
Submitted:
19 December 2024
Posted:
20 December 2024
You are already at the latest version
Abstract
Background/Objectives: To overcome the disadvantages of the methods in the literature, such as the reliance on manual measurements requiring a lot of time and effort and the difficulty of routine clinical application due to large sample sizes, we aimed to automatically estimate tooth age from panoramic radiographs using artificial intelligence (AI) algorithms. Methods: Two Dimensional Deep Convolutional Neural Network (2D-DCNN) and One Dimensional Deep Convolutional Neural Network (1D-DCNN) techniques were used to extract features from panoramic radiographs and patient records. To perform age estimation using feature information, Genetic algorithm (GA) and Random Forest algorithm (RF) are modified and combined and defined as Modified Genetic-Random Forest Algorithm (MG-RF). The performance of the system used in our study was analyzed based on the MSE, MAE, RMSE and R2 value calculated during the implementation of the code. Results: As a result of the applied algorithms, the MSE value was 0.00027, MAE value was 0.0079, RMSE was 0.0888 and R2 score was 0.999. Conclusions: The findings of our study indicate that the AI-based system employed therein is an effective tool for age detection. Consequently, we propose that this technology could be utilized in forensic sciences in the future.
Keywords:
age estimation
; dental age estimation
; forensic odontology
; deep learning
; machine learning
; forensics
; panoramic radiograph
1. Introduction
Identification of individuals represents a crucial area within the discipline of forensic sciences [1,2]. The age of the individual in question carries significant weight in the process of identification [3,4]. In instances of mass disasters, organized crime, and abuse cases, it is imperative to ascertain the age of suspects and victims to facilitate their identification [5]. In the extant literature, the estimation of age in human history and forensic sciences has consistently been highlighted as a research topic, with the objective of developing reliable age estimation techniques for both living and deceased individuals [4].
The term chronological age is used to describe the time that has elapsed since an individual's date of birth. This is calculated by determining the dates of both the individual's birth and death. In the absence of available data regarding the dates of birth and death, the age of an individual can be estimated by examining the biological age of the individual in question. The assessment of biological age is based on the physical development stages of the individual or the changes that occur with aging. This assessment includes the development of various systems such as height, weight, hair, skin, eyes, teeth, bones, and secondary sex characteristics [6].
Dental tissues are the most durable part of the skeleton. It is resistant to extreme conditions and is preserved longer than bone. For this reason, teeth are often used in forensic science to estimate age [11]. Even in cases of major disasters, when the victim's body is so mutilated that it cannot be visually identified, the remains of skull bones, jaw bones, and teeth have proven to be the most valuable source of identification [4,12]. Radiographic estimation of age and sex from radiographs of the jaw bones is considered more feasible because it is a simple and less destructive method that can be applied to both deceased and living cases [4,13].
A variety of methods, including morphological, metric, radio morphological, radio metric, histological, and biochemical approaches, can be utilized for age estimation in dental tissues [2,14,15]. However, further research is necessary to ascertain the applicability and reliability of these methods across diverse populations [11]. The classic age estimation methods rely on manual measurements and observer subjectivity, which are time-consuming and prone to observer bias, potentially increasing the workload of forensic experts and introducing subjectivity into the estimation process [16,17].
AI is defined as the capacity of a machine to imitate the cognitive processes and behaviors observed in humans, enabling the completion of tasks that would otherwise require human input. In recent years, the rapid development of AI has facilitated numerous technological advancements that have enhanced the quality of life for many individuals. Furthermore, AI has advanced rapidly in numerous medical domains, garnering significant interest in recent years, particularly within the radiology community. To date, the implementation of AI in dental radiography has demonstrated considerable potential for a multitude of applications. At this point, it can facilitate critical support for clinicians, novice physicians, and students in the decision-making process [18].
In recent years, studies based on AI have been conducted with the objective of automating tasks in dentistry. These include caries diagnosis and classification [19,20,21,22,23,24,25,26,27], automatic diagnosis of dental diseases and conditions of the teeth [28], diagnostic evaluation and segmentation in periapical radiographs [29], periodontal bone loss [30,31], implant planning [32], detection and classification of periapical pathologies [33], cephalometric analysis and automatic detection of anatomical landmarks [34,35] , detection of impacted mandibular third molars, and detection [36], as well as to detect and classify impacted maxillary supernumerary teeth [41]. Additionally, the research aims to detect vertical root fractures [42,43], classification of osteoporosis [44,45,46] , improve image quality [47,48,49], identify and classify odontogenic tumors and cysts [50,51], diagnose maxillary sinus pathologies [52,53,54], dentification and classification of lymph node metastases [55,56], diagnosis in patients with Sjogren syndrome [57], and detect oral cancer lesions [58].
AI also offers significant potential in the field of forensic sciences for data analysis and ensuring the proper administration of justice [59]. These models have the potential to be promising tools when identifying victims of mass disasters and as an additional aid in medico-legal situations. In the literature, AI-based models have been reported to show similar accuracy and precision as trained forensic scientists. It has been stated that these models can be promising tools when identifying victims of mass disasters and as an additional aid in medico-legal situations [60].
The advent of deep learning represents a significant milestone in the evolution of AI algorithms. Deep learning is a group of algorithms based on the structure of artificial neural networks and defined as a sub-branch of machine learning. Deep learning algorithms offer significant advantages in processing complex data sets and making sense of problems. These algorithms simplify complex problems by classifying data sets in a hierarchical manner through the use of multilayer artificial neural networks. A typical deep learning system consists of an input layer representing the data set of the problem, multiple hidden layers, and an output layer. Hidden layers contain links that help to understand the relationships in the data set. This structure provides more effective results in solving complex problems than classical AI algorithms [61].
Existing classic age estimation methods have been critiqued in the literature for several shortcomings. Observer subjectivity has been identified as a potential source of error in age estimation. Furthermore, manual measurement-based methods are time-consuming and laborious. Additionally, the feasibility of implementing these methods in routine clinical practice has been questioned due to the limited sample sizes typically used. Considering the considerations, the present research endeavors to employ DM-based methodologies for the processing of (panoramic radiograph) OPG images and patient records, with the objective of estimating the age of individuals with the highest estimation rate. The study considers the use of Deep 2D CNN and Deep 1D CNN for feature extraction, as these have the capability to identify applicable features automatically, without the need for human supervision. Furthermore, the study proposes a MG-RF regressor, which can minimize overfitting, enhancing the detection rate, utilizing genetic indications via chromosomes, and affording numerous optimal solutions. Regarding these advantages, the present work considers this AI-based methodology for age estimation.
The primary objectives of this study are as follows:
- To extract the relevant features from OPG images and patient records individually using the proposed Deep 2D CNN and Deep 1D CNN, then concatenate these features to improve the estimation rate by enhancing the model performance.
- To achieve the highest coefficient of determination (R²) for age estimation using the proposed MG-RF regressor.
- To evaluate the efficiency of the proposed methodology with respect to standard deviation (SD), mean absolute error (MAE), mean square error (MSE), root mean square error (RMSE) and, R².
2. Related Work
In recent years, AI-based methodologies have been developed with the objective of overcoming these limitations and automating the age estimation process. These approaches yield consistent and reproducible results and facilitate reduced processing times. These approaches are deemed capable of detecting attributes that are not recognizable to human observers and are not feasible for manual computation. Moreover, the substantial benefits in identifying intricate relationships between features facilitate more accurate predictions with diminished error rates [17]. AI-based approaches in the literature are generally categorized as machine learning, deep learning or a combination of these two methodologies [16]. The objectives of these studies include numerical age regression [16,17,66,68,69,70,71,72,73], staging of teeth [74,75,76], classification of age groups [77] and legal age classification [78].
Galibourg et al. [66] conducted a study with a machine learning approach for numerical age regression. The researchers employed ten machine learning methods including Random Forest (RF), Support Vector Machine (SVM), Decision Tree (DT), Bayesian Ridge Regression (BRR), K-Nearest Neighbors (KNN), AdaBoost (ADAB), Polynomial Regression (POLYREG), Multi-Layer Perceptron (MLP), Stacking (STACK), and Voting (VOTE). The researchers reported that age estimation using machine learning methods yielded superior results compared to manual methods based on radiographic dental staging from childhood to early adulthood.
Similarly, Tao et al. [69] employed machine learning for numerical age regression. The researchers employed an MLP for this purpose. It was demonstrated that the proposed system exhibited superior performance compared to the reference manual methods across all performance metrics.
Shen et al. [70] employed machine learning for numerical age regression, utilizing RF, SVM, and linear regression (LR). The findings of the study indicated that age estimation accuracy was superior in machine learning methods compared to traditional methods.
De Tobel [74] employed a deep learning approach for staging teeth, with transfer learning (Alex-Net) demonstrating the most effective performance for staging.
Boedi et al. [75] employed the Dense Net machine learning algorithm. The objective of the present study was to ascertain and validate the impact of lower third molar segmentations on automatic tooth development staging. The study's findings led to the conclusion that full tooth segmentation and DenseNet CNN optimization facilitate the accurate allocation of dental stages.
Banar et al [75] employed a CNN that was similar in structure to the You Only Look Once (YOLO) algorithm, in conjunction with the U-Net CNN and the DenseNet201 CNN. The objective of this study is to automate the staging process in its entirety, utilizing CNN at each stage of the procedure. The results demonstrate that the proposed fully automated approach yields promising outcomes in comparison to manual staging.
In their study, Kim et al. [77] employed a deep learning approach, ResNet 152, for the classification of age groups. The accuracy of the tooth-wise prediction was found to be between 89.05 and 90.27 percent. The performance accuracy was primarily assessed through the use of the majority voting system and area under the curve (AUC) scores. The AUC scores ranged from 0.94 to 0.98 for all age groups, indicating a superior capability.
Guo et al. [78] employed the SE-ResNet101 model to ascertain the legal age groups. It was reported that end-to-end CNN models demonstrated superior performance, with accuracy rates of 92.5%, 91.3%, and 91.8% for age thresholds of 14, 16, and 18 years, respectively. To-end CNN models demonstrated superior performance, with accuracy rates of 95.9%, 95.4%, and 95.4% for age thresholds of 14, 16, and 18 years, respectively.
Čular et al. [71] employed a combination of Deep Learning Active Shape Model (ASM), Active Appearance Model (AAM), and Radial Basis Network algorithms for the purpose of numerical age regression. In this study, the researchers proposed a semi-automated system based on deep learning techniques to predict tooth age by analyzing the mandibular right third molar tooth on OPGs.
De Back et al. [72] applied deep learning and Bayesian convolutional neural networks methods for numerical age regression. The system achieved a concordance correlation coefficient of ccc = 0.91 in the validation set.
Vila-Blanco et al. [16] developed and applied CNN models, specifically DANet and DASNet, for the purpose of numerical age regression. The results demonstrated that DASNet exhibited superior performance compared to DANet across all evaluated metrics, with a reduction in the median error (E) and median absolute error (AE) of approximately four months for the entire database. The authors concluded that DASNet is an effective method for automatically estimating the chronological age of a subject, particularly in younger individuals with developing teeth.
Wallraff et al. [73] employed the ResNet18 algorithm. In this study, a supervised regression-based deep learning method for automatic age estimation of adolescents aged 11 to 20 years was proposed as a means of reducing the estimation error. In an initial investigation, the proposed methodology demonstrated a mean absolute error (MAE) of 1.08 years and an error rate (ER) of 17.52% on the test dataset, exhibiting superior performance compared to the predictions of dental experts.
In their study, Vila-Blanco et al. [68] employed Rotated R-CNN algorithms to propose a novel, fully automatic methodology for age and gender estimation. The method initially employs a modified CNN to detect teeth and extract oriented bounding boxes for each tooth. These boxes are then fed into a second CNN module, designed to produce probability distributions of age and gender per tooth. Finally, an uncertainty-sensitive approach is used to aggregate these estimated distributions, resulting in an improvement in the absolute error rate.
Milošević et al. [17] employed transfer learning techniques, utilizing a range of convolutional neural network architectures, including DenseNet201, InceptionResNetV2, ResNet50, VGG16, and VGG19. This study aimed to assess the feasibility of utilising AI techniques for chronological age estimation in older individuals through deep learning. The model was developed using contemporary architectures, exhibiting an average prediction error of 2.95 years for OPG images and 4.68 years for individual teeth. The researchers concluded that these AI approaches can be utilized in forensic odontology for older individuals, and this study provides a foundation for future research in this area.
3. Materials and Methods
The present study included all systemically healthy patients between the ages of 6 and 15 years who had undergone a OPGs in the correct position, free of artifacts and distortions, with clearly evaluable OPGs, without any dental deficiencies and dental restorations. The archive of the Department of Oral, Dental and Maxillofacial Radiology, Faculty of Dentistry, Pamukkale University, was the source of the data. The data set was created between March 1, 2020, and March 1, 2022. The patient's chronological age was calculated by subtracting the date of birth from the date of the OPGs.
This study was approved by the Pamukkale University Non-Interventional Clinical Research Ethics Committee (E-60116787-020-202083). The study was conducted in accordance with the principles set forth in the Declaration of Helsinki.
OPGs were obtained with a digital orthopantomograph (OP200D; Instrumentarium Company, Imaging Unit, Tuusula, Finland) with exposure values between 66 kVp, 2.5 mA, 13.4 s and 60 kVp, 6.3 mA, 14.1 s. The OPGs were subsequently evaluated using AI algorithms.
In this study, feature extraction is individually performed using the proposed Deep 2D CNN and Deep 1D CNN. In addition, MG-RF is proposed for estimating the age. The proposed methodologies estimate age through sequence of process as shown in Figure 1. Initially, dataset is loaded. Subsequently, pre-processing is undertaken to make the data easier for interpretation and usage. This process also assists in eliminating the duplicates or inconsistencies in a data that could otherwise negatively impact the prediction rate of a model. Pre-processing a data also assists in ensuring that, there aren’t any missing or incorrect data due to bugs or human error. Following this, feature extraction is performed for eliminating the redundant data. Deep 2D CNN is used to extract the features from OPG images. Simultaneously, Deep ID CNN is utilized to extract features from patient records. These features are individually extracted and then concatenated to attain suitable efficient features for better age estimation using MG-RF. Finally, performance metrics are utilized to validate the effectiveness of the proposed system in comparison to existing methods.
3.1. Feature Extraction-Deep two-dimensional Convolution Neural Network and Deep One-dimensional Convolution Neural Network
Recently, DL has gained paramount significance in medical domain as it possesses the capability for handling huge data. Thus, this study employs two Deep CNN models to perform feature extraction. Deep 2D CNN model is applied to extract features from OPG images, while Deep 1D CNN is utilized for extracting features from the patient records. After extracting individual features, these are concatenated and fed into the trained model for age estimation.
3.1.1. Deep 2D CNN: Deep Two-Dimensional Convolutional Neural Network
Deep 2D CNN is a standard CNN and has obtained use in extensive application areas of deep CNN. It has numerous advantages. The CNNs possess the capability to integrate feature extraction and classification process into one learning body. It could also learn to perform feature optimization during training stage from raw input. Deep CNN are sparsely associated with connected weights and could process many inputs with high computational efficacy. These are also immune to trivial conversions in input data inclusive of translation, skewing, scaling and distortion. Deep CNNs could also adapt to varied input sizes. Generally, Deep 2D CNN is employed on images and its overall architecture is shown in Figure 2 that encompass of numerous layers such as batch normalization, maxpooling, dropout, flatten and dense layer. It is termed 2D CNN as kernel slides with two data dimensions.
Feature extraction from OPG images is performed by Deep 2D CNN based on the below procedure,
1.Input Layer
Features from pre-processed data are declared as input of Deep 2D CNN and is given by equation.1.
In equation.1, represents the feature count per window after computation. To enhance the speed of model’s convergence, min-max normalization is used (as shown in equation.2) by which values in individual data dimension are linearly converted. Then, it is normalized to a range of [0, 1].
In equation.2, represents minimum of individual column, while represents maximum of individual column.
2.Convolution layer
Output from the feature map residing on unit of convolution layer is given by equation.3.
Where represents the bias for feature map, size of kernel is indicated by, indicates the weight of feature map, represents filter-index and represents activation function.
3.Maxpooling layer
Pooling layer descends aggregation measurements for adjacent outcome of that could minimize the dimension as well as the output sensitivity that accomplish scale invariant feature maintenance. Maxpooling is the pooling function utilized in this study that divides convolutional layer’s output features into various partitions and determining maximum in individual partition. Output of this layer is given by equation.4.
In equation.4, indicates pooling stride and represents the pooling size.
4.Training the model
Deep CNN comprise of numerous layers such as Conv2D, batch normalization, maxpooling2D, dropout, flatten and dense layer. Then, input is mapped into feature space of hidden layer. Finally, dense layer integrated varied features of local structure learned from lower layer for performing final prediction. This study uses single pair of convolution layer and maxpooling2D layer. Subsequently, 2D data is flattened into 1D data, in this way, overall neural network is completed with dense layer and is given by equation.5.
In equation.5, indicates class label, represents features of a sample, indicates layer index and indicates the class count. Further, forward-propagations are processed in accordance with equation.3 and equation.5. The information proliferates forward from input layer by hidden to output layer thereby accomplishes output of overall network. Moreover, an iteration of forward propagation will afford network error value. Cross entropy cost function computes error value as given in equation.6.
In equation.6, indicates sample, represents total training samples, indicates actual value, while represents predicted value. The overall algorithm of Deep 2D CNN is given in algorithm-I.
| Algorithm-I: Deep 2D CNN | |
| 1 | Input: OPG Images |
| 2 | Output: Features |
| 3 | STEP 1: Sliding Window Process |
| 4 | STEP 2: sef ← Extract Shadow Features |
| 5 | STEP 3: Normalize sef using equation (2) |
| 6 | regularization feature data, size = 64 Units - 128 Units |
| 7 | repeat: |
| 8 | STEP 4: Forward Propagation |
| 9 | cdf ← Convolution2D(sef); |
| 10 | mp ← Max_pooling(cdf ) ; |
| 11 | fc ← Fully_connected(mp); |
| 12 | class label ← relu(fc); |
| 13 | STEP 5: Backward Propagation |
| 14 | conduct backward propagation with Adam; |
| 15 | Until wi convergences;// wi: weight |
| 16 | STEP 6: Use the trained network to predict the features |
Initially, OPG images are taken as input. Then, sliding window process is performed. Following this, the shadow features are extracted. Then, these features are normalized and regularized using equation.2. Subsequently, forward and backward propagation is performed until the weight converges. Finally, the trained model is used for predicting features.
3.1.2. Deep 1D CNN: Deep One-Dimensional Convolutional Neural Network
Deep 2D CNN is an altered version of Deep 1D CNN which has gained interest in recent times. It requires minimum computational requirements and is suited for low cost and real time applications. Though mainstream models mostly rely on 2D convolution, main idea of 1D CNN is almost same. Main variation is that 2D convolution operates information of the matrix, wherein 1D convolution operates 1D vector information and could be expressed by,
In equation.7, represents the results of and indicates bias.
Non-linear functions are added to fit the actual function in a better way. So, the overall outcome is indicated as,
In equation.8, represents ReLU, activation functions or sigmoid functions.
In CNNs, there exists a significant concept termed receptive fields which represents the region where input data could be viewed by features of CNN. When (3*1) kernel size is utilized, initial hidden layer could view the three characteristic original data values and subsequent hidden layer could view five characteristic original data values. Thus, utilizing two (3*1) convolution kernels instead of single convolution kernel having size (5*1) could minimize the parameters while confirming that similar receptive area is attained. In accordance with this idea, the below block is framed using numerous small kernels for extracting features.
3.1.3. Feature Concatenation
After features are extracted from OPG images and patient records, it is concatenated, and these features are fed into train and test split for age estimation. The total number of OPG images are 622 and total number of records are also 622. Out of 622 OPG images, 60 images are extracted, while, out of 622 patient records, 15 features are extracted. On concatenating, a total of 75 features are obtained.
3.2. Regression-MG-RF (Modified Genetic-Random Forest)
Generally, GA (Genetic Algorithm) is general purpose and optimization search method relying on genetic theory and natural selection of Darwin in the biological systems. In this algorithm, population individual is termed as chromosome that relates to a resolution for specific issue. The individual chromosome indicates a combination of DT (Decision Tree) so length of individual chromosome indicates total DT, when bit possess value as one, DT is retained, while, value 0 represents that DT is denounced. On the other hand, RF includes additional randomness to model while developing trees. Rather than searching significant feature during node split, it searches the suitable feature within random feature subset. This leads to extensive diversity and better model. Due to such advantages this study considers GA and RF as MG-RF to estimate age on specific distinct process as shown in Figure 3.
Initially, features are normalized wherein the numeric column values in dataset are changed to common form without distorting variations in value ranges. This assists in solving the learning challenges of a model. After this, feature ranking is performed using RF for considering important features. Following this, Compact Genetic Algorithm (cGA) is initialized. Subsequently, multiple RF models are created with chromosomes. Then, fitness value is evaluated using selection, crossover and mutation processes of GA. These operations transform chromosome’s initial population for improving quality. The selection represents the process that chooses parents which mate and then reunite for developing offspring for succeeding generation. It is vital for the convergence of GA based on which it could obtain best solutions. Selection process uses fitness for controlling chromosome evolution. Maximum fitness affords more chance to select optimal solutions. Whereas crossover states the integration of the genetic material as well as the elite position chosen for the crossover operation. Further, mutation is employed to chromosome at individual position. Finally, the fitness value is assessed, and current feature is recorded. Then, feature subset is evaluated. For specific issue, fitness function improves the chromosome quality as solution. Hence, it assists in attaining better age estimation. The overall algorithm of GA is shown in algorithm-II.
| Algorithm-II: Genetic algorithm | |
| 1 | Input: (it, n, GA Parameters) |
| 2 | STEP 1: begin |
| 3 | STEP 2: Initialize c=0 and i=0, |
| 4 | STEP 3: Generation: generate random n solutions; |
| 5 | STEP 4: Compute Fitness(s) and Generation c; |
| 6 | STEP 5: While fitness not reached compute for i iterations do |
| 7 | Generation c+1 evolve(Generation c); |
| 8 | STEP 6: fitness computeFitness (s) and Generation c; |
| 9 | i =i + 1 |
| 10 | end |
| 11 | return (solution fitness) |
| 12 | end |
At first, the parameters are initialized. Then, random solutions are generated. Subsequently, fitness and generation are computed. When suitable fitness value is not found, iterations are performed until best fitness solution is attained. After finding this value, best parameters are attained through the use of the obtained best fitness value. The algorithm corresponding to this process is shown in algorithm-III.
| Algorithm-III: Modified fitness computation | |
| 1 | Input: Dataset(D), Chromosome |
| 2 | Output: MAE of the Random Forests |
| 3 | STEP 1: begin |
| 4 | STEP 2: Ds - Dataset; |
| 5 | STEP 3: Compute kvalues, num_trees, mtry by decoding (Chromosome); |
| 6 | Dc - decompose the set as (Ds, kvalues); |
| 7 | STEP 4: Fitnessmodel - RF fit(Dc,num_trees,mtry); |
| 8 | STEP 5: Rank the feature using RF Regressor |
| 9 | STEP 6: MAE - evaluate(model) |
| 10 | STEP 7: return (MAE); |
| 11 | end |
Initially, dataset and chromosome are taken as input. Then, are computed by decoding. Following this, the sets are decomposed. Subsequently, fitness model is determined. After this, the features are ranked using RF regressor. Finally, the MAE of a model is assessed. Lastly, the best parameters are attained from GA as shown in Table 1.
After extraction of the best parameters, optimized solution is obtained based on Algorithm-IV.
| Algorithm-IV: Optimized random forest | ||
| 1 | Input: minK, maxK, minNTree, maxNTree, treeIncrement, RF best, RF fit | |
| 2 | Output: Optimized RF | |
| 3 | STEP 1: begin | |
| 4 | STEP 2: Compute computeFitness(s) and Generation c ; | |
| 5 | STEP 3: Evaluate fitness and return fitness, | |
| 6 | STEP 4: MAE (Fit RF best) | |
| 7 | STEP 5: Fit RF best= Optimized RF | |
| 8 | STEP 6: Optimized RF(D)= solution | |
| 9 | end | |
At first the input is considered. Then, fitness value is computed. Following this, fitness value is evaluated and returned. Subsequently, fitness value is assessed to determine the solution. After this, hyper parameters for RF are attained as shown in Table 2.
Main stages involved in outcome of the optimized RF is summarized below,
Step 1: MG-RF is trained where fitness value is evaluated with GA. In this phase, the classes obtained are optimized in accordance with GA and this attains input for RF that calculates fitness of individual trees in a forest. Iteration continues until optimized trees are determined.
Step 2: Fitness calculation
In this stage, overall fitness of trees is assessed based on values of through decoding of the chromosomes. Decomposed class obtained from phase 2 is assessed for the fitness value with ranked features corresponding to MAE score.
Step 3: Optimized RF
The optimized RF is attained from integration of GA (with the assistance of selection, crossover and mutation process) and multiple class decompositions.
Step 4: Termination
Operation is terminated after obtaining optimal RF.
Step 5: Outcome
This stage comprises of predicted data to estimate age.
4. Results
This study comprises of OPG images and patient records within the dataset. Real-time dataset is considered for this research work. Some sample OPG images from the dataset is shown in Figure 4. Out of 275 male, average age has been 10.94, while, out of 346 female, average age has been 11.1.
4.2. Performance Metrics
The metrics considered for analysis of proposed methods are discussed in this section.
4.2.1. SD (Standard Deviation)
Standard deviation represents the computation of dispersion or variation on particular set of values. Minimum standard deviation denotes that, values incline to be close to mean of set, whereas, maximum standard deviation explores that, values are extended on wide range as given by equation.9.
In equation.9, indicates standard deviation, represents population size, indicates mean of the population and denotes individual value from population.
4.2.2. MAE (Mean Absolute Error)
This is an assessment metric of model utilised with regression models. MAE of a model in terms of test set could be indicated as mean of the absolute values corresponding to individual errors of prediction upon cases of test set afforded by equation.10.
In equation.10, represents the overall data points
4.2.3. MSE (Mean Square Error)
This explores the closeness of a set of regression lines and points as given in equation.11.
4.2.4. R2 (Coefficient-of-determination)
It is stated as the computation of goodness of model fit. In regression, R2 indicates the statistical computation of the degree to which regression predictions determine the actual data-points. When R2=1, it represents that, regression estimations perfectly fit corresponding data and is given by equation.12.
4.2.5. RMSE (Root Mean Square Error)
This is stated as ideal accuracy calculation that only compares model configurations or prediction errors of diverse models for specific variables. It is given by equation.13.
In equation.13, represents overall non-missing data-points and indicates variable.
4.3. Performance Analysis
In this study, the performance of the proposed system is evaluated based on the mean MSE, MAE, RMSE, and, R² values calculated during the implementation of the code. The efficacy of a system is gauged by its maximum prediction rate and minimum error rate. In this regard, the maximum R² score serves as a measure of the proposed system's effectiveness. In this study, the MSE value of the proposed system is 0.00027, the MAE value is 0.0079, the RMSE value is 0.0888, and the R2 score is 0.999. It is shown at Figure 5. A comparative analysis of the predicted and actual values is presented in graphical form in Figure 6.
5. Discussion
In the field of forensic science, the determination of an individual's age is of paramount importance. Consequently, the methodology employed must be both reliable and accurate. This indicates that the degree of accuracy should be high and the mean discrepancy between dental age and chronological age should be as minimal as feasible [66].
The age estimation methods that have been documented in the existing literature are based on the evaluation of specific indicators that assess the stage of dental development that the individual has reached. The earliest known studies on this subject are dated to the 19th century [17]. One of the earliest methods based on dental indicators is the Schour and Massler method, which was developed in 1941. This method involves the morphological evaluation of tooth development through the use of diagrams that illustrate the expected developmental stages of deciduous and permanent teeth [62]. Subsequently, Nolla et al. [63] developed a ten-stage chart for age estimation, which was considered an important milestone in the field of age estimation, prompting the rapid development of new methods [11,17,63,64,65]. Currently in literature, the most commonly used methods for age estimation in children are reported to be the Willems and Demirjian methods [66].
Demirjian et al. [64] developed a method that can be used as a universal tool for assessing dental maturity and estimating dental age in children. Demirjian's method is the first in the literature to provide visualization of the stages of tooth development, descriptive criteria, radiographic examples of each stage, and selection rules for decision-making at borderline stages. In the Willems method, the stages of tooth development described in the Demirjian method are used to estimate tooth age by means of maturity tables that provide the age in years directly [11,64,65].
The classical methods that have been introduced in the literature have been developed through the analysis of large datasets comprising a large number of participants. However, these methods have several shortcomings, including the fact that results are often population-specific and rely on time-consuming manual procedures that are susceptible to observer subjectivity [16,67].
A further limitation of classical manual radiologic tooth age estimation techniques is that they lack the requisite number of stages to enable the closest possible monitoring of the growth process. Another disadvantage is the difficulty in selecting a method that allows researchers to distinguish teeth that are not sufficiently differentiated in terms of developmental stage [16].
The objective of the research was to estimate the age of patients from a real-time dataset comprising patient records and OPG images using AI-based methodologies. This study employed deep CNN with 1D and 2D architectures for feature extraction and a MG-RF for estimating age. The proposed system was evaluated by examining the discrepancies between the actual and predicted values. The results demonstrated a strong correlation between the two variables. Furthermore, the performance of this system was evaluated in comparison to that of the conventional system in terms of MAE, RMSE, MSE, SD, and R2 score. The analytical outcomes revealed that the proposed system outperformed the conventional system, exhibiting a SD rate of 0.0004, an MAE rate of 0.0079, an MSE rate of 0.00027, an RMSE value of 0.0888, and an R2 value of 0.9999.
The performance of the reference methods and machine learning algorithms utilized in the study conducted by Galibourg et al.[66] was evaluated with analogous metrics to those employed in our study, namely R², MAE, RMSE, and SD. The researchers reported that age estimation with machine learning methods demonstrated superior performance compared to manual methods based on radiographic tooth staging from childhood to early adulthood. The results of the study are presented in Table 3, along with a comparison to the findings of our study.
The study of Galibourg et al. was carried out with a methodology based entirely on machine learning. Demirjian and Willems methods were used as the explanatory system in the training of the machine learning system. These methods focus on the left seven mandibular permanent teeth for age estimation.
Our study was carried out with the aim of performing age estimation on OPGs sections containing the left seven mandibular permanent teeth in a fully automatic manner without any explanatory system. From the radiographs and patient records that constitute the dataset of our study, feature extraction was performed using 1D-DCNN and 2D-DCNN architecture from deep learning methods. In the regression step, RF and GA methods were modified and combined and age estimation was performed.
When our study is compared with the study of Galibourg et al. in terms of performance, it is observed that our study has a superior performance than the manual predictions and all machine learning approaches evaluated in the related study. In addition, it was found that the MAE value decreased significantly with the system used in our study. It is thought that the reason for the decrease in the MAE value may be due to the use of deep learning algorithms in the feature extraction step of our study, due to the perception of various age-related indicators that cannot be detected by the human eye by deep learning algorithms and thus more information is transferred to the MG-RF algorithm. In the MG-RF step, the RF algorithm reduces the similarity between individual trees as a methodology. For this reason, it is thought to increase the robustness of the final model by selecting the point of departure from a random subset of the input features at each step in the tree building process. In addition, in our study, it is thought that the integration of four different approaches into the system together with the use of machine learning techniques following deep learning processes results in a significant decrease in the error rate and a significant increase in the performance of the system.
In our study, age estimation is performed completely automatically without using any explanatory reference system. The fact that our study eliminates the disadvantages of exposure to human interpretation and the subjectivity of human observers by automating the age estimation task can be argued as a distinct advantage of our study. In addition, the fact that no explanatory system is used and that it is an automatic method makes our study easy to use, fast and reproducible.
Tao et al. [69] proposed a machine learning-based approach to improve the accuracy of tooth age estimation in 2020 using a dataset of 1636 OPGs of 787 male and 849 female individuals aged 11 to 19 years. In the study, tooth age estimation is considered as a regression problem.
In the methodology of the study, manual measurements were first performed using the Demirjian method and the Willems method. The attributes were determined by entering the real ages of the patients into the system. Then, the MLP algorithm, which is a feed-forward artificial neural network from machine learning approaches, was trained with these features and experiments were conducted. The performance of the proposed system was evaluated using MAE, MSE, RMSE metrics. It is reported that the proposed system outperforms the reference manual methods in terms of all performance metrics [69]. The findings of the study and the findings of our study are presented in Table 4.
The findings of our study, as indicated by the RMSE, MSE, and MAE metrics, demonstrate significantly enhanced performance in comparison to the results obtained for both female and male groups in the study conducted by Tao et al. This discrepancy may be attributed to the fact that the group under examination in our study comprises younger individuals (6-15 years old), and the variations in the age distribution of these individuals. Given that age indicators of growth and development decline with age, it is a well-established fact that studies in the field of age estimation obtain more accurate results with younger study populations [17].
In our study, it is thought that the combination of deep learning and machine learning methods significantly enhances the performance. The use of deep learning techniques allows for the establishment of connections that are not discernible to the human eye, thereby enabling the inclusion of age indicators that cannot be calculated manually in the system under study. It can be proposed that this may be the source of the observed improvement in the system's performance. Furthermore, our study employs an automated system that is not contingent on any explanatory framework. Therefore, our study has the advantages of being fast, repeatable, and less susceptible to human interpretation.
In their 2021 study, Shen et al. [79] employed a series of machine learning systems to estimate age. The dataset utilized in the study comprises 748 OPGs of 356 female and 392 male individuals between the ages of 5 and 13. The study employed a methodology based on random forest (RF), support vector machines (SVM), and linear logistic regression (LR). The machine learning models were trained with the manually realized Cameriere method as an explanatory system and gender information. The target value is set to the subject's chronological age. The accuracy of the proposed systems for estimating age is evaluated based on the following metrics: R², ME, RMSE, MSE, and MAE. The results are then compared with those obtained using the European and Chinese formulas of the Cameriere method, which were employed in the training of the system. The findings of the study and the findings of our study are shown in Table 5. [79].
The performance of the systems proposed in the study is comparable to that observed in our own study in terms of the R² value. It is, however, noteworthy that the error rates of the systems proposed by Shen et al. are significantly higher than those observed in our study with respect to other performance metrics evaluated. It is thought that this discrepancy may be attributed to the utilization of deep convolutional neural networks in the feature extraction phase of the present study, the incorporation of certain age indicators that cannot be discerned by the human eye, and the combination of numerous techniques.
In 2017, Čular et al. [71] conducted a study utilizing OPGs of 203 individuals between the ages of 10 and 25. In this study, the researchers proposed a semi-automated system based on deep learning techniques to estimate tooth age by examining the mandibular right third molar on OPGs. The researchers employed two statistical computer vision models, namely the Active Shape Model (ASM) and the Active Appearance Model (AAM), which have been extensively utilized in face recognition, gender estimation, and medical image interpretation and feature extraction in previous studies, to extract the features describing the right mandibular wisdom teeth selected for this investigation. In the training set, the images were manually segmented. In the study, the extracted features were presented as input to an artificial neural network, specifically the Radial Basis Network, and age estimation was performed as the output. The findings of the age estimation performance of the study were evaluated using the mean absolute error (MAE) in years. The findings of that study indicated that the system demonstrated superior performance when AAM feature extraction was employed. Although AGM was reported to perform better in this study, it was reported that the age estimation performance of the system was adversely affected when AAM and ASM were applied together [71].
The researchers noted that the MAE value of less than 3 years represents a promising preliminary result. Should the prediction error be reduced in future studies, the system proposed in their study may prove a viable option for use within the scope of forensic sciences. Furthermore, the researchers indicated that the system proposed in this study offers two key advantages: minimal user input and the ability to function without the input of an experienced dentist. [71] The findings of the study and the findings of our study are shown in Table 6.
A direct comparison between our study and that of Čular et al. [71] is not feasible due to differences in methodology and age group. As there are a greater number of age indicators of growth and development in younger individuals within the existing literature, the MAE value is typically reported to be lower in studies involving this age group. The present study focuses on individuals between the ages of 6 and 15. Accordingly, the lower MAE value observed in our study relative to that reported by Čular et al. is an anticipated outcome.
In contrast to the present study, the fact that our study does not entail a manual step such as segmentation over radiographs while estimating age can be demonstrated as an advantage of the system utilized in our study. Furthermore, as our study employed OPGs sections encompassing the left seven mandibular permanent teeth, the third molars, which are the most common congenitally missing teeth, were not required, thus conferring another advantage to our study.
In 2021, Wallraff et al. [73] conducted a study on automatic age estimation to reduce the estimation error, which is a disadvantage of traditional manual age estimation methods. In this study, the researchers proposed a deep learning system based on supervised regression to perform age estimation. The study was conducted on 14000 OPGs of individuals between the ages of 11 and 20. The system proposed in the study uses raw OPGs as input. Images do not need to be pre-processed and cropped. The researchers reported that the focus of this study was 11-20 years of age, as teeth develop in a predictable pattern during the first two decades of life. Radiographs in the dataset that were affected by various external factors such as low-contrast images, diseases and jaw malpositions were not excluded. In this study, age estimation is considered as a regression problem and ResNet18 algorithm is used as the network architecture in the proposed system. The MAE of the proposed system was reported to be 1.08 with an SD of +1.41 and an error rate of 17.52%. The researchers stated that the dataset in their study provided comprehensive data for the age range of 11-20 years and that individuals aged 0-20 years should be included in the proposed system in the future [73].
As indicated in the literature, age-related indicators tend to decline as growth and development progress, resulting in lower error rates in studies that examine younger age groups. In the study conducted by Wallraff et al. [73], individuals below the age of 11 were excluded from the analysis. A comparison of our study with that of Wallraff et al. revealed a significantly lower MAE value for our study. It is postulated that this finding is attributable to the fact that our study focused on younger individuals.
In their 2020 study, Vila-Blanco et al. proposed a method based on deep learning algorithms for fully automatic age estimation from OPGs. This method was designed to overcome the limitations of traditional methods, which are affected by observer subjectivity and time-consuming manual operations. The study was conducted on OPGs of 2,289 individuals from the Spanish population, with an age range of 4.5 to 89 years. Only OPGs of the requisite quality were included in the study. In contrast to other studies in the literature, this study did not exclude OPGs with any of the following: orthodontic brackets or appliances, dentures, implants, restorative materials, fillings, endodontic treatment, foreign bodies such as caries, missing teeth, residual tooth roots, or earrings, and external elements such as distorted or blurred images. The images in question have been identified as defective within the system. In this study, convolutional neural networks from deep learning algorithms were employed as the methodology. Two distinct network architectures, namely DANet and DASNet, were devised for the purposes of this study. These architectures were designed and trained specifically for the purpose of age estimation in the context of this study [16].
The results of the study indicate a strong correlation between the DANet and DASNet systems and age. The coefficient of determination was R²=0.87 for DANet and R²=0.90 for DASNet. In the assessment of the data across all age groups, MAE was found to be 2.84 years. As the age of the individuals decreased, MAE value was found to be 0.78 years for DANet and 0.75 years for DASNet in the group of individuals younger than 15 years.
In contrast to the methodology employed by Vila-Blanco et al., our study utilized a OPG section encompassing seven left mandibular permanent teeth as the input data for the system. In the study conducted by Vila-Blanco et al., the raw OPGs were utilized as the input data, and no exclusion criteria were employed. However, radiographs with inadequate acquisition quality were designated as defective and submitted to the system. The present study was conducted using high-quality radiographs of individuals without any dental or bony pathology. It is believed that this contributed to the success of the system used in our study.
With regard to the age group under examination, our study encompasses a much younger population than that considered by Vila-Blanco et al. Given that developmental age indicators are more prevalent in younger age groups, it may be posited that the superior performance of the Vila-Blanco et al. study can be attributed to the findings of our study. Moreover, the integration of deep learning and machine learning methodologies is believed to be a contributing factor to the enhanced performance of the system in our study.
5. Conclusions
The application of AI methodologies has the potential to significantly reduce the time required for the resolution of complex problems. Moreover, these systems provide consistent and reproducible high-performance results.
The systems proposed with deep learning algorithms demonstrate exceptional performance due to their capacity to discern features that are imperceptible to the human eye and to discern the relationships between these features. Nevertheless, the same rationale that underlies the exceptional performance of these systems has yet to be fully elucidated. This represents a disadvantage with regard to the interpretability of these systems.
To address this limitation and enhance interpretability, some researchers have employed visualization techniques such as heat maps. However, the underlying mechanisms that explain the logic behind the study findings have yet to be elucidated. It is therefore recommended that future studies be conducted to test the potential for deep learning-based techniques to replace humans and to elucidate the reasons behind their performance.
Author Contributions
Conceptualization, G.O.U and, B.K.A ; methodology, O.A.H.G; software, O.A.H.G and, B.U; validation, G.O.U and O.A.H.G; formal analysis G.O.U and, O.A.H.G; investigation, G.O.U and, B.K.A.; resources, G.O.U; data curation, G.O.U.; writing—original draft preparation G.O.U; writing—review and editing, O.A.H.G, B.K.A and, B.U; visualization, B.U.; supervision, B.K.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
This study was approved by the Pamukkale University Non-Interventional Clinical Research Ethics Committee (E-60116787-020-202083). The study was conducted in accordance with the principles set forth in the Declaration of Helsinki.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data is available from the corresponding author upon reasonable request.
Acknowledgments
This study is derived from the author's (G.O.U) residency thesis, "The Determination of Individuals' Dental Ages Through Panoramic Radiographs Using Artificial Intelligence Algorithms," under the supervision of (B.K.A) completed at Pamukkale University's Faculty of Dentistry.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Senn DR, Stimson PG. Forensic Dentistry.; 2010.
- Apaydin B, Yasar F. Accuracy of the demirjian, willems and cameriere methods of estimating dental age on turkish children. Niger J Clin Pract. 2018;21(3):257. [CrossRef]
- Limdiwala P, Shah J. Age estimation by using dental radiographs. J Forensic Dent Sci. 2013;5(2):118. [CrossRef]
- Khanagar SB, Albalawi F, Alshehri A, et al. Performance of Artificial Intelligence Models Designed for Automated Estimation of Age Using Dento-Maxillofacial Radiographs—A Systematic Review. Diagnostics. 2024;14(11):1079. [CrossRef]
- Han M, Du S, Ge Y, et al. With or without human interference for precise age estimation based on machine learning? Int J Legal Med. 2022;136(3):821-831. [CrossRef]
- Garn SM, Lewis AB, Kerewsky RS. Genetic, Nutritional, and Maturational Correlates of Dental Development. J Dent Res. 1965;44(1):228-242. [CrossRef]
- Noble HW. The Estimation of Age from the Dentition. Journal of the Forensic Science Society. 1974;14(3):215-221. [CrossRef]
- Huda TFJ, Bowman JE. Age determination from dental microstructure in juveniles. Am J Phys Anthropol. 1995;97(2):135-150. [CrossRef]
- Graham EA. Economic, Racial, and Cultural Influences on the Growth and Maturation of Children. Pediatr Rev. 2005;26(8):290-294. [CrossRef]
- Schmeling A, Grundmann C, Fuhrmann A, et al. Criteria for age estimation in living individuals. Int J Legal Med. 2008;122(6):457-460. [CrossRef]
- Willems G. A review of the most commonly used dental age estimation techniques. J Forensic Odontostomatol. 2001;19(1):9-17.
- Celik S, Zeren C, Çelikel A, Yengil E, Altan A. Applicability of the Demirjian method for dental assessment of southern Turkish children. J Forensic Leg Med. 2014;25:1-5. [CrossRef]
- Uzuner FD, Kaygısız E, Darendeliler N. Defining Dental Age for Chronological Age Determination. In: Post Mortem Examination and Autopsy - Current Issues From Death to Laboratory Analysis. InTech; 2018. [CrossRef]
- Sakuma A, Saitoh H, Suzuki Y, et al. Age Estimation Based on Pulp Cavity to Tooth Volume Ratio Using Postmortem Computed Tomography Images. J Forensic Sci. 2013;58(6):1531-1535. [CrossRef]
- Ge Z pu, Ma R han, Li G, Zhang J zong, Ma X chen. Age estimation based on pulp chamber volume of first molars from cone-beam computed tomography images. Forensic Sci Int. 2015;253:133.e1-133.e7. [CrossRef]
- Vila-Blanco N, Carreira MJ, Varas-Quintana P, Balsa-Castro C, Tomas I. Deep Neural Networks for Chronological Age Estimation From OPG Images. IEEE Trans Med Imaging. 2020;39(7):2374-2384. [CrossRef]
- Milošević D, Vodanović M, Galić I, Subašić M. Automated estimation of chronological age from panoramic dental X-ray images using deep learning. Expert Syst Appl. 2022;189. [CrossRef]
- Putra RH, Doi C, Yoda N, Astuti ER, Sasaki K. Current applications and development of artificial intelligence for digital dental radiography. Dentomaxillofacial Radiology. 2022;51(1). [CrossRef]
- Devito KL, de Souza Barbosa F, Filho WNF. An artificial multilayer perceptron neural network for diagnosis of proximal dental caries. Oral Surgery, Oral Medicine, Oral Pathology, Oral Radiology, and Endodontology. 2008;106(6):879-884. [CrossRef]
- Choi J, Eun H, Kim C. Boosting Proximal Dental Caries Detection via Combination of Variational Methods and Convolutional Neural Network. J Signal Process Syst. 2018;90(1):87-97. [CrossRef]
- Lee JH, Kim DH, Jeong SN, Choi SH. Detection and diagnosis of dental caries using a deep learning-based convolutional neural network algorithm. J Dent. 2018;77:106-111. [CrossRef]
- Geetha V, Aprameya KS, Hinduja DM. Dental caries diagnosis in digital radiographs using back-propagation neural network. Health Inf Sci Syst. 2020;8(1):8. [CrossRef]
- Yu Y, Li Y, Li Y jing, Wang J ming, Lin D hui, Ye W ping. Tooth Decay Diagnosis using Back Propagation Neural Network. In: 2006 International Conference on Machine Learning and Cybernetics. IEEE; 2006:3956-3959. [CrossRef]
- Li W, Kuang W, Li Y, Li YJ, Ye WP. Clinical X-Ray Image Based Tooth Decay Diagnosis using SVM. In: 2007 International Conference on Machine Learning and Cybernetics. IEEE; 2007:1616-1619. [CrossRef]
- Ramzi Ben A, Ejbali R, Zaied M. Detection and Classification of Dental Caries in X-ray Images Using Deep Neural Networks.
- Singh P, Sehgal P. Automated caries detection based on Radon transformation and DCT. In: 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT). IEEE; 2017:1-6. [CrossRef]
- Szabó V, Szabó BT, Orhan K, et al. Validation of artificial intelligence application for dental caries diagnosis on intraoral bitewing and periapical radiographs. J Dent. 2024;147:105105. [CrossRef]
- Orhan K, Aktuna Belgin C, Manulis D, et al. Determining the reliability of diagnosis and treatment using artificial intelligence software with panoramic radiographs. Imaging Sci Dent. 2023;53(3):199. [CrossRef]
- Ari T, Sağlam H, Öksüzoğlu H, et al. Automatic Feature Segmentation in Dental Periapical Radiographs. Diagnostics. 2022;12(12):3081. [CrossRef]
- Lin PL, Huang PY, Huang PW. Automatic methods for alveolar bone loss degree measurement in periodontitis periapical radiographs. Comput Methods Programs Biomed. 2017;148:1-11. [CrossRef]
- Lin PL, Huang PW, Huang PY, Hsu HC. Alveolar bone-loss area localization in periodontitis radiographs based on threshold segmentation with a hybrid feature fused of intensity and the H-value of fractional Brownian motion model. Comput Methods Programs Biomed. 2015;121(3):117-126. [CrossRef]
- Kurt Bayrakdar S, Orhan K, Bayrakdar IS, et al. A deep learning approach for dental implant planning in cone-beam computed tomography images. BMC Med Imaging. 2021;21(1):86. [CrossRef]
- Orhan K, Bayrakdar IS, Ezhov M, Kravtsov A, Özyürek T. Evaluation of artificial intelligence for detecting periapical pathosis on cone-beam computed tomography scans. Int Endod J. 2020;53(5):680-689. [CrossRef]
- Gupta A, Kharbanda OP, Sardana V, Balachandran R, Sardana HK. Accuracy of 3D cephalometric measurements based on an automatic knowledge-based landmark detection algorithm. Int J Comput Assist Radiol Surg. 2016;11(7):1297-1309. [CrossRef]
- Gupta A, Kharbanda OP, Sardana V, Balachandran R, Sardana HK. A knowledge-based algorithm for automatic detection of cephalometric landmarks on CBCT images. Int J Comput Assist Radiol Surg. 2015;10(11):1737-1752. [CrossRef]
- Orhan K, Bilgir E, Bayrakdar IS, Ezhov M, Gusarev M, Shumilov E. Evaluation of artificial intelligence for detecting impacted third molars on cone-beam computed tomography scans. J Stomatol Oral Maxillofac Surg. 2021;122(4):333-337. [CrossRef]
- Vinayahalingam S, Xi T, Bergé S, Maal T, de Jong G. Automated detection of third molars and mandibular nerve by deep learning. Sci Rep. 2019;9(1):9007. [CrossRef]
- Fukuda M, Ariji Y, Kise Y, et al. Comparison of 3 deep learning neural networks for classifying the relationship between the mandibular third molar and the mandibular canal on panoramic radiographs. Oral Surg Oral Med Oral Pathol Oral Radiol. 2020;130(3):336-343. [CrossRef]
- Jaskari J, Sahlsten J, Järnstedt J, et al. Deep Learning Method for Mandibular Canal Segmentation in Dental Cone Beam Computed Tomography Volumes. Sci Rep. 2020;10(1):5842. [CrossRef]
- Kwak GH, Kwak EJ, Song JM, et al. Automatic mandibular canal detection using a deep convolutional neural network. Sci Rep. 2020;10(1):5711. [CrossRef]
- Kuwada C, Ariji Y, Fukuda M, et al. Deep learning systems for detecting and classifying the presence of impacted supernumerary teeth in the maxillary incisor region on panoramic radiographs. Oral Surg Oral Med Oral Pathol Oral Radiol. 2020;130(4):464-469. [CrossRef]
- Johari M, Esmaeili F, Andalib A, Garjani S, Saberkari H. Detection of vertical root fractures in intact and endodontically treated premolar teeth by designing a probabilistic neural network: an ex vivo study. Dentomaxillofacial Radiology. 2017;46(2):20160107. [CrossRef]
- Fukuda M, Inamoto K, Shibata N, et al. Evaluation of an artificial intelligence system for detecting vertical root fracture on panoramic radiography. Oral Radiol. 2020;36(4):337-343. [CrossRef]
- Chu P, Bo C, Liang X, et al. Using Octuplet Siamese Network For Osteoporosis Analysis On Dental Panoramic Radiographs. In: 2018 40th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). IEEE; 2018:2579-2582. [CrossRef]
- Lee KS, Jung SK, Ryu JJ, Shin SW, Choi J. Evaluation of Transfer Learning with Deep Convolutional Neural Networks for Screening Osteoporosis in Dental Panoramic Radiographs. J Clin Med. 2020;9(2):392. [CrossRef]
- Lee JS, Adhikari S, Liu L, Jeong HG, Kim H, Yoon SJ. Osteoporosis detection in panoramic radiographs using a deep convolutional neural network-based computer-assisted diagnosis system: a preliminary study. Dentomaxillofacial Radiology. 2019;48(1):20170344. [CrossRef]
- Liang K, Zhang L, Yang H, Yang Y, Chen Z, Xing Y. Metal artifact reduction for practical dental computed tomography by improving interpolation-based reconstruction with deep learning. Med Phys. 2019;46(12). [CrossRef]
- Minnema J, Eijnatten M, Hendriksen AA, et al. Segmentation of dental cone-beam CT scans affected by metal artifacts using a mixed-scale dense convolutional neural network. Med Phys. 2019;46(11):5027-5035. [CrossRef]
- Hegazy MAA, Cho MH, Cho MH, Lee SY. U-net based metal segmentation on projection domain for metal artifact reduction in dental CT. Biomed Eng Lett. 2019;9(3):375-385. [CrossRef]
- Flores A, Rysavy S, Enciso R, Okada K. Non-invasive differential diagnosis of dental periapical lesions in cone-beam CT. In: 2009 IEEE International Symposium on Biomedical Imaging: From Nano to Macro. IEEE; 2009:566-569. [CrossRef]
- Okada K, Rysavy S, Flores A, Linguraru MG. Noninvasive differential diagnosis of dental periapical lesions in cone-beam CT scans. Med Phys. 2015;42(4):1653-1665. [CrossRef]
- Murata M, Ariji Y, Ohashi Y, et al. Deep-learning classification using convolutional neural network for evaluation of maxillary sinusitis on panoramic radiography. Oral Radiol. 2019;35(3):301-307. [CrossRef]
- Kuwana R, Ariji Y, Fukuda M, et al. Performance of deep learning object detection technology in the detection and diagnosis of maxillary sinus lesions on panoramic radiographs. Dentomaxillofacial Radiology. Published online July 15, 2020:20200171. [CrossRef]
- Kim Y, Lee KJ, Sunwoo L, et al. Deep Learning in Diagnosis of Maxillary Sinusitis Using Conventional Radiography. Invest Radiol. 2019;54(1):7-15. [CrossRef]
- Kann BH, Aneja S, Loganadane G V., et al. Pretreatment Identification of Head and Neck Cancer Nodal Metastasis and Extranodal Extension Using Deep Learning Neural Networks. Sci Rep. 2018;8(1):14036. [CrossRef]
- Ariji Y, Fukuda M, Kise Y, et al. Contrast-enhanced computed tomography image assessment of cervical lymph node metastasis in patients with oral cancer by using a deep learning system of artificial intelligence. Oral Surg Oral Med Oral Pathol Oral Radiol. 2019;127(5):458-463. [CrossRef]
- Kise Y, Ikeda H, Fujii T, et al. Preliminary study on the application of deep learning system to diagnosis of Sjögren’s syndrome on CT images. Dentomaxillofac Radiol. 2019;48(6):20190019. [CrossRef]
- Keser G, Pekiner FN, Bayrakdar İŞ, Çelik Ö, Orhan K. A deep learning approach to detection of oral cancer lesions from intra oral patient images: A preliminary retrospective study. J Stomatol Oral Maxillofac Surg. 2024;125(5):101975. [CrossRef]
- Chinnikatti SK. Artificial Intelligence in Forensic Science. Forensic Sci Addict Res. 2018;2(5). [CrossRef]
- Khanagar SB, Vishwanathaiah S, Naik S, et al. Application and performance of artificial intelligence technology in forensic odontology – A systematic review. Leg Med. 2021;48. [CrossRef]
- Goodfellow I, Bengio Y, Courville A. Deep Learning. MIT Press; 2016.
- chour I, Massler M. The development of the Human Dentition. Journal of the American Dental Association. 1941;28:1153-1160.
- Nolla CM. The development of the permanent teeth. Journal of Dental Children. 1960;27:254-266.
- Demirjian A, Goldstein H, Tanner JM. A new system of dental age assessment. Hum Biol. 1973;45(2):211-227. http://www.ncbi.nlm.nih.gov/pubmed/4714564.
- Demirjian A, Goldstein H. New Systems for Dental Maturity Based on Seven and Four Teeth. Vol 3.; 1976.
- Galibourg A, Cussat-Blanc S, Dumoncel J, Telmon N, Monsarrat P, Maret D. Comparison of different machine learning approaches to predict dental age using Demirjian’s staging approach. Int J Legal Med. 2021;135(2):665-675. [CrossRef]
- Kapoor P, Jain V. Comprehensive Chart for Dental Age Estimation (DAEcc8) based on Demirjian 8-teeth method: Simplified for operator ease. J Forensic Leg Med. 2018;59:45-49. [CrossRef]
- Vila-Blanco N, Varas-Quintana P, Aneiros-Ardao Á, Tomás I, Carreira MJ. XAS: Automatic yet eXplainable Age and Sex determination by combining imprecise per-tooth predictions. Comput Biol Med. 2022;149. [CrossRef]
- Tao J, Wang J, Wang A, et al. Dental Age Estimation: A Machine Learning Perspective. In: Advances in Intelligent Systems and Computing. Vol 921. Springer Verlag; 2020:722-733. [CrossRef]
- Shen S, Liu Z, Wang J, Fan L, Ji F, Tao J. Machine learning assisted Cameriere method for dental age estimation. BMC Oral Health. 2021;21(1). [CrossRef]
- Cular L, Tomaic M, Subasic M, Saric T, Sajkovic V, Vodanovic M. Dental age estimation from panoramic X-ray images using statistical models. In: International Symposium on Image and Signal Processing and Analysis, ISPA. IEEE Computer Society; 2017:25-30. [CrossRef]
- De Back W, Seurig S, Wagner S, Marré B, Roeder I, Scherf N. Forensic Age Estimation with Bayesian Convolutional Neural Networks Based on Panoramic Dental X-Ray Imaging.
- Wallraff S, Vesal S, Syben C, Lutz R, Maier A. Age Estimation on Panoramic Dental X-ray Images using Deep Learning. In: Informatik Aktuell. Springer Science and Business Media Deutschland GmbH; 2021:186-191. [CrossRef]
- De Tobel J, Radesh P, Vandermeulen D, Thevissen PW. An automated technique to stage lower third molar development on panoramic radiographs for age estimation: a pilot study. J Forensic Odontostomatol. 2017;35(2):42-54. http://www.ncbi.nlm.nih.gov/pubmed/29384736.
- Merdietio Boedi R, Banar N, De Tobel J, Bertels J, Vandermeulen D, Thevissen PW. Effect of Lower Third Molar Segmentations on Automated Tooth Development Staging using a Convolutional Neural Network. J Forensic Sci. 2020;65(2):481-486. [CrossRef]
- Banar N, Bertels J, Laurent F, et al. Towards fully automated third molar development staging in panoramic radiographs. Int J Legal Med. 2020;134(5):1831-1841. [CrossRef]
- Kim S, Lee YH, Noh YK, Park FC, Auh QS. Age-group determination of living individuals using first molar images based on artificial intelligence. Sci Rep. 2021;11(1). [CrossRef]
- Guo Y cheng, Han M, Chi Y, et al. Accurate age classification using manual method and deep convolutional neural network based on orthopantomogram images. Int J Legal Med. 2021;135(4):1589-1597. [CrossRef]
- Shen S, Liu Z, Wang J, Fan L, Ji F, Tao J. Machine learning assisted Cameriere method for dental age estimation. BMC Oral Health. 2021;21(1). [CrossRef]
Figure 1.
Overall view of the proposed system.
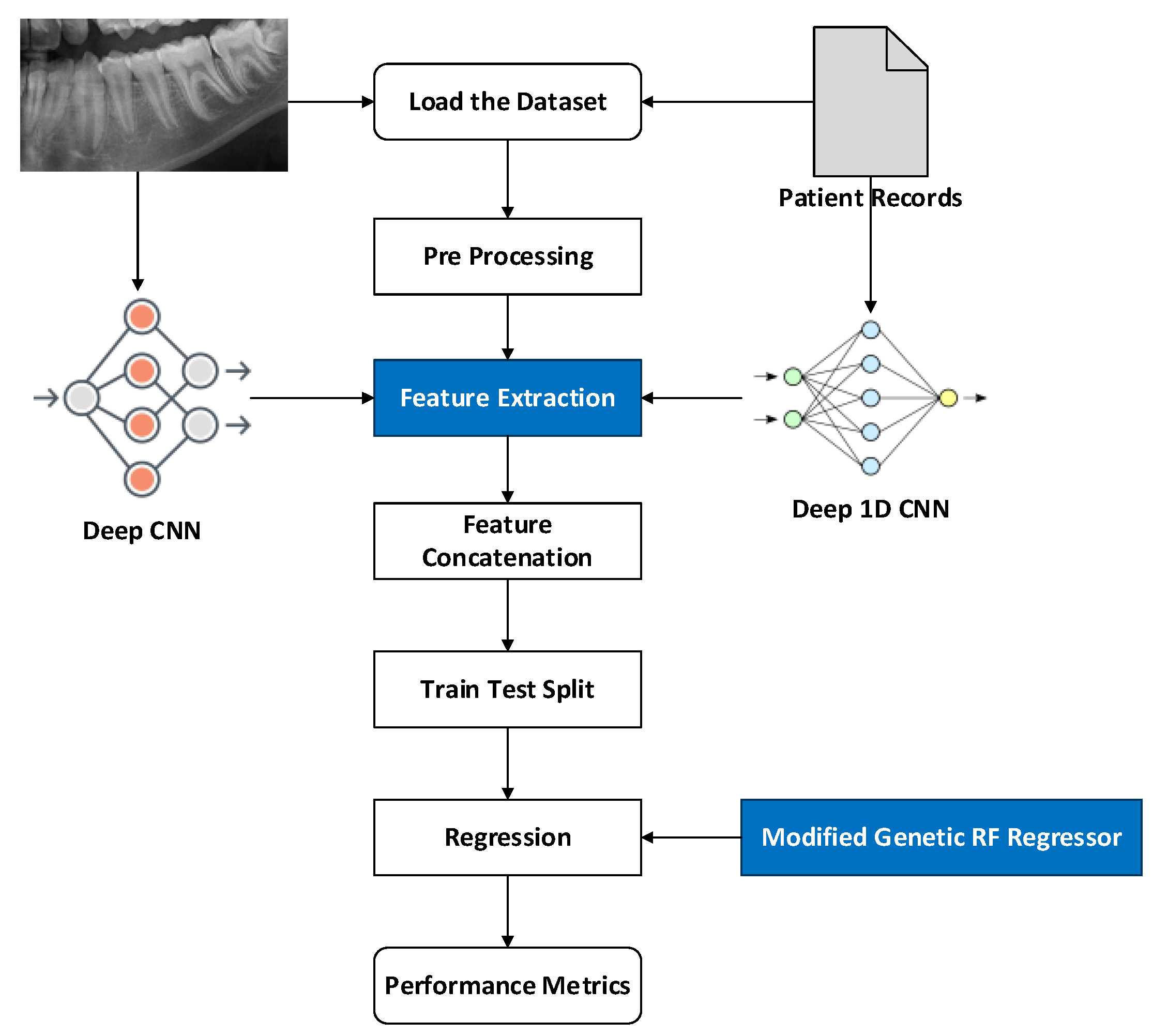
Figure 2.
Overall architecture of Deep 2D CNN.
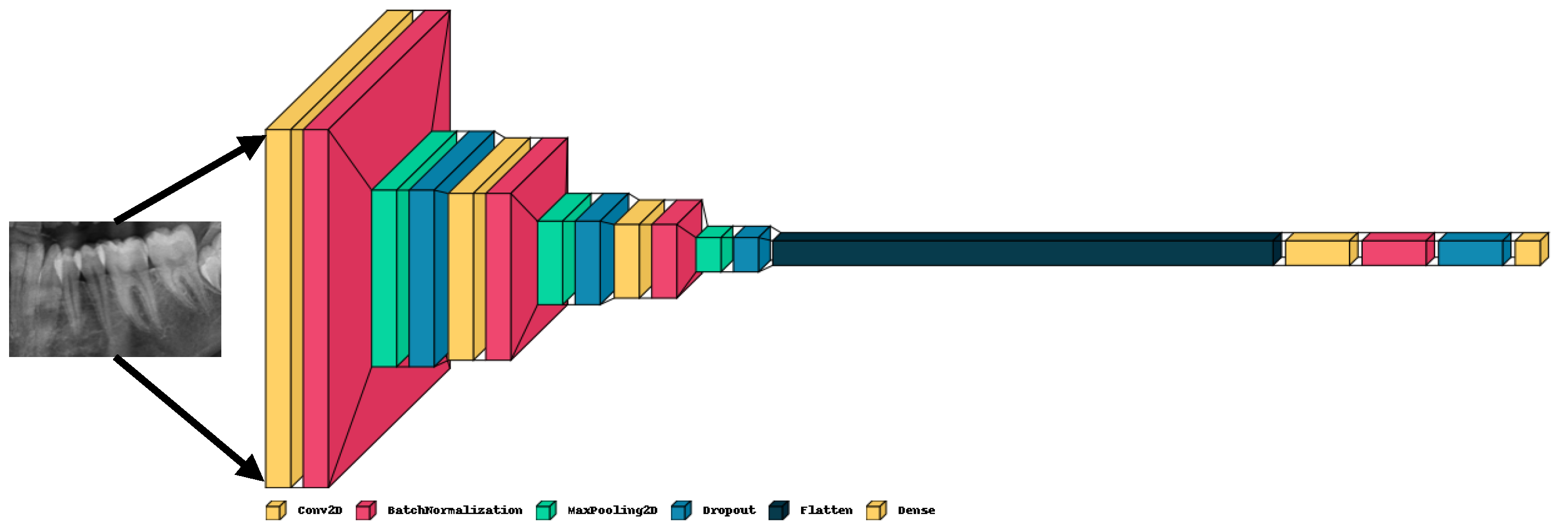
Figure 3.
Overall workflow of Modified Genetic-Random Forest.
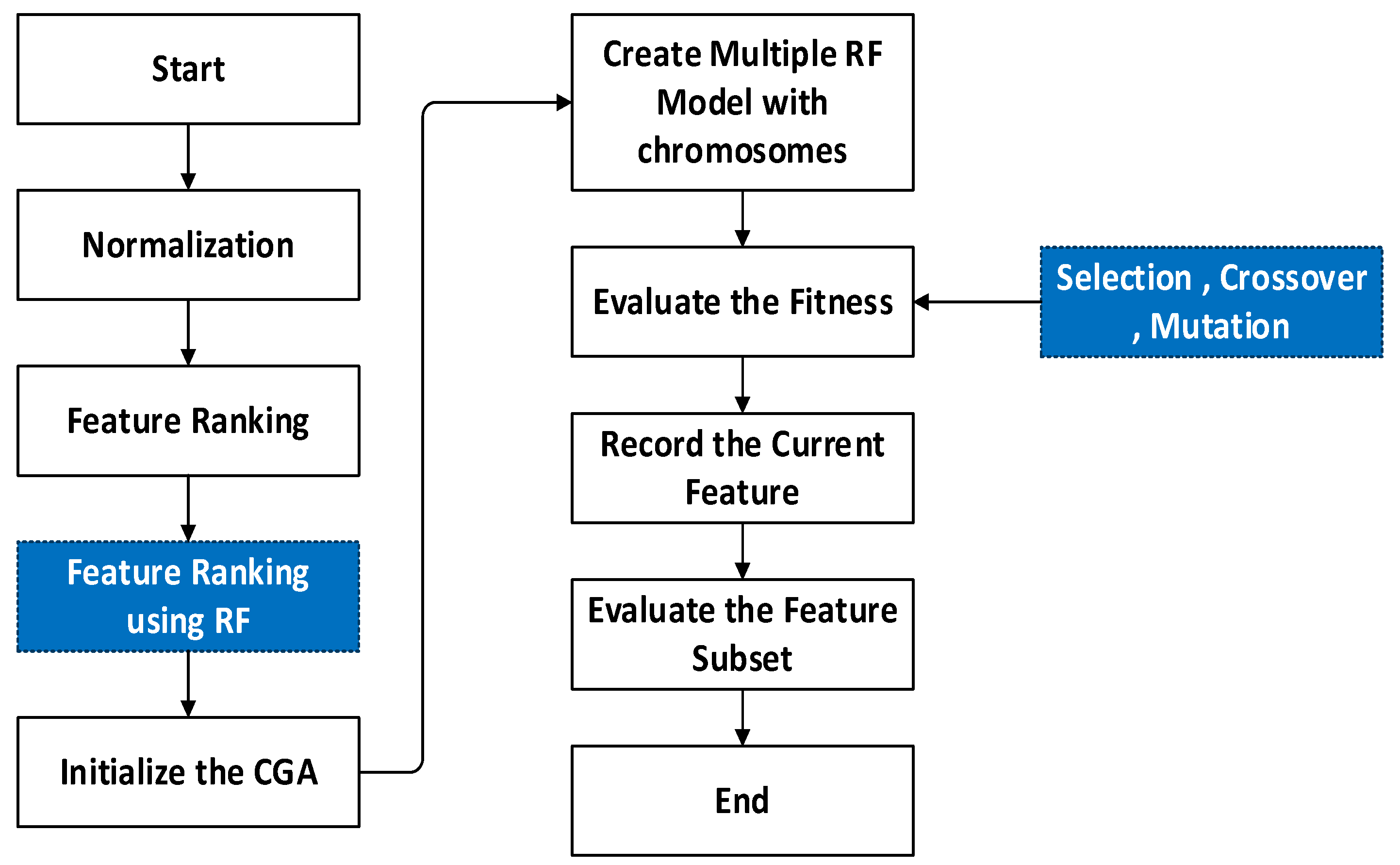
Figure 4.
Sample OPGs from the dataset.
Figure 5.
Analysis of the proposed system with respect to metrics.
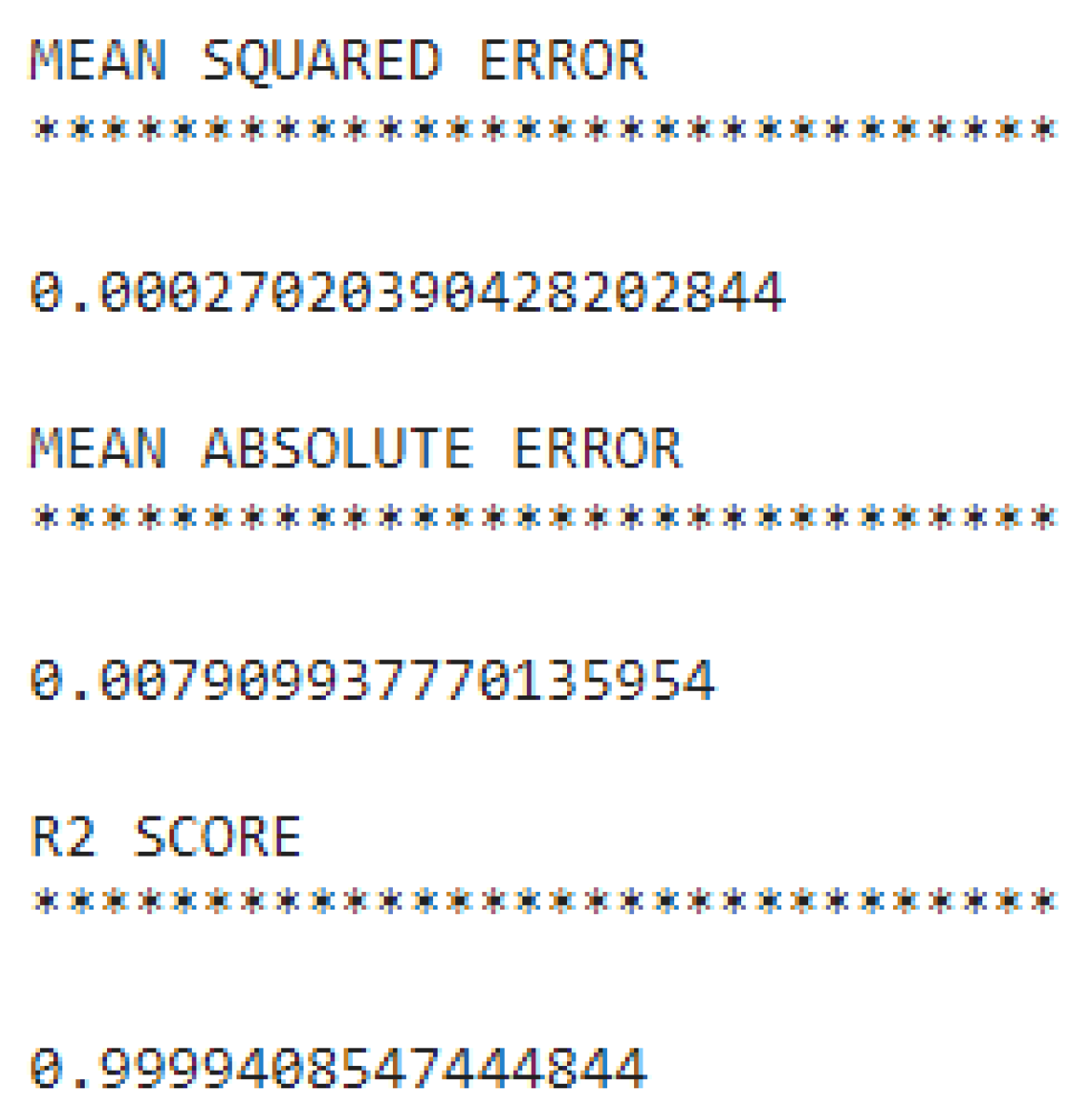
Figure 6.
Plot showing variation degree between the actual and predicted values.
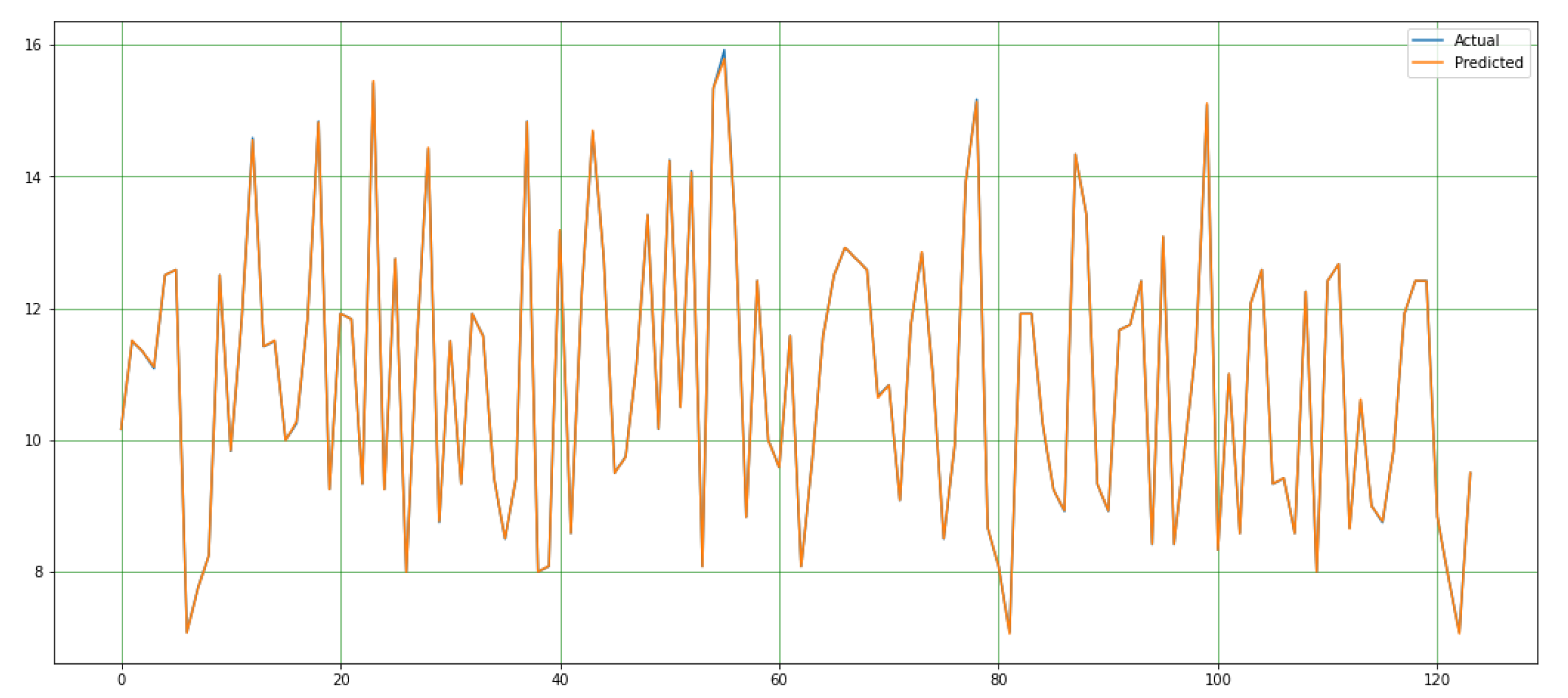

Table 1.
Best parameters from GA.
| Best Parameters from Genetic Algorithm | |
| max_depth' | [10] |
| max_features' | [sqrt'] |
| min_samples_leaf' | [4] |
| min_samples_split' | [10] |
| n_estimators' | [600] |
Table 2.
Hyper parameters for RF.
| Hyper Parameters For RF | ||
| 'max_depth' | [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, None] | |
| 'max_features' | ['auto', 'sqrt'] | |
| 'min_samples_leaf' | [1, 2, 4] | |
| 'min_samples_split' | [2, 5, 10] | |
| 'n_estimators' | [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000] | |
Table 3.
Comparison of the findings of Galibourg et al.[66] study with the findings of our study.
Table 3.
Comparison of the findings of Galibourg et al.[66] study with the findings of our study.
| Methods | SD | MAE | MSE | RMSE | R2 |
| Demirjian | -0.705 | 1,108 | 1,981 | 1,406 | 0,816 |
| Willems | -0,220 | 0,928 | 1,418 | 1,190 | 0,868 |
| BRR | -0,002 | 0,812 | 1,030 | 1,014 | 0,904 |
| SVM | 0,016 | 0,729 | 0,901 | 0,949 | 0,916 |
| DT | -0,012 | 0,758 | 0,973 | 0,985 | 0,910 |
| RF | -0,007 | 0,731 | 0,885 | 0,940 | 0,918 |
| KNN | 0,009 | 0,738 | 0,921 | 0,959 | 0,915 |
| MLP | -0,041 | 0,742 | 0,907 | 0,952 | 0,916 |
| POLYREG | -0,008 | 0,735 | 0,913 | 0,955 | 0,915 |
| ADAB | -0,025 | 0,796 | 1.001 | 1,000 | 0,907 |
| STACK | -0,013 | 0,733 | 0,904 | 0,950 | 0,916 |
| VOTE | 0,068 | 0,770 | 0,995 | 0,984 | 0,908 |
| The proposed method | 0,0004 | 0,0079 | 0,00027 | 0,0888 | 0,9999 |
Table 4.
Comparison of the findings of Tao et al. [69] study with the findings of our study.
Table 4.
Comparison of the findings of Tao et al. [69] study with the findings of our study.
| Male | RMSE | MSE | MAE | Female | RMSE | MSE | MAE |
| Demirjian | 1,596 | 2,548 | 1,307 | Demirjian | 1,677 | 2,812 | 1,364 |
| Willems | 1,602 | 2,556 | 1,291 | Willems | 1,788 | 3,196 | 1,407 |
| MLP | 1,332 | 1,775 | 0,990 | MLP | 1,617 | 2,616 | 1,261 |
| The proposed method | 0,8888 | 0,00027 | 0,0079 | The proposed method | 0,8888 | 0,00027 | 0,0079 |
Table 5.
Comparison of the findings of Shen et al. [79] study with the findings of our study.
Table 5.
Comparison of the findings of Shen et al. [79] study with the findings of our study.
| Methods | MAE | MSE | RMSE | R2 |
| LR | 0,553 | 0,488 | 0,698 | 0,909 |
| SVM | 0,489 | 0,392 | 0,625 | 0,925 |
| RF | 0,495 | 0,389 | 0,623 | 0,928 |
| Cameriere Method (European Formula) |
0,846 | 0,755 | 0,869 | - |
| Cameriere Method (Chinese Formula) |
0,812 | 0,89 | 0,943 | - |
| The proposed method | 0,0079 | 0,0002 | 0,0888 | 0,9999 |
Table 6.
Comparison of the findings of Čular et al. [71] study with the findings of our study.
Table 6.
Comparison of the findings of Čular et al. [71] study with the findings of our study.
| MAE | SD | |
| AAM | 2,481 | 2,148 |
| AGM | 2,283 | 2,168 |
| The proposed method | 0,0079 | 0,0004 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



