents over-replication or aberrant re-replication events. Thus a single set of initiation factors activates hundreds-to-thousands of replication origins on a single eukaryotic linear chromosome.
3.2. Many Origins, One Chromosome: Time to Revisit the Single Replicon Model?
The replicon model was constructed on the dogma that bacterial domain members can be defined by the possession of a single, circular chromosome that encodes a conserved set of essential genes [53,54,55] (see glossary) – however the paradigm was overturned when alphaproteobacteria containing a secondary replicon carrying essential genes were discovered [56], and the expansion to other members of the bacterial domain stimulated a revision of these historically used terms. Moreover, it has been shown that 10% of bacterial genomes differ from E. coli in that they contain numerous replicons which can be both circular or linear [54].

Advances in genome sequencing during the 1970s have led to the identification of the third domain of life – the Archaea [57] – which provided a novel platform for comparative molecular biology. Search similarity techniques to previously known origins in other domains for bona fide origins in archaea have not given results; the nature of the archaeal origin, or if replication was initiated through origins at all, remained unknown long after the archaeal genomes were first sequenced [58]. Since archaea bear a morphological resemblance to bacteria in terms of their chromosomal structure, it was initially proposed that they contain a single replication origin. Indeed, using codon (GGTC) skew analysis, Myllykalio and coworkers [59] have identified the first replication origin (i.e, OriC) in the hyperthermophile Pyrococcus abbysi, corroborated with experimental evidence from 2-dimensional gel [60] and RIP (Replication Initiation Point) mapping [61]. The first archaea with multiple origins to be mapped using gel analysis came from the Sulfolobus genus [62] – stimulating a major shift in thinking at the time. Through the use of MFA techniques [63], it was also shown that bidirectional replication occurs from each of the three origins. These three origins were also found to be involved in complex cross-interaction with the adjacently encoded initiator proteins, Orc 1-1 and Orc1-3 [64], as well as a WhiP (winged-helix initiation protein) [65]. But what makes the Sulfolobus genome especially intriguing is that the genomic region adjacent to OriC3 appears to be ‘captured’ from a virus or an extra-chromosomal element of viral origin (see glossary for extra-chromosomal element). The staggering sequence diversity of the Sulfolobus origins (OriC1-3) also hints at independent derivation through horizontal gene transfer [62].
Similarly to Sulfolobus, other archaeal genomes [65,66,67] were also found to be composed of multiple replicons, with each replicon containing more than one replication origin. What is the exact definition of a replicon or a single replication control point given the divided genomic architecture, and the cross-interaction between multiple replicator-initiator systems? DiCenzo and Finan [53] suggest that classical terms such as ‘replicon’, should be used with caution – if not at all discarded – when describing genomes that fall outside the canonical E.coli model. It was also assumed a priori that genome replication cannot be initiated without replication origins. However some archaeal species, such as Haloferax volcanii, demonstrate that replication without origins occurs faster, and without any phenotypic deficits [68]. Thus we arrive at another critical juncture; what is then the initial evolutionary purpose for replication origins? Are origins of replication ancestral genetic elements or were they recently obtained through horizontal gene transfer? If so, at what point in evolutionary history have origins been captured? And perhaps more importantly, could the extra-chromosomal elements capture postulate be extended to explain the evolution of multiple initiation sites and the linearisation of the chromosome in eukaryotes?
Given the above lines of evidence, the reader might then arrive at the conclusion that the organisation of multireplicon genomes is far from stochastic – that their maintenance must hold some functional or evolutionary purpose [53]. In fact, genome rearrangements such as insertion-deletion events from mobile genetic elements [69], and origin transfer [67] between species was the driving force that shaped genomic organisation in the Haloarchaea class of archaea. What existing studies have failed to resolve is the reasoning behind the ‘hidden cost’ of the multipartite genome– that is, increased complexity. What are the genetic events that led to the expansion into multiple replicons, and do they confer any advantage to the cell?
Taking the conjecture that the modern eukaryotic cell evolved from a lineage of archaea containing multiple origins – the study of archaeal replication origins can therefore provide an understanding of the complex mechanisms in eukaryotes, and potentially give insight into some of the selection pressures present at the primordial times of the LUCA. For this task, the ideal model would be an archaeon that is easy to culture within laboratory conditions, and one which would be amenable to genetic manipulation.
Therefore the next sections aims to familiarise with the events starting from origin-recognition, leading up in stages to full replisome assembly – with a special focus on the archaeal domain – before continuing into some exceptional cases of replication (e.g., recombination-dependent replication; or RDR), and their implications.
4. Where Do We Start? DNA Replication Initiation across the Three Domains of Life
The initiatory steps leading up to replisome formation can be broadly classified into four distinct stages: (I) origin recognition, (II) pre-RC (pre-Replicative Complex) assembly, (III) replicative helicase activation and DNA unwinding, and (IV) loading of replicative DNA polymerases along with other enzymes which support the replisome (V) to ensure high processivity. (see Figure 5 and Table 2) Stages of replication has been separated for comparative analysis between the three domains of life. Each model organism therein was purposefully chosen to demonstrate the evolutionary transitions in genomic organisation.
Figure 4.
Evolutionary timeline of replicator diversification across the 3 domains. Figure adapted from [78].
Figure 4.
Evolutionary timeline of replicator diversification across the 3 domains. Figure adapted from [78].
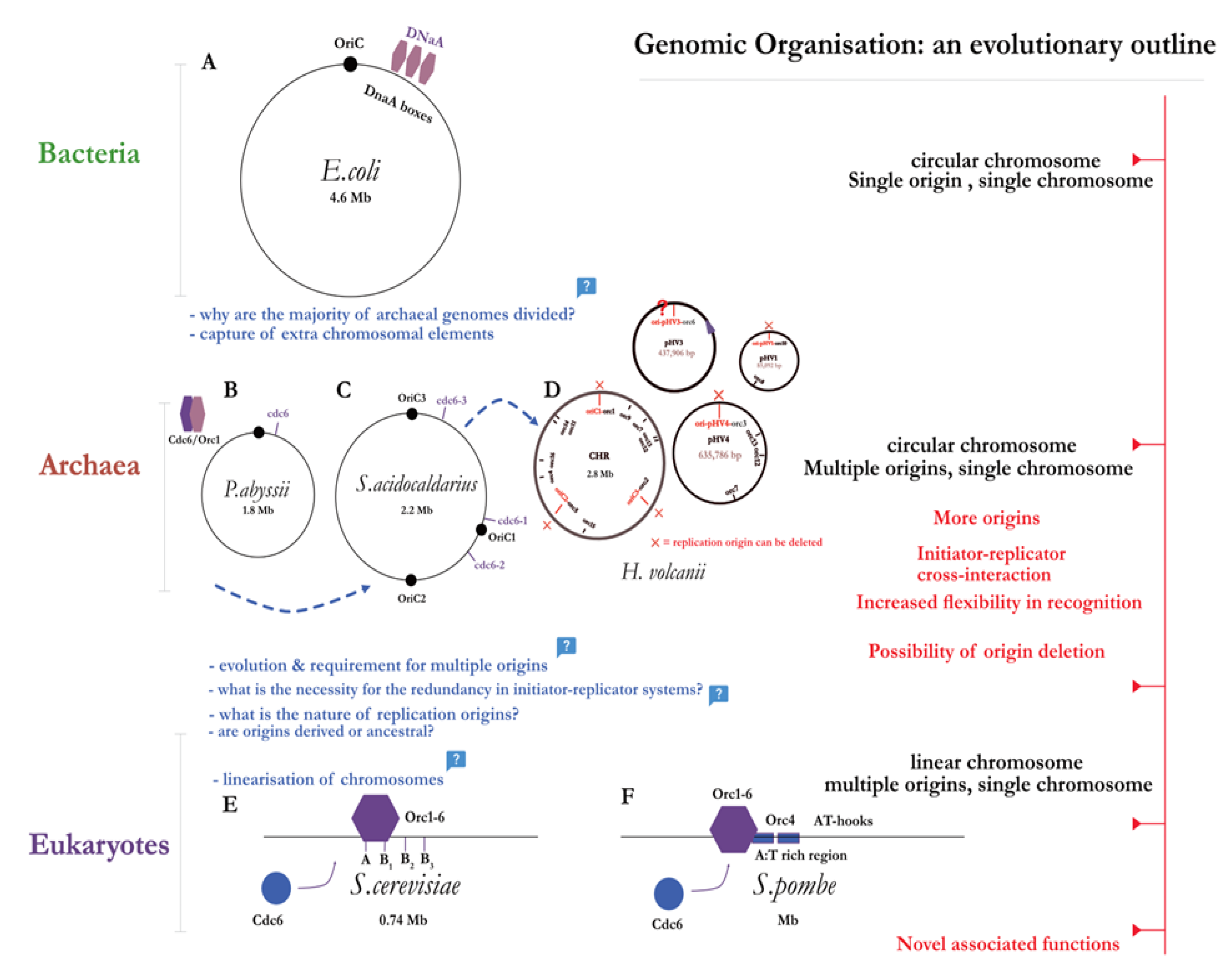
Table 2.
Overview of replication machinery found across the 3 domains of life.
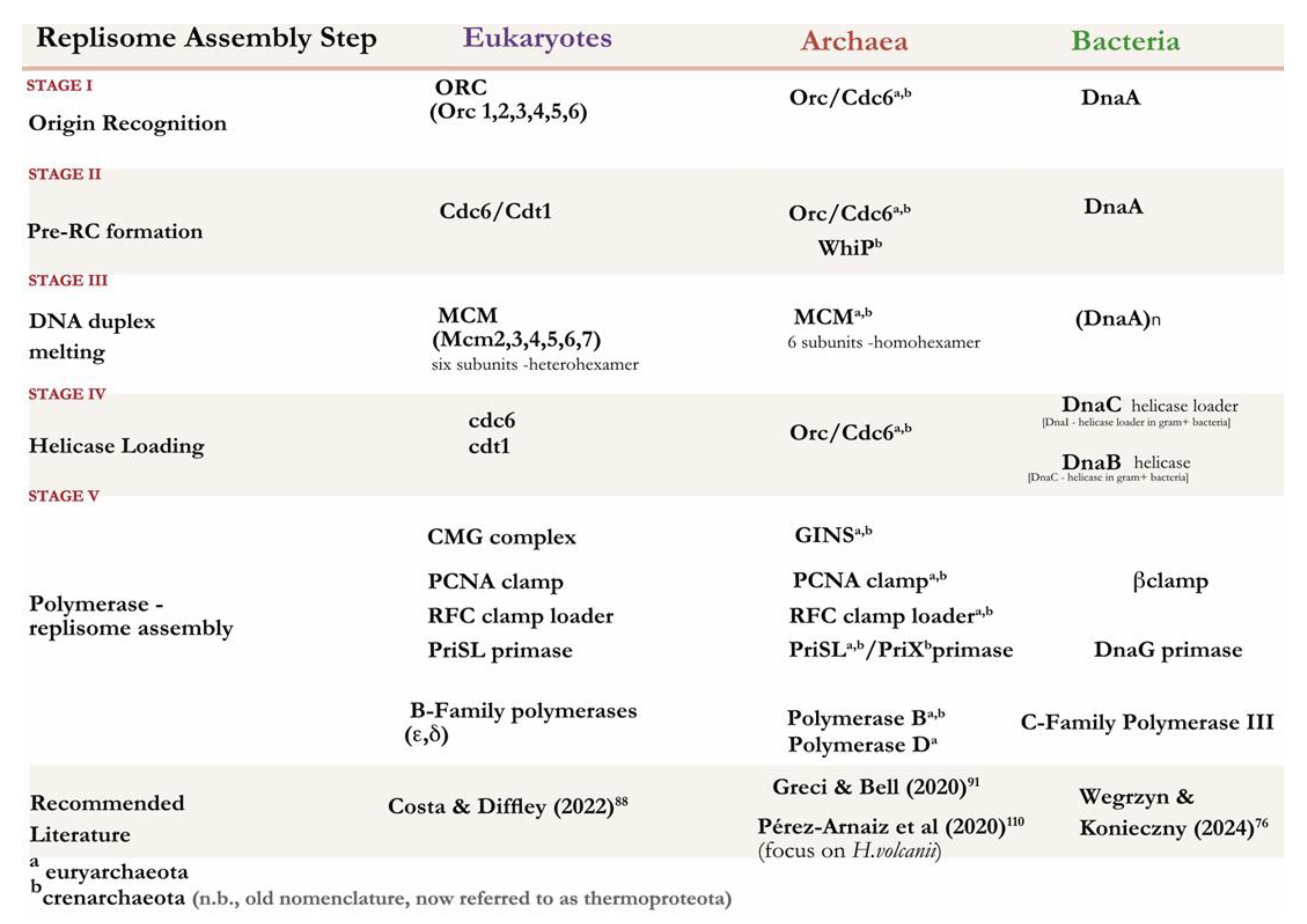 |
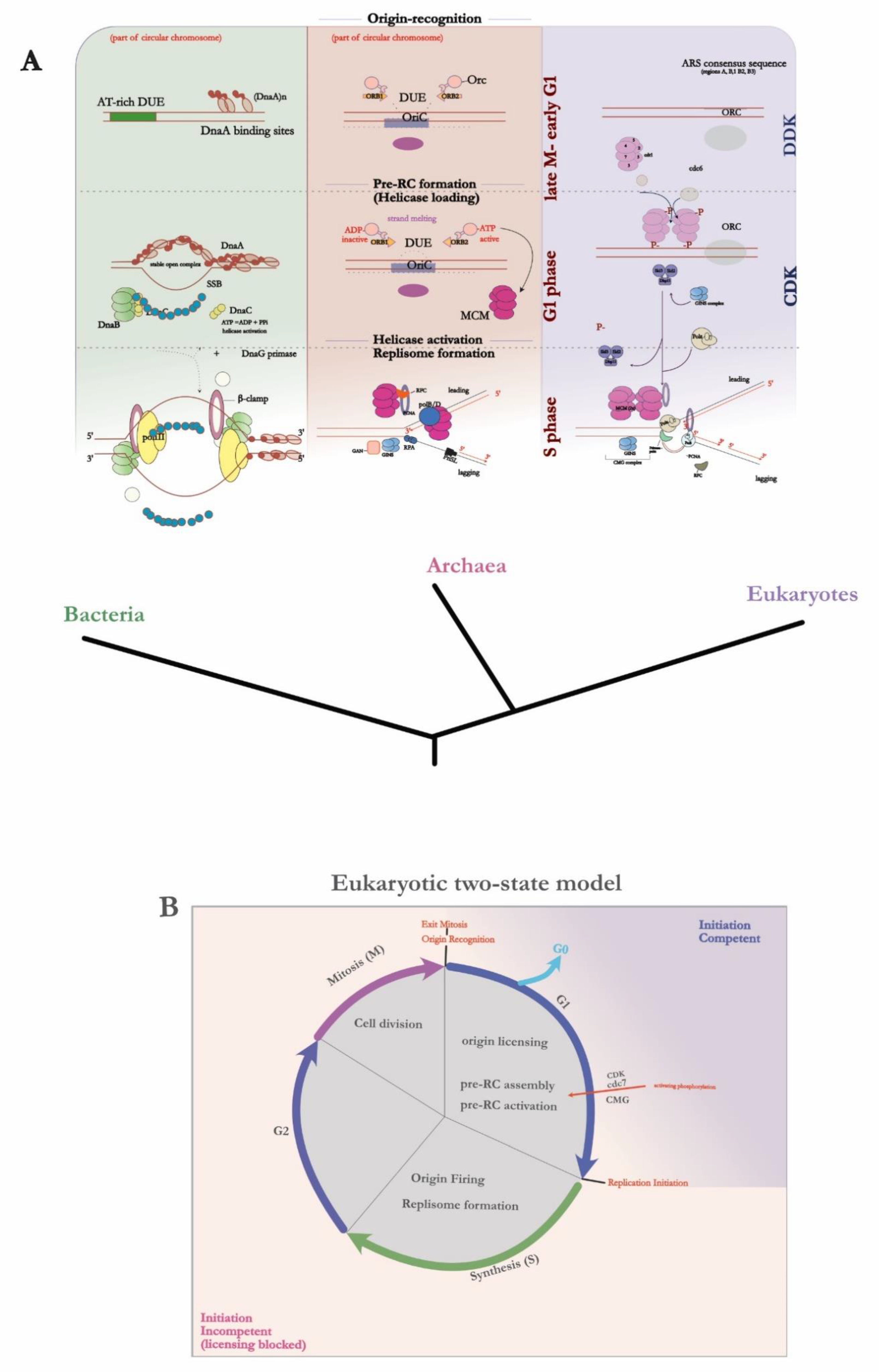
4.1. Bacteria
Before the DNA polymerase can associate and extend the DNA strand, the double helix must first be unwound. This requires the assembly of a higher-order nucleoprotein complex (i.e., pre-RC) which will then recruit the helicase. As previously discussed, the typical bacterial origin, OriC, appears once per chromosome for most bacteria, and its sequence is encoded adjacent to the initiator protein DnaA; hinting at a possible coordination between the levels of initiator and initiation rate (i.e., origin firing). The classic mechanism describes a single monomer of DnaA binding to the consensus sequence – consequently named the DnaA box – to induce a ‘bend’ in the interaction site, and thus facilitate DNA melting. However as with most biological systems, the molecular reality is much more complex. Per single OriC, there have been a total of 12 characterised DnaA boxes to this date [70] – all with varying degrees of conservation to the original consensus. Each DnaA protein monomer binds to the respective DNA box; R1, R2, R4 (high affinity sites) or I, τ, and C (low affinity sites which lie in between of the R-sites) [35,71]. DnaA-ATP and DnaA-ADP can both bind to the sites, depending on the affinity, with the domain III containing ATP-activating and DNA-binding functions [72]. This brings us to the hallmark feature of the protein: its multimodular structure is what confers it with multifunctionality and the ability to coordinate entire replisome assembly. DnaA belongs to the AAA+ superfamily of ATPases (that is, ATPases associated with various cellular activities), and thus has an evolutionary relationship with the eukaryotic (Orc1) and archaeal (Orc1/Cdc6) initiator proteins [73] which bear structural similarities [74].
The collective binding induces topological stress (i.e., superhelical torsion) on the dsDNA, which in turn unwinds the adjacent AT-rich region – termed the DUE (DNA unwinding element) [75]. This creates a stable open complex structure or ‘bubble’ (i.e., the pre-RC) to which the helicase loading protein DnaC, through its interaction with domain I of DnaA, binds two hexamers of DnaB helicase and loads them unto the ssDNA region, at opposite orientations. The helicase then recruits DnaG primase which itself binds to the DnaB-DnaC complex thus leading to ATP-ADP hydrolysis stimulating helicase activation. The DnaB pair of helicases unwind with the directionality of 5’ to 3’ – hence the helicases work in opposing directions, and establish a bidirectional replication fork to which replication machinery can be loaded (for the latest overview of bacterial initiation, see [76]).
4.2. Eukaryotes
Contrary to their bacterial counterpart, progress to fully characterise the eukaryotic origins and initiation process was lagging. This points to an obvious difference: the size of the genome. Take a simple model eukaryote – S. cerevisiae or budding yeast – and compare it to the bacterial model of E. coli: the genomes are 12.2 Mb v. 4.6 Mb, respectively. Hence the first point of contrast in Eukaryotic initiation is increased spatiotemporal control (see figure 5B) to ensure accurate replication of a larger genome. There are multiple origins on a single chromosome – with increased flexibility of initiator interaction as origins become less defined, and have less sequence conservation (with notable exception being S. pombe, which compared to S. cerevisiae, lacks distinct sequences, apart from rich AT regions [77]). Thus we witness another emerging trend: with the increasing number of origins, there is an overall decrease in their specificity (see figure 4). Schwob [78] posits an intriguing explanation: accumulation of recombination intermediates at replication origins in fission yeast drives genomic instability, which in turn may have promoted replicator diversification and redundancy as a counteractive mechanism [79]. In other words, replicator flexibility may have evolved to balance out the ill-effects of genomic instability – proposing an evolutionary relation between replication, recombination, and genomic stability in Eukaryotes. Once per mitotic cell cycle, the genome must be replicated with utmost precision due to the selective pressure of genomic instability and cell death as a result of over or under replication. This is reflected in the tight control mechanisms which couple the process of initiation to the stages of the cell cycle which are centred around preventing re-replication.
The major difficulty that came in characterising eukaryotic origins is that there are multiple origins on a single chromosome that lack discernible sequence motifs, and that the origins in higher eukaryotes are largely defined through complex chromatin interactions (i.e., a subset of origins, termed a ‘cluster’, can be activated according to the developmental phase [80]). This led to the development of the two-state model of initiation (refer to figure 5B) which corresponds to the levels of CDK (Cyclin Dependent Kinase) activity: the origins are ‘licensed’ and the pre-RC established during the G1 phase of low CDK and increased DDK (DBF4-dependent kinase or Cdc7) levels, and then subsequently activated during S-phase [81]. Analogously to previously defined bacterial systems, the ORC – a six-subunit AAA+ ATPase – binds to the ARS sequence in an ATP-dependent manner. However unlike DnaA, ORC-ATP binding cannot directly unwind the DNA region [82]. Upon ORC binding, Cdc6 [83]– a factor displaying sequence homology to the ORC subunit Orc1, suggesting common ancestry – is recruited to form a ring-shaped structure. Concomitantly, the Cdt1 (Chromatin licensing and DNA replication factor 1) initiator protein [84,85] acts as a chaperone to recruit the MCM2-7 helicase; together, this forms the intermediate ORC-Cdc6-Cdt1-MCM2-7 of the pre-RC, where the dsDNA can feed into the pore of the resulting MCM double hexamer [86]. Like DnaB, the MCM molecule must also be activated through ATP hydrolysis reaction – thus many MCM hexamers are loaded following ATP hydrolysis by Cdc6 and ORC, and Cdt1 release in an iterative fashion [87] (for an excellent review on MCM loading, see [88]). We hence arrive at another checkpoint control point: the activation of the MCM2-7 helicase (the ‘core’) depends on the additional proteins Cdc45 and GINS, and together they form the CMG complex which acts as a replicative helicase [89]. The transition from the G to S-phase of the cell cycle is guarded by the increase in the Cdc7 and CDKs. Cdc7 directly phosphorylates the N-terminus of the MCM2-7 alongside a tripartite complex consisting of Sld2-Sid3-Dbp11 factors (SDS complex) [90], which mediates CMG formation and activates the helicase. The above stepwise model is what constitutes the ‘origin firing’ step; the duplex is unwound, and the replicative polymerase ε (pol-ε) alongside other replisome components are loaded.
4.3. Archaea
Archaeal chromosomes are circular and small akin to bacterial, yet they usually come with multiple replication origins on most chromosomes, and share homology with eukaryotic replication factors; the archaeal domain hence represents a unique fusion of bacterial and eukaryotic features. In fact, the first archaeal gene encoding an initiator protein – a distinct sequence located downstream of the replication origin (OriC) [59,60]–was first identified in the hyperthermophile Pyrococcus genome. Due to it sequence homology to regions of the eukaryotic Orc1 and Cdc6 – it was subsequently named Cdc/Orc1 (n.b., for clarity, the archaeal initiator will be referred to as simply ‘Orc’ for the rest of this review). This led to some authors to speculate that the eukaryotic Cdc6 and archaeal Orc1 have diversified from a gene duplication leading back to a common ancestor [91]. Interestingly, the same study found that the promoter region for the DNA polymerase subunit genes (i.e., DP1 and DP2) overlapped with the Pyrococcus OriC sequence, providing a first hint at the replication initiation control through transcription [92]. The same year, a mutational analysis and sequence alignment study proposed a structure of archaeal Cdc6 ortholog, and its functional implications in pre-RC assembly [93]. The crystal structure of Pyrococcus cdc6 protein reveals its multidomain organisation; with domains I and II having an AAA+ ATPase module, and domain III being composed of a winged-helix (WH) fold. Soon after the initial discovery, the postulated mechanism of origin-binding was confirmed in vitro [94]. The purified Orc protein was shown to bind to the origin-recognition sequences termed Origin Recognition Boxes or ORBs (a conserved 13-base repeat), as well as mini-ORB elements in Sulfolobus [62] flanking the AT-rich DUE element within the origin region [61].
The inverted position of the ORBs on either side of the DUE is what precisely determines the polarity of Orc binding. The Orc initiators bend the DNA through their N-terminal AAA+ domain; an extra layer of complexity is added through varying binding affinities between Orc proteins determined by its WH domain. Initially, in vitro studies [95] in P. furiosus led authors to prematurely conclude that Orc binds in an ATP-independent manner, with the resulting structural distortion [96] of the binding site leading to the unwinding of duplex. Intuitively, one would presume that the binding mechanism is analogous to that of DnaA within the bacterial domain. And while the initiator-origin recognition motif interaction is conserved, duplex unwinding upon Orc binding, the helicase recruitment mechanisms, and higher order complex assembly remain a contested topic. This is partly due to the differing methods used to study initiator-origin binding mechanisms. Biochemical studies [35,95,97,98] support strand unwinding upon Orc binding, leading to higher order assembly, while early structural analyses present an obvious conflict. Some authors support DNA unwinding following strand distortion due to the topological stress induced by AAA+ domain binding [96], while others assert that the base-pairing is maintained even after strand distortion [96,99]. This discrepancy persists within other species of archaea: biochemical analysis in Methanothermobacter thermautotrophicus [100] and Aeropyrum pernix [100] support higher order complex assembly, while Sulfolobus appear to be in contradiction (reviewed in [101], p. 60). Nevertheless, it became apparent that Orc binding and the subsequent topological changes serve as an important step in initiation; yet again, we see that the archaeal initiator mirrors the eukaryotic ORC in its main role of helicase recruitment rather than the direct origin melting of DnaA.
Contrary to early Pyrococcus studies [95], Orc needs to be ATP-bound for its activation; however, in vitro studies in the same species have shown that the loading of the helicase itself occurs via an ATP-independent mechanism [102]. Soon after MCM2-7 emerged as a candidate for the eukaryotic helicase, a number of MCM homologues were identified in archaea, with each species containing at least one homologue (for review, see [103]). Although the biochemical properties of the archaeal MCM were known – that is, 3’ to 5’ DNA translocation capabilities, ssDNA and dsDNA binding, and ATPase activities [104] – the mechanism of MCM loading by Orc remained to be elucidated. Work from Bell lab – consistent with earlier chromatin immunoprecipitation studies [60,94] – has shown that the homohexameric open-ring MCM directly binds to the ATP-bound Orc protein in vitro [105,106]. Here, ATP binding and MCM release following ATP hydrolysis serves as a regulatory switch to confer MCM loading to a particular temporal window: a primitive version of spatiotemporal control observed in eukaryotes. Recent atomic force microscopy techniques provided further experimental verification that MCM from can interact with DNA in a variety of conformations under physiological conditions [107]. An important distinction from the eukaryotic MCM2-7 which is only active when part of the CMG (Cdc45-MCM-GINS) complex, is that the archaeal MCM displays intrinsic helicase activity in some species [108]. In others, paradoxically, MCM requires the binding of cdc6 homologues to be activated [109].
The rest of the replisome is then loaded: GAN or GINS-associated nuclease (i.e., Cdc45 or RecJ), and GINS factors which modulate the helicase activity, as well as the PCNA, RFC, primase (PriSLX), RPA, and the polymerases (B/D) [110].
Taking the above evidence together, it becomes apparent that the distribution of functions of replication proteins is highly diverse among archaeal species, as studies reveal a complex interactome leading up to full replisome assembly – understanding of which still remains fragmentary.
Figure 5.
(A) Replication initiation mechanism and associated replication factors – from origin recognition to full replisome assembly – across the 3 domains of life. (B) A schematic diagram representing the temporal control of DNA replication stages in Eukaryotes. Origin licensing through phosphorylation by various CDKs serves as a major control point for the transition between the G1 to S stage of the cell cycle; hence the two-state model provides a temporal window in which origins are ‘initiation competent’.
Figure 5.
(A) Replication initiation mechanism and associated replication factors – from origin recognition to full replisome assembly – across the 3 domains of life. (B) A schematic diagram representing the temporal control of DNA replication stages in Eukaryotes. Origin licensing through phosphorylation by various CDKs serves as a major control point for the transition between the G1 to S stage of the cell cycle; hence the two-state model provides a temporal window in which origins are ‘initiation competent’.
5. DNA Replication & Recombination: A Dynamic Interplay
5.1. Adding a Level of Complexity: The Assymetry of DNA Replication
When the first photographic micrograph of the E. coli replication [111] was presented – just before the 1963 Cold Spring Harbor Symposium – Monod raised a critical question: How is simultaneous bidirectional replication achieved, given that the DNA Polymerase I can only add nucleotides to the hydroxyl end of the strand (i.e., from 5’ to 3’)? The answer arrived five years later, confirming the asymmetric nature of DNA replication: one strand is replicated continuously (i.e., the leading stand – from 5’ to 3’), while the lagging strand is replicated in the opposite direction, and in segments called Okazaki fragments; that is, discontinuously [112]. In bacteria, it was observed that there are more guanine nucleotides compared to cytosines within the leading strand; these strand-specific biases (a technique termed GC skew analysis) can thus be exploited to not only distinguish the leading from lagging strands, but also locate putative origins of replication and termination sites in archaea [113]. The lagging strand differs vastly by its enzymology: RNA primase is required to synthesise the 3’ end primers, SSB protein to protect the exposed ssDNA, RNaseH to remove the RNA primases (DnaG in bacteria, PriSL in eukaryotes, and its homologue PriXLS in archaea), and finally; ligase to seal the synthesised fragments together. It becomes apparent that this universal requirement for a terminal 3’-OH group for DNA polymerase-mediated extension is observed in all living forms across all three domains (as well as non-living viruses). Taken together, one could simplify strand extension to three fundamental requirements: (1) a terminal hydroxyl group provided by a primer or a recombination intermediate (2) DNA polymerase, and (3) interactions with additional factors to help load the replisome.
It is hence tempting to speculate that the LUCA (Last Universal Common Ancestor) relied on using a template-independent RNA polymerase (particularly due to its innate ability to bond nucleotides within its active site) due to the pressures of using RNA as a sole genetic material during the transition from the RNA world [114], with DNA polymerase being a later invention. Intriguingly, comparative genomics has revealed that the main components of the replisome do not share homology between bacteria and archaea/eukaryotes, with a notable exception of sliding clamps; the primordial cell relied on a separate set of enzymes to replicate its RNA genome [115].
6. Recombination Dependent Replication
The viral origin hypothesis – enunciated by Forterre – states that horizontal gene transfer from mobile genetic elements and viruses has contributed to the evolution of the vast array of replication machinery in archaea and eukaryotes [116]. In fact, simple replicators – such as T4 and ΦX174 bacteriophages – possess a unique ability to bypass the primer requirement through rolling circle replication (i.e, mode of RDR), where a simple nick generated by RCR (Rolling Circle Replication) endonuclease is sufficient thus representing the simplest strategies of replication initiation [117,118]. It is worthwhile to investigate the mechanisms of the differing methods employed to overcome the primer requirement, as the ‘clues’ provided may enable to better characterise the ancestral features of replication initiation.
6.1. Clue No.1: Lessons from Viral Models
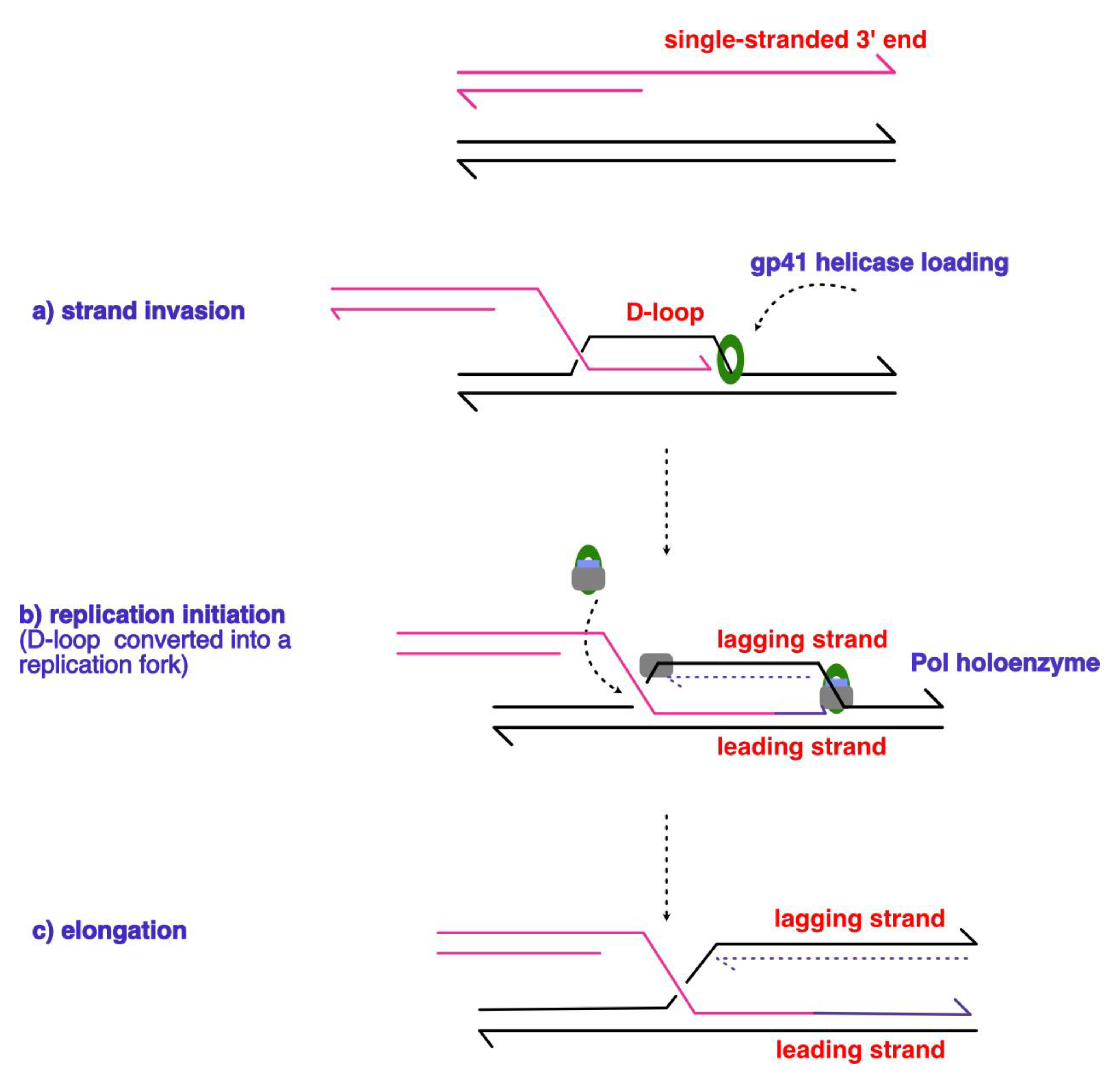
Viruses served as invaluable models of the replisome – for example, Alberts proposed the ‘trombone’ model to explain the coordination of the leading and lagging strands. Studies into the cell cycle of T4 bacteriophage were the first to propose a connecting link between replication and recombination, and initiated a research line into recombination processes, which were regarded as a rudimentary ‘cut-and-paste’ mechanism [119]. As early as in 1980, Mosig (for review of author’s work and citations therein, see [120]) suggested that the replication of the bacteriophage occurs through homologous recombination. In the early stages, the replication initiated from fixed origins; however, at a later stage of the process the 3’ end of the lagging strand cannot be extended. This results in the recruitment of the DNA strand exchange protein called UvsX to the 3’ ssDNA – thereby resulting in the formation of the D-loop (Displacement Loop)through strand invasion. A D-loop can therefore be defined an intermediate structure that is formed during processes involving homologous recombination, whereby a single strand invades the dsDNA molecule in a strand exchange event. The homologous region is used as a template for the DNA synthesis and subsequent ligation events to repair a break in the DNA molecule. A similar mechanism is employed as part of the natural life cycle of bacteriophage T4. Although in the early stages of the cycle, mostly origins are used – some origins utilise the 3’ ends of RNA displacement loops or R-loops (i.e., a three-stranded nucleic acid structure, which involves a RNA-DNA hybrid from a transcript, displacing a DNA strand – commonly occurring due to aborted transcription) to directly prime replication [120,121]. This tells us about the important distinction when it comes to priming replication through recombination intermediates: R-loops possess an advantage over D-loops due to their ability to serve as direct primers. The 3’ ssDNA ends are generated (either as a natural part of the replication process or through end processing via the 5 to 3’ exonuclease activity of T4-encoded RNaseHs). The necessity of these DNA breaks for RDR initiation was confirmed using in vivo models of artificially created DBSs. Then, UvsX protein promoted strand exchange (n.b., UvsX have also been noted to be involved in branch migration and complementary DNA reannealing) to form the D-loop (see Figure 6). Several authors have questioned the necessity of this two-way mode of replication, as a similar mechanism has been utilised in bacteria. Is there any functional advantage, if de novo replication in T4 bacteriophage requires not only a D-loop formed, but also terminal redundancy supplemented by homologous sequences from a second copy of the genome? Syeda [122] reasons that even though RDR restrains genomic structure and ploidy – compared to canonical origin-dependent replication – RDR constitutes an ad hoc mechanism to overcome replicative blocks and ensure replication restart. This presents origins of replication as strict control points that have been favoured through evolution to replace a potentially dysregulated RDR initiation mode of replication.
The UvsX protein in bacteriophages also displays some sequence similarity to the bacterial recA belongs to the RecA/Rad51/RadA superfamily of recombinases, found within the bacterial, eukaryotic, and archaeal domains, respectively. Bacterial RecA, Rad51-family members, and archaeal RadA are all homologous to each other. And although it is tempting to speculate that the viral recombinase follows the same pattern, due to some reports of weak homology of UvsX to RecA119, structural analyses reveal that RecA has evolved through convergent evolution; UvsX and RecA/Rad51/RadA are orthologous [123].
The pressing problem in RDR initiation research line is the missing gap between the initial D-loop formation, and the molecular mechanisms leading up to full replisome assembly; in all 3 domains. However in origin-independent replication E. coli, DNA footprinting assays have revealed that PriA is able to not only recognise the D-loop structure, but can also recruit the φX174-like primasome, and lead to the formation of the replication fork [124,125]. PriA belongs to the 3′−5′ DExH helicases of the Superfamily 2 class. It becomes apparent that interactions between the helicase and the recombination intermediate may serve as a potential clue to the full elucidation of the replisome assembly mechanism; however, research into the interactions that occur between the recombination intermediate, and the proteins which assist in the assembly of the replisome has been lacking. This is partly due to the difficulty of deleting origins in eukaryotic models and sustaining viable originless cells. Archaea encode homologues to number of eukaryotic replication proteins, but in addition have a very flexible genome that allows for genetic manipulation, and a platform to investigate origin-independent mechanisms; implications of which can be extended to other life forms.
Figure 6.
Schematic diagram outlining the steps in the RDR process that occurs during the T4 bacteriophage lifecycle. The schematic depicts a model of D-loop formation through the (a) strand invasion mechanism proposed by Mosig [120], where the 3’ end of the DNA strand from the previous replication cycle is used to prime and initiate the next round of replication, thus the mechanism is described as self-regenerating. The subsequent cleavage (b) of the D-loop by the junction-cleaving nuclease or T4 gp41 establishes the directionality of the replication fork, followed by the loading of the replicative polymerase, and the primer. The (pink) invading strand primes continuous replication in purple on the leading strand in (c), and the discontinuous line denotes lagging strand synthesis, with the 3’ end of the strands depicted as arrowheads. Figure adapted from [119].
Figure 6.
Schematic diagram outlining the steps in the RDR process that occurs during the T4 bacteriophage lifecycle. The schematic depicts a model of D-loop formation through the (a) strand invasion mechanism proposed by Mosig [120], where the 3’ end of the DNA strand from the previous replication cycle is used to prime and initiate the next round of replication, thus the mechanism is described as self-regenerating. The subsequent cleavage (b) of the D-loop by the junction-cleaving nuclease or T4 gp41 establishes the directionality of the replication fork, followed by the loading of the replicative polymerase, and the primer. The (pink) invading strand primes continuous replication in purple on the leading strand in (c), and the discontinuous line denotes lagging strand synthesis, with the 3’ end of the strands depicted as arrowheads. Figure adapted from [119].
6.2. Clue No.2: Break-Induced DNA Replication in Eukaryotes
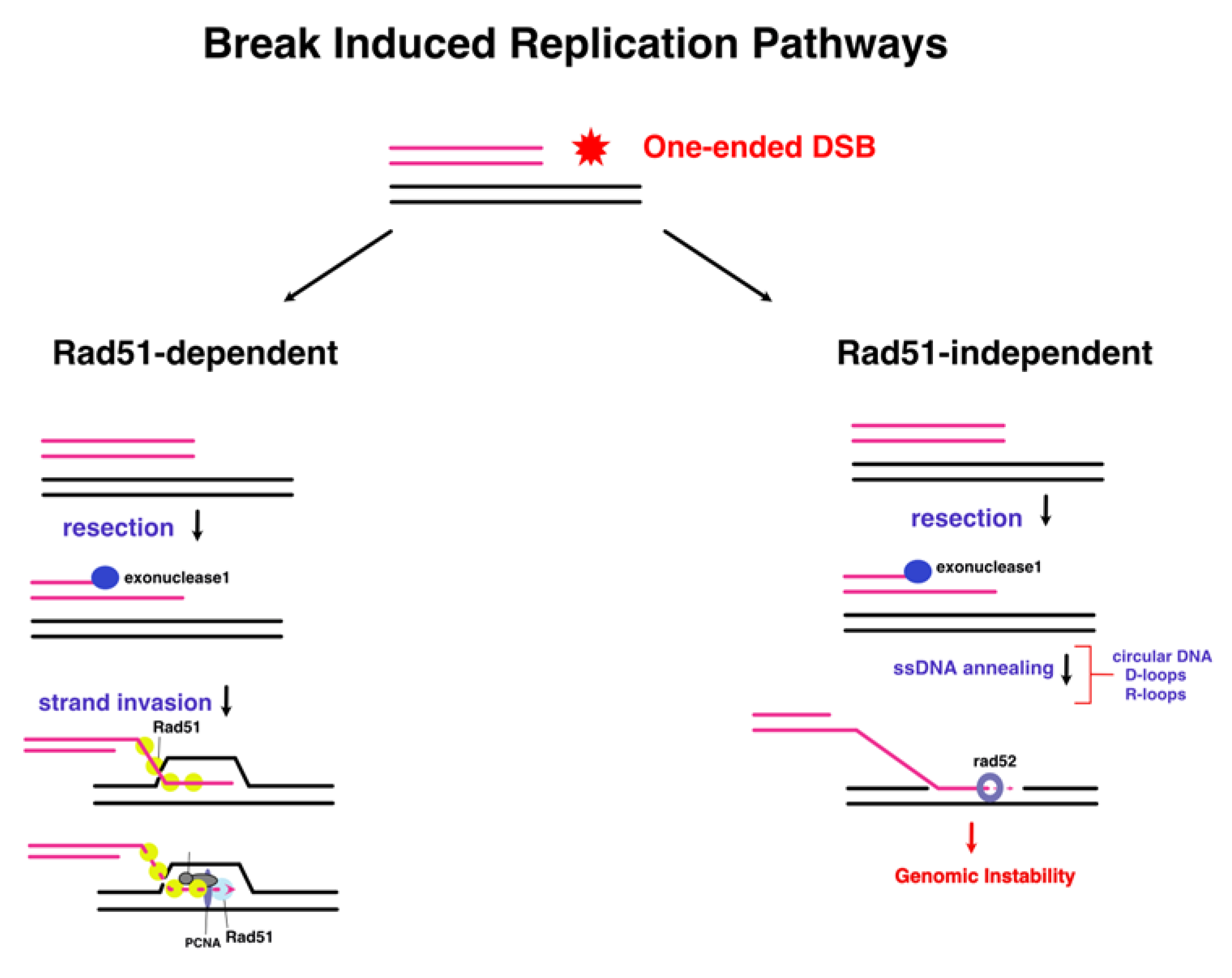
A form of RDR exists within the eukaryotic domain – and is termed BIR (Break Induced Replication) which occurs through homologous recombination. The first evidence came from studies in S. cerevisiae when observing the telomere maintenance mechanisms within cells which lack telomerase [126]. Anand [127] emphasizes the lack of progress in understanding the conversion of D-loop structures into replisomes in BIR of budding yeast, as no homologues of the bacterial PriA have been discovered in eukaryotes. A potential lead is that a subunit of pol-δ – a PolB-like polymerase – has been shown to be essential in all BIR events. In higher eukaryotes, such as humans, HelQ helicase interacts with pol-δ to inhibit DNA synthesis, and in turn, promotes DNA repair pathways such as synthesis-dependent strand annealing [128]. One of the experimental methods employed was to induce artificial chromosomal DSBs using site-specific endonucleases, thereby stimulating strand invasion and initiation through BIR [129]. The simple model involves a 3’end resection of the DBS (Double Strand Break), exposing a DNA strand which invades a homologous DNA molecule sequence to form a D-loop. The 3’end acts as a primer in BIR to initiate synthesis through a migrating bubble thus resulting in conservative inheritance. All pre-RC components of canonical origin-dependent replication were shown to act during BIR, in addition to recombination proteins such as Rad51, Rad52, Rad54, Rad55, and Rad57 which catalyse D-loop formation [130]. As with other helicases, it is still unknown through which interactions MCM (Minichromosome Maintenance Complex) is recruited to the D-loop. In yeast, strains deleted for Rad51 still undergo repair via BIR, albeit without strand invasion, and through a Rad52-mediated mechanism by using R-loops or circular DNA as substrates to facilitate annealing of 3’ ssDNA. The caveat is that this pathway frequently leads to genomic instability, and chromosomal rearrangements [131].
Figure 7.
A distinguishing feature of Rad51-dependent BIR, is that it occurs via a bubble migration mechanism (left). Polα is implicated in the formation of the D-loop, and the replication factors that have been speculated to be involved are indicated. Rad51-independent utilises the annealing activity of Rad52 (right) to reinitiate DNA synthesis on ectopic sites of the genome through the use of transposon elements. Figure adapted from [131] (modified from [119]).
Figure 7.
A distinguishing feature of Rad51-dependent BIR, is that it occurs via a bubble migration mechanism (left). Polα is implicated in the formation of the D-loop, and the replication factors that have been speculated to be involved are indicated. Rad51-independent utilises the annealing activity of Rad52 (right) to reinitiate DNA synthesis on ectopic sites of the genome through the use of transposon elements. Figure adapted from [131] (modified from [119]).
6.3. Clue No.3: Origin-Independent Replication Initiation in Bacteria and Archaea
Kogoma and Lark [132] provided the first experimental evidence of an origin-independent replication process occurring in bacteria, expanding on their earlier paper which characterised E. coli replication which continued through several rounds despite thymine deficiency. Replication initiation through tightly controlled actions of DnaA and OriC is the preferred pathway due to it being highly efficient. However, the ‘cost’ of such mechanism is repeated protein synthesis of all the replication components with every cycle – an energy consuming process. In SOS-induced cells, and low-nutrient environments – an alternative pathway termed iSDR is therefore activated. Interestingly, E. coli with deletions for RNase HI (i.e, rnhA) have displayed another subcategory of SDR: that is, constitutive SDR or cSDR. As ∆rnhA E. coli were able to grow without DnaA and OriC, it was postulated that the increase in R-loop formation due to the deletion of RNase HI, can promote replication. This avoids the use of an initiator protein which is sequence-specific, as replication can initiate at different sites across the genome. In both cSDR and iSDR, RecA and PriA have been shown to be essential [133]. Historically, replication initiation from R-loops has not received much traction, owing to the lack of an experimental way to track R-loop formations in vivo. With the advent of DRIP (i.e, DNA:RNA immunoprecipitation, with S9.6 antibody which binds to DNA:RNA hybrids) , and DRIP-seq (high throughput sequencing) techniques, it became possible to characterise these structures. More importantly, the harmful biological implications of excessive R-loop accumulation have been implicated in human diseases like cancer, which stimulated a revival in research of the correlation between R-loops and genomic instability [134].
Figure 8.
The two pathways of stable DNA replication in E.coli which occurs independent of DnaA and OriC. iSDR differes from cSDR in that it occurs through D-loop formation, as opposed to R-loops. Figure adapted from [130] (modified from [119]).
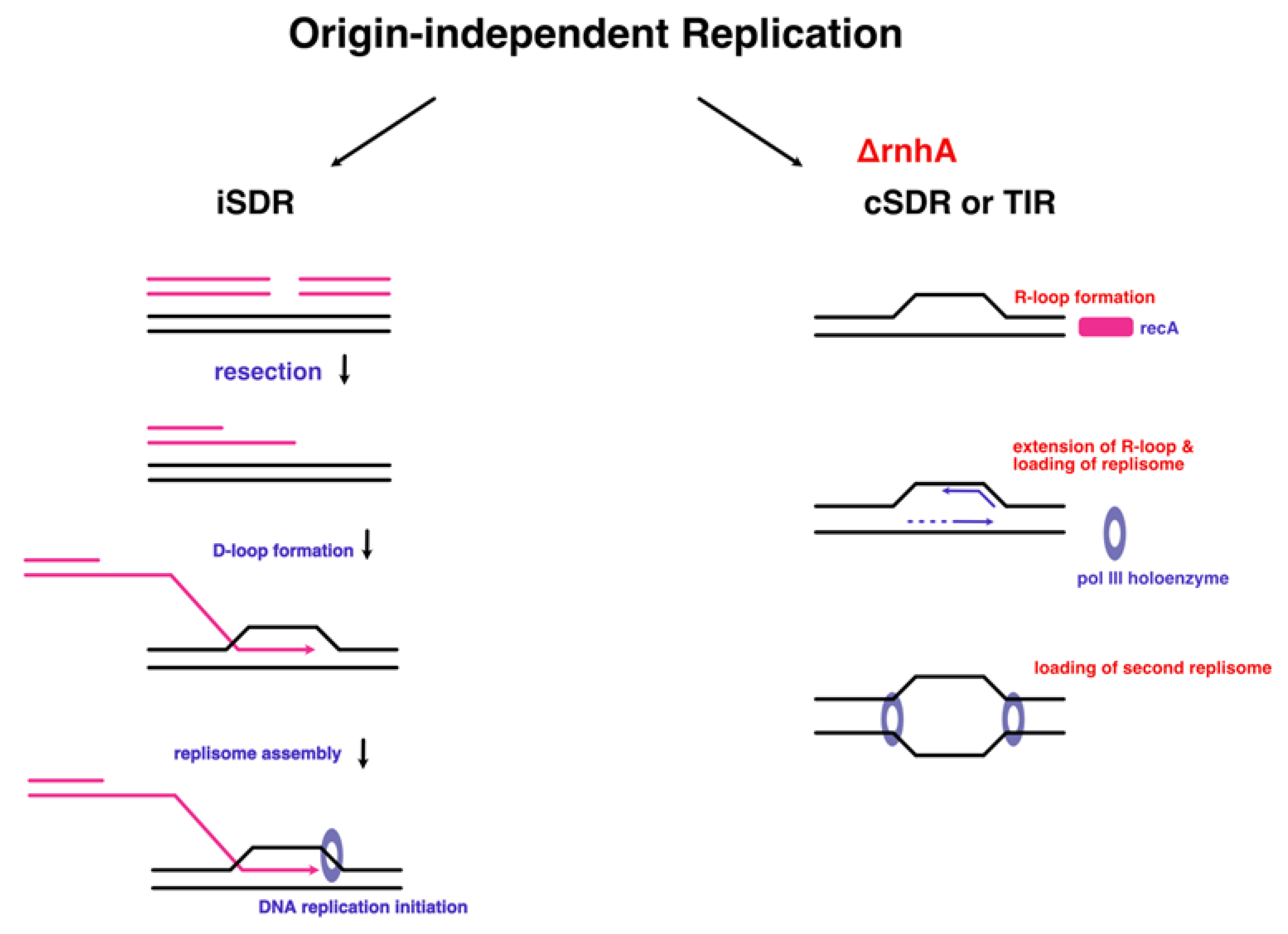
There is a balancing act between efficiency of DnaA-dependent replication and the energy saving advantage of SDR, which allows the bacterium to survive in adverse conditions, but occurs with low sequence specificity, and hence is inefficient for proper survival and growth in the normal environment [135]. It was therefore believed that origin-independent replication was only needed for ensuring survival of the cell in harsh environments, at the expense of replication accuracy.
This paradigm was overturned when a paper in 2013 reported that Haloferax volcanii – a halophilic species found within the archaeal domain – is able to not only survive but also display a 7.5% faster growth phenotype having all of its origins deleted, compared to the wild-type strains [136]. There were several intriguing features. Firstly, replication profiles of genome copy numbers along the length of the chromosome revealed that this type of replication does not initiate from a fixed sequence; but rather, in a stochastic manner with initiation points dispersed all over the genome. Another observation was that when the radA recombinase gene was put under a tryptophan inducible promoter to regulate its levels, originless cells displayed an absolute requirement for this protein. Basing on this body of evidence, alongside the previous known cases of similar type of replication mechanism in E. coli [137], the authors suggested that a RDR mechanism must be involved, where RadA catalyses D-loop formation. The next line of questioning involved the replication machinery that is assembled during RDR; with MCM being a major player in the recruitment to the D-loop structure. The indispensability of RadA in archaeal RDR was confirmed this year [138], where it was shown to fluctuate according to the growth stage.
This phenomenon does not extend to archaeal cells deleted for individual origins which display a growth disadvantage; given the known cases of sexual mating involving HGT in H. volcanii [139], the authors made a suggestion that origins behave akin to selfish genetic elements, which prioritise the maintenance of their own ploidy. This could explain the discrepancy between the deletions of individual origins which have no growth advantage, however the picture was only beginning to emerge. This discovery stimulated the birth of a new subfield – the study of the necessity and the nature of replication origins within the archaeal domain. In the more phylogenetically distant thermophilic archaeon – Thermococcus kodakarensis – the single origin can also be deleted and have no deleterious consequences on the phenotype [140]. Similarly, results from MFA (Marker Frequency Analysis) technique were consistent with the hypothesis of dispersed sites of replication initiation during RDR. The picture becomes less clear when in a closely related species to H. volcanii – H. mediterranei – genuine origin deletion cannot be achieved because a dormant origin becomes activated [141]. What is then so special about the replication origins in H. volcanii? Finding an answer to this question may reveal new insights on the fundamental characteristics of replication origins that were previously unknown, due to being ‘concealed’ during normal replication processes.
7. Conclusions: The Archaeal Domain as a Window into Our Evolutionary Past
The discovery of Archaea as a separate domain has overturned the long-standing paradigm of the two domain tree of life. Woese believed that the studies of protein synthesis at the time lacked an evolutionary underpinning, which was the reason for their lack of progress. His background in biophysics endowed him with a unique perspective: in a letter to Crick, he expressed how he intended to study of the conservation of proteins, and their variation amongst different domains of life [142]. Woese saw the potential in the current technology of Sanger sequencing [143], and utilised it to sequence the small subunit of 16S rRNA which appeared to be evolved from a common ancestor. From that, Woese and his postdoc Fox concluded that Bacteria and Archaebacteria (as Archaea were then called) constitute separate domains on the tree of life [144]– and have redrawn the evolutionary tree to show tripartite division between Eukarya, Bacteria, and Archaea (i.e., the '-bacteria' suffix has been removed to highlight Archaea’s evolutionary distinction). Woese was highly criticised for the reductionist approach of attempting to rewrite the entire tree of life using a single molecule. To his defence, Zillig proposed the structural homology [145,146,147] between the RNAP molecules within the three domains, thus strengthening the proposal, and leading to the establishment a new tripartite tree model [148]. At first glance, archaea share some obvious morphological similarities to bacteria, yet their genetic machinery highly resemble those commonly found within Eukaryotes. Thus archaea are often described as a ‘mosaic blend’ of eukaryotic and bacterial features.
Zillig’s work on RNAPs has unveiled the previously unsuspected evolutionary connection between Archaea and Eukaryotes, and has prompted others to search for evolutionary links between other major enzymes, such as DNA polymerases [145]. With no intermediates between eukaryotes and prokaryotes, we observe a formidable gap (some authors go as far as to call it a ‘quantum leap’ of eukaryotic organisational complexity) in evolutionary history. The moment that finally drew attention to archaea – namely the halophiles – was that haloarchaeon Halobacterium halobium was found to be sensitive to a eukaryotic polymerase inhibitor aphidicolin [149]. Subsequently, it was confirmed that archaea and eukaryotes do indeed share B-family polymerases. One particularly intriguing finding was that DNA polymerase D is unique to the euryarchaeota group of archaea, and is absent from eukaryotes [150].
Several hypotheses emerged which attempted to reconcile the missing link between Archaea and Eukarya, in light of eukaryogenesis. Attempts to characterise the ancestral features of the last eukaryotic common ancestor (i.e., LECA, giving rise to all eukaryotic lineages), have led some to speculate on the archaeal origin of eukaryote, with most commonly proposed scenarios involving an endosymbiotic event between an Asgard archaeon, and alphaproteobacterium (refer to [151], for an in-depth review on eukaryogenesis theories). Many of these theories remained on the speculative side; however, with the recent isolation, and the metagenomic analysis of the Asgard archaeaota superphylum (such as Lokiarchaeota), has revealed them to be the closest living relative of eukaryotes [152], thus strengthening the archaeal involvement in the evolution of the modern eukaryotic cell. Let us not forget about another missing piece – why has the genome evolved to consist of specific origins, yet retain secondary replication mechanisms? Moreover, our understanding of the steps and enzymology of the full replisome assembly from recombination intermediates remains fragmentary. This is due to the small number of culturable model organisms that can replicate in an origin-independent manner.
The so-called ‘black hole’ of evolutionary biology persists; that is, the origin of the eukaryotic cell, and the emergence of eukaryotic organisational complexity. The race is on to reconstitute the proto-eukaryote – and finding a genetically tractable species of Lokiarchaeaota to recapitulate the findings of originless haloarchaea might just be what gets us closer to the finishing line.
Author Contributions
Writing—original draft preparation, A.S. and T.A.; writing—review and editing, A.S. and T.A.; supervision, T.A.; funding acquisition, T.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Biotechnology and Biological Sciences Research Council, studentship [BB/M008770/1] to A.S., and by The Leverhulme Trust, grant number [RF-2023-286\2] to T.A.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Acknowledgments
We thank Laura Mitchell for her continuous technical support to the laboratory.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Gaillard, H.; García-Muse, T.; Aguilera, A. Replication Stress and Cancer. Nat. Rev. Cancer 2015, 15, 276–289. [CrossRef]
- Avery, O.T.; Macleod, C.M.; McCarthy, M. STUDIES ON THE CHEMICAL NATURE OF THE SUBSTANCE INDUCING TRANSFORMATION OF PNEUMOCOCCAL TYPES. J Exp Med 1944, 79, 137–158.
- De Silva, R.T.; Abdul-Halim, M.F.; Pittrich, D.A.; Brown, H.J.; Pohlschroder, M.; Duggin, I.G. Improved Growth and Morphological Plasticity of Haloferax Volcanii. Microbiology 2021, 167, 1–12. [CrossRef]
- Stent, G.S. Prematurity and Uniqueness in Scientific Discovery. Sci. Am. 1972, 227, 84–93.
- Mirsky, A.E.; Pollister, A.W. CHROMOSIN, A DESOXYRIBOSE NUCLEOPROTEIN COMPLEX OF THE CELL NUCLEUS. J. Gen. Physiol. 1946, 30, 117–148. [CrossRef]
- Chargaff, E. Chemical Specificity of Nucleic Acids and Mechanism of Their Enzymatic Degradation. Experientia 1950, 6, 201–209. [CrossRef]
- Levene, P.A.; La Forge, F.B. On Chondrosamine. Proc. Natl. Acad. Sci. 1915, 1, 190–191. [CrossRef]
- Hershey, A.D.; Chase, M. INDEPENDENT FUNCTIONS OF VIRAL PROTEIN AND NUCLEIC ACID IN GROWTH OF BACTERIOPHAGE. J. Gen. Physiol. 1952, 36, 39–56.
- Wyatt, H.V. How History Has Blended. Nature 1974, 249, 803–805.
- Watson, J.D.; Crick, F.H.C. Genetical Implications of the Structure of Deoxyribonucleic Acid. Nature 1953, 171, 964–967.
- Franklin, R.; Gosling, R. Molecular Configuration in Sodium Thymonucleate. Nature 1953, 171, 740–741.
- Wilkins, M.; Stokes, A.; Wilson, H. Molecular Structure of Nucleic Acids: Molecular Structure of Deoxypentose Nucleic Acids. Nature 1953, 171, 738–740.
- Pauling, L.; Corey, R.B. A Proposed Structure For The Nucleic Acids. Proc. Natl. Acad. Sci. 1953, 39, 84–97. [CrossRef]
- Watson, J.D.; Crick, F.H.C. Molecular Structure of Nucleic Acids; a Structure for Deoxyribose Nucleic Acid. Nature 1953, 171, 737–738.
- Bloch, D.P. A POSSIBLE MECHANISM FOR THE REPLICATION OF THE HELICAL STRUCTURE OF DESOXYRIBONUCLEIC ACID. Proc. Natl. Acad. Sci. 1955, 41, 1058–1064. [CrossRef]
- Meselson, M.; Stahl, F.W. THE REPLICATION OF DNA IN ESCHERICHIA COLI. Proc. Natl. Acad. Sci. 1958, 44, 671–682.
- Holmes, F.L. The DNA Replication Problem, 1953–1958. Cell 1998, 23, 117–120.
- Lehman, I.R.; Bessman, M.J.; Simms, E.S.; Kornberg, A. Enzymatic Synthesis of Deoxyribonucleic Acid. J. Biol. Chem. 1958, 233, 163–170. [CrossRef]
- Bessman, M.J.; Lehman, I.R.; Simms, E.S.; Kornberg, A. Enzymatic Synthesis of Deoxyribonucleic Acid. J. Biol. Chem. 1958, 233, 171–177. [CrossRef]
- Lieberman, I.; Kornberg, A.; Simms, E.S. ENZYMATIC SYNTHESES OF PYRIMIDINE AND PURINE NUCLEOTIDES. II.1 OROTIDINE-5’-PHOSPHATE PYROPHOSPHORYLASE AND DECARBOXYLASE. J. Am. Chem. Soc. 1954, 76.
- Cori, G.T.; Cori, C.F. CRYSTALLINE MUSCLE PHOSPHORYLASE. J. Biol. Chem. 1943, 151, 57–63. [CrossRef]
- Brutlag, D.; Kornberg, A. Enzymatic Synthesis of Deoxyribonucleic Acid. J. Biol. Chem. 1972, 247, 241–248. [CrossRef]
- Delarue, M.; Poch, O.; Tordo, N.; Moras, D.; Argos, P. An Attempt to Unify the Structure of Polymerases. Protein Eng. Des. Sel. 1990, 3, 461–467. [CrossRef]
- Joyce, C.M.; Steitz, T.A. FUNCTION AND STRUCTURE RELATIONSHIPS IN DNA POLYMERASES. Annu. Rev. Biochem. 1994, 63, 777–822.
- Bebenek, K.; Kunkel, T.A. Functions of DNA Polymerases. In Advances in Protein Chemistry; Elsevier, 2004; Vol. 69, pp. 137–165 ISBN 978-0-12-034269-3.
- Braithwaite, D.K.; Ito, J. Compilation, Alignment, and Phylogenetic Relationships of DNA Polymerases. Nucleic Acids Res. 1993, 21, 787–802. [CrossRef]
- Beese, L.S.; Derbyshire, V.; Steitz, T.A. Structure of DNA Polymerase I Klenow Fragment Bound to Duplex DNA. Science 1993, 260, 352–355. [CrossRef]
- Morin, J.A.; Cao, F.J.; Lázaro, J.M.; Arias-Gonzalez, J.R.; Valpuesta, J.M.; Carrascosa, J.L.; Salas, M.; Ibarra, B. Active DNA Unwinding Dynamics during Processive DNA Replication. Proc. Natl. Acad. Sci. 2012, 109, 8115–8120. [CrossRef]
- Bérut, A.; Arakelyan, A.; Petrosyan, A.; Ciliberto, S.; Dillenschneider, R.; Lutz, E. Experimental Verification of Landauer’s Principle Linking Information and Thermodynamics. Nature 2012, 483, 187–189. [CrossRef]
- Otsuka, J.; Nozawa, Y. Self-Reproducing System Can Behave as Maxwell’s Demon: Theoretical Illustration under Prebiotic Conditions. J. Theor. Biol. 1998, 194, 205–221. [CrossRef]
- Forterre, P.; Filée, J.; Myllykallio, H. Origin and Evolution of DNA and DNA Replication Machineries. In The Genetic Code and the Origin of Life; Springer US: Boston, MA, 2004; pp. 145–168 ISBN 978-0-306-47843-7.
- Rothwell, P.J.; Waksman, G. Structure and Mechanism of DNA Polymerases. In Advances in Protein Chemistry; Elsevier, 2005; Vol. 71, pp. 401–440 ISBN 978-0-12-034271-6.
- Steitz, T.A. DNA- and RNA-Dependent DNA Polymerases. Curr. Opin. Struct. Biol. 1993, 3, 31–38.
- Bębenek, A.; Ziuzia-Graczyk, I. Fidelity of DNA Replication—a Matter of Proofreading. Curr. Genet. 2018, 64, 985–996. [CrossRef]
- Ekundayo, B.; Bleichert, F. Origins of DNA Replication. PLOS Genet. 2019, 15, e1008320. [CrossRef]
- Jacob, F.; Monod, J. Genetic Regulatory Mechanisms in the Synthesis of Proteins. J. Mol. Biol. 1961, 3, 318–356.
- Ryter, A.; Hirota, Y.; Jacob, F. DNA-Membrane Complex and Nuclear Segregation in Bacteria. Cold Spring Harb. Symp. Quant. Biol. 1968, 33, 669–676. [CrossRef]
- Morange, M. What History Tells Us XXXI. The Replicon Model: Between Molecular Biology and Molecular Cell Biology. J. Biosci. 2013, 38, 225–227. [CrossRef]
- Jacob, F.; Brenner, S.; Cuzin, F. On the Regulation of DNA Replication in Bacteria. Cold Spring Harb. Symp. Quant. Biol. 1963, 28, 329–348. [CrossRef]
- Huberman, J.A.; Riggs, A.D. On the Mechanism of DNA Replication in Mammalian Chromosomes. J. Mol. Biol. 1968, 32, 327–341. [CrossRef]
- Novick, R.P. Plasmid Incompatibility. Microbiol. Rev. 1987, 51, 381–395.
- Kohiyama, M.; Hiraga, S.; Matic, I.; Radman, M. Bacterial Sex: Playing Voyeurs 50 Years Later. Science 2003, 301, 802–803. [CrossRef]
- Yasuda, S.; Hirota, Y. Cloning and Mapping of the Replication Origin of Escherichia Coli. Proc. Natl. Acad. Sci. 1977, 74, 5458–5462. [CrossRef]
- Mackiewicz, P. Where Does Bacterial Replication Start? Rules for Predicting the oriC Region. Nucleic Acids Res. 2004, 32, 3781–3791. [CrossRef]
- Chakraborty, T.; Yoshinaga, K.; Lother, H.; Messer, W. Purification of the E. Coli dnaA Gene Product. EMBO J. 1982, 1, 1545–1549. [CrossRef]
- Fujita, M.Q.; Yoshikawa, H. Structure of the dnaA Region of Pseudomonas Putida: Conservation among Three Bacteria, Bacillus Subtilis, Escherichia Coil and P. Putida.
- Chan, C.S.; Tye, B.K. Autonomously Replicating Sequences in Saccharomyces Cerevisiae. Proc. Natl. Acad. Sci. 1980, 77, 6329–6333. [CrossRef]
- Broach, J.R.; Li, Y.-Y.; Feldman, J.; Jayaram, M.; Abraham, J.; Nasmyth, K.A.; Hicks, J.B. Localization and Sequence Analysis of Yeast Origins of DNA Replication. Cold Spring Harb. Symp. Quant. Biol. 1983, 47, 1165–1173. [CrossRef]
- Bell, S.P.; Stillman, B. ATP-Dependent Recognition of Eukaryotic Origins of DNA Replication by a Multiprotein Complex. Nature 1992, 357, 128–134.
- Gavin, K.A.; Hidaka, M.; Stillman, B. Conserved Initiator Proteins in Eukaryotes. Science 1995, 270, 1667–1671. [CrossRef]
- Taylor, J.H. Increase in DNA Replication Sites in Cells Held at the Beginning of S Phase. Chromosoma 1977, 62, 291–300. [CrossRef]
- Hamlin, J.L.; Mesner, L.D.; Lar, O.; Torres, R.; Chodaparambil, S.V.; Wang, L. A Revisionist Replicon Model for Higher Eukaryotic Genomes. J. Cell. Biochem. 2008, 105, 321–329. [CrossRef]
- diCenzo, G.C.; Finan, T.M. The Divided Bacterial Genome: Structure, Function, and Evolution. Microbiol. Mol. Biol. Rev. 2017, 81, e00019-17. [CrossRef]
- Harrison, P.W.; Lower, R.P.J.; Kim, N.K.D.; Young, J.P.W. Introducing the Bacterial ‘Chromid’: Not a Chromosome, Not a Plasmid. Trends Microbiol. 2010, 18, 141–148. [CrossRef]
- Krawiec, S.; Riley, M. Organization of the Bacterial Chromosome. MICROBIOL REV 1990, 54.
- Suwanto, A.; Kaplan, S. Physical and Genetic Mapping of the Rhodobacter Sphaeroides 2.4.1 Genome: Presence of Two Unique Circular Chromosomes. J BACTERIOL 1989, 171.
- Woese, C.R.; Fox, G.E. Phylogenetic Structure of the Prokaryotic Domain: The Primary Kingdoms. Proc. Natl. Acad. Sci. 1977, 74, 5088–5090. [CrossRef]
- Wu, S.; Beard, W.A.; Pedersen, L.G.; Wilson, S.H. Structural Comparison of DNA Polymerase Architecture Suggests a Nucleotide Gateway to the Polymerase Active Site. Chem. Rev. 2014, 114, 2759–2774. [CrossRef]
- Myllykallio, H.; Lopez, P.; López-Garcı́a, P.; Heilig, R.; Saurin, W.; Zivanovic, Y.; Philippe, H.; Forterre, P. Bacterial Mode of Replication with Eukaryotic-Like Machinery in a Hyperthermophilic Archaeon. Science 2000, 288, 2212–2215. [CrossRef]
- Matsunaga, F.; Forterre, P.; Ishino, Y.; Myllykallio, H. In Vivo Interactions of Archaeal Cdc6/Orc1 and Minichromosome Maintenance Proteins with the Replication Origin. Proc. Natl. Acad. Sci. 2001, 98, 11152–11157. [CrossRef]
- Matsunaga, F.; Norais, C.; Forterre, P.; Myllykallio, H. Identification of Short ‘Eukaryotic’ Okazaki Fragments Synthesized from a Prokaryotic Replication Origin. EMBO Rep. 2003, 4, 154–158. [CrossRef]
- Robinson, N.P.; Dionne, I.; Lundgren, M.; Marsh, V.L.; Bernander, R.; Bell, S.D. Identification of Two Origins of Replication in the Single Chromosome of the Archaeon Sulfolobus Solfataricus. Cell 2004, 116, 25–38. [CrossRef]
- Lundgren, M.; Andersson, A.; Chen, L.; Nilsson, P.; Bernander, R. Three Replication Origins in Sulfolobus Species: Synchronous Initiation of Chromosome Replication and Asynchronous Termination. Proc. Natl. Acad. Sci. 2004, 101, 7046–7051. [CrossRef]
- She, Q.; Peng, X.; Zillig, W.; Garrett, R.A. Gene Capture in Archaeal Chromosomes. Nature 2001, 409, 478–478. [CrossRef]
- Robinson, N.P.; Bell, S.D. Extrachromosomal Element Capture and the Evolution of Multiple Replication Origins in Archaeal Chromosomes. Proc. Natl. Acad. Sci. 2007, 104, 5806–5811. [CrossRef]
- Zhang, R.; Zhang, C.-T. Multiple Replication Origins of the Archaeon Halobacterium Species NRC-1. Biochem. Biophys. Res. Commun. 2003, 302, 728–734. [CrossRef]
- Wu, Z.; Liu, H.; Liu, J.; Liu, X.; Xiang, H. Diversity and Evolution of Multiple Orc/Cdc6-Adjacent Replication Origins in Haloarchaea. BMC Genomics 2012, 13, 478. [CrossRef]
- Hawkins, M.S. DNA Replication Origins in Haloferax Volcanii. Doctoral Thesis, University of Nottingham: Nottingham, United Kingdom, 2009.
- Dyall-Smith, M.L.; Pfeiffer, F.; Klee, K.; Palm, P.; Gross, K.; Schuster, S.C.; Rampp, M.; Oesterhelt, D. Haloquadratum Walsbyi : Limited Diversity in a Global Pond. PLoS ONE 2011, 6, e20968. [CrossRef]
- Rozgaja, T.A.; Grimwade, J.E.; Iqbal, M.; Czerwonka, C.; Vora, M.; Leonard, A.C. Two Oppositely Oriented Arrays of Low-Affinity Recognition Sites in oriC Guide Progressive Binding of DnaA during Escherichia Coli Pre-RC Assembly: DnaA-oriC Interaction at Arrayed Sites. Mol. Microbiol. 2011, 82, 475–488. [CrossRef]
- Matsui, M.; Oka, A.; Takanami, M.; Yasuda, S.; Hirota, Y. Sites of dnaA Protein-Binding in the Replication Origin of the Escherichia Coli K-12 Chromosome. J. Mol. Biol. 1985, 184, 529–533. [CrossRef]
- Shimizu, M.; Noguchi, Y.; Sakiyama, Y.; Kawakami, H.; Katayama, T.; Takada, S. Near-Atomic Structural Model for Bacterial DNA Replication Initiation Complex and Its Functional Insights. Proc. Natl. Acad. Sci. 2016, 113. [CrossRef]
- Erzberger, J.P. The Structure of Bacterial DnaA: Implications for General Mechanisms Underlying DNA Replication Initiation. EMBO J. 2002, 21, 4763–4773. [CrossRef]
- Erzberger, J.P.; Berger, J.M. Evolutionary Relationships and Structural Mechanisms of AAA+ Proteins. Annu. Rev. Biophys. Biomol. Struct. 2006, 35, 93–114. [CrossRef]
- Kowalski, D.; Eddy, M.J. The DNA Unwinding Element: A Novel, Cis-Acting Component That Facilitates Opening of the Escherichia Coli Replication Origin. EMBO J. 1989, 8, 4335–4344. [CrossRef]
- Wegrzyn, K.; Konieczny, I. Toward an Understanding of the DNA Replication Initiation in Bacteria. Front. Microbiol. 2024, 14, 1328842. [CrossRef]
- Robinson, N.P.; Bell, S.D. Origins of DNA Replication in the Three Domains of Life. FEBS J. 2005, 272, 3757–3766. [CrossRef]
- Schwob, E. Flexibility and Governance in Eukaryotic DNA Replication. Curr. Opin. Microbiol. 2004, 7, 680–690. [CrossRef]
- Segurado, M.; Gómez, M.; Antequera, F. Increased Recombination Intermediates and Homologous Integration Hot Spots at DNA Replication Origins. Mol. Cell 2002, 10, 907–916. [CrossRef]
- Gilbert, D.M.; Takebayashi, S.-I.; Ryba, T.; Lu, J.; Pope, B.D.; Wilson, K.A.; Hiratani, I. Space and Time in the Nucleus: Developmental Control of Replication Timing and Chromosome Architecture. Cold Spring Harb. Symp. Quant. Biol. 2010, 75, 143–153. [CrossRef]
- Labib, K. How Do Cdc7 and Cyclin-Dependent Kinases Trigger the Initiation of Chromosome Replication in Eukaryotic Cells? Genes Dev. 2010, 24, 1208–1219. [CrossRef]
- O’Donnell, M.; Langston, L.; Stillman, B. Principles and Concepts of DNA Replication in Bacteria, Archaea, and Eukarya. Cold Spring Harb. Perspect. Biol. 2013, 5, a010108–a010108. [CrossRef]
- Hartwell, L.H. Sequential Function of Gene Products Relative to DNA Synthesis in the Yeast Cell Cycle. J. Mol. Biol. 1976, 104, 803–817. [CrossRef]
- Hofmann, J.F.X.; Beach, D. Cdt 1 Is an Essential Target of the Cdc 1 O/Sct 1 Transcription Factor: Requirement for DNA Replication and Inhibition of Mitosis.
- Nishitani, H.; Lygerou, Z.; Nishimoto, T.; Nurse, P. The Cdt1 Protein Is Required to License DNA for Replication in ®ssion Yeast. 2000, 404.
- Schmidt, J.M.; Yang, R.; Kumar, A.; Hunker, O.; Seebacher, J.; Bleichert, F. A Mechanism of Origin Licensing Control through Autoinhibition of S. Cerevisiae ORC·DNA·Cdc6. Nat. Commun. 2022, 13, 1059. [CrossRef]
- Randell, J.C.W.; Bowers, J.L.; Rodríguez, H.K.; Bell, S.P. Sequential ATP Hydrolysis by Cdc6 and ORC Directs Loading of the Mcm2-7 Helicase. Mol. Cell 2006, 21, 29–39. [CrossRef]
- Costa, A.; Diffley, J.F.X. The Initiation of Eukaryotic DNA Replication. Annu. Rev. Biochem. 2022, 91, 107–131. [CrossRef]
- Ilves, I.; Petojevic, T.; Pesavento, J.J.; Botchan, M.R. Activation of the MCM2-7 Helicase by Association with Cdc45 and GINS Proteins. Mol. Cell 2010, 37, 247–258. [CrossRef]
- Zegerman, P.; Diffley, J.F.X. Phosphorylation of Sld2 and Sld3 by Cyclin-Dependent Kinases Promotes DNA Replication in Budding Yeast. Nature 2007, 445, 281–285. [CrossRef]
- Greci, M.D.; Bell, S.D. Archaeal DNA Replication. Annu. Rev. Microbiol. 2020, 74, 65–80. [CrossRef]
- Lopez, P.; Philippe, H.; Myllykallio, H.; Forterre, P. Identification of Putative Chromosomal Origins of Replication in Archaea. Mol. Microbiol. 1999, 32, 883–886. [CrossRef]
- Liu, J.; Smith, C.L.; DeRyckere, D.; DeAngelis, K.; Martin, G.S.; Berger, J.M. Structure and Function of Cdc6/Cdc18: Implications for Origin Recognition and Checkpoint Control. Mol. Cell 2000, 6, 637–648.
- Matsunaga, F.; Glatigny, A.; Mucchielli-Giorgi, M.-H.; Agier, N.; Delacroix, H.; Marisa, L.; Durosay, P.; Ishino, Y.; Aggerbeck, L.; Forterre, P. Genomewide and Biochemical Analyses of DNA-Binding Activity of Cdc6/Orc1 and Mcm Proteins in Pyrococcus Sp. Nucleic Acids Res. 2007, 35, 3214–3222. [CrossRef]
- Matsunaga, F.; Takemura, K.; Akita, M.; Adachi, A.; Yamagami, T.; Ishino, Y. Localized Melting of Duplex DNA by Cdc6/Orc1 at the DNA Replication Origin in the Hyperthermophilic Archaeon Pyrococcus Furiosus. Extremophiles 2010, 14, 21–31. [CrossRef]
- Gaudier, M.; Schuwirth, B.S.; Westcott, S.L.; Wigley, D.B. Structural Basis of DNA Replication Origin Recognition by an ORC Protein. Science 2007, 317, 1213–1216. [CrossRef]
- Grainge, I. Biochemical Analysis of Components of the Pre-Replication Complex of Archaeoglobus Fulgidus. Nucleic Acids Res. 2003, 31, 4888–4898. [CrossRef]
- Samson, R.Y.; Xu, Y.; Gadelha, C.; Stone, T.A.; Faqiri, J.N.; Li, D.; Qin, N.; Pu, F.; Liang, Y.X.; She, Q.; et al. Specificity and Function of Archaeal DNA Replication Initiator Proteins. Cell Rep. 2013, 3, 485–496. [CrossRef]
- Dueber, E.L.C.; Corn, J.E.; Bell, S.D.; Berger, J.M. Replication Origin Recognition and Deformation by a Heterodimeric Archaeal Orc1 Complex. Science 2007, 317, 1210–1213. [CrossRef]
- Grainge, I.; Gaudier, M.; Schuwirth, B.S.; Westcott, S.L.; Sandall, J.; Atanassova, N.; Wigley, D.B. Biochemical Analysis of a DNA Replication Origin in the Archaeon Aeropyrum Pernix. J. Mol. Biol. 2006, 363, 355–369. [CrossRef]
- Ausiannikava, D.; Allers, T. Diversity of DNA Replication in the Archaea. Genes 2017, 8, 56. [CrossRef]
- Akita, M.; Adachi, A.; Takemura, K.; Yamagami, T.; Matsunaga, F.; Ishino, Y. Cdc6/Orc1 from Pyrococcus Furiosus May Act as the Origin Recognition Protein and Mcm Helicase Recruiter. Genes Cells 2010, 15, 537–552. [CrossRef]
- Kelman, L.M.; O’Dell, W.B.; Kelman, Z. Unwinding 20 Years of the Archaeal Minichromosome Maintenance Helicase. J. Bacteriol. 2020, 202. [CrossRef]
- Kasiviswanathan, R.; Shin, J.-H.; Kelman, Z. Interactions between the Archaeal Cdc6 and MCM Proteins Modulate Their Biochemical Properties. Nucleic Acids Res. 2005, 33, 4940–4950. [CrossRef]
- Samson, R.Y.; Abeyrathne, P.D.; Bell, S.D. Mechanism of Archaeal MCM Helicase Recruitment to DNA Replication Origins. Mol. Cell 2016, 61, 287–296. [CrossRef]
- Samson, R.Y.; Bell, S.D. MCM Loading—An Open-and-Shut Case? Mol. Cell 2013, 50, 457–458. [CrossRef]
- Mohammed Khalid, A.A.; Parisse, P.; Medagli, B.; Onesti, S.; Casalis, L. Atomic Force Microscopy Investigation of the Interactions between the MCM Helicase and DNA. Materials 2021, 14, 687. [CrossRef]
- Kelman, Z.; Lee, J.-K.; Hurwitz, J. The Single Minichromosome Maintenance Protein of Methanobacterium Thermoautotrophicum ⌬H Contains DNA Helicase Activity. Proc. Natl. Acad. Sci. 1999, 96, 14783–14788.
- Haugland, G.T.; Shin, J.-H.; Birkeland, N.-K.; Kelman, Z. Stimulation of MCM Helicase Activity by a Cdc6 Protein in the Archaeon Thermoplasma Acidophilum. Nucleic Acids Res. 2006, 34, 6337–6344. [CrossRef]
- Pérez-Arnaiz, P.; Dattani, A.; Smith, V.; Allers, T. Haloferax Volcanii —a Model Archaeon for Studying DNA Replication and Repair. Open Biol. 2020, 10, 200293. [CrossRef]
- Cairns, J. The Bacterial Chromosome and Its Manner of Replication as Seen by Autoradiography. J. Mol. Biol. 1963, 6, 208–213.
- Okazaki, R.; Okazaki, T.; Sakabe, K.; Sugimoto, K.; Sugino, A. Mechanism of DNA Chain Growth. I. Possible Discontinuity and Unusual Secondary Structure of Newly Synthesized Chains. Proc. Natl. Acad. Sci. 1968, 59, 598–605. [CrossRef]
- Kelman, L.M.; Kelman, Z. Archaea: An Archetype for Replication Initiation Studies? Mol. Microbiol. 2003, 48, 605–615. [CrossRef]
- Georgescu, R.; Langston, L.; O’Donnell, M. A Proposal: Evolution of PCNA’s Role as a Marker of Newly Replicated DNA. DNA Repair 2015, 29, 4–15. [CrossRef]
- Leipe, D.D.; Aravind, L.; Koonin, E.V. Did DNA Replication Evolve Twice Independently? Nucleic Acids Res. 1999, 27, 3389–3401. [CrossRef]
- Forterre, P. Why Are There So Many Diverse Replication Machineries? J. Mol. Biol. 2013, 425, 4714–4726. [CrossRef]
- Lujan, S.A.; Williams, J.S.; Kunkel, T.A. DNA Polymerases Divide the Labor of Genome Replication. Trends Cell Biol. 2016, 26, 640–654. [CrossRef]
- Iyer, L.M. Origin and Evolution of the Archaeo-Eukaryotic Primase Superfamily and Related Palm-Domain Proteins: Structural Insights and New Members. Nucleic Acids Res. 2005, 33, 3875–3896. [CrossRef]
- Kreuzer, K.N. Recombination-Dependent DNA Replication in Phage T4. Trends Biochem. Sci. 2000, 25, 165–173. [CrossRef]
- Mosig, G.; Gewin, J.; Luder, A.; Colowick, N.; Vo, D. Two Recombination-Dependent DNA Replication Pathways of Bacteriophage T4, and Their Roles in Mutagenesis and Horizontal Gene Transfer. Proc. Natl. Acad. Sci. 2001, 98, 8306–8311. [CrossRef]
- Belanger, K.G.; Kreuzer, K.N. Bacteriophage T4 Initiates Bidirectional DNA Replication through a Two-Step Process. Mol. Cell 1998, 2, 693–701. [CrossRef]
- Syeda, A.H.; Hawkins, M.; McGlynn, P. Recombination and Replication. Cold Spring Harb. Perspect. Biol. 2014, 6, a016550–a016550. [CrossRef]
- Yang, S.; VanLoock, M.S.; Yu, X.; Egelman, E.H. Comparison of Bacteriophage T4 UvsX and Human Rad51 Filaments Suggests That RecA-like Polymers May Have Evolved independently11Edited by M. Belfort. J. Mol. Biol. 2001, 312, 999–1009. [CrossRef]
- Liu, J.; Marians, K.J. PriA-Directed Assembly of a Primosome on D Loop DNA. J. Biol. Chem. 1999, 274, 25033–25041. [CrossRef]
- Jones, J.M. The Phi X174-Type Primosome Promotes Replisome Assembly at the Site of Recombination in Bacteriophage Mu Transposition. EMBO J. 1997, 16, 6886–6895. [CrossRef]
- Epum, E.A.; Haber, J.E. DNA Replication: The Recombination Connection. Trends Cell Biol. 2022, 32, 45–57. [CrossRef]
- Anand, R.P.; Lovett, S.T.; Haber, J.E. Break-Induced DNA Replication. Cold Spring Harb. Perspect. Biol. 2013, 5, a010397–a010397. [CrossRef]
- He, L.; Lever, R.; Cubbon, A.; Tehseen, M.; Jenkins, T.; Nottingham, A.O.; Horton, A.; Betts, H.; Fisher, M.; Hamdan, S.M.; et al. Interaction of Human HelQ with DNA Polymerase Delta Halts DNA Synthesis and Stimulates DNA Single-Strand Annealing. Nucleic Acids Res. 2023, 51, 1740–1749. [CrossRef]
- Malkova, A.; Ira, G. Break-Induced Replication: Functions and Molecular Mechanism. Curr. Opin. Genet. Dev. 2013, 23, 271–279. [CrossRef]
- Ravoitytė, B.; Wellinger, R. Non-Canonical Replication Initiation: You’re Fired! Genes 2017, 8, 54. [CrossRef]
- Lee, R.S. Stressed? Break-Induced Replication Comes to the Rescue! DNA Repair 2024, 142.
- Kogoma, T.; Lark, K.G. Characterization of the Replication of Escherichia Coli DNA in the Absence of Protein Synthesis: Stable DNA Replication. J. Mol. Biol. 1975, 94, 243–256. [CrossRef]
- Masai, H.; Asai, T.; Kubota, Y.; Arai, K.; Kogoma, T. Escherichia Coil PriA Protein Is Essential for Inducible and Constitutive Stable DNA Replication. EMBO J. 1994, 13, 5338–5345.
- Crossley, M.P.; Bocek, M.; Cimprich, K.A. R-Loops as Cellular Regulators and Genomic Threats. Mol. Cell 2019, 73, 398–411. [CrossRef]
- Masai, H. Replicon Hypothesis Revisited. Biochem. Biophys. Res. Commun. 2022, 633, 77–80. [CrossRef]
- Hawkins, M.; Malla, S.; Blythe, M.J.; Nieduszynski, C.A.; Allers, T. Accelerated Growth in the Absence of DNA Replication Origins. Nature 2013, 503, 544–547. [CrossRef]
- Kogoma, T. Recombination by Replication. Cell 1996, 85, 625-627,.
- Mc Teer, L.; Moalic, Y.; Cueff-Gauchard, V.; Catchpole, R.; Hogrel, G.; Lu, Y.; Laurent, S.; Hemon, M.; Aubé, J.; Leroy, E.; et al. Cooperation between Two Modes for DNA Replication Initiation in the Archaeon Thermococcus Barophilus. mBio 2024, 15, e03200-23. [CrossRef]
- Rosenshine, I.; Tchelet, R.; Mevarech, M. The Mechanism of DNA Transfer in the Mating System of an Archaebacterium. Science 1989, 245, 1387–1389. [CrossRef]
- Gehring, A.M.; Astling, D.P.; Matsumi, R.; Burkhart, B.W.; Kelman, Z.; Reeve, J.N.; Jones, K.L.; Santangelo, T.J. Genome Replication in Thermococcus Kodakarensis Independent of Cdc6 and an Origin of Replication. Front. Microbiol. 2017, 8, 2084. [CrossRef]
- Yang, H.; Wu, Z.; Liu, J.; Liu, X.; Wang, L.; Cai, S.; Xiang, H. Activation of a Dormant Replication Origin Is Essential for Haloferax Mediterranei Lacking the Primary Origins. Nat. Commun. 2015, 6, 8321. [CrossRef]
- Pace, N.R.; Sapp, J.; Goldenfeld, N. Phylogeny and beyond: Scientific, Historical, and Conceptual Significance of the First Tree of Life. Proc. Natl. Acad. Sci. 2012, 109, 1011–1018. [CrossRef]
- Sanger, F.; Brownlee, G.G.; Barrell, B.G. A Two-Dimensional Fractionation Procedure for Radioactive Nucleotides. J. Mol. Biol. 1965, 13.
- Fox, G.E.; Woese, C.R. Classification of Methanogenic Bacteria by 16S Ribosomal RNA Characterization. Proc. Natl. Acad. Sci. 1977, 74, 4537–4541.
- Albers, S.-V.; Forterre, P.; Prangishvili, D.; Schleper, C. The Legacy of Carl Woese and Wolfram Zillig: From Phylogeny to Landmark Discoveries. Nat. Rev. Microbiol. 2013, 11, 713–719. [CrossRef]
- Zillig, W.; Klenk, H.-P.; Palm, P.; Pühler, G.; Gropp, F.; Garrett, R.A.; Leffers, H. The Phylogenetic Relations of DNA-Dependent RNA Polymerases of Archaebacteria, Eukaryotes, and Eubacteria. Can. J. Microbiol. 1989, 35, 73–80. [CrossRef]
- Zillig, W. Comparative Biochemistry of Archaea and Bacteria. Curr. Opin. Genet. Dev. 1991, 1, 544–551. [CrossRef]
- Woese, C.R. Towards a Natural System of Organisms: Proposal for the Domains Archaea, Bacteria, and Eucarya. Proc. Natl. Acad. Sci. 1990, 87, 4576–4579.
- Forterre, P.; Elie, C.; Kohiyama, M. Aphidicolin Inhibits Growth and DNA Synthesis in Halophilic Arachaebacteria. J. Bacteriol. 1984, 159, 800–802. [CrossRef]
- Ishino, Y.; Komori, K.; Cann, I.K.O.; Koga, Y. A Novel DNA Polymerase Family Found in Archaea. J. Bacteriol. 1998, 180, 2232–2236. [CrossRef]
- Baum, B.; Spang, A. On the Origin of the Nucleus: A Hypothesis. Microbiol. Mol. Biol. Rev. 2023, 87, e00186-21. [CrossRef]
- Rinke, C.; Chuvochina, M.; Mussig, A.J.; Chaumeil, P.-A.; Davín, A.A.; Waite, D.W.; Whitman, W.B.; Parks, D.H.; Hugenholtz, P. A Standardized Archaeal Taxonomy for the Genome Taxonomy Database. Nat. Microbiol. 2021, 6, 946–959. [CrossRef]
Figure 1.
Proposed Mechanisms of DNA Replication: Semi-Conservative, Conservative, and Dispersive. The schematic represents the expected outcomes according to each mode of replication represented by the pioneering groups during the molecular revolution. In semi-conservative replication, the two parental strands separate, with each strand acting as a template to direct the synthesis through complementary base pairing, with the resulting daughter duplex consisting of the newly synthesised, and conserved parental strands. In conservative replication both parental strands are conserved, and in dispersive mode the double helix remains unwound, while segments break and re-join through crossing over thus the newly synthesised DNA appears ‘dispersed’ in the daughter strands. Meselson and Stahl demonstrated semi-conservative replication by taking an alternative approach to radioactive labelling (in contrast to the Phage group’s use of bacteriophage, rendering inconclusive results) – and growing E.coli cells in 14NH4Cl/15NH4Cl media containing 15N (‘heavy’) and 14N (‘light’) nitrogen isotopes, to measure the gradient densities every generation. This elegant experiment was conducted using a combination of Avery’s DNA isolation, and Hershey-Chase’s isotope labelling techniques.
Figure 1.
Proposed Mechanisms of DNA Replication: Semi-Conservative, Conservative, and Dispersive. The schematic represents the expected outcomes according to each mode of replication represented by the pioneering groups during the molecular revolution. In semi-conservative replication, the two parental strands separate, with each strand acting as a template to direct the synthesis through complementary base pairing, with the resulting daughter duplex consisting of the newly synthesised, and conserved parental strands. In conservative replication both parental strands are conserved, and in dispersive mode the double helix remains unwound, while segments break and re-join through crossing over thus the newly synthesised DNA appears ‘dispersed’ in the daughter strands. Meselson and Stahl demonstrated semi-conservative replication by taking an alternative approach to radioactive labelling (in contrast to the Phage group’s use of bacteriophage, rendering inconclusive results) – and growing E.coli cells in 14NH4Cl/15NH4Cl media containing 15N (‘heavy’) and 14N (‘light’) nitrogen isotopes, to measure the gradient densities every generation. This elegant experiment was conducted using a combination of Avery’s DNA isolation, and Hershey-Chase’s isotope labelling techniques.

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



