
Submitted:
07 November 2024
Posted:
08 November 2024
Read the latest preprint version here
Abstract
Using assembly theory of strings of any natural radix $b$ we find some of their salient regularities. In particular, we show that the upper bound of the assembly index depends quantitatively on the radix $b$ and the longest length $N$ of a string that has the assembly index of $N-k$ is given by $N_{(N-1)}=b^2+b+1$ and by $N_{(N-k)}=b^2+b+2k$ for $2 \le k \le 9$. We also provide particular forms of such strings. Knowing the latter bound, we conjecture that the maximum assembly index of a string of length $N_{(N-2)} \le N \le N_{\text{max}}$ is given by $a_{\text{max}}^{(N,b)} = \lfloor N/2 \rfloor + b(b+1)/2$, where $N_{\text{max}} = 4b^4$ if $b$ is even and $N_{\text{max}} = 4(b^4+1)$ otherwise. For $k=1$ such odd length strings are nearly balanced and there are four such different strings if $b=2$ and seventy-two if $b=3$. We also show that each $k$ copies of an $n$-plet contained in a string decrease its assembly index at least by $k(n-1) - a$, where $a$ is the assembly index of this $n$-plet. Finally, we show that the assembly depth of a minimum assembly index string is equal to the assembly index of this string, the assembly depth of a maximum assembly index string satisfies $d_{a_{\text{max}}}^{(N,b)} \ge \left\lceil \log_2(N) \right\rceil$. Since these results are, in general, also valid for $b=1$, assembly theory subsumes information theory.
Keywords:
assembly theory
; information theory
; complexity measures
; information entropy
; mathematical physics
1. Introduction
Assembly theory (AT), formulated in 2017, introduced the concept of an initial pool [1].
Definition 1.
We call a set that contains different basic symbols c, the initial assembly pool.
The reader will find numerous results on AT in refs. [1,2,3,4,5,6,7,8,9,10], for example. Here, we extend the results of our previous study [9] concerning bitstrings to strings of any natural radix b. We consider the formation of strings of length N containing symbols from the initial assembly pool within the AT framework in consecutive assembly steps from basic symbols c and strings (doublets, triplets, n-plets) assembled in previous steps. The ancient Greek verb symbállein means putting only two things (“symbols”) together [11].
In fact, any embodiment of AT, with basic symbols representing LEGO® blocks, chemical bonds, graphs, monomers, etc. assembled in any n-dimensional space () [12] corresponds to the string AT version. This is because in AT an assembly step always consists in joining two parts only, which can be thought of as the left and right fragments of the newly formed string. Put simply, AT explains and quantifies selection and evolution [7] but it is through the word (aka string or message), in particular a nucleotide sequence in the case of , all AT things come into existence [13].
Definition 2.
We call a set that contains basic symbols and strings assembled in previous steps the working assembly pool.
An assembly step s may consist of
where , , and . Using Definitions 1 and 2, the assembly index (ASI) of a string is the minimal achievable value of a difference between the cardinalities of the working and initial assembly pools (ASPs) leading to this string, since at each assembly step the cardinality of the working ASP increases by one. Therefore, the working ASP 2 cannot be identified with the initial ASP 1; the initial ASP 1 must not contain strings of basic symbols (see Appendix G).
2. Results
Theorems 1 and 2 were already stated in our previous study [9] for . We restate them here for clarity.
Theorem 1.
A quadruplet is the shortest string that allows for more than one ASI for all b.
Proof.
provides available doublets with unit ASI. provides available triplets with ASI equal to two. Only provides quadruplets that include quadruplets with ASI equal to two, that is b quadruplets and quadruplets , while the ASI of the remaining quadruplets is three. □
For example, to assemble the quadruplet , we need to assemble the doublet and reuse it from the first step ASP , while there is nothing available to reuse, in the case of the quadruplet .
Where the symbol value can be arbitrary, we write * assuming that it is the same within the string. If we allow for the 2nd possibility different from *, we write ★. Thus, , for example, is a placeholder for all b strings, while a placeholder for all strings. Furthermore, we consider the degenerate case of just one basic symbol ().
Theorem 2.
The minimum ASI as a function of N corresponds to the shortest addition chain for N (OEIS A003313) for all b.
Proof.
Strings for which , can be formed in subsequent steps s by joining the longest string assembled so far with itself until is reached. Therefore, if , then . Only strings have such ASI if , including respectively b and strings
and the assembly pathway of each of the strings (2) is unique. At each assembly step, its length doubles.
An addition chain for having the shortest length (commonly denoted as ) is defined as a sequence of integers such that , for . Thus, an addition chain starts with one, not zero, as zero is the neutral element of addition. For the same reason, two is considered the smallest prime, as one is the neutral element of multiplication. Hence, and the first step in creating an addition chain for N is always ; the ASI of any doublet is one. The second step in creating an addition chain can be , , or . The 1st case does not represent the shortest addition chain, the 2nd one corresponds to assembling a triplet based on the previously assembled doublet, and the 3rd one corresponds to assembling a quadruplet from this doublet. Therefore, four is the smallest number achievable in two ways since and , where the latter case corresponds to assembling a quadruplet by joining a basic symbol to a triplet, which is not the shortest way for assembling a quadruplet having a minimum ASI.
Thus, finding the shortest addition chain for N corresponds to finding the ASI of a string containing basic symbols and/or doublets and/or triplets containing these doublets for since due to Theorem 1 only they provide the same assembly indices . □
The assembly pathways of strings of length are not unique. For example, a string can be assembled in three steps from three working ASPs , , and .
Theorem 3.
The strings can contain at most two symbols if . Other minimum ASI strings of length can contain at most three symbols if .
Proof.
Minimum ASI strings of length are formed by joining the newly assembled string to itself, where a clear or mixed doublet is created in the first step. Minimum ASI strings of other lengths admit a doublet and a triplet containing this doublet and an additional basic symbol.
To formally prove the first part, we can also use mathematical induction on the assembly step s. If , then the minimum ASI strings are doublets of the form , where . If , the string contains one distinct symbol, and if , the string contains two distinct symbols. In both cases, the number of distinct symbols does not exceed two. Now assume that for some , all minimum ASI strings contain at most two distinct symbols. We must show that also contains at most two distinct symbols. Consider constructing by joining two identical minimum ASI strings
with each other. By the inductive hypothesis, each contains at most two distinct symbols. Therefore, their concatenation also contains at most two distinct symbols. By induction, for all , the minimum ASI string contains at most two distinct symbols.
We will now show that other minimum ASI strings of length can contain at most three distinct symbols if . We provide the construction of minimum ASI strings with three symbols. In the first step , we create a doublet where and . Next, we combine the existing doublet with a new symbol where . This forms a triplet , introducing a third distinct symbol and further increasing the ASI by 1. We continue assembling by joining the longest string formed so far with itself or with previously formed strings, maintaining the minimal increase in ASI.
Assume a contrario that there exists a minimum ASI string of length that contains four or more distinct symbols. To incorporate a fourth symbol, at least one additional assembly step is required beyond what is needed for the three symbols. This additional step implies an increase in ASI, which contradicts the minimality of . Thus, Theorem 3 is proven. □
The strings having non-minimum ASI can contain all symbols. For example, the string [14]
has ASI and contains all five basic symbols .
Theorem 4.
A string containing the same three doublets has the same ASI as a string containing two pairs of the same doublets, provided that both strings have the same distributions of other repetitions and have the same lengths.
Proof.
Without loss of generality (w.l.o.g.), consider the following two strings of the same length with and the same distributions of other repetitions (if there are any other repetitions)
where . Creating a doublet takes one assembly step. Each appending of a doublet to an assembled string counts as another assembly step. Hence, in a general case (i.e., for strings , containing also other symbols), the string requires six additional assembly steps, the same as the string , which completes the proof. □
Theorem 5.
A string containing the same three doublets has the same ASI as a string containing the same two triplets, provided that both strings have the same distributions of other repetitions.
Proof.
W.l.o.g. consider the following two strings of the same length with the same distributions of other repetitions
Creating a triplet takes two assembly steps. Hence, in the general case, the string requires four additional assembly steps, the same as the string , which completes the proof. □
Theorem 6.
A string containing the same two triplets has the same ASI as a string containing two pairs of the same doublets, provided that both strings have the same distributions of other repetitions and have the same lengths.
Proof.
The proof stems from Theorems 4 and 5. □
Theorem 7.
A string containing the same two quadruplets of the minimum ASI has the same ASI as a string containing the same three triplets, provided that both strings have the same distributions of other repetitions and have the same lengths.
Proof.
W.l.o.g. consider the following two strings of the same length with the same distributions of other repetitions
Creating such a quadruplet takes two assembly steps. Hence, in a general case, the string requires five additional assembly steps, the same as the string , which completes the proof. □
Theorem 8.
A string containing the same two quadruplets of the maximum ASI has the same ASI as a string containing a doublet and the same two triplets based on this doublet, provided that both strings have the same distributions of other repetitions.
Proof.
W.l.o.g. consider the following two strings of the same length with the same distributions of other repetitions
Creating such a quadruplet takes three assembly steps. Hence, in a general case, the string requires five additional assembly steps, the same as the string , which completes the proof. □
Theorem 9.
A string containing the same two doublets and the same two triplets not based on this doublet has the same ASI as a string containing a doublet and the same two triplets based on this doublet, provided that both strings have the same distributions of other repetitions and have the same lengths.
Proof.
W.l.o.g. consider the following two strings of the same length with the same distributions of other repetitions
where . In a general case, the string requires seven additional assembly steps, the same as the string , which completes the proof. □
In general, Theorems 1-9 show that
- k copies of a doublet in a string decrease the ASI of this string at least by ;
- k copies of a triplet in a string decrease the ASI of this string at least by ;
- k copies of a minimum ASI quadruplet in a string decrease the ASI of this string at least by ;
- k copies of a maximum ASI quadruplet in a string decrease the ASI of this string at least by ;
where, the phrase "at least" is meant to indicate that other repetitions, such as e.g. doublets forming multiple quadruplets, etc. can further decrease the ASI of the string. This observation allows us to state the following theorem.
Theorem 10.
Each copies of an -plet contained in a string decrease its ASI at least by . That is
where R is the total number of repeated -plets.
Proof.
W.l.o.g. consider the following string
containing two copies of an n-plet . The n-plet can be assembled in steps and appended to the assembled string in one step. Consider that the ASI of the n-plet is , i.e. the n-plet does not have any repetitions that can be reused. Then one copy of this n-plet - as expected - does not decrease the ASI of the string , as , while more copies k decrease it by . On the other hand, if then even a single copy of this n-plet will decrease the ASI of . □
For example, due to the presence of three copies of a 5-plet , each with , in a string
its ASI amounts to . The relation (10) provides the upper bound on ASI as it does not describe a situation in which n-plet for is assembled on a doublet also present in one copy in the string. For example, the string , while . We note that the maximum ASI decrease is provided by -plets of the minimum ASI and amounts to .
Another quantity quantifying the complexity of a string is the assembly depth (ASD) defined [15] as
where , and and are the ASDs of two substrings , of the string that were joined in step s, where for , and if there are more assembly pathways with different depths leading to a string, which happens if at least two independent assembly steps are possible, the minimum pathway depth is the ASD of this string. Hence, the ASD captures the notion of an independent assembly step.
Theorem 11.
If a working ASP contains strings having the same ASD they were assembled in independent assembly steps.
Proof.
W.l.o.g. assume a contrario that two strings , in the working ASP have the same ASD, i.e., , but was used in the assembly of along with a basic symbol c. Then
which contradicts our assumption and completes the proof. □
In other words, if two strings , in the working ASP have the same ASD, their assembly pathways are unrelated to each other; by the defining equation (13) neither of them could have been used in the assembly pathway of the other.
Theorem 12.
The ASD of any minimum ASI string is equal to the ASI of this string, .
Proof.
We need to show that . While constructing the minimum ASI string, we start with a doublet and follow the shortest addition chain for N, joining this doublet with itself or with a basic symbol to form a triplet. At each assembly step, the ASD increases by one, as we join the assembled string with a string or a basic symbol from the working ASP and we cannot perform independent assembly steps. Since, by Theorem 2, the minimum ASI corresponds to the length of the shortest addition chain , we have
This completes the proof (see Appendix F for additional comments). □
Theorems 11 and 12 show that
- the working ASP of a minimum ASI string cannot contain strings assembled in independent assembly steps,
- the working ASP of a non-minimum ASI string must contain at least two such strings, and
- the assembly pathway of a maximum ASI string will tend to maximize their number in the working ASP, and hence to minimize the possible ASD, taking into account the saturation of the working ASP, as the number of distinct n-plets in the working ASP cannot exceed .
Theorem 13.
The ASD of any maximum ASI string satisfies
Proof.
Let . For we have , as we are joining basic symbols from the initial ASP. This is the base case. In an assembly tree of ASD , the maximum number of leaves that can be combined is , because at each assembly step, we join two substrings. Therefore, the maximum length of a string that can be assembled with ASD satisfies:
This implies that
and leads to the relation (16), since both and are natural numbers and the latter does not have to be a power of two. We can also use mathematical induction. For and for we have respectively
where implies that either or . Hence,
which completes the proof. □
Theorems 12 and 13 are somehow counterintuitive. For example, the string has the ASI and the ASD , while the string has a smaller ASI but a larger ASD .
For example, the ASD of a string is as
even though this string can be assembled with three larger pathway depths and the ASD of a minimum ASI string is
Similarly, the ASD of a string is as
However, the non-maximum ASI string has only two doublets that can be assembled in independent steps. Hence, its ASD cannot be decreased to
The seven-bit string is the longest string that can have the maximum ASI . There are four such bitstrings containing two clear triplets and the starting bit at the end or the ending bit at the start, that is
and their lengths cannot be increased without a repetition of a doublet, which keeps the ASI at the same level .
This observation and Theorem 2 motivated us to develop a general method to construct the longest possible string having the ASI , as a function of the radix b. We denote the length of this string by or , and we call this string a string.
After a few groping try-outs, we eventually reached two stable methods (cf. Appendices, Methods Appendix A and Appendix B). In both methods, we start with an initial balanced string of length containing b clear triplets ordered as
The doublets that can be inserted into the initial string (26) can be arranged in a matrix
 where the crossed out entries on a diagonal cannot be reused, as they would create repetitions in this string. If we assume that we shall not insert doublets between the clear triplets of the string (26), we can also cross out the entries in the first superdiagonal of the matrix (27). The strings of odd lengths generated by these general methods are not only the longest but also the most balanced. This can be stated in the following theorem.
where the crossed out entries on a diagonal cannot be reused, as they would create repetitions in this string. If we assume that we shall not insert doublets between the clear triplets of the string (26), we can also cross out the entries in the first superdiagonal of the matrix (27). The strings of odd lengths generated by these general methods are not only the longest but also the most balanced. This can be stated in the following theorem.
Theorem 14
(). The longest length of a string that has the ASI of is given by
(OEIS A353887) and this string is nearly balanced, that is
where is the number of occurrences of all but one symbol within the string, and its Shannon entropy is
The proof of Theorem 14 is given in Appendix D. A string must contain all clear triplets and all doublets and if it is generated by Method Appendix A or Appendix B it is terminated with 0 and has a form
Although the case for is degenerate, as no information can be conveyed using only one symbol ( in this case), nothing precludes the assembly of such defunct strings and the formula (28) yields the correct result; the string is the longest string with by Theorem 1, as for the upper and the lower bound on the ASI are the same, (OEIS A003313). This is the only case where the maximum ASI is not a monotonically nondecreasing function of N.
For , only two doublets can be introduced without repetitions into the initial string (26), leading to twelve unique strings of length
Finally, we have to multiply the cardinality of this set by to account for permutations. For example, the first string , is equivalent to five strings , , , , and . Hence, there are seventy-two different strings of length .
Subsequently, we considered other strings of length with the maximum ASI for .
Theorem 15
(). For all and the longest length of a string that has the ASI of is given by
The proof of Theorem 15 is given in Appendix E. This result disproves our upper bound Conjecture 1 for stated in our previous study [9]. If the strings of Theorem 15 are based on strings generated by Method Appendix A or Appendix B, for they owe their properties to the following distributions of symbols
For the strings of the form (34) the fractions in the Shannon entropy are
where , if and , otherwise, as is inserted into , into and or otherwise. This leads to Shannon entropy
The entropies (30) and (36) are shown in Figure 1. Radix is the smallest one at which the entropy (36) is a monotonically decreasing function. For there is a local entropy minimum for and for an additional local entropy minimum for .
Conjecture 16
(). If and then
or equivalently
where
In other words, if , then ASI increases by one, where N increases by two ( are triangular numbers, OEIS A000217).
First, we note that maximum ASI must rise. If it were constant for , then at some even larger N it would inevitably become lower than the minimum ASI bound 2 which also rises, and this would be a contradiction. W.l.o.g. we aim to prove this conjecture for . We note that inserting any doublet into a string (A19) at any position creates a triplet. Using the equation (10) of Theorem 10 we have
for any step s if only . Now, assume that , and , . Then
The proof of the Conjecture 16 must show the conditions for the equations (40) and (41) to hold. We note that the assumption used in the equation (41) is valid only for and . The bounds of Theorems 14 and 15 and Conjecture 16 are illustrated in Figure 2.
The results thus far led us to a simple method of determining the ASI of a maximum ASI and a minimum ASD string and strengthened our Conjectures 3 and 4 stated in the previous study [9]. The method is based on unique -plets and powers of two, as shown in Table 1. First, a maximum ASI string is sequenced, every two symbols to find the number of unique adjoining doublets . In particular, a string (A3) or (A4) contain the maximum of unique adjoining doublets, a string (A13) contains the maximum of unique adjoining doublets, and so on. In general, a string contains the maximum of
unique adjoining doublets, where is given by the relations (28) or (33), which is independent of k.
Subsequently, these doublets form unique adjoining quadruplets, quadruplets form unique adjoining octuples, and so on depending on the length of the string N and the radix b, as there can be at most unique -plets. The columns "last " indicate if the assembled string should be terminated with a single substring of length in descending order. The empty fields in the respective columns for indicate that a given substring can be interpreted as either a "regular" single substring or a last substring if .
For example, the string (A20) of length for can be assembled as


For and for other small N this combinatorics is valid also for , where obviously . For example, the string of length can be assembled in six steps as
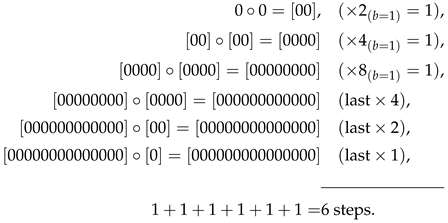 However, this is the 1st exception for as the ASI of this string is five if it is assembled using doublet and triplet . For the method produces OEIS A014701 sequence corresponding to the number of steps to reach 1 starting from and assigning if is odd and otherwise.
However, this is the 1st exception for as the ASI of this string is five if it is assembled using doublet and triplet . For the method produces OEIS A014701 sequence corresponding to the number of steps to reach 1 starting from and assigning if is odd and otherwise.
We further note that the method illustrated in Table 1 cannot be used to construct the maximum ASI string. For example, both the following two distributions of doublets for satisfy the distributions of Table 1. However, only the left one correctly reflects the maximum ASI of the assembled string.
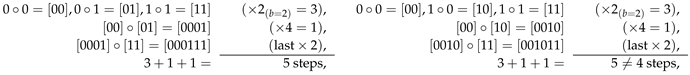 as the right one can be assembled in four steps with . Similarly, only the top distribution of doublets below correctly reflects the maximum ASI of the assembled string for
as the right one can be assembled in four steps with . Similarly, only the top distribution of doublets below correctly reflects the maximum ASI of the assembled string for
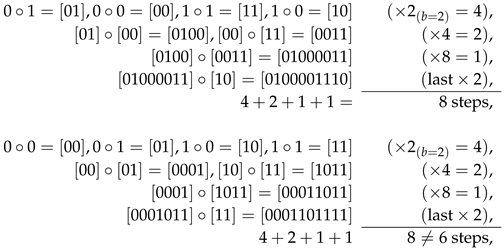 as the bottom one can be assembled in six steps with . Furthermore, this method tends to exaggerate the estimated maximum ASI value, that is,
where is the ASI of a string determined by the method illustrated in Table 1. For example, the first six strings below contain four unique doublets instead of the required three. Therefore
as the bottom one can be assembled in six steps with . Furthermore, this method tends to exaggerate the estimated maximum ASI value, that is,
where is the ASI of a string determined by the method illustrated in Table 1. For example, the first six strings below contain four unique doublets instead of the required three. Therefore
Further research should consider researching the formula equivalent to (28) that captures a quadruplet repetition, similarly as captures a doublet repetition.
3. Discussion
Applications of AT seem to be promising. It offers a new lens for studying the construction of biological molecules like DNA and proteins. By analyzing the steps needed to assemble these molecules from basic building blocks, researchers can gain deeper insights into the evolutionary constraints and optimizations that shape biological pathways. This perspective also sheds light on the efficient construction of cellular structures and helps to identify the minimum number of assembly steps that define biological complexity, reinforcing the idea that life is characterized by highly organized pathways. Furthermore, AT provides an essential tool for understanding the growth of complexity in biological systems over evolutionary time. By quantifying the assembly steps required to form increasingly complex organisms, scientists can map the trajectory of evolutionary development and identify key transitions that lead to higher levels of structural and functional complexity. It can guide the design and optimization of synthetic biological systems by minimizing the number of steps required to build new biological pathways, making bioengineering more efficient and scalable. The ability to model and simplify complex biological processes using AT could lead to the development of more robust and adaptable synthetic organisms.
Strings having lengths (e.g. (A3) or (A4)) are necessarily the most balanced: all but one symbol occur times and one symbol occurs times within a string . However, if the length of a string is constant, it will tend to evolve to decrease the Shannon entropy [16,17] and, hence, to become less balanced. As the energy of a black hole that can be thought of as a balanced bitstring [18] can be two times the energy of the entropy variation sphere that it generates [19], this tendency to imbalance seems to be associated with the minimum energy condition. For example, the Shannon entropy of the SARS-CoV genome containing nucleobases decreased from to within two years after the Wuhan outbreak [9,16]. The minimum ASI for this length of the string, given by the OEIS A003313, is . Perhaps, entropy (36) has other local entropy minima for and for and is a monotonically decreasing function only for . This could be the reason nature has chosen the non-binary radix and four nucleobases to encode genetic information.
Author Contributions
WB: first concept of a general method for constructing the string of length leading to Theorem 14; the concept of the doublet matrix (27); outline of the general Method Appendix A; proposition of Theorem 9; a string with exactly two copies of all doublets idea and the formula for its length; numerous clarity corrections and improvements; PM: outline of the general Method Appendix B; the hint for ASI combinatorics; creation of a software supporting Conjecture 16; creation of a string ; numerous clarity corrections and improvements; AT: formal proof of Theorem 3; proof that the Shannon entropy (30) can be approximated by for large b; proof of the Theorem 12; conceptualization of the proof of the Theorem 13 and equation (17); the 1st paragraph of the discussion Section 3; numerous clarity corrections and improvements; SŁ: The remaining part of the study.
Funding
This research received no external funding.
Data Availability Statement
The public repository for the code written in the MATLAB computational environment and C++ is given under the link https://github.com/szluk/Evolution_of_Information (accessed on 19 September 2024).
Acknowledgments
The authors thank Mariola Bala for her motivation and Rafał Winiarski for noting that the relation (10) is inequality. SŁ thanks his wife, Magdalena Bartocha, for her everlasting support, and his partner and friend, Renata Sobajda, for her prayers.
Conflicts of Interest
Authors Wawrzyniec Bieniawski and Piotr Masierak were employed by the company Łukaszyk Patent Attorneys. The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Appendix A. Method A for Generating C (N-1) String
We start with a string of clear triplets (26). In the 1st step, we create a string containing doublets on the first subdiagonal of the matrix (27) starting with 10
and we append it to the string (26). With this step, we also eliminate the doublets on the second superdiagonal starting with the doublet 02, as well as the doublet . In the 2nd step, we create a string containing doublets on the third superdiagonal beginning with the doublet 03
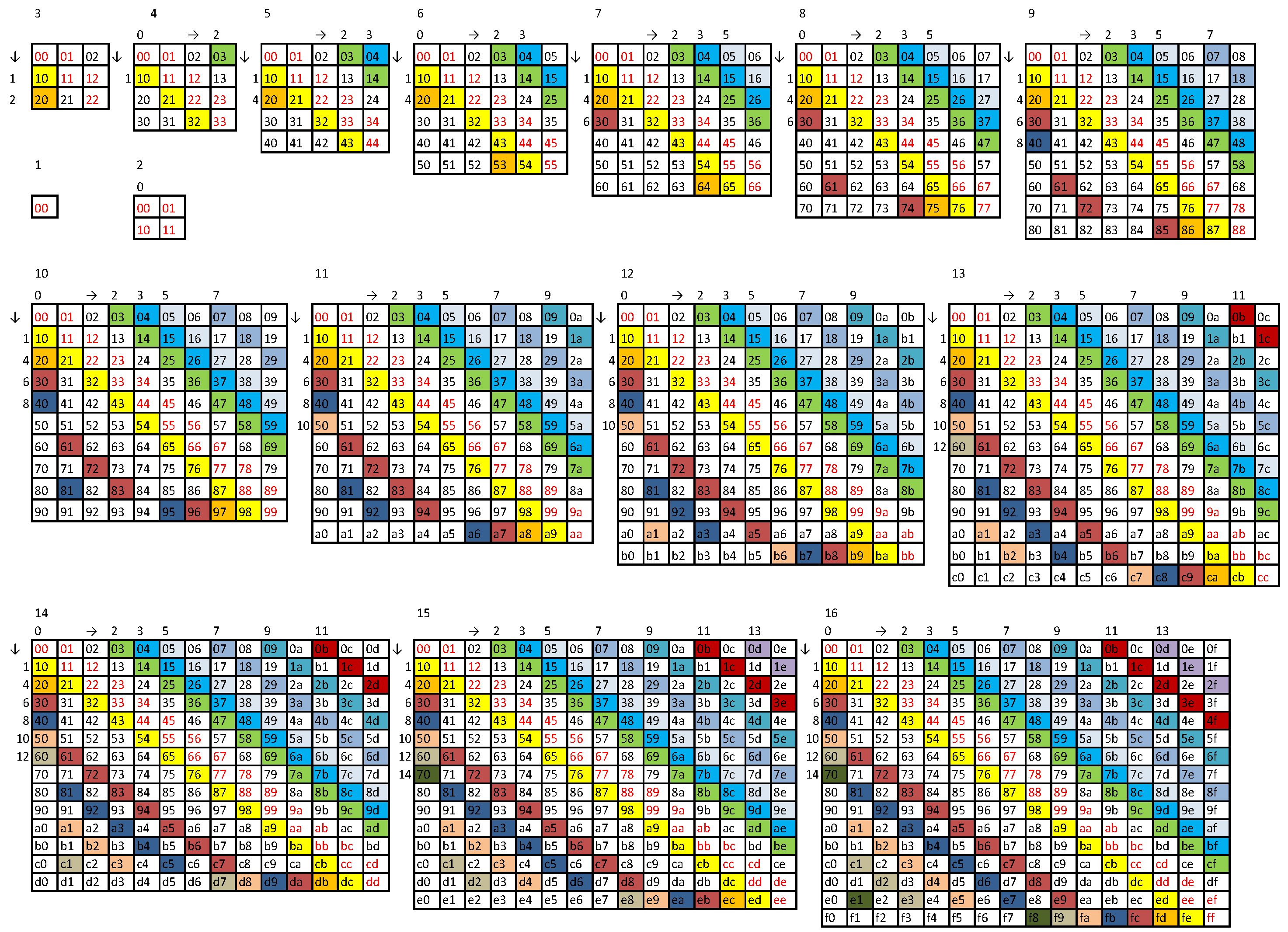
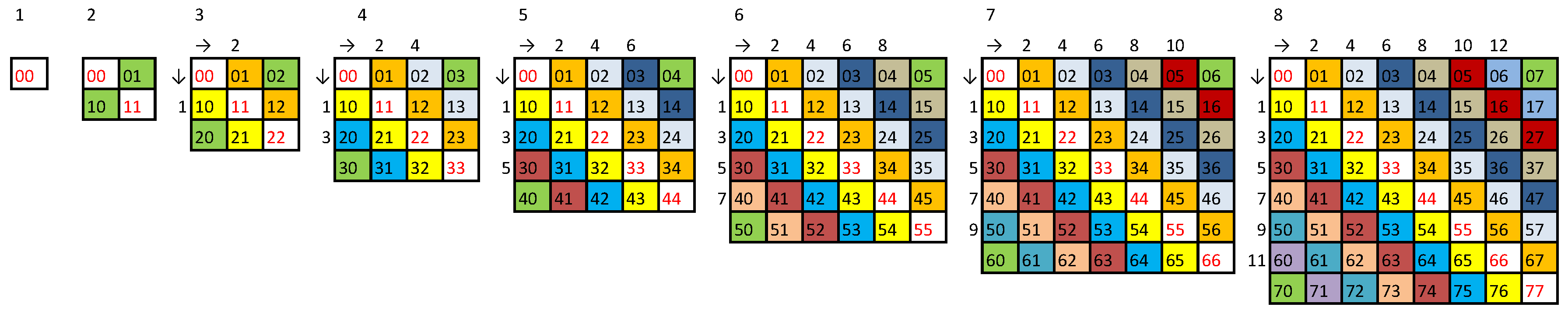
and append it to the string created so far. With this step, we also remove the doublet and the middle part of the second subdiagonal containing . And so on. Finally, we append 0 if b is even. This process is illustrated in Figure A1 and for generates the following strings
Figure A1.
Doublet matrices for that illustrate the generation of strings according to Method Appendix A. Colored doublets are appended to the initial string of clear triplets in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end, if b is even.
Figure A1.
Doublet matrices for that illustrate the generation of strings according to Method Appendix A. Colored doublets are appended to the initial string of clear triplets in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end, if b is even.
Appendix B. Method B for Generating C (N-1) String
This method is similar to the Method Appendix A. We also start with a string of clear triplets (26) and the matrix of doublets (27) with a crossed diagonal and the first superdiagonal. In the first step, we append the doublet (top right doublet of the matrix of doublets (27)) at the end of the string (26). Next, we generally perform the following pairs of iterations:
- 1.
- we check subsequent subdiagonals until we find one that does not contain a doublet present in the string created so far, we append it at the end of this string and proceed to step 2;
- 2.
- we check subsequent superdiagonals until we find one that does not contain a doublet present in the string created so far, we append it at the end of this string and proceed to step 1.
Finally, we append 0 if b is even. The method is illustrated in Figure A2 and for generates the strings in the form
Figure A2.
Doublet matrices for that illustrate the generation of strings according to Method Appendix B. Colored doublets are appended to the initial string of clear triplets in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end, if b is even.
Figure A2.
Doublet matrices for that illustrate the generation of strings according to Method Appendix B. Colored doublets are appended to the initial string of clear triplets in the order indicated by arrows starting from the 1st column or row. Finally, 0 is appended at the end, if b is even.
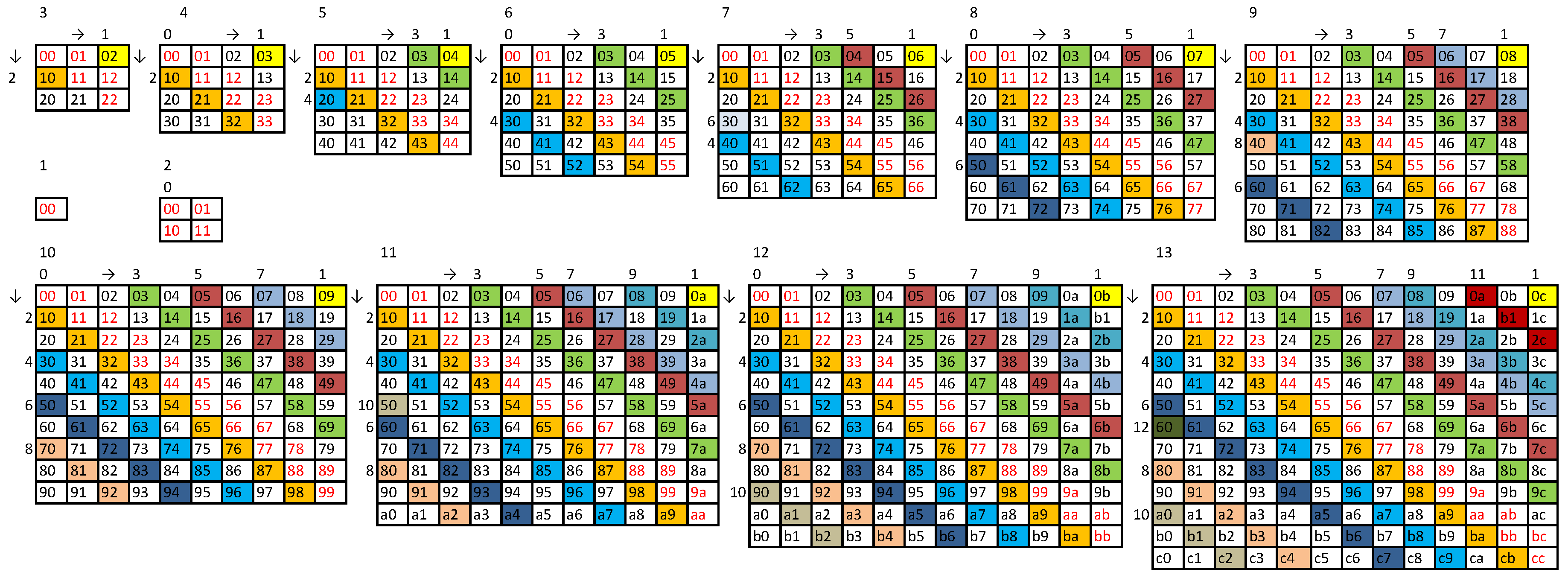
Appendix C. A String with Exactly Two Copies of All Doublets and No Repeated Triplets
A string that has exactly two copies of all doublets and no repeated triplets can have a form (for )
and has a length of
A suboptimal method for its generating (with repeated triplets) is illustrated in Figure A3.
Figure A3.
Doublet matrices for that illustrate the generation of strings containing exactly two copies of all doublets. Colored doublets are appended to the initial string of clear quadruplets in the order indicated by arrows starting from the 1st column or row. Finally, is appended at the end. The 1st superdiagonal is appended as .
Figure A3.
Doublet matrices for that illustrate the generation of strings containing exactly two copies of all doublets. Colored doublets are appended to the initial string of clear quadruplets in the order indicated by arrows starting from the 1st column or row. Finally, is appended at the end. The 1st superdiagonal is appended as .
Appendix D. Proof of C (N-1) String Theorem
The given by the formula (28) is an odd number for all b. The first element is the length of the initial string (26) containing b clear triplets and is the number of doublets available in the matrix (27) after crossing out b doublets on its diagonal and doublets on its superdiagonal that are present in the starting string (26). By definition, a string cannot have any repetitions. To be the longest, it must contain all doublets in the matrix (27) and all clear triplets. Furthermore, to be the most patternless, this string must maximize Shannon entropy; must be the most balanced. For the string of the form (29) the fractions in the Shannon entropy are
where w.l.o.g. we assume that the symbol occurring times within the string is . To see that the Shannon entropy (30) of a string can be approximated by for large b, first notice that and . Furthermore, , , which implies that the first term
Similarly the second term,
Hence, the entropy (30) can be approximated by the dominant contribution from the first term, which is
The strings given by the relation (28) are not the shortest possible ones. Strings satisfying the equation (29) and satisfying are given by (OEIS A002522). They can be constructed to contain all possible doublets but without any triplets, starting with an initial balanced string of length containing b clear doublets ordered from the main diagonal of the doublet matrix (27). Furthermore, their entropies are smaller than the entropies of the strings given by the equation (28). Namely
Appendix E. Proof of C (N-k) String Theorem
We start by noting that for , , as the ASI of is the same as the ASI of , , as the ASI of strings of seven and eight same symbols is three, there is no , and so on. Hence, Theorem 15 does not hold for .
A string contains all doublets. Hence, inserting any basic symbol into any position inevitably leads to a repetition of a doublet. W.l.o.g. we append it at the start of the string, obtaining a string
Another symbol can be introduced to this string without an additional doublet repetition provided that it adjoins the previously introduced symbol, which gives a string
leading to the repetition of the doublet or but not both of them (here we allow ). Hence, both the length and the ASI of this string increase by one. Finally, 0 can be appended at the start of this string without an additional doublet repetition provided that and and the string becomes
leading to the mutually exclusive repetition of the doublet , or 00, so that also both length and the ASI of this string increase by one. An insertion of another symbol into the string (A13) at any position will maintain or even decrease the ASI of this newly formed string. For example, appending 0 at the start of the string (A13), where
creates a 001 triplet based on 00 doublet leading to a decrease of the ASI of this longer string to as compared to of the string (A13).
string (A13) must contain only two copies of a doublet. Hence, a clear quadruplet () and a pattern binding different symbols adjoining this quadruplet, such as , , etc. must be present, so that any string contains only one pair of repeated doublets , , or (See also Appendix C). For example, for , sixteen bitstrings
(an additional eight are given by swapping 0 with 1) have the ASI , where the underlined string (A15) is the one that we created for . Each string (A15) contains three pairs of doublets , , and overlapped in such a way that only one pair can be reused from the ASP to decrease the maximum ASI by one.
Searching for a string, w.l.o.g. we append at the start of the string (A13)
If , we have the same three doublets 10. Otherwise, we have two pairs of the same doublets and 10. Both cases are equivalent by Theorem 4. An insertion of another symbol to this string may maintain or even decrease the ASI of this newly formed string. To maximize its ASI, another symbol must adjoin *. Hence, we append ★ at the start, where and , a string
has an increased length and ASI. W.l.o.g. for we have four bitstrings (A17), wherein three of them
have the same non-maximum ASI and only one have the maximum ASI
and cannot be further extended along with the increment of the ASI. Therefore
and the ASI of this newly formed string increases again. However, the insertion of another symbol into this string will maintain or even decrease the ASI of this newly formed string. Any string must contain only three copies of a doublet, two copies of a triplet, or two pairs of different doublets. W.l.o.g. we have found the following strings for and
which led us to the strings (34) for all . Thus, Theorem 15 is proven.
Appendix F. Additional Comments for the Proof of Theorem 12
We can also use mathematical induction on the length N of the string, if is is a power of two. For the base case () the string consists of a single basic symbol . Hence, its ASI is and its ASD . Therefore, . Assume now that for all strings of length less than N, the ASD equals the minimum ASI, that is
For some integer k, we construct the minimum ASI string as follows. First, we assemble a doublet from two basic symbols:
Its ASI is and its ASD is . Then for each we have with and and we construct by joining two copies of
The ASI of is equal to
and the ASD is equal to
Therefore, in this case.
Appendix G. Misunderstanding Assembly Pools
Consider the following mapping [20] between a working ASP containing five basic symbols and three strings made of these symbols in three steps and the initial ASP of radix
Now consider the string
assembled beginning with the initial ASP and having the ASI only two steps above , as we can assemble this string as the string
of length in 7 steps with the initial ASP and then, using the mapping (A27), it will correspond to the string (A28). However, as we have shown in Section 2, . In fact the latter string (A29) should be assembled as
with the ASI and with the initial ASP , as according to the mapping (A27). Hence, considering a set as the initial ASP is a gross misunderstanding; there is only one initial ASP for a given b and many different working ASPs for and (). Furthermore, basic objects must have the same vanishing ASD (13).
References
- S. M. Marshall, A. R. G. S. M. Marshall, A. R. G. Murray, and L. Cronin, “A probabilistic framework for identifying biosignatures using Pathway Complexity,” Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 375, p. 20160342, Dec. 2017.
- S. Imari Walker, L. S. Imari Walker, L. Cronin, A. Drew, S. Domagal-Goldman, T. Fisher, and M. Line, “Probabilistic biosignature frameworks,” in Planetary Astrobiology (V. Meadows, G. Arney, B. Schmidt, and D. J. Des Marais, eds.), pp. 1–1, University of Arizona Press, 2019.
- V. S. Meadows, G. N. Arney, B. E. Schmidt, and D. J. Des Marais, eds., Planetary astrobiology. University of Arizona space science series, Tucson: The University of Arizona Press; Houston: Lunar and Planetary Institute, 2020. [Google Scholar]
- Y. Liu, C. Y. Liu, C. Mathis, M. D. Bajczyk, S. M. Marshall, L. Wilbraham, and L. Cronin, “Exploring and mapping chemical space with molecular assembly trees,” Science Advances, vol. 7, p. eabj2465, Sept. 2021.
- S. M. Marshall, C. S. M. Marshall, C. Mathis, E. Carrick, G. Keenan, G. J. T. Cooper, H. Graham, M. Craven, P. S. Gromski, D. G. Moore, S. I. Walker, and L. Cronin, “Identifying molecules as biosignatures with assembly theory and mass spectrometry,” Nature Communications, vol. 12, p. 3033, 21. 20 May.
- S. M. Marshall, D. G. S. M. Marshall, D. G. Moore, A. R. G. Murray, S. I. Walker, and L. Cronin, “Formalising the Pathways to Life Using Assembly Spaces,” Entropy, vol. 24, p. 884, 22. 20 June.
- A. Sharma, D. A. Sharma, D. Czégel, M. Lachmann, C. P. Kempes, S. I. Walker, and L. Cronin, “Assembly theory explains and quantifies selection and evolution,” Nature, vol. 622, pp. 321–328, Oct 2023.
- M. Jirasek, A. M. Jirasek, A. Sharma, J. R. Bame, S. H. M. Mehr, N. Bell, S. M. Marshall, C. Mathis, A. MacLeod, G. J. T. Cooper, M. Swart, R. Mollfulleda, and L. Cronin, “Investigating and Quantifying Molecular Complexity Using Assembly Theory and Spectroscopy,” ACS Central Science, vol. 10, pp. 1054–1064, 24. 20 May.
- S. Łukaszyk and W. Bieniawski, “Assembly Theory of Binary Messages,” Mathematics, vol. 12, p. 1600, 24. 20 May.
- S. Raubitzek, A. S. Raubitzek, A. Schatten, P. König, E. Marica, S. Eresheim, and K. Mallinger, “Autocatalytic Sets and Assembly Theory: A Toy Model Perspective,” Entropy, vol. 26, p. 808, Sept. 2024.
- P. Francis, “Dilexit nos: Encyclical letter on the human and divine love of the heart of jesus christ,” 2024. Accessed: 2024-11-01.
- S. Łukaszyk and A. Tomski, “Omnidimensional Convex Polytopes,” Symmetry, vol. 15, mar 2023.
- “Book of John [1.3],” c90.
- L. Cronin, “Exploring assembly index of strings is a good way to show why assembly & entropy are intrinsically different..” https://x.com/leecronin/status/1850289225935257665, 2024. Accessed: 2024-11-01.
- S. Pagel, A. S. Pagel, A. Sharma, and L. Cronin, “Mapping Evolution of Molecules Across Biochemistry with Assembly Theory,” 2024.
- M. M. Vopson, “The second law of infodynamics and its implications for the simulated universe hypothesis,” AIP Advances, vol. 13, p. 105308, Oct. 2023.
- S. Łukaszyk, “Shannon entropy of chemical elements,” European Journal of Applied Sciences, vol. 11, p. 443–458, Jan. 2024.
- S. Łukaszyk, Black Hole Horizons as Patternless Binary Messages and Markers of Dimensionality, ch. 15, pp. 317–374. Nova Science Publishers, 2023.
- S. Łukaszyk, “Life as the explanation of the measurement problem,” Journal of Physics: Conference Series, vol. 2701, p. 012124, Feb 2024.
- L. Ozelim, A. L. Ozelim, A. Uthamacumaran, F. S. Abrahão, S. Hernández-Orozco, N. A. Kiani, J. Tegnér, and H. Zenil, “Assembly Theory Reduced to Shannon Entropy and Rendered Redundant by Naive Statistical Algorithms,” 2024.
Figure 1.
Shannon entropies for and .
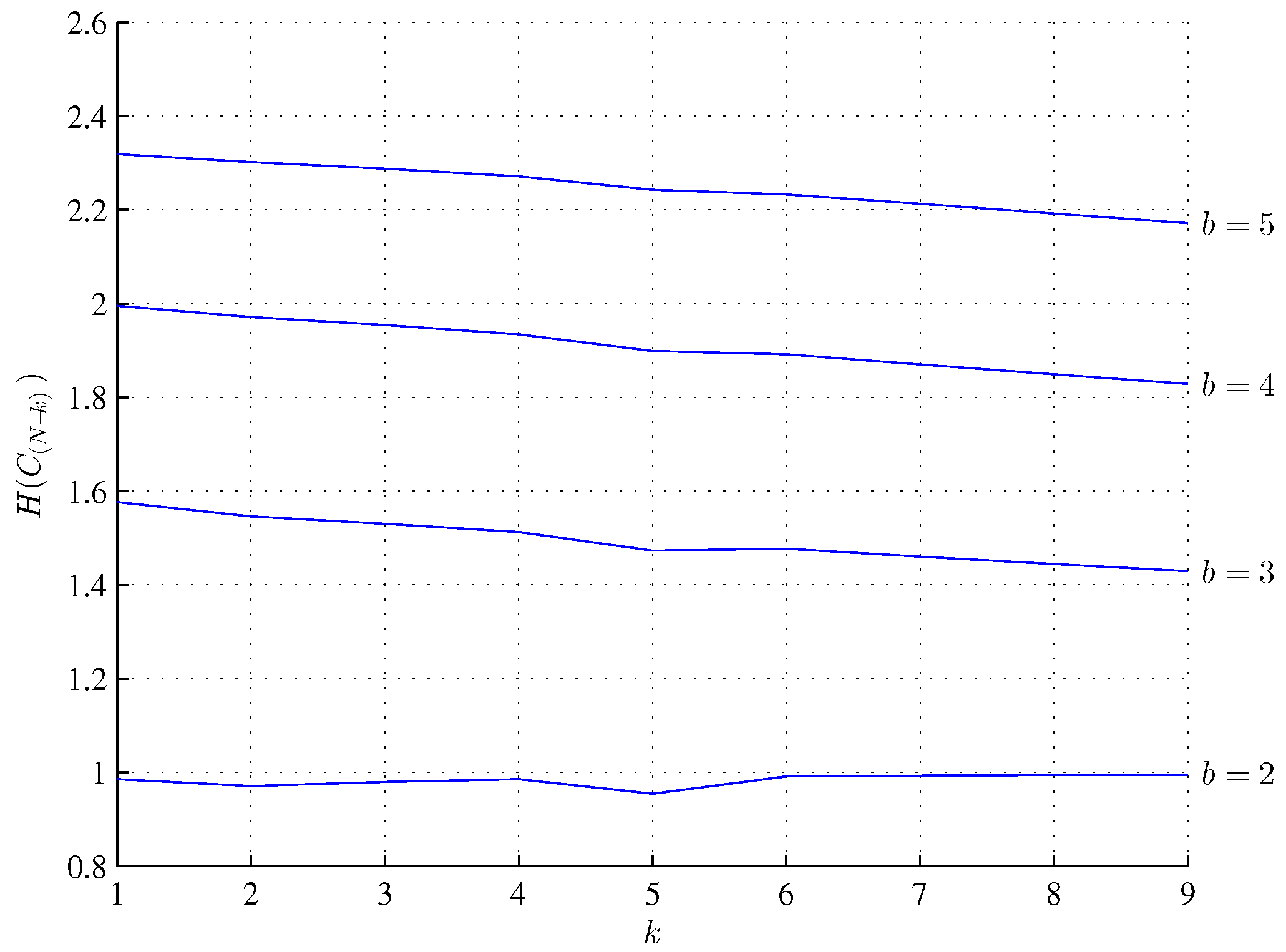
Figure 2.
Lower assembly index bound (red) and upper bounds (green) for , lower assembly depth bound (blue) of strings for , (red, dash-dot), and OEIS A014701 sequence (cyan) for .
Figure 2.
Lower assembly index bound (red) and upper bounds (green) for , lower assembly depth bound (blue) of strings for , (red, dash-dot), and OEIS A014701 sequence (cyan) for .
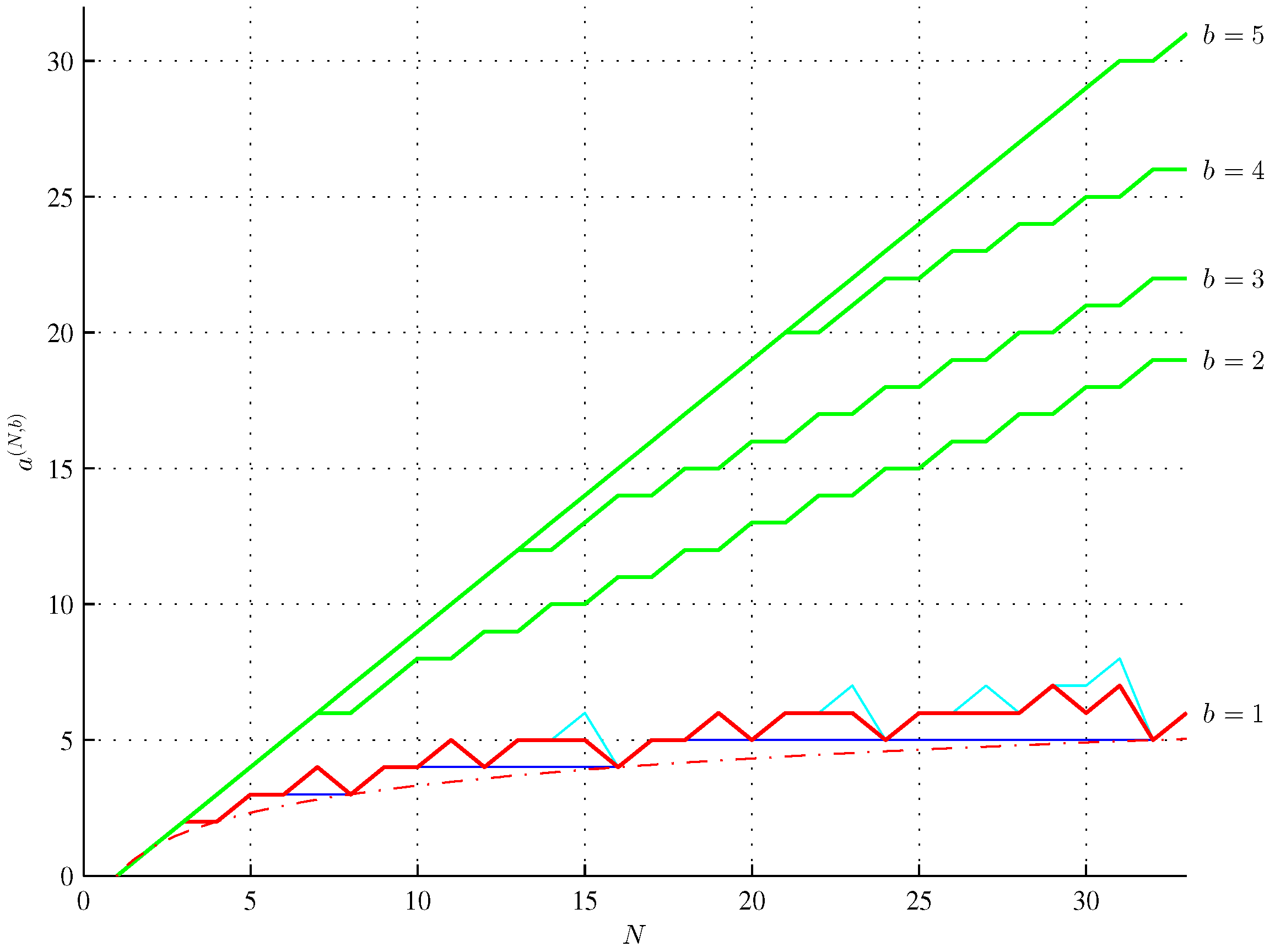

Table 1.
Distributions of n-plets in strings of maximum ASI.
| N | last | last | last | last | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | N | N | N | 0 | 0 | 0 | 0 | |
| 2 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | N | N | N | 1 | 1 | 1 | 1 | |
| 3 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | N | N | Y | 2 | 2 | 2 | 2 | |
| 4 | 1 | 2 | 2 | 2 | 1 | 0 | 0 | 0 | N | N | N | 2 | 3 | 3 | 3 | |
| 5 | 1 | 2 | 2 | 2 | 1 | 0 | 0 | 0 | N | N | Y | 3 | 4 | 4 | 4 | |
| 6 | 1 | 3 | 3 | 3 | 1 | 0 | 0 | 0 | N | Y | N | 3 | 5 | 5 | 5 | |
| 7 | 1 | 3 | 3 | 3 | 1 | 0 | 0 | 0 | N | Y | Y | 4 | 6 | 6 | 6 | |
| 8 | 1 | 3 | 4 | 4 | 2 | 1 | 0 | 0 | N | N | N | 3 | 6 | 7 | 7 | |
| 9 | 1 | 3 | 4 | 4 | 2 | 1 | 0 | 0 | N | N | Y | 4 | 7 | 8 | 8 | |
| 10 | 1 | 4 | 5 | 5 | 2 | 1 | 0 | 0 | N | Y | N | 4 | 8 | 9 | 9 | |
| 11 | 1 | 3 | 5 | 5 | 2 | 1 | 0 | 0 | N | Y | Y | 5 | 8 | 10 | 10 | |
| 12 | 1 | 4 | 6 | 6 | 3 | 1 | 0 | 0 | Y | N | N | 4 | 9 | 11 | 11 | |
| 13 | 1 | 3 | 6 | 6 | 3 | 1 | 0 | 0 | Y | N | Y | 5 | 9 | 12 | 12 | |
| 14 | 1 | 4 | 6 | 7 | 3 | 1 | 0 | 0 | Y | Y | N | 5 | 10 | 12 | 13 | |
| 15 | 1 | 3 | 6 | 7 | 3 | 1 | 0 | 0 | Y | Y | Y | 6 | 10 | 13 | 14 | |
| 16 | 1 | 4 | 7 | 8 | 4 | 2 | 1 | 0 | N | N | N | N | 4 | 11 | 14 | 15 |
| 17 | 1 | 3 | 6 | 8 | 4 | 2 | 1 | 0 | N | N | N | Y | 5 | 11 | 14 | 16 |
| 18 | 1 | 4 | 7 | 9 | 4 | 2 | 1 | 0 | N | N | Y | N | 5 | 12 | 15 | 17 |
| 19 | 1 | 3 | 6 | 9 | 4 | 2 | 1 | 0 | N | N | Y | Y | 6 | 12 | 15 | 18 |
| 20 | 1 | 4 | 7 | 10 | 5 | 2 | 1 | 0 | N | Y | N | N | 5 | 13 | 16 | 19 |
| 21 | 1 | 3 | 6 | 10 | 5 | 2 | 1 | 0 | N | Y | N | Y | 6 | 13 | 16 | 20 |
| 22 | 1 | 4 | 7 | 10 | 5 | 2 | 1 | 0 | N | Y | Y | N | 6 | 14 | 17 | 20 |
| 23 | 1 | 3 | 6 | 10 | 5 | 2 | 1 | 0 | N | Y | Y | Y | 7 | 14 | 17 | 21 |
| 24 | 1 | 4 | 7 | 11 | 6 | 3 | 1 | 0 | Y | N | N | N | 5 | 15 | 18 | 22 |
| 25 | 1 | 3 | 6 | 10 | 6 | 3 | 1 | 0 | Y | N | N | Y | 6 | 15 | 18 | 22 |
| 26 | 1 | 4 | 7 | 11 | 6 | 3 | 1 | 0 | Y | N | Y | N | 6 | 16 | 19 | 23 |
| 27 | 1 | 3 | 6 | 10 | 6 | 3 | 1 | 0 | Y | N | Y | Y | 7 | 16 | 19 | 23 |
| 28 | 1 | 4 | 7 | 11 | 7 | 3 | 1 | 0 | Y | Y | N | N | 6 | 17 | 20 | 24 |
| 29 | 1 | 3 | 6 | 10 | 7 | 3 | 1 | 0 | Y | Y | N | Y | 7 | 17 | 20 | 24 |
| 30 | 1 | 4 | 7 | 11 | 7 | 3 | 1 | 0 | Y | Y | Y | N | 7 | 18 | 21 | 25 |
| 31 | 1 | 3 | 6 | 11 | 7 | 3 | 1 | 0 | Y | Y | Y | Y | 8 | 18 | 21 | 25 |
| 32 | 1 | 4 | 7 | 11 | 8 | 4 | 2 | 1 | N | N | N | N | 5 | 19 | 22 | 26 |
| 33 | 1 | 3 | 6 | 11 | 8 | 4 | 2 | 1 | N | N | N | Y | 6 | 19 | 22 | 26 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Copyright: This open access article is published under a Creative Commons CC BY 4.0 license, which permit the free download, distribution, and reuse, provided that the author and preprint are cited in any reuse.



