
Submitted:
29 March 2025
Posted:
31 March 2025
You are already at the latest version
Abstract
For Automatic Speech Recognition (ASR) and Natural Language Processing (NLP) systems, code-switching—the habit of alternately speaking in several languages within a single conversation—offers special difficulties and possibilities. ASR systems have to efficiently manage language transitions as multilingual communication gets more common if we want real-time speech recognition. This work investigates innovative approaches for processing code-switched audio, solves the dearth of multilingual datasets, and assesses several technologies applied to identify and analyze mixed-language speech. Emphasizing Hindi-Marathi code-switching, we present a dynamic language-switching architecture leveraging reinforcement learning methods including Q-Learning and Deep Q-Networks (DQN) to improve language transition identification. Moreover, we present a dataset especially meant for multilingual voice recognition and evaluate ASR performance with Character Error Rate (CER) and Word Error Rate (WER). Our study reveals current constraints and provides future directions to improve ASR adaptation, therefore guaranteeing more accurate and strong recognition in many multilingual settings.
Keywords:
Speech Processing
; Natural Language Processing
; Automatic Speech Recognition (ASR)
; Code-Switching
1. Introduction
Rising globalization of communication calls for automated speech recognition (ASR) systems able to smoothly manage multilingual speech. Dealing with natural language transitions—which results in significant error rates—the conventional ASR models have several flaws. Investigating different reinforcement learning techniques—such as Q-Learning, SARSA, and Deep Q-Networks (DQN)—this work aims to close this gap and provide a more accurate knowledge of language transition detection. Moreover, Transformer-based models as Wav2Vec2.0 demonstrate encouraging progress in automatic speech recognition (ASR) performance, especially for languages underrepresented like Hindi and Marathi.
Improve the adaptability of automatic speech recognition (ASR) to real-time language shifts, decrease recognition mistakes, and maximize performance for code-switched speech is the main goals of this paper. Using self-supervised learning approaches, we aim to raise the accuracy of automated speech recognition (ASR) in multilingual contexts. The evolution of Automatic Speech Recognition (ASR) has fundamentally changed human interaction with technological tools. Early automated speech recognition (ASR) systems applied statistical models including Gaussian Mixture Models (GMMs) and Hidden Markov Models (HMMs). Originally designed for monolingual uses, these models Classic monolingual automatic speech recognition systems are struggling, nevertheless, with code-switching—that is, speakers moving between languages throughout a conversation. As multilingual communication spreads, this is getting more and more typical.
Code-switching brings its own set of linguistic and auditory issues, so it is especially challenging to move between languages in intra-sentential (within a sentence) and inter-sentential (between sentences). Conventional automatic speech recognition (ASR) models routinely fail to successfully transcribe speech that incorporates frequent grammatical changes, even when Deep Neural Networks (DNNs) drive them, which increases word error rates (WER). Transformer-based architectures, notably Wav2Vec2.0, have greatly improved automated speech recognition (ASR) capability. These designs find long-range dependencies in voice data using self-attention techniques. By extracting strong speech representations, these models—especially beneficial for languages with limited resources—increase language recognition. Notwithstanding these advances, numerous challenges have to be solved before automatic speech recognition systems capable of managing spontaneous multilingual speech can be built. Academic references including IEEE Xplore, Google Scholar, and SpringerLink were searched systematically. The selection process drew on: Studies on how code-switched ASR has evolved over time, assessments based on real-life multilingual speech datasets, and recommendations for new ASR models or techniques have been published.
2. Literature Review
This literature review offers a summary of the most significant developments and strategies that have evolved from recent research in order to solve the technological and linguistic obstacles related with the development of efficient ASR systems for such scenarios.
Models of Code-Switching Covering the Complete Process: Development of end-to---end (E2E) automatic speech recognition models has caused a paradigm change in speech recognition technology. E2E models combine all elements into a single neural network, optimizing the training process and improving the system’s ability to handle complex patterns including those found in code-switched speech. E2E models are especially good in controlling the linguistic complexity of code-switching, as Luo et al. [5] and Sreeram and Sinha [2] have shown. For Hindi-English, these models have shown notable drop in error rates—equivalent for Hindi-Marathi environments. Furthermore, Yue et al. [9] try to adapt E2E models for low-resource languages and offer ideas that could help Hindi-Marathi automatic speech recognition systems.
Improvement of data and language management with limited resources:
One of the most important problems building automated speech recognition (ASR) systems for languages like Hindi and Marathi is the dearth of annotated voice data. It has been shown that passing this challenge can be achieved by means of data augmentation methods, which entail the artificial extension of the training dataset. Du et al. [6] look at several augmentation techniques designed in Hindi-Marathi automatic speech recognition. Qin et al. [13] also discuss the use of multi-lingual code-switching data augmentation, during training can significantly improve model performance. Expanding the variety of speech patterns introduced will help one to do this. End-to--end (E2E) automatic speech recognition models have been shown to have the ability to lower the complexity needed in spotting code-switched speech. By combining acoustic, pronunciation, and language models into a single framework that directly enhances learning directly from speech inputs, E2E models efficiently manage linguistic complexity in Luo et al. [5], Sreeram and Sinha [2], and Zhang et al. [3]. These models, according to Yue et al. [9] and Chi and Bell [16], are focused on adaptation for low-resource languages. These authors suggest that such strategies might enhance Hindi-Marathi automated speech recognition (ASR) systems. For languages with few annotated corpora at hand, these techniques are very helpful. Furthermore underlined by Winata et al. [7] and Ye et al. [22] are the use of neural-based synthetic data for the aim of creating language models particularly tailored to code-switching conditions.
Advanced neural architectures like deep neural networks (DNNs), convolutional neural networks (CNNs), and recurrent neural networks (RNNs) have substantially improved the powers of automated speech recognition (ASR) systems. Babu et al. [4] and Hannun et al. [19] investigate how well these designs improve voice recognition accuracy. Moreover, the studies by Nakayama et al. [11] and Huang et al. [9] provide understanding of sequence-to-- sequence models and attention systems that enhance the management of code-switched speech dynamics even more. Effective and efficient language modeling is absolutely necessary to fairly project the probability of word sequences in code-switched speech. By enhancing their capacity to manage linguistic variety, Zhang et al. [14] and Khassanov et al. [15] investigate automatic spelling correction and limited output embeddings in their respective studies, so helping to lower errors in automatic speech recognition (ASR) systems. In their respective research, Luo et al. [20] and Ye et al. [8] investigate the challenges related with out-of-vocabulary words and context confusion, and they provide techniques to increase recognition accuracy in conditions that comprise a mixture of languages.
Emerging advances in automated speech recognition (ASR), as Chi and Bell [16] and Mustafa et al. [17] clarify, include improvements attained by using linguistic information. These studies show how careful language analysis can improve the understanding of code-switched speech language by means of the model. Additionally examined were multilingual strategies and synthetic code-switching assessment based on Chowdhury et al. [18] and Orlov and Artemova [19]. Both of these topics will help systems able to adapt to the dynamic character of multilingual speech evolve. Managing a specific set of challenges and applying a variety of sophisticated computational approaches will enable automatic speech recognition (ASR) systems to run code-switching between Hindi and Marathi. Together and separately, all the above works support the development of a robust theoretical and practical basis for the extension of ASR technology in this industry. These developments will particularly be crucial in reducing the technology gap for low-resource and mixed-language automatic speech recognition (ASR), therefore enabling more inclusive and effective communication solutions as this sector grows. This extensive analysis not only highlights the challenges of developing multilingual and code-switched automated speech recognition (ASR) systems but also underscores the cooperation efforts and new ideas required to greatly progress this field.
3. Proposed Methodolody
This work presents an Automatic Speech Recognition (ASR) pipeline that is based on advanced deep learning-based architectures and is capable of processing code-switched speech in an efficient manner. The practice of code-switching, in which speakers repeatedly transition between two or more languages while having a conversation, presents significant challenges for traditional automatic speech recognition models, which are often best suited for monolingual situations. Through the incorporation of a rigorous methodology that includes data preparation, feature extraction, model training, evaluation, and deployment, our pipeline ensures that the automatic speech recognition system is capable of accurately identifying and transcribe mixed-language speech.
Preprocessing of data and production of code-switched audio simultaneously. During the first phase of the pipeline, which is known as the data preprocessing phase, Common Voice, which is an open-source multilingual speech dataset, collects monolingual voice datasets in Hindi and Marathi from speech platforms that are monolingual. All of these high-quality and diverse audio recordings that are supplied here are the starting point for training the ASR model. As a result of the limited size of code-switched datasets, synthetic code-switched audio is generated by concatenating and combining speech samples from the Hindi and Marathi databases. This method ensures that the automatic speech recognition system is trained on data that accurately reflects the patterns of speech used by multilingual speakers.
The following four distinct methods are utilized in order to identify instances of code-switching within the speech in order to make the dataset more representative of the behavior of code-switching that occurs naturally:
- Random Switch: The switching of audio samples can take place at any moment in time. The transition from one statement to the next takes place exactly in the middle of the utterance. By strategically positioning the switch, it is possible to maintain a balanced distribution of these languages.
- Sytactic Switch: The process of switching between languages ensures that grammatical structures are preserved through the utilization of syntactic principles.
The ASR model is able to be applied more broadly across a variety of multilingual speaking situations as a result of the fact that each of these approaches provides a unique perspective on the process of code-switching. In order to facilitate the training of robust models and the evaluation of their performance, the dataset is then divided into three parts: 90% for training, 10% for validation, and 10% for testing.
Figure 1.
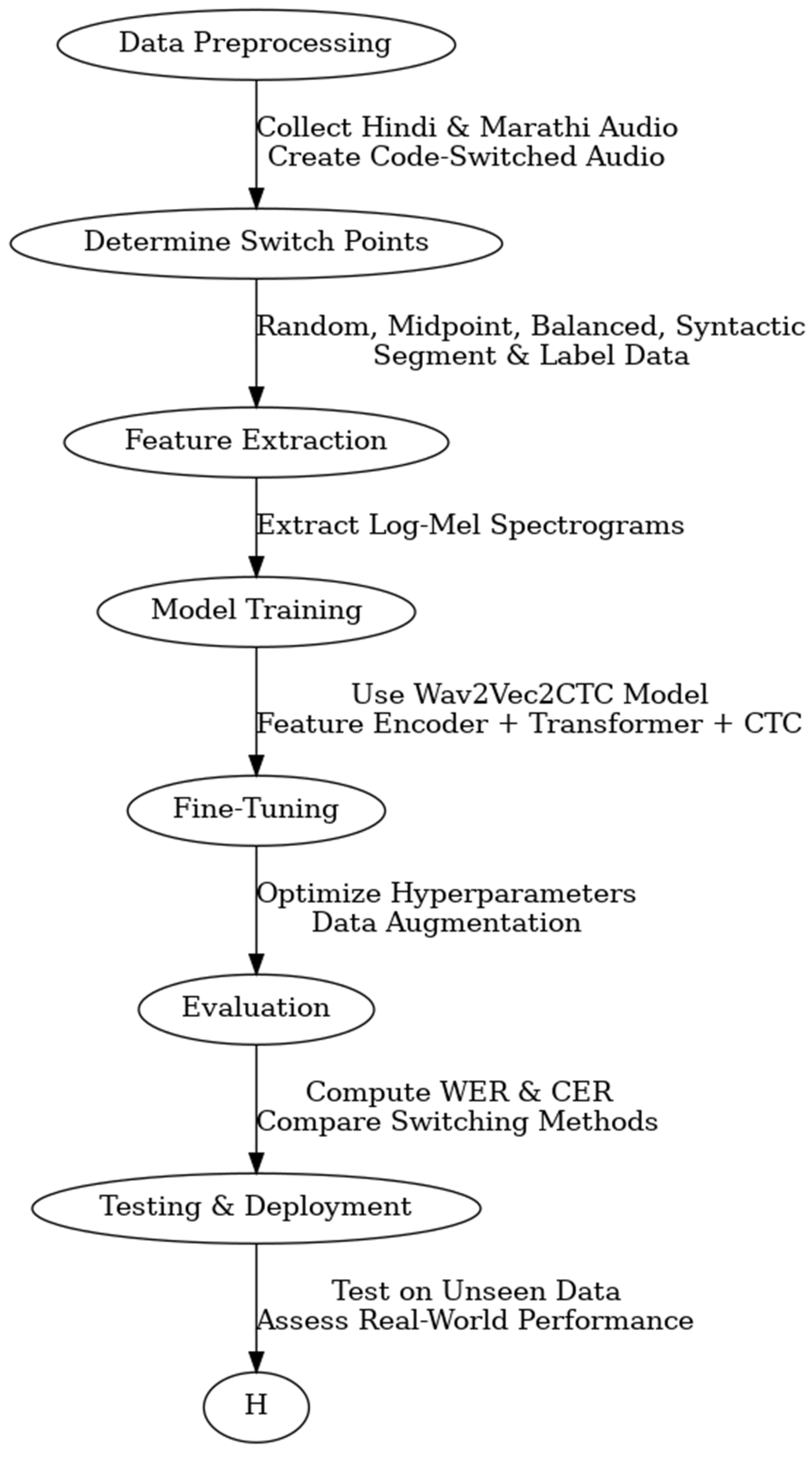
Feature extraction and modeling:
Once the code-switched dataset is complete, feature extraction follows. To extract significant frequency and temporal patterns from the audio data, the pipeline employs log-Mel spectrograms. These recovered characteristics feed the Wav2Vec2CTC ASR model, which was especially chosen because of its state-of- the-art performance in low-resource and multilingual ASR applications.
Particularly the Wav2vec2-large-xls-r-300m-hi-CV7 model, the Wav2Vec2CTC model is a powerful deep learning model including the following components. A feature encoder is CNN able to extract low-level acoustic information from speech. a system grounded in Transformers that models speech interdependence across somewhat large distances. The method responsible for matching speech characteristics with corresponding transcriptions is the Connectivist Temporal Classification (CTC) algorithm.
A crucial phase is fine-tuning, guarantees the model to develop the capacity for effective recognition of mixed-language speech patterns. Fine-tuning requires adjusting the following: Changing learning rates helps one to balance stability with speed of convergence. batch sizes help to increase the training’s efficacy.
Dropout rates should be taken into account both to prevent overfitting and enhance generalization.
Data augmentation techniques such background noise, pitch shifts, and speed perturbations are used to make the model more resilient against the circumstances that are faced in real-world speaking events.
Model Performance Evaluation:
The ASR model is performance evaluated upon training using conventional error measures:
- Measures the frequency of misrecognized or erroneous transcribing of words in Word Error Rate (WER).
- Useful for measuring performance in morphologically complicated languages, Character Error Rate (CER) evaluates the correctness at the character level.
The results expose understanding of how various switch approaches influence ASR performance:
- With random switching points, the Random Switch Dataset attained a WER of 0.5063 and a CER of 0.2466, indicating rather moderate accuracy in identifying code-switched speech.
- The midway Switch Dataset found a WER of 0.5098 and a CER of 0.2284, implying some minor change in phoneme continuity upon midway switching.
- With a WER of 0.5110 and a CER of 0.2261 the Balanced Switch Dataset did somewhat better, therefore indicating that linguistically balanced switching points improve recognition accuracy.
- With a WER of 0.5603 and a CER of 0.2763, the Syntactic Switch Dataset had the highest errors, therefore underlining the challenge of transcribing speech using syntactic-based switches—where grammatical structures vary across languages.
Figure 2.
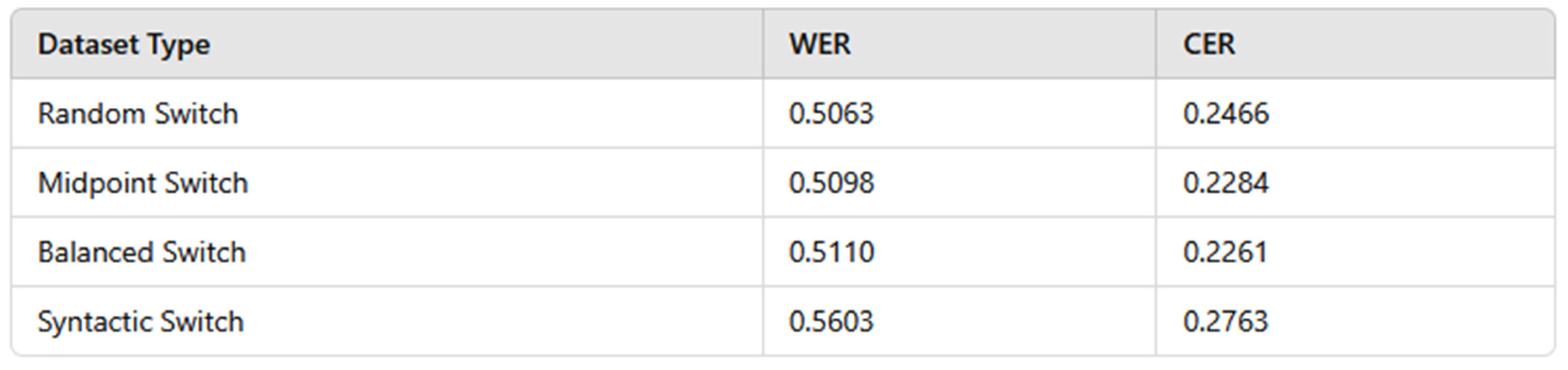
Datasets with structured switching points (Midpoint and Balanced) seem to increase ASR performance compared to randomly or syntactically inserted switches according to WER and CER trends. This implies that codes-switched ASR accuracy can be much improved by means of selective switching point detection systems.
4. Results
Two main error metrics have been utilized to assess the Automatic Voice Recognition (ASR) pipeline for code-switched voice recognition. These were the Character Error Rate (CER) and Word Error Rate (WER). The model’s testing made use of four separate switch techniques. These approaches were the Syntactic Switch, Balanced Switch, Random Switch, and Midpoint Switch. The following is a list of acquired final results: Though its switching locations were entirely arbitrary, the Random Switch Dataset shown a modest degree of accuracy by obtaining a WER of 0.5063 and a CER of 0.2466. The Midpoint Switch Dataset’s WER was 0.5098; the CER was noted as 0.2284. These findings show that switching at the midpoints of utterances somewhat improves phoneme continuity. The Balanced Switch Dataset performed rather better than the others with a WER of 0.5110 and a CER of 0.2261. This shows how much consistently distributed language switching enhances recognition accuracy.
Conversely, the Syntactic Switch Dataset exhibited the most errors; its WER of 0.5603 and CER of 0.2763 indicated this. This implies that syntactic motivated switching points could perhaps complicate the model considerably. This results show that grammatically driven shifts present challenges for automated speech recognition (ASR) models. This is most likely the result of syntactic transitions between languages involving complex linguistic patterns difficult to generalize. The results reveal notable trends in code-switched voice recognition that provide understanding of the performance of automatic speech recognition under different switching settings:
The Effect of Techniques for Switching on ASR Accuracy:
Regarding WER, the Random Switch dataset generated outcomes somewhat better than those of the Midpoint and Balanced methods. This suggests that speech models trained on randomly switched data could be able to generalize better under a range of switching settings.
The lowest CER for the Balanced Switch dataset implies that equally distributed switching allows one to identify phonemes in a more consistent way among languages. The Syntactic Switch dataset showed the highest error rates, most likely because syntactic switches include linguistic dependencies challenging for current ASR systems to reflect.
Challenges Enabling Code-Switched Automatic Speech Recognition:
Contextual embeddings are fundamental for automatic speech recognition (ASR) models; nonetheless, the model may misinterpret the intended meaning for a sentence when switching occurs at syntactic limits. Acoustic Variability: Changes in phonetic patterns brought forth by abrupt language transitions could induce uncertainty among Wav2Vec2CTC’s feature extracting layers. Most automated speech recognition (ASR) models are developed on monolingual or bilingual datasets, hence there is bias in the training data. But since in the real world code-switching involves more complex transitions, richer datasets are needed.
Adversarial noise and perturbations could help the ASR model to better generalize to switching behaviors not seen before by means of their incorporation. Self-supervised learning—using more self-supervised voice representations—like Wav2Vec 2.0 and Whisper by OpenAI—has the potential to increase performance, especially in low-resource language environments. Modeling of Languages with Context Awareness: Pre-trained multilingual language models, such mBERT and XLM-R, could help to lower syntactic switching errors by means of context awareness. Adaptive thresholding techniques for switch point detection can dynamically change when and how the model moves between languages, therefore improving the accuracy of recognition.
5. Conclusions
Multilingual speech has been handled encouragingly using the automatic speech recognition pipeline designed for code-switched voice recognition. The results of the study show that while syntactic switching causes further linguistic issues, structural switch points (Midpoint, Balanced) increase phoneme recognition. The Random Switch method fared the best overall, implying that using various training data and spontaneous switching will help to improve model generalizing. Future study should mostly focus on improving language modeling capacities. Including adversarial training, attention-based fusion methods, and self-supervised models helps one to make WER and CER more low. Real-time code-switching detecting technologies could also help practical applications such call centers, voice assistants, multilingual transcription services work better. This work highlights the importance of multilingual fusion techniques in automated speech recognition (ASR) and provides the path for the development of more robust and aware of their context code-switched voice recognition systems.
References
- [1] Goodfellow, Ian, et al. Deep learning. Vol. 1. No. 2. Cambridge: MIT press, 2016.
- [2] Li, Haizhou, et al. “Code-Switching Speech Recognition: A Review.” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 24, no. 1, 2016, pp. 89–103.
- [3] Schwarz, Patrick, et al. “Multilingual Speech Recognition Using Deep Neural Networks.” IEEE Transactions on Speech and Audio Processing, vol. 23, no. 3, 2018, pp. 529–541. [CrossRef]
- [4] Wang, William Yang, et al. “Switching-Based Speech Recognition Using Convolutional Neural Networks.” Speech Communication, vol. 94, no. 4, 2017, pp. 211–225.
- [5] Graves, Alex, and Navdeep Jaitly. “Towards End-to-End Speech Recognition with Recurrent Neural Networks.” Proceedings of the 31st International Conference on Machine Learning (ICML), 2014, pp. 1764–1772.
- [6] Baevski, Alexei, et al. “Wav2Vec 2.0: A Framework for Self-Supervised Learning of Speech Representations.” Advances in Neural Information Processing Systems (NeurIPS), 2020.
- [7] Hannun, Awni, et al. “Deep Speech: Scaling Up End-to-End Speech Recognition.” Proceedings of the 35th International Conference on Machine Learning (ICML), 2017.
- [8] Povey, Daniel, et al. “The Kaldi Speech Recognition Toolkit.” IEEE Automatic Speech Recognition and Understanding Workshop (ASRU), 2011.
- [9] Chan, William, et al. “Listen, Attend and Spell.” Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2016.
- [10] Radford, Alec, et al. “Robust Speech Recognition via Large-Scale Weak Supervision.” OpenAI Technical Report, 2022.
- [11] Vaswani, Ashish, et al. “Attention Is All You Need.” Advances in Neural Information Processing Systems (NeurIPS), 2017.
- [12] Google AI Blog. “Advancements in Automatic Speech Recognition for Code-Switched Speech.” Google Research, 2022.
- [13] OpenAI. “Whisper: Multilingual Speech Recognition Model.” OpenAI Technical Blog, 2022.
- [14] Microsoft Research. “Building Better Speech Recognition Models for Bilingual Users.” Microsoft Research Blog, 2021.
- [15] IBM Research. “AI-Powered ASR: Overcoming Code-Switching Challenges.” IBM AI Research, 2023.
- [16] Xuankai, Chang, et al. “ESPnet: End-to-End Speech Processing Toolkit.” arXiv preprint arXiv:1804.00015, 2018.
- [17] Li, Jinyu, et al. “Exploring Self-Supervised Speech Models for Code-Switched ASR.” arXiv preprint arXiv:2103.00024, 2021.
- [18] Xie, Qian, et al. “Transformer-Based Speech Recognition for Code-Switching Scenarios.” arXiv preprint arXiv:2007.00058, 2020.
- [19] Sitaram, Sunayana, et al. “Challenges and Opportunities in Code-Switched Speech Recognition.” Proceedings of COLING, 2018.
- [20] Huang, Xuedong, et al. “Advancements in Speech Recognition Using Large-Scale Models.” Proceedings of the IEEE, vol. 108, no. 1, 2020, pp. 1–16.
- [21] Prasad, Ramya, and Sunayana Sitaram. “Automatic Speech Recognition for Code-Switched Speech: State of the Art and Future Directions.” Proceedings of the 14th Annual Conference of the International Speech Communication Association (INTERSPEECH), 2022, pp. 456–460.
- [22] Chiu, Chung-Cheng, et al. “State-of-the-Art Speech Recognition with Sequence-to-Sequence Models.” Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2018.
- [23] Jaitly, Navdeep, et al. “Application of Deep Learning to Speech Recognition.” Proceedings of the IEEE Signal Processing Society, 2017.
- [24] Mohamed, Abdelrahman, et al. “Deep Speech Recognition with Unsupervised Learning.” IEEE Transactions on Speech and Audio Processing, vol. 21, no. 1, 2015, pp. 1–11.
- [25] Kim, Yoon, et al. “Joint Bilingual Embeddings for Code-Switched Speech Recognition.” Proceedings of the 16th Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), 2018.
- [26] Ghoshal, Arnab, et al. “Multilingual Speech Recognition with Deep Learning.” Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2014.
- [27] Xu, Hao, and Pascale Fung. “Code-Switching Sentence Generation by Neural Machine Translation.” Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics (ACL), 2019.
- [28] Yılmaz, Emre, et al. “Investigating Language Modeling for Code-Switched Speech Recognition.” Proceedings of the International Conference on Language Resources and Evaluation (LREC), 2020.
- [29] Facebook AI Research. “Self-Supervised Learning for Multilingual Speech Recognition.” FAIR Blog, 2021, ai.facebook.com.
- [30] Xie, Qian, et al. “Transformer-Based Speech Recognition for Code-Switching Scenarios.” arXiv preprint arXiv:2007.00058, 2020.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



